data deep learning and image classification - webhomeoyallon/13_december_2016.pdf · deep learning...
TRANSCRIPT

DATA
Edouard Oyallon
1
Deep learning and Image Classification
advisor: Stéphane Mallatfollowing the works of Laurent Sifre, Joan Bruna, …

DATA
• Caltech 101, etc
22
Training set to predict labels Rhino
Not a rhinoRhino class from Caltech 101
High Dimensional classification(xi, yi) 2 R5122 ⇥ {1, ..., 100}, i = 1...104 �! y(x)?
introduce deep network, then how wavelets are related to the deep network

DATA
High dimensionality issues
3
x y kx� yk2 = 2
Averaging is the key to get invariants
x y
Translation
Rotation

DATA
Image variabilities4
Geometric variability Class variabilityGroups acting on images:
translation, rotation, scaling
Intraclass variability
Extraclass variabilityOther sources : luminosity, occlusion, small deformations
Not informative
x⌧ (u) = x(u� ⌧(u)), ⌧ 2 C1
I � ⌧

DATAFighting the curse of
dimensionality• Objective: building a representation of such that a
simple (say euclidean) classifier can estimate the label :
• Designing consist of building an approximation of a low dimensional space which is regular with respect to the class:
• How can we do that?
5
�x x
�
�
w<latexit sha1_base64="eqfykHkxP29JLdLAGokHSA1pBNI=">AAAB53icbZDLSgMxFIbP1Futt6pLN8EiuCozCupKC25ctuDYQjuUTHqmjc1khiSjlNIncONCxa3P4hu4821MLwtt/SHw8f/nkHNOmAqujet+O7ml5ZXVtfx6YWNza3unuLt3p5NMMfRZIhLVCKlGwSX6hhuBjVQhjUOB9bB/Pc7rD6g0T+StGaQYxLQrecQZNdaqPbaLJbfsTkQWwZtB6erz9LQCANV28avVSVgWozRMUK2bnpuaYEiV4UzgqNDKNKaU9WkXmxYljVEHw8mgI3JknQ6JEmWfNGTi/u4Y0ljrQRzaypianp7PxuZ/WTMz0UUw5DLNDEo2/SjKBDEJGW9NOlwhM2JggTLF7ayE9aiizNjbFOwRvPmVF8E/KZ+V3ZpXqlzCVHk4gEM4Bg/OoQI3UAUfGCA8wQu8OvfOs/PmvE9Lc86sZx/+yPn4AYu+jmw=</latexit>
<latexit sha1_base64="O0lQJ2xoQXj8ACW3DbgTbPBIgF0=">AAAB53icbZDLSgNBEEVr4ivGV9Slm8YguAozCupKA25cJuCYQDKEnk5N0qbnQXePEoZ8gRsXKm79Fv/AnX9jZ5KFJl5oONxbRVeVnwiutG1/W4Wl5ZXVteJ6aWNza3unvLt3p+JUMnRZLGLZ8qlCwSN0NdcCW4lEGvoCm/7wepI3H1AqHke3epSgF9J+xAPOqDZW47FbrthVOxdZBGcGlavP01z1bvmr04tZGmKkmaBKtR070V5GpeZM4LjUSRUmlA1pH9sGIxqi8rJ80DE5Mk6PBLE0L9Ikd393ZDRUahT6pjKkeqDms4n5X9ZOdXDhZTxKUo0Rm34UpILomEy2Jj0ukWkxMkCZ5GZWwgZUUqbNbUrmCM78yovgnlTPqnbDqdQuYaoiHMAhHIMD51CDG6iDCwwQnuAFXq1769l6s96npQVr1rMPf2R9/ABGL474</latexit>
k�x� �x0k n 1 ) y(x) = y(x0)
RDRd
yy
D � d

DATA
Existing approach
• Unsupervised learning: Bag of Words, Fisher Vector,…
• Supervised learning: Deep Learning,…
• Non learned: HMax, Scattering Transform.
6
{x1, ..., xN} �! �
{G1, ...} �! �
Ref.: Discovering objects and their location in images . Sivic et al.
High-dimensional Signature Compression for Large-Scale Image Classification, Perronnin et al.
Ref.: Robust Object Recognition with Cortex-Like Mechanisms. Serre et al.
{(x1, y1), ..., (xN , yN )} ! �

DATA
Separation - Contraction• In high dimension, typical distances are huge, thus an
appropriate representation must contract the space:
• While avoiding the different classes to collapse:
7
k�x� �x0k kx� x
0k
9✏ > 0, y(x) 6= y(x0) ) k�x� �x0k � ✏
✏
�

DATA
Invariance• Let be a variability that preserves the class, e.g.:
• One wish to build an invariant to this variability.
• A simple way to build an invariant would be linearizing the action of , then projecting it via a first order approximation:
8
y(Lx) = y(x)
�
L
y(�Lx) = y(�x)
�Lx ⇡ �x+ @�x
L+ o(kLk)
L
A linear operatorDisplacement
+ projection

DATA
An example: translation
• Translation is a linear action:
• In many cases, one wish to be invariant globally to translation, a simple way is to perform an averaging:
• Even if it can be localized, the averaging keeps the low frequency structures: the invariance brings a loss of information!
9
8u 2 R2, Lax(u) = x(u� a)
Ax =
ZLaxda =
Zx(u)du
A

DATAWavelets
• Convolutions are the natural operators linked to translation:
• A linear averaging can still build a (trivial) invariant:
• A wavelet is a complex localized filter that describes structures of images, with average 0. It is discriminative. Family of wavelets are obtained by rotating and dilating a mother wavelet :
10
(Lax) ? f = La(x ? f)
Z(Lax) ? f(u)du =
ZLa(x ? f)(u)du =
Zx
Zf
Morlet Wavelets Phase in color
Amplitude in contrast
�(u) =1
|�| (��1.u)

DATA
Wavelets to build invariance• Interestingly, a translation displacement corresponds to
a phase displacement, e.g.:
• If one wish to build an invariant to this variability a modulus helps:
• It implies that more energy are in the low frequency domain: an averaging captures more information.
• Besides, it is possible to reconstruct signal from their modulus wavelet transform
11
a ⌧ 1, (Lax) ? (u) ⇡ e
i�(u,a)x ? (u)
a ⌧ 1, |(Lax) ? (u)| ⇡ |x ? (u)|
Ref.: Phase retrieval for the Cauchy wavelet transform, Mallat S, Waldspurger I

DATA
Scattering Transform• A Scattering Transform is the cascade of wavelets and
modulus non-linearity:
• Sort of super-SIFT.
• Observe that if no non-linearity is applied, the operator would be linear.
12
Sx = {Z
x,
Z|x ? �1 |,
Z||x ? �1 | ? �2 |, ...}
x
� |.|Z
� |.|Z
� |.|Z
…It is a deep cascade!
Ref.: Group Invariant Scattering, Mallat S

DATA
Properties• Non-linear
• Isometric
• Stable to noise
• Invariant to translation
• Linearize the action of small deformation
• Reconstruction properties
13
allow a linear classifier to build class invariants
on informative variability
Ref.: Group Invariant Scattering, Mallat S
Ref.: Reconstruction of images scattering coefficient. Bruna J
kSxk = kxk
kSx� Syk kx� yk
SLax = Sx
Sx
⌧
⇡ Sx+ @
x
r⌧

DATA
Benchmarks14
Dataset Type Paper Accuracy
Caltech101 Scattering 79.9
Unsupervised Ask the locals 77.3
Supervised DeepNet 96.4
CIFAR100 Scattering 56.8
Unsupervised RFL 54.2
Supervised DeepNet 80.4Identical
Representation104101
256⇥ 256
imagesclasses
color images 32⇥ 321005.104
color images
imagesclasses
CALTECH CIFAR
Ref.: Deep Roto-Translation Scattering for Object Classification. EO and S Mallat
There is a gap with supervised architecture

DATADeepNet?
• A scattering transform is a non-learned DeepNet
• A DeepNet is a cascade of linear operators with a point-wise non-linearity.
• Each operators is supervisedly learned
• State of the art on many problems in vision, audio, generation of signals, text, strategy, …
15
Ref.: Rich feature hierarchies for accurate object detection and semantic segmentation. Girshick et al.
Convolutional network and applications in vision. Y. LeCun et al.
operation
layer of neurons

DATA
Benchmarks16
% a
ccur
acy
60
70
80
90
100
2010 2011 2012 2013 2014 2015 2016
SIFT+FV DeepNet
Ref.: image-net.org
human
ImageNet%
acc
urac
y
60
70
80
90
100
2010 2011 2012 2013 2014 2015 2016
UnsupervisedDeepNet
Ref.: http://rodrigob.github.io/are_we_there_yet/build/
human
CIFAR10

DATA
When do you want to do Deep Learning?
• When you have a lot of data
• When you do not need to have guarantee on why it works
• When you do not need to have guarantee it works or have enough data to validate it
• When you’re lazy and want quickly results
17

DATA
Generecity
• For natural images, one can train a DeepNet on ImageNet: 1000 classes, 1 000 000 images.
• A DeepNet pretrained on ImageNet does generalise on Caletch’s datasets.(10k images)
• Also, the deep features are often used in situation where there is no data. (e.g. medical imaging)
• Conclusion: pretrained features can be used as SIFT!
18
Ref.: Visualizing and Understanding Convolutional Networks, M Zeiler, R FergusHow transferable are features in deep neural networks? Yosinski et al.

DATAArchitecture of a CNN
• Cascade of convolutional operator and non-linear operator:
• Can be interpreted as neurons sharing weights:
• Designing a state-of-the-art deep net is generally hard and requires a lot of engineering
19
x0x1 x2
xJ
…
Classifier
xj(u,�2) = f(X
�1
xj�1(.,�1) ? hj,�1(u)) ! xj = f(Fjxj�1)

DATA
AlexNet20
Ref.: ImageNet Classification with Deep Convolutional Network, A Krizhevsky et al.

DATA
Inception Net21
Ref.: Going Deeper with Convolutions, C Szegedy et al.
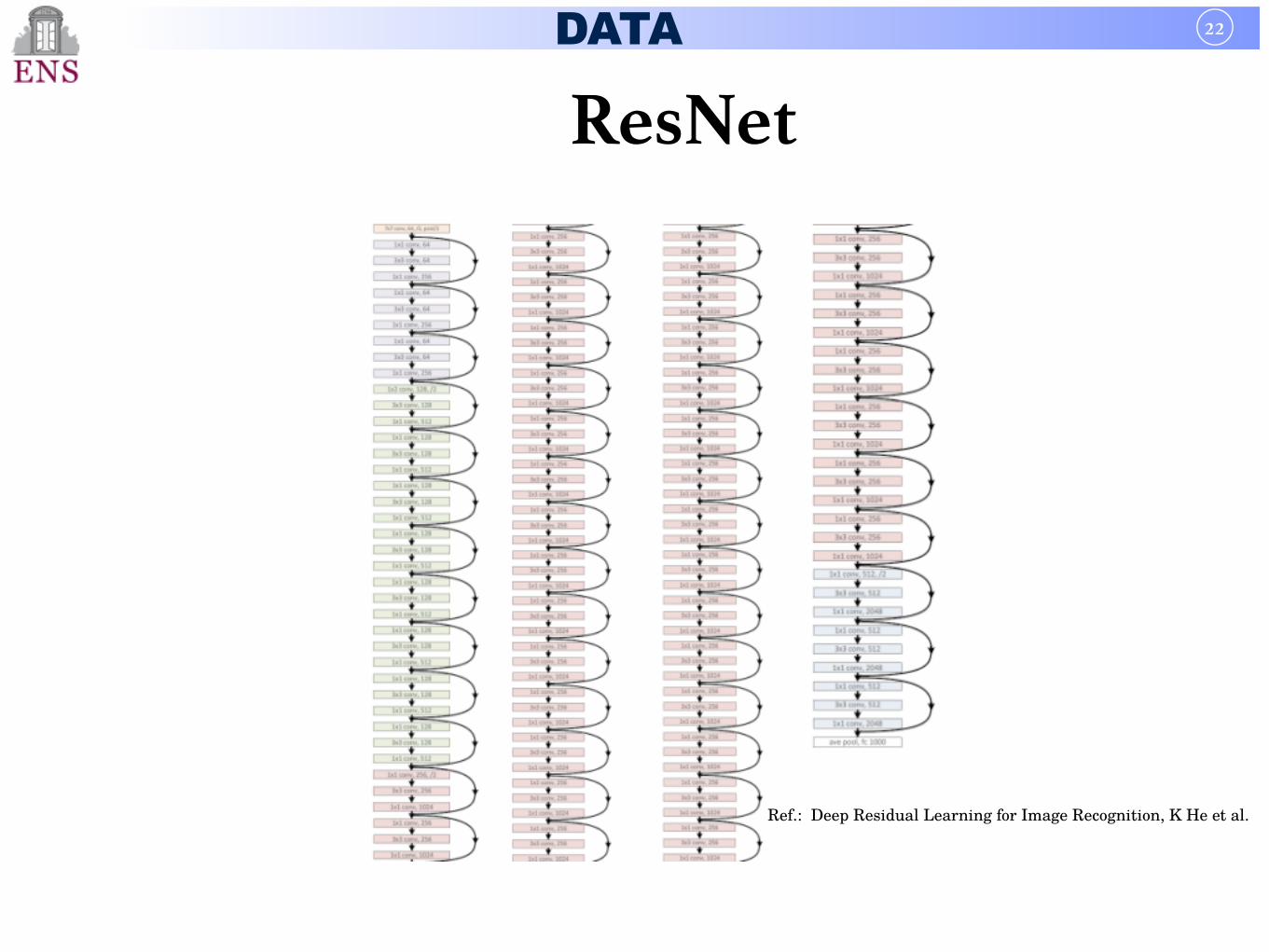
DATA
ResNet22
Ref.: Deep Residual Learning for Image Recognition, K He et al.

DATA
Optimizing a DeepNet• The output of the DeepNet are optimised via the
neg cross entropy:
• All the functions are differentiable: back propagation algorithm:
• It is absolutely non-convex! No guarantee to converge. Besides, many parameters: requires a lot of regularisation:BatchNormalization, DropOut, data augmentation, and many data!
23
�x
�X
xn
X
i
1
y(x)=i
log(�x
n
)
i
x1 ! x2 ! ... ! xn = �x ! loss
@x1 @x2 ... @xn = @�x @loss
Ref.: Convolutional network and applications in vision. Y. LeCun et al.

DATA
DeepNet fancy claims
• In deep learning, deeper networks are better.
• "Highly non-linear" is better
• Your model must overfit your data to generalise
• Universal approximation theorem proves it will work
• Many inspiration from the "brain"
24

DATA
A black box
• Pure black box: few mathematical results explain how it works.
• Hypothesis of low-dimensionality is wrong. Ex: stability to diffeomorphisms
• What is the nature of each operators? Necessary dimensionality reduction
25

DATA
Softwares…• All the packages are based on GPUs, select your favorite
via: simplicity of benchmarking, coding, inputting the data, …
• Torch: based on Lua, in a MATLAB style
• Tensorflow: Python friendly
26
Modularity
Sim
plic
ity to
inpu
t the
dat
a
Hard Simple
SimpleMatConvNet
TheanoTensorflow
Torch
Caffe(This is subjective)

DATA
TensorFlow
• TensorFlow is a deep learning environment in Python/C++.
• It makes easier the data input via a system of queue and multi-threads
• Use on GPU/CPUs is transparent
• Typical code samples: here
27

DATA
TensorBoard!
• A very nice tool of visualisation, demo: here
28

DATA
Understanding deep learning Two strategies:
• Structuring progressively the layers/ obtaining general properties on them
• Specifying a class of CNN that is interpretable and leads to state-of-the-arts results
29

DATAHybrid deep networks
• Cascading a CNN on top of a Scattering Transform:
• Claim: incorporating geometric knowledge regularises the classification process
• It helps in situation with limited samples (ex: medical imaging)
• Interpretability of the first layer: local rotation invariance is learned.
30
Accu
racy
on
CIF
AR10
50
75
100
Samples
1000 2000 4000 8000 50000
Hybrid CNN
S CNN
Ref.: A Hybrid Network: Scattering and Convnet, submitted, EO

DATAA progressively better
representation
• Progressively, there is a linear separation that occurs
• In fact, euclidean distances become more meaningful with depth.
31
Indicates a progressive dimensionality reduction!Ref.: Building a Regular Decision Boundary with Deep Networks, submitted, EO
F1 F2
Acc
urac
y
F3 F4
Ref.: Visualizing and Understanding Convolutional Networks, M Zeiler, R Fergus

DATA
Identifying the variabilities?• Several works showed a deepnet exhibits some
covariance:
• Manifold of faces at a certain depth:
• Can we generalise these?
32
Ref.: Understanding deep features with computer-generated imagery, M Aubry, B Russel
Ref.: Unsupervised Representation Learning with Deep Convolutional GAN, Radford, Metz & Chintalah

DATA
Conclusion33
• Deep Learning architectures are of interest thanks to their outstanding numerical results yet not well understood properties.
• Scattering Network provides a first attempt to structure DeepNets.
• Check my website for softwares and papers: http://www.di.ens.fr/~oyallon/ (or send me an email to get the latest soft!)
Thank you!