
The Longest Common Substring
Problema.k.a Long Repeat
by Donnie Demuth

Sections
1. MapReduce and Hadoop2. Map and Reduce3. Mappers and Reducers4. Using Tools (Amazon)5. Conclusions

1. MapReduce and Hadoop
• What is it?• And how do I get it?

Google MapReduce
• Circa 2003• Based on Map and Reduce (go figure)– and Functional Programming!
• Proprietary

Apache Hadoop
• Circa 2006, released 2009• Named after an Elephant Toy• Seconds, maybe a minute, to install

Installing Hadoop on OSX
• Single Cluster setup is a piece of cake• Download the archive (tar.gz)• Modify conf/hadoop-env.sh:
– # export JAVA_HOME=/usr/lib/j2sdk1.6-sun – export JAVA_HOME=/System/Library/Frameworks/JavaVM.framework/Versions/1.6.0/
• Modify bin/hadoop:– JAVA=$JAVA_HOME/bin/java– JAVA=$JAVA_HOME/Commands/java
• Just run bin/hadoop with arguments

STOP!
• Actually, installing Hadoop wasn’t necessary• We can write parallel code without it
2. Map and Reduce
• What is it?– Quick Primer to Functional Programming• Higher-Order Functions• Alonzo Church (Lamba Calculus)
• Haskell Curry (Spicy Food)
• How do I use it?
(x (y x*x + y*y))(5)(2)↦ ↦

Code w/ Side-Effects
>>> thing = {'name':'Donald'}>>> def change_name(object): object['name'] = 'Donnie'... >>> change_name(thing)>>> thing{'name': 'Donnie'}

Pure Code, Side-effect Free
>>> thing = {'name':'Donald'}>>> def change_name(object): ... new_obj = {'name': 'Donnie'}... # copy any other values... return new_obj... >>> thing = change_name(thing)>>> thing{'name': 'Donnie'}

Benefits of Pure Code / FP
• easy to understand– Local vars = easy– Global vars + side-effects = hard
• it’s easy to parallelize– We only care about what we know RIGHT NOW
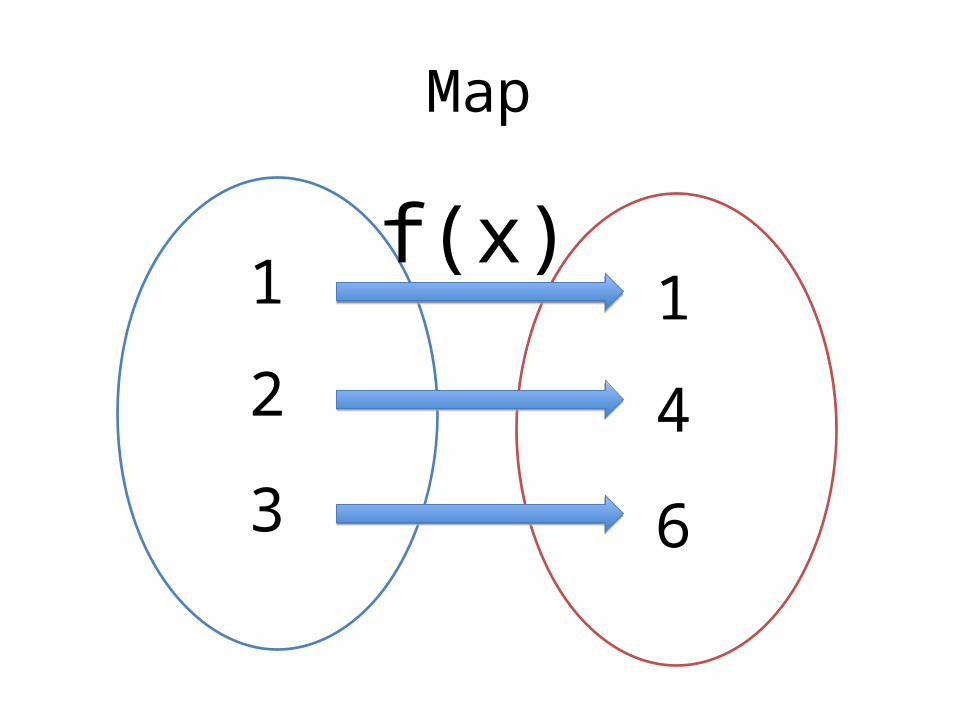
Map
1
2
3
1
4
6
f(x)

Map in Python
• Use the map(<function>, <list>) built-in
>>> map(lambda x: x*x, range(1,100))[1, 4, 9, 16, 25, 36, 49, 64, 81, 100, 121, 144, 169, 196, 225, 256, 289, 324, 361, 400, 441, 484, 529, 576, 625, 676, 729, 784, 841, 900, 961, 1024, 1089, 1156, 1225, 1296, 1369, 1444, 1521, 1600, 1681, 1764, 1849, 1936, 2025, 2116, 2209, 2304, 2401, 2500, 2601, 2704, 2809, 2916, 3025, 3136, 3249, 3364, 3481, 3600, 3721, 3844, 3969, 4096, 4225, 4356, 4489, 4624, 4761, 4900, 5041, 5184, 5329, 5476, 5625, 5776, 5929, 6084, 6241, 6400, 6561, 6724, 6889, 7056, 7225, 7396, 7569, 7744, 7921, 8100, 8281, 8464, 8649, 8836, 9025, 9216, 9409, 9604, 9801]
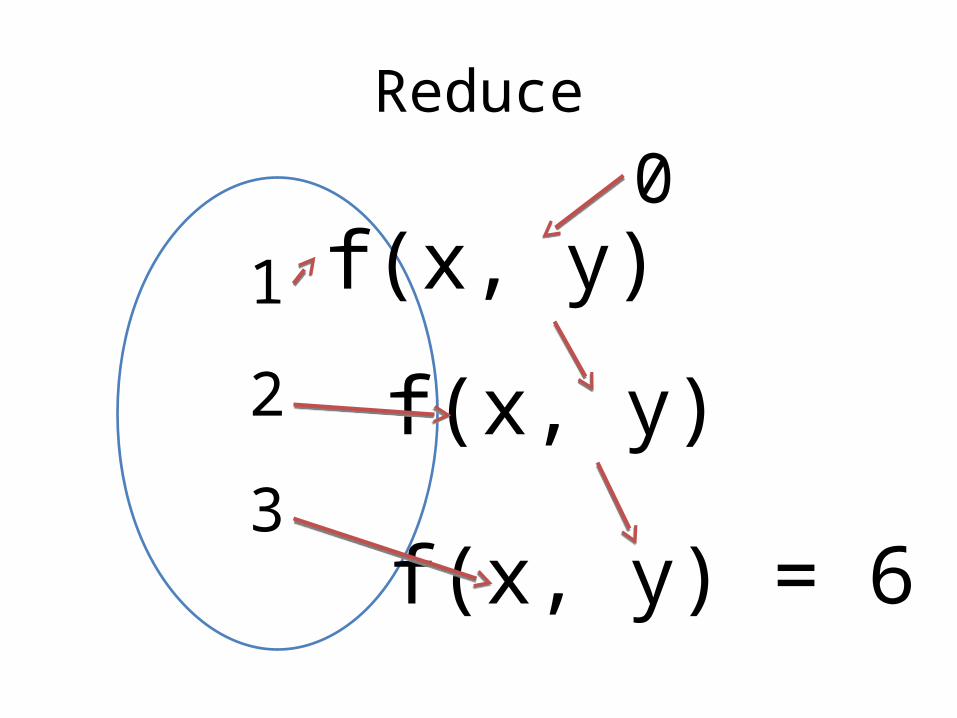
Reduce
1
2
3
0f(x, y)
f(x, y)
f(x, y) = 6

Reduce in Python
• Use the map(<function>, <list>, <unit>) built-in
>>> reduce(lambda x, y: x+y, [1,2,3], 0)6
>>> reduce(lambda x, y: x+y, (map(lambda x: x*x, range(1,100)), 0)
328350
3. Mappers and Reducers
• How do I write them?– Word Count (Hello World for Distrib. Comp.)– Longest Repeat
• Show me how to pipe them

Mappers
• Pseudo-Code– Take some input– Process it– And emit a Key – Value pair

Word Count Mapper
• For some input:– Donald Demuth Donald Draper
• The output should be:– Donald 1– Demuth 1– Donald 1– Draper 1

Word Count Mapper Code
• wordcount/mapper.py
#!/usr/bin/env pythonimport sys, re
word_re = re.compile('[a-zA-Z]+')for line in sys.stdin: line = line.strip().lower() for word in word_re.findall(line): print '%s\t%s' % (word, 1)

Reducers
• Dependant on the Mapper’s emissions• Pseudo-Code for word count– Read an emission from the mapper– Find the key and the value– Store the key in a dictionary with it’s value• But if the key already exists, add the value with the
pre-existing value!
– Emit the dictionary

Word Count Reducer Code
• wordcount/reducer.py#!/usr/bin/env pythonimport sys
counts = {}for line in sys.stdin: line = line.strip() word, count = line.split('\t', 1) count = int(count) counts[word] = counts.get(word, 0) + count
for word, count in counts.items(): print '%s\t%s'% (word, count)

Unix Pipes
• Does this really work??
$ cat books/*.txt | wordcount/mapper.py | wordcount/reducer.py | sort | heada 10526ab 3aback 1abaft 2abaht 1abandon 2abandoned 10abandonment 1abasement 1abash 1

Longest Repeat (LCS)
• Many problems can be solved with a series of Maps and Reduces
• However, Hadoop Streaming is a single Map and Reduce step
• After much trial and error my solution involves a pre-processing step
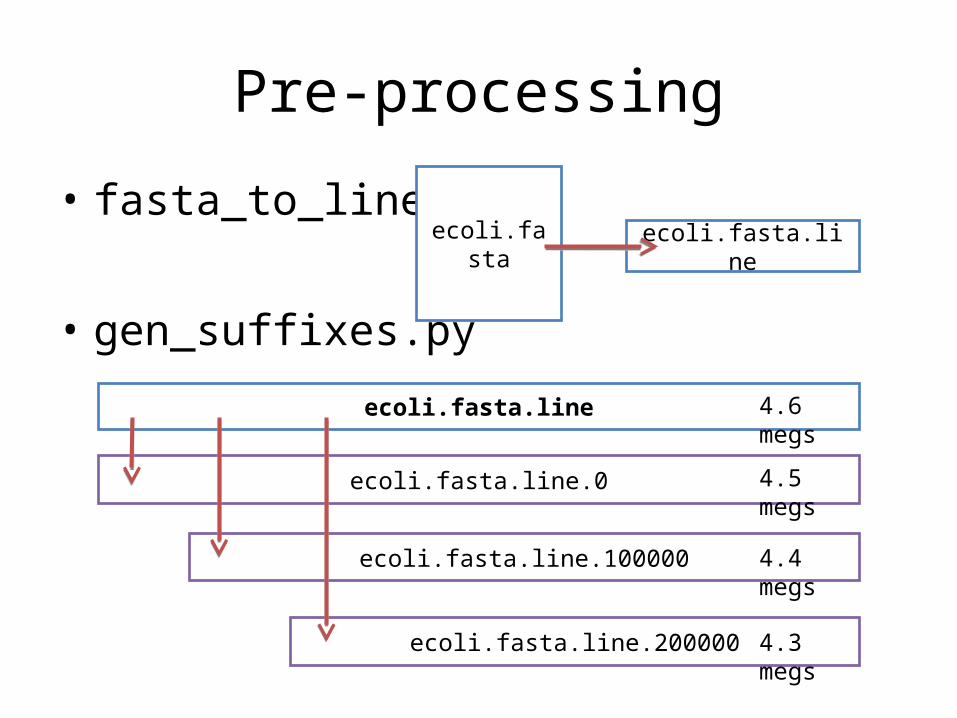
Pre-processing
• fasta_to_line.py
• gen_suffixes.py
ecoli.fasta.line
ecoli.fasta.line.0
ecoli.fasta.line.100000
ecoli.fasta.line.200000
4.6 megs
4.5 megs
4.4 megs
4.3 megs
ecoli.fasta ecoli.fasta.line

LCS Mapper
• Pseudo-code– Read a line from a suffix file– Determine the index (first chars)– Cycle through the first 100,000 positions• Cycle through possible lengths (10 3000)
– Emit the Length (Key) and the Position (Val)
• Emit (-1) and (-1) to STAY ALIVE

LCS Reducer
• Pseudo-Code– Simple– Find the largest KEY emitted by any mapper– Display it

LCS w/ Murmur.txt$ cat murmur.txt.line.0 | lcs/mapper.py | lcs/reducer.py length(63) pos(128)
$ python>>> text = open('murmur.txt.line').read()>>> text[128:128+63]'Dance the cha chaOr the can canShake your pom pomTo Duran Duran'
>>> seq = text[128:128+63]>>> text.index(seq)128>>> text[129:].index(seq) + 1291777>>> text[128:128+63] == text[1777:1777+63]True>>> text[1777:1777+63]'Dance the cha chaOr the can canShake your pom pomTo Duran Duran'

4. Using Tools, Amazon
• Harness the power of many machines at once– Easy to use 20
• Need to sign up for:– Amazon Elastic MapReduce Service (EMS)– Amazon Elastic Compute Cloud (EC2)– Amazon Simple Storage Service (S3)– Amazon SimpleDB

Deploying Data/Code
• First you’ll need to upload it to S3– Create a new bucket (or global folder) named ecoli-lcs
– Create a new path named input, ecoli-lcs/input– Upload all of the generated suffixes to the input
folder– Upload mapper.py and reducer.py to ecoli-lcs
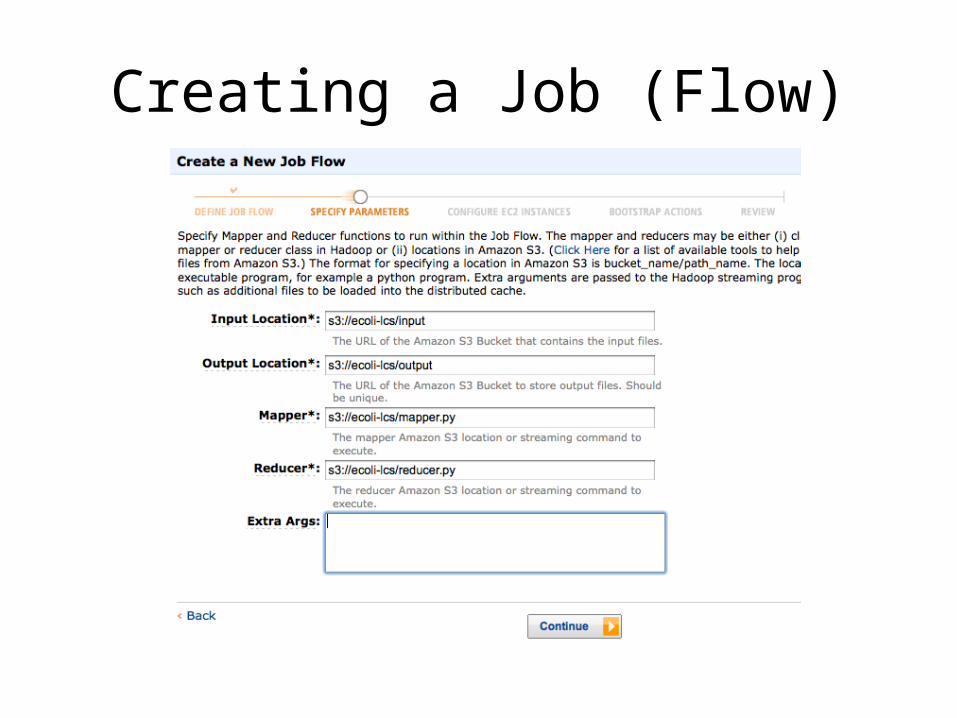
Creating a Job (Flow)

Creating a Job Flow (…)
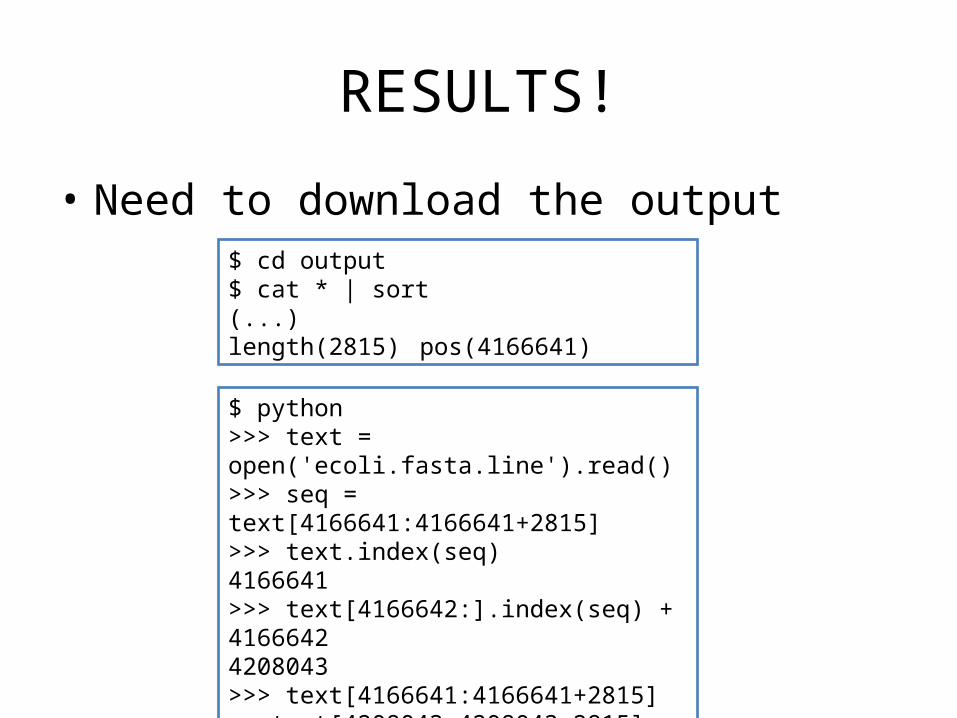
RESULTS!
• Need to download the output$ cd output$ cat * | sort (...)length(2815) pos(4166641)
$ python>>> text = open('ecoli.fasta.line').read()>>> seq = text[4166641:4166641+2815]>>> text.index(seq)4166641>>> text[4166642:].index(seq) + 41666424208043>>> text[4166641:4166641+2815] == text[4208043:4208043+2815]

5. Conclusions
• Costs– It’s about 3 cents an hour for a “medium” VM– One run took 840 instance hours (20+ actual)
• Approx. $25– Used about 2000 instance hours in total
• Hadoop Streaming is EASY– Though requires many (easy) tools– But costly if you have “bugs”

A Better Solution?
• Jeff Parker’s program used the following approach:– Cycle through the sequence and find all repeats of
a given size– Emit the location– Increase the size and use the previously known
locations to find larger matches
• Looks good for MapReduce (Core)







