
Empowering efficient HPC with Dell
Martin HilgemanHPC Consultant EMEA

Global HPC GroupCHPC conference 2013
Amdahl’s Law
Gene Amdahl (1967): "Validity of the Single Processor Approach to Achieving Large-Scale Computing Capabilities". AFIPS Conference Proceedings (30): 483–485.
“The effort expended on achieving high parallel processing rates is wasted unless it is accompanied by achievements in sequential processing rates of very nearly the same magnitude”a: speedupn: number of processorsp: parallel fraction𝑎=
𝑛(𝑝+𝑛 (1−𝑝))
2

Global HPC GroupCHPC conference 2013
Amdahl’s Law limits maximal speedup
95.0% 97.0% 99.0% 99.5%0
50
100
150
200
250
20
33
100
200
Infinite number of processors
Amdahl's Law percentage
Para
llel Speedup
a: speedupn: number of processorsp: parallel fraction
𝑎∞=1
(1−𝑝)
3

Global HPC Group
Amdahl’s Law and Efficiency
4 8 12 16 20 24 32 40 48 56 64 80 96 112 128
50.0%
0.666666666666667
0.857142857142857
0.909090909090909
0.933333333333333
0.947368421052632
0.956521739130435
0.967741935483871
0.974358974358974
0.978723404255319
0.981818181818182
0.984126984126984
0.987341772151899
0.989473684210526
0.990990990990991
0.992125984251969
66.7%
0.833583208395802
0.928678517883915
0.954613602289764
0.966716641679161
0.973723664483548
0.97829346196467
0.983895149199594
0.987198708338139
0.989377651599732
0.990922720457953
0.992075390875991
0.993680375002372
0.99474473289671
0.995502248875562
0.996068894686515
75.0%
0.888888888888889
0.952380952380952
0.96969696969697
0.977777777777778
0.982456140350877
0.985507246376812
0.989247311827957
0.991452991452991
0.99290780141844
0.993939393939394
0.994708994708995
0.9957805907
173
0.996491228070176
0.996996996996997
0.99737532808399
86.5%
88.5%
90.5%
92.5%
94.5%
96.5%
98.5%
Number of processor cores
Am
dahl's L
aw
Perc
enta
ge
Diminishing returns:
Tension between the desire to use more processors and the associated “cost”
𝑒=−( 1𝑝 −𝑛)(𝑛−1 )
4 CHPC conference 2013

Global HPC Group5
The Real Moore’s Law
• The clock speed plateau
• The power ceiling
• IPC limit
CHPC conference 2013

Global HPC Group6
Meanwhile Amdahl’s Law says that you cannot use them all efficiently
Industry is applying Moore’s Law by adding more cores
Moore’s Law vs Amdahl's Law - “too Many Cooks in the Kitchen”
CHPC conference 2013
Global HPC Group7
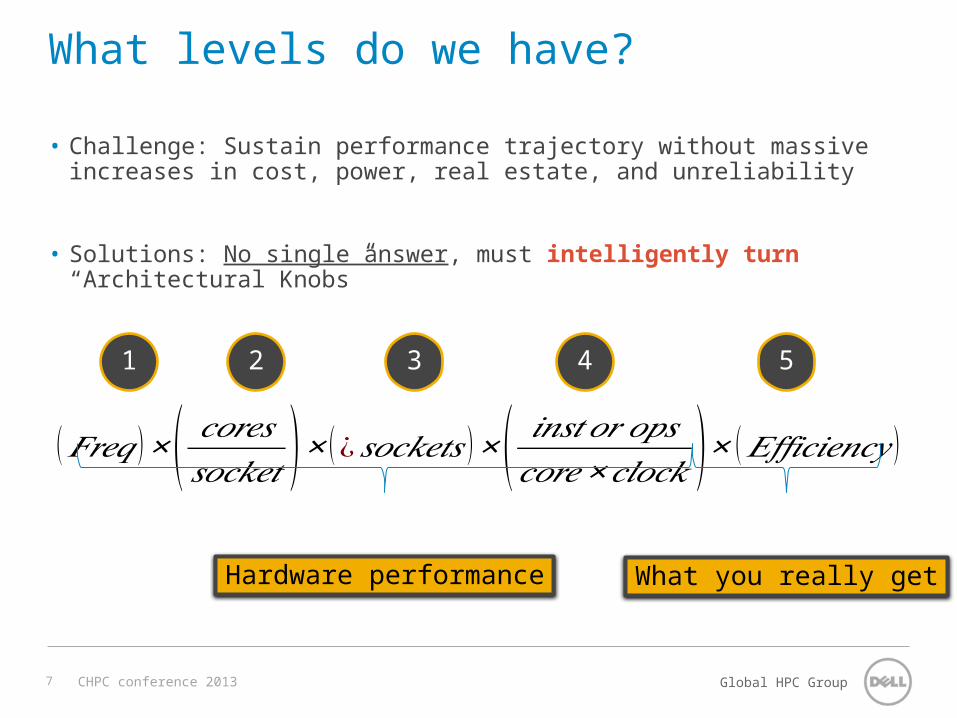
(𝐹𝑟𝑒𝑞 )×( 𝑐𝑜𝑟𝑒𝑠𝑠𝑜𝑐𝑘𝑒𝑡 )× (¿ 𝑠𝑜𝑐𝑘𝑒𝑡𝑠 )×( 𝑖𝑛𝑠𝑡𝑜𝑟 𝑜𝑝𝑠𝑐𝑜𝑟𝑒×𝑐𝑙𝑜𝑐𝑘 )× (𝐸𝑓𝑓𝑖𝑐𝑖𝑒𝑛𝑐𝑦 )
What levels do we have?
• Challenge: Sustain performance trajectory without massive increases in cost, power, real estate, and unreliability
• Solutions: No single answer, must intelligently turn “Architectural Knobs”
Hardware performance What you really get
1 2 3 4 5
CHPC conference 2013

Global HPC Group8
Turning the knobs 1 - 4
1Frequency is unlikely to change much Thermal/Power/Leakage challenges
2 Moore’s Law still holds: 130 -> 22 nm. LOTS of transistors
3Number of sockets per system is the easiest knob.Challenging for power/density/cooling/networking
4 IPC still growsFMA3/4, AVX, FPGA implementations for algorithmsChallenging for the user/developer
CHPC conference 2013

Global HPC Group9
• Traditional IT server utilization rates remain low
• New µServers are emerging, x86 and ARM
• Further movement from 4->2->1 socket systems as their capabilities expand
• What to do with all the capacity?
• Software defined everything…..
Meanwhile… traditional IT is swimming in performance
CHPC conference 2013

Global HPC Group10
Scaling sockets, power and density
ARM/ATOM: potential to disrupt perf/$$, perf/Watt model
Shared Infrastructure evolvingHighest efficiency for power and cooling
Extending design to facility Modularized compute/ storage optimization 2000 nodes, 30 PB storage, 600 kW in 22 m2
CHPC conference 2013

Global HPC Group
Which leaves knob 5: make your hands dirty! DO it=1,noprec
DO itSub=1,subNoprec ix = ir(1,it,itSub) iy = ir(2,it,itSub) iz = ir(3,it,itSub) idx = idr(1,it,itSub) idy = idr(2,it,itSub) idz = idr(3,it,itSub) sum = 0.0 testx = 0.0 testy = 0.0 testz = 0.0 DO ilz=-lsz,lsz irez = iz + ilz IF (irez.ge.k0z.and.irez.le.klz) THEN DO ily=-lsy,lsy irey = iy + ily IF (irey.ge.k0y.and.irey.le.kly) THEN DO ilx=-lsx,lsx irex = ix + ilx IF (irex.ge.k0x.and.irex.le.klx) THEN sum = sum + field(irex,irey,irez)& * diracsx(ilx,idx) & * diracsy(ily,idy) & * diracsz(ilz,idz) * (dx*dy*dz) testx = testx + diracsx(ilx,idx) testy = testy + diracsy(ily,idy) testz = testz + diracsz(ilz,idz) END IF END DO END IF END DO END IF END DO rec(it,itSub) = sum END DOEND DO
11
DO itSub=1,subNoprec DO it=1, noprec ix = ir(1,it,itSub) iy = ir(2,it,itSub) iz = ir(3,it,itSub) idx = idr(1,it,itSub) idy = idr(2,it,itSub) idz = idr(3,it,itSub) sum = 0.0 startz = MAX(iz-lsz,k0z) starty = MAX(iy-lsy,k0y) startx = MAX(ix-lsx,k0x) stopz = MIN(iz+lsz,klz) stopy = MIN(iy+lsy,kly) stopx = MIN(ix+lsx,klx) DO irez = startz, stopz ilz = irez - iz IF (diracsz(ilz,idz) .EQ. 0.d0 ) THEN CYCLE END IF dirac_tmp1 = diracsz(ilz,idz)*(dx*dy*dz) DO irey = starty, stopy ily = irey - iy dirac_tmp2 = diracsy(ily,idy) * dirac_tmp1 DO irex = startx, stopx ilx = irex - ix sum = sum + field(irex,irey,irez) & * diracsx(ilx,idx) & * dirac_tmp2 END DO END DO END DO
rec(it,itSub)=sum END DOEND DO
92 seconds 17 secondsCHPC conference 2013

Global HPC Group12
Efficiency optimization also applies across nodes
1 19 37 55 73 91 109127145163181199217235253 15 33 51 69 87 1051231411591771952132312490
500
1000
1500
2000
2500
3000
R022, lemans_trim_105m, 256 cores, PPN=16
MPI_WaitanyMPI_WaitallMPI_WaitMPI_SendrecvMPI_SendMPI_ScattervMPI_ScatterMPI_RecvMPI_IsendMPI_IrecvMPI_GathervMPI_GatherMPI_BcastMPI_BarrierMPI_AlltoallMPI_AllreduceMPI_AllgathervMPI_AllgatherApp
MPI rank
Wall c
lock t
ime (
s)
AS-IS: 2812 seconds Tuned MPI: 2458 seconds
12.6 % speedup
CHPC conference 2013

Global HPC Group13 CHPC conference 2012







