cuda and the memory model (part ii). code executed on gpu
Post on 21-Dec-2015
230 views
TRANSCRIPT

CUDA and the Memory Model (Part II)

Code executed on GPU

Variable Qualifiers (GPU Code)

CUDA: Features available to kernals
Standard mathematical functions Sinf, powf, atanf, ceil, etc
Built-in vector types Float4, int4, uint4, etc for dimensions 1…4
Texture accesses in kernels Texture<float,2> my_texture // declare texture
reference Float4 texel = texfetch (my_texture, u, v);

Thread Synchronization function

Host Synchronization (for Kalin…)
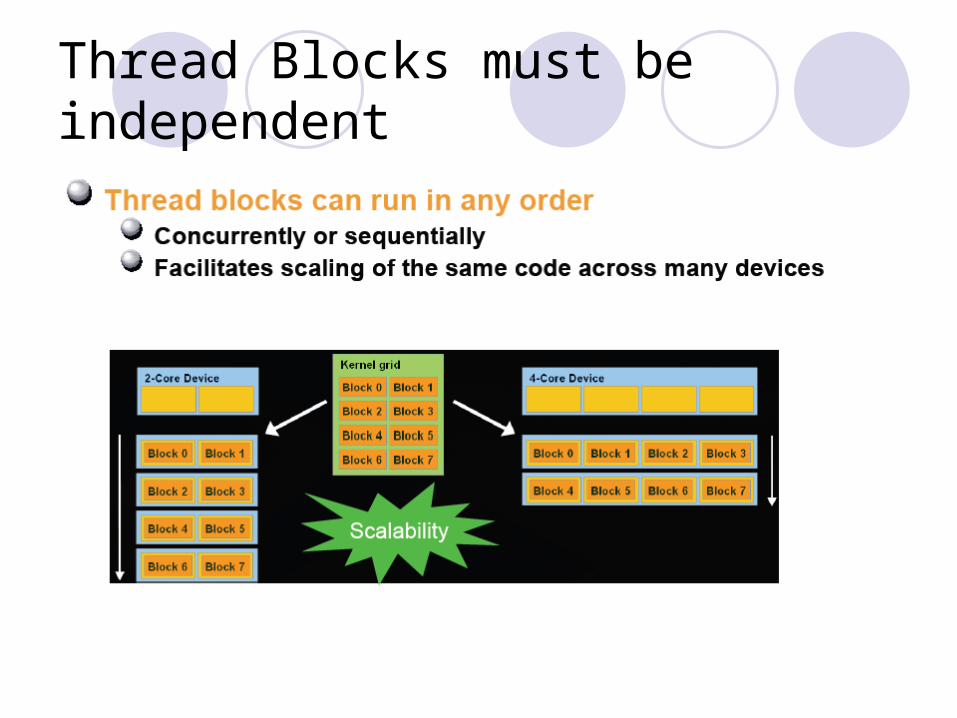
Thread Blocks must be independent

Thread Blocks must be independent

Example: Increment Array Elements

Example: Increment Array Elements

Example: Host Code

CUDA Error Reporting to CPU

CUDA Event API (someone asked out this….)

Shared Memory
On-chip 2 orders of magnitude lower latency than global memory Order of magnitude higher bandwidth than global memory 16KB per multiprocessor
NVIDIA GPUs contain up to ~ 30 multiprocessors
Allocated per threadblock Accessible by any thread in the threadblock
Not accessible to other threadblocks Several uses:
Sharing data among threads in a threadblock User-managed cache (reducing global memory accesses)

Using Shared Memory
Slide Courtesy of NVIDA: Timo Stich

Using Shared Memory

Using Shared Memory

Using Shared Memory

Thread counts
•More threads per block are better for time slicing- Minimum: 64, Ideal: 192-256
•More threads per block means fewer registers per thread- Kernel invocation may fail if the kernel compiles to more
registers than are available
•Threads within a block can be synchronized- Important for SIMD efficiency
•The maximum threads allowed per grid is 64K^3

Block Counts
•There should be at least as many blocks as multiprocessors- The number of blocks should be at least 100 to
scale to future generations
•Blocks within a grid can not be synchronized
•Blocks can only be swapped by partitioning registers and shared memory among them