Download - 02 data warehouse applications with hive

Data Warehouse applications with Hive

Motivation
Limitation of MR
Have to use M/R model
Not Reusable
Error prone
For complex jobs: Multiple stage of Map/Reduce functions
write specify physical execution plan in the database

What is HIVE?
• A system for querying and managing structured data built on top of Map/Reduce and Hadoop
• Example:
– Structured logs with rich data types (structs, lists and maps)
– A user base wanting to access this data in the language of their choice
– A lot of traditional SQL workloads on this data (filters, joins and aggregations)
– Other non SQL workloads

Overview
Intuitive
Make the unstructured data looks like tables regardless how it really lay out
SQL based query can be directly against these tables
Generate specify execution plan for this query
What’s Hive
A data warehousing system to store structured data on Hadoop file system
Provide an easy query these data by execution Hadoop MapReduce plans

Dealing with Structured Data
• Type system
– Primitive types
– Recursively build up using Composition/Maps/Lists
• Generic (De)Serialization Interface (SerDe)
– To recursively list schema
– To recursively access fields within a row object
• Serialization families implement interface
– Thrift DDL based SerDe
– Delimited text based SerDe
– You can write your own SerDe
• Schema Evolution

MetaStore
• Stores Table/Partition properties:
– Table schema and SerDe library
– Table Location on HDFS
– Logical Partitioning keys and types
– Other information
• Thrift API
– Current clients in Php (Web Interface), Python (old CLI), Java (Query Engine and CLI), Perl (Tests)
• Metadata can be stored as text files or even in a SQL backend

Data Model
Tables
Basic type columns (int, float, boolean)
Complex type: List / Map ( associate array)
Partitions
Buckets
CREATE TABLE sales( id INT, items ARRAY<STRUCT<id:INT,name:STRING>
) PARITIONED BY (ds STRING)
CLUSTERED BY (id) INTO 32 BUCKETS;
SELECT id FROM sales TABLESAMPLE (BUCKET 1 OUT OF 32)

Metadata
Database namespace
Table definitions
schema info, physical location In HDFS
Partition data
ORM Framework
All the metadata can be stored in Derby by default
Any database with JDBC can be configed

Hive CLI
• DDL:
– create table/drop table/rename table
– alter table add column
• Browsing:
– show tables
– describe table
– cat table
• Loading Data
• Queries

Architecture
HDFS
Hive CLI
DDLQueriesBrowsing
Map Reduce
MetaStore
Thrift API
SerDeThrift Jute JSON..
Execution
Hive QL
Parser
Planner
Mgm
t. W
eb U
I

Data Model
Logical Partitioning
HashPartitioning
Schema
Library
clicks
HDFS MetaStore
/hive/clicks
/hive/clicks/ds=2008-03-25
/hive/clicks/ds=2008-03-25/0
…
Tables
#Buckets=32Bucketing InfoPartitioning Cols

Hive Query Language• Philosophy
– SQL like constructs + Hadoop Streaming
• Query Operators in initial version– Projections
– Equijoins and Cogroups
– Group by
– Sampling
• Output of these operators can be:– passed to Streaming mappers/reducers
– can be stored in another Hive Table
– can be output to HDFS files
– can be output to local files

Hive Query Language
• Package these capabilities into a more formal SQL like query language in next version
• Introduce other important constructs:
– Ability to stream data thru custom mappers/reducers
– Multi table inserts
– Multiple group bys
– SQL like column expressions and some XPath like expressions
– Etc..

Joins
• Joins
FROM page_view pv JOIN user u ON (pv.userid = u.id)
INSERT INTO TABLE pv_users
SELECT pv.*, u.gender, u.age
WHERE pv.date = 2008-03-03;
• Outer Joins
FROM page_view pv FULL OUTER JOIN user u ON (pv.userid = u.id) INSERT INTO TABLE pv_users
SELECT pv.*, u.gender, u.age
WHERE pv.date = 2008-03-03;
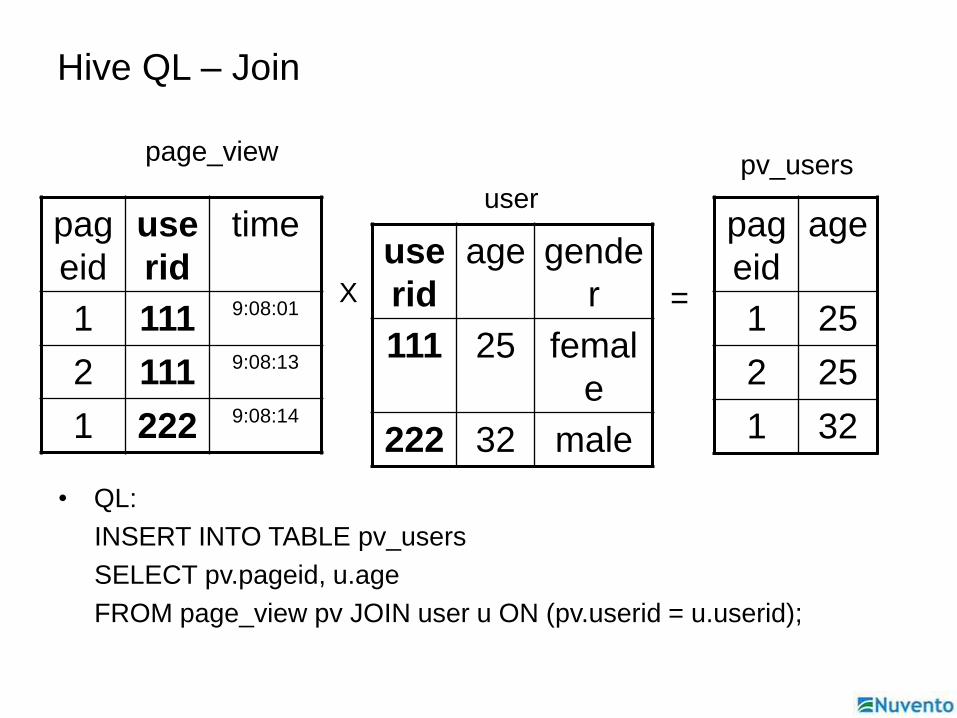
Hive QL – Join
• QL:
INSERT INTO TABLE pv_users
SELECT pv.pageid, u.age
FROM page_view pv JOIN user u ON (pv.userid = u.userid);
pag
eid
use
rid
time
1 111 9:08:01
2 111 9:08:13
1 222 9:08:14
use
rid
age gende
r
111 25 femal
e
222 32 male
pag
eid
age
1 25
2 25
1 32
X =
page_view
user
pv_users

Aggregations and Multi-Table Inserts
FROM pv_users
INSERT INTO TABLE pv_gender_uu
SELECT pv_users.gender, count(DISTINCT pv_users.userid)
GROUP BY(pv_users.gender)
INSERT INTO TABLE pv_ip_uu
SELECT pv_users.ip, count(DISTINCT pv_users.id)
GROUP BY(pv_users.ip);

Running Custom Map/Reduce Scripts
FROM (
FROM pv_users
SELECT TRANSFORM(pv_users.userid, pv_users.date) USING 'map_script'
AS(dt, uid)
CLUSTER BY(dt)) map
INSERT INTO TABLE pv_users_reduced
SELECT TRANSFORM(map.dt, map.uid) USING 'reduce_script' AS (date, count);

Inserts into Files, Tables and Local Files
FROM pv_users
INSERT INTO TABLE pv_gender_sum
SELECT pv_users.gender, count_distinct(pv_users.userid)
GROUP BY(pv_users.gender)
INSERT INTO DIRECTORY ‘/user/facebook/tmp/pv_age_sum.dir’
SELECT pv_users.age, count_distinct(pv_users.userid)
GROUP BY(pv_users.age)
INSERT INTO LOCAL DIRECTORY ‘/home/me/pv_age_sum.dir’
FIELDS TERMINATED BY ‘,’ LINES TERMINATED BY \013
SELECT pv_users.age, count_distinct(pv_users.userid)
GROUP BY(pv_users.age);

Wordcount in Hive
FROM (
MAP doctext USING 'python wc_mapper.py' AS (word, cnt)
FROM docs
CLUSTER BY word
) map_output
REDUCE word, cnt USING 'pythonwc_reduce.py';

Performance
GROUP BY operation
Efficient execution plans based on: Data skew:
how evenly distributed data across a number of physical nodes
bottleneck VS load balance Partial aggregation:
Group the data with the same group by value as soon as possible
In memory hash-table for mapper
Earlier than combiner

Performance
JOIN operation
Traditional Map-Reduce Join
Early Map-side Join very efficient for joining a small table with a large table
Keep smaller table data in memory first
Join with a chunk of larger table data each time
Space complexity for time complexity

Performance
Ser/De
Describe how to load the data from the file into a representation that make it looks like a table;
Lazy load
Create the field object when necessary
Reduce the overhead to create unnecessary objects in Hive
Java is expensive to create objects
Increase performance

Pros
Pros
A easy way to process large scale data
Support SQL-based queries
Provide more user defined interfaces to extend
Programmability
Efficient execution plans for performance
Interoperability with other database tools

Cons
Cons
No easy way to append data
Files in HDFS are immutable

Application
Log processing
Daily Report
User Activity Measurement
Data/Text mining
Machine learning (Training Data)
Business intelligence
Advertising Delivery
Spam Detection

End of session
Day – 4: Data Warehouse applications with Hive







