data mining spatial
TRANSCRIPT

19/04/2015 Taches du dataMining Spatial1
Membres de groupe:
ACHER Hichem BOUZIDI Rokia
BEKKOUCHE Selma LANASRI Dihia
Proposé par: Mme. HAMDAD
2013-2014

19/04/2015 Taches du dataMining Spatial2
Introduction
La donnée spatiale
Le data mining spatial
Les taches de data mining spatial
Implémentation d’une tache
Conclusion

19/04/2015 Taches du dataMining Spatial3

Les données spatiales, décrivent la forme et les
caractéristiques de l'entité géographique ainsi que les
objets situés sur la surface de la terre .Elles sont définies
par leur localisation.
19/04/2015 Taches du dataMining Spatial4
Donnée spatiale
alphanumérique Vecteur

Le Data Mining Spatial (DMS), fouille de données spatiale, est
l’exploration de données ou encore extraction de
connaissances implicite de relations spatiales ou autre
propriétés non explicitement stockés dans les bases de données
spatiale, à partir d’une grande masse de données géographiques
19/04/2015 Taches du dataMining Spatial5
Tâche du data miningspatial
Descriptives prédictives

19/04/2015 Taches du dataMining Spatial6
• Tâche prédictives
• L’association DMS permet de trouver des relations(XY) entre les propriétés des objets et celles de leurs voisins d’une BDD spatiale, selon le thème choisi, avec une certaine probabilité selon deux métriques(S & C).
X & Y sont des ensembles de prédicats .
S : Support de la règle.
C : La confiance.

19/04/2015 Taches du dataMining Spatial7
Est-un(X, “école”) & proche de(X, “station de bus”) ' proche-de (X, “marché”) [20%; 80%]
Problème
le nombre d’association possible entre attribut.
k attributs nombre maximal d’association: K*2k-1

19/04/2015 Taches du dataMining Spatial8
calculer la distance entre deux entités géo-spatiales ponctuelle sur la base
des coordonnées
Raisonnement quantitatif
Extraire différents types de relations spatiales.
Raisonnement qualitatif
Caté
gori
es d
’alg
ori
thm
es

19/04/2015 Taches du dataMining Spatial9
Algorithme APRIORI.
Algorithme Kosperski

19/04/2015 Taches du dataMining Spatial10
Elaboration des règles d’association entre les ensembles des items fréquents de tous les niveaux
Définition de l’ensemble des règles d’associations fortes dans le niveau L.
Evaluation du support et de la confiance de chacune des règles établies.
Elaboration des règles d’association entre tous les éléments de l’ensemble des items fréquents
Extraire le sous-ensemble des items fréquents du niveau L
Définir l’ensemble de tous les items de l’étude

19/04/2015 Taches du dataMining Spatial11

19/04/2015 Taches du dataMining Spatial12
• la prédiction de l’emplacement d’un objet dans des classes préexistantes en examinant certaines propriétés.
•Regrouper les éléments géographiques par classes selon les propriétés en commun.

19/04/2015 Taches du dataMining Spatial13
•Déterminer (prédire) la classe d’un nouvel objet.
•Décrire les liens entre les propriétés de l’objet et la classe à laquelle il appartient.

19/04/2015 Taches du dataMining Spatial14
• La recherche de règles de classement structurer un ensemble d'objets en classes d'objets ayant des propriétés communes.
• Réalisation par apprentissage supervisé qui, à partir de classes fournies partiellement en extension classer les prochaines données.

19/04/2015 Taches du dataMining Spatial15
Les arbres de décision
Principe:
• Diviser récursivement la population d’apprentissage en des populations plus homogènes, en appliquant un critère de subdivision.
• Les résultats de cette classification sont présentés sous forme d’arbres de connaissances.

19/04/2015 Taches du dataMining Spatial16
Les paramètres en entrée
• Table_Cible : table des objets à analyser.
• Table_Voisin : table des objets de voisinage.
• Index_Jointure_Spatial : contient les relations spatiales entre les objets.
Paramètre en sortie
• Arbre de décision spatial binaire.

19/04/2015 Taches du dataMining Spatial17
Appliquer l’opérateur croisement, qui permet de compléter (au lieu de joindre) la Table_cible, par les données présentes dans les autres tables.
Mettre les relations spatiales exactes entre les objets, et les sauvegarder dans une table relationnelle sous forme (objet1, relation spatiale, objet2).
Pour chaque objet voisin, cet opérateur génère un attribut (une colonne)
dans la table résultante.
Initialement, tous les objets de la Table_cible sont affectés à la racine
A chaque étape du processus de division d’un nœud, on calcule le gain informationnel de tous les attributs
explicatifs. Si cet attribut provient de la Table_voisin, alors une formule spécifique est utilisée pour le calcul de
ce gain. On retient l’attribut de segmentation, correspondant au meilleur gain informationnel de tous les
attributs explicatifs. Si le nœud courant n’est pas saturé, alors on fait appel à la procédure d’affectation.

19/04/2015 Taches du dataMining Spatial18
• Le géo-clustering consiste à regrouper les entités similaires dans les mêmes classes.
• Cela revient à maximiser la similarité intra classes et à minimiser la similarité inter classes
• En tenant compte de la particularité des données géo-spatiales, qui se caractérisent par l’interdépendance sous forme de relations géo-spatiales tel que le voisinage

19/04/2015 Taches du dataMining Spatial19
Le clustering est utilisé pour déterminer les "points chauds" dans l'analyse de criminalité et le suivi de maladies.
19/04/2015 Taches du dataMining Spatial20
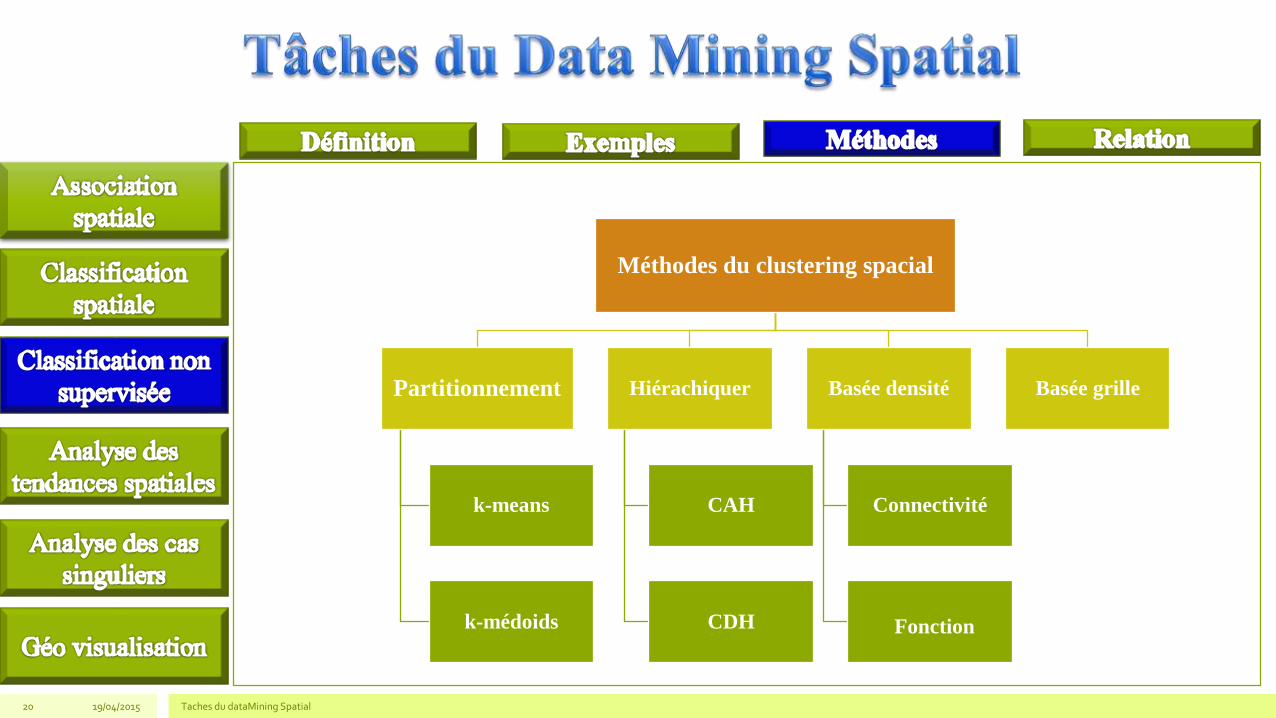
Méthodes du clustering spacial
Partitionnement
k-means
k-médoids
Hiérachiquer
CAH
CDH
Basée densité
Connectivité
Fonction
Basée grille

19/04/2015 Taches du dataMining Spatial21
Le principe de ces méthodes est de chercher les k meilleurs clusters d’un ensemble N, parmi ces méthodes on cite : l’algorithme k-Means, la méthode de Nuée dynamique, Algorithme K-Medoids, Algorithme EM

19/04/2015 Taches du dataMining Spatial22
Algorithme K-means
On définit ou l'on tire au hasard k points
À chaque itération:
• Constitution de classes: chaque élément est associé au centre dont il est le plus proche.
• Calcul des nouveaux centres: centres de gravité des classes.

19/04/2015 Taches du dataMining Spatial23
Les méthodes hiérarchiques se devisent en deux approches, elles peuvent être soient :
Agglomératives (approche bottom-up) .
Divisives (approche Top-down).
Parmi ces méthodes on site par exemple les méthodes DIANA et AGNES Caméléon.

19/04/2015 Taches du dataMining Spatial24
CURE
Parmi ses avantages on note :
• La découverte de clusters de taille intéressante ;
• Le non-sensitivité aux données déviées ;
• Le partitionnement et l’échantillonnage réduisent la taille des données sans influer sur la qualité des clusters ;
• Temps d’exécution réduit.

19/04/2015 Taches du dataMining Spatial25
Parmi ces méthodes nous citons : Algorithme DBSCAN, Algorithme DENCLUE, Algorithme DBCLASD

19/04/2015 Taches du dataMining Spatial26
Algorithme DBCLASD
Contrairement aux algorithmes de même type DBCLASD n’a pas besoin de paramètres en entrée et traite efficacement les données inconsistantes, car il est fondé sur une probabilité basée sur le facteur distance mais cette indépendance des paramètres d’entrée lui coûte une grande consommation de ressources.

19/04/2015 Taches du dataMining Spatial27
• Ces méthodes permettent d’utiliser des grilles pour faire la classification non supervisée,
• son principe est de partitionner l’espace de données en un ensemble de cellules. Parmi ces
• méthodes on peut citer : l’algorithme STING et l’algorithme CLIQUE.

19/04/2015 Taches du dataMining Spatial28
Algorithme CLIQUE
L’identification des clusters au niveau de CLIQUE est réalisée en trois (3) grandes
phases :
• Identification des sous espaces contenant les clusters : cette opération est
réalisée en utilisant un algorithme ascendant de recherche d’unités denses.
• Identification des clusters : consiste à trouver les composants connectés en
utilisant les sommets des unités denses. L’identification des clusters est bien entendue fonction du nombre d’unités denses.
• Génération d’une description minimale des clusters grâce aux composants
déterminés dans la phase précédente.

19/04/2015 Taches du dataMining Spatial29
Relation entre les méthodes du géo-clustering

19/04/2015 Taches du dataMining Spatial30
Evaluation de la qualité d’un cluster
• Dans le clustering, l’évaluation des résultats ainsi que la comparaison entre les différentes méthodes et algorithmes, est une problématique importante. En pratique il existe plusieurs méthodes pour évaluer les groupements obtenus. L’une des méthodes consiste à utiliser des mesures numériques, qui sont l’inertie interclasses et inertie intra-classes. Il s’agit d’une évaluation interne.

19/04/2015 Taches du dataMining Spatial31
• La tendance spatiale : C’est un changement régulier d'un ou de plusieurs attributs non-spatiales lors d’un déplacement géographique.
• Les techniques
la régression
l'analyse de corrélations.
Exemple 1
• Analyser la tendance du taux de chômage selon la distance par rapport à une métropole ou une capitale
Exemple 2
la tendance du changement du climat ou de la végétation selon la distance par rapport à la côte.

19/04/2015 Taches du dataMining Spatial32
• Les cas singuliers( valeurs aberrantes et extrêmes) : sont des objets qui ne respectent pas le comportement général ou le modèle de données
[Han et Kamber 2006].
un objet spatialement référencé dont les valeurs des attributs non-spatiaux sont inconsistants avec celles des autres objets à l'intérieur d'un certains voisinage spatial.
[Shekhar et al 2004]
Exemple
• Un taudis (gourbi) dans un cartier de villas est considéré comme un objet spatial aberrant en se basant sur l'attribut non spatial «type de maison ».

19/04/2015 Taches du dataMining Spatial33
• C’est la visualisation de l’information géographique pour visualiser les connaissances ainsi que les relations implicites entre ce type de données.
• Ça concerne la mise en œuvre d'outils visuels pour extraire des connaissances, les synthétiser , les communiquer et les utiliser
La cartographie :C’est la conception et l'utilisation des cartes de communication de l'information et la consommation publique.
La géo visualisation : C’est le développement de cartes hautement interactifs et des outils associés à l'exploration des données , la formulation d'hypothèses et la construction de la connaissance.

19/04/2015 Taches du dataMining Spatial34
Les techniques de data mining spacial sont très
puissantes car elles offrent la possibilité de décrire un
domaine d’application et même prédire des résultats
en future.

19/04/2015 Taches du dataMining Spatial35