
Thinking Differently About Web Page Preservation
Michael L. Nelson, Frank McCown, Joan A. SmithOld Dominion University
Norfolk VA
{mln,fmccown,jsmit}@cs.odu.edu
Library of Congress
Brown Bag Seminar
June 29, 2006
Research supported in part by NSF, Library of Congress and Andrew Mellon Foundation

Background
• “We can’t save everything!”– if not “everything”, then how much?– what does “save” mean?

“Women and Children First”
image from: http://www.btinternet.com/~palmiped/Birkenhead.htm
HMS Birkenhead, Cape Danger, 1852
638 passengers 193 survivors all 7 women & 13 children

We should probablysave a copy of this…

Or maybe we don’thave to…
the Wikipedia linkis in the top 10, sowe’re ok, right?

Surely we’re savingcopies of this…

2 copies in the UK
2 Dublin Core records
That’s probablygood enough…

What about the things that we know
we don’t need to keep?
You DO support recycling, right?

A higher moral callingfor pack rats?

Just Keep the Important Stuff!

Lessons Learned from the AIHT
images from: http://facweb.cs.depaul.edu/sgrais/collage.htm
(Boring stuff: D-Lib Magazine, December 2005)
Preservation metadata is like a David Hockney Polaroid collage: each image is both true and incomplete,
and while the result is not faithful, it does capture the “essence”

Preservation: Fortress Model
1. Get a lot of $
2. Buy a lot of disks, machines, tapes, etc.
3. Hire an army of staff
4. Load a small amount of data
5. “Look upon my archive ye Mighty, and despair!”
image from: http://www.itunisie.com/tourisme/excursion/tabarka/images/fort.jpg
Five Easy Steps for Preservation:

Alternate Models of Preservation
• Lazy Preservation– Let Google, IA et al. preserve your website
• Just-In-Time Preservation– Wait for it to disappear first, then a “good enough” version
• Shared Infrastructure Preservation– Push your content to sites that might preserve it
• Web Server Enhanced Preservation– Use Apache modules to create archival-ready resources
image from: http://www.proex.ufes.br/arsm/knots_interlaced.htm

Lazy Preservation“How much preservation do I get if I do nothing?”
Frank McCown

• Web Infrastructure as a Resource • Reconstructing Web Sites• Research Focus
Outline: Lazy Preservation


Web Infrastructure


Cost of Preservation
H L H
Publisher’s cost (time, equipment, knowledge)
LOCKSS
Browser cache
TTApacheiPROXY
Furl/Spurl
InfoMonitor
Filesystem backups
Coverage of the Web
H
Client-view Server-view
Web archivesSE caches
Hanzo:web

• Web Infrastructure as a Resource • Reconstructing Web Sites• Research Focus
Outline: Lazy Preservation

Research Questions
• How much digital preservation of websites is afforded by lazy preservation?– Can we reconstruct entire websites from the WI?– What factors contribute to the success of website
reconstruction?– Can we predict how much of a lost website can be
recovered?– How can the WI be utilized to provide preservation
of server-side components?

Prior Work
• Is website reconstruction from WI feasible?– Web repository: G,M,Y,IA– Web-repository crawler: Warrick– Reconstructed 24 websites
• How long do search engines keep cached content after it is removed?

Timeline of SE Resource Acquisition and Release
Vulnerable resource – not yet cached (tca is not defined)
Replicated resource – available on web server and SE cache (tca < current time < tr)
Endangered resource – removed from web server but still cached (tca < current time < tcr)
Unrecoverable resource – missing from web server and cache (tca < tcr < current time)
Joan A. Smith, Frank McCown, and Michael L. Nelson. Observed Web Robot Behavior on Decaying Web Subsites, D-Lib Magazine, 12(2), February 2006. Frank McCown, Joan A. Smith, Michael L. Nelson, and Johan Bollen. Reconstructing Websites for the Lazy Webmaster, Technical report, arXiv cs.IR/0512069, 2005.



Cached Image

Cached PDF
http://www.fda.gov/cder/about/whatwedo/testtube.pdf
MSN version Yahoo version Google version
canonical

Web Repository Characteristics
Type MIME type Typical file ext
Google Yahoo MSN IA
HTML text text/html html C C C C
Plain text text/plain txt, ans M M M C
Graphic Interchange Format image/gif gif M M ~R C
Joint Photographic Experts Group image/jpeg jpg M M ~R C
Portable Network Graphic image/png png M M ~R C
Adobe Portable Document Formatapplication/pdf
pdfM M M C
JavaScript application/javascript js M M C
Microsoft Excel application/vnd.ms-excel xls M ~S M C
Microsoft PowerPoint application/vnd.ms-powerpoint ppt M M M C
Microsoft Word application/msword doc M M M C
PostScript application/postscript ps M ~S C
C Canonical version is storedM Modified version is stored (modified images are thumbnails, all others are html conversions)~R Indexed but not retrievable~S Indexed but not stored

SE Caching Experiment
• Create html, pdf, and images• Place files on 4 web servers• Remove files on regular schedule• Examine web server logs to determine when
each page is crawled and by whom• Query each search engine daily using unique
identifier to see if they have cached the page or image
Joan A. Smith, Frank McCown, and Michael L. Nelson. Observed Web Robot Behavior on Decaying Web Subsites. D-Lib Magazine, February 2006, 12(2)

Caching of HTML Resources - mln

Reconstructing a Website
Warrick
Starting URL
Web Repo
Original URL
Results page
Cached URL
Cached resourceFile system
Retrieved resource
1. Pull resources from all web repositories
2. Strip off extra header and footer html
3. Store most recently cached version or canonical version
4. Parse html for links to other resources

How Much Did We Reconstruct?
A
“Lost” web site Reconstructed web site
B C
D E F
A
B’ C’
G E
F
Missing link to D; points to old resource G
F can’t be found

Reconstruction Diagram
added 20%
identical 50%
changed 33%
missing 17%

Websites to Reconstruct
• Reconstruct 24 sites in 3 categories:
1. small (1-150 resources) 2. medium (150-499 resources)3. large (500+ resources)
• Use Wget to download current website• Use Warrick to reconstruct• Calculate reconstruction vector

Results
Frank McCown, Joan A. Smith, Michael L. Nelson, and Johan Bollen. Reconstructing Websites for the Lazy Webmaster, Technical Report, arXiv cs.IR/0512069, 2005.

Aggregation of Websites
0
25
50
75
100
125
150
175
200
225
html images pdf other ms
MIME type groupings
Number of files
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
Ave # of files inoriginal websitesAggregate % recon
IA % recon
Google % recon
MSN % recon
Yahoo! % recon

Web Repository Contributions
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
Reconstructed websites
Contribution
Yahoo
IA
MSN

Warrick Milestones
• www2006.org – first lost website reconstructed (Nov 2005)
• DCkickball.org – first website someone else reconstructed without our help (late Jan 2006)
• www.iclnet.org – first website we reconstructed for someone else (mid Mar 2006)
• Internet Archive officially “blesses” Warrick (mid Mar 2006)1
1http://frankmccown.blogspot.com/2006/03/warrick-is-gaining-traction.html

• Web Infrastructure as a Resource • Reconstructing Web Sites• Research Focus
Outline: Lazy Preservation

Proposed Work
• How lazy can we afford to be?– Find factors influencing success of website reconstruction
from the WI– Perform search engine cache characterization
• Inject server-side components into WI for complete website reconstruction
• Improving the Warrick crawler– Evaluate different crawling policies
• Frank McCown and Michael L. Nelson, Evaluation of Crawling Policies for a Web-repository Crawler, ACM Hypertext 2006.
– Development of web-repository API for inclusion in Warrick

Factors Influencing Website Recoverability from the WI
• Previous study did not find statistically significant relationship between recoverability and website size or PageRank
• Methodology– Sample large number of websites - dmoz.org– Perform several reconstructions over time using
same policy– Download sites several times over time to capture
change rates

Evaluation
• Use statistical analysis to test for the following factors:– Size– Makeup– Path depth– PageRank– Change rate
• Create a predictive model – how much of my lost website do I expect to get back?

Marshall TR Server – running EPrints

We can recover the missing page and PDF, but what about the services?

Recovery of Web Server Components
• Recovering the client-side representation is not enough to reconstruct a dynamically-produced website
• How can we inject the server-side functionality into the WI?
• Web repositories like HTML– Canonical versions stored by all web repos– Text-based– Comments can be inserted without changing appearance of
page• Injection: Use erasure codes to break a server file
into chunks and insert the chunks into HTML comments of different pages

Recover Server File from WI

Evaluation
• Find the most efficient values for n and r (chunks created/recovered)
• Security– Develop simple mechanism for selecting files that
can be injected into the WI– Address encryption issues
• Reconstruct an EPrints website with a few hundred resources

SE Cache Characterization
• Web characterization is an active field• Search engine caches have never been
characterized• Methodology
– Randomly sample URLs from four popular search engines: Google, MSN, Yahoo, Ask
– Download cached version and live version from the Web– Examine HTTP headers and page content– Test for overlap with Internet Archive– Attempt to access various resource types (PDF, Word, PS,
etc.) in each SE cache

Summary: Lazy Preservation
When this work is completed, we will have…• demonstrated and evaluated the lazy
preservation technique• provided a reference implementation• characterized SE caching behavior• provided a layer of abstraction on top of SE
behavior (API)• explored how much we store in the WI
(server-side vs. client-side representations)

Web Server Enhanced Preservation “How much preservation do I get if I do just a little bit?”
Joan A. Smith

• OAI-PMH• mod_oai: complex objects +
resource harvesting• Research Focus
Outline: Web Server Enhanced Preservation

WWW and DL: Separate Worlds
1994
DL
WWW
Today
The problem is not that the WWW doesn’t work; it clearly does. The problem is that our (preservation) expectations have been lowered.
WWW
DL
“Crawlapalooza”
“Harvester Home Companion”

“A repository is a network accessible server that can process the 6 OAI-PMH requests … A repository is managed by a data provider to expose metadata to harvesters.”
“A harvester is a client application that issues OAI-PMH requests. A harvester is operated by a service provider as a means of collecting metadata from repositories.”
Data Providers /Repositories
Service Providers /Harvesters
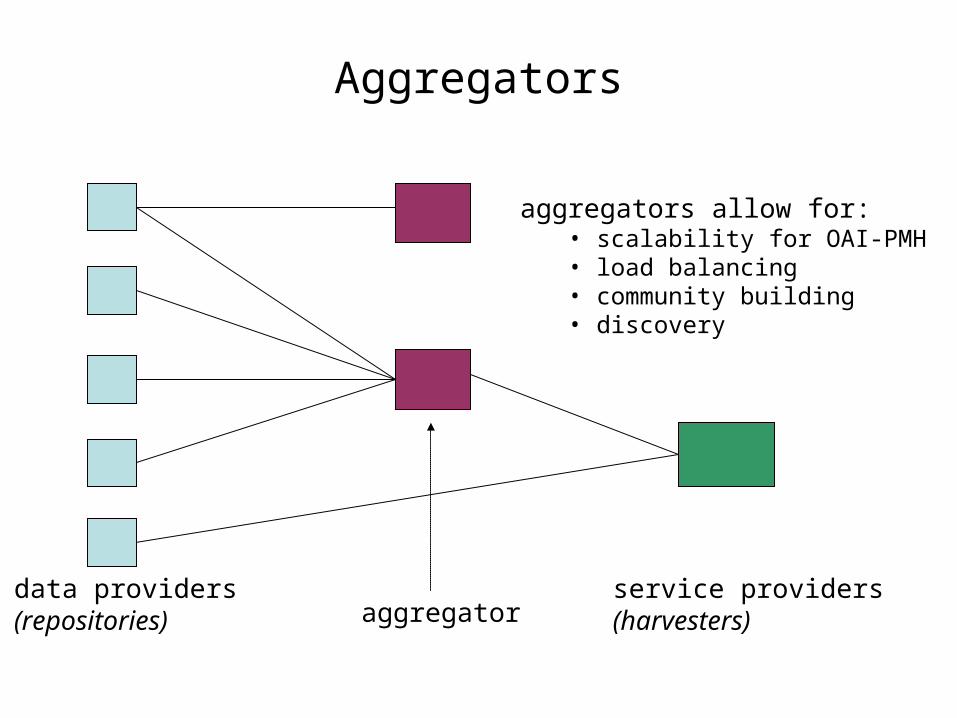
Aggregators
data providers(repositories)
service providers(harvesters)aggregator
aggregators allow for:• scalability for OAI-PMH• load balancing • community building• discovery

OAI-PMH data model
resource
item
Dublin Coremetadata
MARCXMLmetadata records
entry point to all records pertaining to the resource
metadata pertainingto the resource
OAI-PMH identifiermetadataPrefixdatestamp
OAI-PMH identifier
OAI-PMH sets

OAI-PMH Used by Google & AcademicLive (MSN)
Why support OAI-PMH?
$ These guys are in business (i.e., for profit)
Q How does OAI-PMH help their bottom line?
A By improving the search and analysis process

Resource Harvesting with OAI-PMH
resource
item
Dublin Coremetadata METS records
OAI-PMH identifier = entry point to all records pertaining to the resource
MPEG-21DIDL
metadata pertainingto the resource
simple highlyexpressive
more expressive
highlyexpressive
MARCXMLmetadata

• OAI-PMH• mod_oai: complex objects +
resource harvesting• Research Focus
Outline: Web Server Enhanced Preservation

Two Problems
The counting problemThere is no way to determine the
list of valid URLs at a web site
The representation problemMachine-readable formats and human-
readable formats have different requirements

• Integrate OAI-PMH functionality into the web server itself…• mod_oai: an Apache 2.0 module to automatically answer OAI-PMH requests for
an http server– written in C– respects values in .htaccess, httpd.conf
• compile mod_oai on http://www.foo.edu/ • baseURL is now http://www.foo.edu/modoai
– Result: web harvesting with OAI-PMH semantics (e.g., from, until, sets)
mod_oai solution
The human-readable web site Prepped for
machine-friendly harvesting
http://www.foo.edu/modoai?verb=ListIdentifiers&metdataPrefix=oai_dc&from=2004-09-15&set=mime:video:mpeg
Give me a list of all resources, include Dublin Core metadata, dating from 9/15/2004 through today, andthat are MIME type video-MPEG.

A Crawler’s View of the Web Site
Not crawled(unadvertised & unlinked)
web root
Crawled pages
Not crawled (too deep)
Not crawled (protected)
Not crawled(remote link only)
Not crawled(Generated on-the-fly by CGI, e.g.)Not crawled
robots.txtor robots META tag
Remote web site

Apache’s View of the Web Site
web rootRequire authentication
Unknown/not visible
Generated on-the-fly(CGI, e.g.)
Tagged:No robots

The Problem: Defining The “Whole Site”
• For a given server, there are a set of URLs, U, and a set of files F– Apache maps U F– mod_oai maps F U
• Neither function is 1-1 nor onto– We can easily check if a single u maps to F, but given F we cannot (easily) generate U
• Short-term issues:– dynamic files
• exporting unprocessed server-side files would be a security hole
– IndexIgnore• httpd will “hide” valid URLs
– File permissions• httpd will advertise files it cannot read
• Long-term issues– Alias, Location
• files can be covered up by the httpd
– UserDir• interactions between the httpd and the filesystem

Tagged:No robots
A Webmaster’s Omniscient View
web root
Deep
Dynamic
Authenticated
Orphaned
Unknown/not visible
MySQL
1.Data1
2.User.abc
3.Fred.foo
httpd
1.file1
2./dir/wwx
3.Foo.html

Machine-readable
Human-readable
HTTP “Get” versus OAI-PMH GetRecord
mod_oai
HTTP GET
HTTP GetRecord
JHOVE METADATA
MD-5 LS
Complex Object
WEB SITE
Apache Web Server
“GET /headlines.html HTTP1.1”“GET /modoai/?verb=GetRecord&identifier=headlines.html&metadaprefix=oai_didl”

OAI-PMH data model in mod_oai
resource
item
Dublin Coremetadata records
OAI-PMH identifier = entry point to all records pertaining to the resource
MPEG-21DIDL
metadata pertainingto the resource
HTTP headermetadata
http://techreports.larc.nasa.gov/ltrs/PDF/2004/aiaa/NASA-aiaa-2004-0015.pdf
OAI-PMH setsMIME type

Complex Objects That Tell A Story
• First came Lenin• Then came Stalin…
• Resource and metadata packaged together as a complex digital object represented via XML wrapper
• Uniform solution for simple & compound objects• Unambiguous expression of locator of
datastream• Disambiguation between locators & identifiers• OAI-PMH datestamp changes whenever the
resource (datastreams & secondary information) changes
• OAI-PMH semantics apply: “about” containers, set membership
Russian Nesting Doll
http://foo.edu/bar.pdf encoded as an MPEG-21 DIDL
<didl> <metadata source="jhove">...</metadata> <metadata source="file">...</metadata> <metadata source="essence">...</metadata> <metadata source="grep">...</metadata> ... <resource mimeType="application/pdf" identifier=“http://foo.edu/bar.pdf encoding="base64> SADLFJSALDJF...SLDKFJASLDJ </resource>
</didl>
Jhove metadata
DC metadata
Checksum…
Provenance

Resource Discovery: ListIdentifiers
HARVESTER: • issues a ListIdentifiers, • finds URLs of updated
resources• does HTTP GETs updates
only• can get URLs of resources
with specified MIME types

Preservation: ListRecords
HARVESTER:• issues a ListRecords, • Gets updates as MPEG-
21 DIDL documents (HTTP headers, resource By Value or By Reference)
• can get resources with specified MIME types

What does this mean?
• For an entire web site, we can:– serialize everything as an XML stream– extract it using off-the-shelf OAI-PMH harvesters– efficiently discover updates & additions
• For each URL, we can:– create “preservation ready” version with configurable {descriptive|technical|
structural} metadata• e.g., Jhove output, datestamps, signatures, provenance, automatically generated
summary, etc.
Harvest theresource extract
metadata
include an index translations…
or lexical signatures,Summaries, etc
Jhove & otherpertinent info
Wrap it all togetherIn an XML Stream Ready for the future

• OAI-PMH• mod_oai: complex objects +
resource harvesting• Research Focus
Outline: Web Server Enhanced Preservation

Research Contributions
Thesis Question: How well can Apache support web page preservation?
Goal: To make web resources “preservation ready”– Support refreshing (“how many URLs at this site?”): the counting problem– Support migration (“what is this object?”): the representation problem
How: Using OAI-PMH resource harvesting– Aggregate forensic metadata
• Automate extraction– Encapsulate into an object
• XML stream of information– Maximize preservation opportunity
• Bring DL technology into the realm of WWW

Experimentation & Evaluation
• Research solutions to the counting problem– Different tools yield different results– Google sitemap <> Apache file list <> robot crawled pages– Combine approaches for one automated, full URL listing
• Apache logs are detailed history of site activity• Compare user page requests with crawlers’ requests• Compare crawled pages with actual site tree
• Continue research on the representation problem– Integrate utilities into mod_oai (Jhove, etc.)– Automate metadata extraction & encapsulation
• Serialize and reconstitute– complete back-up of site & reconstitution through XML stream

Summary: Web Server Enhanced Preservation
• Better web harvesting can be achieved through:– OAI-PMH: structured access to updates – Complex object formats: modeled representation of digital objects
• Address 2 key problems:– Preservation (ListRecords) – The Representation Problem– Web crawling (ListIdentifiers) – The Counting Problem
• mod_oai: reference implementation– Better performance than wget & crawlers– not a replacement for DSpace, Fedora, eprints.org, etc.
• More info:– http://www.modoai.org/– http://whiskey.cs.odu.edu/
Automatic harvesting of web resources rich in metadata packaged for the future
Today: manual Tomorrow: automatic!

Summary
Michael L. Nelson

Summary
• Digital preservation is not hard, its just big.– Save the women and children first, of course, but there is
room for many more…
• Using the by-product of SE and WI, we can get a good amount of preservation for free– prediction: Google et al. will eventually see preservation as a
business opportunity
• Increasing the role of the web server will solve most of the digital preservation problems– complex objects + OAI-PMH = digital preservation solution

“As you know, you preserve the files you have. They’re not the files you might want or wish to have at a later time”
“if you think about it, you can have all the metadata in the world on a file and a file can be blown up”
image from: http://www.washingtonpost.com/wp-dyn/articles/A132-2004Dec14.html







