developing a multilingual text analysis engine - does using unicode solve all the issues? dr. brian...
TRANSCRIPT

Developing a multilingual text analysis engine - does using Unicode solve all the issues?
Dr. Brian O’Donovan, IBM Ireland, Sept. 2002

Agenda What is IBM LanguageWare? Where/How is it Used? Our Experiences of Conversion to Unicode
Benefits Accruing Challenges to be Overcome
Word Identification problems Future work

What is IBM LanguageWare? A suite of tools to assist in linguistic analysis Initially developed by IBM USA, but now developed by a Globally
distributed team Used in internal and external products Available to OEMs as a toolkit

Where are We? Developers
North Carolina, USA Dublin, Ireland Helsinki, Finland Taipei, Taiwan Yamato, Japan Seoul, Korea
Major Customers Various Locations, USA Böblingen, Germany

28 (or 30+) Languages Supported Afrikaans Arabic Catalan Simplified Chinese Traditional Chinese Czech Danish Dutch (x2) English
x4 regions & x2 domains
Finnish French (x2) German (x3) Greek Hebrew
Hungarian Icelandic Italian Japanese Korean Norwegian (x2) Polish Portuguese (x2) Russian Spanish Swedish Tamil Thai Turkish
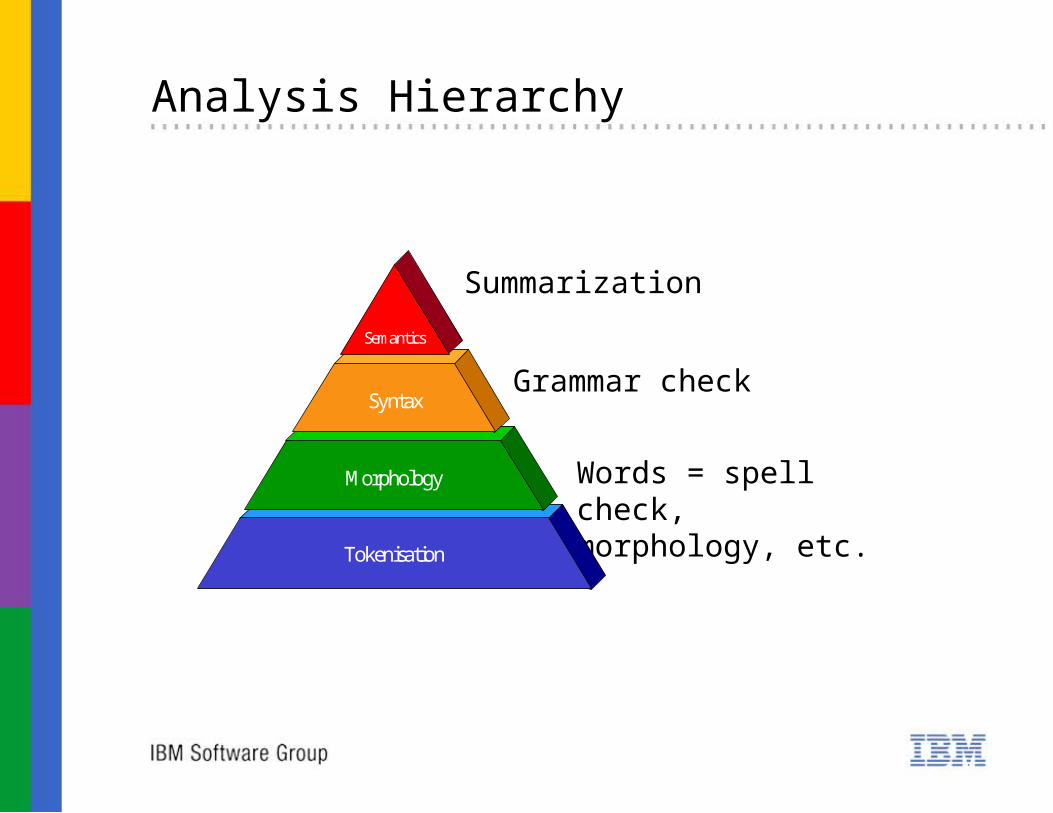
Analysis Hierarchy
Lexical
Summarization
Words = spell check,morphology, etc.
Grammar check
Tokenisation
Morphology
Syntax
Semantics

Where/How is it Used? Word Processors
spell aid, grammar checker
Search Engines & Data Mining Extracting Lemmatized form Query Expansion (e.g. Synonyms) Assisting in Taxonomy Generation
Translation Memory Identification of linguistic units
NLP tools use as first stage of analysis Machine Translation (limited) Speech recognition (not currently)

Conversion to Unicode Previous version used different code pages for each language
In fact a collection of different engines
New version has a single engine for all languages using Unicode (not all languages have been converted yet) Provided many benefits Raised some challenges

Benefits of Unicode No more conversion tables
Standardized on utf-16 Big-Endian Dictionaries Converted to platform byte order on load
Possible to deal properly with multilingual text Able to utilize ICU utilities Can edit/view all test cases on one machine

Issues with Unicode Lots of work Converting dictionaries is not trivial Changing code would be huge (we were rewriting anyway) Large code page Some ambiguous representations & orthographic rules ICU Tokenisation not always to our liking

How we dealt with large code page Our architecture is based upon Finite State Transducers (FSTs) In FSTs you frequently need to build tables with entries for every possible next
character for single byte code page => 256 entries for double byte code page => 64K entries If not careful, dictionaries might grow to 256 times their previous size
We deal with this by building a character transition table per dictionary Each UNICODE character appearing in the dictionary is assigned a code by which it is
referenced within the dictionary– This is not a private code page– The table is dynamically created when building the dictionary and will map
differently each time When looking up dictionary each character is first mapped through the table
If any characters are not in mapping table => we won't find a match in the dictionary New characters are automatically added to the mapping table once words with
the characters are added to the dictionary Typically European languages require fewer than 100 characters
e.g. punctuation symbols do not appear in the dictionary
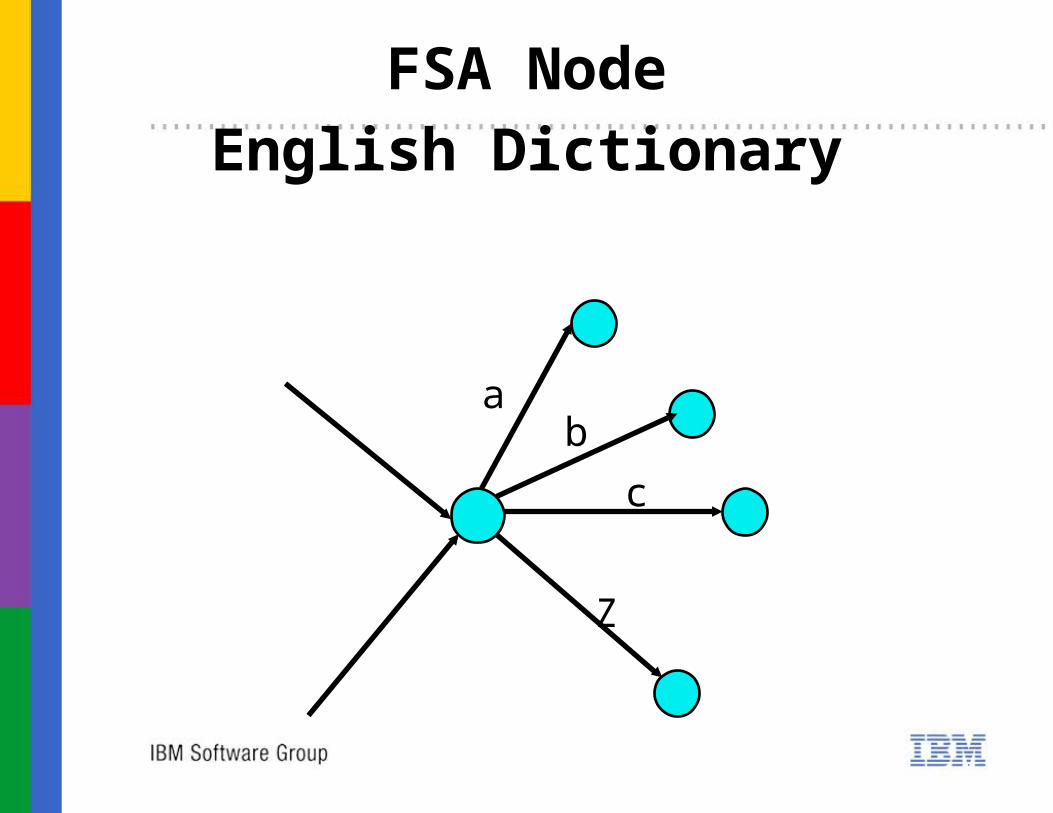
FSA NodeEnglish Dictionary
b
c
Z
a

FSA NodeJapanese Dictionary
山川
部
か

Representation Issues Even with utf-16 as a universal standard representation issues
can arise The letter ë is represented as 0x00EB
But could be e=0x0065 followed by umlaut=0x0308
Arabic letter Heh (ه) = E5 in Windows code page In UNICODE 0x0647
But it has different forms e.g. ههه Unicode defines 4 more code points for presentation forms isolated=0xFEE9, final=0xFEEA, initial=0xFEEB and medial=0xFEEC

Arabic Shape Bitmaps (Heh)
Heh varies with positionIsolated InitialMedialFinal

Arabic Shape Bitmaps (Seen)
Seen varies much lessIsolated InitialMedialFinal

Orthographic Variation
A word may appear differently in a sample text than in the dictionary. All languages have different rules about what is allowed/required.
Some languages have simple rules e.g. English casing rules
– a lowercase dictionary word can appear in text as titlecase or uppercase
– a titlecase dictionary word could appear in text as uppercase– an uppercase or mixed case dictionary word must appear in text
exactly the same.

Other languages have more complex rules In France letters lose their accent when capitalized
e.g. é is capitalized as E not É
but this rule does not apply in French Canada So être becomes Etre in Paris but Être in Montreal
In German capitalization can change the letter count 'ß' is sometimes capitalized as 'SS'
In English we optionally drop accents e.g. the name Zoë can be written Zoe in English But in German dropped umlauts are represented by a following e
– e.g. Böblingen can be written Boeblingen

Vowel dropping in Semitic languages Semitic languages such as Arabic and Hebrew,
have an orthographic rule that short vowels may be dropped.
Imagine that Arabic has the words hat, hit, hut They will be written in dictionary as
Hat = َه�ت Hut = َه�ت Hit = َه�ت
In any piece of text the string َهت could be any of these words

Arabic examples in Large font
Hat = َه�تHut = َه�تHit = َه�تHt = َهت
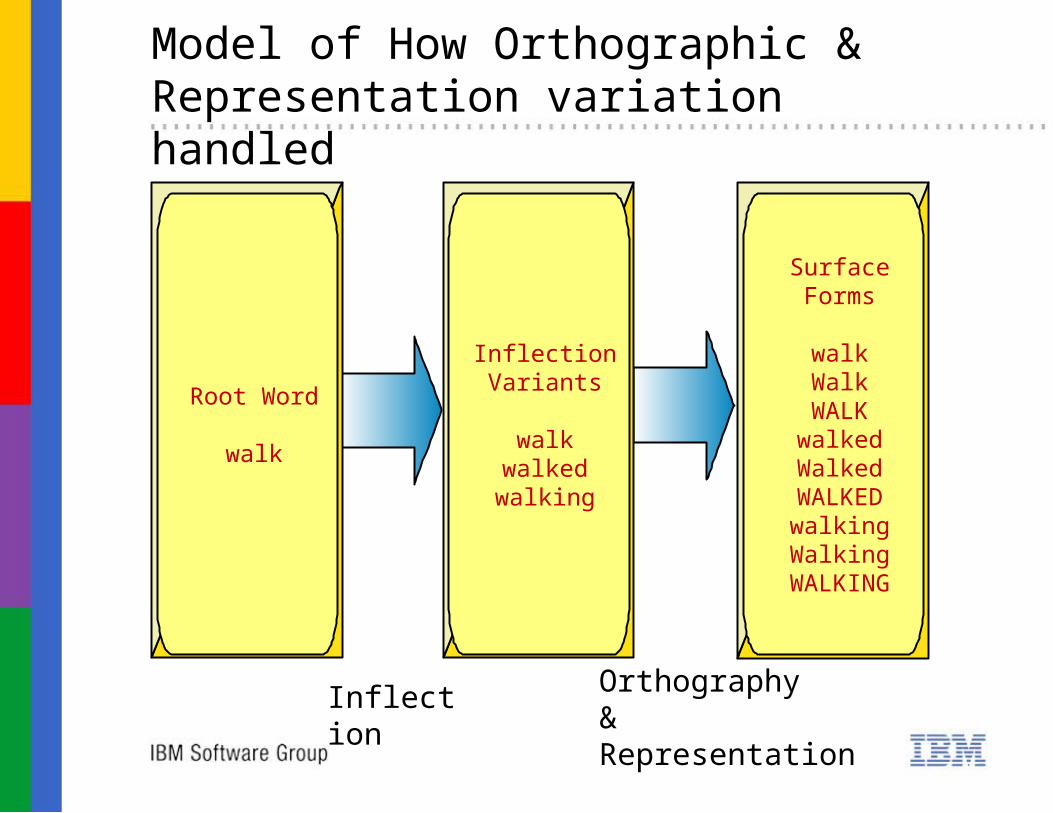
Model of How Orthographic & Representation variation handled
Root Word
walk
InflectionVariants
walkwalkedwalking
Surface Forms
walkWalkWALK
walkedWalkedWALKEDwalkingWalking
WALKING
Inflection Orthography& Representation
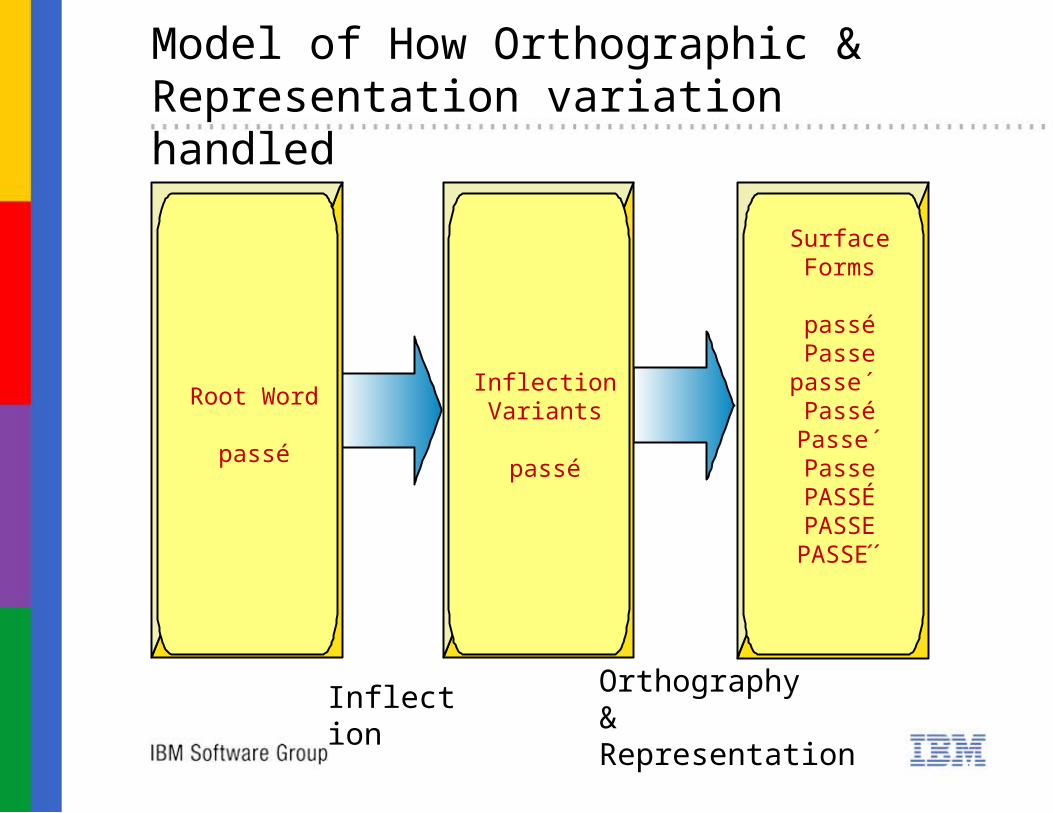
Model of How Orthographic & Representation variation handled
Root Word
passé
InflectionVariants
passé
Surface Forms
passéPasse
passe ́ PasséPasse ́PassePASSÉPASSEPASSE 1´
Inflection Orthography& Representation
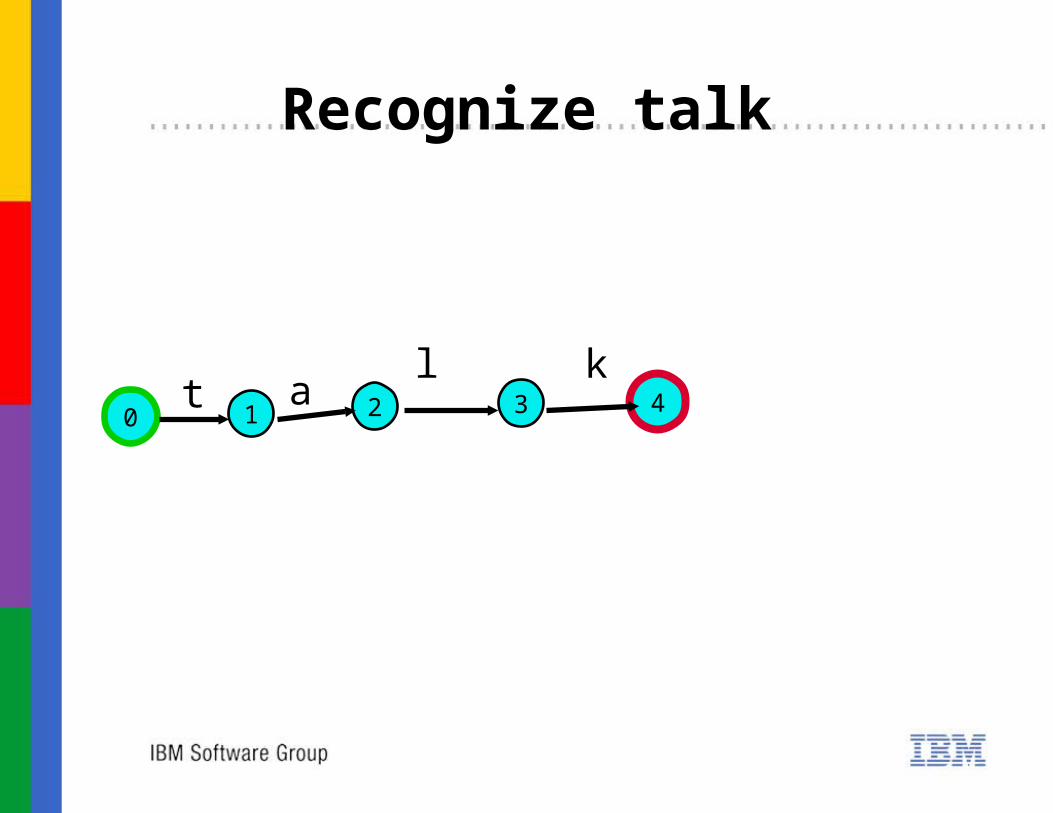
21 3 40
Recognize talk
t al k
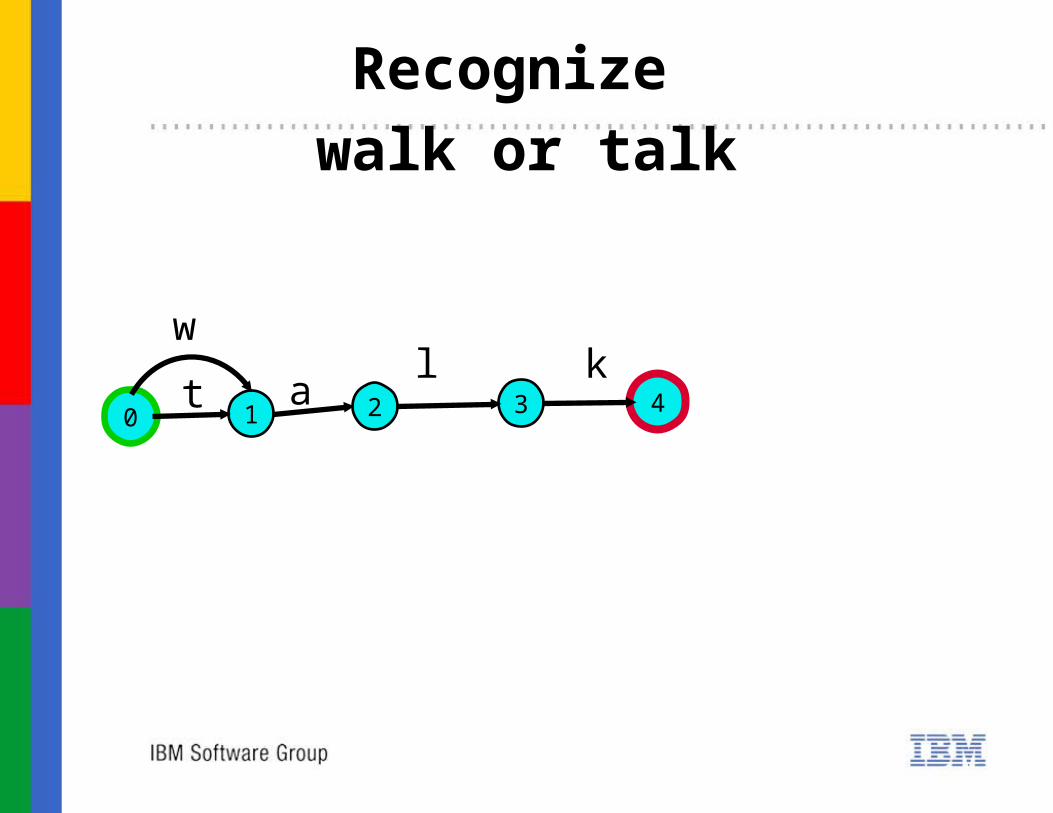
21 3 40
Recognize walk or talk
t
w
al k
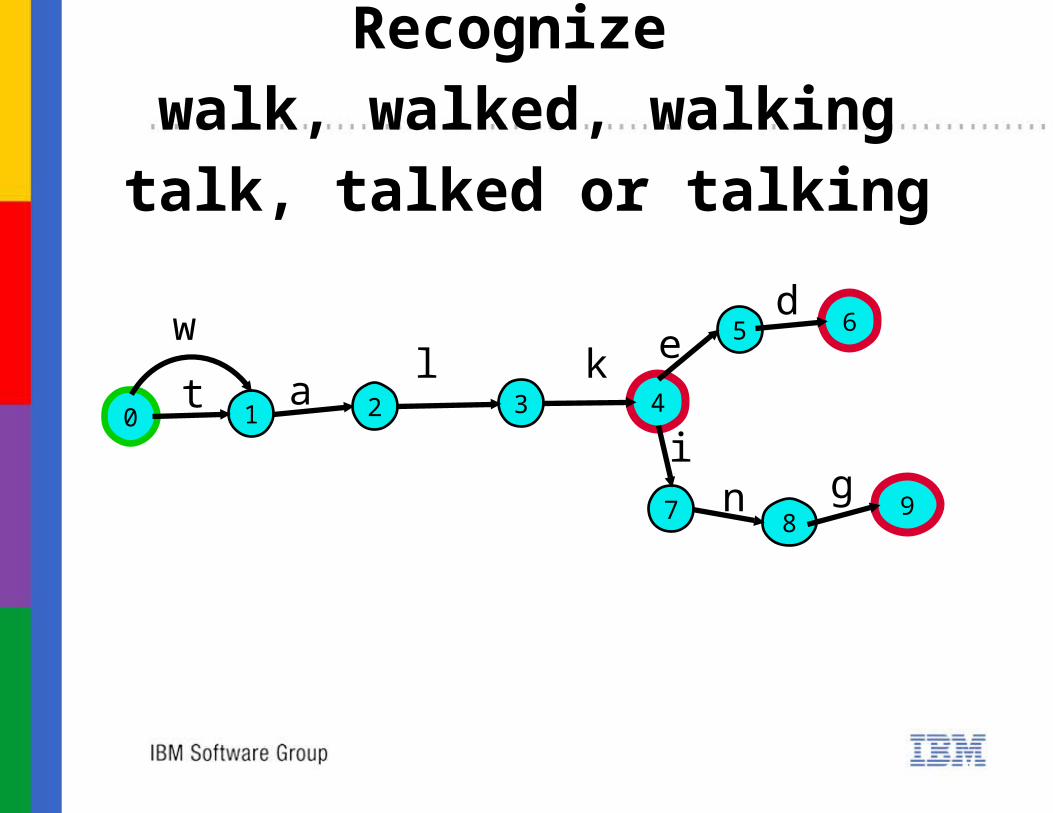
21 3 40
Recognize walk, walked, walkingtalk, talked or talking
5 6
97 8
t
w
al k e
d
in g

11
10
12 13
14 15
1816 17
AL K E
D
IN G
21 3 40
5 6
97 8
t
w
al k e
d
in g
Recognize all variants of walk or talk
T
Wa

11
10
12 13
14 15
1816 17Á
L K ED
IN G
21 3 40
5 6
97 8
t
w
á l k ed
in g
Recognize all variants of wálk or tálk
TW
a19
a
á

Word Breaking
ICU break iterators can only provide us with a first pass of the word segmentation Significant improvements in ICU 2.2
Sometimes the word segmentation is not obvious multi word expressions compound words languages with no spaces

Multiword Expressions Word break is not always obvious
French pommes de terre– as 3 words = apples of the ground– as 1 word = potatoes
French l'intelligence artificielle– really 2 words le and intelligence artificielle
Sometimes the word break is ambigous English red tape
– as 2 words = tape with red color– as 1 word = synonym of bureaucracy

Decompounding German and related languages allow speakers to generate their
own compound words by combining component words typically a series of nouns and/or adjectives
ICU considers these one word but to analyse them properly we need to break it into its constituent words
and look these up in the dictionary
Can be computationally expensive We can also sometimes get ambiguous results

Ambiguous Decompounding - example 1 Wachstube
Option 1 = wax tube– Wachs = wax– Tube = tube
Option 2 = guard room– Wache = guard– Stube = room
Option 3 = awake room– Wach = awake– Stube = room

Ambiguous Decompounding - example 2 Hochschullehrer = University Lecturer 3 component words
Hoch = High Schule = school Lehrer = teacher
Could index under Hochschullehrer = Univesity Lecturer Hochschule = High School & Lehrer = Teacher Hoch = Higher & Shullehrer = school teacher
However Schullehrer (=schoolteacher) is a lexicalised compound The two words are so often used together that native speakers no consider them to
be a single word Hoch & Schullehrer is only valid decomposition In fact most German Speakers would regard Hochschullehrer as a single lexical
word because it is commonly used

Ambiguous Decompounding - example 2 Neuroschaltungsverstärkung
Neuro = neuronal Schaltungs = circuit verstärkung = amplification
Could be Neuroschaltungs|verstärkung interpreted as an amplification of a "neuronal circuit"
Could also be Neuro|schaltungsverstärkung interpreted as a kind of circuit amplification which is done by neuronal
technology

Languages with no spaces
Some languages (e.g. Chinese, Japanese, Thai) do not put spaces between words Therefore, it is difficult to figure out where the word breaks are Sometimes there are multiple possible word segmentations. Sometimes the choice of segmentation can change the meaning
For these languages we use ICU break iterator to find "unambiguous word break" (e.g. punctuation symbol, line break, character type change) Looking in the dictionary we find all possible word combinations within this
text sequence Using statistical techniques we figure out which word sequence is most
likely

Chinese Segmentation Example
此 = this (ci) 路 = road (lu) 不 = no/not (bu) 通 = through (tong) 此路不通 = cul-de-sac (cilubutong) 行 = walk (xing) 得 = get (de) 不得 = forbidden (bu-de) 在 = be (ci) 在此 = here (zaici) 小 = small (xiao) 便 = convenience (bian) 小便 = urinate (xiaobian)
此路不通行 此路不通行不得在此小便 Interp 1
此 / 路 / 不 / 通 / / 行 不得 / 在此 / 小便
No through way for pedestrians. Urination forbidden here.
Interp 2 此路不通 行不 / 得 在此 / 小便 Cul-de-sac. Walking Forbidden.
Urinate here.
此路不通行不得在此小便

Chinese Segmentation Example
此 = this (ci) 路 = road (lu) 不 = no/not (bu) 通 = through (tong) 此路不通 = cul-de-sac (cilubutong) 行 = walk (xing)
Interp 1 此 / 路 / 不 / 通 / / 行 This road not through walk No through way for pedestrians.
此路不通行

Chinese Segmentation Example
此 = this (ci) 路 = road (lu) 不 = no/not (bu) 通 = through (tong) 此路不通 = cul-de-sac (cilubutong) 行 = walk (xing) 得 = get (de) 不得 = forbidden (bu-de) 在 = be (ci) 在此 = here (zaici) 小 = small (xiao) 便 = convenience (bian) 小便 = urinate (xiaobian)
Interp 1 此 / 路 / 不 / 通 / / 行
不得 / 在此 / 小便 This road not through walk
Forbidden here urinate No through way for pedestrians.
Urination forbidden here.
此路不通行 / 不得在此小便

Chinese Segmentation Example
此 = this (ci) 路 = road (lu) 不 = no/not (bu) 通 = through (tong) 此路不通 = cul-de-sac (cilubutong) 行 = walk (xing) 得 = get (de) 不得 = forbidden (bu-de) 在 = be (ci) 在此 = here (zaici) 小 = small (xiao) 便 = convenience (bian) 小便 = urinate (xiaobian)
Interp 1 此 / 路 / 不 / 通 / / 行
不得 / 在此 / 小便 No through way for walkers.
Urination forbidden here.
Interp 2 此路不通 = cul-de-sac 行不 / 得 = walk not 在此 / 小便 = here urinate Cul-de-sac.
Walking Forbidden. Urinate here.
此路不通行不得在此小便

Future Challenges Complete move of all languages to new architecture Improving quality and breadth of linguistic data
more languages more words (better user dictionary support) richer relationships (e.g. part of, type of etc.)
Increasing Accuracy of analysis Part of speech disambiguation Ranking of parse results
Increasing performance speed Latest version exceeds 2.5 Giga Char/hour on standard PC Some customers say it is not fast enough, but this only allows 1.5 micro
seconds/char
Available through ICU API