distributed architectures - vorlesungen
TRANSCRIPT
Distributed Architectures
So�ware Architecture VO (706.706)
Roman Kern
Version 1.3.2
Institute for Interactive Systems and Data Science, TU Graz
1
Outline
Introduction
Distributed Architectures Basics
Asynchronous Architectures
Lambda Architecture
Kappa Architecture
2
Introduction
Goals
Main goal: � Scalability
• In the optimal case a system scales linearly with the objective
• e.g., number of transactions, size of the data, users
3

Solutions
Main solutions
1. More e�icient algorithms
2. Use faster hardware (e.g., more powerful machines)• ô Scale vertically
3. Add more machines• ò Scale horizontally (scale out)• Parallel computing, distributed computing
4
# More e�icient algorithms is in many cases either not possible, or veryexpensive (development cost).
# More powerful machines is o�en a pragmatic solutions, and o�en evencheaper than the development costs - but might only be able to “buy time”until the limit is reached.
# For truly scalable solutions, scaling horizontally is the best/only option.# (Ignoring quantum computing here).
Distributed Architectures
Parallel computing vs. distributed computing
• In parallel computing all component share a common memory, typically threadswithin a single program
• In distributed computing each component has it own memory• Typically in distributed computing the individual components are connected over a
network• Dedicated programming languages (or extensions) for parallel computing
5
# This lecture mainly deals with distributed computing.
Distributed Architectures
Distributed architectures
• Most complex solution• Due to the added parallelism of data and processing• � Increased risk of errors
• Overall latency will be the the one of the slowest machine• � latency cannot be decreased via distributed solutions
• Therefore the architecture needs to be sound
• … focus on abstraction and composition
6
# In practice people are o�en biased towards technologies they know (e.g.SQL).
Distributed Architectures
http://nighthacks.com/roller/jag/resource/Fallacies.html
7
# Known fallacies (traps) that should be avoided.

Distributed Architectures
Di�erent levels of complexity
ø Lowest complexity for operations, which can easily be distributed• If they are independent and short enough be to executed independent from each other• And if the data can be partitioned into independent parts
û Higher degree of complexity for operations, which compute a single result onmultiple nodes
• Synchronisation of data access also raises the complexity
8
Distributed Architectures
Additional aspects of complexity
• Complexity = intrinsic complexity + accidental complexity
• Intrinsic complexity of the problem itself (i.e. how hard is the problem)• Accidental complexity arises from the implementation
• Low accidental complexity good for maintenance• If high accidental complexity, you can never be sure it has been correctly implemented
Risk� The risk of errors rises with the complexity
9
Distributed Architectures - Practical Advise
General advice to deal with complexity
• Design for failure• E.g. hardware will fail, human errors (bugs)• � Limit their consequences
• Push complexity into a single place• Also called “complexity isolation”• � E�ect of bugs will be minimised
• Avoid tricky operations
• Avoid to store aggregates• Prefer to deal with raw data• Treat the data as immutable
10
# Aggregates need to be recomputed as soon as the raw data changes.
Distributed Architectures - Example Failure
Example failure unique to distributed architectures
• Compaction• Maintenance task, which need to take place from time to time• Might need couple of minutes to execute• … comparable to garbage collection
• Typically a machine will be less responsive during this phase
• If multiple machines happen do conduct compaction at the same time
• … the whole cluster may stall
Solution� Try to get rid of the compaction, if possible
11

Distributed Architectures - Theory
CAP theorem
• Not possible to achieve all three properties1. Consistency
• Reads are guaranteed to incorporate all previous writes (all nodes see the same data atthe same time)
2. Availability• Every query returns an answer, instead of an error (failures do not prevent the remaining
system to be operational)3. Partitioning
• The systems runs, even if a part of the system is not reachable (e.g. due to network failure,message loss)
Implications of CAP
One needs to find a trade-o� between the properties ¤ , e.g., choose availability overconsistency
12
# Many relations to other so�ware architecture concepts, e.g.,# Consistency via data-centric architectures,# Availability via reliability of system,# Partitioning via distributed architectures.
Distributed Architectures - Theory
Eventual consistency
• “Best e�ort” for consistency
• In practice, best consistency property
• For highly available systems
• BASE instead of ACID• BASE (Basically Available, So� state, Eventual consistency)• ACID (Atomicity, Consistency, Isolation, Durability)
13
Examples of eventual consistency
• Sloppy quorums
– Temporal replicas for partitions → extreme availability– Some distributed database systems support this, high
complexity
• Conflict free replicated data types (CRDT)
– Specific CRDTs for specific use cases– Example: counting
• Increment only one replica• Sum over all replicas• If unavailable, simply assume the maximum when merging
– For more complex use-cases
• Read/repair algorithms• Complex → error prone
Distributed Architectures - Theory
Eventual accuracy
• Approximations instead of exact results
• Needed, if expensive/not possible to compute exactly
• Might be temporal• Exact results a�er a period of approximations
14
Examples of approximate accuracy
• O�en a true value is not needed, but a rough estimate
– e.g., hit count for a web search
• Examples for approximate algorithms
– Counting → HyperLogLog– Frequencies of members → CountMinSketch– Set membership → Bloom filters
Distributed Architectures - Theory
Locality of Reference
• “Keep related data close”
• Granularity• CPU caches to storage position within the data centre
• In a distributed context: bring the code to the data
• Best practice: position the data in a way it is accessed• Partition the data according to some criteria• e.g., rack awareness of the computing infrastructure
15
# Related data - typically data needed (i) within one operation, (ii) to servethe same/similar use cases.
Architecture for Simple Applications
Share Nothing Architecture
• No centralised data storage
• Can scale almost infinitely
• Used since the beginning of the 80ies, popularised by Google
• Only a few systems allow for such an architecture
ImplicationsIf a system requires some sort of shared resources or orchestrated processing, thecomplexity rises.
16
Distributed Architectures Basics
Distributed Architectures Basics
Number of issues to address
1. Serialisation
2. Group membership
3. Leader election
4. Distributed locks
5. Barriers
6. Shared resources
7. Configuration
17
Distributed Architectures Basics - Serialisation
Serialisation
• Transform an object into a byte array (and back)• Needed to transfer objects between nodes in a distributed environment• Used to store objects, e.g., in databases
• Should work across programming languages
• Therefore serialisation frameworks provide a Schema Definition Language
• Examples: Thri�, Protocol Bu�ers, Avro
18
Distributed Architectures Basics - Group Membership
Group membership
• When a single node comes online…
• How does it know where to connect to?
• How do the other members know of an added node?
19
Distributed Architectures Basics - Group Membership
• � Peer-to-peer architectural style
• Each node is client, as well as server
• Parts of the bootstrapping mechanism
• Dynamic vs. static
• Fully dynamic via broadcast/multicast within local area networks (UDP)
• Centralised P2P - e.g., central login components/servers
• Static lists of group members (needs to be configurable)
20
Distributed Architectures Basics - Leader Election
Leader election
• Not all nodes are equal, e.g., centralised components in P2P networks
• Single node acts as master, others are workers
• Some nodes have additional responsibilities (supernodes)
• Having centralised components makes some functionality easier to implement• e.g., assign work-load
• Disadvantage: might lead to a single point of failure
21
Distributed Architectures Basics - Leader Election
• � Client-server architectural style
• Once the leader has been elected, it takes over the role of the server
• All other group members then act as clients
22
Distributed Architectures Basics - Leader Election
23
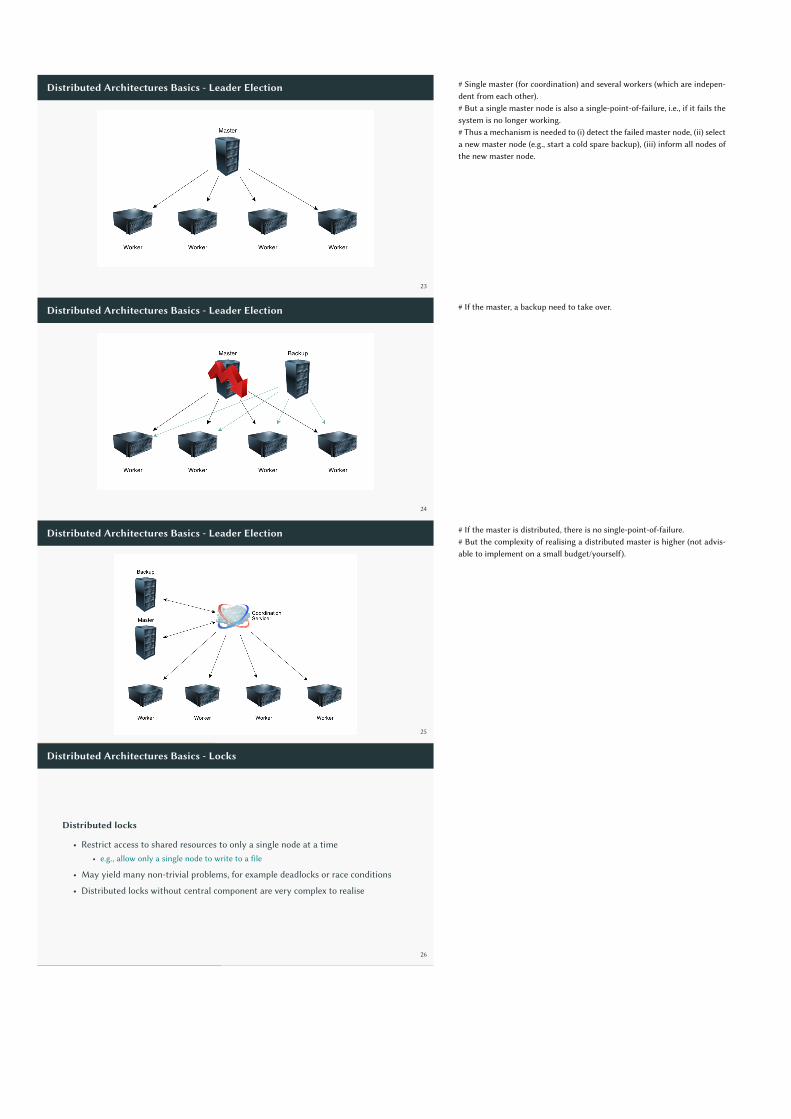
# Single master (for coordination) and several workers (which are indepen-dent from each other).# But a single master node is also a single-point-of-failure, i.e., if it fails thesystem is no longer working.# Thus a mechanism is needed to (i) detect the failed master node, (ii) selecta new master node (e.g., start a cold spare backup), (iii) inform all nodes ofthe new master node.
Distributed Architectures Basics - Leader Election
24
# If the master, a backup need to take over.
Distributed Architectures Basics - Leader Election
25
# If the master is distributed, there is no single-point-of-failure.# But the complexity of realising a distributed master is higher (not advis-able to implement on a small budget/yourself).
Distributed Architectures Basics - Locks
Distributed locks
• Restrict access to shared resources to only a single node at a time• e.g., allow only a single node to write to a file
• May yield many non-trivial problems, for example deadlocks or race conditions
• Distributed locks without central component are very complex to realise
26

Distributed Architectures Basics - Locks
Distributed locks example
• � Blackboard architectural style
• The shared repository is responsible to orchestrate the access to a locks
• Notifies waiting nodes once the lock has been li�ed
• This functionality is o�en coupled with the elected leader
27
Distributed Architectures Basics - Barriers
Barriers
• Specific type of distributed lock
• Sychronise multiple nodes
• e.g., multiple nodes should wait until a certain state has been reached
• Used when a part of the processing can be done in parallel and some parts cannotbe distributed
28
Distributed Architectures Basics - Shared Resources
Shared Resources
• If all nodes need to be able to access a common data-structure
• Read-only vs. read-write
• If read-write, the complexity rises due to synchronisation issues
29
Distributed Architectures Basics - Zookeeper
Example: Apache Zookeeper
• Zookeeper is a framework/library
• Used by LinkedIn, Facebook
• Initially developed by Yahoo!, now managed by Apache
• Features• Coordination kernel• File-system like API• Synchronisation, Watches, Locks• Configuration• Shared data
30

Distributed Architectures Basics - DFS
Distributed File Systems
• Virtual file system distributed over multiple machines• Based on a local file system
• Same semantics like traditional file systems• Folders & files
• Files are internally split into smaller blocks (e.g. 64MB)
• Blocks are redundantly stored on multiple machines
• Logic to record, which block is stored on which machine
31
# Optimised for large files
# Can be used like a traditional file system.
# Works best, if the data needed for a single operation (use case) is locatedon the same machine (� locality of reference).
Distributed Architectures Basics - Sharding
Sharding
• Split the data horizontally ò
• Each node in a network may manage a separate chunk of the data
• For example in web search engines• Each node is responsible for a number of web-pages• Returns search results from the local collection• All results from all shards are then combined into a single result
32
Distributed Architectures Basics - Sharding
Sharding example
33
# One partition of the data (shard) contain all web sites from .at, and anotherall sites from .de.
# The appropriate partitioning logic depends on the application/use case.
Distributed Architectures Basics - Sharding
Sharding - Properties
• Need redundancy, in case a node goes down
• Level of redundancy depends on the data
• e.g., if a node with low-tra�ic web-pages goes down, it might not even have animpact on the quality of the search results (at least on the first page)
34
Distributed Architectures Basics -�ality A�ribute
Anarchic Scalability
• Design for a large distributed system
• Parts of the system are developed independently from each other
• Therefore the system need to be designed for malfunctioning or even maliciouslycomponents
• The web is an example where anarchic scalability is one of the most importantaspects
• Thus clients are not expected to know all servers• … and servers are not supposed to know all clients• Another consequence is the link integrity → only one-directional
35
Asynchronous Architectures
Asynchronous Architectures - Motivation
Synchronous architectures
• Each call terminates a�er the request has been completely processed• e.g., traditional data-centric architectures (databases)
• Ý Easy to use and predictive behaviour
• Ä Does not deal well with load (need to plan with the worst case)
Asynchronous architectures
• The call returns before the request has been processed• The processing happens in the background
• Ä Non predictive behaviour
• Ý Load can be distributed over time, thus be�er scalability
36
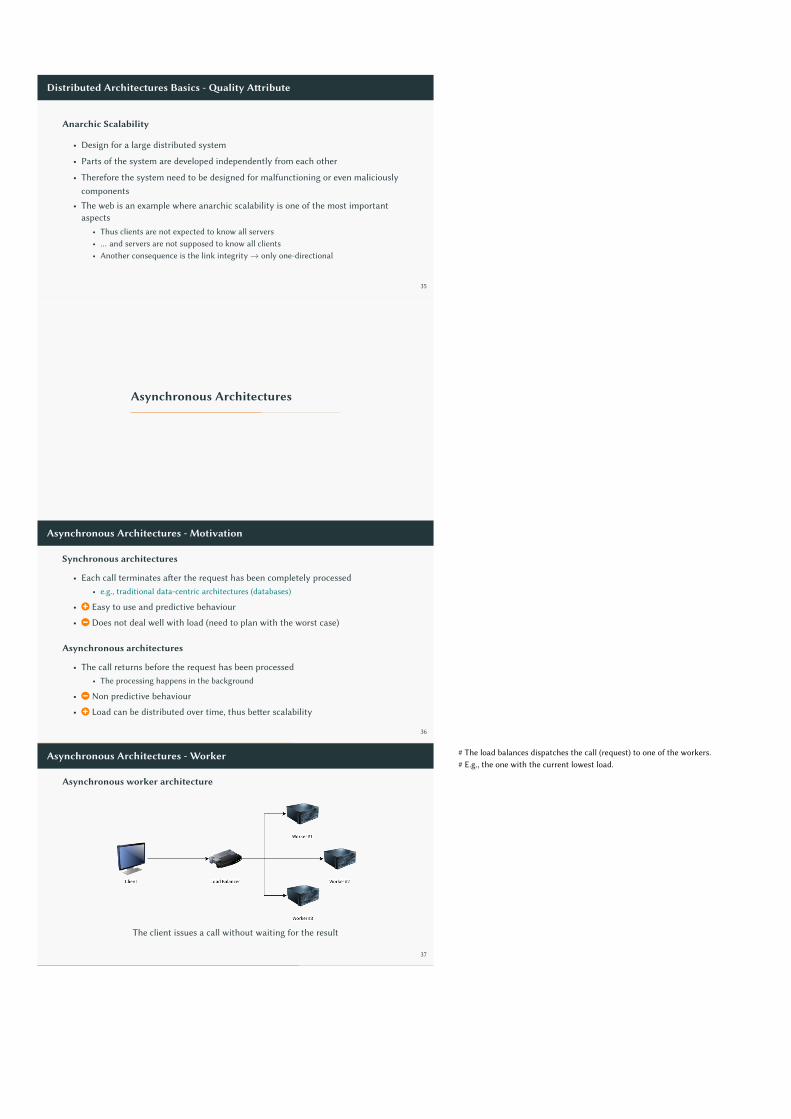
Asynchronous Architectures - Worker
Asynchronous worker architecture
The client issues a call without waiting for the result
37
# The load balances dispatches the call (request) to one of the workers.# E.g., the one with the current lowest load.

Asynchronous Architectures - Worker
Asynchronous worker architecture
• The client does not wait for the end of the processing• I.e. does not track the result
• If the worker fails, all currently processed requests will fail
�eue MotivationIntroduce a new component to track the processing of the requests, e.g. a queueingsystem
38
Asynchronous Architectures -�eue &Worker
Asynchronous queue & worker architecture
The client puts the request into the queue, the workers poll the queue for requests
39
# The queue also tracks the processing of the requests.
Asynchronous Architectures -�eue &Worker
�eue and worker architecture
• The client is decoupled from the worked via a queue component
• The queue component is (usually) responsible to track the status of the requests
• The size of the queue depends on the current load
• If a worker fails, the request will be put back into the queue
• Default architecture choice for many distributed systems
40
# O�en, the queue itself might be distributed and might store the requests(e.g. in a database).
# See also publish-subscribe architectural style (producer-consumer pat-tern).
Asynchronous Architectures -�eue &Worker
�eue and worker architecture aspects
• The number of workers/applications may vary• Single consumer vs. multi consumer queues• Multiple independent workers that execute the same code vs.• … each worker has a di�erent task
• Typically queues are FIFO (first in, first out)• Some queue support items with higher priority
• In some configurations the application is responsible to track the status
• A typical application may consist of multiple layers of queues and workers• I.e. the output of a worker is fed as input to another queue
41

Asynchronous Architectures -�eue &Worker
�eue & worker properties
• The architecture is straightforward, but not simple
• Race conditions may occur
• Partitioning might be hard to implement• � Bad for fault tolerance
• Tedious to build• Much code necessary for serialisation/routing logic/monitoring of queues/etc.
• Complex deployment for all workers and queues
42
Asynchronous Architectures - Stream processing
Stream processing
• The queue & worker architecture can be used for stream processing• Not suitable for real-time applications, due to delay from the queue
• Continuous stream of incoming requests• I.e. the queue is perpetually filled• O�en these reflect events in such se�ings
43
Asynchronous Architectures - Stream Processing
Two basic stream processing types
• One-at-a-time
• Each event is processed individually
• Micro-batch
• Multiple events are combined into a single batch
44
Asynchronous Architectures - Stream Processing
Basic execution semantics
• At-least-once
• Each event is guaranteed to be executed• But might be processed more o�en (thus the same result might be reported multiple
times)• Might introduce inaccuracies
• At-most-once
• Each event is optionally executed, but no more than once
• Exactly-once
• Each event is guaranteed to be executed only once
45

Asynchronous Architectures - Stream Processing
Trade-o� between the stream processing types
One-at-a-time Micro-Batch
Lower Latency XHigher Throughput XAt-least-once semantic X XExactly-once semantic (sometimes) XSimpler programming model X
46
# Depends on the application, which is be�er.# http://data-artisans.com/high-throughput-low-latency-and-exactly-once-stream-processing-with-apache-flink/
Asynchronous Architectures - Stream Processing
Implications
• Exactly-once can be achieved via strictly ordered processing• Fully process an event before continuing
• More e�icient for micro-batches• Multiple batches in parallel• Need to store the batch-id of the last successfully processed batch
47
Asynchronous Architectures - Stream Processing
Strength Examples
Batch High throughput Hadoop, SparkOne-at-a-time Low latency StormMicro-batch Tradeo� Trident, Spark
Table 1: Comparison of the main distributed architectures
48
Lambda Architecture
# The Lambda Architecture is an example on how to deal with large amountsof data.

Lambda Architecture - Motivation
Target scenario
• Large amount of data• Too big for a single machine � distributed system
• Data is continuously updated• Mostly just additions, i.e. new data
• Majority of operations are read-only
• E�ectively, queries on the data
49
Lambda Architecture - Motivation
Typical solution
• The typical solution would be a data-centric architecture
• Data is stored in a distributed traditional RDBMS or noSQL databases• Updates are wri�en into the database (via transactions)• The queries are computed in a distributed manner, over all the data
• As some queries are too slow, they need to be precomputed• … and the precomputed results need to be incrementally updated (as soon a new data
comes in)
Incremental architectureThe incremental architecture is too complex, mainly because of (i) the (distributed)transaction support and (ii) the complex algorithms to merge the new data.
50
Lambda Architecture - Motivation
Target properties
• Robustness & fault tolerance
• Scalability
• Generalisation
• Extensibility
• Ad hoc queries
• Minimal maintainance
• Debuggability
51
Ad-hoc queries for exploratory data analysis
Lambda Architecture - Overview
52
# All data is stored in the master dataset, which is immutable (i.e., no up-dates), which is updated only on specific events (checkpoints), thus the mas-ter dataset will most of the time out-dated.# Instead of pre-computing the results, dedicated data structures are filled,that can be queried (but only specific queries are possible) -¿ known as batchview.# e.g. for each use case there is one precomputed batch view.# To deal with new data, there is the speed layer, which is updated as soonas new data is available (always up-to-date).# For each query, both the speed layer and the serving layer (batch view)are used and the results merged.

Lambda Architecture - Overview
53
# The realtime views in the speed layer, as well as the batch views in theserving layer are o�en (traditional) databases.# On a regular basis the master dataset gets updated:# 1. All pending changes get merged into the master dataset# 2. The batch views get updated# 3. The speed layer gets reset
Kappa Architecture
# Another example of a distributed architecture.
Kappa Architecture - Motivation
Basic idea behind Kappa Architecture
• The Lambda Architecture is relatively complex
• Most of the problems can be solved via a streaming approach
• → treat the batch processing as if it were a stream of data• Have the framework optimise for the two cases (stream vs. batch)
54
8 Rules of Stream Processing (Stonebraker et at., 2005)
1. Keep the Data Moving
2. �ery using SQL on Streams (StreamSQL)
3. Handle Stream Imperfections (Delayed, Missing and Out-of-OrderData)
4. Generate Predictable Outcomes
5. Integrate Stored and Streaming Data
6. Guarantee Data Safety and Availability
7. Partition and Scale Applications Automatically
8. Process and Respond Instantaneously
# http://blog.acolyer.org/2014/12/03/
the-8-requirements-of-real-time-stream-processing/
# Stonebraker, M., Cetintemel, U., & Zdonik, S. (2005). The 8 requirements of real-
time stream processing. ACM Sigmod Record, 34(4), 42-47.
Kappa Architecture - Example
Example of streaming framework: Apache Kafka
• Message queueing system
• Stores all data for a given timespan, e.g. 2 days
• Topics• Partitions within topics• Partitions are chosen by the application, i.e. both producers and consumers need to
agree on the partitions
• Broker
• Each message within a partition has an o�set
• Clients have a unique id and remember their o�set
55

The End
56
# https://www.enterpriseintegrationpatterns.com/patterns/
messaging/