day 3: : land: characteristics, use and investment
DESCRIPTION
Day 3: : Land: Characteristics, Use and Investment. Department of Economics Trinity College Dublin, Ireland. Today’s Commands. _Variables Return a list of saved statistics Distributions and lorenz curves Finding, downloading and using STATA commands - PowerPoint PPT PresentationTRANSCRIPT

Day 3: : Land: Characteristics, Use and Investment
Department of Economics
Trinity College Dublin, Ireland

Today’s Commands1. _Variables2. Return a list of saved statistics3. Distributions and lorenz curves4. Finding, downloading and using STATA commands5. recode variable (value=value) recodes values of a categorical
variable

Exercise 11. Open the data file individual2.dta in the folder 'Day 3‘2. Using the bysort and egen command generate a variable for
the size of the household (‘hhsize’) [Hint: use the variable 'hhmemid‘]
3. Create a household level dataset by collapsing the variables ‘malehead’, ‘married’ and ‘hhsize’ by household
4. Label the household size variable5. Sort data and save as temp1.dta6. Open Day3.dta and merge with temp1.dta7. Tabulate then drop ‘_merge’ to check the number of
observations8. Erase temp1.dta from PC9. Count the number of observations10.Use the describe command to review the data in memory11.Sort by household and save changes to Day3_new.dta

_VariablesSTATA has a number of built in variables that are created after certain
commands are executed.
For example, when you merge files STATA stores information in about the merger in the variable ’_merge’
_n acts as a running counter within a group when used with the bysort and gen commands
For example, if you want a running counter of the number of observations in the province:
bys tinh_2008: gen provcount=_n
This assigns a unique identifier to each observation in the province

Exercise 2A certain number of indicator variables need to be constructed to ensure that you are using the correct sample of plots in constructing the variables and also that you only count each household once when constructing tables of summary statistics for households
1.Generate a variable that assigns a unique identifier to each plot within households and tabulate2.Run the next set of commands that generate an indicator for household that have land use rights to some plots (either owned or rented in) and try and understand what each line of command is doing3.Since we are only interested in agricultural land generate an indicator for agricultural plots at plot (use the variable p6q7_ - see do-file for hints)

Exercise 24. Consider Table 3.1 in the 2006 Statistical Report and run the
set of commands for generating the same table for columns 1 and 2 using the 2008 data
5. Create a variable for the land area used for annual crops at the plot (anplotarea) and household level (totplotarea)
6. Write the commands necessary to create column 3 of Table 3.1
7. Generate a variable ‘nrplot’ for the number of plots used by the household for agricultural purposes
8. Label the variable9. Run the commands that generate the average number of plots
by groups as in column 4 of Table 3.110.Write the commands necessary to create column 5 of Table
3.1

Statistics saved by STATAAfter running commands for descriptive statistics STATA stores
statistics as scalars that can be used in the next set of commands
By using the command return list STATA will display all statistics stored
For example, after using the command summarize STATA stores the following:
r(N) number of observations r(mean) meanr(min) minimum r(max) maximumr(sum_w) sum of the weights r(Var) variancer(sum) sum of variable r(sd) standard dev.
You can use these in subsequent commands. For example if you want to only include observations that are below the mean in a table you would append the command if var<r(mean)

DistributionsWe are often interested in knowing how a variable is distributed
across observations
A histogram can be used to show the frequency at which observations occur across a range of values
histogram varname: Gives a graphical display of the frequencies for varname
Many different options can be appended (see STATA help for a complete list).
One option we will use is to specify whether to use densities, frequencies or fractions in constructing the histogram.
To alternate simply append ,frequency or , fraction (the default is density)

DistributionsWe are often interested in knowing how equal a distribution is
(for example is land equally distributed across households? Does this distribution vary across provinces?)
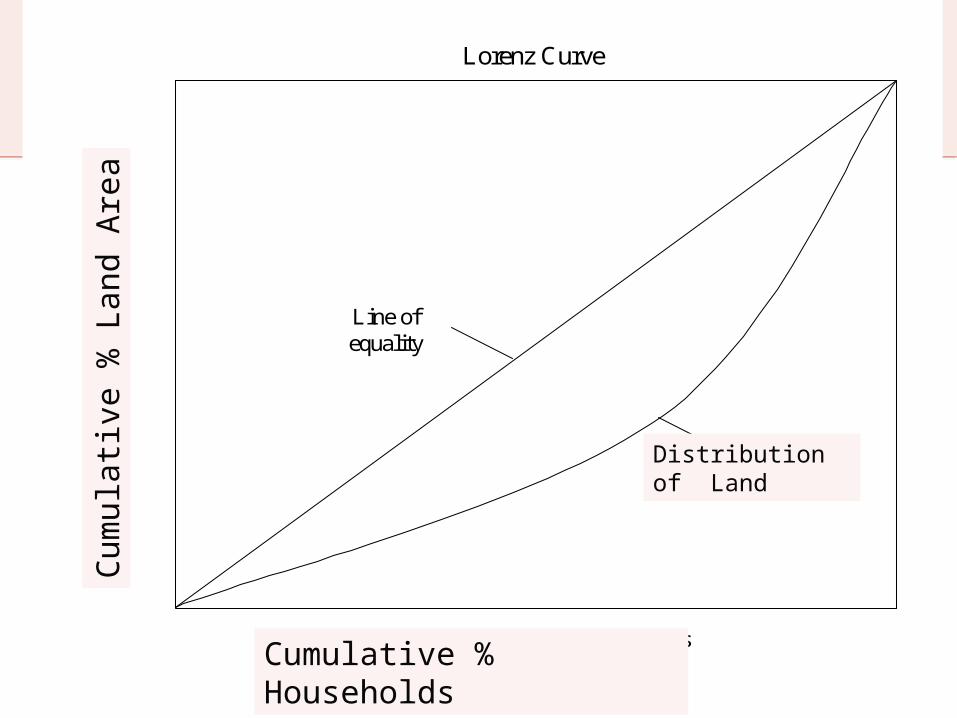
A convenient way of illustrating inequality is to use a Lorenz Curve
This is constructed by first ranking observations from lowest to highest (i.e. Household with smallest area of land at bottom and household with highest area of land at top)
The share of total land that each household owns is then plotted starting with lowest
This produces a Lorenz Curve
Line of equality
Income Distribution
Cum
ulat
ive
% I
ncom
e
Cumulative % of Individuals or Households
Lorenz Curve
Cum
ulat
ive
% L
and
Are
a
Cumulative % Households
Distribution of Land

Finding, downloading and using STATA commands
Before you start creating a commandname/program to apply in STATA a method which is likely to be known and used by others, it might be useful to look into the additional programmes/commands created and tested by other people.
E.g. commands related to poverty calculations can be found by typing:
findit poverty
Stata returns a series of possible commands to calculate poverty indices, to calculate inequality, produce lorenz curves etc…
If you find any of the returned suggestions useful, you can download it. It will be stored and you can use it as a normal STATA command thereafter.
Installing new Commands

Exercise 3Consider Figure 3.1 in the 2006 report. In this figure we eliminate
households in the top 5% of the land area distributionWe call these outliers and their removal will prevent an overly
skewed distributionWe cannot apply weights as we have reduced the size of the sample
in a non-random way1. First we must find the cut off point for the 95th percentile of the
distribution. To find this use the summarize command for the variable ‘totplotarea’ appending , detail[Remember to only use one observation per household!]What is the threshold land area?
2. Use the return list command to see what scalars are stored.3. Generate a variable measuring the 95% cutoff point 4. Draw a histogram of the distribution of the area of agricultural
land for lower 95% of sample

Exercise 35. Generate an indicator variable for "North" vs. "South" regions6. Draw a histogram of the distribution of the area of agricultural
land for lower 95% of sample by region7. In panel c. and panel d. of Table 3.1 we wish to construct lorenz
curves, however, there are is no lorenz curve command built into Stata. Use the findit lorenz command to see if others have created commands like this.
8. Follow the links to install the glcurve command and browse the help file to try and understand the next command in the dofile.
9. Construct a similar curve for plot area of annual crops below 30000 ha
10.Compare to the findings of the 2006 report

Exercise 5aConsider Table 3.7 in the 2006 report. In this table we look at the current
status of land investment and for the purpose of this exercise are specifically interested in irrigation (Columns 1 to 3)
1. Generate indicator variable for plot is irrigated (plotirrig) and the number of plots irrigated in household (nrirrig) [Hint: variable p7q12_]. Consider all agricultural plots used.
2. Generate a variable for the proportion of plots used by household that are irrigated [i.e. Nrirrig as a proportion of nrplot from Exercise 2]
3. Run the command that tabulates the proportion of plots that are irrigated across province and construct the same statistics across gender of head of household and food quintile.
4. Run the commands to construct the statistics for Column 2 of Table 3.7 [The proportion of owned plots without a red book that are irrigated]
5. Write the commands that construct the relevant statistics for Column 3 of Table 3.7 [The proportion of owned plots with a red book that are irrigated]
6. Compare to the findings of the 2006 report

Exercise 5bConsider Figure 3.7 which looks at the dependence on public/cooperative
infrastructure and perceptions of the quality of the irrigation system1. Run the commands that generate a variable indicating that the household
is dependent on irrigation (p20q2_ - note discrepancy in survey and name of data file!)
2. Generate a variable (genirr) for households who are dissatisified with irrigation (p20q3_ )
3. Run the commands that create a bar chart measuring dependence on public/cooperative irrigation and perceptions of irrigation across provinces.
4. Write the commands to construct a similar bar chart across the gender of the household head, food quintile and for the total
5. Compare to the findings of the 2006 report

Exercise 5cConsider Table 3.8 which looks at investment on land. Here we will focus on
irrigation investments1. Generate a variable (invwater) indicating that the household invested in
irrigation/water/soil conservation on agricultural plots that they use [Hint: use variable p13q1_]
2. Generate a variable (nrinvwater) indicating the total number of plots that the household invested in irrigation/water/soil conservation
3. Generate a variable (propinvwater) for the proportion of plots household invested in irrigation/water/soil conservation [i.e. nrinvwater as a proportion of nrplot from Exercise 2]
4. Tabulate proportion of plots household invested in irrigation/water/soil conservation across province, gender of household head and food quintile
5. Generate a variable (valinvwater) indicating that total cash investment the household made in irrigation/water/soil conservation (p13q3)
6. Create a table summarizing investment across province, gender of household head and food quintile
7. Compare to the findings of the 2006 report