driven data odsc
TRANSCRIPT

Using your powers for good:
Data science in the social sector
www.drivendata.org

PART I: THE SOCIAL SECTOR


WWADSD?
DISASTER RELIEF

WHAT ACTUALLY GETS DONE:
ü COUNTS!!
ü SUMS!!
ü AVERAGES!!
DISASTER RELIEF

THE DATA LITERACY GAP
When it comes to data science, nonprofits don’t know what they don’t know.
• Running and publicizing projects with organizations
• Formal education, resources, and training
• Encouraging data scientists to work in the social sector

THE OPPORTUNITY
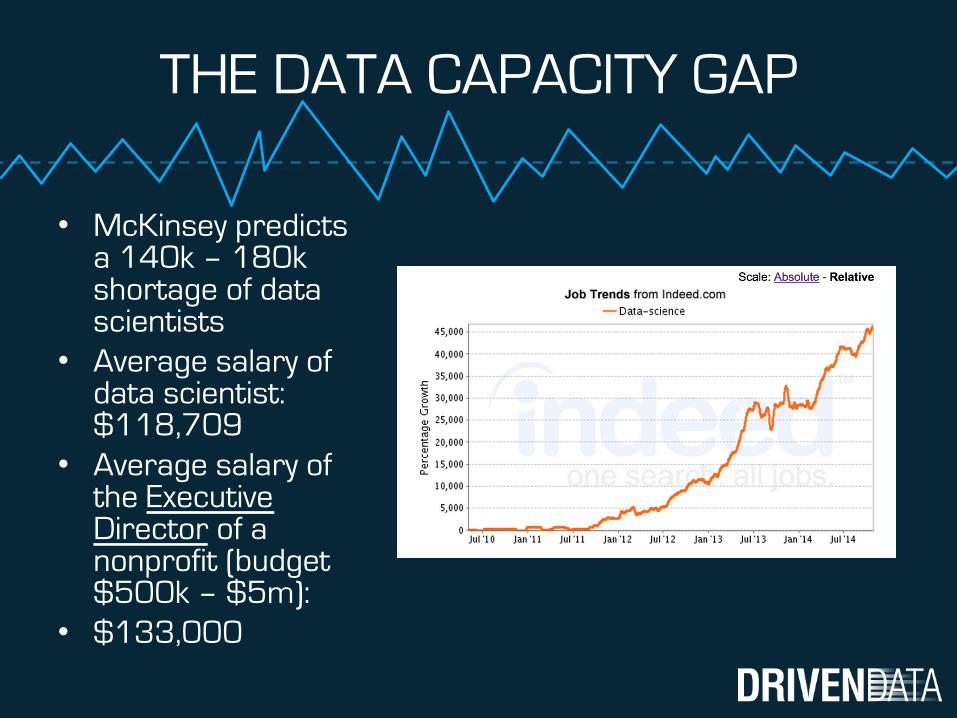
THE DATA CAPACITY GAP
• McKinsey predicts a 140k – 180k shortage of data scientists
• Average salary of data scientist:$118,709
• Average salary of the Executive Director of a nonprofit (budget $500k – $5m):
• $133,000

LITERACY
CAPACITY

“Finding ways to make big data useful to humanitarian decision makers is one of the great challenges and opportunities of the network age.”
-‐ UN Office for the Coordination of Humanitarian Affairs

PART II: CASE STUDY



R
Training set Data shared with contestants to use in generating innovative predictive algorithms
COMPETITION DATASET
T Test set Output data retained to test submissions and automatically rank by predictive accuracy
MEASURING PERFORMANCE
A B C D E F G H
987 xldlk 3.98 sdsd 8.3 9 6.2 32%
987 xldlk 3.98 sdsd 8.3 9 6.2 32%
987 xldlk 3.98 sdsd 8.3 9 6.2 32%
987 xldlk 3.98 sdsd 8.3 9 6.2 32%
987 xldlk 3.98 sdsd 8.3 9 6.2 32%
987 xldlk 3.98 sdsd 8.3 9 6.2 32%
987 xldlk 3.98 sdsd 8.3 9 6.2 32% Competitors submit predictions based on their
statistical algorithms 987 xldlk 3.98 sdsd 8.3 9 6.2 32%
987 xldlk 3.98 sdsd 8.3 9 6.2 32%
987 xldlk 3.98 sdsd 8.3 9 6.2 32%
987 xldlk 3.98 sdsd 8.3 9 6.2 32%
987 xldlk 3.98 sdsd 8.3 9 6.2 32%
987 xldlk 3.98 sdsd 8.3 9 6.2 32%
987 xldlk 3.98 sdsd 8.3 9 6.2 32%
987 xldlk 3.98 sdsd 8.3 9 6.2
987 xldlk 3.98 sdsd 8.3 9 6.2
987 xldlk 3.98 sdsd 8.3 9 6.2
987 xldlk 3.98 sdsd 8.3 9 6.2
987 xldlk 3.98 sdsd 8.3 9 6.2
987 xldlk 3.98 sdsd 8.3 9 6.2
987 xldlk 3.98 sdsd 8.3 9 6.2
31%
32%
29%
30%
27%
32%
31%

Education Resource Strategies
Budget
We are budget-ing our things!
$ Expenditures
Monies for
making students
good
Beware there be dollars here

Lots of Labels! PETRO-VEND FUEL AND FLUIDS
MAINT MATERIALS
SATELLITE COOK
UPPER EARLY INTERVENTION PROGRAM 4-5
Regional Playoff Hosts
Supp.- Materials
ITEMGH EXTENDED DAY
FURNITURE AND FIXTURES
NON-CAPITALIZED AV
Water and Sewage *
Instructional Materials
Food Services - Other Costs
Capital Assets - Locally Defined Groupings
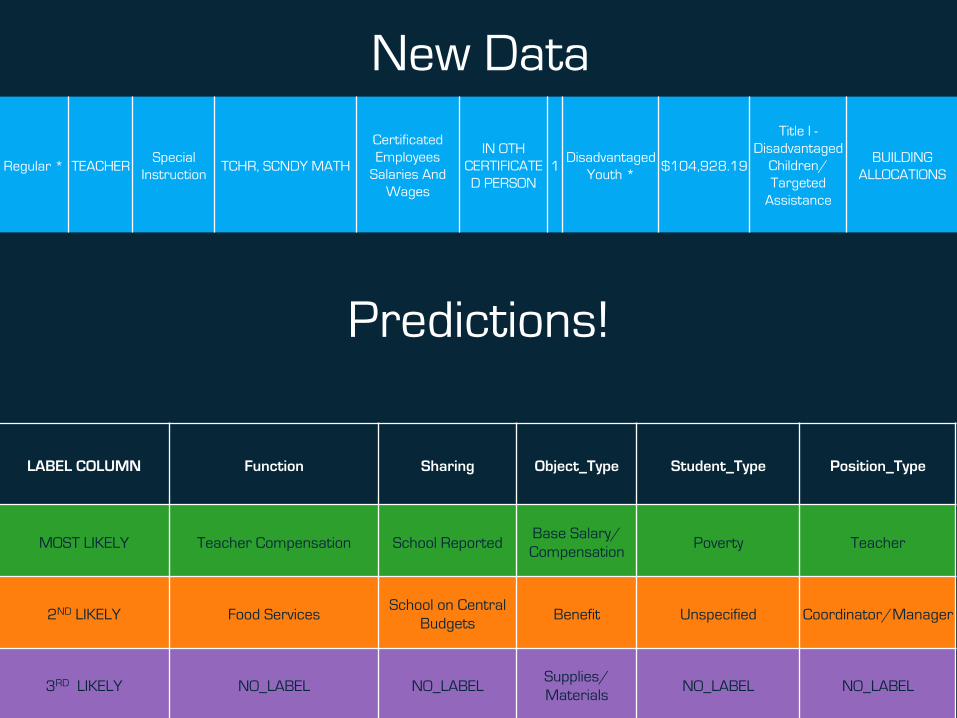
Regular * TEACHER Special
Instruction TCHR, SCNDY MATH
Certificated Employees
Salaries And Wages
IN OTH CERTIFICATED PERSON
1 Disadvantaged
Youth * $104,928.19
Title I - Disadvantaged
Children/Targeted
Assistance
BUILDING ALLOCATIONS
LABEL COLUMN Function Sharing Object_Type Student_Type Position_Type
MOST LIKELY Teacher Compensation School Reported Base Salary/Compensation
Poverty Teacher
2ND LIKELY Food Services School on Central
Budgets Benefit Unspecified Coordinator/Manager
3RD LIKELY NO_LABEL NO_LABEL Supplies/Materials
NO_LABEL NO_LABEL
New Data
Predictions!

Budget
We are budget-ing our things! $
Expenditures Monies for
making students
good
Beware there be dollars here



All about the features!

Text features in scikit-‐learn
from sklearn.feature_extraction.text import CountVectorizer!!vec = CountVectorizer()!!vectorized_data = vec.fit_transform(text_data)!

Processing: Tokenize on Punctuation
PETRO-VEND FUEL AND FLUIDS
PETRO VEND FUEL AND FLUIDS
PETRO-VEND
FUEL AND FLUIDS

Processing: Tokenize on Punctuation
from sklearn.feature_extraction.text import CountVectorizer!!alpha_tokens = lambda text: re.split("[^a-z]", text.lower())!!vec = CountVectorizer(tokenizer=alpha_tokens)!!vectorized_data = vec.fit_transform(text_data)!

Processing: 2-grams and 3-grams
PETRO VEND FUEL AND FLUIDS
1-grams
2-grams
3-grams

from sklearn.feature_extraction.text import CountVectorizer!!alpha_tokens = lambda text: re.split("[^a-z]", text.lower())!!vec = CountVectorizer(tokenizer=alpha_tokens,! ngram_range=(1, 3))!!vectorized_data = vec.fit_transform(text_data)!!!!!!!!!!
Processing: 2-grams and 3-grams

Computational: Hashing Trick
PETRO VEND FUEL AND FLUIDS
2954 9384 4569 1197 8947

Computational: Hashing Trick
from sklearn.feature_extraction.text import HashingVectorizer!!alpha_tokens = lambda text: re.split("[^a-z]", text.lower())!!vec = HashingVectorizer(tokenizer=alpha_tokens,! ngram_range=(1, 3))!!vectorized_data = vec.fit_transform(text_data)!!!!!!!!!!!

Statistical: Pairwise Interaction Terms

from sklearn.feature_extraction.text import HashingVectorizer!from sklearn.preprocessing import PolynomialFeatures!!alpha_tokens = lambda text: re.split("[^a-z]", text.lower())!!vec = HashingVectorizer(tokenizer=alpha_tokens,! ngram_range=(1, 3))!!vectorized_data = vec.fit_transform(text_data)!!prep = PolynomialFeatures(degree=2, !
! ! ! ! ! ! ! interaction_only=True,!! ! ! ! ! ! ! include_bias=False)!
!preprocessed_data = prep.fit_transform(vectorized_data)!!!!
Statistical: Pairwise Interaction Terms

Countable Care: A different kind of dataset

So Many NaNs!


Not Building Features? Build Ensembles.

2nd Place: Stacking

WHAT CAN I DO NOW?


WHAT ELSE CAN I DO?

Questions?
www.drivendata.org @drivendataorg