
Beyond Content-Based Retrieval: Modeling Domains, Users and Interaction
Susan DumaisMicrosoft Research
http://research.microsoft.com/~sdumais
IEEE ADL’99 - May 21, 1998

Research in IR at MS
Microsoft Research (http://research.microsoft.com) Adaptive Systems and Interaction - IR/UI Machine Learning and Applied Statistics Data Mining Natural Language Processing Collaboration and Education MSR Cambridge; MSR Beijing
Microsoft Product Groups … many IR-related

IR Themes & Directions
Improvements in representation and content-matching Probabilistic/Bayesian models - p(Relevant|Document),
p(Concept|Words) NLP: Truffle, MindNet
Beyond content-matching User/Task modeling Domain/Object modeling Advances in presentation and manipulation
WWW8 PanelFinding Anything in the Billion-Page Web: Are Algorithms the Answer? Moderator: Prabhakar Raghavan, IBM Almaden

Traditional View of IR
Query Words
Ranked List
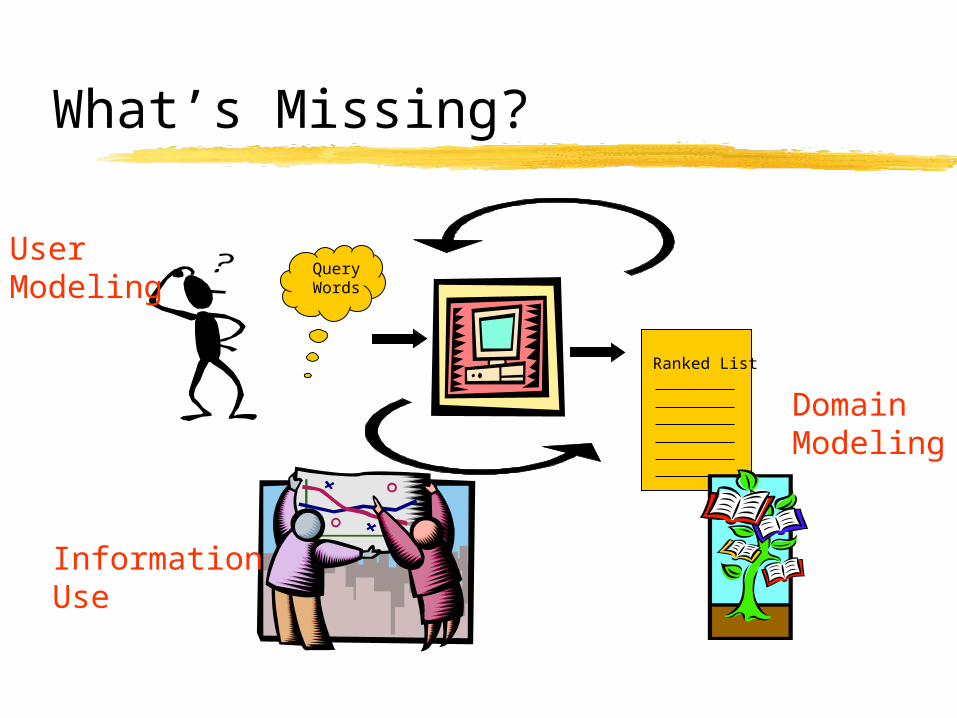
What’s Missing?
Query Words
Ranked List
User Modeling
Domain Modeling
Information Use

Domain/Obj Modeling
Not all objects are equal … potentially big win A priori importance Information use (“readware”; collab filtering)
Inter-object relationships Link structure / hypertext Subject categories - e.g., text categorization.
text clusteringMetadata
E.g., reliability, recency, cost -> combining

User/Task Modeling
Demographics Task -- What’s the user’s goal?
e.g., LumiereShort and long-term content interests
e.g., Implicit queries Interest model = f(content_similarity, time, interest)
e.g., Letiza, WebWatcher, Fab

Information Use
Beyond batch IR model (“query->results”) Consider larger task context Knowledge management
Human attention is critical resource Techniques for automatic information
summarization, organization, discover, filtering, mining, etc.
Advanced UIs and interaction techniques E.g, tight coupling of search, browsing to
support information management

The Broader View of IR
Query Words
Ranked List
User Modeling
Domain Modeling
Information Use

Beyond Content Matching
Domain/Object modelingA priori importanceText classification and clustering
User/Task modeling Implicit queries and Lumiere
Advances in presentation and manipulation Combining structure and search (e.g., DM)




Estimating Priors
Access Count e.g., DirectHit Collaborative Filtering
Link Structure (citation analysis) Clever (Hubs/Authorities) - Kleinberg et
al. Google - Brin & Page Web Archeologist - Bharat, Henzinger

New Relevance Ranking
Relevance ranking can include: content-matching … of couse page/site popularity <external link count; proxy stats>
page quality <site quality, dates, depth> spam or porn or other downweighting etc.
Combining these - relative weighting of these factors tricky and subjective

Text Classification
Text Classification: assign objects to one or more of a predefined set of categories using text features E.g., News feeds, Web data, OHSUMED, Email - spam/no-spam
Approaches: Human classification (e.g., LCSH, MeSH, Yahoo!, CyberPatrol) Hand-crafted knowledge engineered systems (e.g., CONSTRUE) Inductive learning methods
(Semi-) automatic classification

Inductive Learning Methods
Supervised learning from examples Examples are easy for domain experts to provide Models easy to learn, update, and customize
Example learning algorithms Relevance Feedback, Decision Trees, Naïve Bayes,
Bayes Nets, Support Vector Machines (SVMs)
Text representation Large vector of features (words, phrases, hand-
crafted)

Support Vector Machine
Optimization Problem Find hyperplane, h, separating positive and negative
examples Optimization for maximum margin: Classify new items using:
1,1,min2 bxwbxww
support vectors
w
)( xwf

Reuters Data Set (21578 - ModApte split)
9603 training articles; 3299 test articlesExample “interest” article
2-APR-1987 06:35:19.50 west-germany b f BC-BUNDESBANK-LEAVES-CRE 04-02 0052FRANKFURT, March 2 The Bundesbank left credit policies unchanged after today's
regular meeting of its council, a spokesman said in answer to enquiries. The West German discount rate remains at 3.0 pct, and the Lombard emergency financing rate at 5.0 pct.
REUTER
Average article 200 words long

Example: Reuters news
118 categories (article can be in more than one category)
Most common categories (#train, #test)
Overall Results Linear SVM most accurate: 87% precision at
87% recall
• Trade (369,119)• Interest (347, 131)• Ship (197, 89)• Wheat (212, 71)• Corn (182, 56)
• Earn (2877, 1087) • Acquisitions (1650, 179)• Money-fx (538, 179)• Grain (433, 149)• Crude (389, 189)

Reuters ROC - Category Grain
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
0 0.2 0.4 0.6 0.8 1
Precision
Recall
LSVMDecision Tree Naïve BayesFind Similar
Recall: % labeled in category among those stories that are really in categoryPrecision: % really in category among those stories labeled in category

Text Categ Summary
Accurate classifiers can be learned automatically from training examples
Linear SVMs are efficient and provide very good classification accuracy
Widely applicable, flexible, and adaptable representations Email spam/no-spam, Web, Medical abstracts,
TREC

Text Clustering
Discovering structure Vector-based document representation EM algorithm to identify clusters
Interactive user interface

Text Clustering

Beyond Content Matching
Domain/Object modeling Text classification and clustering
User/Task modelingImplicit queries and Lumiere
Advances in presentation and manipulationCombining structure and search (e.g.,
DM)
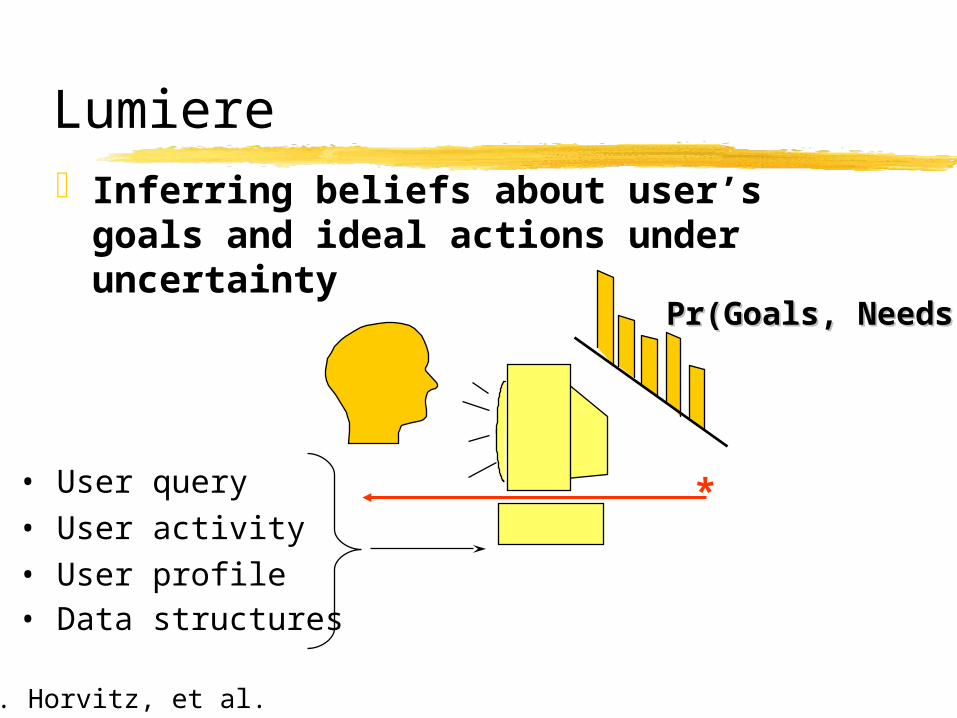
Lumiere Inferring beliefs about user’s goals and ideal
actions under uncertainty
*• User query
• User activity
• User profile• Data structures
Pr(Goals, Needs)Pr(Goals, Needs)
E. Horvitz, et al.
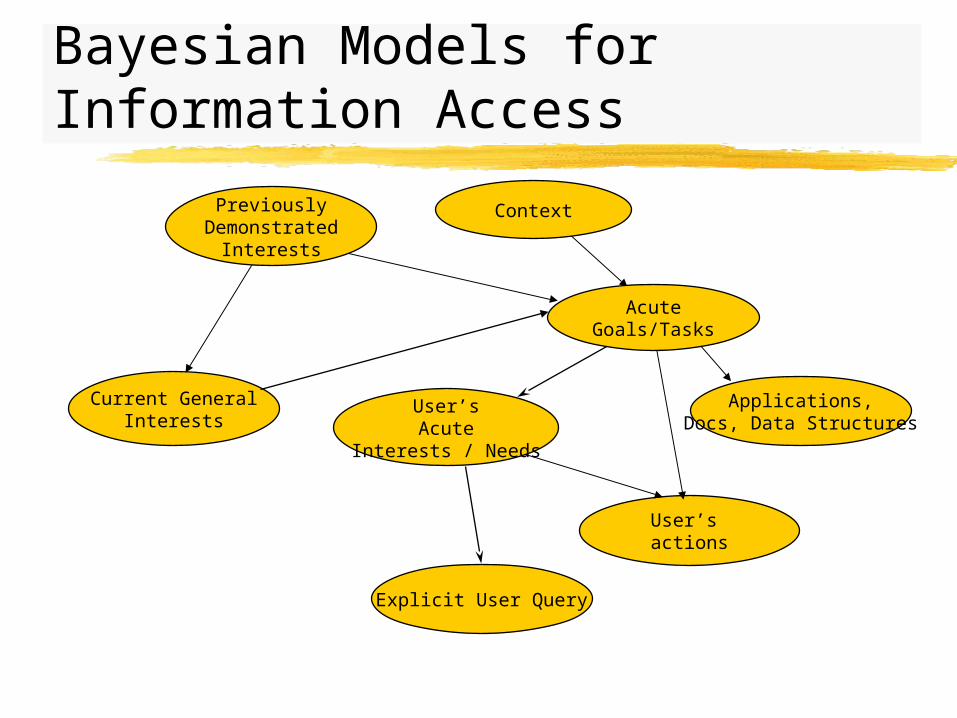
Bayesian Models for Information Access
Current GeneralInterests
User’s actions
Explicit User Query
User’sAcute
Interests / Needs
Applications,Docs, Data Structures
AcuteGoals/Tasks
PreviouslyDemonstrated
Interests
Context

Lumiere
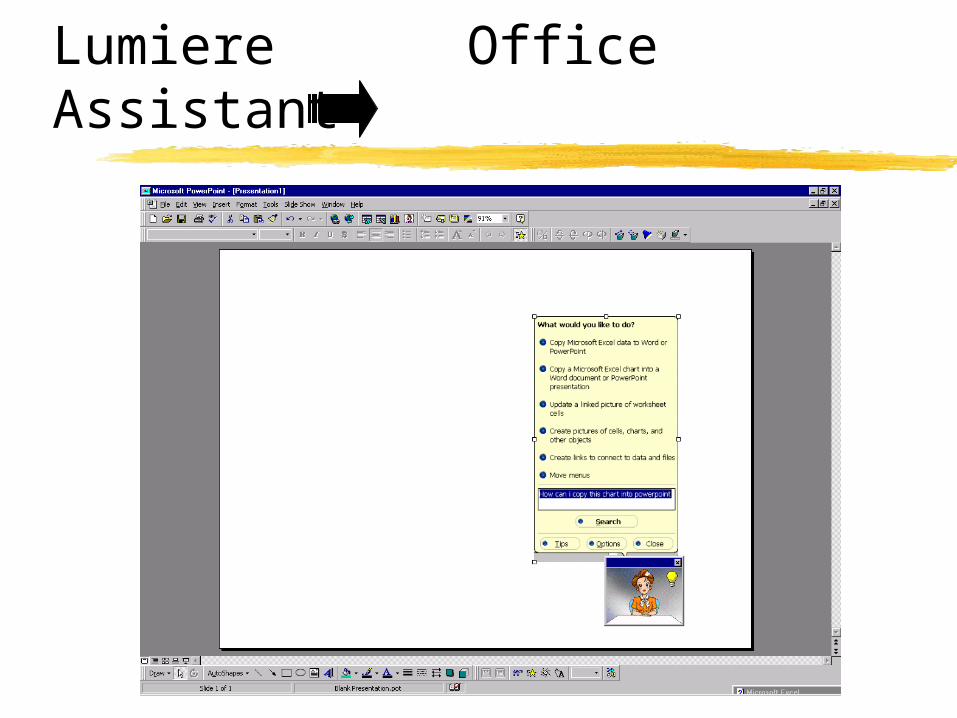
Lumiere Office Assistant

Implicit Queries (IQ)
Explicit queries: Search is a separate, discrete task User types query, Gets results, Tries again …
Implicit queries: Search as part of normal information flow Ongoing query formulation based on user
activities Non-intrusive results display


Figure 2: Data Mountain with 100 web pages.

Data Mountain with Implicit Query results shown (highlighted pages to left of selected page).

IQ Study: Experimental Details
Store 100 Web pages 50 popular Web pages; 50 random pages With or without Implicit Query
IQ1: Co-occurrence based IQIQ2: Content-based IQ
Retrieve 100 Web pages Title given as retrieval cue -- e.g., “CNN Home
Page”
No implicit query highlighting at retrieval

Figure 2: Data Mountain with 100 web pages.Find: “CNN Home Page”

Results: Information Storage
Filing strategies
Filing Strategy IQ Condition Semantic Alphabetic No OrgIQ0: No IQ 11 3 1IQ1: Co-occur based 8 1 0IQ2: Content-based 10 1 0

Results: Information Storage
Number of categories (for semantic
organizers)IQ Condition Average Number of Categories (std error) IQ0: No IQ 12.0 (3.6)IQ1: Co-occur based 15.8 (5.8)IQ2: Content-based 13.6 (5.9)
7 Categ 23 Categ

Results: Retrieval Time
Web Page Retrieval Time
0
2
4
6
8
10
12
14
Im plicit Query Condition
Av
era
ge
RT
(s
ec
on
ds
)
IQ 0
IQ 1
IQ 2

Implicit Query Highlights
IQ built by tracking user’s reading behavior No explicit search required Good matches returned
IQ user model: Combines present context + previous
interestsNew interfaces for tightly coupling search
results with structure -- user study

Summary
Improving content-matching And, beyond ...
Domain/Object Models User/Task Models Information Presentation and Use
Also … non-text, multi-lingual, distributed
http://research.microsoft.com/~sdumais

The View from Wired, May 1996
“information retrieval seemed like the easiest place to make progress … information retrieval is really only a problem for people in library science -- if some computer scientists were to put their heads together, they’d probably have it solved before lunchtime” [GS]


DLI-1
UC Berkeley - Environmental planning and GIS
UC Santa Barbara - The Alexandria project spatially referenced map information
CMU - Informedia digital video library
UIllinois - Federating repositories of scientific literature
UMichigan - Intelligent agents for information location
Stanford - Interoperation mechanisms among heterogeneous services

DLI-2
OHSU/OGI: Tracking footprints through an information space: Leveraging the document selections of expert problem solvers
Stanford: Image filtering for secure distribution of medical information
UWashington: Automatic reference librarians for the WWW
UKentucky: The digital atheneum: New techniques for restoring, searching and editing humanities collection
USCarolina: A software and data library for experiments, simulation and archiving
Johns Hopkins: Digital workflow management: The Lester S. Levy collection of Music
UArizona: High-performance digital library classification systems: From information retrieval to knowledge management

Popularity rankings - e.g., DirectHitLink-based rankings - e.g., Google,
CleverQuestion answering - e.g., AskJeevesPaid advertising - e.g. ,GoToSteve Kirsch’s talk at SIGIR





Example Web Searches
161858 lion lions 163041 lion facts 163919 picher of lions164040 lion picher 165002 lion pictures165100 pictures of lions165211 pictures of big cats165311 lion photos 170013 video in lion 172131 pictureof a lioness172207 picture of a lioness172241 lion pictures 172334 lion pictures cat 172443 lions172450 lions
150052 lion152004 lions152036 lions lion 152219 lion facts153747 roaring153848 lions roaring160232 africa lion160642 lions, tigers, leopards and cheetahs161042 lions, tigers, leopards and cheetahs cats 161144 wild cats of africa 161414 africa cat161602 africa lions161308 africa wild cats161823 mane161840 lion
user = A1D6F19DB06BD694 date = 970916 excite log


Earlier IR Accomplishments in DTAS
Bayesian IR Answer Wizard: words --> p(Concepti | Words)
User Modeling Lumiere, Office Assistant: user words, user
profile, user behavior (events), active data structures --> p(User needs, Goals | Evidence)
Collaborative Filtering

Current DTAS IR Projects
Domain/Object ModelingText Classification (Sue, David, Eric, John,
Mehran) Combining content and collaborative matches
(Carl)
User/Task Modeling Implicit query (Sue, Eric, Krishna) Prefetching information (Eric) Cost-benefit analysis of a search result (Jack)

User Modeling for IQ/IR
IQ: Model of user interests based on actions Explicit search activity (query or profile) Patterns of scroll / dwell on text Copying and pasting actions Interaction with multiple applications
Explicit Queries or Profile Copy and PasteScroll/Dwell on Text
User’sShort- and Long-Term
Interests / Needs
“Implicit Query (IQ)”
Other Applications

Improvements: Using Probabilistic Model
MSR-Cambridge (Steve Robertson)Probabilistic Retrieval (e.g., Okapi)
Theory-driven derivation of matching function
Estimate: PQ(ri=Rel or NotRel | d=document)Using Bayes Rule and assuming conditional
independence given Rel/NotRel
) ( / ) | ( ) ( ) | (d d dP r P r P r Pi i i Q
) ( / ) | ( ) ( ) | (1d dP r x P r P r Pt
ii i i i Q

Improvements: Using Probabilistic Model
Good performance for uniform length document surrogates (e.g., abstracts)
Enhanced to take into account term frequency and document “BM25” one of the best ranking function at TREC
Easy to incorporate relevance feedback
Now looking at adaptive filtering/routing

Improvements: Using NLP
Current search techniques use word forms
Improvements in content-matching will come from:-> Identifying relations between words-> Identifying word meanings
Advanced NLP can provide thesehttp:/research.microspft.com/nlp

Dictionary
MindNet
Morphology
Sketch
Logical Form
Portrait
NL Text
DiscourseGeneration
NL Text
NLP System Architecture
MachineTranslation
Projects Technology
Search and Retrieval
Meaning Representation
Grammar & Style
Checking
DocumentUnderstandingIntelligent
Summarizing
Smart Selection
Word Breaking
Indexing

Result:Result:
2-3 times as many2-3 times as manyrelevant documentsrelevant documentsin the top 10 within the top 10 withMicrosoft NLPMicrosoft NLP
0
10
20
30
40
50
60
70
21.5%21.5%
33.1%33.1%
63.7%63.7%
Engine XEngine X X+X+ NLPNLP
Rel
evan
t h
its
Rel
evan
t h
its
“Truffle”: Word Relations % Relevant In Top Ten Docs
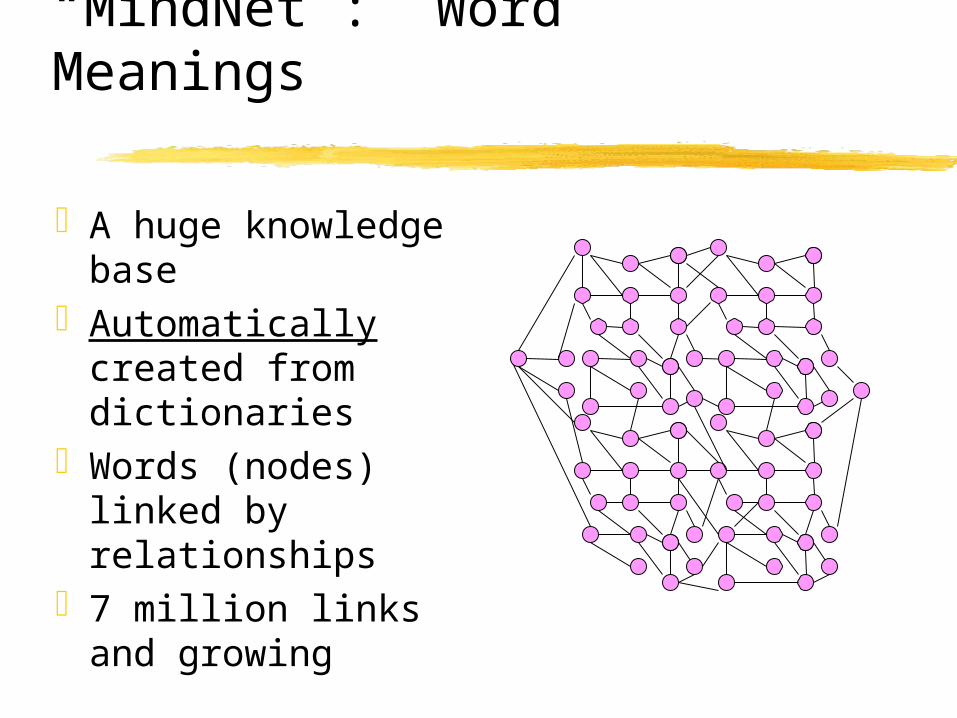
“MindNet”: Word Meanings
A huge knowledge base
Automatically created from dictionaries
Words (nodes) linked by relationships
7 million links and growing

MindNetMindNet





P1 Panel (WWW8) - Finding Anything in the Billion-Page Web: Are Algorithms the Answer?
Moderator: Prabhakar Raghavan, IBM Almaden Research Center,USA
Panelists:- Andrei Z. Broder, Compaq SRC - Monika R. Henzinger, Compaq SRC - Udi Manber, Yahoo! Inc. - Brian Pinkerton, Excite Inc.

Web queries average length 2.2 words 10% use syntax (often incorrectly) 1% use advanced search noun phrase only
Precision more important than recall?

Computer Search Today: large central indices
Human Search Today: ask friends - 6dos human, decentralized
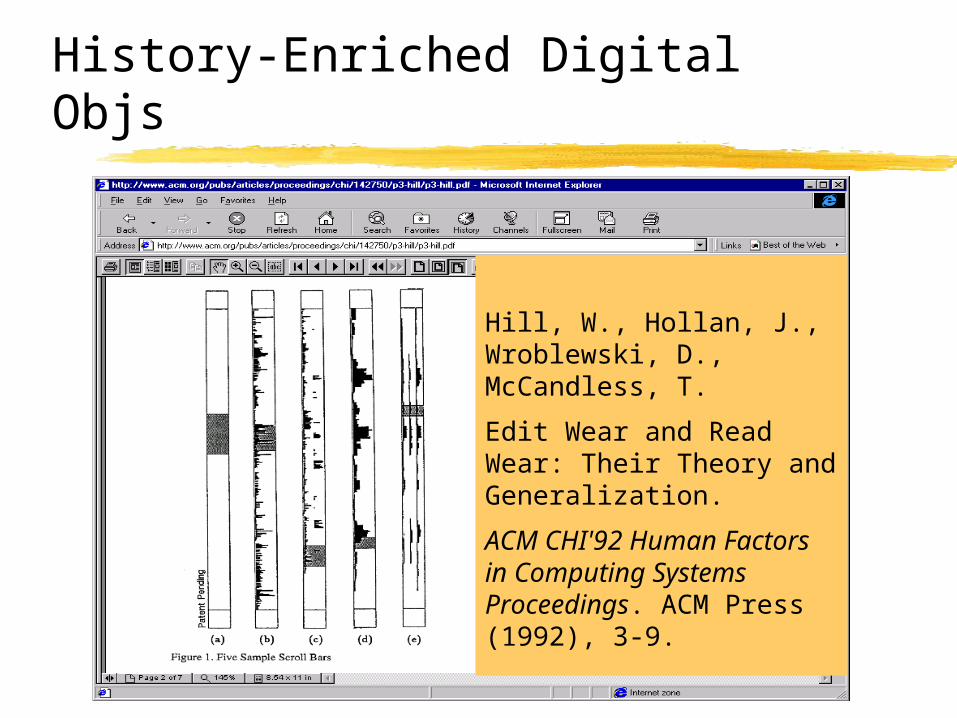
History-Enriched Digital Objs
Hill, W., Hollan, J., Wroblewski, D., McCandless, T.
Edit Wear and Read Wear: Their Theory and Generalization.
ACM CHI'92 Human Factors in Computing Systems Proceedings. ACM Press (1992), 3-9.







