devops overview
TRANSCRIPT

Bridging the Dev-OPS Gap
DevOPS Overview

Omri Spector
• Owner of deveLeap• 20+ years in development, always
active• Former director of Business
Solutions in Actimize• Engineering Practices Consultant to
many companies of varying sizes

What is DevOPS• It’s a Fashionable term • It originated as multiple practices in
several unrelated organizations:– Netflix, Twitter, Facebook, Google,
Amazon, Flickr• Everyone is looking for “devops
people” (?)• Everyone says it has great ROI• But what is it!?
There is no “formal” definition

“Help me define it…”
Adrian Cockroft, Netflix

My take: DevOPS is…(1) A Culture shift in responsibility &
communication(2) A set of:
– Architecture & Design patterns– Tools– PracticesThat allow this shift to happen
In this presentation we will discuss all these aspects

Important Caveat
• DevOPS movement mostly originated in the SAAS arena
• Many of the concepts, tools and practices apply well to any development environment
BUT• In some cases adaptation to the Enterprise
Software arena is a challenge
When starting to implement DevOPS:• Be open minded, not dogmatic• Align with your business and challenges

Why did DevOPS originate at“Consumer” SAAS?
• Fierce competition and low entry barriers
• Direct deploy to production is an internal negotiation
• Risk is limited – limited liability

Dev vs. OPS
• Most of failures can be tracked to dev changes• Most of the changes can be tracked to business need
OPS – is in charge of stability
Dev – is expected to change fast & furious


DevOPS Tenets

Common Goal• Acknowledge the common goal:
To enable the business
• Reflect that in the R&R– Developers that do OPS– All OPS is code
• Reflect that in common metrics:– Operational metrics– Live, visible, accessible

Everything is code
• There is 0 manual OPS
• Code is:– Version controlled– Visible to all – use shared repo!– Deterministic
• Build & deploy must be fully automated

Continuous Integration
• Fully automated from commit to deploy
• Automated stability tests with visible results
• Anyone can prepare a release

Automated Deployment
• Single click from release to deployment
• Continuous Deployment as an option• Clear deployment log – Who, When,
Why
• In an ES company this may map into customer visible staging area

CD in an ES Context

Automated Testing
• If you didn’t test it – it doesn’t work
• Your release is as good as your CI
• Continuous Release relies on massive automated coverage

Release Early, Release Often
Release should be a “non-event”
• Anything that is done 4 times a year is complex, risky and inherently error prone
• Anything that is done multiple times a day is a “non-event”

Do You Have The Guts To Deploy 10 Times A Day?

Does it take guts?
• Deploying often will lower risk if:– Concerns are indeed separated– Everything is automated– Changes are small and managed– Occasional failure is accounted for
• Toggles• Easy Rollbacks• Openness to failure

Fail Fast, Fix Fast
• Daniel Ek: "We aim to make mistakes faster than anyone else.”

Some common techniques

Small Changes, Smaller Risks
We rapidly prototype our satellites. We use "release early, release often" on our software. We take a different risk approach: We take them outside and test them.
We even put satellites in space just to test
Will Marshal, planet-labs

Simplify Deployment Unit
• Separate concerns into services:– Lower bubble effect– Simplify deployment – just define roles– Fast deploy – rollback – roll forward
• Other “Side effects”– Flexible scaling and auto-scaling– Easier to Focus development efforts– Complex overall architecture
• This is the trend to “micro services”

Use Toggle Switches
• Each feature (and less) can be toggled in & out at will
• This allows:– Pushing partial work for higher level of
CI– Partial rollouts– Fast back out
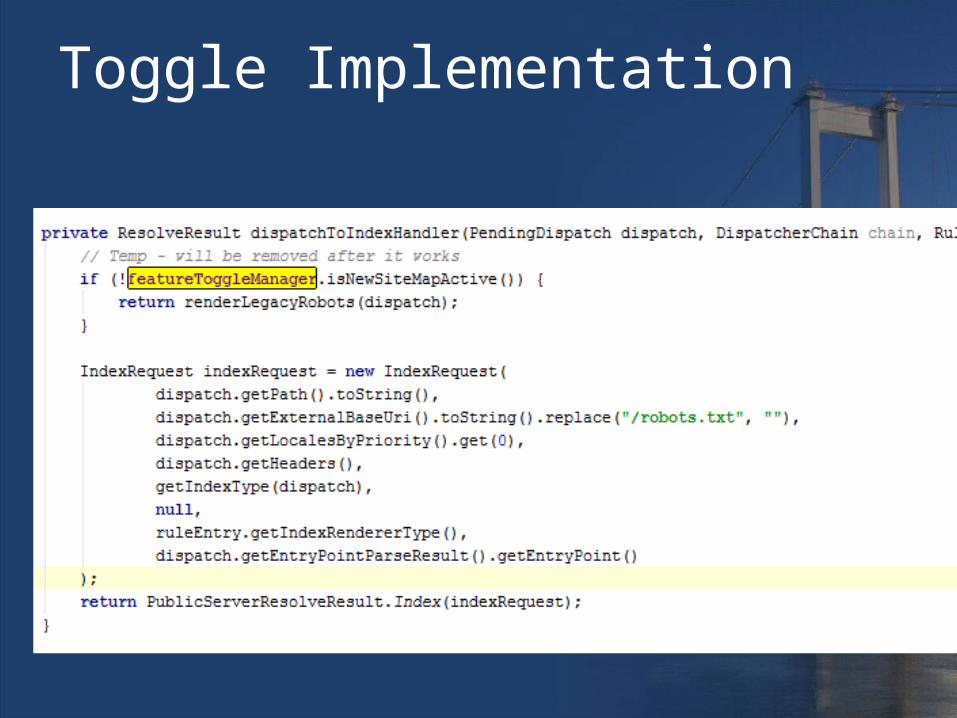
Toggle Implementation

Toggle Dashboard

Apply Canary Releases
• Release gradually:– Specific user group– Specific GEO / BU– Percentage
• Monitor situation – Load– Errors– User satisfaction
• All by/with DEV

Multiple Concurrent Versions• A direct result of Canary release• Has impacts on design
– All communication must be backward compatible
– DB Upgrades must be backward compatible
• Will sometimes lead to multi-phased release– E.g. Migrating database structure
• In the ES world this also presents marketing and support challenges!

Dark Launch
• Toggle-in work load, Toggle-out functionality
• Minimal impact on failure – just toggle out
• Gradual Dark launch makes release an anti climax

Ongoing Incident Management
• Track all deployments:– Type (code, db, cm, …)– Who, When, Why
• Post mortem all incidents:– Dev & OPS – together
We are in the same boat

Central Operational Dashboard
• Operational status is the highest non-business metric
• Dev exposed to “OPS” metrics on daily basis:– Uptime, Downtime, Incidents– Resource consumption– Performance metrics– And even cost

Measurability in every feature
• Measuring feature impact, technical & functional, is part of a feature spec
• Feature released with clear set of metrics
• Metrics are monitored by feature dev (at least at the beginning)

Typical Tools

Using the correct tools
• DevOPS is implemented with many tools & tool sets. There is no silver bullet.
• Following are some of the more popular/relevant ones
• Often people mix “knowledge of tool X” with “knowledge of DevOPS”

Configuration Management
• Pioneered by CFEngine• CM Principles:
– Descriptive– Idempotent– Continuous
• Currently hyped: Puppet, Chef, Ansible

Example: Ansible Playbook
• Defines a set of “roles”: appserver, db, …
• Defines the configuration per role using descriptive yaml
• Allows mapping of a role to a host• Upon call – applies the role to the
host

Virtualization, a.k.a. Cloud Computing
• Services: AWS, Google Cloud, Azure• Products: OpenStack,OpenShift
• Enables us to:– Spin versions in and out, – Scale system components based on
load– Support multiple environments for dev
and QA needs

APM & OPS Analytics
• Application Performance Monitors:– AppDynamics– New Relic
• Log Analytics– ELK Stack (ElasticSearch, LogStash,
Kibabna)– Splunk

Example: AppDynamics Dashboard

Example: ELK Dashboard

Source Control
• Well, you all know SVN, but…• GIT is where the devops world
currently resides:– Distributed– Free– Low install overhead– Integrated with everything

Continuous Integration Servers
• Jenkins• TeamCity• Travis• Bamboo• :

Putting it all together

DevOPS is…
• DevOPS is a cultural change, it is a mindset that must be accompanied by technical changes in architecture, procedures and tooling
• Remove any of these legsat your own peril…

Wrong mindset
• Manager: It is all about responsibility – so lets enforce it!
• Being responsible requires more than good will – it requires a context that allows you to practice this responsibility in an effective manner

Effective context

Supportive Architecture
• Easy swap in/out of components, • Limited bubbling effect, • Fast reload times, • …

Tools in place
• Configuration Management• Automated deployment• Toggle switches, • Online monitoring, • Easy deploy & rollback• …

Acceptable risk
• The worst case is manageable,• Most glitches are low risk,• Occasional failure is accepted,• Reasonable failures are perceived as
a learning opportunity, a price for fast paced innovation

Cooperative Culture
• Dev & OPS cooperation: – Before – content visibility, – During – timeline visibility– After – environment visibility
• OPS is part of every design• Dev is part of every incident handling
and Post Mortem

How long will it take?
• DevOPS is another aspect of becoming a “learning organization”
• And in that sense – it is a journey
