Download - What's new in MariaDB AX webinar

LAYOUT
Title Slide (Dark)
What’s new in MariaDB AX, the database for modern analytics & data warehousing
Dipti JoshiDirector Product ManagementMariaDB

Conrad Hotel, New York CityFebruary 26–27, 2018
m18.mariadb.com
M|18, the second annual MariaDB user conference, is where global MariaDB experts and practitioners meet to exchange ideas, best practices and success stories. Join us in NYC to share journeys on open source strategies and infrastructure modernization with MariaDB.
-2017 SPONSORS-
YOTTA ZETTA EXA

LAYOUT
Title and ContentPowerPoint Default
MariaDB AX
Analytics made easy – simple, fast, scalable…
and open source

LAYOUT
Two ContentPowerPoint Default
Customer Use Case
Industry: healthcare (Medicaid)Data: surveysUse case: decision support systemDetails: 1. Identify trends and patterns 2. Determine population cohorts 3. Predict health outcomes 4. Anticipate funding / capacity 5. Recommend intervention
Can’t do complex queries on current hardware with Oracle and snowflake schemas
Limited to optimizing for simple, known queries (2-3 columns)
Replaced with ColumnStore > a single table > 2.5 million rows, 248 columns >
complex, ad-hoc queries > query 20+ columns in seconds

LAYOUT
Two ContentPowerPoint Default
Customer Use CasesBy industry
Finance
Identify trade patternsDetect fraud and anomoliesPredict trading outcomes
Manufacturing
Simulations to improve design/yieldDetect production anomaliesPredict machine failures (sensor data)
Telecom
Behavioral analysis of customer callsNetwork analysis (perf and reliability)
Healthcare
Find genetic profiles/matchesAnalyze health vs spendingPredict viral outbreaks

LAYOUT
Content with CaptionPowerPoint Default
MariaDB AX
MariaDB Server
MariaDB MaxScale
MariaDB ColumnStore
Parallel queries
Distributed storage
No indexes
Automatic partitioning
Read optimized
High compression
Low disk IO ColumnStoreStorage
ColumnStoreStorage
ColumnStoreStorage
MariaDB Server
ColumnStore
MariaDB Server
ColumnStore
MariaDB MaxScale
MariaDB Server
ColumnStore
ColumnStoreStorage
MariaDB MaxScale

LAYOUT
Title and ContentPowerPoint Default
MariaDB AXGoals
3. Streamline and simplify the process of ingesting data
2. Make it easier to perform custom, complex analytics
1. Expand high availability/disaster recovery options

LAYOUT
Content with CaptionPowerPoint Default
MariaDB AXWhat was there
Manual importManual backup/restoreWindow functionsAggregate functionsUser-defined functionsCross-engine joins
ColumnStore StorageMariaDB Server
ColumnStoreInnoDB
Applications / Spark
MariaDB MaxScale

LAYOUT
Content with CaptionPowerPoint Default
MariaDB AXWhat’s new
MariaDB ColumnStore 1.1Streaming data adapters
Bulk data adapters
User defined
Window functions
Distributed aggregates
Spark support
Phase I: SQL (JDBC)
Phase II: data adapters
High availability
Local storage (GlusterFS)
Parallel backup/restore
ColumnStore Storage
Backup/Restore GlusterFS
MariaDB Server
ColumnStore
Applications / Spark
BulkData Adapters
User DefinedWindow Functions
StreamingData Adapters
User DefinedAggregate Functions
MariaDB MaxScale

LAYOUT
Title OnlyPowerPoint Default
CERTIFICATION
What’s new in MariaDB AX
INGESTION
ANALYTICS
Applications, Apache Kafka, MariaDB MaxScale
User-defined aggregate and window functions
HA / DR GlusterFS support, Parallel backup/restore
DATA TYPES Text, BLOB columns
SECURITY Auditing
Tableau

LAYOUT
Quote (Blue)
Extend high availability/disaster recovery options

LAYOUT
Content with CaptionPowerPoint Default
GlusterFS Volume
Replication
High availability
GlusterFS can replicate files within a volume - HA without the need for an expensive SAN
ColumnStore storage nodes can read other files within a volume - simple, automatic failover
ColumnStoreStorage
(dbroot1)
ColumnStoreStorage
(dbroot2)
MariaDB Server
ColumnStore
MariaDB Server
ColumnStore
ColumnStoreStorage
(dbroot3)
/dbroot1 /dbroot2 /dbroot2 /dbroot3 /dbroot3 /dbroot1

LAYOUT
Content with CaptionPowerPoint Default
High availability
GlusterFS can replicate files within a volume - HA without the need for an expensive SAN
ColumnStore storage nodes can read other files within a volume - simple, automatic failover
MariaDB Server
ColumnStore
MariaDB Server
ColumnStore
GlusterFS Volume
/dbroot1 /dbroot2 /dbroot2 /dbroot3 /dbroot3 /dbroot1
Replication
ColumnStoreStorage
(dbroot1)
ColumnStoreStorage
(dbroot2)
ColumnStoreStorage
(dbroot3)
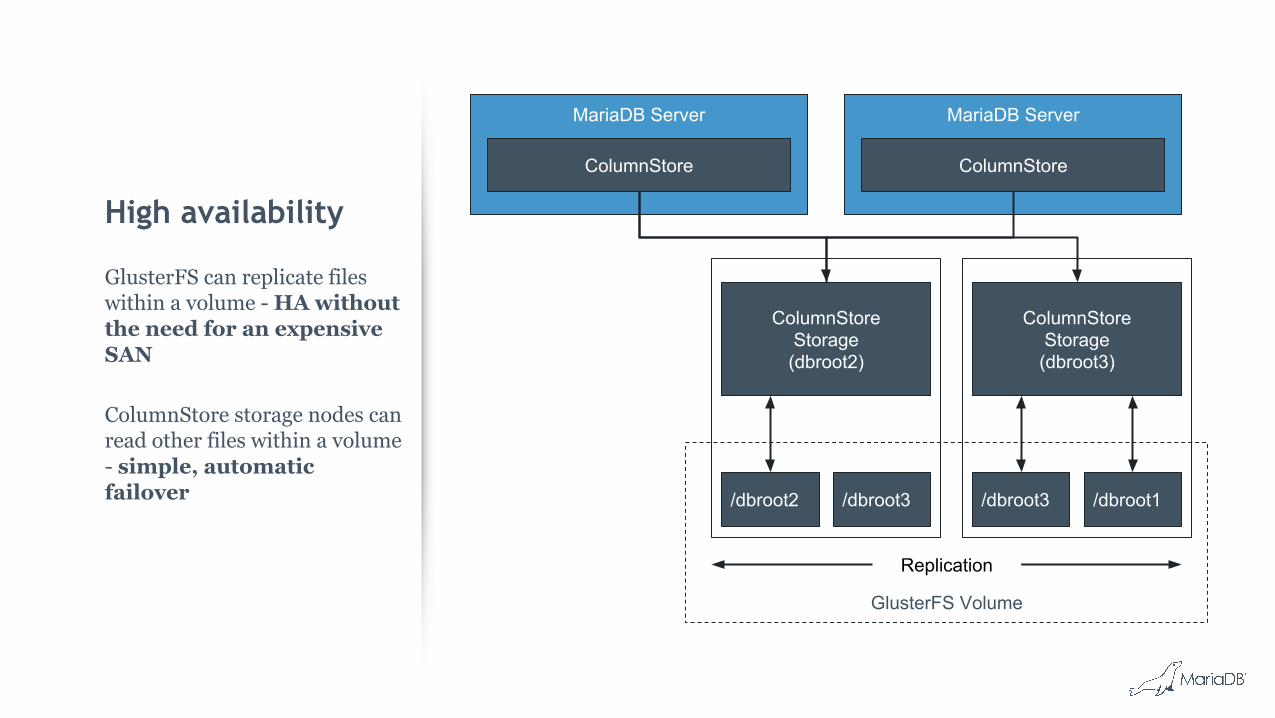
LAYOUT
Content with CaptionPowerPoint Default
GlusterFS Volume
High availability
GlusterFS can replicate files within a volume - HA without the need for an expensive SAN
ColumnStore storage nodes can read other files within a volume - simple, automatic failover
MariaDB Server
ColumnStore
MariaDB Server
ColumnStore
/dbroot2 /dbroot3 /dbroot3 /dbroot1
Replication
ColumnStoreStorage
(dbroot2)
ColumnStoreStorage
(dbroot3)

LAYOUT
Content with CaptionPowerPoint Default
/home/user/columnstoreBackupData/pm1dbroot1/home/user/columnstoreBackupData/pm2dbroot2/home/user/columnstoreBackupData/pm3dbroot3
Parallelbackup/restore
Parallel backup/restore using rsync - faster backup and restore
Support incremental backup and restore - faster backup and restore
Consolidate data from multiple storage nodes in a single backup location - simplified, automatic backups and restores
ColumnStoreStorage
ColumnStoreStorage
MariaDB Server
ColumnStore
MariaDB Server
ColumnStore
ColumnStoreStorage
Backup and restore tool
rsync /data1/* rsync /data2/* rsync /data3/*

LAYOUT
Quote (Blue)
Make it easier to perform custom, complex analytics

LAYOUT
Content with CaptionPowerPoint Default
User-defined aggregate and window functions
User-defined distributed aggregate functions - custom analytical functions and better performance
User-defined window functions
Example: calculate a weighted sum (revenue) $1-10 (0.5) $11-100 (1.0) $100+ (1.5)
MariaDB Server
ColumnStore
MariaDB Server
ColumnStore
ColumnStoreStorage
ColumnStoreStorage
ColumnStoreStorage
$10 $5
$100 $100
$200 $300
Column WSUM
$4 $2
$8 $4
$20 $20
Column WSUM
$12 $6
$60 $60
$300 $450
Column WSUM
WSUM = $405 WSUM = $26 WSUM = $516
WSUM = $947

LAYOUT
Quote (Blue)
Streamline and simplify the process of data ingestion

LAYOUT
Title and ContentPowerPoint Default
Organizations need to make data available for analysis as soon as it arrives
Machine learning results need to be stored where other business/data analysts work with them
Time to insight and time to action are now competitive differentiators for businesses
Motivation

LAYOUT
Content with CaptionPowerPoint Default
Bulk data adapters
Applications can use bulk data adapters to collect and write data - on-demand data loading
Bypass SQL interface, parser and optimizer - faster writes
C++PythonJavaMore on the way
MariaDB Server
ColumnStore
Application
ColumnStore Storage ColumnStore StorageColumnStore Storage
Write API Write API Write API
MariaDB Server
ColumnStore
Bulk Data Adapter
1. For each rowa. For each column
i. bulkInsert->setColumnb. bulkInsert->writeRow
2. bulkInsert->commit
* Buffer 100,000 rows by default

LAYOUT
Two ContentPowerPoint Default
Customer Use Case
Industry: biotechnology (genetics)Data: genotypesUse case: genetic profilingDetails: 1. Find genetic mates for cattle 2. Predict meat production 3. Gene/DNA analysis
Had to convert to CSV files and schedule import jobs (cron)
Always receiving new genetic data
Migrated to data adapter (Python) > streamline import process > remove steps / possible error > remove delays > import data on demand > immediate customer access

LAYOUT
Content with CaptionPowerPoint Default
Streaming data adapters – MaxScale CDC
Stream all writes from MariaDB TX to MariaDB AX automatically and continuously - ensure analytical data is up to date and not stale, no need for batch jobs, manual processes or human intervention
MariaDB Server
InnoDB
MariaDB Server
ColumnStore
MariaDB MaxScale
ColumnStore Storage ColumnStore StorageColumnStore Storage
Write API Write API Write API
MariaDB Server
ColumnStore
Streaming Data Adapter(CDC Client)
CDC Server

LAYOUT
Content with CaptionPowerPoint Default
Streaming data adapters – Apache Kafka
Stream all messages published to Apache Kafka topics to MariaDB AX automatically and continuously - enable data from many sources to be streamed and collected for analysis without complex code
MariaDB Server
ColumnStore
Apache Kafka
ColumnStore Storage ColumnStore StorageColumnStore Storage
Write API Write API Write API
MariaDB Server
ColumnStore
Streaming Data Adapter(Kafka Client)
Topic Topic Topic

LAYOUT
Quote (Blue)
The big picture – putting it all together

LAYOUT
BlankPowerPoint Default
AnalyticsOperations Ingestion
Apache Kafka
Streaming Data Adapters
Data Services
Bulk Data Adapters
Spark / Python / ML
Bulk Data Adapters
Transaction (OLTP)
MariaDB Server
InnoDB
MariaDB MaxScale
Web/Mobile Services
MariaDB MaxScale
Analytics (OLAP)
MariaDB Server
ColumnStore

LAYOUT
Quote (Blue)
Demo
TX to AX data streaming

LAYOUT
Title OnlyPowerPoint Default
Reach me
Resources
Download
Documentation https://mariadb.com/kb/en/library/mariadb-columnstore/
Blogs https://mariadb.com/blog-tags/columnstorehttps://mariadb.com/blog-tags/big-data
MariaDB ColumnStore 1.1 https://mariadb.com/downloads/mariadb-axBulk Data Adapters and Streaming Data Adapters https://mariadb.com/downloads/mariadb-ax/data-adaptersMariaDB ColumnStore Backup/Restore Tool https://mariadb.com/downloads/mariadb-ax/tools-ax

LAYOUT
Two ContentPowerPoint Default
What’s new in MariaDB AXSummary
Improved HA/DR GlusterFS support Parallel backup/restore
Streamlined data ingestion Streaming data adapters Bulk data adapters
Complex, custom analytics User-defined aggregate functions User-defined window functions Text and binary columns
Spark integration (in-progress) JDBC (SQL) Direct (data adapter)

Thank you
LAYOUT
Thank You







