
2007 STARC Forum
Rob A. RutenbarCarnegie Mellon University 1
© R.A. Rutenbar 2007
2007 STARC Forum
Towards Speech Recognition in Silicon:The Carnegie Mellon In Silico Vox Project
2007 STARC Forum
Towards Speech Recognition in Silicon:The Carnegie Mellon In Silico Vox Project
Rob A. RutenbarProfessor, Electrical & Computer [email protected]
© Rob A. Rutenbar 2007 Slide 2
CarnegieMellon
Speech Recognition Today
Quality = OK Vocab = large
Quality = poor Vocab = small
Commonality: all software apps

2007 STARC Forum
Rob A. RutenbarCarnegie Mellon University 2
© Rob A. Rutenbar 2007 Slide 3
CarnegieMellon
Today’s Best Software Speech Recognizers
Best-quality recognition is computationally hardFor speaker-independent, large-vocabulary, continuous speech
1-10-100-1000 ruleFor ~1X real-time recognition rateFor ~10% word error rate (90% accuracy)Need ~100 MB memory footprintNeed ~100 W powerNeed ~1000 MHz CPU
This proves to be very limiting …
© Rob A. Rutenbar 2007 Slide 4
CarnegieMellon
The Carnegie Mellon In Silico Vox Project
The thesis: It’s time to liberate speech recognition from the unreasonable limitations of software
The solution: Speech recognition in silicon

2007 STARC Forum
Rob A. RutenbarCarnegie Mellon University 3
© Rob A. Rutenbar 2007 Slide 5
CarnegieMellon
Aside: About the Name “In Silico Vox”
In VivoLatin: an experiment done in a living organism
In VitroLatin: an experiment done in an artificial lab environment
In Silico(Not real Latin): an experiment done via computation only
VoxLatin: voice, or word
© Rob A. Rutenbar 2007 Slide 6
CarnegieMellon
About This Talk
Some philosophyWhy silicon? Why now? Why us (CMU)?
A quick tour: How speech recognition worksWhat happens in a recognizer
An SoC architectureStripping away all CPU stuff we don’t need, focus on essentials
Results ASIC version: Simulation resultsFPGA version: Live, running hardware-based recognizer

2007 STARC Forum
Rob A. RutenbarCarnegie Mellon University 4
© Rob A. Rutenbar 2007 Slide 7
CarnegieMellon
About This Talk
Some philosophyWhy silicon? Why now? Why us (CMU)?
A quick tour: How speech recognition worksWhat happens in a recognizer
An SoC architectureStripping away all CPU stuff we don’t need, focus on essentials
Results ASIC version: Simulation resultsFPGA version: Live, running hardware-based recognizer
© Rob A. Rutenbar 2007 Slide 8
CarnegieMellon
Why Silicon? Why Now?
Why? Two reasons:
HistoryWe have some successful historical examples of this migration
PerformanceTomorrow’s compelling apps need 100X – 1000X more performance (Not going to happen in software)

2007 STARC Forum
Rob A. RutenbarCarnegie Mellon University 5
© Rob A. Rutenbar 2007 Slide 9
CarnegieMellon
History: Graphics Engines
Nobody paints pixels in software anymore!Too limiting in max performance. Too inefficient in power.
http://www.nvidia.com
http://www.mtekvision.com
True on the desktop (& laptop) …and on your cellphone too
© Rob A. Rutenbar 2007 Slide 10
CarnegieMellon
Performance: Next-Gen Compelling Applications
Audio-miningVery fast recognizers –much faster than realtimeApp: search large media streams (DVD) quickly
Hands-free appliancesVery portable recognizers –high quality result on << 1 wattApp: interfaces to small devices, cellphone dictation
Terminator 2
FIND: “Hasta la vista, baby!”
“send email to arnold –let’s do lunch…”

2007 STARC Forum
Rob A. RutenbarCarnegie Mellon University 6
© Rob A. Rutenbar 2007 Slide 11
CarnegieMellon
Silicon Solution: Speed and Power Wins
A famous graph from Prof. Bob Brodersen of BerkeleyStudy looked at 20 designs published at ISSCC, from 1997-2002In slightly older technologies, relative to today: 180nm – 250nmDedicated designs up to 10,000X better energy efficiency (MOPS/mW)
0.010.1
110
1001000
PPC-
95PP
C1-S
OI-00
Sparc
-95Sp
arc2-9
7PP
C2-S
OI-00
Sparc
1-97
X86-9
7Al
pha-0
0Al
pha-9
7PP
C-00
SA-D
SP-98
Hit-D
SP-98
Fuj-D
SP2-9
8Fu
j-DSP
1-00
NEC-
DSP-
98MP
EG2-9
9En
crypt-
00MU
D-98
MPEG
2-98
802.1
1a-01
Microprocessors General Purpose DSP
Dedicated
2 orders ofmagnitude
2 orders ofmagnitude
2 orders ofmagnitude
2 orders ofmagnitude
Million Ops (MOPS) / milliWatt (mW)
© Rob A. Rutenbar 2007 Slide 12
CarnegieMellon
Recent Example: Parallel Radio Baseband DSP
90nm CMOS: adaptive DSP for multipath MIMO channelPower efficiency = 2.1GOPS/mWArea efficiency = 20GOPS/mm2
Technology 90nm CMOS Core area 1.9 × 1.9 mm Die area 2.3 × 2.3 mm Pad count 120 IO/core VDD 1V / 0.4V Cell count 420,304 Frequency 100 MHz P (act/leak) 30mW / 4mW Efficiency 2.1GOPS/mW
(Source: Prof. Dejan Markovitz, UCLA)
Data rate up to 250Mbps over 16 sub-carriersMeasured 34mW @ VDD=385mV
1st path, α1 = 1
2nd path, α2 = 0.6x y
Txarray
Rxarray

2007 STARC Forum
Rob A. RutenbarCarnegie Mellon University 7
© Rob A. Rutenbar 2007 Slide 13
CarnegieMellon
Why Us...?
1 site (Carnegie Mellon), 3 sets of world-class expertsImpossible to do projects like this without cross-area linkages
Computer Science SPHINX Speech recognition group
Electrical & Computer EngineeringSilicon system implementation group
Electrical & Computer EngineeringMedia / DSP group
Carnegie Mellon Campuswww.cmu.edu
Carnegie Mellon Campuswww.cmu.edu
© Rob A. Rutenbar 2007 Slide 14
CarnegieMellon
Us: the CMU In Silico Vox Team
From left: Kai Yu, Rob Rutenbar, Edward Lin, Richard Stern, Tsuhan Chen, Patrick Bourke(not shown: Jeff Johnston)
From left: Kai Yu, Rob Rutenbar, Edward Lin, Richard Stern, Tsuhan Chen, Patrick Bourke(not shown: Jeff Johnston)

2007 STARC Forum
Rob A. RutenbarCarnegie Mellon University 8
© Rob A. Rutenbar 2007 Slide 15
CarnegieMellon
About This Talk
Some philosophyWhy silicon? Why now? Why us (CMU)?
A quick tour: How speech recognition worksWhat happens in a recognizer
An SoC architectureStripping away all CPU stuff we don’t need, focus on essentials
Results ASIC version: Simulation resultsFPGA version: Live, running hardware-based recognizer
© Rob A. Rutenbar 2007 Slide 16
CarnegieMellon
How Speech Recognition Works
ADCADC
Filter1Filter2Filter3
FilterN
...
Filter1Filter2Filter3
FilterN
...
x1x2x3...xn
x1x2x3...xnSampling
Feature extraction
Featurevector
DSP
ωω
1
a11
a12
b1(.)
2
a22
a23
b2(.)
3
a33
a34
b3(.)
1
a11
a12
b1(.)
1
a11
a12
b1(.)
2
a22
a23
b2(.)
2
a22
a23
b2(.)
3
a33
a34
b3(.)
3
a33
a34
b3(.)
Acoustic
“Rob”
Adaptation
HMMSearch
Word...Rob R AO BBob B AO B...
Language
Rob saysAdaptation
Acoustic units Words Language
Adaptation toenvironment/speaker
“ao”
FeatureScoring
Acoustic Frontend
Scoring Backend Search
HMM / Viterbi SearchLanguage Model Search
2007 STARC Forum
Rob A. RutenbarCarnegie Mellon University 9
© Rob A. Rutenbar 2007 Slide 17
CarnegieMellon
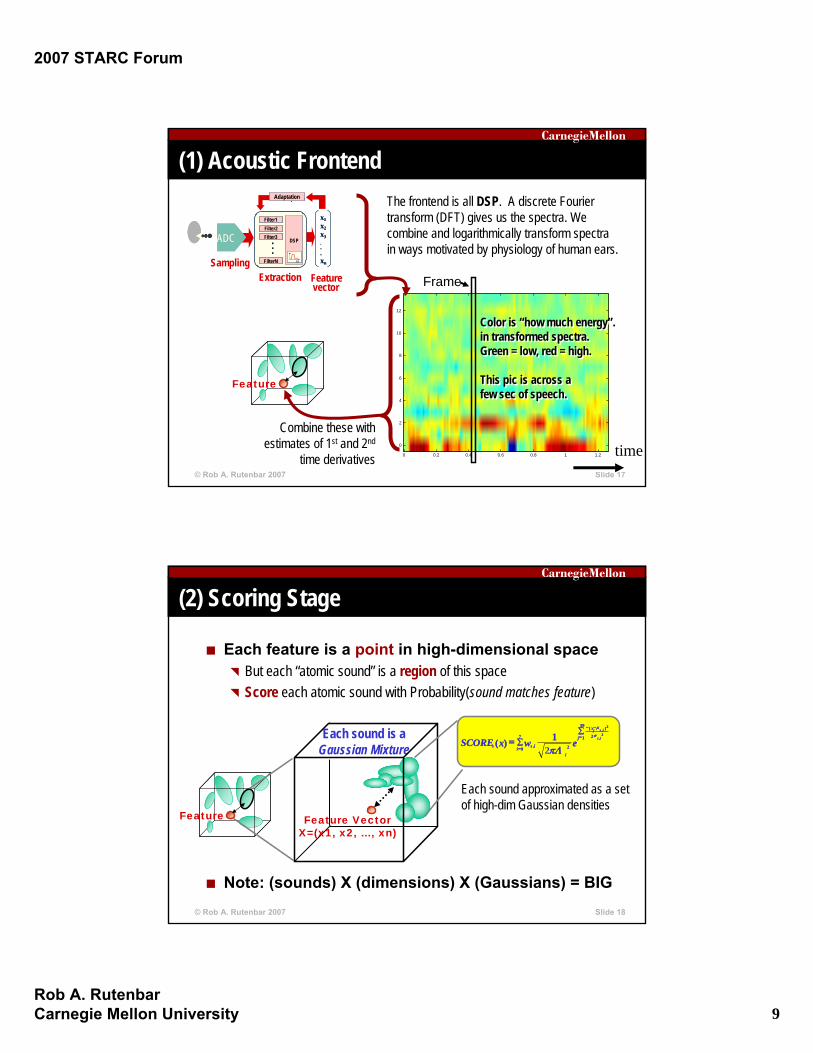
(1) Acoustic Frontend
0 0.2 0.4 0.6 0.8 1 1.2
0
2
4
6
8
10
12
The frontend is all DSP. A discrete Fourier transform (DFT) gives us the spectra. We combine and logarithmically transform spectra in ways motivated by physiology of human ears.
time
Frame
Combine these with estimates of 1st and 2nd
time derivatives
Color is “how much energy”. in transformed spectra.Green = low, red = high.
This pic is across a few sec of speech.
Color is “how much energy”. in transformed spectra.Green = low, red = high.
This pic is across a few sec of speech.
ADCADC
Filter1Filter2Filter3
FilterN
...
Filter1Filter2Filter3
FilterN
...
x1x2x3...
xn
x1x2x3...
xnSamplingExtraction Feature
vector
DSP
ωω
AdaptationAdaptation
Feature
© Rob A. Rutenbar 2007 Slide 18
CarnegieMellon
Each feature is a point in high-dimensional spaceBut each “atomic sound” is a region of this spaceScore each atomic sound with Probability(sound matches feature)
Note: (sounds) X (dimensions) X (Gaussians) = BIG
(2) Scoring Stage
Feature
Each sound is aGaussian Mixture
Feature VectorX=(x1, x2, …, xn)
21)(
7
0
2
)(
2,
2,
2,
i
x
i
iss ewxSCORE is
is
=
−−
= ∑πΛ
σ
μ39
1j=∑ j
1)(7
0
2
)(
2,
2,
2,
i
x
i
iss ewxSCORE is
is
=
−−
= ∑πΛ
σ
μ39
1j=∑ j
Each sound approximated as a set of high-dim Gaussian densities

2007 STARC Forum
Rob A. RutenbarCarnegie Mellon University 10
© Rob A. Rutenbar 2007 Slide 19
CarnegieMellon
(3) Search: Speech Models are Layered Models
YES
NO
/Y/ /EH/ /S/
/N/ /OW/
Waveform
Pitch
Power
Spectrum
15 ms
0 ms
0 kHz
0 dB6 kHz
80 dB0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9
Language X Words X Acoustic Layered Search
words “acousticunits”
1 frame ofsampled sound
“sub-acousticunits”
Classical methods(HMMs, Viterbi)
and idiosyncracies
© Rob A. Rutenbar 2007 Slide 20
CarnegieMellon
Context Matters: At Bottom -- Triphones
English has ~50 atomic sounds (phones) but we recognize ~50x50x50 context-dependent triphones
Because “I” sound in “five” is different than the “I” in “nine”
Five F( -, I )cross-word I( F, V )word-internal V( I, - )cross-word
Nine N( -, I )cross-word I( N, N )word-internal N( I, - )cross-word
“I” in “five” ≠ “I” in “nine”

2007 STARC Forum
Rob A. RutenbarCarnegie Mellon University 11
© Rob A. Rutenbar 2007 Slide 21
CarnegieMellon
Similar for Other Languages, like Japanese...but different basic building blocks (different phones)
Source: Microsoft Speech API 5.3Japanese Phonemeshttp://msdn2.microsoft.com/en-us/library/ms720568.aspx
© Rob A. Rutenbar 2007 Slide 22
CarnegieMellon
Example of Different Phone Building Blocks
Let’s use my name as an example
English: /r/ /OO/ /t/ /n/ /b/ /ar/
Japanese: /ル/ /ー/ /テ/ /ン/ /バ/ /ー/
Aside:Japanese has some reputation as being an “easier” language for automatic recognitionMapping from basic sounds (mora) to words is simpler than English

2007 STARC Forum
Rob A. RutenbarCarnegie Mellon University 12
© Rob A. Rutenbar 2007 Slide 23
CarnegieMellon
Also Context at Top: N-gram Language Model
Unigram
Trigram
Bigram
W13W123…
W122
W111
W112
W113
W114
W121
…
W11
W12
W13
W14
W1
W2
W3
W4
termination
Lets us calculate likelihood of word W3after W2after W1
Suppose we have vocabulary { W1, W2, W3, W4, …}
“W1” “W1 W2”
“W1 W2 W3”
© Rob A. Rutenbar 2007 Slide 24
CarnegieMellon
Good Speech Models are BIG
This is ~64K word “Broadcast News” taskUnfortunately, many idiosyncratic details in how layers of model traversed
Waveform
Pitch
Power
Spectrum
15 ms
0 ms
0 kHz
0 dB6 kHz
80 dB0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9
for each 10 ms time frame
5156Scores
111,593Triphones
64,001Unigrams
9,382,014Bigrams
13,459,879 Trigrams
...... ...
...
...

2007 STARC Forum
Rob A. RutenbarCarnegie Mellon University 13
© Rob A. Rutenbar 2007 Slide 25
CarnegieMellon
19%
6% 15%
27%
33%
ADCADC
Filter1Filter2Filter3
FilterN
...
Filter1Filter2Filter3
FilterN
...
x1x2x3...xn
x1x2x3...xnSampling
Feature extraction
Featurevector
DSP
ωωωω
1
a11
a12
b1(.)
2
a22
a23
b2(.)
3
a33
a34
b3(.)
1
a11
a12
b1(.)
1
a11
a12
b1(.)
2
a22
a23
b2(.)
2
a22
a23
b2(.)
3
a33
a34
b3(.)
3
a33
a34
b3(.)
1
a11
a12
b1(.)
1
a11
a12
b1(.)
2
a22
a23
b2(.)
2
a22
a23
b2(.)
3
a33
a34
b3(.)
3
a33
a34
b3(.)
1
a11
a12
b1(.)
1
a11
a12
b1(.)
2
a22
a23
b2(.)
2
a22
a23
b2(.)
3
a33
a34
b3(.)
3
a33
a34
b3(.)
2
a22
a23
b2(.)
2
a22
a23
b2(.)
3
a33
a34
b3(.)
3
a33
a34
b3(.)
3
a33
a34
b3(.)
3
a33
a34
b3(.)
Acoustic
“Rob”
Adaptation
HMMSearch
Word...Rob R AO BBob B AO B...
Language
Rob saysAdaptation
Acoustic units Words Language
Adaptation toenvironment/speaker
“ao”
FeatureScoring
HMM / Viterbi SearchLanguage Model Search
Where Does Software Spend its Time?CPU time for CMU Sphinx 3.0
Prior studies targeted less capable versions (v1, v2)Tools: SimpleScalar & Intel Vtune64K-word “Broadcast News” benchmark
So: It’s all backend
~0% of time!
© Rob A. Rutenbar 2007 Slide 26
CarnegieMellon
Memory Usage? SPHINX 3.0 vs Spec CPU2000
Cache sizesL1: 64 KB, direct mappedDL1: 64 KB, direct mappedUL2: 512 KB, 4-way set assoc
So…Terrible locality (no surprise, graph search + huge datasets)Load dominated (no surprise, reads a lot, computes a little)Not an insignificant footprint
42 MB186 MB24 MB64 MB
Memory Footprint
0.300.030.060.48L2
0.030.020.020.04 DL1Cache Miss Rates
0.020.080.070.025
Branch Misprediction Rates
0.120.170.20.14Branch’s
0.080.090.150.05Stores
0.270.20.250.27LoadsInstruction Mixes
0.71.050.290.69IPC
23 B15 B55B53 BCycles
EquakeGzipGccSPHINX 3.0

2007 STARC Forum
Rob A. RutenbarCarnegie Mellon University 14
© Rob A. Rutenbar 2007 Slide 27
CarnegieMellon
About This Talk
Some philosophyWhy silicon? Why now? Why us (CMU)?
A quick tour: How speech recognition worksWhat happens in a recognizer
An SoC architectureStripping away all CPU stuff we don’t need, focus on essentials
Results ASIC version: Simulation resultsFPGA version: Live, running hardware-based recognizer
© Rob A. Rutenbar 2007 Slide 28
CarnegieMellon
This Talk: How to Get to Fast…
Audio-miningVery fast recognizers –much faster than realtimeApp: search large media streams (DVD) quickly
Hands-free appliancesVery portable recognizers –high quality result on << 1 wattApp: interfaces to small devices, cellphone dictation
Terminator 2
FIND: “Hasta la vista, baby!”
“send email to arnold –let’s do lunch…”
2007 STARC Forum
Rob A. RutenbarCarnegie Mellon University 15
© Rob A. Rutenbar 2007 Slide 29
CarnegieMellon
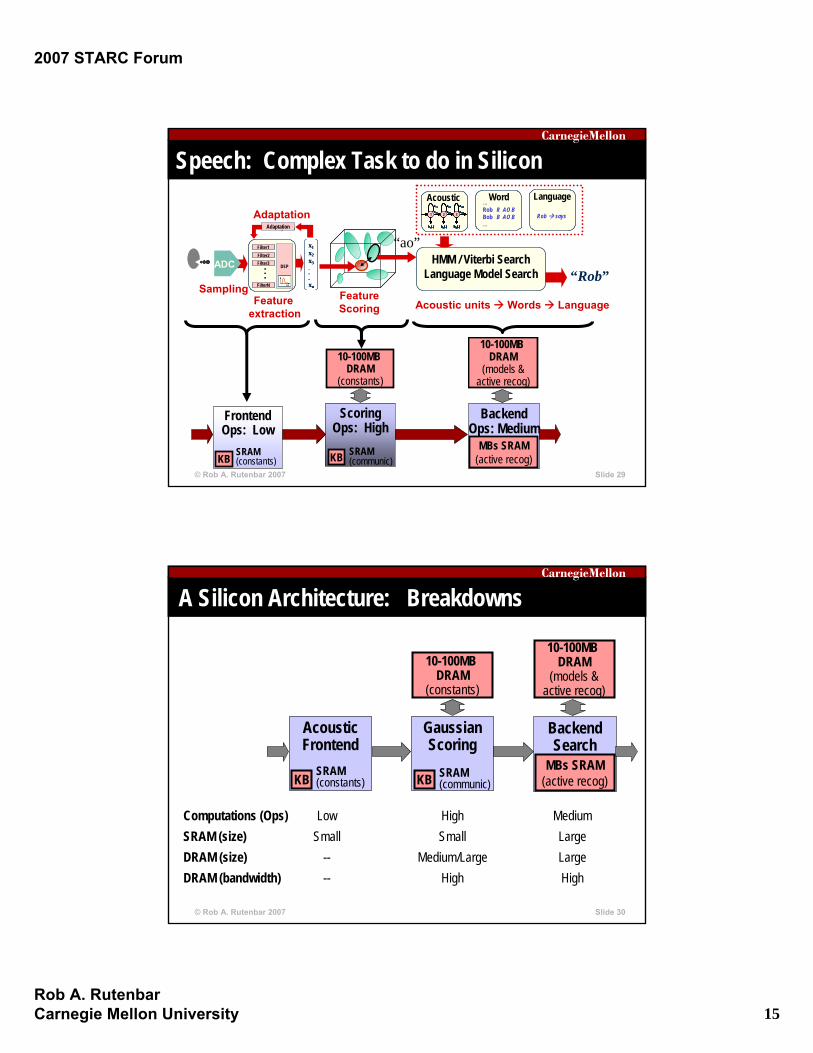
Speech: Complex Task to do in Silicon
ADCADC
Filter1Filter2Filter3
FilterN
...
Filter1Filter2Filter3
FilterN
...
x1x2x3...xn
x1x2x3...xnSampling
Feature extraction
DSP
ωωωω
1
a11
a12
b1(.)
2
a22
a23
b2(.)
3
a33
a34
b3(.)
1
a11
a12
b1(.)
1
a11
a12
b1(.)
2
a22
a23
b2(.)
2
a22
a23
b2(.)
3
a33
a34
b3(.)
3
a33
a34
b3(.)
1
a11
a12
b1(.)
1
a11
a12
b1(.)
2
a22
a23
b2(.)
2
a22
a23
b2(.)
3
a33
a34
b3(.)
3
a33
a34
b3(.)
1
a11
a12
b1(.)
1
a11
a12
b1(.)
2
a22
a23
b2(.)
2
a22
a23
b2(.)
3
a33
a34
b3(.)
3
a33
a34
b3(.)
2
a22
a23
b2(.)
2
a22
a23
b2(.)
3
a33
a34
b3(.)
3
a33
a34
b3(.)
3
a33
a34
b3(.)
3
a33
a34
b3(.)
Acoustic
“Rob”
Adaptation
HMMSearch
Word...Rob R AO BBob B AO B...
Language
Rob saysAdaptation
Acoustic units Words Language
Adaptation
“ao”
FeatureScoring
HMM / Viterbi SearchLanguage Model Search
FrontendOps: Low
KB SRAM(constants)
ScoringOps: High
KB SRAM(communic)
10-100MB DRAM
(constants)
BackendOps: Medium
MBs SRAM(active recog)
10-100MB DRAM
(models &active recog)
© Rob A. Rutenbar 2007 Slide 30
CarnegieMellon
A Silicon Architecture: Breakdowns
AcousticFrontend
GaussianScoring
BackendSearch
KB KBMBs SRAM
(active recog)SRAM(constants)
SRAM(communic)
10-100MB DRAM
(constants)
10-100MB DRAM
(models &active recog)
Computations (Ops) Low High MediumSRAM (size) Small Small LargeDRAM (size) -- Medium/Large LargeDRAM (bandwidth) -- High High

2007 STARC Forum
Rob A. RutenbarCarnegie Mellon University 16
© Rob A. Rutenbar 2007 Slide 31
CarnegieMellon
Essential Implementation Ideas
Custom precision, everywhereEvery bit counts, no extras, no floating point – all fixed point
(Almost) no cachingLike graphics chips: fetch from SDRAM, do careful data placement(Little bit of caching for bandwidth filtering on big language models)
Aggressive pipeliningIf we can possibly overlap computations – we try to do so
Algorithm transformationSome software computations are just bad news for hardwareSubstitute some “deep computation” with hardware-friendly versions
© Rob A. Rutenbar 2007 Slide 32
CarnegieMellon
Example: Aggressive Pipelining
timeFetch HMM/Viterbi
Transition/Prune/WritebackFetch Word
Fetch HMM/Viterbi
Transition/Prune/Writeback Language Model
Fetch HMM/Viterbi
Transition/Prune/WritebackFetch Word
Fetch HMM/Viterbi
Transition/Prune/Writeback
Language Model
Fetch Word Language Model
Fetch HMM/Viterbi
Transition/Prune/WritebackFetch Word
Fetch HMM/Viterbi
Transition/Prune/WritebackFetch Word
Fetch HMM/Viterbi
Transition/Prune/Writeback
Pipelined Get-HMM/Viterbi and Transition stages
Pipelined Get-Word and Get-HMM stages
Pipelined non-LanguageModel and LanguageModel stages
Word #1Word #2HMM #1HMM #2
HMM #3

2007 STARC Forum
Rob A. RutenbarCarnegie Mellon University 17
© Rob A. Rutenbar 2007 Slide 33
CarnegieMellon
Example: Algorithmic ChangesAcoustic-level pruning threshold
Software: Use best score of current frame (after Viterbi on Active HMMs) Silicon: Use best score of previous frame (nixes big temporal bottleneck)
TradeoffsLess memory bandwidth, can pipeline, little pessimistic on scores
Sphinx 3.0 Software Silicon
Initialize Frame
Fetch Active Word
Fetch Active HMM
Viterbi
Transition/Prune/Writeback
LanguageModel
Start Frame
Done
Initialize Frame
Fetch Active Word
Fetch Active HMM
Viterbi
Transition/Prune/Writeback
LanguageModel
Start Frame
DoneFetch Active Word
Fetch Active HMM
Viterbi
Writeback HMM Transition/Prune/Writeback
Language Model
Initialize Frame
Fetch Active Word
Fetch Active HMM
Done
Done all Active HMM
Done all Active HMM
Fetch Active Word
Fetch Active HMM
Viterbi
Writeback HMM Transition/Prune/Writeback
Language Model
Initialize Frame
Fetch Active Word
Fetch Active HMM
Done
Done all Active HMM
Done all Active HMM
© Rob A. Rutenbar 2007 Slide 34
CarnegieMellon
About This Talk
Some philosophyWhy silicon? Why now? Why us (CMU)?
A quick tour: How speech recognition worksWhat happens in a recognizer
An SoC architectureStripping away all CPU stuff we don’t need, focus on essentials
Results ASIC version: Simulation resultsFPGA version: Live, running hardware-based recognizer
2007 STARC Forum
Rob A. RutenbarCarnegie Mellon University 18
© Rob A. Rutenbar 2007 Slide 35
CarnegieMellon
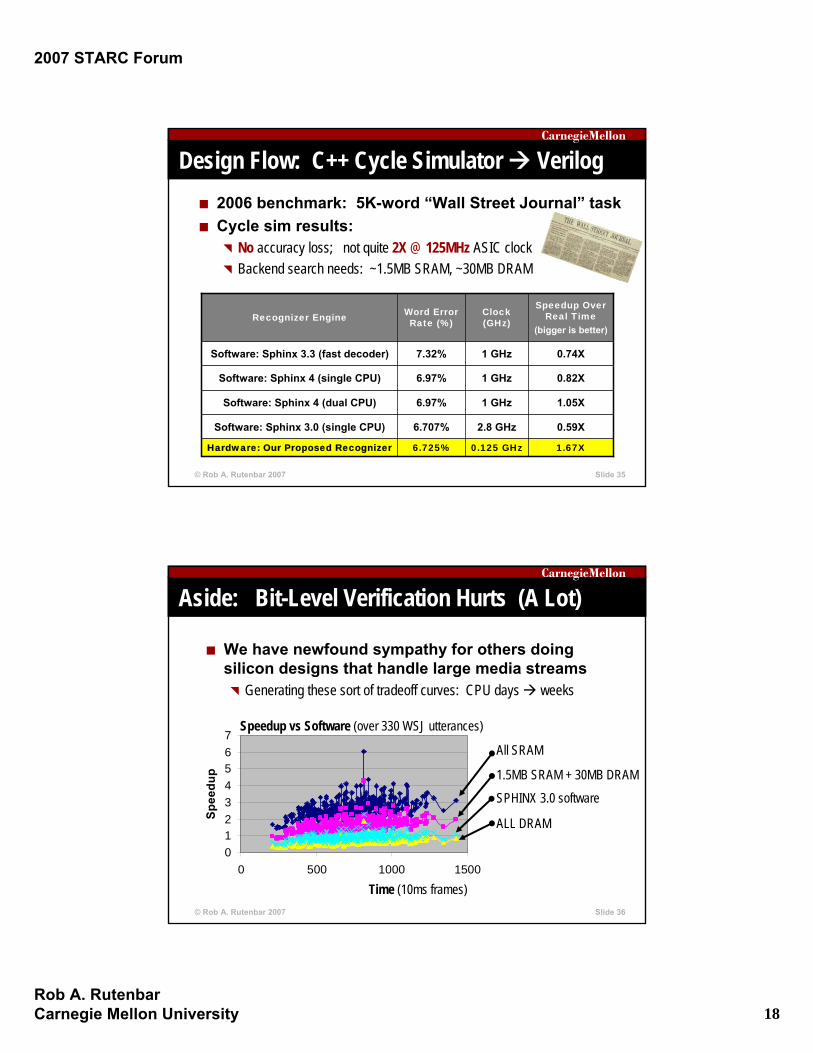
Design Flow: C++ Cycle Simulator Verilog2006 benchmark: 5K-word “Wall Street Journal” taskCycle sim results:
No accuracy loss; not quite 2X @ 125MHz ASIC clockBackend search needs: ~1.5MB SRAM, ~30MB DRAM
1.67X
0.59X
1.05X
0.82X
0.74X
Speedup Over Real Time
(bigger is better)
0.125 GHz
2.8 GHz
1 GHz
1 GHz
1 GHz
Clock (GHz)
6.707%Software: Sphinx 3.0 (single CPU)
6.725%Hardware: Our Proposed Recognizer
6.97%Software: Sphinx 4 (single CPU)
6.97%Software: Sphinx 4 (dual CPU)
7.32%Software: Sphinx 3.3 (fast decoder)
Word Error Rate (%)Recognizer Engine
© Rob A. Rutenbar 2007 Slide 36
CarnegieMellon
Aside: Bit-Level Verification Hurts (A Lot)
We have newfound sympathy for others doing silicon designs that handle large media streams
Generating these sort of tradeoff curves: CPU days weeks
01234567
0 500 1000 1500
Spee
dup
Speedup vs Software (over 330 WSJ utterances)
Time (10ms frames)
All SRAM
1.5MB SRAM + 30MB DRAM
SPHINX 3.0 software
ALL DRAM

2007 STARC Forum
Rob A. RutenbarCarnegie Mellon University 19
© Rob A. Rutenbar 2007 Slide 37
CarnegieMellon
Aside: Pieces of Design = Great Class ProjectsCMU student team: Patrick Chiu, David Fu, Mark McCartney, Ajay Panagariya, Chris Thomas
Floorplan Final Layout
Final Stats
© Rob A. Rutenbar 2007 Slide 38
CarnegieMellon
A Complete Live Recognizer: FPGA DemoIn any “system design” research, you reach a point where you just want to see it work – for real
Goal: Full recognizer 1 FPGA + 1 DRAM
A benchmark that fits on chip1000-word “Resource Mgt” task Slightly simplified: no tri-gramsSlower: not real time, ~2.3X slowerResource limited: slices, mem bandwidth
ADCADC
Filter1Filter2Filter3
FilterN
...
Filter1Filter2Filter3
FilterN
...
x1x2x3...
xn
x1x2x3...
xnSamplingFeature
extractionFeaturevector
DSP
ωωωω
1
a11
a12
b1(.)
2
a22
a23
b2(.)
3
a33
a34
b3(.)
1
a11
a12
b1(.)
1
a11
a12
b1(.)
2
a22
a23
b2(.)
2
a22
a23
b2(.)
3
a33
a34
b3(.)
3
a33
a34
b3(.)
1
a11
a12
b1(.)
1
a11
a12
b1(.)
2
a22
a23
b2(.)
2
a22
a23
b2(.)
3
a33
a34
b3(.)
3
a33
a34
b3(.)
1
a11
a12
b1(.)
1
a11
a12
b1(.)
2
a22
a23
b2(.)
2
a22
a23
b2(.)
3
a33
a34
b3(.)
3
a33
a34
b3(.)
2
a22
a23
b2(.)
2
a22
a23
b2(.)
3
a33
a34
b3(.)
3
a33
a34
b3(.)
3
a33
a34
b3(.)
3
a33
a34
b3(.)
Acoustic
“Rob”
Adaptation
HMMSearch
Word...Rob R AO BBob B AO B...
Language
Rob saysAdaptation
Acoustic units Words Language
Adaptation toenvironment/speaker
“ao”
FeatureScoring
HMM / Viterbi SearchLanguage Model Search
Xilinx XC2VP30 FPGA [13969 slices / 2448 Kb]
Utiliz: 99% of slices 45% of Block RAM~3MB DDR DRAM
50MHz clk; ~200Mb/s IO
Xilinx XC2VP30 FPGA [13969 slices / 2448 Kb]
Utiliz: 99% of slices 45% of Block RAM~3MB DDR DRAM
50MHz clk; ~200Mb/s IO

2007 STARC Forum
Rob A. RutenbarCarnegie Mellon University 20
© Rob A. Rutenbar 2007 Slide 39
CarnegieMellon
FPGA Experimental ResultsAside: as far as we know, this is the most complex recognizer architecture ever fully mapped into a running, hardware-only form
© Rob A. Rutenbar 2007 Slide 40
CarnegieMellon
SummarySoftware is too constraining for speech recognition
Evolution of graphics chips suggests alternative: Do it in siliconCompelling performance and power reasons for silicon speech recog
Several “in silico vox” architectures in designSoC and FPGA versions~10X realtime speedup architecture in progress at CMU
ReflectionsSome of the most interesting experiences happen when you get people from very different backgrounds – silicon + speech – on same team

2007 STARC Forum
Rob A. RutenbarCarnegie Mellon University 21
© Rob A. Rutenbar 2007 Slide 41
CarnegieMellon
Acknowledgements
Work supported byUS National Science Foundation (www.nsf.gov)Semiconductor Research Corporation (www.src.org)FCRP Focus Research Center for Circuit & System Solutions (www.fcrp.org, www.c2s2.org)
We are grateful for the advice and speech recognition expertise shared with us by
Richard M. Stern, CMUArthur Chan, CMUMosur K. Ravishankar, CMU







