
What Changed?
Frank Bereznay
Kaiser Permanente

What Changed?
• Two Questions– Can we use statistical techniques to help us
differentiate between variation that is part of a normal operation and variation due to assignable causes?
– How should data be organized to properly use these techniques?

Agenda
• Frank’s One Hour Stat Class– What is Statistics all about?– Commonly Used Statistical Techniques
• Hypothesis Testing• Statistical Process Control• Analysis of Variance
– Time Series Data– An Example

What is Statistics all about?
• Populations have Parameters.
• Samples have Statistics.
• Statistics is all about estimating Population parameters by taking samples and calculating statistics.
• A Key Question– What is the data population you are trying to
estimate and what are it’s properties?

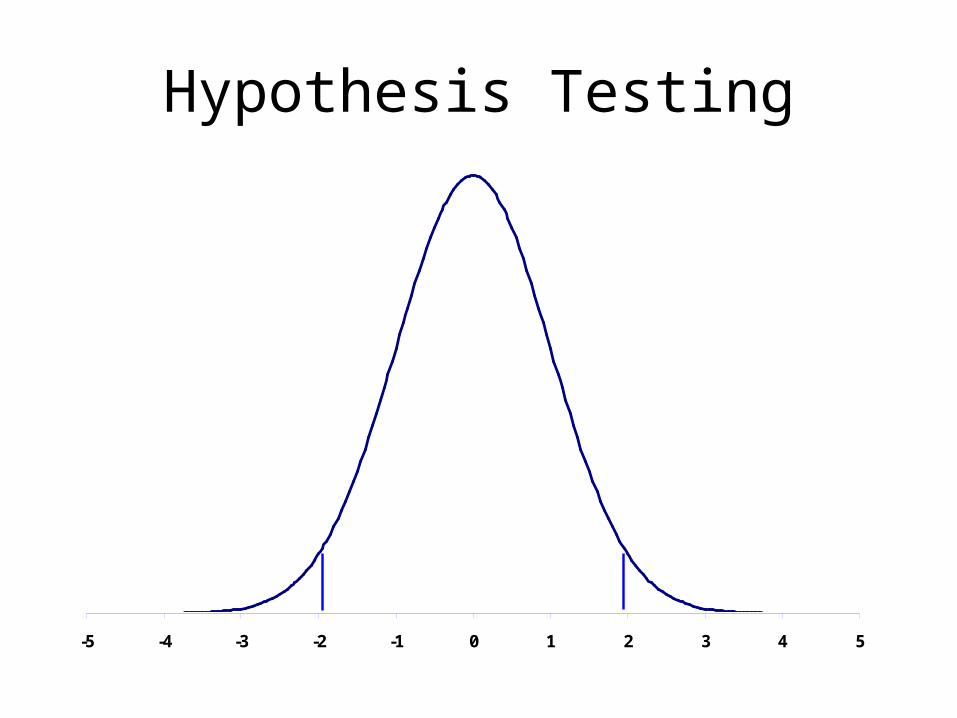
Hypothesis Testing
• A very brief review
• Conduct an experiment to make a decision about a population parameter.
• Relies on the Central Limit Theorem to describe the properties of a sample.– Samples are always normally distributed
irrespective of the underlying population.

Hypothesis Testing
• Classic form of test
H0: µ = 0
Ha: µ ≠0
• A level of confidence, usually 95% is specified.
• You collect a sample set of values and compare the derived statistic against a normal distribution to make the determination.
Hypothesis Testing
-5 -4 -3 -2 -1 0 1 2 3 4 5
95%
2.5% 2.5%

Hypothesis Testing
• So, what can this do for us?– If we know what a metric is supposed to be,
we can sample and test.– This has some value for SLAs and other
metrics that are mandated.– Most of the time we don’t know the population
parameters.

Statistical Process Control
• A bit of History– Walter Shewhart– W Edwards Deming– Post WWII Japan and the Deming Cycle

Statistical Process Control
• Key Concepts and Terms– There is no up front hypothesis test.– No information is required about the
parameters of the process being evaluated.– Control Chart
• Primary method to track a process.• Many forms of the metric can be analyzed.
– Rational Subgroups• Recurring sets of data that are summarized for
analysis.

Statistical Process Control• Sample Control Chart

Statistical Process Control
• A number of CMG papers have been published in this area:– Brey “Managing at the Knee of the Curve(The use
of SPC in Managing a Data Center)”, CMG90– Lipner “Zero-Defect Capacity and Performance
Management”, CMG92– Chu “A Three Sigma Quality Target for 100
Percent SLA”, CMG92– Buzen & Shum “MASF – Multivariate Adaptive
Statistical Filtering”, CMG95

Statistical Process Control
• Following the Buzen & Shum paper, Trubin has published a set of papers on applications of MASF.
• However, the overall interest in this area seemed to wane.– I believe it is primarily due to the complexity of
the data we work with.

Analysis of Variance (ANOVA)
• Developed by Sir Ronald A. Fischer in the early 20th Century.
• Initial use was focused on helping the agriculture industry.– A method was needed to evaluate the
effectiveness of multiple simultaneous attempts to improve crop yield.

Analysis of Variance (ANOVA)
• Take a area of interest and sub-divide it into multiple populations.
• Subject these separate populations to various treatments.
• Make a determination if there are differences in the population means that can be attributed to the treatments.

Analysis of Variance (ANOVA)
• Hypothesis test
H0: µ1 = µ2 = µ3 … = µn
Ha: Not all µi (i=1,2,3,…n) are equal• This can be a very handy tool to determine if
there are differences in the sub-groups within a body of data.– Are business volumes the same Monday thru
Friday?– Is there a difference in Tuesday’s volume week
over week?

Quick Summary
• We have described three techniques:– Hypothesis Testing– Statistical Process Control– Analysis of Variance (ANOVA)
• Time to see an example

Example

Bottling Process
• We have a process that puts a beverage in a bottle– The intended fill volume is 2 liters or 2,000
CM– We collect 36 random samples over a nine
day period.• Sample Mean 1,999.51• Sample Variance 1.89• Standard Deviation 1.37
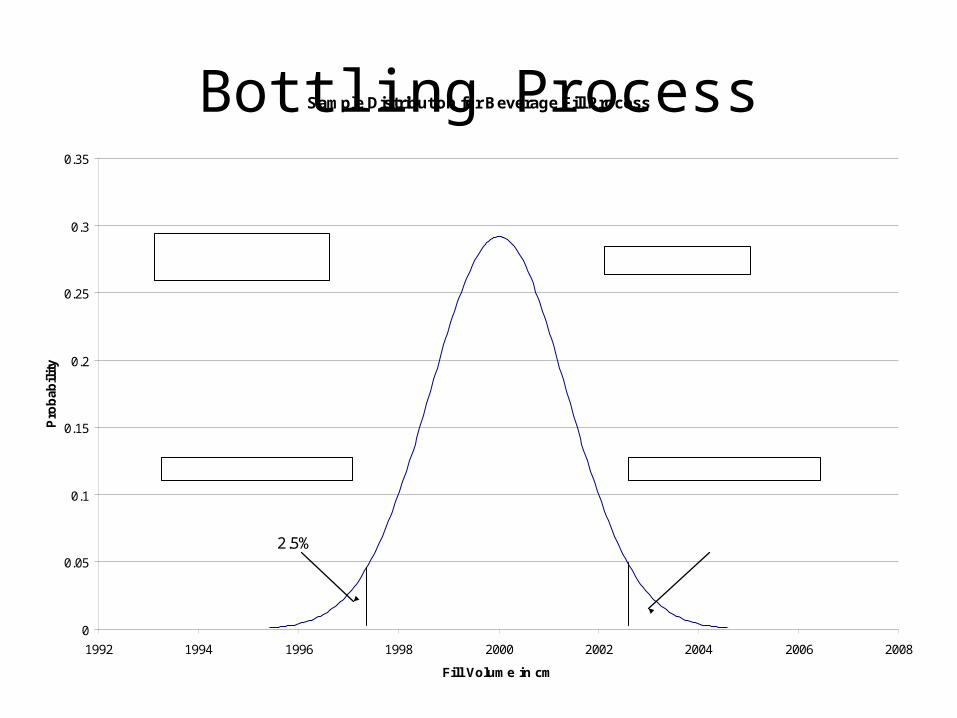
Bottling ProcessSample Distribution for Beverage Fill Process
0
0.05
0.1
0.15
0.2
0.25
0.3
0.35
1992 1994 1996 1998 2000 2002 2004 2006 2008
Fill Volume in cm
Pro
bab
ilit
y
2.5%2.5%
Sample Mean = 1,999.51Standard Deviation = 1.37
Lower Critical Value = 1997.31 Upper Critical Value = 2002.69
Process Range = 5.38

Bottling ProcessLCL_ X
1997
1998
1999
2000
2001
2002
Ti meSt amp
12MAR06 14MAR06 16MAR06 18MAR06 20MAR06 22MAR06
Upper Control Limit = 2001.46
Lower Control Limit = 1997.56
Process Range = 3.9

Bottling ProcessLCL_ R
0
1
2
3
4
5
6
7
Ti meSt amp
12MAR06 14MAR06 16MAR06 18MAR06 20MAR06 22MAR06

The ANOVA Procedure
Class Level Information
Class Levels Values
TimeStamp 9 13MAR06 14MAR06 15MAR06 16MAR06 17MAR06 18MAR06 19MAR06 20MAR06 21MAR06
Number of Observations Read 36 Number of Observations Used 36
Dependent Variable: CM CM
Sum of Source DF Squares Mean Square F Value Pr > F
Model 8 20.23060000 2.52882500 1.49 0.2081
Error 27 45.91587500 1.70058796
Corrected Total 35 66.14647500

Tukey's Studentized Range (HSD) Test for CM
Means with the same letter are not significantly different.
Time Tukey Grouping Mean N Stamp
A 2000.3525 4 13MAR06 A A 2000.3200 4 20MAR06 A A 2000.2050 4 19MAR06 A A 1999.8775 4 18MAR06 A A 1999.8275 4 14MAR06 A A 1999.1275 4 16MAR06 A A 1999.0150 4 21MAR06 A A 1998.8075 4 17MAR06 A A 1998.0650 4 15MAR06

Second Quick Summary
• That was reassuring!– When we purchase a bottle of wine we can be
sure we are getting our money’s worth.
• Why did Frank chose this example?
• What is the relevance to our commercial computing environments?

Time Series Data
• The instrumentation data we analyze is a very complex data aggregate that contains the influences of multiple factors.
• Many of the factors are related to time or duration.– Hour of the day, Day of the week.– Day of the month, Month of the Year.– Growth rate for the enterprise.

Time Series Data
• Example of overall MIPS usage.
0.0
500.0
1,000.0
1,500.0
2,000.0
2,500.0
3,000.0
3,500.0
3/5/
2004
4/5/
2004
5/5/
2004
6/5/
2004
7/5/
2004
8/5/
2004
9/5/
2004
10/5
/200
4
11/5
/200
4
12/5
/200
4
1/5/
2005
2/5/
2005
3/5/
2005
4/5/
2005
5/5/
2005
6/5/
2005
7/5/
2005
8/5/
2005
9/5/
2005
10/5
/200
5
11/5
/200
5
12/5
/200
5

Time Series Data
• Time Series data generally contains four components.– Trend
• Long term constant movement.
– Cycle• Movement pattern greater than a year.
– Seasonal Variations• Movement patterns within a year.
– Irregular Fluctuations• Events not triggered by a duration.

Time Series Data
• To properly work with this type of data you need to decompose it into it’s components before you begin the testing.
• You have four separate questions to ask, one for each component.– Did the trend component change?– Did the cycle component change?– Did the seasonal component change?– Did the irregular component change?

Time Series Data
• While it is possible to perform the decomposition of Time Series data into it’s components, the best strategy is to avoid the need to do so.– Choose granular data intervals.– Keep the number of intervals to a minimum.– Start with a 24x7 type of matrix and use
ANOVA to determine the hours that belong together.

Third Quick Summary
• OK, Now we have a strategy.– Treat each hour of each day as a separate
process.– Use ANOVA to see how similar the day/hour
combination is week over week. Are we selecting the right combination?
– Use SPC to develop a process mean and control limits for this day/hour.
– Plot the results on a day by day basis.
• Lets see how this looks.

Example – Midrange CPUDATE 8 9 10 11 12 13 14 15Grand Total
Wednesday, March 01, 2006 34.7 35.1 29.4 27.9 27.9 27.9 27.9 27.8 29.8Thursday, March 02, 2006 29.0 28.7 28.1 28.2 27.9 27.9 28.4 27.9 28.2
Friday, March 03, 2006 36.0 30.5 29.6 29.4 28.4 27.9 28.4 28.1 29.7Monday, March 06, 2006 29.4 28.9 30.2 28.7 27.9 28.1 28.0 27.9 28.6
Tuesday, March 07, 2006 35.2 29.3 28.2 28.2 28.6 27.9 28.1 28.5 29.2Wednesday, March 08, 2006 36.5 31.9 30.6 32.4 31.9 36.1 30.3 30.3 32.4
Thursday, March 09, 2006 37.2 31.5 29.9 31.0 36.6 31.3 28.4 29.7 31.8Friday, March 10, 2006 27.6 27.9 27.9 27.7 28.0 27.7 27.7 27.8 27.8
Monday, March 13, 2006 30.9 30.2 29.9 30.3 29.6 29.3 29.0 27.9 29.6Tuesday, March 14, 2006 34.9 32.2 33.0 33.9 31.9 31.5 33.3 31.5 32.8
Wednesday, March 15, 2006 35.9 33.3 35.8 36.2 34.6 30.6 37.9 28.6 34.0Thursday, March 16, 2006 34.6 33.8 28.0 38.9 33.9 30.5 28.6 33.7 32.7
Friday, March 17, 2006 31.2 33.3 31.8 31.0 30.7 30.7 29.6 28.3 30.8Monday, March 20, 2006 30.1 28.3 28.4 28.4 28.7 29.4 28.4 28.8 28.8
Tuesday, March 21, 2006 28.1 28.1 28.8 28.2 28.0 30.1 30.6 28.1 28.8Wednesday, March 22, 2006 37.8 28.9 28.1 28.1 28.8 27.9 28.6 28.0 29.5
Thursday, March 23, 2006 38.2 28.7 28.7 33.5 42.0 30.6 27.9 28.0 32.1Friday, March 24, 2006 27.9 28.5 28.1 33.3 27.9 28.0 28.1 27.9 28.6
Monday, March 27, 2006 30.8 33.4 32.3 28.9 28.8 28.2 28.8 28.3 30.0Tuesday, March 28, 2006 32.3 29.0 28.2 30.0 34.9 33.6 32.4 43.8 33.2
Wednesday, March 29, 2006 28.5 29.3 28.8 28.7 28.8 28.2 28.3 28.3 28.6Thursday, March 30, 2006 33.2 31.4 34.8 31.3 28.2 28.2 28.3 28.3 30.4
Friday, March 31, 2006 28.4 28.4 28.2 29.4 28.4 28.2 28.4 28.3 28.4Grand Total 32.4 30.4 29.9 30.6 30.4 29.5 29.3 29.5 30.3

Example – Midrange CPU Tukey's Studentized Range (HSD) Test for CPUAVE
Alpha 0.05 Error Degrees of Freedom 15 Error Mean Square 5.953 Critical Value of Studentized Range 4.36699 Minimum Significant Difference 5.3275
Means with the same letter are not significantly different.
Tukey Grouping Mean N DATE A 34.800 4 30MAR06 A B A 29.850 4 09MAR06 B B 28.650 4 23MAR06 B B 28.075 4 02MAR06 B B 28.025 4 16MAR06
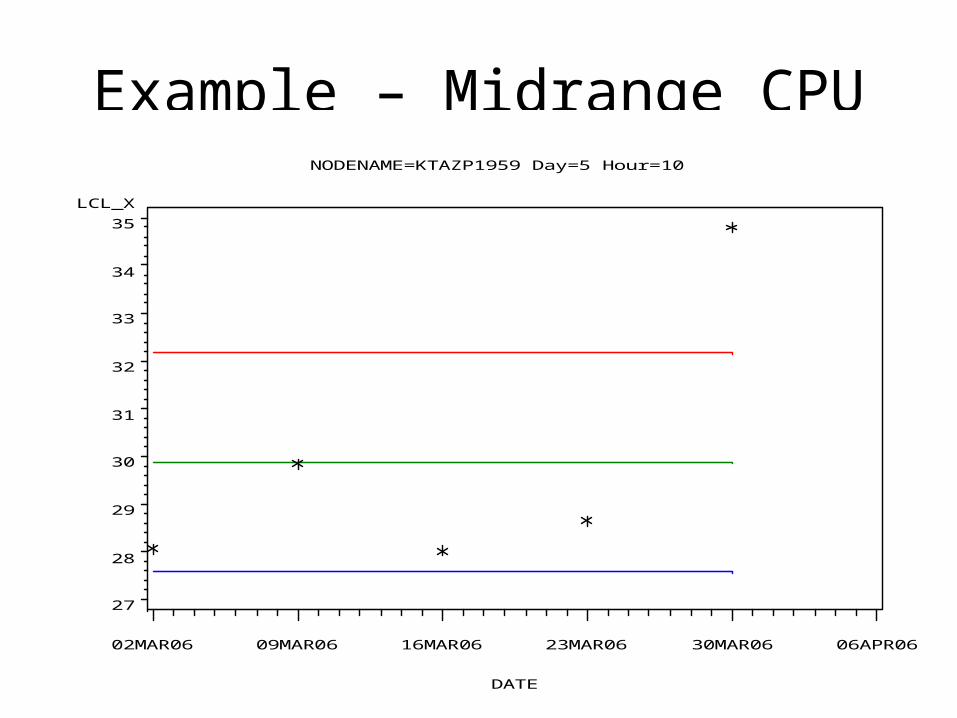
Example – Midrange CPUNODENAME=KTAZP1959 Day=5 Hour =10
LCL_ X
27
28
29
30
31
32
33
34
35
DATE
02MAR06 09MAR06 16MAR06 23MAR06 30MAR06 06APR06
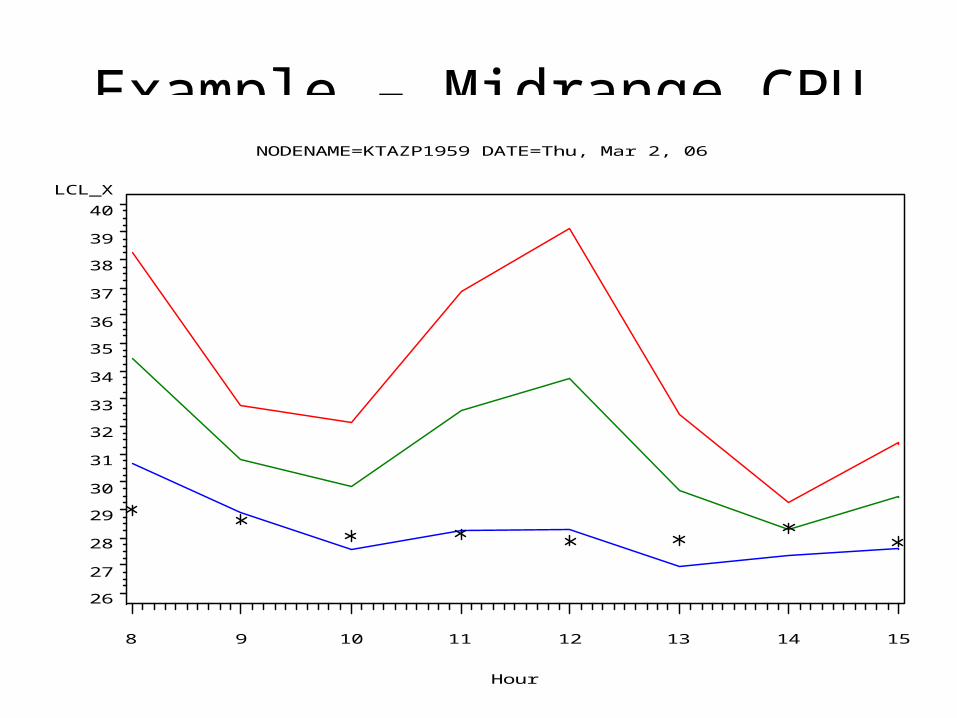
Example – Midrange CPUNODENAME=KTAZP1959 DATE=Thu, Mar 2, 06
LCL_ X
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
Hour
8 9 10 11 12 13 14 15

Example – Midrange CPUNODENAME=KTAZP1959 DATE=Fr i , Mar 3, 06
LCL_ X
26
27
28
29
30
31
32
33
34
35
36
Hour
8 9 10 11 12 13 14 15
Example – Midrange CPU Usage
NODENAME=KTAZP1959 DATE=Mon, Mar 6, 06
LCL_ X
26
27
28
29
30
31
32
33
34
Hour
8 9 10 11 12 13 14 15

Example – Midrange CPUNODENAME=KTAZP1959 DATE=Tue, Mar 7, 06
LCL_ X
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
Hour
8 9 10 11 12 13 14 15

Example – Midrange CPU UsageNODENAME=KTAZP1959 DATE=Wed, Mar 8, 06
LCL_ X
262728293031323334353637383940414243
Hour
8 9 10 11 12 13 14 15

Summary
• These statistical tools can really help.– But it is not a slam dunk to implement.– You need to get to know your data.
• Producing the information is only the beginning.– Recall the problems Shewart and Demming
had.– This really needs to the basis for managing
the environment.







