david f. bacon perry cheng v.t. rajan ibm t.j. watson research center the metronome: a hard...
TRANSCRIPT

David F. BaconDavid F. Bacon
Perry ChengPerry Cheng
V.T. RajanV.T. Rajan
IBM T.J. Watson Research IBM T.J. Watson Research CenterCenter
The Metronome:The Metronome:A Hard Real-timeA Hard Real-timeGarbage CollectorGarbage Collector

The Problem
• Real-time systems growing in importance– Many CPUs in a BMW: “80% of innovation in
SW”
• Programmers left behind– Still using assembler and C– Lack productivity advantages of Java
• Result– Complexity– Low reliability or very high validation cost

Problem Domain
• Hard real-time garbage collection• Uniprocessor
– Multiprocessors very rare in real-time systems
– Complication: collector must be finely interleaved
– Simplification: memory model easier to program• No truly concurrent operations• Sequentially consistent

Metronome Project Goals
• Make GC feasible for hard real-time systems
• Provide simple application interface• Develop technology that is efficient:
– Throughput, Space comparable to stop-the-world
• BREAK THE MILLISECOND BARRIER– While providing even CPU utilization

Outline
• What is “Real-Time” Garbage Collection?
• Problems with Previous Work• Overview of the Metronome• Scheduling• Empirical Results• Conclusions

What is “Real-Time”Garbage Collection?
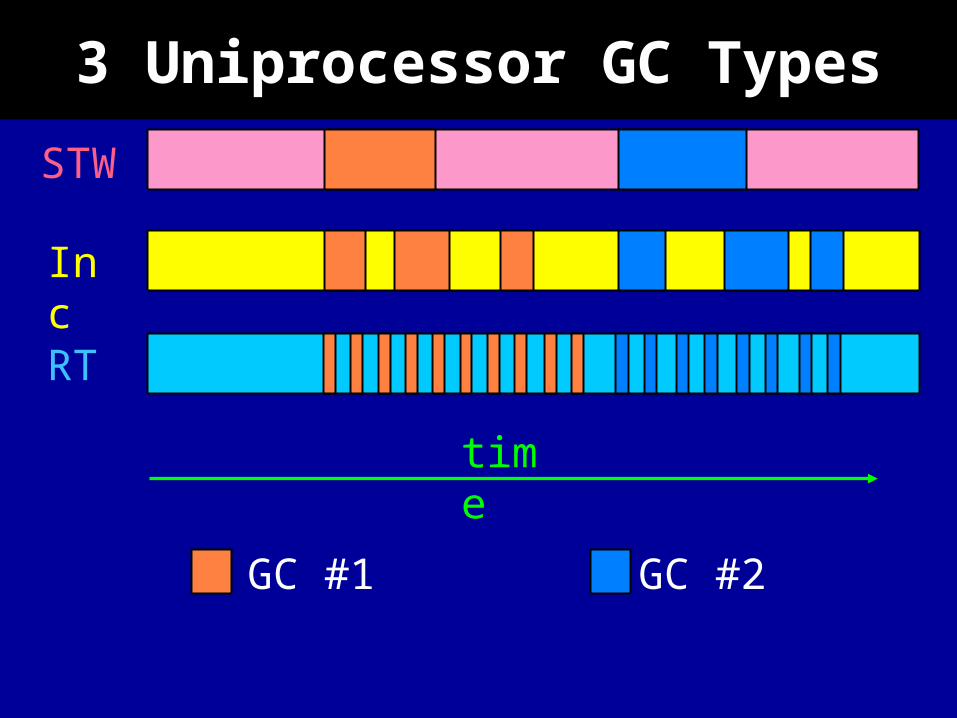
3 Uniprocessor GC Types
STW
Inc
RT
time
GC #1 GC #2

Utilization vs Time: 2s Window
0
0.2
0.4
0.6
0.8
1
0 0.5 1 1.5 2 2.5 3 3.5 4 4.5 5 5.5 6 6.5 7 7.5 8
Time (s)
Uti
liza
tio
n (
%)
STW
Inc
RT

Utilization vs Time: .4 s Window
STW
Inc
RT
0
0.2
0.4
0.6
0.8
1
Time (s)
Uti
lizat
ion

Minimum Mutator Utilization
STW
Inc
RT
0
20
40
60
80
100
Window Size (s) - logarithmic scale
MM
U

What is Real-time? It Is…
• Maximum pause time < required response
• CPU Utilization sufficient to accomplish task– Measured with MMU
• Memory requirement < resource limit

Problems with Previous Work
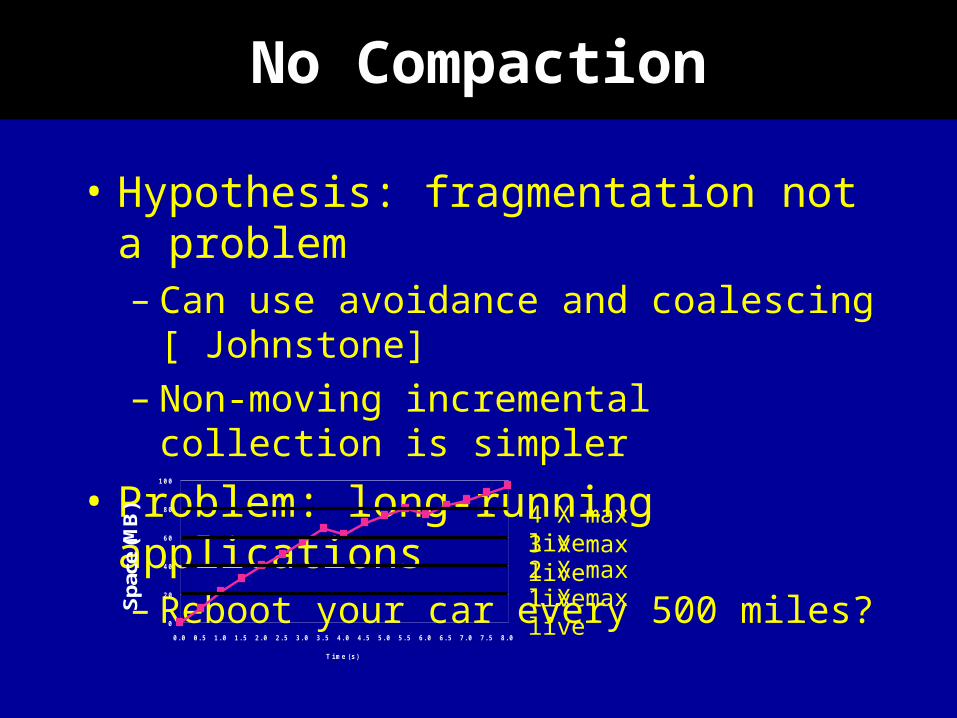
No Compaction
• Hypothesis: fragmentation not a problem– Can use avoidance and coalescing
[ Johnstone]– Non-moving incremental collection is
simpler
• Problem: long-running applications– Reboot your car every 500 miles?
0
20
40
60
80
100
0. 0 0. 5 1. 0 1. 5 2. 0 2. 5 3. 0 3. 5 4. 0 4. 5 5. 0 5. 5 6. 0 6. 5 7. 0 7. 5 8. 0
T i me (s )
Spa
ce (M
B)
1 X max live2 X max live3 X max live4 X max live
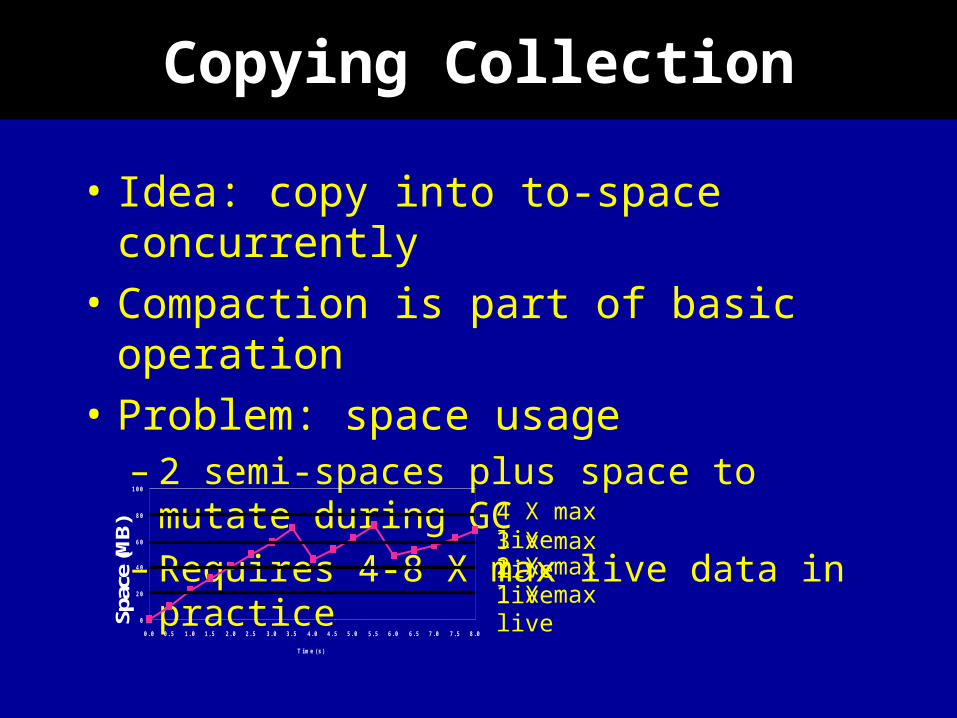
Copying Collection
• Idea: copy into to-space concurrently
• Compaction is part of basic operation
• Problem: space usage– 2 semi-spaces plus space to mutate
during GC– Requires 4-8 X max live data in
practice0
20
40
60
80
100
0. 0 0. 5 1. 0 1. 5 2. 0 2. 5 3. 0 3. 5 4. 0 4. 5 5. 0 5. 5 6. 0 6. 5 7. 0 7. 5 8. 0
T i me (s )
Spa
ce (M
B)
1 X max live2 X max live3 X max live4 X max live

Work-Based Scheduling
• The Baker fallacy:– “A real-time list processing system is one in which the
time required by the elementary list processing operations…is bounded by a small constant” [Baker’78]
• Implicitly assumes GC work done in mutator– What does “small constant” mean?– Typically, constant is not so small
• And there is variability (fault rate analogy)
0
20
40
60
80
100
T i me (s )
MM
U

Overview of the Metronome
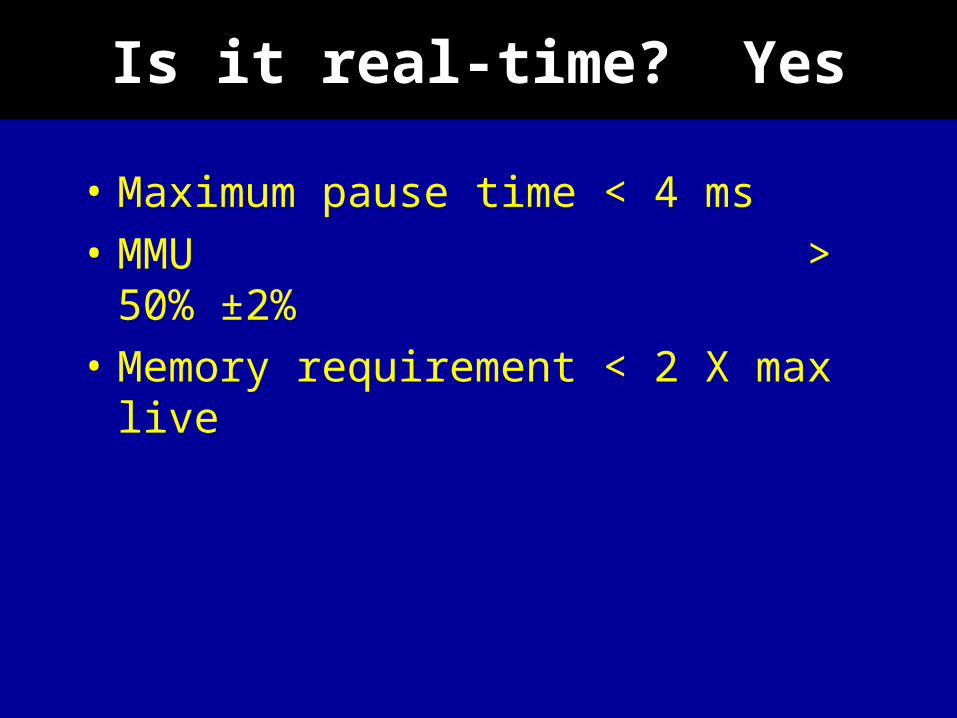
Is it real-time? Yes
• Maximum pause time < 4 ms• MMU > 50% ±2%• Memory requirement < 2 X max
live

Components of the Metronome
• Segregated free list allocator– Geometric size progression limits internal
fragmentation
• Write barrier: snapshot-at-the-beginning [Yuasa]• Read barrier: to-space invariant [Brooks]
– New techniques with only 4% overhead
• Incremental mark-sweep collector– Mark phase fixes stale pointers
• Selective incremental defragmentation– Moves < 2% of traced objects
• Arraylets: bound fragmentation, large object ops• Time-based scheduling
Old New

Segregated Free List Allocator
• Heap divided into fixed-size pages• Each page divided into fixed-size
blocks• Objects allocated in smallest block
that fits
24
16
12

Fragmentation on a Page
• Internal: wasted space at end of object
• Page-internal: wasted space at end of page
• External: blocks needed for other size
external
internal page-internal

Limiting Internal Fragmentation
• Choose page size P and block sizes sk such that– sk = sk-1(1+ρ)
– smax = P ρ
• Then– Internal and page-internal fragmentation < ρ
• Example:– P =16KB, ρ =1/8, smax = 2KB
– Internal and page-internal fragmentation < 1/8

Fragmentation: ρ=1/8 vs ρ=1/2
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Internal Page-Internal External Recently Dead Live

Write Barrier: Snapshot-at-start
• Problem: mutator changes object graph• Solution: write barrier prevents lost objects• Logically, collector takes atomic snapshot
– Objects live at snapshot will not be collected– Write barrier saves overwritten pointers
[Yuasa]– Write buffer must be drained periodically
WB
A
C
BB

Read Barrier: To-space Invariant
• Problem: Collector moves objects (defragmentation)– and mutator is finely interleaved
• Solution: read barrier ensures consistency– Each object contains a forwarding pointer [Brooks]– Read barrier unconditionally forwards all pointers– Mutator never sees old versions of objects
From-spaceTo-space
A
X
Y
Z
A
X
Y
Z
A′
BEFORE AFTER

Read Barrier Optimizations
• Barrier variants: when to redirect– Lazy: easier for collector (no fixup)– Eager: better for performance (loop over a[i])
• Standard optimizations: CSE, code motion
• Problem: pointers can be null– Augment read barrier for GetField(x,offset):
tmp = x[offset];return tmp == null ? null : tmp[redirect]
– Optimize by null-check combining, sinking
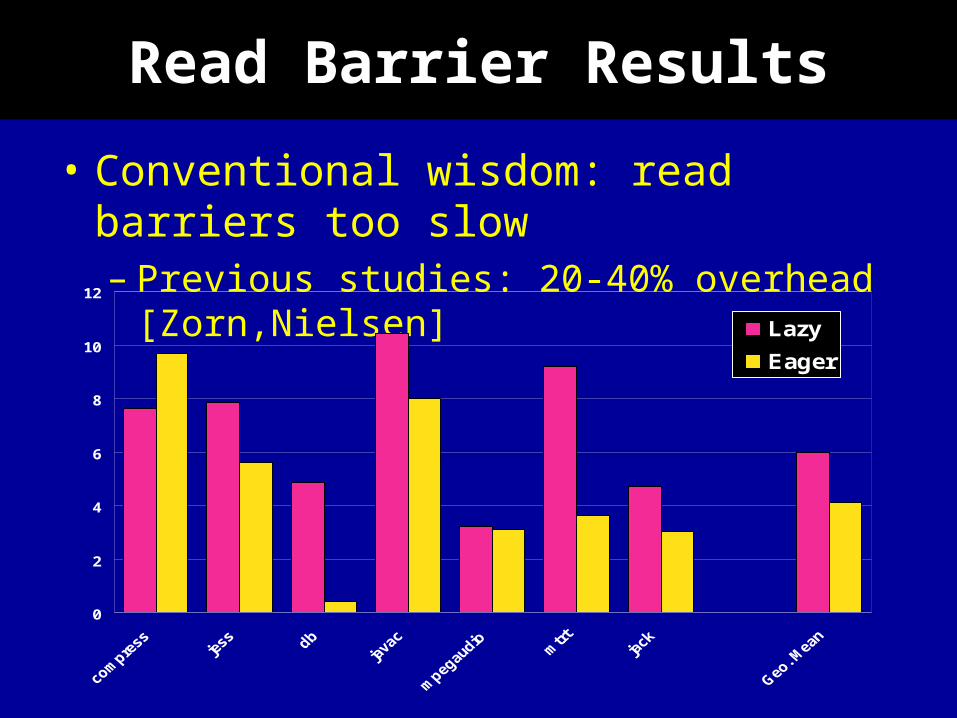
Read Barrier Results
• Conventional wisdom: read barriers too slow– Previous studies: 20-40% overhead
[Zorn,Nielsen]
0
2
4
6
8
10
12
Lazy
Eager

Incremental Mark-Sweep
• Mark/sweep finely interleaved with mutator
• Write barrier ensures no lost objects– Must treat objects in write buffer as roots
• Read barrier ensures consistency– Marker always traces correct object
• With barriers, interleaving is simple

Pointer Fixup During Mark• When can a moved object be freed?
– When there are no more pointers to it• Mark phase updates pointers
– Redirects forwarded pointers as it marks them• Object moved in collection n can be freed:
– At the end of mark phase of collection n+1
From-spaceTo-space
A
X
Y
Z
A′

Selective Defragmentation
• When do we move objects?– When there is fragmentation
• Usually, program exhibits locality of size– Dead objects are re-used quickly
• Defragment either when– Dead objects are not re-used for a GC cycle– Free pages fall below limit for performing a GC
• In practice: we move 2-3% of data traced– Major improvement over copying collector

Arraylets
• Large arrays create problems– Fragment memory space– Can not be moved in a short, bounded time
• Solution: break large arrays into arraylets– Access via indirection; move one arraylet at a time
• Optimizations– Type-dependent code optimized for contiguous case– Opportunistic contiguous allocation
A1 A2 A3A

Scheduling

Work-based Scheduling
• Trigger the collector to collect CW bytes– Whenever the mutator allocates QW
bytes
0
0.2
0.4
0.6
0.8
1
0.01 10
Smooth AllocUneven AllocHigh Alloc
MM
U (
CP
U
Uti
liza
tio
n)
Window Size (s) - log
0
20
40
60
80
100
Any
Sp
ace
(M
B)
Time (s)

Time-based Scheduling
• Trigger collector to run for CT seconds– Whenever mutator runs for QT
seconds
Sp
ace
(M
B)
Time (s)
0
10
20
30
40
50
60
70
80
90
100
Smooth Alloc
Uneven Alloc
High Alloc0
0.2
0.4
0.6
0.8
1
0.01 10
Any
MM
U (
CP
U
Uti
liza
tio
n)
Window Size (s) - log

Parameterization
Mutator
a*(ΔGC)m
Collector
R
Tuner
Δtsu
Allocation Rate
Maximum LiveMemory
Collection Rate
Real TimeInterval
Maximum UsedMemory
CPU Utilization

Empirical Results

Pause time distribution: javac
12 ms 12 ms
Time-based Scheduling Work-based Scheduling

Utilization vs Time: javac
Time (s) Time (s)
0.4
0.2
0.0
0.6
0.8
1.0
Uti
liza
tio
n
(%)
0.4
0.2
0.0
0.6
0.8
1.0
Time-based Scheduling Work-based Scheduling
0.45

MMU: javac

Space Usage: javac

Conclusions

Conclusions
• The Metronome provides true real-time GC– First collector to do so without major
sacrifice• Short pauses (4 ms)• High MMU during collection (50%)• Low memory consumption (2x max live)
• Critical features– Time-based scheduling– Hybrid, mostly non-copying approach– Integration w/compiler

Future Work
• Two main goals:– Reduce pause time, memory requirement– Increase predictability
• Pause time:– Expect sub-millisecond using current
techniques– For 10’s of microseconds, need interrupt-
based• Predictability
– Studying parameterization of collector– Good research area