dan mazur, mcgill hpc [email protected] … outline - morning login and setup review of cuda-c...
TRANSCRIPT


3
Outline - Morning
✔ Login and Setup● Review of CUDA-C and dot product● Warps
– Memory coalescing
– Thread divergence
● Profiling and the Nvidia visual profiler (nvvp)● Profiling and optimizing dot product
– shared memory
– shared memory bank conflicts
– instruction overhead / loop unrolling

4
Scheduling GPU Jobs
● Workshop jobs run on a single CPU core + single GPU device
● Submission to Guillimin is same as a serial job, except to the lmgpu queue
● $ msub -q lmgpu ./subJob.sh● Example: subTrivial.sh

5
Exercise 1: CUDA pre-requisites
#include <stdio.h>
__global__ void foo(){}
int main(){ foo<<<1,1>>>(); printf("CUDA error: %s\n", cudaGetErrorString(cudaGetLastError())); return 0;}
$ nvcc trivial.cu -o trivial$ msub -q lmgpu ./subTrivial.sh trivial.out: CUDA error: no error
Compile and submit trivial.cu:

6
Simple CUDA Program
Allocate Memory on Device
Copy data from host to device
Perform parallel computations on data
Copy results from device to host
Serial CPU code
Free device memory

7
Simple CUDA Kernel
Perform parallel computations on data
kernel (instructions)
data
po
ol
Thread 0
Thread 1
Thread 2
Thread 3
“Single Instruction, Multiple Data” (SIMD) or “Single Instruction, Multiple Thread” (SIMT) model

8
Simple CUDA Program
Allocate Memory on Device
Copy data from host to device
Perform parallel computations on data
Copy results from device to host
cudaMalloc()
cudaMemcpy()
MyKernel<<<nB, nT>>>()
cudaMemcpy()
Free device memory cudaFree()

9
Dot Product Kernel
xxxxxxxxx
a b cache cache cache
Compute products in parallel
Compute the sum using “parallel reduction”
Store theproducts
note: parallel reduction requires some cooperationbetween threads
cache

10
Exercise 2: Dot Product Kernel
● Take a few minutes to look through dotprod_soln.cu– Implementation of dot product
● Understand how it works– We will be looking at several dot product
implementations soon
● Ask questions

11
Review from 'intro' workshop
● We learned how to:– Use OpenACC pragmas to easily accelerate loops
– Allocate and free device memory
– Copy data between host and device
– Implement programs with SIMT parallelism
– Identify and fix errors based on CUDA error messages
– use shared memory for cooperation between threads
– Compile CUDA programs using nvcc
– Identify whether an algorithm is a good candidate for ‘easy’ performance gains on a GPU.

12
Efficient GPU Applications
● Today: Not just getting the GPU to work, but getting it to work efficiently● Maximizing parallelism
– Algorithm design
– Execution configuration
– Concurrent execution
● Optimize memory usage– Minimize transfers to/from device
– Minimize global memory usage
– Avoid uncoalesced access and shared memory bank conflicts
● Maximize instruction throughput● We will touch on many ideas, but we only have time to discuss a few of
these in depth

13
Warps

14
Warps
The quadruple forkcollects all the meatballswith one stab(transaction)

15
Warps
This configurationmust be performed with multiple transactions.
Cannot collect the meatballs as quickly.

16
Warps
● The quadruple fork is designed to pick up four adjacent meatballs (advanced users: 16 adjacent peas)
● For other uses, it may require multiple transactions and will not perform optimally
● Similarly, CUDA threads don't operate independently, they are in units called warps that operate in lock-step
● A warp is 32 threads
17
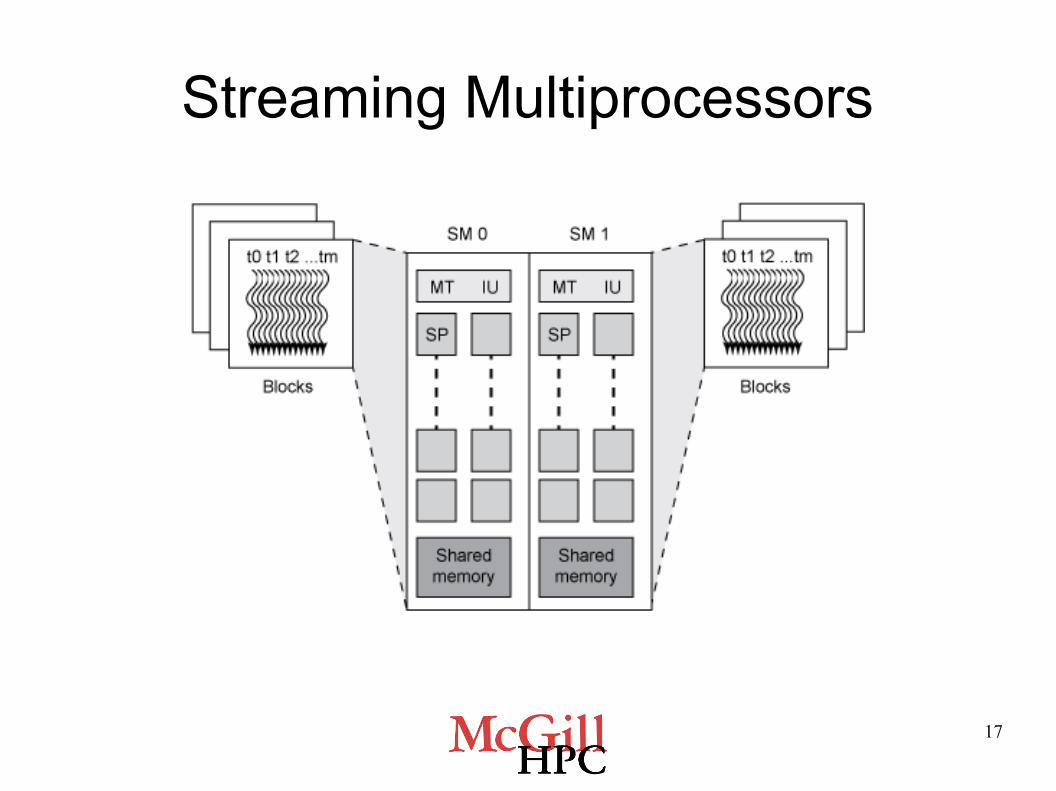
Streaming Multiprocessors

18
Why are warps important?
● Since threads in a warp act in lock-step...– When one thread accesses memory, they all
access memory
– If 2 threads in a warp diverge at an if statement, every thread evaluates both paths
● They activate and deactivate to achieve the desired effects

19
Memory Coalescing
● Each half-warp (16 threads) accesses global memory at the same time
● The warp is designed to access adjacent 4-byte words (such as floats) in global memory with a single 'coalesced' transaction
● Gotcha: non-coalesced memory reads are slow● Compute-capability dependant. See CUDA best
practices guide (http://docs.nvidia.com)

20
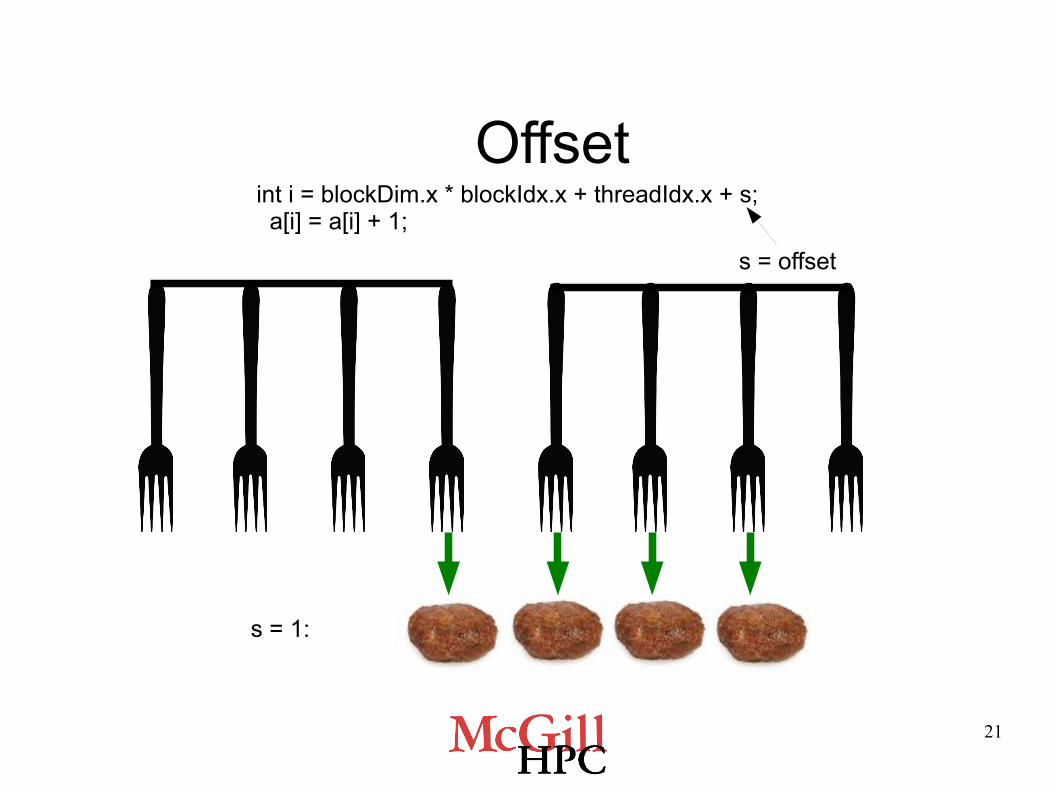
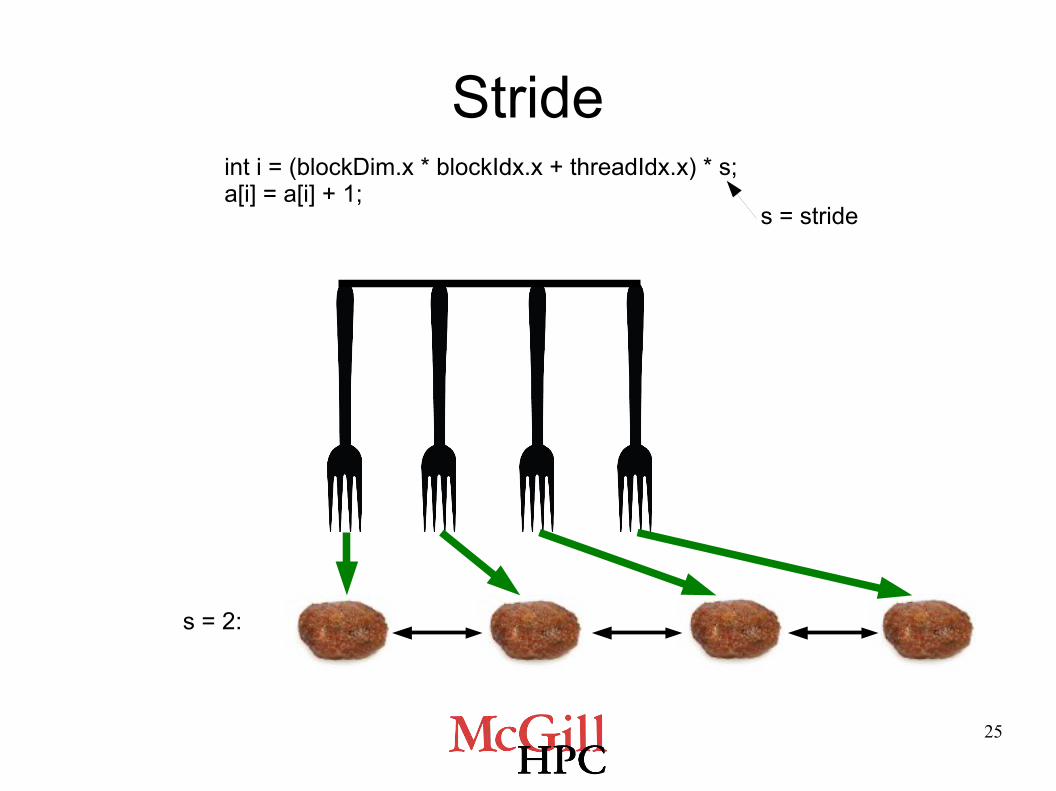
Memory Coalescing: Stride and Offset
● Offset memory access:
● Strided memory access:
int i = blockDim.x * blockIdx.x + threadIdx.x + s; a[i] = a[i] + 1;
int i = (blockDim.x * blockIdx.x + threadIdx.x) * s; a[i] = a[i] + 1;
s = offset
s = stride
21
Offsetint i = blockDim.x * blockIdx.x + threadIdx.x + s; a[i] = a[i] + 1;
s = offset
s = 1:

22
Which figure is a likely plot for memory bandwidth versus offset, s?
int i = blockDim.x * blockIdx.x + threadIdx.x + s; a[i] = a[i] + 1;
s = offset
E) More than oneof these
A) B)
C)D)
23
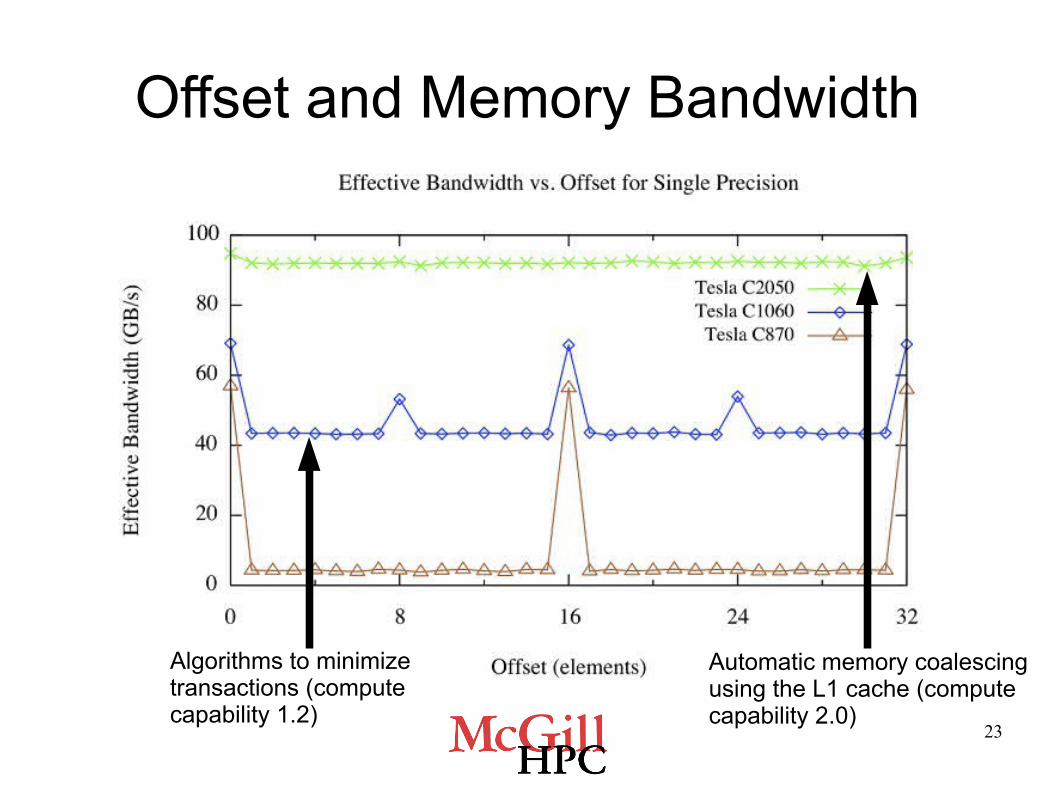
Offset and Memory Bandwidth
Automatic memory coalescingusing the L1 cache (computecapability 2.0)
Algorithms to minimizetransactions (computecapability 1.2)

24
Warps
Modern (compute capability>= 2.x) gpus will automaticallycoalesce permuted accesseslike this one using L1 cache
25
Stride int i = (blockDim.x * blockIdx.x + threadIdx.x) * s; a[i] = a[i] + 1;
s = stride
s = 2:

26
Which figure is a likely plot for memory bandwidth versus stride, s?
s = stride
E) More than oneof these
A) B)
C)D)
int i = (blockDim.x * blockIdx.x + threadIdx.x) * s; a[i] = a[i] + 1;
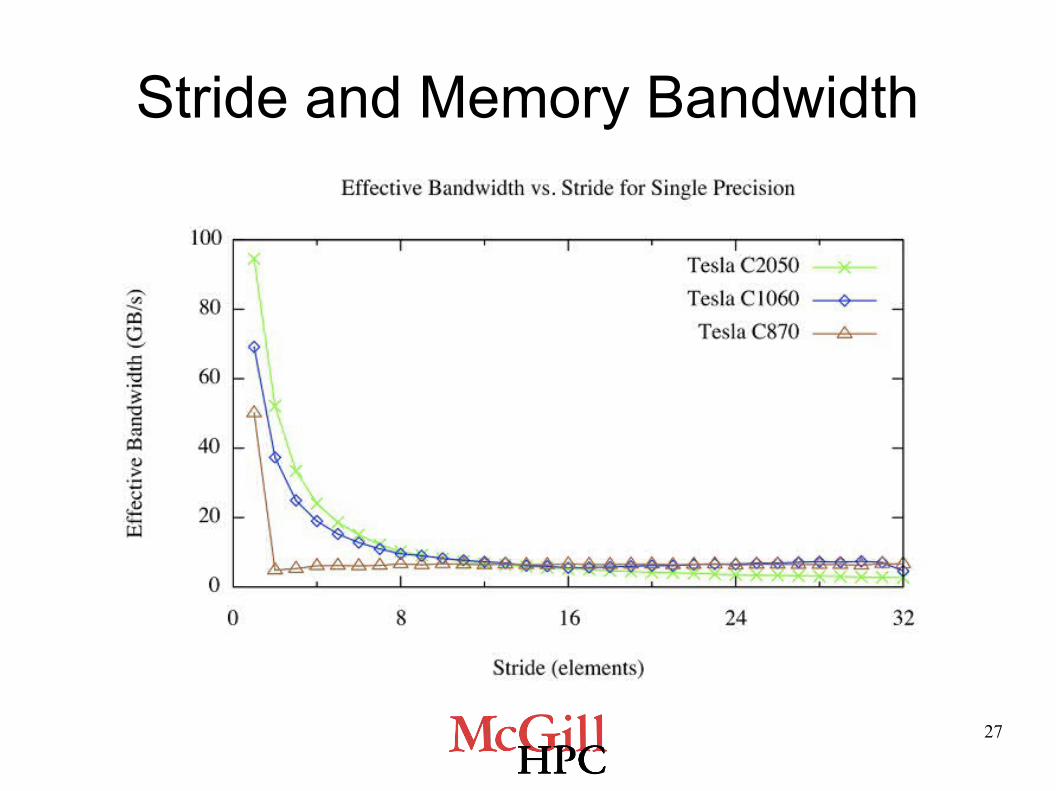
27
Stride and Memory Bandwidth

28
Memory Coalescing
● Whenever possible:– Read/Write global memory
● Only once● Without stride or offset
– Use shared memory (150x faster than global)● To coalesce global memory loads/stores ● To arrange data in useful patterns● To avoid multiple global memory accesses

29
Thread Diverging
● Entire warp executes every branch path taken by any thread in serial
● Threads can diverge at any...– if, switch, do, for, while
● Gotcha: Diverging threads within a warp are slow

30
Exercise 3: Thread Diverging
● Create a simple kernel where threads within a warp diverge between two or more paths
● Each path should do some work● Compare to same amount of work done
without thread divergence● Use diverge.cu as a template

31
CUDA Profiling
● Profiling– Provides timing information for many aspects of your application
● host/device functions● kernels● memory copies and allocations
– Provides information about hardware utilization● occupancy (how full are the multiprocessors)● kernel concurrency● Memory and instruction throughput
● Profiling Tools– Command-line profiler ($ export CUDA_PROFILE=1)
– nvprof (command-line tool, new for CUDA Toolkit 5.0)
– Nvidia Visual Profiler ($ nvvp)
– gprof (standard UNIX profiling tool, useful for host code) ● compile with '$ nvcc -profile'

32
Exercise 4: Profiling Dot Product
● dotprod_slow.cu is a dot product code with inefficient memory access without shared memory caching
● Compile this code– $ nvcc -o dotprod_slow dotprod_slow.cu
● Launch nvvp and profile the executable– $ nvvp &
Unix tip: & runs programs in the 'background' andreturns control to the command prompt

33
new session

34
Browse for file
35

36
Execution Timeline
Analysis/Details/Console/Settings
Kernel Properties

37
Exercise 4: Profiling Dot Product
● Record on a sheet of paper:● What is the duration of the kernel, 'dot'?● What is the global load efficiency for 'dot'?● What is the DRAM utilization for 'dot'?

38
Exercise 5: Optimizing Dot Product
● Optimization 1: use shared memory to cache the products before the parallel reduction
● Compile an executable from dotprod_shared.cu and launch it in a new session in nvvp
● What effect does shared memory have on the kernel duration and the global load efficiency?
● What effect does shared memory have on the DRAM utilization (GB/s)?
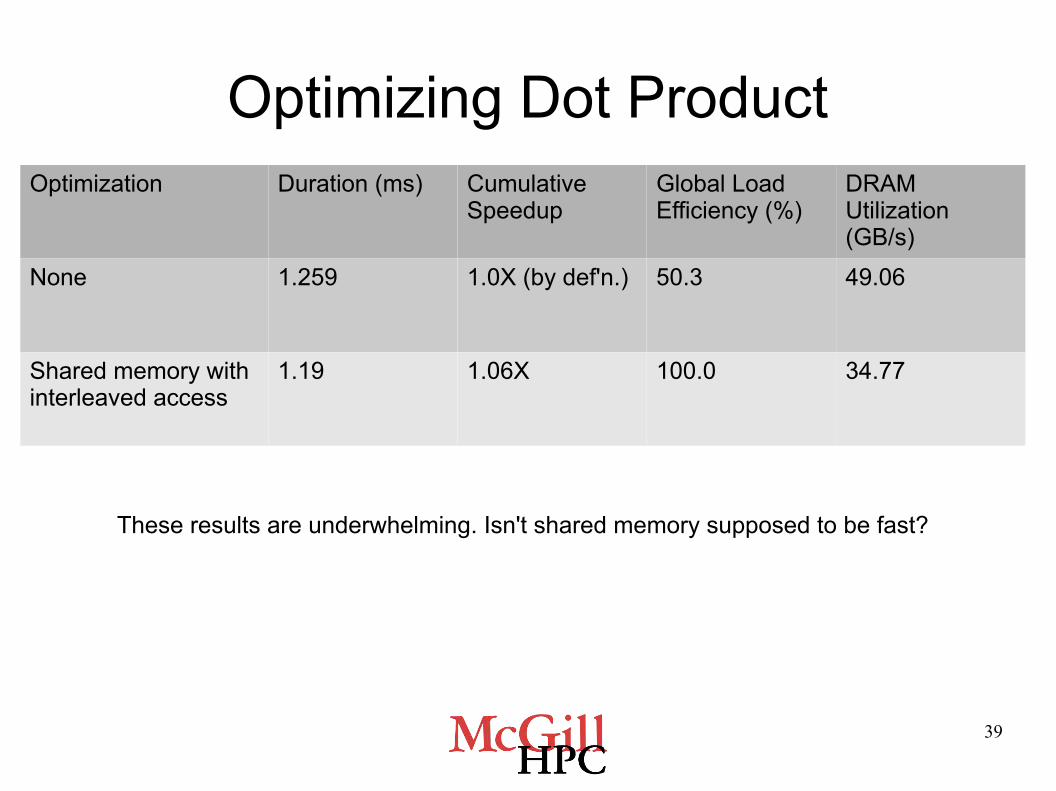
39
Optimizing Dot ProductOptimization Duration (ms) Cumulative
SpeedupGlobal Load Efficiency (%)
DRAM Utilization (GB/s)
None 1.259 1.0X (by def'n.) 50.3 49.06
Shared memory with interleaved access
1.19 1.06X 100.0 34.77
These results are underwhelming. Isn't shared memory supposed to be fast?

40
Shared Memory Banks
● Shared memory is stored in banks● Successive 32-bit or 64-bit words are stored in
successive banks– cudaDeviceGetSharedMemConfig()
– cudaDeviceSetSharedMemConfig()
● If two threads from a warp access different addresses within a bank, the requests are serialized– shared memory bank conflict
● There are 32 banks, data is distributed cyclicly

41
Sequential vs. Interleaved Access
● Interleaved Access● for(unsigned int s=1; s < blockDim.x; s *= 2)
{
if (cacheIndex % (2*s) == 0)
cache[cacheIndex] +=
cache[cacheIndex + s];
__syncthreads();
}
● Sequential Access● int s = blockDim.x/2;
while (s != 0) {
if (cacheIndex < i)
cache[cacheIndex] +=
cache[cacheIndex + s];
__syncthreads();
s /= 2;
}
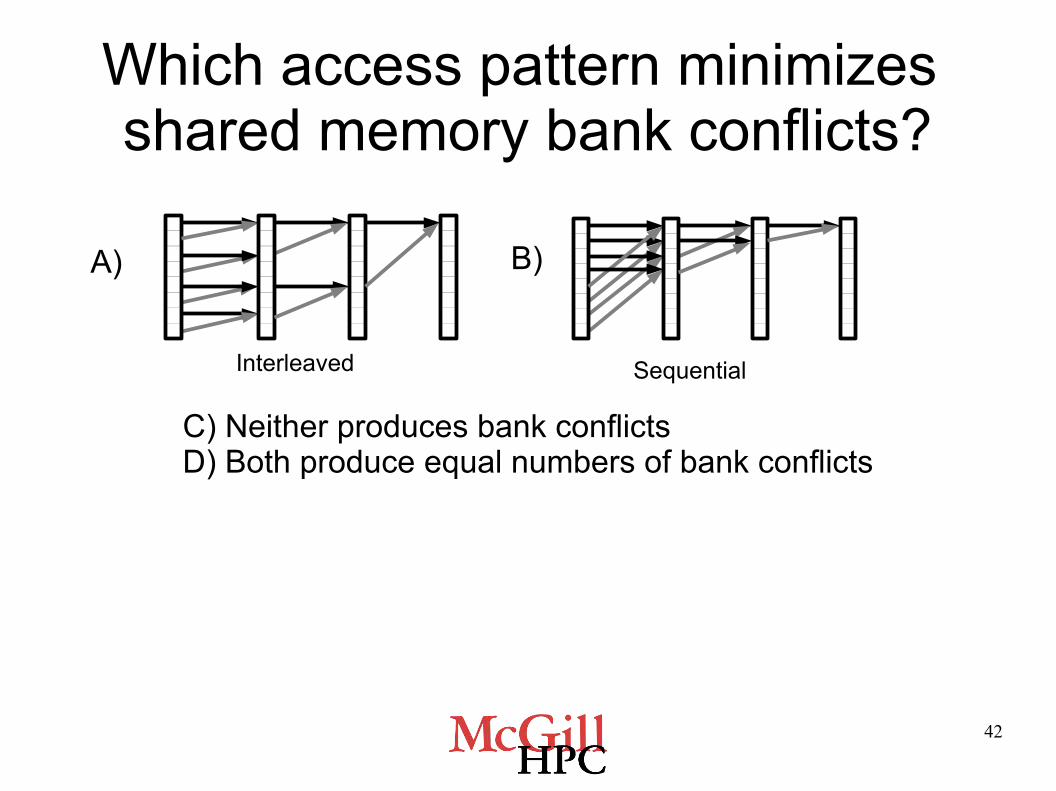
42
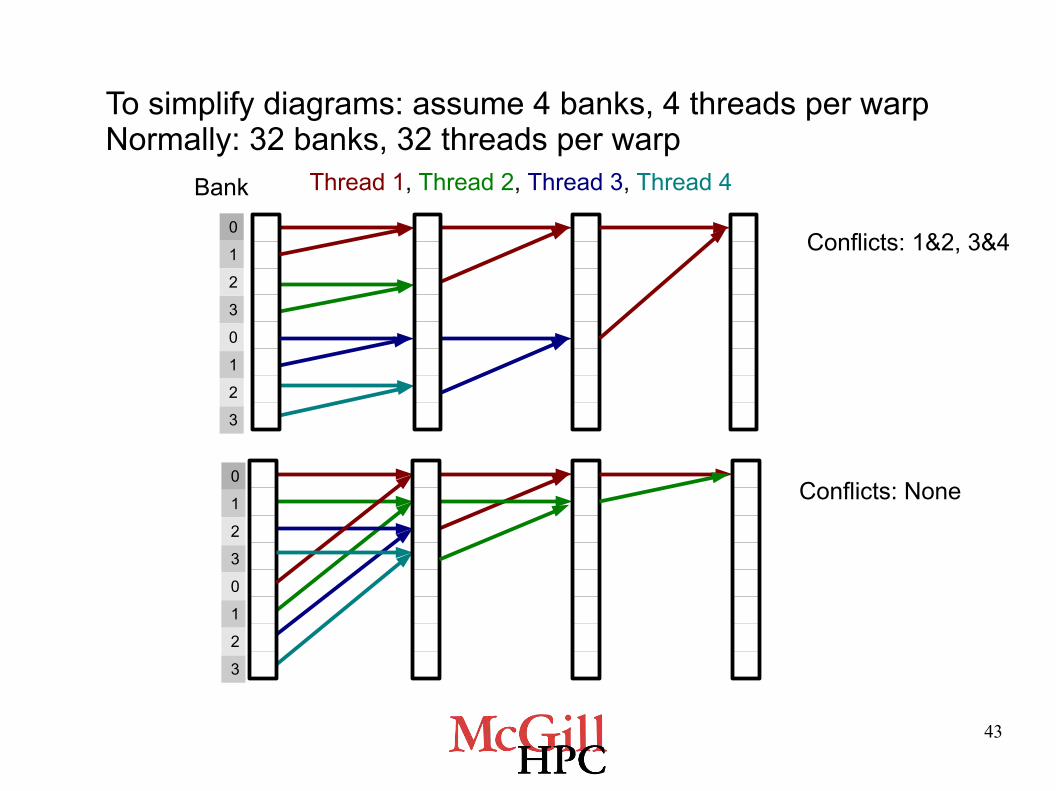
Which access pattern minimizes shared memory bank conflicts?
A) B)
C) Neither produces bank conflictsD) Both produce equal numbers of bank conflicts
Interleaved Sequential
43
Bank
0
1
2
3
0
1
2
3
0
1
2
3
0
1
2
3
To simplify diagrams: assume 4 banks, 4 threads per warpNormally: 32 banks, 32 threads per warp
Thread 1, Thread 2, Thread 3, Thread 4
Conflicts: 1&2, 3&4
Conflicts: None

44
Bank Conflictscache cache cache
Interleavedaccess, bank conflicts
Sequentialaccess,no bank conflicts

45
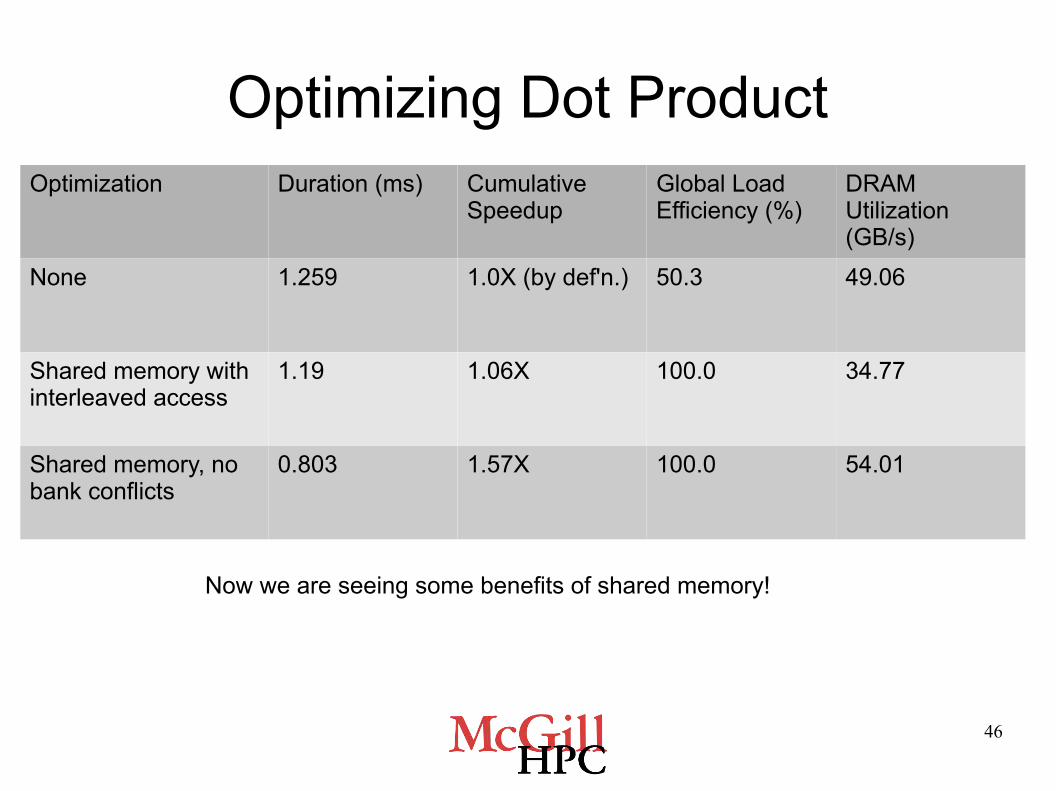
Exercise 6: Optimizing Dot Product
● Optimization 2: Use sequential memory access to avoid shared memory bank conflicts
● Compile an executable from dotprod_seq.cu and launch it in a new session in nvvp
● What effect does shared memory have on the kernel duration and the DRAM utilization?
46
Optimizing Dot ProductOptimization Duration (ms) Cumulative
SpeedupGlobal Load Efficiency (%)
DRAM Utilization (GB/s)
None 1.259 1.0X (by def'n.) 50.3 49.06
Shared memory with interleaved access
1.19 1.06X 100.0 34.77
Shared memory, no bank conflicts
0.803 1.57X 100.0 54.01
Now we are seeing some benefits of shared memory!

47
Instruction Overhead
● My card advertises a maximum memory bandwidth of 150GB/s, but we are still not achieving this
● One consideration is avoiding unnecessary instruction overhead– Loops are instructions that aren't loads, stores, or
our core calculation
● Consider unrolling the loop for the last warp to save instruction overhead

48
Loop Unrolling● Rolled ● Unrolled
int i = blockDim.x/2; while (i != 0) { if (cacheIndex < i) cache[cacheIndex] += cache[cacheIndex + i]; __syncthreads(); i /= 2; }
int i = blockDim.x/2; while (i > 32) { if (cacheIndex < i) cache[cacheIndex] += cache[cacheIndex + i]; __syncthreads(); i /= 2; } if(cacheIndex < 32) { cache[cacheIndex] += cache[cacheIndex + 32]; __syncthreads(); cache[cacheIndex] += cache[cacheIndex + 16]; __syncthreads(); cache[cacheIndex] += cache[cacheIndex + 8]; __syncthreads(); cache[cacheIndex] += cache[cacheIndex + 4]; __syncthreads(); cache[cacheIndex] += cache[cacheIndex + 2]; __syncthreads(); cache[cacheIndex] += cache[cacheIndex + 1]; __syncthreads(); }

49
Exercise 7: Optimizing Dot Product
● Optimization 3: Unroll the reduction loop for the final warp to save instruction overhead for all warps
● Compile an executable from dotprod_unrolled.cu and launch it in a new session in nvvp
● What effect does shared memory have on the kernel duration and the DRAM utilization?

50
Optimizing Dot ProductOptimization Duration (ms) Cumulative
SpeedupGlobal Load Efficiency (%)
DRAM Utilization (GB/s)
None 1.259 1.0X (by def'n.) 50.3 49.06
Shared memory with interleaved access
1.19 1.06X 100.0 34.77
Shared memory, no bank conflicts
0.803 1.57X 100.0 54.01
Shared memory, no bank conflicts, unrolled last warp
0.573 2.20X 100.0 80.82

51
Optimizing Dot Product
● There are still significant optimizations we could make to this kernel
● Discussion: what else could we try?● Homework Challenge: Try to write a faster dot
product kernel

52
Review
● Briefly reviewed basic CUDA-C, dot product● Learned that threads operate in groups called warps
– Allow for coalesced global memory reads– Thread divergence slows down kernel
● Learned how to profile CUDA applications● Showed how optimizations can make a factor of 2.2 difference to dot
product speed– Used shared memory to coalesce and minimize global memory reads– Re-designed access patterns to avoid shared memory bank conflicts
– Eliminated instruction overhead with loop unrolling

53
Outline - Afternoon
● Finite differencing overview● Computing the Laplacian with CUDA
– Parallelism– Constant memory– Memory access issues– Block-Stride loops

54
Finite-Differencing
● A common task is to approximate derivatives– important step in solving P.D.E's
● Basic idea: Using Taylor expansions, we find approximations for derivatives in terms of a weighted sum of the function evaluated at several points

55
Laplace Equation
● Steady-state heat equation● Electric or gravitational potential in a vacuum● Steady, incompressible, irrotational fluid flow● “Solutions to Laplace's equation are...as boring
as they could possibly be,” and still satisfy the boundary conditions
-David J. Griffiths

56
Laplace Equation
● Example: Determine the steady-state heat distribution in a thin square metal plate with dimensions 1m x 1m. Two adjacent boundaries are held at 0 degrees C, and the heat on the other boundaries increases linearly from 0 degrees C at one corner to 100 degrees C at the other. (Burden and Faires, 7th ed.)
● Solution:

57
Laplace Equation
● Example: Determine the steady-state heat distribution in a thin square metal plate with dimensions 1m x 1m. Two adjacent boundaries are held at 0 degrees C, and the heat on the other boundaries increases linearly from 0 degrees C at one corner to 100 degrees C at the other. (Burden and Faires, 7th ed.)
● Solution:

58
Finite Difference Stencil
● We will use this 7-point stencil for approximating a second derivative (without proof)
Each value of phi is used 7 times per dimension

59
Simplifications
● Focus on derivatives, not solving– To solve PDEs with finite differencing, must also set up and
solve a matrix equation
– We will assume the exact solution everywhere
● Focus on internal points, not boundaries– This problem: must use forward/backward-difference
stencils near the boundaries
– Other problems: may have periodic boundary conditions
– We will assume the exact derivatives near boundaries

60
Exercise 8: Plan Laplacian Kernel
● In groups, plan a CUDA kernel (or CUDA kernels) for computing the Laplacian of a function on a 256x256 grid
● Use pseudocode on a piece of paper● No more than 15 minutes
– Don't attempt complete solution, just identify the basic steps and strategies

61
Parallelization Strategy● Keeping in mind parallelism and memory access, which of these is
the 'best' strategy for computing the laplacian on a 256x256 grid?– A) Use a single block of 256x256 threads, cache entire grid in shared
memory
– B) Use smaller square blocks (e.g. 16x16), cache the grid portion plus 'halo points' (22x22) in shared memory
– C) Use long blocks with separate kernels for each direction (e.g. 256 x1 and 1x256), cache entire rows or columns in shared memory
– D) Use separate kernels and separate block sizes for each direction (explain), cache only needed points in shared memory

62
Parallelization Strategy● Keeping in mind parallelism and memory access, which of these is the
'best' strategy for computing the laplacian on a 256x256 grid?– A) Use a single block of 256x256 threads, cache entire grid in shared memory
● Violates max threads per block and shared memory size for all existing GPUs
– B) Use smaller square blocks (e.g. 16x16), cache the grid portion plus 'halo points' (22x22) in shared memory
● redundant global memory loads, possible coalescing problems (32x32 is better, but too large for some older GPUs)
– C) Use long blocks with separate kernels for each direction (e.g. 256x1 and 1x256), cache entire rows or columns in shared memory
● Good strategy for x-direction, bad for y-direction (why? we will discuss this soon)
– D) Use separate kernels and separate block sizes for each direction (explain), cache only needed points in shared memory
● Because memory access along different directions is asymmetric, we require an asymmetric strategy (more on this soon)

63
Which memory type is the best choice for the stencil constants?
Option Description Bandwidth Accessible to...
Notes example
A Global Memory
Slow, high latency
All threads same as cudaMalloc(), ~5.4Gb
__device__ float data[N];
B Constant Memory
Slow, cached
All Threads read-only __constant__ float data[N];
C Shared Memory
150x faster than global
Threads in same block
Lifetime of block, 50kb/block
__shared__ float data[N];
D Register Memory
Even faster, no latency
Local thread only
very limited resource, lifetime of thread
float data[N];
Want to store the four stencil constants to be accessed by each thread.

64
Which memory type is the best choice for the stencil constants?
Option Description Explanation
A Global Memory
Not cached - Separate global memory access for each thread
B Constant Memory
Cached - Can be read once and used many times by different threads
C Shared Memory
Lifetime of block, scope of block - Must be rewritten to memory for each block
D Register Memory
Local to thread - Fast, but many redundant copies of same data in very limited memory space
Want to store the four stencil constants to be accessed by each thread.

65
Constant Memory
● Data is cached on-chip and can be broadcast across a warp– Use when all threads read the same address
● Declared with global scope● Read/Write from host code● Read only from device code● Initialized with cudaMemcpyToSymbol()

66
Constant Memory
#include<stdio.h>__constant__ float pi_c;
__global__ void piKernel() { printf("%f\n", pi_c);}
int main( void ) { const float pi_h = 3.14; cudaMemcpyToSymbol(pi_c, &pi_h, sizeof(float), 0, cudaMemcpyHostToDevice ); piKernel<<<1,1>>>(); cudaDeviceReset(); return 0;}
Declare with global scope
Copy symbol from host to device
Can be used in kernel using the global declaration

67
Exercise 9: Implement x-derivative kernel
● Using laplace.cu as a template, – declare constant memory symbols for the coefficients
– copy host code coefficients to the constant memory symbols
– Finish implementing the d2phi_dx2() kernel by caching data in the shared memory variable phi_s, computing the approximate derivative and storing the results in d2phi
● If you are very experienced with CUDA, consider trying laplace_med.cu or laplace_adv.cu for an added challenge.

68
y-derivative
● The y-derivative is trickier. Why?

69
y-derivative
● The y-derivative is trickier. Why?● Naively, global memory access would have a
stride of the number of x positions– Badly uncoalesced
– Using the x-derivative kernel algorithm is an order of magnitude slower for the y-derivative
● Discussion: How can we compute y-derivatives using coalesced global memory loads?

70
0 1 2 3 4 5 6 7
x-positions
y-positions
Threads
Strided memory access => uncoalescedstride = grid size in x-direction

71
y-derivative
● One idea:– Wider, shorter blocks
– Each thread computes derivative at more than one point● Successive threads compute successive x-positions
– Coalesced memory loads– For perfect coalescing, block width = warp size
● Each thread loops over several y-positions
– Same threads per block, fewer blocks● Will we maintain parallelism?● In 3D problem, there are plenty of blocks (e.g. 256X)● In 2D problem, we might compromise between occupancy and memory
coalescing

72
0 1 2 3 4 5 6 7
Loop overseveraly-positions
x-positions
y-positions
Threads
Coalesced memory loads

73
Block-Stride Loop
● Block-stride and grid-stride loops are common CUDA practices
● Scales to problems larger than block or grid size
● Will work even for <<<1,1>>>● Portability
for (int sj = threadIdx.y; sj < my; sj += blockDim.y) { int globalIdx = sj * mx + i; d2phi[globalIdx] = ...;}

74
Exercise 10: Implement y-derivative kernel
● Continuing work with your modified laplace.cu, – Finish implementing the d2phi_dy2() kernel by
caching data in the shared memory variable phi_s, computing the approximate derivatives in a loop and storing the results in d2phi
– What block size (yTileSize) produces the fastest results?
● Small yTileSize => less coalescing● Large yTileSize => less parallelism

75
Review
● Reviewed the finite-differencing approach to approximating a differential operator
● Asymmetric memory access in x- and y-directions implies different strategies are needed for different directions– Differently shaped shared memory tiles ensure coalesced global
memory access
● Learned to use constant memory to store coefficients needed by every thread
● Learned that block-stride and grid-stride loops are commonly useful in CUDA applications

76
Keep Learning...
● Documentation:– http://docs.nvidia.com
● Tutorials:– http://www.drdobbs.com/parallel/cuda-supercomputing-for-the-masses-part/207200659
– http://developer.nvidia.com/cuda/cuda-education-training
● Examples:– http://developer.nvidia.com/cuda/cuda-downloads
● Courses:– http://code.google.com/p/stanford-cs193g-sp2010/
● Questions:– http://stackoverflow.com
– https://forums.geforce.com/

77
What Questions Do You Have?

78
Bonus Topics
● Debugging with cuda-gdb and cuda-memcheck
● Built-in vector types● Multi-GPU● OpenCL for CUDA developers

79
Debugging in CUDA
● Debugging poses a special problem because:– Massive parallelism
– Device memory inaccessible to host
– printf output buffered and copied to host
● Solution: cuda-gdb– Set breakpoints
– Focus on specific threads
– print variable values from device memory
● Also available: Emulation mode (nvcc -deviceemu)

80
Debugging with cuda-gdb
● cuda-gdb is a command line CUDA debugger– gdb + cuda-specific features
● Compiling CUDA code for debugging– $ module add CUDA-Toolkit
– $ nvcc -g -G myProgram.cu -o myProgram
● Launching a debugging session– $ cuda-gdb ./myProgram [Arguments]

81
Debugging with cuda-gdbTask Command Examples
List source code list (l) ll myKernel
Set a breakpoint breakpoint (b) b 42b myKernel
Run program from beginning run (r) r
Move to next line of code next (n) n (return repeats last command)
Continue to next breakpoint (or end)
continue (c) c
Print value of variable print (p) p myFloatp myArray[100]@10
View stack/backtrace backtrace (bt) bt
View or set cuda thread focus cuda thread cuda threadcuda thread (0,0,1)
View or set cuda block focus cuda block cuda blockcuda block (0,0,1)
List active kernels cuda kernel cuda kernel

82
Debugging with cuda-memcheck● Tracks device memory errors
● No special compiler flags needed$ cuda-memcheck ./vectorload========= CUDA-MEMCHECKelapsed time = 0.000000 ms========= Invalid __global__ read of size 4========= at 0x00000090 in loadvector(float*)========= by thread (703,0,0) in block (992,0,0)========= Address 0xf010a00b0 is out of bounds========= Saved host backtrace up to driver entry point at kernel launch time========= Host Frame:/usr/lib64/libcuda.so (cuLaunchKernel + 0x3dc) [0xc9d0c]========= Host Frame:/software/tools/cuda-5.0/lib64/libcudart.so.5.0 [0x11d54]========= Host Frame:/software/tools/cuda-5.0/lib64/libcudart.so.5.0
(cudaLaunch + 0x182) [0x38152]========= Host Frame:./vectorload [0xdc0]========= Host Frame:./vectorload [0xcaf]========= Host Frame:./vectorload [0xccc]========= Host Frame:./vectorload [0xbe4]========= Host Frame:/lib64/libc.so.6 (__libc_start_main + 0xfd) [0x1ecdd]========= Host Frame:./vectorload [0xa19]========= ERROR SUMMARY: 1 error

83
Bonus Exercise: Debugging
● Explore any of todays codes with cuda-gdb and cuda-memcheck
● Search the web for the article “Supercomputing for the Masses: Part 14” by Rob Farber– Work through the cuda-gdb tutorial

84
Memory Coalescing
● What about vectors? (e.g. four component)
8 9 10 114 5 6 70 1 2 3 12 13 14 15
0 1 2 3
This type of memory access would not be coalesced.Q: How to store and load vectors?
Threads

85
Memory Coalescing
● What about vectors? (e.g. four-component)
8 9 10 114 5 6 70 1 2 3 12 13 14 15
0 1 2 3
This type of memory access would not be coalesced.Q: How to store and load vectors?A: CUDA has built-in vector data types to abstract away this problem. They are stored for efficient access by neighbouring threads.int2, int3, int4, float2, float3, float4, double2, etc.e.g.) float4 coords; coords.x = x; coords.y = y; coords.z = z; coords.w = time;
Threads X

86
Loading an array of 4-Component Vectors
● Uncoalesced ● Coalesced using float4
__global__ void loadvector(float * vec_d){ __shared__ float vec_s[veclength][TPB]; int idx = blockIdx.x*blockDim.x
+ threadIdx.x; int tid = threadIdx.x; vec_s[0][tid] = vec_d[veclength*idx]; vec_s[1][tid] = vec_d[veclength*idx+1]; vec_s[2][tid] = vec_d[veclength*idx+2]; vec_s[3][tid] = vec_d[veclength*idx+3];}
__global__ void loadvector(float4 * vec_d){ __shared__ float4 vec_s[TPB]; int idx = blockIdx.x*blockDim.x
+ threadIdx.x; int tid = threadIdx.x; vec_s[tid] = vec_d[idx];}
Requires 4X as many transactions!
vec_s[tid].x, vec_s[tid].y, vec_s[tid].z, vec_s[tid].w

87
Multi-GPU
● CUDA programs may use multiple devices at once to allow greater parallelism
● Can be straightforwardly combined with OpenMP or MPI– May access devices on other nodes
● Stream: A queue of events to be executed in order on a device– Multiple streams are required to...
● Run multiple kernels concurrently on a device● Run multiple devices concurrently
● Context: All data necessary to run an application on a device– Allocated memory, streams, events, etc.
– Only one context active per device at a time
– Device can manage multiple contexts the way an operating system manages multiple processes

88
Multi-GPU
Device 0 - Context 1 active Device 1 - Context 0 active
Context 0 Context 1 Context 0 Context 1
Streams from active context may execute concurrently
Context 2

89
Multi-GPU
Device 0 Device 1
Context 0 Context 0
Simplest case of multiple GPUS

90
Multi-GPU
Task Function
Count devices on a node cudaGetDeviceCount(&nGPU);
Set to the device 0 context cudaSetDevice(0);
Create a new context and stream for the device, and allocate memory
cudaMalloc();
Create additional streams in current context
cudaStreamCreate();
Initiate a data copy to device and immediately return control to host
cudaMemcpyAsync();
Ensure that all streams on all devices have completed
cudaDeviceSynchronize();

91
int main(int argc, char* argv[]){ ... int nGPU; cudaGetDeviceCount(&nGPU);
for (int i=0; i < nGPU; i++) { cudaSetDevice(i); cudaMalloc(&d_A[i], size); }
cudaHostAlloc(&h_A, nGPU*n*sizeof(int), cudaHostAllocPortable);
for(int i=0; i < nGPU; i++) { int nThreadsPerBlock=512; int nBlocks=n/nThreadsPerBlock + ((n%nThreadsPerBlock)?1:0); cudaSetDevice(i); fillKernel<<<nBlocks, nThreadsPerBlock>>>(d_A[i], n, i*n); cudaMemcpyAsync(&h_A[i*n], d_A[i], size, cudaMemcpyDeviceToHost); }
cudaDeviceSynchronize(); ...}
Creates contexts on each device
Chooses a device/context
Copy without waiting
See: multigpu.cu

92
Bonus Exercise: Multi GPU
● Compile and run the program multigpu.cu● When is the context and stream created on
device 0?● When is the context and stream created on
device 1?● What determines which stream CUDA events
are executed on?

93
OpenCL for CUDA developers
● CUDA– Kernels built by
compiler
– Allows C-language extensions
– Automatic initialization and clean up of device
● OpenCL– Kernels stored as
strings and built at run time
– Uses standard C + API only
– Explicit initialization and clean up of device by programmer

94
Terminology Differences
CUDA OpenCL
Thread Work-item
Block Work-group
Warp Hardware concept not defined in OpenCL: SIMD width / execution group / warp (NVidia) / wavefront (AMD)
Global memory Global memory
Constant memory Constant memory
Shared memory Local memory
Local memory Private memory

95
Syntax DifferencesCUDA OpenCL
cudaMemcpy() clEnqueueReadBuffer() / clEnqueueWriteBuffer()
cudaMalloc() clCreateBuffer()
cudaFree() clReleaseMemObject()
__global__ __kernel
int idx = blockIdx.x*blockDim.x + threadIdx.x;
int idx = get_global_id(0);
kern<<<nB,nT>>>(data); cl_kernel k = clCreateKernel(prog, “myfunction”, 0);clSetKernelArg(k, 0, sizeof(data), &data);clEnqueueNDRangeKernel(...);