
Three Design Dimensionsof Secure Embedded Systems
P. Schaumont
Bradley Department of Electrical and Computer EngineeringVirginia Tech
Blacksburg, VA
Third International Conference on Security,Privacy, and Applied Cryptography Engineering
21 October 2013
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

Three Design Dimensions for Embedded Security
Hardware Software CodesignPerformance and Area
I Eg Montgomery Multiplication
The third dimension: RiskRisk and Performance
I Eg SCA CountermeasuresRisk and Flexibility
I Eg PUFs
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

Hardware Software Codesignand the First Two Dimensions:Flexibility and Performance
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

The Wave of Embedded Systems
The CloudServersBackbone NetworkingStorage
The Edge (of the cloud)Personal Environment
I Personal Media, Laptop, Tablet, Watch, Health monitor, ImplantedElectronics
Home EnvironmentI Gateway, Appliances, TV, Game Machine, Utility Metering,
Thermostat, ..Infrastructure
I Road tolling, Camera, Car, ..
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

The Wave of Embedded Systems
The CloudHomogeneous: High-end CPUs1000 users per computerCost Sensitive: Maximize users per machinePower Sensitive: Thermal issuesGrows unconstrained: Efficiency through Scale
The Edge (of the cloud)Heterogeneous: 32-bit Micro downto dedicated hardware1000 computers per user (eventually ...)Cost Sensitive: Dedicated consumer-oriented devicesEnergy Sensitive: Battery powered, Energy-harvestedConstrained in environment: Efficiency through Specialization
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

Embedded Efficiency-Knob is Specialization
Architecture SpecializationDedicated Computation (sub)modulesDedicated InterconnectDedicated Storage
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

Specialized Architecture is incredibly efficient
Architecture Specialization1 full-adder cell is 28 transistors32-bit ripple-carry adder is 896 transistorsIntel i7 920 (45nm, 2008) is 731M transistorsIntel i7 920 is 816K 32-bit addersIntel i7 920 has 30.9 DOps/cycle (peak).. or 26,400 times less ops/cycle than raw silicon
CaveatIntrinsic efficiency unachievable because of power, routing issues!The factor 26,400 shows what specialization may offer
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

Specialized Interconnect is incredibly efficient
Routing BandwidthCMOS stcells 45 nm 6LM (2X, 2Y, 2 Power/Ground)8 wires per micron is 80K wires along a 10mm dieAt 1 Ghz, can make 160K x 1G = 160 Tbit connections/s!Caveat: As before, theoretical bandwidth, not realizable
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

Summing it up: The efficiency of Specialization
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

The Challenge of HW/SW Codesign
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

Defining Hardware Software Codesign
Hardware Software CodesignHardware/Software Codesign is the partitioning and design of anapplication in terms of fixed and flexible components
Fixed FlexibleHardware Software
FPGA Fabric FGPA BitstreamDSP Instructionset DSP SoftwareASIP Instructionset ASIP Software
SoC IP Modules SoC Specific SoftwareMicro-Architecture Microprogram
IP Module IP ParametersRTL
Performance, Efficiency Cost
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

ECE 4530 Course at Virginia Tech
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

ECE 4530 Codesign Challenge
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

ECE 4530 Codesign ChallengeResults from Fall 2012 (Mandelbrot Fractal Drawing)
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

ECE 4530 Codesign ChallengeResults from past years (different challenge every year)
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

Flexibility and Performancein Cryptographic Engineering:The Montgomery Multiplication
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

Montgomery in a nutshell
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

Montgomery in a nutshell (2)
Montgomery Reduction MR
z.R−1 mod m = {z + v .m}.R−1 mod mwithv = ((z.(−m−1)) mod R)
1 v chosen such that z + v .m is a multiple of R2 Therefore {z + v .m}.R−1 is an integer q3 q can be shown to be 0 <= q < 2.m
Montgomery Product MPMR is the basis for the Montgomery Product MPTwo m-residue numbers Am and Bm are multiplied asMP = Am.Bm.R−1 mod m
In crypto (eg RSA), all wordlengths become 1000’s of bit !
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

Seminal Work: Koc’s multiprecision algorithms (1990)
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

Exploring the MP Design Space
Koc’s algorithms for a sequential implementation (microprocessor);how can we improve performance without cranking up themicroprocessor clock?
Novel ways of formulating the AlgorithmI Bipartite Multiplication (Kaihara 2008)I Tripartite Multiplication (Sakiyama 2011)I k-Partite Multiplication (Giorgi 2013)
Optimized Usage of the Memory HierarchyI Hybrid Multiplication (Gura 2004)I Operand Caching (Hutter 2011)
Optimized Parallel Mapping at Word - and Task LevelI VLIW design (Fan 2008)I parallel Separated Hybrid Scanning (Chen 2011)I SIMD design (Bos 2013)
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

Exploring the MP Design Space
Architecture TargetExamples address Hardware, MicroCtl, Emb Core, Core
New ways of Algorithmic PartitioningI Bipartite Multiplication (Kaihara 2008) HardwareI Tripartite Multiplication (Sakiyama 2011) HardwareI k-Partite Multiplication (Giorgi 2013) Core
Exploiting the Memory HierarchyI Hybrid Multiplication (Gura 2004) MicroCtlI Operand Caching (Hutter 2011) MicroCtl
Parallel Implementations at Word - and Task LevelI VLIW design (Fan 2008) HardwareI parallel Separated Hybrid Scanning (Chen 2011) Emb CoreI SIMD design (Bos 2013) Core
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

MP Partitioning
Bi-partite MP
MP = Am.Bm.R−1 mod mMP = Am.(Bh,m.R + Bl,m).R−1 mod mMP = Am.Bh,m mod m + Am.Bl,m.R−1 mod m
Separates MP as two independent tasks of 1/2 complexityI A regular modmultI A Montgomery modmult
Task-parallel implementation increases performanceI Kaihara’s Hardware Implementation shows a speedup of 1.4 for
1024 bit MP, 1.33 for 512 bit MPI Iterative Partitioning (Sakiyama) Speedup 1.88 over MP for 192 bit
MP
n-partite techniques are application-specific; increasedimplementation cost
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

Exploiting the Memory Hierarchy
The insightIn an MP, the number of data multiplies is fixed, but the number ofmemory accesses is not
The number of partial products grows quadratically with operandsize: An MP with longer operands has a larger working set
I Working set = variables most likely to be referencedOn microcontrollers, number of registers is limited
I Spilling = Extra memory accesses caused by register limit
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

Gura 2004: Hybrid MultiplicationRow-wise MultiplicationGentle operand working set, aggressive accumulator working setNeeds more registers (for accumulator)
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

Gura 2004: Hybrid MultiplicationColumn-wise MultiplicationGentle accumulator working set, aggressive operand working setNeeds more memory-loads (for operands)
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

Gura 2004: Hybrid MultiplicationHybrid MultiplicationCompromise solution, enables a choice of d that is suitable for thenumber of available registers (d scales from colwise to rowwise)
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

Hutter 2011: Operand CachingHybridOperand Caching improves upon Hybrid Multiplication by looking forthe smallest changes to the working set
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

Parallel Implementations
Parallel versions of Koc’s scanning algorithmsI Data-parallel implementations: Fan (2008), Bos (2013)I Task-parallel implementations: Chen (2011)I Developed in Hardware (Fan), Multi-core Network (Chen), Core
(Bos)Key challenges in Parallel Implementations for VLIW, SIMD
I Identify and Exploit Data parallelismKey challenges in Task-Parallel Implementations
I Balanced partitioning, SynchronizationI Intertask Communication Latency
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

Parallel Implementations: Chen 2011pSHSColumn-based partitioning, with different columns on differentprocessors; Interprocessor communication includes the carry
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

Parallel Implementations: Chen 2011
Evenly distributed load results in almost ideal speedupI 512 bit ModMult speedup 1.58, 2.46, 3.20 for 2, 4, 8 coresI 2048 bit ModMult speedup 1.98, 3.74, 6.53 for 2, 4, 8 cores
As the processor latency increases, performance degradesIdeal case (communication time = 0)
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

Parallel Implementations: Chen 2011
Evenly distributed load results in almost ideal speedupI 512 bit ModMult speedup 1.58, 2.46, 3.20 for 2, 4, 8 coresI 2048 bit ModMult speedup 1.98, 3.74, 6.53 for 2, 4, 8 cores
As the processor latency increases, performance degradesDegraded case (communication time > block computation time)
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

The Third DimensionRisk
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

Security and Hardware/Software Codesign
RiskRisk is the potential for lossRisk = (Probablity of Incident) x (Cost of Incident)
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

Example: Key Storage in SoC
Risk: High - Medium - Low - Very Low - Even Lower
C. Brocius, "My Arduino can beat up your hotel room", BlackHat 2012
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

Example: Key Storage in SoC
Risk: High - Medium - Low - Very Low - Even Lower
Standard Embedded-OSI Software Memory Management and Access ControlI Separation through Privilege Level
Risk: High - Medium - Low - Very Low - Even Lower
Hardware Isolation Technology (eg. ARM TrustZone)Trusted Boot Technology (eg. Intel TXT)
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

Example: Key Storage in SoC
Risk: High - Medium - Low - Very Low - Even Lower
Systems with off-chip integrity/confidentiality (eg. AEGIS Suh 2004).
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

Example: Key Storage in SoC
Risk: High - Medium - Low - Very Low - Even Lower
Systems with Tamper-protected (SCA, Faults) processing (eg.Regazzoni 2009).
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

Risk and Performance:SCA Countermeasures
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

The Risk-Performance Tradeoff:SCA Countermeasures
Author Technique Technology SCA Area PerfGain Cost Cost(ratio) (ratio) (ratio)
Tiri’05 Hiding AES, ASIC 120x x3.1 (GE) x3.9 (fclock )Bhasin’11 Hiding AES, FPGA 10.9x x2 (RAM+LUT) x1.3 (fclock )Suzuki’10 Masking AES, ASIC x2.1 (GE) x1.8 (fclock )Moradi’11 Threshold AES, ASIC x4.5 (GE) x1.2 (time)Chen’13 VSC AES, SW 25x x3.3 (KB) x6.5 (time)Rivian’11 Masking AES, SW x36 (time)Genelle’11 Masking AES, SW x12 (time)GE = Gate Equivalent = Area of a NAND2 gate.
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

Side-Channel Leakage
Side-channel LeakagePower, time, EMAdversary can break the exponential complexity of cryptography
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

Side-channel Analysis Mitigation
Side-channel Analysis mitigation affects system performanceI Overhead in Area (2-5x) and Time (2-30x)
ObjectiveI Build a countermeasure with a better cost-benefit trade-offI Evaluate a countermeasure as a CPU extension
Virtual Secure CircuitVSC = a CPU with a hiding modeSCA-resistant instructions next to normal instructions
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

Principle of hiding as SCA CountermeasureDual-rail Pre-charge Circuits (Tiri 2004)
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

Principle of hiding as SCA Countermeasure
Dual-rail Pre-charge Circuits (Tiri 2004)
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

VSC: Hiding-based Software
Classic CPU is not suited for Hiding-based OperationsNo Balanced Data FormatNo Balanced InstructionsNo Pre-charge
Virtual Secure CircuitAdopt Balanced Data Format (16b computations on 32b CPU)Add minimal set of balanced instructionsEmulate Pre-charge with Register-Load
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

VSC: Balanced InstructionsMany standard instructions work fine on balanced data
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013
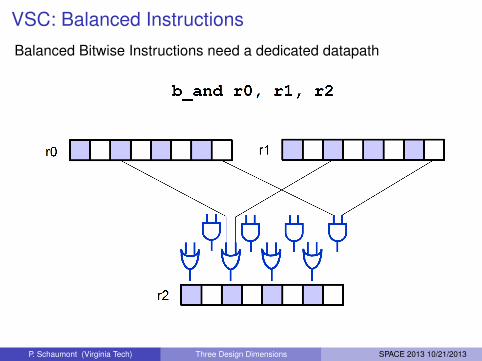
VSC: Balanced Instructions
Balanced Bitwise Instructions need a dedicated datapath
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

VSC Programming
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

How many VSC Instruction Types for we need? (1)
Assumption: Secret/sensitive state not used as controller flagI Secret-key ciphers and constant-time public-key ciphers
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

How many VSC Instruction Types for we need? (2)
Two balanced instructions (b_and, b_or) are sufficient
Bitslice programming to expand complex computationsI Execute N (32, 128) parallel 1-bit copies of algorithmI Proposed by [Biham 97] for crypto to achieve high-performanceI Demonstrated on a wide variety of crypto, eg AES [Kasper 09],
ECC [Bernstein 09]General VSC programs developed using a bitslice-technique
I Execute N/2 (32, 128) parallel bit-complementary copies ofalgorithm
I (b_and, b_or) are sufficientI Extensions may include: complex operations, memory load/store
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

VSC CPU Prototype
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

Implementation Issues
Asymmetry between direct and complementary part yieldsresidual leakageAsymmetry can be structural or electrical differences, in loadingand/or in timing of complementary pairsEnforcing symmmetry (through careful place and route, carefulmanipulation of FPGA implementation) yields expensive(slower/larger) hardware circuitsIn VSC, bitslice design can help enforce symmetry.
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

Experimental Results
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

VSC Results (Risk-Performance Trade-off)
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

An alternate strategy: VSC on multi-core
Multicore Balancing ConceptRun two complementary programs on precisely synchronized cores
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

An alternate strategy: VSC on multi-corePrecise synchronizationSynchronizing the bus is not sufficient, we need synchronous pipelines
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

VSC Summary
It’s possible to port WDDL (Hiding) to softwareValuable trade-off between performance and risk
I CPU can run as a normal CPU on non-sensitive codeI CPU is also able to run in a hiding mode
Performance hit is about 6.5x (competitive with masking)Depending on the level of effort, DPA gains from 25x .. 1000x
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

Risk and Flexibility:CPU-Integrated PUFs
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

PUF in the embedded space
PUF technology harvests entropy from a substrateEntropy converted into discrete, digital data using logicApplications: authentication, anti-counterfeiting, binding of dataand software to a platform, commitments, key exchange, ...
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

The PUF Challenge
Challenge 1: PUF QualityHow to separate random, spatial variations from a physicalmeasurement that contains other variations as well?
Sources of variationI Fast temporal variations (noise)I Slow temporal variations (aging)I (Spatial) Systematic, static variationsI (Spatial) Random, spatial variations
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

PUF Quality
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

PUF Attack Vectors
Challenge 2: Attack VectorsCan we keep the entropy in a PUF secret?
An attack vector is any method that extracts one or more (C/R) pairsfrom a PUF.
Malicious querying of C/R pairs [Gassend 08]Building a model of the PUF to predict C/R pairs
I .. through machine learning [Ruhrmair 10]I .. through side-channel analysis [Merli 11]
Clone the PUF (physically) [Helfmeier 13]
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

Delay-intrinsic PUF
HELP PUF [Aarestad 2013],Hardware Embedded DelayPUFFull-hardware DesignUniqueness 50.00%,Reliability 99.99 %Area
I AES Macro 3122 LUT, 1297Reg
I full PUF 7098 LUT, 1749Reg
I Clock control: 3 DCM
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

Delay-intrinsic PUF: Software Version
Software PUF [Maiti 2012]Full-software DesignUniqueness 37.54%,Reliability 97.91 %Area
I Reuse of existing Leon-3I External Clock Control
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

Delay-intrinsic PUF: Codesigned Version
PASC [Aysu 2013],Custom-instruction PUFCo-designed solutionUniqueness 38.2%,Reliability 99.92 %Area
I Nios-II designI Custom Instruction HW
(3072 LUT, 2114 Reg)
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

PUF as a Custom Instruction
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

Risk Versus Flexibility
Full HW design (AES Delay Paths)Best reliability/uniquenessLargest pool of C/R pairs
Full SW design (CPU instructions)Worst reliability/uniquenessMost agile (flexible) solution
Codesigned PUF (Custom instruction)Compromise solutionEntropy source in custom hardware, post-processing in SW
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

Conclusions and Open Issues
HW/SW Codesign balances risk, flexibility, performanceCryptographic Engineering examples demonstrate the concept ofrisk
We don’t yet understand how to quantify risk wellWe need more tools to navigate this third dimension
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013

Thank You!AcknowledgementsMy studentsThe National Science Foundation
Further Reading and RefsPatrick Schaumont, Aydin Aysu: Three Design Dimensions of SecureEmbedded Systems. SPACE 2013: 1-20.http://dx.doi.org/10.1007/978-3-642-41224-0_1
My CoordinatesPatrick SchaumontECE Department Virginia Tech302 Whittemore HallBlacksburg VA 24060Email: [email protected]: http://www.ece.vt.edu/schaum
P. Schaumont (Virginia Tech) Three Design Dimensions SPACE 2013 10/21/2013







