data mining -volinsky - 2011 - columbia university 1 text mining
TRANSCRIPT

Data Mining -Volinsky - 2011 - Columbia University 1
Text Mining

What is Text Mining?
• There are many examples of text-based documents (all in ‘electronic’ format…)– e-mails, corporate Web pages, customer surveys,
résumés, medical records, DNA sequences, technical papers, incident reports, news stories and more…
• Not enough time or patience to read– Can we extract the most vital kernels of information…
• So, we wish to find a way to gain knowledge (in summarised form) from all that text, without reading or examining them fully first…!– Some others (e.g. DNA seq.) are hard to comprehend!
2Data Mining -Volinsky - 2011 - Columbia University

What is Text Mining?
• Traditional data mining uses ‘structured data’ (n x p matrix)
• The analysis of ‘free-form text’ is also referred to as ‘unstructured data’, – successful categorisation of such data can be a
difficult and time-consuming task…
• Often, can combine free-form text and structured data to derive valuable, actionable information… (e.g. as in typical surveys) – semi-structured
3Data Mining -Volinsky - 2011 - Columbia University

Data Mining -Volinsky - 2011 - Columbia University 4
Text Mining: Examples
• Text mining is an exercise to gain knowledge from stores of language text.
• Text:– Web pages– Medical records– Customer surveys– Email filtering (spam)– DNA sequences– Incident reports– Drug interaction reports– News stories (e.g. predict stock movement)

Data Mining -Volinsky - 2011 - Columbia University 5
What is Text Mining
• Data examples– Web pages– Customer surveys
Customer Age Sex Tenure Comments Outcome
123 24 M 12 years Incorrect charges on bill customer angry
Y
243 26 F 1 month Inquiry about charges to India
N
346 54 M 3 years Question about charges on bill
N

Data Mining -Volinsky - 2011 - Columbia University 6
Amazon.com

Data Mining -Volinsky - 2011 - Columbia University 7
Of Mice and Men: Concordance
Concordance is an alphabetized list of the most frequently occurring words in a book, excluding common words such as "of" and "it." The font size of a word is proportional to the number of times it occurs in the book.
Data Mining -Volinsky - 2011 - Columbia University 8
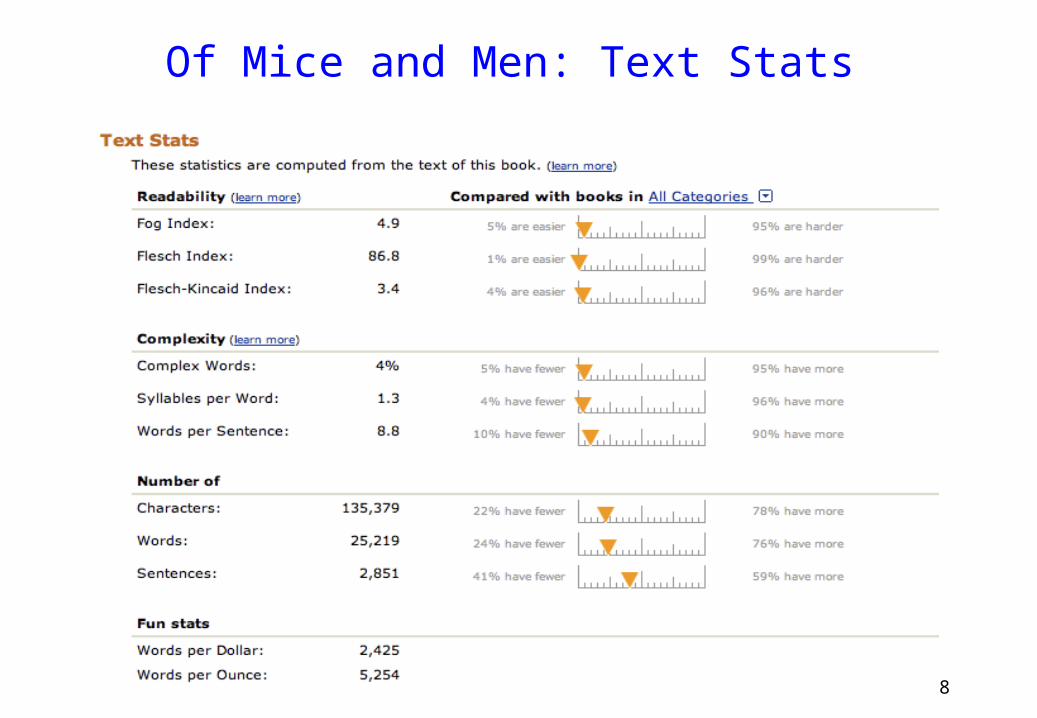
Of Mice and Men: Text Stats
Data Mining -Volinsky - 2011 - Columbia University 9
Text Mining: Yahoo Buzz
Data Mining -Volinsky - 2011 - Columbia University 10
Text Mining: Google News

Data Mining -Volinsky - 2011 - Columbia University 11
Text Mining
• Typically falls into one of two categories– Analysis of text: I have a bunch of text I
am interested in, tell me something about it• E.g. sentiment analysis, “buzz” searches
– Retrieval: There is a large corpus of text documents, and I want the one closest to a specified query• E.g. web search, library catalogs, legal and
medical precedent studies

Data Mining -Volinsky - 2011 - Columbia University 12
Text Mining: Analysis
• Which words are most present• Which words are most surprising• Which words help define the
document• What are the interesting text
phrases?

Data Mining -Volinsky - 2011 - Columbia University 13
Text Mining: Retrieval
• Find k objects in the corpus of documents which are most similar to my query.
• Can be viewed as “interactive” data mining - query not specified a priori.
• Main problems of text retrieval:– What does “similar” mean?– How do I know if I have the right
documents? – How can I incorporate user feedback?

Data Mining -Volinsky - 2011 - Columbia University 14
Text Retrieval: Challenges
• Calculating similarity is not obvious - what is the distance between two sentences or queries?
• Evaluating retrieval is hard: what is the “right” answer ? (no ground truth)
• User can query things you have not seen before e.g. misspelled, foreign, new terms.
• Goal (score function) is different than in classification/regression: not looking to model all of the data, just get best results for a given user.
• Words can hide semantic content– Synonymy: A keyword T does not appear anywhere in the
document, even though the document is closely related to T, e.g., data mining
– Polysemy: The same keyword may mean different things in different contexts, e.g., mining

Data Mining -Volinsky - 2011 - Columbia University 15
Basic Measures for Text Retrieval
• Precision: the percentage of retrieved documents that are in fact relevant to the query (i.e., “correct” responses)
• Recall: the percentage of documents that are relevant to the query and were, in fact, retrieved
€
recall =|{Relevant}∩ {Retrieved} |
|{Relevant} |
|}{||}{}{|
RetrievedRetrievedRelevant
precision∩=

Data Mining -Volinsky - 2011 - Columbia University 16
Precision vs. Recall
• We’ve been here before!– Precision = TP/(TP+FP)– Recall = TP/(TP+FN)– Trade off:
• If algorithm is ‘picky’: precision high, recall low• If algorithm is ‘relaxed’: precision low, recall high
– BUT: recall often hard if not impossible to calculate
Truth:Relvant Truth:Not Relevant
Algorithm:Relevant TP FP
Algorithm: Not Relevant
FN TN
16
1 0
1 a b
0 c d
predictedoutcome
actualoutcome

Data Mining -Volinsky - 2011 - Columbia University 17
Precision Recall Curves• If we have a labelled training set, we can calculate recall.• For any given number of returned documents, we can plot a point
for precision vs. recall. (similar to thresholds in ROC curves)• Different retrieval algorithms might have very different curves -
hard to tell which is “best”

Data Mining -Volinsky - 2011 - Columbia University 18
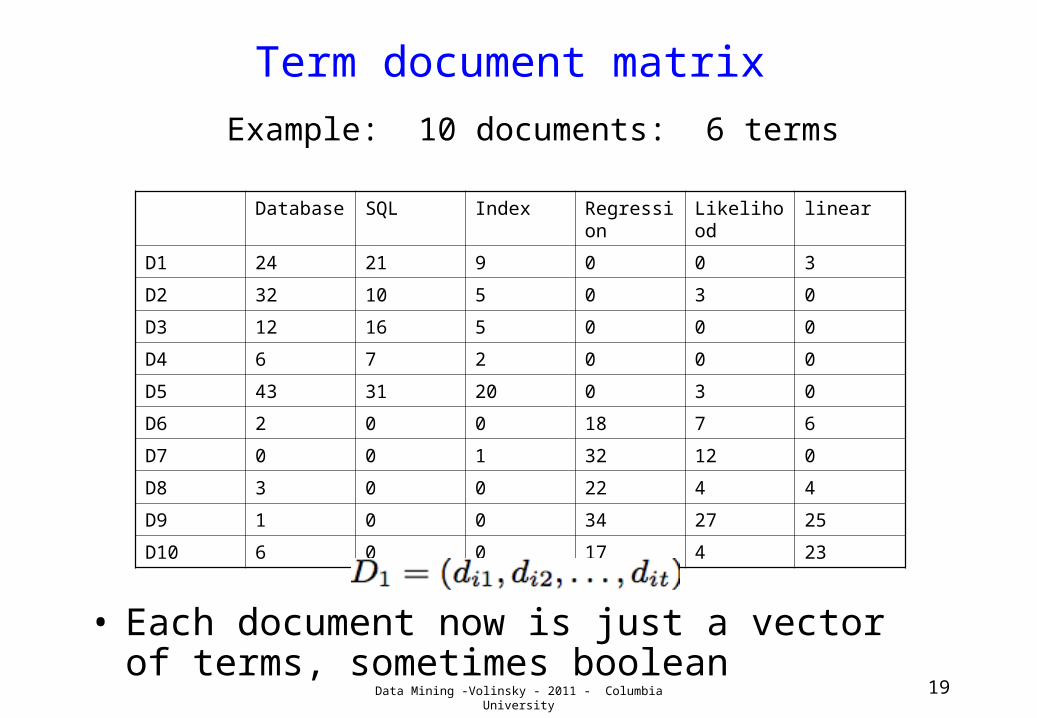
Term / document matrix
• Most common form of representation in text mining is the term - document matrix– Term: typically a single word, but could be a
word phrase like “data mining”– Document: a generic term meaning a
collection of text to be retrieved– Can be large - terms are often 50k or larger,
documents can be in the billions (www). – Can be binary, or use counts
Data Mining -Volinsky - 2011 - Columbia University 19
Term document matrix
• Each document now is just a vector of terms, sometimes boolean
Database SQL Index Regression
Likelihood
linear
D1 24 21 9 0 0 3
D2 32 10 5 0 3 0
D3 12 16 5 0 0 0
D4 6 7 2 0 0 0
D5 43 31 20 0 3 0
D6 2 0 0 18 7 6
D7 0 0 1 32 12 0
D8 3 0 0 22 4 4
D9 1 0 0 34 27 25
D10 6 0 0 17 4 23
Example: 10 documents: 6 terms

Data Mining -Volinsky - 2011 - Columbia University 20
Term document matrix
• We have lost all semantic content
• Be careful constructing your term list!– Not all words are created equal!– Words that are the same should be treated the
same!
• Stop Words• Stemming

Data Mining -Volinsky - 2011 - Columbia University 21
Stop words
• Many of the most frequently used words in English are worthless in retrieval and text mining – these words are called stop words.– the, of, and, to, ….– Typically about 400 to 500 such words– For an application, an additional domain specific stop words
list may be constructed
• Why do we need to remove stop words?– Reduce indexing (or data) file size
• stopwords accounts 20-30% of total word counts.
– Improve efficiency• stop words are not useful for searching or text mining• stop words always have a large number of hits

Data Mining -Volinsky - 2011 - Columbia University 22
Stemming
• Techniques used to find out the root/stem of a word:– E.g.,
– user engineering – users engineered – used engineer – using
• stem: use engineer
Usefulness• improving effectiveness of retrieval and text
mining – matching similar words
• reducing indexing size– combing words with same roots may reduce
indexing size as much as 40-50%.

Data Mining -Volinsky - 2011 - Columbia University 23
Basic stemming methods
• remove ending– if a word ends with a consonant other than s, followed by an s, then delete s.– if a word ends in es, drop the s.– if a word ends in ing, delete the ing unless the remaining
word consists only of one letter or of th.– If a word ends with ed, preceded by a consonant, delete the
ed unless this leaves only a single letter.– …...
• transform words– if a word ends with “ies” but not “eies” or “aies” then “ies --
> y.”

Data Mining -Volinsky - 2011 - Columbia University 24
Feature Selection
• Performance of text classification algorithms can be optimized by selecting only a subset of the discriminative terms– Even after stemming and stopword removal.
• Greedy search– Start from full set and delete one at a time– Find the least important variable
• Can use Gini index for this if a classification problem
• Often performance does not degrade even with orders of magnitude reductions– Chakrabarti, Chapter 5: Patent data: 9600 patents in
communcation, electricity and electronics.– Only 140 out of 20,000 terms needed for classification!

Data Mining -Volinsky - 2011 - Columbia University 25
Distances in TD matrices
• Given a term doc matrix represetnation, now we can define distances between documents (or terms!)
• Elements of matrix can be 0,1 or term frequencies (sometimes normalized)
• Can use Euclidean or cosine distance• Cosine distance is the angle between the two vectors• Not intuitive, but has been proven to work well
• If docs are the same, dc =1, if nothing in common dc=0
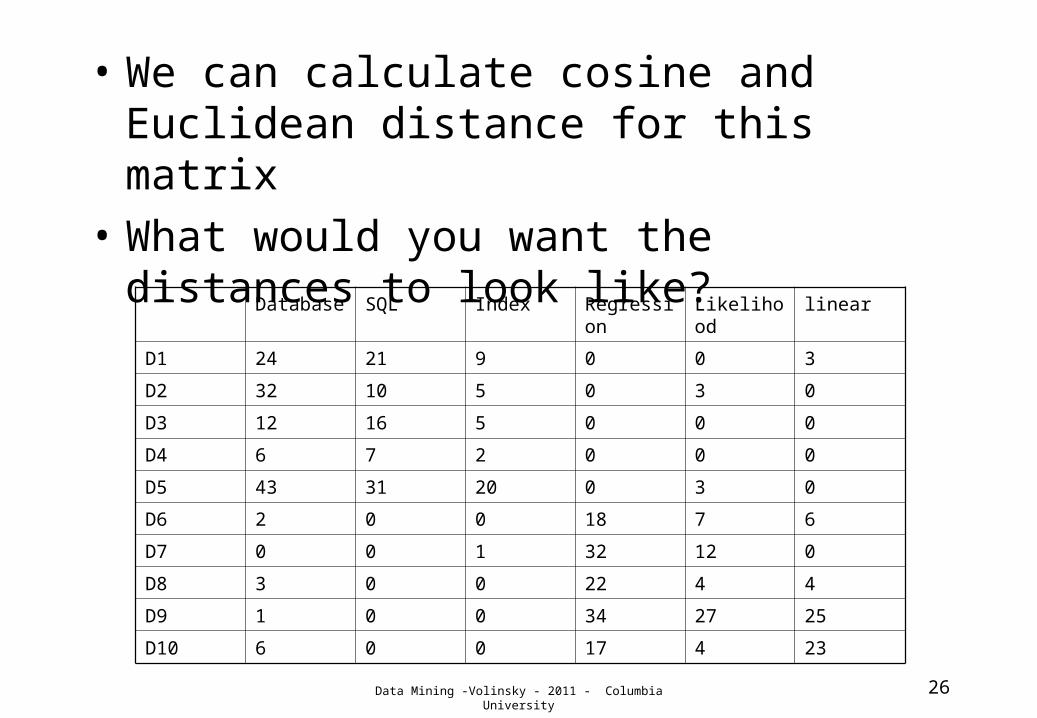
• We can calculate cosine and Euclidean distance for this matrix
• What would you want the distances to look like?
Data Mining -Volinsky - 2011 - Columbia University 26
Database SQL Index Regression
Likelihood
linear
D1 24 21 9 0 0 3
D2 32 10 5 0 3 0
D3 12 16 5 0 0 0
D4 6 7 2 0 0 0
D5 43 31 20 0 3 0
D6 2 0 0 18 7 6
D7 0 0 1 32 12 0
D8 3 0 0 22 4 4
D9 1 0 0 34 27 25
D10 6 0 0 17 4 23
Data Mining -Volinsky - 2011 - Columbia University 27
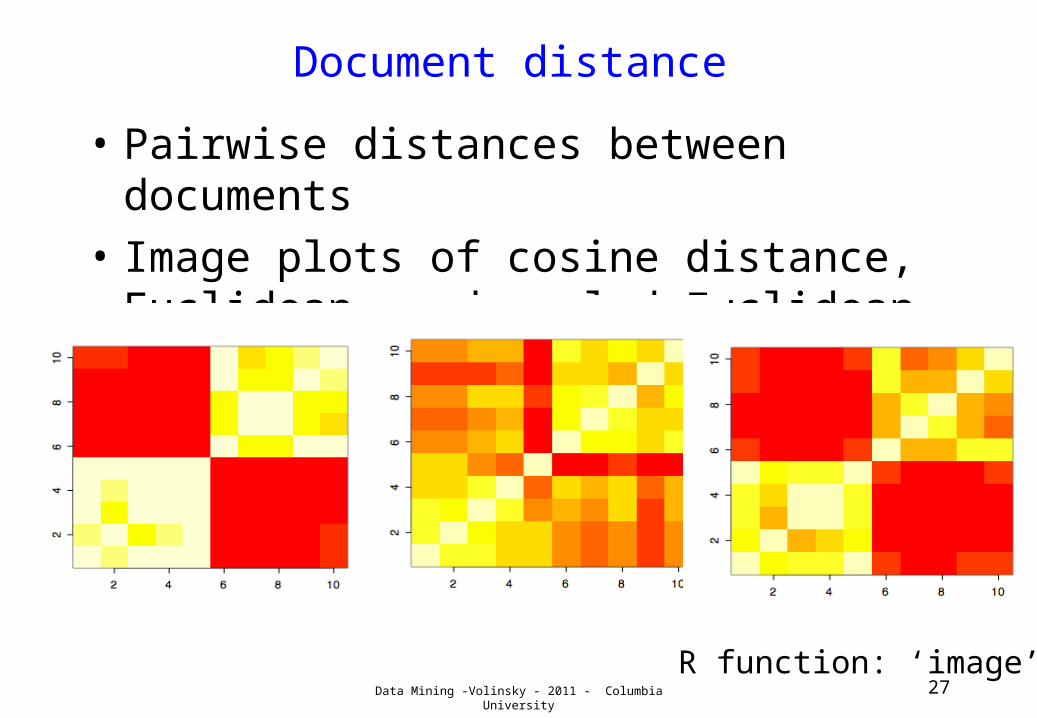
Document distance
• Pairwise distances between documents
• Image plots of cosine distance, Euclidean, and scaled Euclidean
R function: ‘image’

Data Mining -Volinsky - 2011 - Columbia University 28
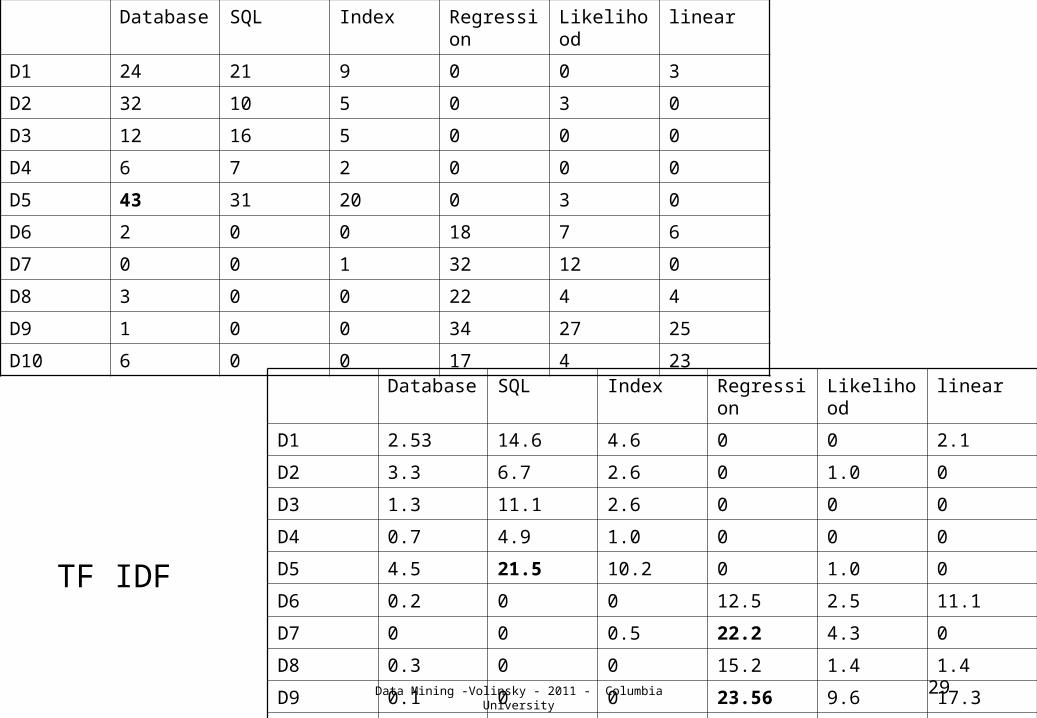
Weighting in TD space
• Not all phrases are of equal importance– E.g. David less important than Beckham– If a term occurs frequently in many documents it has less
discriminatory power– One way to correct for this is inverse-document frequency
(IDF).
– Term importance = Term Frequency (TF) x IDF– Nj= # of docs containing the term– N = total # of docs– A term is “important” if it has a high TF and/or a high IDF.– TF x IDF is a common measure of term importance
Data Mining -Volinsky - 2011 - Columbia University 29
Database SQL Index Regression
Likelihood
linear
D1 24 21 9 0 0 3
D2 32 10 5 0 3 0
D3 12 16 5 0 0 0
D4 6 7 2 0 0 0
D5 43 31 20 0 3 0
D6 2 0 0 18 7 6
D7 0 0 1 32 12 0
D8 3 0 0 22 4 4
D9 1 0 0 34 27 25
D10 6 0 0 17 4 23Database SQL Index Regressi
onLikelihood
linear
D1 2.53 14.6 4.6 0 0 2.1
D2 3.3 6.7 2.6 0 1.0 0
D3 1.3 11.1 2.6 0 0 0
D4 0.7 4.9 1.0 0 0 0
D5 4.5 21.5 10.2 0 1.0 0
D6 0.2 0 0 12.5 2.5 11.1
D7 0 0 0.5 22.2 4.3 0
D8 0.3 0 0 15.2 1.4 1.4
D9 0.1 0 0 23.56 9.6 17.3
D10 0.6 0 0 11.8 1.4 16.0
TF IDF

Data Mining -Volinsky - 2011 - Columbia University 30
Queries• A query is a representation of the user’s information
needs– Normally a list of words.
• Once we have a TD matrix, queries can be represented as a vector in the same space– “Database Index” = (1,0,1,0,0,0)
• Query can be a simple question in natural language
• Calculate cosine distance between query and the TF x IDF version of the TD matrix
• Returns a ranked vector of documents

Data Mining -Volinsky - 2011 - Columbia University 31
Latent Semantic Indexing• Criticism: queries can be posed in many ways,
but still mean the same– Data mining and knowledge discovery– Car and automobile– Beet and beetroot
• Semantically, these are the same, and documents with either term are relevant.
• Using synonym lists or thesauri are solutions, but messy and difficult.
• Latent Semantic Indexing (LSI): tries to extract hidden semantic structure in the documents
• Search what I meant, not what I said!

Data Mining -Volinsky - 2011 - Columbia University 32
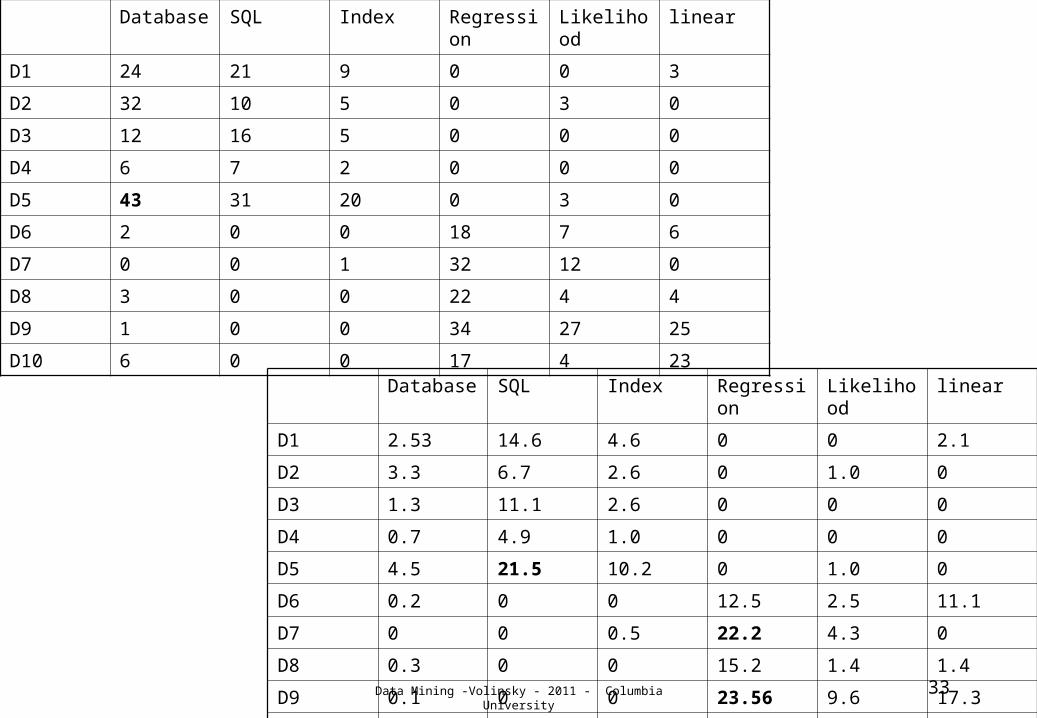
LSI
• Approximate the T-dimensional term space using principle components calculated from the TD matrix
• The first k PC directions provide the best set of k orthogonal basis vectors - these explain the most variance in the data. – Data is reduced to an N x k matrix, without much
loss of information
• Each “direction” is a linear combination of the input terms, and define a clustering of “topics” in the data.
• What does this mean for our toy example?
Data Mining -Volinsky - 2011 - Columbia University 33
Database SQL Index Regression
Likelihood
linear
D1 24 21 9 0 0 3
D2 32 10 5 0 3 0
D3 12 16 5 0 0 0
D4 6 7 2 0 0 0
D5 43 31 20 0 3 0
D6 2 0 0 18 7 6
D7 0 0 1 32 12 0
D8 3 0 0 22 4 4
D9 1 0 0 34 27 25
D10 6 0 0 17 4 23Database SQL Index Regressi
onLikelihood
linear
D1 2.53 14.6 4.6 0 0 2.1
D2 3.3 6.7 2.6 0 1.0 0
D3 1.3 11.1 2.6 0 0 0
D4 0.7 4.9 1.0 0 0 0
D5 4.5 21.5 10.2 0 1.0 0
D6 0.2 0 0 12.5 2.5 11.1
D7 0 0 0.5 22.2 4.3 0
D8 0.3 0 0 15.2 1.4 1.4
D9 0.1 0 0 23.56 9.6 17.3
D10 0.6 0 0 11.8 1.4 16.0

Data Mining -Volinsky - 2011 - Columbia University 34
LSI
• Typically done using Singular Value Decomposition (SVD) to find principal components
TD matrix
Term weighting by document - 10 x 6
New orthogonal basis for the data (PC directions) -
Diagonal matrix of eigenvalues
For our example: S = (77.4,69.5,22.9,13.5,12.1,4.8)Fraction of the variance explained (PC1&2) = = 92.5%
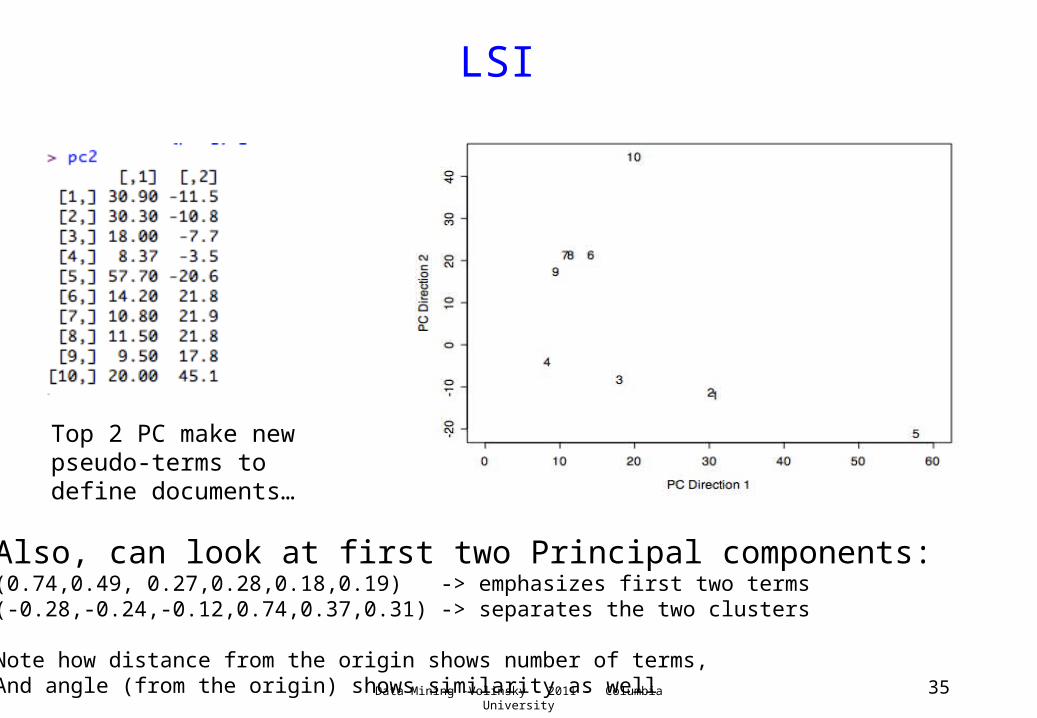
Data Mining -Volinsky - 2011 - Columbia University 35
LSI
Top 2 PC make new pseudo-terms to define documents…
Also, can look at first two Principal components:(0.74,0.49, 0.27,0.28,0.18,0.19) -> emphasizes first two terms(-0.28,-0.24,-0.12,0.74,0.37,0.31) -> separates the two clusters
Note how distance from the origin shows number of terms,And angle (from the origin) shows similarity as well
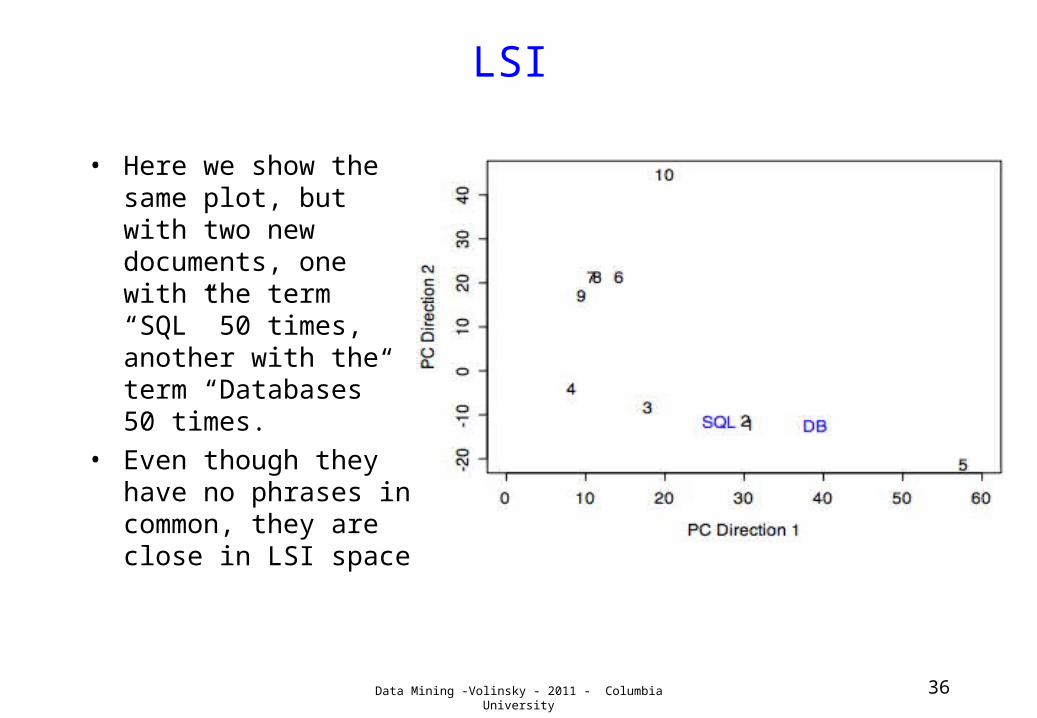
Data Mining -Volinsky - 2011 - Columbia University 36
LSI
• Here we show the same plot, but with two new documents, one with the term “SQL” 50 times, another with the term “Databases” 50 times.
• Even though they have no phrases in common, they are close in LSI space

Data Mining -Volinsky - 2011 - Columbia University 37
Textual analysis
• Once we have the data into a nice matrix representation (TD, TDxIDF, or LSI), we can throw the data mining toolbox at it:– Classification of documents
• If we have training data for classes
– Clustering of documents• unsupervised

Data Mining -Volinsky - 2011 - Columbia University 38
Automatic document classification
• Motivation– Automatic classification for the tremendous number of on-line
text documents (Web pages, e-mails, etc.) – Customer comments: Requests for info, complaints, inquiries
• A classification problem – Training set: Human experts generate a training data set– Classification: The computer system discovers the classification
rules– Application: The discovered rules can be applied to classify
new/unknown documents
• Techniques– Linear/logistic regression, naïve Bayes– Trees not so good here due to massive dimension, few
interactions

Data Mining -Volinsky - 2011 - Columbia University 39
Naïve Bayes Classifier for Text
• Naïve Bayes classifier = conditional independence model – Also called “multivariate Bernoulli”
– Assumes conditional independence assumption given the class: p( x | ck ) = p( xj | ck )
– Note that we model each term xj as a discrete random variable
In other words, the probability that a bunch of words comes
from a given class equals the product of the individual probabilities of those words.

jNx
j
kjkxk
ncxpcNpcp ∏
=
∝1
)|()|()|(x
Data Mining -Volinsky - 2011 - Columbia University 40
Multinomial Classifier for Text• Multinomial Classification model
– Assumes that the data are generated by a p-sided die (multinomial model)
– where Nx = number of terms (total count) in document x
– xj = number of times term j occurs in the document
– ck = class = k
– Based on training data, each class has its own multinomial probability across all words.
.

Naïve Bayes vs. Multinomial
• Many extensions and adaptations of both• Text mining classification models usually a version
of one of these• Example: Web pages
– Classify webpages from CS departments into:• student, faculty, course,project
– Train on ~5,000 hand-labeled web pages from Cornell, Washington, U.Texas, Wisconsin
– Crawl and classify a new site (CMU)
Data Mining -Volinsky - 2011 - Columbia University 41
Student Faculty Person Project Course DepartmtExtracted 180 66 246 99 28 1Correct 130 28 194 72 25 1Accuracy: 72% 42% 79% 73% 89% 100%
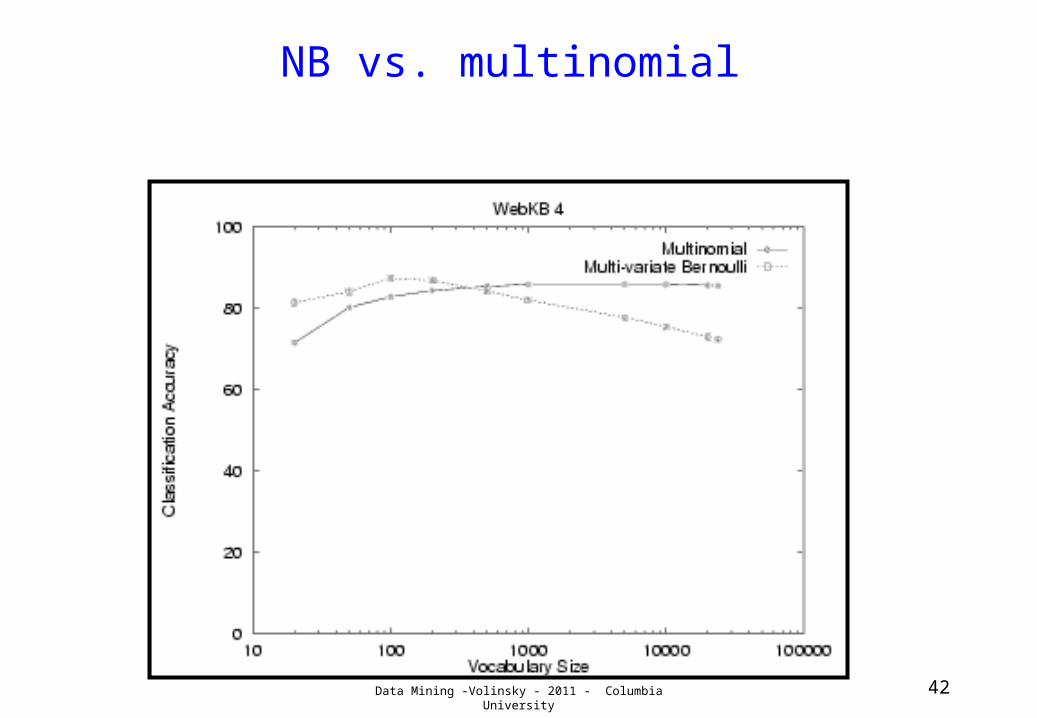
NB vs. multinomial
Data Mining -Volinsky - 2011 - Columbia University 42
Data Mining -Volinsky - 2011 - Columbia University 43
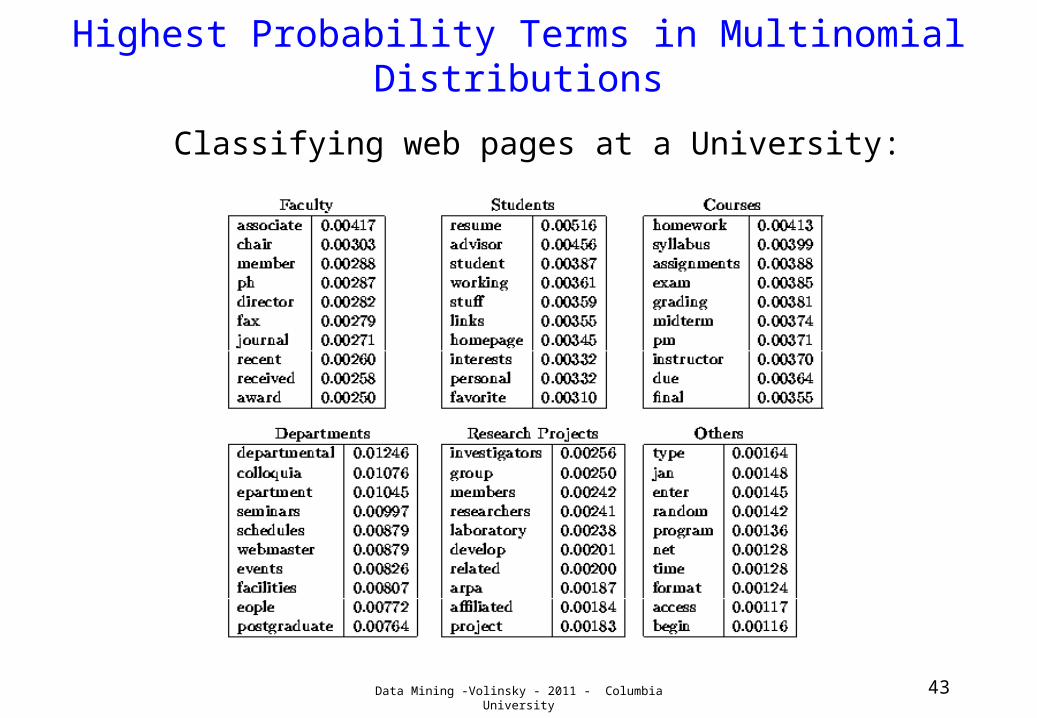
Highest Probability Terms in Multinomial Distributions
Classifying web pages at a University:

Data Mining -Volinsky - 2011 - Columbia University 44
Document Clustering• Can also do clustering, or unsupervised learning of
docs.• Automatically group related documents based on their
content.• Require no training sets or predetermined taxonomies.• Major steps
– Preprocessing• Remove stop words, stem, feature extraction, lexical
analysis, …– Hierarchical clustering
• Compute similarities applying clustering algorithms, …– Slicing
• Fan out controls, flatten the tree to desired number of levels.
• Like all clustering examples, success is relative

Document Clustering
• To Cluster:– Can use LSI– Another model: Latent Dirichlet Allocation (LDA)– LDA is a generative probabilistic model of a corpus.
Documents are represented as random mixtures over latent topics, where a topic is characterized by a distribution over words.
• LDA:– Three concepts: words, topics, and documents– Documents are a collection of words and have a
probability distribution over topics– Topics have a probability distribution over words– Fully Bayesian Model
Data Mining -Volinsky - 2011 - Columbia University 45

LDA• Assume data was generated by a generative process: is a document - made up from topics from a probability
distribution• z is a topic made up from words from a probability distribution• w is a word, the only real observables (N=number of words in all
documents)
• Then, the LDA equations are specified in a fully Bayesian model:
Data Mining -Volinsky - 2011 - Columbia University 46
=per-document topic distributions

Which can be solved via advance computational techniques
see Blei, et al 2003
Data Mining -Volinsky - 2011 - Columbia University 47

LDA output• The result can be an often-useful classification of documents
into topics, and a distribution of each topic across words:
Data Mining -Volinsky - 2011 - Columbia University 48
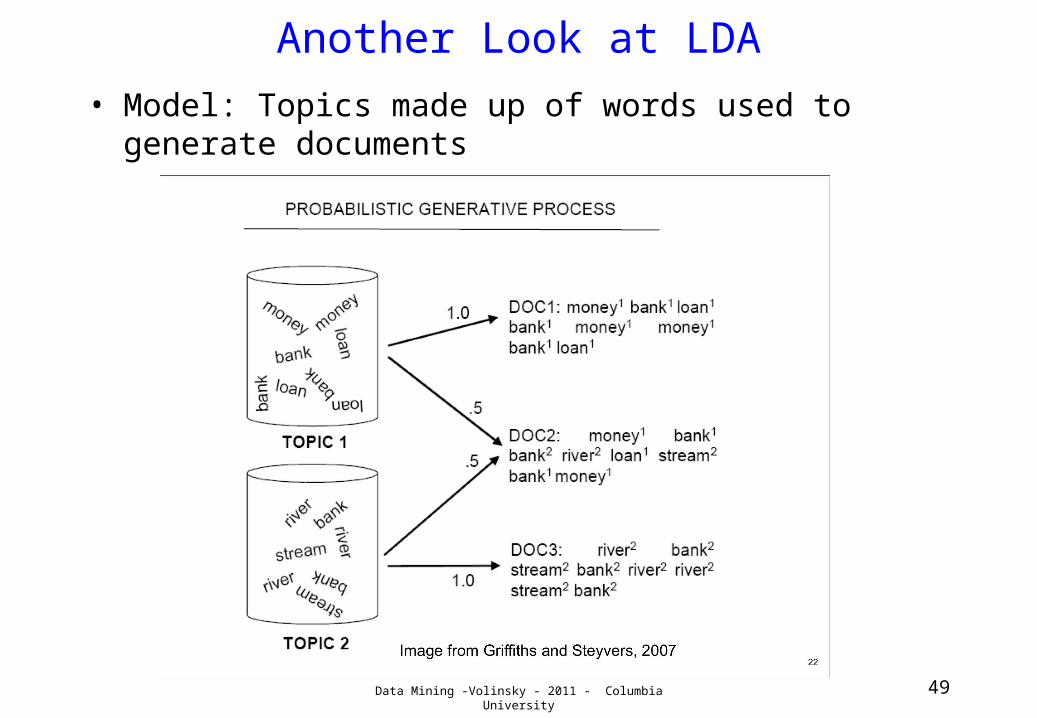
Another Look at LDA• Model: Topics made up of words used to generate
documents
Data Mining -Volinsky - 2011 - Columbia University 49
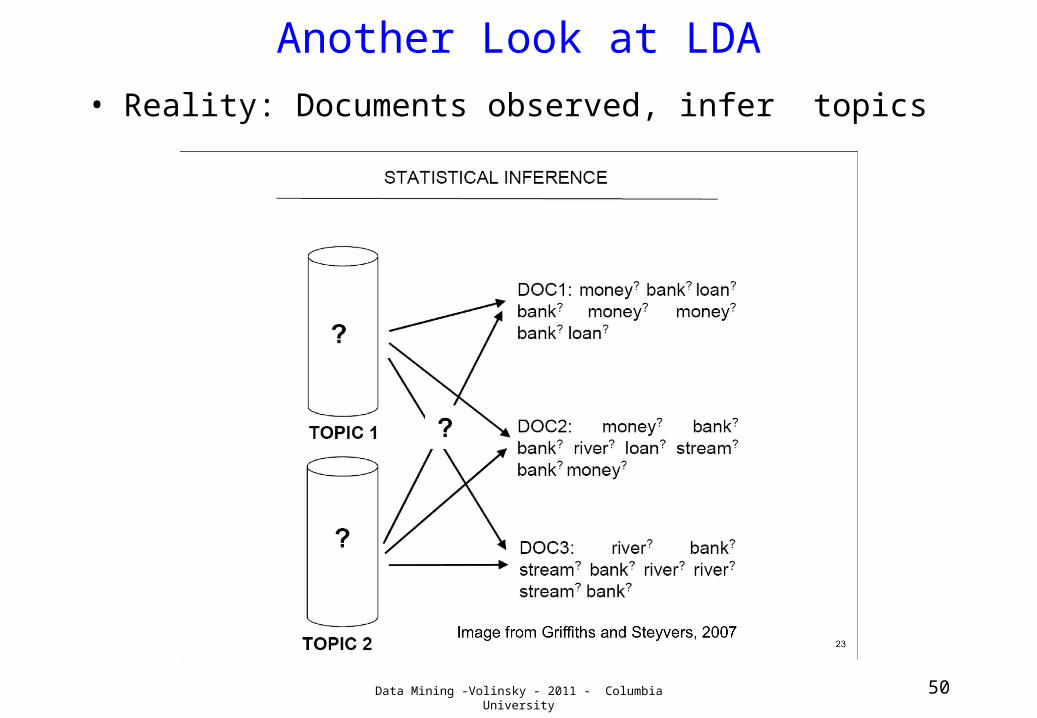
Another Look at LDA• Reality: Documents observed, infer topics
Data Mining -Volinsky - 2011 - Columbia University 50

Case Study: TV Listings
• Use text to make recommendations for TV shows
Data Mining -Volinsky - 2011 - Columbia University 51

Data Issues
• 10013|In Harm's Way|In Harm's Way|A tough Naval officer faces the enemy while fighting in the South Pacific during World War II.|A tough Naval officer faces the enemy while fighting in the South Pacific during World War II.|en-US| Movie,NR Rating|Movies:Drama|||165|1965|USA||||||STARS-3||NR|John Wayne, Kirk Douglas, Patricia Neal, Tom Tryon, Paula Prentis s, Burgess Meredith|Otto Preminger||||Otto Preminger|
Parsed Program Guide entries – 2 weeks, ~66,000 programs, 19,000 words
• Collapse on series (syndicated shows are still a problem)• Stopwords/stemming, duplication, paid programming,
length normalization
Data Mining -Volinsky - 2011 - Columbia University 52

Data Processing• Combine shows from one series into a ‘canonical’ format
Data Mining -Volinsky - 2011 - Columbia University 53

Results
• We fit LDA– Results in a full distribution of words, topics and
documents– Topics are unveiled which are a collection of words
Data Mining -Volinsky - 2011 - Columbia University 54

Results• For user modelling, consider the collection of
shows a single user watches as a ‘document’ – then look to see what topics (and hence, words) make up that document
Data Mining -Volinsky - 2011 - Columbia University 55

Data Mining -Volinsky - 2011 - Columbia University 56

Show mining via text
Data Mining -Volinsky - 2011 - Columbia University 57

Text Mining: Helpful Data
• WordNet
Data Mining -Volinsky - 2011 - Columbia University 58Courtesy: Luca Lanzi

Data Mining -Volinsky - 2011 - Columbia University 59
Text Mining - Other Topics• Part of Speech Tagging
– Assign grammatical tags to words (verb, noun, etc)– Helps in understanding documents : uses Hidden Markov
Models
• Named Entity Classification– Classification task: can we automatically detect proper nouns
and tag them– “Mr. Jones” is a person; “Madison” is a town.– Helps with dis-ambiguation: spears

Data Mining -Volinsky - 2011 - Columbia University 60
Text Mining - Other Topics
• Sentiment Analysis– Automatically determine tone in text: positive, negative or
neutral– Typically uses collections of good and bad words– “While the traditional media is slowly starting to take John
McCain’s straight talking image with increasingly large grains of salt, his base isn’t quite ready to give up on their favorite son. Jonathan Alter’s bizarre defense of McCain after he was caught telling an outright lie, perfectly captures that reluctance[.]”
– Often fit using Naïve Bayes
• There are sentiment word lists out there: – See http://neuro.imm.dtu.dk/wiki/Text_sentiment_analysis

Data Mining -Volinsky - 2011 - Columbia University 61
Text Mining - Other Topics
• Summarizing text: Word Clouds– Takes text as input, finds the
most interesting ones, and displays them graphically
– Blogs do this– Wordle.net
Data Mining -Volinsky - 2011 - Columbia University 62
Modest Mouse lyrics

References• Text classification
– Excellent lecture by William Cohen – quite detailed, uses knn, TFIDF,nerural nets, other models
– http://videolectures.net/mlas06_cohen_tc/
• LDA and topic models– Seminal paper: Blei, David M.; Ng, Andrew Y.; Jordan, Michael I (January 2003).
Lafferty, John. ed. "Latent Dirichlet allocation". Journal of Machine Learning Research 3
– Tutorial on text topic modelling from David Blei: http://www.cs.princeton.edu/~blei/papers/Blei2011.pdf
• General text mining topics– Many text mining tutorial available at LingPipe:
• http://alias-i.com/lingpipe/demos/tutorial/cluster/read-me.html
– Code available but written in Java
• Sentiment Analysis– Bing Liu tutorial: http://www.cs.uic.edu/~liub/FBS/Sentiment-Analysis-tutorial-
AAAI-2011.pdf– Searching for Bing Liu will find many resources on this topic– Sentiment analysis in Twitter: http://danzambonini.com/self-improving-bayesian-
sentiment-analysis-for-twitter/
• Twitter text mining tutorial– http://jeffreybreen.wordpress.com/2011/07/04/twitter-text-mining-r-slides/
Data Mining -Volinsky - 2011 - Columbia University 63