david&sontag,&kevyncollinsthompson,&...
TRANSCRIPT

Probabilis)c Models for Personalizing Web Search (WSDM ‘12)
David Sontag, Kevyn Collins-‐Thompson, Paul N. Benne=, Ryen W. White, Susan Dumais,
Bodo Billerbeck

Personalizing web search Query “Michael Jordan”
Results Pr(relevance)
en.wikipedia.org/wiki/Michael_Jordan .9
www.nba.com/playerfile/�michael_�jordan .7
www.nba.com/history/players/�jordan_�summary.html .6
… … www.eecs.berkeley.edu/Faculty/Homepages/�jordan.html
.0001
Personalized results Pr(relevance to me)
www.eecs.berkeley.edu/Faculty/Homepages/�jordan.html .8
… … en.wikipedia.org/wiki/Michael_Jordan .1
www.nba.com/playerfile/�michael_�jordan .08
www.nba.com/history/players/�jordan_�summary.html .07
Key problems to solve: • RepresentaRon – how to compactly summarize user preferences?
• Learning – how to discover user profiles from historical data? • Ranking – how to balance preferences with other relevance signals?

Previous approaches • Re-‐Finding (Teevan ‘04)
– Remember user’s browsing history – Re-‐rank search results, boosRng score of previously visited pages
• Term-‐based profiles (Teevan et al. ’05, Tan et al. ’06, Ma=hijs and Radlinski ’11) – Construct personalized vocabulary from browsing history – Use to re-‐weight term-‐based scoring methods such as BM25 or
TF-‐IDF
• Topic-‐based profiles (Gauch et al. ‘03, Liu et al. ’04, Chirita et al. ’05, Dou et al. ’07) – Learn distribuRon over a priori query intents for user – Re-‐rank search results using linear combinaRon of user topic-‐
document topic match and other relevance scores

Our representaRon
• Fundamental goal is to predict query intent
• User preferences summarized as (user specific) parameters,
of the condiRonal distribuRon:
New query Computers
ArRficial Intelligence
Soiware Games
Sports
Soccer
Basketball Golf
Football
Arts
Performing Arts People
(top 2 levels of human-‐generated ontology, dmoz.org)
Pr ( intent | query ; θu )
User u history θu

Our ranking method
www.nba.com /playerfile/Michael_Jordan
.9
0 Pr (relevance |query, intent = Sports/Golf)
.6 Pr (relevance |query, intent = Sports/Golf)
0 Pr (relevance |query, intent = Sports/Basketball)
1 Pr (relevance |query, intent = Computers/A.I.)
.92 Pr (relevance |query, intent = Sports/Basketball)
0 Pr (relevance |query, intent = Computers/A.I.)
eecs.berkeley.edu /Faculty/Homepages /�jordan.html
.0001
Background model, Pr ( intent | “Michael Jordan”; generic user)
User model, Pr ( intent | “Michael Jordan” ; θu)
Deconvolve
Query “Michael Jordan”
Pr (relevance) Re-‐combine
.1
.8
Pr (relevance to user u)

Example Query “Rockefeller” issued by Biologist
(a) (b)
Pr(topic | query) for generic user
Business: 0.213
Society: 0.107
Shopping/Health: 0.096
Business/Consumer Goods+Services: 0.077
Arts: 0.062 !
Pr(topic | query) for biologist
Science/Biology: 0.402
Science: 0.228
Society: 0.052
Reference: 0.040
Health: 0.031 !
Web search engine results Categories
1. http://en.wikipedia.org/wiki/John_D._Rockefeller Society
2. http://en.wikipedia.org/wiki/Rockefeller_family Science, Society
3. http://www.rockefeller.edu Reference, Science !
Personalized re-ranking results (using Model 1) Categories
1. http://en.wikipedia.org/wiki/Rockefeller_family (2) Science, Society
2. http://www.rockefeller.edu (3) Reference, Science
3. http://en.wikipedia.org/wiki/John_D._Rockefeller (1) Society
Personalized re-ranking results (using Model 2) Categories
1. http://www.rockefeller.edu (3) Reference, Science
2. http://en.wikipedia.org/wiki/Rockefeller_family (2) Science, Society
3. http://bridges.rockefeller.edu/?page=news (12) Science, Health !
!
Pr ( intent | “Rockefeller”; generic user)
Pr ( intent | “Rockefeller” ; θu)
(original rank)
Original
Personalized

Query “Rockefeller” issued by Biologist
(a) (b)
Pr(topic | query) for generic user
Business: 0.213
Society: 0.107
Shopping/Health: 0.096
Business/Consumer Goods+Services: 0.077
Arts: 0.062 !
Pr(topic | query) for biologist
Science/Biology: 0.402
Science: 0.228
Society: 0.052
Reference: 0.040
Health: 0.031 !
Web search engine results Categories
1. http://en.wikipedia.org/wiki/John_D._Rockefeller Society
2. http://en.wikipedia.org/wiki/Rockefeller_family Science, Society
3. http://www.rockefeller.edu Reference, Science !
Personalized re-ranking results (using Model 1) Categories
1. http://en.wikipedia.org/wiki/Rockefeller_family (2) Science, Society
2. http://www.rockefeller.edu (3) Reference, Science
3. http://en.wikipedia.org/wiki/John_D._Rockefeller (1) Society
Personalized re-ranking results (using Model 2) Categories
1. http://www.rockefeller.edu (3) Reference, Science
2. http://en.wikipedia.org/wiki/Rockefeller_family (2) Science, Society
3. http://bridges.rockefeller.edu/?page=news (12) Science, Health !
!
Pr ( intent | “Rockefeller”; generic user)
Document distribuRons
• For every document we have a distribuRon,
over the topic that the document is about
• Learned using logisRc regression; training data is from the Open Directory Project
• Stored in the index and accessible quickly
Original
(Benne=, Svore, Dumais, WWW ‘10)
Pr ( doc d about | d’s text )

Our ranking method: intuiRon
www.nba.com /playerfile/Michael_Jordan
.9 .6 Pr (relevance |query, intent = Sports/Golf)
.92 Pr (relevance |query, intent = Sports/Basketball)
0 Pr (relevance |query, intent = Computers/A.I.)
Deconvolve Pr (relevance)
Step 1.
Pr ( d relevant) = Σ Pr ( intent = T | “Michael Jordan”; generic user) * Pr( d relevant | intent = T)
We assume that Pr (relevance) is the expected relevance across all users:
T
Suppose that doc d is about topic and Pr( d relevant | intent ≠ Td) = 0

Our ranking method: intuiRon
Pr ( d relevant) = Σ Pr ( intent = T | “Michael Jordan”; generic user) * Pr( d relevant | intent = T)
Step 1.
We assume that Pr (relevance) is the expected relevance across all users:
T
Suppose that doc d is about topic and Pr( d relevant | intent ≠ Td) = 0
Td = Sports/Basketball
Pr ( d relevant |query, intent = Sports/Basketball) = Pr( d relevant)
Pr ( intent = Sports/Basketball | “Michael Jordan”; generic user)
www.nba.com /playerfile/Michael_Jordan
.9 0 Pr (relevance |query, intent = Sports/Golf)
.92 Pr (relevance |query, intent = Sports/Basketball)
0 Pr (relevance |query, intent = Computers/A.I.)
Deconvolve Pr (relevance)

Our ranking method: intuiRon
Pr ( d relevant) = Σ Pr ( intent = T | “Michael Jordan”; generic user) * Pr( d relevant | intent = T)
Step 1.
We assume that Pr (relevance) is the expected relevance across all users:
T
Suppose that doc d is about topic and Pr( d relevant | intent ≠ Td) = 0
Td = Computers/A.I. 0 Pr (relevance |query, intent = Sports/Golf) 0 Pr (relevance |query, intent = Sports/Basketball)
1 Pr (relevance |query, intent = Computers/A.I.)
eecs.berkeley.edu /Faculty/Homepages /�jordan.html
.0001
Deconvolve Pr (relevance)
Pr ( d relevant |query, intent = Computers/A.I.) = Pr( d relevant)
Pr ( intent = Computers/A.I. | “Michael Jordan”; generic user)

Our ranking method: intuiRon
Step 2.
Pr ( d relevant to u) = Σ Pr (u’s intent = T | “Michael Jordan” ; θu) * Pr( d relevant | intent = T)
To re-‐combine, we marginalize over the user’s intent,
T
Td = Computers/A.I. Pr (relevance |query, intent = Sports/Golf) Pr (relevance |query, intent = Sports/Basketball)
Pr (relevance |query, intent = Computers/A.I.)
eecs.berkeley.edu /Faculty/Homepages /�jordan.html
Re-‐combine .8
Pr (relevance to user u)
0 0 1
Putng steps 1 and 2 together, we obtain:
Pr ( intent = Computers/A.I.| “Michael Jordan”; generic user)
Pr ( d relevant to u) = Pr( d relevant) Pr (u’s intent = Computers/A.I. | “Michael Jordan” ; θu)

• Recall our simplifying assumpRons:
• Ranking formula:
• Obtained by probabilisRc inference – see paper for the formal probabilisRc model
Our ranking method
Suppose that doc d is about topic and Pr( d relevant | intent ≠ Td) = 0
Treat as a random variable and marginalize over it
Use the distribuRon Pr ( d relevant | u’s intent = tu, doc about topic td)
Call this f (tu, td)
Σ Pr ( intent = tg | query; generic user) f (tg, td)
Pr( d relevant to u) = Pr( d relevant) Σ Pr ( doc d about topic | d’s text ) Σ Pr (u’s intent = tu | query ; θu) f (tu, td) td tu
tg

Algorithm properRes
• Ranking formula:
• Ranking unchanged if user intent = generic user’s for query • Ranking can exhibit big effects for less-‐common intents vs.
generic user • Very fast to compute:
– Ranking N docs takes Rme O( Nk + T2)
– k = # topics per doc (e.g. 3), and T is total number of topics (e.g. 300)
Σ Pr ( intent = tg | query; generic user) f (tg, td)
Pr( d relevant to u) = Pr( d relevant) Σ Pr ( doc d about topic | d’s text ) Σ Pr (u’s intent = tu | query ; θu) f (tu, td) td tu
tg
1

What is lei to specify?
• Ranking formula:
Σ Pr ( intent = tg | query; generic user) f (tg, td)
Pr( d relevant to u) = Pr( d relevant) Σ Pr ( doc d about topic | d’s text ) Σ Pr (u’s intent = tu | query ; θu) f (tu, td) td tu
tg
✓
We learn this (details in paper)
✓
These staRsRcs can be pre-‐computed for common queries
AlternaRvely, use weighted average of document topics for top docs in original ranking,
Σ Pr( d relevant) * Pr ( doc d about topic | d’s text )
(White, Benne=, Dumais, CIKM ‘10)
d
✓ If not available, can use 1/rank
✓
✓ Next slides

PredicRng user intent
• Long term personalizaRon, using historical user click-‐through data:
• Pr (u’s intent = t | query ; θu) esRmated using two approaches, 1. GeneraRve model 2. DiscriminaRve model
• We use an ensemble method, interpolaRng between the predicRons of both methods
User u’s history = { (queryi, intenti), i=1, …, c }

PredicRng user intent: GeneraRve model
• From single user u’s history, { (queryi, intenti), i=1, …, c }, esRmate a priori query intents:
• Using data from all users, esRmate language model,
i.e. staRsRcs on frequency of queries seen for each intent
• Use Bayes’ rule to “invert”:
Pru ( intent )
Pr ( query | intent ),
Pr ( u’s intent = t | query ) = Pru ( intent = t )* Pr ( query | intent = t)
Σ Pru ( intent = t’ )* Pr ( query | intent = t’) t’

PredicRng user intent: DiscriminaRve model
• Choose user-‐specific parameters θu which correctly predict intent on historical data:
• We assume log-‐linear model for the distribuRon
• T+1 dimensional feature vector, where T = # topics • Parameters specify how to re-‐weight Pr ( intent | query;
generic user)
θu i=1
c
Complexity penalty to avoid over-‐fitng

Large-‐scale EvaluaRon
• Data set: September 2010 search logs (Bing) – 20 days training, 6 days test – ~600K queries, ~200K users
• Re-‐rank top 10 results – Assign posiRve judgment to URL in top 10 if it is the last saRsfied
result click in the session
– NegaRve judgment to other 9 URLs
• We report the mean reciprocal rank (MRR):
• Compare original Bing ranking with personalized ranking
MRR = (1/|Q|) Σ 1
rank of last saRsfied click URL q in Q
(a) (b)
Pr(topic | query) for generic user
Business: 0.213
Society: 0.107
Shopping/Health: 0.096
Business/Consumer Goods+Services: 0.077
Arts: 0.062 !
Pr(topic | query) for CS researcher
Computers/Artificial Intelligence: 0.663
Arts/People: 0.098
Science: 0.044
Computers: 0.042
Arts/Performing Arts: 0.036 !
Web search engine results Categories
1. http://www.kevinmurphy.com.au Business, Shopping
2. http://en.wikipedia.org/wiki/Kevin_Murphy_(actor) Arts
3. http://www.kevinmurphystore.com Health, Shopping !
Personalized re-ranking results (using Model 1) Categories
1. http://en.wikipedia.org/wiki/Kevin_Murphy_(actor) (2) Arts
2. http://www.kevinmurphy.com.au (1) Business, Shopping
3. http://www.cs.ubc.ca/~murphyk (13) Reference, Computers
Personalized re-ranking results (using Model 2) Categories
1. http://www.cs.ubc.ca/~murphyk (13) Reference, Computers
2. http://en.wikipedia.org/wiki/Kevin_Murphy_(actor) (2) Arts
3. http://www.kevinmurphystore.com (3) Health, Shopping !
!Figure 3: (a) Top categories based on Pr(topic | query) for a generic user and a computer
science researcher for the query [kevin murphy]. (b) The original top three results from a
Web search engine for query [kevin murphy], and re-ranked results using Models 1 and 2.
Also shown to the right of each result is the original rank in parentheses and the top-level
ODP categories, as predicted by the text classifier used throughout this paper.
2010. 20 days of search logs from Sept. 1-20 were used to
construct users’ long-term profiles. The queries in five days
of search logs from Sept. 21-25 were used to evaluate the
performance of our personalization algorithms. We selected
users from the 5-day test period who had at least 100 sat-
isfied result clicks in the 20-day profile building period (see
Table 1). For this subset of users, we also identified search
sessions using a session extraction methodology similar to
[22]. Search sessions begin with a query and contain result
clicks and any subsequent queries and clicks that occurred.
Sessions terminated following 30 minutes of inactivity. We
used these sessions to obtain personalized relevance judg-
ments for each query (see below for more details).
Table 1: Descriptive statistics about our users, after
filtering for those who had at least 100 SAT clicks, com-
puted on the 20 days of search history.
average stdev median
num days 16.21 3.72 17
num queries 229.60 112.28 204
num SAT clicks 143.82 52.80 128
To explore parameter choices, we use a set of five weeks
of hold-out log-data from the same search engine and of
a similar type to our evaluation data described above but
non-overlapping with it. In particular, this hold-out data
was used to explore the parameter choices mentioned in this
section (e.g., β), learn the coverage function as described
earlier, and set a threshold for the entropy criteria used to
identify ambiguous queries, described later.
To focus on underspecified queries which [20] have found
especially amenable to personalization, we filtered the test
queries to only include one word queries. We also filtered
out the one word queries that we have not seen sufficiently
many times in the historical query logs to reliably estimate
the language model.2
This resulted in 571598 queries from 195108 users. In
our primary experiments, to further emphasize ambiguity,
we retained only non-navigational queries (using a classifier)
and queries where the entropy of the ODP topics of the
top 10 URLs (i.e., the entropy of Prr(Td | q)) is above a
threshold. We refer to the queries that have passed the
entropy filter as “ambiguous” in our results below. After
these filters, our test set consisted of 54581 users with at
least one query, and 102417 queries in total.
Evaluation of our personalized ranking algorithms required
a personalized relevance judgment for each result. Obtain-
ing relevance judgments from a large number of real users is
impractical, and there is no known approach to train expert
judges to provide reliable personalized judgments that reflect
real user preferences. Instead, we obtained these judgments
using a log-based methodology inspired by [8]. Specifically,
we assign a positive judgment to one of the top 10 URLs if
it is the last satisfied result click in the session (Last SAT).
The remaining top-ranked URLs receive a negative judg-
ment. This gives us one positive judgment and nine negative
judgments for each of the top-10 URLs for each session.
One consequence of evaluating on retrospective data is
that we can only evaluate based on the search results which
were shown. Since items below the last clicked item may
have been unexamined by the user and actually be relevant,
treating them as irrelevant serves as a lower bound on the
performance of our algorithms.
The rank position of the single positive judgment is used
to evaluate retrieval performance before and after re-ranking.
Specifically, we measure our performance using the inverse
2In particular, we considered words w that had at least one
category c such that w was part of at least 50 queries leading
to a click on a document with category c.
User staRsRcs for training data
3rd → 2nd posiRon: ∆MRR = 0.1667

Filter condi)ons Set Size Change in Filter Set MRR
Change in Overall MRR
One Word 100.00% 0.1213 0.1213
MRR on subset of queries where last saRsfied result click moves posiRon
Large-‐scale EvaluaRon

Filter condi)ons Set Size Change in Filter Set MRR
Change in Overall MRR
One Word 100.00% 0.1213 0.1213
One Word. Ambig. 68.21% 0.1361 0.0928
One Word, non-‐Nav 73.28% 0.1442 0.1064
One Word, Ambig., non-‐Nav 54.81% 0.1686 0.0924
MRR on subset of queries where last saRsfied result click moves posiRon
Large-‐scale EvaluaRon

Filter condi)ons Set Size Change in Filter Set MRR
Change in Overall MRR
One Word 100.00% 0.1213 0.1213
One Word. Ambig. 68.21% 0.1361 0.0928
One Word, non-‐Nav 73.28% 0.1442 0.1064
One Word, Ambig., non-‐Nav 54.81% 0.1686 0.0924
Acronym 31.73% 0.1745 0.0554
Acronym, Ambig, non-‐Nav 21.08% 0.2269 0.0478
MRR on subset of queries where last saRsfied result click moves posiRon
Large-‐scale EvaluaRon
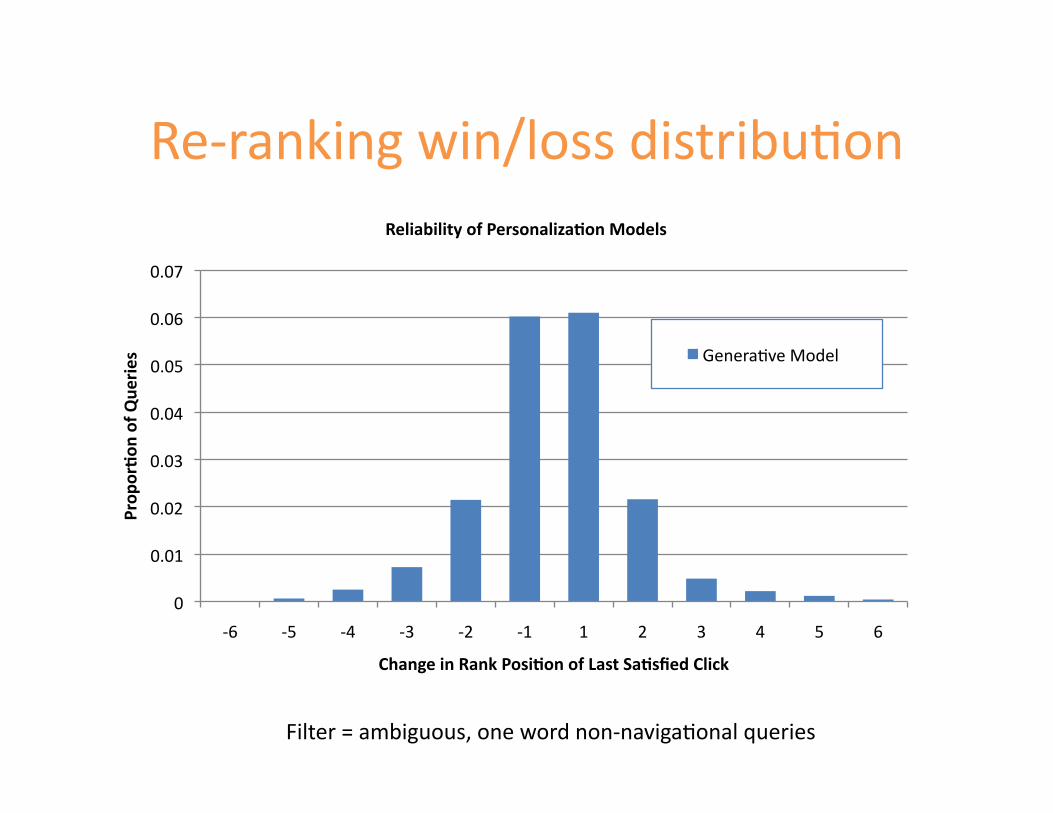
0
0.01
0.02
0.03
0.04
0.05
0.06
0.07
-‐6 -‐5 -‐4 -‐3 -‐2 -‐1 1 2 3 4 5 6
Prop
or)on
of Q
ueries
Change in Rank Posi)on of Last Sa)sfied Click
Reliability of Personaliza)on Models
GeneraRve Model 2
Filter = ambiguous, one word non-‐navigaRonal queries
Re-‐ranking win/loss distribuRon

0
0.01
0.02
0.03
0.04
0.05
0.06
0.07
-‐6 -‐5 -‐4 -‐3 -‐2 -‐1 1 2 3 4 5 6
Prop
or)on
of Q
ueries
Change in Rank Posi)on of Last Sa)sfied Click
Reliability of Personaliza)on Models
DiscriminaRve Model 2
Filter = ambiguous, one word non-‐navigaRonal queries
Re-‐ranking win/loss distribuRon

0
0.01
0.02
0.03
0.04
0.05
0.06
0.07
-‐6 -‐5 -‐4 -‐3 -‐2 -‐1 1 2 3 4 5 6
Prop
or)on
of Q
ueries
Change in Rank Posi)on of Last Sa)sfied Click
Reliability of Personaliza)on Models
InterpolaRon Model 2 Ensemble Model
Filter = ambiguous, one word non-‐navigaRonal queries
Re-‐ranking win/loss distribuRon

Framework is broadly applicable
• Short-‐term personalizaRon (within session)
• Different personalizaRon criteria – Geographic locaRon – Reading proficiency – MulRple topics per document or user intent

Summary of contribuRons
• ProbabilisRc framework for personalizaRon
• Learning user profiles formalized as intent predicRon (condiRoned on query)
• Use of a background model (generic user’s intent) to interpret ranker’s relevance scores
• Large-‐scale evaluaRon of long-‐term personalizaRon using query logs
• SubstanRal gains over compeRRve baseline on ambiguous queries such as acronyms and names

Many direcRons to explore! • PredicRng intent given query and user history:
– Expand the set of features used in condiRonal model
– Transfer learning across users – Learn from non-‐search data, e.g. browsing, mobile, social
– Online learning of user profiles • Understanding when and how to personalize
– Consider both potenRal for personalizaRon and confidence in user’s query intent
• RepresentaRon – (Un)supervised learning of topics rather than using ODP – Use relaRonal classificaRon to improve accuracy of web page
classificaRon
– Cross-‐product of many variables, e.g. topic and reading proficiency