
Arquitecturas ParalelasMultiprocesadores
William Stallings, Organización y Arquitectura de Computadores, 5ta. ed., Capítulo 16: Procesamiento Paralelo.
Andrew S. Tanenbaum, Organización de Computadoras 4ta. ed., Capítulo 8: Arquitecturas de computadoras paralelas.
Hesham El-Rewini & Mostafa Abd-El-Barr, Advanced Computer Architecture and Parallel Processing. Willey.

Arquitecturas Paralelas
Taxonomía de Flynn
Massively ParallelProcessor
(MPP)

Arquitecturas Paralelas
Taxonomía de Flynn-Johnson

Arquitecturas Paralelas
Clasificación MIMD Tanenbaum
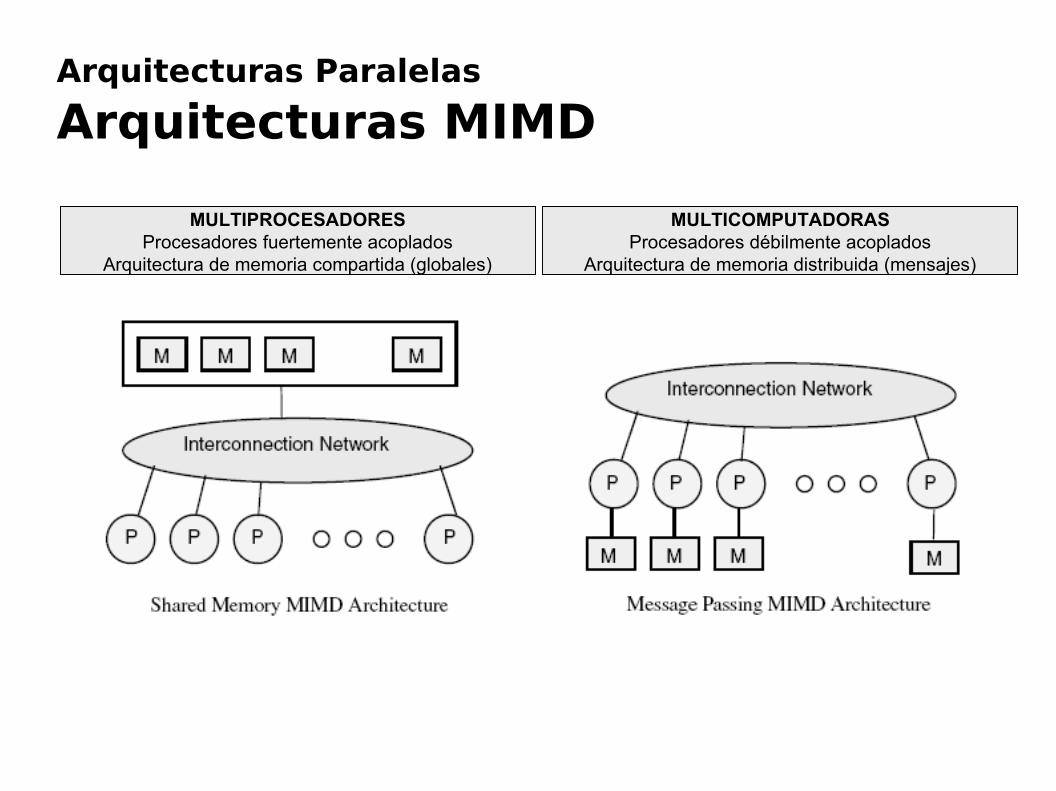
Arquitecturas Paralelas
Arquitecturas MIMD
MULTIPROCESADORESProcesadores fuertemente acoplados
Arquitectura de memoria compartida (globales)
MULTICOMPUTADORASProcesadores débilmente acoplados
Arquitectura de memoria distribuida (mensajes)

Multiprocesadores
Introducción
VENTAJASDatos, sincronización y coordinación usando variables globales. Modelo simple de programación. Espacio único de memoria. Una sola copia del sistema operativo (con planificador adecuado). Threads. Los sistemas operativos modernos coordinan la distribución de los recursos. Es fácil mover procesos entre procesadores. Menos espacio. Menos potencia. Más estable.
DESVENTAJASPerformance de la memoria. Se soluciona con caches, pero aparece el problema de la coherencia de caches. La red de interconexión es complicada (acceso a memoria). Dinámica: bus, crossbar o multistage. Se satura rápidamente. Soporta pocos procesadores (2-16). Poco escalables.

Multiprocesadores
Clasificación
Lar arquitecturas multiprocesador pueden clasificarse según la estrategia de distribución de la memoria compartida, siempre con un único mapa de memoria:
UMA (o SMP): Uniform Memory Access (o Symetric MultiProcessor)
NUMA: Non Uniform Memory Access
COMA: Cache Only Memory Architecture

Multiprocesadores
UMA (SMP)La organización con bus es la más utilizada en multiprocesadores multiple core. En esta categoría entran también las organizaciones con memoria multipuerto (no escalable). La memoria compartida es accedida por todos los procesadores de la misma forma en que un monoprocesador accede a su memoria. Todos los procesadores son similares y tienen capacidades equivalentes. Todos los procesadores tienen el mismo tiempo de acceso a cualquier posición de memoria. Comparten I/O.
Redes: multipuerto, bus o crossbar. Ej: Sun Starfire, Intel Xeon/Pentium/Core2.

Multiprocesadores
NUMAUtiliza (como SMP) un único espacio de direcciones, pero en este caso cada procesador es dueño de una parte de la memoria, a la cual puede acceder más rápido. Utiliza pasaje de mensajes escondido. El problema de coherencia es más complicado. El sistema operativo (más sofisticado) puede ayudar mediante migración de páginas. Sin coherencia de cache, multicomputador.
Redes de interconexión: tree, bus jerárquico.Ejemplos: SGI Origin 3000, Cray T3E, AMD Opteron.

Multiprocesadores
COMAComo en NUMA, cada procesador tiene una parte de la memoria, pero es sólo cache. El espacio de memoria completo es la suma de los caches. Utilizan un mecanismo de directorio distribuído.
Ejemplo: KSR-1.

Multiprocesadores
SMP vs. NUMA
Multicore SMP, c/core superescalar SMT
IMPORTANTEDependencia con la naturaleza de la aplicación.
Cada instancia del programa dispone de sus propios datos?

Multiprocesadores
INTEL Pentium III.
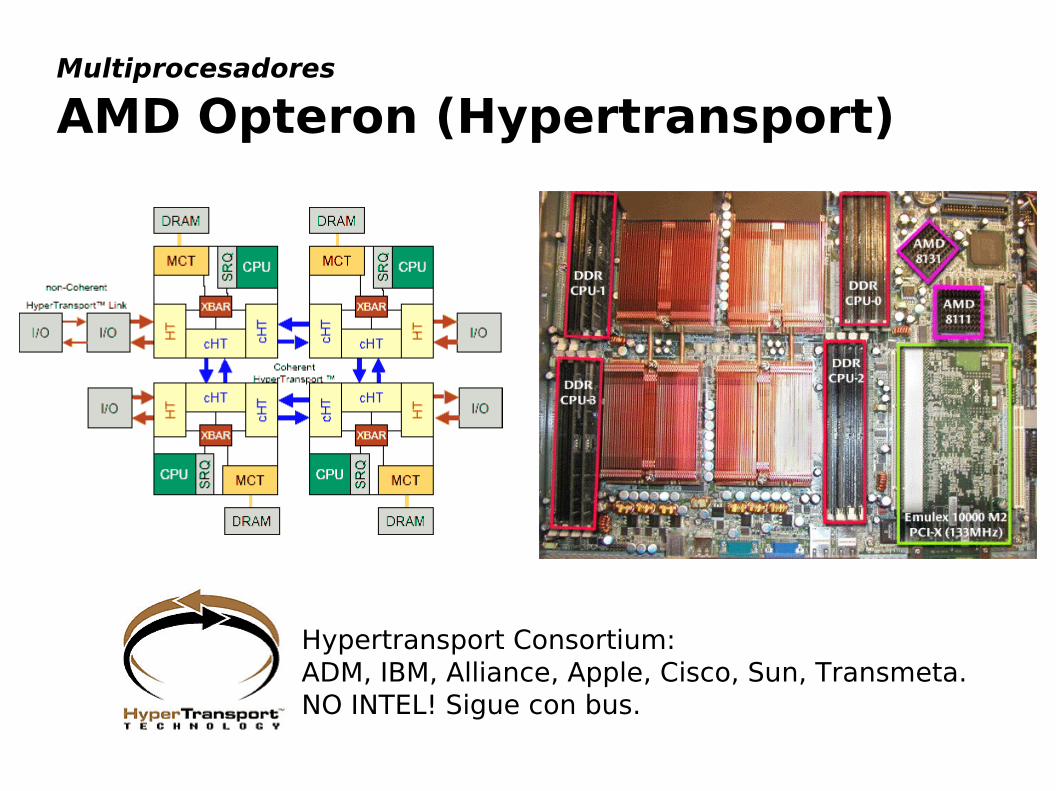
Multiprocesadores
AMD Opteron (Hypertransport)
Hypertransport Consortium: ADM, IBM, Alliance, Apple, Cisco, Sun, Transmeta.NO INTEL! Sigue con bus.

Multiprocesadores
IBM POWER5 (Fabric Switch)
1 Mother: 4 MCMs x 4 Power5 x 2 cores x 2 SMT = 64 threads simultáneas
+ NIC -> cluster con pasaje de mensajes
MCM: multi chip module
Motherboard

Multiprocesadores
Intel (Multicore - Bus)

Multiprocesadores
Análisis de SMP basado en bus
El bus es la red más simple para memoria compartida. Es un medio compartido, con arbitraje y capacidad de direccionamiento. La arquitectura bus/cache elimina la necesidad de memorias multipuerto. El principal problema es la saturación del bus. Depende fuertemente de la eficiencia del hardware de cache (debe minimizarse el número de veces que el procesador necesita acceder al bus). Depende también de las características del programa de aplicación.
Ejemplo.I=1, B=100MHz, V=300MIPS, h=90%. Resulta N<3,3.¿Cuánto debe valer h para soportar 32 procesadores? Resulta h>99%. Qué tamaño debe tener la memoria caché?!?!
N ≤BI
V (1−h )
N: número de procesadoresh: hit rate del cache (1-h): miss rateB: ancho de banda del bus [c/s]I: duty cycle del procesador [fetch/c] uperesc>1V: velocidad pico del procesador [fetch/s] B.I: ancho de banda efectivo [fetch/s]
HINT: N procesadores a velocidad V producen N(1-h)V fallos, entonces N(1-h)V<B.I

Multiprocesadores
Coherencia de cache
Existen múltiples copias de los datos en diferentes caches. Si un procesador modifica su copia y los demás caches no se actualizan se producirán errores en el resultado final. Solo es un problema si hay escrituras. Se utilizan distintos algoritmos para mantener la coherencia.
REM Coherencia cache-memoria:a) write-through: la memoria se actualiza inmediatamente.b) write-back: se actualiza cuando se reemplaza el bloque.
Coherencia cache-cache:a) write-update: actualización inmediata.b) write-invalidate: al modificar setea el dirty-bit y se queda con la única copia válida. Los demás deben esperar la actualización. (PowerPC y PII, ver protocolo MESI)
Existen cuatro combinaciones. La a-a satura rápidamente.

Multiprocesadores
Protocolos de coherencia de cache
a) Protocolos de sondeo (snooping protocols): observan la actividad del bus y ejecutan, mediante broadcasts, los pasos necesarios para mantener la coherencia. Costoso en terminos de bw, sobre todo en redes multistage. Quien escribe avisa con un broadcast (a todos). Todos los procesadores sondean el bus para detectar modificaciones que le incumban.
b) Protocolos de directorio (directory based protocols): Los comandos de actualización se envían sólo a los caches afectados por una actualización. Almacena información en un directorio acerca de dónde se encuentran las copias de los bloques. Cuando un procesador quiere escribir una posición, debe solicitar autorización al controlador, quien luego invalida las demás copias. El directorio puede estar centralizado (cuello de botella) o distribuído (cada cache sabe lo que tiene).

Multiprocesadores
El protocolo MESI
Es un protocolo tipo write-invalidate, implementado por Intel en la linea Pentium y por IBM en la Power. Utiliza dos bits por linea de cache para indicar el estado de la misma: Modified, Exclusive, Shared, Invalid. Stallings 16.3.
Ver (Wikipedia)MSI
MOSIMOESI
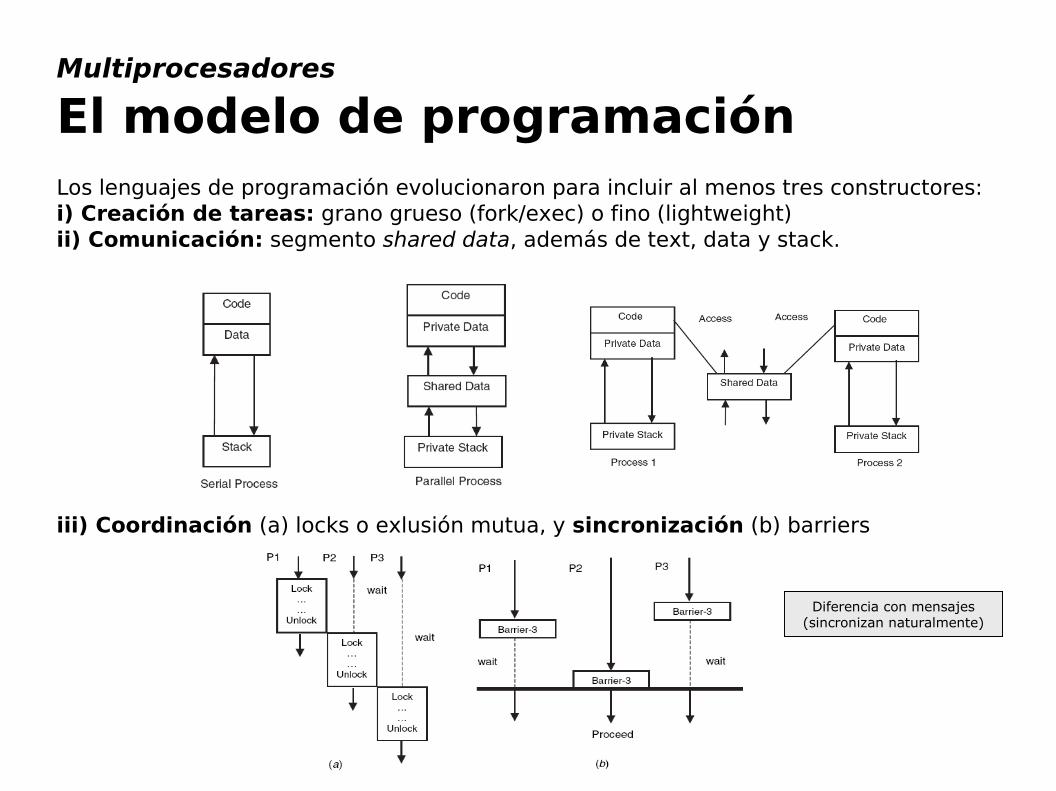
Multiprocesadores
El modelo de programaciónLos lenguajes de programación evolucionaron para incluir al menos tres constructores:i) Creación de tareas: grano grueso (fork/exec) o fino (lightweight)ii) Comunicación: segmento shared data, además de text, data y stack.
iii) Coordinación (a) locks o exlusión mutua, y sincronización (b) barriers
Diferencia con mensajes (sincronizan naturalmente)

Multiprocesadores
pThreads – Hello world/************************************************************************"hello world" Pthreads. Compilar con: gcc -lpthread -o hello hello.c*************************************************************************/#include <pthread.h>#include <stdio.h>#define NUM_THREADS 5
void *PrintHello(void *threadid){ printf("\n%d: Hello World!\n", threadid); pthread_exit(NULL);}
int main(){ pthread_t threads[NUM_THREADS]; int rc, t; for(t=0;t<NUM_THREADS;t++){ printf("Creating thread %d\n", t); rc = pthread_create(&threads[t], NULL, PrintHello, (void *)t); if (rc){ printf("ERROR; return code from pthread_create() is %d\n", rc); exit(-1); } } pthread_exit(NULL);}
IEEE POSIX 1003.1c standard (1995)

Multiprocesadores
OpenMP – Hello world/********************************************************************** OpenMP hello world. Compilar con gcc -fopenmp -o hello_omp hello_omp.c ***********************************************************************/ #include <omp.h> #include <stdio.h>
int main (int argc, char *argv[]) { int id, nthreads; #pragma omp parallel private(id) {
id = omp_get_thread_num(); printf("Hello World from thread %d\n", id); #pragma omp barrier
if ( id == 0 ) { nthreads = omp_get_num_threads(); printf("There are %d threads\n",nthreads);
} } return 0;
}
Open specificatios for Multi Processing: API definida por un grupo de frabricantes de HW y SW (ANSI en el futuro?). Modelo portable (C, C++, Fortran, Unix, WinXP) y escalable para desarrolladores de aplicaciones paralelas en sistemas multi-theaded de memoria compartida.

Multiprocesadores
OpenMP – π/********************************************************************** Calculo de pi por montecarlo con OpenMP ***********************************************************************/ #include <omp.h> #include <stdio.h> #include <stdlib.h> #include <math.h> #define N 20
int main (int argc, char *argv[]) { int i, j=0, n=10000000; double x, y, d; omp_set_num_threads(N); # pragma omp parallel for private(i,x,y,d) reduction(+:j)
for(i=0;i<n;i++){ x=(double)rand()/RAND_MAX; y=(double)rand()/RAND_MAX; d=sqrt(x*x+y*y); if(d<=1.0) j++;
} printf("PI = %f\n", 4.0*j/n); return 0;
}

Arquitecturas ParalelasMulticomputadoras
William Stallings, Organización y Arquitectura de Computadores, 5ta. ed., Capítulo 16: Procesamiento Paralelo.
Andrew S. Tanenbaum, Organización de Computadoras 4ta. ed., Capítulo 8: Arquitecturas de computadoras paralelas.
Hesham El-Rewini & Mostafa Abd-El-Barr, Advanced Computer Architecture and Parallel Processing. Willey.
CAP 5

Arquitecturas Paralelas
Taxonomía de Flynn
Massively ParallelProcessor
(MPP)

Arquitecturas Paralelas
Arquitecturas MIMD
MULTIPROCESADORESProcesadores fuertemente acoplados
Arquitectura de memoria compartida (globales)
MULTICOMPUTADORASProcesadores débilmente acoplados
Arquitectura de memoria distribuida (mensajes)

Diferencia entre MPP (loosely coupled) y Clusters (very-loosely coupled). Al no existir recursos compartidos, la comunicación se realiza a través de mensajes enviados por la red. El mensaje es una unidad lógica que puede transportar datos, instrucciones, sincronización o interrupciones.
Multicomputadoras
Clasificación

Multicomputadoras
Características generales
VENTAJASEscala mejor y soporta más nodos. Se eliminan las construcciones de sincronización. No está limitado por el ancho de banda de la memoria (si por el de la red). Puede utilizar redes estáticas no completamente conectadas (routing, bw, latencia). Sincronización y comunicación son lo mismo.
DESVENTAJASProgramación con mensajes explícitos (send/receive en lugar de load/store); los programas son diferentes. Tiempo de transmisión del mensaje. Una copia del SO en cada computadora. Difícil mover procesos entre computadoras.
Filosofía opuesta a los Multiprocesadores. Depende del tipo de problema.Cuál es el punto justo?…

Multicomputadoras
Granularidad
El programa se divide en N procesos concurrentes que se ejecutan en n computadoras. Si n<N existirán varios procesos (time-sharing) en cada computadora (canales externos vs. canales internos, no se puede compartir). Definimos, para un proceso:
Granularidad gruesa: cada proceso tiene muchas instruccionesGranularidad fina: pocas (incluso 1)
Los multiprocesadores funcionan mal en aplicaciones de granularidad fina debido el alto costo de las comunicaciones.
Granularidad=tiempo de cómputo
tiempo de comunicación

Multicomputadoras
Ruteo (routing)
A menos que se disponga de una red completamente conectada, esta problemática estará presente. Se define como el conjunto de técnicas utilizadas para:
a) Identificación de todos los caminos posibles.b) Selección del mejor a través de una función.
Las técnicas pueden clasificarse según su dinámica: Adaptivas (dependen del estado de la red) o Determinísticas (oblivious).O según su organización: Centralizadas (conozco la ruta al conocer la fuente y el destino) o Distribuídas (solo conozco el próximo salto)
Ejemplo: XOR en Hipercubo

Multicomputadoras
Routing (cont)
Tipos de operaciones:a) Unicastb) Multicastc) Broadcast
Problemas:a) Deadlock (solución monotónica) Ej: regla y lápizb) Livelock (solo en adaptivas) Ej: pasilloc) Starvation

Multicomputadoras
Conmutación (switching)
Técnica utilizada para pasar un mensaje de la entrada a la salida.a) Circuit-switching: reserva el camino. Ej: telefonía.b) Store-and-forward:
i) Packet-switching: El mensaje es dividido en paquetes que pueden viajar por diferentes caminos. Cada paquete lleva información de routing. Overhead. Pueden llegar desordenados. Ej: TCP.ii) Message-switching: el mensaje viaja entero.
c) Cut-Through-switching (wormhole routing): Todos los paquetes (flits – flow control bits – 32 bits low latency) se mueven tipo pipeline, siguiendo la misma ruta. El primero la fija. Cada nodo debe llevar la cuenta de los mensajes que está transmitiendo. Util en direcciones cortas. Ejemplo: hipercubo.

Multicomputadoras
Soporte en el procesador
Ejemplos de procesadores que implementan recursos específicamente diseñados con el objetivo de intercambiar mensajes entre procesadores.
Historia: Intel iPAX 432, IBM AS/400, Caltech Hypercube, Inmos Transputer, Cosmic Cube.
2000 - IBM Scalable POWERparallel 3: ver Willey cap 5

Multicomputadoras
El modelo de programaciónPrimitivas de comunicación: send, receive, broadcast, barrier.Mensajes bloqueantes (3 way) y no bloqueantes.PVM y MPI: bibliotecas de comunicaciones para C. Open Source: LAM-MPI y MPICH (tutoriales on-line)
/********************************************************************** Hello World MPI ***********************************************************************/ #include <stdio.h>#include <mpi.h>
int main(){int rank, size;MPI_Init( &argc, &argv );MPI_Comm_size( MPI_COMM_WORLD, &size );MPI_Comm_rank( MPI_COMM_WORLD, &rank );printf( "Hello world from process %d of %d\n", rank, size );MPI_Finalize();return 0;
}

SMP vs. MPP
En el medio NUMA (enmascara mensajes de HW por medio de SW)

Multicomputadoras - MPP
Ejemplos MPP
Blue GeneIBM #1 Nov2006360 TeraFLOPS (teorico)280 TeraFLOPS (real)Toriode 3d 32x32x64=65536 procesadores dual core

Multicomputadoras - MPP
Ejemplos MPP
Red StormCray #2 Nov2006Nodos: AMD Opteron dual coreRed: Cray SeaStar2 chipHypertransport 6 canales 6.4GB/sToriode 3d

Arquitecturas on-chip
Las mejoras en la tecnología se utilizan, en lugar de para incorporar mejoras al procesador, para implementar multiprocesadores o multicomputadoras dentro de un integrado (MpoC, Multiprocessor on Chip, o SoC, System on Chip).
Arquitecturas de memoria compartidaMismas consideraciones. Además: no siempre se comparte la memoria principal, puede ser el cache L2 o L3. Además: eterogeneidad, pocos procesadores complejos (Core de Intel) vs muchos procesadores simples; un procesador complejo y varios simples (Cell de IBM); un procesador complejo y procesadores específicos (DSP, SIMD, etc.)
Arquitecturas de memoria distribuidaIncluyen Network on Chip (NoC). Eterogeneidad.

Multicomputadoras - MPP
Casos de estudio1. Arquitectura Cell de IBM y las consolas de juegos de séptima generación (Xbox 360 de Microsoft, Playstation 3 de Sony y Wii de Nintendo).
2. www.top500.org (2012)
Titan - Cray XK7 , Opteron 6274 16C 2.200GHz, Cray Gemini interconnect, NVIDIA K20xManufacturer: Cray Inc.Cores: 560640Linpack Performance (Rmax) 17590.0 TFlop/sTheoritical Peak (Rpeak) 27112.5 TFlop/sPower: 8209.00 kWMemory: 710144 GBInterconnect: Cray Gemini interconnectOperating System: Cray Linux Environment

2008 - Intel Core i7
Nehalem represents the largest architectural change in the Intel x86 family since the Pentium Pro in 1995. The Nehalem architecture has many new features. The ones that represent significant changes from the Core 2 include:
FSB is replaced by QuickPath interface. Motherboards must use a chipset that supports QuickPath. As of November 2008, only the Intel X58 does this. The Intel QuickPath Interconnect is a point-to-point processor interconnect developed by Intel to compete with HyperTransport. It will replace the Front Side Bus (FSB) for Desktop, Xeon, and Itanium platforms. Intel will first deliver it in November 2008 on the Intel Core i7 desktop processor and the X58 chipset, and it will be used on new Nehalem-based Xeon processors and Tukwila-based Itanium processors.
On-die memory controller: the memory is directly connected to the processor. Three channel memory: each channel can support one or two DDR3 DIMMs. Motherboards for Core i7 have
four (3+1) or six DIMM slots instead of two or four, and DIMMs should be installed in sets of three, not two. Support for DDR3 only.
Single-die device: all four cores, the memory controller, and all cache are on a single die. "Turbo Boost" technology allows the cores to intelligently clock themselves to 133MHz or 266MHz over the
design clock speed so long as the CPU's thermal requirements are still met. This mode isn't enabled when the CPU is manually over-clocked by the user.
Re-implemented Hyper-threading. Each of the four cores can process two threads simultaneously, so the processor appears to the OS as eight CPUs. This feature was present in the older Netburst architecture but was dropped in Core.
On-die, shared, inclusive 8MB L3 cache. Only one QuickPath interface: not intended for multi-processor motherboards. 45nm process technology. 731M transistors. Sophisticated power management can place an unused core in a zero-power mode.







