Download - BD-ACA week7a

Word co-occurrences Some suggestions on where to look further Next meetings
Big Data and Automated Content AnalysisWeek 7 – Monday
»Word co-occurrances, Gephi— and some suggestions«
Damian Trilling
[email protected]@damian0604
www.damiantrilling.net
Afdeling CommunicatiewetenschapUniversiteit van Amsterdam
11 May 2015Big Data and Automated Content Analysis Damian Trilling

Word co-occurrences Some suggestions on where to look further Next meetings
Today
1 Integrating word counts and network analysis: Wordco-occurrences
The ideaA real-life example
2 Some suggestions on where to look furtherUseful packagesSome more tips
3 Next meetings, & final project
Big Data and Automated Content Analysis Damian Trilling

Word co-occurrences Some suggestions on where to look further Next meetings
Integrating word counts and network analysis:Word co-occurrences
Big Data and Automated Content Analysis Damian Trilling

Word co-occurrences Some suggestions on where to look further Next meetings
The idea
Simple word count
We already know this.1 from collections import Counter2 tekst="this is a test where many test words occur several times this is
because it is a test yes indeed it is"3 c=Counter(tekst.split())4 print "The top 5 are: "5 for woord,aantal in c.most_common(5):6 print (aantal,woord)
Big Data and Automated Content Analysis Damian Trilling

Word co-occurrences Some suggestions on where to look further Next meetings
The idea
Simple word count
The output:1 The top 5 are:2 4 is3 3 test4 2 a5 2 this6 2 it
Big Data and Automated Content Analysis Damian Trilling

Word co-occurrences Some suggestions on where to look further Next meetings
The idea
What if we could. . .
. . . count the frequency of combinations of words?
As in: Which words do typical occur together in the sametweet (or paragraph, or sentence, . . . )
Big Data and Automated Content Analysis Damian Trilling

Word co-occurrences Some suggestions on where to look further Next meetings
The idea
What if we could. . .
. . . count the frequency of combinations of words?
As in: Which words do typical occur together in the sametweet (or paragraph, or sentence, . . . )
Big Data and Automated Content Analysis Damian Trilling

Word co-occurrences Some suggestions on where to look further Next meetings
The idea
We can — with the combinations() function
1 >>> from itertools import combinations2 >>> words="Hoi this is a test test test a test it is".split()3 >>> print ([e for e in combinations(words,2)])4 [(’Hoi’, ’this’), (’Hoi’, ’is’), (’Hoi’, ’a’), (’Hoi’, ’test’), (’Hoi’,
’test’), (’Hoi’, ’test’), (’Hoi’, ’a’), (’Hoi’, ’test’), (’Hoi’, ’it’), (’Hoi’, ’is’), (’this’, ’is’), (’this’, ’a’), (’this’, ’test’), (’this’, ’test’), (’this’, ’test’), (’this’, ’a’), (’this’, ’test’), (’this’, ’it’), (’this’, ’is’), (’is’, ’a’), (’is’, ’test’), (’is’, ’test’), (’is’, ’test’), (’is’, ’a’), (’is’, ’test’), (’is’, ’it’), (’is’, ’is’), (’a’, ’test’), (’a’, ’test’), (’a’, ’test’), (’a’, ’a’), (’a’, ’test’), (’a’, ’it’), (’a’, ’is’), (’test’, ’test’), (’test’, ’test’), (’test’, ’a’), (’test’, ’test’), (’test’,’it’), (’test’, ’is’), (’test’, ’test’), (’test’, ’a’), (’test’, ’
test’), (’test’, ’it’), (’test’, ’is’), (’test’, ’a’), (’test’, ’test’), (’test’, ’it’), (’test’, ’is’), (’a’, ’test’), (’a’, ’it’),(’a’, ’is’), (’test’, ’it’), (’test’, ’is’), (’it’, ’is’)]
Big Data and Automated Content Analysis Damian Trilling

Word co-occurrences Some suggestions on where to look further Next meetings
The idea
Count co-occurrences
1 from collections import defaultdict2 from itertools import combinations34 tweets=["i am having coffee with my friend","i like coffee","i like
coffee and beer","beer i like"]5 cooc=defaultdict(int)67 for tweet in tweets:8 words=tweet.split()9 for a,b in set(combinations(words,2)):
10 if (b,a) in cooc:11 a,b = b,a12 if a!=b:13 cooc[(a,b)]+=11415 for combi in sorted(cooc,key=cooc.get,reverse=True):16 print (cooc[combi],"\t",combi)
Big Data and Automated Content Analysis Damian Trilling

Word co-occurrences Some suggestions on where to look further Next meetings
The idea
Count co-occurrences
The output:1 3 (’i’, ’coffee’)2 3 (’i’, ’like’)3 2 (’i’, ’beer’)4 2 (’like’, ’beer’)5 2 (’like’, ’coffee’)6 1 (’coffee’, ’beer’)7 1 (’and’, ’beer’)8 ...9 ...
10 ...
Big Data and Automated Content Analysis Damian Trilling

Word co-occurrences Some suggestions on where to look further Next meetings
The idea
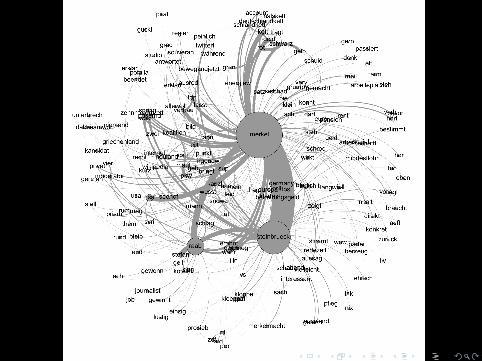
From a list of co-occurrences to a network
Let’s conceptualize each word as a node and eachcooccurrence as an edge
• node weight = word frequency• edge weight = number of coocurrences
A GDF file offers all of this and looks like this:
Big Data and Automated Content Analysis Damian Trilling

1 nodedef>name VARCHAR, width DOUBLE2 coffee,33 beer,24 i,45 and,16 with,17 friend,18 having,19 like,3
10 am,111 my,112 edgedef>node1 VARCHAR,node2 VARCHAR, weight DOUBLE13 coffee,beer,114 i,beer,215 and,beer,116 with,friend,117 coffee,with,118 i,and,119 having,friend,120 like,beer,221 am,friend,122 i,am,123 i,coffee,324 i,with,125 am,having,126 i,having,127 coffee,and,128 like,coffee,229 am,coffee,130 with,my,131 i,friend,132 like,and,133 am,with,134 having,with,135 i,my,136 having,coffee,137 i,like,338 coffee,friend,139 having,my,140 am,my,141 coffee,my,142 my,friend,1

Word co-occurrences Some suggestions on where to look further Next meetings
The idea
How to represent the cooccurrences graphically?
A two-step approach
1 Save as a GDF file (the format seems easy to understand, sowe could write a function for this in Python)
2 Open the GDF file in Gephi for visualization and/or networkanalysis
Big Data and Automated Content Analysis Damian Trilling

Word co-occurrences Some suggestions on where to look further Next meetings
The idea
Gephi
• Install (NOT in the VM) from https://gephi.org• By problems on MacOS, see what I wrote about Gephi here:
http://www.damiantrilling.net/setting-up-my-new-macbook/
• I made a screencast on how to visualize the GDF file in Gephi:https://streamingmedia.uva.nl/asset/detail/t2KWKVZtQWZIe2Cj8qXcW5KF
• Further: see the materials I mailed to you
Big Data and Automated Content Analysis Damian Trilling

Word co-occurrences Some suggestions on where to look further Next meetings
A real-life example
A real-life example
Trilling, D. (2014). Two different debates? Investigating therelationship between a political debate on TV and simultaneouscomments on Twitter. Social Science Computer Review, Advanceonline publication. doi: 10.1177/0894439314537886
Big Data and Automated Content Analysis Damian Trilling

Word co-occurrences Some suggestions on where to look further Next meetings
A real-life example
Commenting the TV debate on Twitter
The debating politicians
• issues largely set by the interviewers• but candidates actively try to highlight the issues (⇒ agendasetting) and aspects of the issues (⇒ framing).
Big Data and Automated Content Analysis Damian Trilling
Word co-occurrences Some suggestions on where to look further Next meetings
A real-life example
Commenting the TV debate on Twitter
The viewers
• Commenting television programs on social networks hasbecome a regular pattern of behavior (Courtois & d’Heer, 2012)
• User comments have shown to reflect the structure of thedebate (Shamma, Churchill, & Kennedy, 2010; Shamma, Kennedy, & Churchill, 2009)
• Topic and speaker effect more influential than, e.g., rhetoricalskills (Nagel, Maurer, & Reinemann, 2012; De Mooy & Maier, 2014)
Big Data and Automated Content Analysis Damian Trilling

Word co-occurrences Some suggestions on where to look further Next meetings
A real-life example
Research Questions
To which extent are the statements politicians make during aTV debate reflected in online live discussions of the debate?
RQ1 Which topics are emphasized by the candidates?RQ2 Which topics are emphasized by the Twitter users?RQ3 With which topics are the two candidates associated
on Twitter?
Big Data and Automated Content Analysis Damian Trilling
Word co-occurrences Some suggestions on where to look further Next meetings
A real-life example
Method
The data
• debate transcript• tweets containing#tvduell
• N = 120, 557 tweetsby N = 24, 796 users
• 22-9-2013,20.30-22.00
The analysis
• Series of self-written Pythonscripts:
1 preprocessing (stemming,stopword removal)
2 word counts3 word log likelihood (corpus
comparison)• Stata: regression analysis
Big Data and Automated Content Analysis Damian Trilling
Word co-occurrences Some suggestions on where to look further Next meetings
A real-life example
Method
The data
• debate transcript• tweets containing#tvduell
• N = 120, 557 tweetsby N = 24, 796 users
• 22-9-2013,20.30-22.00
The analysis
• Series of self-written Pythonscripts:
1 preprocessing (stemming,stopword removal)
2 word counts3 word log likelihood (corpus
comparison)• Stata: regression analysis
Big Data and Automated Content Analysis Damian Trilling

Word co-occurrences Some suggestions on where to look further Next meetings
A real-life example
Method
The data
• debate transcript• tweets containing#tvduell
• N = 120, 557 tweetsby N = 24, 796 users
• 22-9-2013,20.30-22.00
The analysis
• Series of self-written Pythonscripts:
1 preprocessing (stemming,stopword removal)
2 word counts3 word log likelihood (corpus
comparison)• Stata: regression analysis
Big Data and Automated Content Analysis Damian Trilling
02
00
04
00
06
00
08
000
−60 −50 −40 −30 −20 −10 10 20 30 40 50 60 70 80 100 110 120 130 140 150start
end

Word co-occurrences Some suggestions on where to look further Next meetings
A real-life example
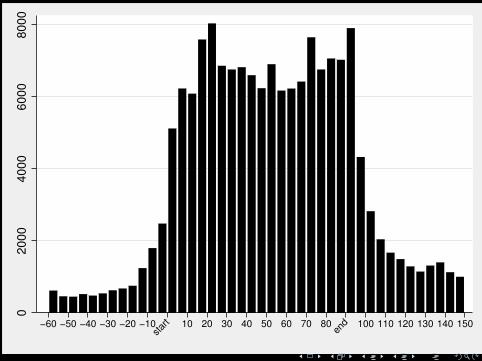
Relationship between words on TV and on Twitter
02
46
81
0ln
(w
ord
on
Tw
itte
r +
1)
0 1 2 3ln (word on TV +1)
Big Data and Automated Content Analysis Damian Trilling

Word co-occurrences Some suggestions on where to look further Next meetings
A real-life example
Word frequency TV ⇒ word frequency Twitter
Model 1 Model 2 Model 3ln(Twitter +1) ln(Twitter +1) ln(Twitter +1)
together w/ M. together w/ S.b (SE) b(SE) b(SE)beta beta beta
ln (TV M. +1) 1.59 (.052) *** 1.54 (.041) *** .77 (.037) ***.21 .26 .14
ln (TV S. +1) 1.29 (.051) *** .88 (.041) *** 1.25 (.037) ***.17 .15 .24
intercept 1.64 (.008) *** .87 (.007) *** .60 (.006) ***R2 .100 .115 .100b M. & S. differ? F(1, 21408) = 12.29 F(1, 21408) = 96.69 F(1, 21408) =
p <.001 p <.001 63.38p <.001
M = Merkel; S = Steinbrück
Big Data and Automated Content Analysis Damian Trilling

Word co-occurrences Some suggestions on where to look further Next meetings
A real-life example
Most distinctive words on TV
LL word Frequency Merkel Frequency Steinbrück27,73 merkel 0 2019,41 arbeitsplatz [job] 14 015,25 steinbruck 11 09,70 koalition [coaltion] 7 09,70 international 7 09,70 gemeinsam [together] 7 08,55 griechenland [Greece] 10 18,32 investi [investment] 6 06,93 uberzeug [belief] 5 06,93 okonom [economic] 0 5
Big Data and Automated Content Analysis Damian Trilling

Word co-occurrences Some suggestions on where to look further Next meetings
A real-life example
Most distinctive words on Twitter
LL word Frequency Merkel Frequency Steinbrück32443,39 merkel 29672 030751,65 steinbrueck 0 177801507,08 kett [necklace] 1628 341241,14 vertrau [trust] 1240 12863,84 fdp [a coalition partner] 985 29775,93 nsa 1809 298626,49 wikipedia 40 502574,65 twittert [tweets] 40 469544,87 koalition [coalition] 864 77517,99 gold 669 34
Big Data and Automated Content Analysis Damian Trilling

Word co-occurrences Some suggestions on where to look further Next meetings
A real-life example
Putting the pieces together
Merkel
• necklace• trust (sarcastic)• nsa affair• coalition partners
Steinbrück
• suggestion to look sth. upon Wikipedia
• tweets from his accountduring the debate
Big Data and Automated Content Analysis Damian Trilling
Word co-occurrences Some suggestions on where to look further Next meetings
Useful packages
Some suggestions on where to look further
Big Data and Automated Content Analysis Damian Trilling
Word co-occurrences Some suggestions on where to look further Next meetings
Useful packages
Further analysis
Ways to further analyze the data
• Write the data in a specific format to link to special extenralprogram (GDF-example)
• Export to CSV files and analyze using R, Stata, SPSS, Excel,. . .
• Do it in Python, using. . . . . . . . .
Big Data and Automated Content Analysis Damian Trilling

Word co-occurrences Some suggestions on where to look further Next meetings
Useful packages
Further analysis
Ways to further analyze the data
• Write the data in a specific format to link to special extenralprogram (GDF-example)
• Export to CSV files and analyze using R, Stata, SPSS, Excel,. . .
• Do it in Python, using. . . . . . . . .
Big Data and Automated Content Analysis Damian Trilling
Word co-occurrences Some suggestions on where to look further Next meetings
Useful packages
Further analysis
Ways to further analyze the data
• Write the data in a specific format to link to special extenralprogram (GDF-example)
• Export to CSV files and analyze using R, Stata, SPSS, Excel,. . .
• Do it in Python, using. . . . . . . . .
Big Data and Automated Content Analysis Damian Trilling

Word co-occurrences Some suggestions on where to look further Next meetings
Useful packages
Further analysis
Ways to further analyze the data
• Write the data in a specific format to link to special extenralprogram (GDF-example)
• Export to CSV files and analyze using R, Stata, SPSS, Excel,. . .
• Do it in Python, using. . . . . . . . .
Big Data and Automated Content Analysis Damian Trilling
Word co-occurrences Some suggestions on where to look further Next meetings
Useful packages
Packages for statistics and graphics
Already installed with anaconda:
• numpy• scipy• pandas• mathplotlib
We won’t cover these packages in detail, but you are very muchencouraged to have a look at these packages yourself if you feelthey are useful.
Big Data and Automated Content Analysis Damian Trilling

Word co-occurrences Some suggestions on where to look further Next meetings
Useful packages
numpy
1 >>> x = [1,2,3,4,3,2]2 >>> y = [2,2,4,3,4,2]3 >>> np.mean(x)4 2.55 >>> np.std(x)6 0.95742710775633817 >>> np.corrcoef(x,y)8 array([[ 1. , 0.67883359],9 [ 0.67883359, 1. ]])
Big Data and Automated Content Analysis Damian Trilling

Word co-occurrences Some suggestions on where to look further Next meetings
Useful packages
pandas
1 import pandas as pd2 from pandas.stats.api import ols3 df = pd.DataFrame({"A": [10,20,30,40,50], "B": [20, 30, 10, 40, 50], "C
": [32, 234, 23, 23, 42523]})4 result = ols(y=df[’A’], x=df[[’B’,’C’]])5 print(result)
prints a regression table like you would expect from any statisticsprogram:
Big Data and Automated Content Analysis Damian Trilling
Word co-occurrences Some suggestions on where to look further Next meetings
Useful packages
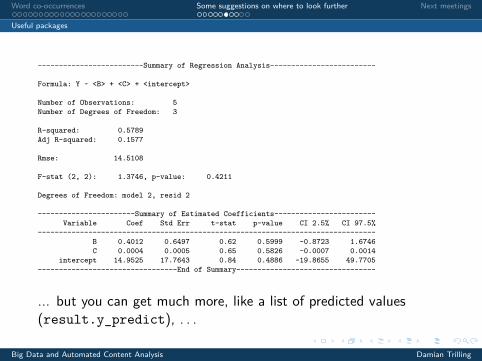
-------------------------Summary of Regression Analysis-------------------------
Formula: Y ~ <B> + <C> + <intercept>
Number of Observations: 5Number of Degrees of Freedom: 3
R-squared: 0.5789Adj R-squared: 0.1577
Rmse: 14.5108
F-stat (2, 2): 1.3746, p-value: 0.4211
Degrees of Freedom: model 2, resid 2
-----------------------Summary of Estimated Coefficients------------------------Variable Coef Std Err t-stat p-value CI 2.5% CI 97.5%
--------------------------------------------------------------------------------B 0.4012 0.6497 0.62 0.5999 -0.8723 1.6746C 0.0004 0.0005 0.65 0.5826 -0.0007 0.0014
intercept 14.9525 17.7643 0.84 0.4886 -19.8655 49.7705---------------------------------End of Summary---------------------------------
... but you can get much more, like a list of predicted values(result.y_predict), . . .
Big Data and Automated Content Analysis Damian Trilling
Word co-occurrences Some suggestions on where to look further Next meetings
Useful packages
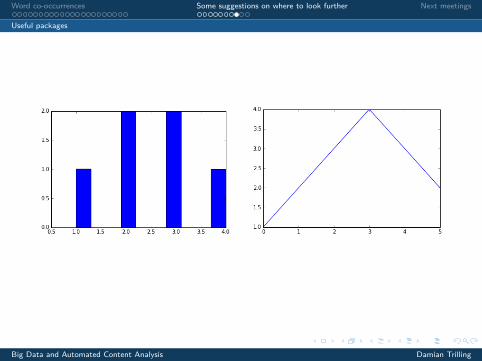
matplotlib
1 import matplotlib.pyplot as plt2 x = [1,2,3,4,3,2]3 y = [2,2,4,3,4,2]4 plt.hist(x)5 plt.plot(x,y)
Big Data and Automated Content Analysis Damian Trilling
Word co-occurrences Some suggestions on where to look further Next meetings
Useful packages
Big Data and Automated Content Analysis Damian Trilling

Word co-occurrences Some suggestions on where to look further Next meetings
Some more tips
Some tips
• Make use of IPython features in Spyder (tab completion,object inspector)
• Try things out in the IPython console (think of RStudio ofSTATA!)
• Watch this video on “Python for data analysis" with pandas:https://vimeo.com/59324550
Big Data and Automated Content Analysis Damian Trilling


Word co-occurrences Some suggestions on where to look further Next meetings
Final project Next meetings
Big Data and Automated Content Analysis Damian Trilling
Word co-occurrences Some suggestions on where to look further Next meetings
Final project
On 29–5, you have to hand in your final project
• Details and rules: ⇒ course manual• Similar to take-home exam• But: Much more advanced, and now, the result counts as well• And: Be creative! You can use code from class, but you needto extend it
• Start working on it!
Big Data and Automated Content Analysis Damian Trilling

Word co-occurrences Some suggestions on where to look further Next meetings
Next meeting
Wednesday, 13–5Lab session, focus on INDIVIDUAL PROJECTS! Prepare!(No common exercise)
Big Data and Automated Content Analysis Damian Trilling







