deep reinforcement learning and control - carnegie · pdf filedeep reinforcement learning and...
TRANSCRIPT

Learning and Planning with Tabular Methods
Deep Reinforcement Learning and Control
Katerina Fragkiadaki
Carnegie MellonSchool of Computer Science
Lecture 6, CMU 10703
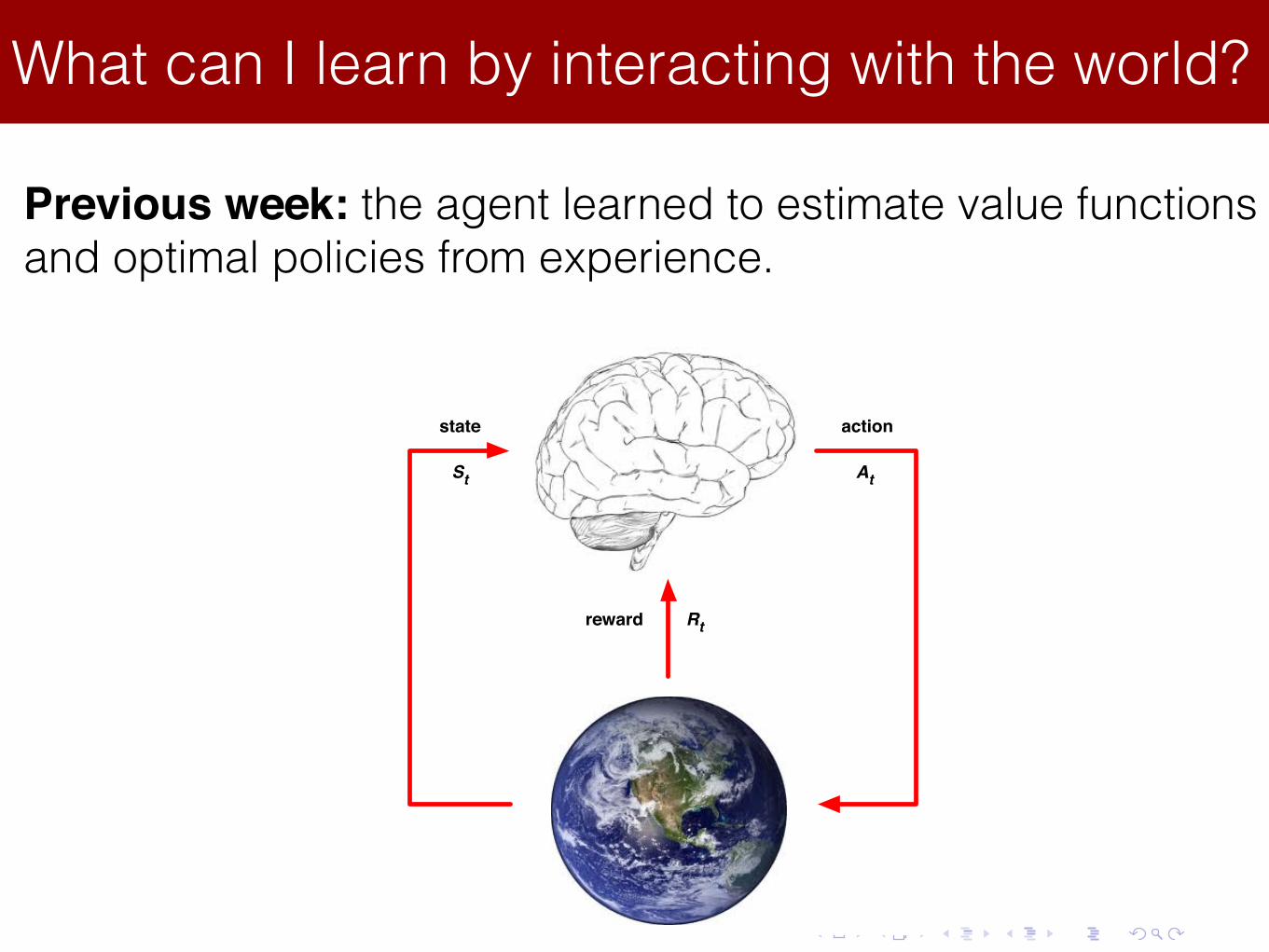
What can I learn by interacting with the world?Lecture 8: Integrating Learning and Planning
Introduction
Model-Free RL
state
reward
action
At
Rt
St
Previous week: the agent learned to estimate value functions and optimal policies from experience.
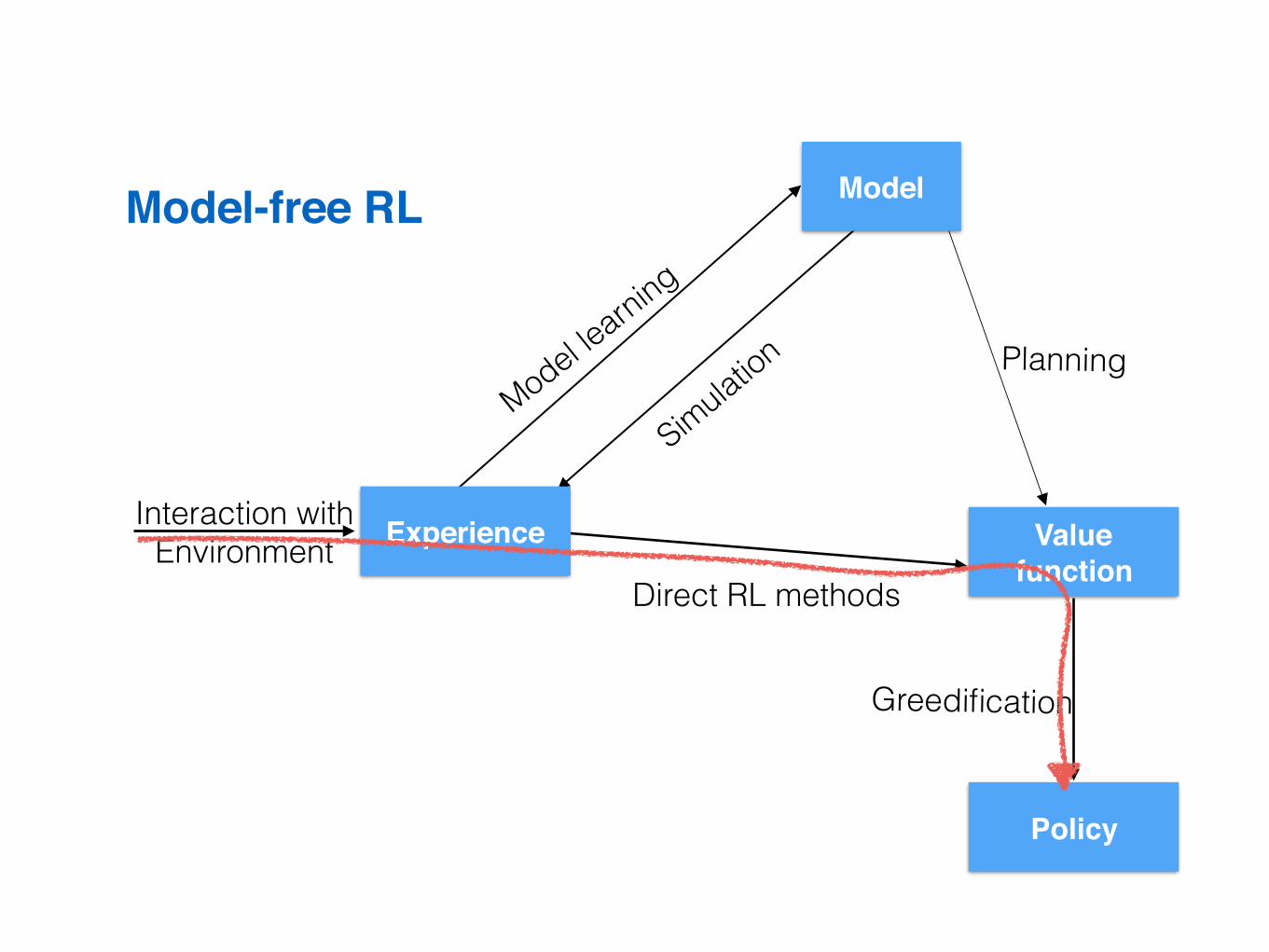
Paths to a policy
Model
Valuefunction
Policy
Experience
Direct RLmethods
Directplanning
Greedification
Modellearning
SimulationEnvironmentalinteraction
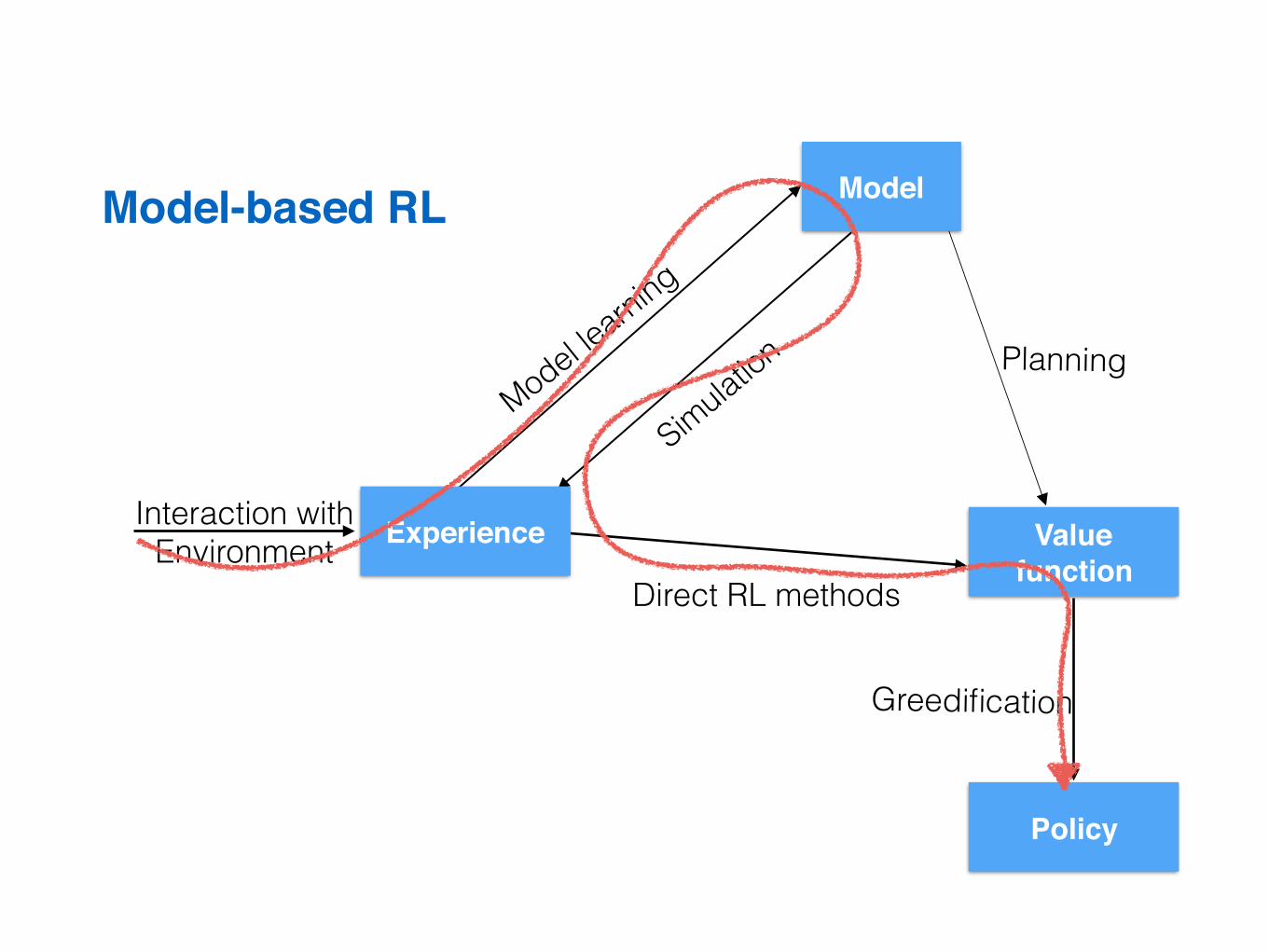
Model-based RL
Model
Experience
Policy
Value function
Interaction with Environment
Model learning
Simulation Planning
Greedification
Direct RL methods
Model-free RL
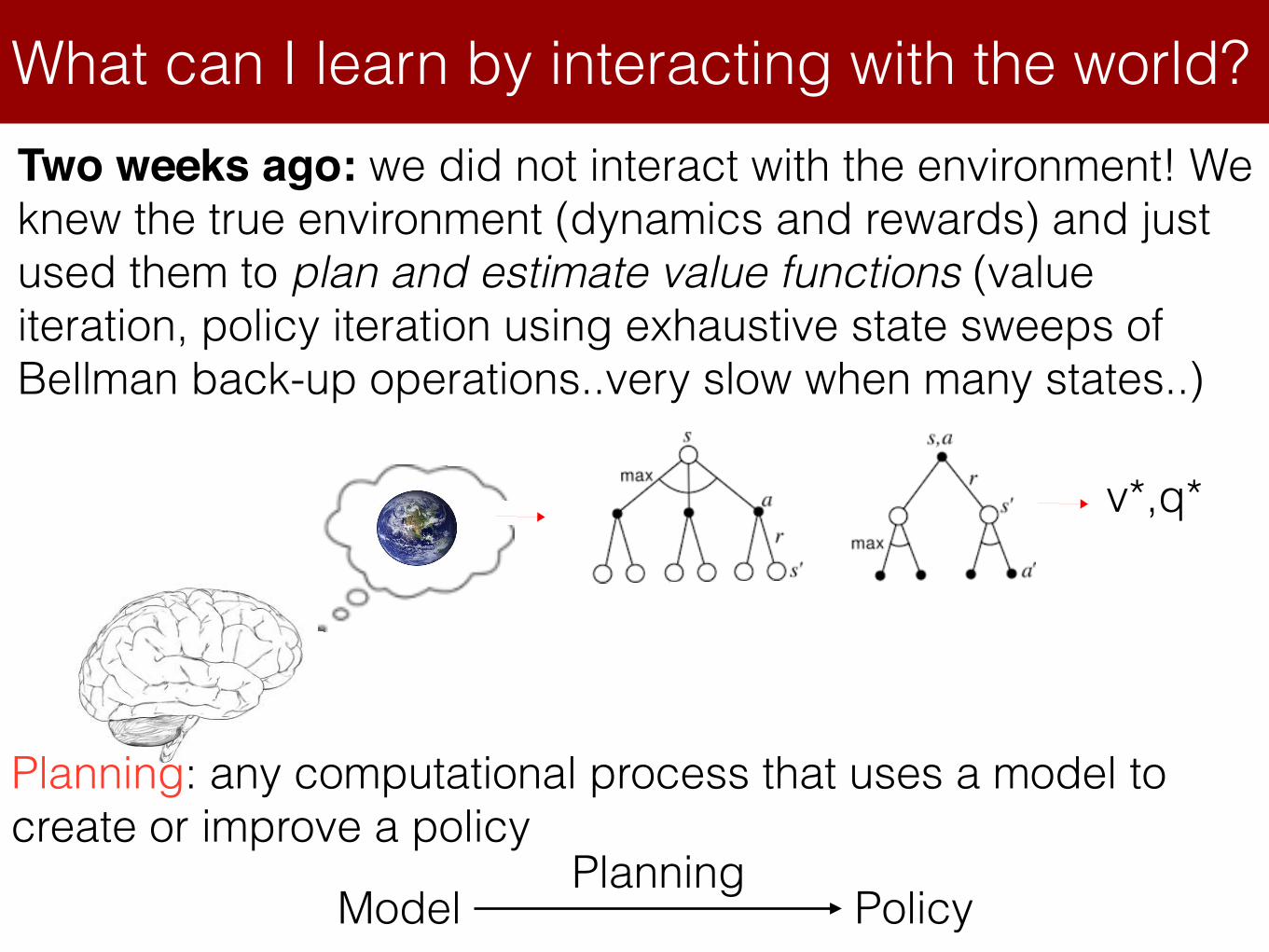
What can I learn by interacting with the world?Two weeks ago: we did not interact with the environment! We knew the true environment (dynamics and rewards) and just used them to plan and estimate value functions (value iteration, policy iteration using exhaustive state sweeps of Bellman back-up operations..very slow when many states..)
Lecture 8: Integrating Learning and Planning
Introduction
Model-Free RL
state
reward
action
At
Rt
St
Lecture 8: Integrating Learning and Planning
Introduction
Model-Free RL
state
reward
action
At
Rt
St
L
e
c
t
u
r
e
8
:
I
n
t
e
g
r
a
t
i
n
g
L
e
a
r
n
i
n
g
a
n
d
P
l
a
n
n
i
n
g
I
n
t
r
o
d
u
c
t
i
o
n
Model-FreeRL
state
reward
action
At
Rt
St
L
e
c
t
u
r
e
8
:
I
n
t
e
g
r
a
t
i
n
g
L
e
a
r
n
i
n
g
a
n
d
P
l
a
n
n
i
n
g
I
n
t
r
o
d
u
c
t
i
o
n
Model-FreeRL
state
reward
action
At
Rt
St
v*,q*
Planning: any computational process that uses a model to create or improve a policy
Model PolicyPlanning
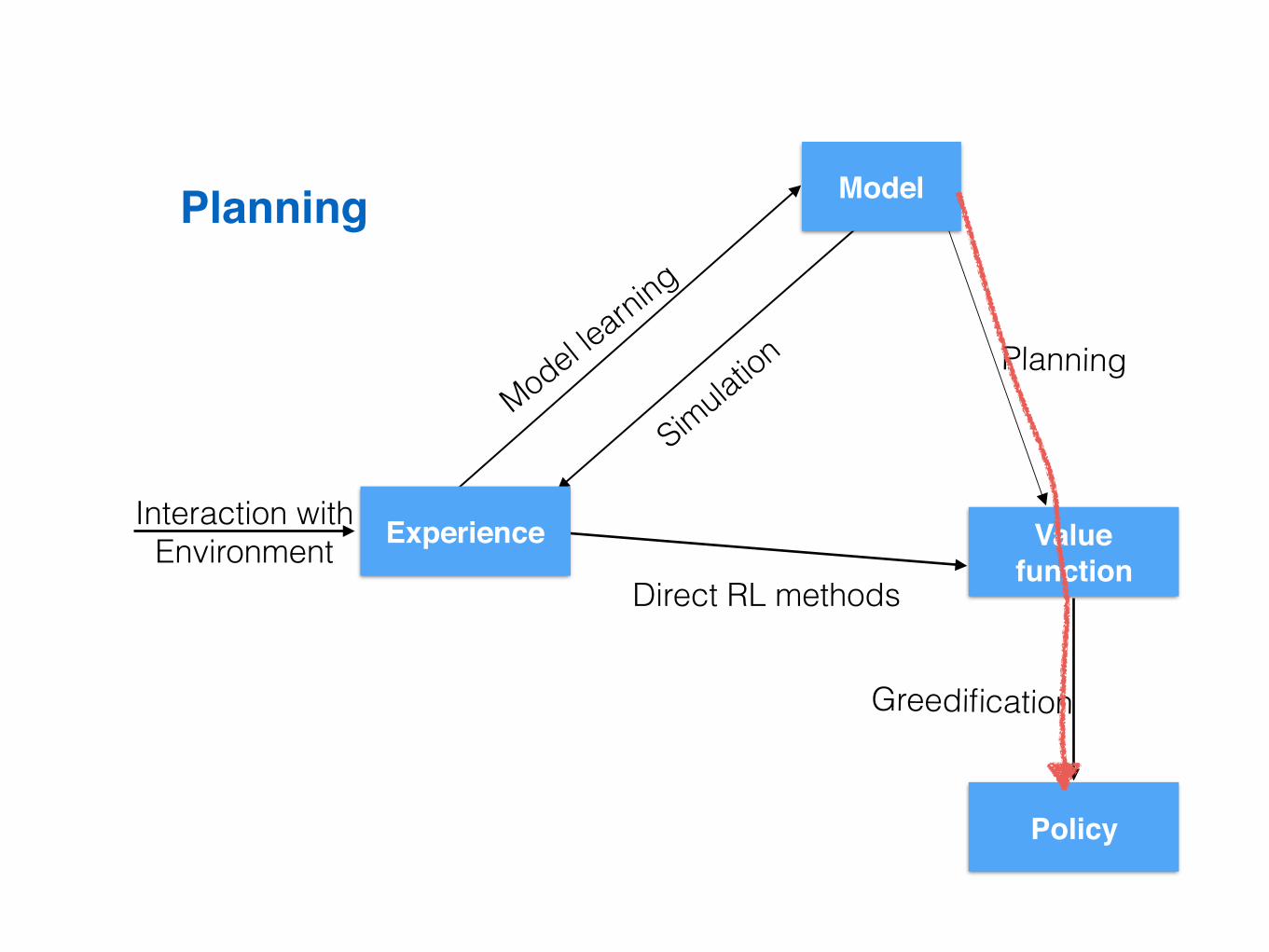
Paths to a policy
Model
Valuefunction
Policy
Experience
Direct RLmethods
Directplanning
Greedification
Modellearning
SimulationEnvironmentalinteraction
Model-based RL
Model
Experience
Policy
Value function
Interaction with Environment
Model learning
Simulation Planning
Greedification
Planning
Direct RL methods
What can I learn by interacting with the world?This lecture: Model-based RL, we will combine both, learning from experience and planning: 1. If the model is unknown, we will learn the model.
Lecture 8: Integrating Learning and Planning
Introduction
Model-Free RL
state
reward
action
At
Rt
St
Lecture 8: Integrating Learning and Planning
Introduction
Model-Free RL
state
reward
action
At
Rt
St
Lecture 8: Integrating Learning and Planning
Introduction
Model-Free RL
state
reward
action
At
Rt
StLecture 8: Integrating Learning and Planning
Introduction
Model-Free RL
state
reward
action
At
Rt
St
L
e
c
t
u
r
e
8
:
I
n
t
e
g
r
a
t
i
n
g
L
e
a
r
n
i
n
g
a
n
d
P
l
a
n
n
i
n
g
I
n
t
r
o
d
u
c
t
i
o
n
Model-FreeRL
state
reward
action
At R
t
St
Lecture 8: Integrating Learning and Planning
Introduction
Model-Based RL
state
reward
action
At
Rt
St
What can I learn by interacting with the world?This lecture: Model-based RL, we will combine both, learning from experience and planning: 1. If the model is unknown, we will learn the model. 2. Learn value functions using both real and simulated
experience Lecture 8: Integrating Learning and Planning
Introduction
Model-Free RL
state
reward
action
At
Rt
St
Lecture 8: Integrating Learning and Planning
Introduction
Model-Free RL
state
reward
action
At
Rt
St
Lecture 8: Integrating Learning and Planning
Introduction
Model-Free RL
state
reward
action
At
Rt
StLecture 8: Integrating Learning and Planning
Introduction
Model-Free RL
state
reward
action
At
Rt
St
L
e
c
t
u
r
e
8
:
I
n
t
e
g
r
a
t
i
n
g
L
e
a
r
n
i
n
g
a
n
d
P
l
a
n
n
i
n
g
I
n
t
r
o
d
u
c
t
i
o
n
Model-FreeRL
state
reward
action
At R
t
St
Lecture 8: Integrating Learning and Planning
Introduction
Model-Based RL
state
reward
action
At
Rt
St
Lecture 8: Integrating Learning and Planning
Introduction
Model-Free RL
state
reward
action
At
Rt
St
What can I learn by interacting with the world?This lecture: we will combine both, learning from experience and planning: 1. If the model is unknown, we will learn the model. 2. Learn value functions using both real and simulated
experience 3. Learning value functions online using model-based look-
ahead search
Lecture 8: Integrating Learning and Planning
Introduction
Model-Free RL
state
reward
action
At
Rt
St
Lecture 8: Integrating Learning and Planning
Introduction
Model-Free RL
state
reward
action
At
Rt
St
Lecture 8: Integrating Learning and Planning
Introduction
Model-Free RL
state
reward
action
At
Rt
St
Lecture 8: Integrating Learning and Planning
Introduction
Model-Free RL
state
reward
action
At
Rt
StLecture 8: Integrating Learning and Planning
Introduction
Model-Free RL
state
reward
action
At
Rt
St
L
e
c
t
u
r
e
8
:
I
n
t
e
g
r
a
t
i
n
g
L
e
a
r
n
i
n
g
a
n
d
P
l
a
n
n
i
n
g
I
n
t
r
o
d
u
c
t
i
o
n
Model-FreeRL
state
reward
action
At R
t
St
What can I learn by interacting with the world?This lecture: we will combine both, learning from experience and planning: 1. If the model is unknown, we will learn the model. 2. Learn value functions using both real and simulated
experience 3. Learning value functions online using model-based look-
ahead search
Lecture 8: Integrating Learning and Planning
Introduction
Model-Free RL
state
reward
action
At
Rt
St
Lecture 8: Integrating Learning and Planning
Introduction
Model-Free RL
state
reward
action
At
Rt
St
Lecture 8: Integrating Learning and Planning
Introduction
Model-Free RL
state
reward
action
At
Rt
StLecture 8: Integrating Learning and Planning
Introduction
Model-Free RL
state
reward
action
At
Rt
St
L
e
c
t
u
r
e
8
:
I
n
t
e
g
r
a
t
i
n
g
L
e
a
r
n
i
n
g
a
n
d
P
l
a
n
n
i
n
g
I
n
t
r
o
d
u
c
t
i
o
n
Model-FreeRL
state
reward
action
At R
t
St
Lecture 8: Integrating Learning and Planning
Introduction
Model-Based RL
state
reward
action
At
Rt
St
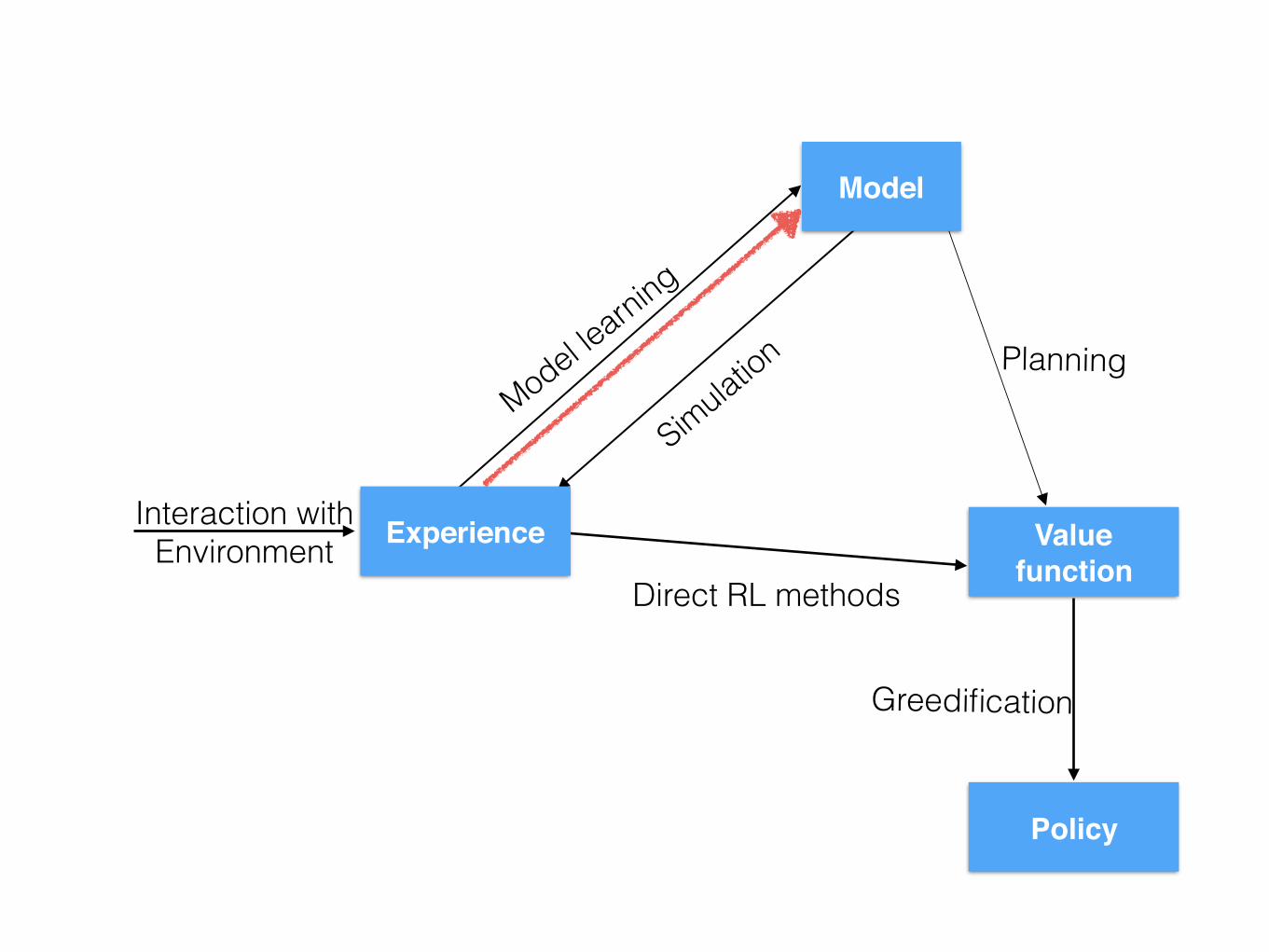
Paths to a policy
Model
Valuefunction
Policy
Experience
Direct RLmethods
Directplanning
Greedification
Modellearning
SimulationEnvironmentalinteraction
Model-based RL
Model
Experience
Policy
Value function
Interaction with Environment
Model learning
Simulation Planning
Greedification
Model-based RL
Direct RL methods

Advantages of Model-Based RL
Advantages:
• Model learning transfers across tasks and environment configurations (learning physics)
• Better exploits experience in case of sparse rewards
• It is probably what the brain does (more to come)
• Helps exploration: Can reason about model uncertainty
Disadvantages:
• First learn model, then construct a value function: Two sources of approximation error

What is a Model?
Model: anything the agent can use to predict how the environment will respond to its actions, concretely, the transition (dynamics) T(s’|s,a) and reward functions R(s,a).
this includes transitions of the state of the environment and the state of the agent..
Lecture 8: Integrating Learning and Planning
Introduction
Model-Based RL
state
reward
action
At
Rt
St
s
as0
r

What is a Model?Model: anything the agent can use to predict how the environment will respond to its actions, concretely:
1. the transition function (dynamics)
2. reward function
Distribution model: description of all possibilities and their probabilities, T(s’|s,a) for all (s, a, s’)
Sample model, a.k.a. a simulation model: produces sample experiences for given s, often much easier to come by
Both types of models can be used to produce hypothetical experience (what if…)

Model Learning
Lecture 8: Integrating Learning and Planning
Introduction
Model-Free RL
state
reward
action
At
Rt
St
Lecture 8: Integrating Learning and Planning
Introduction
Model-Free RL
state
reward
action
At
Rt
St
Lecture 8: Integrating Learning and Planning
Introduction
Model-Free RL
state
reward
action
At
Rt
StLecture 8: Integrating Learning and Planning
Introduction
Model-Free RL
state
reward
action
At
Rt
St
L
e
c
t
u
r
e
8
:
I
n
t
e
g
r
a
t
i
n
g
L
e
a
r
n
i
n
g
a
n
d
P
l
a
n
n
i
n
g
I
n
t
r
o
d
u
c
t
i
o
n
Model-FreeRL
state
reward
action
At R
t
St
Lecture 8: Integrating Learning and Planning
Introduction
Model-Based RL
state
reward
action
At
Rt
St
1. If the model is unknown, we will learn the model. 2. Learn value functions using both real and simulated
experience 3. Learning value functions online using model-based lookahead
search

Model Learning• Goal: estimate model from experience
• This can be thought as a supervised learning problem
• Learning is a regression problem
• Learning is a density estimation problem
• Pick loss function, e.g. mean-squared error, KL divergence, …
• Find parameters that minimize empirical loss
M⌘
S1,A1 ! R2,S2
S2,A2 ! R3,S3
...
ST �1,AT �1 ! RT ,ST
{S1,A1, R2, ...,ST }
s, a ! r
s, a ! s0
⌘
Lecture 8: Integrating Learning and Planning
Introduction
Model-Based RL
state
reward
action
At
Rt
St
s
as0
r
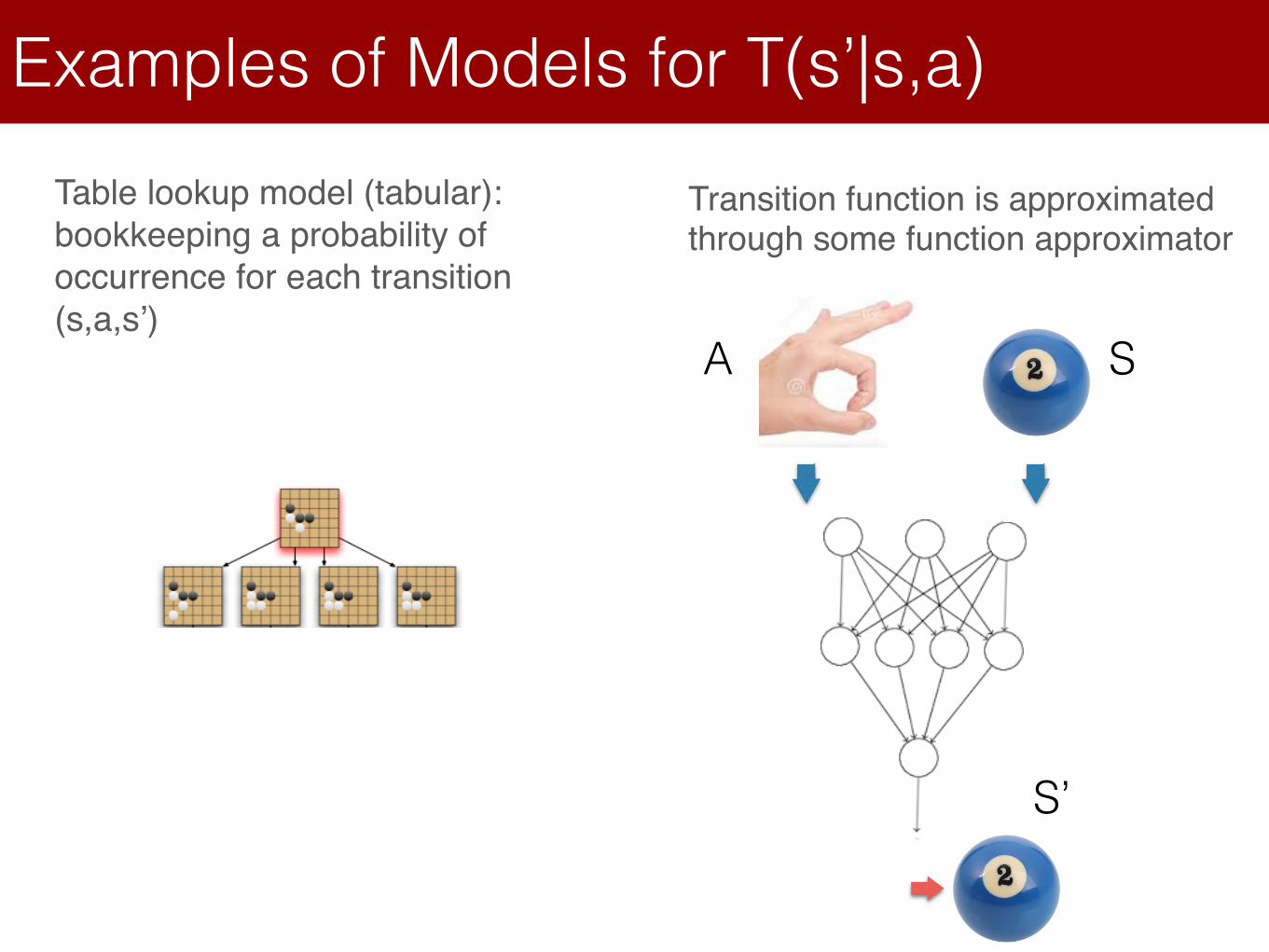
Transition function is approximated through some function approximator
Examples of Models for T(s’|s,a)Table lookup model (tabular): bookkeeping a probability of occurrence for each transition (s,a,s’)
Lecture 8: Integrating Learning and Planning
Simulation-Based Search
MCTS in Go
Monte-Carlo Evaluation in Go
Current position s
Simulation
1 1 0 0 Outcomes
V(s) = 2/4 = 0.5
SA
S’

A supervised learning problem?
• To look ahead far in the future you need to chain your dynamic predictions
• Data is sequential • i.i.d. assumptions break, • errors accumulate in time! • Solutions:
• Hierarchical dynamics models
• Linear local approximations, etc (later lectures)
Lecture 8: Integrating Learning and Planning
Introduction
Model-Based RL
state
reward
action
At
Rt
St
s
as0
r

Transition function is approximated through some features
Examples of Models for T(s’|s,a)Table lookup model (tabular): bookkeeping a probability of occurrence for each transition (s,a,s’)
Lecture 8: Integrating Learning and Planning
Simulation-Based Search
MCTS in Go
Monte-Carlo Evaluation in Go
Current position s
Simulation
1 1 0 0 Outcomes
V(s) = 2/4 = 0.5
This Lecture Later..
Paths to a policy
Model
Valuefunction
Policy
Experience
Direct RLmethods
Directplanning
Greedification
Modellearning
SimulationEnvironmentalinteraction
Model-based RL
Model
Experience
Policy
Value function
Interaction with Environment
Model learning
Simulation Planning
Greedification
Direct RL methods

Table Lookup Model
• Model is an explicit MDP,
• Count visits to each state action pair
• Alternatively
• At each time-step , record experience tuple
• To sample model, randomly pick tuple matching
T̂ , R̂N(s, a)
T̂ (s0|s, a) = 1
N(s, a)
TX
t=1
1(St, At, St+1 = s, a, s0)
R̂(s, a) =1
N(s, a)
TX
t=1
1(St, At = s, a)Rt
thSt, At, Rt+1, St+1i
hs, a, ·, ·i

A simple Example
Two states A,B; no discounting; 8 episodes of experience
We have constructed a table lookup model from the experience
Lecture 8: Integrating Learning and Planning
Model-Based Reinforcement Learning
Learning a Model
AB Example
Two states A,B ; no discounting; 8 episodes of experience
A, 0, B, 0!B, 1!B, 1!B, 1!B, 1!B, 1!B, 1!B, 0!We have constructed a table lookup model from the experience

Given a model
Solve the MDP
Using favorite planning algorithm
• Value iteration
• Policy iteration
• Tree search
Planning with a Model
M⌘ = hT⌘,R⌘ihS,A, T⌘R⌘i

Given a model
Solve the MDP
Using favorite planning algorithm
• Value iteration
• Policy iteration
• Tree search
Planning with a Model
curse of dimensionality!
M⌘ = hT⌘,R⌘ihS,A, T⌘R⌘i

Given a model
Solve the MDP
Using favorite planning algorithm
• Value iteration
• Policy iteration
• Tree search
• Sample-based planning (right next)
Planning with a Model
M⌘ = hT⌘,R⌘ihS,A, T⌘R⌘i

• Use the model only to generate samples, not using its transition probabilities and expected immediate rewards
• Sample experience from model
• Apply model-free RL to samples, e.g.:
• Monte-Carlo control
• Sarsa
• Q-learning
• Sample-based planning methods are often more efficient: rather than exhaustive state sweeps we focus on what is likely to happen
Sample-based Planning
Rt+1 = R⌘(Rt+1|St, At)
St+1 ⇠ T⌘(St+1|St, At)

Paths to a policy
Model
Valuefunction
Policy
Experience
Direct RLmethods
Directplanning
Greedification
Modellearning
SimulationEnvironmentalinteraction
Model-based RL
Model
Experience
Policy
Value function
Interaction with Environment
Model learning
Simulation Planning
Greedification
Direct RL methods
Sample-based planning

A Simple Example
• Construct a table-lookup model from real experience
• Apply model-free RL to sampled experience
Lecture 8: Integrating Learning and Planning
Model-Based Reinforcement Learning
Planning with a Model
Back to the AB Example
Construct a table-lookup model from real experience
Apply model-free RL to sampled experience
Real experienceA, 0, B, 0B, 1B, 1B, 1B, 1B, 1B, 1B, 0
Sampled experienceB, 1B, 0B, 1A, 0, B, 1B, 1A, 0, B, 1B, 1B, 0
e.g. Monte-Carlo learning: V (A) = 1,V (B) = 0.75e.g. Monte-Carlo learning: v(A) = 1, v(B) = 0.75

Given an imperfect model
• Performance of model-based RL is limited to optimal policy for approximate MDP
• i.e. Model-based RL is only as good as the estimated model
When the model is inaccurate, planning process will compute a suboptimal policy
• Solution 1: when model is wrong, use model-free RL
• Solution 2: reason explicitly about model uncertainty
Planning with an Inaccurate Model
< T⌘,R⌘ > 6=< T ,R >
< S,A, T⌘,R⌘ >
Combine real and simulated experience
Lecture 8: Integrating Learning and Planning
Introduction
Model-Free RL
state
reward
action
At
Rt
St
Lecture 8: Integrating Learning and Planning
Introduction
Model-Free RL
state
reward
action
At
Rt
St
Lecture 8: Integrating Learning and Planning
Introduction
Model-Free RL
state
reward
action
At
Rt
StLecture 8: Integrating Learning and Planning
Introduction
Model-Free RL
state
reward
action
At
Rt
St
L
e
c
t
u
r
e
8
:
I
n
t
e
g
r
a
t
i
n
g
L
e
a
r
n
i
n
g
a
n
d
P
l
a
n
n
i
n
g
I
n
t
r
o
d
u
c
t
i
o
n
Model-FreeRL
state
reward
action
At R
t
St
Lecture 8: Integrating Learning and Planning
Introduction
Model-Based RL
state
reward
action
At
Rt
St
Lecture 8: Integrating Learning and Planning
Introduction
Model-Free RL
state
reward
action
At
Rt
St
1. If the model is unknown, we will learn the model. 2. Learn value functions using both real and simulated
experience 3. Learning value functions online using model-based look-
ahead search

Real and Simulated Experience
We consider two sources of experience
• Real experience - Sampled from environment (true MDP)
• Simulated experience - Sampled from model (approximate MD)
S0 ⇠ T (s0|s, a)
R = r(s, a)
S0 ⇠ T⌘(S0|S,A)
R = R⌘(R|S,A)

Integrating Learning and Planning
Model-Free RL
• No model
• Learn value function (and/or policy) from real experience

Integrating Learning and Planning
Model-Free RL
• No model
• Learn value function (and/or policy) from real experience
Model-Based RL (using Sample-Based Planning)
• Learn a model from real experience
• Plan value function (and/or policy) from simulated experience

Integrating Learning and Planning
Model-Free RL
• No model
• Learn value function (and/or policy) from real experience
Model-Based RL (using Sample-Based Planning)
• Learn a model from real experience
• Plan value function (and/or policy) from simulated experience
Dyna
• Learn a model from real experience
• Learn and plan value function (and/or policy) from real and simulated experience
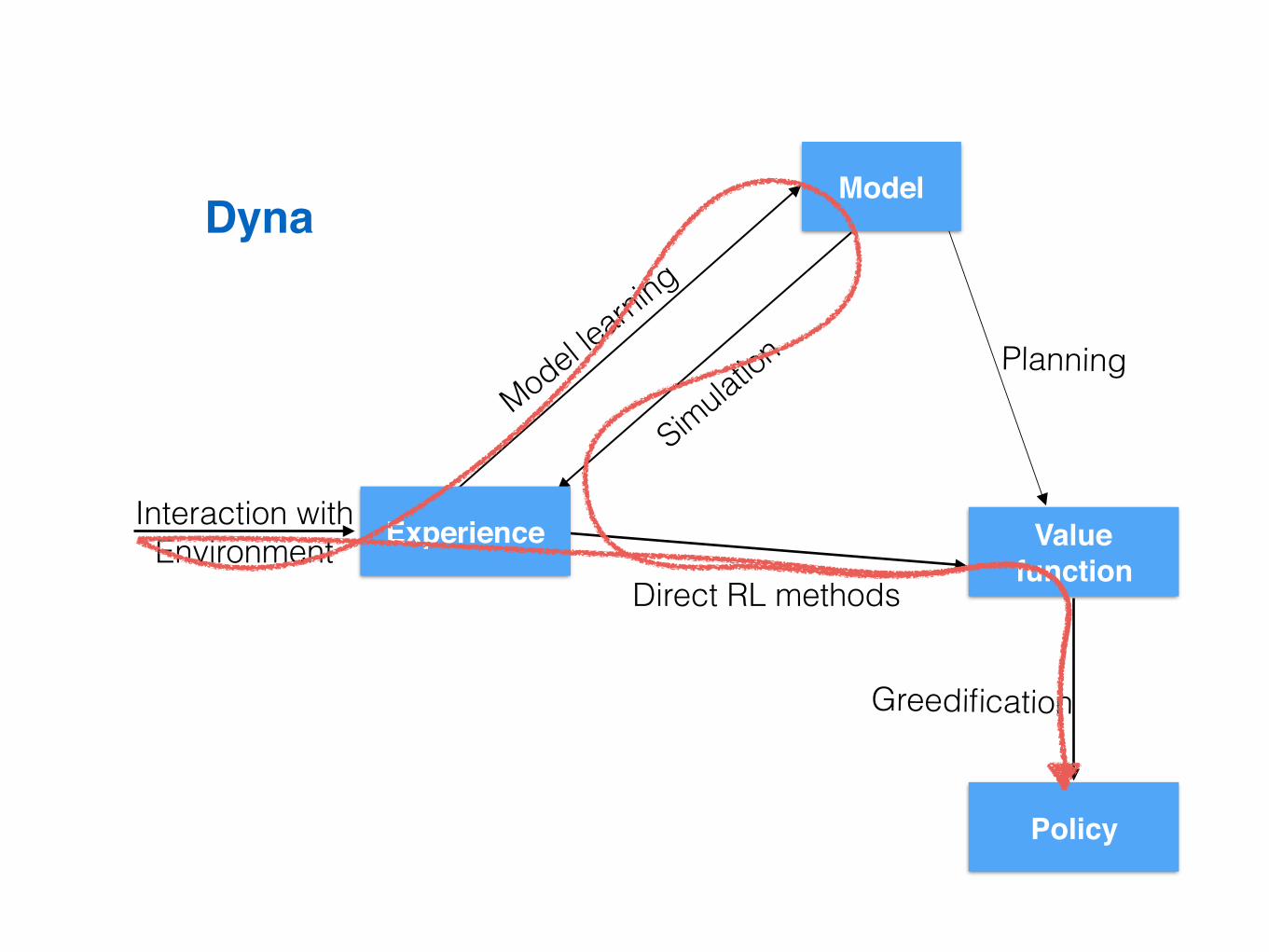
Paths to a policy
Model
Valuefunction
Policy
Experience
Direct RLmethods
Directplanning
Greedification
Modellearning
SimulationEnvironmentalinteraction
Model-based RL
Model
Experience
Policy
Value function
Interaction with Environment
Model learning
Simulation Planning
Greedification
Dyna
Direct RL methods

Dyna-Q AlgorithmLecture 8: Integrating Learning and Planning
Integrated Architectures
Dyna
Dyna-Q Algorithm

Dyna-Q on a Simple MazeLecture 8: Integrating Learning and Planning
Integrated Architectures
Dyna
Dyna-Q on a Simple Maze
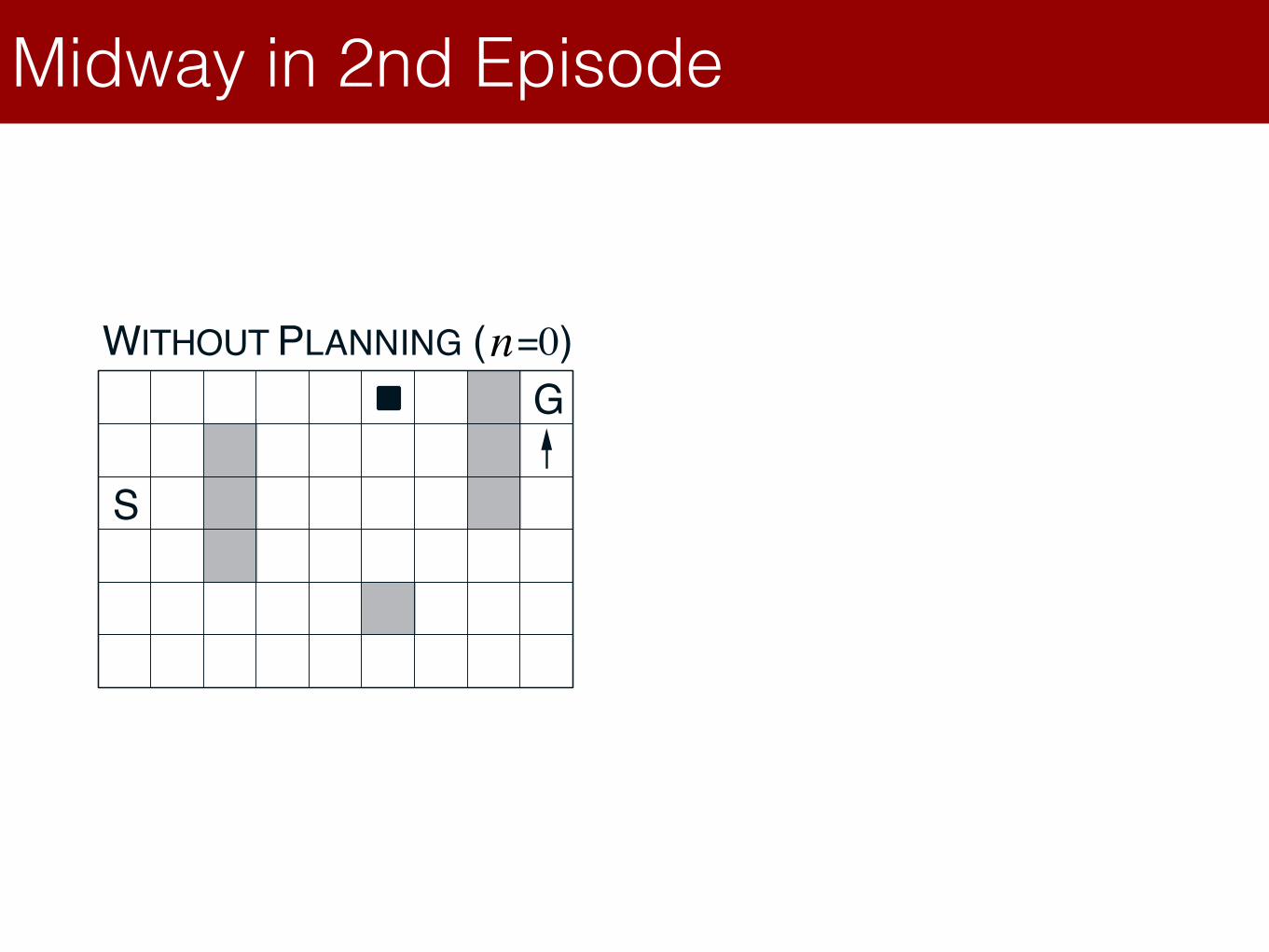
Midway in 2nd Episode
R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 13
Dyna-Q Snapshots: Midway in 2nd Episode
S
G
S
G
WITHOUT PLANNING (N=0) WITH PLANNING (N=50)n n
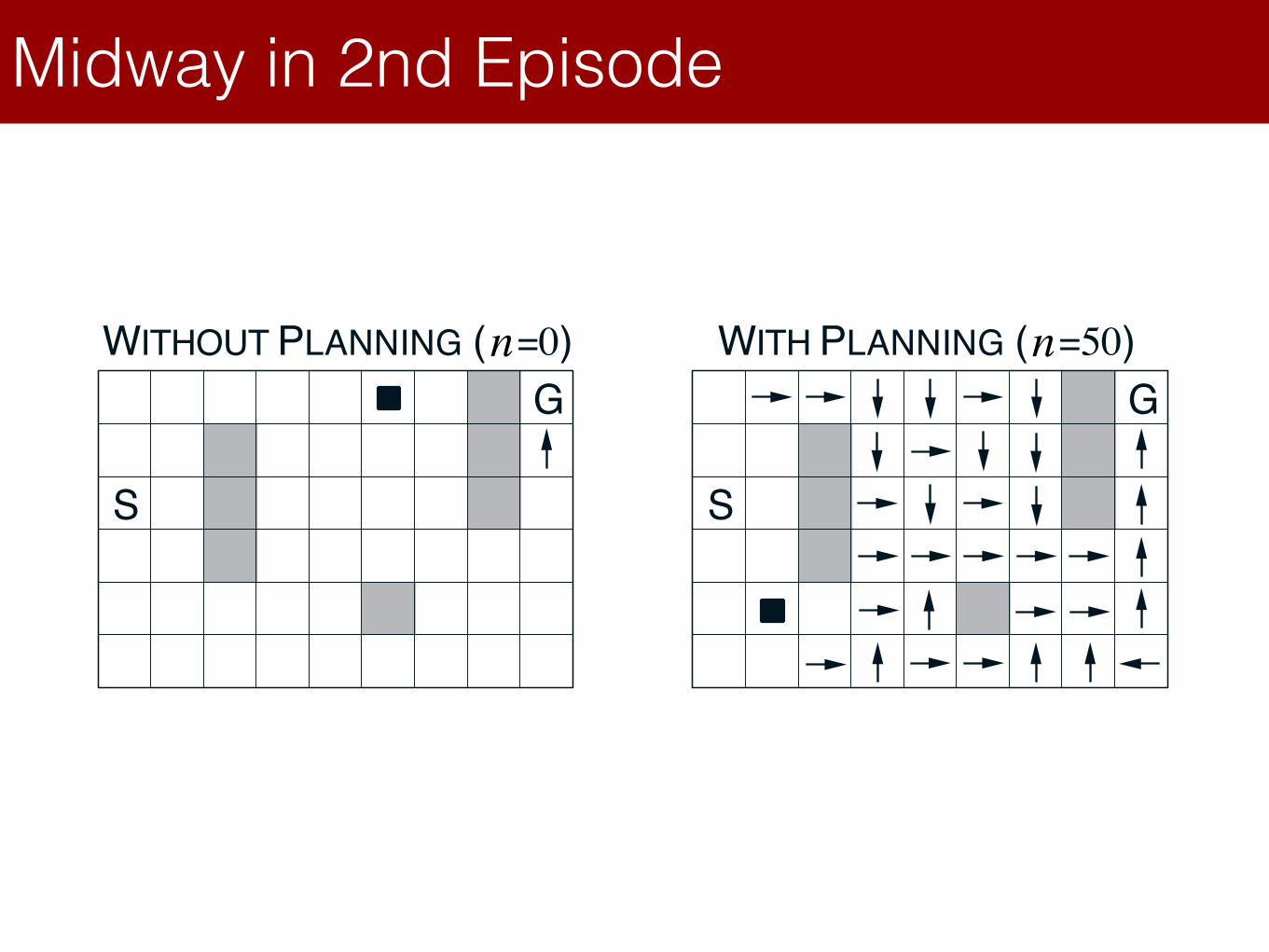
Midway in 2nd Episode
R. S. Sutton and A. G. Barto: Reinforcement Learning: An Introduction 13
Dyna-Q Snapshots: Midway in 2nd Episode
S
G
S
G
WITHOUT PLANNING (N=0) WITH PLANNING (N=50)n n
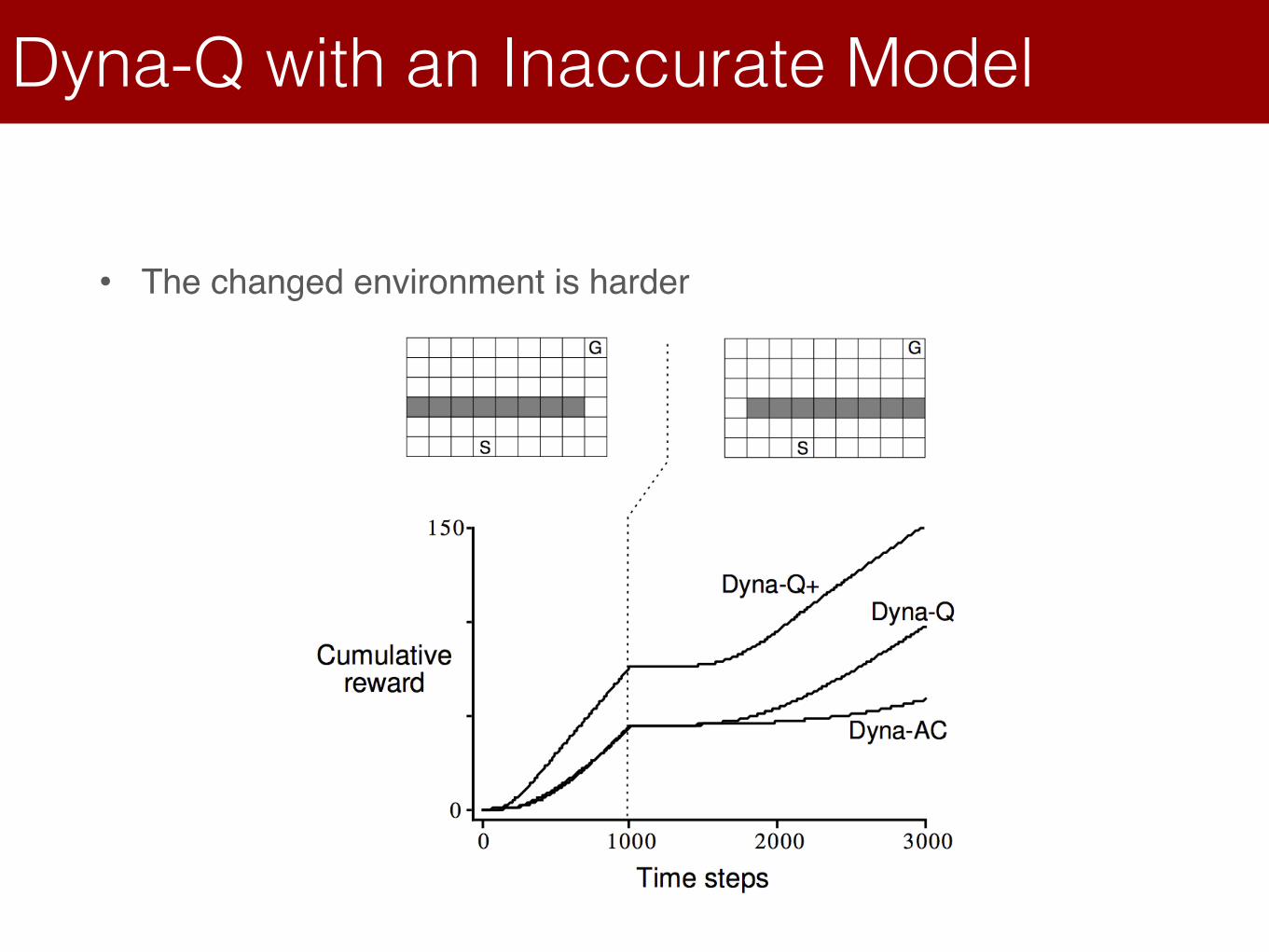
Dyna-Q with an Inaccurate Model
• The changed environment is harder
Lecture 8: Integrating Learning and Planning
Integrated Architectures
Dyna
Dyna-Q with an Inaccurate Model
The changed environment is harder

Dyna-Q with an Inaccurate model Cont.
• The changed environment is easier
Lecture 8: Integrating Learning and Planning
Integrated Architectures
Dyna
Dyna-Q with an Inaccurate Model (2)
The changed environment is easier

Sampling-based look-ahead search
Lecture 8: Integrating Learning and Planning
Introduction
Model-Free RL
state
reward
action
At
Rt
St
Lecture 8: Integrating Learning and Planning
Introduction
Model-Free RL
state
reward
action
At
Rt
St
Lecture 8: Integrating Learning and Planning
Introduction
Model-Free RL
state
reward
action
At
Rt
St
Lecture 8: Integrating Learning and Planning
Introduction
Model-Free RL
state
reward
action
At
Rt
StLecture 8: Integrating Learning and Planning
Introduction
Model-Free RL
state
reward
action
At
Rt
St
L
e
c
t
u
r
e
8
:
I
n
t
e
g
r
a
t
i
n
g
L
e
a
r
n
i
n
g
a
n
d
P
l
a
n
n
i
n
g
I
n
t
r
o
d
u
c
t
i
o
n
Model-FreeRL
state
reward
action
At R
t
St
1. If the model is unknown, we will learn the model. 2. Learn value functions using both real and simulated
experience 3. Learning value functions online using model-based look-
ahead search

Paths to a policy
Model
Valuefunction
Policy
Experience
Direct RLmethods
Directplanning
Greedification
Modellearning
SimulationEnvironmentalinteraction
Model-based RL
Model
Experience
Action(from a given state s)
Value function
Interaction with Environment
Model learning
Simulation Planning
Greedification
Forward Search
Direct RL methods
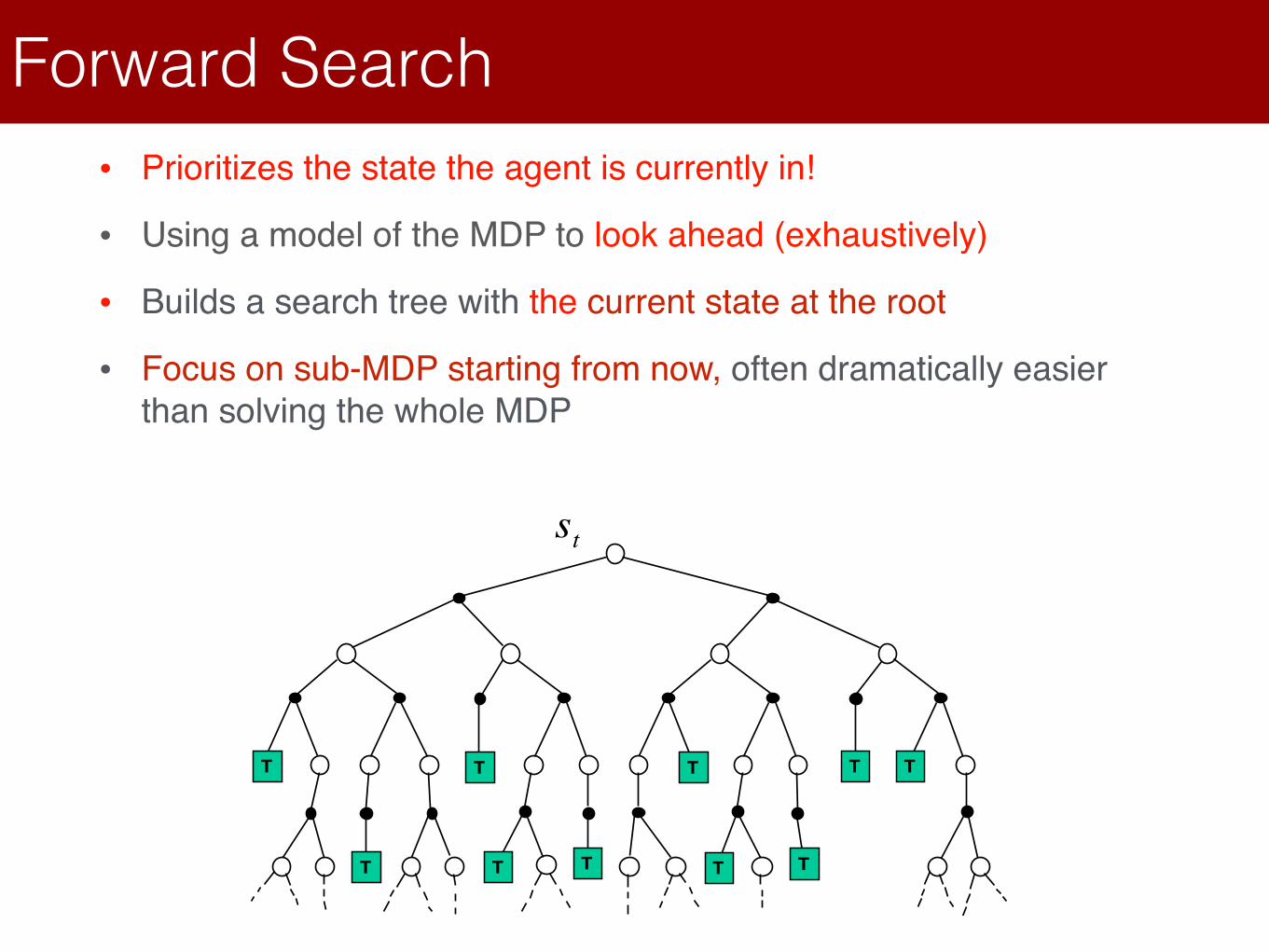
Forward Search• Prioritizes the state the agent is currently in!
• Using a model of the MDP to look ahead (exhaustively)
• Builds a search tree with the current state at the root
• Focus on sub-MDP starting from now, often dramatically easier than solving the whole MDP
• Image
Lecture 8: Integrating Learning and Planning
Simulation-Based Search
Forward Search
Forward search algorithms select the best action by lookaheadThey build a search tree with the current state st at the rootUsing a model of the MDP to look ahead
T! T! T! T!T!
T! T! T! T! T!
st
T! T!
T! T!
T!T! T!
T! T!T!
No need to solve whole MDP, just sub-MDP starting from now

Why Forward search?
Why don’t we learn a value function directly for every state offline, so that we do not waste time online?
• Because the environment has many many states (consider Go 10^170, ChessL 10^48, real world ….)
• Very hard to compute a good value function for each one of them, most you will never even visit
• Thus, it makes sense, condition on the current state you are in, to try to estimate the value function of the relevant part of the state space online! Focus your resources.
• Use the the online forward search to pick the best action
Disadvantages:
• Nothing is learnt from episode to episode
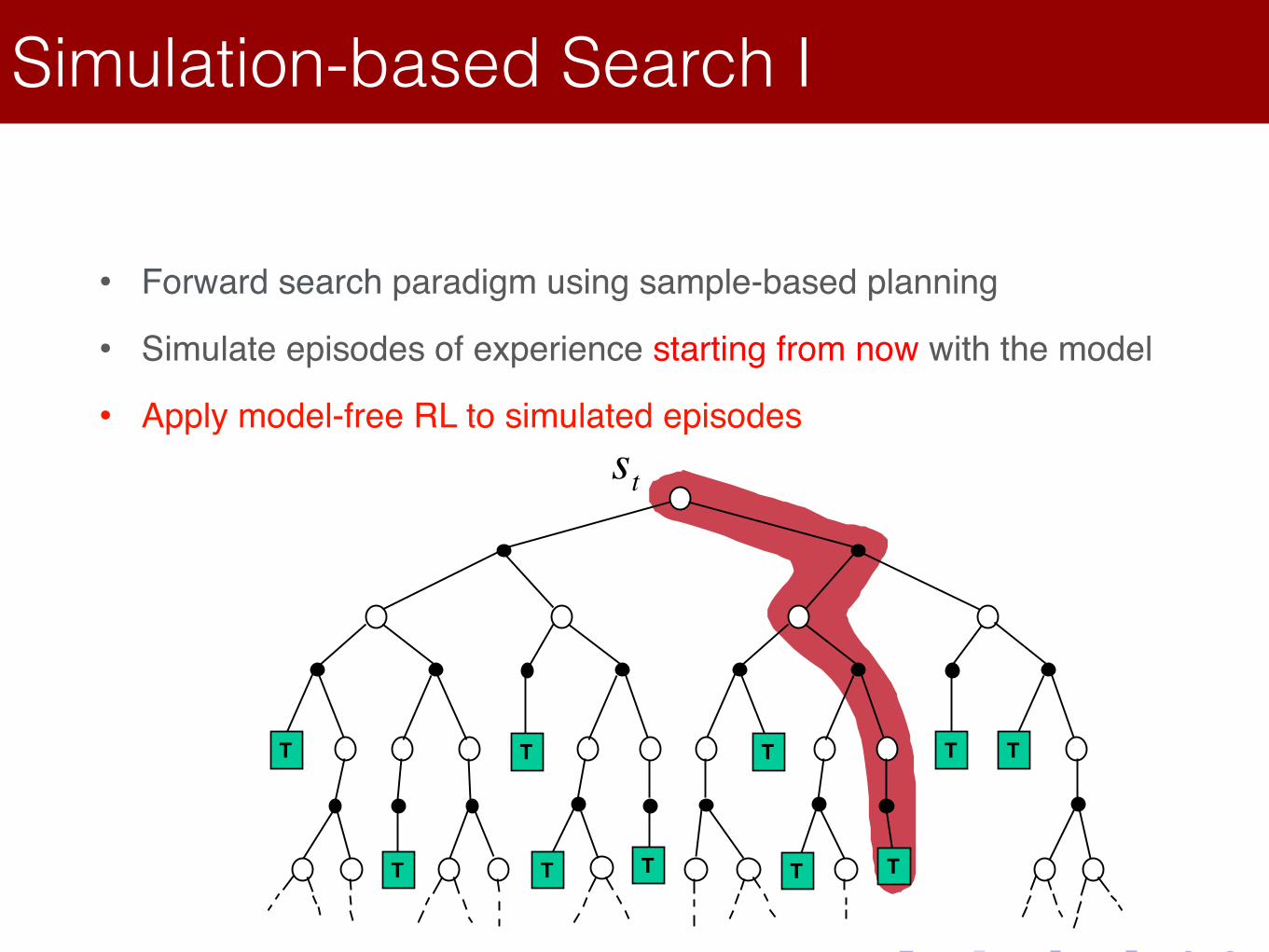
Simulation-based Search I
• Forward search paradigm using sample-based planning
• Simulate episodes of experience starting from now with the model
• Apply model-free RL to simulated episodes
• Image
Lecture 8: Integrating Learning and Planning
Simulation-Based Search
Simulation-Based Search
Forward search paradigm using sample-based planning
Simulate episodes of experience from now with the model
Apply model-free RL to simulated episodes
T! T! T! T!T!
T! T! T! T! T!
st
T! T!
T! T!
T!T! T!
T! T!T!

• Simulate episodes of experience from now with the model
• Apply model-free RL to simulated episodes
• Monte-Carlo control Monte-Carlo search
Simulation-Based Search II
!
{skt ,Akt , R
kt+1, ..., S
kT }Kk=1 ⇠ M⌫

• Given a model and a simulation policy
• For each action
• Simulate episodes from current (real) state :
• Evaluate action value function of the root by mean return (Monte-Carlo evaluation)
• Select current (real) action with maximum value
Simple Monte-Carlo Search
M⌫ ⇡
a 2 AK s
Q(st, a) =1
K
KX
k=1
GtP�! q⇡(st, a)
at = argmax
a2AQ(st, a)
{st, a, Rkt+1, S
kt+1, A
kt+1, ..., S
kT }Kk=1 ⇠ M⌫ ,⇡

Monte-Carlo Tree Search (Evaluation)
• Given a model
• Simulate episodes from current state using current simulation policy
• Build a search tree containing visited states and actions
• Evaluate states by mean return of episodes from for all states and actions in the tree
• After search is finished, select current (real) action with maximum value in search tree
M⌫
K st⇡
{st, Akt , R
kt+1, S
kt+1, ..., S
kT }Kk=1 ⇠ M⌫ ,⇡
Q(st, a) =1
N(s, a)
KX
k=1
TX
u=t
1(Su, Au = s, a)GuP�! q⇡(s, a)
Q(s, a) s, a
at = argmax
a2AQ(st, a)

Monte-Carlo Tree Search (Simulation)
• In MCTS, the simulation policy improves
• Each simulation consists of two phases (in-tree, out-of-tree)
• Tree policy (improves): pick actions to maximize
• Default policy (fixed): pick actions randomly
• Repeat (each simulation)
• Evaluate states by Monte-Carlo evaluation
• Improve there policy, e.g. by
• Monte-Carlo control applied to simulated experience
• Converges on the optimal search tree,
⇡
Q(s, a)
Q(s, a)
✏� greedy(Q)
Q(S,A) ! q ⇤ (S,A)

Case Study: the Game of Go
• The ancient oriental game of Go is 2500 years old
• Considered to be the hardest classic board game
• Considered a grand challenge task for AI (John McCarthy)
• Traditional game-tree search has failed in Go
Lecture 8: Integrating Learning and Planning
Simulation-Based Search
MCTS in Go
Case Study: the Game of Go
The ancient oriental game ofGo is 2500 years old
Considered to be the hardestclassic board game
Considered a grandchallenge task for AI(John McCarthy)
Traditional game-tree searchhas failed in Go

Rules of Go
• Usually played on 19x19, also 13x13 or 9x9 board
• Simple rules, complex strategy
• Black and white place down stones alternately
• Surrounded stones are captured and removed
• The player with more territory wins the game
Lecture 8: Integrating Learning and Planning
Simulation-Based Search
MCTS in Go
Rules of Go
Usually played on 19x19, also 13x13 or 9x9 board
Simple rules, complex strategy
Black and white place down stones alternately
Surrounded stones are captured and removed
The player with more territory wins the game

Position Evaluation in Go
• How good is a position ?
• Reward function (undiscounted):
for all non-terminal steps
• Policy selects moves for both players
• Value function (how good is position ):
s
Rt = 0 t < T
RT =
(1, if Black wins.
0, if White wins.
⇡ = h⇡B ,⇡W is
v⇡(s) = E⇡[RT |S = s] = P[Black wins|S = s]
v⇤(s) = max
⇡B
min
⇡W
v⇡(s)

Monte-Carlo Evaluation in GoLecture 8: Integrating Learning and Planning
Simulation-Based Search
MCTS in Go
Monte-Carlo Evaluation in Go
Current position s
Simulation
1 1 0 0 Outcomes
V(s) = 2/4 = 0.5
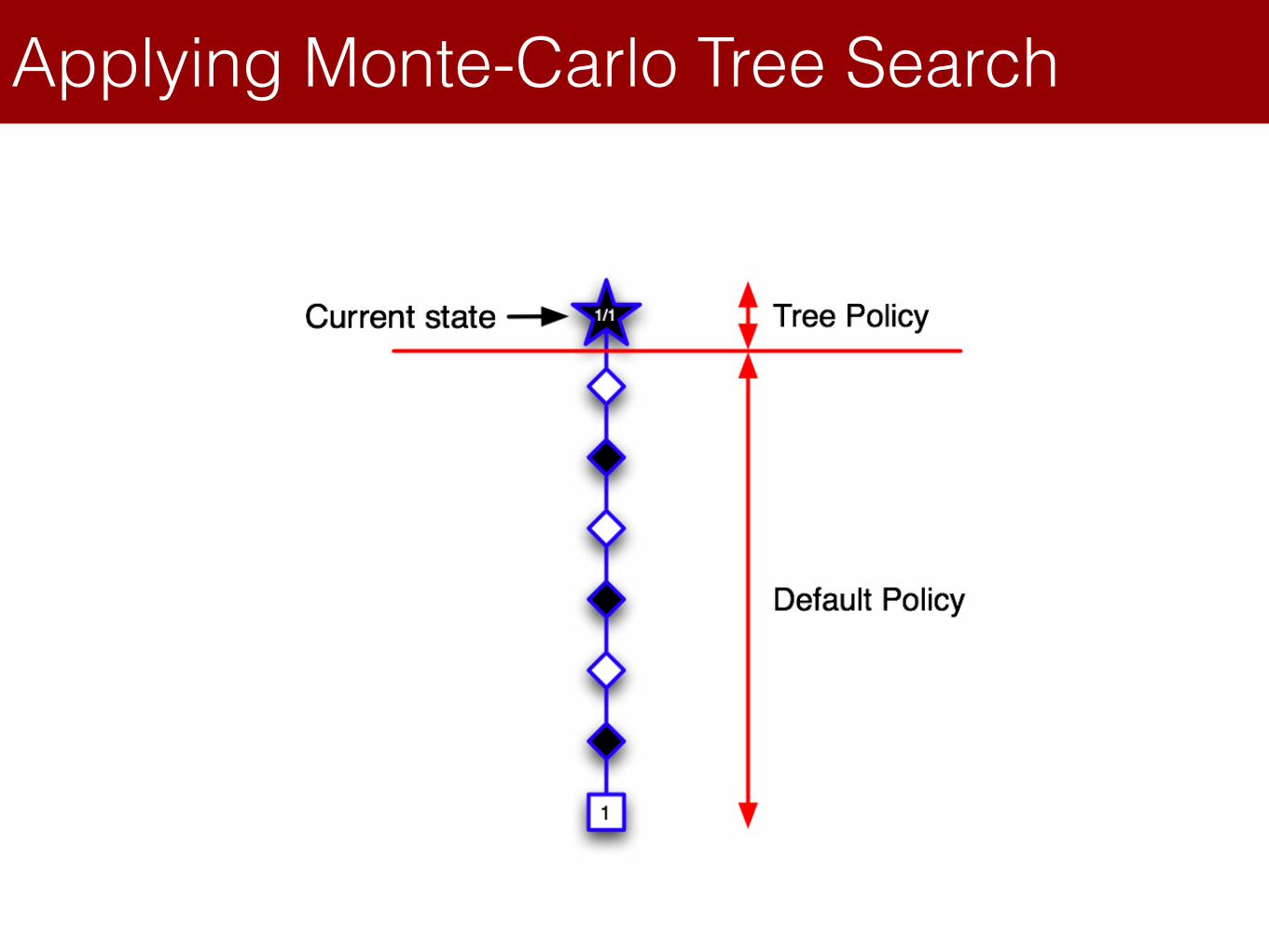
Applying Monte-Carlo Tree SearchLecture 8: Integrating Learning and Planning
Simulation-Based Search
MCTS in Go
Applying Monte-Carlo Tree Search (1)
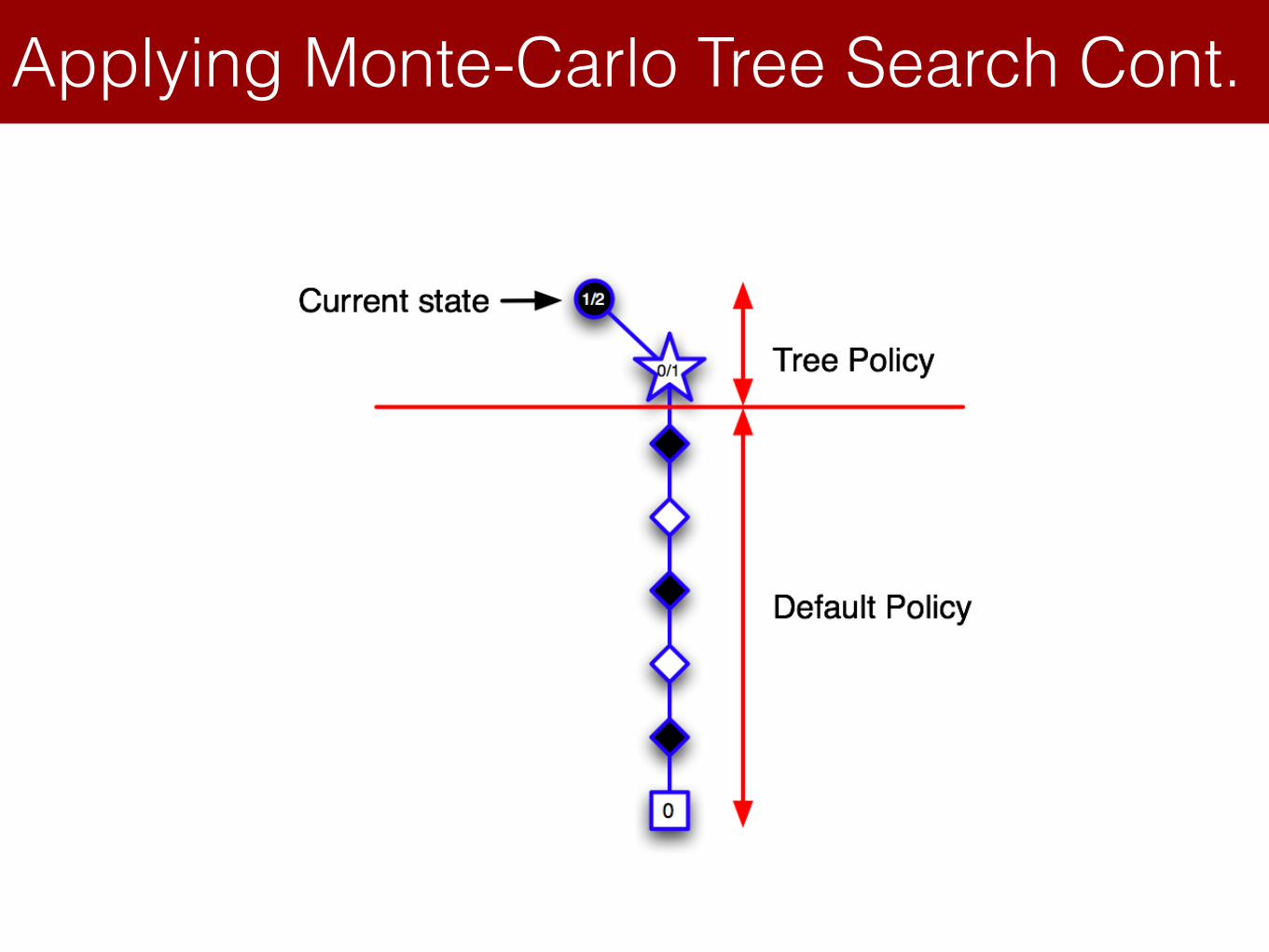
Applying Monte-Carlo Tree Search Cont.Lecture 8: Integrating Learning and Planning
Simulation-Based Search
MCTS in Go
Applying Monte-Carlo Tree Search (2)
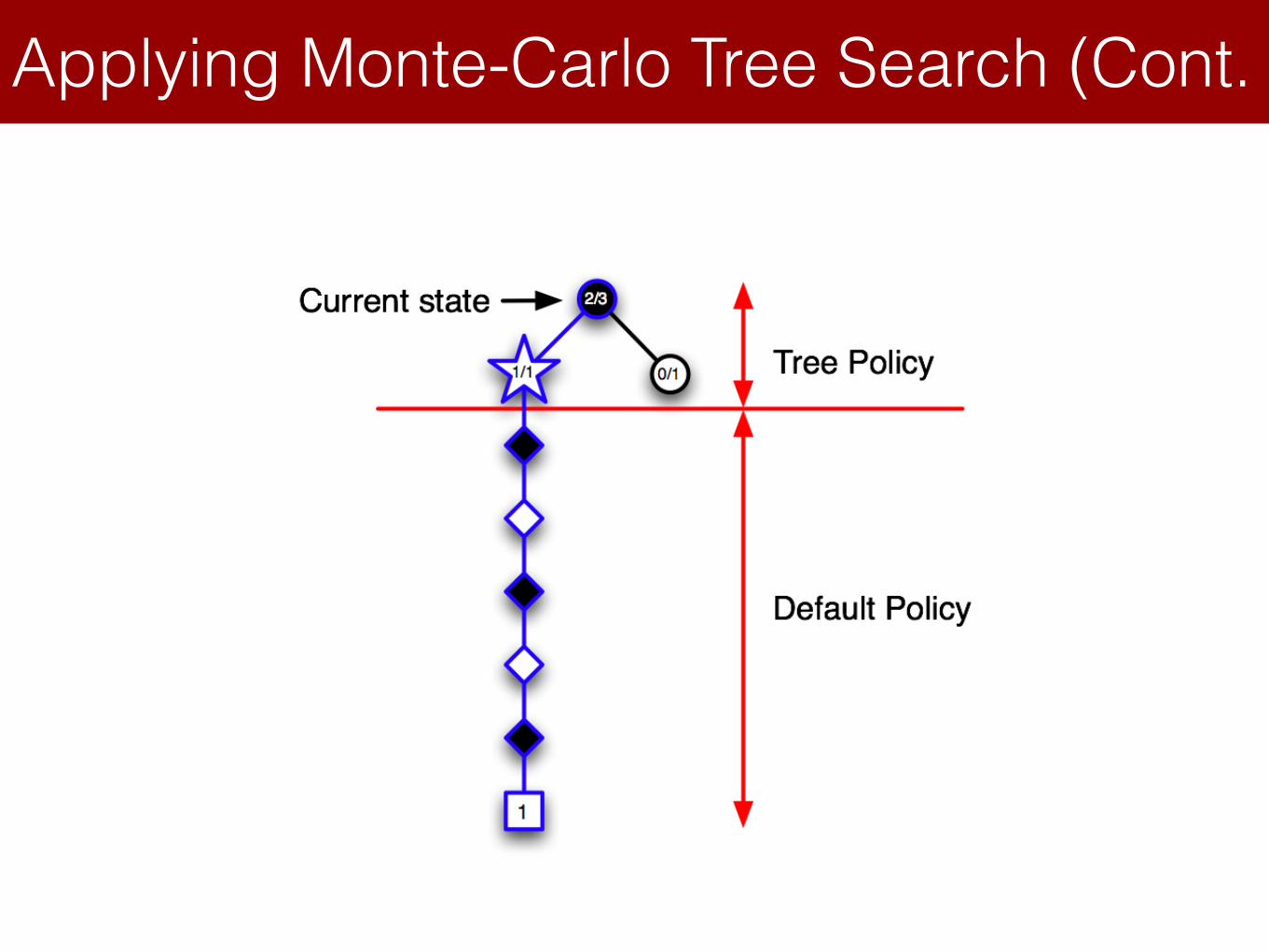
Applying Monte-Carlo Tree Search (Cont.Lecture 8: Integrating Learning and Planning
Simulation-Based Search
MCTS in Go
Applying Monte-Carlo Tree Search (3)
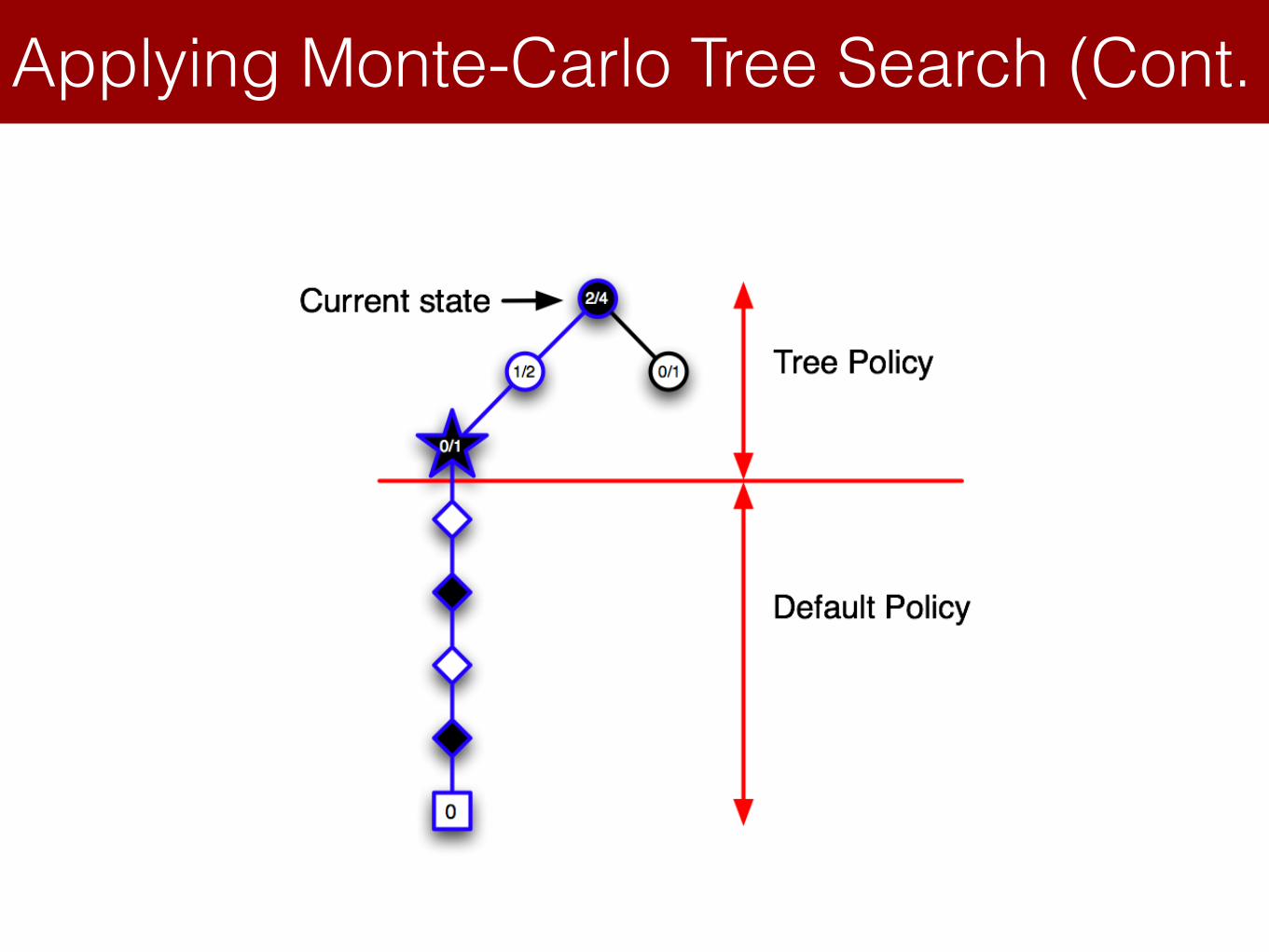
Applying Monte-Carlo Tree Search (Cont.Lecture 8: Integrating Learning and Planning
Simulation-Based Search
MCTS in Go
Applying Monte-Carlo Tree Search (4)
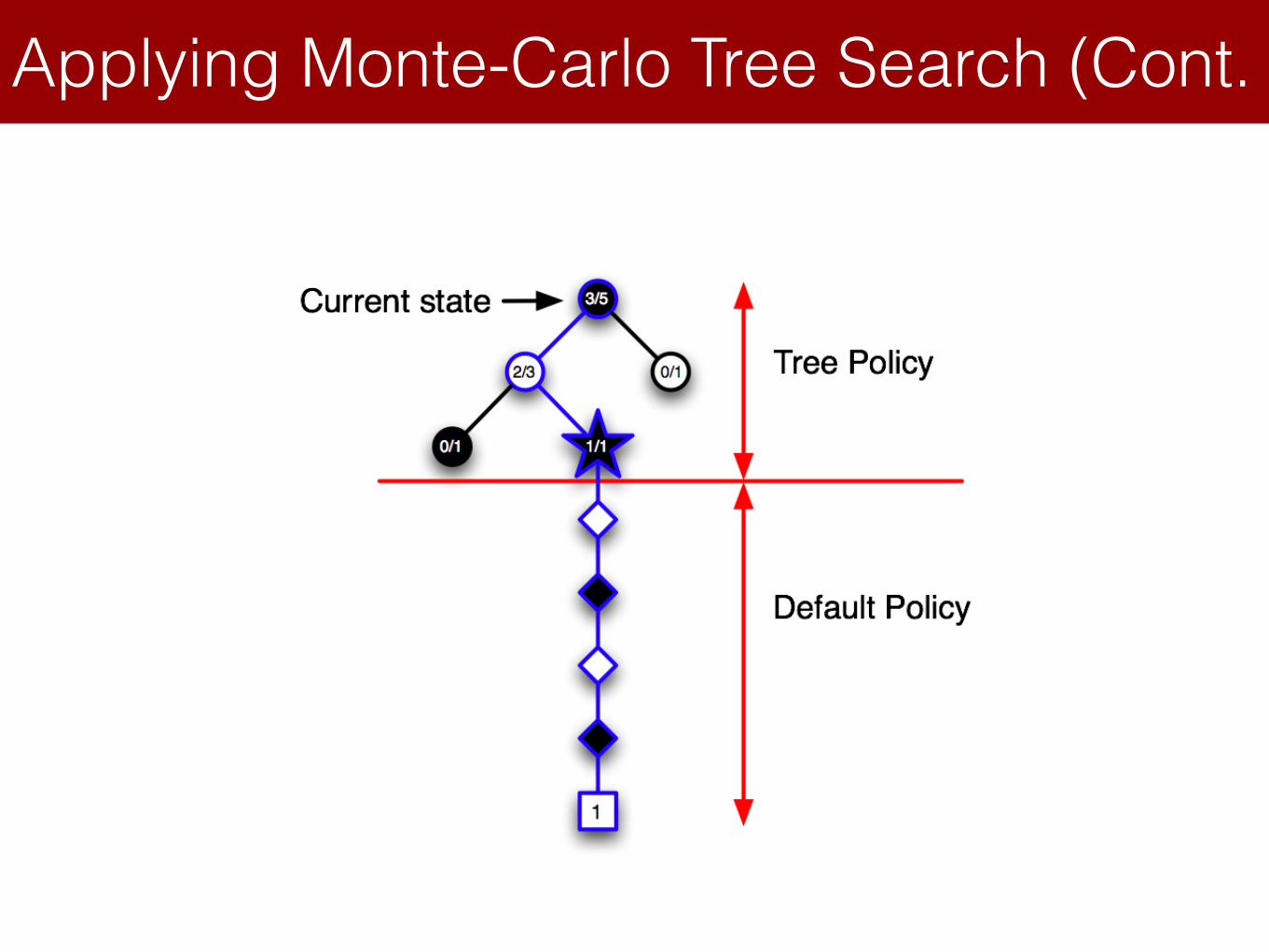
Applying Monte-Carlo Tree Search (Cont.Lecture 8: Integrating Learning and Planning
Simulation-Based Search
MCTS in Go
Applying Monte-Carlo Tree Search (5)

Advantages of MC Tree Search
• Highly selective best-first search
• Evaluate states dynamically (unlike e.g. DP)
• Uses sampling to break curse of dimensionality
• Computationally efficient, anytime, parallelizable

• Use policy networks to have priors on Q(s,a):
• Use fast and light policy networks for rollouts (instead of random policy)
• Use value function approximation computed offline to evaluate nodes in the tree:
Combining offline and online value function estimation
at = argmaxa(Q(st, a) + u(st, a))
u(s, a) / P (s, a)
1 +N(s, a)P (s, a) = ⇡�(a|s)
v(sL) = (1� �)v✓(sL) + �zL
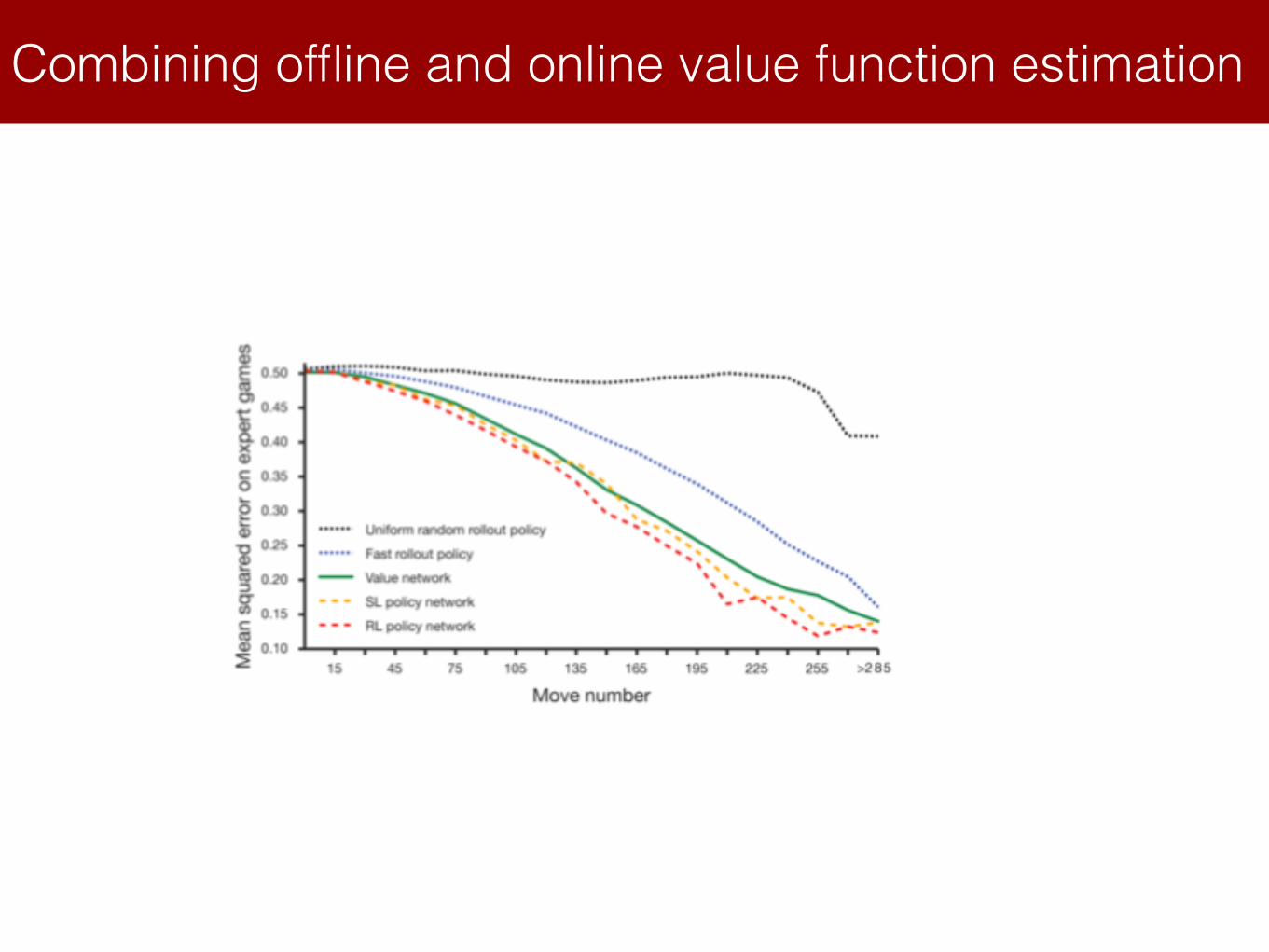
Combining offline and online value function estimation