distributed anomaly detection in wireless sensor networks ksutharshan rajasegarar, christopher...
TRANSCRIPT

Distributed Anomaly Detection in Wireless Sensor
Networks
Ksutharshan Rajasegarar, Christopher Leckie, Marimutha Palaniswami,
James C. Bezdek
IEEE ICCS2006(Institutions of Communications and Computer Systems)

Contents
1.Overview 2.Introduction3.Problem statement4.Anomaly Detection5.Evaluation6.Conclusion

Overview • Identifying misbehaviors is important in
sensor networks – Monitoring – Fault diagnosis – Intrusion detection
• Key problems is minimization – Communication overhead– Energy consumption
• This paper propose anomaly detection based on below, – Distributed operation in sensors – Cluster based algorithm

Introduction
WSN is vulnerable by fault and malicious attack due to the facts Large number of tiny sensor nodes in WSNLimited power, bandwidth, memory, CPU
power
The distribution of misbehaviorsMay not be known a prioriCan be identified by sensor or traffic
measurements

Problem statement A set of sensor node:
At time interval each sensor measures a feature vector
, each vector is composed of features or attributes
where , and After a window size of m measurements each sensor
has collected a set of measurements
An anomaly is defined as an observation that is
appears to be inconsistent with other data in the combined set of measurements
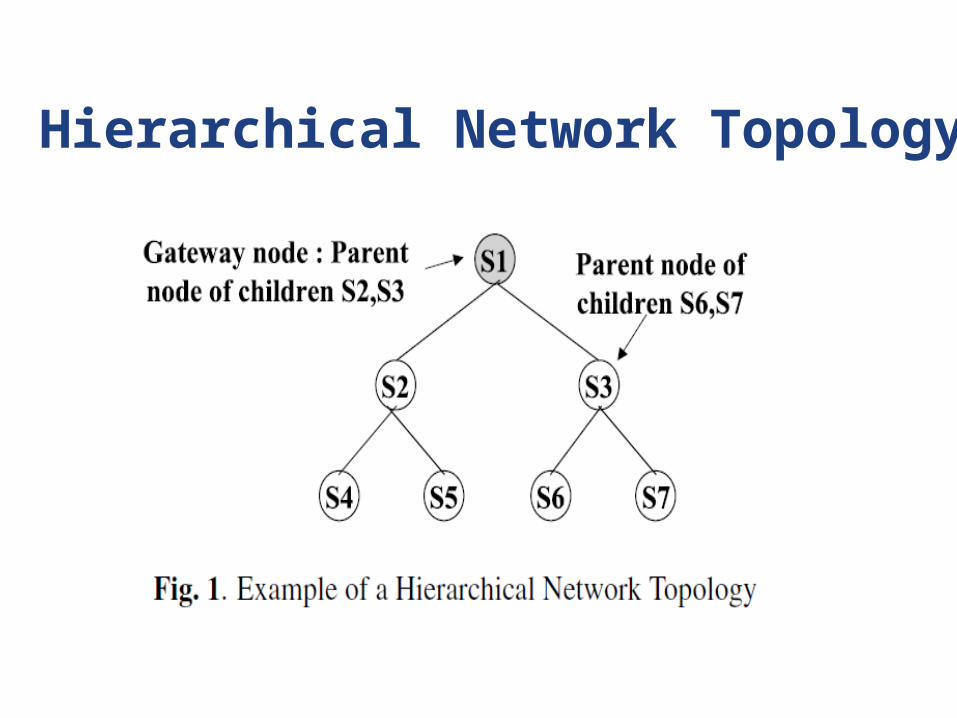
Hierarchical Network Topology

Anomaly Detection
• Clustering (fixed width clustering) based– Finding groups of similar data points
by Euclidian distance as a similarity measure between pair of data• Fixed width clustering
• Detection algorithm – Use nearest neighbor algorithm
• Detection Approaches– Centralized – Distributed

Centralized approach
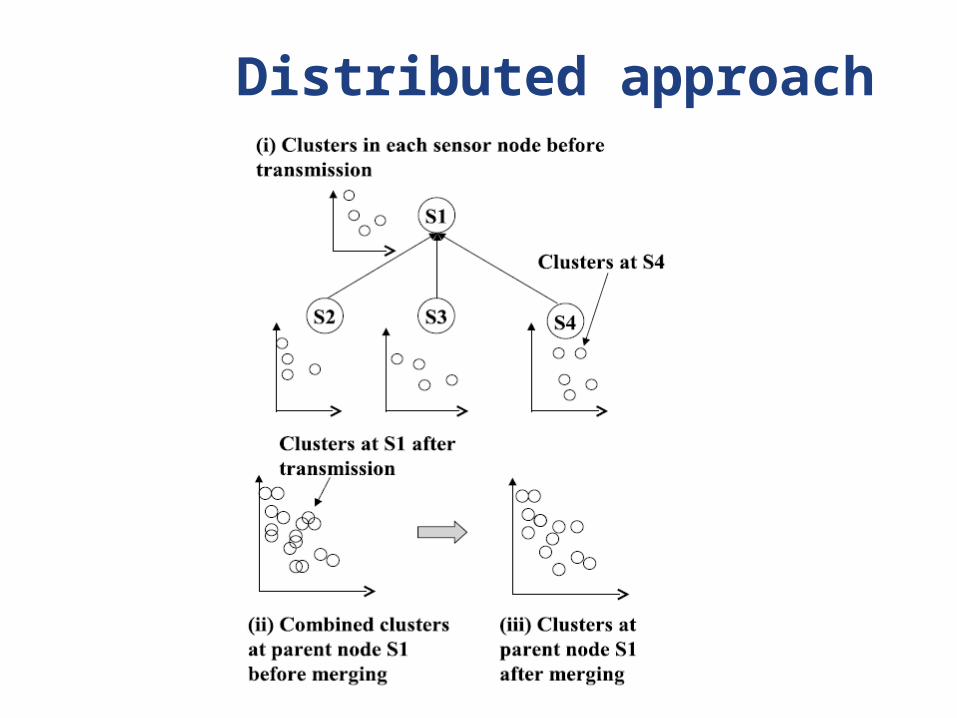
Distributed approach

Distributed approach

Basic data conditioning
1. Standardization for the values of the feature in different range for using as a distance
2. Feature data scaling into range [0,1] :

Data conditioning in Sensor node

Data conditioning in Gateway
• Gateway collect linear sum, linear sum of square, number of local data vectors, vector of maximum and minimum values
for each attribute from each sensor node and computes the global data below.

Gateway node distributes global data to sensors

Anomaly detection
1. Merging of clusters– Compare each Ci with all other Cj where
i!=j and merges Ci with Cj where d(Ci, Cj) < w and j>i Eg) a pair of cluster c1 and c2 are similar if
inter-cluster distance d(C1, C2) <= w (width)
Then new cluster C3 is produced – Center is the mean of the centers of C1 and C2– Number of data vectors is the sum of those in C1
and C2

Anomaly detection
2. Classify clusters as normal or anomaly– Use KNN(K nearest neighbor) algorithm
• For each cluster Ci, a set of inter cluster distances DCi={d(Ci, Cj): j=1…(|C|-1), j != i} is computed between centroids of them
• Among the set of DCi for cluster Ci, the shorest K distances are selected, and computes average inter-cluster distance ICDi of cluster Ci is computed

Anomaly detection
3. Ci is anomalous if ICDi > one standard deviation of the inter-cluster distance SD(ICD) from the mean inter-cluster distance AVG(ICD) – anomaly Ca :
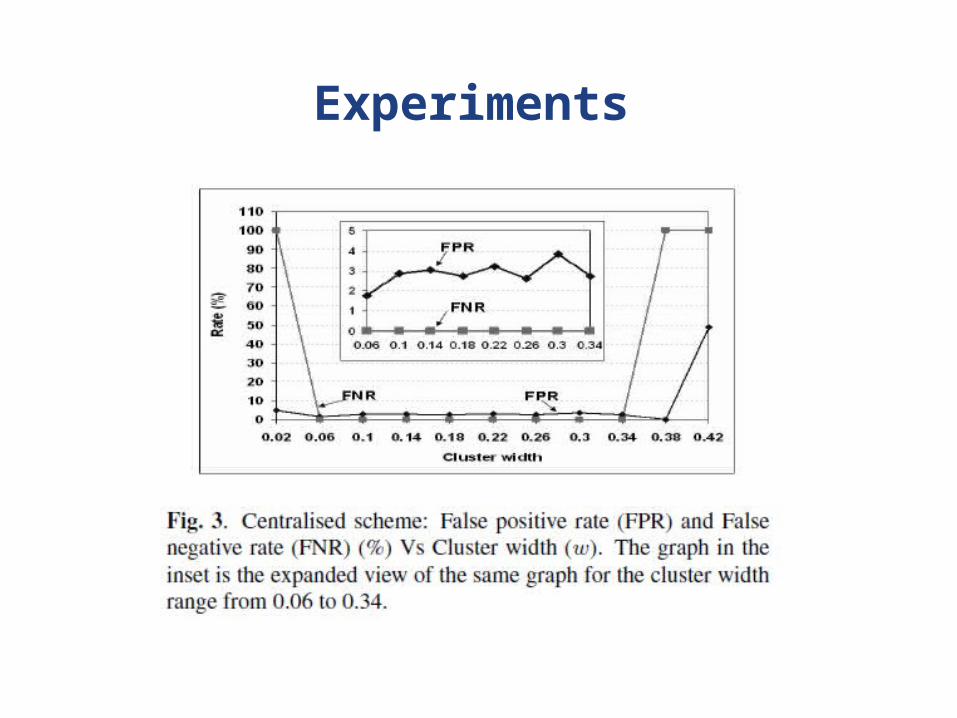
Experiments
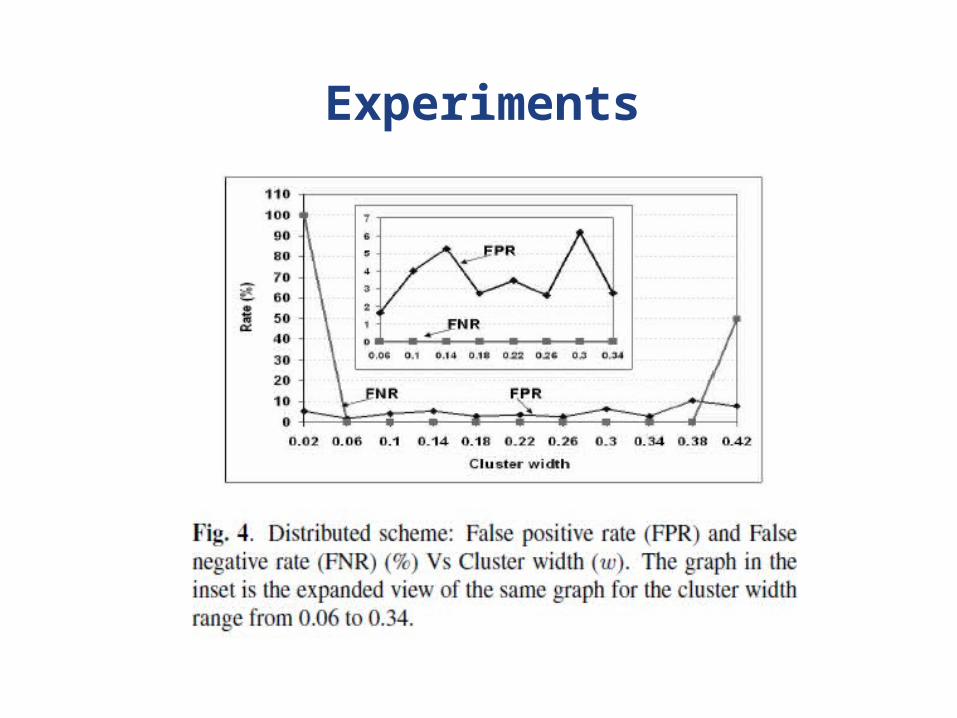
Experiments

Complexity• Each sensor node send once the data
–
• Gateway send to each sensor –
• Computational complexity of each sensor – O(m) , m is the number of measurement during time
window
• Fix width clustering algorithm. where is it done ?– For each data vectors, computes distance to each exsiting
cluster : O(mNc)
• Cluster merging. where is it done? And for what? – O(Nc^2), Nc is number of cluster

Conclusion
• Presented anomaly detection algorithm – distributed based on the data clustering
• Simulation – using real data gathered from Great Duck Island
• Evaluation results – Distributed approach achieves comparable
performance with centralized approach– Significant reduction in communication overhead
• Future research in distributed approach– Using multiple KNN parameters– Different kind of anomaly (network attack)