cse 160/berman lecture 6 -- programming paradigms and algorithms w+a 3.1, 3.2, p. 178, 5.1, 5.3.3,...
Post on 22-Dec-2015
214 views
TRANSCRIPT

CSE 160/Berman
Lecture 6 -- Programming Paradigms and Algorithms
W+A 3.1, 3.2, p. 178, 5.1, 5.3.3, Chapter 6, 9.2.8, 10.4.1,
Kumar 12.1.3

CSE 160/Berman
Common Parallel Programming Paradigms
• Embarrassingly parallel programs
• Workqueue
• Master/Slave programs
• Monte Carlo methods
• Regular, Iterative (Stencil) Computations
• Pipelined Computations
• Synchronous Computations

CSE 160/Berman
Pipelined Computations
• Pipelined program divided into a series of tasks that have to be completed one after the other.
• Each task executed by a separate pipeline stage• Data streamed from stage to stage to form
computation
P1 P2 P3 P4 P5f, e, d, c, b, a

CSE 160/Berman
Pipelined Computations• Computation consists of data streaming through pipeline stages• Execution Time = Time to fill pipeline (P-1)
+ Time to run in steady state (N-P+1) + Time to empty pipeline (P-1)
P1 P2 P3 P4 P5f, e, d, c, b, a
a b fedca b fedc
a b fedca b fedc
a b fedc
time
P5P4P3P2P1
P = # of processorsN = # of data items(assume P < N)

CSE 160/Berman
Pipelined Example: Sieve of Eratosthenes• Goal is to take a list of integers greater than 1 and produce a list of primes
– E.g. For input 2 3 4 5 6 7 8 9 10, output is 2 3 5 7
• Fran’s pipelined approach (a little different than the book): – Processor P_i divides each input by the ith prime– If the input is divisible (and not equal to the divisor), it is marked (with a negative sign) and forwarded– If the input is not divisible, it is forwarded– Last processor only forwards unmarked (positive) data [primes]

CSE 160/Berman
Sieve of Eratosthenes Pseudo-Code• Code for processor Pi (and
prime p_i):– x=recv(data,P_(i-1))– If (x>0) then
• If (p_i divides x and p_i = x ) then send(-x,P_(i+1)
• If (p_i does not divide x or p_i = x) then send(x, P_(i+1))
– Else • Send(x,P_(i+1))
• Code for last processor– x=recv(data,P_(i-1))– If x>0 then
send(x,OUTPUT)
P2 P3 P5 P7 out
/

CSE 160/Berman
Programming Issues• Algorithm will take N+P-1 to run where N is the number
of data items and P is the number of processors. – Can also consider just the odds or do some initial part separately
• In given implementation, number of processors must store all primes which will appear in sequence– Not a scalable approach
– Can fix this by having each processor do the job of multiple primes, i.e. mapping logical “processors” in the pipeline to each physical processor
– What is the impact of this on performance?
P2 P3 P5 P7 P11 P13 P17

CSE 160/Berman
More Programming Issues• In pipelined algorithm, flow of data moves through
processors in lockstep, attempt to balance work so that there is no bottleneck at any processor
• In mid-80’s, processors developed to support in hardware this kind of parallel pipelined computation
• Two commercial products from Intel: Warp (1D array) and iWarp (components for 2D array)
• Warp and iWarp were meant to operate synchronously Wavefront Array Processor (S.Y. Kung) was meant to operate asynchronously, i.e. arrival of data would signal that it was time to execute

CSE 160/Berman
Systolic Arrays
• Warp and iWarp were examples of systolic arrays– Systolic means regular and rhythmic, data was supposed
to move through pipelined computational units in a regular and rhythmic fashion
• Systolic arrays meant to be special-purpose processors or co-processors and were very fine-grained– Processors implement a limited and very simple
computation, usually called cells– Communication is very fast, granularity meant to be
around 1!

CSE 160/Berman
Systolic Algorithms
• Systolic arrays built to support systolic algorithms, a hot area of research in the early 80’s
• Systolic algorithms used pipelining through various kinds of arrays to accomplish computational goals– Some of the data streaming and applications were very
creative and quite complex
– CMU a hotbed of systolic algorithm and array research (especially H.T. Kung and his group)

CSE 160/Berman
Example Systolic Algorithm: Matrix Multiplication
• Problem: multiply two nxn matrices A ={a_ij} and B={b_ij}. Product matrix will be R={r_ij}.
• Systolic solution uses 2D array with NxN cells, 2 input streams and 2 output streams

CSE 160/Berman
Systolic Matrix Multiplication
P34
P31
P32
P33
P44
P41
P42
P43
P14
P11
P12
P13
P24
P21
P22
P23
a44 a34 a24 a14 == == ==
a43 a33 a23 a13 == ==
a42 a32 a22 a12 ===
a41 a31 a21 a11
-- -- --
-- --
--
b41 b42 b43 b44
b31 b32 b33 b34
b21 b22 b23 b24
b11 b12 b13 b14
-- -- --
-- --
-- ----

CSE 160/Berman
Operation at each cell• Each cell updates at each time step as shown below
• initialized to 0
kjir ,
0, jir
jkkikji
kji
bar
r
,,1
,
,
kia , jkb ,
kia ,jkb ,

CSE 160/Berman
Data Flow for Systolic MM
• Beat 1 • Beat 2
1
1,1r
11a 11b2
1,1r
1
1,2r 1
2,1r
12a
21a21b
12b
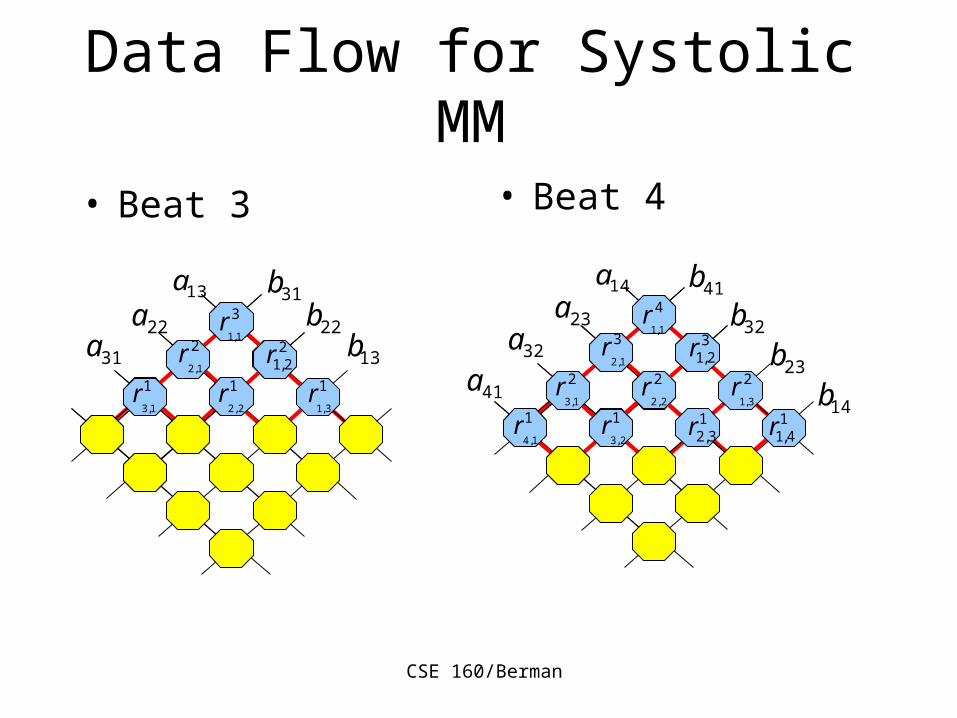
CSE 160/Berman
Data Flow for Systolic MM
• Beat 3 • Beat 4
3
1,1r
2
1,2r 2
2,1r
13a
22a31b
13b31a22b
1
1,3r 1
2,2r 1
3,1r
4
1,1r
3
1,2r 3
2,1r
14a
23a41b
23b32a32b
2
1,3r 2
2,2r 2
3,1r41a
14b1
1,4r 1
2,3r 1
3,2r14,1r

CSE 160/Berman
Data Flow for Systolic MM
• Beat 5 • Beat 6
42a
1,1r
4
1,2r 4
2,1r24a
33b33a42b
3
1,3r 3
2,2r 3
3,1r
24b2
1,4r 2
2,3r2
3,2r24,1r
12,4r
13,3r
14,2r
1,1r
1,2r 2,1r
43a43b34a
4
1,3r 4
2,2r 4
3,1r
34b3
1,4r 3
2,3r3
3,2r34,1r
22,4r
23,3r
24,2r
13,4r
14,3r

CSE 160/Berman
Data Flow for Systolic MM
• Beat 7 • Beat 8
1,1r
1,2r 2,1r
44a1,3r
2,2r
3,1r
44b4
1,4r 4
2,3r 4
3,2r44,1r
32,4r
33,3r
34,2r
23,4r
24,3r
14,4r
1,1r
1,2r 2,1r
1,3r
2,2r
3,1r
1,4r
2,3r 3,2r
42,4r
43,3r
44,2r
33,4r
34,3r
24,4r
4,1r

CSE 160/Berman
Data Flow for Systolic MM• Beat 9 • Beats 10 and 11
1,1r
1,2r 2,1r
1,3r
2,2r
3,1r
1,4r
2,3r 3,2r
2,4r 3,3r 4,2r4
3,4r44,3r
34,4r
4,1r
1,1r
1,2r 2,1r
1,3r
2,2r
3,1r
1,4r
2,3r 3,2r
2,4r 3,3r 4,2r
3,4r 4,3r4
4,4r
4,1r
1,1r
1,2r 2,1r
1,3r
2,2r
3,1r
1,4r
2,3r 3,2r
2,4r 3,3r 4,2r
3,4r 4,3r
4,4r
4,1r

CSE 160/Berman
Programming Issues
• Performance of systolic algorithms based on fine granularity (1 update about the same as a communication) and regular dataflow– Can be done on asynchronous platforms with
tagging but must ensure that idle time does not dominate computation
• Many systolic algorithms do not map well to more general MIMD or distributed platforms

CSE 160/Berman
Synchronous Computations
• Synchronous computations have the form(Barrier)ComputationBarrierComputation…
• Frequency of the barrier and homogeneity of the intervening computations on the processors may vary
• We’ve seen some synchronous computations already (Jacobi2D, Systolic MM)

CSE 160/Berman
Synchronous Computations
• Synchronous computations can be simulated using asynchronous programming models– Iterations can be tagged so that the appropriate data is
combined
• Performance of such computations depends on the granularity of the platform, how expensive synchronizations are, and how much time is spent idle waiting for the right data to arrive

CSE 160/Berman
Barrier Synchronizations
• Barrier synchronizations can be implemented in many ways:– As part of the algorithm – As a part of the communication library
• PVM and MPI have barrier operations
– In hardware
• Implementations vary

CSE 160/Berman
Review• What is time balancing? How do we use time-balancing to
decompose Jacobi2D for a cluster?
• Describe the general flow of data and computation in a pipelined algorithm. What are possible bottlenecks?
• What are the three stages of a pipelined program? How long will each take with P processors and N data items?
• Would pipelined programs be well supported by SIMD machines? Why or why not?
• What is a systolic program? Would a systolic program be efficiently supported on a general-purpose MPP? Why or why not?

CSE 160/Berman
Common Parallel Programming Paradigms
• Embarrassingly parallel programs
• Workqueue
• Master/Slave programs
• Monte Carlo methods
• Regular, Iterative (Stencil) Computations
• Pipelined Computations
• Synchronous Computations

CSE 160/Berman
Synchronous Computations
• Synchronous computations are programs structured as a group of separate computations which must at times wait for each other before proceeding
• Fully synchronous computations = programs in which all processes synchronized at regular points
• Computation between synchronizations often called stages

CSE 160/Berman
Synchronous Computation Example: Bitonic Sort
• Bitonic Sort an interesting example of a synchronous algorithm
• Computation proceeds in stages where each stage is a (smaller or larger) shuffle-exchange network
• Barrier synchronization at each stage

CSE 160/Berman
Bitonic Sort• A bitonic sequence is a list of keys
such that1 For some i, the keys have the ordering
or2 The sequence can be shifted cyclically so that
1) holds
110 ,,, naaa
110 ni aaaa
0a 1a 2a 3a ia 1na

CSE 160/Berman
Bitonic Sort Algorithm• The bitonic sort algorithm recursively calls
two procedures:– BSORT(i,j,X) takes bitonic sequence
and produces a non-decreasing (X=+) or a non-increasing sorted sequence (X=-)
– BITONIC(i,j) takes an unsorted sequence and produces a bitonic sequence
• The main algorithm is then– BITONIC(0,n-1)– BSORT(0,n-1,+)
jii aaa ,,, 1
jii aaa ,,, 1

CSE 160/Berman
How does it do this?• We’ll show how BSORT and BITONIC work but
first consider an interesting property of bitonic sequences:
Assume that is bitonic and that n is even. Let
Then and are bitonic sequences and for all
110 ,,, naaa
},max{,},,max{},,max{
},min{,},,min{},,min{
11
21
2
1
2
02
11
21
2
1
2
01
nnnn
nnnn
aaaaaaB
aaaaaaB
1B 2B
21, ByBx yx

CSE 160/Berman
Picture “Proof” of Interesting Property
• Consider
• Two cases: and
},max{,},,max{},,max{
},min{,},,min{},,min{
11
21
2
1
2
02
11
21
2
1
2
01
nnnn
nnnn
aaaaaaB
aaaaaaB
2
ni
2
ni
2
na0a 1a 2a ia 1na2
na0a 1a 2a ia 1na

CSE 160/Berman
Picture “Proof” of Interesting Property
• Consider
},max{,},,max{},,max{
},min{,},,min{},,min{
11
21
2
1
2
02
11
21
2
1
2
01
nnnn
nnnn
aaaaaaB
aaaaaaB
2
ni
2
na0a 1a 2a ia 1na 1na0a 1a 2a ia
21, ByBx
yx

CSE 160/Berman
Picture “Proof” of Interesting Property
• Consider
},max{,},,max{},,max{
},min{,},,min{},,min{
11
21
2
1
2
02
11
21
2
1
2
01
nnnn
nnnn
aaaaaaB
aaaaaaB
2
ni
2
na0a 1a 2a ia 1na2
na0a 1a 2a ia 1na
21, ByBx yx

CSE 160/Berman
Back to Bitonic Sort• Remember
– BSORT(i,j,X) takes bitonic sequence and produces a non-decreasing (X=+) or a non-increasing sorted sequence (X=-)
– BITONIC(i,j) takes an unsorted sequence and produces a bitonic sequence
• Let’s look at BSORT first …
jii aaa ,,, 1
jii aaa ,,, 1
sortedbitonic
min bitonic
max bitonic

CSE 160/Berman
Here’s where the shuffle-exchange comes in …
• Shuffle-exchange network routes the data correctly for comparison
• At each shuffle stage, can use + switch to separate B1 and B2
bitonic
min bitonicsubsequence
max bitonicsubsequence
ab
min{a,b}max{a,b}
+
shuffle unshuffle
+
+
+
+

CSE 160/Berman
Sort bitonic subsequences to get a sorted sequence
• BSORT(i,j,X)– If |j-i|<2 then return [min(i,i+1), max(i,i+1)]– Else
• Shuffle(i,j,X)• Unshuffle(i,j)• Pardo
– BSORT (i,i+(j-i+1)/2 - 1,X)– BSORT (i+(j-i+1)/2 +1,j,X)
bitonic
shuffle unshuffle
+
+
+
+
Sortmaxs
Sortmins

CSE 160/Berman
BITONIC takes an unsorted sequence as input and returns a bitonic sequence
• BITONIC(i,j)– If |j-i|<2 then return [i,i+1]– Else
• Pardo– BITONIC(i,i+(j-i+1)/2 – 1); BSORT (i,i+(j-i+1)/2 - 1,+)– BITONIC(i+(j-i+1)/2 +1,j); BSORT (i+(j-i+1)/2 +1,j,-)
unsorted
Sortfirst half
Sortsecond half
(note that any 2 keys arealready a bitonic sequence)
ab
max{a,b}min{a,b}
-
+
+
-
-
}
}2-waybitonic
4-waybitonic
8-waybitonic

CSE 160/Berman
Putting it all together
• Bitonic sort for 8 keys:
unsorted
4-waybitonics
4 ordered2-way bitonics
Sortedsequence
2 orderedbitonics
ab
ab
+
+
+
+
-
+
-
+
+
-
-
++
+
+
+
+
+
+
+
+
-
-
+
8-waybitonic

CSE 160/Berman
Complexity of Bitonic Sort
)(log
)()2()1(2
)2(2)2( 1
nO
jOTJ
TnT jjBSORT
)(log
)(
1)1(2
1)1(2)2()2(
2
2
1
2
1
nO
jO
i
jTnTj
i
jjBITONIC

CSE 160/Berman
Programming Issues
• Flow of data is assumed to transfer from stage to stage synchronously; usual issues with performance if algorithm is executed asynchronously
• Note that logical interconnect for each problem size is different– Bitonic sort must be mapped efficiently to target
platform
• Unless granularity of platform very fine, multiple comparators will be mapped to each processor

CSE 160/Berman
Review
• What is a a synchronous computation? What is a fully synchronous computation?
• What is a bitonic sequence?
• What do the procedures BSORT and BITONIC do?
• How would you implement Bitonic Sort in a performance-efficient way?

CSE 160/Berman
Mapping Bitonic Sort
For every stage the 2X2 switches compare keys which differ in a single bit
011
011
0
1
aaaa
aaaa
iik
iik
110111
101
000
011100
010001
012 aaa 012 aaa012 aaa
+
+
+
+
-
+
-
+
+
-
-
+
+
+
+
+
+
+
+
+
+
-
-
+

CSE 160/Berman
Supporting Bitonic Sort on a hypercube
• Switch comparisons can performed in constant time on hypercube interconnect.
011
011
0
1
aaaa
aaaa
iik
iik
2 3
0 1
6 7
4 5
2 3
0 1
6 7
4 5X Y
X Compare(X,Y)
Min{X,Y} Max{X,Y}

CSE 160/Berman
Mappings of Bitonic Sort
• Bitonic sort on a multistage full shuffle– Small shuffles do not map 1-1 to larger shuffles!
– Stone used a clever approach to map logical stages into full-sized shuffle stages while preserving O(log^2 n) complexity
?

CSE 160/Berman
Outline of Stone’s Method • Pivot bit = index being shuffled• Stone noticed that for successive stages, the pivot
bits are• If the pivot bit is in place, each subsequent stage
can be done using a full-sized shuffle (a_0 done with a single comparator)
• For pivot bit j, need k-j full shuffles to position bit j for comparison
• Complexity of Stone’s method:
,,,,,,,,,,,, 011012010 aaaaaaaaaa ii
1001 jkjjjk aaaaaaaa
)(log)()1(
]11)[(]11)2[(]1)1[(22 nOkOkk
kkkkk

CSE 160/Berman
Many-one Mappings of Bitonic Sort
• For platforms where granularity is coarser, it will be more cost-efficient to map multiple comparators to one processor
• Several possible conventional mappings
• Compare-split provides another approach …
-
--- +
--
+--
+-
--- +
--
+--
+

CSE 160/Berman
Compare-Split• For a block of keys, may want to use a compare-
split operation (rather than compare-exchange) to accommodate multiple keys at a processor
• Idea is to assume that each processor is assigned a block of keys, rather than 2 keys– Blocks are already sorted with a sequential sort– To perform compare-split, a processor compares blocks
and returns the smaller half of the aggregate keys as the min block and the larger half of the aggregate keys as the max block
Block A
Block B
Compare-split
Min Block
Max Block

CSE 160/Berman
Compare-Split• Each Block represents more than one datum
– Blocks are already sorted with a sequential sort
– To perform compare-split, a processor compares blocks and returns the smaller half of the aggregate keys as the min block and the larger half of the aggregate keys as the max block
Block A
Block B
Compare-split
Min Block
Max Block
+
+
+
+
-
+
-
+
+
-
-
++
+
+
+
+
+
+
+
+
-
-
+

CSE 160/Berman
Performance Issues
• What is the complexity of compare-split?
• How do we optimize compare-split?– How many datum per block?– How to allocate blocks per processors?– How to synchronize intra-block sorting with
inter-block communication?