cuda meetup presentation 5
TRANSCRIPT

CUDA PARELLELPROGRAMMING AND
GAMING MEETUP
RIGA, LATVIA, JANUARY 12, 2015


• Personal Introductions;
• CES Nvidia news;
• Jetson TK1;
• Anouncements;
• Summary
Agenda

Who am I
What I am doing
What is my parallel programmingexperience [CUDA] experience
Introduction

Exponential Technologies
Drones AUTOMOTIVE 3D Printing Artificial intelligence
Biotechnology Design ROBOTICS Computer Vision

CES 2015


Parrot drone + Jetson TK1



Featured events

The Startup
Universi ty
Latvia Tech and
Entrepreneurship
meetup network
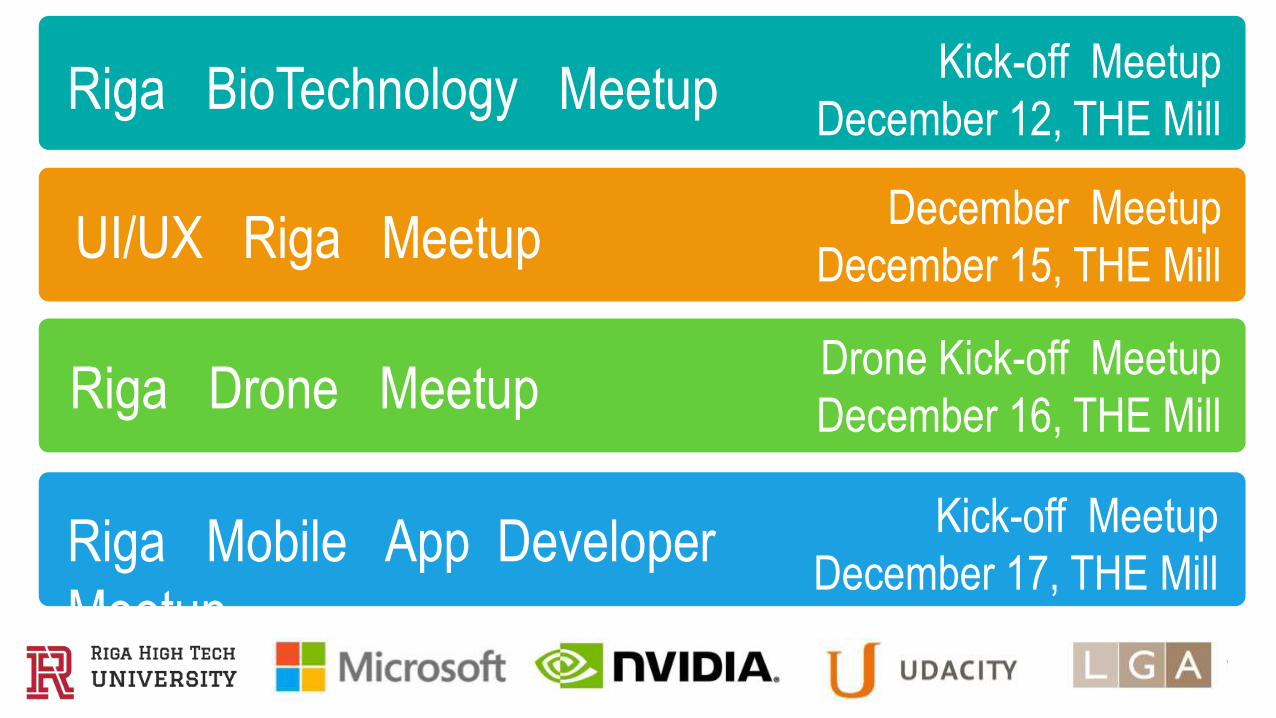
Riga BioTechnology Meetup
UI/UX Riga Meetup
Riga Drone Meetup
Riga Mobile App Developer
Meetup
Kick-off Meetup
December 12, THE Mill
December Meetup
December 15, THE Mill
Drone Kick-off Meetup
December 16, THE Mill
Kick-off Meetup
December 17, THE Mill
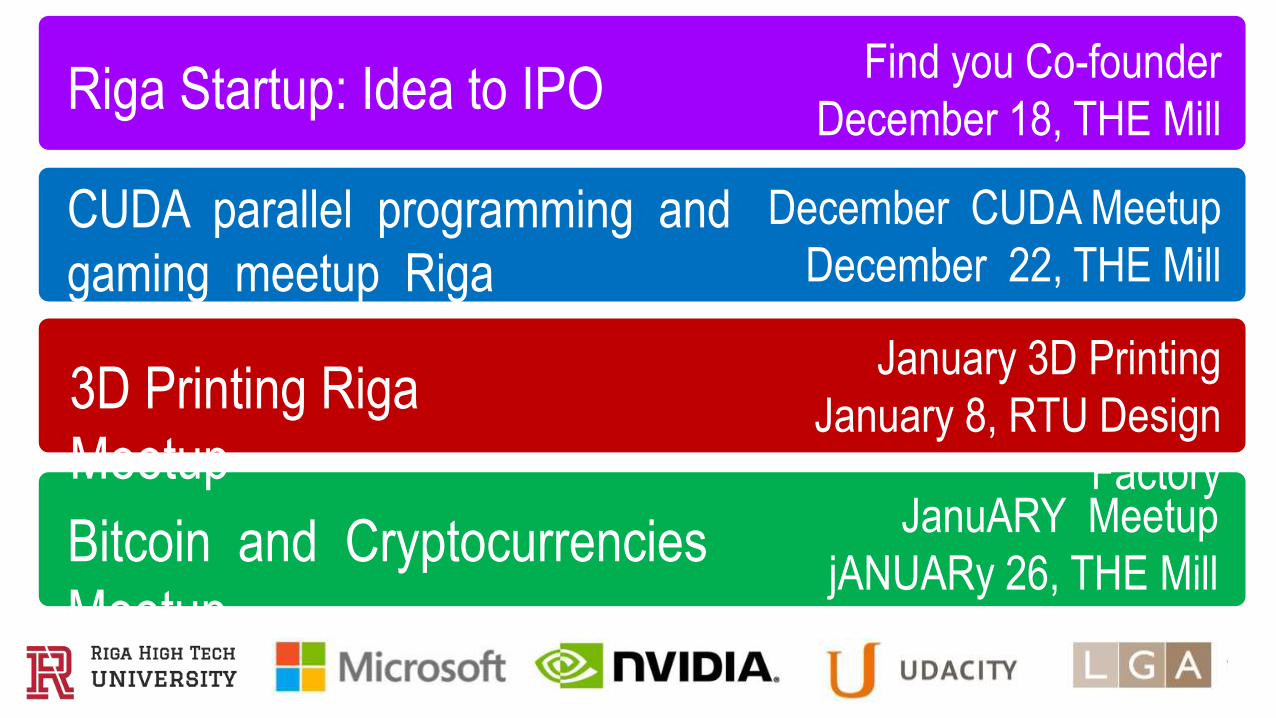
Riga Startup: Idea to IPO
CUDA parallel programming and
gaming meetup Riga
3D Printing Riga
Meetup
Bitcoin and Cryptocurrencies
Meetup
Find you Co-founder
December 18, THE Mill
December CUDA Meetup
December 22, THE Mill
January 3D Printing
January 8, RTU Design
FactoryJanuARY Meetup
jANUARy 26, THE Mill

Sponsors

Technology and Entrepreneurship education

Paralell computing Research Center
CUDA LABORATORY

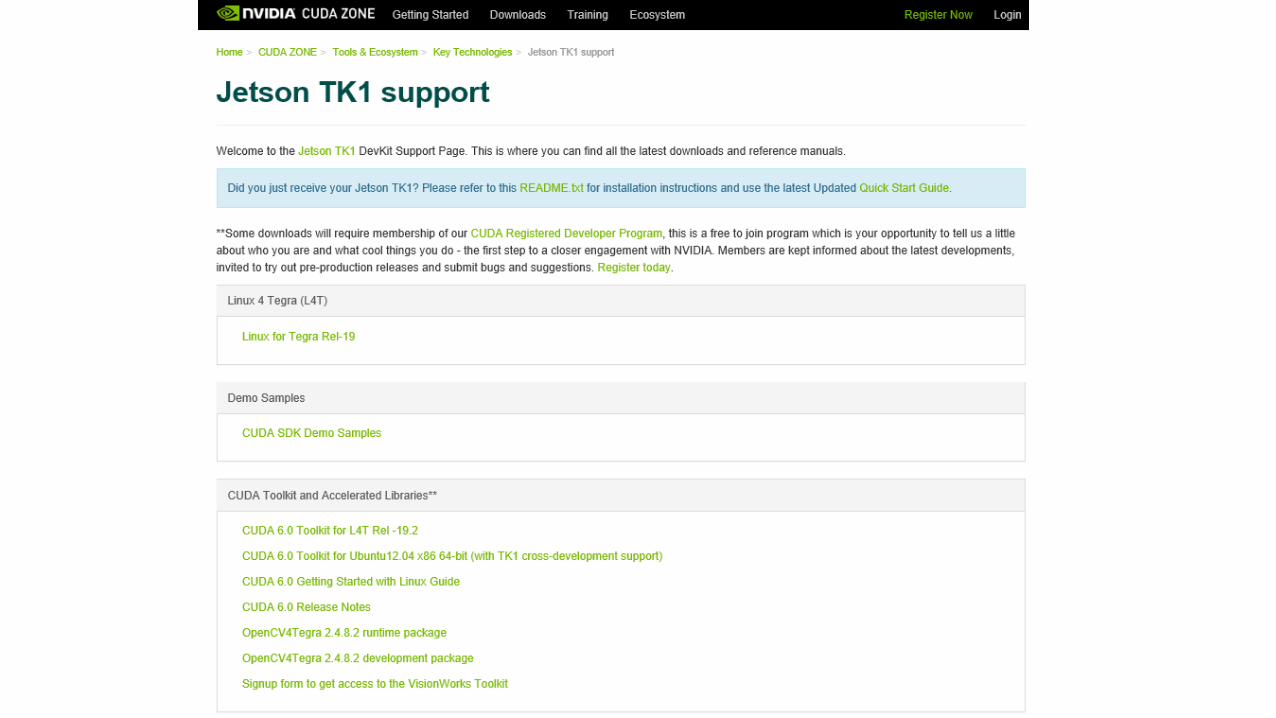
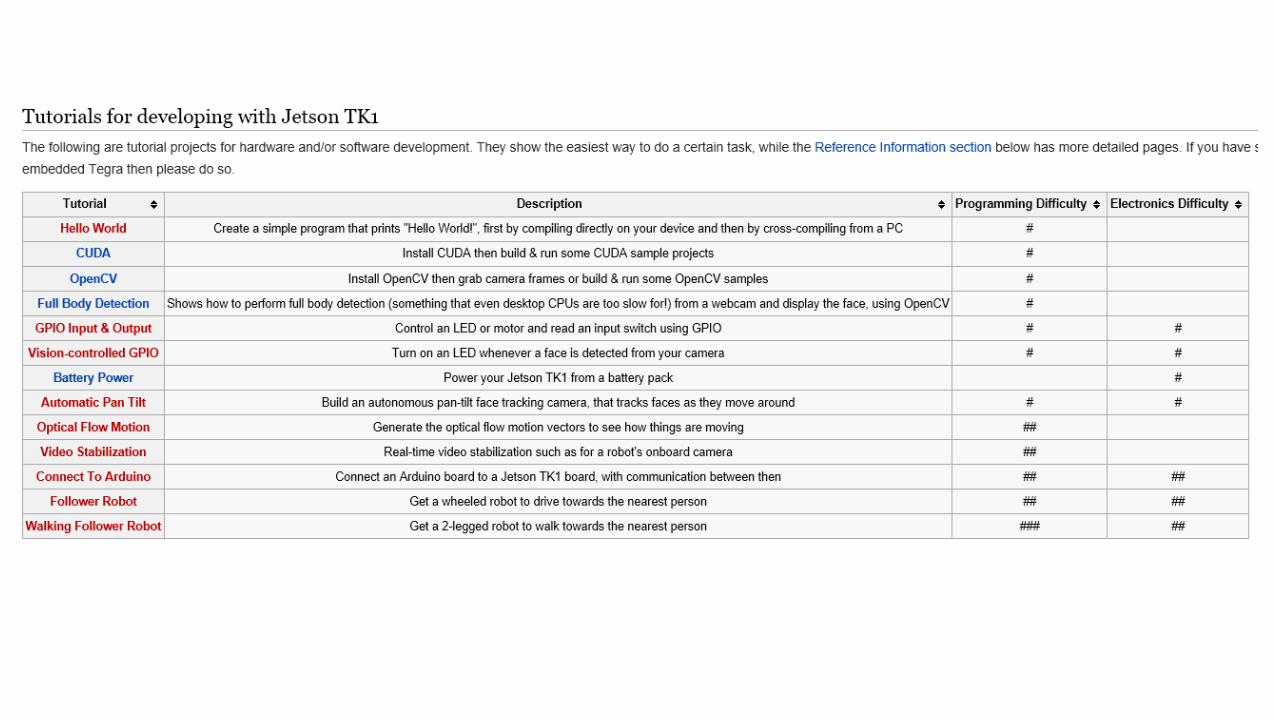
Jetson TK1



http://www.anandtech.com/show/7905/nvidia-announces-jetson-tk1-dev-board-adds-erista-to-tegra-roadmap


Whats in the Box


Login Credentials
Username: ubuntuPassword: ubuntu

Install the NVIDIA Linux driver binary release on your target located in:
${HOME}/NVIDIA-INSTALLER
Step 1)
Change directories into the NVIDIA installation directory:
cd ${HOME}/NVIDIA-INSTALLER
Step 2)
Run the installer script to extract and install the Linux driver binary release:
sudo ./installer.sh
Step 3)
Reboot the system to have the graphical desktop UI come up.

CUDA SDK Demo Samples
• Particles
• Nbody
• Smokeparticles
• waves

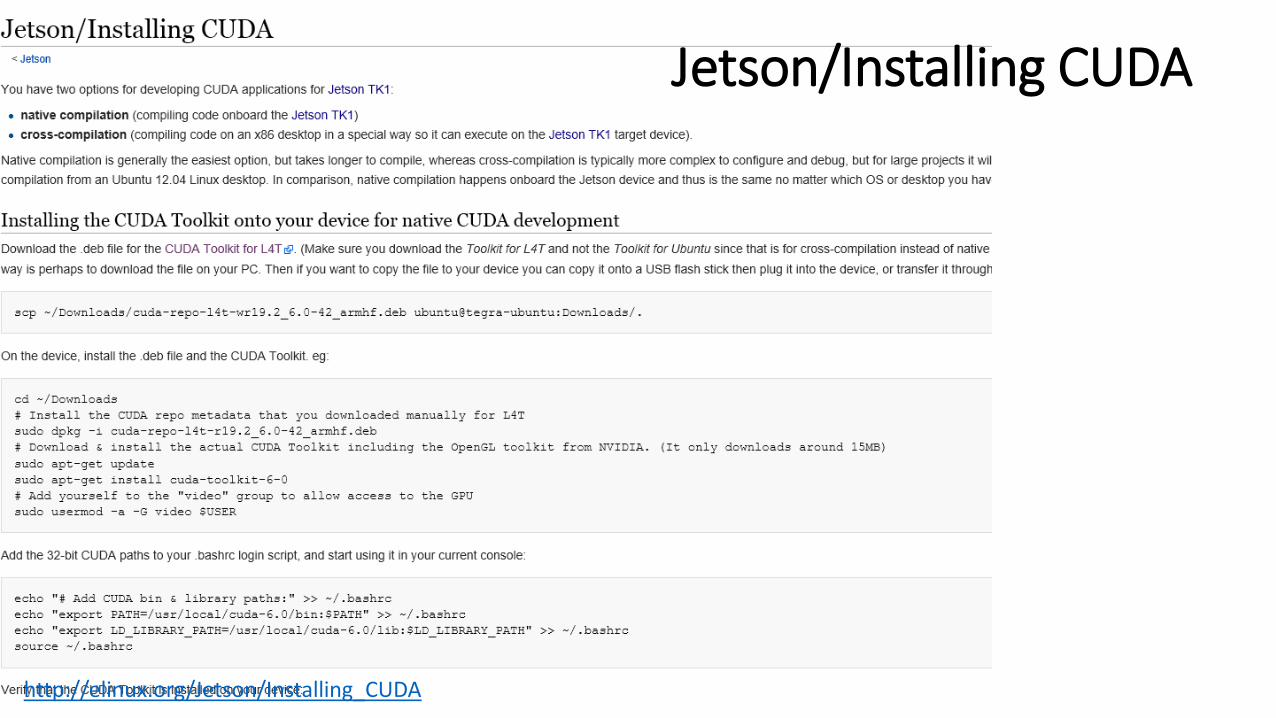
Jetson/Installing CUDA
http://elinux.org/Jetson/Installing_CUDA
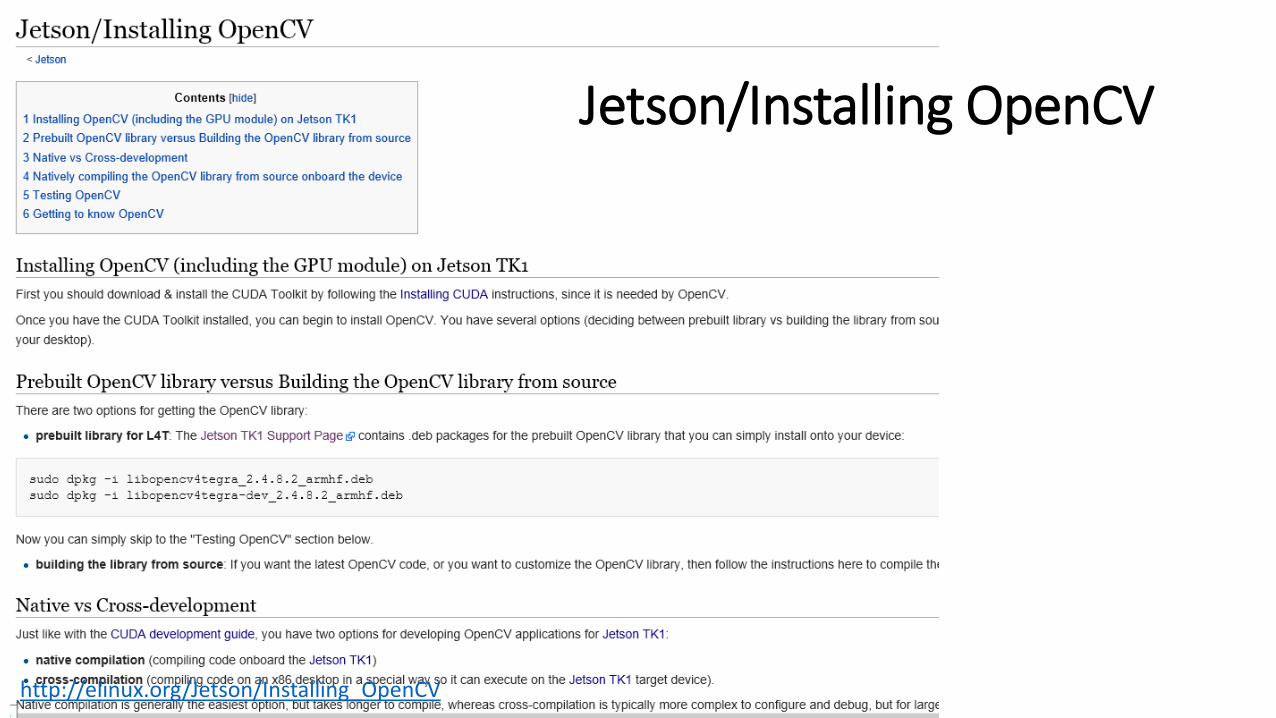
Jetson/Installing OpenCV
http://elinux.org/Jetson/Installing_OpenCV
Open CV
http://docs.opencv.org/doc/tutorials/tutorials.html
http://docs.opencv.org/doc/tutorials/objdetect/cascade_classifier/cascade_classifier.html#cascade-classifier
Object Detection

Jetson TEGRA TK1Tegra K1 SOC
• Kepler GPU with 192 CUDA cores• 4-Plus-1 quad-core ARM Cortex A15 CPU
• 2 GB x16 memory with 64 bit width
• 16 GB 4.51 eMMC memory
• 1 Half mini-PCIE slot
• 1 Full size SD/MMC connector
• 1 Full-size HDMI port
• 1 USB 2.0 port, micro AB
• 1 USB 3.0 port, A
• 1 RS232 serial port
• 1 ALC5639 Realtek Audio codec with Mic in and Line out
• 1 RTL8111GS Realtek GigE LAN
• 1 SATA data port
• SPI 4MByte boot flash

Research projects?

• IT industry experiences an increasing growth for display surfaces with high resolution• Use cases for such surfaces include satellite and map data, x-ray and microscope images, multimedia, CCTV, etc.• Existing solutions are not scalable, do not offer hardware abstraction, suffer from wiring limitations
Proposed Virtual Machine Based Monitor Wall Architecture
Introduction Scalability
Conclusions
• The current experiments show that this architecture is very feasiblefor non FPS intensive use cases where the display wall can be drivenby a single physical GPU
• The total resolution provided by this architecture even using thecurrently available compression technology greatly exceeds theresolutions of existing solutions, it would be expected for theresolution to grow in the future
• The architecture itself scales very good, it is limited mainly by OSsupport for multiple monitors (this can be overcome by simulatinga single high resolution display in the virtual machine that spans thewhole resolution of the physical wall) and the possibility to stackmultiple GPU’s in the host system
• Future work should focus on the ability to virtualize OpenGL andDirect3D to remove the advantages of non-virtualized architectures
OSGPU
GPUMonit
orMonit
or
Monitor
Monitor
OS GPU
Monitor
Monitor
Monitor
Monitor
Splitter / Scaler
Currently there are two main alternatives to be used as the H.264 encoder in this architecture – Intel Quick Sync and NVENC. NVCENC is more feasible because:• The total encoding power can be increased by stacking up multiple GPUs that support NVENC without penalties while not all Intel Quick Sync GPUs have built in video memory so scaling these cards introduce a performance penalty
of using system memory• NVENC does not put any limitations on other components of the system, while Intel Quick Sync supports a limited amount of CPUs• Current benchmarks seem to show that the overall FPS performance for a single GPU (which is the main criteria for this architecture) is better for NVENC than Intel Quick Sync
Why NVENC?
Pro: OS can natively manage the displaysCon: Power consumption, supported monitor count limited by the output count of the GPUs and expansion slots for the GPUs on the motherboard, deployment is limited by wiring
Pro: Software complexity is reduced since it does not have to be multiple monitor awareCon: Small resolution and DPI, visualization is not displayed in it’s native resolutionCon: Expensive
Currently Popular Monitor Wall Architectures
Pro: Scalable, host machine can run multiple virtual machines, multiple virtualized GPU’s map to physical GPU’s to maximize efficiencyPro: LAN connection to the display wall removes wire lengthlimitations forced by DVI/HDMI cablesPro: Total resolution of the wall goes beyond the ones that can be achieved using physical hardwareCon: Lossy compressionCon: No Direct3D, OpenGL support
• The host machine collects the frame buffer data from the virtual machine GPUs and performs H.264 encoding of the video stream on the physical host GPU thus the architecture heavily relies on a fast hardware H.264 encoder allowing the hosted virtual machines to fully use the CPU
• Non FPS intensive use cases allow a great number of virtual monitors to be hosted on a single physical GPU thus reducing the power consumption
0
50
100
Using Video…
Max
imu
m
The graph below demonstrates the scalability possibilities in terms of possible maximal amount of connected monitors for the traditional architecture versus the proposed one on a Quadro K4000 card that has 4 outputs.
Display wall architecture where each output of the GPU maps to a tile on the display wall Display wall architecture where each output of the GPU is split/upscaled among the tiles on the display wall
Host Machine
Virtual MachineGPU
GPU
GPU
GPUG
PU
GPU
GPU
GPUG
PU
GPU
GPU
GPUG
PU
GPU
GPU
GPU
H.2
64
/RTP
/LA
N
GP
U
The proposed display wall architecture where each output of a virtual GPU maps to a tile on the display wall and is transmitted as a H.264 stream over LAN
Virtual machine based monitor wall running Google maps inside Chrome web browser on 16 tiles at 1920x1080 pixels each giving a total resolution of 32 megapixels
Each tile has a dedicated LAN connection and H.264 decoder
Scalability of supported monitor count
NVENC Based H.264 Encoding for Virtual Machine Based Monitor Wall Architecture
R. Bundulis ([email protected]), G. Arnicans ([email protected]), and R. Gailums ([email protected])
University of Latvia / Riga High Tech University, Latvia

For Startups by Meetup members:
$1800 per year of FREE Azure cloud servicesFree Microsoft software and tools

Latvijas Garantiju Aģentūra
Government corporations which supports Latvian entepreneurs
and helps in realisation of their business ideas.

Featured Resources

Featured Startup

Speakers

Mobile APP Startup pitch

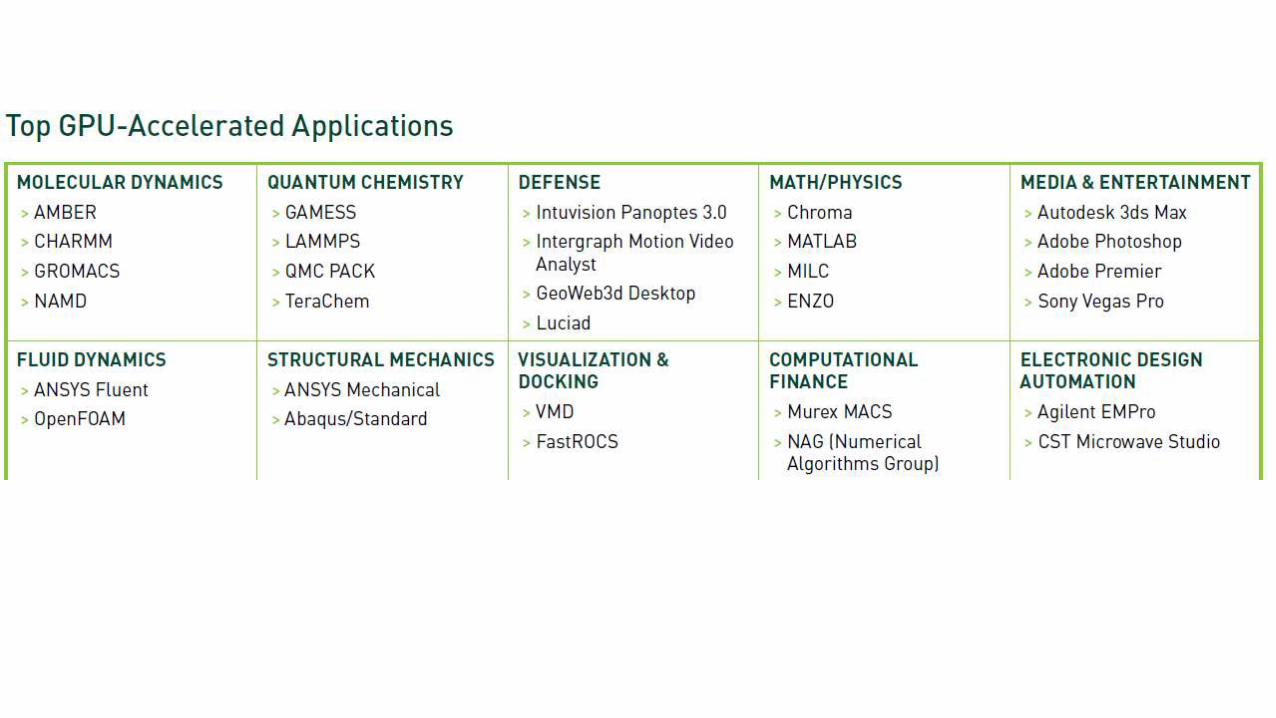
Why GPU Computing
GPUCPU
Add GPUs: Accelerate Science Applications
© NVIDIA 2013
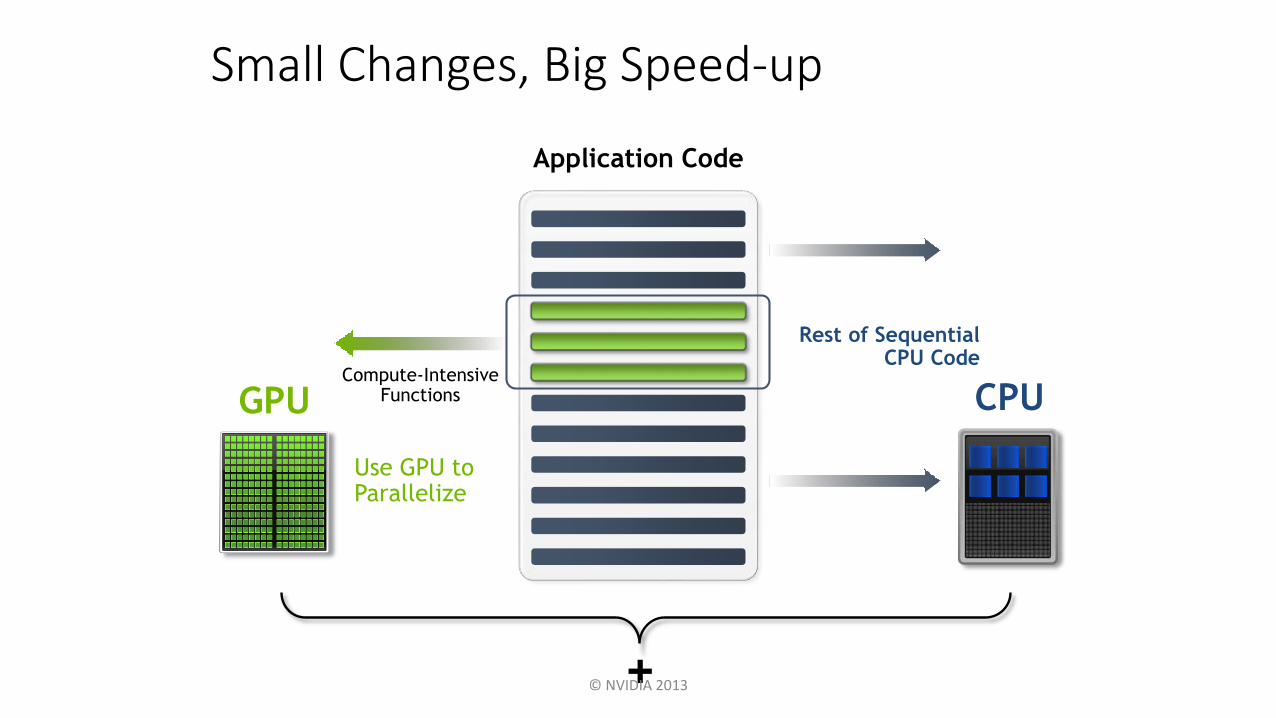
Small Changes, Big Speed-up
Application Code
+
GPU CPU
Use GPU to Parallelize
Compute-Intensive Functions
Rest of SequentialCPU Code
© NVIDIA 2013
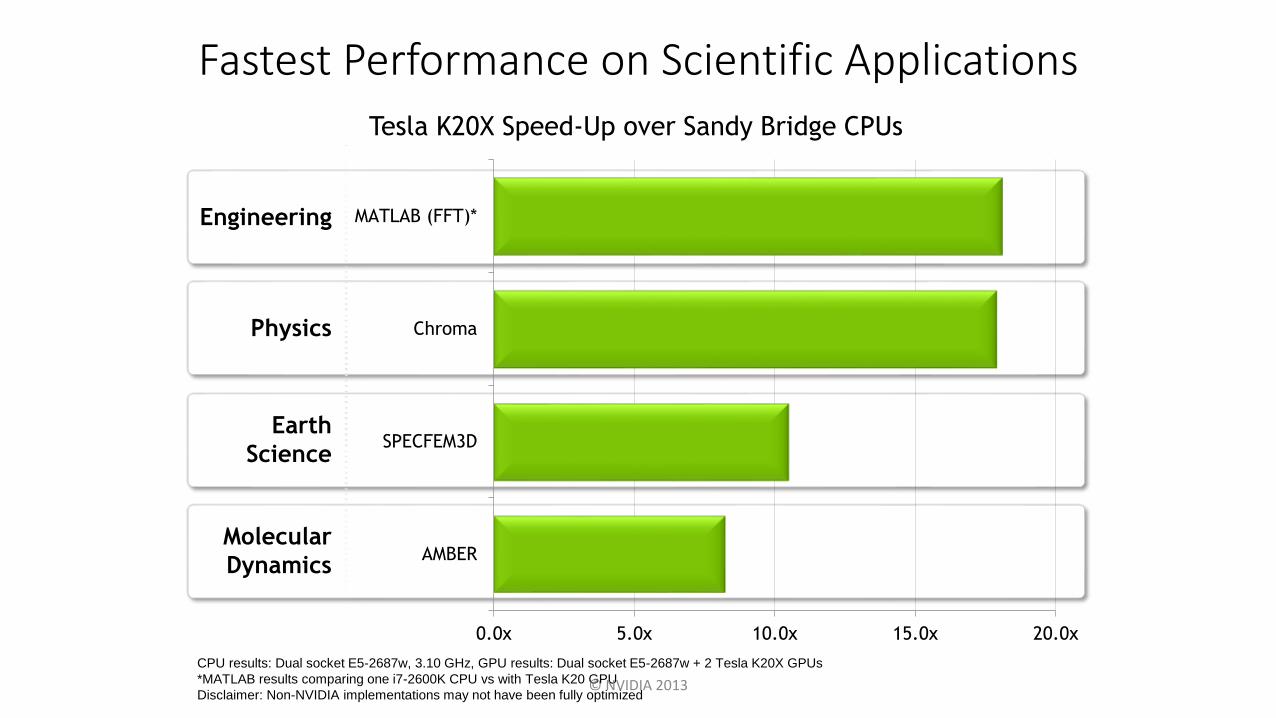
Fastest Performance on Scientific Applications
Tesla K20X Speed-Up over Sandy Bridge CPUs
CPU results: Dual socket E5-2687w, 3.10 GHz, GPU results: Dual socket E5-2687w + 2 Tesla K20X GPUs
*MATLAB results comparing one i7-2600K CPU vs with Tesla K20 GPU
Disclaimer: Non-NVIDIA implementations may not have been fully optimized
0.0x 5.0x 10.0x 15.0x 20.0x
AMBER
SPECFEM3D
Chroma
MATLAB (FFT)*Engineering
Earth
Science
Physics
Molecular
Dynamics
© NVIDIA 2013

Why Computing Perf/Watt Matters?
Traditional CPUs arenot economically feasible
2.3 PFlops 7000 homes
7.0 Megawatts
7.0 Megawatts
CPUOptimized for Serial Tasks
GPU AcceleratorOptimized for Many
Parallel Tasks
10x performance/socket
> 5x energy efficiency
Era of GPU-accelerated computing is here
© NVIDIA 2013
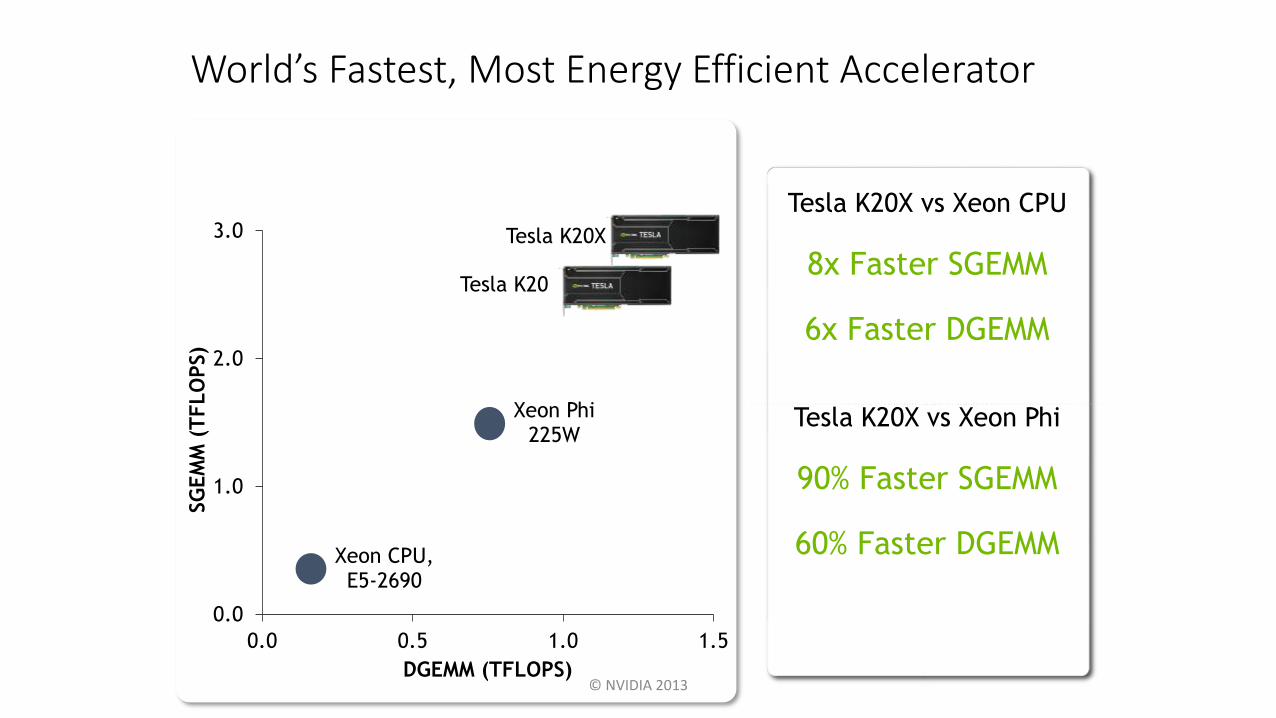
World’s Fastest, Most Energy Efficient Accelerator
Tesla K20X
Tesla K20
Xeon CPU, E5-2690
Xeon Phi225W
0.0
1.0
2.0
3.0
0.0 0.5 1.0 1.5
SG
EM
M (
TFLO
PS)
DGEMM (TFLOPS)
Tesla K20X vs Xeon CPU
8x Faster SGEMM
6x Faster DGEMM
Tesla K20X vs Xeon Phi
90% Faster SGEMM
60% Faster DGEMM
© NVIDIA 2013

Introduction to the CUDA Platform
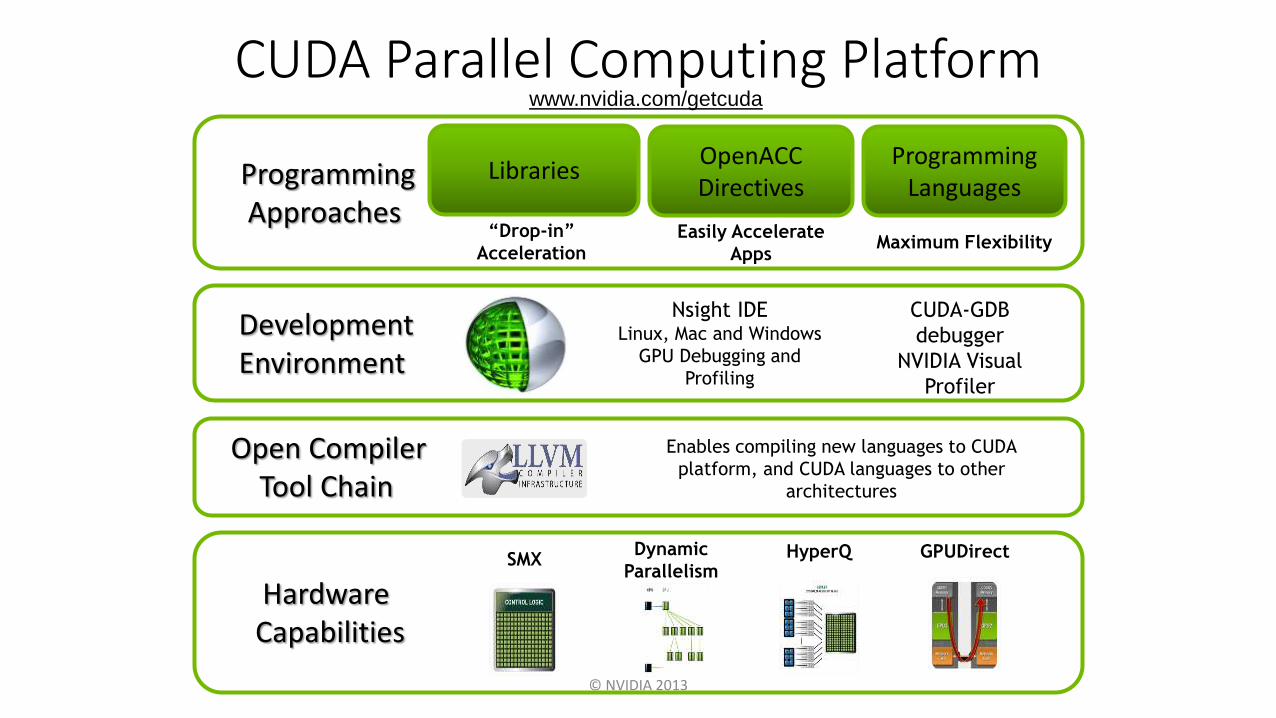
CUDA Parallel Computing Platform
Hardware Capabilities
GPUDirectSMXDynamic
ParallelismHyperQ
Programming Approaches
Libraries
“Drop-in”
Acceleration
Programming Languages
OpenACC Directives
Maximum FlexibilityEasily Accelerate
Apps
DevelopmentEnvironment
Nsight IDELinux, Mac and Windows
GPU Debugging and
Profiling
CUDA-GDB
debugger
NVIDIA Visual
Profiler
Open CompilerTool Chain
Enables compiling new languages to CUDA
platform, and CUDA languages to other
architectures
www.nvidia.com/getcuda
© NVIDIA 2013
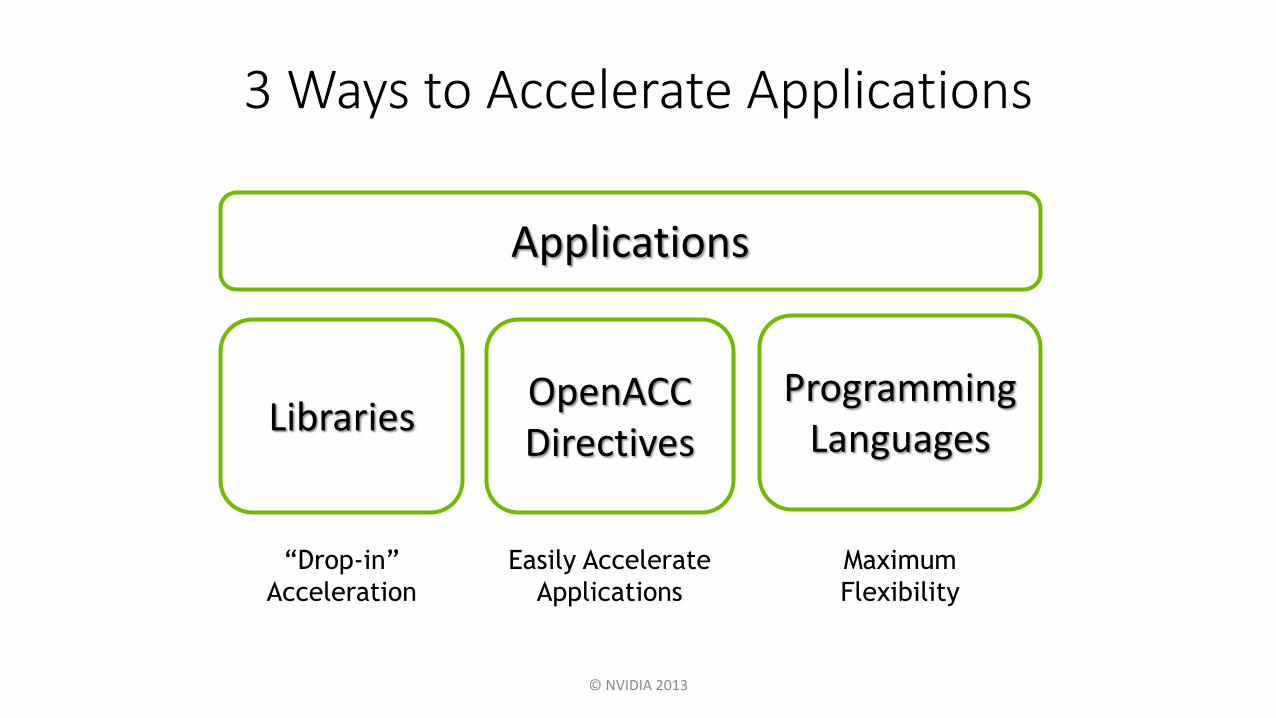
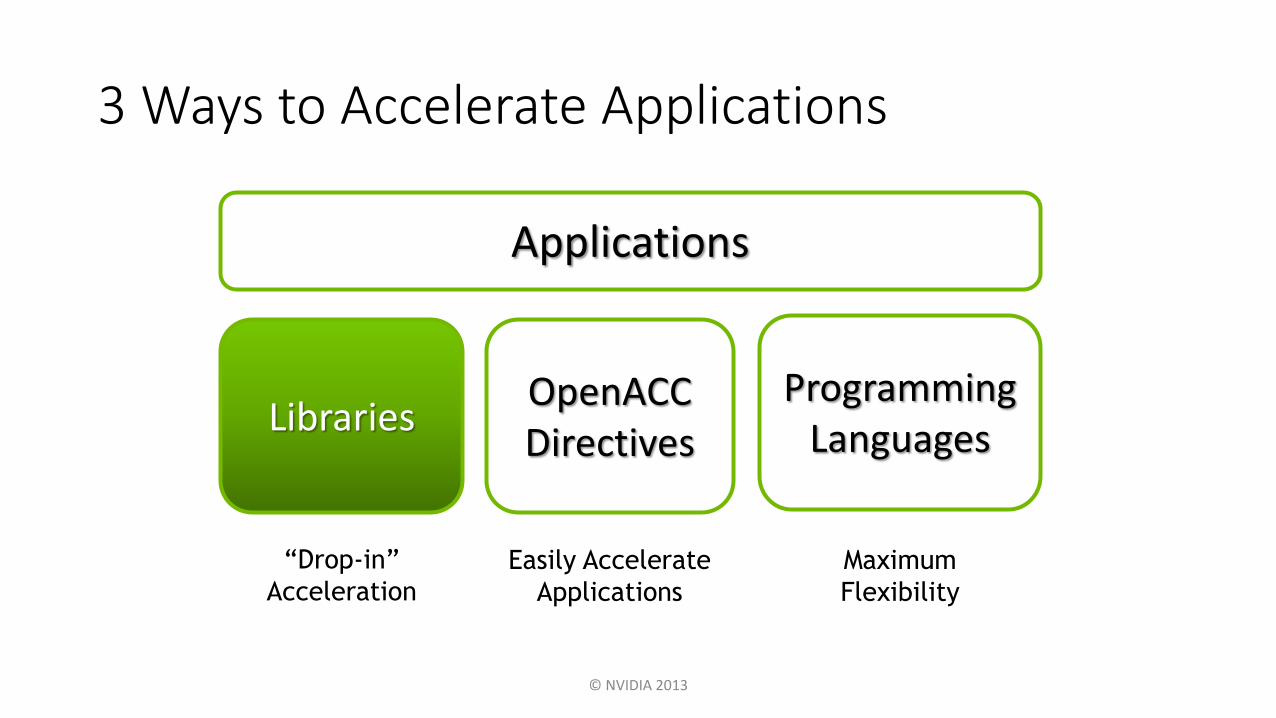
Applications
Libraries
“Drop-in”
Acceleration
Programming Languages
OpenACC Directives
Easily Accelerate
Applications
3 Ways to Accelerate Applications
Maximum
Flexibility
© NVIDIA 2013
3 Ways to Accelerate Applications
Applications
Libraries
“Drop-in”
Acceleration
Programming Languages
OpenACCDirectives
Maximum
Flexibility
Easily Accelerate
Applications
© NVIDIA 2013

Libraries: Easy, High-Quality Acceleration
• Ease of use: Using libraries enables GPU acceleration without in-depth
knowledge of GPU programming
• “Drop-in”: Many GPU-accelerated libraries follow standard APIs, thus
enabling acceleration with minimal code changes
• Quality: Libraries offer high-quality implementations of functions
encountered in a broad range of applications
• Performance: NVIDIA libraries are tuned by experts
© NVIDIA 2013

Some GPU-accelerated Libraries
NVIDIA cuBLAS NVIDIA cuRAND NVIDIA cuSPARSE NVIDIA NPP
Vector SignalImage Processing
GPU AcceleratedLinear Algebra
Matrix Algebra on GPU and Multicore
NVIDIA cuFFT
C++ STL Features for
CUDAIMSL Library
Building-block Algorithms for
CUDAArrayFire Matrix
Computations
Sparse Linear Algebra
© NVIDIA 2013

3 Steps to CUDA-accelerated application
• Step 1: Substitute library calls with equivalent CUDA library calls
saxpy ( … ) cublasSaxpy ( … )
• Step 2: Manage data locality
- with CUDA: cudaMalloc(), cudaMemcpy(), etc.
- with CUBLAS: cublasAlloc(), cublasSetVector(), etc.
• Step 3: Rebuild and link the CUDA-accelerated library
nvcc myobj.o –l cublas
© NVIDIA 2013

Explore the CUDA (Libraries) Ecosystem
• CUDA Tools and Ecosystem described in detail on NVIDIA Developer Zone:developer.nvidia.com/cuda-tools-ecosystem
© NVIDIA 2013
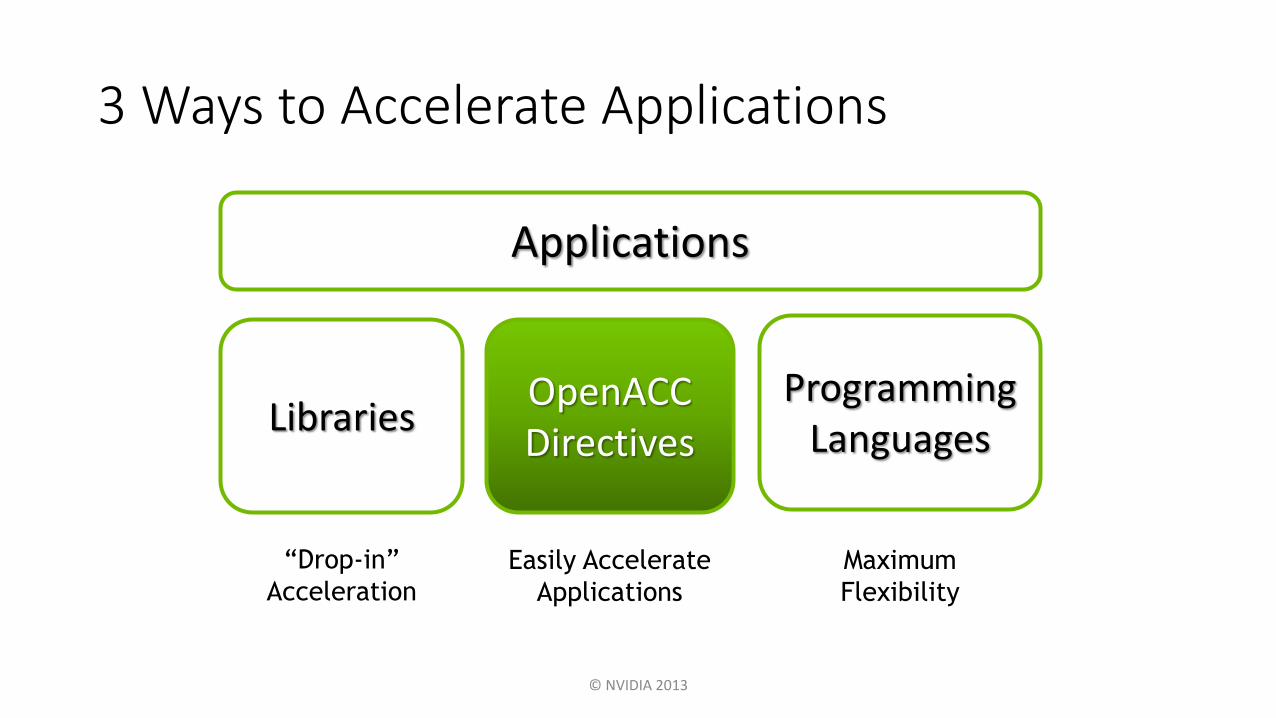
3 Ways to Accelerate Applications
Applications
Libraries
“Drop-in”
Acceleration
Programming Languages
OpenACCDirectives
Maximum
Flexibility
Easily Accelerate
Applications
© NVIDIA 2013
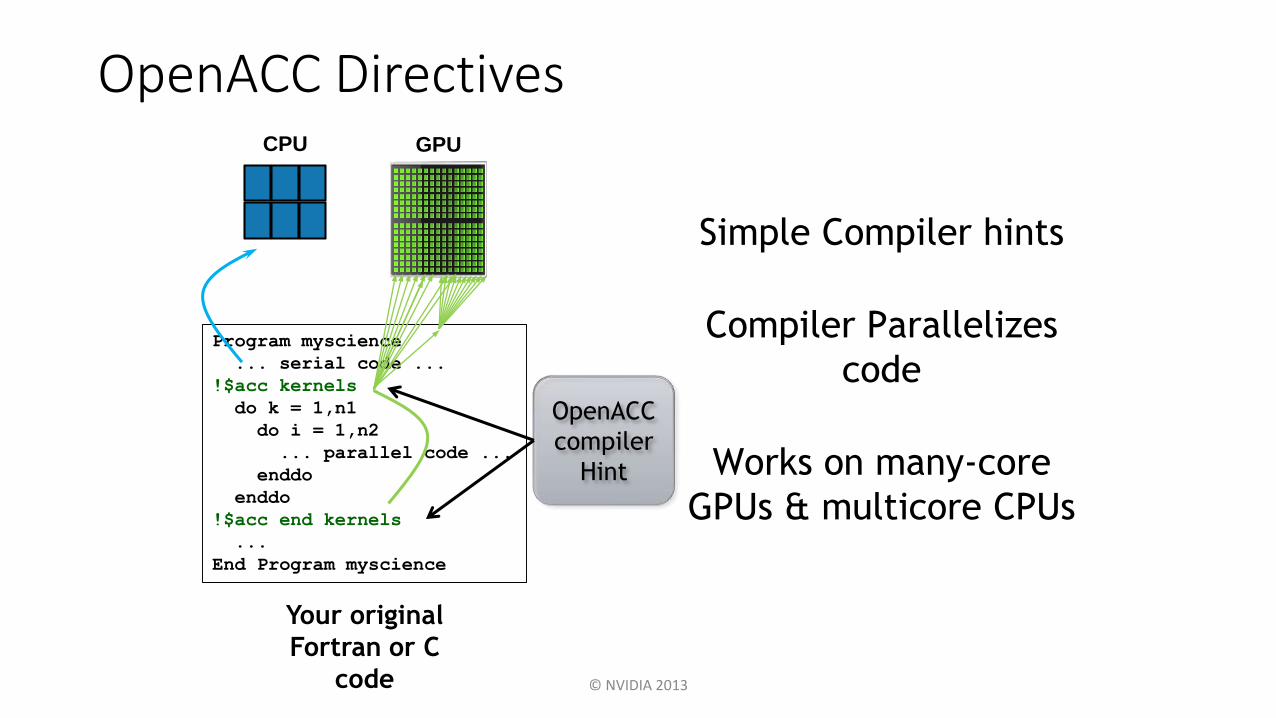
OpenACC Directives
© NVIDIA 2013
Program myscience
... serial code ...
!$acc kernels
do k = 1,n1
do i = 1,n2
... parallel code ...
enddo
enddo
!$acc end kernels
...
End Program myscience
CPU GPU
Your original
Fortran or C
code
Simple Compiler hints
Compiler Parallelizes
code
Works on many-core
GPUs & multicore CPUs
OpenACC
compiler
Hint

• Easy: Directives are the easy path to accelerate compute intensive applications
• Open: OpenACC is an open GPU directives standard, making GPU programming straightforward and portable across parallel and multi-core processors
• Powerful: GPU Directives allow complete access to the massive parallel power of a GPU
OpenACCThe Standard for GPU Directives
© NVIDIA 2013

Real-Time Object Detection
Global Manufacturer of Navigation Systems
Valuation of Stock Portfolios using Monte
Carlo
Global Technology Consulting Company
Interaction of Solvents and Biomolecules
University of Texas at San Antonio
Directives: Easy & Powerful
Optimizing code with directives is quite easy, especially compared to CPU threads or writing CUDA kernels. The most important thing is avoiding restructuring of existing code for production applications. ” -- Developer at the Global Manufacturer of
Navigation Systems
“
5x in 40 Hours 2x in 4 Hours 5x in 8 Hours
© NVIDIA 2013

Start Now with OpenACC Directives
Free trial license to PGI Accelerator
Tools for quick ramp
www.nvidia.com/gpudirectives
Sign up for a free trial of
the directives compiler
now!
© NVIDIA 2013
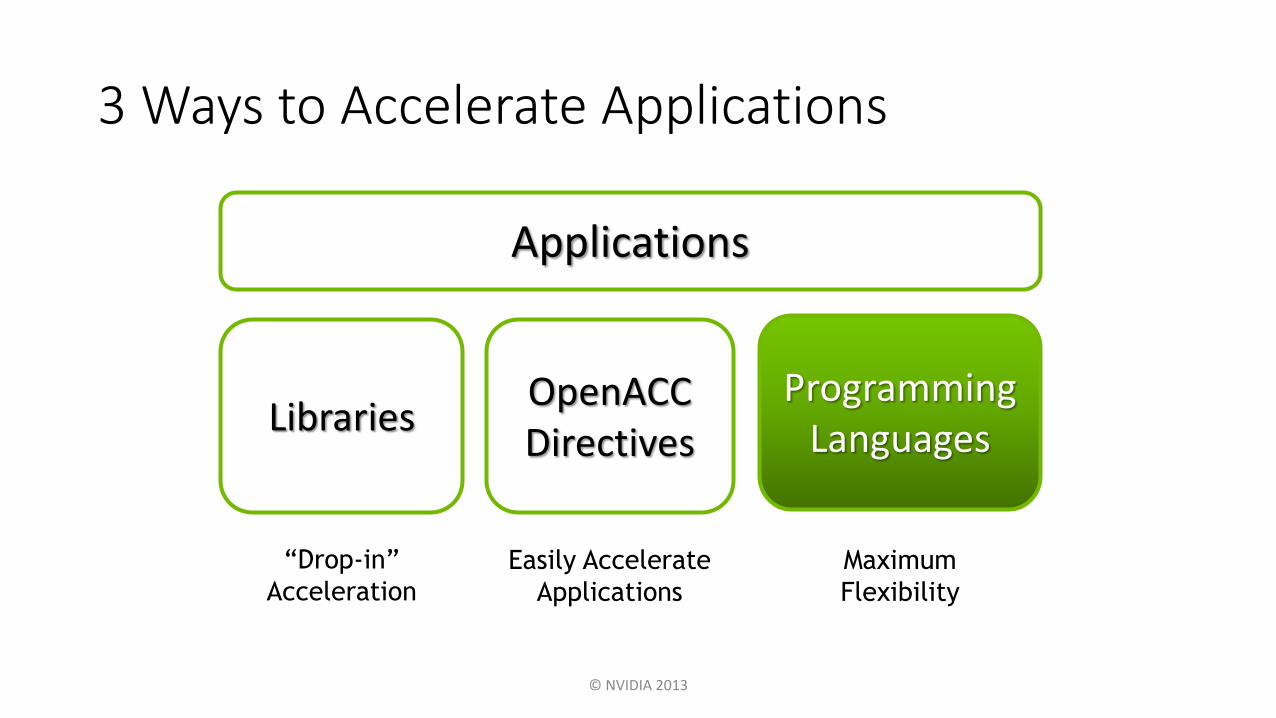
3 Ways to Accelerate Applications
Applications
Libraries
“Drop-in”
Acceleration
Programming Languages
OpenACCDirectives
Maximum
Flexibility
Easily Accelerate
Applications
© NVIDIA 2013

GPU Programming Languages
OpenACC, CUDA FortranFortran
OpenACC, CUDA CC
Thrust, CUDA C++C++
PyCUDA, CopperheadPython
Alea.cuBaseF#
MATLAB, Mathematica, LabVIEWNumerical analytics
© NVIDIA 2013
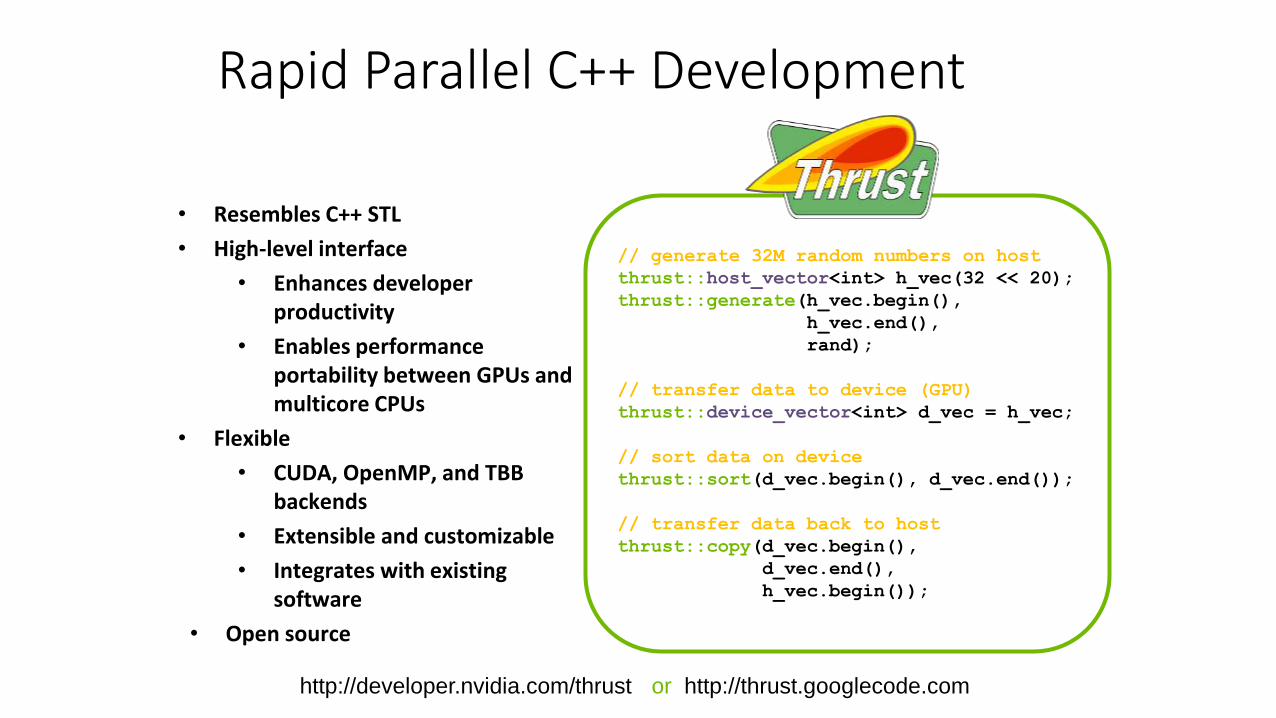
// generate 32M random numbers on host
thrust::host_vector<int> h_vec(32 << 20);
thrust::generate(h_vec.begin(),
h_vec.end(),
rand);
// transfer data to device (GPU)
thrust::device_vector<int> d_vec = h_vec;
// sort data on device
thrust::sort(d_vec.begin(), d_vec.end());
// transfer data back to host
thrust::copy(d_vec.begin(),
d_vec.end(),
h_vec.begin());
Rapid Parallel C++ Development
• Resembles C++ STL
• High-level interface
• Enhances developer productivity
• Enables performance portability between GPUs and multicore CPUs
• Flexible
• CUDA, OpenMP, and TBB backends
• Extensible and customizable
• Integrates with existing software
• Open source
http://developer.nvidia.com/thrust or http://thrust.googlecode.com
MATLAB
http://www.mathworks.com/discovery/
matlab-gpu.html
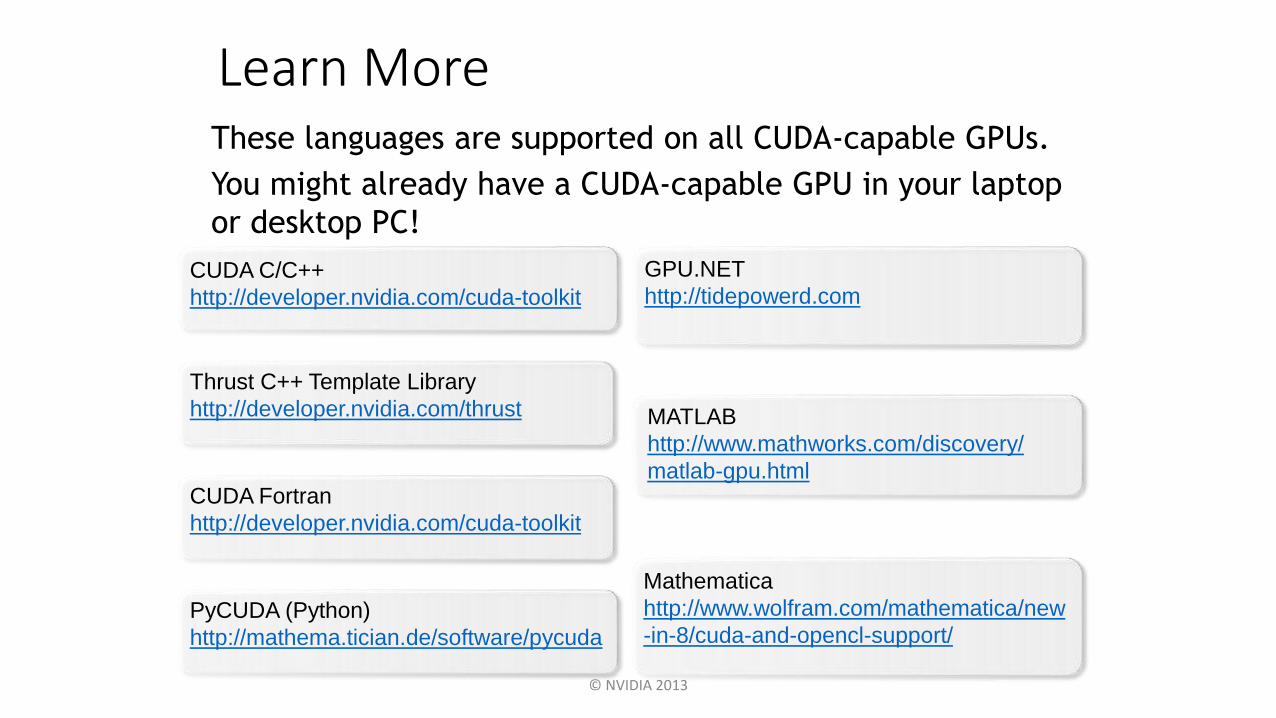
Learn MoreThese languages are supported on all CUDA-capable GPUs.
You might already have a CUDA-capable GPU in your laptop
or desktop PC!
CUDA C/C++
http://developer.nvidia.com/cuda-toolkit
Thrust C++ Template Library
http://developer.nvidia.com/thrust
CUDA Fortran
http://developer.nvidia.com/cuda-toolkit
GPU.NET
http://tidepowerd.com
PyCUDA (Python)
http://mathema.tician.de/software/pycuda
Mathematica
http://www.wolfram.com/mathematica/new
-in-8/cuda-and-opencl-support/
© NVIDIA 2013

Getting Started
© NVIDIA 2013
• Download CUDA Toolkit & SDK: www.nvidia.com/getcuda
• Nsight IDE (Eclipse or Visual Studio): www.nvidia.com/nsight
• Programming Guide/Best Practices:• docs.nvidia.com
• Questions:• NVIDIA Developer forums: devtalk.nvidia.com
• Search or ask on: www.stackoverflow.com/tags/cuda
• General: www.nvidia.com/cudazone
© NVIDIA 2013
https://www.youtube.com/watch?v=IzU4AVcMFys
Intro to CUDA - An introduction, how-to, to NVIDIA's GPU parallel
Mythbusters Demo GPU versus CPU: http://youtu.be/-P28LKWTzrI

Research projects?

Jetson TEGRA TK1Tegra K1 SOC
• Kepler GPU with 192 CUDA cores• 4-Plus-1 quad-core ARM Cortex A15 CPU
• 2 GB x16 memory with 64 bit width
• 16 GB 4.51 eMMC memory
• 1 Half mini-PCIE slot
• 1 Full size SD/MMC connector
• 1 Full-size HDMI port
• 1 USB 2.0 port, micro AB
• 1 USB 3.0 port, A
• 1 RS232 serial port
• 1 ALC5639 Realtek Audio codec with Mic in and Line out
• 1 RTL8111GS Realtek GigE LAN
• 1 SATA data port
• SPI 4MByte boot flash

NVIDIA GTX 750Ti
• Nvidia MAXWELL technology
• Cost – 170 USD
• Only 60 W of power, no dedicated power connections
• 250 MHash/sek
Vs
• Nvidia GTX 780 – 350 MHash/sek + Power cosumption
• Nvidia TESLA K40 – 560 MHash/sek + Power cosumption

Latvian CUDA & parallel programmingecosystemNext meetups, frequencySpeakersTopicsGroup marketing channels