Download - Scalable and Reliable Logging at Pinterest


Agenda
• What is Pinterest?
• Logging Infrastructure Deep-dive
• Managing Log Quality
• Summary & Questions

What is Pinterest?

What is Pinterest?
Pinterest is a discovery engine

What is the weather in SF today?


What is central limit theorem?


What do I cook for dinner today?

What’s my style?

Where shall we travel this summer?

Pinterest is solving this
discovery problem



Humans +
Algorithms



Kafka
App
Data Architecture
Singer
Qubole (Hadoop, Spark)
Merced
Pinball Skyline
Redshift
Pinalytics
Product
Storm Stingray
A/B Testing

Logging Infrastructure

Logging Infrastructure Requirements
• High availability
• Minimum data loss
• Horizontal scalability
• Low latency
• Minimum operation overhead

Pinterest Logging Infrastructure• thousands of hosts
• >120 billion messages, tens of terabytes per day
• Kafka as the central message transportation hub
• >500 Kafka brokers
• home-grown technologies for logging to Kafka and moving data from Kafka to cloud storage
AppServers
events
Kafka
Cloud storage

Logging Infrastructure v1
events
Kafka 0.7Host
app
app
app
data uploader
Real-time consumers

Problems with Kafka 0.7 pipelines
• Data loss
• Kafka 0.7 broker failure —> data loss
• high back pressure —> data loss
• Operability
• broker replacement —> reboot all dependent services to pick up the latest broker list

Challenges with Kafka that supports replication
• Multiple copies of messages among brokers
• cannot copy message directly to S3 to guarantee exact once persistence
• Cannot randomly pick Kafka brokers to write to
• Need to find the leader of each topic partition
• Handle various corner cases
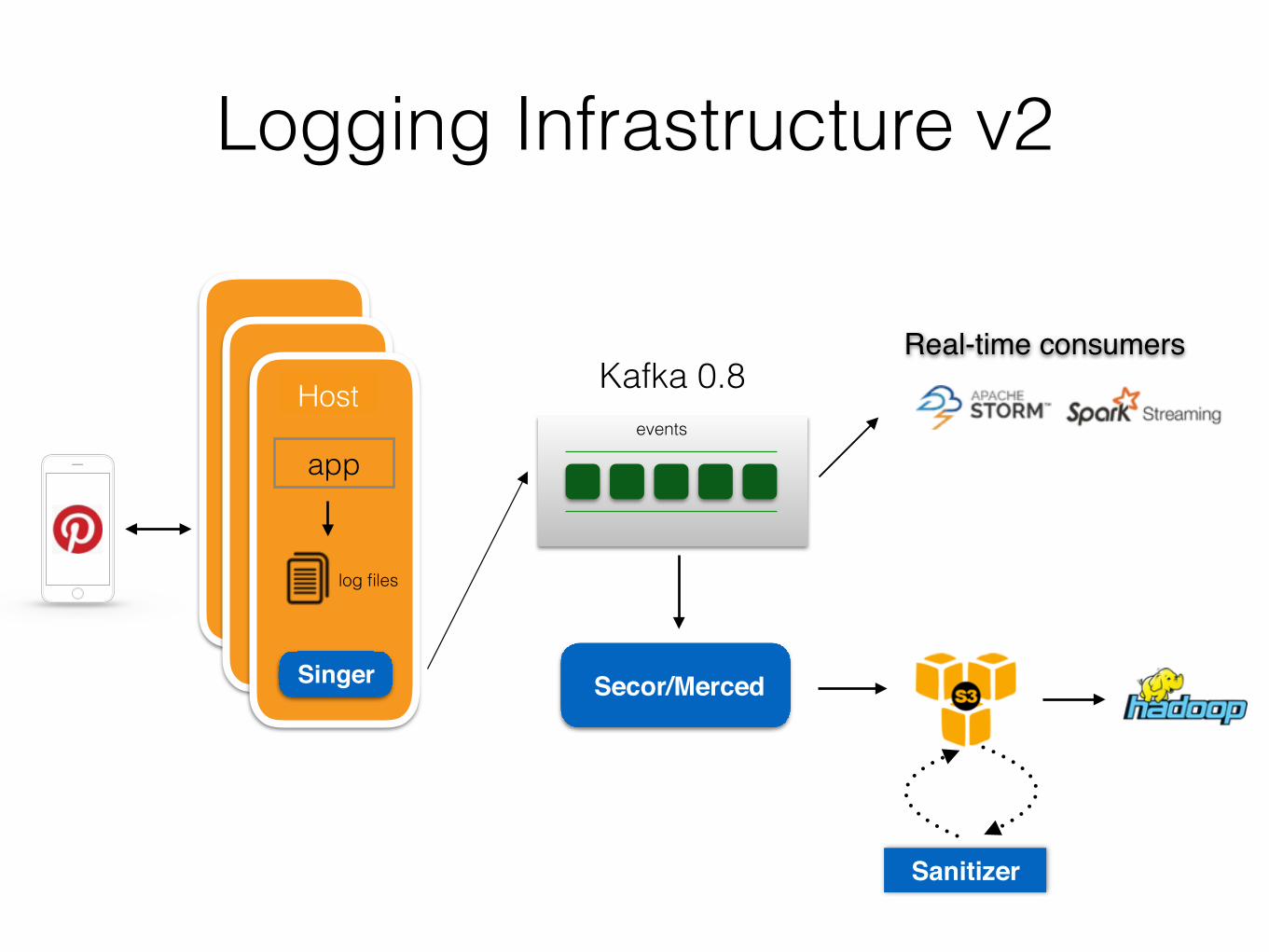
Logging Infrastructure v2
events
Kafka 0.8Host
app
log files
Singer Secor/Merced
Sanitizer
Real-time consumers

Logging Agent Requirement
• reliability
• high throughput, low latency
• minimum computation resource usage
• support various log file format (text, thrift, etc.)
• fairness scheduling

Singer Logging Agent• Simple logging mechanism
• applications log to disk
• Singer monitors file system events and uploads logs to Kafka
• Isolate applications from Singer agent failures
• Isolate applications from Kafka failures
• >100MB/second for log files in thrift
• Production Environment Support
• dynamic configuration detection
• adjustable log uploading latency
• auditing
• heartbeat mechanism
Host
app
log files
Singer

Singer InternalsSinger Architecture
LogStream monitor
Configuration watcher
Reader Writer
Log repository
Reader Writer
Reader Writer
Reader Writer
Log configuration
LogStream processors A - 1
A -2
B - 1
C - 1
Log configuration
Staged Event Driven Architecture

Running Kafka in the Cloud• Challenges
• brokers can die unexpectedly
• EBS I/O performance can degrade significantly due to resource contention
• Avoid virtual hosts co-location on the same physical host
• faster recovery

Running Kafka in the Cloud• Initial settings
• c3.2xlarge + EBS
• Current settings
• d2.xlarge
• local disks help to avoid EBS contention problem
• minimize data on each broker for faster recovery
• availability zone aware topic partition allocation
• multiple small clusters (20-40 brokers) for topic isolation

Scalable Data Persistence
33
• Strong consistency: each message is saved exactly once
• Fault tolerance: any worker node is allowed to crash
• Load distribution
• Horizontal scalability
• Configurable upload policies
events
Kafka 0.8
Secor/Merced

Secor
34
• Uses Kafka high level consumer
• Strong consistency: each message is saved exactly once
• Fault tolerance: any worker node is allowed to crash
• Load distribution
• Configurable upload policies
events
Kafka 0.8
Secor

Challenges with consensus-based workload distribution
• Kafka consumer group rebalancing can prevent consumer from making progress
• It is difficult to recover when high-level consumer lags behind on some topic partitions
• Manual tuning is required for workload distribution of multiple topics
• Inconvenient to add new topics
• Efficiency
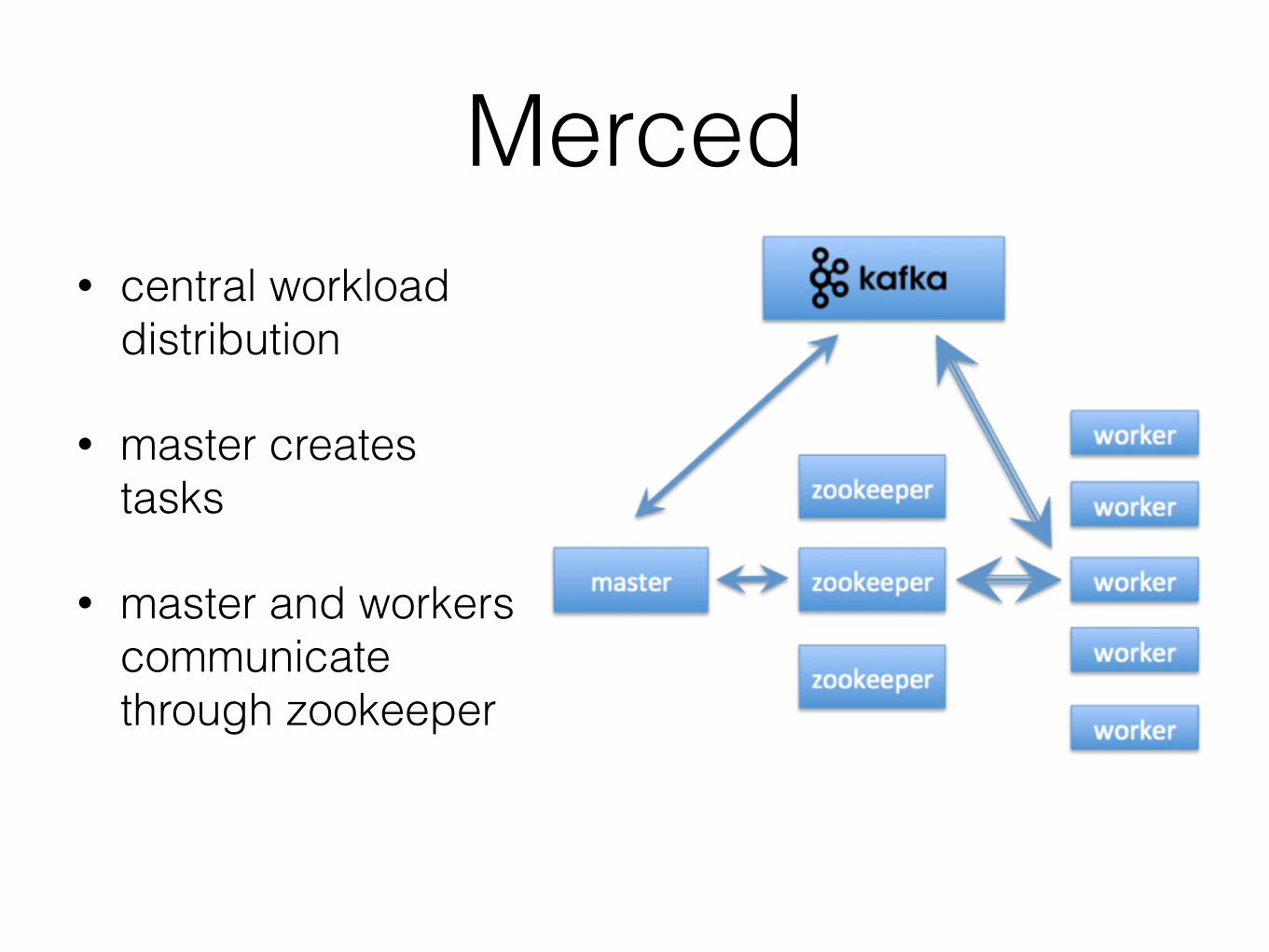
Merced• central workload
distribution
• master creates tasks
• master and workers communicate through zookeeper

Merced

Log Quality

Log Quality
Log quality can be broken down into two areas:
• log reliability - Reliability is fairly easy to measure: did we lose any data?
• log correctness - Correctness, on the other hand, is much more difficult as it requires the interpretation of data.

Challenges• Instrumentation is an after-thought for most feature
developers
• Features can get shipped breaking existing logging or no logging
• Once an iOS or Android release is out, it will keep generating bad data for weeks
• Data quality bugs are harder to find and fix compared to code quality

Tooling

Anomaly Detection• Started with a simple model based
on the assumption that daily changes are normally distributed.
• Revised that model until it has only a few alerts, mostly real and important.
• Hooked it up to a daily email to our metrics avengers.

How did we do?• Interest follows went up after we started emailing
recommended interests to follow
• Push notifications about board follows broke
• Signups from Google changed as we ran experiments
• Our tracking broke when we released a new repin experience
• Our tracking of mobile web signups changed

Auditing LogsManual audits will have their limitations, especially with regards to coverage but will catch critical bugs.
• However, we need two things: • Repeatable process that can scale • Tooling required to support the process
• Regression Audit • Maintain a playbook of "core logging actions" • Use tooling to verify the output of the actions
• New Feature Audit • Gather requirements for analysis and produce a list of events that
need to be captured with the feature • Instrument the application • Test the logging output using existing tooling

Summary• Invest in your logging infra pretty early on.
• Kafka has matured a lot and with some tuning works well in the Cloud.
• Data quality is not free, need to proactively ensure it.
• Invest in automated tools to detect quality issues both pre- and post-release.
• Culture building and education go a long way.

Thank you!
Btw, we’re hiring :)

Questions?







