Download - Deeplearning in finance

Deep learning in finance
Data science in finance
28 / 07
Sébastien Jehan

CAPITAL FUND MANAGEMENT
Fundamental research applied to financial markets
CFM invests in Science, Technology and Finance
23 years of experience in managing trading systems
A rational process that produces robust Trading Algorithms
Proprietary software able to execute & control large volumes
Opportunities :
• Software Engineers mastering C++, Python…
• System, Network & Database Administrators
• PhDs in theoretical physics, applied mathematics,
informatics…
PROPRIETARY AND CONFIDENTIAL - NOT FOR REDISTRIBUTION

Artificial Neural Networks
- History of Artificial Neural Networks
- Recurrent Neural Networks- Applications in Finance
AI for the enterprise
2015 $220 millions
2025 $11.1 billions (+56% / year)

Current applications to neural networks
• Medical image processing: mostly feed forward neural network
• Robokinetics and robovision: smooth moves and object detection
• Military: DARPA Synapse, objective 10 billion neurons (86 billions human brain) in 2 liters space for end of 2016.
• Email spam detection, Image classification
• Text recognition

10/201390-99/100
ON CAPTCHAS

1957: The perceptron
-
d
D0
D1
D2
InputLayer
OutputLayer
Destinations

1957: The perceptron
D0
D1
D2
InputLayer
OutputLayer
Destinations
FEED FORWARD

1957: The perceptron
D0
D1
D2
InputLayer
OutputLayer
Destinations
SINGLE LAYER

Teaching
-
d
D0
D1
D2
InputLayer
OutputLayer
Theorical
Y0
Y1
Y2
-
-
-
Supervised objective function

Application .NET

Applications
Is A or B
Linear problem

Applications
Is A or B
Not linearly separable => no convergence

1986: Multilayers perceptron
input vector
hidden layers
outputs
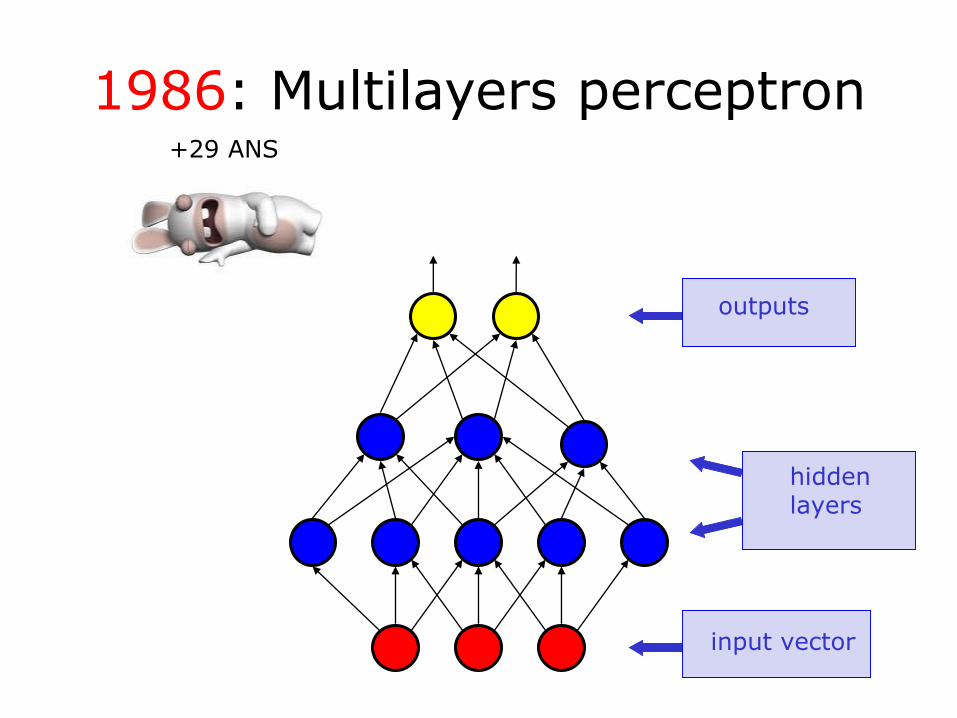
1986: Multilayers perceptron
input vector
hidden layers
outputs
+29 ANS

1986: Multilayers perceptron
input vector
hidden layers
outputsBack-
propagate error signal

Back propagationA
cti
vati
on
s
The error:
UpdateWeights:
0
1
0
.5
-5 5
Slide credit : Geoffrey Hinton

Back propagationA
ctiv
atio
ns
The error:
UpdateWeights:
0
1
0
.5
-5 5
Slide credit : Geoffrey Hinton
err
ors
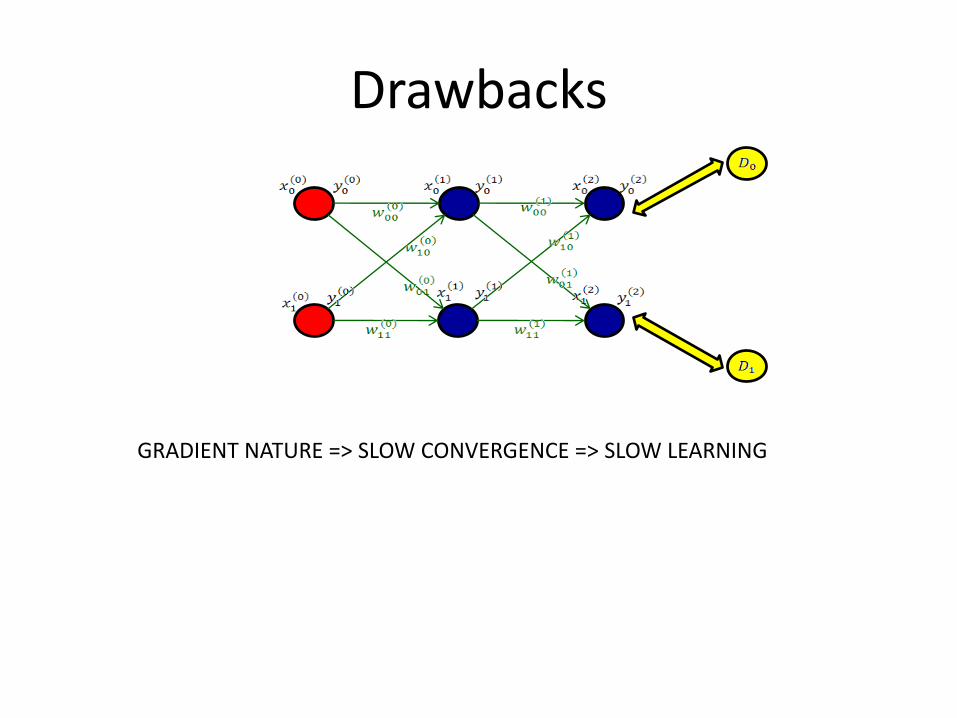
Drawbacks
GRADIENT NATURE => SLOW CONVERGENCE => SLOW LEARNING

Drawbacks
GRADIENT NATURE => SLOW CONVERGENCE => SLOW LEARNING LEARNING DECREASE WITH HIDDEN LAYERS NUMBERS

Drawbacks
GRADIENT NATURE => SLOW CONVERGENCE => SLOW LEARNING LEARNING DECREASE WITH HIDDEN LAYERS NUMBERSCAN FIND ONLY LOCAL MINIMA OF ERRORS
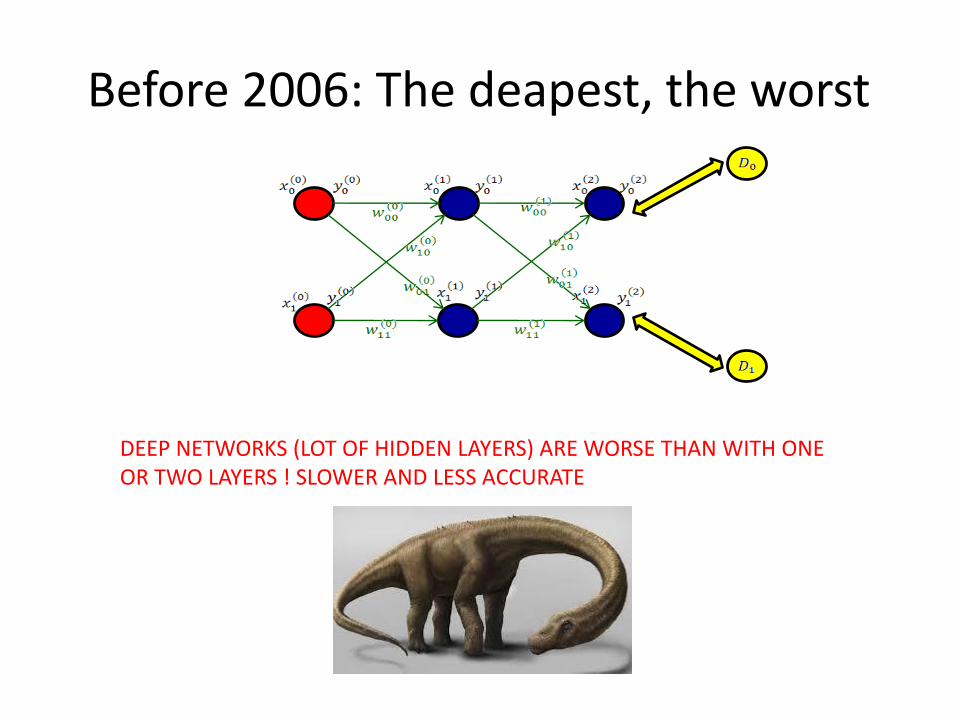
Before 2006: The deapest, the worst
DEEP NETWORKS (LOT OF HIDDEN LAYERS) ARE WORSE THAN WITH ONE OR TWO LAYERS ! SLOWER AND LESS ACCURATE

Deep ? How deep ?
DEEP IS >=5 LAYERS

2006: breakthrough

Who cares ?
2013: Director of FacebookAI research
Google distinguished researcher
Montreal University
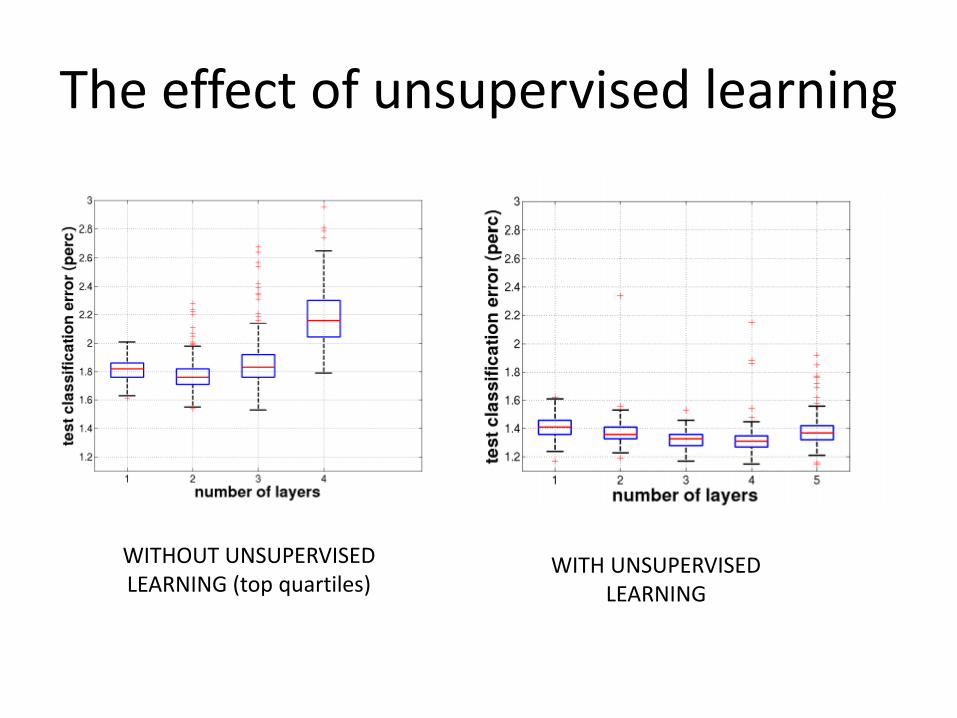
The effect of unsupervised learning
WITHOUT UNSUPERVISEDLEARNING (top quartiles)
WITH UNSUPERVISEDLEARNING

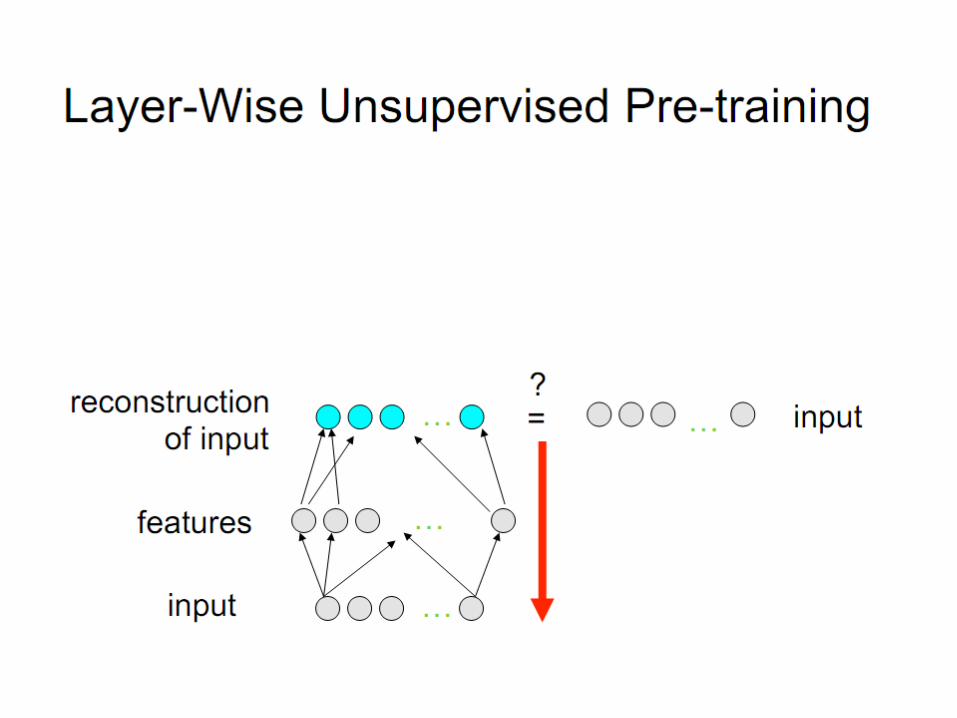

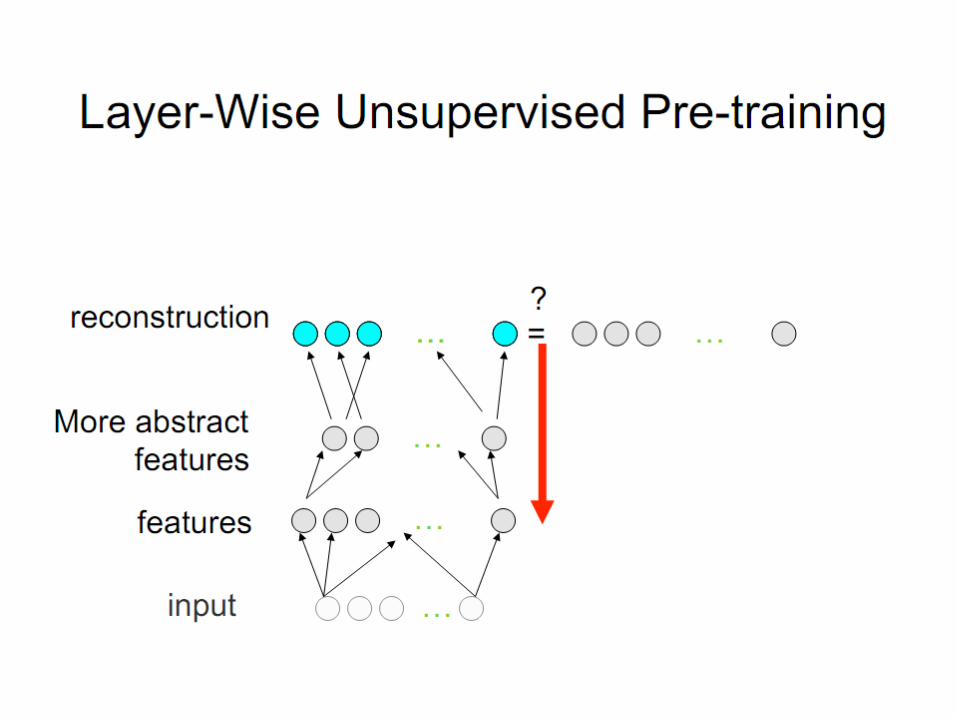
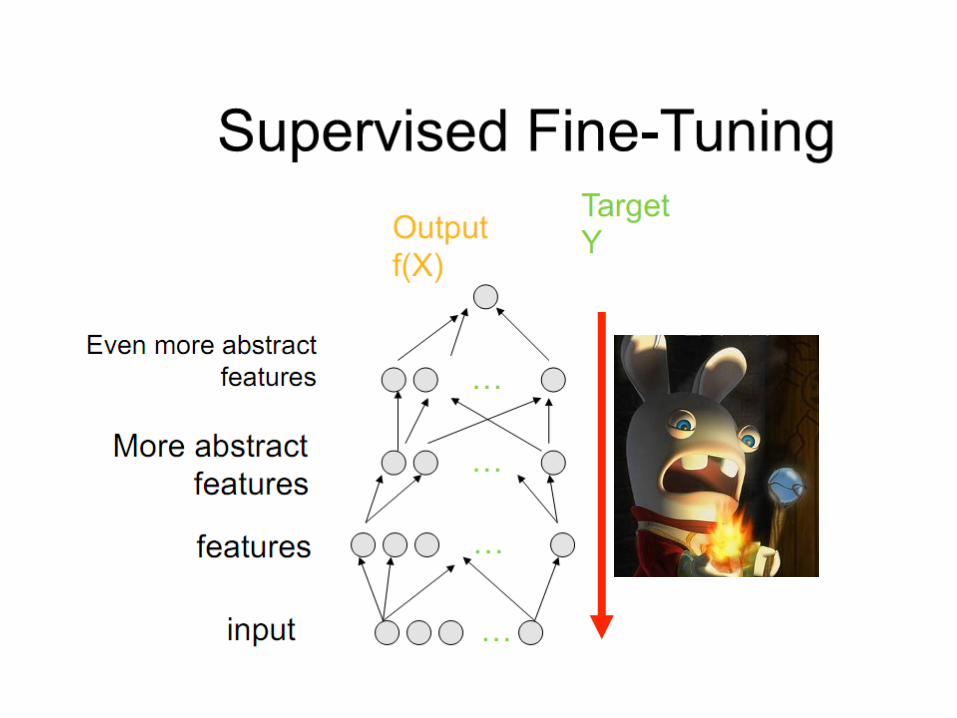
Becomes more non-linear, and this is good: it prevents the gradient learning to be transferred to previous layers for local optima
The first layer should react to input changes.

Becomes more non-linear, and this is good: it prevents the gradient learning to be transferred to previous layers for local optima
Yet we don’t know how.Just represent the dominant factors of variation of the input.




Size matters

Connectivity cost
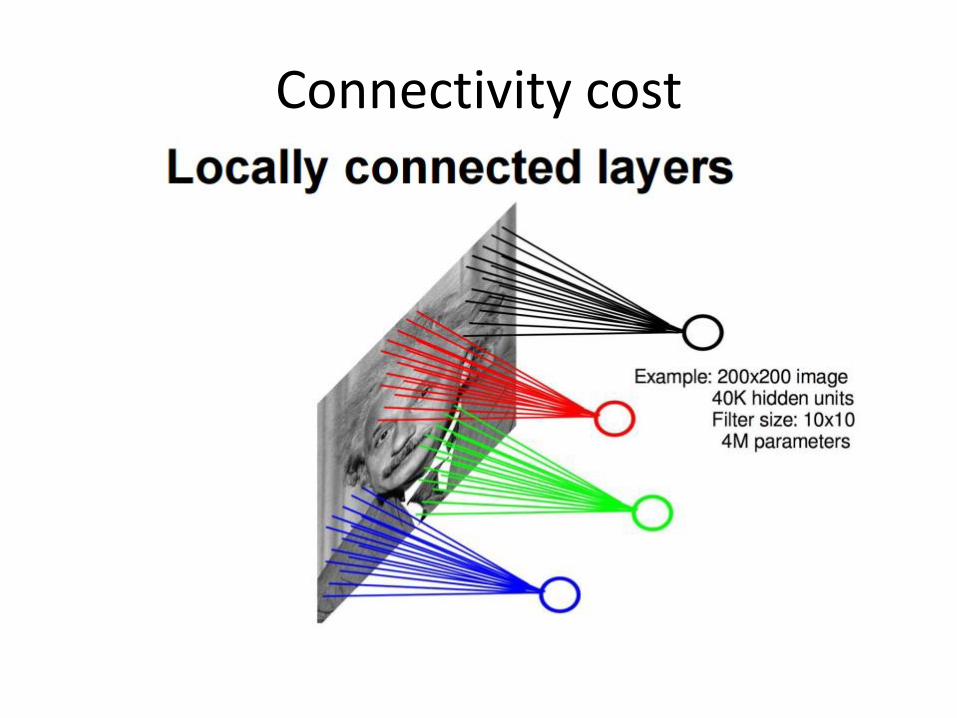
Connectivity cost

Infrastructure costs
• The bad news
In 2012, It took Google 16.000 CPU to have a single process real time cat face identifier http://hexus.net/tech/news/software/41537-googles-16000-cpu-neural-network-can-identify-cat/
• The good news
In 2017, public Beta testing of HP “The machine”, based on Memristors replacing transistors for some parts of the chip.http://insidehpc.com/2015/01/video-memristor-research-at-hp-labs/

Imagenet classification results
2012
2014 Deep Learning GoogleNet 6.66%
2015 Microsoft Research 4.94 %
ai is learned
http://arxiv.org/pdf/1502.01852v1.pdf

Reverse engineering deep learning results(2012)
SUPERVISED IMAGE CLASSIFICATIONS+ OTHER TRAININGS
First layer: always Gabor Filters like or Color Blob

Reverse engineering deep learning results(Nov 2014)
SUPERVISED IMAGE CLASSIFICATIONS+ OTHER TRAININGS
General or Specific Layer ?? Transfer ANN layers among trained models

Static deep learning in finance
+
Persondetection
PMFG
Performance heat map
… Trade opportunity detection
Market States
Current markets
…
Reduce information redundancy for a goal
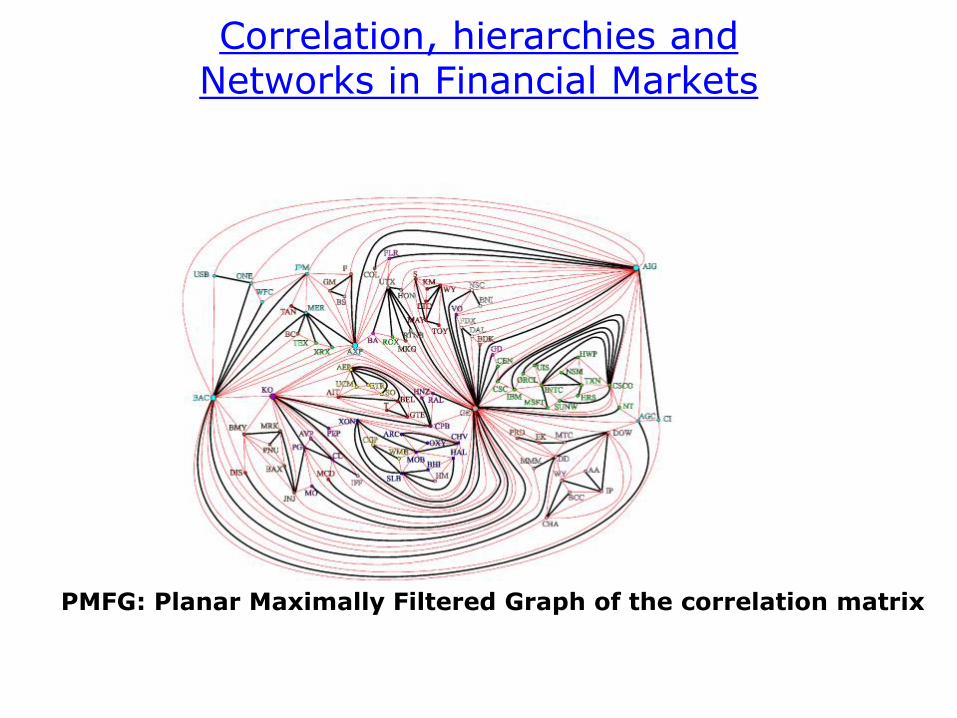
PMFG: Planar Maximally Filtered Graph of the correlation matrix
Correlation, hierarchies and Networks in Financial Markets
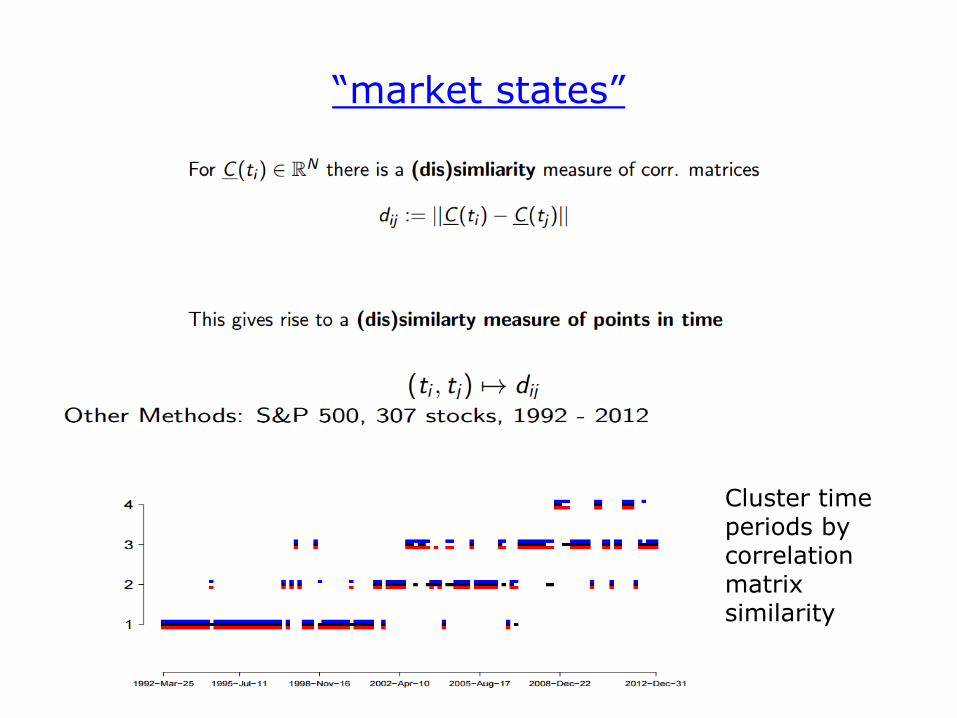
“market states”
Cluster time periods by correlation matrix similarity

Heat map 1 year perf, 23/07

1990: RNN
nonstationary I/O mapping, Y(t)f(X(t)), X(t) and Y(t) are
timevarying patterns

1990: RNN
nonstationary I/O mapping, Y(t)f(X(t)), X(t) and Y(t) are
timevarying patterns
The closest thing to computer dreams

RNN detailed
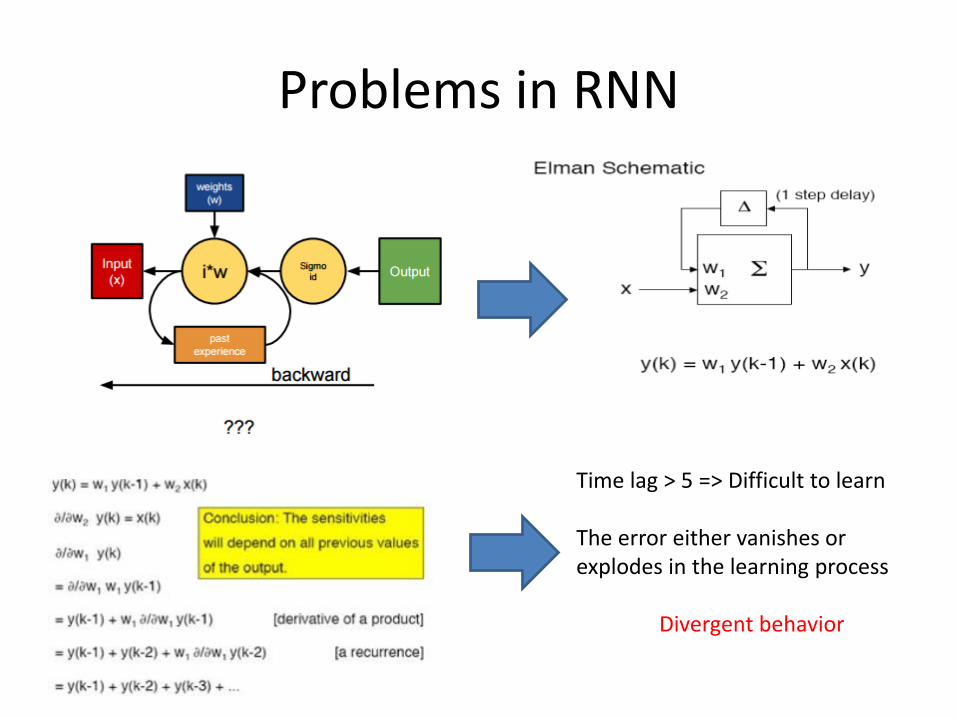
Problems in RNN
Time lag > 5 => Difficult to learn
The error either vanishes or explodes in the learning process
Divergent behavior

RNN for GARCH(1,1) predictions
IN SAMPLE:665 observations 01/2011 09/2013
OUT OF SAMPLE:252 observations 09/2013 09/2014
LAG=1, NO PROBLEM

A new approach: RNN with wavelet sigmoid (2D, time and frequency) April
2015
PREDICT “SEMI-CHAOTIC” TIME SERIE(MACKEY-GLASS), SOLUTION OF
Rapidly vanishingproperty of wavelet
function => No divergent behavior

Particle swarm optimization
• Concepts• Applications: Training a neural network
using PSO instead of backpropagation
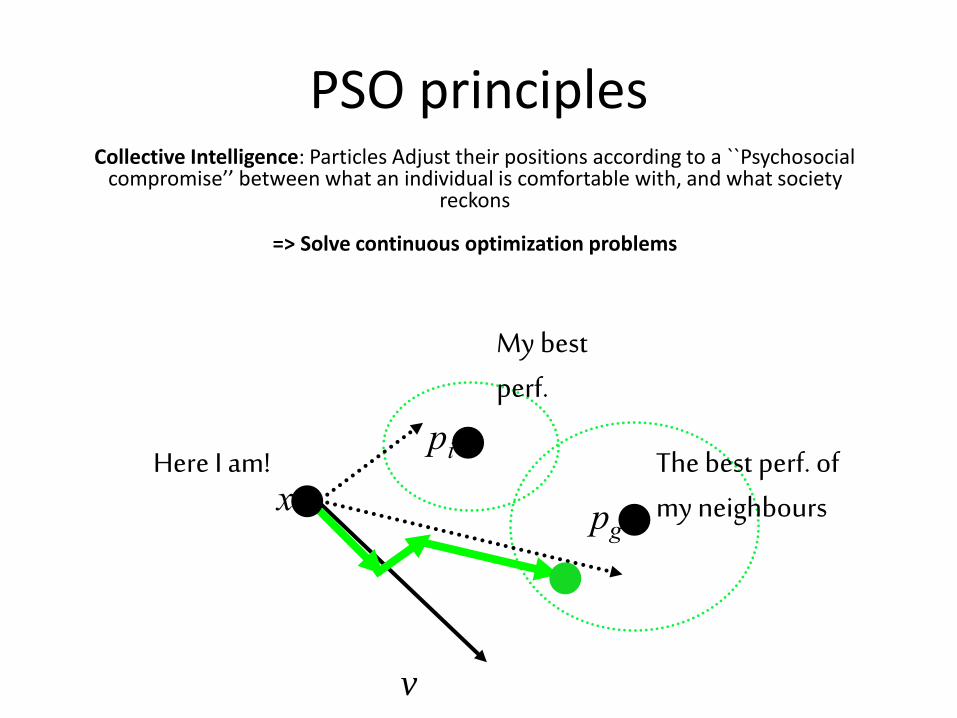
PSO principles
Here I am! The best perf. of my neighbours
My best perf.
xpg
pi
v
Collective Intelligence: Particles Adjust their positions according to a ``Psychosocial compromise’’ between what an individual is comfortable with, and what society
reckons
=> Solve continuous optimization problems

Training neural network with PSO (started in 2006)
Unsupervised training with PSO:
Not trapped in local minima Faster than back propagation

PSO ANN accuracy (July 2014)
Levenberg-Marquadt: second order in BP error evaluation
Credit Approval dataset, UCI

The challenge of multidimensionality
- Dimensionality reduction techniques
Dimension reduction techniques
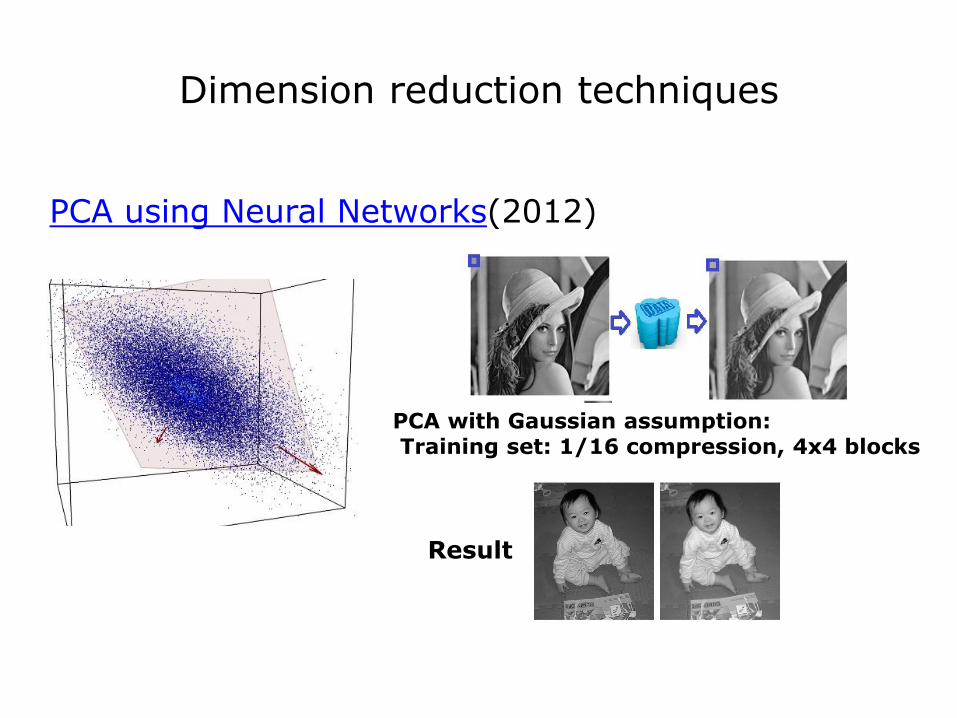
PCA using Neural Networks(2012)
PCA with Gaussian assumption:Training set: 1/16 compression, 4x4 blocks
Result
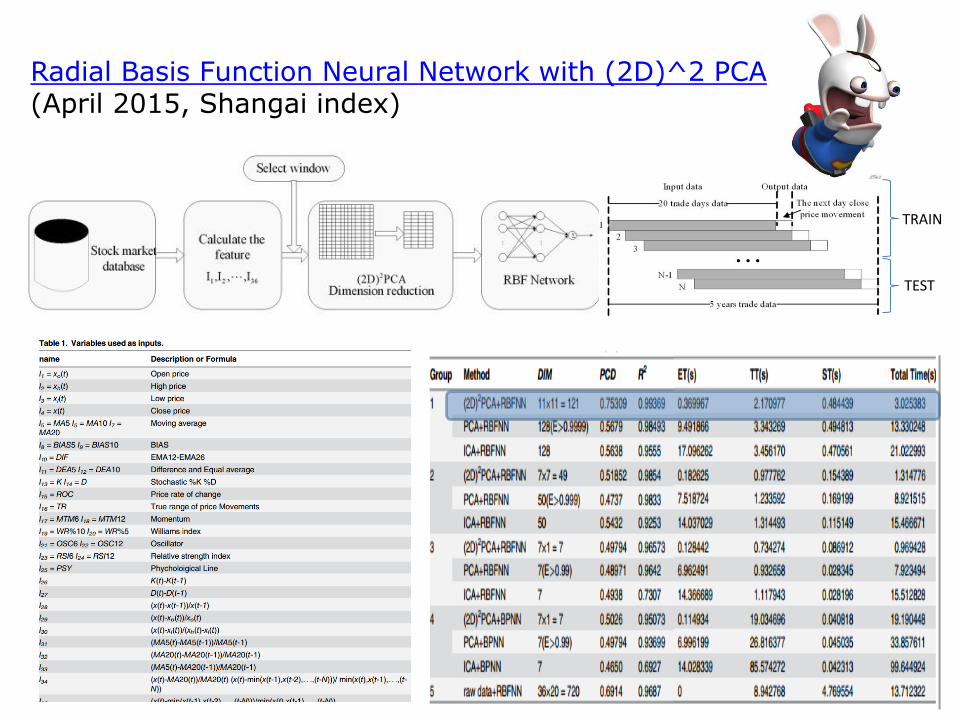
Radial Basis Function Neural Network with (2D)^2 PCA(April 2015, Shangai index)
TRAIN
TEST

Radial Basis Function Neural Network with (2D)^2 PCA(April 2015, Shangai index)
TRAIN
TEST
Exercise: find the issue

Thank you
International workshop on Deep Learning, Lille, France (July 10/11 2015): https://sites.google.com/site/deeplearning2015/accepted-papers







