data structures and algorithms lecture (binarytrees) instructor: quratulain
TRANSCRIPT

Data Structures and Algorithms
Lecture (BinaryTrees)
Instructor: Quratulain
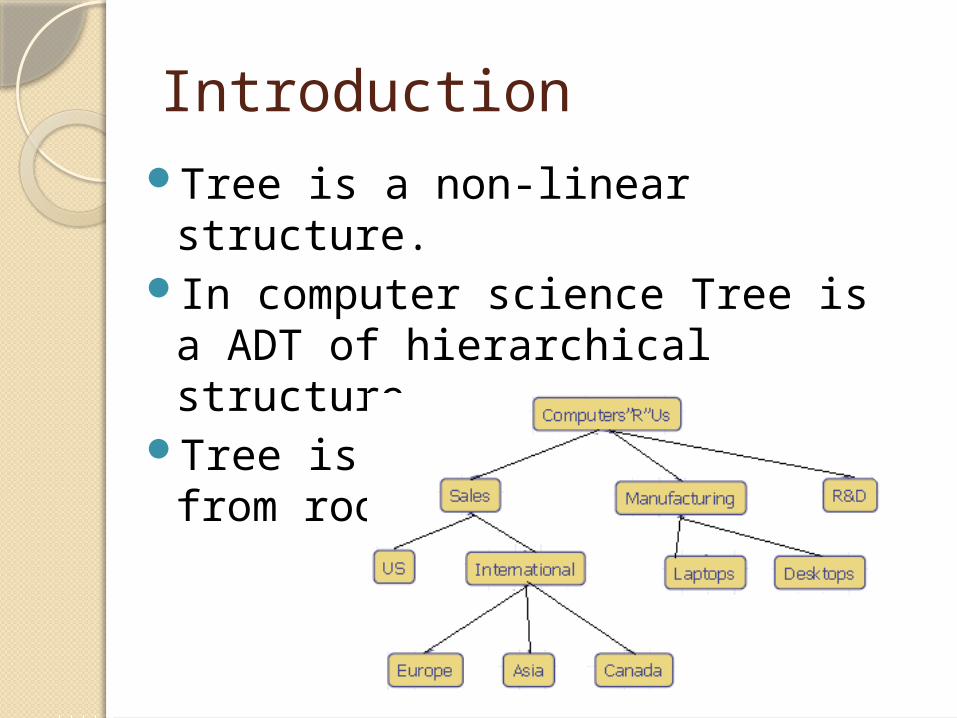
IntroductionTree is a non-linear structure.In computer science Tree is a ADT
of hierarchical structure.Tree is divided into levels from
root to leaf nodes.
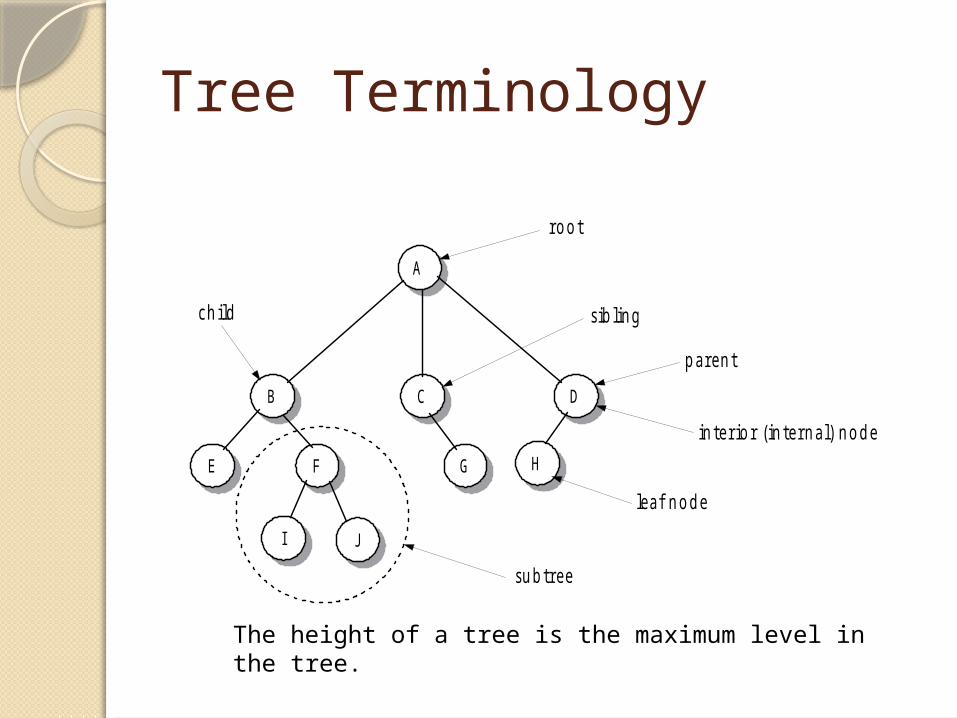
Tree Terminology
A
JI
HGFE
DCB
ro o t
parent
ch ild
subtree
leaf no de
sib ling
in ter io r (in ternal) no de
The height of a tree is the maximum level in the tree.

Terminology
Node, branch, root, indegree, outdegree, leaf, parent, child, siblings, ancestor, descendent, path, level, height, depth, subtree

Binary TreeEach node has 0, 1 and 2 childs
Each node of a binary tree defines a left and a right subtree. Each subtree is itself a tree.

© 2005 Pearson Education, Inc., Upper Saddle River, NJ. All rights reserved.
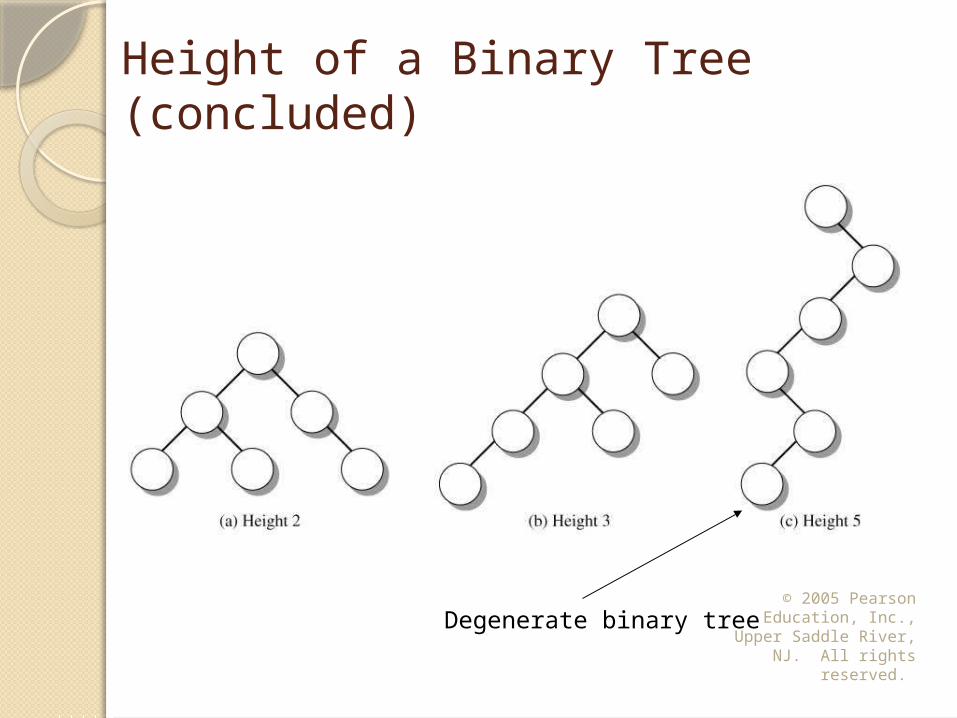
Height of a Binary TreeThe height of a binary tree is the
length of the longest path from the root to a leaf node. Let TN be the subtree with root N and TL and TR be the roots of the left and right subtrees of N. Then -1 if TN is empty
1+max( height(TL), height(TR)) if TN not emptyheight(N) = height(TN) = {
© 2005 Pearson Education, Inc., Upper Saddle River,
NJ. All rights reserved.
Height of a Binary Tree (concluded)
Degenerate binary tree

Types Binary TreesComplete binary tree: A complete
binary tree of height h has all possible nodes through level h-1, and some nodes on depth h exist left to right with no gaps.
Full binary tree: A tree in which every node other than the leaves has two children
Perfect binary tree: A full binary tree in which all leaves are at the same level

Binary treeTotal number of nodes in
complete binary tree is from 2h – 1 to 2h+1
The height of complete binary tree h=(log2n)
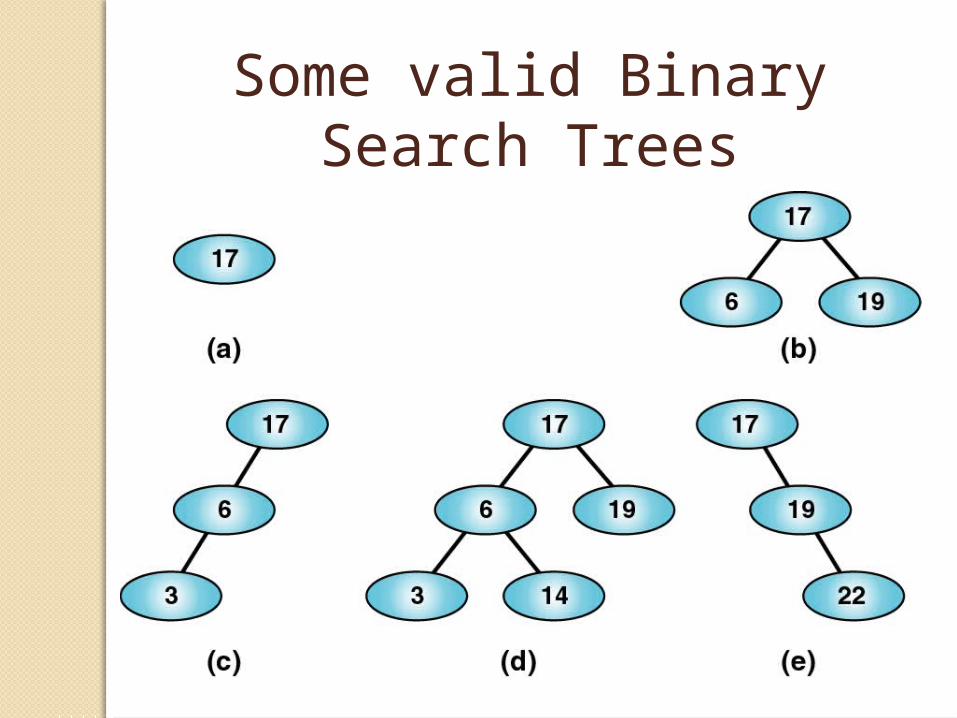
Some valid Binary Search Trees
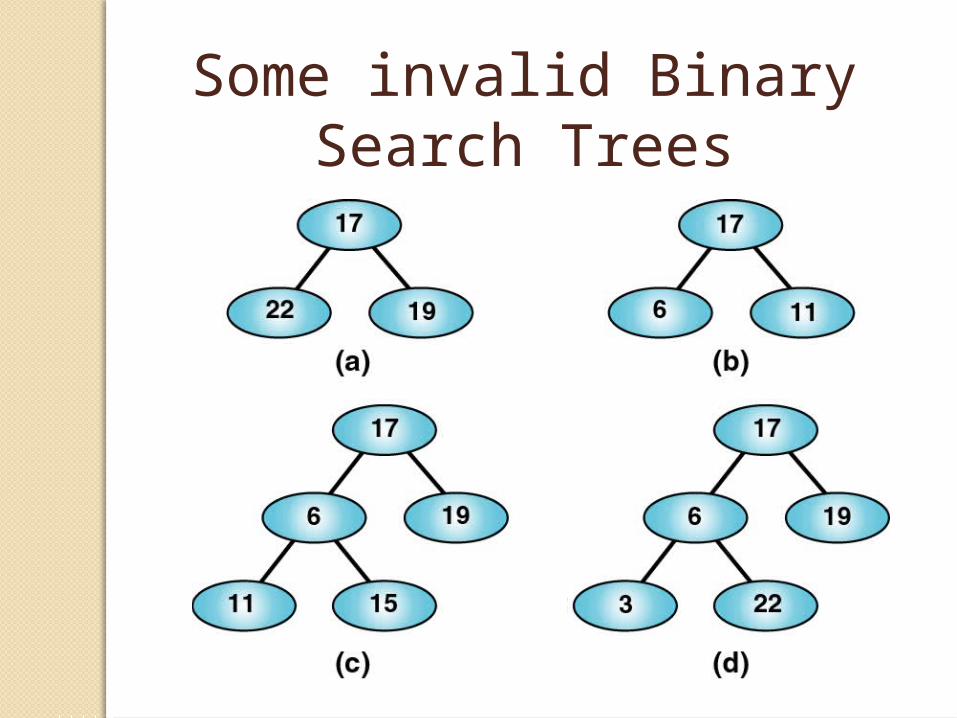
Some invalid Binary Search Trees

Application of Binary TreesFor two-way decisions at each
point in a process. Then the number of comparison could be reduced.
to path finding, connected components.
Application of SortingApplication of searchingExpression tree

Linklist and Arrays for binary tree
Store in array using formula:2n+1 for left child2n+2 for right child

Binary Trees: Traversals
• There are three classic ways to traverse a tree: NLR, LNR and LRN
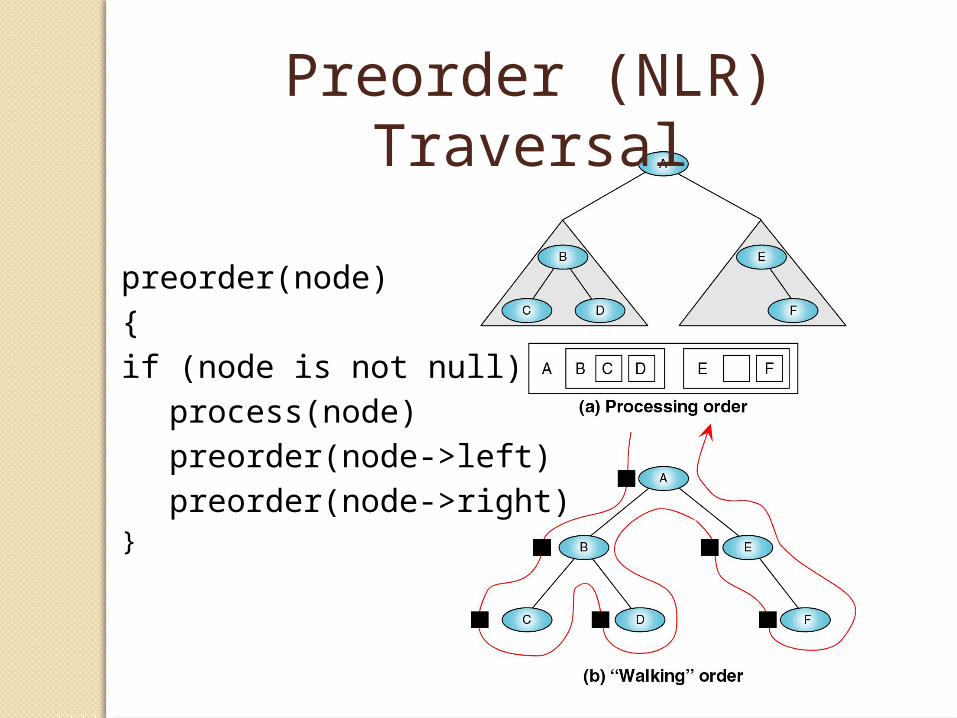
Preorder (NLR) Traversal
preorder(node)
{
if (node is not null)
process(node)
preorder(node->left)
preorder(node->right)}
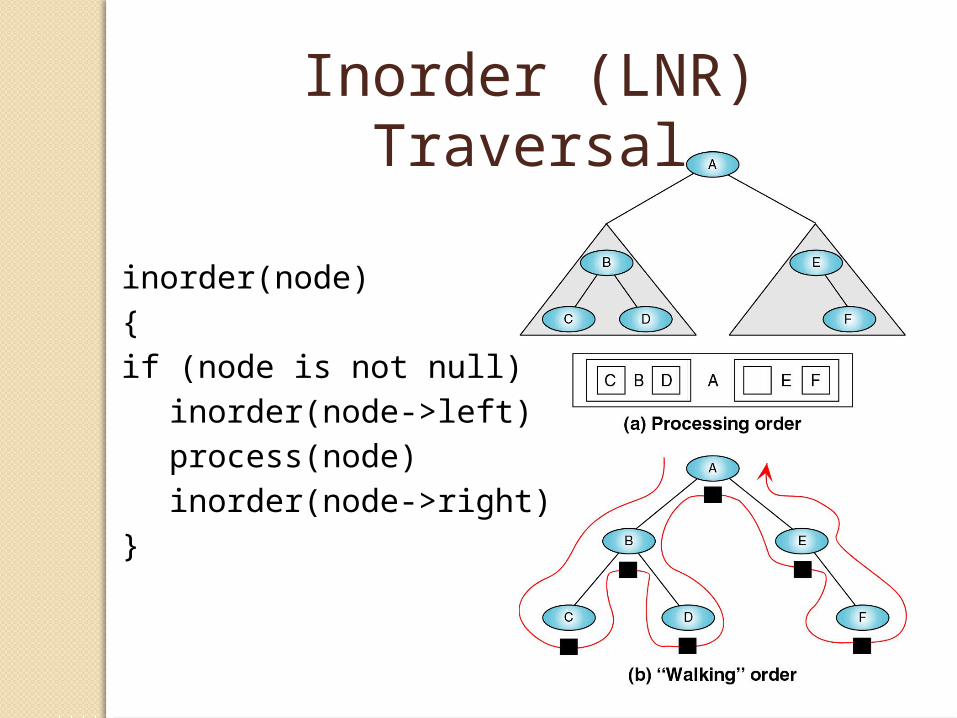
Inorder (LNR) Traversal
inorder(node)
{
if (node is not null)
inorder(node->left)
process(node)
inorder(node->right)
}
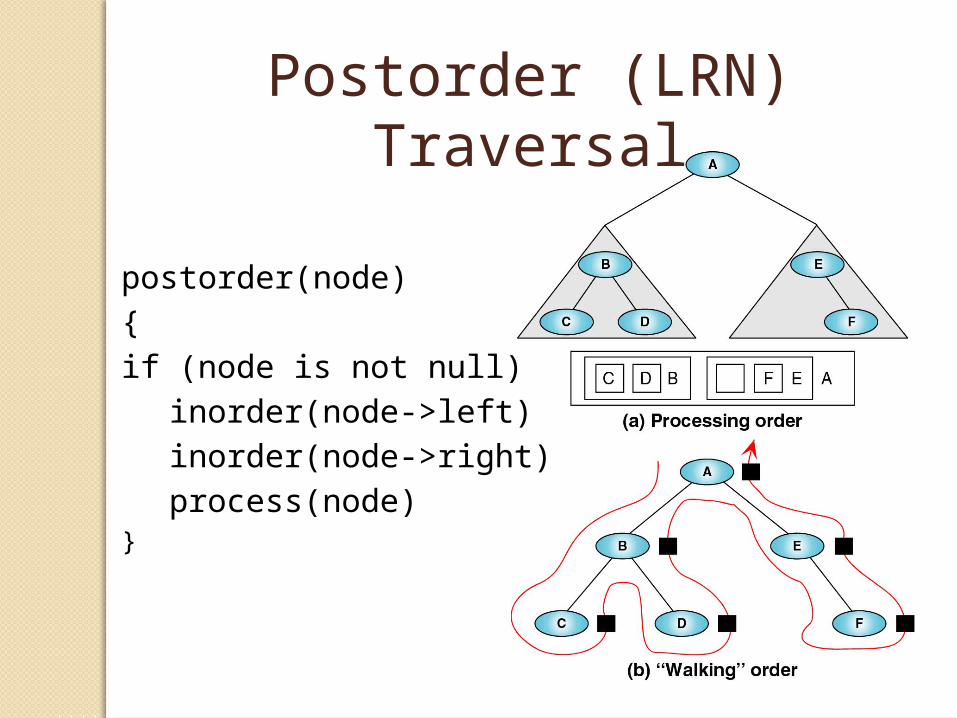
Postorder (LRN) Traversal
postorder(node)
{
if (node is not null)
inorder(node->left)
inorder(node->right)
process(node)}
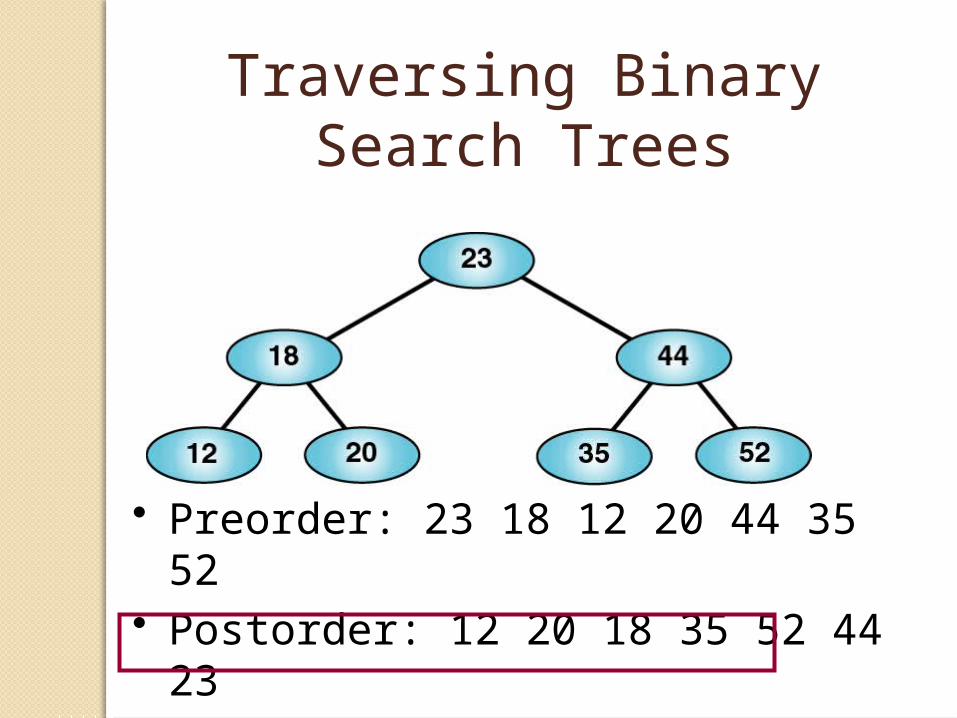
Traversing Binary Search Trees
• Preorder: 23 18 12 20 44 35 52• Postorder: 12 20 18 35 52 44 23• Inorder: 12 18 20 23 44 35 52

Delete to Binary Search Trees
The deletion algorithm is more complicated, because after a non-leaf node is deleted, the "hole" in the structure needs to be filled by a leaf node. There are three possibilities: ◦ To delete a leaf node (no children): disconnect it. ◦ To delete a node with one child: bypass the node
and directly connect to the child. ◦ To delete a node with two children: find the
smallest node in its right subtree (or the largest node in its left subtree), copy the minimum value into the info field of the "node to be deleted" and then delete the minimum node instead, which can only have a right child, so the situation becomes one of the above two.

Binary Search Trees vs. ArraysSame O(log2N) searchBetter insertion time: O(log2N)
vs. O(N)Better deletionWhat is worse? O(N)BST requires more space - 2
references for each data element

Huffman Codes Binary trees can be used in an
interesting way to construct minimal length encodings for messages when the frequency of letters used in the messages is known.
A special kind of binary tree, called a Huffman coding tree is used to accomplish this. (Chapter 8 for detail)

Huffman CodesHuffman is a coding algorithm
presented by David Huffman in 1952. It's an algorithm which works with integer length codes.
Huffman is the best option because it's optimal.
The position of the symbol depends on its probability. Then it assigns a code based on its position in the tree. The codes have the prefix property and are instantaneously decodable thus they are well suited for compression and decompression.

Example
suppose we know that the frequency of occurrences for six letters in a message are as given below:
To build the Huffman tree, we sort the frequencies into increasing order (4, 5, 7, 8, 12, 29). Then we choose the two smallest values, 4 and 5, and construct a binary tree with labeled edges:
E 29
I 5
N 7
P 12
S 4
T 8
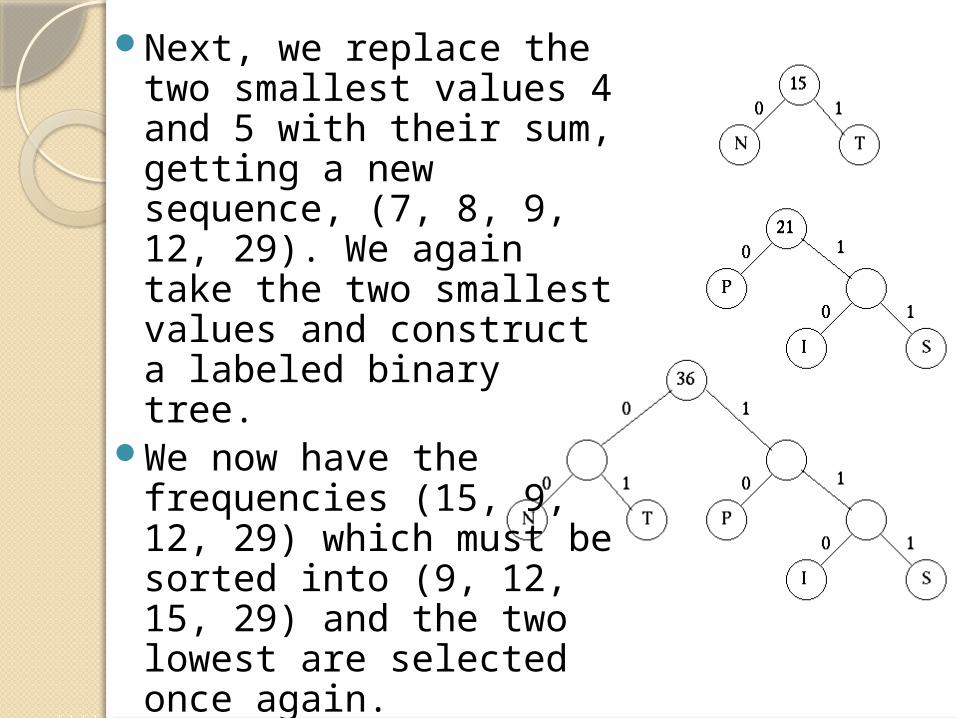
Next, we replace the two smallest values 4 and 5 with their sum, getting a new sequence, (7, 8, 9, 12, 29). We again take the two smallest values and construct a labeled binary tree.
We now have the frequencies (15, 9, 12, 29) which must be sorted into (9, 12, 15, 29) and the two lowest are selected once again.
Now, we combine the two lowest which are 15 and 21 to give the tree.

The two remaining frequencies, 36 and 29, are now combined into the final tree. Notice that it does not make any difference which one is placed as the left subtree and which in the right subtree.
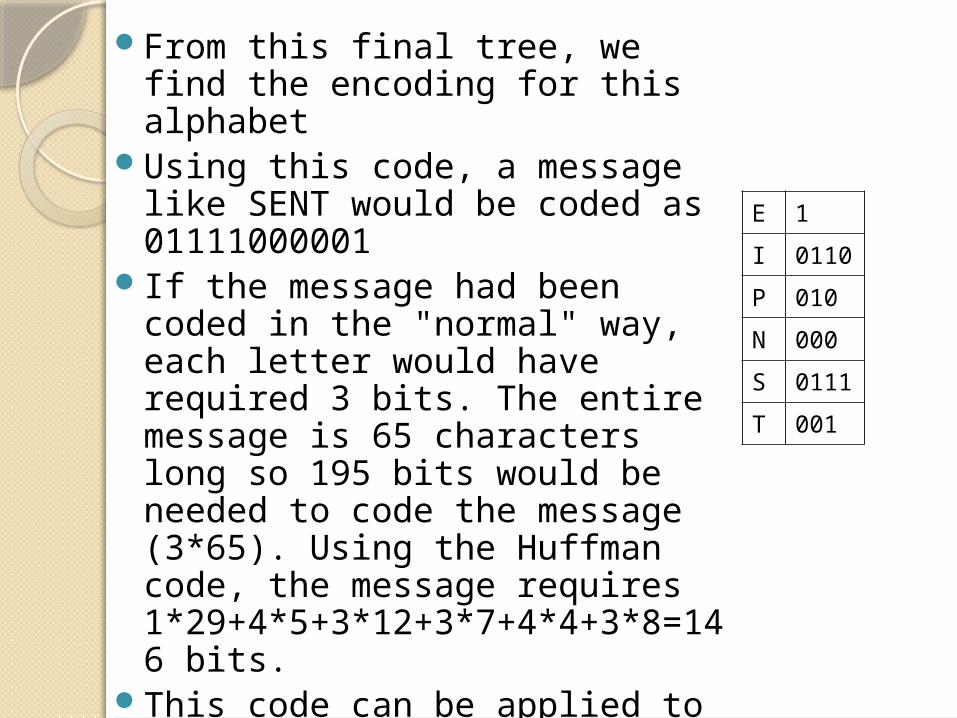
From this final tree, we find the encoding for this alphabet
Using this code, a message like SENT would be coded as 01111000001
If the message had been coded in the "normal" way, each letter would have required 3 bits. The entire message is 65 characters long so 195 bits would be needed to code the message (3*65). Using the Huffman code, the message requires 1*29+4*5+3*12+3*7+4*4+3*8=146 bits.
This code can be applied to the English Language by using average frequency counts for the letters.
E 1
I 0110
P 010
N 000
S 0111
T 001