
montblanc-project.eu | @MontBlanc_EU
This project has received funding from the European Union's Horizon 2020 research and innovation program under grant agreement n° 671697
The Mont-Blanc project Updates from the Barcelona Supercomputing Center
Filippo Mantovani

Mont-Blanc
The “legacy” Mont-Blanc vision
Denver, Nov 13th 2017 Arm HPC User Group 2
Vision: to leverage the fast growing market of mobile technology for scientific computation, HPC and data centers.
2012 2013 2014 2016 2015 2017 2018
Mont-Blanc 2
Mont-Blanc 3

Mont-Blanc
The “legacy” Mont-Blanc vision
Phases share a common structure
Experiment with real hardware
Android dev-kits, mini-clusters, prototypes, production ready systems
Push software development
System software, HPC benchmarks/mini-apps/production codes
Study next generation architectures
Learn from hardware deployment and evaluation for planning new systems
Denver, Nov 13th 2017 Arm HPC User Group 3
Vision: to leverage the fast growing market of mobile technology for scientific computation, HPC and data centers.
2012 2013 2014 2016 2015 2017 2018
Mont-Blanc 2
Mont-Blanc 3

We started here We ended up here
Hardware platforms
Denver, Nov 13th 2017 Arm HPC User Group 4
N. Rajovic et al., “The Mont-Blanc Prototype: An Alternative Approach for HPC Systems,” in Proceedings of SC’16, p. 38:1–38:12.

We started here We ended up here
Different OS flavors
Arm HPC Compiler
Arm Performance Libraries
Allinea tools
…
All well packed and distributed through OpenHPC
Several complex HPC production codes have run on Mont-Blanc Alya
AVL codes
WRF
FEniCS
System Software and Use Cases
Denver, Nov 13th 2017 Arm HPC User Group 5
Source files (C, C++, FORTRAN, Python, …)
GNU Arm HPC Mercurium
Compilers
Network driver OpenCL driver
Linux OS / Ubuntu
LAPACK Boost PETSc Arm PL
FFTW HDF5 ATLAS clBLAS
Scientific libraries
Scalasca Perf Extrae Allinea
Developer tools
SLURM Ganglia NTP
OpenLDAP Nagios Puppet
Cluster management
Nanos++ OpenCL CUDA MPI
Runtime libraries
Power monitor Power
monitor Lustre NFS DVFS
Hardware support / Storage
CPU GPU CPU
CPU Network
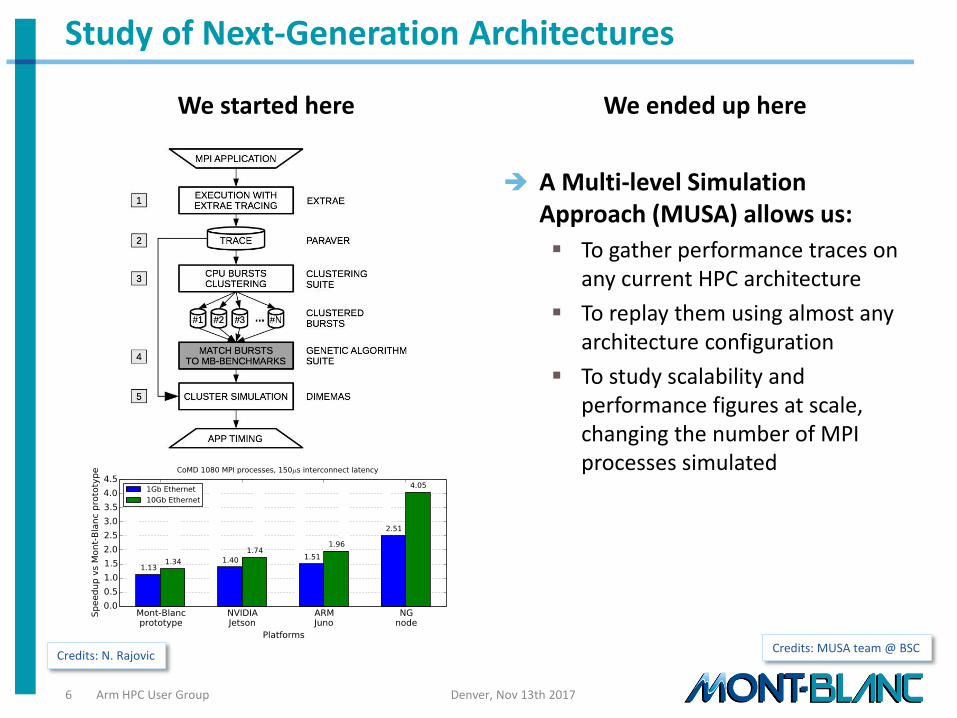
We started here
We ended up here
A Multi-level Simulation Approach (MUSA) allows us:
To gather performance traces on any current HPC architecture
To replay them using almost any architecture configuration
To study scalability and performance figures at scale, changing the number of MPI processes simulated
Study of Next-Generation Architectures
Denver, Nov 13th 2017 Arm HPC User Group 6
Credits: N. Rajovic Credits: MUSA team @ BSC

Where BSC is contributing today?
Evaluation of solutions
Hardware solutions
• Mini-clusters deployed liaising with SoC providers and system integrators
Software solutions
• Arm Performance Libraries, Arm HPC Compiler
Use cases
Alya: finite element code where we experiment atomics-avoiding techniques
• GOAL: test new runtime features to be pushed into OpenMP
HPCG: benchmark where we started looking at vectorization
• GOAL: explore techniques for exploitation of the Arm Scalable Vector Extension
Simulation of next generation large clusters
MUSA: Combining detailed trace driven simulation with sampling strategies for exploring how architectural parameters affects the performance at scale.
Denver, Nov 13th 2017 Arm HPC User Group 7
T. Grass et al., “MUSA: A Multi-level Simulation Approach for Next-Generation HPC Machines,” in SC16 proceedings, pp. 526–537.
F. Banchelli et al., “Is Arm software ecosystem ready for HPC?”, poster at SC17.

Evaluation of Arm Performance Libraries
Goal Test an HPC code making use of arithmetic and FFT libraries
Method Quantum Espresso pwscf input
Compiled with GCC 7.1.0
Platform configuration #1 (poster SC17) AMD Seattle
Arm PL 2.2
ATLAS 3.11.39
OpenBLAS 0.2.20
FFTW 3.3.6
Platform configuration #2 Cavium ThunderX2
Arm PL v18.0
OpenBLAS 0.2.20
FFTW 3.3.7
Denver, Nov 13th 2017 Arm HPC User Group 8

Evaluation of the Arm HPC Compiler
Goal
Evaluate the Arm HPC Compilers v18.0 vs v1.4
Method
Run Polybench benchmark suite
Including 30 benchmarks by Ohio State University
Run on Cavium ThunderX2
Denver, Nov 13th 2017 Arm HPC User Group 9
Execution time increment v18.0 vs v1.4
SIMD instructions v18.0 vs v1.4
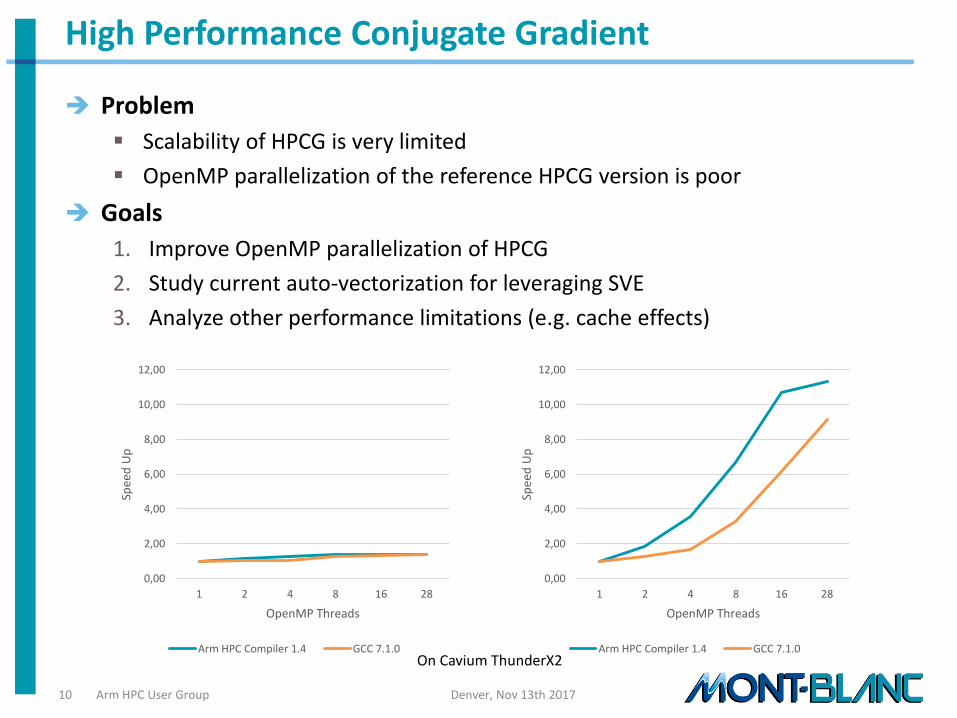
High Performance Conjugate Gradient
Problem
Scalability of HPCG is very limited
OpenMP parallelization of the reference HPCG version is poor
Goals
1. Improve OpenMP parallelization of HPCG
2. Study current auto-vectorization for leveraging SVE
3. Analyze other performance limitations (e.g. cache effects)
Denver, Nov 13th 2017 Arm HPC User Group 10
0,00
2,00
4,00
6,00
8,00
10,00
12,00
1 2 4 8 16 28
Spee
d U
p
OpenMP Threads
Arm HPC Compiler 1.4 GCC 7.1.0
0,00
2,00
4,00
6,00
8,00
10,00
12,00
1 2 4 8 16 28
Spee
d U
p
OpenMP Threads
Arm HPC Compiler 1.4 GCC 7.1.0On Cavium ThunderX2

High Performance Conjugate Gradient
Problem
Scalability of HPCG is very limited
OpenMP parallelization of the reference HPCG version is poor
Goals
1. Improve OpenMP parallelization of HPCG
2. Study current auto-vectorization for leveraging SVE
3. Analyze other performance limitations (e.g. cache effects)
Denver, Nov 13th 2017 Arm HPC User Group 11
On Cavium ThunderX2

HPCG - SIMD parallelization
First approach
Check auto-vectorization in current platforms
Method
Count SIMD instructions in the “ComputeSYMGS” region
On Cavium ThunderX2 using Arm HPC Compiler v18.0
On Intel Xeon Platinum 8160 (Skylake) using ICC supporting AVX512
Denver, Nov 13th 2017 Arm HPC User Group 12
x106

HPCG - SVE emulation
First approach
Check auto-vectorization when SVE is enabled
Method
Evaluate auto-vectorization in a whole execution of HPCG (one iteration)
Generate binary using Arm HPC Compiler v1.4 enabling SVE
Emulate SVE instruction using Arm Instruction Emulator in Cavium ThunderX2
Denver, Nov 13th 2017 Arm HPC User Group 13
0
5
10
15
20
25
30
35
SVE 128b SVE 256b SVE 512b SVE 1024b SVE 2048b
Incr
emen
t in
SIM
D in
stru
ctio
ns
agai
nst
NEO
N
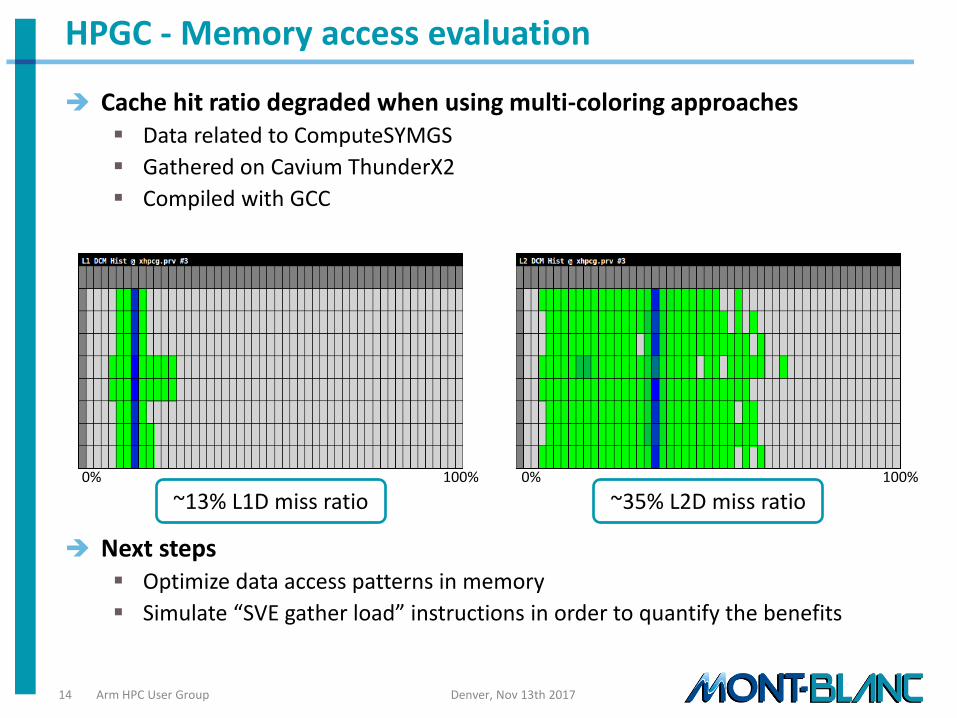
HPGC - Memory access evaluation
Cache hit ratio degraded when using multi-coloring approaches Data related to ComputeSYMGS
Gathered on Cavium ThunderX2
Compiled with GCC
Next steps Optimize data access patterns in memory
Simulate “SVE gather load” instructions in order to quantify the benefits
Denver, Nov 13th 2017 Arm HPC User Group 14
~13% L1D miss ratio ~35% L2D miss ratio 0% 100% 0% 100%

Alya: BSC code for multi-physics problems
Analysis with Paraver:
Reductions with indirect accesses on large arrays using No coloring
Use of atomics operations harms performance
Coloring Use of coloring harms locality
Commutative Multidependences • (OmpSs feature to be hopefully
included in OpenMP)
Denver, Nov 13th 2017 Arm HPC User Group 15
Parallelization of finite elements code
Credits: M. Garcia, J. Labarta

Alya: taskification and dynamic load balancing
Goal
Quantify the effect of commutative dependences and DLB on an HPC code
Method
Run the “Assembly phase” of Alya (containing atomics)
On MareNostrum 3, 2x Intel Xeon SandyBridge-EP E5-2670
On Cavium ThunderX, 2x CN8890
Denver, Nov 13th 2017 Arm HPC User Group 16
16 nodes x P processes/node x T threads/process
Assembly phase
Credits: M. Josep, M. Garcia, J. Labarta

Multi-Level Simulation Approach
Level 1: Trace generation
Denver, Nov 13th 2017 Arm HPC User Group 17
HPC application execution
OpenMP Runtime System Plugin
MPI Call Instrumenatation
Pintool / DynamoRIO
Task / chunk creation events, dependencies
MPI calls Dynamic
instructions
Trace Credits: T. Grass, C. Gomez, M. Casas, M. Moreto

Level 2: Network simulation (Dimemas)
Level 3: Multi-core simulation (TaskSim + Ramulator + McPAT)
Multi-Level Simulation Approach
Time
Rank 1
Rank 2
… …
Network simulator
Multi-core simulator
Thread 1
Thread 2
… …
Time
Denver, Nov 13th 2017 Arm HPC User Group 18
Trace
Credits: T. Grass, C. Gomez, M. Casas, M. Moreto

Multi-Level Parameters
Architectural
CPU architecture
Number of cores
Core frequency
Threads per core
Reorder buffer size
SIMD width
Micro-architectural
L1/2/3 Cache size/latency
Main memory
Memory technology
Capacity
Bandwidth
Latency
Problem: Simulation time diverges Solution:
We supported different modes (Burst, Detailed, Sampling) trading accuracy for speed
Denver, Nov 13th 2017 Arm HPC User Group 19
Credits: T. Grass, C. Gomez, M. Casas, M. Moreto

MUSA: status
SC’16 paper
Validation of the methodology with 5 applications
• BT-MZ, SP-MZ, LU-MZ, HYDRO, SPECFEM3D
Proven performance figures at scale up to 16 kMPI ranks
Status update
Added parameter sets for state-of-the art architectures
Support for power consumption modeling
• Including CPU, NoC and memory hierarchy
Incremented set of applications
Expanded trace database
• Including traces gathered on MareNostrum4 (Intel Skylake + OmniPath)
Included support for DynamoRIO
Denver, Nov 13th 2017 Arm HPC User Group 20
Credits: T. Grass, C. Gomez, M. Casas, M. Moreto

Student Cluster Competition
Rules
12 teams of 6 undergraduate students
1 cluster operating within 3 kW power budget
3 HPC applications + 2 benchmarks
One team from University Politècnica de Catalunya (UPC-Spain)
Participating with Mont-Blanc technology
3 awards to win
Best HPL
1st, 2nd, 3rd overall places
Fan favorite We are looking for
an Arm-based cluster for 2018!!!
Denver, Nov 13th 2017 Arm HPC User Group 21

Interested in any of the topics presented?
Follow us!
montblanc-project.eu @MontBlanc_EU [email protected]
Visit our booths @ SC17!
booth #1694
booth #1925
booth #1975
Denver, Nov 13th 2017 Arm HPC User Group 22







