Download - IE: Named Entity Recognition (NER)

Seman&c Analysis in Language Technology http://stp.lingfil.uu.se/~santinim/sais/2016/sais_2016.htm
Information Extraction (I)
Named Entity Recognition (NER) Marina San(ni
Department of Linguis(cs and Philology
Uppsala University, Uppsala, Sweden
Spring 2016
1

Previous Lecture: Distribu$onal Seman$cs • Star(ng from Shakespeare and IR (term-‐document matrix) …
• Moving to context ”windows” taken from the Brown corpus…
• Ending up to PPMI to weigh word distribu(on…
• Men(oning cosine metric to compare vectors….
2

As#You#Like#It Twelfth#Night Julius#Caesar Henry#Vbattle 1 1 8 15soldier 2 2 12 36fool 37 58 1 5clown 6 117 0 0
IR: Term-‐document matrix
• Each cell: count of term t in a document d: Nt,d: • Each document is a count vector in ℕv: a column below
3
Term frequency of t in d

Document similarity: Term-‐document matrix
• Two documents are similar if their vectors are similar
4
As#You#Like#It Twelfth#Night Julius#Caesar Henry#Vbattle 1 1 8 15soldier 2 2 12 36fool 37 58 1 5clown 6 117 0 0

The words in a term-‐document matrix
• Two words are similar if their vectors are similar
5
As#You#Like#It Twelfth#Night Julius#Caesar Henry#Vbattle 1 1 8 15soldier 2 2 12 36fool 37 58 1 5clown 6 117 0 0

Term-‐context matrix for word similarity
• Two words are similar in meaning if their context vectors are similar
6
aardvark computer data pinch result sugar …apricot 0 0 0 1 0 1pineapple 0 0 0 1 0 1digital 0 2 1 0 1 0information 0 1 6 0 4 0
we say, two words are similarin meaning if their context vectors are similar.

Compu$ng PPMI on a term-‐context matrix
• Matrix F with W rows (words) and C columns (contexts) • fij is # of $mes wi occurs in context cj
7
pij =fij
fijj=1
C
∑i=1
W
∑pi* =
fijj=1
C
∑
fijj=1
C
∑i=1
W
∑ p* j =fij
i=1
W
∑
fijj=1
C
∑i=1
W
∑
pmiij = log2pij
pi*p* jppmiij =
pmiij if pmiij > 0
0 otherwise
!"#
$#
The count of all the words that occur in that context
The count of all the contexts where the word appear
The sum of all words in all contexts = all the numbers in the matrix

Summa$on: Sigma Nota$on (i)
8
It means: sum whatever appears after the Sigma: so we sum n. What is the value of n ? The values are shown below and above the Sigma. Below --> index variable (eg. start from 1); Above --> the range of the sum (eg. from 1 up to 4). In this case, it says that n goes from 1 to 4, which is 1, 2, 3 and 4 (http://www.mathsisfun.com/algebra/sigma-notation.html )
pij =fij
fijj=1
C
∑i=1
W
∑we can’t delete f(i,j) !!!
Sum from i=1 to 4

Summa$on: Sigma Nota$on (ii)
• Addi(onal examples
• Sums can be nested
9

Alterna$ve nota$ons… (Levy, 2012)
• When, the range of the sum can be understood from context, it ca be le\ out;
• or we want to be vague about the precise range of the sum. For example, suppose that there are n variables, x1 through xn.
• In order to say that the sum of all n variables is equal to 1, we might simply write:
10

Formulas: Sigma Nota$on
11
pij =fij
fijj=1
C
∑i=1
W
∑
pi* =fij
j=1
C
∑
fijj=1
C
∑i=1
W
∑
p* j =fij
i=1
W
∑
fijj=1
C
∑i=1
W
∑
• Numerator: f ij = a single cell
• Denominators: sum the cells of all the words and the cells of all the contexts
• Numerator: sum the cells of all contexts (all the columns)
• Numerator: sum the cells of all the words (all the rows)

Living lexicon: built upon an underlying con$nously updated corpus
12 Drawbacks: Updated but unstable & incomplete: missing words, missing linguis(c informa(on, etc.
Mul(lingualiy, func(on words, etc.

Similarity: • Given the underlying sta(s(cal model, these words are similar
13
Fredrik Olsson

Gavagai blog • Further reading (Magnus Sahlgren) :
heps://www.gavagai.se/blog/2015/09/30/a-‐brief-‐history-‐of-‐word-‐embeddings/
14

End of previous lecture
15

Acknowledgements Most slides borrowed or adapted from:
Dan Jurafsky and Christopher Manning, Coursera
Dan Jurafsky and James H. Mar(n
J&M(2015, dra\): heps://web.stanford.edu/~jurafsky/slp3/

Preliminary: What’s Informa$on Extrac$on (IE)?
• IE = text analy(cs = text mining = e-‐discovery, etc.
• The ul(mate goal is to convert unstructured text into structured informa(on (so informa(on of interest can easily be picked up).
• unstructured data/text: email, PDF files, social media posts, tweets, text messages, blogs, basically any running text...
• structured data/text: databases (xlm, sql, etc.), ontologies, dic(onaries, etc.
17

Informa$on Extrac$on and Named En$ty Recogni$on
Introducing the tasks: Gelng simple structured informa(on out of text

Informa$on Extrac$on
• Informa(on extrac(on (IE) systems • Find and understand limited relevant parts of texts • Gather informa(on from many pieces of text • Produce a structured representa(on of relevant informa(on: • rela3ons (in the database sense), a.k.a., • a knowledge base
• Goals: 1. Organize informa(on so that it is useful to people 2. Put informa(on in a seman(cally precise form that allows further
inferences to be made by computer algorithms

Informa$on Extrac$on: factual info
• IE systems extract clear, factual informa(on • Roughly: Who did what to whom when?
• E.g., • Gathering earnings, profits, board members, headquarters, etc. from company reports • The headquarters of BHP Billiton Limited, and the global headquarters of the combined BHP Billiton Group, are located in Melbourne, Australia.
• headquarters(“BHP Biliton Limited”, “Melbourne, Australia”)
• Learn drug-‐gene product interac(ons from medical research literature

Low-‐level informa$on extrac$on
• Is now available – and I think popular – in applica(ons like Apple or Google mail, and web indexing
• O\en seems to be based on regular expressions and name lists

Low-‐level informa$on extrac$on

• A very important sub-‐task: find and classify names in text.
• An en(ty is a discrete thing like “IBM Corpora(on” • Named” means called “IBM” or “Big Blue” not “it” or
“the company”
• often extended in practice to things like dates, instances of products and chemical/biological substances that aren’t really entities…
• But also used for times, dates, proteins, etc., which aren’t entities – easy to recognize semantic classes
Named En$ty Recogni$on (NER)

Named En$ty Recogni$on (NER) • A very important sub-‐task: find and
classify names in text, for example:
• The decision by the independent MP Andrew Wilkie to withdraw his support for the minority Labor government sounded drama(c but it should not further threaten its stability. When, a\er the 2010 elec(on, Wilkie, Rob Oakeshoe, Tony Windsor and the Greens agreed to support Labor, they gave just two guarantees: confidence and supply.
you have a text, and you want to: 1. find things that are
names: European Commission, John Lloyd Jones, etc.
2. give them labels: ORG, PERS, etc.

• A very important sub-‐task: find and classify names in text, for example:
• The decision by the independent MP Andrew Wilkie to withdraw his support for the minority Labor government sounded drama(c but it should not further threaten its stability. When, a\er the 2010 elec(on, Wilkie, Rob Oakeshoe, Tony Windsor and the Greens agreed to support Labor, they gave just two guarantees: confidence and supply.
Named En$ty Recogni$on (NER)
Person Date Loca(on Organi-‐ za(on

Named En$ty Recogni$on (NER)
• The uses: • Named en((es can be indexed, linked off, etc. • Sen(ment can be aeributed to companies or products • A lot of IE rela(ons are associa(ons between named en((es • For ques(on answering, answers are o\en named en((es.
• Concretely: • Many web pages tag various en((es, with links to bio or topic pages, etc. • Reuters’ OpenCalais, Evri, AlchemyAPI, Yahoo’s Term Extrac(on, …
• Apple/Google/Microso\/… smart recognizers for document content

Summary: Gelng simple structured informa(on out of text

Evalua$on of Named En$ty Recogni$on
The extension of Precision, Recall, and the F measure to
sequences

The Named En$ty Recogni$on Task
Task: Predict en((es in a text
Foreign ORG Ministry ORG spokesman O Shen PER Guofang PER told O Reuters ORG : :
} Standard evalua(on is per en(ty, not per token

P/R
30
P=TP/TP+FP; R=TP/TP+FN FP=false alarm (it is not a NE, but it has been classified as NE)
FN =it is true that it is a NE, but d system failed to recognised it

Precision/Recall/F1 for IE/NER
• Recall and precision are straighNorward for tasks like IR and text categoriza(on, where there is only one grain size (documents)
• The measure behaves a bit funnily for IE/NER when there are boundary errors (which are common): • First Bank of Chicago announced earnings …
• This counts as both a fp and a fn • Selec(ng nothing would have been beeer • Some other metrics (e.g., MUC scorer) give par(al credit
(according to complex rules)

Summary: Be careful when interpre(ng the P/R/F1 measures

Sequence Models for Named En$ty Recogni$on

The ML sequence model approach to NER
Training 1. Collect a set of representa(ve training documents 2. Label each token for its en(ty class or other (O) 3. Design feature extractors appropriate to the text and classes 4. Train a sequence classifier to predict the labels from the data
Tes(ng 1. Receive a set of tes(ng documents 2. Run sequence model inference to label each token 3. Appropriately output the recognized en((es
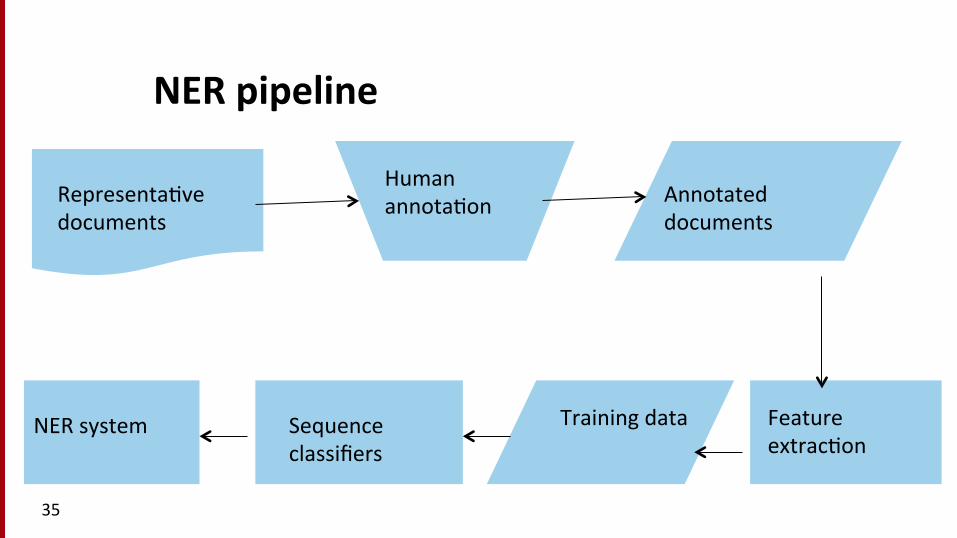
NER pipeline
35
Representa(ve documents
Human annota(on Annotated
documents
Feature extrac(on
Training data Sequence classifiers
NER system

Encoding classes for sequence labeling
IO encoding IOB encoding
Fred PER B-‐PER showed O O Sue PER B-‐PER Mengqiu PER B-‐PER Huang PER I-‐PER ‘s O O new O O pain(ng O O

Features for sequence labeling
• Words • Current word (essen(ally like a learned dic(onary) • Previous/next word (context)
• Other kinds of inferred linguis(c classifica(on • Part-‐of-‐speech tags
• Label context • Previous (and perhaps next) label
37

Features: Word substrings
4 17
14
4
241
drug
company
movie
place
person
Cotrimoxazole Wethersfield
Alien Fury: Countdown to Invasion
000
18
0
oxa
708
0006
: 0 8
6
68
14
field

Features: Word shapes
• Word Shapes • Map words to simplified representation that encodes attributes
such as length, capitalization, numerals, Greek letters, internal punctuation, etc.
Varicella-zoster Xx-xxx
mRNA xXXX
CPA1 XXXd

Sequence models
• Once you have designed the features, apply a sequence classifier (cf PoS tagging), such as: • Maximum Entropy Markov Models • Condi(onal Random Fields • etc.
40

The end







