

Building, deploying and running production code at Dropbox
Leonid Vasilyev, SRE at Dropbox. United Dev Conf ’17
•Intro & Background •Building Code •Deploying Packages •Running Services •Recap & Conclusion

Intro & Background


Dropbox Backend Infrastructure:
Something one might call a “Hybrid Cloud”. Few datacenters + AWS VPCs + Edge Network (POPs).
Running Ubuntu Server, Puppet/Chef and Nagios. Rest of the stack is pretty custom.
Dropbox today is not just “file storage”, but dozens of services, running on tens of thousands of machines.


I. Building Code

Early days: few code repos, mostly Python. No build system.
Period.

Why Bother?

Ruby Python
JavaC/C++ Node.js
Rust
GoPHP
Exhibit 1: Runtimes & Packages (ಠ_ಠ)

Problems: Repo is growing, new languages are in use: Golang, Node.js, Rust.
No way to track dependencies, dependencies installed in runtime via Puppet.
Global Encap repo deployed via rsync onto the whole fleet.

In search of a better build system
What are the requirements? •Fast •Reproducible •Hermetic •Flexible •Explicit dependencies


A Historical Perspective* •(2006) Google got annoyed with Make and began “Blaze” •(2012) Looks like ex-googlers at Twitter were missing “Blaze”, hence began “Pants”
•(2013) Looks like ex-googlers at Facebook were missing “Blaze”, hence began “Buck”
•(2014) Google realised what’s going on and released “Blaze” as “Bazel”
•(2016) Ex-googlers at Thought Machine are still missing “Blaze”, hence began “Please”, in Go this time :)

Bazel Concepts
•WORKSPACE: one per repo, defines external dependencies
•BUILD files: Python-like DSL for describing build targets (test is also a build target)
•`*.bzl` files: Macro and extensions •`//dropbox/aws:ec2allocate` — labels to specify build targets

native.new_http_archive( name = "six_archive", urls = [ “http://pypi.python.org/.../six-1.10.0.tar.gz”, ], sha256 = “…”, strip_prefix = "six-1.10.0", build_file = str(Label("//third_party:six.BUILD")),)
External Dependencies(1)

py_library( name = "six", srcs = ["six.py"], visibility = ["//visibility:public"],)
External Dependencies(2)

py_library( name = "platform_benchmark", srcs = ["platform/benchmark.py"], deps = [ ":client", ":platform", "@six_archive//:six", ],)
External Dependencies(3)

Bazel adoption at Dropbox

•Migration started in July, 2015
•~6,400 Bazel BUILD files (~314,094 lines)
•~9,000 lines of custom *.bzl code
•Custom rules for: python, golang, rust, node.js
•BUILD file generator for Cmake, Python
•Mostly done, still work in progress …
Migration Status

Key Insights•Robust remote build cache is essential. •Keep explicit dependencies between components.
•It is possible to retrofit new build system into old codebase.
•Bazel, Pants, Buck, Please — pick one, or write your own :)

II. Deploying Packages

Deployment System: YAPS
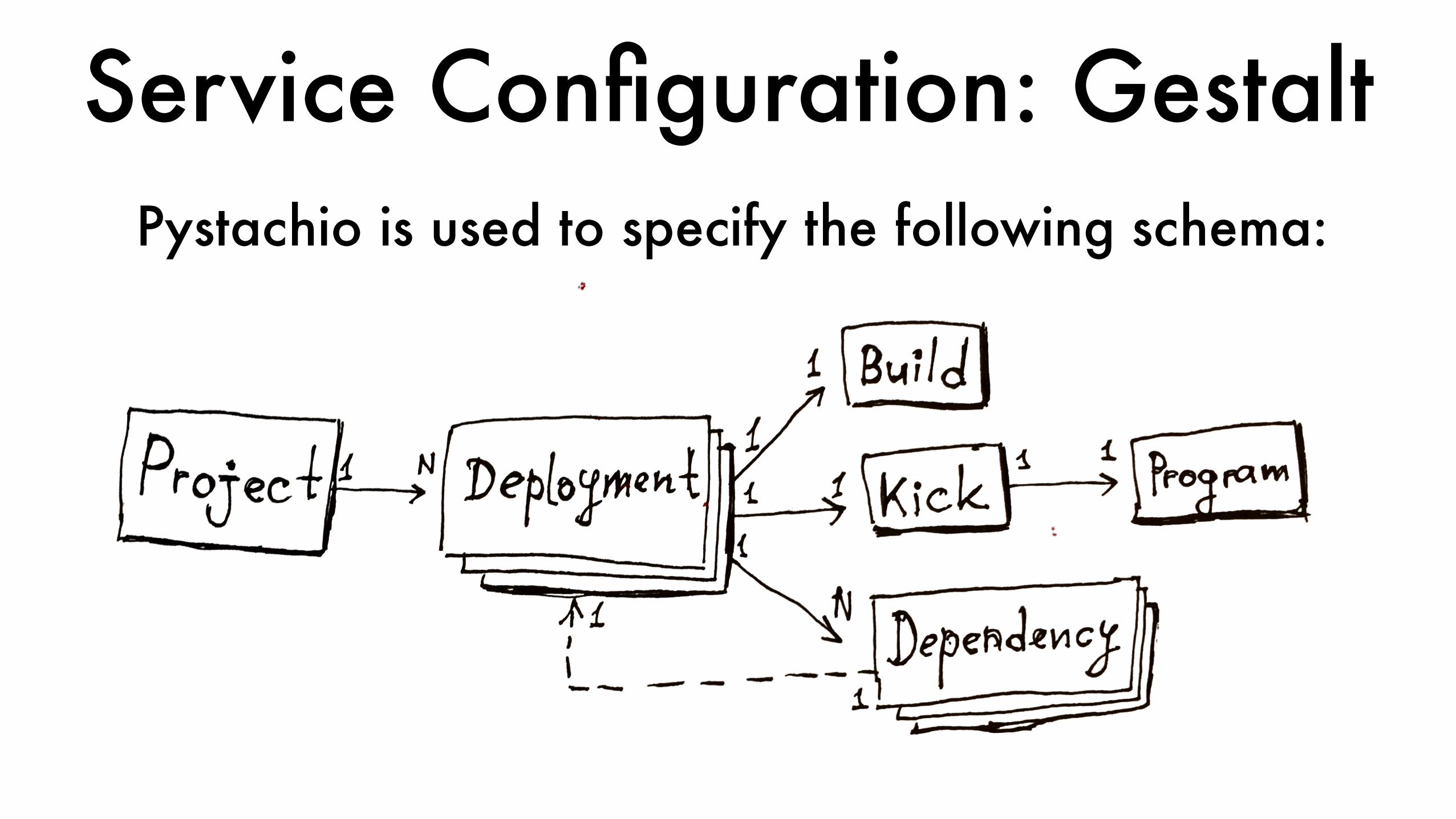
Service Configuration: GestaltPystachio is used to specify the following schema:

class Project(Struct): name = Required(String) owner = Required(String) deployments = Required(List(Deployment))
class Deployment(Struct): name = Required(String) build = Required(Build) kick = Required(Kick) dependencies = List(Dependency)
Service Configuration: Gestalt

class Build(Struct): name = Required(String) bazel_targets = Required(List(String)) timeout_s = Default(Integer, 3600)
class Kick(Struct): name = Required(String) package_dir = Required(String) dbxinit = Required(Program) host_kick_ration = Default(Float, 0.25)
Service Configuration: Gestalt

class Program(Struct): name = Required(String) num_procs = Default(Integer, 1) env = Map(String, String) cmd = Required(List(String))
limits = Limits # rss, max_fd, nice logfile = Default(String, DEFAULT_LOG_DIR) root_fs = String # docker os image health_check = HealthCheck
Service Configuration: Gestalt

•About 500 files and 60,000 SLOC •Complex evaluation rules •Configuration tends to become a Turing-complete language
•Advanced linters and validation needed •Specifying resource limits is tricky
Gestalt: Challenges

YAPS Packages

YAPS Packages: Historical approach
•Install Debian packages via Puppet/Chef •Use Python’s Virtualenv & PyPI •Encap — “Bag of rats” dependencies :) •Blast the whole repo via rsync every few minutes
by CRON

YAPS Packages: Current approach
•SquashFS images. Native Linux in-kernel support •Transparent compression and de-duplication •Read-only mounts, +1 from security •Loopback device mounts are fast •SquashFS image has 1+ Bazel targets and transitive dependency closure for each target

$ cd /srv/aws-tools$ tree -L 3.|-- ec2terminate # <- executable file`-- ec2terminate.runfiles # <- transitive closure |-- MANIFEST # <- list of all files `-- __main__ # <- dependencies |-- _solib_k8 |-- configs |-- dbops |-- devsecrets |-- dpkg `-- dropbox...

YAPS Packages: Challenges •*.pyc files have to be in the package •Unmountable packages due to open file descriptors •If code has to be modified on the prod server
(YOLO), special procedure — “Hijacking” is required
•Full package has be pushed even with a 1 line change (Xdelta compression might help)

III. Running Services

Process Manager: Historical approach
•Using Supervisord and configuration generated by Puppet
•Update of Supervisord requires tasks to be restarted •Loosing tasks if Supervisord killed by OOM •Supervisord is really old, from 2004 (has
XMLRPC?!)

Process Manager: Current approach
•Using Dbxinit: in-house project written in Go •Keeps local state, thus can be updated without tasks
downtime, can survive OOM •Supports health-checks for tasks •Has resource limits: RSS, max fds, OOM score •Speaks JSON HTTP

Configuration Management: Historical approach
•Puppet 2.x in server mode •Perf problems with server as fleet grew in size •No linters or unit tests, caused a lot of errors •“Blast to the fleet” deployment model •Single global run via CRON, runs all modules - slow

Configuration Management: Current approach
•Chef 12.x in Zero mode •Invested heavily into linters and unit-testing •Easy to test on a single production machine •Has 3 runs: “platform”, “global” and “service” •Cookbooks deployed via YAPS •Generally trying to move service owners out of CM

It wouldn’t be 2017 if not … containers!

Containers: Runc for stateless services
•Runc is integrated with Dbxinit, each task runs inside its own container
•Runc uses minimal Ubuntu Docker image •Main use case is dependency isolation via mount
namespaces •Doesn’t use network namespaces yet

Containers: Challenges •Log rotation. Logs should be moved from the box
ASAP, since machine with stateless service can be shut down without notice
•Looking into ELK stack to solve that problem •Resource accounting. Currently doesn’t enforce any
resource limits

VS
Human Automation

VS
Human Automation
BRAINS!
Attitude

Ops Automation: Nagios & Naoru
•Nagios runs on all production machines & AWS EC2 instances
•Common problems are automatically fixed by auto-remediation system called “Naoru”
•Its input is a stream of Nagios alerts and output is a set of remediations that can be executed automatically


Talk SummaryBuilding: •Unified build system with clean dependencies Deploying: •One deployment system and sound packaging Running: •Robust process management and automation of simple tasks

Thank You!{twttr: @leo_vsl}





![[Vasilyev S.N.] Interpolation by Fractal Functions(BookZa.org)](https://cdn.vdocument.in/doc/165x107/55cf914e550346f57b8c6b70/vasilyev-sn-interpolation-by-fractal-functionsbookzaorg.jpg)

