
1DSM Innovations
Software Distributed Shared Memory (SDSM):
The MultiView ApproachAgenda:
1. SDSM, false sharing, previous solutions.
2. The MultiView approach.
3. Limitations.
4. Dynamic granularity adaptation.
5. Transparent SDSM.
6. Integrated services by the memory management.
Ayal Itzkovitz, Assaf Schuster

2DSM Innovations
1. In-core multi-threading
2. Multi-core/SMP multi-threading
3. Tightly-coupled cluster,
customized interconnect (SGI’s Altix)
4. Tightly-coupled cluster,
of-the-shelf interconnect (InfiniBand)
5. WAN, Internet, Grid, peer-to-peer
Traditionally: 1+2 are programmable using shared memory, 3+4 are programmable using message passing, in 5 peer processes communicate with central control only.
HDSM: systems in 3 move towards presenting a shared memory interface to a physically distributed system.
What about 4,5? Software Distributed Shared Memory = SDSM
Types of Parallel Systems
Scalability
Communication Efficiency

3DSM Innovations
A multi-core system - simplistic view
A parallel program may spawn processes (threads) to concurrently work together, in order to utilize all computing units
Processes communicate through write to/read from shared memory, physically located on the local machine
core
Local memory
core core
core

4DSM Innovations
Network
A distributed system
core
Local memory
core
Local memory
core
Local memory
Virtual Shared Memory
Emulation of the same programming paradigm No changes to source

5DSM Innovations
Matrix Multiplication
R R W
two threads
Read/only matrices Write matrix
A = malloc(MATSIZE);B = malloc(MATSIZE);C = malloc(MATSIZE);
parfor(n) mult(A, B, C);
mult(id):
for (line=Nxid .. Nx(id+1)) for(col=0..N) C[line,col] = multline(A[line],B[col]);

6DSM Innovations
Network
Matrix Multiplication
RO RO
RO RO
RO RO
RW RW
RO RO
RO RO
RO RO
RW RW
A
x
B
=
C
A
x
B
=
C
Sent once
Sent once

7DSM Innovations
Network
Matrix Multiplication
RO RO
RO RO
RO RO
RW RW
RO RO
RO RO
RO RO
RW RW
A
x
B
=
C
A
x
B
=
C
R WR

8DSM Innovations
Network
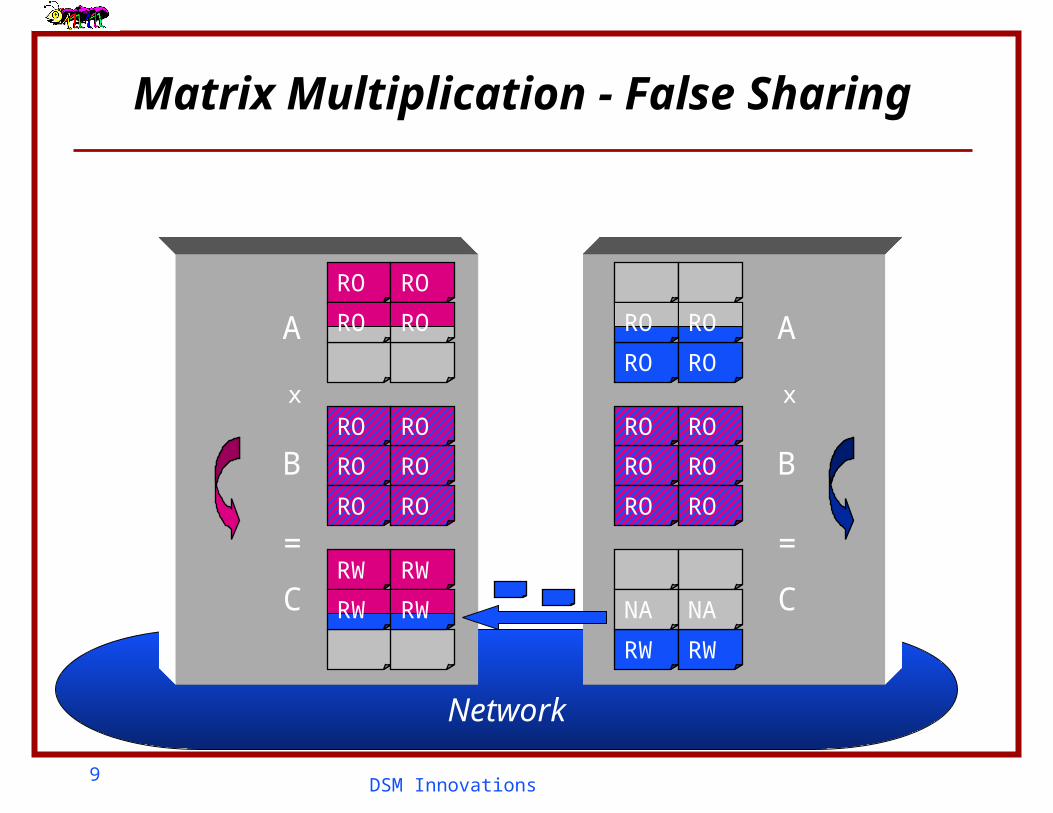
Matrix Multiplication - False Sharing
RO RO
RO RO
NA
RO RO
RO RO
A
x
B
=
C
A
x
B
=
C
Sent once
RO RO
RW RW
RO RO
RO RO
RO RO
RW RW
Sent once
NA
RO RO RO RO
RW RW
9DSM Innovations
Network
Matrix Multiplication - False Sharing
RO RO
RO RO
RO RO
RO RO
A
x
B
=
C
A
x
B
=
CRW RW
RO RO RO RO
RW RW
NA NA
RO RO
RO RO
RO RO
RO RO
RW RW

10DSM Innovations
Network
Matrix Multiplication - False Sharing
RO RO
RO RO
RO RO
RO RO
A
x
B
=
C
A
x
B
=
CRW RW
RO RO RO RO
RW RW
RO RO
RO RO
RO RO
RO RO
RW RWNA NA

11DSM Innovations
RR W
Network
Matrix Multiplication - False Sharing
RO RO
RO RO
RO RO
RO RO
A
x
B
=
C
A
x
B
=
C
RO RO RO RO
RO RO
RO RO
RO RO
RO RO
RW RW
RW RW
RW RW
RW RW
12DSM Innovations
N-Body Simulation - False Sharing

13DSM Innovations
Network
N-Body Simulation - False Sharing

14DSM Innovations
The False Sharing Problem
Two variables that happen to reside in the same page can cause false sharing
Causes ping-pong between processes Slows down the computation Can even lead to livelocks
Possible solution: Delta mechanism [Munin, Rice] A page is not allowed to leave the process for a time interval Delta Setting this Delta value is difficult (fine tuning required)
– Large Deltas cause delays, short Deltas may not solve the livelock.
The best Delta value is application specific and even page specific
SDSM systems do not work well for fine-grain applications! Because they use page-based OS protection on pages But: hardware DSMs using cache lines are slow too

15DSM Innovations
The First SDSM System
The first software SDSM system, Ivy [Li & Hudak, Yale, ‘86] Page-based SDSM Provided strict semantics (Lamport’s sequential consistency)
The major performance limitation:Page size False sharing
Two traditional approaches for designing SDSMs Weak semantics (Relaxed consistencies) Code instrumentation

16DSM Innovations
First Approach: Weak Semantics
Example - Release Consistency: Allow multiple writers to page
(assume exclusive update for any portion of the page) Each page has a twin copy At synchronization time, all pages perform “diff” with their twins, and
send diffs to managers Managers hold master copies
twin twin
RW RW
Apply diff Apply diff

17DSM Innovations
First Approach: Weak Semantics
Allow memory to reside in an incosistent state for time intervals
Enforce consistency only at synchronization points Reaching a consistent view of the memory requires
computation
Reduces (but not always eliminate) false sharing Reduces number of protocol messages
Weak memory semantics Involves both memory and processing time overhead
Still: coarse-grain sharing (why diff at locations not touched? )

18DSM Innovations
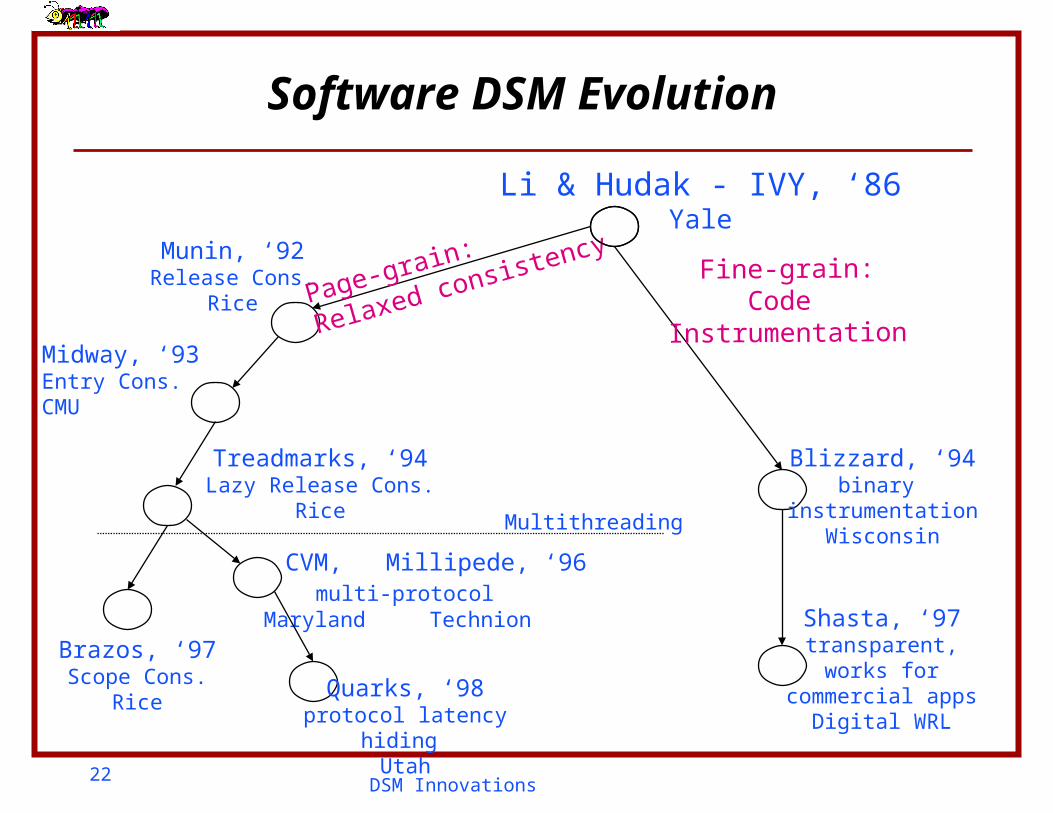
Software DSM Evolution - Weak Semantics
Li & Hudak - IVY, ‘86Yale
Munin, ‘92Release Cons.
Rice
Midway, ‘93Entry Cons.CMU
Treadmarks, ‘94Lazy Release Cons.
Rice
Brazos, ‘97Scope Cons.
Rice
Page-grain:
Relaxed consistency

19DSM Innovations
Software DSM Evolution - Multithreading
Li & Hudak - IVY, ‘86Yale
Munin, ‘92Release Cons.
Rice
Midway, ‘93Entry Cons.CMU
Treadmarks, ‘94Lazy Release Cons.
Rice
Brazos, ‘97Scope Cons.
Rice
Page-grain:
Relaxed consistency
CVM, Millipede, ‘96 multi-protocol
Maryland Technion
Quarks, ‘98protocol latency hiding
Utah
Multithreading

20DSM Innovations
Second Approach:Code Instrumentation
Example - Binary Rewriting: wrap each load and store with instructions that check whether
the data is available locally
load r1, ptr[line]load r2, ptr[v] add r1, 3hstore r1, ptr[line]sub r2, r1store r2, ptr[v]
push ptr[line]call __check_rload r1, ptr[line]push ptr[v]call __check_r load r2, ptr[v] add r1, 3hpush ptr[line]call __check_wstore r1, ptr[line]push ptr[line]call __done sub r2, r1push ptr[v]call __check_w store r2, ptr[v]push ptr[v]call __done
CodeInstr.
push ptr[line]call __check_wload r1, ptr[line]push ptr[v]call __check_w load r2, ptr[v] add r1, 3hstore r1, ptr[line]push ptr[line]call __done sub r2, r1store r2, ptr[v]push ptr[v]call __done
Opt.
line += 3; v = v - line;
Compile

21DSM Innovations
Second Approach:Code Instrumentation
Provides fine-grain access control, thus avoids false sharing
Bypasses the page protection mechanism Usually, fixed granularity for all application data (Still, false
sharing ) Needs a special compiler or binary-level rewriting tools
Cost: High overheads (even on single machine) Inflated code Not portable (among architectures)
22DSM Innovations
Software DSM Evolution
Li & Hudak - IVY, ‘86Yale
Munin, ‘92Release Cons.
Rice
Midway, ‘93Entry Cons.CMU
Treadmarks, ‘94Lazy Release Cons.
Rice
Brazos, ‘97Scope Cons.
Rice
Page-grain:
Relaxed consistency
CVM, Millipede, ‘96 multi-protocol
Maryland Technion
Quarks, ‘98protocol latency hiding
Utah
Multithreading
Blizzard, ‘94binary
instrumentationWisconsin
Shasta, ‘97transparent,
works forcommercial apps
Digital WRL
Fine-grain:Code
Instrumentation

23DSM Innovations
The MultiView Approach
Attack the major limitation in SDSMs: the page size.Implement small-size pages through novel mechanisms [OSDI’99]
More Goals: W/O compromising the strict memory consistency
[ICS’04,EuroPar’04] Utilize Low-Latency Networks [DSM’00, IPDPS’04] Transparency [EuroPar’03] Adaptive Sharing Granularity [ICPP’00, IPDPS’01 best paper] Maximize Locality through Migration and Load Sharing
[DISK’01] Additional “service layers”: Garbage Collection, Data-Race
Detection. [ESA’99,JPDC’01,JPDC02]

24DSM Innovations
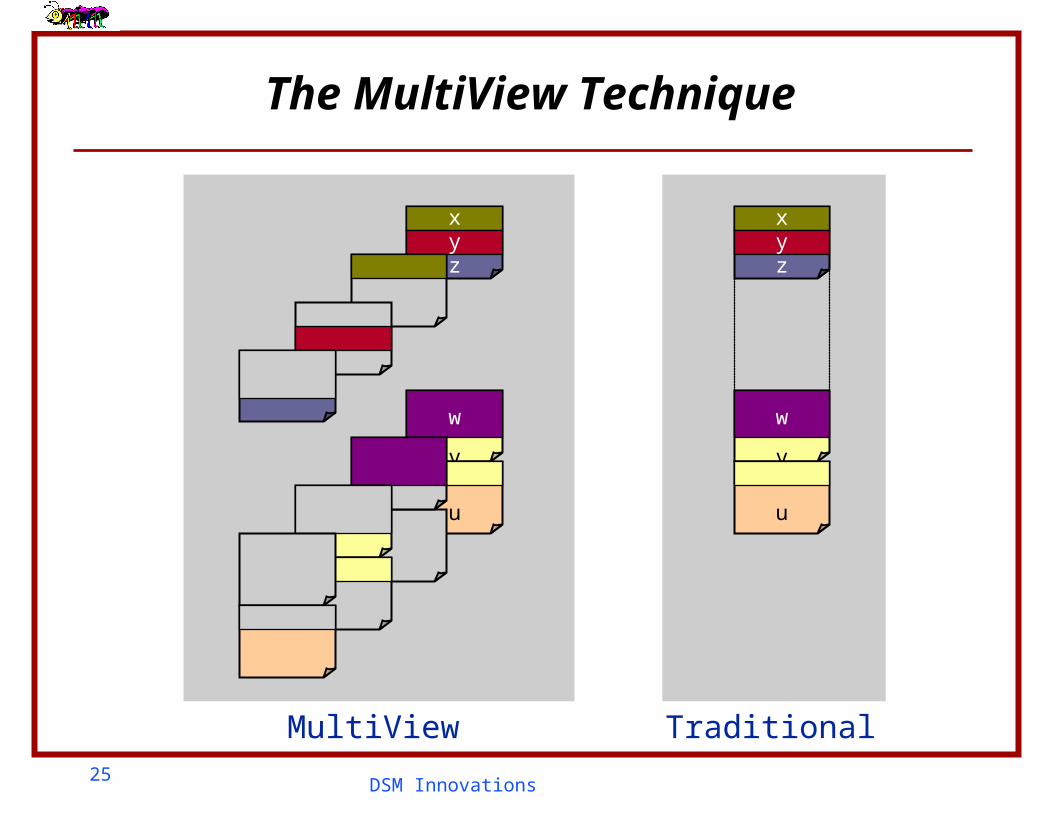
The Traditional Memory Layout
xyz
Traditional
w
v
u
struct a { …};struct b; int x, y, z;
main() { w = malloc(sizeof(struct a)); v = malloc(sizeof(struct a)); u = malloc(sizeof(struct b));
…}
struct a { …};struct b; int x, y, z;
main() { w = malloc(sizeof(struct a)); v = malloc(sizeof(struct a)); u = malloc(sizeof(struct b));
…}
25DSM Innovations
xyz
The MultiView Technique
TraditionalMultiView
w
v
u
w
v
u
xyz

26DSM Innovations
The MultiView Technique
TraditionalMultiView
w
v
u
xyz
xyz
w
v
u
Protection is now set independently
RW
NAR
Variables reside in the same page but are not shared
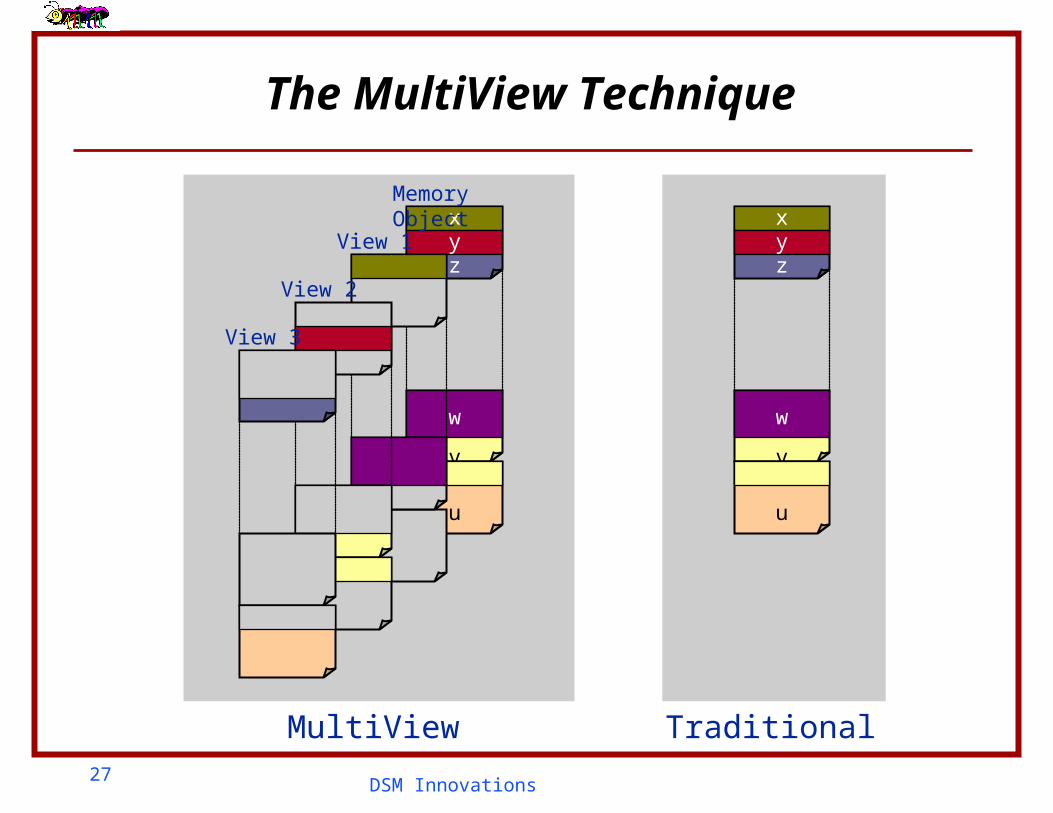
27DSM Innovations
The MultiView Technique
TraditionalMultiView
w
v
u
xyz
xyz
w
v
u
View 1
View 2
View 3
Memory Object

28DSM Innovations
The MultiView Technique
Memory Layout
View 1
View 2
Memory Object
xyz
MultiView
w
v
u
MemoryObjectView 1
View 2
View 3
View 3

29DSM Innovations
The MultiView Technique
Host A
View 1
View 2
Memory Object
View 3
Host B
View 1
View 2
Memory Object
View 3
R R
NA RW
NA
R
R
R
R
R
RW
RW
NA
NA
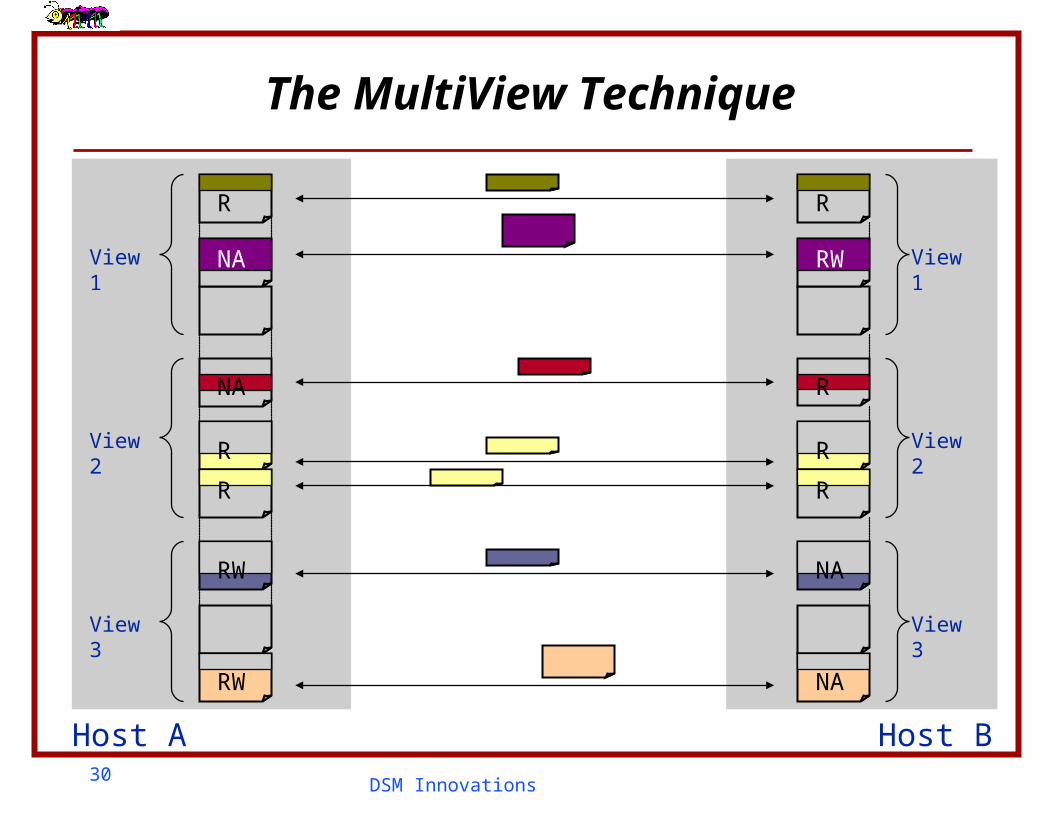
30DSM Innovations
The MultiView Technique
View 1
View 2
View 3
View 1
View 2
View 3
R R
NA RW
NA
R
R
R
R
R
RW
RW
NA
NA
Host A Host B
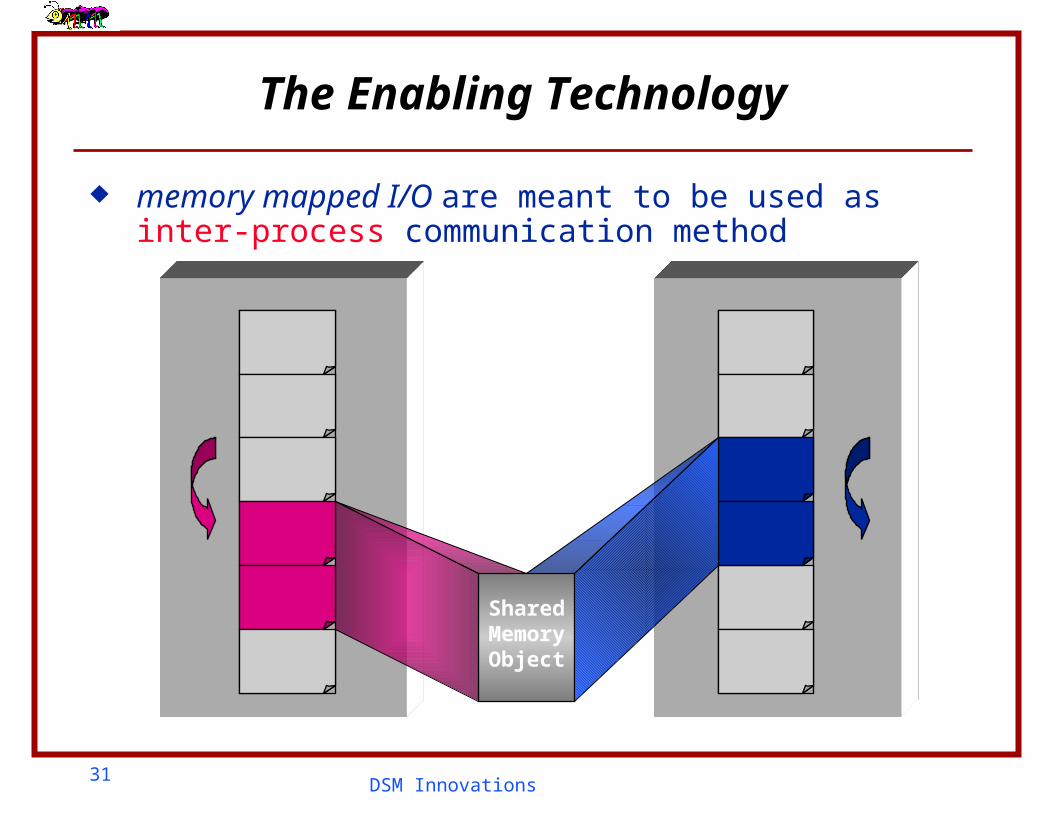
31DSM Innovations
The Enabling Technology
SharedMemoryObject
memory mapped I/O are meant to be used as inter-process communication method
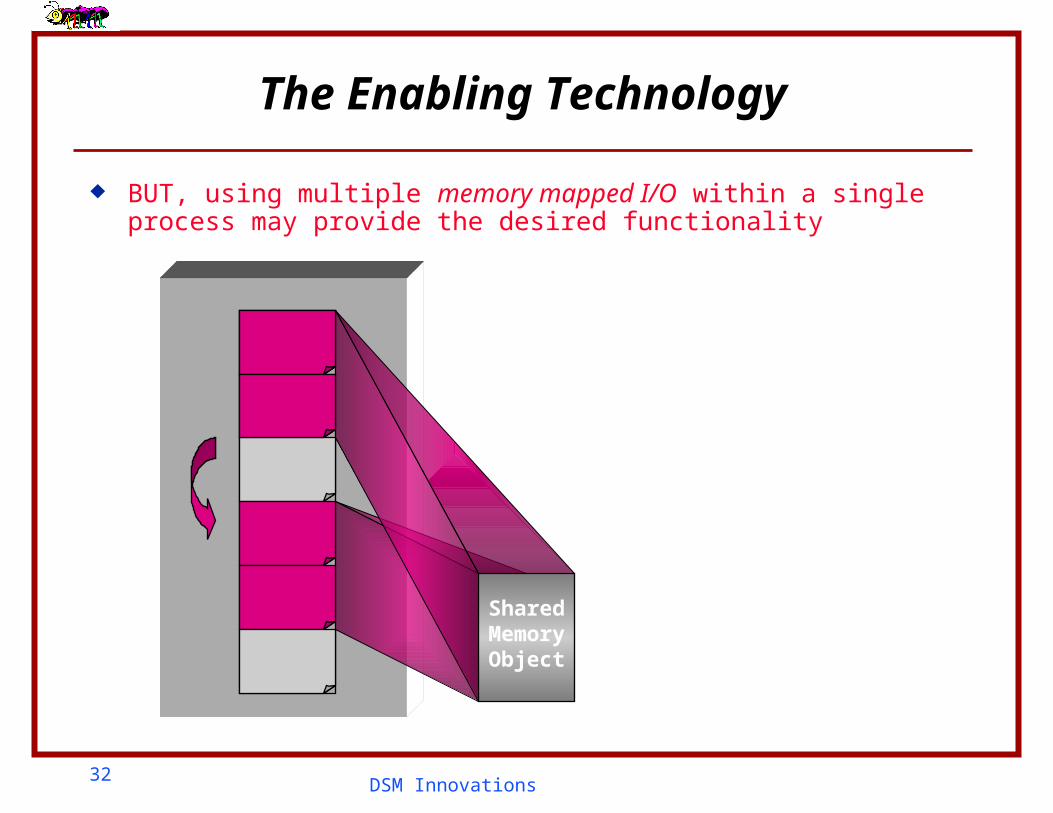
32DSM Innovations
The Enabling Technology
BUT, using multiple memory mapped I/O within a single process may provide the desired functionality
SharedMemoryObject

33DSM Innovations
MultiView – Implementation in Millipede
Implementation in Windows-NT 4.0 (now portable to all of Solaris, BSD, Linux, and NT)
Use CreateFileMapping() and MapViewOfFileEx() for allocating views
Views are constructed at initialization time Minipage Table (MPT) provides translation from pointer
address to minipage boundaries

34DSM Innovations
MultiView - Overheads
Application:traverse an array of integers, all packed up in minipages
The number of minipages is derived from the value of max views in page
Limitations of the experiments: 1.63GB contiguous address space available Up to 1664 views Need 64 bits!!!

35DSM Innovations
MultiView - Overheads
As expected, committed (physical) memory is constant Only a negligible overhead (< 4%): Due to TLB misses
0.96
0.98
1
1.02
1.04
1.06
1.08
512Kb
1 MB 2 MB 4 MB 8 MB 16MB
Slo
wdo
wns
1 2 4 8 16 32Num views

36DSM Innovations
MultiView - Taking it to the extreme
Beyond critical points overhead becomes substantial
0
2
4
6
8
10
12
14
16
18
20
Number of views
Slo
wd
ow
n
512 Kb 1 MB 2 MB4 MB 8 MB 16 MB
8MB
4MB
2MB
1MB
Number of minipages at critical points is 128K Slowdown due to L2 cache exhausted by PTEs

37DSM Innovations
MultiView - Taking it to the extreme
Beyond critical points overhead becomes substantial
0
2
4
6
8
10
12
14
16
18
20
Number of views
Slo
wd
ow
n
512 Kb 1 MB 2 MB4 MB 8 MB 16 MB
8MB
4MB
2MB
1MB
Number of minipages at critical points is 128K Slowdown due to L2 cache exhausted by PTEs
SDSM

38DSM Innovations
SDSMs on Emerging Fast Networks
Fast networking is an emerging technology MultiView provides only one aspect: reducing message sizes
The next magnitude of improvement shifts from the network layer to the system architectures and protocols that use those networks
Challenges: Efficiently employ and integrate fast networks Provide a “thin” protocol layer: reduce protocol complexity, eliminate
buffer copying, use home-based management, etc.

39DSM Innovations
Adding the Privileged View
Constant Read/Write permissions
Separate application threads from SDSM injected threads
Atomic updates DSM threads can access (and
update) memory while application threads are prohibited
Direct send/receive Memory-to-memory No buffer copying
xyz
Application Views
RW
NAR
RW
The Privileged View
Memory Object

40DSM Innovations
Basic Costs in Millipage (using a Myrinet, 1998)
Access fault 26 usec
get protection 7 usec
set protection 12 usec
messages (one way)
header msg 12 usec
a data msg (1/2 KB) 22 usec
a data msg (1 KB) 34 usec
a data msg (4 KB) 90 usec
MPT translation 7 usec
Message sizes directly influence latency
The most compute demanding operation: Minipage translation - 7 usec
In relaxed consistency systems, protocol operations might take hundreds of usecs
example:Run-length diff for 4KB page: 250 usec

41DSM Innovations
Minimal Application Modifications
Minipages are allocated at malloc time (via malloc-like API) The memory layout is transparent to the programmer
Allocation routines should be slightly modified
mat = malloc(lines*cols*sizeof(int));…mat[i][j] = mat[i-1][j]+mat[i][j-1]; …
mat = malloc(lines*sizeof(int*));for(i=0;i<N;i++) mat[i] = malloc(cols*sizeof(int));…mat[i][j] = mat[i-1][j]+mat[i][j-1]; …
SOR and LU have not been modified at all WATER- changed ~20 lines out of 783 lines IS- changed 5 lines out of 93 lines TSP- changed ~15 lines out of ~400 lines

43DSM Innovations
Tradeoff: False Sharing vs. Aggregation (e.g. WATER)
0
1000
2000
3000
4000
5000
6000
7000
8000
9000
10000
1 2 3 4 5 6 none
chunking level
0.50
0.60
0.70
0.80
0.90
1.00
1.10
eff
icie
nc
y
compete req. (4) x 10 compete req. (8) x 10
Read/Write faults(4) Read/Write faults(8)
efficiency (4 hosts) efficiency (8 hosts)

44DSM Innovations
Performance with Fixed GranularityNBodyW application on 8 nodes
50
52
54
56
58
60
62
allocation granularity
run
tim
e [
s]

45DSM Innovations
Dynamic Sharing Granularity
Use the best sharing granularity, as determined by application requirements (not architecture constants!).
Dynamically adapt the sharing granularity to the changing behavior of the application.
Adaptation done transparently by the SDSM.
No special hardware support, compiler modifications, application code changes.

46DSM Innovations
Dynamic Sharing Granularity
Application run time
Sha
red
data
ele
men
ts

47DSM Innovations
Coarse Granularity
1
2
3
5
6
4
Manager
Memory Access Request(1-6) Request
Request
Host 1 Host 2
Host 3
Reply (Data 2,4,5)
Reply (Data 1,3) 1
2
3
5
6
4
1
2
3
5
6
4

48DSM Innovations
Automatic Adaptation of Granularity
1
2
3
4
5
6
Recompose
When same host accesses consecutive minipages
Coarse granularity
1
2
3
4
5
6
Coarse granularityHost A
Host A
Split
When different hosts update
different minipages
Host A
Host B
Fine granularity
1
2
3
4
5
6
Fine granularity

49DSM Innovations
Memory Faults ReductionBarnes application
0
10000
20000
30000
40000
50000fa
ult
s
read faults write faults
Millipede

50DSM Innovations
Water-nsq Performance
1 2 4 6 8 10 120
2
4
6
8
10
12Water-nsq speedup (one thread per node)
nodes
spee
dup
1 2 4 6 8 10 1202468
1012141618202224
Water-nsq speedup (two threads per node)
nodes
spee
dup
SC/MV - fine granularityHLRCMixed consistencySC/MV - best static granularitySC/MV - dyn. gran. (speculated)

51DSM Innovations
Water-nsq Performance (cont’d)
SC/MV-f.g. HLRC Mixed SC/MV-b.g.0
20
40
60
80
100
120
140
160
180
200
run
time
brea
kdow
ns (s
ec)
Water-nsquared breakdown
computationread faultswrite faultsbarrierslocks
1 2 3 4 5 6 7 80
0.5
1
1.5
2
2.5
3
3.5
4x 10
4
chunking level (molecules)
Pro
toco
l ove
rhea
d
read faultswrite faultscompete requests
run-
time
(sec
)
run-time
The effect of chunking in Water - nsquared
162
164
166
168
170
172
174
176
178
180

52DSM Innovations
The Transparent DSM: System Initialization
For most DSM systems, initialization is an almost trivial task
The transparent DSM system cannot use such a simple solution
In order to initialize a DSM system transparently we have to inject the initialization code into the loaded application

53DSM Innovations
Standard Initialization
…call c_init…call main…
crtStartup:
…application code…
main:
Startup code from in the C standard library. This code is
identical for all C applications.crtStartup is the entry point of
the executable.
Standard C application
This instruction lies at a fixed offset from crtStartup. We
denote this offset as main_call_offset
Initialize the C runtime library
Start the application

54DSM Innovations
Transparent DSM System Initialization
…call c_init…call main…
crtStartup:
…application code…
main:
mainPtr dd NULL
hookedMain: dsm_init(…); dsm_create_thread(…,mainPtr,…); …
DllMain: … crtStartup = get_entry_point(); mainPtr = *(crtStartup + main_call_offset); *(crtStartup + main_call_offset) = hookedMain; …
main
hookedMain
Injected DLL
The OS passes control to DllMain() after
the DLL has been loadedThe main thread is resumed
Initialize the C runtime library
Initialize the DSM system(the OS API is intercepted,
globals are moved to the DSM)
The application main threadis created using the DSM
system thread creation API

55DSM Innovations
SOR SPLASH Benchmark
SOR speedup
012345678
0 2 4 6 8 10
Number of threads
Spe
edup
Transparent DSM
Millipede 4.0
Transparent+Barrier
SMP (2 processors)

56DSM Innovations
Integrating on-the-fly Data Race Detection
Overhead dropping down two orders of magnitude
by matching the detection to the “native application granularity” Implementation requires advance use of protection mechanisms
Overheads 1 proc
0.8
0.9
1
1.1
1.2
1.3
1.4
1.5
1.6
1.7
SOR LU IS TSP W ATER
no
rmal
ized
exe
cuti
on
tim
e
NO_DR BAS PCT OPT
Overheads 8 proc
0.8
0.9
1
1.1
1.2
1.3
1.4
1.5
1.6
1.7
SOR LU IS TSP W ATER
no
rmal
ized
exe
cuti
on
tim
e
NO_DR BAS PCT OPT

57DSM Innovations
Integrating Distributed Garbage CollectionRemote Reference Counting
Collection in application sharing granularity. GC becomes a natural “add on” service of the DSM.
0.20%
2.50% 2.60%
37.70%
0%
5%
10%
15%
20%
25%
30%
35%
40%
IS 0.8 LU 30 WATER 31 SOR 1140
garbage creation ratio (obj/sec)
ove
rhe
ad

58DSM Innovations
GC overhead breakdowns
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
LU Water IS SOR
GC messages transfer
invalidation
unmarshalling
marshalling
pointer operations
allocation
GC messages processing

59DSM Innovations
THIS IS THE LAST SLIDE.
DON’T GO FURTHER !!

60DSM Innovations
A Major Challenge: SSI Transparency
In order for SDSM to become popular, multithreaded applications (after compilation) should be able to transfer untouched to work on a distributed environment.
Must intercept OS calls and provide cluster-aware services.
For performance, transparently provide: Elimination of False Sharing and Ping-Pongs Dynamic Adaptation of Granularity Efficient Multithreaded DLM – Distributed Lock Manager Dynamic Co-location of Related Threads Dynamic Load Balancing Etc.

61DSM Innovations
A Major challenge: Fault Tolerance
To be efficient, logging must integrate with the SDSM protocol.
Transparent fault tolerance for shared memory app’s?

62DSM Innovations
Benefits of Using MultiView to Resolve False Sharing
1
10
100
1000
10000
1 2 3 4 5 6 7 8Number of processors
# co
mpe
tein
g re
ques
ts
SOR_f SOR_cLU_f LU_cWATER_f WATER_cIS_f IS_c

63DSM Innovations
Reduction in Number of Faults
0
20
40
60
80
100
120
Num
ber o
f fau
lts (%
)
W rite FaultsRead Faults

“…the conventional wisdom remains that the overhead of false sharing […] in page-based consistency protocols is the primary factor limiting the performance of software SDSM”
[Amza, Cox, Ramajamni, and Zwaenepoel, PPoPP ‘97]
“[The] conventional wisdom holds that fine-grain performance and false sharing
doom page-based approaches”[Buck and Keleher, IPPS ‘98]
“MultiView and Millipage – Fine-grain Sharing in Page-based SDSMs”[Itzkovitz and Schuster, OSDI ‘99]
Conclusions







