
Probabilistic and Lexicalized Parsing
CS 4705

Probabilistic CFGs: PCFGs
• Weighted CFGs– Attach weights to rules of CFG– Compute weights of derivations– Use weights to choose preferred parses
• Utility: Pruning and ordering the search space, disambiguate, Language Model for ASR
• Parsing with weighted grammars: find the parse T’ which maximizes the weights of the derivations in the parse tree for all the possible parses of S
• T’(S) = argmaxT∈τ(S) W(T,S)
• Probabilistic CFGs are one form of weighted CFGs

Rule Probability
• Attach probabilities to grammar rules• Expansions for a given non-terminal sum to 1
R1: VP V .55
R2: VP V NP .40
R3: VP V NP NP .05• Estimate probabilities from annotated corpora
– E.g. Penn Treebank– P(R1)=counts(R1)/counts(VP)

Derivation Probability
• For a derivation T= {R1…Rn}:
– Probability of the derivation: • Product of probabilities of rules expanded in tree
– Most likely probable parse: – Probability of a sentence:
• Sum over all possible derivations for the sentence
• Note the independence assumption: Parse probability does not change based on where the rule is expanded.
)(maxarg* TPTT
n
iiRPTP
1
)()(
T
STPSP )|()(

One Approach: CYK Parser
• Bottom-up parsing via dynamic programming– Assign probabilities to constituents as they
are completed and placed in a table– Use the maximum probability for each
constituent type going up the tree to S• The Intuition:
– We know probabilities for constituents lower in the tree, so as we construct higher level constituents we don’t need to recompute these

CYK (Cocke-Younger-Kasami) Parser
• Bottom-up parser with top-down filtering• Uses dynamic programming to store intermediate results
(cf. Earley algorithm for top-down case)• Input: PCFG in Chomsky Normal Form
– Rules of form Aw or ABC; no ε• Chart: array [i,j,A] to hold probability that non-terminal A
spans input i-j
– Start State(s): (i,i+1,A) for each Awi+1
– End State: (1,n,S) where n is the input size– Next State Rules: (i,k,B) (k,j,C) (i,j,A) if ABC
• Maintain back-pointers to recover the parse

Structural Ambiguity
• S NP VP• VP V NP• NP NP PP• VP VP PP• PP P NP
• NP John | Mary | Denver• V -> called• P -> from
John called Mary from Denver
S
VP PP
NP VP
V NP NPP
John called Mary from Denver
S
NP
NP VP
V NP PP
PJohn called Mary
from Denver
NP

Example
John called Mary from Denver

Base Case: Aw
NP
P Denver
NP from
V Mary
NP called
John

Recursive Cases: ABC
NP
P Denver
NP from
X V Mary
NP called
John

NP
P Denver
VP NP from
X V Mary
NP called
John

NP
X P Denver
VP NP from
X V Mary
NP called
John

PP NP
X P Denver
VP NP from
X V Mary
NP called
John

PP NP
X P Denver
S VP NP from
V Mary
NP called
John

PP NP
X X P Denver
S VP NP from
X V Mary
NP called
John
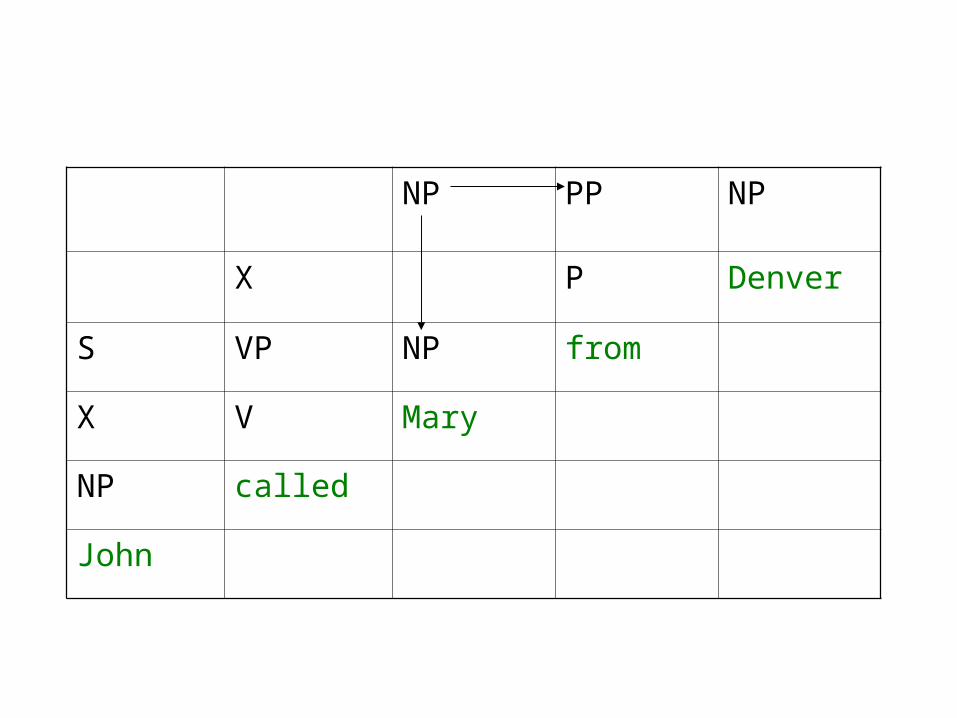
NP PP NP
X P Denver
S VP NP from
X V Mary
NP called
John

NP PP NP
X X X P Denver
S VP NP from
X V Mary
NP called
John

VP NP PP NP
X X X P Denver
S VP NP from
X V Mary
NP called
John

VP NP PP NP
X X X P Denver
S VP NP from
X V Mary
NP called
John

VP1
VP2
NP PP NP
X X X P Denver
S VP NP from
X V Mary
NP called
John

S VP1
VP2
NP PP NP
X X X P Denver
S VP NP from
X V Mary
NP called
John
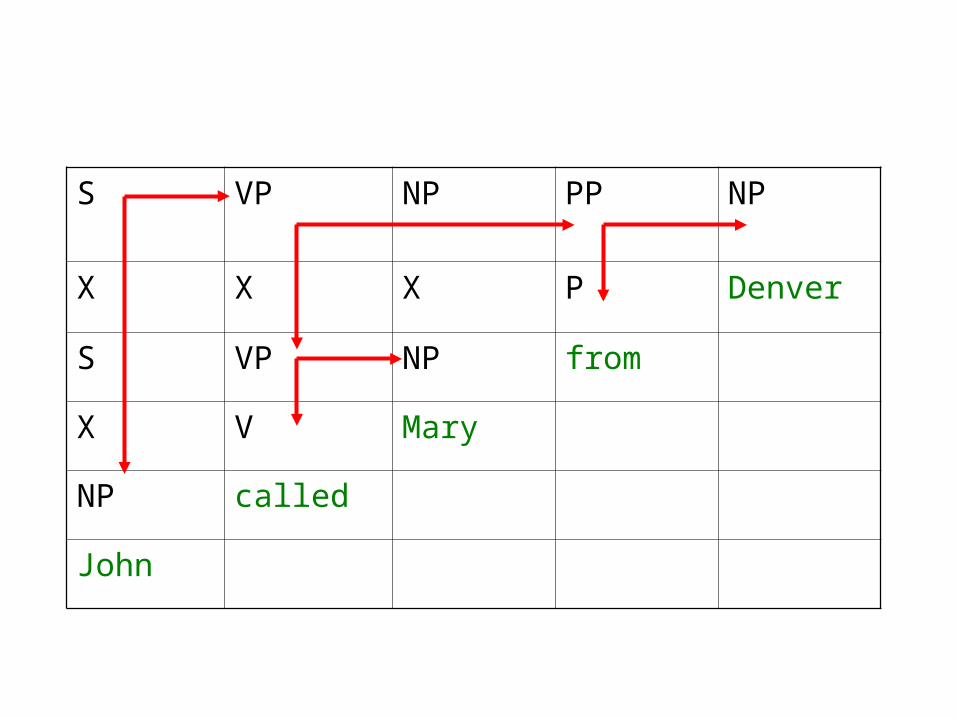
S VP NP PP NP
X X X P Denver
S VP NP from
X V Mary
NP called
John

Problems with PCFGs• Probability model just based on rules in the derivation.• Lexical insensitivity:
– Doesn’t use words in any real way– But structural disambiguation is lexically driven
• PP attachment often depends on the verb, its object, and the preposition
• I ate pickles with a fork. • I ate pickles with relish.
• Context insensitivity of the derivation– Doesn’t take into account where in the derivation a rule is used
• Pronouns more often subjects than objects • She hates Mary. • Mary hates her.
• Solution: Lexicalization– Add lexical information to each rule– I.e. Condition the rule probabilities on the actual words

An example: Phrasal Heads
• Phrasal heads can ‘take the place of’ whole phrases, defining most important characteristics of the phrase
• Phrases generally identified by their heads– Head of an NP is a noun, of a VP is the main verb, of a
PP is preposition
• Each PFCG rule’s LHS shares a lexical item with a non-terminal in its RHS

Increase in Size of Rule Set in Lexicalized CFG
• If R is the number of binary branching rules in CFG and ∑ is the lexicon, O(2*|∑|*|R|)
• For unary rules: O(|∑|*|R|)

Example (correct parse)
Attribute grammar

Example (less preferred)

Computing Lexicalized Rule Probabilities
• We started with rule probabilities as before– VP V NP PP P(rule|VP)
• E.g., count of this rule divided by the number of VPs in a treebank
• Now we want lexicalized probabilities– VP(dumped) V(dumped) NP(sacks)
PP(into)• i.e., P(rule|VP ^ dumped is the verb ^ sacks is the
head of the NP ^ into is the head of the PP)
– Not likely to have significant counts in any treebank

Exploit the Data You Have
• So, exploit the independence assumption and collect the statistics you can…
• Focus on capturing– Verb subcategorization
• Particular verbs have affinities for particular VPs
– Objects’ affinity for their predicates• Mostly their mothers and grandmothers• Some objects fit better with some predicates than
others

Verb Subcategorization
• Condition particular VP rules on their heads– E.g. for a rule r VP -> V NP PP
• P(r|VP) becomes P(r ^ V=dumped | VP ^ dumped)
– How do you get the probability?• How many times was rule r used with dumped,
divided by the number of VPs that dumped appears in, in total
• How predictive of r is the verb dumped?
– Captures affinity between VP heads (verbs) and VP rules

Example (correct parse)

Example (less preferred)

Affinity of Phrasal Heads for Other Heads: PP Attachment
• Verbs with preps vs. Nouns with preps• E.g. dumped with into vs. sacks with into
– How often is dumped the head of a VP which includes a PP daughter with into as its head relative to other PP heads or… what’s P(into|PP,dumped is mother VP’s head))
– Vs…how often is sacks the head of an NP with a PP daughter whose head is into relative to other PP heads or… P(into|PP,sacks is mother’s head))

But Other Relationships do Not Involve Heads (Hindle & Rooth ’91)
• Affinity of gusto for eat is greater than for spaghetti; and affinity of marinara for spaghetti is greater than for ate
Vp (ate) Vp(ate)
Vp(ate) Pp(with)
Pp(with)
Np(spag)
npvvAte spaghetti with marinaraAte spaghetti with gusto
np

Log-linear models for Parsing
• Why restrict to the conditioning to the elements of a rule?– Use even larger context…word sequence, word
types, sub-tree context etc.
• Compute P(y|x); where fi(x,y) tests properties of context and i is weight of feature
• Use as scores in CKY algorithm to find best parse
Yy
yxf
yxf
ii
ii
e
exyP
),(*
),(*
)|(
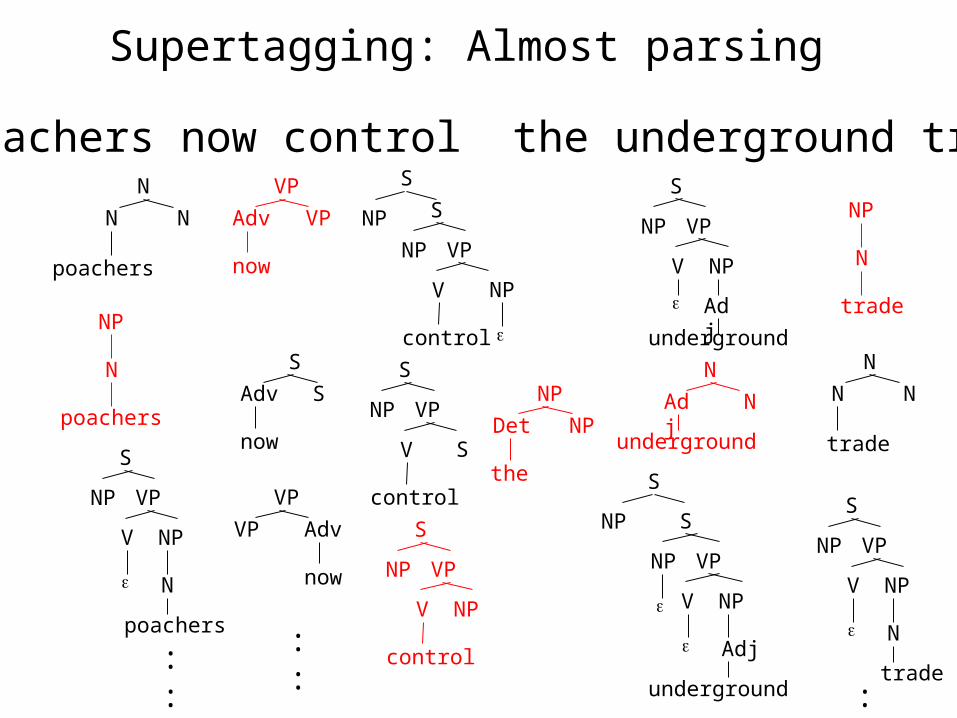
Supertagging: Almost parsing
Poachers now control the underground trade
NP
N
poachers
N
NN
tradeS
NP
VP
V
NP
N
poachers
::
S
SAdv
now
VP
VPAdv
now
VP
AdvVP
now
::
S
S
VP
V
NP
control
S
NP
VP
V
NP
control
S
NP
VP
V
NP
control
S
NP
NPDet
the
NP
NP
N
trade
N
NN
poachers
S
NP
VP
V
NP
N
trade
N
NAdj
underground
S
NP
VP
V
NP
Adj
underground
S
NP
VP
V
NP
Adj
underground
S
NP
:

Summary
• Parsing context-free grammars– Top-down and Bottom-up parsers– Mixed approaches (CKY, Earley parsers)
• Preferences over parses using probabilities– Parsing with PCFG and PCKY algorithms
• Enriching the probability model– Lexicalization– Log-linear models for parsing– Super-tagging







