
1. Regresión lineal simple
1
1
___________________
Correlación y regresión lineal simple
1. Introducción
La correlación entre dos variables (X e Y) se refiere a la relación existente entre ellas de
tal manera que a determinados valores de X se asocian determinados valores de Y. Por
ejemplo, la correlación entre la altura y el peso, el número de horas que un alumno pasa
estudiando una asignatura y la nota que obtiene en la misma, la cantidad de horas de
sueño y el rendimiento en una determinada tarea, o el número de amigos que uno tiene
en un grupo y su grado de implicación en la tarea que va a acometer con dicho grupo,
etc...
Estas relaciones funcionales en las que las variables son medidas como mínimo en
escala de intervalo, pueden presentar dos sentidos diferentes. Si a medida que aumentan,
crecen o se hacen mayores los valores de X se produce un incremento en los de Y la
correlación es positiva; si por el contrario, valores altos en Y se asocian con valores
bajos en X y bajos en Y con altos en X la correlación es de tipo negativo. Por ejemplo,
sería el caso de observar menor rendimiento en un examen cuanto más tiempo pasan los
alumnos distraídos en una clase: A más distracción (X), menos rendimiento (Y), es
decir, a mayores valores de X, menores son los de Y
En el estudio de las correlaciones la asociación entre dos variables puede manifestar
diferentes grados. Cuanto mayormente estén asociadas X e Y mayor será su correlación
(positiva o negativa), mayor la fuerza en que se encuentran ligadas. Cuando la
correlación es perfecta se dice entonces que X e Y se encuentran al 100% asociadas, es
decir, comparten al máximo sus variaciones y que la información suministrada por una
de ellas informa cabalmente de las variaciones que manifiesta la otra. Este tipo de
relaciones perfectas son propias de variables físicas, por ejemplo, la relación entre el
volumen y la presión (a determinados valores de volumen le corresponden unos
determinados y específicos valores de presión) o la del voltaje y la corriente en un
circuito eléctrico con resistencia constante. En nuestra ciencia, sin embargo, estas
correlaciones perfectas son impensables. La conducta (que es nuestro objeto de estudio)
-en sus múltiples manifestaciones- se halla relacionada con multiplicidad de factores, a
veces no controlados, a veces desconocidos. La medida de la asociación entre
cualesquiera de ellos y la conducta nos proporcionará como máximo información sobre
determinadas tendencias –más o menos claras, significativas o no- entre la ocurrencia de
ciertos comportamientos y determinadas circunstancias o factores que los acompañan.
Esto quiere decir que nunca podremos predecir al 100% un comportamiento por mucho
que sepamos sobre el tipo y cantidad de sus condicionantes, aunque sí podremos
predecirlo en algún grado. Para ello hacemos investigación.

1. Regresión lineal simple
2
2. Covariación y correlación entre variables.
De cara a medir de alguna manera cómo ser relacionan entre sí dos variables (por
ejemplo, X e Y) es importante en primera instancia partir del concepto de covariación.
La covariación entre dos variables hace referencia a la medida en que la variabilidad de
los valores de X tiende a estar aparejada en cierto sentido o tendencia con la
variabilidad de los valores de Y.
De la manera que mejor se entiende la covariación entre dos variables es representando
dicha relación en un eje de coordenadas. Pongamos unos supuestos valores de X en el
eje de abcisas y sus correspondientes de Y en la ordenada. Por ejemplo, midamos de 0 a
10 el nivel de competencia autopercibida (X) por una muestra de 10 sujetos para superar
una asignatura y la nota obtenida en la misma (Y).
012345678910
0 1 2 3 4 5 6 7 8 9 10
X
Y
Cada uno de los puntos de la gráfica representa a un sujeto. Esto quiere decir que el
primero de ellos puntuó en la escala de competencia percibida un valor de 1 y su nota en
la asignatura fue de 2,5 puntos aproximadamente. Por su parte otro de los sujetos que
puntuó en la escala de competencia un 7 obtuvo una nota de 7 y otro con una
puntuación de 9 en X, obtuvo también una puntuación de 7 en Y. Interpretando en
general esta gráfica podemos afirmar que este conjunto de puntos – esta nube de puntos-
presenta una tendencia o relación ascendente entre X e Y por lo que parece ser que en
líneas generales, a medida que aumenta la competencia percibida de los sujetos éstos
obtienen notas superiores en la asignatura. Lo que sigue es medir o cuantificar de alguna
manera este grado de relación mostrada en la gráfica entre X e Y. A continuación
llevaremos a cabo esta tarea.
El concepto de variabilidad1 hace referencia a la dispersión que presenta un conjunto de
datos entre sí o respecto a un determinado referente. Tal referente puede ser la media. Si
relacionamos las desviaciones de cada uno de los datos de X respecto a su media con las
desviaciones de sus parejas en los valores de Y respecto a la media de Y y calculamos
su promedio tenemos:
1
))((1
−
−−=∑
N
YYXXCov
N
XY
Con esta fórmula se calcula el grado de asociación o covariación entre X e Y. Su
resultado es positivo si ocurre que los datos con desviaciones altas y positivas respecto a
su media en la variable X se emparejan con datos con desviaciones altas y positivas
1 En estadística las medidas de dispersión más usadas son la desviación típica (S) y la varianza (S
2)

1. Regresión lineal simple
3
respecto a la media en Y, así como si desviaciones altas en negativo de los datos en la
variable X se aparejan igualmente con desviaciones altas también negativas en la
variable Y. Esto ocurre cuando, por ejemplo, en el caso graficado arriba, sujetos con alta
competencia percibida obtienen notas altas en la asignatura y sujetos con baja
competencia notas bajas. Por otra parte, el resultado de la fórmula de la covariación será
negativo si, por el contrario, desviaciones altas positivas en X se aparejan con
desviaciones altas negativas en Y y viceversa.
La fórmula de la covariación, por tanto, nos mide hasta qué punto las dos variables
están asociadas en su propia escala puesto que estamos utilizando las puntuaciones
directas que han proporcionado los sujetos. Supongamos que los resultados de medir a 8
sujetos en las variables horas de estudio empleadas en una asignatura (X) y su nota en la
misma -de 0 a 10- (Y) han sido las siguientes.
Sujetos X Y )( xx − )( yy − ))(( yyxx −−
1
2
3
4
5
6
7
8
4
5
7
12
10
9
8
3
3
5
8
10
9
9
8
2
-3.25
-2.25
-0.25
4.75
2.75
1.75
0.75
-4.75
-3.75
-1.75
1.25
3.25
2.25
2.25
1.25
-4.75
12.19
3.94
-0.31
15.44
6.19
3.94
0.94
22.56
Medias 7.25 6.75 ∑= 62.51
)( xx − son las puntuaciones diferenciales que corresponden a cada sujeto en X y
)( yy − son las puntuaciones diferenciales en Y. Dichas puntuaciones indican a cuántos
puntos de la media –por encima o por debajo de ésta- se sitúa la puntuación de cada
sujeto tanto en X como en Y. Así pues, una puntuación diferencial positiva indica una
superioridad respecto a la media y una negativa un defecto respecto a la misma.
¿Cuál es la medida de covariación entre ambas variables en este caso?
93.87
51.62
1
))((1 ==
−
−−=∑
N
YYXXCov
N
XY
Supongamos que la nota en la asignatura se hubiera medido en una escala de 0 a 20 –
por ejemplo si el examen constara de 20 preguntas cortas- en vez de con la escala de 0 a
10 como antes. Si mantenemos las mismas notas previas, es decir, teniendo igual
rendimiento por alumno que antes pero en esta última escala, las puntuaciones hubieran
sido (nótese que en Y, una puntuación de, por ejemplo, 5 en una escala de 0 a 10 se
corresponde con una de 10 –el doble- en la escala de 0 a 20):

1. Regresión lineal simple
4
Sujetos X Y )( xx − )( yy − ))(( yyxx −−
1
2
3
4
5
6
7
8
4
5
7
12
10
9
8
3
6
10
16
20
18
18
16
4
-3.25
-2.25
-0.25
4.75
2.75
1.75
0.75
-4.75
-7.5
-3.5
2.5
6.5
4.5
4.5
2.5
-9.5
24.38
7.88
-0.63
30.88
12.38
7.87
1.87
45.13
Medias 7.25 13.5 ∑= 124.95
En esta nueva escala de la variable Y, la medida de covariación entre las dos variables
será:
85.177
95.124
1
))((1 ==
−
−−=∑
N
YYXXCov
N
XY
un valor sensiblemente superior al de antes (17.85 > 8.93). ¿Quiere decir esto que el
grado de asociación entre X e Y resulta superior en este segundo ejemplo cuando
sabemos que las puntuaciones de Y son las mismas que antes pero medidas en otra
escala? La respuesta es no. La explicación está en la amplitud de la escala de medición
de la segunda de nuestras variables. Este ejemplo nos conduce a afirmar que la medida
de la covariación entre dos variables depende del tipo de escala utilizada. Cuanto más
alto es el rango de variación de las escalas más alto es el resultado de la covariación
entre los datos manteniendo equivalente las puntuaciones de los sujetos en la nueva
escala respecto a la original. Es por eso que necesitamos, para establecer comparativas
entre datos provenientes de diferentes escalas (o de diferentes investigaciones) y para
los mismos conceptos o temas, de una medida de covariación que no dependa de ellas.
Esta medida es la correlación de Pearson.
La fórmula de la correlación de Pearson (r), la más utilizada para medir la asociación
entre dos variables nos proporciona, respecto a la covarianza, una medida de
covariación libre de escala. El coeficiente de correlación de Pearson oscila entre +1 y -
1, representado el primero un valor de correlación perfecta positiva entre las variables y
el último de correlación perfecta negativa. Un valor de r = 0 significa la ausencia total
de correlación entre las variables.
Para calcular r se procede a estimar el promedio de los productos cruzados de X y de Y
(tal y como en la fórmula de la covariación se hacía con las puntuaciones diferenciales)
pero en sus puntuaciones típicas.
N
ZZ
r
N
yx∑= 1
siendo Zs las puntuaciones típicas, es decir, representan el número de desviaciones
típicas a que se encuentra la puntuación de cada sujeto respecto a la media del grupo
tanto en X como en Y. Supongamos que una determinada variable tiene de media 5 y
de desviación típica 1.5. Un sujeto que obtiene en dicha variable una puntuación de 6.5,

1. Regresión lineal simple
5
se encuentra a 1 desviación típica por encima (positiva) de la puntuación media. Esta
sería, pues, su puntuación en Z. Formalmente lo calcularíamos así2:
X
ii
S
XXZ
)( −=
15.1
5.1
5.1
)55.6(==
−=iZ
Por ejemplo, transformemos en puntuaciones Z los valores de X e Y para el sujeto 2 de
la investigación anterior. Dicho sujeto invirtió 5 horas en el estudio de la materia y
obtuvo una calificación de 5 en la misma. Para este sujeto su puntuación diferencial en
X será:
25.2)25.75()( −=−=− XX lo que indica que su puntuación es 2.25 puntos menor que
la media del grupo.
Y en Y:
75.1)75.65()( −=−=−YY lo que indica que su nota es 1.75 puntos menor que la nota
media del grupo
Veamos cuáles son las correspondientes puntuaciones típicas.
En X:
72.1.3
25.2)(−=
−=
−=
X
ii
S
XXZ lo cual indica que su puntuación en horas de estudio
invertidas en la materia se encuentra a .72 desviaciones típicas por debajo de la media
de horas invertidas del grupo.
En Y:
583.3
75.1)(=
−=
−=
Y
ii
S
YYZ lo que muestra que su nota se encuentra a .583
desviaciones típicas por debajo de la nota media del grupo.
A continuación calculamos r para el conjunto de datos anteriores (primero para las notas
de examen en la escala de 0 a 10):
2 Si SX para el cálculo de las puntuaciones típicas es
1
)(1
2
−
−=∑
N
XX
S
N
X (cuasivarianza), la fórmula de la
correlación de forma equivalente debería ser 1−
=N
zzr YXXY

1. Regresión lineal simple
6
Sujetos X Y )( XX − 2)( XX − )( YY − 2)( YY − Zx Zy yxZZ
1
2
3
4
5
6
7
8
4
5
7
12
10
9
8
3
3
5
8
10
9
9
8
2
-3,25
-2,25
-,25
4,75
2,75
1,75
,75
-4,25
10,56
5,06
,06
22,56
7,56
3,06
,56
18,06
-3,75
-1,75
1,25
3,25
2,25
2,25
1,25
-4,75
14,06
3,06
1,56
10,56
5,06
5,06
1,56
22,56
-1,05
-,72
-,08
1,53
,89
,56
,24
-1,37
-1,25
-,58
,42
1,08
,75
,75
,42
-1,58
1,30
,42
-,03
1,65
,66
,42
,10
2,16
Sumas (Σ) 58 50 67.5 63.5 6.68
Medias 7.25 6.75
D.T. 3.1 3
Ya que:
307.97
49.63
1
)(
1.364.97
5.67
1
)(
2
1
1
2
===−
−=
===−
−=
∑
∑
N
YYS
N
XXS
N
Y
N
X
entonces para cada puntuación en X, por ejemplo, la primera:
04.11.3
25.3)(−=
−=
−=
X
ii
S
XXZ
Finalmente, el coeficiente de correlación de Pearson valdrá:
955.07
68.6
1
1 ==−
=∑N
zz
r
N
YX
Una correlación muy alta positiva (teniendo en cuenta que 1 sería la correlación
perfecta). Ello indica que cuantas más horas de estudio se emplee para estudiar la
materia más altas son las notas obtenidas. A continuación calculamos r para los datos en
el caso en que los datos Y se toman en la escala de 0 a 20:
Sujetos X Y )( xx − 2)( xx − )( yy − 2)( yy − zx zy yx zz
1
2
3
4
5
6
7
8
4
5
7
12
10
9
8
3
6
10
16
20
18
20
16
4
-3,25
-2,25
-,25
4,75
2,75
1,75
,75
-4,25
10,56
5,06
,06
22,56
7,56
3,06
,56
18,06
-7,50
-3,50
2,50
6,50
4,50
4,50
2,50
-9,50
56,25
12,25
6,25
42,25
20,25
20,25
6,25
90,25
-1,05
-,72
-,08
1,53
,89
,56
,24
-1,37
-1,25
-,58
,42
1,08
,75
,75
,42
-1,58
1,30
,42
-,03
1,65
,66
,42
,10
2,16
Sumas 58 108 67.5 254 6.68
Medias 7.25 13.5
D.T. 3.1 6.02

1. Regresión lineal simple
7
02.67
254
1
)(
1.37
5.67
1
)(
2
1
1
2
==−
−=
==−
−=
∑
∑
N
YYS
N
XXS
N
Y
N
X
Y su valor r:
955.07
68.6
1
1 ==−
=∑N
zz
r
N
yx
xy
Observemos cómo el coeficiente de correlación entre X e Y no varía cambiando la
escala en que se puntúa Y. Tanto en el primer caso (escala de 0 a 10) como en el
segundo (escala de 0 a 20) el valor de r es .955.
En el SPSS la petición del cálculo de la correlación nos puede proporcionar además otra
información adicional que puede resultar útil. Los resultados los encontramos en
Analizar/correlaciones/bivariadas. En el último cuadro de diálogo a partir de estos
comandos se pueden solicitar las medias y los productos cruzados de las variables así
como sus covarianzas.
Su salida nos proporciona la información siguiente (para las variables horas de estudio y
notas –de 0 a 10-):
Estadísticos descriptivos
Media Desviación típica N
HORAS 7,2500 3,10530 8
NOTAS 6,7500 3,01188 8
Correlaciones
HORAS NOTAS
Correlación de Pearson
1 ,955(**)
Sig. (bilateral) . ,000
Suma de cuadrados y productos cruzados 67,500 62,500
Covarianza 9,643 8,929
HORAS
N 8 8
Correlación de Pearson
,955(**) 1
Sig. (bilateral) ,000 .
Suma de cuadrados y productos cruzados 62,500 63,500
Covarianza 8,929 9,071
NOTAS
N 8 8
** La correlación es significativa al nivel 0,01 (bilateral).
La correlación entre ambas variables, tal y como antes indicamos es .955. Su covarianza
8.93 (véase este mismo resultado cuando se calculaba a mano previamente). La suma de

1. Regresión lineal simple
8
cuadrados de X (∑ −N
XX1
2)( ) vale 67.5, la de Y (∑ −N
YY1
2)( ) 63.5; sus
correspondientes varianzas 9.643 y 9.0713. Por último, la suma de productos cruzados
entre X e Y (∑NXY
1) vale 62.5, un dato útil para calcular a mano el coeficiente r como
veremos a continuación.
El coeficiente de correlación de Pearson puede ser calculado de manera más cómoda
utilizando la siguiente fórmula que deriva de la anterior expresada en valores Zs:4
YX
N
XYSS
YXN
XY
r
−=
∑1
A partir de ahora utilizaremos esta última formulación en vez de la expresión original.
Si por cualquier razón conocemos las puntuaciones diferenciales de los datos la fórmula
de la correlación de Pearson se plantea así:
∑∑∑=
NN
N
xy
yx
xyr
1
2
1
2
1
donde YYyeXXx iiii −=−=
Una medida directamente relacionada con la correlación de Pearson es el denominado
coeficiente de determinación -R2-. Dicho coeficiente se calcula elevando la cuadrado el
valor de r y simboliza la cantidad de variabilidad explicada por X en la determinación
de los valores de Y. O dicho de otra forma, la proporción de la variabilidad de los
valores de Y que es debida al efecto de X, o de forma más inespecífica (cuando no
queremos inducir sentido causal alguno entre las variables), la cantidad de variabilidad
compartida entre las variables X e Y. Mientras que r proporciona la información sobre
el sentido de la correlación (positiva o negativa), R2 informa sobre su fuerza. Así que un
valor de r = -.9 se corresponde con un R2=0.81 (el mismo coeficiente de determinación
que para una r = .9). La diferencia entre los dos casos es el sentido en que X afecta a Y.
El coeficiente de determinación o proporción de variabilidad explicada del modelo de
relación planteado entre X e Y suele representarse en diagramas de Venn. Un círculo
completo representa la cantidad de variación de los datos en la variable Y y sus
diferentes áreas representan la proporción de la variabilidad de dicha variable que se
debe a X, por un lado, y a factores diferentes a X, por otro. Obviamente, cuanto mayor
es el área de variación explicada por X más habremos explicado de Y, es decir, más
conocemos de ella. Por el contrario, cuanto menor es este área mayor cantidad de
factores desconocidos (que no están bajo nuestro conocimiento) afectan a lo que
tratamos de explicar. A continuación tenemos un ejemplo:
3 Hay que tener en cuenta que más que varianzas estas son cuasivarianzas puesto que resultan de dividir
las sumas cuadráticas por N-1. 4 En esta fórmula, al igual que anteriormente, N debe sustituirse por N-1 si las desviaciones típicas del
denominador están calculadas a partir de N-1.

1. Regresión lineal simple
9
Delimitación de la variabilidad de Y
V. Explicada por X
V. No explicada por X
3. La representación gráfica de la correlación. La ecuación de regresión.
La representación gráfica de la relación entre dos variables (X e Y) constituye un
instrumento a veces muy útil tanto para interpretar el tipo de relación estudiada como
para detectar posibles casos extremos o perturbadores de la relación entre ellas. Como
ya hemos visto, se suele utilizar un eje de coordenadas donde los valores de X se
representan en la abscisa y los de Y en la ordenada. En el SPSS, una vez configurado el
archivo de datos en su hoja correspondiente, el diagrama de dispersión de los mismos se
solicita con la siguiente sucesión de comandos: Gráficos/Dispersión/Simple. El gráfico
resultante del ejemplo que tratamos anteriormente sería:
Horas de estudio y notas
HORAS
1412108642
NOTAS
12
10
8
6
4
2
0
Los puntos rojos en el gráfico sitúan las diferentes puntuaciones en el examen de cada
uno de los ocho sujetos analizados en función del número de horas de estudio que han
dedicado a estudiar la asignatura.
Una interpretación general de esta gráfica (si aún no hubiésemos calculado los
estadísticos anteriores como la correlación de Pearson o la covariación entre X e Y) nos
conduce a afirmar que la correlación entre X e Y es positiva puesto que los valores
describen una disposición hacia arriba a medida que aumentan los valores de X.
Además la visión de dicha gráfica nos permite vislumbrar cómo se distribuyen los
puntos respecto a una hipotética línea recta que los define de la forma más satisfactoria
posible y si respecto a dicha línea recta se da mucha o poca dispersión de los valores
dibujados. (Imagina visualmente dicha recta).
totalárea
azuláreaR =2

1. Regresión lineal simple
10
Con estas puntualizaciones estamos introduciendo algunos conceptos de interés que se
barajan en los estudios de la regresión. Por un lado el concepto de linealidad; por otro,
el grado de dispersión de los datos respecto a dicha linealidad o también la
consideración del grado de inclinación de la línea dibujada, etc...
En primer lugar es importante dejar claro que el tipo de estudios que vamos a tratar en
estas páginas se circunscriben exclusivamente a relaciones de tipo lineal entre variables.
Si esta condición no se cumple, las estimaciones de los diferentes estadísticos aplicados
para el análisis de la relación lineal estarán sesgados o serán inoportunos.
Consideremos por ejemplo que entre X (ansiedad) e Y (rendimiento) se produce el
siguiente tipo de relación que representamos gráficamente (una relación de U invertida):
ansiedad y rendimiento
ANSIEDAD
161412108642
RENDIMIE
10
9
8
7
6
5
4
3
2
Si en este caso tratamos de aplicar empecinadamente la supuesta recta que representa a
estos puntos, erraremos en el empeño puesto que dicha recta y sus correspondientes
valores de parámetros no constituyen estimaciones veraces y/o adecuadas de la relación
real que existe entre las variables que es de tipo curvilínea (cuadrática). Empeñándonos
en definir una relación lineal entre ellas (obsérvese la recta dibujada que representa
estos puntos) la conclusión sería que a medida que crece la ansiedad aumenta el
rendimiento mientras que en la gráfica se aprecia precisamente que esto ocurre hasta
cierto nivel de ansiedad a partir del cual el rendimiento empieza a decaer.
Si somos capaces de asegurar de que la relación entre las variables X e Y es de hecho de
carácter lineal y por lo tanto puede ser representada mediante una línea recta, el paso
siguiente será calcular la ecuación de dicha recta, es decir, la expresión matemática que
la define. Esta recta se denomina recta de regresión y su expresión matemática es:
bXaY +=ˆ
donde a es la ordenada en el origen o valor de y (estimado o predicho) cuando X vale 0;
b representa la inclinación de la recta, o si se quiere, el cambio estimado en la variable
Y por cada unidad de cambio en X.
Para esta ecuación suele utilizarse la siguiente nomenclatura cuando se trata de estimar
la relación estudiada en la población:

1. Regresión lineal simple
11
110ˆ XY ββ +=
siendo β0 el parámetro o valor poblacional de a y β1 el correspondiente parámetro de b,
esto es los valores de a y b de la recta anterior en la población de la que supuestamente
procede la muestra con la que hemos trabajado.
La recta de regresión no sólo permite formalizar la relación entre las variables
estudiadas asignándole un referente gráfico sino que, lo que es casi más importante,
permite predecir valores de Y a partir de valores de X que no se encuentran inicialmente
en la muestra de partida. A este respecto, sin embargo, conviene apuntar la conveniencia
de no estimar valores de X fuera del rango de medida sobre la que ha versado la muestra
original ya que lo que en principio puede ser una relación de tipo lineal puede no serlo
cuando se exploran medidas de X fuera (hacia arriba o abajo) del rango en un principio
contemplado.
Pues bien, la recta de regresión constituye la recta que mejor representa la nube de
puntos representados en la gráfica del modo como hemos hecho antes. Dicha recta
puede estimarse por diversos procedimientos siendo la intención identificar, de las
infinitas rectas que pudieran pintarse, aquélla que ajuste mejor con esta nube de puntos
empírica. Con otras palabras, aquélla recta respecto a la cual las distancias de los
numerosos puntos respecto a la misma sea mínima.
El procedimiento más utilizado y que comporta menor sesgo es el de mínimos
cuadrados. Consiste en hacer mínima la distancia de los variados puntos de la nube
respecto a los puntos que se encuentran en la recta, esto es, que la definen. Si
denominamos ei a la distancia de cada uno de los diferentes puntos (N) hasta la recta, el
procedimiento de mínimos cuadrados tratará de estimar la recta tal que:
∑ →N
i mínimoe1
2
es decir, las distancias al cuadrado de los puntos hasta la recta, sumados, deben tender al
mínimo.
Gráficamente y planteando para cada punto o dato ( iY ) su ecuación correspondiente se
tiene:
iii ebXaY ++=
por lo que:
ii
ii
eYY
ebXaY
=−
=+−
ˆ
)(
ya que bXaY +=ˆ

1. Regresión lineal simple
12
iY
Horas de estudio y notas
HORAS
1412108642
NOTAS
12
10
8
6
4
2
0
La distancia que va desde la media de Y (Y ) hasta cualquier punto de la recta ( Y ),
dado un determinado valor de X, queda explicado por la recta de regresión, es decir por
el cambio que sufre Y como efecto de X. Por otro lado, la distancia entre dicho punto
de la recta ( Y ) y el valor empírico de Y se denomina e y no lo explica X sino otras
variables ajenas a ella (errores de medición, factores desconocidos, aleatoriedad del
propio comportamiento de Y, etc...).
3.1. Supuestos.
Los valores de e deben cumplir una serie de requisitos para que sea pertinente el uso del
modelo de regresión tal y como lo estamos realizando. Estos requisitos pueden además
ser aplicados a la variable Y, que es la otra variable aleatoria implicada en el modelo de
regresión. Formalmente estos requisitos o supuestos se expresan así:
SUPUESTOS En términos de Y En términos de ε Linealidad
1)/( XXYE i βα += 0)( =εE
Homocedasticidad 2)/( σ=iXYVar 2)( σε =iVar
Independencia puntuaciones 0)( =iiYYCov 0)( =iiCov εε
Normalidad normalleyunasigueYi normalleyunasigueiε
Gráficamente algunos de estos supuestos en datos muy simples pueden ilustrarse de esta
manera:
Y
2
4/
2
3/
2
2/
2
1/ XYXYXYXY σσσσ ===
)ˆ( YYi −
)ˆ( YY −
iY

1. Regresión lineal simple
13
Como puede apreciarse en la gráfica, basta observar si los puntos verdes acompañan a la
recta, más o menos, en todo su recorrido para tener cierta evidencia de linealidad. En
este sentido sería incompatible con dicha linealidad (o sospecha de falta de linealidad)
observar un alejamiento de los puntos empíricos en algún momento del recorrido de la
recta, por ejemplo, al final o en su curso medio aunque la recta estimada fuera la misma
o casi la misma. Por otro lado, la homocedasticidad se aprecia si la dispersión de los
valores de Y en cada una de las condiciones de X son equivalentes; es decir, si no se
dan dispersiones claramente diferentes entre las diferentes líneas de puntos verdes
correspondientes a cada valor de X (las longitudes de las llaves dibujadas son
semejantes). Por último, la normalidad –aunque en la gráfica dibujada no se aprecia
directamente- se refiere a la existencia de una concentración mayor de puntos verdes en
las zonas próximas a la línea recta y menores concentraciones en los extremos hacia
arriba y hacia abajo. Las líneas rojas que delimitan la forma de campana de Gauss para
los datos dentro de cada condición de X describen este tipo de distribución que
explicamos.
A continuación veamos cómo pueden estimarse los diferentes parámetros involucrados
en la recta de regresión tal y como expresamos antes.
Prescindiendo de los efectos aleatorios de ε y expresando la ecuación sin los mismos
tenemos:
bXaY +=ˆ
donde Y estimada ( Y ) hace referencia a la puntuación de Y libre de error, es decir,
aquella que coincide exactamente con la recta de regresión.
A partir de estas estimaciones mínimo cuadráticas se llega a dilucidar cómo se calculan
cada uno de los parámetros de la ecuación de la recta siendo:
XbYa −=
y
X
YXY
S
Srb =
Normalidad
2X1X 3X 4X
Homocedasticidad
Linealidad

1. Regresión lineal simple
14
3.2. Ecuación en directas, diferenciales y típicas.
La ecuación de regresión puede expresarse de formas diferentes según el tipo de
puntuaciones de las que partimos para estimarla. Así pues podemos también expresar
los parámetros a y b, además de forma directa, a partir de las puntuaciones diferenciales
de los sujetos (sus desviaciones respecto a las medias de X y de Y) y en puntuaciones
típicas (los valores correspondientes de Z). Las primeras –en puntuaciones
diferenciales- tienen la peculiaridad de estimar la ecuación de regresión a partir de los
valores de 0 en X e Y, es decir, la ordenada en el origen de dicha recta en puntuaciones
diferenciales coincide con el 0. Por otro lado, expresar la ecuación de regresión en
puntuaciones típicas tiene la gran ventaja de expresar la relación entre X e Y en
puntuaciones no dependientes de la escala en que se miden estas variables por lo que
resulta en ocasiones muy conveniente a la hora de comparar rectas de regresión de
diferentes investigaciones que utilizan diferentes escalas de medición para las mismas
variables. En la siguiente tabla se presentan las ecuaciones de la recta en sus diferentes
modalidades según el tipo de puntuaciones de las que parten y la forma de calcular sus
correspondientes parámetros.
P. directas P. diferenciales P. típicas
bXaY +=ˆ iii eXXbYY +−=− )()( iiXXYiY eZrZ +=
XbYa −=
X
YXY
S
Srb =
∑
∑=
=
N
N
x
xy
b
a
1
1
0
X
iiX
N
yx
S
XXz
N
ZZ
r
)(
1
−=
=∑
Veamos cómo serían las ecuaciones en diferenciales y típicas de los datos de la
investigación que nos ocupa donde se correlacionaba el número de horas invertidas en
el estudio de una asignatura y la nota obtenida (en escala de 0 a 10 y en otra escala de 0
a 20).
Tipo de puntuaciones Valores Y (Escala de 0 a 10) Valores Y (Escala de 0 a 20)
Directas
ii XY 926.037. +=
ii XY 852.1074. +=
Diferenciales
ii xy 926.=
ii xy 852.1=
Típicas
iXiY ZZ 955.=
iXiY ZZ 955.=
Observemos que el parámetro b de las rectas de regresión para el cambio de escala de la
variable Y difiere cuando se estiman dichas rectas en puntuaciones directas y
diferenciales (lo que podría apreciarse por sus diferentes inclinaciones si las
representásemos gráficamente). El parámetro b es más grande cuando la escala tiene un
rango mayor, es decir, se espera un cambio mayor en Y –notas- por cada hora más de

1. Regresión lineal simple
15
estudio cuando la escala es de rango más amplio que cuando su rango es menor. La
diferencia entre diferenciales y directas radica en el parámetro a (ordenada en el origen)
que queda igualado a 0 en el caso de las diferenciales.
En este ejemplo, conociendo los datos y la manera en que han sido simulados casi
podemos despreocuparnos de estos desajustes, ya que sabemos de antemano que las
puntuaciones en Y en la primera escala son equivalentes –proporcionales- a las de Y en
la segunda escala. Estamos sobre aviso de que las diferencias en b entre ambas escalas
son sólo aparentes, es decir, dependen de ellas, del rango de medición de las notas. En
consecuencia, el análisis de ambas rectas no nos llevará a concluir que la relación entre
X e Y es más fuerte en el segundo caso que en el primero. Sin embargo, quizás en otras
circunstancias no seamos tan conocedores de la justa escala en que se miden las
variables y queriendo comparar rectas de regresión de investigaciones diferentes
erremos en el intento. En estas situaciones, pues, tiene especial utilidad la estimación de
las rectas de regresión mediante puntuaciones típicas o estandarizadas. En el cuadro
anterior apreciamos que ambas rectas coinciden perfectamente en una escala y en otra.
En el SPSS la salida que nos proporciona la petición de la ecuación de regresión para un
fichero de datos muestra tanto los coeficientes en directas como en estandarizadas. La
orden a aplicar es: Analizar/Regresión/Lineal. Algunos de los resultados presentados en
su salida (para las puntuaciones de los ejemplos que estamos utilizando) son:
Coeficientes
Coeficientes no estandarizados Coeficientes estandarizados
Modelo B Error típ. Beta t Sig.
(Constante) ,037 ,921 ,040 ,969 1
HORAS ,926 ,118 ,955 7,854 ,000
a Variable dependiente: NOTAS (0-10)
Coeficientes
Coeficientes no estandarizados Coeficientes estandarizados
Modelo B Error típ. Beta t Sig.
(Constante) ,074 1,842 ,040 ,969 1
HORAS 1,852 ,236 ,955 7,854 ,000
a Variable dependiente: NOTAS (0-20)
donde pueden localizarse en las tercera y cuarta columnas los parámetros de las rectas
de regresión estimadas en uno y otro caso: En directas (subrayados en rojo) y en
estandarizadas (en azul). La información restante presentada en estos cuadros será
tratada a continuación en el apartado sobre significación de los parámetros y del
modelo.
4. Significación de la correlación y de los parámetros del modelo de regresión.
Hasta el momento hemos planteado la medición de la relación existente entre dos
variables (covarianza y coeficiente de correlación de Pearson) y también su
especificación en un modelo formal que permite describir a nivel gráfico su naturaleza
(ecuación de la recta de regresión).
1. Regresión lineal simple
16
Sin embargo aún no hemos planteado ningún interrogante acerca de la significación de
nuestros datos, es decir, de la medida en que la relación estimada entre nuestras
variables y la función que describen (lineal y de determinado sentido) son o no
diferentes de lo que pueda esperarse por meros efectos del azar. Estamos planteando
ahora el tema de la significación estadística.
4.1. Significación de la correlación y del coeficiente b.
En primer lugar reparemos en el coeficiente de la correlación entre las variables. Desde
el punto de vista de su significación se trata de conocer si r es o no diferente de 0. Si lo
es, diremos que aunque su valor no coincida exactamente con 0 sí será uno de las
fluctuaciones aleatorias que pueda adoptar dicho valor en las muestras que pueden
extraerse aleatoriamente de la población (de correlación media igual a 0). En este caso,
el valor de probabilidad de que nuestro estadístico proceda de dicha población debe ser
grande (p>.05), es decir, será grande la probabilidad de que nuestro valor pertenezca a
dicha distribución de valor medio 0. Si por el contrario el valor de la correlación
empírica sobrepasa los límites de acción del azar la conclusión es que dicha correlación
no puede considerarse igual a 0, por lo tanto es diferente de este valor y resulta
estadísticamente significativa. Así pues, la probabilidad de que proceda de la población
cuyo valor promedio es cero es pequeña o nula (p<.05).
Lo mismo ocurre si deseamos evaluar el poder de predicción del estimador b en la
ecuación de regresión. Será o no considerado diferente de 0 si supera el valor prefijado
por los efectos del azar en la distribución muestral del estadístico b.
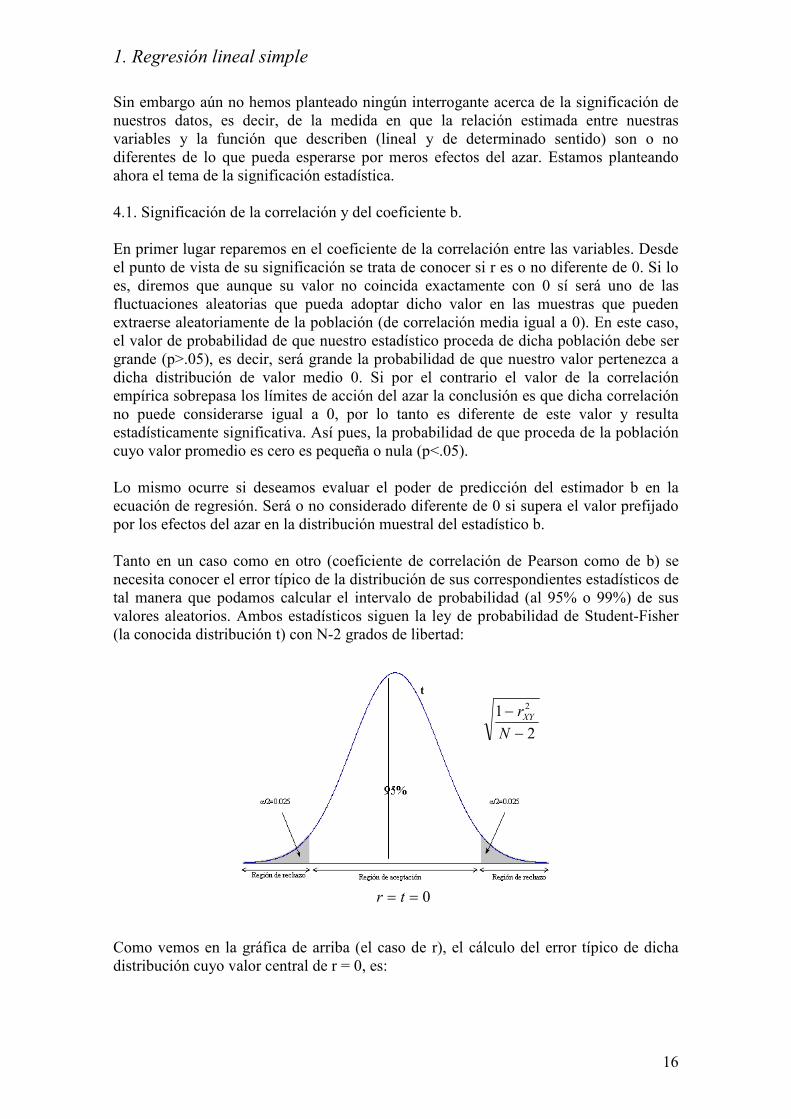
Tanto en un caso como en otro (coeficiente de correlación de Pearson como de b) se
necesita conocer el error típico de la distribución de sus correspondientes estadísticos de
tal manera que podamos calcular el intervalo de probabilidad (al 95% o 99%) de sus
valores aleatorios. Ambos estadísticos siguen la ley de probabilidad de Student-Fisher
(la conocida distribución t) con N-2 grados de libertad:
Como vemos en la gráfica de arriba (el caso de r), el cálculo del error típico de dicha
distribución cuyo valor central de r = 0, es:
2
1 2
−−N
rXY
0== tr

1. Regresión lineal simple
17
2
1 2
−−N
rXY
lo que significa que el error típico de variación del conjunto de valores de r calculados
en infinitas muestras de tamaño N extraídas de una población caracterizada por una
correlación igual a 0 entre ellos es ésta.
Para transformar un determinado valor de r a su a su correspondiente t se hace así:
2
1
0
2
−−
−=
N
r
rt
XY
XY
En el caso del parámetro b de la recta de regresión, el error típico de su distribución es:
∑ −N
res
XX
S
1
2
2
)(
y por tanto su valor en t:
∑ −
−=
N
res
XX
S
bt
1
2
2
)(
0
siendo 2
resS el valor de la varianza residual (de los errores –e-) o no explicada por el
modelo. Más tarde abundaremos más sobre este valor.
Para nuestros datos que estudiaban la relación entre las horas de estudio y las notas en
una asignatura (0-10), la significación de los valores de r y b en la ecuación de regresión
estimada se analizaría tal y como se plantea en la siguiente tabla:
Estadístico Valor t Decisión p/sig (SPSS)
955.=r
85.712.
955.
28
955.1
0955.
2==
−−
−=t
44.2)6,05(. =tt
Rechazo Ho ya que
7.85>2.44
.000
(<.05)
926.=b
85.711.
926.
14.77
938.
0926.==
−=t
44.2)6,05(. =tt
Rechazo Ho ya que
7.85>2.44
.000
(<.05)
Obsérvese que el valor de t referido al parámetro de la ecuación de regresión b, coincide
plenamente con la salida de resultados aportado en el SPSS presentada antes. Además,
ambos valores de t (el de r y de b) coinciden igualmente y en consecuencia sus
correspondientes valores p. Esto ocurre siempre en el modelo de regresión simple.

1. Regresión lineal simple
18
Para el caso ejemplificado concluiremos, respecto al valor obtenido en r, que existe una
correlación significativa y positiva entre el número de horas empleadas para estudiar la
asignatura y la nota obtenida de tal manera que dicha nota se verá incrementada cuantas
más horas se inviertan en el estudio. De manera más general puede decirse que las notas
y las horas de estudio comparten variación y dicha covariación (/correlación) resulta
significativa al .000 (< a.05 si trabajásemos teóricamente con este valor nominal).
Respecto al parámetro b, diremos que por cada hora de estudio que se invierte en la
asignatura en cuestión se incrementa en .926 puntos –aproximadamente 1 punto- la nota
obtenida en la misma. Esta predicción resulta relevante a nivel estadístico (p = .000) por
lo que dicho cambio en la nota en función del estudio puede considerarse mayor a los
límites explicados por el azar. Si queremos interpretar este parámetro de manera
estandarizada diremos que por cada hora de estudio más en la asignatura se incrementa
la nota en .955 desviaciones típicas.
4.2. Validación del modelo mediante el índice F de Snedecor.
A continuación, evaluemos desde otro punto de vista y de forma más general, el modelo
de regresión planteado, la relación especificada entre X e Y. Esto supone plantearse si
los parámetros conocidos o explicativos del modelo – en este caso la variable X-
aportan información esclarecedora y relevante para explicar el comportamiento –la
variable Y-. Dicho de otra manera, si dicho componente explicativo (X) es mucho más
relevante en la determinación de la variable criterio (Y) que el componente de error del
modelo (o efecto de otras variables desconocidas, extrañas y/o no medidas).
Para llevar a cabo este proceso de validación se suele utilizar el índice F de Snedecor.
Como ya se sabe, es un cociente entre la varianza explicativa (conocida) del modelo –la
variable manipulada, en los diseños experimentales- y la varianza no explicada o error.
El índice evalúa en qué medida la varianza del numerador es capaz de sobrepasar
aquella representada en el denominador. Para el modelo de regresión que nos ocupa se
trata de medir por un lado la variación de Y condicionada por X (si se quiere,
compartida con ella) y por otro, la variación de Y no explicada o no atribuida a X.
Los componentes de variabilidad del modelo de regresión son dos: b y e. Si traemos de
nuevo a colación la representación gráfica del modelo en ejes cartesianos:
Horas de estudio y notas
HORAS
1412108642
NOTAS
12
10
8
6
4
2
0
)ˆ( ii YYe −=
)ˆ( YYi −

1. Regresión lineal simple
19
Entenderemos que el error de cualquier puntuación (Yi) es su desviación respecto a su
puntuación estimada -predicha por el modelo-, es decir, la que debería pasar por la recta
(distancia o desviación en rosa en la gráfica). Por otro lado (en azul) dicha puntuación
estimada por la recta o el modelo para ese dato se desvía o es diferente a la Y (que sería
la puntuación estimada -la considerada más probable- para cualquier sujeto de la
muestra en la situación de total desconocimiento de la puntuación correspondiente de
dicho sujeto en X o incluso de desconocer o no existir el efecto de X).
A partir de estas desviaciones planteadas y sumando ambas para estimar la
complementariedad de las diferentes fuentes que hacen que una puntuación determinada
en Y se distancie, diferencie o varíe respecto a Y –la más probable ante la ausencia
total de información- tenemos:
errorVlicadaVtotalVariación
YYYYYY iii
.exp.
)ˆ()ˆ()(
+=
−+−=−
Si elevamos al cuadrado ambos miembros de esta igualdad y sumamos todas y cada una
de las desviaciones de cada uno de los sujetos de la muestra (suma de diferencias al
cuadrado –SC-) llegamos a la siguiente igualdad:
errorlicadanoSClicadaSCtotalSC )exp(exp +=
Que es precisamente el desglose de variabilidad que se realiza mediante el índice F ya
conocido. Recuérdese que dicho índice se plantea así:
∑∑
−−−
−==
N
ii
N
i
eerror
licada
kNYY
kYY
glSC
glSCF
1
2
1
2
expexp
)1(/)ˆ(
/)ˆ(
/
/
donde k indica el número de regresores o variables predictoras a considerar (en la
regresión simple siempre será uno).
Si la varianza explicada por la regresión –la variable utilizada como predictora-
consigue manifestarse lo suficientemente por encima de la varianza atribuida al error –o
a variables ajenas a la regresión-, dicho índice resultará significativo. Dicho de otra
forma, si aún a pesar de que el modelo queda en cierta medida desvirtuado por los
componentes aleatorios la información aportada por el componente explicativo logra
mantener con suficiente grado de esclarecimiento el valor del modelo, éste se manifiesta
relevante para explicar la conducta de manera relevante. Esto es, el modelo planteado
resultará en este caso un referente válido para la explicación del comportamiento.
En términos gráficos y tal y como se apuntaba anteriormente, el índice F consiste en la
medición la variabilidad de Y (área total del círculo) y el desglose de dicha variabilidad
en función de sus diferentes causas (áreas azul y roja):

1. Regresión lineal simple
20
Delimitación de la variabilidad (SC) de Y
V. (SC de Y) explicada por X
V. (SC de Y) no explicada por X
En el SPSS el comando “regresión” que hemos utilizado antes proporciona también por
defecto el desglose de los componentes de variabilidad del modelo para llegar a F. De
forma similar al ANOVA en los diseños experimentales, el cuadro de ANOVA en
regresión se presenta tal que así (utilizando los datos de la investigación que nos ocupa
sobre horas de estudio y notas):
ANOVA
Modelo Suma de cuadrados gl
Media cuadrática F Sig.
Regresión 57,870 1 57,870 61,678 ,000
Residual 5,630 6 ,938
1
Total 63,500 7
Variable dependiente: NOTAS
Por lo que se aprecia en la tabla anterior, el valor de F para estos datos es 61.68 y la
probabilidad de que dicho resultado pueda ser producto del azar es .000. Asumimos,
pues como conclusión, que el modelo resulta relevante: Las horas de estudio empleadas
en la asignatura se muestra un factor suficientemente explicativo de la nota obtenida en
la misma.
La información contenida en este cuadro y la conclusión derivada de ella pueden
complementarse con la información aportada por el denominado índice de bondad de
ajuste (R2) que representa la proporción que de la variación total del modelo asume el
efecto de la variación explicada por la regresión, es decir, por la variable utilizada como
predictora. Se calcula a partir de la información proporcionada en el ANOVA:
total
licada
N
i
N
i
SC
SC
YY
YYR
exp
1
2
1
2
2
)(
)ˆ(=
−
−=∑∑
en nuestro caso,
91.5.63
87.572 ==R
lo que indica que el 91% de las variaciones apreciadas en las notas se debe a la cantidad
de horas empleadas en el estudio de la asignatura, una proporción muy alta. Otra forma
de llegar a este resultado es elevando al cuadrado el coeficiente r que coincide además,
tal y como hemos visto, con el coeficiente b estandarizado (Beta = .955):
91.955. 22 ==R

1. Regresión lineal simple
21
5. La predicción en el modelo de regresión simple.
Apuntamos anteriormente que una de las utilidades del modelo de regresión lineal es su
capacidad para predecir qué puntuaciones obtienen en Y ciertos sujetos con valores en
X no contemplados directamente en la muestra de estudio. Ello le concede a la ecuación
de regresión, una vez validada y probada su bondad, un valor inestimable.
Se trata de calcular, a partir de la ecuación de regresión validada, el valor de Y estimado
para un sujeto que tiene en X otro determinado. Por ejemplo, en nuestro caso, ¿qué nota
obtendría en la asignatura, según la ecuación de regresión estimada, un sujeto que ha
dedique 4.5 horas a su estudio?.
Recordemos la ecuación estimada:
ii XY 926.037.ˆ +=
sustituyendo:
20.45.4926.037.ˆ =⋅+=iY
La nota estimada para dicho sujeto estudiando 4,5 horas es de 4.20 (en una escala de 0 a
10).
Obviamente, este valor sería el estimado tomando como base únicamente la parte
explicada por la recta de regresión, es decir, sin tener en cuenta las posibles
fluctuaciones que pueden producirse en este valor por efecto de la parte aleatoria del
modelo. Resulta entonces más preciso estimar la puntuación de dicho sujeto por
intervalo, es decir, apuntando los límites entre los que puede esperarse –con una cierta
probabilidad- se encontrará su puntuación en Y conocido su valor en X. La pregunta es
entonces: ¿entre qué valores –trabajando con un nivel de confianza del 95%- se
encontrará la nota de un sujeto que ha estudiado 4.5 horas?, o de otra forma, ¿entre qué
valores se encontrará el 95% de posibles notas que puede obtener dicho sujeto, notas
que fluctúan aleatoriamente alrededor de 4.20?
Si recordamos la representación gráfica de la recta de regresión y apreciamos la
distribución de los valores de Y a partir de su estimación Y -dado un determinado valor
de X-, trataremos de captar el 95% de dichos valores Y y medir el intervalo que los
define conociendo cuál es el valor de la varianza residual –aleatoria- (de los valores e)
de la muestra.

1. Regresión lineal simple
22
Yˆ
)(ˆ verdaderaXY βα +=
Para nuestro caso:
91.1938.44.220.4
49.6938.44.220.4
=⋅−
=⋅+
Es decir, la nota esperada para un sujeto que ha dedicado a estudiar la asignatura 4.5
estará entre 1.91 y 6.49 pudiéndonos equivocar en dicha estimación en un 5%. Es un
intervalo tal vez muy amplio pero tenemos muy pocos datos en la muestra lo que
condiciona sustancialmente este valor. Con muestras más grandes el intervalo estimado
tiende a reducirse siendo más preciso.
Deseando aún ser más precisos en la predicción podemos incluso dejar en entredicho la
recta de regresión estimada pensando que es un tanto diferente de la recta de regresión
real (verdadera) que define nuestros datos –aquella recta de la población de la que
proceden nuestros datos o muestra con la que, de hecho, la hemos estimado-. En este
caso se trata de estimar en qué medida ambas rectas difieren de la forma en que se
indica en la siguiente tabla:
1
3
5
7
9
1 3 5 7 9 11 13 15 17 19
Horas de estudio
Notas
Es necesario calcular pues cuáles son las varianzas esperadas de cada uno de los
parámetros de la recta de regresión (a y b) para conocer cuáles son sus dispersiones
esperadas. Se sabe que:
X1
2
),2(ˆ
resN StY α−±
)(ˆ estimadabXaY +=
Y

1. Regresión lineal simple
23
2
1
2
2
)(
1)( resN
SXX
X
NaVar
−+=∑
y que
∑ −=
N
res
XX
SbVar
1
2
2
)()(
Por lo que la ecuación de regresión expresada en las varianzas de sus correspondientes
parámetros será:
22
1
2
22
1
2
2
)()(
1)( resiN
resresN
SXXX
SS
XX
X
NYVar +
−+
−+=
∑∑
Haciendo operaciones nos queda que el intervalo de confianza estimado para Y dada la
posible fluctuación de la recta estimada respecto a la verdadera es:
−
−++±∑
− N
iresN
XX
XX
NStY
1
2
22
),2(
)(
)(11ˆ
α
Para nuestro caso, la puntuación estimada (verdadera) utilizando un intervalo de
confianza del 95% para la puntuación 4.5 en X será:
57.163.220.45.67
)25.75.4(
8
11938.44.220.4
83.663.220.45.67
)25.75.4(
8
11938.44.220.4
2
2
=−=
−++−
=+=
−+++
Esto es, la nota verdadera esperada para un sujeto que ha estudiado 4.5 horas estará con
un 95% de probabilidad entre 6.83 y 1.57, un intervalo más amplio –como era de
esperar- que el delimitado anteriormente a partir de la recta de regresión estimada.







