
MesosandBorg(Lecture17,cs262a)
Ion Stoica, UC Berkeley
October 24, 2016

Today’s Papers Mesos:APla+ormforFine-GrainedResourceSharingintheDataCenter,BenjaminHindman,AndyKonwinski,MateiZaharia,AliGhodsi,AnthonyD.Joseph,RandyKatz,ScoKShenker,IonStoica,NSDI’11(hKps://people.eecs.berkeley.edu/~alig/papers/mesos.pdf)
Large-scaleclustermanagementatGooglewithBorg,AbhishekVerma,LuisPedrosa,MadhukarR.Korupolu,DavidOppenheimer,EricTune,JohnWilkes,EuroSys’15(sta]c.googleusercontent.com/media/research.google.com/en//pubs/archive/43438.pdf)
Mo7va7onl Rapidinnova]onincloudcompu]ng
l Today
l Nosingleframeworkop]malforallapplica]onsl Eachframeworkrunsonitsdedicatedclusterorcluster
par]]on
Dryad
Pregel
CassandraHypertable
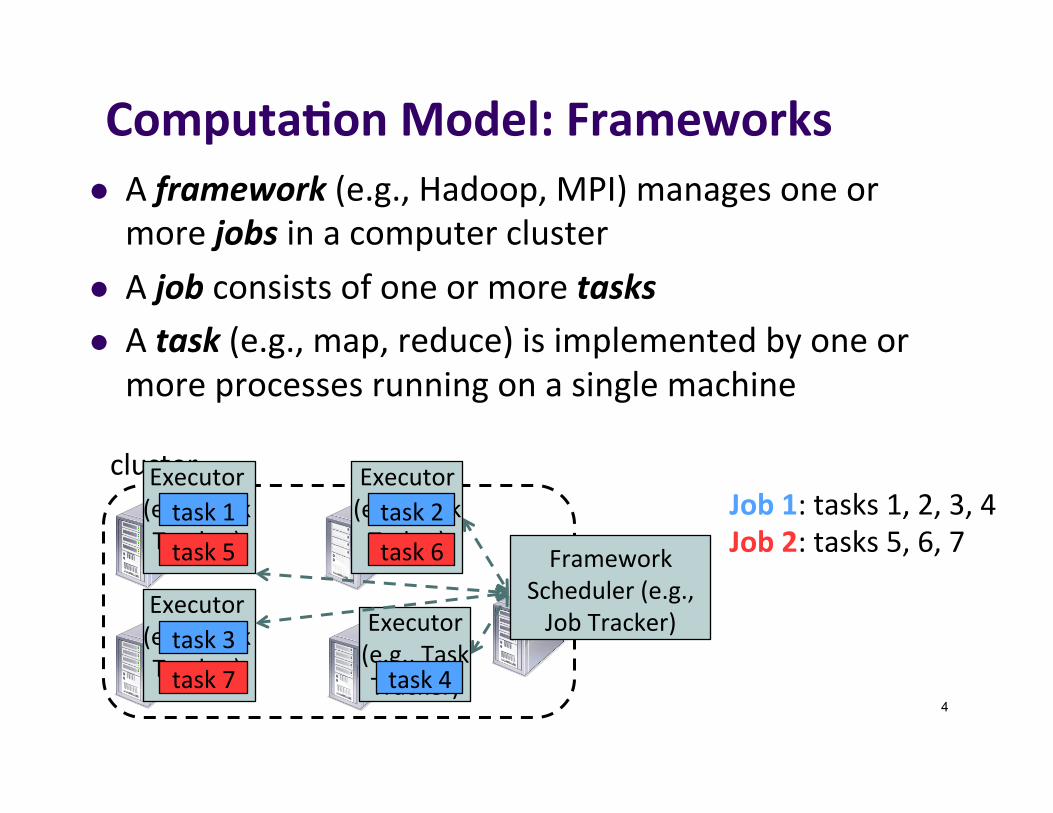
Computa7onModel:Frameworksl Aframework(e.g.,Hadoop,MPI)managesoneormorejobsinacomputercluster
l Ajobconsistsofoneormoretasksl Atask(e.g.,map,reduce)isimplementedbyoneormoreprocessesrunningonasinglemachine
4
cluster
FrameworkScheduler(e.g.,JobTracker)
Executor(e.g.,TaskTracker)
Executor(e.g.,TaskTraker)
Executor(e.g.,TaskTracker)
Executor(e.g.,TaskTracker)
task1task5
task3task7 task4
task2task6
Job1:tasks1,2,3,4Job2:tasks5,6,7

OneFrameworkPerClusterChallengesl Inefficientresourceusage
l E.g.,HadoopcannotuseavailableresourcesfromPregel’scluster
l Noopportunityforstat.mul]plexing
l Hardtosharedatal Copyoraccessremotely,expensive
l Hardtocooperatel E.g.,NoteasyforPregeltouse
graphsgeneratedbyHadoop
5
Hadoop
Pregel
0%#
25%#
50%#
0%#
25%#
50%#
Hadoop
Pregel
2011slideNeedtorunmul]pleframeworksonsamecluster
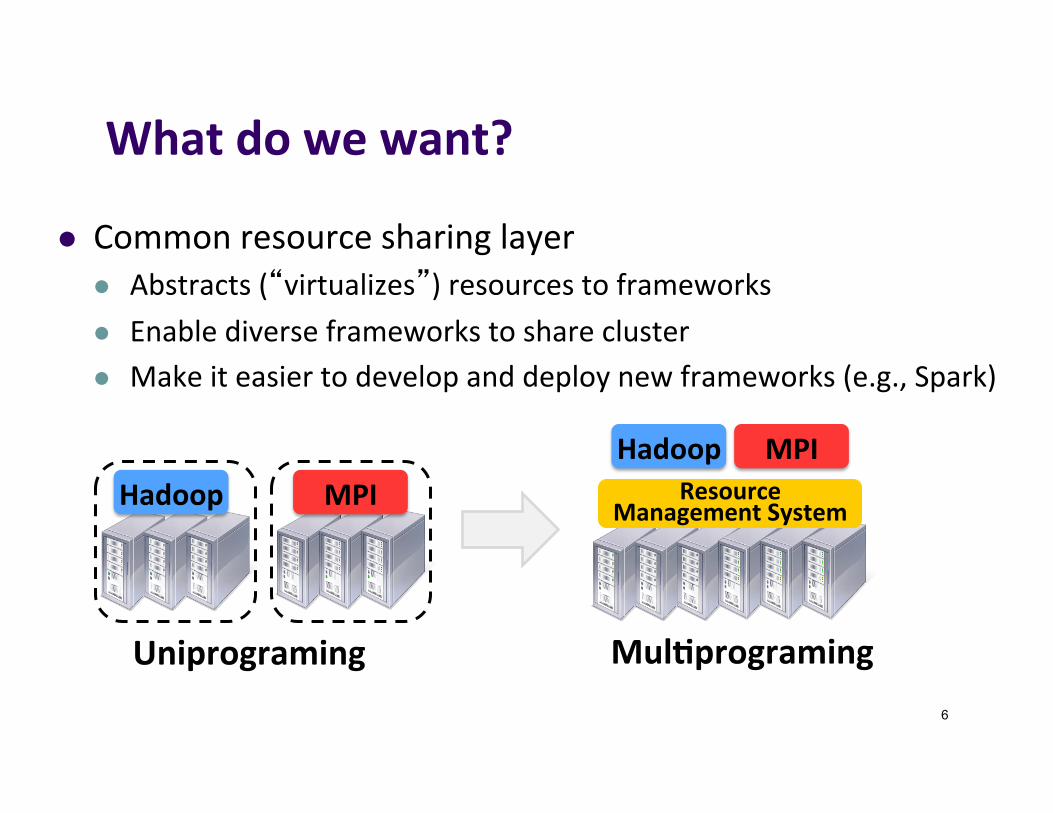
Whatdowewant?
l Commonresourcesharinglayerl Abstracts(“virtualizes”)resourcestoframeworksl Enablediverseframeworkstoshareclusterl Makeiteasiertodevelopanddeploynewframeworks(e.g.,Spark)
6
MPIHadoopMPIHadoop
ResourceManagementSystem
Uniprograming Mul7programing

FineGrainedResourceSharing
l Taskgranularitybothin7me&spacel Mul]plexnode/]mebetweentasksbelongingtodifferent
jobs/frameworks
l Taskstypicallyshort;median~=10sec,minutes
l Whyfinegrained?l Improvedatalocalityl Easiertohandlenodefailures
7

Goals
l Efficientu7liza7onofresources
l Supportdiverseframeworks(exis]ng&future)
l Scalabilityto10,000’sofnodes
l Reliabilityinfaceofnodefailures

Approach:GlobalScheduler
9
GlobalScheduler
Organiza]onpoliciesResourceavailability
• Response]me• Throughput• Availability• …
Jobrequirements
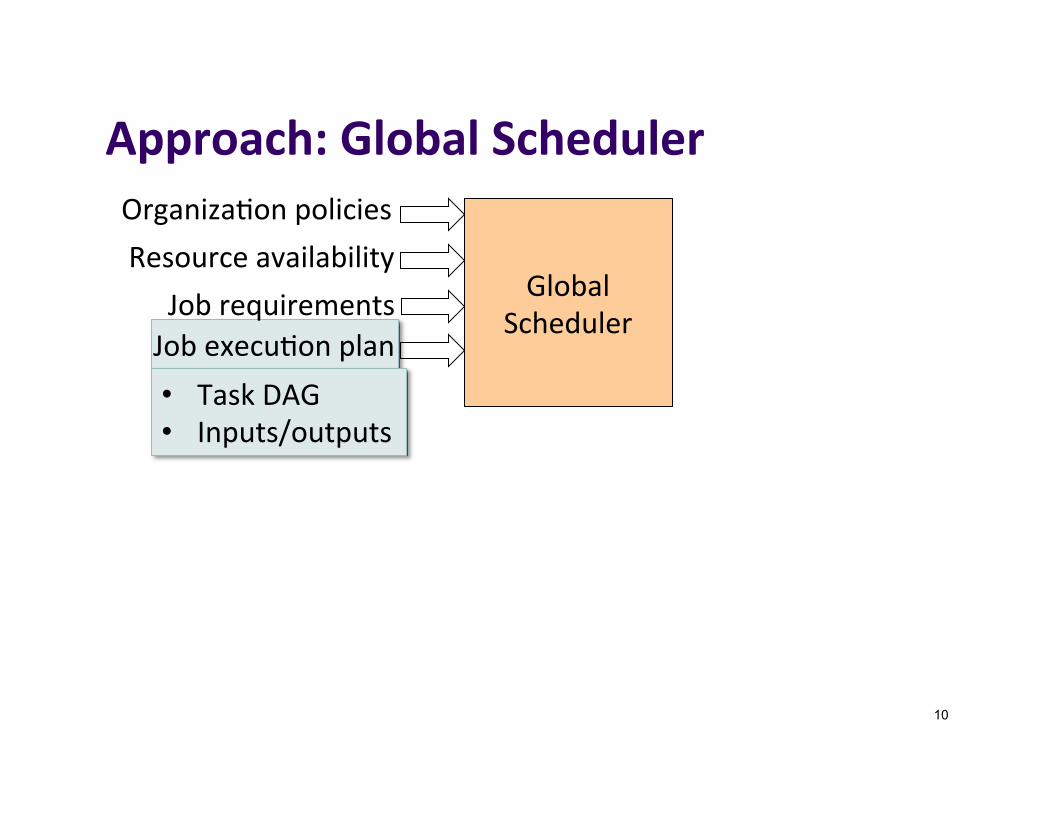
Approach:GlobalScheduler
10
GlobalScheduler
Organiza]onpoliciesResourceavailability
• TaskDAG• Inputs/outputs
JobrequirementsJobexecu]onplan
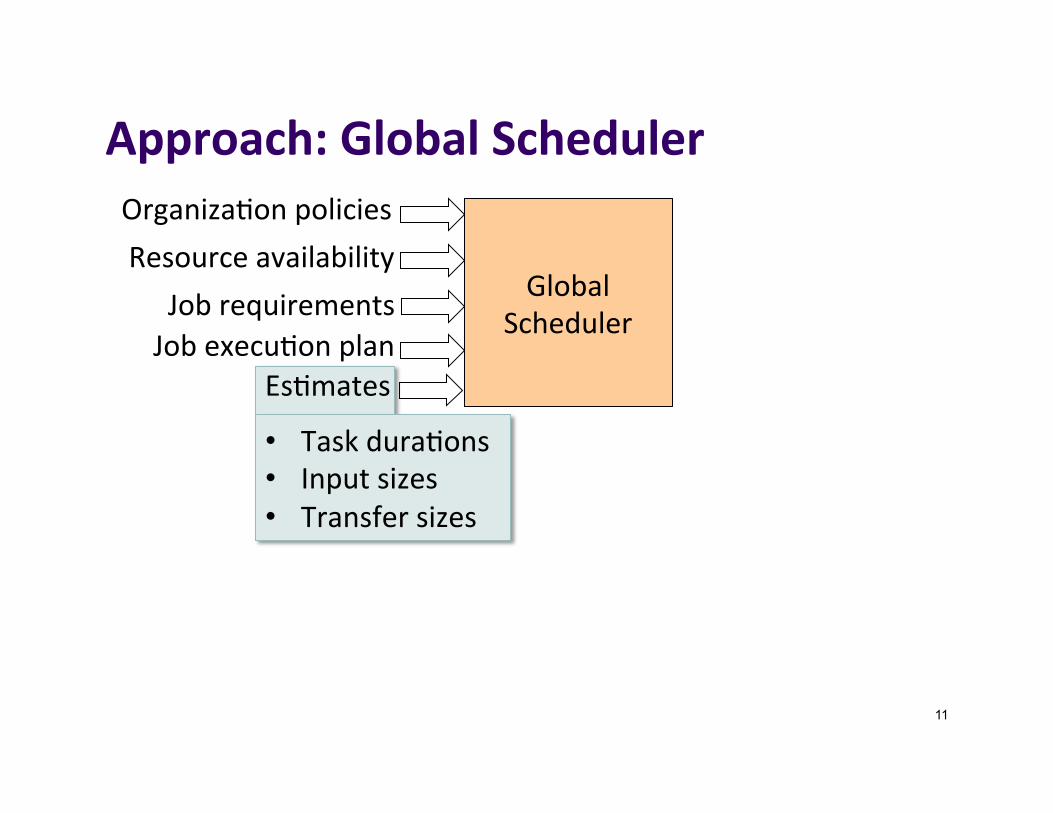
Approach:GlobalScheduler
11
GlobalScheduler
Organiza]onpoliciesResourceavailability
• Taskdura]ons• Inputsizes• Transfersizes
JobrequirementsJobexecu]onplan
Es]mates
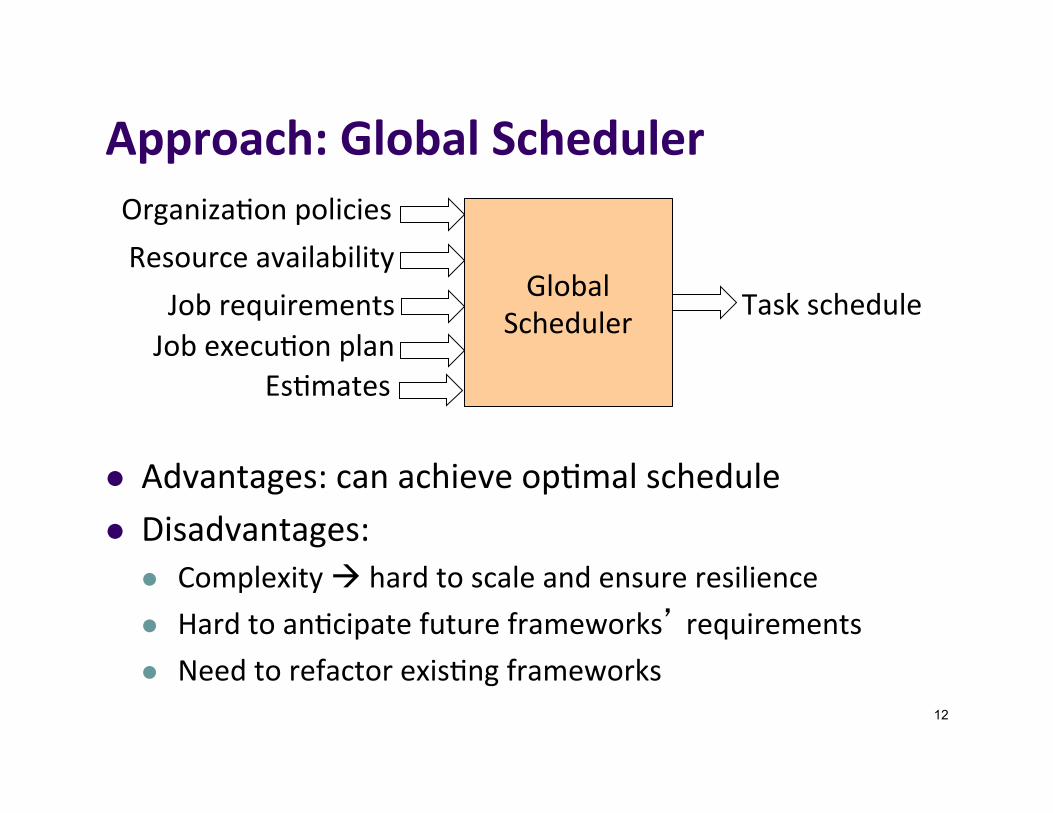
Approach:GlobalScheduler
l Advantages:canachieveop]malschedulel Disadvantages:
l Complexityàhardtoscaleandensureresiliencel Hardtoan]cipatefutureframeworks’requirementsl Needtorefactorexis]ngframeworks
12
GlobalScheduler
Organiza]onpoliciesResourceavailability
TaskscheduleJobrequirementsJobexecu]onplan
Es]mates

Mesos

ResourceOffers
l Unitofalloca]on:resourceofferl Vectorofavailableresourcesonanodel E.g.,node1:<1CPU,1GB>,node2:<4CPU,16GB>
l Mastersendsresourceofferstoframeworks
l Frameworksselectwhichofferstoacceptandwhichtaskstorun
14
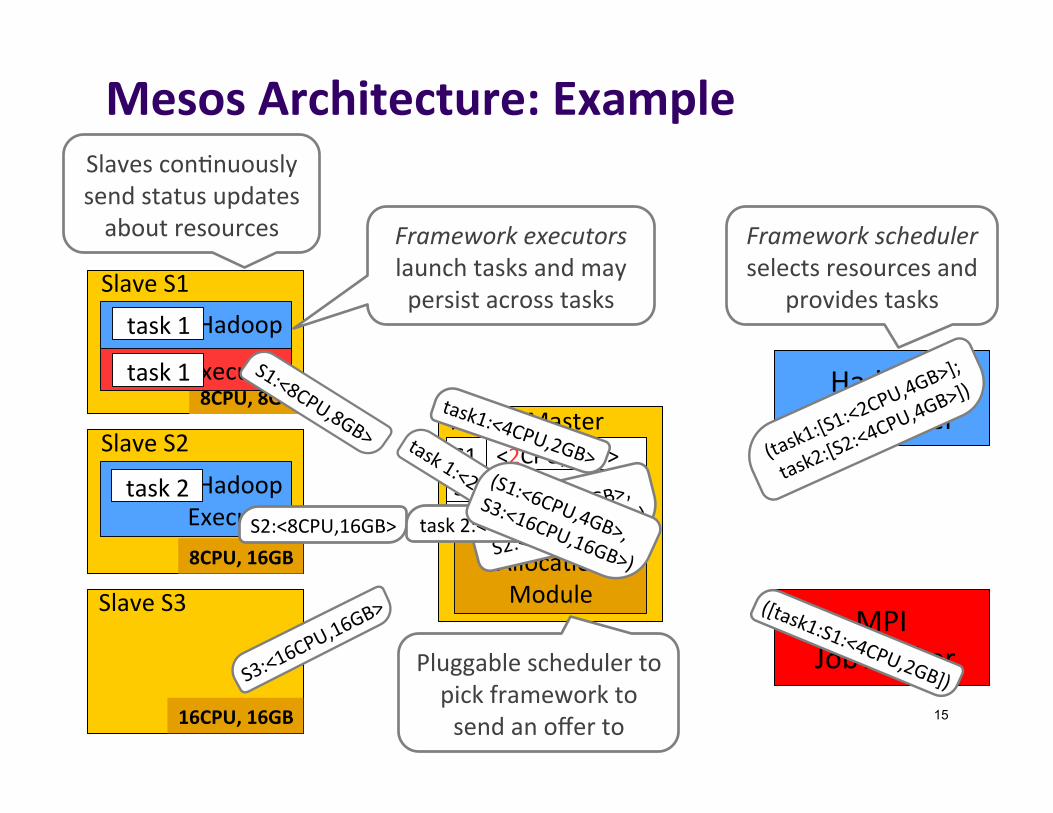
Pushtaskschedulingtoframeworks
HadoopJobTracker
MPIJobTracker
8CPU,8GB
HadoopExecutorMPIexecutor
task1
task1
8CPU,16GB
16CPU,16GB
HadoopExecutor
task2
Alloca]onModule
S1 <8CPU,8GB>S2 <8CPU,16GB>S3 <16CPU,16GB>
S1 <6CPU,4GB>S2 <4CPU,12GB>S1 <2CPU,2GB>
MesosArchitecture:Example
15
(S1:<8CPU,8GB
>,
S2:<8CPU,16G
B>)S2:<8CPU,16GB>
Slavescon]nuouslysendstatusupdatesaboutresources
Pluggableschedulertopickframeworktosendanofferto
Frameworkschedulerselectsresourcesand
providestasks
Frameworkexecutorslaunchtasksandmaypersistacrosstasks
task2:<4CPU,4GB>
SlaveS1
SlaveS2
SlaveS3
MesosMaster
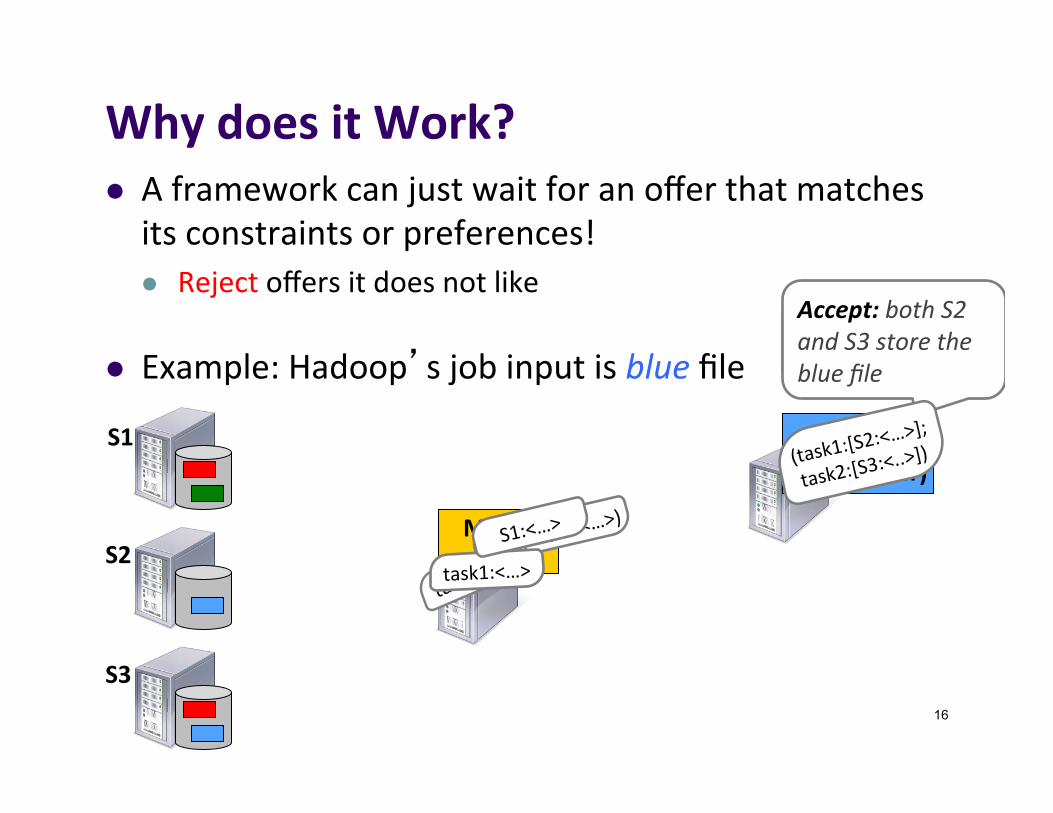
WhydoesitWork?l Aframeworkcanjustwaitforanofferthatmatchesitsconstraintsorpreferences!l Rejectoffersitdoesnotlike
l Example:Hadoop’sjobinputisbluefile
16
S1
S2
S3
Reject:S1doesn’tstorebluefile
Accept:bothS2andS3storethebluefile
Hadoop(Jobtracker)
Mesosmaster(S2:<…>
,S3:<…>)
(task1:[S2:<…>
];
task2:[S3:<..>]
)
task1:<…>
S1:<…>

TwoKeyQues7ons
l Howlongdoesaframeworkneedtowait?
l Howdoyouallocateresourcesofdifferenttypes?l E.g.,ifframeworkAhas(1CPU,3GB)tasks,andframework
Bhas(2CPU,1GB)tasks,howmuchweshouldallocatetoAandB?
17

TwoKeyQues7ons
Ø Howlongdoesaframeworkneedtowait?
l Howdoyouallocateresourcesofdifferenttypes?
18

HowLongtoWait?l Dependon
l Distribu]onoftaskdura]onl “Pickiness”–setofresourcessa]sfyingframeworkconstraints
l Hardconstraints:cannotrunifresourcesviolateconstraintsl Sovwareandhardwareconfigura]ons(e.g.,OStypeandversion,
CPUtype,publicIPaddress)l Specialhardwarecapabili]es(e.g.,GPU)
l So]constraints:canrun,butwithdegradedperformancel Data,computa]onlocality
19

Model
l Onejobperframeworkl Onetaskpernodel Notaskpreemp]on
l Pickiness,p = k/n l k–numberofnodesrequiredbyjob,e.g.,it’stargetalloca]onl n–numberofnodessa]sfyingframework’sconstraintsinthe
cluster
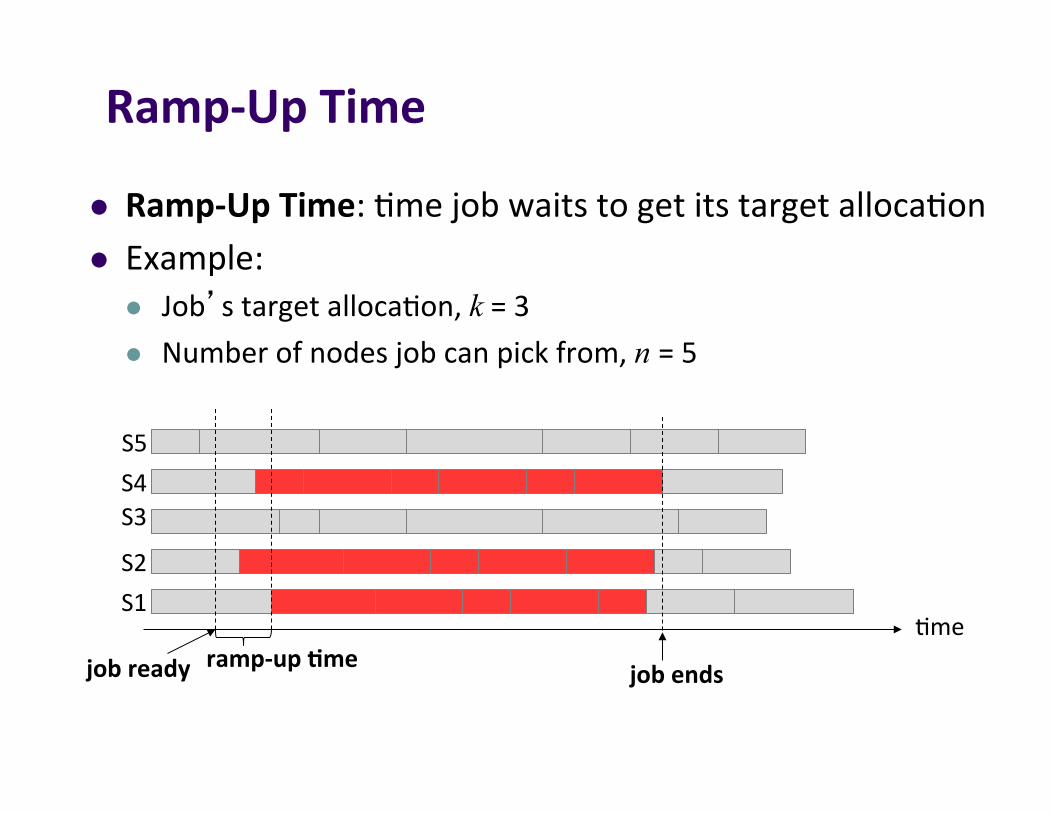
S5S4S3
S2S1
]me
Ramp-UpTime
l Ramp-UpTime:]mejobwaitstogetitstargetalloca]onl Example:
l Job’stargetalloca]on,k=3l Numberofnodesjobcanpickfrom,n =5
jobready jobendsramp-up7me

Pickiness:Ramp-UpTime
Es]matedramp-up]meofajobwithpickinesspis≅(100p)-thpercen7leoftaskdura]ondistribu]on
l E.g.,ifp=0.9,es]matedramp-up]meisthe90-thpercen]leoftaskdura]ondistribu]on(T)
l Why?Assume:k = 3, n = 5, p = k/n
S5S4S3
S2S1
]mejobready ramp-up7me
• jobneedstowaitforfirstk(= p×n)taskstofinish• Ramp-up7me:k-thordersta]s]csoftaskdura]ondist.sample,i.e.,(100p)thperc.ofdist.
22

AlternateInterpreta7ons
23
l Ifp=1,es]mated]meofajobgexngfrac]onqofitsalloca]onis≅(100q)-thpercen]leofT l E.g.,es]mate]meofajobgexng0.9ofitsalloca]onisthe90-
thpercen]leofT
l Ifu]liza]onofresourcessa]sfyingjob’sconstraintsisq,es]mated]metogetitsalloca]onis≅(100q)-thperc.ofT l E.g.,ifresourceu]liza]onis0.9,es]mated]meofajobtogetits
alloca]onisthe90-thpercen]leofT
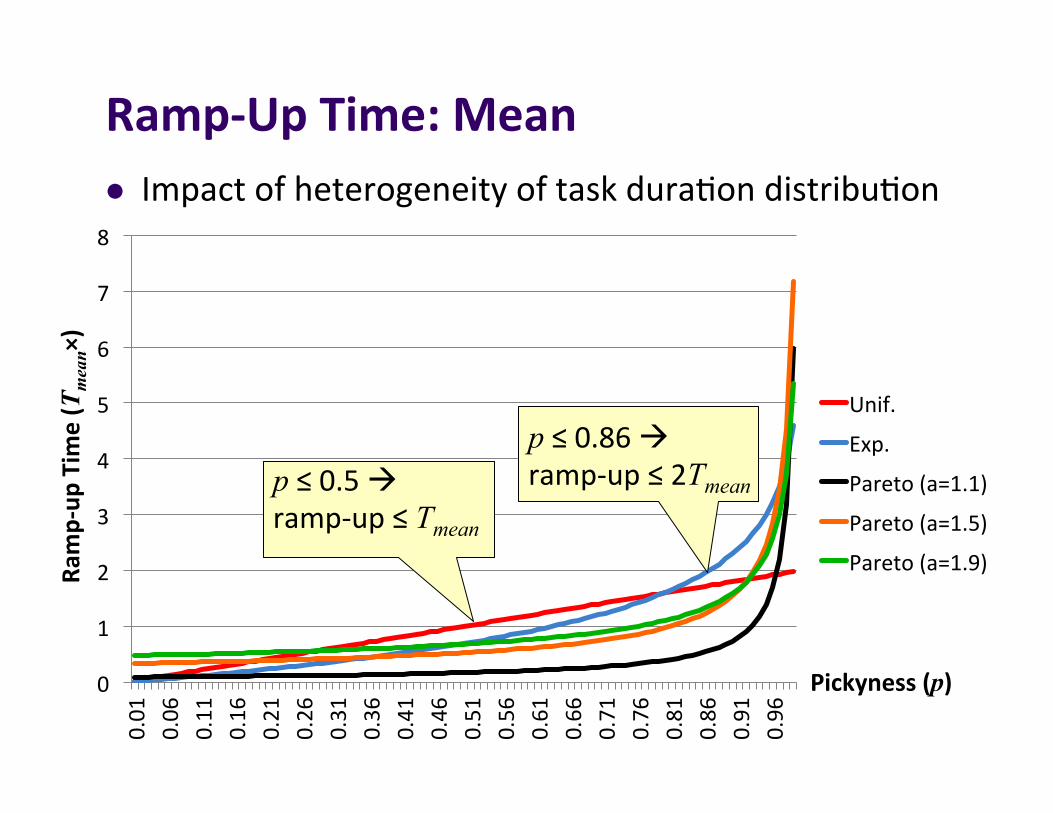
Ramp-UpTime:Meanl Impactofheterogeneityoftaskdura]ondistribu]on
Ramp-up
Tim
e(T
mea
n×)
Pickyness(p)0
1
2
3
4
5
6
7
8
0.01
0.06
0.11
0.16
0.21
0.26
0.31
0.36
0.41
0.46
0.51
0.56
0.61
0.66
0.71
0.76
0.81
0.86
0.91
0.96
Unif.
Exp.
0
1
2
3
4
5
6
7
8
0.01
0.06
0.11
0.16
0.21
0.26
0.31
0.36
0.41
0.46
0.51
0.56
0.61
0.66
0.71
0.76
0.81
0.86
0.91
0.96
Unif.
Exp.
Pareto(a=1.1)
Pareto(a=1.5)
Pareto(a=1.9)
Pickyness(p)
p≤0.86àramp-up≤2Tmean p≤0.5à
ramp-up≤Tmean
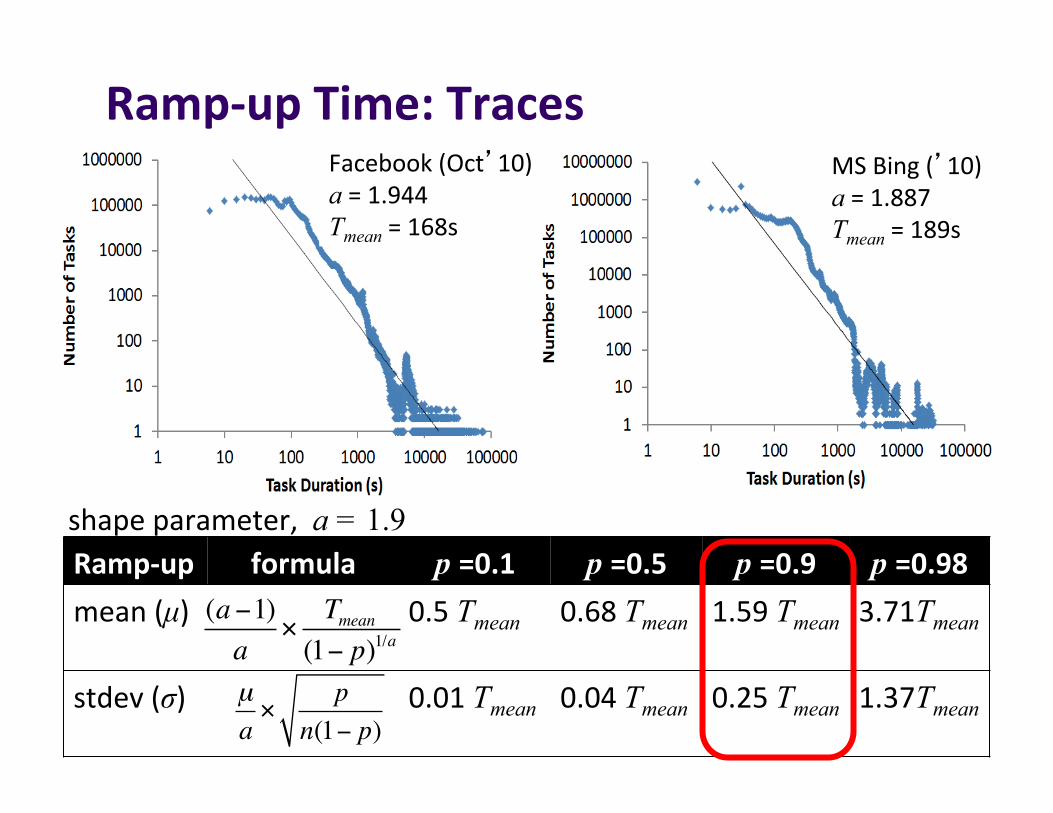
Ramp-upTime:Traces
Ramp-up formula p =0.1 p =0.5 p =0.9 p =0.98mean(µ) 0.5Tmean 0.68Tmean 1.59Tmean 3.71Tmean
stdev(σ) 0.01Tmean 0.04Tmean 0.25Tmean 1.37Tmean
(a−1)a
×Tmean(1− p)1/a
µa×
pn(1− p)
Facebook(Oct’10)a=1.944Tmean=168s
MSBing(’10)a=1.887Tmean=189s
shapeparameter,a = 1.9

l Preemp7on:preempttasks
l Migra7on:movetasksaroundtoincreasechoice,e.g.,
l Exis]ngframeworksimplementl Nomigra]on:expensivetomigrateshorttasksl Preemp]onwithtaskkilling(e.g.,Dryad’sQuincy):expensive
tocheckpointdata-intensivetasks
Job1constraintset={m1,m2,m3,m4}Job2constraintset={m1,m2}
m1 m2 m3 m4
ImprovingRamp-UpTime?
26
wait!
task task
task task

Macro-benchmarkl Simulatean1000-nodecluster
l Jobandtaskdura]ons:Facebooktraces(Oct2010)l Constraints:modeledaverGoogle*
l Alloca]onpolicy:fairsharing
l Schedulercomparisonl ResourceOffers:nopreemp]on,andnomigra]on(e.g.,
Hadoop’sFairScheduler+constraints)l Global-M:globalschedulerwithmigra]onl Global-MP:globalschedulerwithmigra]onandpreemp]on
*Sharmaetal.,“ModelingandSynthesizingTaskPlacementConstraintsinGoogleComputeClusters”,ACMSoCC,2011.
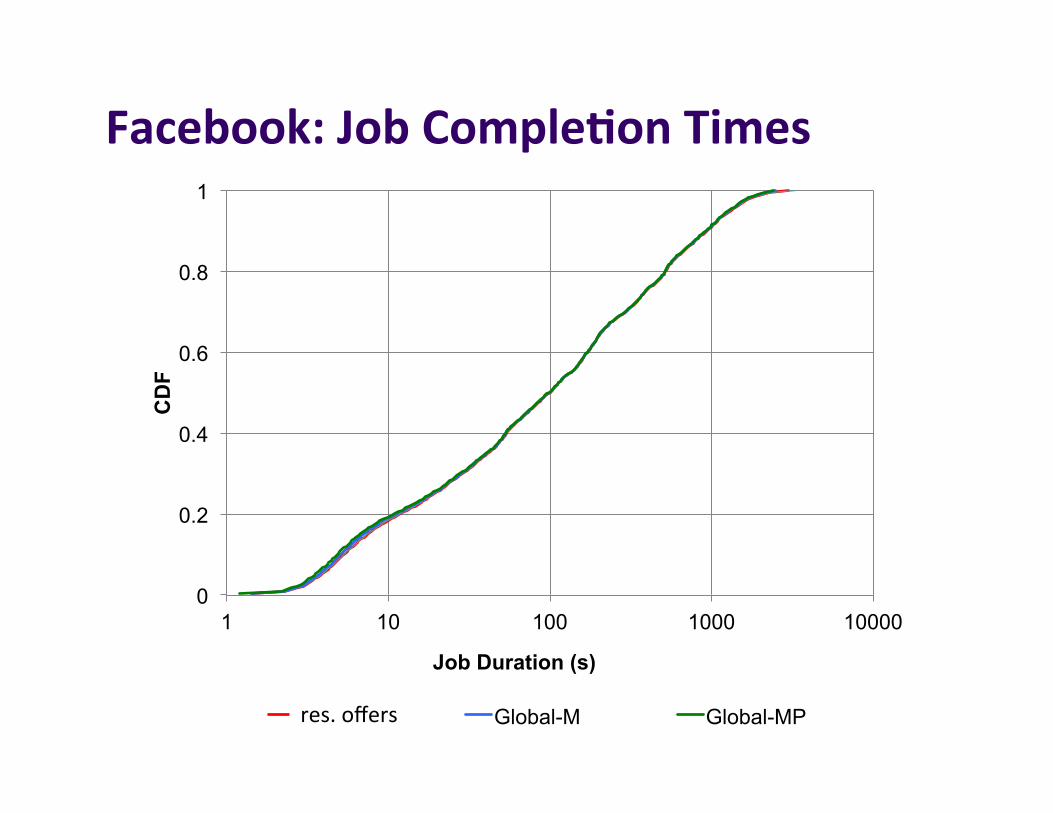
Facebook:JobComple7onTimes
0
0.2
0.4
0.6
0.8
1
1 10 100 1000 10000
CD
F
Job Duration (s)
Choosy Global-M Global-MP res.offers
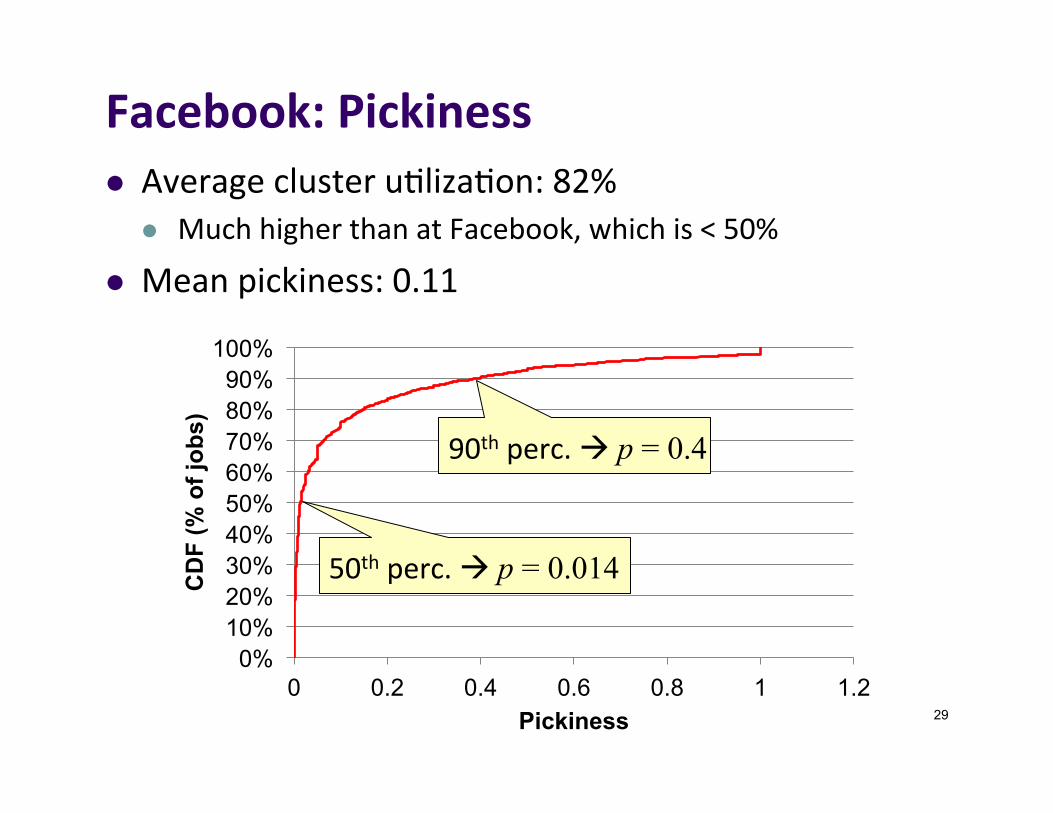
Facebook:Pickinessl Averageclusteru]liza]on:82%
l MuchhigherthanatFacebook,whichis<50%
l Meanpickiness:0.11
29
0% 10% 20% 30% 40% 50% 60% 70% 80% 90%
100%
0 0.2 0.4 0.6 0.8 1 1.2
CD
F (%
of j
obs)
Pickiness
50thperc.àp = 0.014
90thperc.àp = 0.4

Summary:ResourceOffers
l Ramp-up]melowundermostscenarios
l BarelyanyperformancedifferencesbetweenglobalanddistributedschedulersinFacebookworkload
l Op]miza]onsl Masterdoesn’tsendanofferalreadyrejectedbya
framework(nega]vecaching)l Allowframeworkstospecifywhiteandblacklistsofnodes
30

Borg

Borg
ClustermanagementsystematGooglethatachieveshighu]liza]onby:l Admissioncontroll Efficienttask-packingl Over-commitmentl Machinesharing
32

TheUserPerspec7ve
l Users:Googledevelopersandsystemadministratorsmainly
l Theworkload:Produc]onandbatch,mainlyl Cells,around10Knodesl Jobsandtasks
33

TheUserPerspec7ve
l Allocsl Reservedsetofresources
l Priority,Quota,andAdmissionControll Jobhasapriority(preemp]ng)l Quotaisusedtodecidewhichjobstoadmitforscheduling
l NamingandMonitoringl 50.jfoo.ubar.cc.borg.google.coml Monitoringhealthofthetaskandthousandsof
performancemetrics
34

SchedulingaJob
35
job hello_world = { runtime = { cell = “ic” } //what cell should run it in? binary = ‘../hello_world_webserver’ //what program to run? args = { port = ‘%port%’ } requirements = { RAM = 100M disk = 100M CPU = 0.1 } replicas = 10000 }
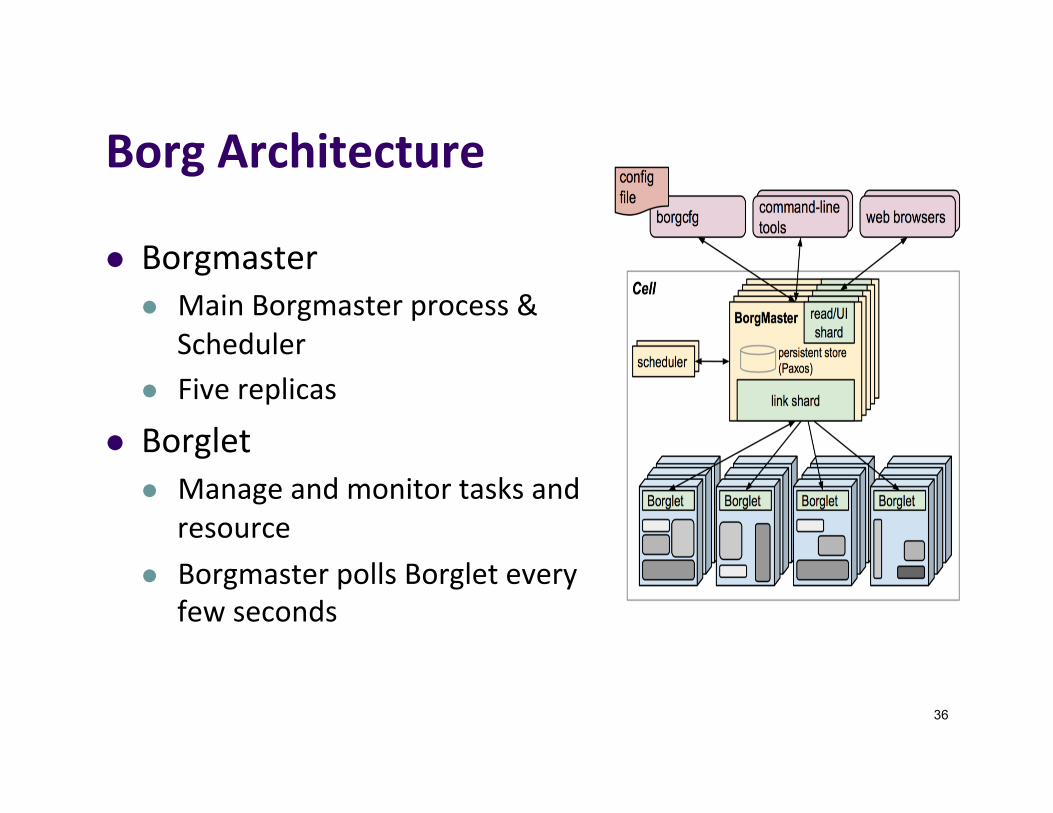
BorgArchitecture
l Borgmasterl MainBorgmasterprocess&
Schedulerl Fivereplicas
l Borgletl Manageandmonitortasksand
resourcel BorgmasterpollsBorgletevery
fewseconds
36
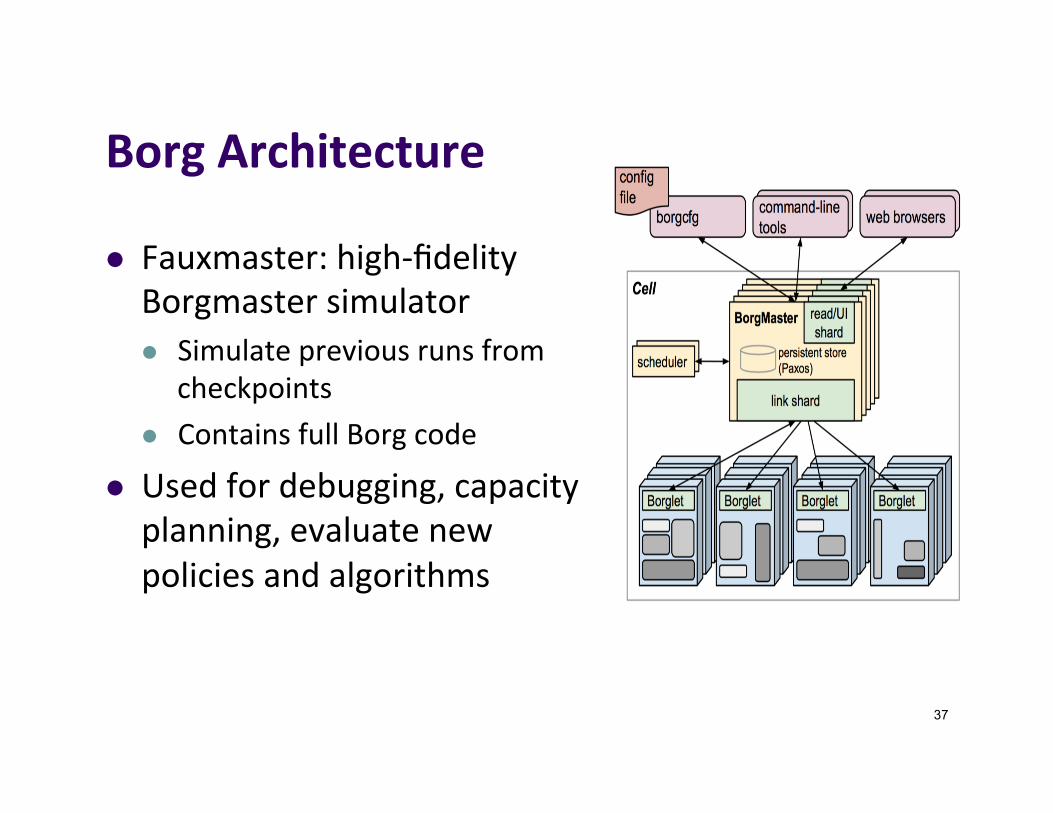
BorgArchitecture
l Fauxmaster:high-fidelityBorgmastersimulatorl Simulatepreviousrunsfrom
checkpointsl ContainsfullBorgcode
l Usedfordebugging,capacityplanning,evaluatenewpoliciesandalgorithms
37
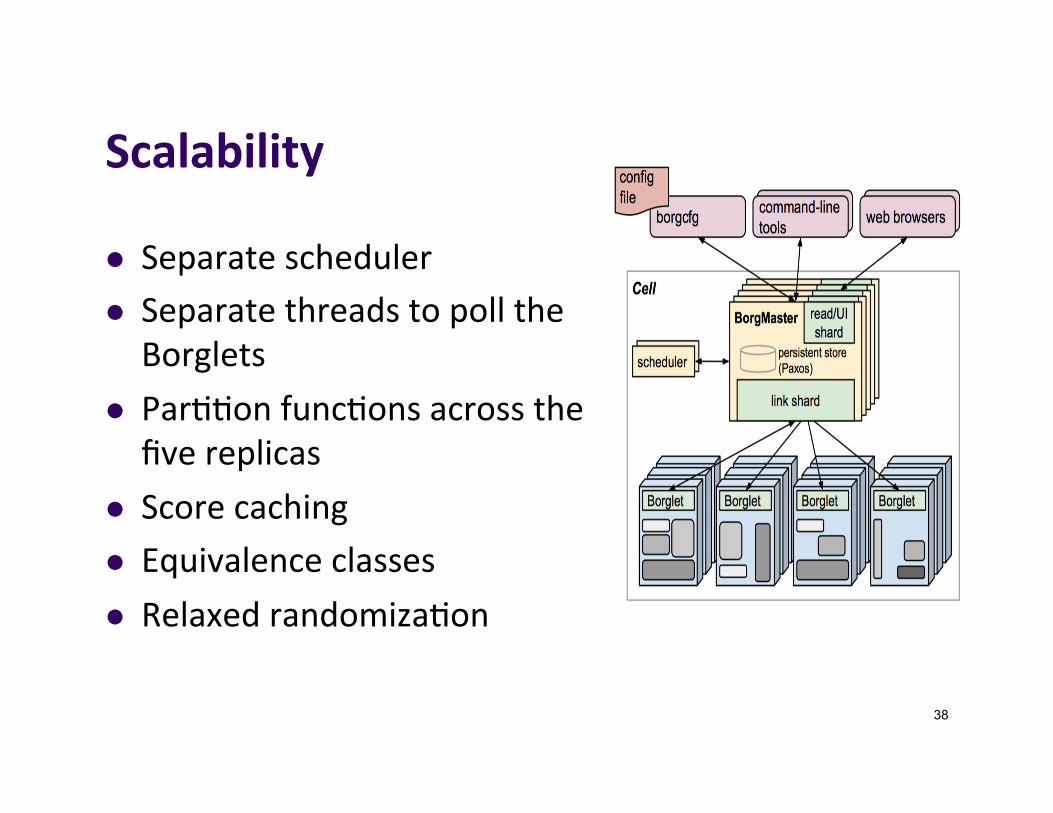
Scalability
l Separateschedulerl SeparatethreadstopolltheBorglets
l Par]]onfunc]onsacrossthefivereplicas
l Scorecachingl Equivalenceclassesl Relaxedrandomiza]on
38
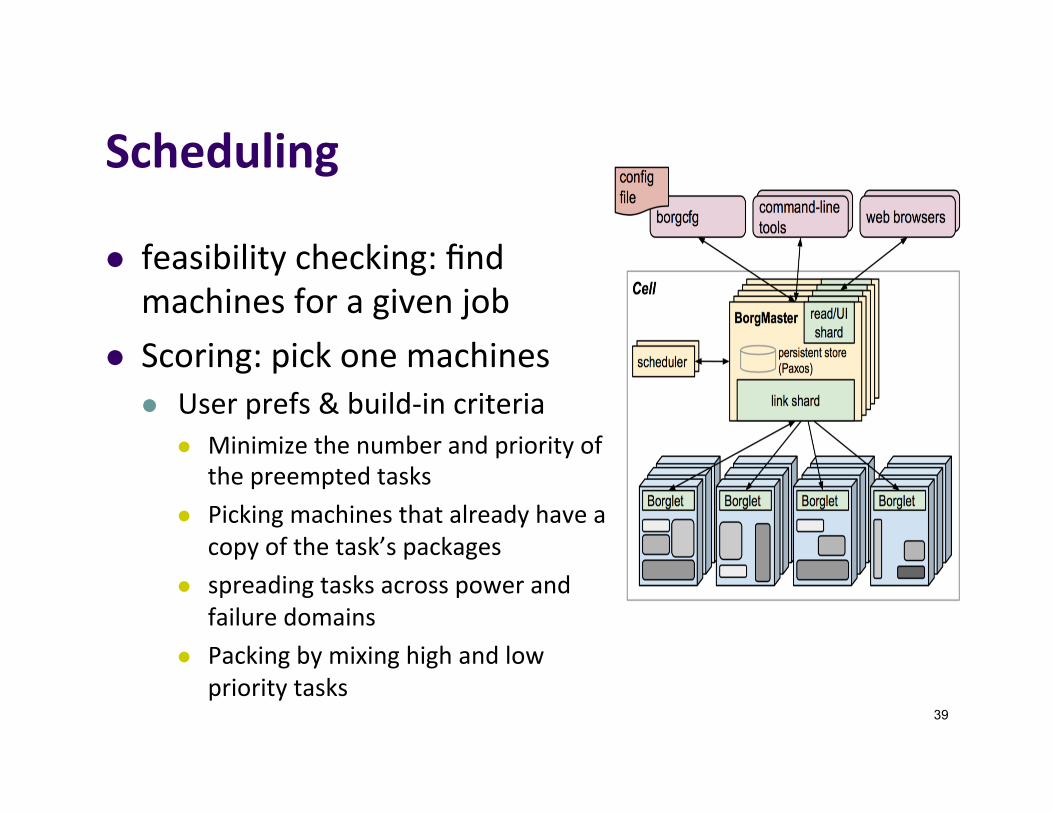
Scheduling
l feasibilitychecking:findmachinesforagivenjob
l Scoring:pickonemachinesl Userprefs&build-incriteria
l Minimizethenumberandpriorityofthepreemptedtasks
l Pickingmachinesthatalreadyhaveacopyofthetask’spackages
l spreadingtasksacrosspowerandfailuredomains
l Packingbymixinghighandlowprioritytasks
39
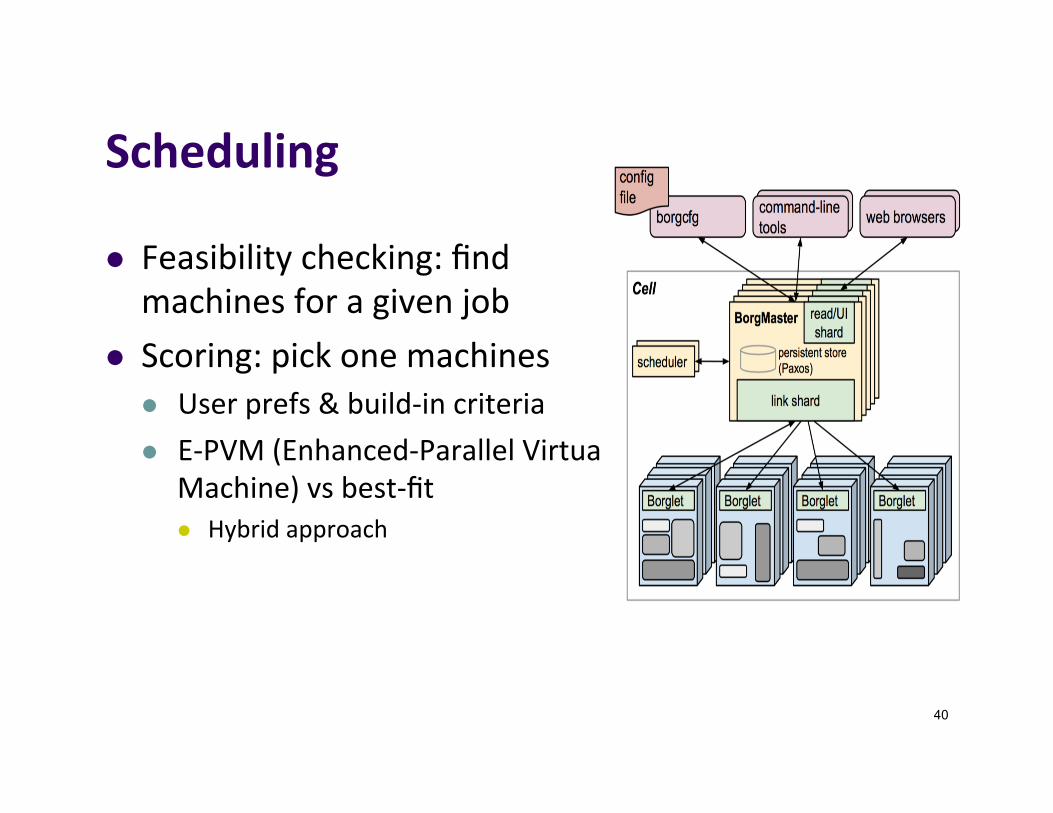
Scheduling
l Feasibilitychecking:findmachinesforagivenjob
l Scoring:pickonemachinesl Userprefs&build-incriterial E-PVM(Enhanced-ParallelVirtuall
Machine)vsbest-fitl Hybridapproach
40

Borg’sAlloca7onAlgorithmsandPolicies
AdvancedBin-Packingalgorithms:l AvoidstrandingofresourcesEvalua]onmetric:Cell-compac]onl Findsmallestcellthatwecanpacktheworkloadinto…l Removemachinesrandomlyfromacelltomaintaincellheterogeneity
Evaluatedvariouspoliciestounderstandthecost,intermsofextramachinesneededforpackingthesameworkload
41
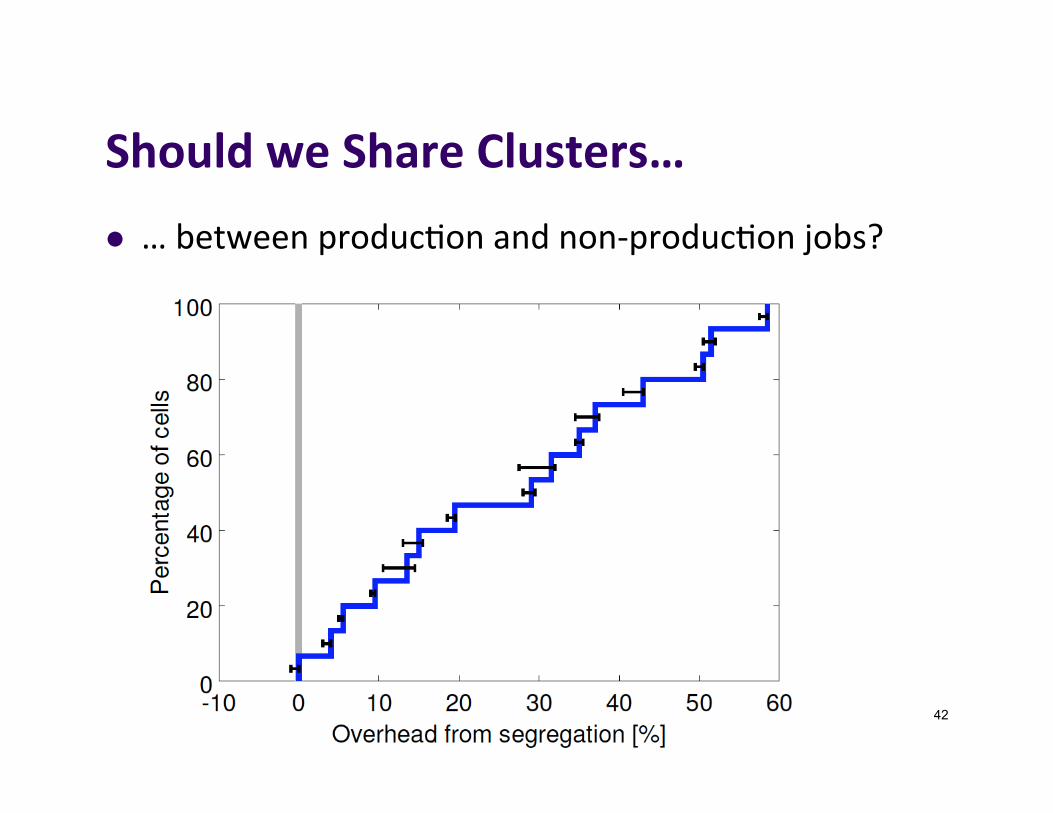
ShouldweShareClusters…l …betweenproduc]onandnon-produc]onjobs?
42
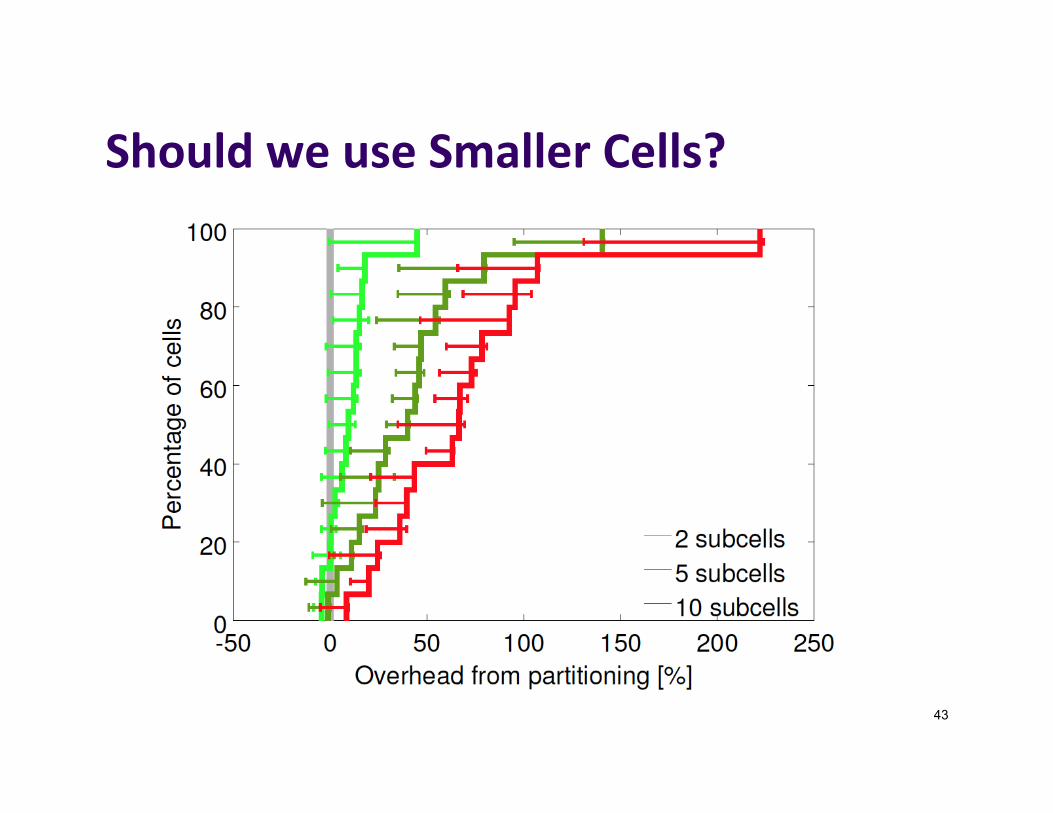
ShouldweuseSmallerCells?
43
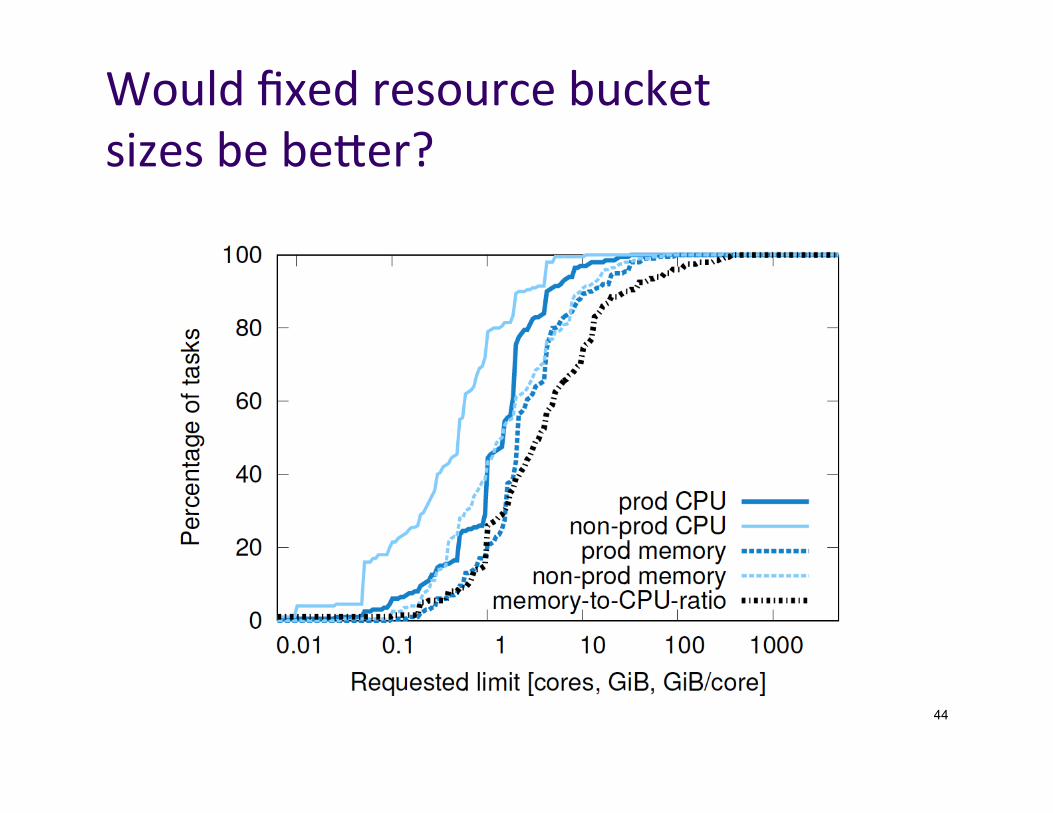
WouldfixedresourcebucketsizesbebeKer?
44

Kubernetes
Directlyderived
l Borglet=>Kubeletl alloc=>podl Borgcontainers=>dockerl Declara]vespecifica]ons
Improved
l Job=>labelsl managedports=>IPper
podl Monolithicmaster=>
micro-services
45
GoogleopensourceprojectlooselyinspiredbyBorg




![Resource Management and Query Optimization in the Cloud · Centralized Resource Management [YARN, Mesos, Omega, Borg] Node Manager Node Manager Node Manager • •](https://cdn.vdocument.in/doc/165x107/5e9bd5e04173cb1b83218738/resource-management-and-query-optimization-in-the-cloud-centralized-resource-management.jpg)


![Optimizing the Cost of Executing Mixed Interactive and ...deirwin/tr-kubernetes.pdf · Container Orchestration Platforms (COPs), such as Kubernetes [9], Borg [22], Mesos [13], Docker](https://cdn.vdocument.in/doc/165x107/5ed3bf55a0e09216242fe106/optimizing-the-cost-of-executing-mixed-interactive-and-deirwintr-container.jpg)