
Maximizing Intel® Compiler Performance using
Iterative Feedback Directed Optimization (IFDO)
Ilya ChernySoftware Manager
Software and Services Group
Thanks to Leonid Brusencov, Sergey Ermolaev, Artem Chirtsov, Sergey Grebenkin!October 23, 2008

22
Maximizing Intel® Compiler
Performance using IFDOSoftware and Services Group 2
SECR 2008 October 23
Agenda
•Why IFDO
•What is IFDO
•Alternative approaches
•Experimental Results
•Future plans

33
Maximizing Intel® Compiler
Performance using IFDOSoftware and Services Group 3
SECR 2008 October 23
A Performance Experiment•Take 3 nested loops for matrix multiplication
for(i = 0; i < N; i++) {
for(j = 0; j < N; j++) {
c[i][j] = 0;
for(k = 0; k < N; k++) {
c[i][j] += a[i][k] * b[k][j];
} } }
•Compile with maximum optimization−‘icl –O3 matmul.c’
•Run and measure time – 20 sec
•Compile with enforced vectorization−‘icl -O3 –mP2OPT_vec_always=T’
•Run and measure time – 11 sec
Why don’t switch on vectorization always?
>icl –help
..
/O3 optimize for maximum speed and enable high-level optimizations..

44
Maximizing Intel® Compiler
Performance using IFDOSoftware and Services Group 4
SECR 2008 October 23
A Performance Experiment II•Switch ‘i’ and ‘j’ loops, move initialization loop outside
for(i = 0; i < N; i++)
for(j = 0; j < N; j++)
c[i][j] = 0;
for(j = 0; j < N; j++) {
for(i = 0; i < N; i++) {
for(k = 0; k < N; k++) {
c[i][j] += a[i][k] * b[k][j];
} } }
•Compiler with O3 optimization
•Measure run time – 18 sec
•Compile with enforced vectorization
•Measure run time – 21 sec
Thoughtless optimization loses 15%

55
Maximizing Intel® Compiler
Performance using IFDOSoftware and Services Group 5
SECR 2008 October 23
Why Optimizations Do Not Always Win?
Source code adding 4 integers for(i=0;i<4;i++) A[i]=A[i]+B[i]
loop_start:
mov ebx, B[edi]
add A[edi], ebx
inc edi
loop loop_start
movdqa xmm1, A
paddd xmm1, B
movdqa A, xmm1
•Vector code could be 2-4x times faster, but..
−..what if array size is not a multiple of 4?
−..what if A is not aligned by 16 bytes?
−..what if A and B aligned differently?
•Final code has an overhead of these 3 ‘if’
Compile to vector codeCompile to scalar code

66
Maximizing Intel® Compiler
Performance using IFDOSoftware and Services Group 6
SECR 2008 October 23
Heuristics for Parameterization of Compiler Optimizations
•Compiler has hundreds of performance optimizations
•Each optimization has at least 1 Boolean parameter
•Compiler has heuristics to make a decision about each optimization
•But still code produced by the compiler is far from optimal
−Each application has unique behavior (loop counts, memory accesses)
−Each machine has unique characteristics (latencies, caches)
−It is impossible to target ALL compiler heuristics for ALL machines for ALL applications
Compiler optimizations have considerableperformance headroom if parameterized right

77
Maximizing Intel® Compiler
Performance using IFDOSoftware and Services Group 7
SECR 2008 October 23
Agenda
•Why IFDO
•What is IFDO
•Alternative approaches
•Experimental Results
•Future plans

88
Maximizing Intel® Compiler
Performance using IFDOSoftware and Services Group 8
SECR 2008 October 23
IFDO process
1. Optimization: Compile executable from the sources
2.Feedback:Run executable with profiling
3.Directed:Analyze results, define options for the next compilation
4.Iterative:Repeat while time permits

99
Maximizing Intel® Compiler
Performance using IFDOSoftware and Services Group 9
SECR 2008 October 23
Search Algorithms
Search algorithms find the maximum much faster than after 2n iterations
•Implemented 6 algorithms to do search in the options space [20]
−exhaustive search with priorities
−batch elimination
−iterative elimination
−combined elimination
−genetic algorithm
−statistical selection [23]

1010
Maximizing Intel® Compiler
Performance using IFDOSoftware and Services Group 10
SECR 2008 October 23
Compiler Optimization Options•Selected 6 undocumented options which seem to have the
highest impact
−loop vectorization
−loop fusion
−loop distribution
−loop unrolling
−data blocking
−memory prefetch
•Number of total independent option values is 13
•Search space for these 6 options has 7000 combinations
•Extracted all compiler options from the sources and just started the runs for more than 1000 options

1111
Maximizing Intel® Compiler
Performance using IFDOSoftware and Services Group 11
SECR 2008 October 23
IFDO Tool
IFDO tool automates iteration process
•User defines how to build and execute his application
•IFDO tool outputs the best binary and all performance data
•Based on IFDO results user can
−change compilation options or pragmas
−modify sources
−improve compiler
::User
1: Build application
application launcher
IFDO_compiler
application builder
application executable log_data [iteration]

1212
Maximizing Intel® Compiler
Performance using IFDOSoftware and Services Group 12
SECR 2008 October 23
IFDO Sample Output - SPEC CPU2000 173.applu
41% performance gain!
iter stat proc ticks impr% noise% parameter val parameter val
-------------------------------------------------------------------------------
1 ... *Total* 9571493442 +0.00 0.21
1 ... _SSOR 7335205487 +0.00 0.26 VectorizeP 1 BlockP 1
1 ... _RHS 2218915958 +0.00 0.02 VectorizeP 1 BlockP 1
2 ... *Total* 6234529813 +34.86 0.01 2 ... SSOR 4048766558 +44.80 0.01 VectorizeP 1 BlockP 2
2 ... _RHS 2168605738 +2.27 0.05 VectorizeP 1 BlockP 2
3 ... *Total* 12889959745 -34.67 0.06
3 ... SSOR 11309558116 -54.18 0.07 VectorizeP 2 BlockP 1
3 ... RHS 1563970212 +29.52 0.01 VectorizeP 2 BlockP 1
4 ... *Total* 10806270474 -12.90 0.15
4 ... _SSOR 8657609979 -18.03 0.10 VectorizeP 3 BlockP 1
4 ... _RHS 2102104477 +5.26 0.01 VectorizeP 3 BlockP 1
5 *.. *Total* 5602632636 +41.47 0.00 5 *.. SSOR 4043669682 +44.87 0.02 VectorizeP 1 BlockP 2
5 *.. RHS 1542238426 +30.50 0.06 VectorizeP 2 BlockP 1
But Intel® Compiler improved since 10.0 & SPEC 173.applu has 8% only headroom now!

1313
Maximizing Intel® Compiler
Performance using IFDOSoftware and Services Group 13
SECR 2008 October 23
Agenda
•Why IFDO
•What is IFDO
•Alternative approaches
•Experimental Results
•Future plans

1414
Maximizing Intel® Compiler
Performance using IFDOSoftware and Services Group 14
SECR 2008 October 23
Comparison to other publications
Our work has two novel characteristics
•There are 23 references to the similar papers
•No publications have compiler with procedure level granularity
•All publications were limited by about 50 options, while we started exploring 1000 of undocumented compiler options

1515
Maximizing Intel® Compiler
Performance using IFDOSoftware and Services Group 15
SECR 2008 October 23
Comparison to other toolsGranularity Profiling Conclusion
Manual options search
-
whole application or source changes
-/+
any profiler, but manually
user time consuming
PGOprof_gen/prof_use)
+
basic block level
-
basic block counters only
2 iterations only
PathScale PathOpt2
-
whole application
-
whole application
40% less results
IFDO +
function or loop
+
instrumentation, VTune
not available in the product

1616
Maximizing Intel® Compiler
Performance using IFDOSoftware and Services Group 16
SECR 2008 October 23
Agenda
•Why IFDO
•What is IFDO
•Alternative approaches
•Experimental Results
•Future plans

1717
Maximizing Intel® Compiler
Performance using IFDOSoftware and Services Group 17
SECR 2008 October 23
0
1
2
3
4
5
1 11 21 31 41 51 61 71 81 91 101
Number of iteration
Per
form
an
ce g
ain
, % ES
BE
IE
CE
GA
SS
Search Algorithms – Performance Growth dependency on Iteration
All algorithms gain 2.5%-4% in CPU2000 total time
•BE works for independent options only, but just 14 iterations
•IE and CE get 99% in 30 iterations – the most effective
1818
Maximizing Intel® Compiler
Performance using IFDOSoftware and Services Group 18
SECR 2008 October 23
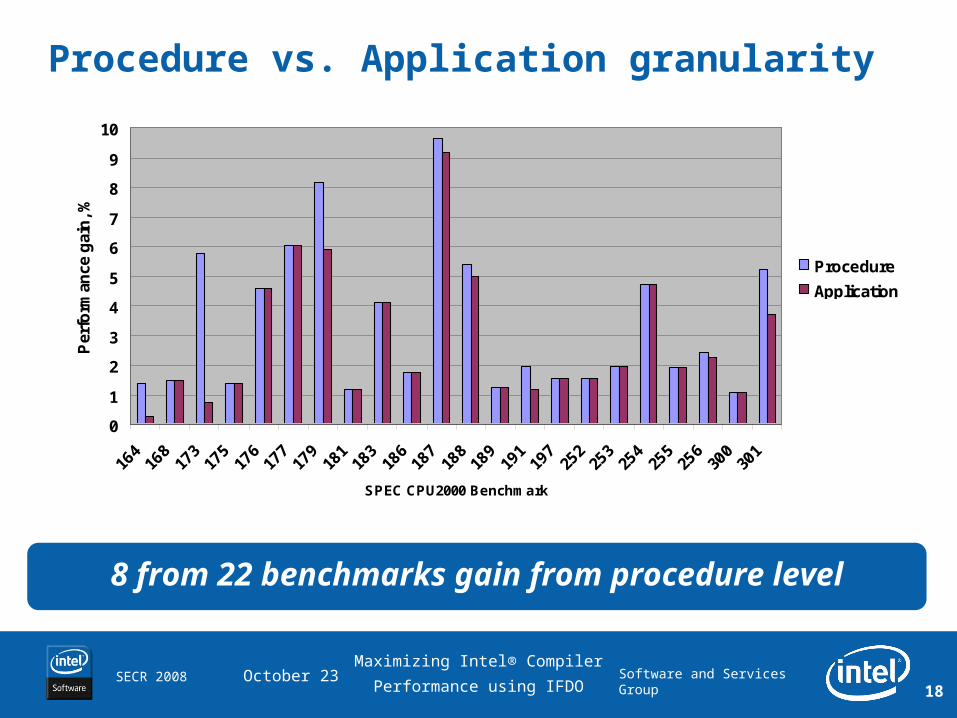
Procedure vs. Application granularity
8 from 22 benchmarks gain from procedure level
0
1
2
3
4
5
6
7
8
9
10
164
168
173
175
176
177
179
181
183
186
187
188
189
191
197
252
253
254
255
256
300
301
SPEC CPU2000 Benchmark
Per
form
ance
gai
n, %
Procedure
Application

1919
Maximizing Intel® Compiler
Performance using IFDOSoftware and Services Group 19
SECR 2008 October 23
Options & Values Contribution to Performance Increase
Each option gives about 2 percent
0
0.5
1
1.5
2
2.5
3
Block
P{2}
Distri
butio
nP{2}
Distri
butio
nP{3}
Distri
butio
nP{4}
FusionP
{2}
FusionP
{3}
HLOUnro
llFac
torP
{1}
HLOUnro
llFac
torP
{2}
HLOUnro
llFac
torP
{3}
HLOUnro
llFac
torP
{4}
Unrol
lAndJ
amP{2
}
Vecto
rizeP
{2}
Vecto
rizeP
{3}
Options
Pe
rfo
rma
nc
e in
cre
as
e, %

2020
Maximizing Intel® Compiler
Performance using IFDOSoftware and Services Group 20
SECR 2008 October 23
0.00
100.00
200.00
300.00
400.00
500.00
600.00
700.00
800.00
900.00
1000.00
< -100%
-80% -100%
-80% -40%
-40% -20%
-20% -10%
-10% -5%
-5%-2%
-2%-1%
-1% 0%
0% 1%
1% 2%
2% 5%
5% 10%
10% 20%
20% 40%
40% 80%
80% 100%
>100%
Ranges of performance impact, %
Nu
mb
er
of
op
tio
ns
1000 Options Impact on Performance
Only 600 from 3000 options have zero impact

2121
Maximizing Intel® Compiler
Performance using IFDOSoftware and Services Group 21
SECR 2008 October 23
Agenda
•Why IFDO
•What is IFDO
•Alternative approaches
•Experimental Results
•Future plans

2222
Maximizing Intel® Compiler
Performance using IFDOSoftware and Services Group 22
SECR 2008 October 23
Future Plans
Useful to both compiler developers and users
•Make experiments with all undocumented options
−3000 values if no impact on each other
−more than 23000 combinations!
•Implement storing of application properties
−number of FP expressions, number of loops, etc.
•Implement expert/machine learning system
−suggest options according to application properties
−may decrease number of iterations down to 1
−can substitute existing compiler heuristics?

2323
Maximizing Intel® Compiler
Performance using IFDOSoftware and Services Group 23
SECR 2008 October 23
Summary
•If performance’s critical, try at least ‘icl –O3’!

Спасибо!
Thanks!

2525
Maximizing Intel® Compiler
Performance using IFDOSoftware and Services Group 25
SECR 2008 October 23
References 1-13[1] F. Bodin, T. Kisuki, P. Knijnenburg, M. O’Boyle, and E. Rohou, “Iterative compilation in a non-linear optimization space”, In Proc. ACM
Workshop on Profile and Feedback Directed Compilation, 1998, Organized in conjunction with PACT98.
[2] K. Cooper, D. Subramanian, and L. Torczon, “Adaptive optimizing compilers for the 21st century”, J. of Supercomputing, 32(1), 2002.
[3] J. Bilmes, K. Asanovic, C. Chin, and J. Demmel, “Optimizing matrix multiply using PHiPAC: A portable, high- performance, ANSI C coding methodology”, In Proc. ICS, pages 340-347, 1997.
[4] M. Stephenson and S. Amarasinghe, “Prediction unroll factor using supervised classification”, In ERRR/ACM International Symposium on Code Generation and Optimization (CGO 2005), ERRR Computer Society, 2005.
[5] Yom-Toy, J. Thomson, O. Temam, A. Zaks, H. Leather, C. Miranda, M. Namolaru, E. Bonilla, Saclay, B. Mendelson, C. Williams, Haifa, M. O’Boyle, P. Barnard, E. Ashton, E. Courtois, F. Bodin “MILEPOST GCC: machine learning based research compiler”, ARC, International, UK, CAPS Enterprise, France, 2007.
[6] K. Hoste, L. Eeckhout, “COLE: Compiler Optimization Level Exploration”, ELIS Department, Ghent University, Sing-Pietersnieuwstraat 41, B-9000 Gent, Belgium, 2008.
[7] K. Deb, “Multi-Objective Optimization using Evolutionary Algorithms”, Wiley, 2001.
[8] G. Fursin, J. Cavazos, M. O’Boyle, and O. Temam, “MiDataSets: Creating the Conditions for a More Realistic Evaluation of Iterative Optimization”, ALCHEMY Group, INRIA Futurs and LRI, Paris-Sud University, France, 2007.
[9] M. Byler, M. Wolfe, J.R.B. Davies, C. Huson, and B. Leasure, “Multiple version loops.” In ICPP, 1987, pages 312-318, 2005.
[10] K. D. Cooper, M. W. Hall, and K. Kennedy, “Procedure cloning”, In Proceedings of the 1992 IEEE International Conference on Computer Language, pages 99-105, 1992.
[11] P. Diniz and M. Rinard. “Dynamic feedback: An effective technique for adaptive computing”, In Proc. PLDI, pages 71-84, 1997.
[12] G. Fursin, C. Miranda, S. Pop, A. Cohen, O. Temam, “Practical Run-time Adaptation with Procedure Cloning to Enable Continuous Collective Compilation”, Alchemy group, INRIA Futurs and LRI, Paris-Sud 11 University, Orsay, France, 2007.
[13] V. Bala, E. Duesterwald, and S. Banerjia, “Dynamo: A transparent dynamic optimization system”, In ACM SIGPLAN Notices, 2000.

2626
Maximizing Intel® Compiler
Performance using IFDOSoftware and Services Group 26
SECR 2008 October 23
References 14-23[14] R. H. Saavedra and D. Park, “Improving the effectiveness of software prefetching with adaptive execution”, In Conference on
Parallel Architectures and Compilation Techniques (PACT’96), 1996.
[15] M. Voss and R. Eigemann, “High-level adaptive program optimization with adapt”, In Proceedings of the Symposium on Principles and practices of parallel programming, 2001.
[16] G. Fursin, A. Cohen, M. O’Boyle, and O. Temam, “A Practical Method For Quickly Evaluating Program Optimizations”, Institute for Computing Systems Architecture, University of Edinburgh, UK, 2005.
[17] T. Sherwood, E. Perelman, G. Hamerly, and B. Calder, “Automatically characterizing large scale program behavior”, In 10th International Conference on Architectural Support for Programming Languages and Operating Systems, 2002.
[18] J. Lau, S. Schoenmackers, and B. Calder, “Transition phase classification and prediction”, In International Symposium on High Performance Computer Architecture, 2005.
[19] Z. Pan, R. Eignmann, “Fast and Effective Orchestration of Compiler Optimizations for Automatic Performance Tuning.”, Proceedings of the International Symposium on Code Generation and Optimization, 2006.
[20] S. Triantafyllis, M.J. Bridges, E. Raman, G. Ottoni and D. August, “A Framework for Unrestricted Whole-Program Optimization.”, Proceedings of the 2006 ACM SIGPLAN Conference on Programming Language Design and Implementation, 2006.
[21] Z. Pan, R. Eignmann, “Fast, Automatic, Procedure-Level Performance Tuning.”, Proceedings of the 15th International Conference on Parallel Architecture and Compilation Techniques, 2006.
[22] H. Feltl, “Ein Genetischer Algorithmus fuer das Generalized Assignment Problem”, Diplomarbeit, 2003.
[23] M. Haneda, P. Knijnenburg, H. Wijshoff “Automatic Selection of Compiler Options Using Non-Parametristic Inferential Statistics.”, Proceedings of the 14th International Conference on Parallel Architecture and Compilation Techniques, 2005.

2727
Maximizing Intel® Compiler
Performance using IFDOSoftware and Services Group 27
SECR 2008 October 23
Standard Take-Away Banner. Add Text Here!
Basic Foil with Take-Away BannerUse Verdana Bold for Main Body Subheadings
•Use Verdana regular for main body text.
•Use charcoal gray (RGB 51 – 51 – 51) color as the default
•Text size can vary. Use these minimum recommended font sizes
−Slide title: 32 pt
−Main body subheadings: 20 pt
−Bullet points: 18 pt (with sub-bullets reducing by 2 pt each – 16 pt, 14 pt, etc)
−Tables: 14 pt
−Diagram and chart labels: 12 pt
•Emphasize with italics, bold or color (blue)
•Use text boxes to highlight content
•Primary text should be on background color, not photos, etc.
•Use bullets same color as text







