Download - Data loss prevention (dlp)

SUBMITTED BY HUSSEIN M. AL-SANABANI
SUPERVISOR
YRD.DOÇ.DR. MURAT İSKEFİYELİ
Overview of Data Loss Prevention (DLP) Technology
DLP 11/23/2014
1

Outline
What is Data Loss Prevention ?DLP ModelsDLP Systems and ArchitectureData Classification and IdentificationTechnical Challenges ReferenceResearches
DLP 11/23/2014
2

What Is Data Loss Prevention?
What is Data Loss Prevention? Data loss prevention (DLP) is a data security technology that
detects potential data breach incidents in timely manner and prevents them by monitoring data in-use (endpoints), in-motion (network traffic), and at-rest (data storage) in an organization’s network.
DLP 11/23/2014
3

What Is Data Loss Prevention?
What drives DLP development? Regulatory compliances such as PCI,SOX, HIPAA, GLBA,
SB1382 and etc Confidential information protection Intellectual property protection
What data loss incidents does a DLP system handle? Incautious data leak by an internal worker Intentional data theft by an unskillful worker Determined data theft by a highly technical worker Determined data theft by external hackers or advanced
malwares or APT DLP 11/23/2014
4

What Is Data Loss Prevention?
The evolution of naming Information Leak Prevention (ILP) Information Leak Detection and Prevention (ILDP) DLP
Data Leak Prevention Data Loss Prevention
DLP 11/23/2014
5

DLP Models
A model is used to describe a technology with rigorous terms
We need models to define/scope what a DLP system should do?
Three States of Data Data in Use (endpoints) Data in Motion (network) Data at Rest (storage)
DLP 11/23/2014
6

DLP Models
The data in use at endpoints can be leaked via USB Emails Web mails HTTP/HTTPS FTP …
The data in motion can be leaked via SMTP FTP HTTP/HTTPS …
DLP 11/23/2014
7

DLP Models
The data at rest could reside at wrong place Be accessed by wrong person Be owned by wrong person
DLP 11/23/2014
8
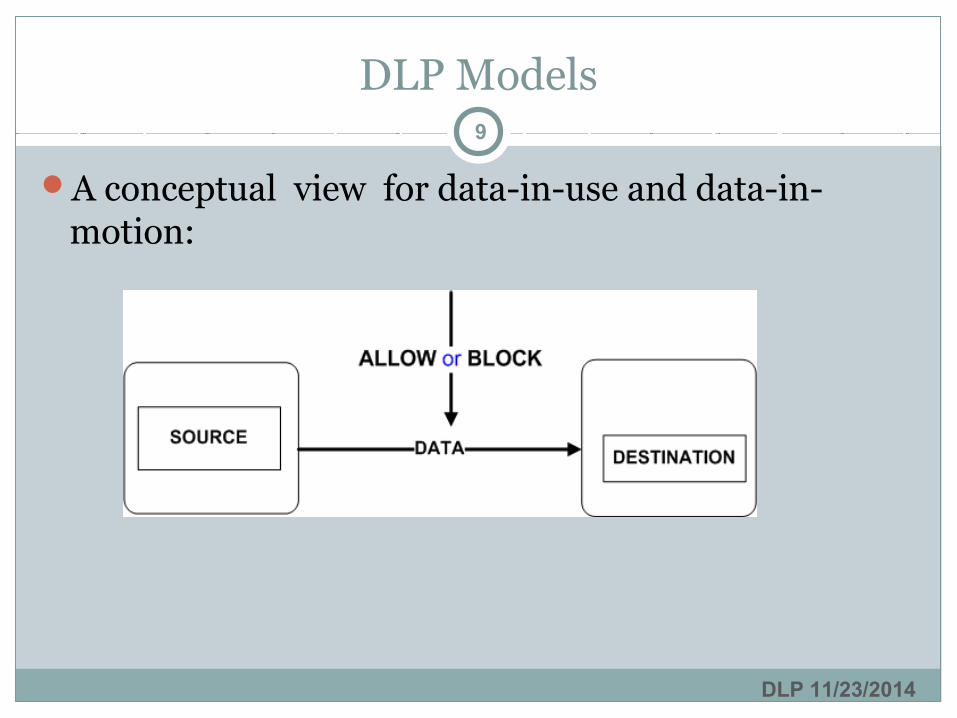
DLP Models
A conceptual view for data-in-use and data-in-motion:
DLP 11/23/2014
9

DLP Models
Technical views for data-in-use and data-in-motion:
DLP 11/23/2014
10

DLP Models
DLP Model for data-in-use and data-in-motion: DATA flows from SOURCE to DESTINATION via CHANNEL
do ACTIONs
DATA specifies what confidential data is SOURCE can be an user, an endpoint, an email address, or a group
of them DESTINATION can be an endpoint, an email address, or a group
of them, or simply the external world CHANNEL indicates the data leak channel such as USB, email,
network protocols and etc ACTION is the action that needs to be taken by the DLP system
when an incident occurs
DLP 11/23/2014
11

DLP Models
DLP Model for data-at-rest
DLP 11/23/2014
12

DLP Models
DLP Model for data-at-rest DATA resides at SOURCE do ACTIONs
DATA specifies what the sensitive data (which has potential for leakage) is
SOURCE can be an endpoint, a storage server or a group of them ACTION is the action that needs to be taken by the DLP system
when confidential data is identified at rest.
DLP 11/23/2014
13

DLP Models
These two DLP models are fundamental
They basically define the formats of DLP security rules (or DLP security policies)
DLP 11/23/2014
14

DLP Systems and Architecture
Typical DLP systems DLP Management Console DLP Endpoint Agent DLP Network Gateway Data Discovery Agent (or Appliance)
DLP 11/23/2014
15

DLP Systems and Architecture
Typical DLP system architecture
DLP 11/23/2014
16

Data Classification and Identification
One expects a DLP system can answer the following questions What is sensitive information? How to define sensitive information? How to categorize sensitive information? How to check if a given document contains sensitive information? How to measure data sensitivity?
Data inspection is an important capability for a content-aware DLP solution. It consists of two parts: To define sensitive data, i.e., data classification To identify sensitive data in real time
DLP 11/23/2014
17

Data Classification and Identification
Sensitive data is contained in textual documents.What does a document mean to you?We need text models to describe a text:
DLP 11/23/2014
18

Data Classification and Identification
prefered to use UTF-8 text model Handling all languages, especially for CJK group. A textual document is normalized into a sequence of UTF-8
characters
Four fundamental approaches for sensitive data definition and identification: Document fingerprinting Database record fingerprinting Multiple Keyword matching Regular expression matching
DLP 11/23/2014
19

Data Classification and Identification
What is document fingerprinting about? It is a solution to a problem of information retrieval:
Identify modified versions of known documents Near duplicate document detection (NDDD)
A technique of variant detection for documents
DLP 11/23/2014
20

Data Classification and Identification
What is database record fingerprinting about? Also known as Exact Match in DLP field It is a technique to detect if there exist sensitive data records
within a text.
Use Case: We have several personal data records of <SSN, Phone#,
address> that are included in a text, we want to extract all records from the file to determine the sensitivity of the file.
DLP 11/23/2014
21

Data Classification and Identification
Multiple keyword match and RegEx match They are well-known & well-defined problems Very useful in DLP data inspection
Problem Definition for Keyword Match: Let S= {K1,K2,…,Kn} be a dictionary of keywords. Given any text T, one needs to identify all keyword occurrences from T.
Problem Definition for RegEx Match: Let S= {P1,P2,…,Pm} be a set of RegEx patterns. Given any text T, one needs to identify all pattern instances from T.
Easy problems? Not at all. For large n and m, one will have performance issue. That’s the problem of scalability. Scalable algorithms must be provided.
DLP 11/23/2014
22

Data Classification and Identification
How to evaluate a classification algorithm? Accuracy in terms of false positive and false negative Performance Language independence
DLP 11/23/2014
23

Data Classification and Identification
Data template framework:
DLP 11/23/2014
24

Data Classification and Identification
DLP rule engine works on top of both DLP models and data template framework:
DLP 11/23/2014
25

Technical Challenges
Some areas with challenges Concept Match Data Discovery Document Classification Automation Determined Data Theft Detection
DLP 11/23/2014
26

Reference
http://www.trendmicro.com/us/enterprise/data-protection/data-loss-prevention/http://www.mcafee.com/us/products/total-protection-for-data-loss-prevention.aspxhttp://www.symantec.com/data-loss-prevention/http://www.manageengine.com/products/eventlog/eventlog-compliance.html
DLP 11/23/2014
27

Researches (1)
Title: Text Classification for Data Loss Prevention
Author: Michael Hart, Pratyusa Manadhata, and Rob Johnson
Institute: Computer Science Department, Stony Brook University and
HP Labs
Published on: Copyright 2011 Hewlett-Packard Development Company, L.P.
DLP 11/23/2014
28

Research: 1 cont. cont.
This paper present automatic text classification algorithms for classifying enterprise documents as either sensitive or non-sensitive.
This paper also introduce a novel training strategy, supplement and adjust, to create a classifier that has a low false discovery (positive) rate, even when presented with documents unrelated to the enterprise.
And evaluated the classifier on several corpora that assembled from confidential documents published on WikiLeaks and other archives. this classifier had a false negative rate of less than 3.0% and a false discovery (positive) rate of less than 1.0% on all tests (i.e, in a real deployment, the classifier can identify more than 97% of information leaks while raising at most 1 false alarm every 100th time).
DLP 11/23/2014
29

Research: 1 contcont..
Target: Create automatic document classification techniques to identify confidential
data in a scalable and accurate manner. And to make the finer distinction between enterprise public and private
documents.
How: They performed a brute search evaluating multiple machine learning
algorithms for text classifier performance, including SVMs, Naive Bayesian classifiers, and Rocchio classifiers from the WEKA toolkit to determine the best classifier across all the datasets. They found that a support vector machine with a linear kernel, performed the best on the test corpora.
And they builded a well-studied machine learning technique, Support Vector Machines (SVMs), that scales well to large data sets.
DLP 11/23/2014
30

Supplement and Adjust
An SVM trained on enterprise documents achieves reasonable performance on enterprise documents, but has an unacceptably high false positive rate on non-enterprise (NE) documents. The poor performance can be explained by identifying weaknesses in the training approach.
To solve this problem , they supplement the classifier by adding training data from non-enterprise collections such as Wikipedia, Reuters. The presence of supplementary data does not train the classifier to recognize NE documents, but prevents it from overfitting the enterprise data.
DLP 11/23/2014
31

Research: 1 cont.cont.
Adding supplemental training data will likely introduce a new problem: class imbalance. Supplemental instances will bias the classifier towards public documents because the size of this class will overwhelm the size of secret documents.
This will result in a high false-negative rate on secret documents. Therefore, they need to adjust the decision boundary towards public instances. This will reduce the false negative rate while increasing the false positive rate.
DLP 11/23/2014
32

Researches (2)
Title: Classification of Corporate and Public Text
Author: Kevin Nguyen
Published on: December 16, 2011
DLP 11/23/2014
33

Research: 2 cont. cont.
In this project they try to tackle the problem of classifying a body of text in corporate message as private or public.
In comparison of text classifiers , they used Naive Bayes, Logistic Regression, and Support Vector Machine classifiers and found that SVMs showed better results.
DLP 11/23/2014
34







