
Conceptual Clustering Using Lingo Algorithm:Evaluation on Open Directory Project Data
Stanis law Osinski Dawid Weiss
Institute of Computing SciencePoznan University of Technology
May 20th, 2004

Some background: how to evaluate an SRC algorithm?
About various goals of evaluation. . .
Reconstruction of a predefined structureTest data: merge-then-cluster, manual labeling
Measures: precision-recall, entropy measures. . .
Labels “quality”, descriptivenessUser surveys, click-distance methods

Some background: how to evaluate an SRC algorithm?
What types of “errors” can an algorithm make structure-wise?
Misassignment errors (document→cluster)
Missing documents in a cluster
Incorrect clusters (unexplainable)
Missing clusters (undetected)
Granularity level confusion (subcluster domination problems)

Evaluation of Lingo’s performance
We tried to answer the following questions:
Clusters’ structure:
1 Is Lingo able to cluster similar documents?2 Is Lingo able to highlight outliers and “minorities”?3 Is Lingo able to capture generalizations of closely-related
subjects?4 How does Lingo compare to Suffix Tree Clustering?
Quality of cluster labels
Are clusters labelled appropriately? Are they informative?

Data set for the experiment
Data set: a subset of the Open Directory Project
Rationale:
Human-created and maintained structureHuman-created and maintained labelsDescriptions resemble search results (snippets)Free availability

ODP Categories chosen for the experiment
BRunner
LRings
MOVIES
Ortho
HEALTH CARE
PHOTOGRAPHY
COMPUTER SCIENCE
DATABASES MISC.
Infra
MySQL DWare
PostgrXMLDB
JavaTut
Vi
Test sets for the experiement
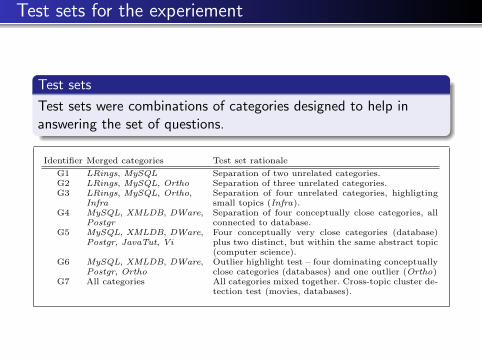
Test sets
Test sets were combinations of categories designed to help inanswering the set of questions.
Conceptual Clustering Using Lingo—Evaluation on ODP Data 5
Identifier Merged categories Test set rationale
G1 LRings, MySQL Separation of two unrelated categories.G2 LRings, MySQL, Ortho Separation of three unrelated categories.G3 LRings, MySQL, Ortho,
InfraSeparation of four unrelated categories, highligtingsmall topics (Infra).
G4 MySQL, XMLDB, DWare,Postgr
Separation of four conceptually close categories, allconnected to database.
G5 MySQL, XMLDB, DWare,Postgr, JavaTut, Vi
Four conceptually very close categories (database)plus two distinct, but within the same abstract topic(computer science).
G6 MySQL, XMLDB, DWare,Postgr, Ortho
Outlier highlight test – four dominating conceptuallyclose categories (databases) and one outlier (Ortho)
G7 All categories All categories mixed together. Cross-topic cluster de-tection test (movies, databases).
Fig. 2. Merged categories – test sets for the experiment
4.2 Algorithm’s implementation and thresholds
We used Lingo’s implementation available as part of the Carrot2 system (www.cs.put.poznan.pl/dweiss/carrot). Lingo component uses Porter stemmingalgorithm for documents it recognizes as being in English and an appropriatestop-word list. We initially kept all control thresholds of the algorithm (see [7]for explanation) at their default values (cluster assignment threshold—0.15,candidate cluster threshold—0.775). Later we repeated the experiment forother threshold levels and observed no noticeable change that would affectour conclusions from the experiment. The experiment was performed on a liveon-line demo of Carrot2, using a set of automatic scripts written in BeanShelland XSLT.
4.3 Criteria for evaluation of results
As mentioned in the introduction, numerical evaluation of search results clus-tering is always problematic. Fuzzy definitions of cluster’s value, such as:“good”, “meaningfull” or “concise” are hard to define numerically. Besides,even human evaluation performed by experts can vary a great deal betweenindividuals, as shown in in [6]. In our previous work [8] we made an attemptto employ a statistical approach to comparing a clustered set of search resultsto an “ideal, ground truth” set of clusters acquired from human experts. Un-fortunately, any differences between the result of automated clustering andthe “ideal” structure would count as a mistake of the algorithm, even if infact the algorithm just made a different, equally justified decision—for in-stance splitting a larger subject into its sub hierarchy. We did not want topenalize Lingo like this, because it was not the objective of the experiment.Instead, we decided to manually investigate the structure of created clusters,represented by classes-in-cluster distribution (see Fig. 3), and try to answerthe experiment’s questions based on such analysis.

The experiment
Lingo’s implementation → Carrot2 framework
The algorithm’s thresholds:
Fixed at “good guess” values (same as those used in theon-line demo)Stemming and stop-word detection applied to the input data

The results
Method of analysis
Manual investigation of document-to-cluster assignment charts.
Helps understand the internal structure of results
Prevents compensations inherent in aggregative measures
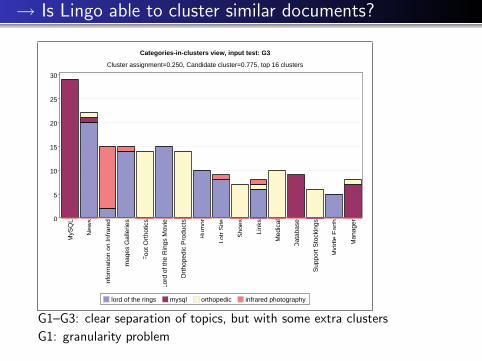
→ Is Lingo able to cluster similar documents?
Categories-in-clusters view, input test: G3
Cluster assignment=0.250, Candidate cluster=0.775, top 16 clusters
lord of the rings mysql orthopedic infrared photography
MyS
QL
New
s
Info
rmat
ion
on In
frar
ed
Imag
es G
alle
ries
Foo
t Ort
hotic
s
Lord
of t
he R
ings
Mov
ie
Ort
hope
dic
Pro
duct
s
Hum
or
Lotr
Site
Sho
es
Link
s
Med
ical
Dat
abas
e
Sup
port
Sto
ckin
gs
Mid
dle
Ear
th
Man
ager
0
5
10
15
20
25
30
G1–G3: clear separation of topics, but with some extra clusters
G1: granularity problem
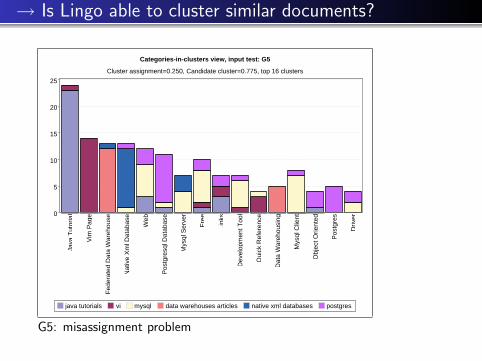
→ Is Lingo able to cluster similar documents?
Categories-in-clusters view, input test: G5
Cluster assignment=0.250, Candidate cluster=0.775, top 16 clusters
java tutorials vi mysql data warehouses articles native xml databases postgres
Java
Tut
oria
l
Vim
Pag
e
Fed
erat
ed D
ata
War
ehou
se
Nat
ive
Xm
l Dat
abas
e
Web
Pos
tgre
sql D
atab
ase
Mys
ql S
erve
r
Fre
e
Link
s
Dev
elop
men
t Too
l
Qui
ck R
efer
ence
Dat
a W
areh
ousi
ng
Mys
ql C
lient
Obj
ect O
rient
ed
Pos
tgre
s
Driv
er
0
5
10
15
20
25
G5: misassignment problem

→ Is Lingo able to highlight outliers and “minorities”?
Categories-in-clusters view, input test: G6
Cluster assignment=0.250, Candidate cluster=0.775, top 16 clusters
mysql data warehouses articles native xml databases postgres orthopedic
Mys
ql D
atab
ase
Fed
erat
ed D
ata
War
ehou
se
Foo
t Ort
hotic
s
Ort
hope
dic
Pro
duct
s
Acc
ess
Pos
tgre
sql
Web
Mys
ql S
erve
r
Med
ical
Sho
es D
esig
ned
Ort
hopa
edic
Pos
tgre
s
Mys
ql C
lient
Dat
a W
areh
ousi
ng
Offe
rs S
oftw
are
Dev
elop
men
t Too
l
Inno
vativ
e0
2
4
6
8
10
12
14
16
18
Ortho category (outlier), XMLDB consumed by MySQL!

→ Is Lingo able to highlight outliers and “minorities”?
Categories-in-clusters view, input test: G7
Cluster assignment=0.250, Candidate cluster=0.775, top 16 clusters
blade runner infrared photography java tutorials lord of the rings mysql orthopedic
vi data warehouses articles native xml databases postgres
Bla
de R
unne
r
Mys
ql D
atab
ase
Java
Tut
oria
l
Lord
of t
he R
ings
New
s
Mov
ie R
evie
w
Info
rmat
ion
on In
frar
ed
Dat
a W
areh
ouse
Imag
es G
alle
ries
BB
C F
ilm
Vim
Mac
ro
Web
Site
Fan
Fic
tion
Fan
Art
Cus
tom
Ort
hotic
s
Layo
ut M
anag
emen
t
DB
MS
Onl
ine0
5
10
15
20
25
30
35
40
45
50
Infra category (outlier)

→ Is Lingo able to highlight outliers and “minorities”?
Categories-in-clusters view, input test: G5
Cluster assignment=0.250, Candidate cluster=0.775, top 16 clusters
java tutorials vi mysql data warehouses articles native xml databases postgres
Java
Tut
oria
l
Vim
Pag
e
Fed
erat
ed D
ata
War
ehou
se
Nat
ive
Xm
l Dat
abas
e
Web
Pos
tgre
sql D
atab
ase
Mys
ql S
erve
r
Fre
e
Link
s
Dev
elop
men
t Too
l
Qui
ck R
efer
ence
Dat
a W
areh
ousi
ng
Mys
ql C
lient
Obj
ect O
rient
ed
Pos
tgre
s
Driv
er
0
5
10
15
20
25
XMLDB category (outlier)

→ Is Lingo able to capture generalizations?
Categories-in-clusters view, input test: G7
Cluster assignment=0.250, Candidate cluster=0.775, top 16 clusters
blade runner infrared photography java tutorials lord of the rings mysql orthopedic
vi data warehouses articles native xml databases postgres
Bla
de R
unne
r
Mys
ql D
atab
ase
Java
Tut
oria
l
Lord
of t
he R
ings
New
s
Mov
ie R
evie
w
Info
rmat
ion
on In
frar
ed
Dat
a W
areh
ouse
Imag
es G
alle
ries
BB
C F
ilm
Vim
Mac
ro
Web
Site
Fan
Fic
tion
Fan
Art
Cus
tom
Ort
hotic
s
Layo
ut M
anag
emen
t
DB
MS
Onl
ine0
5
10
15
20
25
30
35
40
45
50
“movie review” cluster is a generalization, but. . .

→ Is Lingo able to capture generalizations?
Categories-in-clusters view, input test: G7
Cluster assignment=0.250, Candidate cluster=0.775, top 16 clusters
blade runner infrared photography java tutorials lord of the rings mysql orthopedic
vi data warehouses articles native xml databases postgres
Bla
de R
unne
r
Mys
ql D
atab
ase
Java
Tut
oria
l
Lord
of t
he R
ings
New
s
Mov
ie R
evie
w
Info
rmat
ion
on In
frar
ed
Dat
a W
areh
ouse
Imag
es G
alle
ries
BB
C F
ilm
Vim
Mac
ro
Web
Site
Fan
Fic
tion
Fan
Art
Cus
tom
Ort
hotic
s
Layo
ut M
anag
emen
t
DB
MS
Onl
ine0
5
10
15
20
25
30
35
40
45
50
Clusters are usually orthogonal with SVD, so no good results should be
expected in this area.

→ How does Lingo compare to Suffix Tree Clustering?
Categories-in-clusters view, input test: G7
Cluster assignment=0.250, Candidate cluster=0.775, top 16 clusters
blade runner infrared photography java tutorials lord of the rings mysql orthopedic
vi data warehouses articles native xml databases postgres
Bla
de R
unne
r
Mys
ql D
atab
ase
Java
Tut
oria
l
Lord
of t
he R
ings
New
s
Mov
ie R
evie
w
Info
rmat
ion
on In
frar
ed
Dat
a W
areh
ouse
Imag
es G
alle
ries
BB
C F
ilm
Vim
Mac
ro
Web
Site
Fan
Fic
tion
Fan
Art
Cus
tom
Ort
hotic
s
Layo
ut M
anag
emen
t
DB
MS
Onl
ine0
5
10
15
20
25
30
35
40
45
50
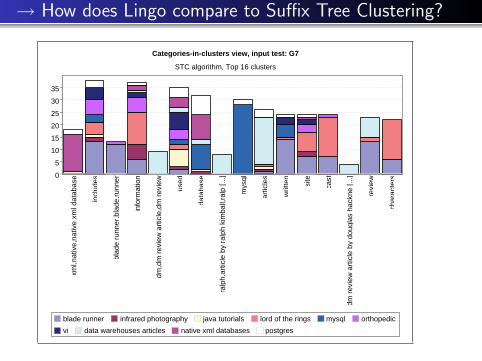
→ How does Lingo compare to Suffix Tree Clustering?
Categories-in-clusters view, input test: G7
STC algorithm, Top 16 clusters
blade runner infrared photography java tutorials lord of the rings mysql orthopedic
vi data warehouses articles native xml databases postgres
xml,n
ativ
e,na
tive
xml d
atab
ase
incl
udes
blad
e ru
nner
,bla
de,r
unne
r
info
rmat
ion
dm,d
m r
evie
w a
rtic
le,d
m r
evie
w
used
data
base
ralp
h,ar
ticle
by
ralp
h ki
mba
ll,ra
lp [.
..]
mys
ql
artic
les
writ
ten
site
cast
dm r
evie
w a
rtic
le b
y do
ugla
s ha
ckne
[...]
revi
ew
char
acte
rs0
5
10
15
20
25
30
35

Key differences between Lingo and STC
Size-dominated clusters in STC
Cluster labels much less informative
Common-term clusters in STC

Cluster labels quality
Performed manually
Problems:
Single term labels usually ambiguous or too broad (“news”,“free”)Level of granularity usually unclear (need for hierarchicalmethods?)

A word about analytical comparison methods. . .
Can these conclusions be derived using formulas?
We think so: cluster contamination measures might help.

Online demo
A nice form of evaluation (although scientifically doubtful), is theonline demo’s popularity and feedback we get from users.









