
1"©"Cloudera,"Inc."All"rights"reserved."
Ibis:"Scaling"Python"Analy=cs"on"Hadoop"and"Impala"Wes"McKinney,"StrataDHadoop"World"NYC"2015D09D30"@wesmckinn"

2"©"Cloudera,"Inc."All"rights"reserved."
Me"
• R&D"at"Cloudera"• Serial"creator"of"structured"data"tools"/"user"interfaces"• Mathema=cian"—"MIT"‘07"• “Professional"SQL"programmer”"2007D2010"(@"AQR)"• Created"pandas"(Python"library)"in"2008"• Wrote"bestseller"Python'for'Data'Analysis'2012"• Founder"of"DataPad""

3"©"Cloudera,"Inc."All"rights"reserved."
Python"is"popular…"
• Python"has"become"a"standard"language"of"data"science"• Why"is"it"popular?"• Maximizes"produc=vity"for"data"engineers"and"data"scien=sts"• Build"robust"soeware"and"do"interac=ve"data"analysis"with"100%"Python"code""• EasyDtoDlearn"and"makes"happy"and"produc=ve"data"teams""• Large,"diverse"open"source"development"community"• Comprehensive"libraries:"data"wrangling,"ML,"visualiza=on,"etc."
• Main"use"case:"data"science"&"engineering"swiss"army"knife"on"smallDtoDmedium"size"data"

4"©"Cloudera,"Inc."All"rights"reserved."
…but"Python"does"not"scale"today"
• Python"ecosystem"confined"to"singleDnode"analysis"• Great"for"smaller"data"sets"• Requires"sampling"or"aggrega=ons"for"larger"data"• Distributed"tools"compromise"in"various"ways"
• Extrac=ng"samples"or"aggrega=ons"for"larger"data"means:"• “Scales”"by"losing"more"fidelity"• Addi=onal"ETL"overhead"to"extract"samples/aggrega=ons"• Loss"of"produc=vity"with"mul=ple"languages,"tools,"etc"• Blocks"certain"analysis"and"use"cases"

5"©"Cloudera,"Inc."All"rights"reserved."
Industry"Analy=cs" Scien=fic"Compu=ng"
Heterogeneous"data"""""Flat"tables"and"JSON"Spark"/"MapReduce"SQL"DFSDfriendly"/"streaming"data"formats"More"physical"machines"
Homogeneous"data"""""Mul=dimensional"arrays"HPC"tools"Linear"algebra"Scien=fic"data"formats"Fewer"physical"machines"
Some"simplis=c"generaliza=ons"

6"©"Cloudera,"Inc."All"rights"reserved."
Industry"Analy=cs" Scien=fic"Compu=ng"
Heterogeneous"data"""""Flat"tables"and"JSON"Spark"/"MapReduce"SQL"DFSDfriendly"/"streaming"data"formats"More"physical"machines"
Homogeneous"data"""""Mul=dimensional"arrays"HPC"tools"Linear"algebra"Scien=fic"data"formats"(e.g."HDF5)"Fewer"physical"machines"
Some"simplis=c"generaliza=ons"
Python:(heavy(investment,((generally(
Python:(light(investment,(generally(

7"©"Cloudera,"Inc."All"rights"reserved."
Industry"Analy=cs:"Python’s"existen=al"crisis"

8"©"Cloudera,"Inc."All"rights"reserved."Source:"Wikipedia"

9"©"Cloudera,"Inc."All"rights"reserved."
Our"(Python’s)"biggest"mistake:"approaching"Big"Data"like"a"scien=fic"compu=ng"problem"

10"©"Cloudera,"Inc."All"rights"reserved."
pandas"
• Hugely"popular"Python"table"/"“data"frame”"library"• Labeled"table,"array,"and"=me"series"data"structures"
• Popular"for"data"prepara=on,"ETL,"and"inDmemory"analy=cs"• Built"using"Python’s"scien=fic"compu=ng"stack"• User"API"/"domain"specific"language"• Bespoke"inDmemory"analy=cs"/"rela=onal"algebra"engine"• IO"interfaces"(CSV,"SQL,"etc.)"• Expanded"data"type"system"(beyond"NumPy)"
• Supports"flat"data"only"(or"semiDstructured"data"that"can"be"flasened)"

11"©"Cloudera,"Inc."All"rights"reserved."
Many"SQL"engines"
…"and"more"
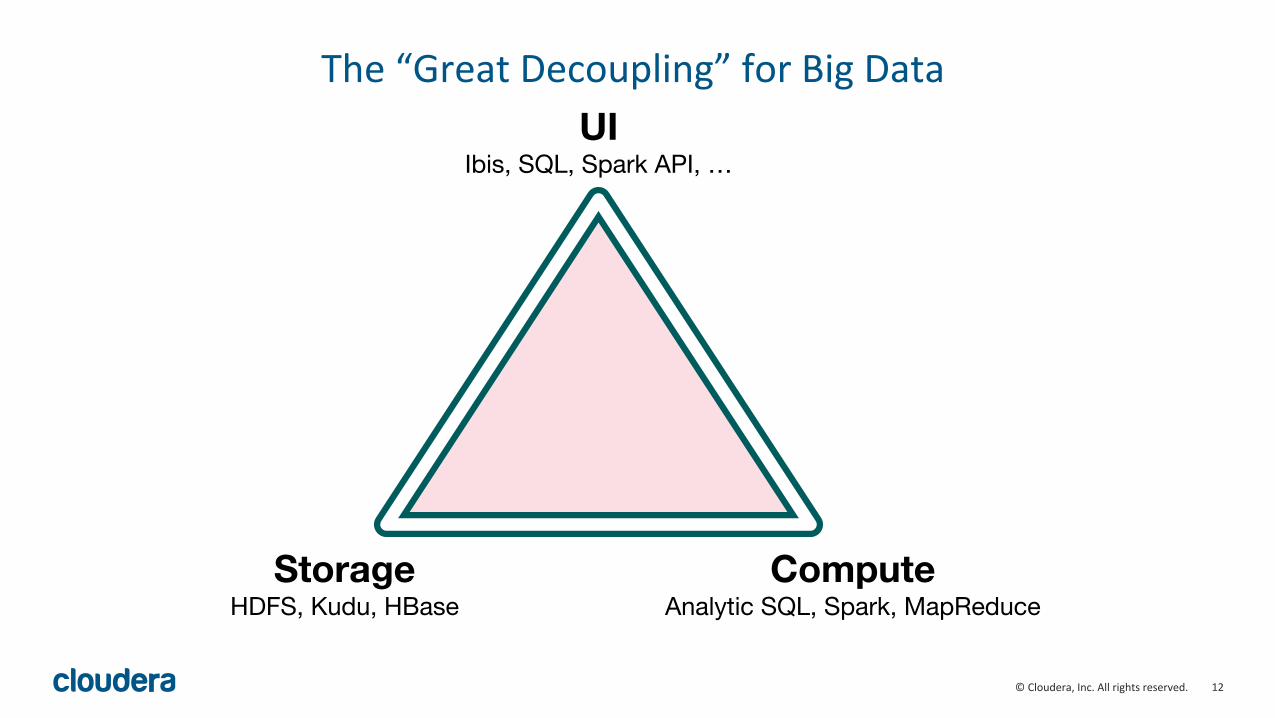
12"©"Cloudera,"Inc."All"rights"reserved."
The"“Great"Decoupling”"for"Big"Data"UI
Ibis, SQL, Spark API, …
ComputeAnalytic SQL, Spark, MapReduce
StorageHDFS, Kudu, HBase
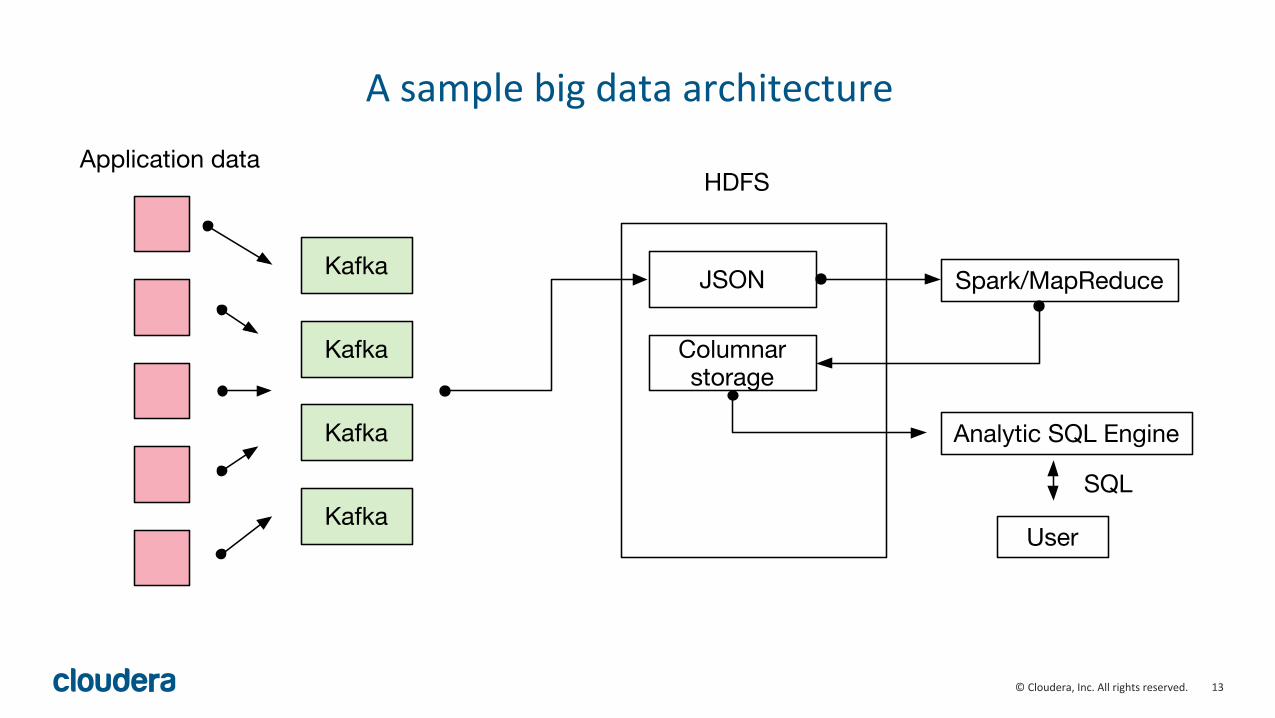
13"©"Cloudera,"Inc."All"rights"reserved."
A"sample"big"data"architecture"
Kafka
Kafka
Kafka
Kafka
Application dataHDFS
JSON Spark/MapReduce
Columnar storage
Analytic SQL Engine
User
SQL

14"©"Cloudera,"Inc."All"rights"reserved."
Big"data"architectures"currently"dominated"by"JVM"languages,"with"a"increasing"amounts"of"C++""Python/R/Julia"don’t"have"much"of"a"“seat"at"the"table”"

15"©"Cloudera,"Inc."All"rights"reserved."
Nested"/"Complex"types"support"
• Arrays,"structs,"maps,"and"unions"as"firstDclass"value"types"• Analyze"JSONDlike"data"directly"without"flasening"or"normaliza=on"• Most"new"SQL"engines"have"some"level"of"support"• Impala"• Presto"• Drill"• BigQuery"• Spark"SQL"• Hive"• …"

16"©"Cloudera,"Inc."All"rights"reserved."
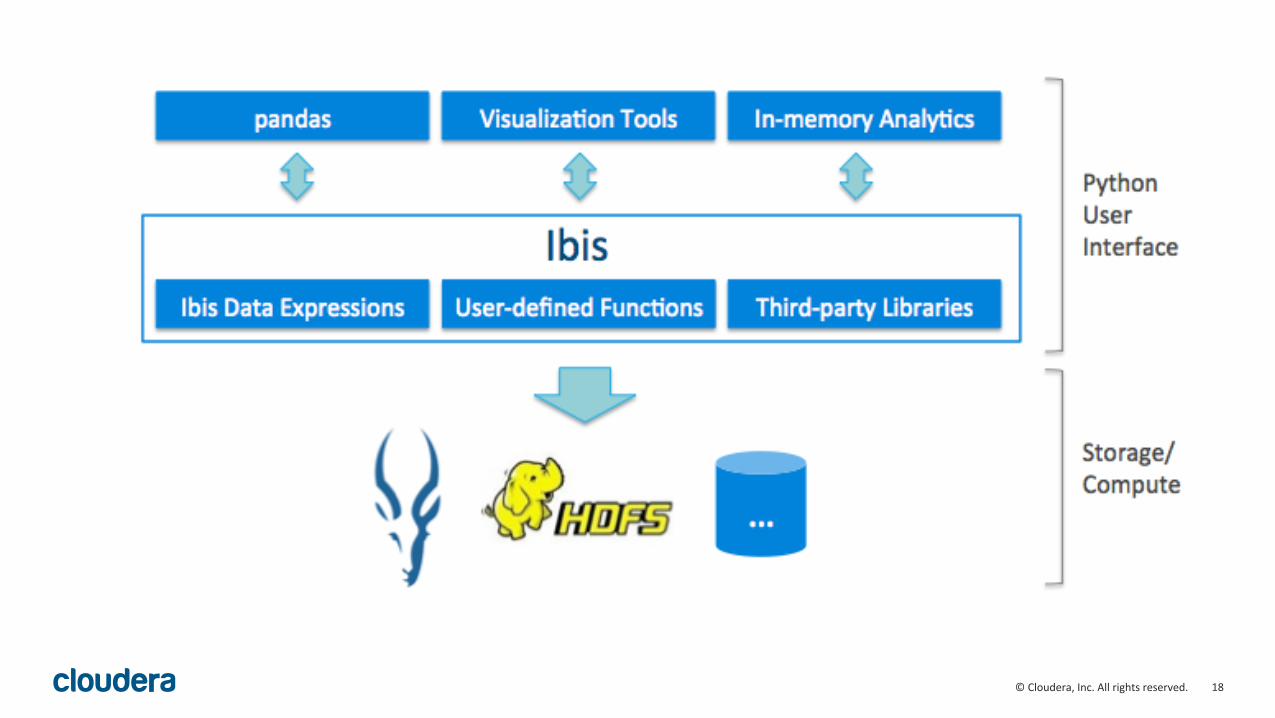
Ibis"in"a"nutshell"
• For"Python"programmers"doing"analy=cs"in"industry"• Project"Blog:"hsp://blog.ibisDproject.org"• Joint"project"with"Impala"team"@"Cloudera"• ApacheDlicensed,"open"source"hsp://github.com/cloudera/ibis""• Craeing"a"compelling"PythonDonDHadoop"user"experience"• Remove"SQL"coding"from"user"workflows"• Develop"high"performance"Python"extension"APIs"

17"©"Cloudera,"Inc."All"rights"reserved."
Ibis"in"a"nutshell,"cont’d"
• Composable"Python"DSL"(“Ibis"expressions”)"makes"handDcoding"SQL"SELECT"statements"unnecessary"• Ibis"for"SQL"Programmers:"hsp://docs.ibisDproject.org/sql.html"• Development"roadmap"targets"Impala"(C++"/"LLVM)"query"engine"• …"but"SQL"compiler"toolchain"is"general"purpose"
• Current"supports"Impala"and"SQLite,"but"soon"other"dialects"• We"welcome"external"contributors"for"other"Analy=c"SQL"engines"
18"©"Cloudera,"Inc."All"rights"reserved."

19"©"Cloudera,"Inc."All"rights"reserved."
Benefits"of"Ibis"
• Maximize"developer"produc=vity"• Mirrors"singleDnode"Python"experience"• Solve"big"data"problems"without"leaving"Python"• Leverage"Python"skills,"ecosystem,"and"tools"
• Python"as"firstDclass"language"for"Hadoop"• FullDfidelity"analysis"without"extrac=ons"• Python"analysis"at"any"scale"• Na=ve"hardware"speeds"for"a"broad"set"of"use"cases"

20"©"Cloudera,"Inc."All"rights"reserved."
Brief"interac=ve"demo"

21"©"Cloudera,"Inc."All"rights"reserved."
Ibis/Impala"Joint"Roadmap"
• More"natural"data"modeling"• Complex"types"support"
• Integra=on"with"full"Python"data"ecosystem"• Advanced"analy=cs"+"machine"learning"• Enable"use"of"performance"compu=ng"tools"
• User"extensibility"with"na=ve"performance"• InDmemory"columnar"format"• PythonDtoDLLVM"IR"compila=on"
• Workflow"and"usability"tools"
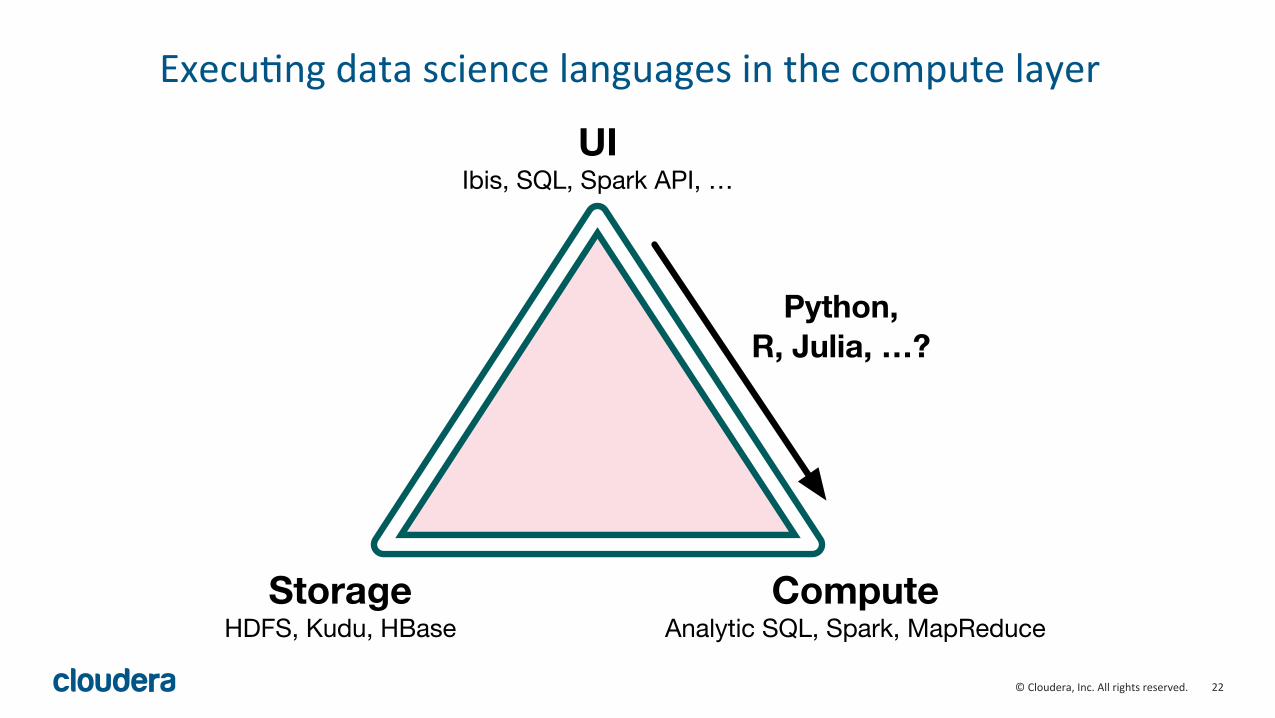
22"©"Cloudera,"Inc."All"rights"reserved."
Execu=ng"data"science"languages"in"the"compute"layer"
UIIbis, SQL, Spark API, …
ComputeAnalytic SQL, Spark, MapReduce
StorageHDFS, Kudu, HBase
Python, R, Julia, …?

23"©"Cloudera,"Inc."All"rights"reserved."
Enabling"interoperability"with"big"data"systems"
• Distributed"/"MPP"query"engines:"implemented"in"a"host(language"• Typically"C/C++"or"Java/Scala"
• UserDdefined"func=ons"(UDFs)"through"various"means"• Implement"in"host"language"• Implement"in"user"language"through"some"external"language"protocol"(oeen"RPCDbased)"
• External"UDFs"are"usually"very"slow"(cf:"PL/Python,"PySpark,"etc.)"

24"©"Cloudera,"Inc."All"rights"reserved."
What"are"UDFs"good"for?"
• Note:"industry"data"scien=sts"have"libraries"containing"100s"of"UDFs"for"Hive"or"other"distributed"query"engines"
• Custom"data"transforma=ons"• Custom"domain"logic"(date"/"=me"/"data"types)"• Custom"data"types"• Custom"aggrega=ons"(incl."machine"learning"/"sta=s=cs"expressible"as"reduc=ons)"

25"©"Cloudera,"Inc."All"rights"reserved."
Why"are"external"UDFs"slow?"
• Serializa=on"/"deserializa=on"overhead"• Scalar"vs"vectorized"computa=ons"• RPC"overhead"

26"©"Cloudera,"Inc."All"rights"reserved."
Example:"Vectoriza=on"for"interpreted"languages"
SUM(CASE WHEN x > y THEN x ELSE x + y END)
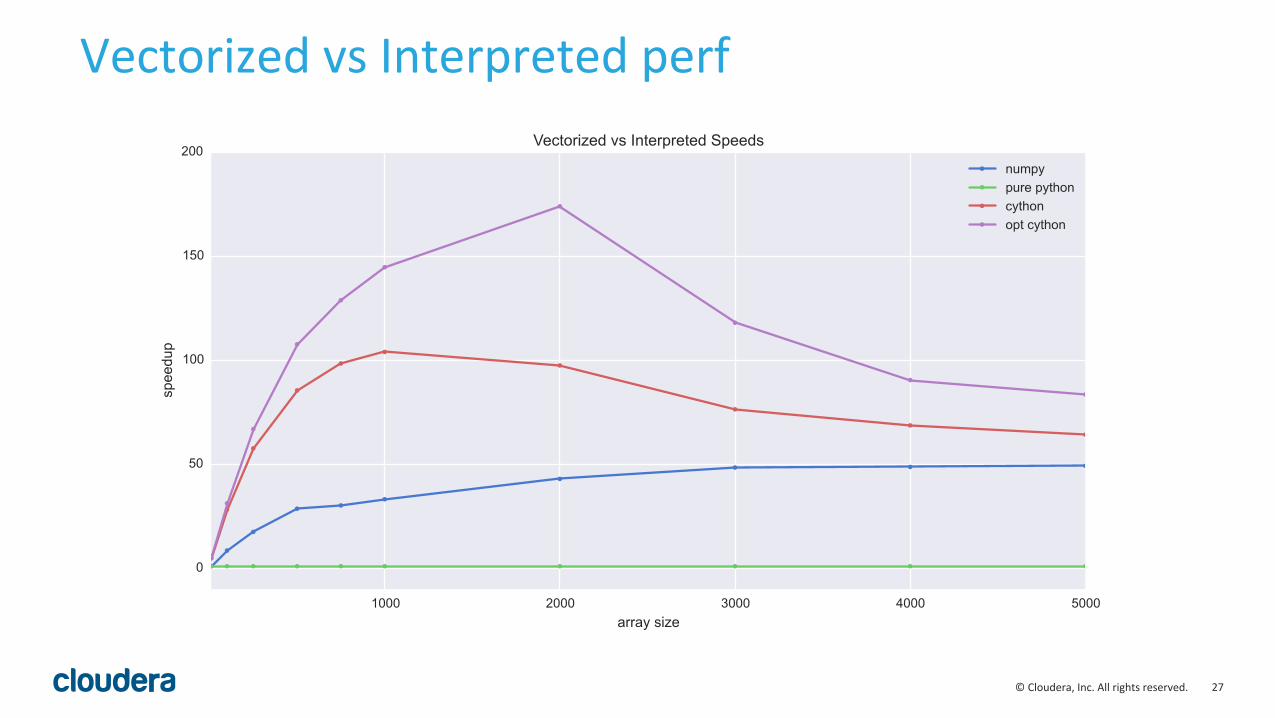
27"©"Cloudera,"Inc."All"rights"reserved."
Vectorized"vs"Interpreted"perf"

28"©"Cloudera,"Inc."All"rights"reserved."
How"to"make"them"fast?"
• Common"run=me"memory"representa=on"for"tabular"data"• ShareDmemory"(zeroDcopy"or"memcpyDonly)"external"UDF"protocol"• Vectorized"UDF"interface"(for"interpreted"languages)"• Impala"is"uniquely"posi=oned"to"play"well"with"Ibis"• BestDinDclass"performance"and"scalability"• C++"and"LLVMDbased"(JIT"compiler)"run=me"• Unified,"efficient"data"interchange"amongst"Ibis,"Impala,"and"Kudu"will"enable"high"performance"real"=me"analy=cs"from"Python"

29"©"Cloudera,"Inc."All"rights"reserved."
Memory"representa=on"
• Many"query"engines"are"standardizing"on"inDmemory"columnar"rep’n"of"materialized"transient"data"• Impala:"hsp://blog.cloudera.com/blog/2015/07/whatsDnextDforDimpalaDmoreDreliabilityDusabilityDandDperformanceDatDevenDgreaterDscale/"• Apache"Drill:"hsps://drill.apache.org/faq/"
• IndustryDstandard"serializa=on"format:"Apache"Parquet"• hsps://parquet.apache.org/"

30"©"Cloudera,"Inc."All"rights"reserved."
Serializa=on"vs"InDmemory"
• Serializa=on"formats"(e.g."Parquet)""• Op=mize"for"IO"/"DFS"throughput"at"expense"of"CPU/memory"bus"throughput"• Do"not"consider"random"access"or"inDmemory"analy=cs"as"a"goal"
• No"standardized"inDmemory"containers"for"materialized"data"from"file"/"RPC"protocols"(Parquet,"Thrie,"protobuf,"Avro,"etc.)"

31"©"Cloudera,"Inc."All"rights"reserved."
Standardized"inDmemory"columnar"(IMC)"
• Compact"inDmemory"representa=on"for"semistructured"data"• Part"of"Impala’s"upcoming"dev"roadmap"• Some"prior"IMCDforDSQL"work:"Apache"Drill"• Standardized"memory"representa=on"means"data"can"be"shared"without"serializa=on"• Create"a"canonical"C/C++"implementa=on"for"use"in"Python"/"R"/"Julia"

32"©"Cloudera,"Inc."All"rights"reserved."
Ibis’s"Vision"
• Uncompromised"Python"experience"• 100%"Python"endDtoDend"user"workflows""• Enable"integra=on"with"the"exis=ng"Python"data"ecosystem"(pandas,"scikitDlearn,"NumPy,"etc)"
• Interac=ve"at"big"data"scale"• FullDfidelity"analysis"without"extrac=ons"• Scalability"for"big"data"• Na=ve"hardware"speeds"for"a"broad"set"of"use"cases"

33"©"Cloudera,"Inc."All"rights"reserved."
Thank"you"Wes"McKinney"@wesmckinn"Views"are"my"own"







