dev490 easy multi-threading for native.net apps with openmp ™ and intel ® threading toolkit...
TRANSCRIPT

DEV490Easy Multi-threadingfor Native .NET Apps with OpenMP™ and Intel® Threading Toolkit
[email protected] Application Engineer, Intel EMEA

Agenda
Hyper-Threading technology and What to do about it
The answer is: multithreading!
Introduction to OpenMP™
Maximizing performance with OpenMP and Intel® Threading Tools
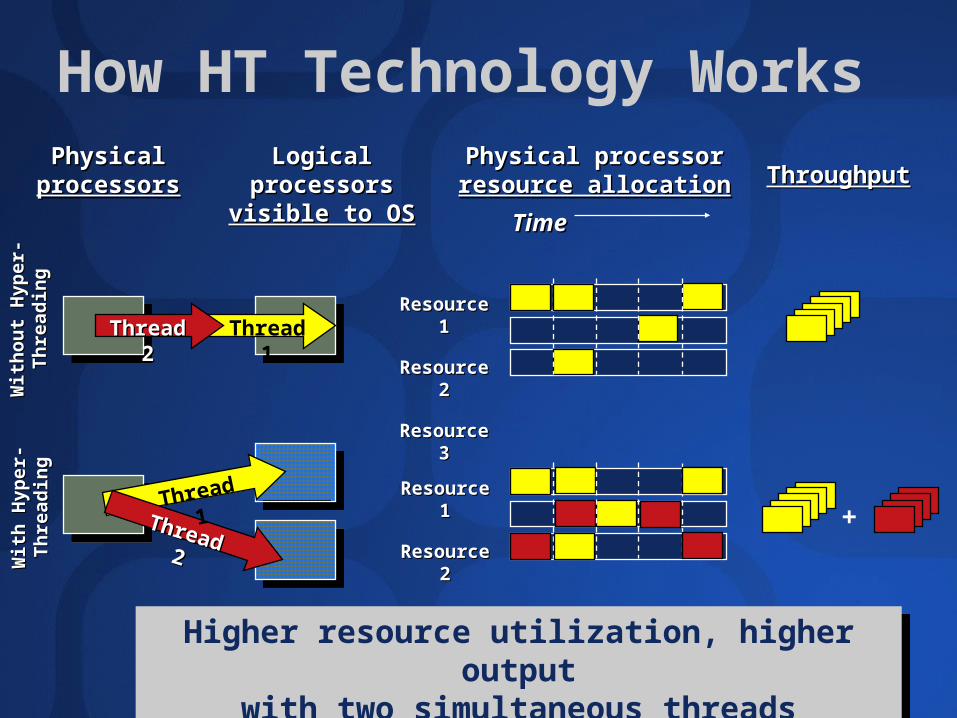
How HT Technology WorksPhysical Physical
processorsprocessorsLogical processors Logical processors
visible to OSvisible to OSPhysical processor Physical processor resource allocationresource allocation ThroughputThroughput
TimeTime
Resource 1Resource 1
Resource 2Resource 2
Resource 3Resource 3
Thread 2Thread 2 Thread 1
Wit
ho
ut
Hyp
er-
Wit
ho
ut
Hyp
er-
Th
read
ing
Th
read
ing
Wit
h H
yp
er-
Wit
h H
yp
er-
Th
read
ing
Th
read
ing
Thread 2Thread 2
Thread 1 Resource 1Resource 1
Resource 2Resource 2
Resource 3Resource 3
+
Higher resource utilization, higher outputwith two simultaneous threads
Higher resource utilization, higher outputwith two simultaneous threads
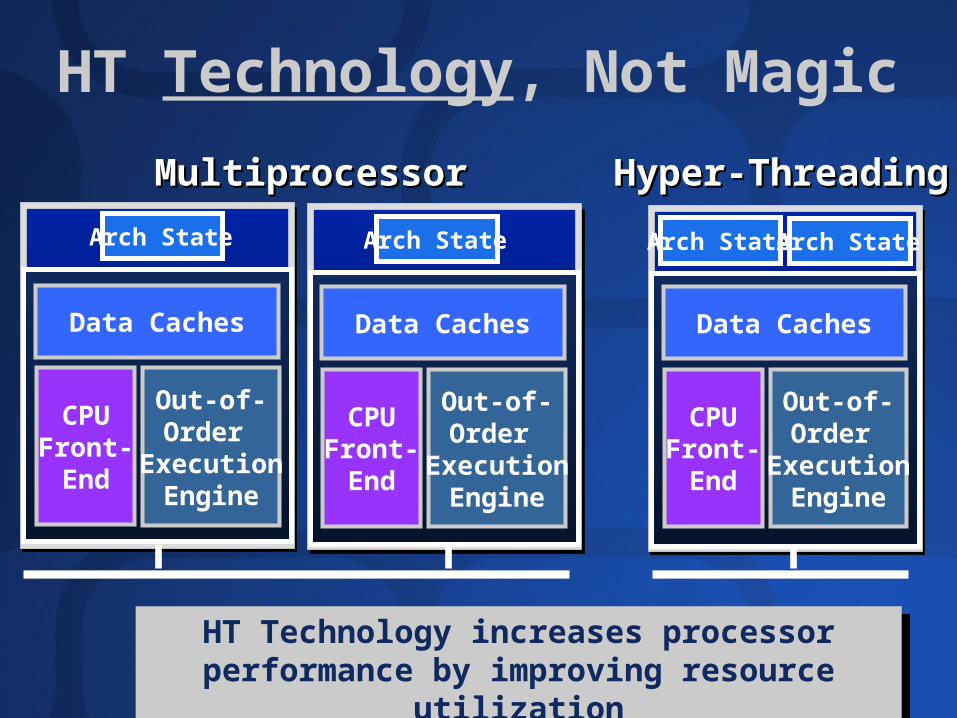
HT Technology, Not Magic
Arch State Arch State
MultiprocessorMultiprocessor Hyper-ThreadingHyper-Threading
Arch StateArch State
Data Caches
CPUFront-End
Out-of-Order
ExecutionEngine
Data Caches
CPUFront-End
Out-of-Order
ExecutionEngine
Data Caches
CPUFront-End
Out-of-Order
ExecutionEngine
HT Technology increases processor performance by improving resource utilization
HT Technology increases processor performance by improving resource utilization
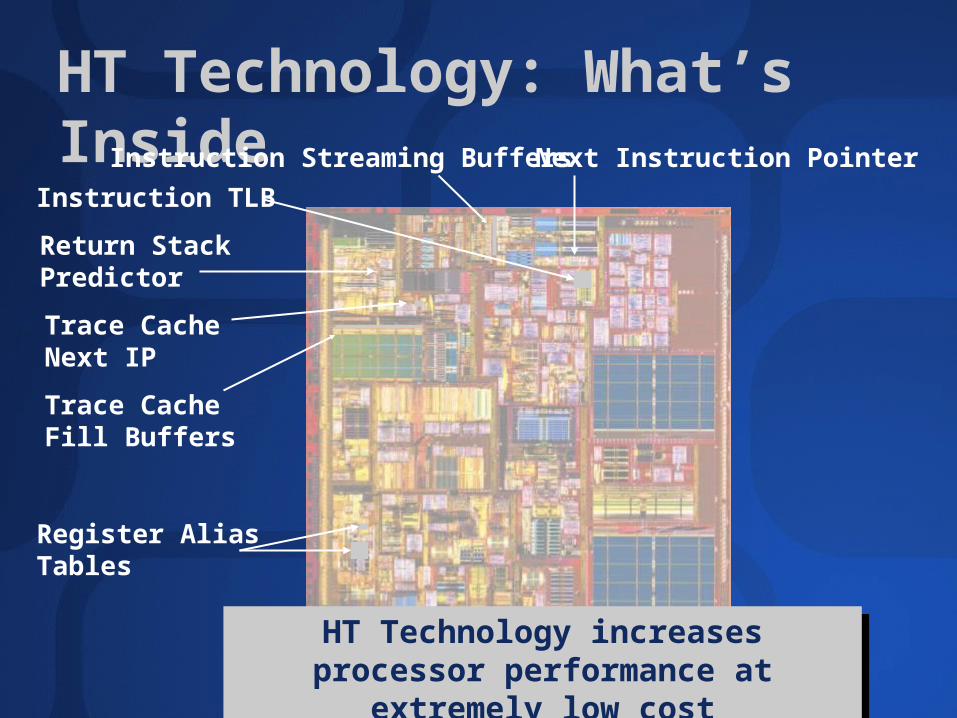
HT Technology: What’s Inside
Instruction TLB
Next Instruction PointerInstruction Streaming Buffers
Trace Cache Fill Buffers
Register Alias Tables
Trace Cache Next IP
Return Stack Predictor
HT Technology increases processor performance at extremely low cost
HT Technology increases processor performance at extremely low cost

Taking Advantage of HTHT is transparent to OS and apps
Software simply “sees” multiple CPUs
Software usage scenarios to benefit from HT:Multithreading – inside one application
Multitasking – among several applications
OS support enhances HT benefits:smart scheduling to account for logical CPUs
halting logical CPUs in the idle loop
implemented in: Windows* XP, Linux* 2.4.x
To take advantage of HT Technology,multithread your application!
To take advantage of HT Technology,multithread your application!

What? Multithreading Strategy
How? Multithreading Implementation
Multithreading Your Application

Multithreading Strategy
Exploit Task Parallelism
Exploit Data Parallelism

Exploiting Task Parallelism
Partition work into disjoint tasks
Execute the tasks concurrently(on separate threads)
Compress Thread
Encrypt ThreadData Data DataData DataData Data

Exploiting Data Parallelism
Thread A
Thread N
…
Partition data into disjoint sets
Assigns the sets to concurrent threads

Multithreading Implementation
API / LibraryWin32* threading APIP-threadsMPI
Programming language mechanismsJava*C#
Programming language extensionOpenMP™

What is OpenMP™?
Compiler extension for easy multithreadingIdeally WITHOUT CHANGING C/C++ CODEThree components:
#pragmas (compiler directives) – most important API and Runtime LibraryEnvironment Variables
Benefits:Easy way to exploit Hyper-ThreadingPortable and standardizedAllows incremental parallelizationDedicated profiling tools
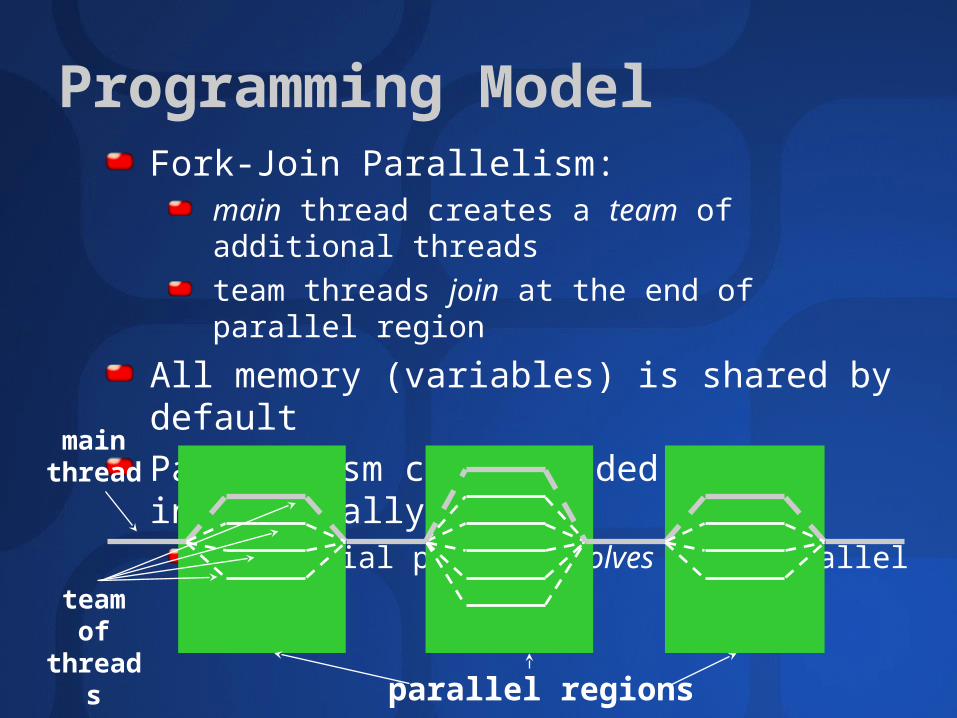
Programming ModelFork-Join Parallelism:
main thread creates a team of additional threads
team threads join at the end of parallel region
All memory (variables) is shared by default
Parallelism can be added incrementallysequential program evolves into parallel
parallel regions
team of threads
main thread

Our First OpenMP™ Program
All OpenMP™ pragmas start with omp
Pragma parallel starts team of n threads
Everything inside is executed n times!
All memory is shared!
void func(){
int a, b, c, d;
a = a + b;c = c + d;
}
void func(){
int a, b, c, d;#pragma omp parallel{
a = a + b;c = c + d;
}}
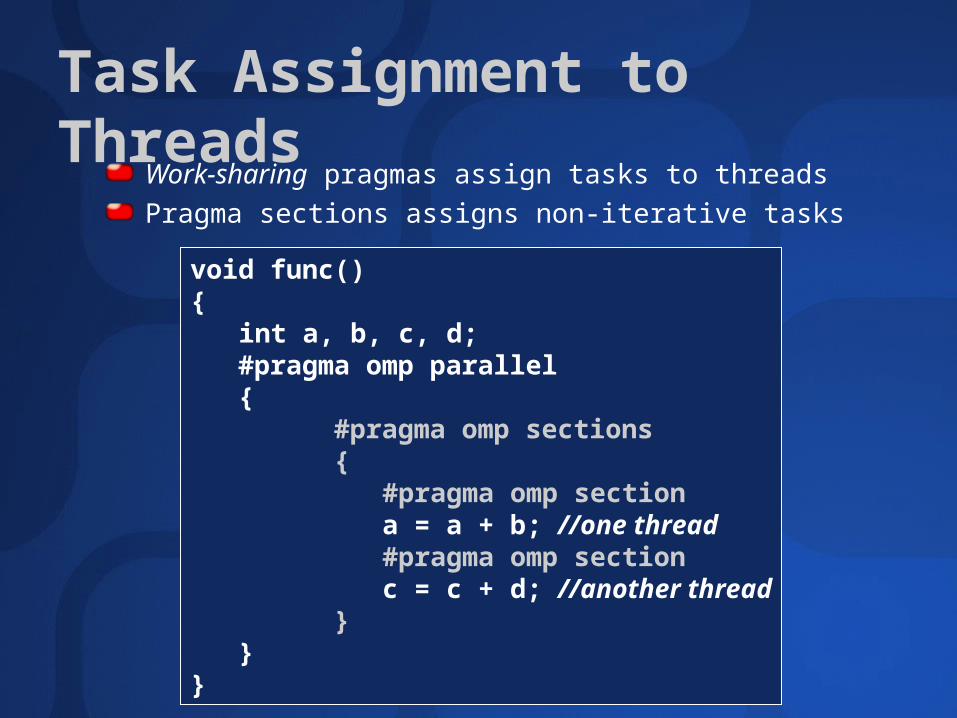
Task Assignment to Threads
Work-sharing pragmas assign tasks to threads
Pragma sections assigns non-iterative tasksvoid func(){
int a, b, c, d;#pragma omp parallel{
#pragma omp sections{
#pragma omp sectiona = a + b; //one thread#pragma omp sectionc = c + d; //another thread
}}
}

Work-sharing Pragmas
Work-sharing pragmas can be merged with pragma parallel
void func(){
int a, b, c, d;#pragma omp parallel sections{
#pragma omp sectiona = a + b; //one thread#pragma omp sectionc = c + d; //another thread
}}
#pragma omp parallel sections{
#pragma omp sectiondo_compress();#pragma omp sectiondo_encrypt();
}
Two functions executein parallel:
#pragma omp parallel sectionsimplements Task-Level Parallelism!
#pragma omp parallel sectionsimplements Task-Level Parallelism!
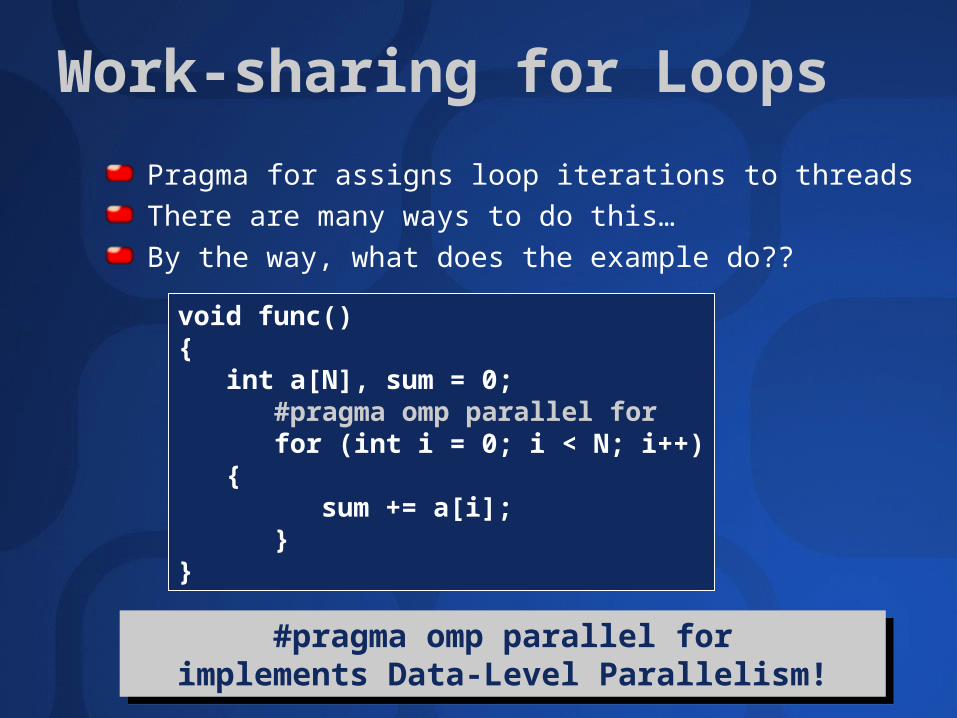
Work-sharing for Loops
Pragma for assigns loop iterations to threads
There are many ways to do this…
By the way, what does the example do??void func(){
int a[N], sum = 0;#pragma omp parallel forfor (int i = 0; i < N; i++)
{sum += a[i];
}}
#pragma omp parallel forimplements Data-Level Parallelism!
#pragma omp parallel forimplements Data-Level Parallelism!

Variable Scope Rules
Implicit Rule 1: All variables defined outside omp parallel are shared by all threads
Implicit Rule 2: All variables defined inside omp parallel are local to every thread
Implicit Exception: In omp for, the loop counter is always local to every thread
Explicit Rule 1: Variables listed in shared() clause are shared by all threads
Explicit Rule 2: Variables listed in private() clause are local to every threads
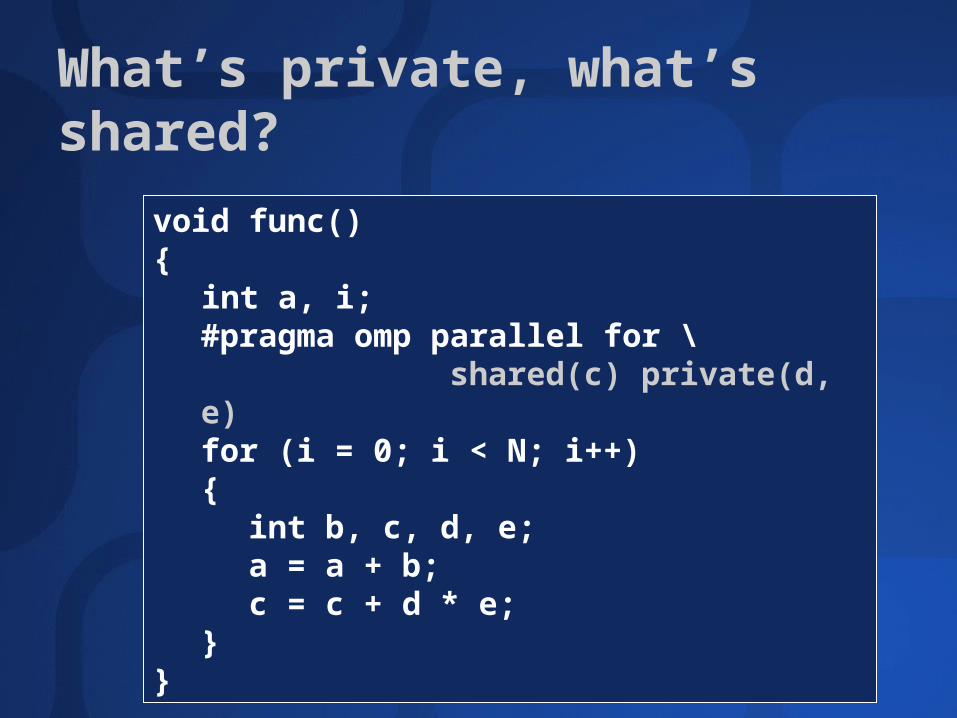
What’s private, what’s shared?
void func(){
int a, i;#pragma omp parallel for \
shared(c) private(d, e)for (i = 0; i < N; i++){
int b, c, d, e;a = a + b;c = c + d * e;
}}

Synchronization Problem
sum++;mov eax, [sum]add eax, 1mov [sum], eax
mov eax, [sum] mov eax, [sum]
add eax, 1 add eax, 1
mov [sum], eax
s
s+1
s+1
s
s
s+1
s
s+1
s+1
thread 1 executesthread 1 executes thread 2 executesthread 2 executesthrd 1’sthrd 1’s
eaxeaxthrd 2’sthrd 2’s
eaxeaxs
sum
t+0
t+1
t+2
clks
s+1
C codeCPU instructions
mov [sum], eaxs+1t+3
Not what we expected!Not what we expected!

Synchronization Pragmas#pragma omp single – execute next operator by one (random) thread only
#pragma omp barrier – hold threads here until all arrive at this point
#pragma omp atomic – executes next memory access op atomically (i.e. w/o interruption from other threads)
#pragma omp critical [name] – let only one thread at a time execute next op
int a[N], sum = 0;#pragma omp parallel forfor (int i = 0; i < N; i++){
#pragma omp criticalsum += a[i]; // one thread at a
time}

omp for schedule Schemes
schedule clause defines how loop iterations assigned to threads
Compromise between two opposite goals:Best thread load balancing
With minimal controlling overhead
N
N/2C
f
single thread
schedule(static)
schedule(dynamic, c)
schedule(guided, f)
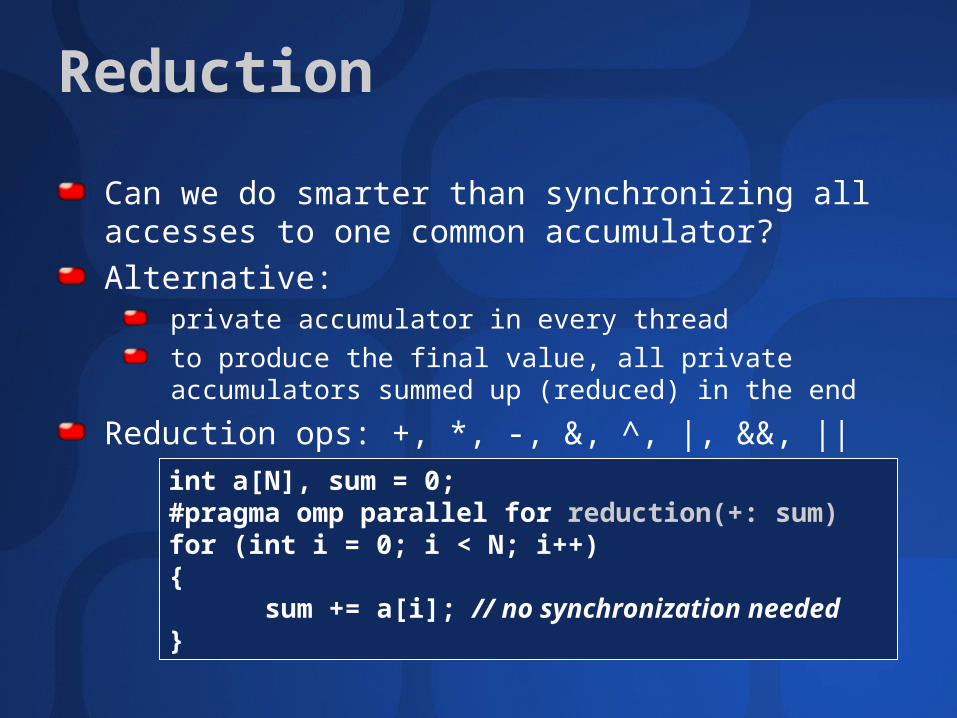
Reduction
Can we do smarter than synchronizing all accesses to one common accumulator?
Alternative:private accumulator in every thread
to produce the final value, all private accumulators summed up (reduced) in the end
Reduction ops: +, *, -, &, ^, |, &&, ||
int a[N], sum = 0;#pragma omp parallel for reduction(+: sum)for (int i = 0; i < N; i++){
sum += a[i]; // no synchronization needed
}

OpenMP™ Quiz
What do these things do??omp parallelomp sectionsomp foromp parallel forprivatesharedreductionscheduleomp criticalomp barrier

OpenMP™ Pragma Cheatsheet
Fundmental pragma, starts team of threadsomp parallel
Work-sharing pragmas (can merge w parallel)omp sections
omp for
Clauses for work-sharing pragmasprivate, shared, reduction – variable’s scope
schedule – scheduling control
Synchronization pragmasomp critical [name]
omp barrier

What Else Is in OpenMP™?
Advanced variable scope and initialization
Advanced synchronization pragmas
OpenMP™ API and environment variablescontrol number of threads
manual low-level synchronization…
Task queue model of work-sharingIntel-specific extension until standardized
Compatibility with Win32* and P-threads
www.openmp.org

Task Queue Work-sharing
For more complex iteration models beyond counted for-loops
struct Node { int data; Node* next; };Node* head;for (Node* p = head; p != NULL; p = p->next){
process(p->data);}
Node* p;#pragma intel omp taskq shared(p)for (p = head; p != NULL; p = p->next) //only 1 thrd{
#pragma intel omp taskprocess(p->data); // queue task to be executed
} // on any available thread

Related TechEd Sessions
DEV490: Easy Multi-threading for Native Microsoft® .NET Apps With OpenMP™ and Intel® Threading Toolkit
HOLINT02: Multithreading for Microsoft® .NET Made Easy With OpenMP™ and Intel® Threading Toolkit
HOLINT01: Using Hyper-Threading Technology to enhance your native and managed Microsoft® .NET applications

Summary & Call to Action
Hyper-Threading Technology increases processor performance at very low cost
HT Technology is available on mass consumer desktop today
To take advantage of HT Technology, multithread your application!
Use OpenMP™ to multithread your application incrementally and easily!
Use Intel Threading Tools to achieve maximum performance
Resources
developer.intel.com/software/products/compilers/
www.openmp.org
Intel® Compiler User Guide

THANK YOU!
developer.intel.comPlease remember to completeyour online Evaluation Form!!
Please remember to completeyour online Evaluation Form!!

Reference

Quest to Exploit Parallelism
Level of Parallelism
Exploited by Technology Problem
Instruction Multiple, pipelined, out-of-order exec. units,branch prediction
NetBurst™ microarch.(pipelined, superscalar, out-of-order, speculative)
Utilization
Data SIMD MMX, SSE, SSE2 Scope
Task, Thread Multiple processors
SMP Price
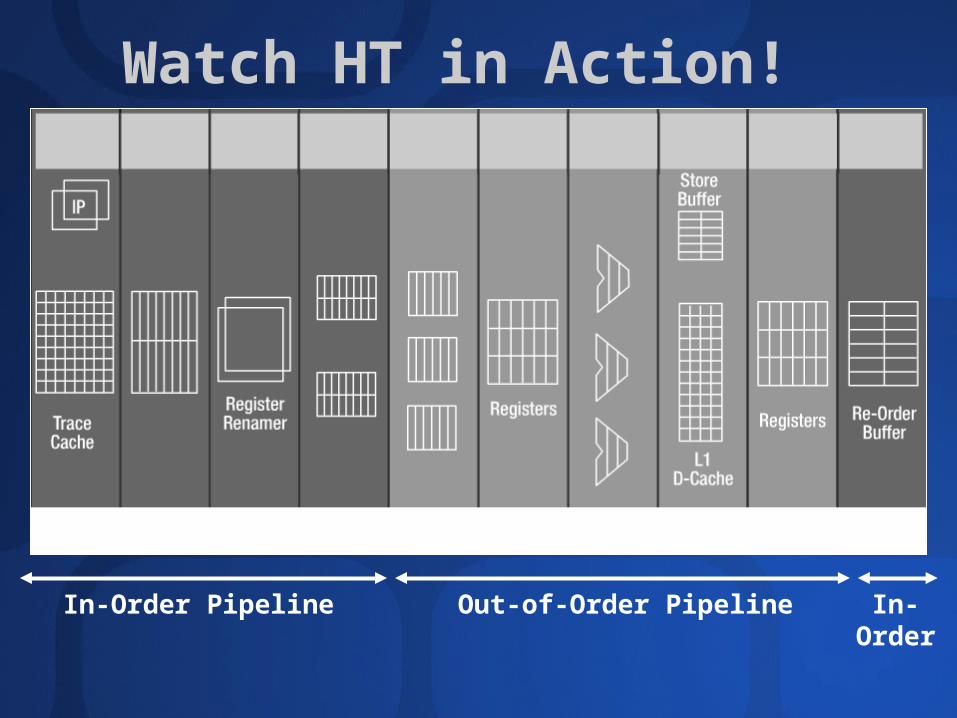
Watch HT in Action!
In-Order Pipeline Out-of-Order Pipeline In-Order

Intel® Compiler Switches for Multithreading & OpenMP™
Automatic parallelization/Qparallel
OpenMP™ support/Qopenmp
/Qopenmp_report{0|1|2}

Key Terms
Multiprocessing (MP)hardware technology to increase processor performance by increasing number of CPUs
Hyper-Threading Technology (HT)hardware technology to increase processor performance by improving CPU utilization
Multithreading (MT)software technology to improve software functionality & increase software performance by utilizing multiple (logical) CPUs

Community Resources
Community Resourceshttp://www.microsoft.com/communities/default.mspx
Most Valuable Professional (MVP)http://www.mvp.support.microsoft.com/
NewsgroupsConverse online with Microsoft Newsgroups, including Worldwidehttp://www.microsoft.com/communities/newsgroups/default.mspx
User GroupsMeet and learn with your peershttp://www.microsoft.com/communities/usergroups/default.mspx

evaluationsevaluations

© 2003 Microsoft Corporation. All rights reserved.© 2003 Microsoft Corporation. All rights reserved.This presentation is for informational purposes only. MICROSOFT MAKES NO WARRANTIES, EXPRESS OR IMPLIED, IN THIS SUMMARY.This presentation is for informational purposes only. MICROSOFT MAKES NO WARRANTIES, EXPRESS OR IMPLIED, IN THIS SUMMARY.