current issues in forensic dna testing issues in forensic dna testing michael coble, phd national...
TRANSCRIPT

Current Issues in
Forensic DNA Testing
Michael Coble, PhD
National Institute of Standards and Technology
Eighth Annual Prescriptions for Criminal Justice Forensics
June 02, 2017

Official Disclaimer
The opinions and assertions contained herein are solely
those of the author and are not to be construed as official or
as views of the U.S. Department of Commerce.
Commercial equipment, instruments, software programs and
materials are identified in order to specify experimental
procedures as completely as possible. In no case does such
identification imply a recommendation or endorsement by the
U.S. Department of Commerce nor does it imply that any of
the materials, instruments, software or equipment identified
are necessarily the best available for the purpose.
Research Funding by the NIST Special Programs Office

Where Do We Come From? What Are We?
Where Are We Going?
http://en.wikipedia.org/wiki/File:Woher_kommen_wir_Wer_sind_wir_Wohin_gehen_wir
.jpg
Paul Gauguin, 1897

How did we get here?(1998 – 2010)

Clayton et al. 1998

Clayton et al. 1998
“In our experience two-person mixtures account for the overwhelming majority of mixtures encountered during casework, but occasionally three-person mixtures are seen. For this reason, the remaining text deals with the interpretation of two-person mixtures and the issue of higher-order mixtures will be discussed in a later section.”
Emphasis added

NIJ Study

“The Quote”

April 14, 2005
“If you show 10 colleagues a mixture, you will
probably end up with 10 different answers.”
- Dr. Peter Gill

ISFG DNA Commission on Mixture Interpretation
Gill et al. (2006) DNA Commission of the International Society of Forensic Genetics: Recommendations on the interpretation of mixtures. Forensic Sci. Int. 160: 90-101

Gill et al. (2006) and SWGDAM (2010)
• Establish Stochastic Thresholds for use in interpreting data.

ISFG Recommendations
on Mixture Interpretation
1. The likelihood ratio (LR) is the preferred statistical method for mixtures over RMNE
2. Scientists should be trained in and use LRs
3. Methods to calculate LRs of mixtures are cited
4. Follow Clayton et al. (1998) guidelines when deducing component genotypes
5. Prosecution determines Hp and defense determines Hd and multiple propositions may be evaluated
6. When minor alleles are the same size as stutters of major alleles, then they are indistinguishable
7. Allele dropout to explain evidence can only be used with low signal data
8. No statistical interpretation should be performed on alleles below threshold
9. Stochastic effects limit usefulness of heterozygote balance and mixture proportion estimates with low level DNA
Gill et al. (2006) DNA Commission of the International Society of Forensic Genetics: Recommendations on the interpretation of mixtures. Forensic Sci. Int. 160: 90-101
http://www.isfg.org/Publication;Gill2006

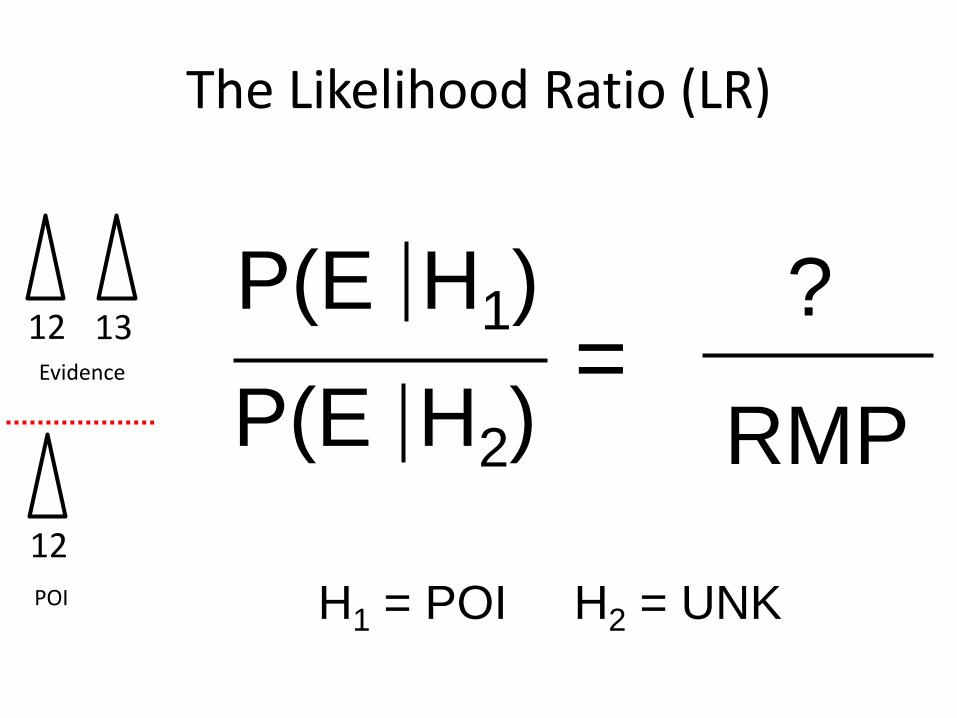
The Likelihood Ratio (LR)
P(E H2)
P(E H1)=
H1 = POI H2 = UNK
RMP
112 13
Evidence
12 13POI

The Likelihood Ratio (LR)
P(E H2)
P(E H1)=
H1 = POI H2 = UNK
RMP
012 13
Evidence
12 14POI
The Likelihood Ratio (LR)
P(E H2)
P(E H1)=
H1 = POI H2 = UNK
RMP
?12 13
Evidence
12
POI

2005 - 2010
• Major shift in the types of casework being submitted to the lab.
• Movement away from high-quantity DNA, 2-person sexual assault evidence to more “touch” DNA samples often with multiple numbers of contributors.

What are we doing? (2013 - 2015)




Forensic Magazine (June 2016)

(July 2016)

April 2017
The Washington Post
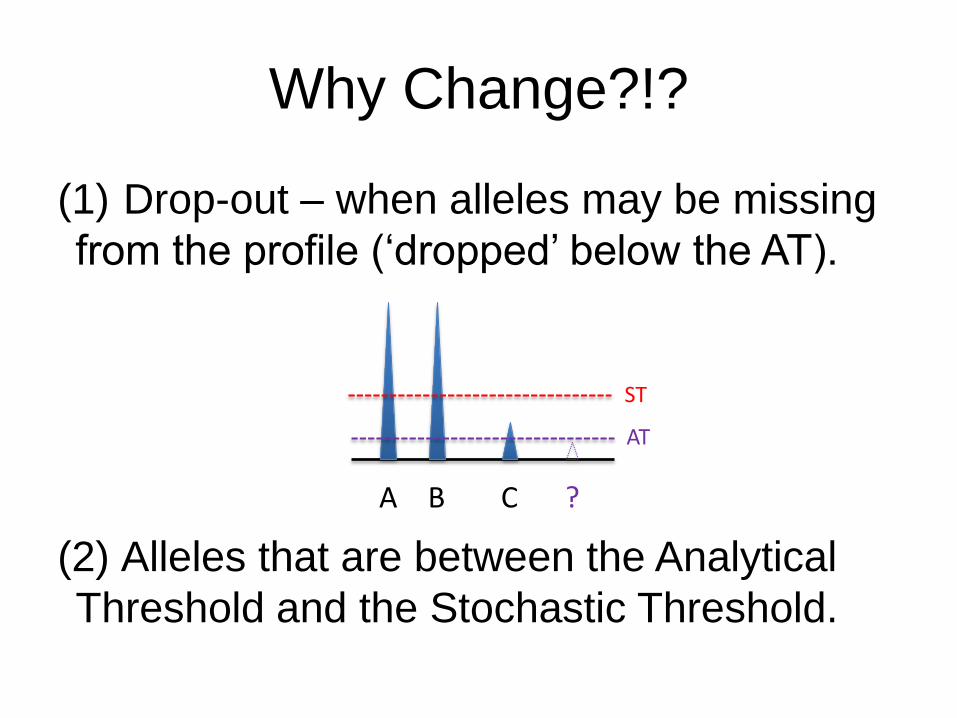
Why Change?!?
(1) Drop-out – when alleles may be missing
from the profile (‘dropped’ below the AT).
(2) Alleles that are between the Analytical
Threshold and the Stochastic Threshold.
A B C
ST
AT
?
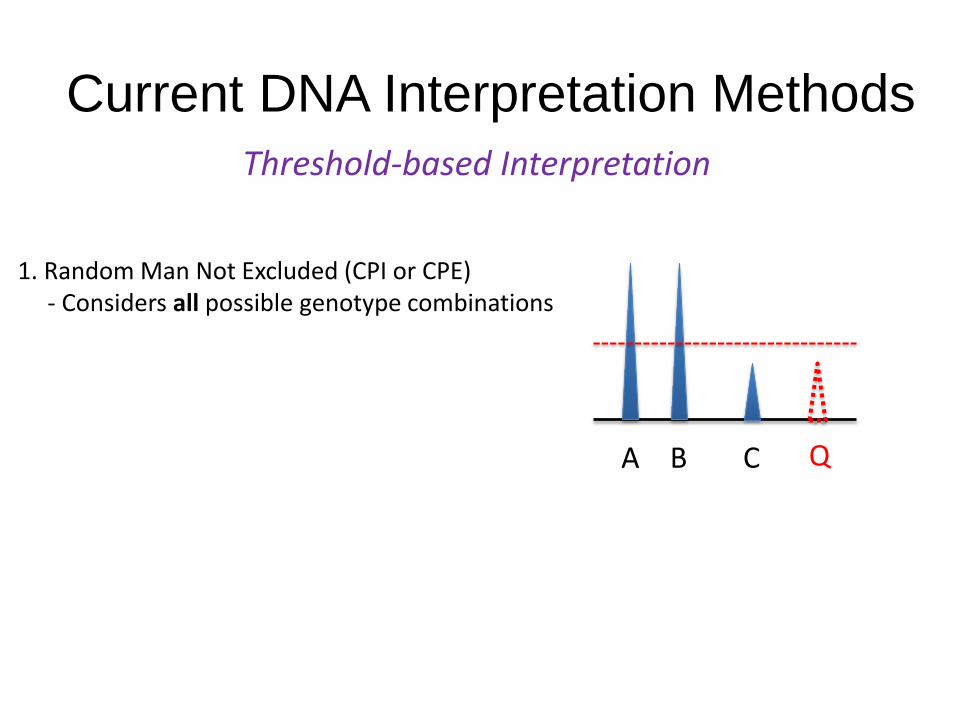
Current DNA Interpretation Methods
Threshold-based Interpretation
A B C
1. Random Man Not Excluded (CPI or CPE)- Considers all possible genotype combinations
Q

Current DNA Interpretation Methods
Threshold-based Interpretation
A B C
1. Random Man Not Excluded (CPI or CPE)- Considers all possible genotype combinations
(fa + fb + fc+ fq)2
Any genotype is possible
Q

Current DNA Interpretation Methods
Threshold-based Interpretation
1. Random Man Not Excluded (CPI or CPE)- Considers all possible genotype combinations
(fa + fb + fc+ fq)2
Any genotype is possible
This locus is no longeravailable for statistics
CPI = 1.0

CPI

CPI

CPI
1 in 24,600

CPI
1 in 24,600
Drop-out is possible over here
NO Drop-out in the blue boxes
Drop-out is possible over here

The Motivation for Change
• STR kits and CE instruments have become more sensitive than in the past.
• Evidence submitted to the lab has moved from predominately high quality/quantity sources to more trace profiles.
• More mixtures and increased stochastic effects

Where are we going? (2015 - )

Probabilistic Genotyping in the U.S.
• 18 laboratories are using STRmix1
– 55 more labs are at various stages of installation, validation, and training.
• At least 7 laboratories are using TrueAllele2
• 1 laboratory is using Lab Retriever
1https://americansecuritytoday.com/fbi-validates-strmix-use-five-person-mixtures-video/2No response from an email request to Cybergenetics on 05/25/17

Probabilistic Interpretation of Alleles
A B C
A B C
Lower Probability of missing alleles
Higher Probability of missing alleles

Breaking the Code
XZ STAVRK HXVR MYAZ OAKZM JKSSO SO MYR OKRR XDP JKSJRK XBMASD SO YAZ TWDHZ MYR JXMBYNSKF BSVRKTRM NYABY NXZ BXKRTRZZTQ OTWDH SVRK MYR AKSD ERPZMRXP KWZMTRP MYR JXTR OXBR SO X QSWDH NSIXD NXZ KXAZRP ORRETQ OKSI MYR JATTSN XDP X OXADM VSABR AIJRKORBMTQ XKMABWTXMRP MYR NSKPZ TRM IR ZRR MYR BYATP XDP PAR MYR ZWKHRSD YXP ERRD ZAMMADH NAMY YAZ OXBR MWKDRP MSNXKPZ MYR OAKR HAVADH MYR JXTIZ SO YAZ YXDPZ X NXKI XDP X KWE XTMRKDXMRTQ XZ MYR QSWDH NSIXD ZJSFR YR KSZR XDP XPVXDBADH MS MYR ERP Z YRXP ZXAP NAMY ISKR FADPDRZZ MYXD IAHYM YXVR ERRD RGJRBMRP SO YAI
Your Mission – Determine the code and solve the piece of classic literature presented here

Breaking the Code
• Option 1 (Brute Force) – try substituting each letter until you break the code…
• 26 permutatons = 26! = 1026 combinations

Breaking the Code
• Option 2 – try some trial and error by substituting each letter two at a time to find some common key words. We will need to determine if the new (proposed) letters are better or worse than what we currently have.
• Markov Chain Monte Carlo with the Metropolis-Hastings algorithm (used by STRmix and TrueAllele)

Markov Chain Monte Carlo
• We need a model!
• Use some reference text (War and Peace) to see how often, for example, the letters (TH) occur together as opposed to (XZ).
• Now determine if allowing a substitution of TH to XZ is better, if so, accept. If not, move on…

Markov Chain Monte Carlo
After 2,000 iterations, the code is broken!

Probabilistic Weights (MIX13 ex.4)
D16S539
[12,12] [11,11] 0.0441
[12,12] [-1,11] 0.0007
[12,12] [11,12] 0.7428
[12,12] [12,12] 0.2123
[12,12] [-1,12] 0.0001

Probabilistic Weights (MIX13 ex.4)D16S539
[12,12] [11,11] 0.0441
[12,12] [-1,11] 0.0007
[12,12] [11,12] 0.7428
[12,12] [12,12] 0.2123
[12,12] [-1,12] 0.0001LR =
0.7428
0.0441 * f 211
+ 0.0007 * 2f11fQ + 0.7428 * 2f11f12 + etc…

Summary
• We are in the midst of a sea change in the forensic DNA community in how we interpret complex DNA profiles.
• This requires a movement away from CPI and RMP to the LR.
• Probabilistic methods of interpretation can make better use of the data compared to binary methods (peaks are included or excluded).
• Forensic Scientists and the Legal community will need to understand these programs and not just rely on a “black box” to spit out numbers!!

Drew

Drew
Probabilistic Modeling: Posterior Odds or Odds from the Posterior?

What is behind the numbers?
Is it a fancy way of saying CPI?
What are these numbers based upon?
How do you explain these concepts to a jury?
What the F*** is a Likelihood Ratio?

Read the report wording carefully.
PM software provides continuous answer to binary problem.
Ensure that jury understands the question presented, and the limitations of the answer.
What the F*** is an Inferred Genotype?

Question as presented in the report is not what the most likely profile is, but rather whether the profile in question is a possibility.
The harder part is dealing with the likelihood ratio numbers. (i.e. how do you get a jury to internalize that a 3000 to one LR is inconclusive.)
What the F*** is an Inferred Genotype?

PM algorithm uses “hundreds of variables” for their calculation.
Always explained in generalities
Requests for the source code may be rebuffed. (“All you need are the validation studies.)
Is it one size fits all software?
How are these numbers calculated?

How does the software measure these variables?
Look to the source code?
Validations?
Data as interpreted by PM software and not by DNA analyzer
What does a PM Algorithm do?

Is the algorithm correctly modeling all the possible variables that could affect how the peaks appear in the results?
• Drop out
• Stutter
• Allele sharing
• Drop in
What does a PM Algorithm do?

Drew

Drew

Gun Sample Results, pt. 1
Major: X,X 16,17 12,16 11,13 15,15 10,12 11,20Minor: X,Y 15,? 14,15 12,? 12,13 ?,? ?,?
Client: X,Y 15,16 13,14 12,14 11,13 11, 12 8,13

Gun Sample Results, pt. 2
Major: 11,11 11,21 18,23 11,12 10,10 or 10,14Minor: 10,? 15,16,17 17,? ?,? 14,? or ?,?
Client: 10,11 16,17 20,21 7,8 10,10

Gun Sample Results, pt. 3
Major: 8,9.3 16,18 31.2,33.2 9,11 9,12 8,9 -Minor: 9,? 15,? ?,? ?,? ?,? ?,? ?
Client: 9,9 15,18 29, 32.2 8,11 12,12 8,11 12

Gun Sample Results, pt.4
Client: 12,12 18,25 11,12.2 21,21 15,17
Major: 14,15 19,? 13,14 22,23 11,17 Minor: 12,? ?,? ?,? ?,? ?,?


2nd Contributor Inferred Genotypes?
Ask for the inferred genotype tables.Places the “match” between evidence in person in perspective.
locus allele 1 allele 2 probabilityCSF1PO 10 11 0.3931
11 11 0.132710 12 0.0876
7 10 0.06547 11 0.06448 10 0.05648 11 0.052
10 10 0.049111 12 0.041112 12 0.0156
7 12 0.01338 12 0.01097 8 0.00817 7 0.0014
2nd Contributor?

locus allele 1 allele 2 probability
D10S1248 13 14 0.615812 13 0.090112 14 0.063813 15 0.057614 15 0.05513 13 0.045914 14 0.038412 15 0.010615 15 0.00311 14 0.002714 16 0.002511 13 0.002513 16 0.001812 12 0.0016
2nd Contributor?

locus allele 1 allele 2 probability
D12S391 17 18 0.260118 18 0.24618 19 0.131618 23 0.062617 19 0.038818 20 0.022517 23 0.019618 25 0.016318 21 0.014417 17 0.013619 23 0.011417 20 0.009517 21 0.009218 22 0.008915 18 0.007
2nd Contributor?

locus allele 1 allele 2 probability
D13S317 11 12 0.570810 11 0.196911 11 0.13299 11 0.029112 12 0.021711 14 0.012510 12 0.01139 12 0.006712 14 0.00398 11 0.00279 14 0.001311 13 0.0013
2nd Contributor?

locus allele 1 allele 2 probabilityD16S539 9 10 0.2858
10 11 0.1807
10 10 0.0814
10 13 0.0718
9 12 0.0625
10 12 0.0567
9 13 0.0562
9 11 0.0553
12 13 0.0384
11 12 0.0368
11 13 0.0336
9 9 0.0126
12 12 0.0103
11 11 0.0091
2nd Contributor?

locus allele 1 allele 2 probabilityD18S51 15 16 0.1998
15 17 0.127216 17 0.096614 15 0.060914 16 0.051714 17 0.043415 18 0.039616 18 0.032915 20 0.032617 18 0.028316 20 0.027113 15 0.025215 15 0.022413 16 0.020814 18 0.020713 17 0.019317 20 0.017116 16 0.015613 14 0.015114 20 0.0112
2nd Contributor?

locus allele 1 allele 2 probabilityD19S433 (1) 13 14 0.2023
12 14 0.1963
14 14 0.1648
12 13 0.1523
13 13 0.0852
12.2 14 0.0445
12 12.2 0.0338
12.2 13 0.0277
14 15 0.0163
13 15 0.0088
14 16 0.0059
12 15 0.0054
13 16 0.0048
12 12 0.0042
2nd Contributor?

locus allele 1 allele 2 probabilityD19S433 (2)
14 15.2 0.002913.2 14 0.0024
13 15.2 0.002314 16.2 0.002314 14.2 0.001512 15.2 0.001511 14 0.001415 16.2 0.001313 14.2 0.001312 14.2 0.001215 15 0.000914 18.2 0.000812 16 0.0007
2nd Contributor?
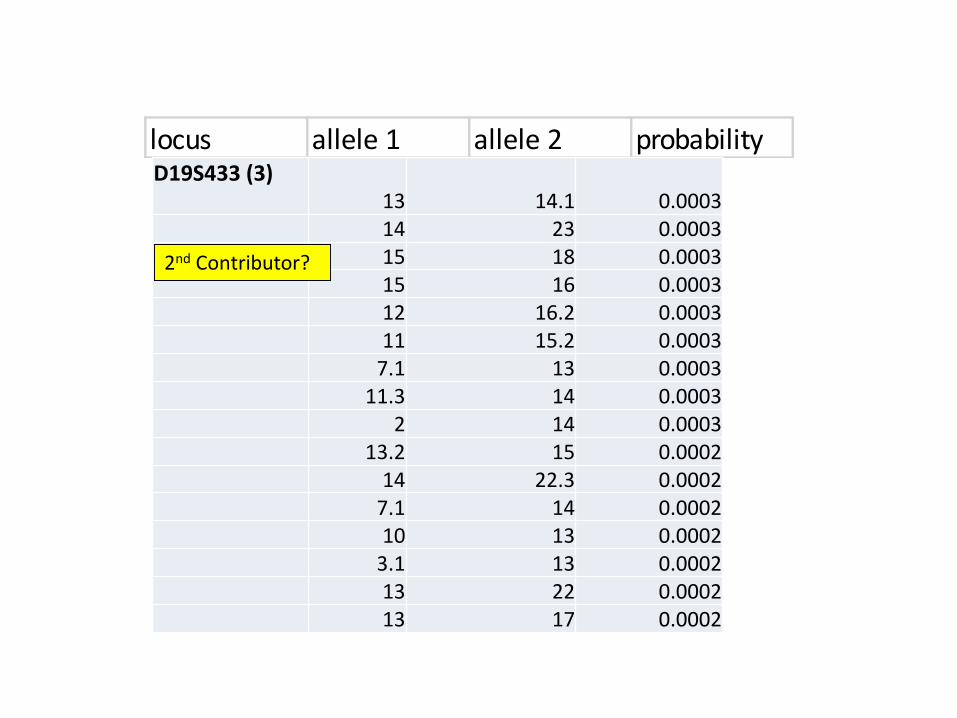
locus allele 1 allele 2 probabilityD19S433 (3)
13 14.1 0.000314 23 0.000315 18 0.000315 16 0.000312 16.2 0.000311 15.2 0.0003
7.1 13 0.000311.3 14 0.0003
2 14 0.000313.2 15 0.0002
14 22.3 0.00027.1 14 0.000210 13 0.0002
3.1 13 0.000213 22 0.000213 17 0.0002
2nd Contributor?

locus allele 1 allele 2 probability1 13 0.00011 12 0.0001
13 20.1 0.000112 17 0.000111 14.2 0.000110 14 0.0001
7 14 0.00016.3 14 0.00016.1 14 0.0001
3 14 0.00019.2 13 0.00015.1 13 0.00016.2 12 0.0001
5 12 0.00014 12 0.0001
13 20.3 0.000112.2 19.2 0.0001
8 14 0.0001
D19S433 (4)
61 Genotype probabilities:None match the Defendant
2nd Contributor?

locus allele 1 allele 2 probability
D2S1338 (1) 17 18 0.4664
17 17 0.142917 19 0.128217 22 0.079317 23 0.063817 21 0.025818 19 0.012519 22 0.009219 23 0.00818 22 0.006319 21 0.005519 19 0.004922 23 0.004518 23 0.004118 18 0.003418 21 0.003221 23 0.0031
2nd Contributor?

locus allele 1 allele 2 probability
D2S1338 (2) 20 23 0.003121 22 0.002517 20 0.002117 25 0.001923 23 0.001817 24 0.001520 21 0.001417 26 0.001118 20 0.000921 21 0.000816 17 0.000720 22 0.000621 25 0.000619 25 0.000616 24 0.0006
2nd Contributor?

Parting Thoughts
Never take report at face value
Understand the question presented
Get the discovery
Don’t be intimidated by the science
Always keep juror’s perspective in mind

Rock

Probabilistic Genotyping

FL Murder Case Reaffirms
Reliability of STRmix™
State of Florida v. Dwayne Cummings (12th
Judicial Circuit in and for Manatee County, FL,
Case No. 2016-CF-239) – in which the
defendant was charged with two counts of first
degree murder, as well as one count each of
armed kidnapping and possession of a firearm
by a convicted felon – also affirms that going
forward, Florida will use the Daubert Standard


Early Cases
Homicides
Rapes
Discrete stains located
Simple interpretation
Mixture- victim/suspect

Touch DNA
1997 article
Awareness
Previously untyped items
Not LCN. Low template
Property crimes/possession/use

Touch DNA
Touch DNA is a forensic method for
analysing DNA left at the scene of a
crime. It is called "touch DNA" because
it only requires very small samples, for
example from the skin cells left on an
object after it has been touched or
casually handled.

The touch DNA method—named for the
fact that it analyzes skin cells left behind
when assailants touch victims, weapons
or something else at a crime scene—
has been around for the last five years.

Processing?
Large area
No discreet stain
Entire item- handgun
Create mixtures from discrete stains
Difficult interpretation

Technique?
LCN/low template more
complicated
Test methods more sensitive
BOTH

Review Responsibilities?
Pending cases
Convictions
All over the board
Something
Nothing

Texas Forensic Commission
Problems identified
Joint undertaking
Truth seeking
Tendency for lab to report inconclusive or
greatly weaken conclusion
Notorious case
– Strong- weak/LR strong
PG to the rescue


Complex Mixture
Strong LR for one of 5 persons
Others unidentified
Not likely to be charged without
corroboration
Reasonable doubt without

Familial Searching

Kinship Review
Parent and Child Share 1/2 of their DNA
(barring a mutation)
SiblingsShare 1/2 of their DNA
(on average)

Kinship Review
Parent and Child Share 1/2 of their DNA(barring a mutation)
genotype genotypeCSF1PO 10, 13 10, 10D18S51 17, 19 15, 19
D19S433 15, 15.2 13, 15.2
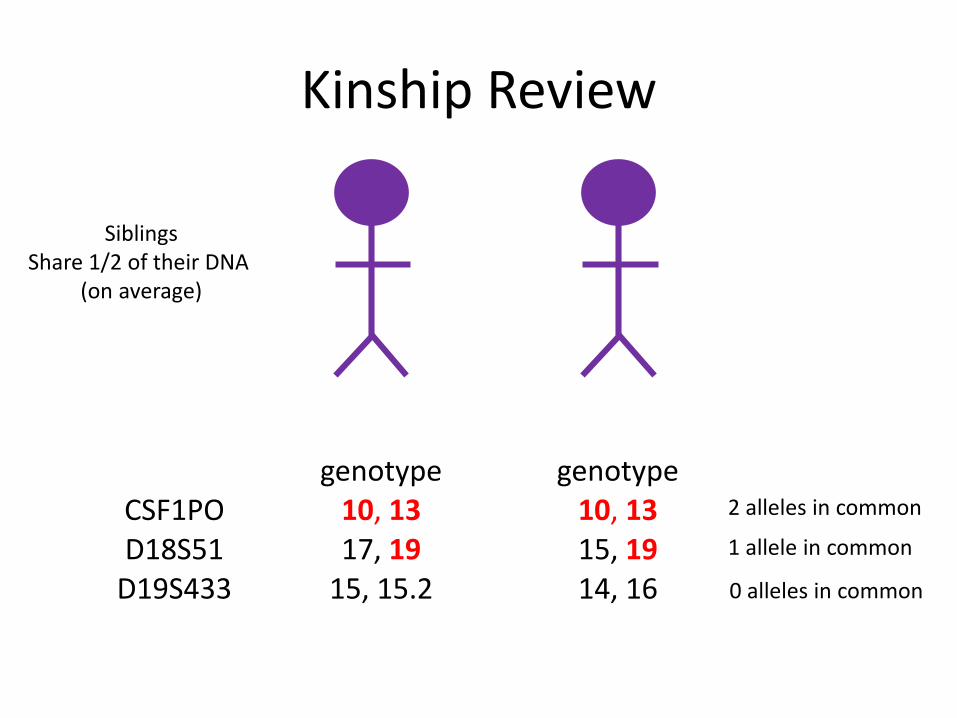
Kinship Review
genotype genotypeCSF1PO 10, 13 10, 13D18S51 17, 19 15, 19
D19S433 15, 15.2 14, 16
SiblingsShare 1/2 of their DNA
(on average)
2 alleles in common
1 allele in common
0 alleles in common

The Kinship Index (KI) is a Likelihood Ratio
P(E H2)
P(E H1)=
Probability of genotypes if individuals are related as claimed
Probability of genotypes if individuals are unrelated

Familial Searching
Parent/Child?
Expect LR = 0 (if unrelated)
Expect LR >> 1 (to support relationship)

Additional Loci
Data from Kristen O’Connor

Data from Kristen O’Connor
False Negatives with Full Siblings

Ways to decrease false positives
• Use more autosomal STR loci (kits now have 20+ loci)
• Use Y-STRs to eliminate false positives – new Y-STR kits are even more highly discriminating than those in the past (Yfiler).
• “2-step” approach – autosomal STR followed by Y-STR testing.

Conclusions
• Cal-DOJ study found that 89-97% of the authentic fathers and 59-74% of the authentic full-siblings detected through their approach.
• This provides confidence that their process will more likely than not detect a true relative should a paternally-related full-sibling, parent, or child be present in the database.
• Similar results to other studies.
Myers et al. 2011, FSI-Genetics

Drew

Familial Searching Haiku
Behold, this profileKind of matches the sample.
Test the relatives!

Familial Searches
Maryland explicitly bans familial searches.Came about when Maryland expanded DNA databases to include arrestees.
Would have a disparate impact on minorities, many of whom had not (or were even related to anyone who had) committed a crime

Familial Searches
Creates a new class of people.People who are in a suspect class through no fault of their own.
Subject to being investigated.
Subject to being interrogated.
Subject to having their DNA searched.

Familial Searches
How effective are the Searches?
As of 2012, CA’s familial searching failed to find a viable suspect 9 times out of 10.

Familial Searches
What regulations are necessary when:1. Searching the database2. Investigating the case

Familial Searches
What regulations are necessary when:1. Searching the databaseCase Requirements
Serious casesExhaustionSample RequirementsSingle sourceDirect connection to crime

Familial Searches
2. Investigating the lead:Can this information serve as reasonable suspicion?Can it be used in an application for court order?Can this information be used in a warrant?What should be told to a judge?If they do get a sample, what can they do with it?

Familial Searches
What is the role of Judicial Oversight?1. Is judicial authority needed for
the database search?
2. How involved are they in overseeing each step of the investigation?

Familial Searches
Need to be thoughtful and deliberate about this.
Assume that once this power is granted, the use will expand and never contract.

Rock

Familial DNA Searching

They then went through “exhaustive protocols”
to request a familial DNA search, a
controversial method that looks for partial
matches that indicate the relative of a
suspect.
When Borjas was seen spitting on the sidewalk,
the opportunity for a DNA sample struck.
What was collected turned out to be an exact
match in Lozano’s and Guzman’s killings,
police said.
How a rare DNA match cracked open a
cold case of two young women dumped
on L.A. freeways


Familial DNA searching, as practiced in
the US, is a 2 step process.
Step one is a search/ranking process that
produces a candidate list of persons in
the database who are likely to be a
close relative of the person whose DNA
is at the crime scene. These lists vary
due to the size of the offender
database- typically from 75-150
persons.

Step two uses lineage testing to
confirm/refute whether the offender is in
fact a close relative.
These two processes are designed to
only provide investigative leads pointing
to true close relatives. The majority of
FS investigations have produced no
investigative leads.

Experience has shown that virtually every
investigative lead to date has led
directly to the actual offender. Typically
the relative of the offender was
extremely high on the candidate list. No
false leads have been produced. No
samples were collected from family
members who were not the source of
the crime scene DNA.

Grim Sleeper #1 example:
Candidate list
No concordant Y
No investigative lead
Son not in database

Occasionally 2 concordant lineage testing
Y-STR results have produced two
investigative leads that were in fact full
siblings.

Most of the critics say there are false
investigative leads with no proof.
FS is designed not to produce false
leads, in practice produces no false
leads.

Among the 10 states using familial DNA
searching, each state’s protocol is
fundamentally the same. A few different
search/rank softwares are being used.

Anecdotal success rates demonstrate
that FS has been as efficient as CODIS,
using CODIS success metrics.
Using 25% projection- 54,000= over
13,000 crimes might be solved in NY.

There is nothing about FS that
necessarily implicates anyone’s 4th
Amendment rights. Whatever 4th
Amendment rights existed before FS,
they still exist today. Legal challenges
are available to question law
enforcement’s actual use of the
investigative leads, as they always have
been.

Grim Sleeper #2 example:
search rank
one Y concordant- #3 on list
father-son
son's age
dates of crime
surveil father
abandoned dna
arrest when typing done
Motion to suppress the abandoned DNA
sample collection. Denied

Legal Challenges
A handful of prosecutions based on FS
investigative leads have resulted in
convictions. There have been no legal
challenges to FS itself during any of
those prosecutions. The reason is that
there is no cognizable legal issue upon
which a challenge to FS can be
mounted.

Legal Authority
Of the ten states using FS, none has
sought legislative change of their
existing database law. They considered
FS to be a permissive use within the
statutory purpose of their law and self
regulated in order to implement FS.

Opponents urge that FS must be
legislatively authorized. They also
assert vague 4th and 14th Amendment
issues inherent in the process. The two
positions are incompatible. Legislation
cannot cure 4th and 14th Amendment
defects.

Race
The FS process itself is race blind. Any
investigative lead is based on genetic
and familial relatedness, not on race.
FS identifies the relative because of
genetic relatedness, not because of
race.

Thank You!
Matthew GametteKenneth Melson
Carol Rose
Rock HarmonAndrew Northrup
Past and present funding agencies:NIJ – Interagency Agreement and the NIST Special Programs Office