dynamics, causation, duration in the predicate-argument ... · universit e de gen eve facult e des...
TRANSCRIPT

Universite de Geneve
Faculte des Lettres
Doctoral Dissertation
Dynamics, causation, duration in the
predicate-argument structure of verbs:
A computational approach based on
parallel corpora
Tanja Samardzic
June 25, 2014
Supervisor: Prof. Paola Merlo


Abstract
This dissertation addresses systematic variation in the use of verbs where two syntacti-
cally different sentences are used to express the same event, such as the alternations in
the use of decide, break, and push shown in (0.1-0.3). We study the frequency distribu-
tion of the syntactic alternants showing that the distributional patterns originate in the
meaning of the verbs.
(0.1) a. Mary took/made a decision. b. Mary decided (something).
(0.2) a. Adam broke the laptop. b. The laptop broke.
(0.3) a. John pushed the cart. b. John pushed the cart for some time.
Both intra-linguistic and cross-linguistic variation in morphological and syntactic re-
alisations of semantically equivalent items are taken into account by analysing data
extracted from parallel corpora. The dissertation includes three case studies: light verb
constructions (0.1) in English and German, lexical causatives (0.2) also in English and
German, and verb aspect classes (0.3) in English and Serbian.
The core question regarding light verb constructions is whether the verbs such as take
and make, when used in expressions such as (0.1a), turn into functional words losing
their lexical meaning. Arguments for both a positive and a negative answer have been
put forward in the literature. The results of our study suggest that light verbs keep at
least force-dynamic semantics of their lexical counterparts: the inward dynamics in verbs
such as take and the outward dynamics in verbs such as make. The inward dynamics
results in a cross-linguistic preference for compact grammatical forms (single verbs) and
the outward dynamics results in a preference for analytical forms (constructions).
3

The study on lexical causatives (0.2) addresses the question of why some verbs in some
languages do not alternate while their counterparts in other languages do. The results
of the study suggest that the property which underlies the variation is the likelihood of
external causation. Events described by the alternating verbs are distributed on a scale
of increasing likelihood for an external causer to occur. The verbs which alternate in
some but not in other languages are those verbs which describe events on the two ex-
tremes of the scale. The preference for one alternant is so strong in these verbs that the
other alternant rarely occurs, which is why it is not attested in some languages. There
are two ways in which the likelihood of external causation can be empirically assessed:
a) by observing the typological distribution of causative vs. anticausative morpholog-
ical marking across a wide range of languages and b) by the frequency distribution of
transitive vs. intransitive uses of the alternating verbs in a corpus of a single language.
Our study shows that these two measures are correlated. By applying the corpus-based
measure, the position on the scale of likelihood of external causation can be determined
automatically for a wide range of verbs.
The subject of the third case study is the relationship between two temporal properties
encoded by the grammatical category of verb aspect: event duration and temporal
boundedness. The study shows that these two properties interact in a complex but
predictable way giving rise to the observed variation in morphosyntactic realisations of
verbs. English native speakers’ intuitions about possible duration of events described by
verbs (short vs. long) are predicted from the patterns of formal aspect marking in the
equivalent Serbian verbs. The accuracy of the prediction based on the bi-lingual model
is superior to the best performing monolingual model.
One of the main contributions of the dissertation is a novel experimental methodology,
which relies on automatic processing of parallel corpora and statistical inference. The
three properties of the events described by verbs (dynamics orientation, the likelihood
of external causation, duration) are empirically induced on the basis of the observations
automatically extracted from large parallel corpora (containing up to over a million
sentences per language), which are automatically parsed and word-aligned. The gener-
alisations are learned from the extracted data automatically using statistical inferences
and machine learning techniques. The accuracy of the predictions made on the basis of
the generalisations is assessed experimentally on an independent set of test instances.
4

Resume
Cette these porte sur la variation systematique dans l’usage des verbes ou deux phrases,
differentes par rapport a leurs structures syntactiques, peuvent etre utilisees pour ex-
primer le meme evenement. La variation concernee est montree dans les exemples (0.4-
0.6). Nous etudions la distribution des frequences des alternants syntactiques en mon-
trant que la source des patterns distributionnels est dans le contenu semantique des
verbes.
(0.4) a. MaryMarie
took/madepris/fait
aune
decision.decision
Marie a pris une decision.
b. MaryMarie
decideddecide
(something).(quelque chose)
Marie a decide (quelque chose)
(0.5) a. AdamAdam
brokecasse
thele
laptop.ordinateur
Adam a casse l’ordinateur.
b. Thele
laptopordinateur
broke.casse
L’ordinateur c’est casse.
(0.6) a. JohnJean
pushedpousse
thele
cart.chariot
Jean a pousse le chariot.
5

b. JohnJean
pushedpousse
thele
cartchariot
forpour
somequelque
time.temps
Jean poussait le chariot pendent quelque temps.
La variation intra-linguistique ainsi que la variation a travers des langues concernant
les realisations morphologiques et syntactiques des items semantiquement equivalents
sont prises en compte. Ceci est effectue par une analyse des donnees extraites de corpus
paralleles. La these contient trois etudes de cas: constructions a verbes legers (0.4) en
anglais et allemand, les verbes causatifs lexicaux (0.5), egalement en anglais et allemand,
et les classes d’aspect verbal (0.6) en anglais et serbe.
La question centrale par rapport aux constructions a verbes legers est de savoir si les
verbes comme take et make utilises dans des expressions comme (0.4a) deviennent
des mots fonctionnels perdant donc entierement leur contenu lexical. Des arguments
en faveur des deux reponses, positive et negative, ont ete cites dans la litterature.
Les resultats de notre etude suggerent que les verbes legers maintiennent au moins la
semantique de dynamique de force appartenant au contenu des verbes lexicaux equivalents:
La dynamique orientee vers l’agent de l’evenement (a l’interieur) des verbes comme
take et la dynamique orientee vers d’autres participants dans l’evenement (a l’exterieur)
des verbes comme make. La dynamique orientee vers l’interieur a pour consequence
une preference pour des realisations compactes (des verbes individuelles) a travers des
langues, tandis que la dynamique orientee vers l’exterieur a pour consequence une
preference pour des formes analytiques (des constructions).
L’etude des verbes causatifs lexicaux (0.5) porte sur la variation a travers des langues
concernant la participation de ces verbes dans l’alternance causative: Pourquoi certains
verbes dans certaines langues n’entrent pas dans l’alternance causative tandis que leurs
verbes correspondants dans d’autres langues le font? Les resultats de l’etude suggerent
que la caracteristique semantique qui est a la source de la variation est la probabilite
de la causalite externe de l’evenement decrit par un verbe. Les evenements decrits par
les verbes causatifs lexicaux sont places au long d’une echelle de probabilite croissante
de la causalite externe. Les verbes qui entrent dans l’alternance dans une langue, mais
ne le font pas dans d’autres langues, sont les verbes decrivant des evenements qui se
trouvent aux deux extremites de l’echelle. Ces verbes ont une preference pour l’un
6

des deux alternants si forte que l’autre alternant n’apparaıt que rarement. Ceci est la
raison pour laquelle un de deux alternants n’est pas observe dans certaines langues. Il
y a deux moyens empiriques pour estimer la probabilite de la causalite externe: a) en
observant la distribution typologique des morphemes causatifs vs. anticausatifs dans la
structure des verbes causatifs lexicaux au travers d’un grand nombre des langues et b)
en observant la distribution de frequences des realisations transitives vs. intransitives
des verbes dans un corpus d’une langue individuelle. Notre etude montre que ces deux
mesures sont correlees. En appliquant la mesure basee sur le corpus, la position sur
l’echelle de la causalite externe peut etre determinee automatiquement pour un grand
nombre de verbes.
Le sujet de la troisieme etude de cas est la relation entre les deux caracteristiques tem-
porales des evenements encodees par la categorie grammaticale d’aspect verbale: la
longueur et la delimitation temporelle. L’etude montre que ces deux caracteristiques
interagissent d’une maniere complexe mais previsible, ce qui est a l’origine de la vari-
ation observee dans les realisations morphosyntactiques des verbes. Les intuitions des
locuteurs natifs anglais sur la longueur possible d’un evenement decrit par un verbe
(court vs. long) peuvent etre predites sur la base du marquage formel d’aspect verbal
dans les verbes correspondants serbes. L’exactitude des predictions basees sur le modele
bi-linguistique est superieure a la performance du meilleur modele monolanguistique.
Une parmi les contributions principales de cette these est la nouvelle methodologie
experimentale qui se base sur le traitement automatique des corpus paralleles et sur
l’inference statistique. Les trois caracteristiques semantiques des evenements decrits
par des verbes (la dynamique, la probabilite de la causalite externe, la longueur) sont
inferees empiriquement a partir d’observations extraites automatiquement des grands
corpus paralleles (contenant jusqu’a plus d’un million de phrases pour chaque langue)
automatiquement analyses et alignes. Les generalisations generalisations sont acquises
de donnees de corpus de maniere automatique en utilisant l’inference statistique et les
techniques d’apprentissage automatique. L’exactitude des predictions effectuees sur la
base des generalisations est estimee de maniere experimentale en utilisant un echantillon
separe de donnees de test.
7


Acknowledgements
This dissertation has greatly benefited from the help and support of numerous friends
and colleagues and I wish to express my gratitude to all of them here.
First and foremost, I would like to thank my supervisor, Paola Merlo, for the com-
mitment with which she has supervised this dissertation, for sharing generously her
knowledge and experience in countless hours spent discussing my work and reading my
pages, for treating my ideas with care and attention, and for showing me that I can do
better than I thought I could.
I am most thankful to Vesna Polovina and Jacques Mœschler, who made it possible for
me to move from Belgrade to Geneva and who have discretely looked after me throughout
my studies.
I thank Balthasar Bickel, Jonas Kuhn, and Martha Palmer, who kindly agreed to be
members of the defence committee, and to Jacques Mœschler, who agreed to be the
president of the jury.
I have gathered much of the knowledge and skills necessary for carrying out this research
in the discussions and joint work with Boban Arsenijevic, Effi Georgala, Andrea Ges-
mundo, Kristina Gulordava, Maja Milicevic, Lonneke van der Plas, Marko Simonovic,
and Balsa Stipcevic. I am thankful for the time they spent working and thinking with
me.
I appreciate very much the assistance of James Henderson, Jonas Kuhn, and Gerlof
Bouma, who shared their data with me, allowing me to spend less time processing
corpora, so I could spend more time thinking about the experiments.
9

I am thankful to my colleagues in the Department of General Linguistics in Belgrade,
in the Linguistics Department in Geneva, and in the CLCL research group for their
kindness and support. On various occasions, I felt lucky to be able to talk to Tijana
Asic, Lena Baunaz, Anamaria Bentea, Frederique Berthelot, Giuliano Bocci, Eva Cap-
itao, Maja Djukanovic, Nikhil Garg, Jean-Philippe Goldman, Asheesh Gulati, Tabea
Ihsane, Borko Kovacevic, Joel Lang, Antonio Leoni de Leon, Gabriele Musillo, Goljihan
Kashaeva, Alexis Kauffmann, Christopher Laenzlinger, Jasmina Moskovljevic Popovic,
Luka Nerima, Natalija Panic Cerovski, Genoveva Puskas, Lorenza Russo, Yves Scherrer,
Violeta Seretan, Gabi Soare, Zivka Stojiljkovic, Eric Wehrli, and Richard Zimmermann.
I would also like to thank Pernilla Danielsson, who helped me start doing computa-
tional linguistics while I was a visiting student at the Centre for Corpus Research at the
University of Birmingham.
In the end, I would like to express my gratitude to Fabio, who has stayed by my side
despite all the evenings, weekends, and holidays dedicated to this dissertation.
10

Contents
1. Introduction 21
1.1. Grammatically relevant components of the meaning of verbs . . . . . . . 22
1.2. Natural language processing in linguistic research . . . . . . . . . . . . . 24
1.3. Using parallel corpora to study language variation . . . . . . . . . . . . . 25
1.4. The overview of the dissertation . . . . . . . . . . . . . . . . . . . . . . . 29
2. Overview of the literature 33
2.1. Theoretical approaches to the argument structure . . . . . . . . . . . . . 34
2.1.1. The relational meaning of verbs . . . . . . . . . . . . . . . . . . . 36
2.1.2. Atomic approach to the predicate-argument structure . . . . . . . 38
2.1.3. Decomposing semantic roles into clusters of features . . . . . . . . 42
Proto-roles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
The Theta System . . . . . . . . . . . . . . . . . . . . . . . . . . 45
Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
2.1.4. Decomposing the meaning of verbs into multiple predicates . . . . 49
Aspectual event analysis . . . . . . . . . . . . . . . . . . . . . . . 50
Causal event analysis . . . . . . . . . . . . . . . . . . . . . . . . . 52
2.1.5. Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
2.2. Verb classes and specialised lexicons . . . . . . . . . . . . . . . . . . . . . 54
2.2.1. Syntactic approach to verb classification . . . . . . . . . . . . . . 54
2.2.2. Manually annotated lexical resources . . . . . . . . . . . . . . . . 57
FrameNet . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
The Proposition Bank (PropBank) . . . . . . . . . . . . . . . . . 62
VerbNet . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 64
Comparing the resources . . . . . . . . . . . . . . . . . . . . . . . 67
11

Contents
2.3. Automatic approaches to the predicate-argument structure . . . . . . . . 70
2.3.1. Early analyses . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
2.3.2. Semantic role labelling . . . . . . . . . . . . . . . . . . . . . . . . 73
Standard semantic role labelling . . . . . . . . . . . . . . . . . . . 73
Joint and unsupervised learning . . . . . . . . . . . . . . . . . . . 80
2.3.3. Automatic verb classification . . . . . . . . . . . . . . . . . . . . . 81
2.4. Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85
3. Using parallel corpora for linguistic research — rationale and methodology 87
3.1. Cross-linguistic variation and parallel corpora . . . . . . . . . . . . . . . 88
3.1.1. Instance-level microvariation . . . . . . . . . . . . . . . . . . . . . 89
3.1.2. Translators’ choice vs. structural variation . . . . . . . . . . . . . 92
3.2. Parallel corpora in natural language processing . . . . . . . . . . . . . . . 94
3.2.1. Automatic word alignment . . . . . . . . . . . . . . . . . . . . . . 94
3.2.2. Using automatic word alignment in natural language processing . 98
3.3. Statistical analysis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101
3.3.1. Summary tables . . . . . . . . . . . . . . . . . . . . . . . . . . . . 101
3.3.2. Statistical inference and modelling . . . . . . . . . . . . . . . . . 103
3.3.3. Bayesian modelling . . . . . . . . . . . . . . . . . . . . . . . . . . 108
3.4. Machine learning techniques . . . . . . . . . . . . . . . . . . . . . . . . . 112
3.4.1. Supervised learning . . . . . . . . . . . . . . . . . . . . . . . . . . 113
3.4.2. Unsupervised learning . . . . . . . . . . . . . . . . . . . . . . . . 120
3.4.3. Learning with Bayesian Networks . . . . . . . . . . . . . . . . . . 125
3.4.4. Evaluation of predictions . . . . . . . . . . . . . . . . . . . . . . . 127
3.5. Summary . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 128
4. Force dynamics schemata and cross-linguistic alignment of light verb con-
structions 131
4.1. Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 131
4.2. Theoretical background . . . . . . . . . . . . . . . . . . . . . . . . . . . . 134
4.2.1. Light verb constructions as complex predicates . . . . . . . . . . . 134
4.2.2. The diversity of light verb constructions . . . . . . . . . . . . . . 138
12

Contents
4.3. Experiments . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 141
4.3.1. Experiment 1: manual alignment of light verb constructions in a
parallel corpus . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 144
Materials and methods . . . . . . . . . . . . . . . . . . . . . . . . 145
Results and discussion . . . . . . . . . . . . . . . . . . . . . . . . 148
4.3.2. Experiment 2: Automatic alignment of light verb constructions in
a parallel corpus . . . . . . . . . . . . . . . . . . . . . . . . . . . 150
Materials and methods . . . . . . . . . . . . . . . . . . . . . . . . 150
Results and discussion . . . . . . . . . . . . . . . . . . . . . . . . 152
4.4. General discussion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 159
4.4.1. Two force dynamics schemata in light verbs . . . . . . . . . . . . 159
4.4.2. Relevance of the findings to natural language processing . . . . . 161
4.5. Related work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 162
4.6. Summary of contributions . . . . . . . . . . . . . . . . . . . . . . . . . . 165
5. Likelihood of external causation and the cross-linguistic variation in lexical
causatives 167
5.1. Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 167
5.2. Theoretical accounts of lexical causatives . . . . . . . . . . . . . . . . . . 171
5.2.1. Externally and internally caused events . . . . . . . . . . . . . . . 172
5.2.2. Two or three classes of verb roots? . . . . . . . . . . . . . . . . . 174
5.2.3. The scale of spontaneous occurrence . . . . . . . . . . . . . . . . 176
5.3. Experiments . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 179
5.3.1. Experiment 1: Corpus-based validation of the scale of spontaneous
occurrence . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 181
Materials and methods . . . . . . . . . . . . . . . . . . . . . . . . 182
Results and discussion . . . . . . . . . . . . . . . . . . . . . . . . 185
5.3.2. Experiment 2: Scaling up . . . . . . . . . . . . . . . . . . . . . . 186
Materials and methods . . . . . . . . . . . . . . . . . . . . . . . . 187
Results and discussion . . . . . . . . . . . . . . . . . . . . . . . . 188
5.3.3. Experiment 3: Spontaneity and cross-linguistic variation . . . . . 190
Materials and methods . . . . . . . . . . . . . . . . . . . . . . . . 191
Results and discussion . . . . . . . . . . . . . . . . . . . . . . . . 199
13

Contents
5.3.4. Experiment 4: Learning spontaneity with a probabilistic model . 202
The model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 204
Experimental evaluation . . . . . . . . . . . . . . . . . . . . . . . 206
5.4. General discussion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 211
5.4.1. The scale of external causation and the classes of verbs . . . . . . 212
5.4.2. Cross-linguistic variation in English and German . . . . . . . . . 213
5.4.3. Relevance of the findings to natural language processing . . . . . 214
5.5. Related work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 215
5.6. Summary of contributions . . . . . . . . . . . . . . . . . . . . . . . . . . 218
6. Unlexicalised learning of event duration using parallel corpora 221
6.1. Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 221
6.2. Theoretical background . . . . . . . . . . . . . . . . . . . . . . . . . . . . 226
6.2.1. Aspectual classes of verbs . . . . . . . . . . . . . . . . . . . . . . 226
6.2.2. Observable traits of verb aspect . . . . . . . . . . . . . . . . . . . 231
6.2.3. Aspect encoding in the morphology of Serbian verbs . . . . . . . . 233
6.3. A quantitative representation of aspect based on cross-linguistic data . . 238
6.3.1. Corpus and processing . . . . . . . . . . . . . . . . . . . . . . . . 240
6.3.2. Manual aspect classification in Serbian . . . . . . . . . . . . . . . 243
6.3.3. Morphological attributes . . . . . . . . . . . . . . . . . . . . . . . 244
6.3.4. Numerical values of aspect attributes . . . . . . . . . . . . . . . . 245
6.4. Experiment: Learning event duration with a statistical model . . . . . . 248
6.4.1. The model . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 249
The Bayesian net classifier . . . . . . . . . . . . . . . . . . . . . . 251
6.4.2. Experimental evaluation . . . . . . . . . . . . . . . . . . . . . . . 253
Materials and methods . . . . . . . . . . . . . . . . . . . . . . . . 254
Results and discussion . . . . . . . . . . . . . . . . . . . . . . . . 259
6.5. General discussion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 260
6.5.1. Aspectual classes . . . . . . . . . . . . . . . . . . . . . . . . . . . 260
6.5.2. Relevance of the findings to natural language processing . . . . . 261
6.6. Related work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 262
6.7. Summary of contributions . . . . . . . . . . . . . . . . . . . . . . . . . . 264
14

Contents
7. Conclusion 265
7.1. Theoretical contribution . . . . . . . . . . . . . . . . . . . . . . . . . . . 267
7.2. Methodological contribution . . . . . . . . . . . . . . . . . . . . . . . . . 269
7.3. Directions for future work . . . . . . . . . . . . . . . . . . . . . . . . . . 270
Bibliography 273
A. Light verb constructions data 293
A.1. Word alignment of the constructions with ’take’ . . . . . . . . . . . . . . 293
A.2. Word alignment of the constructions with ’make’ . . . . . . . . . . . . . 297
A.3. Word alignments of regular constructions . . . . . . . . . . . . . . . . . . 301
B. Corpus counts and measures for lexical causatives 305
C. Verb aspect and event duration data 317
15


List of Figures
1.1. Cross-linguistic mapping between morphosyntactic categories. . . . . . . 26
1.2. Cross-linguistic mapping between morphosyntactic categories. . . . . . . 28
3.1. Word alignment in a parallel corpus . . . . . . . . . . . . . . . . . . . . . 95
3.2. Probability distributions of the morphological forms and syntactic reali-
sations of the example instances. . . . . . . . . . . . . . . . . . . . . . . 105
3.3. Probability distributions of the example verbs and their frequency. . . . . 106
3.4. A general graphical representation of the normal distribution. . . . . . . 107
3.5. An example of a decision tree . . . . . . . . . . . . . . . . . . . . . . . . 116
3.6. An example of a Bayesian network . . . . . . . . . . . . . . . . . . . . . 126
4.1. A schematic representation of the structure of a light verb construction
compared with a typical verb phrase . . . . . . . . . . . . . . . . . . . . 132
4.2. Constructions with vague action verbs . . . . . . . . . . . . . . . . . . . 143
4.3. True light verb constructions . . . . . . . . . . . . . . . . . . . . . . . . . 144
4.4. Extracting verb-noun combinations . . . . . . . . . . . . . . . . . . . . . 146
4.5. The difference in automatic alignment depending on the direction. . . . . 152
4.6. The distribution of nominal complements in constructions with take . . . 155
4.7. The distribution of nominal complements in constructions with make . . 155
4.8. The distribution of nominal complements in regular constructions . . . . 156
4.9. The difference in automatic alignment depending on the complement fre-
quency . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 157
5.1. The correlation between the rankings of verbs on the scale of spontaneous
occurrence . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 185
5.2. Density distribution of the Sp value in the two samples of verbs . . . . . 188
17

List of Figures
5.3. Collecting data on lexical causatives . . . . . . . . . . . . . . . . . . . . . 193
5.4. Density distribution of the Sp value over instances of 354 verbs . . . . . . 198
5.5. Joint distribution of verb instances in the parallel corpus . . . . . . . . . 201
5.6. Bayesian net model for learning spontaneity. . . . . . . . . . . . . . . . . 204
5.7. The Interaction of the factors involved in the causative alternation . . . . 211
6.1. Traditional lexical verb aspect classes, known as Vendler’s classes . . . . 227
6.2. Serbian verb structure summary . . . . . . . . . . . . . . . . . . . . . . . 237
6.3. Bayesian net model for learning event duration . . . . . . . . . . . . . . . 251
18

List of Tables
2.1. Frame elements for the verb achieve . . . . . . . . . . . . . . . . . . . . . 61
2.2. Some combinations of frame elements for the verb achieve. . . . . . . . . 62
2.3. The PropBank lexicon entry for the verb pay. . . . . . . . . . . . . . . . 65
2.4. The VerbNet entry for the class Approve-77. . . . . . . . . . . . . . . . . 66
3.1. Examples of instance variables . . . . . . . . . . . . . . . . . . . . . . . . 102
3.2. Examples of type variables . . . . . . . . . . . . . . . . . . . . . . . . . . 102
3.3. A simple contingency table summarising the instance variables . . . . . . 102
3.4. An example of data summary in Bayesian modelling . . . . . . . . . . . . 109
3.5. An example of a data record suitable for supervised machine learning . . 114
3.6. Grouping values for training a decision tree . . . . . . . . . . . . . . . . . 118
3.7. An example of a data record suitable for supervised machine learning . . 120
3.8. An example of probability estimation using the expectation-maximisation
algorithm . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 122
3.9. Precision and recall matrix . . . . . . . . . . . . . . . . . . . . . . . . . . 127
4.1. Types of mapping between English constructions and their translation
equivalents in German. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 148
4.2. Well-aligned instances of light verb constructions . . . . . . . . . . . . . 153
4.3. The three types of constructions partitioned by the frequency of the com-
plements in the sample. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 154
4.4. Counts and percentages of well-aligned instances in relation with the fre-
quency of the complements in the sample . . . . . . . . . . . . . . . . . . 158
5.1. Cross-linguistic variation in lexical causatives . . . . . . . . . . . . . . . 169
5.2. Morphological marking of cause-unspecified verbs . . . . . . . . . . . . . 175
19

List of Tables
5.3. Morphological marking across languages . . . . . . . . . . . . . . . . . . 177
5.4. An example of an extracted instance of an English alternating verb and
its translation to German . . . . . . . . . . . . . . . . . . . . . . . . . . 195
5.5. Examples of parallel instances of lexical causatives. . . . . . . . . . . . . 196
5.6. Contingency tables for the English and German forms in different samples
of parallel instances. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 200
5.7. Examples of the cross-linguistic input data . . . . . . . . . . . . . . . . . 207
5.8. Agreement between corpus-based and typology-based classification of verbs.
The classes are denoted in the following way: a=anticausative (interanally
caused), c=causative (externally caused) , m=cause-unspecified. . . . . . 208
5.9. Confusion matrix for monolingual and cross-linguistic classification on 2
classes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 210
5.10. Confusion matrix for monolingual and cross-linguistic classification on 3
classes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 210
6.1. A relationship between English verb tenses and aspectual classes. . . . . 231
6.2. Serbian lexical derivations . . . . . . . . . . . . . . . . . . . . . . . . . . 234
6.3. Serbian lexical derivations with a bare perfective . . . . . . . . . . . . . . 237
6.4. An illustration of the MULTEX-East corpus . . . . . . . . . . . . . . . . 241
6.5. A sample of the verb aspect data set. . . . . . . . . . . . . . . . . . . . . 248
6.6. A sample of the two versions of data . . . . . . . . . . . . . . . . . . . . 256
6.7. Results of machine learning experiments . . . . . . . . . . . . . . . . . . 258
20

1. Introduction
Languages use different means to express the same content. Variation in the choice of
lexical items or syntactic constructions is possible without changing the meaning of a
sentence. For example, any of the sentences in (1.1a-c) can be used to express the same
event. Similarly, the meaning of the sentences in (1.2a-b), (1.3a-b), and (1.4a-b) can
be considered as equivalent. The sentences in (1.1) illustrate the variation in the choice
of lexical items, while the sentences in (1.2-1.4) show that the syntactic structure of a
sentence can be changed without changing the meaning. In both cases, the variation
is limited to the options which are provided by the rules of grammar. In order to be
exchangeable, linguistic units have to share certain properties. Identifying the properties
shared by different formal expressions of semantically equivalent units is, thus, a way of
identifying abstract elements of the structure of language.
(1.1) a. Mary drank a cup of tea.
b. Mary took a cup of tea.
c. Mary had a cup of tea.
d. Mary had a cup of coffee.
As illustrated in (1.1d), verbs allow alternative expressions more easily than other cat-
egories. Replacing the noun tea, for example, by coffee changes the meaning of the
sentence so that (1.1d) can no longer be considered as equivalent with (1.1a-c). The
property which allows verbs to alternate more easily than other categories is their re-
lational meaning. In the given examples, the verbs drink, take, and have relate the
nouns Mary and tea. The relational meaning of a verb is commonly represented as the
predicate-argument structure, where a verb is considered as a predicate which takes other
21

1. Introduction
constituents of a sentence as its arguments. The number and the type of the arguments
that a verb takes in a particular instance is partially determined by the verb’s meaning
and partially by the contextual and pragmatic factors involved in the instance.
(1.2) a. Mary laughed.
b. Mary had a laugh.
(1.3) a. Adam broke the laptop.
b. The laptop broke.
(1.4) a. John pushed the cart.
b. John pushed the cart for some time.
In this dissertation, we study systematic variation in the use of verbs involving alterna-
tion in the syntactic structure, as in (1.2-1.4). We study frequency distributions of the
syntactic alternants as an observable indicator of the underlying meaning of verbs with
the aim of discovering the components of verbs’ meaning which are relevant for their
predicate-argument structure and for the grammar of language.
1.1. Grammatically relevant components of the meaning
of verbs
As argued by Pesetsky (1995) and later by Levin and Rappaport Hovav (2005), only some
of the potential components of the meaning of verbs are grammatically relevant. For
example, the distinction between verbs describing loud speaking (e.g. shout) and verbs
describing quiet speaking (e.g. whisper) is grammatically irrelevant in the sense that it
does not influence any particular syntactic behaviour of these verbs (Pesetsky 1995).
Contrary to this, the distinction between verbs which describe primarily the manner of
speaking (whisper) and verbs which describe primarily the content of speaking (e.g. say)
is grammatically relevant in the sense that the latter group of verbs can be used without
the complementizer that, while the former cannot. Along the same lines, Levin and
22

1.1. Grammatically relevant components of the meaning of verbs
Rappaport Hovav (2005) argue that the quality of sound described by verbs of sound
emission — volume, pitch, resonance, duration — does not influence their syntactic
behaviour. Syntactic behaviour of these verbs is, in fact, influenced by the source of the
sound: verbs which describe sound emission with the source of the sound external to the
emitting object (e.g. rattle) can alternate between transitive and intransitive uses (in a
similar fashion as break in (1.3)), while verbs which describe sound emission with the
source of the sound internal to the emitting object (e.g. rumble) do not alternate.
Our research continues in the same direction investigating other semantic properties of
verbs which are potentially relevant for the grammar. We take into consideration a
wide range of verbs and their syntactic realisations. If a particular observed distribution
of syntactic alternants can be predicted from a semantic poperty of a verb, then we
can say that this property underlies the distribution. If a semantic property undrlies a
frequency distribution of syntactic alternants, then this property can be considered as
grammaticaly relevant.
We focus on three kinds of alternations in realisation of verbs’ arguments. First, by
studying the alternation between light verb constructions (1.2b) and the corresponding
single verbs (1.2a), we address the issue of whether certain lexical content, in the form of
the predicate-argument structure, is present in the verbs which are used as light verbs,
such as have in (1.2b). Determining whether some components of meaning are present
in light verbs is important for understanding whether the choice of the light verb in
a construction is arbitrary or it is constrained by the meaning of light verbs. Second,
we study the alternation in the use of lexical causatives such as break in (1.3). Lexical
causatives are the verbs which can be used in two ways: as causative (1.3a), where the
agent or the causer of the event described by the verb is realised as a constituent of a
sentence, and as anticausative (1.3b), where the agent or the causer is not syntactically
realised. Many verbs across many different languages can alternate in this way. However,
the fact that some verbs in some languages do not alternate raises the question which
is addressed in this dissertation: What property of verbs is responsible for allowing or
blocking the alternation? Finally, we study the factors involved in the interpretation of
temporal properties of events described by verbs. As illustrated in (1.4), the temporal
properties of events described by verbs play a role in syntactic structuring of a sentence.
For example, the event of pushing is interpreted as short by default (1.4a). With the
23

1. Introduction
appropriate temporal modifier, as in (1.4b), it can also be interpreted as lasting for a
longer time. In contrast to this, other verbs, such as tick, stay, walk, describe events
which are understood as lasting for some time by default. We look for observable indica-
tors in the use of a wide range of verbs pointing to the event duration which is implicit
to their meaning.
1.2. Natural language processing in linguistic research
The approach that we take in addressing the defined questions is empirical and com-
putational. We take advantage of automatic language processing to collect and analyse
large data sets, applying established statistical approaches to infer elements of linguistic
structure from the patterns in the observed variation. The tools, methods, and re-
sources which we use are originally developed for practical natural language processing
tasks which fall within the domain of computational linguistics. The developments in au-
tomatic language processing are directly related to the increasing demand for automatic
analysis of large amounts of linguistic contents which are now freely available (mostly
through the Internet). Natural language processing tasks include automatic informa-
tion extraction, question answering, translation etc. Despite the fact that it provides
extremely rich resources for empirical linguistic investigations, natural language pro-
cessing technology has rarely been used for theoretical linguistic research. On the other
hand, linguistic representations that are used in developing language technology rarely
reflect the current state-of-the-art in linguistic theory. Our research should contribute
to bridging the gap between theoretical and computational linguistics by addressing
current theoretical discussion with a computational methodology.
The work in this dissertation draws on the work in natural language processing in two
ways. First, we use automatic processing tools to extract the information from large
language corpora. For example, to identify syntactic forms of the realisations of verbs, we
use automatically parsed corpora. The information provided by the parses is then used to
extract automatically the instances which are relevant for a particular question. Second,
we use natural language processing methodology to analyse the extracted instances. This
methodology involves three main components: a) the generalisations in the observations
24

1.3. Using parallel corpora to study language variation
are captured by designing statistical models; b) the parameters of the models are learnt
automatically from the extracted data applying machine learning techniques; c) the
predictions of the models are tested on an independent set of data, quantifying and
measuring the performance. Adopting this methodology for our research allows us not
only to study language use in a valid experimental framework, but also to discover
generalisations which can be integrated into further development of natural language
processing more easily than the generalisations based on linguistic introspection.
1.3. Using parallel corpora to study language variation
Our approach to the relationship between the variation in language use and the structure
of language takes into account both language-internal and cross-linguistic variation. This
is achieved by extracting verb instances from parallel corpora. By studying the variation
in the use of verbs in parallel corpora, we combine and extend two main approaches to
language variation: the corpus-based approach to language-internal variation and the
theoretical approach to cross-linguistic variation.
Corpus-based studies of linguistic variation have been mostly monolingual, following the
use of linguistic units either over a period of time or across different language registers.
Extending the corpus-based approach to parallel corpora allows a better insight into
structural linguistic elements, setting them apart from other potential factors of varia-
tion. Consider, for example, the alternations in (1.2-1.4). An occurrence of one or the
other syntactic alternant in a monolingual corpus depends partially on the predicate-
argument structure of the verbs and partially on the contextual and pragmatic factors.
However, if we can observe actual translations of the sentences, then we can observe at
least two uses of semantically equivalent units in the same contextual and pragmatic
conditions, since these conditions are constant in translation. In this way, we control
for contextual and pragmatic factors while potentially observing the variation due to
structural factors.
Unlike language-internal variation, which has become the subject of research relatively
recently, with the development of corpus-based approaches, cross-linguistic variation is
25

1. Introduction
traditionally one of the core issues in theoretical linguistics. Differences in the expres-
sions of the same contents across languages have always been analysed with the aim of
discovering universally invariable elements of the structure of language which constrain
the variation. Consider, for example, the English sentence in (1.5a) and its corresponding
German, Serbian, and French sentences in (1.5b-d).
(1.5) a. Mary has just sent the letter. (English)
b. Maria hat gerade eben den Brief geschickt. (German)
c. Marija je upravo poslala pismo. (Serbian)
d. Marie vein d’envoyer la lettre. (French)
English German Serbian French
presentperfect
adverb+perfect
prefixvenir+infinitive
Figure 1.1.: Cross-linguistic mapping between morphosyntactic categories.
All the four sentences describe a short completed action that happened immediately
before the time in which the sentence is uttered, but the meaning of shortness, com-
pleteness, and time (immediate precedence) is expressed in different ways in the four
languages. In English, this meaning is encoded with a verb tense, present perfect.
German uses more general perfect tense, and the immediate precedence component is
encoded in the adverbs (gerade eben). French, on the other hand, does not use any
particular verb conjugation to express this meaning, but rather a construction which
consists of a semantically impoverished verb (venir ’come’) and the main verb (envoyer
’send’) in the neutral, infinitive form. The corresponding Serbian expression is formed
in yet another different way: through lexical derivation. The verb poslati used in (1.5c)
is derived from the verb slati, which does not encode any specific temporal properties,
by adding the prefix po-. Figure 1.1 summarises the identified grammatical mappings
across languages. Note also that, unlike the sentences in other languages, the French
sentence does not contain a temporal adverb. The meaning of immediate precedence
26

1.3. Using parallel corpora to study language variation
is already encoded as part of the meaning of the constructions formed with the verb
’venir’.
These examples illustrate systematic variation across languages, and not just incidental
differences between these particular sentences. If we replace the constituents of the
sentences with some other members of their paradigms, we will observe the same patterns
of variation. For instance, we can replace the phrase send the letter in the English
sentence and its lexical counterparts in German, Serbian, and French by some other
phrases, such as open the window, read the message, arrive to the meeting and so on.
The choice of the corresponding morphosyntactic categories can be expected to stay
the same. The regular patterns in cross-linguistic variation are due to the fact that
sentences are composed of the same abstract units. As mentioned before, all the four
sentences in (1.5) express the same event, with the same temporal properties (shortness,
completeness, immediate precedence). The fact that they influence (morpho)syntactic
realisations of verbs makes these properties grammatically relevant. The fact that they
are equally interpreted across languages, despite the differences in the morphosyntactic
realisations, makes them candidates for universal elements of the structure of language.
Theoretical approaches to cross-linguistic variation are concerned with identifying not
only the elements of linguistic structure which are invariable across languages, but also
the parameters of variation and their possible settings. With these two elements one
could then construct a general representation of language capacity shared by all speakers
of all languages. In this system, the grammar of any particular language instantiates the
general grammar by setting the parameters to a certain value. For example, temporal
properties of events in our example, which are invariable across languages, can be en-
coded in a syntactic construction (French), in the morphology (English), or in the lexical
derivation (Serbian). Ideally, the number of possible values for a parameter should be
small.
However, identifying the parameters of cross-linguistic variation and their possible set-
tings is far from being a trivial task. Even though there are some regular patterns of
cross-linguistic mapping, as we saw earlier, it is hard to define general rules which apply
to all instances of a given category, independently of a given context. In fact, when we
take a closer look, finding regularities in cross-linguistic variation turns out to be a very
27

1. Introduction
difficult task for which no common methodology has been proposed. To illustrate the
difficulties, we will look again at the example of English present perfect tense, for which
we have defined cross-linguistic mappings shown in Figure 1.1. As we can see in (1.6),
the mappings in Figure 1.1 do not hold for all the instances of English present perfect
tense. A different use of this tense in English brings to rather different mappings.
(1.6) a. Mary still has not seen the film. (English)
b. Maria hat noch immer nicth den Film gesehen. (German)
c. Marija jos nije gledala film. (Serbian)
d. Marie n’a pas encore vu le film. (French)
English German Serbian French
presentperfect
perfectbareform
passecompose
Figure 1.2.: Cross-linguistic mapping between morphosyntactic categories.
Figure 1.2 summarises the mappings between the sentences in (1.6). We can see that,
iinstead of the construction with the verb venir, the corresponding French form n this
case is a verb tense (passe compose). The corresponding Serbian verb in this context is
neither prefixed nor perfective. This means that the English present perfect tense has
multiple cross-linguistic mappings even in this small sample of only two other languages
(the German form can be considered invariable in this case). Other uses might be
mapped in yet different ways. For instance, there can be a use which maps to French
as in Figure 1.2, and to Serbian as in Figure 1.1. If we take into account all the other
languages and all possible uses of present perfect tense in English, the number of possible
cross-linguistic mappings of this single morphological category is likely to become very
big. We can expect to encounter the same situation with all the other categories and
their combinations. This creates a very large space of possible cross-linguistic mappings,
which is hard to explore and to account for in an exhaustive fashion.
28

1.4. The overview of the dissertation
Extracting verb instances from parallel corpora allows us to observe directly a wide range
of cross-linguistic mappings of the target morphosyntactic categories at the instance
level, taking into account contextual factors. With a large number of instances analysed
using computational and statistical methods, we can take a new perspective on the
cross-linguistic variation. Zooming out to analyse general tendencies in the data, rather
than individual cases, we can identify patterns signalling potential constraints on the
variation. Even though this approach is not exhaustive, it is systematic in the sense
that it allows us to observe patterns in cross-linguistic variation in large samples and
to use statistical inference to formulate generalisations which hold beyond the observed
samples.
1.4. The overview of the dissertation
The dissertation consists of seven chapters. In addition to Introduction and Conclusion,
there are five central chapters which are divided between two main parts. The first
part (Chapters 2 and 3) presents the conceptual and technical background of our work,
the rationale for our methodological choices, as well as a detailed description of general
methods used in our experiments. The second part (Chapters 4, 5, and 6) contains three
case studies in which our experimental methodology is used to address three specific
theoretical questions.
In Chapter 2, we discuss the issues in the predicate-argument structure of verbs from
two points of view: theoretical and computational. The theoretical track follows the
development in the view of the predicate argument structure from the first proposals
which divide the grammatical and the idiosyncratic components of the lexical structure
of verbs to the current view of verbs as composed of multiple predicates, which is adopted
in our research. We review theoretical arguments for abandoning the initial “atomic”
view of the predicate-argument structure, as well as some proposals for its systematic
decomposition into smaller components. We then proceed by reviewing the work on
extensive verb classification, which relates the grammatical and the idiosyncratic layer of
the lexical structure of verbs. We discuss the principles of semantic classification of verbs
on the basis of their syntactic behaviour, as well as practical implementations of verb
29

1. Introduction
classification principles in developing extensive language resources. Finally, we review
approaches to automatic acquisition of verb classification and the predicate-argument
structure, discussing the representations and methods used for these tasks.
Chapter 3 deals with the methodology of using parallel corpora for linguistic research.
Since parallel corpora are not commonly used as a source of data for linguistic research,
we first present our rationale for this choice, discussing its advantages, but also its
limitations. We then give an overview of natural language processing approaches based
on parallel corpora and the contributions of this line of research. The second part of the
chapter deals with the technical and practical issues in using natural language processing
methodology for linguistic research. We first describe steps in processing parallel corpora
for extracting linguistic data, in particular, automatic word alignment, which is crucial
for our approach. We then turn to the methods used for analysing the extracted data
providing the technical background necessary to follow the discussion in the three case
studies. The background includes an introduction to statistical inference and modelling
in general, as well as to Bayesian modelling in particular, which is followed by an overview
of four standard machine learning classification techniques which are used or referred
to in our case studies: naıve Bayes, decision tree, Bayesian net, and the expectation-
maximisation algorithm.
The first case study, on light verb constructions, is presented in Chapter 4. We first
give an overview of the theoretical background and the questions raised by light verb
constructions. We introduce two classes of light verb constructions discussed in the liter-
ature, true light verb constructions and constructions with vague action verbs. We then
introduce our proposed classification which is based on verb types. We argue that light
verb constructions headed by light take behave like true light verb constructions, while
the constructions headed by light make behave like the constructions with vague action
verbs. We relate this behaviour to the force dynamics representation of the predicate-
argument structure of these verbs. We then present two experiments in which we test
two hypotheses about the relationship between the force dynamics in the meaning of the
verbs and the cross-linguistic frequency distribution of the alternating morhosyntactic
forms.
The case study on the causative alternation is presented in Chapter 5. We start by
30

1.4. The overview of the dissertation
reviewing the proposed generalisations addressing the meaning of the verbs which par-
ticipate in the causative alternation. In particular, we address the notions of change of
state, external vs. internal causation, and cross-linguistic variation in the availability of
the alternation. We then introduce the discussion on the number of classes into which
verbs should be classified with respect to these notions. Two proposal have been put
forward in the literature: a) a two-way distinction between alternating and not alter-
nating verbs, where alternating verbs are characterised as describing externally caused
events, while the verbs which do not alternate describe internally caused events; b) a
three-way classification involving a third class of verbs situated between the two previ-
ously proposed classes. We then discuss the distribution of the morphological marking
on alternating verbs across languages as a potential indicator of the grammatically rel-
evant meaning of the alternating verbs. This leads us to introducing the notion of the
likelihood of external causation. The experimental part of this study consists of four
steps. In the first step, we validate a corpus based measure of the likelihood of external
causation showing that it correlates with the typological distribution of the morphologi-
cal marking. In the second step, we show that the corpus based measure can be extended
to a large sample of verbs. In the third step, we extract the instances of the large sam-
ple of verbs from a parallel corpus and test the influence of the likelihood of external
causation on the cross-linguistic distribution of their morphosyntactic realisations. In
the fourth step, we address the issue of classifying the alternating verbs by designing a
statistical model which takes as input cross-linguistic realisations of verbs and outputs
their semantic classification. We test the model in two modes, on the two-way and on
the three-way classification.
The last case study, presented in Chapter 6, deals with the representation of grammati-
cally relevant temporal properties of events described by a wide range of verbs. We start
by introducing verb aspect as a grammatical category usually thought to encode tempo-
ral meaning. More specifically, we discuss two notions related to verb aspect: temporal
boundedness and event duration. We then discuss Serbian verb derivations associated
with verb aspect as a potential observable indicator of these two temporal properties
of events described by verbs. We proceed by proposing a quantitative representation of
Serbian verb aspect based on cross-linguistic realisations of verbs extracted from par-
allel corpora. We then design a Bayesian model which predicts the duration (short vs.
31

1. Introduction
long) of events taking this representation as input. We test the performance of the
model against English native speakers’ judgments of the duration of events described by
English verbs. We compare our results to the results of models based on monolingual
English input.
In Chapter 7, we draw some general conclusions, pointing to the limitations of the
current approach as well as to some directions for future research.
32

2. Overview of the literature
The conceptual and methodological framework of the experiments presented in this dis-
sertation encompasses three partially interrelated lines of research: theoretical accounts
of the grammatically relevant meaning of verbs, its extensive descriptions in specialised
lexicons, and its automatic acquisition from language corpora.
Theoretical accounts of the meaning of verbs are crucial for defining the hypotheses
which are tested in our experiments. Our hypotheses are formulated in the context and
framework of recent developments in theoretical accounts of lexical representation of
verbs. While using the tools and the methodology developed in computational linguis-
tics, our main goal is not to develop a new tool or resource, but to extend the general
knowledge about what kinds of meaning are actually part of the lexical representation
of verbs and how they are related to the grammar. Our work is related to the work
on constructing comprehensive specialised lexicons of verbs because we work with large
sets of verbs assigning specific lexical and grammatical properties to each verb in each
sample. Finally, we follow the work on automatic acquisition of the meaning of verbs
in that we learn the elements of their lexical representation automatically from the ob-
served distributions of their realisations in a corpus. This aspect distinguishes our work
from theoretical approaches, as well as from the work on developing specialised lexicons,
which are based on linguistic introspection rather than on empirical observations.
This chapter contains an overview of the existing research in all three domains. In Sec-
tion 2.1, we follow the developments in theoretical approaches to the meaning of verbs.
We start by introducing the notion of predicate-argument structure of verbs, discussing
its role in the grammar of language, as well as in linguistic theory (2.1.1). We proceed by
reviewing proposed theoretical accounts which represent general views of the predicate-
argument structure in the literature, discussing at length crucial turning points in the
33

2. Overview of the literature
theoretical development leading to the temporal and causal decomposition of the mean-
ing of verbs which is adopted in our experiments. In Section 2.2, we discuss the principles
of large-scale implementations of some views of the predicate-argument structure. We
summarise the main ideas behind the syntactic behavioural approach to the meaning
of verbs (2.2.1), which is followed by descriptions of three lexical resources which con-
tain thousands of verbs with explicit analyses of their predicate-argument structure. In
Section 2.3, we discuss approaches to automatic acquisition of the predicate-argument
structure from language corpora which rely on the described lexical resources conceptu-
ally (they adopt the principles of syntactic approach to verb meaning) and practically
(they use the resources for training and testing systems for automatic acquisition).
2.1. Theoretical approaches to the argument structure
It is generally assumed in linguistic theory that the structure of a sentence depends,
to a certain degree, on the meaning of its main verb. Some verbs, such as see in
(2.1) require a subject and an object; others, such as laugh in (2.2), form grammatical
sentences expressing only the subject; others, such as tell in (2.3) require expressing
three constituents. (Clauses with more than three principal constituents are rare.) The
assumption concerning these observations is that the association of certain verbs with a
certain number and kind of constituents is not due to chance, but that it is part of the
grammar of language.
(2.1) [Mary]subject
saw [a friend].object
(2.2) [Mary]subject
laughed.
(2.3) [Mary]subject
told [her friend]indirect-object
[a story].object
34

2.1. Theoretical approaches to the argument structure
Although the relation between the meaning of verbs and the available syntactic patterns
seems obvious, defining precise rules to derive a phrase structure from the lexical struc-
ture of a verb proves to be a difficult task. The task, known in the the linguistic literature
as the linking problem, is one of the central concerns of the theory of language (Baker
1997). The main difficulty in linking the meaning of verbs and the form of the phrases
that they head is in analysing verbs’ meaning so that the components responsible for
the syntactic forms of the phrases are identified.
There are many different ways in which the meaning of verbs can be analysed and it is
hard to see what kind of analysis is relevant for the grammar. Consider, for example,
basic dictionary definitions of the verbs used in (2.1-2.3) given in (2.4).
(2.4)
see to notice people and things with your eyes
laugh to smile while making sounds with your voice that
show you are happy or think something is funny
tell to say something to someone, usually giving them
information
Cambridge Dictionaries Online
http://dictionary.cambridge.org/
In the definitions above, the meaning of the verbs is analysed into smaller components.
They state, for example, that seeing involves eyes, things, and people, that laughing
involves sounds, showing that you are happy, and something funny, and that telling
involves something, someone, and giving information. The units which are identified as
components of the verbs’ meaning are very different in nature: some are nouns with
specific meaning, some are pronouns with very general meaning, some are complex
phrases.
In theoretical approaches to the meaning of verbs, like in lexicography, the analysis re-
sults in identifying smaller, more primitive notions of which the meaning is composed.
Unlike lexicographic analysis, however, theoretical analysis aims at defining and organ-
ising these notions having in mind the language system as a whole, and not only the
meaning of each verb separately. This implies establishing general components which
apply across lexical items and which play a role in the rules of grammar.
35

2. Overview of the literature
2.1.1. The relational meaning of verbs
The most important general distinction made in the theory of lexical structure of verbs
is the one between the relational meaning and the idiosyncratic lexical content. In the
definition of the verb see given in (2.4), for example, things and people belong to the
relational structure, while eyes belong to the idiosyncratic content. In the case of the
verb laugh, all the components listed in the definition are idiosyncratic. The verb tell
has two relational components (something, someone).
The relational meaning expresses the fact that the verb relates its subject with another
entity or with a property. In this sense, verbs are analysed as logical predicates which can
take one, two, three, or more arguments. This part of their lexical structure is usually
called the predicate-argument structure. It is seen as an abstract component of meaning
present in all verbs. There are only a few possible predicate-argument structures, so that
they are typically shared by many verbs, while the idiosyncratic content characterises
each individual verb.
The predicate-argument structure is the part of the lexical representation of verbs which
determines the basic shape of clauses. In a simplified scenario, a verbal predicate which
takes two arguments forms a clause with two principal constituents, as in (2.1) and in
(2.5a). One argument in the lexical structure of a verb results in intransitive clauses
(2.2 and 2.5b) and so on. Formally, the transfer of the information from the lexicon
to syntax is handled by more general mechanisms, by projection in earlier accounts
(Chomsky 1970; Jackendoff 1977; Chomsky 1986) and feature checking in newer
proposals (Chomsky 1995; Radford 2004).
In the accounts that are based on the notion of projection, lexical items project their
relational properties into syntax by forming a specific formal structure which can then be
combined only with the structures with which it is compatible. So, for instance, a two-
argument verb will form a structure with empty positions intended for its subject and
object. In principle, these positions can only be filled by nominal structures, while other
verbal, adjectival, or adverbial structures will not be compatible with these positions.
In the feature checking account, lexical items do not form any specific structures, but
they carry their properties as features, which, by a general rule, need to match between
36

2.1. Theoretical approaches to the argument structure
the items which are to be combined in a phrase structure. For instance, the list of
features of a two-argument verb will contain one feature requiring a subject and one
requiring an object. A verb with these features can be combined only with items which
have the matching features, that is with nominal items which bear the same features.
Characterisation of possible semantic arguments of verbs depends on the theoretical
framework adopted for an analysis, but all approaches make distinctions between at
least several kinds of arguments. The kind of meaning expressed by a verb’s argument
is usually called a semantic role. Two traditional semantic roles, agent and theme are
illustrated in (2.5).
(2.5) a. [Mary]subject/agent
stopped [the car].object/theme
b. [The car]subject/theme
stopped.
There is a certain alignment between semantic roles and syntactic functions. Agents,
for instance, tend to be realised as subjects across languages, while themes are usually
objects as in (2.5a). However, the same semantic role can be realised with different
syntactic functions, as it is the case with the theme role assigned to the car in (2.5a-
b). The phenomenon of multiple syntactic realisations of the same predicate-argument
structure is known as argument alternation. The alternation illustrated in (2.5) is called
the causative alternation, because the argument which causes the car to stop (Mary) is
present in one expression (2.5a), but not in the other (2.5b). Other well-known examples
of argument alternations include the dative alternation (2.6) and the locative alternation
(2.7).
(2.6) a. [Mary]subject/agent
told [her friend]indirect-object/recipient
[a story].object/theme
b. [Mary]subject/agent
told [a story]object/theme
[to her friend].prep-complement/recipient
37

2. Overview of the literature
(2.7) a. [People]subject/agent
were swarming [in the exhibition hall].prep-complement/location
b. [The exhibition hall]subject/location
was swarming [with people].prep-complement/agent
In the dative alternation, the recipient role (her friend in (2.6)) can be expressed as the
indirect object which usually takes dative case (2.6a),1 or as a prepositional complement
(2.6b). In the locative alternation, the arguments which express the location and the
agent of the situation described by the verb swap syntactic functions: the location
(exhibition hall) is the prepositional complement in (2.7a) and the subject in (2.7b). The
agent (people) is in the subject position in (2.7a) and it is the prepositional complement
in (2.7b).
The view of the predicate argument structure has evolved with the developments in
linguistic theory, from the quite intuitive notions illustrated in the examples so far to
more formal and general analyses. The main changes in the theory are reviewed in the
following sections.
2.1.2. Atomic approach to the predicate-argument structure
In the earliest approaches, the roles of the semantic arguments of verbs are regarded
as simple, atomic labels. Apart from the roles illustrated in (2.5-2.7), the set of labels
commonly includes: experiencer, instrument, source, and goal, illustrated in
(2.8-2.11).2 The atomic semantic labels of the constituents originate in the notions of
“deep cases” in Case grammar (Fillmore 1968).
These labels capture common intuitions about the relational meaning of verbs which
cannot be addressed using only the notions of syntactic functions. For example, the
meanings of the subjects in (2.5a-b), as well as the role that they play in the event
1Although the dative case is not visible in most of English phrases, including (2.6a), it can be shownthat it exists in the syntactic representation of the phrases.
2The labels patient and theme are often used as synonyms (as, for example, in (Levin and RappaportHovav 2005)). If a difference is made, patient is the participant undergoing a change of state, andtheme is the one that undergoes a change of location.
38

2.1. Theoretical approaches to the argument structure
described by the verb stop, are rather different. Mary refers to a human being who is
actively (and possibly intentionally) taking part in the event, while the car refers to
an object which cannot have any control of what is happening. This difference cannot
be formulated without referring to the semantic argument label of the constituents. A
similar distinction is made between people and the exhibition hall in (2.7a-b).
Another important intuition which is made evident by the predicate-argument repre-
sentation is that the sentences such as (2.5a) and (2.5b) are related in the sense that
they are paraphrases of each other. The same applies for (2.6a) and (2.6b) and (2.7a)
and (2.7b). The fact that the predicate-argument structure is shared by the two para-
phrases, while their syntactic structure is different, represents the intuition that the two
sentences have approximately the same meaning, despite the different arrangements of
the constituents.
(2.8) [Mary]experiencer
enjoyed the film.
(2.9) Mary opened the door [with a card].instrument
(2.10) Mary borrowed a DVD [from the library].source
(2.11) Mary arrived [at the party].goal
Finally, the predicate-argument representation is useful in establishing the relationship
between the sentences which express the same content across languages. As the exam-
ples in (2.12) show, the relational structure of the verbs like in English and plaire in
French is the same, despite the fact that their semantic arguments have inverse syntactic
functions.
(2.12) a. [Mary]subject/experiencer
liked [the idea].object/theme
(English)
39

2. Overview of the literature
b. [L’idee]subject/theme
a plu [a Marie].prep-complement/experiencer
(French)
Although the predicat-argument structure proves to be a theoretically necessary level of
representation of the phrase structure, it was soon shown that the concept of semantic
roles as atomic labels for the verbs’ arguments is too naıve with respect to the reality of
the observations that it is intended to capture.
First of all, the set of roles is not definitive. There are no common criteria which
define all possible members of the set. New roles often need to be added to account for
different language facts. For example, the sentence in (2.9) can be transformed so that
instrument is the subject as in (2.13), but if we replace the card with the wind as
in (2.14), the meaning of this subject cannot be described with any of the labels listed
so far. It calls for a new role — cause or immediate cause (Levin and Rappaport
Hovav 2005). Similarly, many other sentences cannot be described with the given set
of roles. This is why different analyses keep adding new roles (such as beneficiary,
destination, path, time, measure, extent etc.) to the set.
(2.13) [The card]instrument
opened the door.
(2.14) [The wind]cause
opened the door.
Another problem posed by the atomic view of semantic roles is that there are no trans-
parent criteria or tests for identifying a particular role. Definitions of semantic roles do
not provide sets of necessary and sufficient conditions that can be used in identifying
the semantic role of a particular argument of a verb. For example, agent is usually de-
fined as the participant in an activity that deliberately performs the action, goal is the
participant toward which an action is directed,3 and source is the participant denoting
the origin of an action. These definitions, however, do not apply in many cases, as noted
by Dowty (1991). For example, both Mary and John in (2.15) seem to act voluntarily
3Dowty analyses to Mary in (2.15a) as goal, while the role of this constituent would be analysed asrecipient by other authors, which further illustrates the problem.
40

2.1. Theoretical approaches to the argument structure
in both sentences, which means that they both bear the role of agent. Furthermore,
John is not just agent, but also source, while Mary is both agent and goal.
(2.15) (a) [John]?
sold the piano [to Mary]?
for $1000.
(b) [Mary]?
bought the piano [from John]?
for $1000.
(Dowty 1991: 556)
The example in (2.15) shows that the relational structure of such sentences cannot be
described by assigning a single and distinct semantic label to each principal constituent
of the clause. The meaning of the verbs’ arguments seems to express multiple relations
with the verbal predicate.
There is one more observation which cannot be addressed with the simple view of se-
mantic labels. This is the fact that the meaning of the roles is not equally distinct in all
the cases. Some roles obviously express similar meanings, while others are very differ-
ent. Furthermore, semantic clustering of the roles seems to be related with the kinds of
syntactic functions that the arguments have in a phrase. For example, the arguments
which are realised as subjects in (2.9), (2.13), and (2.14), agent, instrument, cause
respectively, constitute a paradigm — they can be replaced by each other in the same
context. It has been noticed that two of these roles, agent and cause, can never occur
together in the same phrase. On the other hand, the roles such as source and goal
are in a syntagmatic relation: they tend to occur together in the same phrase. The
traditional view of semantic roles as a set of atomic notions does not provide a means
to account for these facts.
Different theoretical frameworks have been developed in the linguistic literature to
deal with these problems and to provide a more adequate definitions of the predicate-
argument relations. Studying in more detail how semantic arguments of verbs are re-
alised in the phrase structure, some authors (Larson 1988; Grimshaw 1990) propose a
universal hierarchy of the arguments. The order in the hierarchy is imposed by the syn-
tactic prominence of the arguments. For example, agents are at the top of the hierarchy,
41

2. Overview of the literature
which means that they take the most prominent position in the sentence, the subject
position. Next in the hierarchy are themes. They are typically realised as direct objects,
but they can also be realised as subjects if agents are not present in the representation.
Lower arguments are realised as indirect objects and prepositional complements. We do
not discuss these proposals further as the view of the arguments does not significantly
depart from the atomic notions.
In the following sections, we take a closer look into the analyses which propose decom-
posing the predicate-argument structure into a set of more primitive notions. We start
with the approaches based on a decomposition of semantic roles into features or proper-
ties. Then we move to the approaches based on a decomposition of verbal meaning into
multiple predicates.
2.1.3. Decomposing semantic roles into clusters of features
An obvious direction for overcoming the problems posed by the atomic view of the
predicate-argument relationship is to decompose the notions of individual roles into
features or properties. Using a limited set of features for defining all the roles should
provide more systematic and more precise definitions of roles. It should also enable
defining a role hierarchy that can group the roles according to properties that they
share. Two approaches to the feature-based approaches to semantic roles are described
in this section.
Proto-roles
Dowty (1991) concentrates on argument selection — the principles that languages use
to determine which argument of a predicate can be expressed with which grammatical
function. Dowty (1991) argues that discrete semantic types of arguments do not exist
at all, but that the arguments are rather divided into only two conceptual clusters —
proto-agent and proto-patient. These clusters are understood as categories in the
sense of the theory of prototypes (Rosch 1973), which means that they have no clear
boundaries, and that they are not defined with sets of necessary and sufficient conditions.
42

2.1. Theoretical approaches to the argument structure
These categories are represented with their prototypical members, with other members
belonging to the categories to a different degree. The more the members are similar to
the prototypes the more they belong to the category.
Looking into different realisations of subjects and objects and the semantic distinctions
that they express in different languages, Dowty proposes lists of features that define the
agent and the patient prototype. Each feature is illustrated by the sentence whose
number is indicated.
agent:
a. volitional involvement in the event or state (2.16)
b. sentence (and/or perception) (2.17)
c. causing an event or change of state in another participant (2.18)
d. movement (relative to the position of another participant) (2.19)
(e. exists independently of the event named by the verb) (2.20)4
patient
a. undergoes change of state (2.21)
b. incremental theme (2.22)
c. causally affected by another participant (2.23)
d. stationary relevant to movement of another participant (2.24)
(e. does not exist independently of the event, or not at all) (2.25)
(2.16) [Bill] is ignoring Mary.
(2.17) [John] sees Mary.
4Dowty uses the parentheses to express his own doubts about the relevance of the last feature in bothgroups.
43

2. Overview of the literature
(2.18) [Teenage unemployment] causes delinquency.
(2.19) [Water] filled the boat.
(2.20) [John] needs a new car.
(2.21) John made [a mistake].
(2.22) John filled [the glass] with water.
(2.23) Smoking causes [cancer].
(2.24) The bullet overtook [the arrow].
(2.25) John built [the house].
These examples illustrate the properties in isolation, the phrases used in contexts where
syntactic constituents are characterised with only one of the properties. Prototypical
realisations would include all agent properties for subjects and all patient properties
for objects.
These properties are conceived as entailments that are contained in verbs meaning spec-
ifying the value for the cognitive categories that people are actually concerned with:
whether an act was volitional, whether it was caused by something, whether there were
emotional reactions to it, and so on. (Dowty 1991: 575)
The relation between a verb’s meaning and its syntactic form can be formulated in the
following way: If a verb has two arguments, the one that is closer to the agent prototype
is realised as the subject, and the one that is closer to the patient prototype is realised
as the object. If there are three arguments of a verb, the one that is in between these two
ends is realised as a prepositional object. This theory can be applied to explain certain
phenomena concerning the interface between semantics and syntax. For example, the
existence of “double lexicalizations” such as those in (2.15) that are attested in many
different languages with the same types of verbs can be explained by the properties of
their arguments. Both arguments that are realised in (2.15) are agent-like arguments
(none of them being a prototypical agent), so the languages tend to provide lexical
elements (verbs) for both of them to be realised as subjects.
44

2.1. Theoretical approaches to the argument structure
Dowty’s theory provides an elaborate framework for distinguishing between verbs’ argu-
ments, accounting for numerous different instances of arguments. These characteristics
make it a suitable conceptual framework for large-scale data analysis. Recently, Dowty’s
notions have been used as argument descriptors in a large-scale empirical study of mor-
phosyntactic marking of argument relations across a wide range of languages (Bickel
et al. To appear), as well as in a large-scale annotation project (Palmer et al. 2005a).
Dowty’s approach, however, does not address issues related to syntax, such as different
syntactic realisations of the same arguments. The approach reviewed in the following
subsection is more concentrated on these issues.
The Theta System
Unlike Dowty, who assumes monostratal syntactic structure of phrases (Levin and Rap-
paport Hovav 2005), Reinhart (2002) sets the discussion on semantic roles in the context
of derivational syntax. The account proposed by Reinhart (2002) offers an elaborate
view of the interface between lexical representation of verbs and syntactic derivations.
It assumes three independent cognitive modules — the systems of concepts, the compu-
tational system (syntax), and the semantic inference systems. Linguistic information is
first processed in the systems of concepts, then passed on to the computational system,
and then to the semantic inference systems. The theta system5 belongs to the systems
of concepts. It enables the interface between all the three modules. It consists of three
parts:
a. Lexical entries, where theta-relations of verbs are defined.
b. A set of arity operations on lexical entries, where argument alternations are pro-
duced.
c. Marking procedures, which finally shape a verb entry for syntactic derivations.
5In the generative grammar theoretical framework, semantic roles are often referred to as thematicroles or, sometimes, as Θ-roles, indicating that the meaning expressed by the semantic argumentsof verbs is not as specific as the traditional labels would suggest.
45

2. Overview of the literature
There are eight possible theta relations that can be defined for a verb and that can
be encoded in its lexical entry. They represent different combinations of values for two
binary features: cause change (feature [c]) and mental state (feature [m]). They
can be related to the traditional semantic role labels in the following way:
a) [+c+m] — agent
b) [+c−m] — instrument (. . .)
c) [−c+m] — experiencer
d) [−c−m] — theme / patient
e) [+c] — cause (unspecified for / m); consistent with either (a) or (b)
f) [+m] — ? (Candidates for this feature-cluster are the subjects of verbs like love,
know, believe)
g) [−m] — (unspecified for / c): subject matter / locative source
h) [−c] — (unspecified for / m): roles like goal, benefactor; typically dative (or
PP).
The verb entries in the lexicon can be basic or derived. There are three operations that
can be applied to the basic entries resulting in derived entries: saturation, reduction,
and expansion.
Saturation is applied to the entries that are intended for deriving passive constructions.
It defines that one of the arguments is just an existential quantification and that it is
not realised in syntax. It is formalised as described in the example of the verb wash:
a) Basic entry: wash(θ1, θ2)
b) Saturation: ∃x(wash(x, θ2))
c) Max was washed : ∃x(x washed Max)
46

2.1. Theoretical approaches to the argument structure
Reduction can apply in two ways. If it applies to the argument that is realised within
the verb phrase in syntax (typically, the direct object) it reduces the verb’s argument
array to only one argument, so that the meaning of the verb is still interpreted as a
two-place relation, but as its reflexive instance ((2.26b) vs. (2.26a)). If it applies to the
argument that is realised outside of the verb phrase, which means as the subject in a
sentence, it eliminates this argument from the array of verb’s arguments completely, so
that the verb is interpreted as a one-place relation ((2.26c) vs. (2.26a)).
(2.26) (a) Mary stopped the car.
(b) Mary stopped.
(c) The car stopped.
Expansion is an operation usually known as causativization. It adds one argument —
agent — to the array of the verb (2.27b vs. 2.27a).
(2.27) (a) The dog walked slowly.
(b) Mary walked the dog slowly.
All these operations take place in the lexicon, producing different outputs. While the op-
erations of saturation and reduction produce new variations of the same lexical concept,
expansion creates a whole new concept.
Before entering syntactic derivations, the concepts undergo one more procedure, the
marking procedure, which assigns indices to the arguments of verbs. These indices serve
as a message to the computational system as to where to insert each argument in the
phrase structure. Taking into consideration the number and the type of the feature
clusters that are found in a verb entry, they are assigned according to the following
rules:
Given an n-place verb entry, n > 1,6
6Insertion of a single argument as subject follows from a more general syntactic rule, namely theExtended Projection Principle, which states that each clause must have a subject.
47

2. Overview of the literature
a) Mark a [−] cluster with index 2.
b) Mark a [+] cluster with index 1.
c) If the entry includes both a [+] cluster and a fully specified cluster [/α, /−c],7
mark the verb with the ACC feature.8
This marking is associated with the following instructions for the computational sys-
tem:
a) When nothing rules this out, merge externally.
b) An argument realising a cluster marked 2 merges internally.
c) An argument with a cluster marked 1 merges externally.
The operation of internal merging joins a new constituent to an existing structure within
a verb phrase, while the operation of external merging inserts a new constituent in the
existing structure of a sentence outside of the phrase headed by the verb in question.
The result of an internal merge is usually a syntactic relation between a verb and its
object, while external merge forms a relation between a verb and its subject.
With this system, some generalizations concerning the relation between theta roles and
syntactic functions can be stated. Arguments that realise [+] clusters ([+m−c] agent,
[+c] cause, [+m] ?) are subjects. Since there can be only one subject in a sentence,
they exclude each other. Arguments that realise [−] clusters ([−m−c] patient, [−m]
subject matter, [−c] goal) are objects. Only the fully specified one can be the direct
object (introducing the ACC feature to the verb). The others (underspecified ones) have
to be marked with a preposition or an inherent case (e.g. dative), thus realised as indirect
objects.
7A cluster that is specified for both features, where one of them has to be [−c] and the other can beany of the following: [+m], [−m], [+c], [−c].
8ACC stands for accusative. This feature determines whether a verb assign accusative case to itscomplement.
48

2.1. Theoretical approaches to the argument structure
Arguments that are specified for both features, but with opposite values ([+m−c] expe-
riencer and [−m+c] instrument) are neutral. They have no indices, so they can be
inserted into any position in the phrase structure that is available at the moment of their
insertion. The same applies to the arguments that are encoded as the only argument of
a verb.
Summary
The approaches of Dowty (1991) and Reinhart (2002) reviewed in this section deal with
issues in the traditional predicate-argument analysis by proposing small sets of primitive
notions which can be seen as semantic components of the traditional argument labels.
With such decomposition, the similarities between some arguments (e.g. agent, cause,
and instrument), as well as the constraints in their realisations in phrases (e.g. if a
clause expresses an agent of an event, it cannot express another distinct cause of
the same event), follow from the features that characterise them. The generalisations
proposed as part of these approaches contribute to a better understanding of how the
interface between lexicon and syntax operates, capturing a wide range of observations.
However, the sets of features used in these accounts are not motivated by some other
more general principles. In other words, these accounts do not address the issue of why
we have exactly the sets of features proposed in the two theories and not some others.
The approaches to the predicate-argument structure reviewed in the following section
propose deeper semantic analysis exploring the origins of the argument types.
2.1.4. Decomposing the meaning of verbs into multiple predicates
In theories of predicate decomposition, it is assumed that verbs do not describe one
single relation, but more than one. These relations are regarded as different components
of an event described by the meaning of a verb, often referred to as subevents. Some
of these components can be rather general and shared by many verbs, while others
are idiosyncratic and characteristic of a particular verb entry. In this framework, each
predicate included in the lexical representation of a verb assigns semantic roles to its
49

2. Overview of the literature
arguments. The syntactic layout of a clause depends, thus, on the number and the
nature of the predicates of which the meaning of its heading verb is composed.
Many approaches to predicate decomposition are influenced by the work of Hale and
Keyser (1993) who are the first to prpose a formal syntactic account the relational
meaning of verbs. Hale and Keyser (1993) propose a separate level of lexical repre-
sentation of verbs — lexical relational structure (LRS). The components of conceptual,
idiosyncratic meaning of a verb are the arguments of the relations grouped in the LRS.
The relational part of lexical representation, for example, is the same for the verbs get in
(2.28) and bottle in (2.29) indicating that machine did something to the wine. The dif-
ference in meaning between these two verbs is explained by two different incorporations
of idiosyncratic components in the relational structure. In the first case, the relational
structure incorporates the verb get with its own complex structure, while in the second
case, it incorporates the noun bottle.
(2.28) A machine got the wine into bottles.
(2.29) A machine bottled the wine.
Different approaches which follow this kind of analysis offer different representations of
the relational structure, depending on what organizational principle is taken as a basis
for event decomposition.
Aspectual event analysis
Aspectual analysis of events takes into consideration temporal properties of verbs’ mean-
ing. More precisely, it decomposes the relational part of lexical representation of verbs
into a number of predicates which correspond to the stages in the temporal development
of the event. These predicates take arguments which are then realised as the principal
constituents of clauses. As an illustration of the phenomena that are of interest for the
aspectual decomposition of verbs’ meaning, consider the sentences in (2.30-2.31).
(2.30) a. Mary drank [a bottle of wine] in 2 hours / ? for two hours.
b. Mary drank [wine] for 2 hours / * in two hours.
50

2.1. Theoretical approaches to the argument structure
(2.31) a. Mary crammed [the pencils] into the jar.
b. Mary crammed [the jar] with the pencils.
The examples in (2.30) show that the choice of the adverbial with which the verb drink
can be combined (in two hours vs. for two hours) depends on the presence or absence
of the noun bottle in the object of the verb. Intuitively, we know that the adverbials
such as in two hours are compatible only with the events which are understood as
completed. The event expressed in the sentence in (2.30a), for example, is completed
because the sentence implies that there is no more wine in the bottle. What makes this
event completed and, thus, compatible with the adverbial in two hours is precisely the
presence of the noun bottle in the object. This noun quantifies the substance which is
the object (wine) and, at the same time, it quantifies the whole event which includes
it. This fact points to the presence of a predicate in the relational structure of the verb
which takes the noun bottle as its argument. This predicate relates the other parts of the
lexical structure of the verb (or of the event described by the verb) with an end point.
The nature of the end point is specified by the argument of this predicate, that is by the
argument which is realised as the direct object in the phrase. If the direct object does
not provide the quantification, the whole event is interpreted as not quantified, as in
(2.30b). The verb in (2.30b) is not compatible with the adverbial in two hours because
its object is not quantified.
The examples in (2.31) show how an alternation of the arguments of a verb can change
the temporal interpretation of the event described by the verb. The event in (2.31a)
lasts until all the pencils are in the jar, while the event in (2.31b) lasts until the jar is
full. The argument of the temporal delimitation predicate, which is usually realised as
the direct object in a phrase, is known as the incremental theme (Krifka 1998). The
adjective incremental in the term refers to the fact that the theme argument of the verb
changes incrementally in the course of the event described by the verb. The degree of
change in the theme “measures out” the development of the event.
An influential general approach to aspectual decomposition of verbal predicates is pro-
posed by Ramchand (2008). Looking at the event as a whole, Ramchand (2008) proposes
several predicates which take arguments such as initiator, undergoer, path, and
resultee. The predicates represent the subevents of the event described by a verb:
51

2. Overview of the literature
the predicate whose argument is initiator represents the beginning of the event, those
that take the arguments undegoer and path are in the middle, and the one whose
argument is resultee is in the end. These predicates are added to the representation in
the course of syntactic derivations, but only if this is allowed by the lexical specifications
of verbs.
In an analysis of the example (2.31a) in this framework, Mary is initiator, the pencils
are both undergoer and resultee, and the jar is another argument of the last (re-
sulting) predicate. In (2.31b) on the other hand, the argument of both the middle and
the end predicate is the jar.
This view of the semantic structure relates the complexity of the event described by the
verb with the complexity of its argument structure, and by this, with the complexity of
the structure of the clause that is formed with the verb. It should be noted, however,
that this decomposition does not address all the temporal properties of phrases, but
only those which are implicit to the meaning of the verbs.
Causal event analysis
In a causal analysis, events are analysed into entities (participants) that interact accord-
ing to a particular energy flow or force-dynamic schemata (Talmy 2000). The main
concept in this framework is the direction that the force can take. Semantic properties
of verbs such as aspect and argument structure are seen as a consequence of a particular
energy flow involved in the event described by the verb. If a verb describes an event
were some energy is applied, it will be an action verb, otherwise it will describe a state.
In the domain of argument structure, the participant that is the source of energy will
have the role of agent and the one that is the sink of the energy will have the role of
patient.
This approach has been applied to account for different senses of the same verb, as well
as for its different syntactic realisations. Both different verb senses and their argument
alternations are explained by the shifts in the energy flow with the idiosyncratic meaning
that stays unchanged. The following examples illustrate different force-dynamic patterns
for the verb take.
52

2.1. Theoretical approaches to the argument structure
(2.32) Sandy took the book { from Ashley / off the table }.
(2.33) (a) Sandy took the book to Ashley.
(b) Sandy took Ashley (to the movies).
The action in (2.32) is self-oriented, with Sandy being the energy source and sink at the
same time. In (2.33), another participant (Ashley / to the movies) is more important,
since it indicates the direction of energy. These are two different senses of the verb take.
The difference is reflected in the fact that this argument can be omitted in sentences
like (2.32) whenever it is indefinite or indeterminate, while in sentences like (2.33), it
can only be omitted if it can be interpreted from the context.
2.1.5. Summary
In the approaches to the analysis of the predicate-argument structure outlined so far, the
meaning of verbs and their arguments is described with relatively small inventories of
descriptive notions. The proposed accounts decompose the predicate-argument structure
into more primitive notions in an attempt to reduce the number of theoretical notions
to a minimum. The Theta system by Reinhart (2002), for example, accounts for a
wide range of linguistic facts using only three notions: mental state, cause change,
and presence/absence. Similarly, the aspectual decomposition proposed by Ramchand
(2008) results in only four principal components which play a role in accounting for
many different argument realisations and interpretations.
Theoretical accounts reviewed in this section identify important generalisations about
the lexical representation of verbs. The generalisations are, however, not tested on a
wide range of verbs, but mostly on a small set of examples either provided by the authors
of the proposals themselves or taken from a common set of examples frequently cited in
the literature. Applying theoretical generalisations to a larger set of verb instances in a
more practical analysis is not straightforward. Some approaches to large-scale analysis
of the predicate-argument structure are discussed in the following section.
53

2. Overview of the literature
2.2. Verb classes and specialised lexicons
We have assumed so far that the predicate-argument relational structure is the part of
lexical representation which is shared by different verbs, while the idiosyncratic lexical
content is specific to each individual verb. However, if we take a closer look at the
inventory of verbs in a language, this distinction turns out to be a simplified view of the
organisation the inventory. We intuitively group together not only the verbs with the
same predicate-argument structure, but also the verbs with similar lexical content. Such
groups are, for example, verbs of motion (e.g. come, go, fall, rise, enter, exit, pass),
state verbs (e.g. want, need, belong, know), verbs of perception (e.g. see, watch, notice,
hear, listen, feel) etc.
2.2.1. Syntactic approach to verb classification
The members of semantic classes tend to be associated with the same types of syntactic
structures. For example, verbs of motion are usually intransitive, verbs of perception are
usually transitive, while the verbs that describe states can be associated with a variety
of different structures. However, it has been noticed that verbs which belong to the
same semantic class do not always participate in the same argument alternations. For
example, the verbs bake in (2.34) and make in (2.35) have similar meanings in that they
are both verbs of creation and that they can take the same kind of objects.
(2.34) a. Mary baked a cake.
b. The cake baked for 40 minutes.
(2.35) a. Mary made a cake.
b. *The cake made for 40 minutes.
Despite the obvious parallelism, the verb bake participates in the causative alternation
(2.34b) is grammatical), while the verb make does not ((2.35b) is not grammatical).
This contrast suggests that the two verbs have different lexical representations. There
54

2.2. Verb classes and specialised lexicons
should be an element which is present in the structure of one verb and missing in the
structure of the other, causing the difference in the syntactic patterns.
On the basis of this assumption Levin (1993) studies possible argument realisations of
a large number of verbs and proposes a comprehensive classification which combines
semantic and syntactic groupings. The aim of Levin’s analysis is to use the information
about argument alternations as behavioural, observable indicators of the components of
verbs’ meaning which are grammatically relevant.
Having pointed out many constraints and distinctions which call for theoretical accounts,
Levin’s classification has been often referred to in the subsequent work on the predicate-
argument structure, including Levin’s own work (Levin and Rappaport Hovav 1994;
1995). An example of a phenomenon identified in Levin’s classification which has re-
ceived a proper theoretical account is the distinction between verbs such as freeze, melt,
grow, which are known as unaccusatives, and emission verbs such as glow, shine, beam,
sparkle. The two groups are similar in that they consist of intransitive verbs which
take the same kind of arguments — non-agentive, non-volitional — as subjects. The
syntactic properties of the two groups, however, are different. While unaccusatives par-
ticipate in the causative alternation, the emission verbs do not, which groups them with
semantically very different agentive intransitive verbs such as walk, run, march, gallop,
hurry. Reinhart (2002) employs the notions developed in the framework of the Theta
System (see Section 2.1.3) to explain this fact by different derivations of unaccusatives
and emission verbs. Unaccusatives are derived lexical entries (derived from transitive
verbs). Their argument is marked with the index 2, as the internal argument of the
transitive verb. By the operation of reduction, the other argument is removed. The
remaining argument is merged internally, even if it stays the only argument of the verb
due to the fact that is marked with the index 2. It then moves to the position of the
subject to satisfy general syntactic conditions. As for emission verbs, their subject is
originally the only argument. This is why it cannot be marked. And since it is not
marked, it is merged to the first position available — and this is the external position
of the subject.
The systematic analysis of a large set of verbs proposed by Levin (1993) proved to be es-
pecially important for the subsequent empirical approaches to the meaning of verbs. The
55

2. Overview of the literature
classification has often been cited as the reference resource for selecting specific groups
of verbs for various purposes, including the experiments presented in this dissertation.
The more recent work on the argument alternation is concentrated on the conditions
which determine different syntactic realisations of verbs’ arguments in alternations.
Beavers (2006) revisits a range of alternations, especially those which involve arguments
switching between the direct object and a prepositional complement, arguing that gen-
eral semantic relationships between syntactic constituents directly influence their posi-
tion in a clause, and not only the relationship of the arguments with verbal predicates.
Beavers (2006) proposes a set of semantic hierarchies along different dimensions, such
as the one illustrated in (2.36): the higher the interpretation of an argument in the
hierarchy, the more distant its syntactic realisation from the direct object.
(2.36) Affectedness scale:
PARTICIPANT ⊂ IMPINGED ⊂ AFFECTED
⊂ TOTALLY AFFECTED
Bresnan (2007) takes an empirical approach proposing a statistical model of speakers’
choice between two options provided by the dative alternation. The study first shows
that human judgement of acceptability of syntactic constructions are influenced by the
frequency of the constructions. It then shows that several factors are good predictors
of human judgements. If the recipient role is characterised as nominal, non-given, in-
definite, inanimate, and not local in the given spacial context, it is likely to be realised
as a prepositional complement, while it is characterised with the opposite features (as
pronominal, given, definite, animate, and local) it is likely to be realised as the indirect
object. Bresnan and Nikitina (2009) offer an explanation of the speaker’s choice based
on the interaction of two opposed tendencies. On the one hand, there is the tendency
of semantic arguments to be aligned with the syntactic functions, more prominent argu-
ments are realised as more prominent syntactic functions (like the direct and the indirect
object), while less prominent arguments are realised as prepositional complements. On
the other hand, the form of the prepositional phrase expresses the relationship between
the verb and its complement in a more transparent way. Hence, if the argument is seman-
tically prominent enough, it will be assigned a less transparent, but more syntactically
prominent functions. Otherwise, it will be realised as a prepositional complement.
56

2.2. Verb classes and specialised lexicons
The more recent developments in the approach to argument alternations, however, have
not been followed by a large-scale implementation. The comprehensive resources which
have been developed up to the present day do not make reference to these generalisa-
tions.
2.2.2. Manually annotated lexical resources
Three big projects are concerned with providing extensive descriptions of the predicate-
argument relations for English words. They are described in the following subsections.
We start by describing FrameNet. As our detailed review shows, this resource imple-
ments the least theoretical view of the predicate argument structure based on the atomic
semantic role analysis. Nevertheless, this resource is the one that is most frequently used
as a reference for developing similar resources for other languages. The second resource,
PropBank, implements Dowty (1991)’s view of the predicate-argument structure, but
with significant simplifications which brings the implementation closer to the atomic
view. This resource has been frequently used for machine learning experiments due to
the fact that, in addition to the lexicon of verbs, it provides a large corpus of texts
manually annotated with the proposed predicate-argument analysis. The last resource
that we discuss is VerbNet. Although it implements Levin (1993)’s classification, this
resource too relies on the atomic view of semantic roles, assigning traditional semantic
role labels to the arguments of verbs.
FrameNet
FrameNet is an electronic resource and a framework for explicit description of the lexical
semantics of words. It is intended to be used by lexicographers, but also by systems for
natural languages processing (Baker et al. 1998). It consists of three interrelated
databases:
a. Frame database, the core component describing semantic frames that can be expressed
by lexical units.
57

2. Overview of the literature
b. Annotated example sentences extracted from the British National Corpus (Burnard
2007) with manually annotated frames and frame elements that are described in the
Frame database.
c. Lexicon, a list of lexical units described in terms of short dictionary definitions and
detailed morpho-syntactic specifications of the units that can realise their arguments in
a sentence.
The frame database (1 179 frames)9 contains descriptions of frames or scenes that can
be described by predicating lexical units (Fillmore 1982), such as verbs, adjectives,
prepositions, nouns. Each scene involves one or more participants. The predicating units
are referred to as “targets”, and the participant which are combined with predicating
units as “frame elements”. One frame can be realised in its “core” version including
“core” frame elements, or it can be realised as a particular variation, including additional
frame elements that are specific for the variation. For example, the target unit for the
frame Accomplishment can be one of the verbs accomplish, achieve, bring about, or one of
the nouns accomplishment, achievement. The core frame elements for this frame are:
a. agent: The conscious entity, generally a person, that performs the intentional act
that fulfills the goal.
b. goal: The state or action that the agent has wished to participate in.
The definition of the frame itself specifies the interaction between the core frame ele-
ments:
After a period in which the agent has been working on a goal, the agent
manages to attain it. The goal may be a desired state, or be conceptualised
as an event.
For the non-core realisations, only the additional frame elements are defined.
The frames are organised into a network by means of one or more frame-to-frame rela-
tions that are defined as attributes of frames. (Note thought that not all frames could
9Online documentation at https://framenet.icsi.berkeley.edu/fndrupal/current_status, ac-cessed on 5 June 2014.
58

2.2. Verb classes and specialised lexicons
be related to other frames.) Defining the relations enables grouping related frames ac-
cording to different criteria, so that the annotation can be used with different levels of
granularity. There are six types of relations that can be defined:
• Inherits From / Is Inherited By: relates an abstract to a more specified frame with
the same meaning, e.g. Activity (no lexical units) inherits from Process (lexical
unit process.n) and it is inherited by Apply heat (lexical units bake.v, barbecue.v,
boil.v, cook.v, fry.v, grill.v, roast.v, toast.v, ...).
• Subframe of / Has Subframes: if an event described by a frame can be divided
into smaller parts, this relation holds between the frames that describe the parts
and the one that describes the whole event, e.g. Activity has subframes: Activity
abandoned state, Activity done state (lexical units done.a, finished.a, through.a),
Activity finish (lexical units complete.v, completion.n, ...), Activity ongoing (lexical
units carry on.v, continue.v, keep on.v, ...), Activity pause (lexical units freeze.n,
freeze.v, pause.n, take break.v, ...), Activity paused state, Activity prepare, Activ-
ity ready state (lexical units prepared.a, ready.a, set.a), Activity resume (lexical
units renew.v, restart.v, resume.v), Activity start (lexical units begin.v, beginner.n,
commence.v, enter.v, initiate.v, ...), Activity stop (lexical units quit.v, stop.v, ter-
minate.v, ...).
• Precedes / Is Preceded by: holds between the frames that describe different parts of
the same event, e.g. Activity pause precedes Activity paused state and is preceded
by Activity ongoing.
• Uses / Is Used By: connects the frames that share some elements, e.g. Accom-
plishment (lexical units accomplish.v, accomplishment.n, achieve.v, achievement.n,
bring about.v) uses Intentionally act (lexical units act.n, act.v, action.n, activity.n,
carry out.v,, ...).
• Perspective on / Is perspectivised in: holds between the frames that express differ-
ent perspectives on the same event, e.g. Giving (lexical units gift.n, gift.v, give.v,
give out.v, hand in.v, hand.v, ...) is a perspective on Transfer (lexical units trans-
fer.n, transfer.v), Transfer can also be perspectivised in Receiving (lexical units
accept.v, receipt.n, receive.v).
59

2. Overview of the literature
• Is Causative of: e.g. Apply heat is causative of Absorb heat (lexical units bake.v,
boil.v, cook.v, fry.v,...)
The relations of inheritance, using, subframe, and perspective connect specific frames
to the corresponding more general frames, but in different ways. The specific frame is
a kind of the general frame in inheritance. Only a part of the specific frame is a kind
of the general frame in using. A subframe is a part of another frame. The other two
relations do not involve abstraction, they hold between the frames of the same level of
specificity.
Frames and frame elements can also be classified into semantic types that are not based
on the hierarchies described above, but that correspond to some ontologies that are
commonly referred to (such as WordNet (Fellbaum 1998)). For example, frames are
divided into non-lexical (e.g. Activity) and lexical (e.g. Accomplishment). Similarly, the
frame element agent belongs to the type “sentient”, and theme belongs to the type
“physical object”.
Annotated examples such as (2.37-2.41) are provided for most of the frame versions.
(2.37) [Iraq]agent
had [achieved]target
[its programme objective of producing nuclear weapons].goal
(2.38) Perhaps [you]agent
[achieved]target
[perfection]goal
[too quickly].manner
(2.39) [He]agent
has [only partially]degree
[achieved]target
[his objective].goal
(2.40) [These positive aspects of the Michigan law]goal
may, however, have been
[achieved]target
at the expense of simplicity. [CNI]agent
60

2.2. Verb classes and specialised lexicons
Frame element Syntactic realization (phrase types and their functions)agent CNI.– NP.Ext PP[by].Dep PP[for].Depcircumstances PP[in].Dep PP[despite].Dep PP[as].Dep AJP.Dep
PP[on].Depdegree AVP.Depexplanation PP[since].Dep PP[because of].Depgoal NP.Ext NP.Obj NP.Dep PP[in].Depinstrument PP[with].Dep NP.Ext VPing.Depmanner AVP.Dep PP[in].Depmeans PP[through].Dep PP[by].Dep PP[in].Dep NP.Extoutcome PP[at].Dep NP.Extplace PP[in].Dep PP[at].Deptime Sfin.Dep AVP.Dep PP[in].Dep PP[at].Dep
PP[after].Dep
Table 2.1.: Frame elements for the verb achieve
(2.41)A programme of national assessment began in May 1978 and concerned itself with
[the standard]goal
[achieved]target
[by 11 year olds].agent
The units of the lexicon are word senses (12 754 units). The entries contain a short
lexical definition of the sense of the word, the frame that the unit realises, as well as the
list of the frame elements that can occur with it. They also contain two more pieces of
information on frame elements: the specification of the syntactic form that each frame
element can take and a list of possible combinations of the frame elements in a sentence.
For example, the verb achieve realises the frame Accomplishment. The frame elements
that can occur with it are listed in Table 2.1.
The first row in Table 2.1 states that the frame element agent occurs with the verb
achieve and that it can be realised as Constructional null instantiation (CNI), which
is most often the case in passive sentences (2.40), or as a noun phrase external to the
61
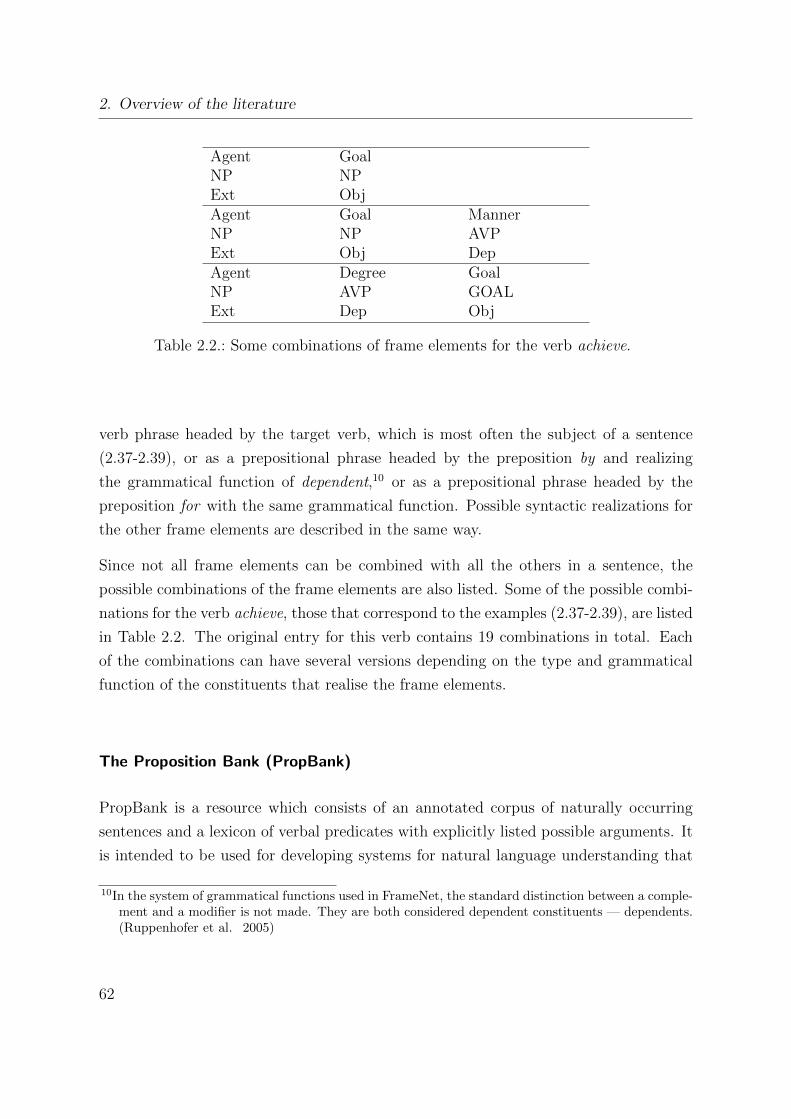
2. Overview of the literature
Agent GoalNP NPExt ObjAgent Goal MannerNP NP AVPExt Obj DepAgent Degree GoalNP AVP GOALExt Dep Obj
Table 2.2.: Some combinations of frame elements for the verb achieve.
verb phrase headed by the target verb, which is most often the subject of a sentence
(2.37-2.39), or as a prepositional phrase headed by the preposition by and realizing
the grammatical function of dependent,10 or as a prepositional phrase headed by the
preposition for with the same grammatical function. Possible syntactic realizations for
the other frame elements are described in the same way.
Since not all frame elements can be combined with all the others in a sentence, the
possible combinations of the frame elements are also listed. Some of the possible combi-
nations for the verb achieve, those that correspond to the examples (2.37-2.39), are listed
in Table 2.2. The original entry for this verb contains 19 combinations in total. Each
of the combinations can have several versions depending on the type and grammatical
function of the constituents that realise the frame elements.
The Proposition Bank (PropBank)
PropBank is a resource which consists of an annotated corpus of naturally occurring
sentences and a lexicon of verbal predicates with explicitly listed possible arguments. It
is intended to be used for developing systems for natural language understanding that
10In the system of grammatical functions used in FrameNet, the standard distinction between a comple-ment and a modifier is not made. They are both considered dependent constituents — dependents.(Ruppenhofer et al. 2005)
62

2.2. Verb classes and specialised lexicons
depend on semantic parsing, but also for quantitative analysis of syntactic alternations
and transformations.
The corpus contains 2 499 articles (1 million words) published in the Wall Street Journal
for which the syntactic structure was annotated in the The Penn Treebank Project (Mar-
cus et al. 1994). The semantic roles were annotated in the PropBank project (Palmer
et al. 2005a). The labels for the semantic roles were attached to the corresponding
nodes in the syntactic trees. A simplified example of an annotated sentence is given in
(2.42). The added semantic annotation is placed between the “@” characters.
(2.42)
S
VP
VP
PP-TMP@ARGM-TMPpay01@
NN
year
JJ
last
NP@ARG1pay01@
RB
little
RB
very
VBN@rel-pay01@
paid
VBZ
has
NP-SBJ@ARG0pay01@
NN
nation
DT
The
Only a limited set of labels was used for annotation. Verbs are marked with the label
rel for relation and the participants in the situation described by the verb are marked
with the labels arg0 to arg5 for the verb’s arguments and with arg-m for adjuncts.
The numbered labels represent semantic roles of a very general kind. The labels arg0
and arg1 have approximately the same value with all verbs. They are used to mark
instances of proto-agent (arg0) and proto-patient (arg1) roles (see 2.1.3). The
value of other indices varies across verbs. It depends on the meaning of the verb, on the
type of the constituent that they are attached to, and on the number of roles present
in a particular sentence. arg3, for example, can mark the purpose, or it can mark
a direction or some other role with other verbs. The indices are assigned according
to the roles’ prominence in the sentence. More prominent are the roles that are more
closely related to the verb.
63

2. Overview of the literature
The arg-m can have different versions depending on the semantic type of the con-
stituent: loc denoting location, cau for cause, ext for extent, tmp for time, dis for
discourse connectives, pnc for purpose, adv forgeneral-purpose, mnr for manner, dir
for direction, neg for negation marker, and mod for modal verb. The last three labels
do not correspond to adjuncts, but they are added to the set of labels for semantic an-
notation nevertheless, so that all the constituents that surround the verb could have a
semantic label (Palmer et al. 2005a). The labels for adjuncts are more specific than the
labels for arguments. They do not depend on the presence of other roles in the sentence.
They are mapped directly from the syntactic annotation.
For example, the verb pay in (2.42) assigns two semantic roles to its arguments and one
to an adjunct. arg0 is attached to the noun phrase that is the subject of the sentence
(NP-SUBJ: The nation) and it represents the (proto-)agent. arg1 is attached to
the direct object (NP: very little). The label for the adjunct (PP-TMP: last year),
arg-m-tmp, is mapped from the syntactic label for the corresponding phrase.
The annotated corpus is accompanied with a lexicon that specifies the interpretation of
the roles for each verb in its different senses. The unit of the lexicon is a lemma (3300
verbs) containing one or more lexemes (4 500 verb senses). The interpretations for the
numbered roles are given for each lexeme separately. Table 2.3 illustrates the lexical
entry for the verb pay.
Possible syntactic realisations of the roles are not explicitly described as in FrameNet, but
they are illustrated with a number of annotated sentences, each representing a different
syntactic realisation of the role. These sentences are mostly drawn from the corpus. For
some syntactic realizations that are not attested in the corpus, example sentences are
constructed.
VerbNet
VerbNet is a database which is primarily concerned with classification of English verbs.
The approach to classification is based on the framework proposed by Levin (1993). It
takes into account two properties: a) the lexical meaning of a verb and b) the kind of
64

2.2. Verb classes and specialised lexicons
pay.01 Arg0: payer or buyerArg1: money or attentionArg2: person being paid, destination of attentionArg3: commodity, paid for what
pay.02 Arg0: payer(pay off) Arg1: debt
Arg2: owed to whom, person paidpay.03 Arg0: payer or buyer(pay out) Arg1: money or attention
Arg2: person being paid, destination of attentionArg3: commodity, paid for what
pay.04 Arg1: thing succeeding or working outpay.05 Arg1: thing succeeding or working out(pay off)pay.06 Arg0: payer(pay down) Arg1: debt
Table 2.3.: The PropBank lexicon entry for the verb pay.
argument alternations that can be observed in the sentences formed with a particular
verb (see Section 2.2.1 for more details).
The unit of classification in VerbNet is a verb sense. It currently covers 6 340 verb senses.
The classification is partially hierarchical, including 237 top-level classes with only three
more levels of subdivision (Kipper Schuler 2005). Each class entry includes:
• Member verbs.
• Semantic roles — All the verbs in the class assign the same roles. These roles are
semantic roles that are more general than frame elements in FrameNet, but more
specific than the numbered roles in PropBank. The label for a role in VerbNet does
not depend on context, as in FrameNet and PropBank. There is a fixed set of roles
that have the same interpretation with all verbs. Although the set of roles is fixed
in principle, its members are revised in the course of the resource development
(Bonial et al. 2011). Initially the set included the following roles:
65

2. Overview of the literature
Members accept, discourage, encourage, understandRoles agent [+animate | +organization] , propositionFrames HOW-S:
Example: “I accept how you do it.”Syntax: Agent V Proposition <+how-extract>Semantics: approve(during(E), Agent, Proposition)
Table 2.4.: The VerbNet entry for the class Approve-77.
Original Role set in VerbNet (23): actor, agent, asset, attribute,
beneficiary, cause, location, destination, source, experi-
encer, extent, instrument, material, product, patient, pred-
icate, recipient, stimulus, theme, time, topic.
The set was later revised to include the following roles:
Updated Role set in VerbNet (33): actor, agent, asset, attribute,
beneficiary, cause, co-agent, co-patient, co-theme, destina-
tion, duration, experiencer, extent, final time, frequency,
goal, initial location, initial time, instrument, location, ma-
terial, participant, patient, pivot, place, product, recipi-
ent, result, source, stimulus, theme, trajectory, topic.
The revised set is accompanied by a hierarchy, where all the roles are classified
into four categories: actor, undergoer, time, place.
• Selectional restrictions — defining characteristics of possible verbs’ arguments,
such as [+animate | +organization] for the role agent in Table 2.4. They can be
compared with the semantic types in FrameNet.
• Frames — containing a description of syntactic realizations of the arguments and
some additional semantic features of verbs. (Note that the VerbNet frames are
different from the FrameNet frames.) In the example class entry given in Table
2.4, only one (HOW-S) of the 5 frames that are defined in the original entry is
66

2.2. Verb classes and specialised lexicons
included, since the other frames are defined in the same way. The semantics of the
verb describes the temporal analysis of the verbal predicates (see Section 2.1.4).
The VerbNet database contains also information about the correspondence between the
classes of verbs and lexical entries in other resources. 5 649 links with the PropBank
lexicon entries have been specified, as well as 4 186 with the FrameNet entries.
No annotated example sentences are provided directly by the resource. However, natu-
rally occurring sentences with annotated VerbNet semantic roles can be found in another
resource, SemLink (Loper et al. 2007), which maps the PropBank annotation to the
VerbNet descriptions. Each numbered semantic role annotated in the PropBank corpus
is also annotated with the corresponding mnemonic role from the set of roles used in
VerbNet. This resource enables comparison between the two annotations and exploration
of their usefulness for the systems for automatic semantic role labelling.
Comparing the resources
The three resources that are described in the previous subsections all provide informa-
tion on how predicating words combine with other constituents in a sentences: what
kind of constituents they combine with and what interpretation they impose on these
constituents. They are all intended to be used for training systems for automatic seman-
tic parsing. However, there are considerable differences in the data provided by these
resources.
The overlap between the sets of lexical items covered by the three resources is rather
limited. For example, 25.5% of the word instances in PropBank are not covered by
VerbNet (Loper et al. 2007)), despite the fact that VerbNet contains more entries
than PropBank (3 300 verbs in PropBank vs. 3 600 verbs in VerbNet). The coverage
issue has been pointed out in the case of FrameNet too. Burchardt et al. (2009) use
English FrameNet to annotate a corpus of German sentences manually. They find that
the vast majority of frames can be applied to German directly. However, around one
third of the verb senses identified in the German corpus were not covered by FrameNet.
Also, a number of German verbs were found to be underspecified. Contrary to this,
Monachesi et al. (2007) use PropBank labels for semi-automatic annotation of a corpus
67

2. Overview of the literature
of Dutch sentences. Although not all Dutch verbs could be translated to an equivalent
verb sense in English, these cases were assessed as relatively rare. Samardzic et al. (2010)
and van der Plas et al. (2010) use PropBank labels to annotate manually a corpus of
French sentences. The coverage reported in these studies is around 95%. Potential
explanation of the coverage differences lies in the fact that PropBank is the only of the
three resources which is based on text samples. While the criteria for including lexical
items in the lexicons are not clear in the other two resources, the verbs and verb senses
included in PropBank are those that are found in the corpus which is taken as a starting
point.
The criteria for distinguishing verb senses are differently defined, which means that
different senses are described even for the same words. It can be noted, for example,
in Table 2.3 that PropBank introduces a new verb sense for a phrasal verb even if its
other properties are identical to those of the corresponding simplex verb, which is not
the case in the other two databases.
The information that is included in the lexicon entries is also different. We can see, for
example, that the morpho-syntactic properties of the constituents that combine with
the predicating words are described in different way. While FrameNet provides detailed
specifications (Table 2.1), VerbNet defines these properties only for some argument re-
alizations (Table 2.4). PropBank does not contain this information in the lexicon at all,
but all the instances of the roles are attached to nodes in syntactic trees in the annotated
corpus.
Finally, different sets of roles are used in the descriptions. FrameNet uses many different
role labels that depend on which frame they occur in. These roles can have a more specific
meaning such as buyer in the frame Commerce-buy, but they can also refer to a more
general notions such as agent in the frame Accomplishment (see Section 2.2.2). VerbNet
uses a set of 23 roles with general meaning that are interpreted in the same way with
all verbs. PropBank uses only 6 role labels, but their interpretation varies depending
on the context (see Section 2.2.2). Interestingly, all the three resources adopt atomic
notions and relatively arbitrary role sets, despite the arguments for decomposing the
predicate-argument structure, put forward in the linguistic literature (see Section 2.1.2).
PropBank labels are based on Dowty (1991)’s notions of proto-roles, but the properties
68

2.2. Verb classes and specialised lexicons
which define to what degree a role belongs to one of the two types (see Section 2.1.3)
are not annotated separately.
A number of experiments have been conducted to investigate how the differences between
the PropBank and the VerbNet annotation schemes influence the systems for automatic
role labelling. The task of learning the VerbNet labels can be expected to be more
difficult, since there are more different items to learn. On the other hand, the fact that
the labels are used in a consistent way with different verbs could make it easier because
the labels should be better associated with the other features used by the systems.
Loper et al. (2007) show that the system trained on the VerbNet labels predicts better
the label for new instances than the system trained on the PropBank labels, especially
if the new instances occur in texts of a different genre. However, this finding only holds
if the performance is compared for the arg1 and arg2 labels in PropBank vs. the
sets of VerbNet labels that correspond to them respectively. The VerbNet labels were
grouped in more general labels for this experiment, 6 labels corresponding to arg1 and
5 corresponding to arg2. If the overall performance is compared, the PropBank labels
are better predicted, which is also confirmed by the findings of Zapirain et al. (2008).
Merlo and van der Plas (2009) compare different quantitative aspects of the two anno-
tation schemes and propose the ways in which the resources can be combined. They
first reconsider the evaluation of the performances of the systems for automatic seman-
tic role labelling. They point out that an uninformed system that predicts only one
role, the most frequent one, for every case would be correct in 51% cases if it learned
the PropBank roles, and only in 33% cases if it learned the VerbNet roles, due to the
different distributions of the instances of the roles in the corpus. They neutralise this
bias by calculating and comparing the reduction in error rate for the two annotations.
According to this measure, the overall performance is better for the VerbNet labels,
but it is more degraded in the cases where the verb is not known (not observed in the
training data) compared to the cases where it is known, due to the stronger correlation
between the verb and its role set. Thus, they argue that the VerbNet labels should be
used if the verb is known, and the PropBank labels if it is new.
Looking at the joint distribution of the labels in the corpus, Merlo and van der Plas
(2009) note different relations for roles with different frequencies. The frequent labels in
69

2. Overview of the literature
PropBank can be seen as generalizations of the frequent labels in VerbNet. For example
agent and experiencer are most frequently labelled as arg0, while theme, topic,
and patent are most frequently labelled as arg1, which means that the PropBank
labels group together the similar VerbNet labels. The PropBank labels of low frequency
are more specific and more variable, due to the fact that they depend on the context,
and the VerbNet labels are more stable. Thus for interpretation for a particular instance
of a PropBank label a VerbNet label could be useful.
The comparisons of the sets of labels used in PropBank and VerbNet annotation schemes
indicate that they can be seen as complementary sources of information about semantic
roles. However, other aspects of combining the resources are still to be explored. The
described comparisons are performed only for the lexical units which are included both
in PropBank and VerbNet. Since these two resources contain different lexical items, their
combination might be used for increasing the coverage. Also, the potential advantages of
using the other data provided by the resources (e.g. the hierarchies defined in FrameNet
and VerbNet) are still to be examined.
2.3. Automatic approaches to the predicate-argument
structure
The relational meaning of verbs, represented as the predicate-argument structure, is not
only interesting from a theoretical point of view. As a relatively simple representation of
the meaning of a clause, which can also be related with some observable indicators (see
Section 2.2.1), this representation has attracted considerable attention in the domain of
automatic analysis of the structure of natural language. An automatic analysis of the
predicate-argument structure can be useful for improving human-machine interface so
that computers can be exploited in searching for information in texts and databases,
automatic translation, automatic booking, and others. For example, an automatic rail-
way information system could use such an analysis to “understand” that from Geneva
denotes the starting point and to Montreux the destination of the request in (2.43).
(2.43) What is the shortest connection from Geneva to Montreux?
70

2.3. Automatic approaches to the predicate-argument structure
Automatic analysis of the predicate-argument structure relies on the observations of
the instances of verbs in large samples of texts, electronic corpora. The observable
characteristics of the instances of verbs are formulated as features which are then used
to train machine learning algorithms. Most of the algorithms used in computational
approaches to the predicate-argument structure are not tailored specifically for natural
language processing, but they are general algorithms which can be applied to a wider
range of machine learning tasks. Nevertheless, with well chosen feature representation,
statistic modelling of data, and an appropriate architecture, systems generally manage
to capture semantically relevant aspects of the uses of verbs showing high agreement
with human judgments.
In this dissertation, we regard computational approaches to the predicate-argument
structure of verbs as a suitable experimental framework for testing our theoretical
hypotheses. To achieve a good performance in automatic analysis of the predicate-
argument structure, it is necessary to capture generalisations about the relationship
between the meaning of verbs, which people interpret intuitively, and the distribution
of different observable characteristics of verb uses in language corpora. Since the same
relationship is modelled in our work, we study and apply methods used in computational
approaches.
As opposed to theoretical approaches, computational approaches put the accent on pre-
dictions rather than on the generalisations themselves. In theoretical accounts of lin-
guistic phenomena, generalisations are usually stated explicitly in the form of grammar
rules. In computational approaches, generalisations are often formulated in terms of
statistical models expressing explicitly relationships between structural elements, but
not necessarily in the form of grammar rules. Predictions which follow from the gener-
alisations can be explicitly formulated in theoretical accounts, but this is not necessary.
Contrary to this, predictions are precisely formulated in computational approaches and
tested experimentally.
Another important difference between theoretical and computational approaches is in
the theoretical context which is assumed for each particular problem. While theoreti-
cal accounts treat particular problems in relation to a more general theory of linguistic
structure, computational approaches are focused on specific tasks treating them as inde-
71

2. Overview of the literature
pendent of other tasks. The task orientation in computational approaches allows specific
definitions of predictions and measuring the performance, but theoretical relevance of
discovered generalisations is often not straightforward.
In this section, we discuss the work in the natural language processing framework which
involves analysing the predicate-argument structure of verbs. We concentrate especially
on two tasks which deal with the relationship between the meaning of verbs and the
structure of the clauses: semantic role labelling and verb classification. We briefly de-
scribe other related tasks which are less directly concerned with the relationship studied
in our own experiments.
2.3.1. Early analyses
Early work on automatic analysis of the syntactic realisations of verbs’ semantic argu-
ments centred around automatic development of lexical resources which would be used
for syntactic parsing and text generation. The work was based on the assumption that
the number of potential syntactic analyses can be significantly reduced if the information
about the verb’s subcategorisation frame is known (Manning 1993; Brent 1993; Briscoe
and Carroll 1997). It was soon understood that the notion of verb subcategorisation
alone does not capture the relevant lexical information. Due to the alternations of ar-
guments, many verbs are systematically used with multiple subcateogrisation frames.
The subsequent work brought some proposals for automatic identification of argument
alternations of verbs (McCarthy and Korhonen 1998; Lapata 1999). These proposals
still concerned mostly syntactic issues.
Early approaches, as well as the majority of the subsequent work on lexical and syn-
tactic properties of verbs, do not target the nature of the relationship between a verbal
predicate and its semantic arguments. The tasks are defined in terms syntactic sub-
categorisation and selectional preferences. The aim of this research is to improve the
performance of automatic parsers by limiting the range of possible syntactic constituents
with which a verb can be combined (the taks of identifying the subcategorisation frames)
and the range of possible lexical items which can head these constituents (the task of
identifying selectional preferences).
72

2.3. Automatic approaches to the predicate-argument structure
Identifying the nature of the semantic relationships between verbs and their arguments
was established as a separate task, called semantic role labelling. In the following section,
we discuss in detail the methods used in this task.
2.3.2. Semantic role labelling
The work on automatic semantic role labelling was enabled by the creation of the re-
sources described in Section 2.2.2, which provided enough annotated examples to be used
for training and testing the systems. Since the first experiments (Gildea and Jurafsky
2002), semantic role labelling has received considerable attention, which has resulted in
a variety of proposed approaches and systems. Many of the systems have been devel-
oped and directly compared within shared tasks such as the CoNLL-2005 shared task
on semantic role labelling (Carreras and Marquez 2005) and the CoNLL-2009 shared
task on syntactic and semantic dependencies in multiple languages (Hajic et al. 2009).
Most of the numerous proposed solutions follow what can be considered the standard
approach.
Standard semantic role labelling
The most widely adopted view of the task of automatic semantic role labelling is the
supervised machine learning approach defined by Gildea and Jurafsky (2002). The term
supervised refers to the fact that a machine learning system is trained to recognise the
predicate-argument structure of a clause by first observing a range of examples where
the correct structure is explicitly annotated.
(2.44)
73

2. Overview of the literature
a)
S
VP
NP/theme
a cake
V
made
NP/agent
Mary
b)
S
VP
NP
a cake
V
made
NP
Mary
The annotation guides the system in selecting the appropriate indicators of the structure.
The program reads the training input (a simplified example of a training sentence is
shown in (2.44a)) and collects the information about the co-occurrence of the annotated
structure and other observable properties of the phrase (lexical, morphological, and
syntactic). The collected observations are transformed into structured knowledge and
generalisations are made by means of a statistical model. Once the model is built using
the training data, it is asked to predict the predicate-argument structure of new (test)
phrases (illustrated in (2.44b)), by observing their lexical, morphological and syntactic
properties.
In the standard approach, the task of predicting the predicate argument structure of
a sentence is divided into two sub-tasks: identifying the constituents that bear a se-
mantic role (distinguishing them from the constituents that do not) and identifying the
semantic role label for all the constituents that bear one. Both sub-tasks are defined
as a classification problem: each constituents is first classified as either bearing or not
bearing a semantic role. Each constituent bearing a role is then classified into one of the
predefined semantic role classes. All the constituents belonging to the same class bear
the same semantic role. The two classification steps constitute the core of the semantic
role labelling task, which is usually performed in a pipeline including some pre- and
post-processing.
The pre-processing part provides the information which is considered given. First, the
predicates which assign semantic roles to the constituents are identified prior to semantic
role labelling proper. They are usually identified as the main verbs which head clauses.
Second, the syntactic analysis of the sentence that is being analysed is considered given.
Both pieces of information are obtained by morphological and syntactic processing of
74

2.3. Automatic approaches to the predicate-argument structure
the sentence. The relatively good performances of current morphological and syntactic
analysers allow these analyses to be performed automatically.
In practice, most of the systems use resources in which predicates are manually annotated
(see Section 2.2.2). However, Merlo and Musillo (2008) show that this information can
also be automated with comparable results, exploiting the relevant syntactic phenomena
already encoded in the syntactic annotation. In deciding which arguments belongs to
which predicate in a sentence, two sets of conditions are informative. First, the mini-
mality conditions determine whether another verb intervenes between a constituent and
its potential verb predicate. Second, the locality constraints determine whether the con-
stituent is realised outside of a verb phrase, either as the subject of a sentence or an
extracted constituent.
The post-procesing part can include various operations depending on the particular
system. In most cases, this part includes optimising at the sentence level. This step is
needed to account for the fact that semantic roles which occur in one sentence are not
mutually independent. For example, if one role is assigned to one syntactic constituent,
it is unlikely that the same role is assigned to another constituent in the same sentence.
In the standard approach, all the constituents are first assigned a role independently,
then the assignments are reconsidered in the post-processing phase taking into account
the information about the other roles in the sentence.
We do not discuss in detail all the aspects of automatic semantic role labelling, but
we focus on two aspects which are most relevant to our own experiments: knowledge
representation using features and statistical modelling of the collected data.
Features. The grammatical properties of phrases which are relevant for semantic role
labelling are described in terms of features.11 Different systems may use different fea-
tures, depending on the approach, but, as noted by Carreras and Marquez (2005) and
Palmer et al. (2010), a core set of features is used in almost all approaches. Those are
mainly the features defined already by Gildea and Jurafsky (2002):
11Note that the term feature is used in a different way in computational and in theoretical linguistics.Features in theoretical linguistics are more or less formal properties of lexical units which indicatewith what other lexical units they can be combined in syntactic derivations. In computationallinguistics, a feature can be any fact about a particular use of some word of a phrase.
75

2. Overview of the literature
• Phrase type — reflects the fact that some semantic roles tend to be realised by
one and others by another type of phrase. For example, the role goal tends to be
realised by noun phrases, and the role place is realised by prepositional phrases.
In training, the phrase type of each constituent annotated as a realisation of a
semantic argument of a verb is recorded. In the toy example given in (2.44), both
roles would be assigned the same value for this feature: NP.
• Governing category — defines the grammatical function of the constituent that
realises a particular semantic role. This feature captures the fact that some se-
mantic roles are realised as the subject in a sentence, and others are realised as the
direct object. The feature is defined so that it can only have two possible values:
S and VP. If a constituent bearing a semantic role is governed by the node S in a
syntactic tree, it is the subject of the sentence (Mary in (2.44)); if it is governed
by the node VP, it means that it belongs to the verb phrase, which is the position
of the object (a cake in (2.44)). The difference between the direct and the indirect
object is not made.
• Parse tree path — defines the path in the syntactic tree which connects a given
semantic role to its corresponding predicate. The value of this feature is the
sequence of nodes that form the path, starting with the verb node and ending
with the phrase that realises the role. The direction of moving from one node to
another is marked with arrows. For example, the value of the feature for the agent
role in the example (2.44) relating it to the verb made would be: V↑VP↑S↓NP; the
value of this feature for the theme role would be: V↑VP↓NP. The whole string is
regarded as an atomic value. Possible values for this feature are numerous. Gildea
and Jurafsky (2002) count 2 978 different values in their training data.
• Position — defines the position of the constituent bearing a semantic role rela-
tive to its corresponding predicate, whether the constituent occurs before or after
the predicate. This is another way to describe the grammatical function of the
constituent, since subjects tend to occur before and objects after the verb.
• Voice — marking whether the verb is used as passive or active. This feature is
needed to capture the systematic alternation of the relation between the gram-
matical function and semantic role of a constituent. While agent is the subject
76

2.3. Automatic approaches to the predicate-argument structure
and theme is the object in typical realisations, the reverse is true if the passive
transformation takes place.
• Head word — describes the relation between the lexical content of a constituent
and the semantic role that it bears. The value of this feature is the lexical item
that heads the constituent. For example, a constituent which is headed by Mary is
more likely to be an agent than a theme, while the constituent headed by cake
is more likely to be a theme, as it is the case in (2.44).
The overview of the features shows that the systems for automatic identification of the
roles of verbs’ arguments largely rely on the syntactic analysis and the relation between
the type of a semantic role and the syntactic form. Three of the listed features, path,
government, and position are different indicators of the grammatical function of the
constituents. Gildea and Jurafsky (2002) compare performances of the system using
only one or two features at a time to the performance using the whole set. They find
that using both the position and either of the other two feature is redundant. On the
other hand, including any of these features is necessary.
More recent systems use more features. In addition to the government feature, for
instance, the information about the siblings of the constituent in the tree is collected.
Also, information about the subcategorization frame or syntactic pattern of the verb is
often used (Carreras and Marquez 2005).
Selecting a particular set of features to represent the relevant knowledge about the
predicate-argument structure does not rely on any particular theoretical framework or
study. The choice of features tends to be arbitrary with little research on its linguistic
background. An exception to this is the study of Xue and Palmer (2004), which shows
that the feature set which should be used for argument identification is not the same as
the set which should be used for assigning the labels.
Modelling. When predicting the correct semantic role for a string of words (usually
representing a constituent of a sentence) the system observes the values of the defined
features in the test data and calculates the probability that each of the possible roles oc-
curs in the given conditions. The role that is most likely to occur in the given conditions
is assigned to the constituent.
77

2. Overview of the literature
The probability that is calculated for each possible role is formulated in the following
way (Gildea and Jurafsky 2002):
P (r|h, pt, gov, position, voice, t) (2.45)
The knowledge about the current instance which is being classified consists of the values
of the features listed on the right-hand side of the bar. The formula in (2.45) reads in the
following way: What is the probability that a particular constituent bears a particular
semantic role r knowing that the head of the constituent is h, the path between the
constituent and the predicate is pt, the category governing the constituent is gov, the
position of the constituent relative to the predicate is position, the voice of the verb
predicate is voice, and the verb predicate is t?
To choose the best role for a particular set of feature values, the probability of each
role in the given context needs to be assessed. One could assume that the role which
occurs most frequently with a given combination of values of the features in the training
data is the role that is most likely to occur with the same features in the test data
too. In this case, the probability could be calculated as the relative frequency of the
observations: the number of times the role occurs with the combination of features out
of all the occurrences of the combination of features in question:
P (r|h, pt, gov, position, voice, t) =#(r, h, pt, gov, position, voice, t)
#(h, pt, gov, position, voice, t)(2.46)
The problem with this approach is that some features can have many different values
(e.g. the value of the feature head word can be any word in the language), which results
in a large number of possible combinations of the values. Many of the combinations will
not occur in the training data, even if large-scale resources are available. Thus, the set
of features has to be divided into subsets that occur enough times in the training data.
The values for each subset are then considered for each possible semantic role and the
decision on the most probable role is made by combining the information. Gildea and
Jurafsky (2002) divide the set of features into 8 subsets:
78

2.3. Automatic approaches to the predicate-argument structure
P (r|t), P (r|pt, position, voice, t),P (r|pt, t), P (r|h),
P (r|pt, gov, t), P (r|h, t),P (r|pt, position, voice), P (r|h, pt, t).
They explore several methods of combining the information based on the subsets achiev-
ing the best results by combining linear interpolation with the back-off method. Linear
interpolation provides the average value of the probabilities based on the subsets of
features. It is calculated in the following way:
P (r|constituent) =λ1P (r|t) + λ2P (r|pt, t)+
λ3P (r|pt, gov, t) + λ4P (r|pt, position, voice)+
λ5P (r|pt, position, voice, t) + λ6P (r|h)+
λ7P (r|h, t) + λ8P (r|h, pt, t) (2.47)
where λi represents interpolation weight of each of the probabilities and Σiλi = 1.
It can be noted that not all subsets include the same number of features. By including
more features, the subset (pt, position, voice, t), for instance, defines more specific con-
ditions than the subset (t). The back-off method enables combining the more specific
features, that provide more information, when they are available and turning to the
more general features only if the specific features are not available. The values for the
most specific subsets ((pt, position, voice, t), (pt, gov, t), (h, pt, t)) are considered first. If
the probability cannot be estimated for any of them, it is replaced by its corresponding
less specific subset. For example, (pt, position, voice, t) is replaced by (pt, position, t),
(pt, gov, t) by (pt, t), (h, pt, t) by (h, t) and so on.
Different systems apply different machine learning methods to estimate the probabilities.
A range of different methods, including those based on maximum entropy, support vector
machines, decision tree learning and others, have been applied in more recent systems
(Carreras and Marquez 2005) .
79

2. Overview of the literature
The described classification applies to the task of assigning a semantic role to a con-
stituent which is known to bear one. The same methods can be used for the first step
in semantic role labelling, that is to identifying the constituents which bear semantic
roles. The estimated probability in this case is the probability that a constituent bears
any semantic role in given conditions, described by a reduced set of features. Gildea and
Jurafsky (2002) use the information on the head word (feature h), target word t and the
path between them.
Joint and unsupervised learning
There are two kinds of approaches which can be seen as not following the standard
pipeline framework. One line of the development explores the potential of joint mod-
elling. These statistical models and computational methods exploit the relationship
between the syntactic and the predicat-argument structure in a more systematic way.
Toutanova et al. (2005) shows that moving the account of the global outline of a sentence
from the post-processing phase to the core statistical model improves the classification
results. Henderson et al. (2008) propose a model for joint learning of both syntactic
and semantic labelling in a single model, moving the syntactic information from the
pre-processing phase to the core statistical model. The advantage of such approaches
compared to the standard approach is that the syntactic structure of a phrase is not
definitely assigned before the semantic structure, so that the semantic information can
be used for constructing a better syntactic representation, reducing error propagation
between the levels of analysis.
Recently, the attention has been focused on unsupervised learning, where the information
about correct semantic role labels (assigned by human annotators) is not available for
training. The advantage of unsupervised approaches (Lang and Lapata 2011; Titov and
Klementiev 2012; Garg and Henderson 2012) compared to the standard approach is
that they do not require manually annotated training data, which are costly and hard to
develop (see Section 2.2.2 for more detail). Unsupervised learning exploits the overlap
between syntactic representation and the predicate-argument structure. The models
cluster the instances of syntactic constituents described in terms of features (similar to
the features used in the standard approaches). The constituents which are similar in
80

2.3. Automatic approaches to the predicate-argument structure
terms of their feature representations are grouped together. The models include a hidden
layer representing semantic roles which potentially underlie the observed distribution of
the constituents.
2.3.3. Automatic verb classification
The task of automatic verb classification addresses not only the predicate-argument
structure of verbs, but also the semantic classification of verbs. An in-depth analysis
of the relationship between the lexical semantics of verbs and the distribution of their
uses in a corpus is performed by Merlo and Stevenson (2001). The study addresses the
fine distinctions between three classes of verbs which all include verbs that alternate
between transitive and intransitive use. The classes in question are manner of motion
verbs (2.48), which alternate only in a limited number of languages, change of state
verbs (2.49), alternating across languages, and performance/creation verbs (2.50).
(2.48) a. The horse raced past the barn.
b. The jockey raced the horse past the barn.
(2.49) a. The butter melted in the pan.
b. The cook melted the butter in the pan.
(2.50) a. The boy played.
b. The boy played soccer.
Although the surface realisations of phrases formed with these verbs are the same (they
all appear both in transitive and intransitive uses), the underlying semantic analysis of
the predicate-argument structure is different in each class. The subject of intransitive
realisation is agentive (animate, volitional) in (2.48a) and (2.50a), while it is not in
(2.49a). On the other hand, the transitive realisation contains one agentive and one
non-agentive role in (2.49b) and (2.50b), while the realisation in (2.48b) contains two
agentive arguments. Correct classification of verbs into one of the three classes defines,
thus, the correct analysis of the semantic relations that they express.
81

2. Overview of the literature
Merlo and Stevenson (2001) base their approach to automatic classification of verbs on
the theoretical notion of linguistic markedness. The main idea of the theory of marked-
ness is that linguistic marking occurs in elements which are unusual, unexpected, while
the common, expected elements are unmarked. To use a common simple example, the
plural of nouns in English is marked with an ending (’-s’) because it is more uncommon
than singular which is unmarked. Linguistic markedness has direct consequences on
the frequency of use: it has been shown that marked unites are rarer than unmarked
unites.
Applied to the choice between the intransitive and transitive use of the verbs addressed
by Merlo and Stevenson (2001), the theory of linguistic markedness results in certain
expectations about the distribution of the uses. It can be expected, for example, that
the uses such as (2.48a) are unmarked, which means more frequent, while the uses
such (2.48b) are marked, which means less frequent. In the case of verbs represented in
(2.50) the expected pattern is reversed: the intransitive use (2.50a) is marked here, while
the transitive use (2.50b) is unmarked. For the verbs illustrated in (2.49) none of the
uses is marked, which means that roughly equal number of transitive and intransitive
realisations is expected.
Features. In the classification task, the uses of verbs are described in terms of features
which are based on a combination of the markedness analysis with an analysis of semantic
properties of the arguments of the verbs. Three main features are defined:
• Transitivity — captures the fact that transitive use is not equally common for
all the verbs. It is very uncommon for manner of motion verbs (2.48b), much
more common for change of state verbs (2.49b), and, finally, very common for
performance/creation verbs (2.50b). This means that manner of motion verbs are
expected to have consistently a low value for this feature, change of state verbs
middle, and performance/creation verbs high.
• Causativity — represents the fact that, in the causative alternation, the same
lexical items can occur both as subjects and as objects of the same verb. This
can be expected for arguments such as butter in (2.49) and horse in (2.48). This
feature is operationally defined as the rate of overlap between lexical units found
as the head of the subject of the intransitive uses and those found as the head
82

2.3. Automatic approaches to the predicate-argument structure
of the object in the transitive uses of the same verb. The quantity is expected
to distinguish between the two classes illustrated in (2.48) and (2.49) on one side
and the class illustrated in (2.50) on the other side, because the alternation in the
latter class is not causative (the object of the transitive use does not appear as the
subject of the intransitive use, it is simply left out).
• Animacy — is used to distinguish between the verbs that tend to have animate
subjects (manner of motion verbs (2.48) and performance verbs (2.50)) and those
that do not (change of state verbs (2.49)). It is operationally defined as the rate
of personal pronouns that appear as the subjects of verbs.
Additional features are also used (the information about the morphological form of the
verb) but they are not as theoretically prominent as the main three features.
Classification. The experiments in classification are performed on 60 verbs (20 per
class) listed as belonging to the relevant verb classes by Levin (1993). Each verb is
described as a vector of feature values, where the values are calculated automatically
from corpus data, as shown for the verb form opened in (2.51).
(2.51) a)verb trans pass vbn caus anim class-code
opened .69 .09 .21 .16 .36 unacc
b)verb trans pass vbn caus anim class-code
opened .69 .09 .21 .16 .36 ?
The co-occurrence of the feature values with a particular class is observed in the training
data and registered. The training input is illustrated in (2.51a). The first six positions
in the vector represent the values of the defined features extracted from instances of the
verb in a corpus. The the last position in the vector is the class that should be assigned
to the verb. The code unacc refers to the term unaccusative verbs, which is often used
to refer to the change-of-state verbs. In predicting the class that is assigned to a verb
in the test input (illustrated in (2.51b)), the probability of each class being associated
with the observed vector of feature values is assessed. The algorithm used for calculating
the most probable class is a supervised learning algorithm, the decision tree, which is
described in more detail in Chapter 3.
83

2. Overview of the literature
The results of the study show that the classifier performs best if all the features are
used. They also show that the discriminative value of the features differs when they are
used separately and when they are used together, which means that information about
the use of verbs that they encode is partially overlapping. Subsequent studies develop
in different directions. While Merlo et al. (2002) explore using cross-linguistic informa-
tion as a kind of additional general supervision in the classification task, most of the
remaining work concerns two interrelated lines of research: unsupervised classification
and generalisation.
Lapata and Brew (2004) propose a statistical model of verb class ambiguity for unsuper-
vised learning the classification preferences of verbs which can be assigned to multiple
classes. The model does not use a predefined set of linguistically motivated features as in
the approach of Merlo and Stevenson (2001), but it takes into account the distribution
of a wide range of verbs (those listed by Levin (1993)) and their syntactic realisations
in combination with the distribution of classes. The resulting preferences are then used
to improve verb senses disambiguation.
Several studies deal with the required feature set (Stevenson and Joanis 2003; Joanis and
Stevenson 2003; Joanis et al. 2008; Schulte im Walde 2003; Schulte im Walde 2006;
Li and Brew 2008), especially in the unspervised and partially supervised setting. This
work suggests that the set of features which is useful for verb classification is not specific
to this task. Schulte im Walde (2003) argues that no generally useful features can be
identified, but that the usefulness of a feature depends on the idiosyncratic properties of
verb classes. Baroni and Lenci (2010) explore further potential generalisations in lexical
acquisition from corpora, proposing a framework for constructing a general memory
of automatically acquired lexical knowledge about verbs. This knowledge can be used
directly for different classifications required by different applications. Schulte im Walde
et al. (2008), Sun and Korhonen (2009) explore further the effects of incorporating the
information about lexical preferences of verbs into verb classification, which had proved
to be less helpful than expected in earlier experiments (Schulte im Walde 2003).
84

2.4. Summary
2.4. Summary
We have shown in this chapter how the view of the lexical representation of verbs has
evolved in linguistic theory and how it was followed in computational linguistics. Three
turning points in theoretical approaches to the meaning of verbs can be identified. First,
the relational meaning of verbs is separated from the other, idiosyncratic semantic com-
ponents. The relational meaning, called the predicate-argument structure, is then further
analysed. There are two main approaches to the decomposition of the predicate argu-
ment structure: decomposition of the arguments into sets of features and decomposition
of the verbal predicates into sets of predicates. In the latter approach, an attempt is
made to derive the decomposition from more general semantic templates (such as causal
or temporal).
The predicate-argument structure has recently been recognised in computational lin-
guistics as a level of linguistic representation that is suitable and useful for automatic
analysis. The view of the predicate argument structure underlying the computational ap-
proaches, however, does not follow the developments in linguistic theory. The overview of
the knowledge representation in the resources used for training automatic systems shows
that the predicate-argument structure which is annotated and automatically learnt is
still based on the atomic view of the predicates and arguments, despite the fact that this
view is shown to be theoretically inadequate in the linguistic literature. The feature-
based knowledge representation used in the statistical models is also not closely related
to the notions discussed in the linguistic literature. However, the work on automatic se-
mantic role labelling and verb classification shows the potential of using the information
about verb instances in corpora for recognising fine components of verbal meaning.
In this dissertation, we use the methods developed in the approaches to automatic
acquisition of the meaning of verbs to learn automatically the components of the lexical
representation which are relevant to the current discussion in linguistic theory. The
components of verbs’ meaning which we identify on the basis of the distributions of their
syntactic realisations observed in a corpus are defined in terms of causal and temporal
decomposition of events described by the verbs.
Studying the uses of verbs in parallel corpora is the main novelty of this work. By
85

2. Overview of the literature
taking this approach, we make a step further with respect to both existing computational
approaches and the standard linguistic methodology. Previous corpus-based explorations
of the meaning of verb are generally monolingual and they do not address the patterns in
the cross linguistic variation. On the other hand, cross-linguistic data are crucial for the
standard methodology of linguistic research. However, the standard approaches usually
involve just a few instances of the studied phenomena which are discussed in depth. In
contrast to this, the approach which we propose allows studying cross-linguistic variation
in a more systematic way, taking into consideration large data sets. The details of our
approach based on parallel corpora are discussed in the following chapter.
86

3. Using parallel corpora for linguistic
research — rationale and
methodology
A parallel corpus is a collection of translations between two (or more) languages, where
each sentence in one language is aligned with the corresponding sentence in the other
language. The work on constructing numerous parallel corpora of different languages was
primarily motivated by the developments in statistical machine translation in the early
nineties. With the emergence of systems able to learn to translate from one language
to another by observing a set of examples of translated sentences, resources for training
and evaluating such systems started growing rapidly. Current versions of some popular
sentence-aligned parallel corpora, such as Europarl (Koehn 2005) or OPUS (Tiedemann
2009), contain tens of languages, with some languages being represented with millions of
sentences. These resources are still used mostly for experiments in machine translation,
but potential other uses are increasingly proposed and explored.
In this dissertation, parallel corpora are used for investigating lexical representation of
verbs. To address theoretical questions concerning the meaning of verbs, we design a
novel methodology which combines methods originating in several disciplines. We for-
mulate our research hypotheses on the basis of theoretical discussions and arguments
put forward in the linguistic literature. We then collect a large number of empirical
observations relevant to the hypotheses from parallel corpora using state-of-the-art nat-
ural language processing. We perform different statistical analyses of the collected data.
Some interesting insights are obtained by a simple descriptive analysis where a summary
of a large number of observations reveals significant patterns in the use of verbs. In some
87

3. Using parallel corpora for linguistic research — rationale and methodology
cases, we use standard statistical tests to determine whether some identified tendencies
are statistically and scientifically significant. When a more complex analysis is required,
we design statistical models, which are intended to explain the observations with a set of
generalisations. To test the predictive performance of the models, we employ standard
machine learning methods which are commonly used in natural language processing, but
not in theoretical linguistics. We train the models on a large set of examples of verbs’
use extracted from parallel corpora using machine learning algorithms. We then test and
evaluate the predictions made by the models on an independent set of test examples.
The methods are described in more detail in the remaining of this chapter.
The chapter consists of two major parts. In the first part (Section 3.1 and Section 3.2) we
discuss several methodological issues related to parallel corpora. We start by presenting
our arguments for using parallel corpora for linguistic research, showing that our method
based on parallel corpora can be regarded as an extension of the standard theoretical
approach to cross-linguistic variation (3.1.1). We then discuss potential methodological
problems posed by translation effects, which can influence the representativeness of par-
allel corpora (3.1.2). In Section 3.2, we first discus in detail automatic word alignment,
which is crucial for automatic extraction of data from parallel corpora (3.2.1). We then
give a brief overview of how parallel corpora have been used for research in natural
language processing as in illustration of the potential of parallel corpora as sources of
linguistic data (3.2.2). In the second part (Section 3.3 and Section 3.4), we present
the technical details of the methodology which we apply to analyse the data extracted
from parallel corpora. Section 3.3 contains an introduction to statistical inferences and
modelling. In Section 3.4 we lay out machine learning approaches to training statisti-
cal models, providing more details about the learning algorithms which are used in the
experiments in this dissertation.
3.1. Cross-linguistic variation and parallel corpora
In theoretical linguistics, cross-linguistic variation has always been studied as a means of
discovering elements of linguistic structure which are invariably present in all languages,
the atoms of language as metaphorically put by Baker (2001). Linguistic analysis almost
88

3.1. Cross-linguistic variation and parallel corpora
inevitably involves parallel sentences such as the pair Gungbe-English in (3.1), taken
from Aboh (2009), or the pair Ewe-English in (3.2) by Collins (1997).
(3.1) AsıbaAsiba
dacook/prepare/make
lεsırice
du.eat
Asiba cooked the rice eat(i.e. she ate the rice).
(3.2) KofiKofi
tsotake
ati-εstick-def
fohit
YaoYao
(yi).P
Kofi took the stick and hit Yao with it.
Such parallel sentences are usually constructed on the basis of native-speaker competence
to illustrate apparently different realisations of a particular construction in different
languages ((3.1) and (3.2) are examples of complex predicates) and to identify the level
of representation at which the languages do not differ. For the reason of simplification,
we do not show the full analysis of the examples (3.1) and (3.2), but they illustrate
a situation where the same kind of complex predicate-argument structures are realised
with two separate clauses in English, and with a single clause in Gungbe and Ewe. In
this case, the predications expressed in the sentences are invariable across languages,
while the structural level at which they are realised is varied.
Parallel sentences cited and analysed in the linguistic literature usually represent the
most typical realisations, abstracting away from potential variation in realisations in
both languages. The corpus of analysed cases rarely exceeds several examples for each
construction studied.
3.1.1. Instance-level microvariation
In this dissertation, parallel realisations of particular constructions are studied on a
much larger scale taking into consideration the potential variation in realisations. We see
parallel corpora as samples of sentences naturally produced in two (or more) languages,
from which we extract all instances of the studied constructions, and not just typical
uses, relying on statistical methods in addressing the variation. This approach allows
us to observe many different realisations of constructions that actually occur in texts
89

3. Using parallel corpora for linguistic research — rationale and methodology
and to address the non-canonical uses as well as the canonical realisations. Since we
work with actual translations, the cross-linguistically equivalent expressions are directly
observed. We do not have to rely on our intuition about which construction in one
language corresponds to which construction in the other language. We simply observe the
realisations in the aligned sentences and then summarise (or classify) the observations. In
this way, we can identify grammatically relevant tendencies which cannot be observed
using standard approaches. For example, passive constructions are available both in
English and German and they can be seen as equivalent forms. However, verbs in one
of the two languages may show a tendency to be realised in passive forms in the same
context where intransitive realisations are preferred by the other language. Such an
asymmetry might prove to be grammatically relevant.
Studying instances of verbs in a parallel corpus makes it possible to control for any
pragmatical and contextual factors that may be involved in a particular realisation
of a verb, allowing us to isolate structural factors which underlie the variation in the
realisations. Since translation is supposed to express the same meaning in the same
context, we can assume that the same factors that influence a particular realisation
of a verb in a clause in one language influence the realisation of its translation in the
corresponding clause in another language. Any potential differences in the form of the
two parallel clauses should be explained by the lexical properties of the verbs or by
structural differences between languages.
Studying many different instances of verbs in parallel corpora fits well with some re-
cent general trends in theoretical linguistics. In the current methodology of linguistic
research, small lexical variation between similar languages has been given an important
place. As discussed in several places in a collection of articles consecrated to the theoret-
ical aspects of cross-linguistic variation (Biberauer 2008), a distinction is made between
macro-parameters and micro-parameters.
In making this distinction, the term macro-parameters is used for those parameters
of variation which are traditionally studied, mostly in the framework of the theory
of principles and parameters (Chomsky 1995). Such a parameter is, for example, the
famous pro-drop parameter, which divides languages into two major groups: those where
expressing the subject of a sentence is obligatory, such as English and French, and those
90

3.1. Cross-linguistic variation and parallel corpora
where the subject can be omitted when it is expressed by a pronoun (hence the term
pro-drop), such as Italian. The term macro-parameter does not only refer to the fact
that these parameters concern all (or almost all) languages, but also to the fact that
they concern large structural chunks. Presence vs. absence of the subject is the kind of
variation that affects the basic layout of sentences, causing substantial differences in the
structure of sentences across languages.
As opposed to macro-parameters, micro-parameters concern the variation which is lim-
ited to smaller portions of sentences. They affect the structure of small phrases and,
especially, the choice of lexical items. They also apply to a smaller number of languages.
Micro-parameters are typically studied when structures are compared between closely
related languages, which have the same setting of macro-parameters. An example of a
micro-parametric category is the difference between the French quantifier beacoup and
its apparently corresponding English quantifier many. In an influential study, Kayne
(2005) shows that the two lexical items have different representations, although they are
considered equivalent. Kayne’s study is set within the programme of isolating minimal
abstract units of language structure by identifying minimal structural divergence in two
similar languages or even dialects of the same language.
We see parallel corpora as a suited resource for studying micro-variation. Numerous
examples of uses of lexical items can be extracted from parallel corpora and studied in a
systematic way. Applying automatic methods for extraction allows us to analyse not only
many instances of lexical items, but also many items. While theoretical investigations
are usually limited to just several items which are analysed at the type level, our studies
include thousands of instances of hundreds of verbs, which provides a strong empirical
basis for new theoretical insights. We underline that this advantage applies only to
those phenomena which are frequent enough so that a sample of instances can be found
in corpora. Lexical items with grammatically relevant properties, like the quantifiers
studied by Kayne (2005) and the verbs studied in this dissertation, represent exactly
that kind of linguistic phenomena.
Although cross-linguistic variation is one of the crucial issues in linguistic theory, parallel
corpora are rarely used in linguistic research outside natural language processing. The
importance of parallel corpora for linguistic research has been recognised mostly by the
91

3. Using parallel corpora for linguistic research — rationale and methodology
researchers in the domain of language typology. A collection of papers edited by Cysouw
and Walchli (2007) brings several case studies demonstrating the kind of language facts
that can be extracted from parallel corpora. A broader study is performed by von
Waldenfels (2012) who uses a parallel corpus of eleven Slavic languages to study the
variation in the use of imperative forms. The patterns that are found in the corpus
data are shown to correspond to the traditional genetic and areal classification of Slavic
languages.
Linguistic investigations of parallel corpora are not only rare, but they are also lit-
tle automated. Data collection and, especially, analyses are performed almost entirely
manually, which means that the number of observations which can be analysed is rather
small compared to the available information in the resources. In contrast to this, the
methodology proposed in this dissertation is entirely automatic, drawing heavily on the
approaches in natural language processing.
3.1.2. Translators’ choice vs. structural variation
One important limitation of using parallel corpora for linguistic research is the fact
that, despite controlling for context and discourse factors, translations might still include
variation which is not necessarily caused by linguistic divergences. Consider, for example,
the English sentence in (3.3a) and its French translation in (3.3b).
(3.3) a. I hope that the President of the Commission [...] tells us what he intends to
do.
b. J’espereI hope
quethat
lethe
presidentpresident
deof
lathe
Commissioncommission
[...] nousus
ferawill make
partpart
deof
seshis
intentions.intentions
Even if the English sentence in (3.3a) can be translated into French keeping the parallel
structure, it is not. As a result, the phrases tells us what he intends to do and nous fera
part de ses intentions (will make us part of his intentions) cannot be seen as structural
92

3.1. Cross-linguistic variation and parallel corpora
counterparts, although the two languages can express the content in question in a struc-
turally parallel way. There is a verb in French (communiquer) that corresponds to the
English verb tell, taking the same types of the complements as the English verb. How-
ever, at the instance level, these two sentence are not parallel. The factors that influence
the translations at the instance level are numerous, including discourse factors, broader
cultural context, translators attitudes, and other factors. An interesting question to ask,
then, is to what degree the existing translations actually show the structural divergence
between languages.
In an experimental study on a sample of 1 000 sentences containing potentially parallel
frames in the sense of FrameNet (see Section 2.2.2 in Chapter 2), extracted from the
Europarl corpus and manually annotated, Pado (2007) finds that 72% of English frames
that could have a parallel frame in German were realized as parallel instances. The ratio
is 65% for the pair English-French. However, once the frames are parallel, the parallelism
between the roles (frame elements in FrameNet) within the frames is assessed as “almost
perfect”.
We address this limitation by extracting only the most parallel sentences. We use the
information obtained by automatic alignment of words in parallel sentences and auto-
matic linguistic analysis of the sentences on both sides of a parallel corpus (described in
more detail in Section 3.2.1) to control the kind of constructions which are extracted.
We extract only the realisations which show certain levels of parallelism, minimising the
variation which is potentially irrelevant for linguistic studies.
Another potential problem for using parallel corpora for linguistic research are the known
translation effects. It has been argued that the language of translated texts differs
from the language of texts originally produced in some language in several respects.
Baroni and Bernardini (2006) have shown, for example, that, given a choice between an
expressions which is similar to the one in the source language and an expression which is
different, translators tend to chose the different expression. The result of this tendency is
more divergence in the translations than it is imposed by structural differences between
the languages. Also, different translators might have different strategies in choosing the
expressions.
93

3. Using parallel corpora for linguistic research — rationale and methodology
This limitation is partially addressed by the strategy of maximising parallelism in ex-
tracting the instances of verbs. Another strategy that we apply to addresses this issue is
using large-scale data. It can be expected that the variation which represents noise for
a linguistic analysis is marginalised in a big sample of instances which includes transla-
tions produced by many different translators. Patterns observed in a big sample can be
assigned to linguistic factors. The reasoning behind this expectation is that translators’
choice of expression is still limited by linguistic factors: they can only choose between
options provided by structural elements available in a language.
3.2. Parallel corpora in natural language processing
Collecting large data samples, which is crucial for studying parallel corpora, necessarily
involves automatic processing of texts. The information which is crucial for collecting
the data on cross-linguistic realisations of verbs is word alignment. If we want to ex-
tract verbs that are translations if each other in parallel sentences, the sentences need
to be word-aligned, so that, for each word in the sentence in one language, we know its
corresponding word in the sentence in the other language. Given that collecting large
samples implies extracting verb instances from hundreds of thousands of parallel sen-
tences, the required information can only be obtained automatically. In this section, we
discuss methods for automatic alignment of words in parallel corpora which have been
developed in the context of statistical machine translation.
3.2.1. Automatic word alignment
Word alignment establishes links between individual words in each sentence and their
actual translations in the parallel sentence. Figure 3.1 illustrates such an alignment,
where the German pronoun ich is aligned with the English pronoun I, German verb
form mochte, with the English forms would like and so on. As the example in Figure 3.1
shows, correspondences between the words in sentences are often rather complex. The
range of existing alignment possibilities can be described with the following taxonomy:
94

3.2. Parallel corpora in natural language processing
Figure 3.1.: Word alignment in a parallel corpus
• One-to-one alignment is the simplest and the prototypical case, where corre-
sponding single words are identified, such as I � Ich or lesson � Lehre in Figure
3.1
• One-to-null alignment can be used to describe words which occur in one language
but no corresponding words can be identified in the other language. In the example
in Figure 3.1, such words are English There, is, to and German daß.
• One-to-many alignment holds between a single word in one language and multiple
words in the other language. Examples of this relationship in Figure 3.1 are mochte
� would like and daraus � from this.
• Many-to-many alignment is necessary when no single word in any of the aligned
sentences can be identified as an alignment unit. This is usually case in aligning
idioms. The sentences in Figure 3.1 do not contain such an example. To illustrate
this case, we use the example in (3.4) taken from Burchardt et al. (2009). The
phrase nehmen in Kauf aligns with English put up with, but they can only be
aligned in the many-to-many fashion because no subpart of neither expression can
be identified as an alignment unit.
(3.4) a. Die Glaubiger nehmen Nachteile in Kauf. (German)
95

3. Using parallel corpora for linguistic research — rationale and methodology
b. The creditors put up with disadvantages. (English)
Note that identifying alignments between words and phrases is not always straightfor-
ward. Although it is clear that units smaller than a sentence can be aligned, it is not
always clear what kind of alignment holds and between which words exactly. As an
illustration, consider the word to in the English sentence in Figure 3.1. Its alignment
is subject to interpretation. It can be seen as not corresponding to any word in the
parallel German sentence (one-to-null alignment), which is how it is aligned in our ex-
ample. However, since to marks the infinitive form in English and the corresponding
German verb is in the infinitive form, the one-to-many alignment to learn � ziehen is
also correct.
The alignment between English learn and German ziehen illustrates an important dif-
ference between word alignments and lexical translations. The two verbs are clearly
aligned in the example in Figure 3.1, but they are not lexical translations of each other.
Outside of the given context, German ziehen would translate to English draw or pull,
while English learn would translate to German lernen.
For the purpose of automatic extraction from parallel corpora, word alignment is usually
represented as a set of ordered pairs, which is a subset of the Cartesian product of the
set of words of the sentence in one language and the set of words of the aligned sentence
in the other language (Brown et al. 1993). Technically, one language is considered the
source and the other the target language, although this distinction does not depend on
the true direction of translation in parallel corpora. With the words being represented
by their position in the sentence, the first member in each ordered pair is the position
of the target word (j in 3.5) and the second member is the position of the source word
that the target word is aligned with (i in 3.5).
A ⊆ {(j, i) : j = 1, ..., J ; i = 1, ..., I} (3.5)
The set A is generated by a a single-valued function which maps each word in the target
sentence to exactly one word in the source sentence. For example, taking English as the
target and German as the source language in Figure 3.1, the alignment between I and
ich can be represented as the ordered pair (6, 1). Alignment of would like with mochte,
96

3.2. Parallel corpora in natural language processing
is represented with two ordered pairs (7, 2) and (8, 2). To account for the fact that
some target language words cannot be aligned with any source language word, a special
empty word (“NULL”) is introduced in the source sentence. In this way, all the words
that have no translation (such as English There, is, to in Figure 3.1) can be aligned with
this word, satisfying the general condition which requires that they are aligned with one
word in the source sentence.
Note that the given formal definition only approximates the intuitive notion of word
alignment described above. The definition simplifies the listed alignment relations in
two ways. First, one-to-many alignments are possible only in one direction; one source
word can be aligned with multiple target words, but not the other way around. As
a consequence, switching the target-source assignment of a pair of sentences changes
the alignment. Second, the single-valued function definition excludes many-to-many
relations entirely. Despite these limitations, the described formalisation is widely used
because it expresses the main properties of word alignment in a way that is suitable for
implementing algorithms for its automatic extraction from parallel corpora.
Word alignment is usually computed from sentence alignment by means of the expectation-
maximisation algorithm. The algorithm considers all possible alignments of the words in
a pair of sentences (the number of possible word alignment pairs is length(source))(length(target))
and outputs the one which is most probable. The probability of alignments is assessed
at the level of a sentence. Individual words are aligned so that the alignment score of
the whole sentence is maximised. The algorithm starts by assigning a certain initial
probability to all possible alignments. The probabilities are then iteratively updated on
the basis of observations in a parallel corpus. If a pair of words is observed together
in other pairs of sentences, the probability of aligning the two words increases. The
algorithm is described in more detail in Section 3.4.2.
A commonly used program that provides automatic word alignment of parallel corpora,
GIZA++ (Och and Ney 2003)), which is also used in our experiments, assumes the
alignment definition described above. In addition to the described basic elements (in-
dividual word alignment and global sentence alignment), the system implements some
refinements, which improve its actual performance. We do not discuss these refinements
since they do not introduce major conceptual changes.
97

3. Using parallel corpora for linguistic research — rationale and methodology
The experiments performed to evaluate this alignment method (Och and Ney 2003)
showed that, apart from setting the required parameters, the quality of alignment de-
pends on the language pair, as well as on the direction of alignment (e.g. the performance
is better for the direction English → German than the other way around). They also
showed that combining the alignments made in both directions has a very good effect
on the overall success rate.
3.2.2. Using automatic word alignment in natural language
processing
Since parallel corpora have been available to the research community they have inspired
research in natural language processing beyond machine translation. A number of pro-
posals have been put forward to exploit translations of words automatically extracted
from parallel corpora for improving performance on different natural language process-
ing tasks. The work on part-of-speech tagging (Snyder et al. 2008) shows that data
from another language can help in disambiguating word categories. For example, the
English word can is ambiguous between three readings: it can be a modal verb, a noun,
or a lexical verb. Each of the three categories is translated with a different word in
Serbian, for example: the corresponding modal is moci, the noun is konzerva, and the
lexical verb is konzervirati. Knowing what is Serbian translation of the English word in
a given sentence can help decide which category to assign to the word.
The work of van der Plas and Tiedemann (2006) shows that the data from parallel cor-
pora can improve automatic detection of synonyms. The main difficulty for monolingual
approaches is distinguishing synonyms from other lexical relations such as antonyms,
hyponyms, and hypernyms, which all occur in similar contexts. For example, a mono-
lingual system would propose as synonyms the words apple, fruit, and pear because
they all occur in similar contexts. However, the fact that the three words are consis-
tently translated with different words into another language indicates that they are not
synonyms.
The potential of the data from parallel corpora for reducing ambiguity at different levels
of natural language representation has been used to improve syntactic analysis (Kuhn
98

3.2. Parallel corpora in natural language processing
2004; Snyder et al. 2009; Zarrieß et al. 2010), the analysis of the predicate-argument
structure (Fung et al. 2007; Wu and Palmer 2011), as well as machine translation
(Collins et al. 2005; Cohn and Lapata 2007).
An interesting application of parallel corpora is transferring structural annotation (mor-
phological, syntactic, semantic) from one language to another. Developing resources
such as FrameNet or PropBank (see Chapter 2, Section 2.2.2), which have enabled
progress in automatic predicate-argument analysis, requires substantial investments in-
volving linguistic expertise, financial support, and technical infrastructure. This is why
such resources are only available for a small number of languages. Parallel corpora have
been seen as a means of automatic development of the resources for multiple languages.
The assumption behind the work on transferring annotation is that languages share
abstract structural representations and that whatever analysis applies to a sentence in
one language should be applied to its translation in another language. This assumption
is generally shared by theoretical linguists, as discussed in more detail in Section 3.1.
However, when tested on large corpora, the portability of a structural annotation is not
straightforward (Yarowsky et al. 2001; Hwa et al. 2002; Pado 2007; Burchardt et al.
2009; van der Plas et al. 2011). The work on automatic annotation transfer, although
primarily motivated by more practical goals, has provided some general insights con-
cerning the difference between the elements of the structure which are universal and
those which are language-specific.
The issue of parallelism vs. variation in the predicate-argument structure between En-
glish and Chinese is addressed by Fung et al. (2007), who study a sample of the Parallel
English-Chinese PropBank corpus containing over 1 000 manually annotated and man-
ually aligned semantic arguments of verbs (Palmer et al. 2005b). They find that the
roles do not match in 17.24% cases. English arg0 role (see Section 2.2.2 in Chapter
2) for more details), for instance, is mapped to Chinese arg1 77 times. Although the
sources of the mismatches are not discussed, the findings are interpreted as evidence
against the assumption that this level of linguistic representation is shared in the case
of English and Chinese.
The plausibility of a strong version of the assumption of structural parallelism is explored
by Hwa et al. (2002). It is formulated as the Direct Correspondence Assumption:
99

3. Using parallel corpora for linguistic research — rationale and methodology
Given a pair of sentences E and F that are (literal) translations of each other
with syntactic structures TreeE and TreeF , if nodes xE and yE of TreeE
are aligned with nodes xF and yF of TreeF , respectively, and if syntactic
relationship R(xE, yE) holds in TreeE, then R(xF , yF ) holds in TreeF .
The evaluation of the annotation transferred from English to Chinese against a man-
ually annotated Chinese gold standard shows that syntactic relations are not directly
transferable in many cases. However, a limited set of regular transformations can be
applied to the result of direct projection to improve significantly the overall results. For
example, while English verb tense forms express verbal aspect at the same time (whether
the activity denoted by the verb is completed or not), Chinese forms are composed of
two words, one expressing the tense and the other the aspect. Projecting the annotation
from English, the relation between the aspect marker and the verb in Chinese cannot
be determined, since the aspect marker is either aligned with the same word as the verb
(the English verb form), or it is not aligned at all. In this case, a rule can be stated
adding the relation between the aspect marker and the verb to the Chinese annotation
in a regular way.
The work reviewed in this section illustrates the variety of cross-linguistic issues which
can be addressed on the basis of data automatically extracted from parallel corpora.
Despite the limitations discussed in Section 3.1.2, parallel corpora, in combination with
automatic word alignment, provide a new rich resource for studying various aspects of
cross-linguistic variation.
Note that, in addition to word alignment, which is common to all studies, extracting
linguistic information from parallel corpora requires other kinds of automatic processing.
If we want to extract all the instances of a certain verb in a corpus, we need to make sure
that, when we look for the verb go, for example, we obtain the instances of goes, went,
gone, and going as well. This means that the corpus needs to be lemmatised. The corpus
also needs to be morphologically tagged, so that we know that our extracted instances
are all verbs, and not some other categories. For example, we need to make sure that
the extracted instances do not include cases such as have a go, where go is a noun. If
we want to count how many times a verb is used as transitive and how many times
as intransitive, the corpus needs to be syntactically parsed. The details of linguistic
100

3.3. Statistical analysis
processing used in our experiments are explained in the methodological sections of each
case study separately, because the approaches to the studied constructions required
different linguistic analyses.
3.3. Statistical analysis
Once the aligned instances of verbs that interest us are extracted from parallel cor-
pora, we analyse them using various statistical methods. Statistical analysis allows us
to identify tendencies in the use of verbs which are relevant for studying their lexical
representation. In this section, we lay out the methods used in our studies together with
the technical background necessary for following the discussion in the dissertation. The
survey of the notions in the technical background relies mostly on two sources, Baayen
(2008) and Upton and Cook (1996).
3.3.1. Summary tables
In all the three case studies in this dissertation, observations are stored as two kinds
of variables. We distinguish between instance observations which refer to the charac-
teristics of use of verbs at the token level, and type observations, which refer to the
properties of verbs as separate entries in the lexicon. As an illustration of the two kinds
of data extracted from corpora, simple artificial examples are shown in Tables 3.1 and
3.2. Instance variables contain the information about each occurrence of a verb in the
corpus. Table 3.1, for example, contains two variables: the morphological form of the
verb in the given instances and its syntactic realisation (whether it is used as transi-
tive or not). Type variables contain the information that is relevant for lexical items
at the type level. Frequency in the corpus shown in Table 3.2 is typically the kind of
information that applies to types.
Simple tables that list the values of the variables usually do not help much in spotting
interesting patterns; individual observations are of little interest for a statistical analysis.
What is more interesting is the relationship between the values in two or more variables.
101
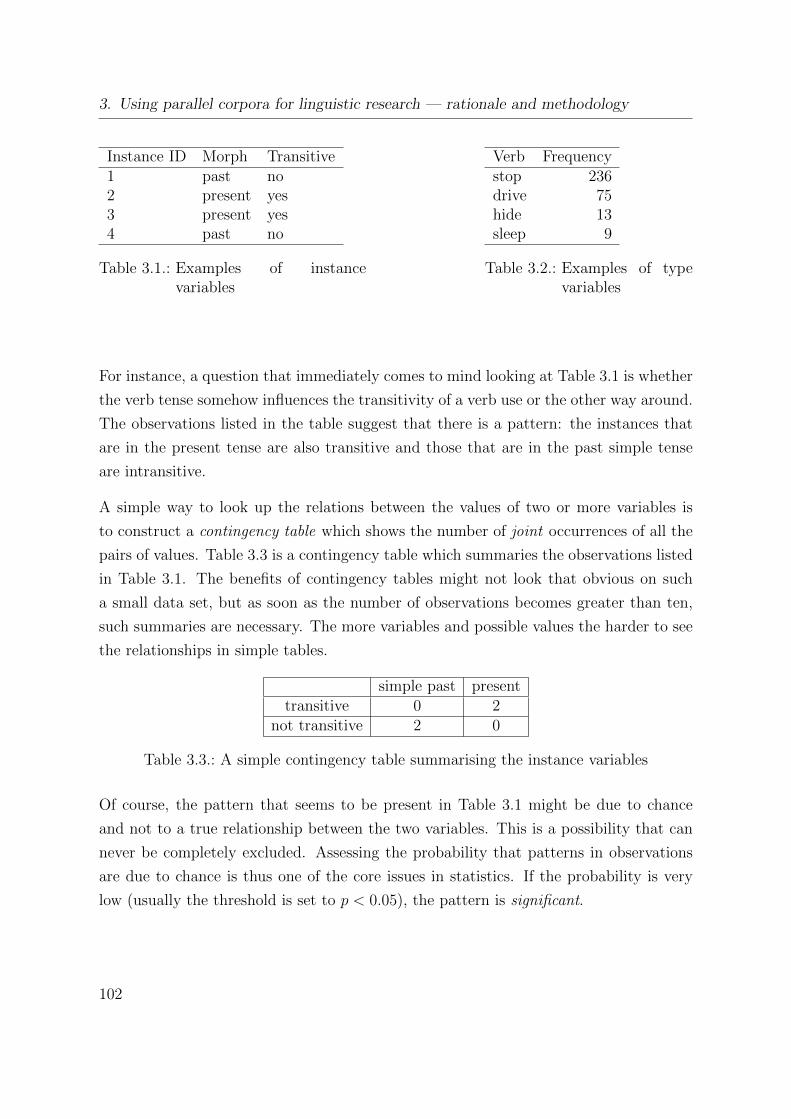
3. Using parallel corpora for linguistic research — rationale and methodology
Instance ID Morph Transitive1 past no2 present yes3 present yes4 past no
Table 3.1.: Examples of instancevariables
Verb Frequencystop 236drive 75hide 13sleep 9
Table 3.2.: Examples of typevariables
For instance, a question that immediately comes to mind looking at Table 3.1 is whether
the verb tense somehow influences the transitivity of a verb use or the other way around.
The observations listed in the table suggest that there is a pattern: the instances that
are in the present tense are also transitive and those that are in the past simple tense
are intransitive.
A simple way to look up the relations between the values of two or more variables is
to construct a contingency table which shows the number of joint occurrences of all the
pairs of values. Table 3.3 is a contingency table which summaries the observations listed
in Table 3.1. The benefits of contingency tables might not look that obvious on such
a small data set, but as soon as the number of observations becomes greater than ten,
such summaries are necessary. The more variables and possible values the harder to see
the relationships in simple tables.
simple past presenttransitive 0 2
not transitive 2 0
Table 3.3.: A simple contingency table summarising the instance variables
Of course, the pattern that seems to be present in Table 3.1 might be due to chance
and not to a true relationship between the two variables. This is a possibility that can
never be completely excluded. Assessing the probability that patterns in observations
are due to chance is thus one of the core issues in statistics. If the probability is very
low (usually the threshold is set to p < 0.05), the pattern is significant.
102

3.3. Statistical analysis
What assessing this probability easier in a general sense is a greater number of observa-
tions. Misleading patterns occur much easier in small than in big samples. On the other
hand, true relationships can also go unnoticed in small samples. This is why we insist on
collecting and analysing large data sets. Patterns that are obvious in large samples are
very likely to be statistically significant. But one should bear in mind that, no matter
how large our collections of observations are, they still represent just small samples of
the phenomena that are generally possible in language. Their analysis makes sense only
in the context of statistical inference.
3.3.2. Statistical inference and modelling
The main purpose of a statistic analysis, as underlined by Upton and Cook (1996), is not
describing observed phenomena, but making predictions about unobserved phenomena
on the basis of a set of observations. The pattern that we observe in our toy example
in Table 3.1 is not very interesting by itself. It would become much more interesting
if we could conclude on the basis of it what the morphological form and the syntactic
realisation of every new instance of the verb will be.
Good predictions rely on good understanding of the relationships between the values
of variables. If the relationships are understood well enough, we can identify a general
rule that generates and at the same time explains the observations in the sample. As
an illustration of these notions, we adapt a simple example composed by Abney (2011).
Consider the variables recorded in (3.6).
(3.6)
t d
1 0.5
1 1
2 2
3 ?
4 7
The column t specifies the time at which an observation is made. The column d specifies
the values recorded: the distance travelled by a ball rolling down an inclined plane.
103

3. Using parallel corpora for linguistic research — rationale and methodology
There are two measurements for the time t = 1 (0.5 and 1). There is no observation at
t = 3.
d = 2t−1 d = 12t2 (3.7)
In this case, the rules that generate the observed sequences can be stated as formulas.
Two possible generalisations are given in (3.7). They both capture the sequence of
observations only partially. Even if we were allowed to choose the values which are
easier to explain (which we are not), and to ignore the value 0.5 at t = 1, the formula
on the left hand side does not predict the value 7 at t = 4, but 8. The value 0.5 at t = 1
would suit better the formula on the right hand side, but neither this formula explains
the value at t = 4.
If we knew all the distances at all time points with certainty and if these values fol-
lowed a perfectly regular pattern, this pattern could be described in terms of a single
generalisation which would have no exceptions and on the basis of which any distance
at any time could be predicted, including the missing value at t = 3. Such reasoning is
common to all inductive scientific methods. Certain facts are, however, rare in science
and observations are hardly ever explainable with a single powerful generalisation. The
situation usually resembles much more the example in (3.6): we do not know the facts
for sure and we cannot explain them entirely. This perhaps applies especially to linguis-
tic phenomena, which are essentially subject to interpretation. Statistical inference is
a way to make predictions taking into consideration the uncertainty and the limits of
explanation.
Statistical predictions are formulated as the probability that a certain variable will take
a certain value (or that it will be situated within a certain range of values) under certain
conditions. The probability is usually assessed as the relative frequency of the variable
values in a sample of the studied phenomena. For example, the sample of observations
in Table 3.1 contains four observations for the morphological form variable and four for
the syntactic realisation variable. Out of four morphological forms, two are the simple
present tense and two are the past tense. The probability that the next verb is in
the simple present tense is thus equal to the probability that it is in the past tense,
104
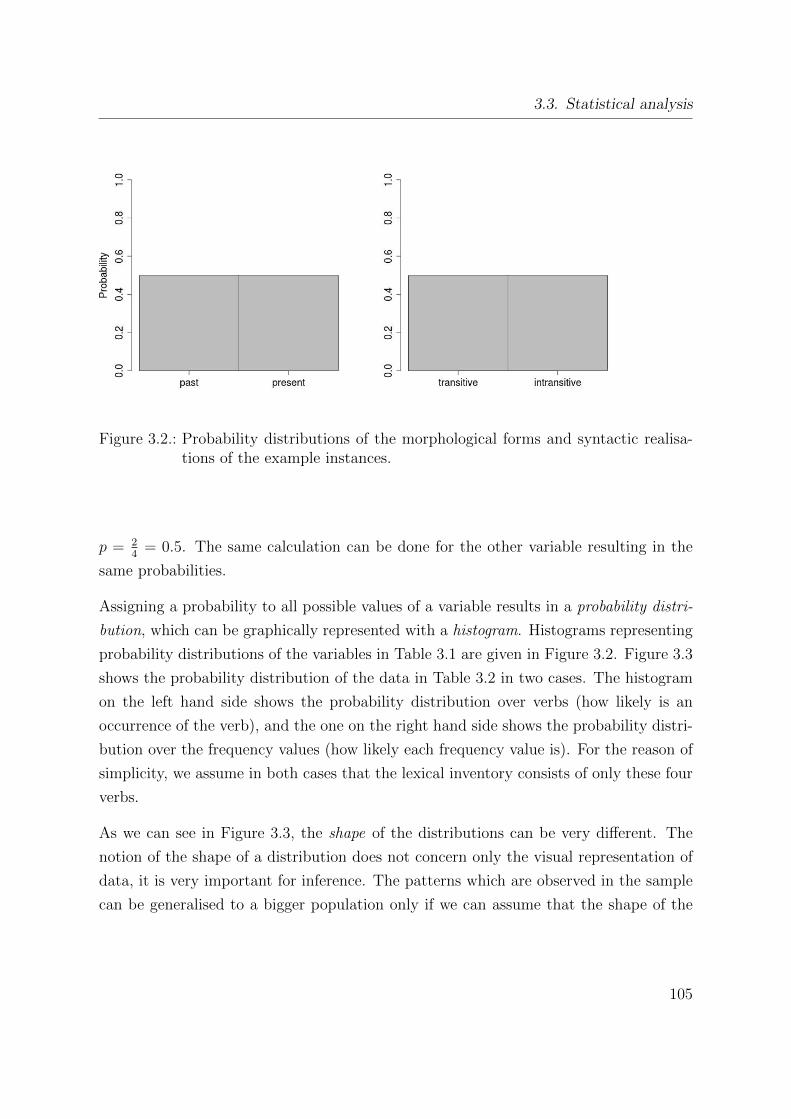
3.3. Statistical analysis
Figure 3.2.: Probability distributions of the morphological forms and syntactic realisa-tions of the example instances.
p = 24
= 0.5. The same calculation can be done for the other variable resulting in the
same probabilities.
Assigning a probability to all possible values of a variable results in a probability distri-
bution, which can be graphically represented with a histogram. Histograms representing
probability distributions of the variables in Table 3.1 are given in Figure 3.2. Figure 3.3
shows the probability distribution of the data in Table 3.2 in two cases. The histogram
on the left hand side shows the probability distribution over verbs (how likely is an
occurrence of the verb), and the one on the right hand side shows the probability distri-
bution over the frequency values (how likely each frequency value is). For the reason of
simplicity, we assume in both cases that the lexical inventory consists of only these four
verbs.
As we can see in Figure 3.3, the shape of the distributions can be very different. The
notion of the shape of a distribution does not concern only the visual representation of
data, it is very important for inference. The patterns which are observed in the sample
can be generalised to a bigger population only if we can assume that the shape of the
105

3. Using parallel corpora for linguistic research — rationale and methodology
Figure 3.3.: Probability distributions of the example verbs and their frequency.
probability distribution in the unobserved values is the same as in the values observed in
the sample. Moreover, generalisations are often only possible if we can assume a specific
shape of the probability distribution.
The shape of a distribution is determined by the values of a certain number of parameters.
The most typical examples of such parameters are the mean value and the standard
deviation (showing how much the values deviate from the mean value). There can be
other parameters depending on what kind of variation in the values of variables needs
to be captured.
The normal distribution, illustrated in Figure 3.4, is frequently referred to in science, as
many statistical tests require this particular distribution. It is characterised as symmetric
because the values around the mean value are at the same time the most probable values.
The values which are lower and higher than the mean value are equally probable, with
the probability decreasing as they are further away from the mean. Many quantitative
variables follow this pattern. A typical example is people’s height: most people are of a
medium height, while extremely tall and extremely short people are very rare. Frequency
of words in texts, for example, does not follow this pattern. There are usually only
106
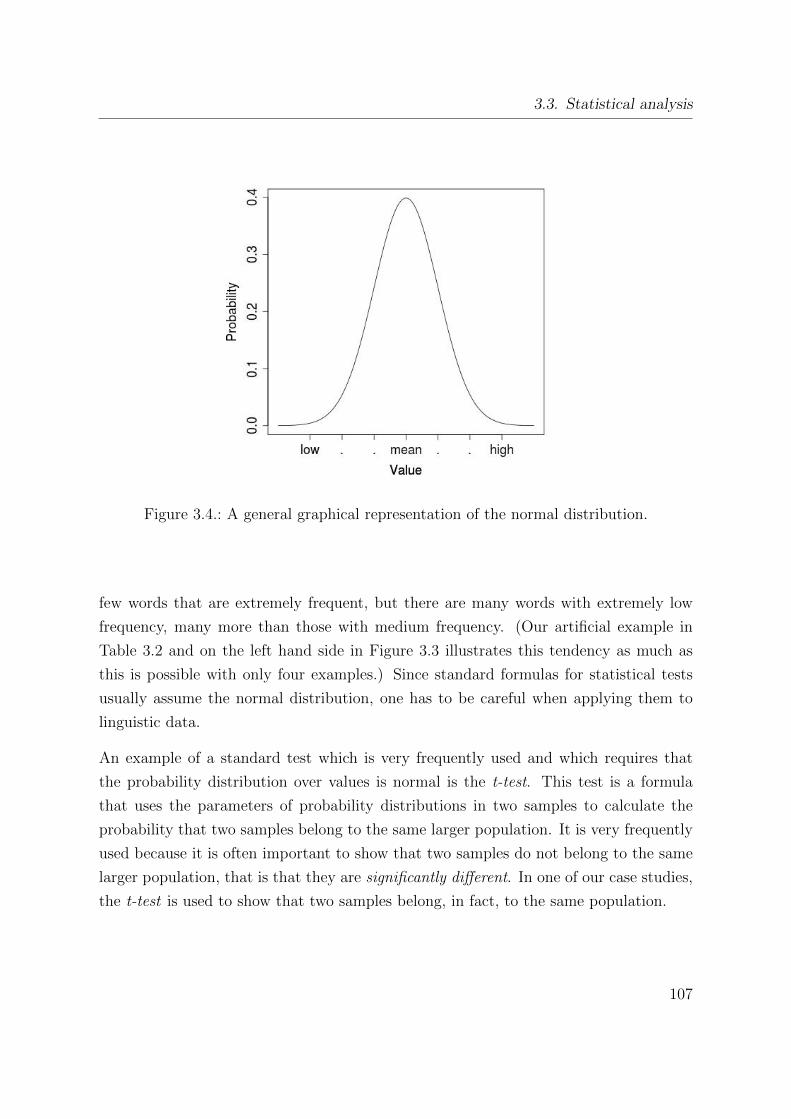
3.3. Statistical analysis
Figure 3.4.: A general graphical representation of the normal distribution.
few words that are extremely frequent, but there are many words with extremely low
frequency, many more than those with medium frequency. (Our artificial example in
Table 3.2 and on the left hand side in Figure 3.3 illustrates this tendency as much as
this is possible with only four examples.) Since standard formulas for statistical tests
usually assume the normal distribution, one has to be careful when applying them to
linguistic data.
An example of a standard test which is very frequently used and which requires that
the probability distribution over values is normal is the t-test. This test is a formula
that uses the parameters of probability distributions in two samples to calculate the
probability that two samples belong to the same larger population. It is very frequently
used because it is often important to show that two samples do not belong to the same
larger population, that is that they are significantly different. In one of our case studies,
the t-test is used to show that two samples belong, in fact, to the same population.
107

3. Using parallel corpora for linguistic research — rationale and methodology
As already mentioned above, real predictions based on statistical inference rarely con-
cern only one single variable. What is usually studied in statistical approaches are the
relationships between the values of two or more variables. By observing the values in
the sample, we try to determine whether the values of one variable (called dependent,)
depend on other, independent, variables. If we can determine that the values in the
dependent variable systematically increase as the values in the independent variables
increase, then we say that there is a positive correlation between the variables. If the
changes in the values in the dependent and independent variables are consistent but
in the opposite direction (increasing in one and decreasing in the other), we say that
there is a negative correlation. For example, people’s height and weight are positively
correlated: taller people generally have more weight, despite the fact that this is not
always the case. There are a number of statistical tests which measure the strength and
the significance of correlation between two variables.
The notion of correlation is fundamental to constructing statistical models. If there is
a correlation between an independent and a dependent variable and if the values of
both variables are normally distributed, then the values in the dependent variable can
be predicted from the values in the independent variables. In this case, we say that
the variation in the dependent variable is explained by the variation in the independent
variable. The purpose of statistical models is to predict values of one variable on the basis
of information contained in other variables. They model a piece of reality in terms of a
set of independent variables, potential predictors, one dependent variable, and precisely
described relationships between them. The prediction is usually based on a regression
analysis which shows to what degree the variation in the dependent variable is explained
by each factor represented with an independent variable.
3.3.3. Bayesian modelling
An alternative approach to predicting values in one variable on the basis of values in
other variables is Bayesian modelling. In this framework, the probability of some variable
taking a certain value is assessed in terms of a prior and a posterior probability. The
prior probability represents our general knowledge about some domain before learning a
new piece of information about it. The posterior probability is the result of combining
108

3.3. Statistical analysis
Variable Value Notation Probabilitya burglary in the given neighbour-hood
happens p(b) 0.014
the alarm if there is a burglary activated p(a|b) 0.75the alarm if there is no burglary activated p(a|¬b) 0.1
a burglary in the neighbourhoodif the alarm is activated
happens p(b|a) ?
Table 3.4.: An example of data summary in Bayesian modelling
the prior probability with some newly acquired knowledge. Probability updating is
formulated as conditional probability, which can be calculated from joint probability (the
probability that the variable A takes the value a and that the variable B at the same
time takes the value b) using the general conditional probability rule given in (3.8).
P (A|B) =P (A,B)
P (B)(3.8)
Bayesian modelling is based on the assumption that our knowledge about the world
is formed in a sequence of updating steps and that it can be expressed in terms of
conditional probabilities, as illustrated in Table 3.4. The example, based on Silver
(2012), concerns assessing the probability that a burglary actually took place if an
alarm is activated. In assessing this probability, we rely on several facts (listed in Table
3.4). From previous experience, we know that the probability of a burglary in the given
neighbourhood is 0.014. This is the prior probability of a burglary in our example. We
also have an assessment on how efficiently the alarm detects the burglary: it gives a
positive signal in 75% of cases of an actual burglary, and in 10% cases where there is
no burglary. We combine this knowledge by applying the equation in (3.9), known as
Bayes’ rule, which is derived from the conditional probability rule (3.8) applying the
commutative law.
P (A|B) =P (B|A) · P (A)
P (B)(3.9)
109

3. Using parallel corpora for linguistic research — rationale and methodology
When we replace general symbols in (3.9) with the notation from our data summary,
we obtain the equation in (3.10). Replacing the terms with actual probability given
in Table 3.4, as in (3.11) we obtain the answer to the initial question: the probability
that a burglary took place when the alarm is activated is around 0.1, which is still low
considering that the signal from the alarm is positive.
p(b|a) =p(a|b) · p(b)
p(a)(3.10)
p(b|a) =0.75 · 0.014
0.1091= 0.096 (3.11)
Note that the term p(a) was not listed in the table. It is calculated from the conditional
probabilities which are available. As shown in (3.12), the probability that the alarm is
activated is first expressed as the sum of two joint probabilities: the probability that the
alarm is activated and there is a burglary and the probability that the alarm is activated
and there is no burglary (the probability of the complement set of values). Since the
two joint probabilities are not listed in our data, we calculate them from the conditional
probabilities which are known applying the rule in (3.8). The term p(¬b), which is
required for this calculation is given by p(b). Since these two cases are complementary,
their probability sums to 1, which yields p(¬b) = 1− p(b) = 0.986.
p(a) = p(a, b) + p(a,¬b)= p(a|b) · p(b) + p(a,¬b) · p(¬b)= 0.75 · 0.014 + 0.1 · 0.986
= 0.0105 + 0.0986
= 0.1091
(3.12)
These relatively simple calculations provide a formal framework for updating the prior
probability after having encountered new evidence related to the question that is inves-
tigated. In our example, the prior probability of a burglary in the given neighbourhood
is updated having learnt that the alarm had been activated. This updating is performed
110

3.3. Statistical analysis
taking into consideration the uncertainty that is inherent to the knowledge about the
phenomenon at each step.
An advantage of Bayesian modelling compared to the “standard” statistical inference
laid out in Section 3.3.2 is that it offers a more straightforward mechanism for combining
evidence. In the standard approach, the influence of all potential predictors on the pre-
dicted variable is assessed directly. The explanations from predictors can be combined
in a linear or weighted fashion, but not hierarchically. Contrary to this, Bayesian calcu-
lations can be applied recursively: once a posterior probability is calculated, it can be
used as a prior for some other posterior probability. For example, the prior probability
of a burglary in a particular neighbourhood, which is used in the calculations above,
could have been calculated as a posterior probability relating the chance of a burglary in
general to the relationship between some characteristics of a particular neighbourhood
and its proneness to burglaries.
Another advantage of Bayesian modelling is that it assumes no particular parameters of
probability distributions over the values of variables. The accent in Bayesian modelling
is on combining the probabilities, while their origin is less important. The probability
assessments can be expressions of intuitive (expert) knowledge, of previous experience,
or of a relative frequency in a sample. The calculations yielding new assessments apply
to any kind of probability distributions over the values as long as the probability of all
the values sums to 1 (like the probability that a burglary happens and the probability
that it does not happen in our example).
Both underlined advantages are especially important in the context of modelling linguis-
tic phenomena. The recursive nature of Bayesian models makes them a well-adapted
framework for a statistical approach to linguistic structures, which are, according to the
majority of theoretical accounts, recursive. The fact that the inference in this approach
does not depend on a particular probability distribution (notably, on the normal distribu-
tion) is important because linguistic data are often associated with unusual distributions
for which it is hard to define a small set of appropriate parameters.
These advantages, however, come at a cost. Stepping out of the standard statistical
inference framework makes evaluating the predictions in Bayesian modelling harder.
Good predictions in the traditional statistical modelling are guaranteed by the notion
111

3. Using parallel corpora for linguistic research — rationale and methodology
of statistical significance. If a statistically significant effect of a predictor on a predicted
variable is identified, the predictions based on this relationship can be expected to be
correct in the majority of cases. The notion of statistical significance is not incorporated
in the predictions in Bayesian modelling. The quality of predictions has to be evaluated
in another way, usually by measuring the rate of successful predictions.
In this dissertation, both approaches are used. We apply standard tests in the situation
where we can assume the normal probability distribution over the values of a variable and
where the hierarchical relationships between the components of a model are not complex.
Otherwise, we formalise our generalisations in terms of Bayesian models and we test the
predictions comparing the predicted and the actual values on a sample of test examples.
The generalisations which are addressed by the models concern the relationship between
semantic properties of verbs and the observable formal properties of their realisations in
texts. We explain the variation in the verb instances by the variation in their semantic
properties.
3.4. Machine learning techniques
Statistical models which are proposed in this dissertation are developed by combing
theoretical insight with some standard machine learning techniques. Theoretical analysis
results in a small number of variables which define the studied domain. It also provides
the hypotheses about the dependency relationship between the variables, but the exact
numerical values of the relationships between the values of the variables are acquired
automatically from the data set.
Automatic acquisition of generalisations from data is studied in the domain of machine
learning. Using the general terminology of learning, the data which machine learning
algorithms take as input are regarded as experience. A computer program is said to learn
from experience if its performance at some task improves with the experience, that is
by observing the data. In our experiments, we assume that the machine learning task
is defined as classification. The notions used in the section are mostly based on three
sources, Mitchell (1997), Russell and Norvig (2010), and Witten and Frank (2005).
112

3.4. Machine learning techniques
There are two main approaches that can be taken in inferring the relationships between
the values of variables: supervised and unsupervised learning. In this section, we first
illustrate the two approaches by describing standard algorithms which are most widely
used. We then show how the two approaches are implemented with Bayesian models in
this dissertation.
3.4.1. Supervised learning
In the supervised learning setting, the training data include the information about the
values in the predicted variable, which we call the target variable. To illustrate these
notions, we adapt an example constructed by Russell and Norvig (2010) (see the data
summary in Table 3.5). Suppose we are at work and we receive a message that our
neighbour Mary called some time ago. We want to assess the probability that this call
means that there was a burglary at our place. We have an old-fashion alarm that rings
when some shock is detected, but we cannot hear the ringing when we are away from
home. So we ask our neighbours Mary and John to call us if they hear the alarm. The
day when we receive a call from Mary, we did not hear from John. We should also bear
in mind that Mary could have called for some other reason. Also the alarm could have
been activated by some other shock, not burglary (like an earthquake, for example). The
question that we ask is: What is the probability that there was a burglary, given that
Mary called, John did not call and there was no earthquake, p(b = yes|m = yes, j =
no, e = no) (the bottom row in Table 3.5)?
In assessing the probability, we look up the records of the last ten cases when one of our
neighbours called us at work (the other rows in Table 3.5). What we want to find is the
same situations in the past and to see whether a burglary actually happened in these
cases. We find that only one of the previous situations (row seven) was the same and
that a burglary actually happened then. However, we are still not convinced because in
the majority of our records there was no burglary.
To use all the data available, we look how the burglary was related to each of the values
separately and then we recompose the probability for the case in queastion. To illustrate
113

3. Using parallel corpora for linguistic research — rationale and methodology
Mary calls John calls Earthquake Burglary1 yes yes no yes2 yes yes no yes3 yes no yes no4 no yes no no5 no yes no no6 no yes no no7 yes no no yes8 no yes no no9 no yes no no
10 yes yes yes noQ yes no no ?
Table 3.5.: An example of a data record suitable for supervised machine learning
how this can be done, we describe two algorithms which are usually regarded as rather
simple, but often well performing.
The Naıve Bayes algorithm decomposes the records assuming that the values of the three
predictors are mutually independent. The term naıve in the name of the algorithm refers
to the fact that the variables are usually not independent in reality, but that the potential
dependencies are ignored. With the assumed independence, the probability which we
look for can be expressed as the product of individual conditional probabilities, as shown
in (3.13). Since our task is classification, we look for the probability of a particular class
cj based on the values of predictor variables, which are attributes a1,...,n of each instance
of a class.
P (a1, a2, a3, ...an|cj) ≈∏i
P (ai|cj) (3.13)
We calculate the most probable class for a given set of values of attributes by applying
Bayes’ rule in (3.9) repeated here as (3.14), which gives the general formula in (3.15),
where the 1z
is a constant when the values of the attributes are known, as in our example.
When we apply the general classification formula to our data, we obtain (3.16).
114

3.4. Machine learning techniques
P (A|B) =P (B|A) · P (A)
P (B)(3.14)
P (cj|ai, ...an) ≈ 1
zP (cj)
n∏i
P (ai|cj) (3.15)
p(b = yes|m = yes, j = no, e = no) ≈ 1z· p(b = yes) · p(m = yes|b = yes)
·p(j = no|b = yes) · p(e = no|b = yes) (3.16)
With the separated conditional probabilities, we can use more records to estimate each
factor of the product. For example, applying the conditional probability rule in (3.8),
we can calculate:
p(m = yes|b = yes) =p(m = yes, b = yes)
p(b = yes)=
3
3
Burglary actually happened in three of our ten records and in all three of them, Mary
called. The score would be different for John, since he failed to call in one of the three
cases.
In deciding whether to classify the current situation as burglary or not, we calculate
the product of all the conditional probabilities for both potential values of the target
variable, we multiply this product with the probability of the value of the target variable,
and then we select the higher probability. The constant can be omitted because it is the
same for both classes. In this particular example, the calculation would give:
p(b = yes|m = yes, j = no, e = no) ≈ 3
10· 3
3· 1
3· 3
3=
1
10(3.17)
p(b = no|m = yes, j = no, e = no) ≈ 7
10· 2
7· 1
7· 5
7=
1
49(3.18)
115

3. Using parallel corpora for linguistic research — rationale and methodology
Mary calls?
Yes.
Earthquake?
Yes.
No burglary.
No.
Burglary!
No.
No burglary.
Figure 3.5.: An example of a decision tree
Since 110> 1
49, the final decision should be to classify Mary’s call as signalling a bur-
glary.
Applying the decision tree algorithm to the same data set, we proceed by querying each
variable in the order of informativeness, as shown in Figure 3.5. We first determine
that Mary called. If she had not called there would have been no reason to worry. But
Mary did call in this case, so then we check if there was an earthquake immediately
preceding Mary’s call. If there was an earthquake, there is no need to worry; it was the
earthquake that probably activated the alarm, which made Mary call. But if there was
no earthquake, which is the case in the current situation, then we should better hurry
home, because there was a burglary.
The decision tree which brought us to this conclusion is constructed on the basis of
the same records which were used for assessing the probabilities for the naıve Bayes
algorithm (Table 3.5). In deciding which variable should be in the root of the tree, we
look up the joint distributions of values combining each predictor with the target variable
separately. This procedure results in groupings shown in the upper part of Table 3.6
(Step 1). We compare the resulting divisions to identify the most discriminative variable.
The variable which gives the “purest” groups is the most discriminative. In our example,
two variables give entirely pure goupings. We can see in Table 3.6 that every time the
116

3.4. Machine learning techniques
value of Marry calls is “no”, the value of the target variable is also “no”. But also every
time the value of Earthquake is “yes”, the value of the target variable is “no”. Since
they give pure classes, these two variables are candidates for the most discriminative
variable. Mary calls wins because it gives the bigger pure group and also because the
size of the two resulting groups, which depends on the distribution of the values in the
variable, is more balanced (there are five occurrences of each value).
If all the values of the target variable were the same when the value of Mary calls is
“yes”, we could stop at this point, ignore the other two variables and predict the target
variable only from the values of Mary calls. This is, however, not the case, so we need
to continue constructing the tree by looking up the combinations of values of Mary calls
with the other two variables. The aim here is to see if some of these combinations will
result in pure groupings of the values in the target variable. The resulting groupings of
the second step are shown in the bottom part of Table 3.6 (Step 2).
We can see that the combination of values of Mary calls and Earthquake divides the set
of values of the target variable into entirely pure classes (for both values of Mary calls).
Since all the groupings of the values in the target variable are pure at this point, the tree
is completed. We can ignore the variable John calls because it provides no information
about whether there was a burglary or not.
We have used the notion of the purity of a class in an intuitive way so far. We have
considered the classes purer if they contain more of the same kind of items. For example,
the group of values of the target variable associated with the value “yes” of the variable
John calls in the upper part of Table 3.6 is “purer” than the group of values associated
with the value “no” of the same variable because the proportion of the same items is
bigger in the first group (five out of seven) than in the second (two out of three). The
same principle applies when working with large data set, but the purity of classes has
to be measured at each step as it is hard to assess larger classes intuitively.
The measure that is most commonly used to assess the purity of classes is entropy,
which is calculated from the probability distribution of a variable, using the formula in
(3.19), where S denotes the variable for which we measure the entropy and c denotes the
number of possible values of the variable. It shows the degree to which the probabilities
117
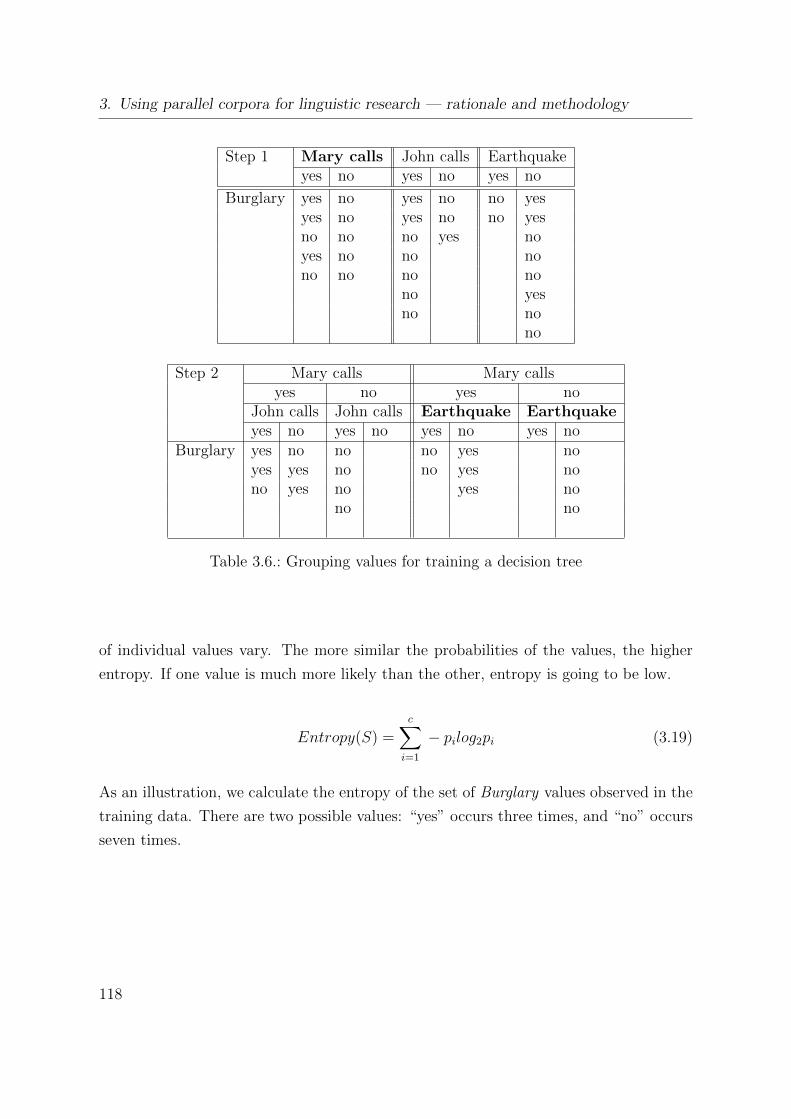
3. Using parallel corpora for linguistic research — rationale and methodology
Step 1 Mary calls John calls Earthquakeyes no yes no yes no
Burglary yes no yes no no yesyes no yes no no yesno no no yes noyes no no nono no no no
no yesno no
no
Step 2 Mary calls Mary callsyes no yes no
John calls John calls Earthquake Earthquakeyes no yes no yes no yes no
Burglary yes no no no yes noyes yes no no yes nono yes no yes no
no no
Table 3.6.: Grouping values for training a decision tree
of individual values vary. The more similar the probabilities of the values, the higher
entropy. If one value is much more likely than the other, entropy is going to be low.
Entropy(S) =c∑
i=1
− pilog2pi (3.19)
As an illustration, we calculate the entropy of the set of Burglary values observed in the
training data. There are two possible values: “yes” occurs three times, and “no” occurs
seven times.
118

3.4. Machine learning techniques
Entropy(B) = − 310log2
310− 7
10log2
710
= −(0.3 · −1.74)− (0.7 · −0.51)
= 0.52 + 0.36
= 0.88
(3.20)
To choose the attribute which should be put in the root of the decision tree, we compare
the entropy of the starting set of values with the entropy of the subsets of values of the
target variable which are associated with each value of each attribute (the columns in
the upper part of Table 3.6). The variable that is considered the most discriminative at
each node in constructing a decision tree is the one which reduces the most the entropy
of the target variable. The measure which is most commonly used for this comparison
is called information gain. It is calculated using the formula in (3.21), where A is the
attribute which is considered and |Sv| is the subset of S for which the value of A is v.
Gain(S,A) = Entropy(S)−∑
v∈V alues(A)
|Sv||S|
Entropy(Sv) (3.21)
As an illustration, we calculate the information gain of the attribute Marycalls in our
example:
GainB,M = Entropy(B)∑
v∈V alues(M)|Bv ||B| Entropy(Bv)
= Entropy(B)− |BM=yes||B| Entropy(BM=yes)− |BM=no|
|B| Entropy(BM=no)
= 0.88− 510· 0.97− 5
10· 0
= 0.88− 0.48− 0
= 0.40
(3.22)
The same calculations are performed for the other two attributes and the one which
provides the highest information gain is taken as the first split attribute. The calculations
are performed recursively until the entropy of all resulting subsets is 0. Note that
the entropy of BM=no in our example is 0 because all the values in this subset are
the same. In this case, the recursive calculations are performed only for the subset
119

3. Using parallel corpora for linguistic research — rationale and methodology
Mary calls Earthquake Burglary1 yes no ?2 yes no ?3 yes yes ?4 no no ?5 no no ?6 no no ?7 yes no ?8 no no ?9 no no ?
10 yes yes ?Q yes no ?
Table 3.7.: An example of a data record suitable for supervised machine learning
BM=yes. In practice, the programs that implement the decision tree algorithm work
with some additional constraints, but we do not discuss these issues further because
such a discussion would exceed the scope of this survey.
3.4.2. Unsupervised learning
In the unsupervised learning setting, the values of the target variable are not known
in the training data. The task of deciding what class to assign to a particular case
resembles the data summary in Table 3.7. The data in Table 3.7 represent basically
the same records as in Table 3.5, with the variable John calls omitted for the reason of
simplicity. The question marks in the last column represent the fact that the values of
the target variable are not recorded. However, we can assume that such a variable exists
and that its values can be explained by the values of the other, known variables. Such
variables are called hidden variables.
In principle, hidden variables are not necessarily the target variables. Any variable in a
model can be regarded as hidden. In some models, the values of the target variable itself
are known in training, but they are assumed to be influenced by some other variable with
an unknown probability distribution. In this case, the learning setting is supervised,
120

3.4. Machine learning techniques
but estimating the probability distribution of the hidden variable requires a special
approach.
In this subsection, we describe the expectation-maximisation algorithm, which is often
used in assessing the probability distribution of a hidden variable, regardless of whether
it is a target variable. It is a general algorithm which has been applied to many different
learning tasks. The algorithm is applied to an independently constructed model and to a
set of data in an iterative fashion. As its name suggests, it consists of two main parts. In
the expectation part, expected values in the data set are generated based on hypothesised
parameters of distributions. In the maximisation part, the hypothesised parameters of
distributions are combined with the observations in the data set and updated so that they
are more consistent with the observed data. As a result, the parameters of distributions
of both observed and unobserved variables are consistent with the observed data. The
algorithm starts with arbitrary hypothesised parameters which are combined with the
observations and updated in a number of iterations. It ends when the parameters reach
the values which are consistent with the data and they are no longer updated.
The mathematical background of the algorithm is much more complex than in the case
of the two supervised algorithms which we have introduced so far. Its precise general
mathematical formulation would exceed the scope of this survey. We thus limit the
discussion in this subsection to the particular application of the algorithm which is used
in this dissertation. To illustrate the functioning of the algorithm, we use the same model
and the same data set which were used for the naıve Bayes algorithm in Section 3.4.1,
modified as shown in Table 3.7. With the variable John calls omitted (for simplicity),
the model is formulated as in (3.23).
p(m, e, b) = p(b) · p(m|b) · p(e|b) (3.23)
The model formulation which we use in this example is more general than in the previous
calculations. Instead of specifying concrete values, we refer to any value that a variable
can take. Thus the small letter m stands for both Mary calls = “yes” and Mary calls
= “no”, e stands for both values of Earthquake, and b for both values of Burglary. Note
also that the value on the left side of the equation is not a conditional, but a joint
121
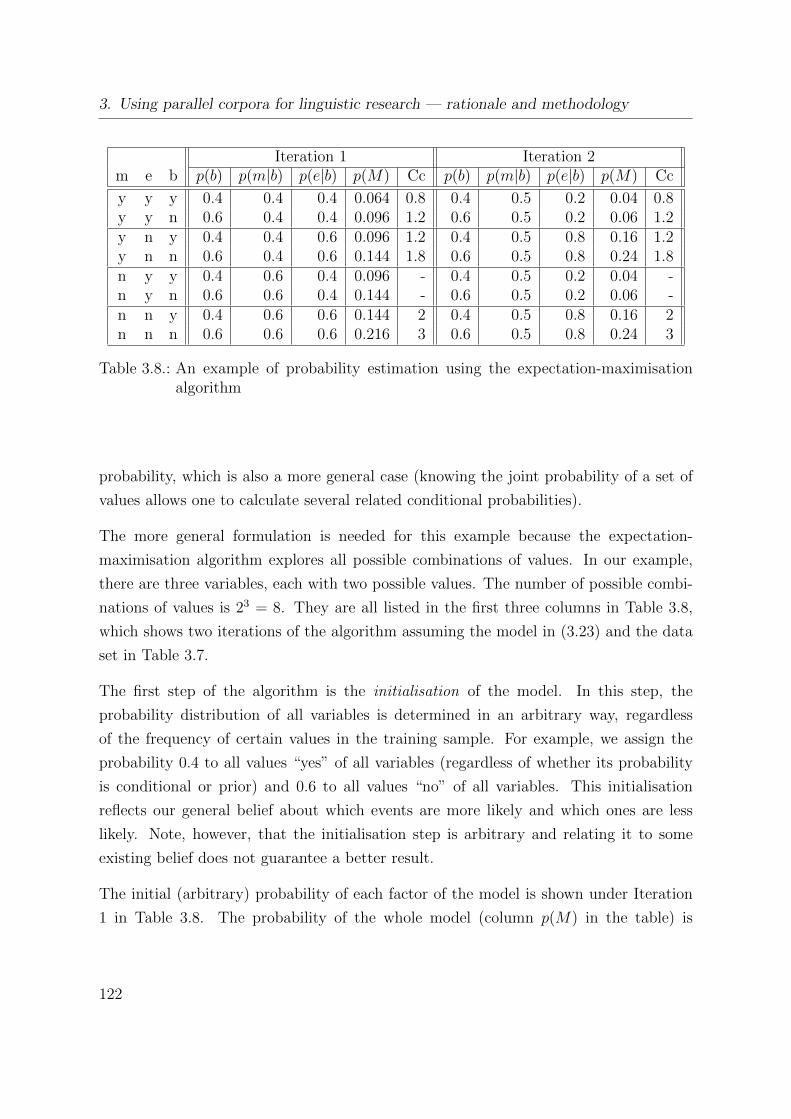
3. Using parallel corpora for linguistic research — rationale and methodology
Iteration 1 Iteration 2m e b p(b) p(m|b) p(e|b) p(M) Cc p(b) p(m|b) p(e|b) p(M) Cc
y y y 0.4 0.4 0.4 0.064 0.8 0.4 0.5 0.2 0.04 0.8y y n 0.6 0.4 0.4 0.096 1.2 0.6 0.5 0.2 0.06 1.2y n y 0.4 0.4 0.6 0.096 1.2 0.4 0.5 0.8 0.16 1.2y n n 0.6 0.4 0.6 0.144 1.8 0.6 0.5 0.8 0.24 1.8n y y 0.4 0.6 0.4 0.096 - 0.4 0.5 0.2 0.04 -n y n 0.6 0.6 0.4 0.144 - 0.6 0.5 0.2 0.06 -n n y 0.4 0.6 0.6 0.144 2 0.4 0.5 0.8 0.16 2n n n 0.6 0.6 0.6 0.216 3 0.6 0.5 0.8 0.24 3
Table 3.8.: An example of probability estimation using the expectation-maximisationalgorithm
probability, which is also a more general case (knowing the joint probability of a set of
values allows one to calculate several related conditional probabilities).
The more general formulation is needed for this example because the expectation-
maximisation algorithm explores all possible combinations of values. In our example,
there are three variables, each with two possible values. The number of possible combi-
nations of values is 23 = 8. They are all listed in the first three columns in Table 3.8,
which shows two iterations of the algorithm assuming the model in (3.23) and the data
set in Table 3.7.
The first step of the algorithm is the initialisation of the model. In this step, the
probability distribution of all variables is determined in an arbitrary way, regardless
of the frequency of certain values in the training sample. For example, we assign the
probability 0.4 to all values “yes” of all variables (regardless of whether its probability
is conditional or prior) and 0.6 to all values “no” of all variables. This initialisation
reflects our general belief about which events are more likely and which ones are less
likely. Note, however, that the initialisation step is arbitrary and relating it to some
existing belief does not guarantee a better result.
The initial (arbitrary) probability of each factor of the model is shown under Iteration
1 in Table 3.8. The probability of the whole model (column p(M) in the table) is
122

3.4. Machine learning techniques
calculated by multiplying the factors, as shown for the first two cases in (3.24) and
(3.25) respectively. The probability of the model in each case is then combined with the
counts observed in Table 3.7 to distribute the counts to different cases. The distributed
counts are called complete counts (Ccounts in the formulas, Cs columns in Table 3.8)
as opposed to the incomplete counts which are available in the data set. For example,
what we can see in Table 3.7 is that there were two cases where both Mary called and
there was an earthquake (F (y, y, ∗) in the formula, the asterisk stands for any value of
the third variable), but we do not know whether there was a burglary in these cases. We
apply the formula shown in (3.24) and (3.25) to assign the count of 0.8 to the first case
(where there is a burglary) and the count 1.2 to the second case (where there was no
burglary). Note that the counts are fractional, which would not be possible in reality,
but this is acceptable because they are only an intermediate step in calculating the
probability of each factor of the model. Applying the formula gives complete counts for
all the cases, as shown in the column Cc under Iteration 1 in Table 3.8.
b=y, m=y, e=y:
p(M) = p(b = y) · p(m = y|b = y) · p(e = y|b = y)
= 0.4 · 0.4 · 0.4 = 0.064
Ccounts =F (y,y,∗)·p(M(y,y,y))
p(M(y,y,y))+p(M(y,y,n))= 2·0.064
0.064+0.096= 0.128
0.16= 0.8
p(b = y) = F (b=y)Total
= 0.8+1.2+0+210
= 410
= 0.4
p(m = y|b = y) = F (m=y,b=y)F (b=y)
= 0.8+1.24
= 0.5
p(e = y|b = y) = F (e=y,b=y)F (b=y)
= 0.8+04
= 0.2
New P(M) = 0.4 · 0.5 · 0.2 = 0.04
(3.24)
123

3. Using parallel corpora for linguistic research — rationale and methodology
b=n, m=y, e=y:
p(M) = p(b = n) · p(m = y|b = n) · p(e = y|b = n)
= 0.6 · 0.4 · 0.4 = 0.096
Ccounts =F (y,y,∗)·p(M(y,y,n))
p(M(y,y,y))+p(M(y,y,n))= 2·0.096
0.064+0.096= 0.192
0.16= 1.2
p(b = n) = F (b=n)Total
= 1.2+1.8+0+310
= 610
= 0.6
p(m = y|b = n) = F (m=y,b=n)F (b=n)
= 1.2+1.86
= 0.5
p(e = y|b = n) = F (e=y,b=n)F (b=n)
= 1.2+06
= 0.2
New P(M) = 0.6 · 0.5 · 0.2 = 0.06
(3.25)
To update the probability of each factor of the model, we sum up the counts for each
relevant case and calculate the conditional probability applying the conditional proba-
bility rule (3.8), as shown for the first two cases in (3.24) and (3.25). All the counts
which are added up can be looked up in the corresponding cells under Iteration 1 in
Table 3.8, and all the resulting updated probabilities of each factor of the model in each
case are listed under Iteration 2.
In the next step, we calculate the probability of the model by multiplying the updated
probabilities of the factors. We then calculate new complete counts (the Cc column
under Iteration 2 in Table 3.8) using the updated model probability and then use the
new counts to update again the probability of the factors of the model. We then repeat
applying and updating the model till the probabilities of the factors of the model converge
to the true probabilities. The convergence is not guaranteed in all the cases, but if the
patterns in the data are clear enough, it is very likely.
Looking at the values in Table 3.8, we can see that the initial arbitrary probabilities
of the models have changed when combined with the information about the incomplete
counts. In both cases which are of interest in our example (the cases (y, n, y) and (y,
124

3.4. Machine learning techniques
n, n), the probability of the model has increased. The probability of no burglary is
still higher than the probability of burglary, which does not correspond to the results
of supervised learning in Section 3.4.1. However, the ranking of the two models would
change if there were more instance to learn from.
Unsupervised learning is harder than supervised learning because crucial information
about the values of the target variable is not available for training. However, it is
increasingly used in natural language processing because linguistic data sets with known
target variables, such as manually annotated corpora presented in Chapter 2, Section
2.2.2, are hard to construct. Another reason why unsupervised learning is seen as an
attractive framework for approaching linguistic phenomena is the fact that it allows using
corpus data for discovering new structures, not pre-defined in linguistic annotation, such
as in the experiments on grammar induction by Klein (2005).
3.4.3. Learning with Bayesian Networks
Since the main purpose of the models proposed in our case studies is representing gen-
eralisations about the structure of language, the accent is not as much on assessing the
probabilities as it is on the structure of the relationships between the variables. We
use rather basic learning methods for training the models on a set of data extracted
from corpora, putting more complexity on the structure of the models. To represent
the hierarchical relationships between the variables, we formulate our models in terms
of Bayesian networks.
A Bayesian network is a directed acyclic graph where the nodes represent the variables
of a model and the edges represent the dependency relationships between the variables.
A Bayesian network would be very useful, for example, if we wanted to add the variable
Alarm to the model discussed in Section 3.4.1. Although we know that Mary’s and
John’s calls depend, to a certain degree, on whether they have heard the alarm, this
dependence is only implicitly present in the data set. A graph such as the one in Figure
3.6 can be used to represent the role of the alarm explicitly.
The edges in the graph show that the alarm can be caused by an earthquake or by a
burglary, and also that it causes John and Mary to call. Each edge is associated with a
125

3. Using parallel corpora for linguistic research — rationale and methodology
Earthquake Burglary
Alarm
Mary calls John calls
Figure 3.6.: An example of a Bayesian network
conditional probability distribution showing how the two variables which are connected
with it are related. For example, we can specify the probability of the alarm being
activated by an earthquake as p(a|e) = 0.7, which also specifies p(¬a|e) = 0.3. We
can specify the probability of a burglary activating the alarm as higher, for example
as p(a|b) = 0.9 and p(¬a|b) = 0.1. Such conditional probabilities are specified for each
node and each edge. They can be estimated on the basis of intuition or on the basis of
training on a set of examples using machine learning algorithms. Some of the variables
can be regarded as hidden and their distribution estimated using approaches such as the
one described in Section 3.4.2.
The probability of the whole model represented in Figure 3.6 is given in (3.26):
p(e, b, a,m, j) = p(e) · p(b) · p(a|e) · p(a|b) · p(m|a) · (j|a) (3.26)
The decomposition of the model into the factors is based on the notion of conditional
independence, which allows us to reduce the complexity of the potential dependencies
between the variables avoiding at the same time oversimplifications, such as for example
the independence assumption used in the naıve Bayes algorithm (see Section 3.4.1). Note,
for example, that the variables Mary calls and John calls are not directly connected in
the graph. This represents the fact that these two variables are conditionally independent
given Alarm. If we know whether the alarm rang or not, then Mary’s and John’s call
do not depend on each other, but they both depend on the state of the alarm. Also,
126

3.4. Machine learning techniques
Predicted 1 Predicted 0True 1 A BTrue 0 C D
Table 3.9.: Precision and recall matrix
note that each node in the graph depends only on the parent node (or nodes). This
means that, if we know the value of the alarm, then the calls from Mary and John are
not relevant for assessing the probability that there was a burglary. The probability of
any particular value of any variable in the network can be inferred applying Bayes’ rule
(3.9).
3.4.4. Evaluation of predictions
The success of a model in making predictions is evaluated on a test data set which
contains new instances. The values of the target variable in each instance is predicted
based on the values of predictor variables (like in the bottom rows of Tables 3.5 and
3.7). The predictions are then compared with the correct answers, usually called gold
standard, and a measure of success is calculated. The predictions of the model are
counted as correct if the predicted values are identical to the values in the gold standard.
Since a number of values can be identical to the gold standard due to chance, the success
of a model is usually defined as an improvement relative to the baseline — the result
that would be achieved by chance, or by a very simple technique.
The most commonly used measure is the F1 measure. It is the harmonic mean of two
measures: precision (p) and recall (r):
F1 =2 · (p · r)p+ r
(3.27)
Precision shows how many of the predictions made are correct (p = A(A+C)
in the matrix
in Table 3.9). Recall shows how many of the values that exist in the gold standard are
127

3. Using parallel corpora for linguistic research — rationale and methodology
also predicted by the model (r = A(A+B)
).
The difference in recall and precision is important for the tasks where some instances
can be left without a response by the model (for example, these measures are typically
used in the tasks of information retrieval). Since in our experiments every instances
is given a prediction, the appropriate measure is accuracy. It is calculated using the
formula in (3.28).
Accuracy =Correct
All(3.28)
The correct predictions include true positives and true negatives, while the difference
between correct predictions and the total number of predictions includes false positives
and false negatives.
3.5. Summary
In this chapter, we have discussed two methodological issues concerning the use of par-
allel corpora for linguistic research. We have first addressed the question of why use
parallel corpora. We propose this approach as an extension of standard analysis of
cross-linguistic variation in the context of studying microparametric variation. To deal
with the linguistically irrelevant variation, which is seen as one of the main obstacles for
using parallel corpora for linguistic research, we propose collecting large data sets con-
taining maximally parallel verb instances. In addition to the methodological discussion,
we present additional arguments in favour of this approach coming from the experiments
in natural language processing, which demonstrate that automatically word-aligned cor-
pora provide a rich new resource for studying various questions related to cross-linguistic
variation. Having argued in favour of using parallel corpora, we have then discussed ap-
plying the methodology of natural language processing to address theoretical linguistic
issues by processing large data sets. As this methodology has not been commonly used
in linguistic research so far, we provide the technical background necessary for following
the presentations of our experiments in the three case studies. The introduction to the
notions in statistical inference and modelling in combination with machine learning is
128

3.5. Summary
carefully adapted specifically for the purpose of this dissertation, providing all the neces-
sary technical details, but in a way which is adapted to an audience with little experience
in these disciplines. The general methodology outlined in this chapter is applied in three
cases studies which are presented in the following chapters.
129


4. Force dynamics schemata and
cross-linguistic alignment of light
verb constructions
4.1. Introduction
Light verb constructions are special verb phrases which are identified as periphrastic
paraphrases of verbs. English expressions put the blame on, give someone a kick, take a
walk are instances of such paraphrases for the verbs blame, kick, and walk. These con-
structions are attested in many different languages representing a wide-spread linguistic
phenomenon, interesting both for theoretical and computational linguistics. They are
characterised by a special relation between the syntax and the semantics of their con-
stituents. The overall meaning of the phrase matches the meaning of the complement,
instead of matching the meaning of the head word (the verb), which is the case in typi-
cal verb phrases. Figure 4.1 illustrates the difference between regular verb phrases and
phrases headed by a light verb. Despite the same syntactic structures, the two phrases
are interpreted differently: have a yacht is about having, while have a laugh is about
laughing.
The special relation between the meaning and the structure makes light verb construc-
tions semantically non-compositional or opaque to a certain degree. The meaning of the
phrase cannot be calculated from the meaning of its constituents using general rules of
grammar. Moreover, the use of these phrases is partially conventionalised. They show
131

4. Force dynamics schemata and cross-linguistic alignment of light verb constructions
Regular VP Light verb construction
VP[syntactic features]
[semantic features]VP
[syntactic features]
[semantic features]
Verb Complement Light verb Complement
have a yaht have a laugh
Figure 4.1.: A schematic representation of the structure of a light verb constructioncompared with a typical verb phrase. The dashed arrows show the directionof projection.
some properties of idiomatic expressions, but, unlike collocations and idioms, they are
formed according to the same “semi-productive” pattern in different languages.
The semi-productive and semi-compositional nature of light verb constructions has im-
portant consequences for their cross-linguistic mappings. Consider the following exam-
ples of English constructions and their translations into German and Serbian.
(4.1) a. Mary [had a laugh]. (English)
b. Maria [lachte]. (German)
c. Marija se [na-smejala]. (Serbian)
(4.2) a. Mary [gave a talk]. (English)
b. Maria [hielt einen Vortrag]. (German)
c. Marija [je o-drzala predavanje]. (Serbian)
English expression had a laugh in (4.1a) is translated to German with a single verb
(lachte in (4.1b)). The Serbian counterpart of the English expression (nasmejala in
(4.1c)) is also a single verb, but with a prefix attached to it. By contrast, the English
expression in (4.2a) is translated with phrases both in German and in Serbian, but the
132

4.1. Introduction
heading verbs are not lexical counterparts. Unlike English gave, German hielt means
’held’, and Serbian odrzala means approximately ’held for a moment’.
Distinguishing between regular verb phrases and light verb constructions is crucial both
for constructing correct representations of sentences and for establishing cross-linguistic
mappings (Hwang et al. 2010). Moreover, one needs to distinguish between different
kinds of light verb constructions to account for the fact that they are not distributed
across languages in the same way. In some cases, cross-linguistically equivalent expres-
sions are constructions, as in (4.2), while in other cases, cross-linguistic equivalence holds
between constructions and individual lexical items, as in (4.1). However, these distinc-
tions are hard to make because there are no formal indicators which would mark the
differences either morphologically or syntactically.
The issue of distinguishing between different types of light verb constructions has been
addressed in both theoretical and computational linguistics. It has been argued that
these constructions should be seen as a continuum of verb usages with different degrees
of verbs’ lightness and different degrees of compositionality of the meaning of construc-
tions. There has been a number of proposals as to how to distinguish between different
kinds of constructions. Despite the fact that light verb constructions are headed by
several different verbs in all the studied languages (for example, take, make, have, give,
pay in English), the proposed accounts do not address the potential influence of lexical
properties of the heading verb on the overall interpretation of the construction. Regard-
ing light verbs as semantically empty or impoverished, the proposed accounts rely on the
characteristics which are common to all of them. Contrary to this, our study addresses
potential lexical differences between light verbs. We perform two experiments showing
that cross-linguistic mappings of English light verb constructions depend on the kind of
meaning of the heading light verbs. We describe the meaning in terms of force dynamics
schemata (see Chapter 2, Section 2.1.4).
The chapter consists of four main parts. In the first part, we present the questions
raised by light verb constructions and the proposed accounts which constitute the the-
oretical background of our study. We start by introducing the problem of semantic role
assignment in light verb constructions (4.2.1), which is followed by the discussion of
the proposed distinctions between different constructions (4.2.2). In the second part,
133

4. Force dynamics schemata and cross-linguistic alignment of light verb constructions
we present two experiments. In the first experiment (4.3.1), we examine the differences
in cross-linguistic alignments between two kinds of light verb constructions in a sample
of instances extracted from a parallel corpus based on manual word alignment. In the
second experiment (4.3.2), we evaluate automatic word alignment of the same sample of
instances which is manually analysed in the first experiment. The aim of this analysis
is to determine whether the quality of automatic alignment of light verb constructions
depends on the semantic properties of the heading light verbs. In the third part (Sec-
tion 4.4, we interpret the results of our experiments in light of the theoretical discussion
presented in the first part. We compare the findings of our study with the related work
in Section 4.5.
4.2. Theoretical background
Theoretical accounts of light verb constructions are mostly concerned with the question
of whether light verbs assign semantic roles to some constituents in a sentence or not.
While some authors argue that light verbs are functional words with no lexical content
and no predicate-argument structure, others argue that some semantic roles are assigned
by light verbs. In the following subsection, we discuss theoretical challenges posed by
light verb constructions and the proposed accounts. We then turn to the issue of semi-
compositionality and semi-productivity of the constructions.
4.2.1. Light verb constructions as complex predicates
The question of whether light verbs assign semantic roles or not is theoretically inter-
esting because it relates directly to the general theory of the relationship between the
lexical properties of verbs and the rules of phrase structure (see Chapter 2, Section
2.1.1). Note that the nouns which head the complements of light verbs, for example
look in (4.3a), are derived from verbs. Contrary to other, regular nouns, these nouns
retain the relational meaning of the original verb. For example, the noun look in (4.3a)
relates the nouns daughter and Mary in a similar way as the verb look in (4.3b). If a
light verb which heads a light verb construction (for example, took in (4.3a)) assigns
134

4.2. Theoretical background
some semantic roles too, then there are more arguments of verbs with semantic roles
than constituents in the clause that can realise them syntactically.1 This problem is
characteristic for a range of phenomena usually called complex predicates.
(4.3) a. Mary took a look [at her daughter].
b. Mary looked [at her daughter].
In some languages, such as Urdu, (Butt and Geuder 2001), light verbs can take both
verbs and deverbal nouns as complements. In others, such as English, they only take
deverbal nouns, but these nouns can be more or less similar to the corresponding verbs.
Their form can be identical to the verb form, as it is the case with look in (4.3), or it can
be derived from a verb with a suffix (e.g. inspectV vs. inspectionN). In some cases, the
same semantic arguments of deverbal nouns and their corresponding verbs are realised
as the same syntactic complement. For example, the same prepositional phrase at her
daughter in 4.3 occurs as a complement of both the noun and the verb look. In other
cases, the same semantic argument can be differently realised in syntax (her brother vs.
to her brother in (4.4)) or it can be left unspecified (the project site vs. no complement
in (4.5)).
(4.4) a. Mary visited [her brother].
b. Mary paid a visit [to her brother].
(4.5) a. They inspected [the project site] last week.
b. They made an inspection last week.
The meaning of a deverbal noun can be more or less similar to the meaning of the
corresponding verb. Grimshaw (1990) distinguishes between event and result nominal
structures called nominals, arguing that only event nominals actually denote an action
and can take arguments. For example, the expression in (4.6a) is grammatical, while
the expression in (4.6b) is not. According to this test, the deverbal noun examination
1Note that auxiliary and modal verbs constitute a single lexical unit with a main verb. The problemof syntactic realisation of verbal arguments does not arise with these items because they are purelyfunctional words with no idiosyncratic lexical content; they do not assign to their arguments anysemantic roles that need to be interpreted.
135

4. Force dynamics schemata and cross-linguistic alignment of light verb constructions
refers to an activity, while exam refers to a result of an activity. In addition to this test,
Grimshaw (1990) proposes several syntactic indicators to distinguish between deverbal
nouns which refer to an activity and which are, thus, more similar to the corresponding
verbs and the nouns which refer to a result state, which is closer to the typical nominal
meaning. One of the test is the indefinite article. As illustrated in (4.7), result nominals
(4.7a) can occur in an indefinite context, while event nominals cannot ((4.7b) is not
acceptable).
(4.6) a. the examination of the papers
b. * the exam of the papers
(4.7) a. * take an examination
b. take an exam
According to this analysis, most light verb complements would be classified as result
nominals, since the indefinite article seems to be one of the characteristic determiners
in light verb constructions (see also the examples below). This characteristic, however,
does not necessarily hold in all languages.
Based on an analysis of Japanese light verb constructions, Grimshaw and Mester (1988)
provide evidence for a distinction between transparent noun phrases which are comple-
ments of the verb suru and opaque noun phrases which are complements of the verb
soseru. The former are special noun phrases which occur only as complements of light
verbs. They are described as transparent because the predicate-argument relations are
syntactically marked (by cases). The latter are more typical noun phrases which occur in
other contexts as well. They are described as opaque because the semantic relationships
in these phrases are interpreted implicitly.
According to Grimshaw and Mester (1988), English light verb constructions would all be
formed with the opaque nominals. For example, the relationship between the predicate
visit and its argument her brother is transparent in (4.4a), where visit is a verb: her
brother is theme and this relationship is syntactically expressed as the direct object.
Contrary to this, the same semantic relationship is not transparent in (4.4b), where
visit is a noun. The attachment of the prepositional phrase to her brother is ambiguous
136

4.2. Theoretical background
(it can be attached to the light verb paid or the noun visit), and its semantic role is
interpreted implicitly (the preposition to does not encode the role theme).
Wierzbicka (1982), on the other hand, underlines the difference in meaning between the
complements of light verbs in English. For example, the meaning of the verb have in
(4.8) is contrasted to the one in (4.9-4.11). The nouns like swim in (4.8) are claimed to
be verbs “despite the fact that they combine with an indefinite article” and should be
distinguished from deverbal nouns. All the derived forms are considered to be nouns,
together with some nouns that have the same form as verbs, but whose meaning is clearly
that of a noun, such as smile in (4.9), cough in (4.10), or quarrel in (4.11). Wierzbicka
(1982), however, does not use any observable criterion or test to distinguish between the
nouns such as swim in (4.8) and the nouns such as smile, cough, quarrel in (4.9-4.11)
relying only on individual judgements.
(4.8) He had a swim.
(4.9) She has a nice smile.
(4.10) He has a nasty cough.
(4.11) They had a quarrel.
Kearns (2002) notices that the complements of light verbs in English are not “real nouns”
in some constructions, but that they are coined for light verb constructions and do not
occur freely in other nominal environments. This characteristic makes some light verb
constructions in English similar to the suru-constructions in Japanese.
The degree to which the complement of a light verb is similar to its corresponding verb
influences the overall representation of the light verb construction. The more verbal the
complement the less straightforward the assignment of semantic roles in the construction.
The more typical the noun which heads the complement, the more compositional and
regular the construction. Light verb constructions are distributed on a scale ranging
from complex predicates to near regular constructions. The variety of constructions is
discussed in the following subsection.
137

4. Force dynamics schemata and cross-linguistic alignment of light verb constructions
4.2.2. The diversity of light verb constructions
Several degrees of “lightness” of light verbs are illustrated by expressions in (4.12-4.16)
taken from Butt and Geuder (2001). The sequence of expressions shows the gradual
extension of the prototypical meaning of give (4.12) to its lightest use (4.16) .
(4.12) a. give him the ball
b. give the dog a bone
c. give the costumer a receipt
(4.13) a. Tom gave the children their inheritance money before he died.
b. The king gave the settlers land.
(4.14) a. give advice
b. give someone the right to do something
c. give someone information
(4.15) a. give someone emotional supported
b. give someone one’s regards
(4.16) a. give someone a kiss / a push / a punch / a nudge / a hug
b. give the car a wash, give the soup a stir
The change in the meaning of give depends on the sort of the complement. The most
prototypical variant in (4.12) involves a change in possession of the object together with
a change of its location. Having a more abstract object, or an object that does not move,
excludes the component of moving from give in (4.13). The possession is excluded with
objects that are not actually possessed, such as advice or right in (4.14), and replaced
with a more abstract component of a result state. The action of “giving” in (4.15) is
realised without “giver’s” control over the recipient’s state. Finally, the light give in
(4.16) does not describe a transfer at all, but just “the exertion of some effect on the
138

4.2. Theoretical background
recipient”. The difference between the two groups of expressions is made by the presence
of the component of moving in (4.16a), while in (4.16b), even this is gone.
The presence of an agent (the participant that performs or causes the action described
by the verb), the completion of the action, and its “directedness” are the components
of meaning present in all the realisations. By comparing the range of uses of give in
English and its corresponding verb de in Urdu, Butt and Geuder (2001) argue that the
same components of meaning which are shared by all the illustrated uses of English give
are also the components that the English give and the Urdu de have in common.
Brugman (2001) takes a more formal approach to identifying the relevant components
of meaning on the basis of which light verb constructions can be differentiated. Instead
of analysing the properties of the nominal complements, Brugman (2001) turns to the
light verbs themselves, focusing on the English verbs give, take, and have. In an analysis
that assumes the force-dynamic schemata (Talmy 2000) (see Section 2.1.4 in Chapter
2 for more details), Brugman (2001) argues that light verbs retain the pattern of force
dynamics (or a part of it) of their prototypical (semantically specified) counterparts.
The differences in meaning between light verbs such as take in (4.17) and give in (4.18)
are explained in terms of different force-dynamics patterns. The overall flow in the
events described by the verbs is differently oriented in the two examples.
(4.17) Take a { sniff / taste } of the sauce, will you?
(4.18) Give the sauce a { sniff / taste }, will you?
In (4.17) it is the opinion of the addressee that is asked for, so that the energy is directed
towards the agent. This orientation corresponds to the force-dynamic pattern of the verb
take, which is a self-oriented activity. The question in (4.18) is about the sauce. One
wants to know whether it had spoiled. This direction corresponds to the pattern of the
verb give, which is a directed activity, oriented outwards with respect to the agent of
the event.
The account of Brugman (2001) provides a general framework for discussing the meaning
of light verbs. However, it does not relate the identified components of meaning with
139

4. Force dynamics schemata and cross-linguistic alignment of light verb constructions
the discussion concerning the degree of lightness of the verbs and the variety of light
verb constructions.
Kearns (2002) proposes a set of formal syntactic tests to distinguish between the con-
structions with “lighter” verbs and the constructions with “heavier” verbs. The former
group is called true light verb constructions and the latter group is called constructions
with vague action verbs. True light verb constructions are identified as special syntactic
forms, while the constructions with vague action verbs are regarded as regular phrases.
(4.19) a. The inspection was made by the man on the right.
b. * A groan was given by the man on the right.
(4.20) a. Which inspection did John make?
b. * Which groan did John give?
(4.21) a. I made an inspection and then Bill made one too.
b. * I gave the soup a heat and then Bill gave it one too.
The formal distinction between true light verbs and vague action verbs is illustrated in
(4.19-4.21), where the expression make an inspection represents constructions with vague
action verbs, and the expression give a groan represents true light verb constructions.
The examples show that the complement of a true light verb cannot be moved or omitted
in regular syntactic transformations. While the passive form of the expression make an
inspection (4.19a) is grammatical, the passive form of the expression give a groan (4.19b)
is not grammatical. The same asymmetry holds for the WH-question transformation in
(4.20) and for the co-ordination transformation in (4.21).
Kearns (2002)’s analysis points to some observable indicators on the basis of which
various light verb constructions can be differentiated and classified. However, it does
not relate the observed behaviour with the meaning of the verbs, regarding true light
verbs as semantically empty.
The empirical case study presented in this chapter addresses both issues discussed in
the literature: the components of meaning of light verbs discussed by Brugman (2001)
140

4.3. Experiments
and the degree of compositionality of light verb constructions discussed in the other
presented accounts. Following Grimshaw and Mester (1988) and Kearns (2002), we
distinguish between two kinds of constructions. We use Kearns (2002)’s terminology
referring to the more idiomatic constructions as true light verb constructions and to
the less idiomatic constructions as constructions with vague action verbs. We follow
Brugman (2001) in using force-dynamic schemata for describing the meaning of light
verbs. In the experiments presented in the following section, we examine the relationship
between the meaning of light verbs and their cross-linguistic syntactic behaviour.
An in-depth empirical study of light verb constructions in the specific context of par-
allel corpora and alignment can lead to new generalisations concerning the correlation
of their linguistic and statistical properties. On the one hand, the statistical large-scale
analysis of the behaviour of these constructions in a general cross-linguistic word align-
ment process provides novel linguistic information, which enlarges the empirical basis
for the analysis of these constructions, and complements the traditional grammaticality
judgments. On the other hand, the linguistically fine-grained analysis of the statistical
behaviour of these constructions provides linguistically-informed performance and error
analyses that can be used to improve systems for automatic word alignment.
4.3. Experiments
The purpose of our study is to examine the translation equivalents of a range of English
light verb constructions and the effect that lexical properties of light verbs have on the
cross-linguistic variation. We take as a starting point the observation that the cross-
linguistic distribution of light verb constructions depends on their structural properties,
as shown in (4.1-4.2), repeated here as (4.22-4.23).
(4.22) a. Mary [had a laugh]. (English)
b. Maria [lachte]. (German)
c. Marija se [na-smejala]. (Serbian)
(4.23) a. Mary [gave a talk]. (English)
141

4. Force dynamics schemata and cross-linguistic alignment of light verb constructions
b. Maria [hielt einen Vortrag]. (German)
c. Marija [je o-drzala predavanje]. (Serbian)
Recall that English light verb constructions are paraphrases of verbs. The expressions
had a laugh in (4.22a) and gave a talk in (4.23) can be replaced by the corresponding
verbs laughed and talked respectively without changing the meaning of the sentences.
(Obtaining natural sentences with the verbs instead of the constructions would require
adding some modifiers, but this does not influence their semantic equivalence.) The
corresponding cross-linguistic realisations of the constructions illustrated in (4.22-4.23)
can be either single verbs or constructions. The cross-linguistic variation can therefore
be seen as an extension of the within-language variation. We analyse the cross-linguistic
frequency distribution of the two alternants as an observable indicator of the lexical
properties of the constructions which spread across languages.
We explore the potential relationship between the meaning of light verbs and the cross-
linguistic realisations of light verb constructions by examining a sample of constructions
formed with two light verbs widely discussed in the literature. We select the verb take as
a representative of self-oriented force dynamic schemata (following Brugman (2001), as
discussed in Section 4.2.2). We select the verb make as a representative of directed force
dynamic schemata, similar in this respect to give, as analysed by Brugman (2001). The
reason for studying the verb make instead of give is to keep the number of arguments
constant across the verbs (give takes three arguments, while take takes two), excluding
this factor as a possible source of variation.
To compare the realisations of light verbs with realisations of regular lexical verbs,
we compose a set of verbs which are “heavy” lexical entries comparable in meaning
with the verb make. The set consists of the following verbs: create, produce, draw,
fix, (re)construct, (re)build, establish. It is obtained from WordNet (Fellbaum 1998),
which is a widely cited lexical resource specifying lexical relationships between words.
Including several representatives of regular verbs is necessary to deal with the differences
in frequency. Since the two light verbs are much more frequent than any of the regular
verbs, comparable samples cannot be drawn from corpora of the same size. For example,
in the same portion of a corpus which contains fifty occurrences of the verb make, one
can expect less than ten occurrences of the verb create. To obtain comparable samples,
142

4.3. Experiments
Figure 4.2.: Constructions with vague action verbs
we sum up the numbers of occurrences of all regular verbs regarding them as a single
regular verb during the analysis.
Our samples consist of instances of English light verbs and their German equivalents
automatically extracted from a word-aligned parallel corpus. We use this language pair
as a sample of many possible language pairs. In principle, the same analysis can be
performed for any given language pair.
We identify two aspects of the alignment of these constructions as the relevant objects of
study. First, we quantify the amount and nature of correct word alignments for light verb
constructions compared to regular verbs, as determined by human inspection. Given the
cross-linguistic variation between English, German, and Serbian, described in (4.1-4.2),
it can be expected that English light verb constructions will be aligned with a single word
more often than constructions headed by a regular verb. Assuming that the properties of
the heading light verbs do influence semantic compositionality of the constructions, it can
also be expected that light verb constructions headed by different verbs will be differently
aligned to the translations in other languages. Different patterns of alignment would thus
indicate different types of constructions. Second, we evaluate the quality of automatic
word alignments of light verb constructions. Translations that deviate from one-to-one
word alignments, as it is the case with light verb constructions, are hard to handle in
the current approaches to automatic word alignment (see Section 3.2.1 in Chapter 3).
Because of the cross-linguistic variation illustrated in (4.1-4.2), light verb constructions
can be expected to pose a problem for automatic word alignment. Specifically, we
expect lower overall quality of word alignment in the sentences containing light verb
constructions than in the sentences that contain corresponding regular constructions.
143

4. Force dynamics schemata and cross-linguistic alignment of light verb constructions
Figure 4.3.: True light verb constructions
4.3.1. Experiment 1: manual alignment of light verb constructions
in a parallel corpus
In the first experiment, we address the relationship between two distinctions pointed
out in the theoretical accounts of light verb constructions: a) the distinction between
self-oriented vs. directed dynamics in the meaning of light verbs and b) the distinc-
tion between idiomatic true light verb constructions vs. regular-like constructions with
vague action verbs. The experiment consists of manual word alignment and a statistical
analysis of a random sample of three kinds of constructions: constructions with the verb
take, constructions with the verb make, and regular constructions.
We test the following hypotheses:
1. Light verb constructions in English are aligned with a single word in German more
often than constructions headed by a regular verb.
2. True light verb constructions in English are aligned with a single word in German
more often than constructions with vague action verbs.
3. The degree of compositionality of light verb constructions depends on the force
dynamic schemata represented in the meaning of light verbs.
We assume that the lack of cross-linguistic parallelism indicates idiosyncratic structures.
In the case of light verb constructions, we assume that the one-to-two word alignment
illustrated in Figure 4.3 indicates idiomatic true light verb constructions, while the one-
to-one word alignment illustrated in Figure 4.2 indicates more regular constructions with
144

4.3. Experiments
vague action verbs. We assume that both types have some semantic content, but that
this content is richer in the latter group than in the former.
Materials and methods
We analyse three samples of the constructions, one for each of the types defined by the
heading verb. Each sample contains 100 instances randomly selected from a parallel
corpus. Only the constructions where the complement is the direct object were included
in the analysis. This means that constructions such as take something into consideration
are not included. The only exception to this were the instances of the construction take
something into account. This construction was included because it is used as a variation
of take account of something with the same translations to German. All the extracted
instances are listed in Appendix A.
Corpus. The instances of the phrases were taken from the English-German portion
of the Europarl corpus (Koehn 2005). The texts in Europarl are collected from the
website of the European Parliament. They are automatically segmented into sentences
and aligned at the level of sentence. The version of the corpus which we use contains
about 30 million words (1 million sentences) of each of the 11 formerly official languages
of the European Union: Danish (da), German (de), Greek (el), English (en), Spanish
(es), Finnish (fin), French (fr), Italian (it), Dutch (nl), Portuguese (pt), and Swedish
(sv). Most of the possible language pairs are not direct translations of each other,
since for each text, there is one source language and the others are translations. Some
translations are also mediated by a third language. All the instances analysed in this
study are extracted from the portion of the corpus which contains the proceedings of the
sessions held in 1999. The selected portion of the corpus is parsed using a constituent
parser (Titov and Henderson 2007).
Sampling. Instances of light verb constructions are sampled in two steps. First, a
sample of random 1000 bi-sentences is extracted using a sampler based on computer-
generated random numbers (Algorithm 1). Each sentence is selected only once (sampling
without replacement). All verb phrases headed by the verbs take and make, as well as the
six regular verbs in the randomly selected 1000 bi-sentences are extracted automatically.
145

4. Force dynamics schemata and cross-linguistic alignment of light verb constructions
1. Extract verb-noun pairs from the randomly selected automat-ically parsed sentences; Tgrep2 query:
’VP < ‘/^VB/ & <-1 (/^NP/ < (‘/^NN/ !. /^NN/))’
3. Select light verb construction candidates:a. the pairs which contain the verb take and a deverbalnominal complement listed in NOMLEXb. the pairs which contain the verb make and a deverbalnominal complement listed in NOMLEX.
4. Select the pairs which contain one of the regular verbs.
Figure 4.4.: Extracting verb-noun combinations
The extraction is performed in several steps, as summarised in Figure 4.4. We first
extract all the verb-noun pairs using Tgrep2, a specialised search engine for parsed
corpora (Rohde 2004). We formulate the query shown in Figure 4.4 to extract all the
verbs which head a verb phrase containing a nominal complement together with the head
of the complement. The noun which is immediately dominated by the noun phrase and
which is not followed by another noun is considered the head of the noun phrase. The
extracted verb noun pairs are then compared with the list of deverbal nominals in the
NOMLEX database (Macleod et al. 1998) to select the pairs which consist of one of the
light verbs and a nominalisation. The selected pairs are then manually examined and
uses which are not light are removed from the list. Regular constructions are extracted
from the verb-noun pairs by comparing the heading verb with our predefined sample of
regular verbs.
After assessing the frequency of the selected constructions in the initial random sample
of 1000 sentences, we assess that the number of sentences needed to extract 100 instances
of each of the three types of constructions is 6000. In the second step, we add 5000 ran-
domly selected bi-sentences to the initial sample using the same sampler and repeat the
extraction procedure. The final sample which was analysed in the experiment consists
of the first 100 occurrences of each construction type in the sample of 6000 randomly
selected bi-sentences.
146

4.3. Experiments
Algorithm 1: Selecting a random sample of bi-sentencesInput : Aligned corpus of bi-sentences S,
each sentence s ∈ S is assigned a unique number n
Output : A random sample of K bi-sentences
for i = 1 to i = K do
generate a random number r in the range from 1 to S;
for j = 1 to j = S do
if r(i) == n(s) then
select s;
remove s from S;
break;
end
end
end
Feature representation. The constructions are represented as ordered pairs of words
V + N, where the first word is the verb that heads the construction and the second is
the noun that heads the verb’s complement. For a word pair in English, we identify
the corresponding word or word pair in German which is its actual translation in the
parallel corpus. If either the English or the German verb form included auxiliary verbs
or modals, these were not considered. Only the lexical part of the forms were regarded
as word translations.
(4.24) Erhe
hatAUX
einena
Vorschlagproposal
gemacht.made
He made a proposal.
(4.25) English instance: made + proposal
German alignment: Vorschlag + gemacht (note that hat is left out)
Type of mapping: 2-2
We then determine the type of mapping between the translations. If the German
translation of an English word pair includes two words too (e.g. take+decision ↔Beschluss+fassen), this was marked as the “2-2” type. If German translation is a single
word, the mapping was marked with “2-1”. This type of alignment is further divided
147

4. Force dynamics schemata and cross-linguistic alignment of light verb constructions
EnglishLVC take LVC make Regular
Ger
man
tran
slat
ion 2 → 2 57 50 94
2 → 1N 8 18 22 → 1V 30 28 22 → 0 5 4 2
Total 100 100 100
Table 4.1.: Types of mapping between English constructions and their translation equiv-alents in German.
into “2-1N” and “2-1V”. In the first subtype, the English construction corresponds to a
German noun (e.g. initiative+taken ↔ Initiative). In the second subtype, the English
construction corresponds to a German verb (e.g. take+look↔ anschauen). In the cases
where a translation shift occurs so that no translation can be found, the mapping is
marked with “2-0”.
For example, a record of an occurrence of the English construction “make + proposal”
extracted from the bi-sentence in (4.24) would contain the information given in (4.25).
For more examples, see Appendix A.
Results and discussion
We summarise the collected counts in a contingency table and compare the observed
distributions with the distributions which are expected under the hypothesis that the
type of the construction does not influence the variation.
χ2 =∑ (E −O)2
E(4.26)
To asses whether the difference between the observed and the expected distributions
is statistically significant, we use the χ2-test, which is calculated using the equation in
(4.26), where O stands for observed counts, E for expected counts.
148

4.3. Experiments
Table 4.1 shows how many times each of the four types of mapping (2-2; 2-1N; 2-1V;
2-0) between English constructions and their German translation equivalents occurs in
the sample.
We can see that the three types of constructions tend to be mapped to their German
equivalents in different ways. First, both types of light verb constructions are mapped to
a single German word much more often than the regular constructions (38 instances of
light verb constructions with take and 46 instances of light verb constructions with make
vs. only 4 instances of regular constructions.). This difference is statistically significant
(χ2 = 56.89, p < 0.01). Confirming our initial hypothesis No. 1, this result suggests
that the difference between fully compositional phrases and light verb constructions
in English can be described in terms of the amount of the “2-1” mapping to German
translation equivalents.
The number of “2-1” mappings is not significantly different between light verb construc-
tions headed by take and those headed by make (χ2 = 4.54, p < 0.90). However, an
asymmetry can be observed concerning the two subtypes of the “2-1” mapping. The
German equivalent of an English construction is more often a verb if the construction
is headed by the verb take (in 30 occurrences, that is 79% of the 2-1 cases) than if the
construction is headed by the verb make (28 occurrences, 61% cases). This difference is
statistically significant (χ2 = 3.90, p < 0.05).
When the German translation equivalent for an English construction is a verb, the mean-
ing of both components of the English construction are included in the corresponding
German verb, the verbal category of the light verb and the lexical content of the nominal
complement. These instances are less compositional, more specific and idiomatic (e.g.
take+care ↔ kummern, take+notice ↔ berucksichtigen).
On the other hand, English constructions that correspond to a German noun are more
compositional, less idiomatic and closer to the regular verb usages (e.g. make+proposal
↔ Vorschlag, make+changes ↔ Korrekturen). The noun that is regarded as their Ger-
man translation equivalent is, in fact, the equivalent of the nominal part of the con-
struction, while the verbal part is simply omitted. This result suggests that English
light verb constructions with take are less compositional than the light verb construc-
tions with make.
149

4. Force dynamics schemata and cross-linguistic alignment of light verb constructions
This result does not confirm the hypothesis No. 2, but it does confirm the hypothesis
No. 3. Although the number of “2-1” mappings is not different between the two light
verbs, two kinds of these mappings can be distinguished. The statistically significant
difference in the mappings suggests that the degree of compositionality of light verb
constructions depends on the force dynamic schemata represented in the meaning of
light verbs. The agent-oriented dynamics of the verb take gives rise to more divergent
cross-linguistic mappings than the directed dynamics of the verb take.
4.3.2. Experiment 2: Automatic alignment of light verb
constructions in a parallel corpus
In the second experiment, we address the relationship between the degree of composi-
tionality of light verb constructions and the quality of automatic word-alignment. On
the basis of the results of the first experiment and of the assumption that divergent
alignments are generally more difficult for an automatic aligner than the one-to-one
alignments, we expect the quality of automatic alignment to depend on the heading
verb. In particular, we test the following hypotheses:
1. The quality of word alignment in the sentences containing light verb constructions
is lower than in the sentences that contain corresponding regular constructions.
2. The quality of word alignment in the sentences containing light verb constructions
headed by take is lower than in the sentences that contain light verb constructions
headed by make.
Materials and methods
Corpus and sampling. The same sample of sentences as in the first experiment
is analysed. Before sampling, the corpus was word-aligned in both directions using
GIZA++ (Och and Ney 2003). As discussed in Section 3.2.1 in Chapter 3, the formal
definition of alignment used by this system excludes the possibility of aligning multiple
words in one language to multiple words in the other language, which is an option needed
150

4.3. Experiments
for representing alignment of non-compositional constructions. However, it does provide
the possibility of aligning multiple words in one to a single word in the other language,
which is the option needed to account for some of the described divergences between
English and German, such as the mappings shown in Figure 4.3. Such alignment is
possible in the setting where English is the target and German is the source language,
since in this case, both English words, the light verb and its complement can be aligned
with one German word. By contrast, if German is the target language, its single verb
that can be the translation for the English construction cannot be aligned with both
English words, but only with one of them. The direction of alignment can influence the
quality of automatic alignment, since the probability of alignment can only be calculated
for the cases that can be represented by the formal definition of alignment. The definition
of alignment implies that all the words in the target language sentence are necessarily
aligned, while some of the source sentence words can be left unaligned. This is another
reason why the quality of alignment can depend both on the type of the constructions
and on the direction of alignment.
Taking only the intersection of the alignments of both directions as the final automatic
alignment is a common practice. Its advantage is that it provides almost only good
alignments (precision 98.6% as evaluated by Pado (2007) and Och and Ney (2003)),
which can be very useful for some tasks. However, it has two disadvantages. First,
many words are left unaligned (recall only 52.9%). Second, it excludes the possibility
of many-to-one word alignment that is allowed by the alignment model itself and that
could be useful in aligning segments such as constructions with true light verbs. We
therefore do not use the intersection alignment, but rather analyse both directions.
(4.27) Target language German
EN: He made a proposal.
DE: Er(1) hat(1) einen(3) Vorschlag(4) gemacht(3).
Target language English
DE: Er hat einen Vorschlag gemacht.
EN: He(1) made(5) a(3) proposal(4).
(4.28) Automatic alignment, target German, noun: good, verb: no align
Automatic alignment, target English, noun: good, verb: good
151
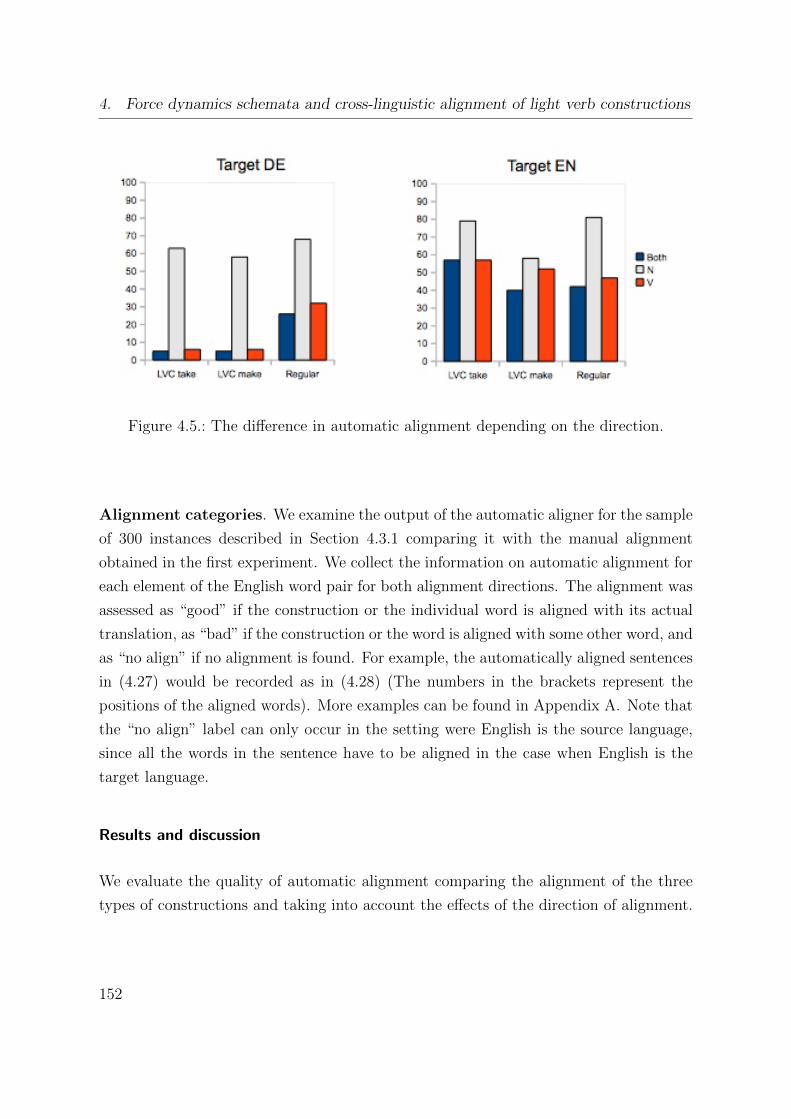
4. Force dynamics schemata and cross-linguistic alignment of light verb constructions
Figure 4.5.: The difference in automatic alignment depending on the direction.
Alignment categories. We examine the output of the automatic aligner for the sample
of 300 instances described in Section 4.3.1 comparing it with the manual alignment
obtained in the first experiment. We collect the information on automatic alignment for
each element of the English word pair for both alignment directions. The alignment was
assessed as “good” if the construction or the individual word is aligned with its actual
translation, as “bad” if the construction or the word is aligned with some other word, and
as “no align” if no alignment is found. For example, the automatically aligned sentences
in (4.27) would be recorded as in (4.28) (The numbers in the brackets represent the
positions of the aligned words). More examples can be found in Appendix A. Note that
the “no align” label can only occur in the setting were English is the source language,
since all the words in the sentence have to be aligned in the case when English is the
target language.
Results and discussion
We evaluate the quality of automatic alignment comparing the alignment of the three
types of constructions and taking into account the effects of the direction of alignment.
152

4.3. Experiments
Target DE Target EN
LVCs withtake
Both EN words 5 57EN noun 63 79EN verb 6 57
LVCs withmake
Both EN words 5 40EN noun 58 58EN verb 6 52
Regularconstruction
Both EN words 26 42EN noun 68 81EN verb 32 47
Table 4.2.: Well-aligned instances of light verb constructions with take, with make, andwith regular constructions (out of 100), produced by an automatic alignment,in both alignment directions (target is indicated).
As in the first experiment, the statistical significance of the observed differences in
frequency distributions is assessed using the χ2-test.
Table 4.2 shows how the quality of automatic alignment varies depending on the type of
construction, but also on the direction of alignment (see also Figure 4.5). Both words are
well aligned in light verb constructions with take in 57 cases and with make in 40 cases
if the target languages is English, which is comparable with regular constructions (42
cases). However, if the target language is German, both types of light verb constructions
are aligned well (both words) in only 5 cases, while regular constructions are well aligned
in 26 cases.
The effect of the direction of alignment is expected in light verb constructions given the
underlying formal definition of alignment which does not allow multiple English words
to be aligned with a single German word when German is the target language. However,
the fact that the alignment of regular phrases is degraded in this direction too shows that
the alignment of light verb constructions influences other alignments. The difference in
the amount of correct alignments in two directions also shows the amount of the correct
alignments which remain out of the intersection alignment.
Looking into the alignment of the elements of the constructions (verbs and nouns) sepa-
153
4. Force dynamics schemata and cross-linguistic alignment of light verb constructions
Frequency take LVC make LVC RegularLow 12 25 62High 76 40 8
Table 4.3.: The three types of constructions partitioned by the frequency of the comple-ments in the sample.
rately, we can notice that nouns are generally better aligned than verbs for all the three
types of constructions, and in both directions. However, this difference is not the same
in all the cases. The difference in the quality of alignment of nouns and verbs is the
same in both alignment directions for regular constructions, but it is more pronounced
in light verb constructions if German is the target. On the other hand, if English is the
target, the difference is smaller in light verb construction than in regular phrases. These
findings suggest that the direction of alignment influences more the alignment of verbs
than the alignment of nouns in general. This influence is much stronger in light verb
constructions than in regular constructions.
Given the shown effects of the direction of alignment, we focus only on the direction
which allows for better alignments in all three groups (with English as the target lan-
guage) and perform statistical tests only for this direction. The difference between
alignments of both members of the three types of constructions (both EN words in Ta-
ble 4.2) is statistically significant (χ2=6,97, p < 0.05). However, this does not confirm
the initial hypothesis No. 1 that the quality of alignment of light verb constructions is
lower than the quality of alignment of regular constructions. The quality of alignment in
light verb constructions is, in fact, better than in regular constructions. The difference
in the quality of automatic alignment between the two kinds of light verb constructions
is also statistically significant (χ2=5.74, p < 0.05), but the difference is again opposite
to the hypothesis No. 2: constructions with take are better aligned than constructions
with make. On the other hand, there is no significant difference between constructions
with make and regular constructions. These results suggest that the type of construction
which is the least compositional and the most idiomatic of the three is best aligned if
the direction of alignment suits its properties.
154

4.3. Experiments
Figure 4.6.: The distribution of nominal complements in constructions with take. In 12out of 100 instance the complement is headed by a low-frequency noun (lowfrequency = 1 occurrence in the sample). There are 76 instances where thecomplement is headed by a high frequency noun: 5 (one noun with frequency5) + 7 (one noun with frequency 7) + 27 (three nouns with frequency 9) +17 (one noun with frequency 17) + 20 (one noun with frequency 20).
Figure 4.7.: The distribution of nominal complements in constructions with make. In25 out of 100 instance the complement is headed by a low-frequency noun(low frequency = 1 occurrence in the sample). There are 40 instances wherethe complement is headed by a high frequency noun: 15 (three nouns withfrequency 5) + 7 (one noun with frequency 7) + 8 (one noun with frequency8) + 10 (one noun with frequency 10).
155
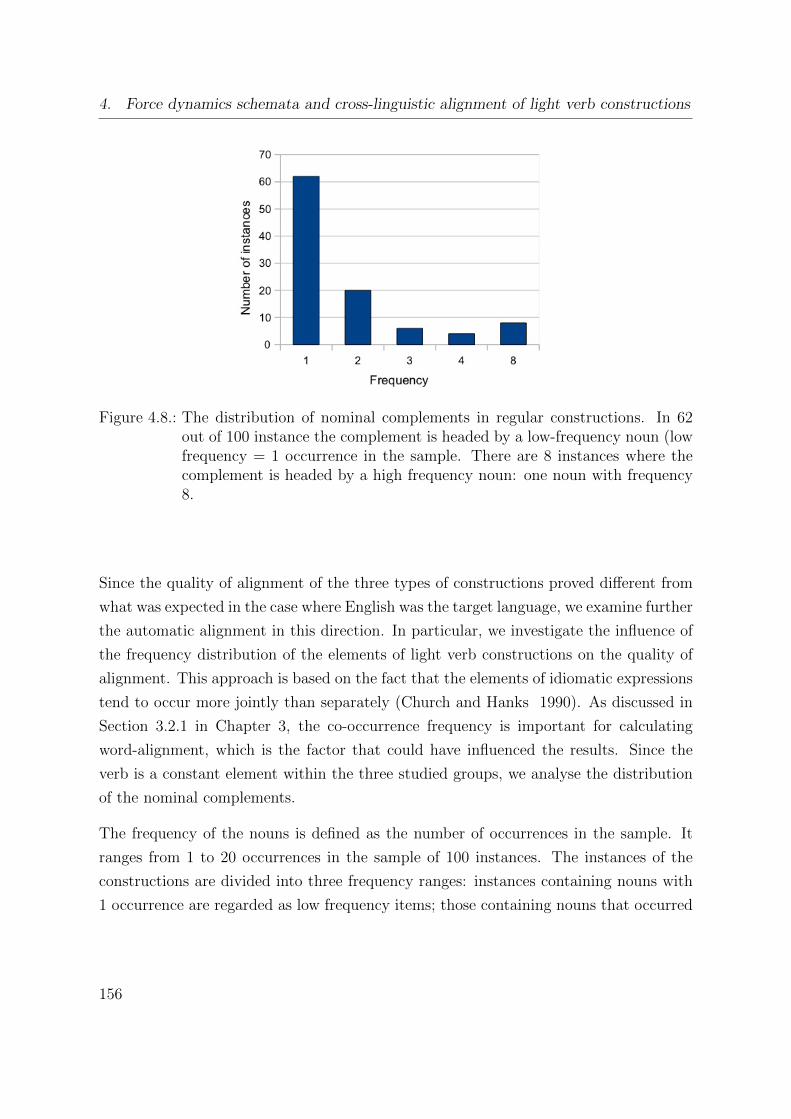
4. Force dynamics schemata and cross-linguistic alignment of light verb constructions
Figure 4.8.: The distribution of nominal complements in regular constructions. In 62out of 100 instance the complement is headed by a low-frequency noun (lowfrequency = 1 occurrence in the sample. There are 8 instances where thecomplement is headed by a high frequency noun: one noun with frequency8.
Since the quality of alignment of the three types of constructions proved different from
what was expected in the case where English was the target language, we examine further
the automatic alignment in this direction. In particular, we investigate the influence of
the frequency distribution of the elements of light verb constructions on the quality of
alignment. This approach is based on the fact that the elements of idiomatic expressions
tend to occur more jointly than separately (Church and Hanks 1990). As discussed in
Section 3.2.1 in Chapter 3, the co-occurrence frequency is important for calculating
word-alignment, which is the factor that could have influenced the results. Since the
verb is a constant element within the three studied groups, we analyse the distribution
of the nominal complements.
The frequency of the nouns is defined as the number of occurrences in the sample. It
ranges from 1 to 20 occurrences in the sample of 100 instances. The instances of the
constructions are divided into three frequency ranges: instances containing nouns with
1 occurrence are regarded as low frequency items; those containing nouns that occurred
156

4.3. Experiments
Figure 4.9.: The difference in automatic alignment depending on the complement fre-quency. English is the target language.
5 and more times in the sample are regarded as high frequency items; nouns occurring
2, 3, and 4 times are regarded as medium frequency items. Only low and high frequency
items were considered in this analysis.
Table 4.3 shows the number of instances belonging to different frequency ranges. It
can be noted that light verb constructions with take exhibit a small number of low
frequency nouns (see also Figure 4.6). The number of low frequency nouns increases
in the constructions with make (25/100, see also Figure 4.7), and it is much bigger
in regular constructions (62/100, see also Figure 4.8). The opposite is true for high
frequency nouns (LVCs with take: 76/100, with make: 40/100, regular: 8/100). Such
distribution of low/high frequency items reflects different collocational properties of the
constructions. In the most idiomatic constructions (with take), lexical selection is rather
limited, which results in little variation. Verbs in regular constructions select for a wide
range of different complements with little reoccurrence. Constructions with make can
be placed between these two types.
Different trends in the quality of automatic alignment can be identified for the three
157
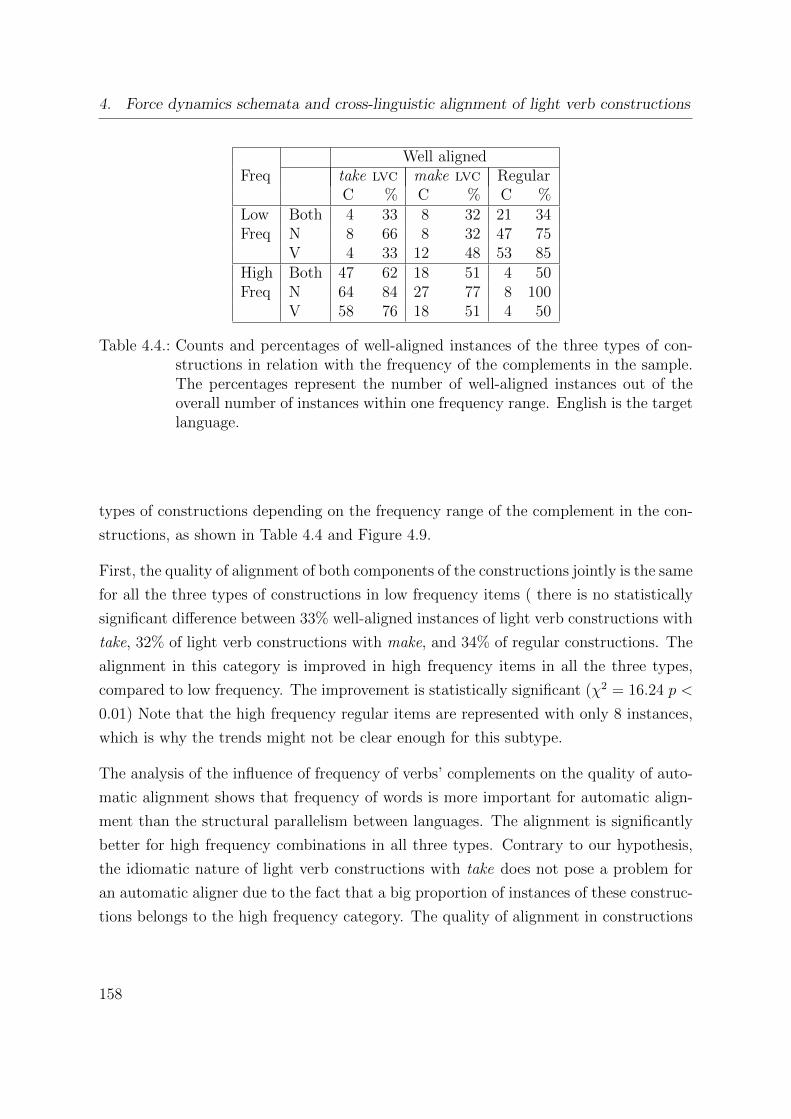
4. Force dynamics schemata and cross-linguistic alignment of light verb constructions
Well alignedFreq take lvc make lvc Regular
C % C % C %Low Both 4 33 8 32 21 34Freq N 8 66 8 32 47 75
V 4 33 12 48 53 85High Both 47 62 18 51 4 50Freq N 64 84 27 77 8 100
V 58 76 18 51 4 50
Table 4.4.: Counts and percentages of well-aligned instances of the three types of con-structions in relation with the frequency of the complements in the sample.The percentages represent the number of well-aligned instances out of theoverall number of instances within one frequency range. English is the targetlanguage.
types of constructions depending on the frequency range of the complement in the con-
structions, as shown in Table 4.4 and Figure 4.9.
First, the quality of alignment of both components of the constructions jointly is the same
for all the three types of constructions in low frequency items ( there is no statistically
significant difference between 33% well-aligned instances of light verb constructions with
take, 32% of light verb constructions with make, and 34% of regular constructions. The
alignment in this category is improved in high frequency items in all the three types,
compared to low frequency. The improvement is statistically significant (χ2 = 16.24 p <
0.01) Note that the high frequency regular items are represented with only 8 instances,
which is why the trends might not be clear enough for this subtype.
The analysis of the influence of frequency of verbs’ complements on the quality of auto-
matic alignment shows that frequency of words is more important for automatic align-
ment than the structural parallelism between languages. The alignment is significantly
better for high frequency combinations in all three types. Contrary to our hypothesis,
the idiomatic nature of light verb constructions with take does not pose a problem for
an automatic aligner due to the fact that a big proportion of instances of these construc-
tions belongs to the high frequency category. The quality of alignment in constructions
158

4.4. General discussion
with take is better than the quality in the other two types due to the difference in the
distribution of high frequency items. As it can been seen in Figures 4.6, 4.7, and 4.8,
the sample of constructions with take consists mostly of high frequency items. Low
frequency items, on the other hand, prevail in regular constructions, while constructions
with make are in between the two.
4.4. General discussion
The results of our study confirm the hypotheses about the relationship between cross-
linguistic alignment of light verb constructions and the meaning of the heading light
verb tested in Experiment 1. On the other hand, the hypotheses about the relationship
between the type of light verb constructions and automatic word alignment in a parallel
corpus tested in Experiment 2 are not confirmed. However, the identified behaviour
of the automatic aligner with respect to light verb constructions provides additional
evidence for the distinctions confirmed in Experiment 1. In this section, we interpret
the results in light of the theoretical discussion concerning light verb constructions.
4.4.1. Two force dynamics schemata in light verbs
The main finding of the study is the fact that the constructions headed by light take
behave as idiomatic phrases more than the constructions headed by make. The differ-
ence between more idiomatic and less idiomatic light verb constructions has been widely
discussed in the literature, especially from the point of view of analysing the predicate-
argument structure of the constructions. The structure of true light verb constructions,
which are idiomatic and non-compositional, is argued to be similar to complex predicates,
while the structure of constructions with vague action verbs, which are less idiomatic
and compositional, is argued to be similar to regular phrases. Our study shows that
the idiomatic properties of light verb constructions can be related to the meaning of the
heading verbs. The self-oriented force dynamics in the meaning of light take results in
more compact cross-linguistic morphosyntactic realisations than the directed dynamics
of light make. Cross-linguistic equivalents of English light verb constructions with take
159

4. Force dynamics schemata and cross-linguistic alignment of light verb constructions
tend to be single verbs (which is a compact representation), while cross-linguistic equiv-
alents of English light verb constructions with make tend to stay constructions with two
main elements. This does not hold only for the language pair English-German, but also
for the pair English-Serbian, as discussed by Samardzic (2008).
The idiomatic nature of true light verb constructions (represented by the constructions
with take in our study) is additionally confirmed by the finding that these construc-
tions are better aligned automatically than regular constructions. This finding, which
is opposed to our hypotheses, is due to the same interaction between frequency and ir-
regularity which has been established in relation with different language processing and
acquisition phenomena. Idiosyncratic (irregular) elements of language are known to be
more frequent than regular unites. This is the case, for example, with English irregular
verbs, which are, on average, more frequent than regular verbs. In the case of light
verb constructions in our study, the idiosyncratic units are the constructions with take
which are idiomatic with high co-occurrence of the two elements (the heading verb and
the nominal complement). The constructions with make, which represent constructions
with vague action verbs in our study, can be positioned somewhere between irregular and
regular items. This additionally confirms the claim that these two types of constructions
differ in the level of semantic compositionality.
Our analysis of corpus data has shown that there is a clear difference between regular
phrases and light verb constructions (including the constructions with make) in the
way they are cross-linguistically mapped in a parallel corpus. Regular constructions
are mapped word-by-word, with the English verb being mapped to the German verb,
and the English noun to the German noun. A closer look into the only 4 examples
where regular constructions were mapped as “2-1” shows that this mapping is not due
to the “lightness” of the verb. In two of these cases, it is the content of the verb that
is translated, not that of the noun (produce+goods ↔ Produktion; establishes+rights
↔ legt). This never happens in light verb constructions. On the other hand, light
verb constructions are much more often translated with a single German word. In both
subtypes of the “2-1” mapping of light verb constructions, it is the content of the nominal
complement that is translated, not that of the verb. The noun is either transformed into
a verb (take+look↔ anschauen) or it is translated directly with the verb being omitted
(take+initiative ↔ Initiative).
160

4.4. General discussion
The frequency distribution observed in out data represents a new piece of empirical ev-
idence of the distinctions made. The observable differences in cross-linguistic alignment
are especially useful for distinguishing between regular constructions and constructions
with vague action verbs (represented in our sample by the constructions with make). It
has been shown in other studies that true light verb constructions have characteristic
syntactic behaviour. Constructions with vague action verbs, however, can not be distin-
guished using the same tests, while they are clearly distinguished on the basis of their
cross-linguistic mappings.
4.4.2. Relevance of the findings to natural language processing
The findings of our study show that the interactions between automatic alignment and
types of constructions is actually more complicated than the simple hypotheses which we
initially formulated. To summarise, we find, first, better alignment of regular construc-
tions compared to light verb constructions only if the target language is German; second,
overall, alignment if English is target is better than if German is target; and third, we
found a clear frequency by construction interaction in the quality of alignment.
The quality of automatic alignment of both regular constructions and light verb con-
structions interacts with the direction of alignment. First, the alignment is considerably
better if the target language is English than if it is German, which confirms the findings
of Och and Ney (2003). Second, the expected difference in the quality of alignment
between regular constructions and light verb constructions has only been found in the
direction of alignment with German as the target language, that is where the “2-1”
mapping is excluded. However, the overall quality of alignment in this direction is lower
than in the other.
This result could be expected, given the general morphological properties of the two
languages, as well as the formalisation of the notion of word alignment used in the system
for automatic alignment. According to this definition, multiple words in the target
language sentence can be aligned with a single word in the source language sentence, but
not the other way around. Since English is a morphologically more analytical language
161

4. Force dynamics schemata and cross-linguistic alignment of light verb constructions
than German, multiple English words often need to be aligned with a single German
word (a situation allowed if English is the target but not if German is the target).
The phrases in (4.29) illustrate the two most common cases of such alignments. First,
English tends to use functional words (the preposition of in (3a)), where German applies
inflection (genitive suffixes on the article des and on the noun Bananensektors in (3b).
Second, compounds are regarded as multiple words in English (banana sector), while
they are single words in German (Bananensektors). This asymmetry explains both the
fact that automatic alignment of all the three types of constructions is better when the
target language is English and that the alignment of light verb constructions is worse
than the alignment of regular phrases when it is forced to be expressed as one-to-one
mapping, which occurs when German is the alignment target.
(4.29) a. the infrastructure of the banana sector
b. die Infrastruktur des Bananensektors
Practically, all these factors need to be taken into consideration in deciding which version
of alignment should be taken, be it for evaluation or for application in other tasks such as
automatic translation or annotation projection. The intersection of the two directions
has been proved to provide most reliable automatic alignment Pado (2007); Och and
Ney (2003). However, it excludes, by definition, all the cases of potentially useful good
alignments that are only possible in one direction of alignment.
4.5. Related work
Corpus-based approaches to light verb constructions belong to the very developed do-
main of collocation extraction. General methods developed for automatic identification
of collations in texts based on various measures of association between words can also be
applied to light verb constructions. However, light verb constructions differ from other
types of collocations in that they are partially compositional and relatively productive,
which calls for a special treatment.
162

4.5. Related work
The methods which combine syntactic parsing with standard measures of association
between words prove to be especially well adapted for automatic identification of light
verb constructions (Seretan 2011). Identifying the association between syntactic con-
stituents rather than between the words in a context window allows identifying light
verb constructions as collocations despite the variation in their realisations due to their
partially compositional meaning.
Grefenstette and Teufel (1995) present a method for automatic identification of an appro-
priate light verb for a derived nominal on the basis of corpus data. Making a difference
between the cases where the derived nominals can be ambiguous between more verb-like
(e. g. make a proposal) and more noun-like (e.g. put the proposal in the drawer) uses,
Grefenstette and Teufel (1995) extract only those usages where the noun occurs in a
context similar to a typical context of the corresponding verb. The most frequent gov-
erning verbs for these noun occurrences are their light verbs. As noted by the authors,
this technique proves to be insufficient on its own for identifying light verbs. It does
not differentiate between the light verb and other frequent verbal collocates for a given
nominalisation (e. g. reject a proposal vs. make a proposal). But it can be used as
a step in automatic processing of corpora, since light verbs do occur in the lists of the
most frequent collocates.
The method for extracting verb-noun collocations proposed by Tapanainen et al. (1998)
is based on the assumption that collocations of the type verb-noun are asymmetric in
such a way that it is the object (i. e. the noun) that is more indicative of the construction
being a collocation. If a noun occurs as the object of only few verbs in a big corpus,
its usage is idiomatical. For example, the noun toll occurs mainly with the verb take.
It can be used with other verbs too (e. g. charge, collect), but not with many. The
measure proposed in the study, the distributed frequency of the object, is better suited
for extracting light verb constructions than some symmetric measures of association.
However, this approach does not provide a means to distinguish light verb constructions
from the other collocations of the same type.
Using the information from cross-linguistic word alignment for identifying collocations
is explored by Zarrieß and Kuhn (2009). The study shows that many-to-one automatic
word alignment in parallel corpora is a good indicator of reduced compositionality of ex-
163

4. Force dynamics schemata and cross-linguistic alignment of light verb constructions
pressions. Combined with syntactic parsing, this information can be used for automatic
identification of a range of collocation types, including light verb constructions.
Semantic characteristics of light verb constructions are studied in more detail by Fazly
(2007), who proposes a statistical measure that quantifies the degree of figurativeness of
the light verb in conjunction with a predicating noun. The degree of figurativeness of a
verb is regarded as the degree to which its meaning is different from its literal meaning
in a certain realisation. It is assumed that constructions of the type verb-noun can be
placed on a continuum of figurativeness of meaning, including literal combinations (e. g.
give a present), abstract combinations (e. g. give confidence), light verb constructions
(e. g. give a groan), and idiomatic expressions (e. g. give a whirl). More figurative
meanings of the verb are considered closer to true light verbs, while more literal meanings
are closer to vague action verbs (i. e. to the abstract combinations on the presented
continuum).
The measure of figurativeness is based on indicators of conventionalised use of the con-
structions: the more the two words occur together and the more they occur within a
particular syntactic pattern the more figurative the meaning of the verb. Thus, the
figurativeness score is composed of two measures of association: association of the two
words and association of the verb with a particular syntactic pattern.
The syntactic pattern that is expected for figurative combinations is defined in terms of
three formal properties associated with typical light verb constructions (see the examples
in (4.19-4.21) in Section 4.2.2): active voice, indefinite (or no) article, and singular form
of the noun. The association of a verb-noun combination with the expected syntactic
pattern is expressed as the difference between the association of the combination with
this pattern (positive association) and the association of the combination with any of
the patterns where any of the features has the opposite value (passive voice, definite
article, plural noun).
For a sample of expressions, the scores assigned by the measure of figurativeness are
compared with the ratings assigned by human judges. The results show that a measure
which includes linguistic information about expressions performs better in measuring
the degree of their figurativeness than a simple baseline measure of association between
the words in the expressions.
164

4.6. Summary of contributions
The work of Stevenson et al. (2004) deals with semantic constraints on light verb com-
plements. They focus on true light verb constructions trying to identify the classes of
complements that would be preferred by a given light verb. Light verb constructions are
first identified automatically and then the relations between light verbs and some classes
of complements are examined. Following the analysis of Wierzbicka (1982) (see Section
4.2.1), the nominal complements of light verbs are identified with their corresponding
verbs. With this, it was possible to use Levin’s lexical semantic classification of verbs
(see Section 2.2.1 in Chapter 2 for more details) to divide the complements into semantic
classes and to examine if certain light verbs prefer certain classes of complements.
The study shows that light verbs have some degree of systematic and predictable be-
haviour with respect to the class of their complement. For example, light give tend to
combine with deverbal nouns derived from the Sound Emission verbs, while light take
combines better with the nouns derived from the Motion (non-vehicle) verbs. As the
light verb construction score gets higher, the pattern gets clearer. It shows as well that
some of the verbs (e. g. give and take) behave in a more consistent way than others (e.
g. make).
The computational approaches presented in this section show that the compositionality
of the meaning of light verb constructions does not correspond directly to the strength of
the association of their components. Adding specific linguistic information improves the
correlation between human judgements and automatic rankings. The studies, however,
do not address the lexical properties of light verbs verbs as one of the potential causes
of the observed variation. Also, they do not address the patterns in cross-linguistic
variation which are potentially caused be caused by different degrees of compositionality
of light verb constructions. Our study focuses on these two issues.
4.6. Summary of contributions
In the study of light verb constructions, we have proposed using data automatically
extracted from parallel corpora to identify two kinds of meaning of light verbs. We have
shown that English light verb constructions headed by the verb take tend to be aligned
165

4. Force dynamics schemata and cross-linguistic alignment of light verb constructions
with a German single verb more than the constructions headed by the verb make. The
difference in the cross-linguistic mapping is predicted from the meaning of the verbs
described in terms of force dynamics: the self-oriented schemata of light take gives rise
to more compact cross-linguistic realisations than the directed schemata of the verb
make.
The difference in the force dynamics of the two verbs is related to the level of composi-
tionality of their corresponding light verb constructions. The constructions with take are
less compositional and more irregular than the constructions with make. The idiomatic
nature of light verb constructions represented in our study by the constructions with
take is additionally confirmed by the finding that these constructions are better auto-
matically aligned than the constructions represented with the verb make, as well as the
comparable regular constructions. Although this finding sounds surprising, it actually
follows from the interaction of frequency and regularity which plays an important role
in automatic word alignment.
166

5. Likelihood of external causation
and the cross-linguistic variation in
lexical causatives
5.1. Introduction
The causative(/inchoative) alternation has been recognised in the linguistic literature a
wide- spread linguistic phenomenon, attested in almost all languages (Schafer 2009).
This alternation involves verbs such as break in (5.1), which can be realised in a sentence
both as transitive (5.1a) and as intransitive (5.1b). Both realisations express the same
event, with the only difference being that the transitive version specifies the causer of
the event (Adam in (5.1a)), and the intransitive version does not. The transitive version
is thus termed causative and the intransitive anticausative. The verbs that participate
in this alternation are commonly referred to as lexical causatives.1
(5.1) a. Causative: Adam broke the laptop.
b. Anticausative: The laptop broke.
1The lexical causative alternation, which we address in this study, is to be distinguished from thesyntactic causative alternation illustrated in (i), which has been studied more extensively in thelinguistic literature, as a case of verb serialisation (Baker 1988; Williams 1997; Alsina 1997;Collins 1997; Aboh 2009).
(i.) a. Lexical causative: Adam broke the laptop.
b. Syntactic causative: Adam made the laptop break.
167

5. Likelihood of external causation and the cross-linguistic variation in lexical causatives
What makes this alternation an especially attractive topic for our research is the wide
range of cross-linguistic variation in surface forms of the clauses formed with the alter-
nating verbs. The causative alternation appears in different languages with a diversity
of lexical, morphological, and syntactic realisations which defies linguists’ attempts at
generalisation.
First of all, the variation is observed in the sets of alternating verbs. Most of the
alternating verbs are lexical counterparts across many languages. However, there are
still many verbs which alternate in some languages, while their lexical counterparts in
other languages do not. The verbs that do not alternate in some languages can be divided
into two groups: only intransitive and only transitive. Examples of only intransitive and
only transitive verbs in English are given in Table 5.1. As the examples, taken from
Alexiadou (2010), show, the English verbs arrive and appear do not alternate: their
transitive realisation (causative in Table 5.1) is not available in English. However, their
counterparts in Japanese, or Salish languages, for example, are found both as transitive
and intransitive, that is as alternating. Similarly, the verbs such as cut and kill are only
found as transitive in English, while their counterparts in Greek or Hindi, for example,
can alternate between intransitive and transitive use.
Languages also differ in the morphological realisation of the alternation. Some exam-
ples of morphological variation, taken from Haspelmath (1993), are given in Table 5.1.
In some languages, such as Russian, Mongolian, and Japanese, the alternation is mor-
phologically marked. The morpheme that marks the alternation can be found on the
intransitive form, while the corresponding transitive form is not marked (the case of Rus-
sian in Table 5.1). In other languages, such as Mongolian, the morpheme that marks the
alternation is found on the transitive version, while the intransitive version is unmarked.
There are also languages where both forms are attached a causative marker, one mark-
ing the transitive and the other the intransitive version, like in the Japanese example in
Table 5.1. English, on the other hand, is an example of a language where the alternation
is not marked at all. (Note that both forms of the verbs melt and gather in Table 5.1
are the same.) The different marking strategies illustrated in Table 5.1 represent only
the most common markings. Languages can use different options for different verbs. For
example, anticausative versions of some verbs are not marked in Russian. In principle,
any option can be found in any language, but with different probability.
168

5.1. Introduction
Availability :Causative Anticausative
arrive, appear +Japanese, +Salish,-English
+all languages
kill, cut +all languages +Greek, +Hindi,-English
Morphological marking :Causative Anticausative
Mongolian xajl-uul-ax xajl-ax’melt’ ’melt’
Russian rasplavit’ rasplavit’-sja’melt’ ’melt’
Japanese atum-eru atum-aru’gather’ ’gather’
Table 5.1.: Availability of the alternation (Alexiadou 2010) and morphological marking(Haspelmath 1993) in some examples of verbs and languages.
169

5. Likelihood of external causation and the cross-linguistic variation in lexical causatives
The variation in the availability of the alternation illustrated in Table 5.1 raises the ques-
tion of why some verbs do not alternate in some languages. Answering this question
can help understanding why alternating verbs do alternate. The variation in morpho-
logical marking is even more puzzling: Why is it that languages do not agree on which
version of the alternating verbs to mark? Also, what needs to be addressed is the inter-
action between the categories of variation: Is there a connection between the alternation
availability and morphological marking?
In this study, we address the issues raised by the causative alternation in a novel approach
which combines the knowledge about the use of verbs in a corpus with the knowledge
about the typological variation.2 We analyse within-language variation in realisations of
lexical causatives, as well as cross-linguistic variation in a parallel corpus with the aim of
identifying common properties of lexical causatives underlying the variation. Our anal-
ysis relates the variation observed in language corpora with the observed cross-linguistic
variation in a unified account of the lexical representation of lexical causatives. The
findings of our study are expected to extend the knowledge about the nature of the
causative alternation by taking into consideration much more data than the previous
accounts. On the other hand, they are also expected to be applicable in natural lan-
guage processing. Being able to predict the cross-linguistic transformations of phrases
involving lexical causatives based on their common lexical representation can be useful
for improving automatic alignment of phrase constituents, which is a necessary step
in machine translation and other tasks in cross-linguistic language processing. Having
both purposes in mind, we propose and account of lexical causatives suitable for machine
learning. We model all the the studied factors so that the values of the variables can be
learned automatically by observing the instances of the alternating verbs in a corpus.
The chapter is organised in the following way. We start by discussing the questions raised
by lexical causatives. In Section 5.2.1, we introduce the distinction between internally
and externally caused events in relation to the argument structure of lexical causatives
and to the causative alternation. In Section 5.2.2, we discuss cross-linguistic variation in
the causative alternation and the challenges that it poses for the account based on the
two-way distinction between internally and externally caused event. In Section 5.2.3,
we discuss a more elaborate typological approach to cross-linguistic variation in lexical
2Some pieces of the work presented in this chapter are published as Samardzic and Merlo (2012).
170

5.2. Theoretical accounts of lexical causatives
causatives which proposes an account of their meaning in terms of a scale, rather than
two or three classes. After defining the theoretical context of our study, we present our
experimental approach to the questions discussed in the literature. The study consists
of four experiments. The first two experiments (Sections 5.3.1 and 5.3.2) establish a
corpus-based measure which can be used to distinguish between lexical causatives with
different lexical representations. In the third experiment (Section 5.3.3), we examine
the influence of the meaning of lexical causatives on their cross-linguistic realisations. In
the fourth experiment (Section 5.3.4), we test a statistical model which classifies lexical
causatives based on their cross-linguistic realisations. In Section 5.4, we interpret the
results of our experiments in light of the theoretical discussion and also in relation to
more practical issues concerning natural language processing. We compare our study
with the related work in Section 5.5.
5.2. Theoretical accounts of lexical causatives
Among other issues raised by the causative alternation which have been discussed in
the linguistic literature, theoretical accounts have been proposed for the interrelated
questions which we address in our study:
1. What are the properties of alternating verbs that distinguish them from the verbs
that do not alternate?
2. Which one of the two realisations is the basic form and which one is the derivation?
3. What is the source of cross-linguistic variation in the sets of alternating verbs?
Most of the proposed accounts are focused on the specific properties of alternating verbs
(Question No. 1) and on the structural relationship between the two alternants (Ques-
tion No. 2). The issues in cross-linguistic variation are usually not directly addressed
except in typological studies. Our study addresses the issue of cross-linguistic variation
directly, but the findings are relevant for the other two questions too. In this section, we
present theoretical accounts of lexical causatives introducing the notions and distinctions
which are addressed in our study. We focus on the proposals and ideas concerning the
171

5. Likelihood of external causation and the cross-linguistic variation in lexical causatives
relationship between the meaning of lexical causatives and the variation in their mor-
phosyntactic realisations, especially cross-linguistic variation, leaving on the side the
accounts of the structure of clauses formed with these verbs.
The most apparent common property of the alternating verbs in different languages
is their meaning. Most of these verbs describe an event in which the state of one of
the participants (patient or theme) changes (Levin and Rappaport Hovav 1994). If a
verb describes some kind of change of state, it can be used both as causative and as
anticausative. This is the case illustrated in (5.1) repeated here as (5.2). In the causative
use (5.2a), the verb is transitive, the changing participant is its object, and the agent
is expressed as its subject. In the anticausative use, the verb is intransitive, with the
changing participant being expressed as its subject (5.2b).
(5.2) a. Adam broke the laptop.
b. The laptop broke.
If the change-of-state condition is not satisfied, the alternation does not take place. The
example in (5.3a) illustrates a case of an intransitive verb whose subject does not undergo
a change, which is why it cannot be used transitively, as shown in (5.3b). Similarly, the
object of the verb bought in (5.4a) is not interpreted as changing, so the verb cannot be
used intransitively (5.4b).
(5.3) a. The children played.
b. * The parents played the children.
(5.4) a. The parents bought the toys.
b. * The toys bought.
5.2.1. Externally and internally caused events
Taking other verbs into consideration, however, it becomes evident that the meaning
of change of state is neither necessary nor sufficient condition for the alternation to
take place. Verbs can alternate even if they do not describe a change-of-state event.
On the other hand, some verbs do describe a state-of-change event but they still do
172

5.2. Theoretical accounts of lexical causatives
not alternate. For example, verbs with the meaning of positioning such as hanging in
(5.5) do alternate although their meaning, at least in the anticausative version, does not
involve change of state. On the other hand, verbs such as transitive cut in (5.6) and
intransitive bloomed in (5.7) do not alternate although their meaning involves a change
of state, of bread in (5.6) and of flowers in (5.7).
(5.5) a. Their photo was hanging on the wall.
b. They were hanging their photo on the wall.
(5.6) a. The baker cut the bread.
b. * The bread cut.
(5.7) a. The flowers suddenly bloomed.
b. * The summer bloomed the flowers.
To deal with the issue of non-change-of-state verbs entering the alternation, Levin and
Rappaport Hovav (1994) introduce the notion of “externally” and “internally” caused
events. Externally caused events can be expressed as transitive forms, while internally
caused events cannot. On this account, verbs such as hanging in (5.5) can alternate even
though they do not describe a change of state event, because they mean something that
is externally caused. The hanging of the photo in (5.5a) is not initiated by the photo
itself, but by some other, external cause, which can then be expressed as the agent in a
transitive construction. The same distinction explains the ungrammaticality of (5.7b).
Since blooming is something that flowers do on their own, themselves, the verb bloom
does not specify an external causer which would be realised as its subject, which is why
this verb cannot occur in a transitive construction.
This distinction still does not account for all the problematic cases. It leaves without
an explanation the case of transitive verbs which describe a change of state, and which
are clearly externally caused, but which do not alternate such as cut in (5.6). To deal
with these cases, Levin and Rappaport Hovav (1994) introduce the notion of agentivity.
According to this explanation, the meaning of some verbs is such that specifying the
agent in the event described by the verb is obligatory, which is why they cannot occur
as intransitive. Levin and Rappaport Hovav (1994) argue that this happens with verbs
whose subject can only be the agent (and not the instrument, for example). Schafer
173

5. Likelihood of external causation and the cross-linguistic variation in lexical causatives
(2009) challenges this view showing that the alternation can be blocked in verbs with
different subjects. Such a verb is English destroy whose subject can be some natural
force, an abstract entity, or even an instrument, but which still does not alternate.
Haspelmath (1993) argues that it is the level of specificity of the verb that plays a role
in blocking the alternation. If a verb describes an event that is highly specified, such as
English decapitate, the presence of specific details in the interpretation of the meaning
of the verb can block the alternation.
5.2.2. Two or three classes of verb roots?
Since the discussed properties concern the meaning of verbs, one could expect that the
verbs which are translations of each other alternate in all languages. This is, however,
not always true. There are many verbs that do alternate in some languages, while
their counterparts in other languages do not. For example, in Greek and Hindi, the
counterparts of kill and destroy have intransitive versions (Alexiadou et al. 2006).
On the other hand, typically intransitive verbs of moving (run, swim, walk, fly) can
have transitive versions in English, which is not possible in French or German (Schafer
2009).
An explanation for these cases is proposed by Haspelmath (1993), who argues that a
possible cause of these differences is a slightly different meaning of the lexical coun-
terparts across languages. Russian myt’, for example, which does alternate, does not
mean exactly the same as English wash, which does not alternate. Haspelmath (1993),
however, does not propose a particular property which differs in the two verbs.
The question of cross-linguistic variation has received more attention in the work of
Alexiadou (2010) who examines a wide range of linguistic facts including the variation
in the availability of the alternation and in morphological marking. Alexiadou (2010)
argues that the account of the examined facts requires introducing one more class of
verbs3. In addition to the classes of externally caused and internally caused verbs,
proposed by Levin and Rappaport Hovav (1994), Alexiadou (2010) proposes a third
3More precisely, Alexiadou (2010) refers to verb roots rather than to verbs to emphasise that thediscussion concerns this particular level of the lexical representation.
174

5.2. Theoretical accounts of lexical causatives
Causative AnticausativeGreek: spao ’break’ spao ’break’
klino ’close’ klino ’close’aniyo ’open’ aniyo ’open’
Japanese: war-u ’break’ war-er-u ’break’Turkish : kapa ’close’ kapa-n ’close’
Table 5.2.: The examples of morphological marking of cause unspecified verbs discussedby Alexiadou (2010).
group of “unspecified roots”. The generalisations based on the proposed framework are
summarised in (5.8).
(5.8) a. Anticausative verbs that are characterised as internally caused and/or cause
unspecified are not morphologically marked, while those that are characterised as
externally caused are marked.
b. Cause unspecified verbs alternate in all languages, while internally caused and
externally caused verbs alternate only in languages that allow anticausative
morphological marking.
Although Alexiadou’s (2010) analysis relates the two important aspects of the crosslin-
guistic variation in an innovative way, it fails to explain the tendency observed in many
languages regarding the morphological marking of the anticausative variant. In partic-
ular, of all the examples mentioned in Alexiadou (2010) (see Table 5.2) as support to
(5.8a), only the Greek examples can be clearly classified. The other examples in Table
5.2 illustrate that verbs classified as prototypical cause-unspecified (Class I) (e.g., break,
open, close (Alexiadou et al. 2006; Alexiadou 2010)) tend to allow rather than disallow
morphological marking of their anticausative variant (compare the examples in Table
5.2).4
Looking up the verbs in other languages shows some limitations for the generalisation
in (5.8b) too. For example, the Serbian verb rasti ’grow’ would be classified as cause
4These verbs are mostly classified as Class II (externally caused) in the data overview, but they areclassified as Class I in the summary of the data.
175

5. Likelihood of external causation and the cross-linguistic variation in lexical causatives
unspecified according to Alexiadou’s 2010 criteria, implying that it is expected to alter-
nate in all languages. However, this verb does not alternate in Serbian; it exists only as
intransitive.
5.2.3. The scale of spontaneous occurrence
The approach proposed by Haspelmath (1993) does not address the syntactic aspects
of the variation, but it provides a better account of the data which pose a problem
for the generalisations proposed by Alexiadou (2010). Haspelmath (1993) analyses the
typology of morphological marking of the two realisations of alternating verbs across a
wade range of languages. Alternating verbs can be divided into several types according to
the morphological differences between the causative and the anticausative version of the
verb. The alternation can be considered morphologically directional if one form is derived
from the other.5 There are two directional types: causative, if the causative member of
the pair is marked, and anticausative, with morphological marking on the anticausative.
Morphologically non-directed alternations are equipollent, if both members of the pair
bear a morphological marker, suppletive, if two different verbs are used as alternants,
and labile if there is no difference in the form between the two verbs.
One language typically allows several types of marking, but it prefers one or two types.
For example, both English and German allow anticausative, equipollent, labile, and
suppletive alternations. There is a strong preference for labile pairs in English, while
German prefers anticausative and labile pairs (Haspelmath 1993).6
Despite the different morphological marking types of languages, a study of twenty-one
pairs of alternating verbs showed that certain alternating verbs tend to bear the same
5Certain authors (Alexiadou 2006a) argue against the direct derivation. Since precise account of thederivation of the structures is not relevant for our work, we maintain the morphological distinctionsdescribed in (Haspelmath 1993).
6The issue of whether these preferences can be related to some other properties of the languagesis still unresolved. The only correlation that could be observed is the fact that the anticausativemorphology is observed mostly in European languages, even if they are not closely genetically related.For example, Greek is as close to the other European languages as Hindi-Urdu. While Greek shows apreference for anticausative morphology, Hindi-Urdu prefers causative morphology. Languages thatprefer causative morphology are more spread, being located in almost all the continents, while thepreference for anticausative morphology is restricted mainly to Europe.
176
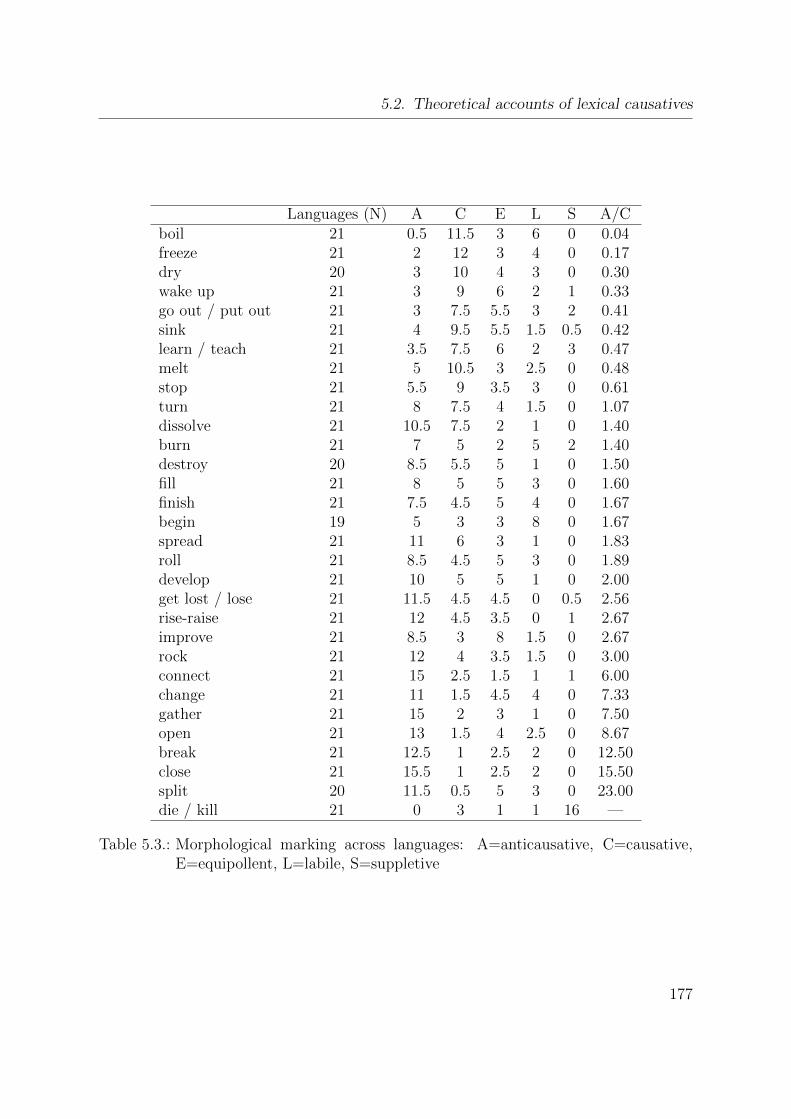
5.2. Theoretical accounts of lexical causatives
Languages (N) A C E L S A/Cboil 21 0.5 11.5 3 6 0 0.04freeze 21 2 12 3 4 0 0.17dry 20 3 10 4 3 0 0.30wake up 21 3 9 6 2 1 0.33go out / put out 21 3 7.5 5.5 3 2 0.41sink 21 4 9.5 5.5 1.5 0.5 0.42learn / teach 21 3.5 7.5 6 2 3 0.47melt 21 5 10.5 3 2.5 0 0.48stop 21 5.5 9 3.5 3 0 0.61turn 21 8 7.5 4 1.5 0 1.07dissolve 21 10.5 7.5 2 1 0 1.40burn 21 7 5 2 5 2 1.40destroy 20 8.5 5.5 5 1 0 1.50fill 21 8 5 5 3 0 1.60finish 21 7.5 4.5 5 4 0 1.67begin 19 5 3 3 8 0 1.67spread 21 11 6 3 1 0 1.83roll 21 8.5 4.5 5 3 0 1.89develop 21 10 5 5 1 0 2.00get lost / lose 21 11.5 4.5 4.5 0 0.5 2.56rise-raise 21 12 4.5 3.5 0 1 2.67improve 21 8.5 3 8 1.5 0 2.67rock 21 12 4 3.5 1.5 0 3.00connect 21 15 2.5 1.5 1 1 6.00change 21 11 1.5 4.5 4 0 7.33gather 21 15 2 3 1 0 7.50open 21 13 1.5 4 2.5 0 8.67break 21 12.5 1 2.5 2 0 12.50close 21 15.5 1 2.5 2 0 15.50split 20 11.5 0.5 5 3 0 23.00die / kill 21 0 3 1 1 16 —
Table 5.3.: Morphological marking across languages: A=anticausative, C=causative,E=equipollent, L=labile, S=suppletive
177

5. Likelihood of external causation and the cross-linguistic variation in lexical causatives
kind of marking across languages. Verbs such as lexical equivalents of English freeze, dry,
melt tend to be marked when used causatively in many different languages, while the
equivalents of English gather, open, break, close tend to be marked in their anticausative
uses. Table 5.3 shows the distribution of morphological marking for all the verbs included
in Haspelmath’s (1993) study. Note that the verbs are ranked according to the ratio
between anticausative and causative marking. The verbs with a low ratio are found on
the top of the table and those with a high ratio are in the bottom.
Assuming that the cross-linguistic distribution of the kinds of morphological marking
is a consequence of the way lexical items are used in language in general, Haspelmath
(1993) interprets these findings as pointing to a universal scale of increasing likelihood
of spontaneous occurrence. The verbs with a low A/C ratio describe events that are
likely to happen with no agent or external force involved. If the verb is used with an
expressed agent, the form of the verb contains a morphological marker in the majority
of languages. The verbs with a high A/C ratio typically specify an agent, and if the
agent is not specified, the verb tends to get some kind of morphological marking across
languages. In this interpretation, the cross-linguistic A/C ratio is an observable and
measurable indicator of a lexical property of verbs. It expresses the degree to which an
agent or an external cause is involved in the event described by the verb. A summary
of the notion of the scale of spontaneous occurrence is given in (5.9).
(5.9) The scale of spontaneous occurrence:
freeze > dry > melt > ..... > gather > open > break > close
low A/C (spontaneous) high A/C (non-spontaneous)
The notion of spontaneous occurrence can be related to the distinction between internally
and externally caused events argued for in the other analyses. Both notions concern the
same lexical property of verbs — the involvement of an agent in the event described by a
verb. The events that are placed on the spontaneous extreme of the scale would be those
that can be perceived as internally caused. The occurrence of an agent or an external
cause in these events is very unlikely. Since the externally caused events are considered
to give rise to the causative alternation, they would correspond to a wider portion of the
178

5.3. Experiments
scale of spontaneous occurrence, including not just the events on the non-spontaneous
extreme of the scale, but also those in the middle of the scale.
However, there are important theoretical and methodological differences between the
two conceptions. The qualitative notion of internal vs. external causation implies that
there are two kinds of events: those where the agent is present in the event and those
with no agent involved. Verbs describing internally caused event can only be used as
anticausative. A causative use of a verb describing an internally caused event is expected
to be ungrammatical (as in (5.7b)). The notion of scale of spontaneous occurrence
does not imply complete absence of the agent in any event. It does not predict the
ungrammaticality of uses such as (5.7b). What follows from this notion is that such uses
are possible, but very unlikely.
The difference between the two conceptions is even more important with respect to the
events perceived as externally caused. The qualitative analyses imply that all externally
caused events have the same status with respect to the causative alternation — the verbs
describing these events alternate. The attested cases of verbs that describe externally
caused events, but do not alternate, such as (5.6b), are considered exceptions due to some
idiosyncratic semantic properties of events described by the verbs (Section 5.2). The
quantitative notion of scale of spontaneous occurrence allows expressing the differences
between the verbs that describe externally caused events. Each point on the scale
represents a different probability for an agent to occur in an event described but a verb.
Opposite to the spontaneous extreme of the scale there is the non-spontaneous extreme.
It predicts cases of verbs describing events that are very unlikely to occur spontaneously.
An intransitive use of these verbs would be unlikely, although possible. The case in (5.6b)
could be explained in these terms with no need to treat it as an exception.
5.3. Experiments
Our approach to lexical causatives is based on statistical analysis and modelling of large
data sets. Assuming that the use of verbs is related to their semantic and grammatical
properties, we observe the distribution of the causative and anticausative realisations of a
179

5. Likelihood of external causation and the cross-linguistic variation in lexical causatives
large number of verbs extracted from a corpus of around 1’500’000 syntactically analysed
sentences identifying the properties of verbs which generated this distribution.
We first show that the distribution of the two realisations of the alternating verbs in
a corpus is correlated with the distribution of morphological marking across languages.
We measure the correlation for a sample of 29 verbs for which typological descriptions
are available (Haspelmath 1993). Regarding this correlation as a piece of evidence that
the two distributions are generated by the same underlying property of the alternating
verbs, we define this property as the degree of involvement of an external causer in an
event described by a verb. Following Haspelmath (1993), we call this property the degree
of spontaneity of an event. The more spontaneous an event, the less is an external causer
involved in the event. We see the degree of spontaneity as a general scalar component of
the meaning of lexical causatives whose value has an impact on the observable behaviour
of all the verbs which participate in the alternation in any language.
Showing that the corpus-based measure of spontaneity is correlated with the typological
measure allows us to extend the account to a larger sample of verbs. Since the corpus-
based value is assigned to the verbs entirely automatically, it can be quickly calculated for
practically any given set of verbs, replacing the typology-based value for which the data
are harder to collect. We calculate the corpus-based value of the spontaneity of events
described by 354 verbs cited as participating in the causative alternation in English
(Levin 1993). We show, by means of a statistical test, that the smaller set of verbs
(the 29 verbs for which we measured the correlation) is a proper sample of the bigger
set (the 354 verbs from Levin (1993)). This implies that the correlation established for
the smaller set applies to the bigger set as well.
To study how exactly the spontaneity value influences the cross-linguistic variation, we
analyse the distribution of causative and anticausative realisations in German transla-
tions of English lexical causatives. We extract the data from the corpus of German
translations of the 1’500’000 English sentences which were used in the monolingual part
of the study. The sentences on the German side are, like English sentences, syntactically
analysed. All the sentences are word-aligned so that German translations of individual
English words are known. By a statistical analysis of parallel instances of verbs, we
180

5.3. Experiments
identify certain trends in the cross-linguistic variation which are due to the spontaneity
value.
Based on these findings, we design a probabilistic model which exploits the information
about the cross-linguistic variation at the level of token to assess the spontaneity value
of lexical causatives abstracting away from the potential language-specific biases.
5.3.1. Experiment 1: Corpus-based validation of the scale of
spontaneous occurrence
Haspelmath (1993) does not discuss a potential relation between the likelihood of spon-
taneous occurrence of an event and the frequency of different uses of the verb which
describes it in a single language. Nevertheless, it is logical to suppose that such a rela-
tion should exist, since the indicator of the likelihood, the morphological marking on the
verbs, is considered to be a consequence of the way the verbs are used in general. The
placement of an event described by a verb on the scale can be expected to correspond
to the probability for the verb to be used transitively or intransitively in any single lan-
guage. On the other hand, the ratio of the frequencies of intransitive to transitive uses of
verbs in a single language can be influenced by other factors as well, which can result in
cross-linguistic variation. The relation between the scale of spontaneous occurrence and
the patterns of use of verbs in different languages thus needs to be examined. Note that
the causative alternation is realised in different ways across languages: some languages
mark the causative use of a verb, some mark the anticausative use, some mark both and
some none of them (see Tables 5.1 and 5.3). Morphological markers themselves can be
special causative morphemes, but they can often be morphemes that have other func-
tions as well, such as the reflexive anticausative marker in most of European languages.
These factors might have influence on the ratio of intransitive to transitive uses in a
given language.
To validate empirically the hypothesis that the alternating verbs can be ordered on the
scale of spontaneous occurrence of the events that they describe, we test it on corpus
data. More precisely, we test the hypothesis that the distribution of morphological
181

5. Likelihood of external causation and the cross-linguistic variation in lexical causatives
marking on the verbs across languages and the distribution of their transitive to intran-
sitive uses in a corpus are correlated. We can expect this correlation on the basis of the
well established correspondence between markedness and frequency. In general, marked
forms are expected to be less frequent than unmarked forms. Therefore, we expect the
verbs that tend to have anticausative marking across languages to be used more often as
causative (transitive), and verbs that tend to have causative marking to be used more
often as anticausative (intransitive). To make the discussion easier to follow, we opt for
a positive, and not a negative correlation. We thus calculate the C/A and not the A/C
ratio as Haspelmath (1993).
We calculate the ratio between the frequencies of causative (active transitive) and an-
ticausative (intransitive) uses of verbs in a corpus of English for the verbs for which
Haspelmath’s study provides the typological A/C ratio, as shown in (5.10).
C/A(verb) =frequency of causative uses
frequency of anticausative uses(5.10)
We then measure the strength of the correlation between the ranks obtained by the two
measures.
Materials and methods
Several explanations are needed regarding the matching between the verbs in Haspel-
math’s and our study and the criteria that were used to exclude some verbs. Most of
the verbs analysed by Haspelmath are also listed as participating in the causative al-
ternation by Levin (1993) (e.g. freeze, dry, melt, open, break, close). Some verbs are
not listed by Levin (e.g. boil, gather). We include them in the calculation neverthe-
less because they clearly alternate. Four entries in Haspelmath’s list are not English
alternating verbs, but complement pairs: learn/teach, rise/raise, go out/put out, and
get lost/lose. We treat the former two pairs as single verb entries adding up counts of
occurrences of both members of the pair. We do not calculate the ratio for the latter two
because automatic extraction of their instances from the corpus could not be done using
the methods already developed to extract the other verb instances. We exclude the verb
182

5.3. Experiments
destroy because it does not alternate in English and no complement verb is proposed by
Haspelmath. Finally, the pair kill/die is excluded because its typology-based ranking is
not available. This leaves us with 27 verbs for which we calculate the corpus-based C/A
ratio.
Transitive, intransitive, and passive instances of the verbs were extracted from the En-
glish side of the parallel corpus Europarl (Koehn 2005), version 3, which contains around
1’500’000 sentences for each language (the same corpus which was used for the study on
light verb construction presented in Chapter 4). Syntactic relations needed for deter-
mining whether a verb is realised as transitive (with a direct object) or as intransitive
(without object) are identified on the basis of automatic parsing with the MaltParser, a
data-driven system for building parsers for different languages (Nivre et al. 2007).
Instance representation. Each instance is represented with the following elements:
the verb, the head of its subject, and the head of its object (if there is one). An English
causative use of a verb is identified as an alternating verb realised in an active transitive
clause. The anticausative use is identified as an intransitive use of an alternating verb.
Passive is identified as the verb used in the form of passive participle and headed by
the corresponding passive auxiliary verb. Identification of the form of the clause which
contains a lexical causative is performed automatically, using the algorithm shown in
Algorithm 2.
Regarding all the transitive uses of the alternating verbs as causatives, and intransitive
uses as anticausatives is a simplification, because this is not always true. It can happen
that a verb alternates in one sense, but not in another. For instance, the phrase in (5.12)
is not the causative alternation of (5.11), but only of (5.13).
(5.11) Mary was running in the park this morning.
(5.12) Mary was running the program again.
(5.13) The program was running again.
By a brief manual inspection of the lexical entries of the verbs in the Proposition Bank
(Palmer et al. 2005a), we assessed that this phenomenon is not very frequent and that
it should not have an important influence on the results. In our sample, only the verb
183

5. Likelihood of external causation and the cross-linguistic variation in lexical causatives
freeze proved to be affected by this phenomenon. This verb was discarded as an outlier
while calculating the correlation between corpus based and typology based rankings of
the verbs, but this was the only such example in the sample of verbs.
Algorithm 2: Identifying transitive, intransitive, and passive uses of lexical causatives.Input : 1. A corpus S consisting of sentences s parsed with a dependency parser
2. A list of lexical causatives V
Output : The number of transitive, intransitive, and passive instances of each verb v ∈ V in
the corpus S
for i = 1 to i = S do
for j = 1 to j = V do
if vj in si then
if there is SUBJ which depends on vj then
if there is OBJ which depends on vj then
return transitive;
else
if vj is passive then
return passive;
else
return intransitive;
end
end
end
end
end
end
As it can be seen in Algorithm 2, only the instances with all the arguments realised in
the same clause were taken into account. This is obtained by the constraint that the
extracted verb has to have a subject. We exclude the realisations of verbs where either
the subject or the object are moved or elided in order to control for potential influence
that the specific syntactic structures can have on the interpretation of the meaning of
verbs. Single clause realisations can be considered the typical and the most simple
case.
184
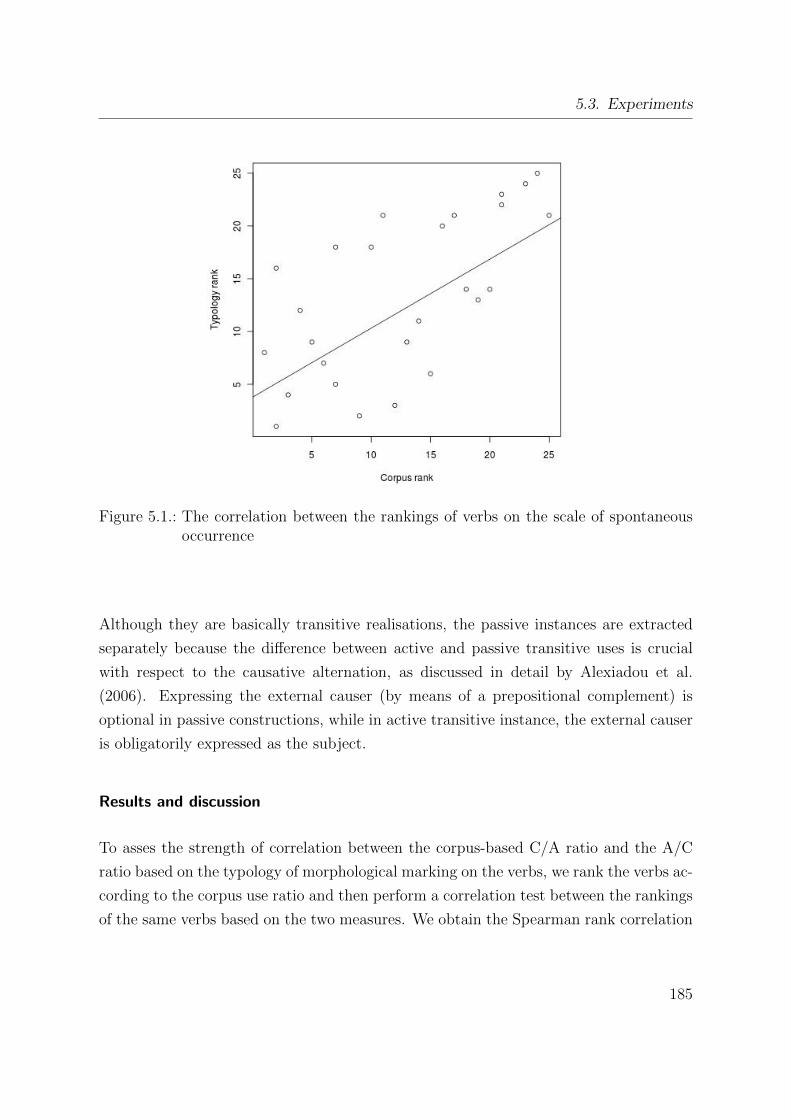
5.3. Experiments
Figure 5.1.: The correlation between the rankings of verbs on the scale of spontaneousoccurrence
Although they are basically transitive realisations, the passive instances are extracted
separately because the difference between active and passive transitive uses is crucial
with respect to the causative alternation, as discussed in detail by Alexiadou et al.
(2006). Expressing the external causer (by means of a prepositional complement) is
optional in passive constructions, while in active transitive instance, the external causer
is obligatorily expressed as the subject.
Results and discussion
To asses the strength of correlation between the corpus-based C/A ratio and the A/C
ratio based on the typology of morphological marking on the verbs, we rank the verbs ac-
cording to the corpus use ratio and then perform a correlation test between the rankings
of the same verbs based on the two measures. We obtain the Spearman rank correlation
185

5. Likelihood of external causation and the cross-linguistic variation in lexical causatives
score rs = 0.67, p < 0.01, with one outlier7 removed. The score suggests good correla-
tion between the two sources of data. Figure 5.1 shows the scattergram representing the
correlation.
The coefficient of the correlation is strong enough to be taken as an empirical confir-
mation of Haspelmath’s hypothesis. Given that the two distributions are significantly
correlated, it is reasonable to assume that the same factor which underlies the typolog-
ical distribution of morphological marking on verbs underlies the distribution of their
transitive and intransitive realisations in a monolingual corpus too. Since the correlation
is established based on the intuition that the underlying cause of the observed distribu-
tions is the meaning of verbs, we can conclude that the lexical property on which the
two distributions depend is the probability of occurrence of an external causer in an
event described by a verb.
5.3.2. Experiment 2: Scaling up
The fact that automatically obtained corpus-based ranking of verbs corresponds to the
scale of spontaneous occurrence is a useful finding, not only because it confirms Haspel-
math’s theoretical hypothesis, but also because it means that the spontaneity feature
can be calculated automatically from corpus data. In this way, it is possible to extend
the account beyond the small group of example verbs that are discussed in the literature
and cover many more cases. To test whether the correlation that we find for the small
sample of verbs discussed in Section 5.3.1 applies to a larger set, we compare the distri-
bution of the corpus-based measure of spontaneity over this sample and the distribution
of the same value for the 354 verbs listed by Levin (1993) (see Section 2.2.1 in Chapter
2 for more details).
7Verb freeze is frequently used in our corpus in its non-literal sense (e.g. freeze pensions, freeze assets),while the sense that was taken into account by Haspelmath (1993) is most likely the literal meaningof the verb (as in The lake freezed.). This is why the verb’s corpus-based ranking was very differentfrom its typology based ranking.
186

5.3. Experiments
Materials and methods
The list of English lexical causatives is extracted from the (Levin 1993) verb index. Since
the index referred with the same number to the verbs that do not enter the alternation
(the book sections 1.1.2.1, 1.1.2.2, and 1.1.2.3), the verbs that do not alternate were
removed from the list manually.
All the instances where these verbs occur as transitive, intransitive, and passive were
extracted from the automatically parsed English side of the Europarl corpus. We extract
the same counts which were extracted for the small sample discussed in Section 5.3.1.
We reduce the variance in the corpus-based measure preserving the information about
the ordering of verbs by transforming the frequency ratio into a more limited measure of
spontaneity. We calculate the value of spontaneity (Sp in 5.14) for each verb v included
in the study as the logarithm of the ratio between the rates of anticausative and causative
uses of the verb in the corpus, as shown in (5.14).
Sp = ln
(rate(v, caus)
rate(v, acaus)
)(5.14)
The rates of uses of the three extracted constructions form ∈ {anticaus, caus, pass} for
each verb are calculated as in (5.15).
rate(form) =F (form, v)∑
form F (form, v)(5.15)
The verbs that tend to be used as anticausative will have negative values for the variable
Sp, the verbs that tend to be used as causative will be represented with positive values,
and those that are used equally as anticausative and causative will have values close to
zero. The distribution of the Sp-value over the 354 verbs is shown in Figure 5.4.
In the cases of verbs that were not observed in one of the three forms, we calculated the
rate values as the rate of uses of the form in the instances of all verbs with frequency one
divided by the total frequency of the verb in question. For example, the verb attenuate
occurred three times in the corpus, once as causative, and two times as passive. The
187
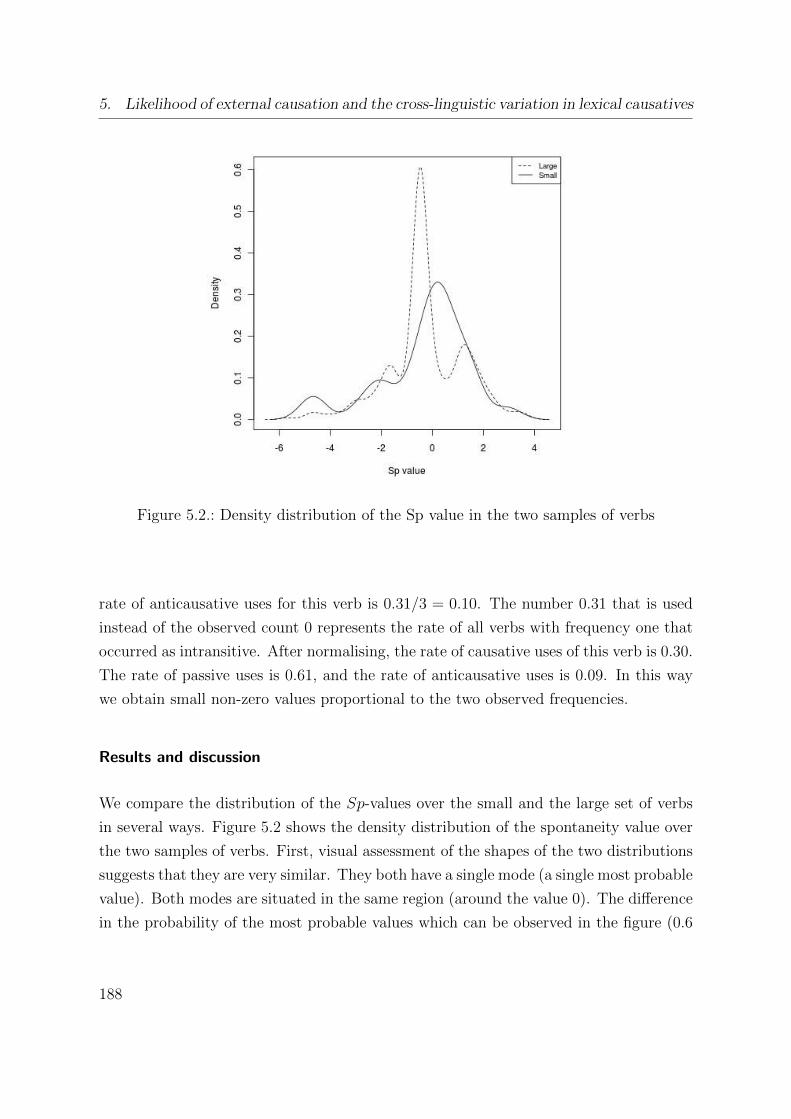
5. Likelihood of external causation and the cross-linguistic variation in lexical causatives
Figure 5.2.: Density distribution of the Sp value in the two samples of verbs
rate of anticausative uses for this verb is 0.31/3 = 0.10. The number 0.31 that is used
instead of the observed count 0 represents the rate of all verbs with frequency one that
occurred as intransitive. After normalising, the rate of causative uses of this verb is 0.30.
The rate of passive uses is 0.61, and the rate of anticausative uses is 0.09. In this way
we obtain small non-zero values proportional to the two observed frequencies.
Results and discussion
We compare the distribution of the Sp-values over the small and the large set of verbs
in several ways. Figure 5.2 shows the density distribution of the spontaneity value over
the two samples of verbs. First, visual assessment of the shapes of the two distributions
suggests that they are very similar. They both have a single mode (a single most probable
value). Both modes are situated in the same region (around the value 0). The difference
in the probability of the most probable values which can be observed in the figure (0.6
188

5.3. Experiments
for the large sample as opposed to 0.3 for the small sample) does not necessarily reflect
the real difference in the two distributions. It can be explained by the fact that the
large sample contains a number of unobserved verbs for which are assigned the same Sp-
value, estimated on the basis of the values of low frequency verbs, as discussed earlier.
In reality, the verbs would not have exactly the same value, so that the density would be
more equally distributed around zero, which is exactly the case in the small sample.
Another indication that the two samples are the same is the value of two-vector t-test
t = −0.0907, p = 0.9283, which indicates a very small difference in the means of the two
distribution and a high probability that it is observed by chance. The t-test works with
the assumption that the distributions which are compared belong to the family of normal
distributions. It does not apply to other kinds of distributions. To make sure that the
distributions of our data can be compared with the t-test, we perform the Shapiro-Wilk
test which shows how much a distribution deviates from a normal distribution. This
test was not significant (W = 0.9355, p = 0.07), which means that the distribution of
our data can be considered normal.
We conclude that the verbs for which the corpus-based ranking is shown to correspond
to the typology-based ranking represent an unbiased sample of the larger population of
verbs that participate in the causative alternation. This implies that the corpus-based
method for calculating the spontaneity value presented in this section can be applied to
all the verbs that participate in the alternation.
The limitation of this method, however, is that it is based on the observations in a mono-
lingual corpus. Given the well-documented cross-linguistic variation in the behaviour of
the alternating verbs, discussed in Section 5.2.2 and 5.2.3, and summarised in Table 5.1,
a monolingual measure is likely to be influenced by language-specific biases in the data.
In the following section, we take a closer look at the relationship between the patterns
of cross-linguistic variation in the instances of lexical causatives and their spontaneity
value.
189

5. Likelihood of external causation and the cross-linguistic variation in lexical causatives
5.3.3. Experiment 3: Spontaneity and cross-linguistic variation
In analysing cross-linguistic variation in the realisations of lexical causatives, we try to
determine whether a verb can be expected to have consistent or inconsistent realisations
across languages depending on the degree to which an external causer is involved in the
event described by the verb.
We approach this task by analysing German translations of English lexical causatives
as they are found in a parallel corpus. Studying instances of translations of lexical
causatives in a parallel corpus allows us to control for any pragmatical and contextual
factors that may be involved in a particular realisation of a lexical causative. Since
translation is supposed to express the same meaning in the same context, we can assume
that the same factors that influence a particular realisation of a verb in a clause in one
language influence the realisation of its translation in the corresponding clause in another
language. Any potential differences in the form of the two parallel clauses should be
explained by the lexical properties of the verbs or by structural differences between the
languages.
We perform a statistical analysis of a sample of parallel instances of lexical causatives
in English and German, which we divide into three subsamples: expressions of sponta-
neous events, expressions of non-spontaneous events and expressions of the events that
are neutral with respect to spontaneity. Given that spontaneity of an event, as a univer-
sal property, correlates with causative and anticausative use monolingually, and given
that translations are meaning-preserving, we expect to find an interaction between the
level of spontaneity of the event described by the verb and its cross-linguistic syntactic
realisation. Assuming that cross-linguistic variation is an extension of within-language
variation, as discussed in the end of Section 4.3 in Chapter 4, we expect syntactic reali-
sations consistent with the lexical semantics of the verb to be carried across languages in
a parallel fashion, while those that are inconsistent are expected to show a tendency to-
wards the consistent realisation. For example, we expect intransitive realisations to stay
intransitive, and transitives to be often transformed into intransitives when verbs de-
scribe spontaneous events. Since the probability of both realisations is similar in neutral
instances, we expect to find fewer transformations than in the other two groups.
190

5.3. Experiments
Materials and methods
The data collected for this analysis comes from large and complex resources. To know
which English form is aligned with which German form, we first need to extract the
English lexical causative from the English side of the parallel corpus. We then determine
its form based on the automatic syntactic analysis of the sentence. Once we know which
sentence in the English side of the parallel corpus contains a lexical causative, we find the
German sentence which is aligned with the English sentence based on automatic sentence
alignment in the parallel corpus. Once the aligned German sentence is identified, we
look for the German verb which is aligned with the English verb. To do this, we first
search the automatic word-alignments to find the German word which is aligned with
the English verb. If we find such a word, we then look into the syntactic analysis of the
German sentence to determine whether this word is a verb. If it is a verb, we then search
the German syntactic parse to find the constituents of the clause where the verb is found.
Once we know the constituents, we can determine whether the German translation of
the English lexical causative is transitive, intransitive or passive (using the same criteria
as for extracting English instances in Section 5.3.2). The methods used to collect the
data are described in more detail in the following subsection.
The verbs included in this study are the 354 English verbs listed as alternating by Levin
(1993), for which we have calculated the Sp-value applying the procedure described in
Section 5.3.2. We extract the parallel instances of these verbs from a parallel English-
German Europarl (Koehn 2005) corpus, version 3 (the same corpus which is used in the
study in Chapter 4). The corpus consists of German translations of around 1’500’000
English sentences which are used in the previous two experiments (see Section 5.3.1).
Note that by German translation we mean German translation equivalents, since the
direction of translation is not known for most of the corpus.
To extract the information about the syntactic form of the instances, needed for our
research, the German side of the corpus is syntactically parsed using the same parser as
for the English side, the MaltParser (Nivre et al. 2007). The corpus was word-aligned
using the system GIZA++ (Och and Ney 2003) (the same tool which is used in the
study in Chapter 4.) Both for the syntactic parses and word alignments are provided by
Bouma et al. (2010) who used these tools to process the corpus for their own research.
191

5. Likelihood of external causation and the cross-linguistic variation in lexical causatives
We extract the data for our research reusing the processed corpus (with some adaptation
and conversion of the format of the data).
In extracting the data for our analysis, we search the processed parallel corpus looking
for four pieces of information: English syntactic parse, alignment between English and
German sentences, alignment between English and German words, and German syntac-
tic parse. All four pieces of information are not available for all the sentences in the
processed resource. Some English sentences are syntactically analysed, but the corpus
does not contain their translations to German. Likewise, there are German sentences for
which English translations are not available. Finally, syntactic parses are not available
for all the sentences which are aligned. Having established these mismatches, we first
search the whole resource to find the items which contain all the required information.
Once we have found the intersection between the English parses, the German parses and
the sentence alignment, we search the English side of these sentences to identify English
lexical causatives in the same way as in Section 5.3.2.
The German translation of each instance of an English lexical causative is extracted on
the basis of word alignments. Instances where at least one German element was word-
aligned with at least one element in the English instance were considered aligned. The
extraction procedure is shown in more detail in Algorithm 3.
192

5.3. Experiments
Levin (1993)verb index
Parsed EnglishEuroparl,Prolog format
Parsed GermanEuroparl,Prolog format
List of lexicalcausatives
Parsed EnglishEuroparl,CoNLL format
Parsed GermanEuroparl,CoNLL format
Extract Englishinstances
Englishcausativescounts
Englishinstances
Word alignedEnglish-GermanEuroparl, Prologformat
Corpus-based spontaneitymeasure
Extractwordalignmentof Englishinstances
Correctedwordalignment
Experimentaldata set
Figure 5.3.: Data collecting workflow. The shaded boxes represent external resources.The dashed boxes represent the scripts which are written for specific tasks inextracting data and performing the calculations. The other boxes representthe input and the output data at each stage of data processing.
193

5. Likelihood of external causation and the cross-linguistic variation in lexical causatives
Algorithm 3: Extracting parallel cross-linguistic realisations of lexical causatives.Input : 1. A corpus E consisting of English sentences e which
a. contain realisations of lexical causatives
b. are parsed with a dependency parser
c. annotated with the form of the realisation (transitive, intransitive, or passive)
-
2. A corpus G consisting of German sentences g which are
a. sentence- and word-aligned with English sentences in E
b. parsed with a dependency parser.
Output : Parallel instances consisting of:
a. the form of the English realisation (transitive, intransitive, or passive)
b. the form of the aligned German realisation (transitive, intransitive, or passive)
for i = 1 to i = E do
if align(verbj) is a German verb then
g-verb = align(verbj);
do Algorithm-2(g-verb)
else
if there is align(OBJj) then
g-verb = the verb on which align(OBJj) depends;
do Algorithm-2(g-verb)
else
if there is align(SUBJj) then
g-verb = the verb on which align(SUBJj) depends;
do Algorithm-2(g-verb)
else
return no align;
end
end
end
end
We define the alignment in this way to address the issue of missing alignments. As
discussed in more detail in Section 4.4 in Chapter 4, the evaluation of the performance
of the word-alignment system GIZA++ on the Europarl data for English and German
(Pado 2007) showed a recall rate of only 52.9%, while the precision is very high (98.6%).
194

5.3. Experiments
This evaluation applies to the intersection of both directions of word alignment, which is
the setting used in the processing of our data. The low recall rate means that around half
of the word alignments are not identified by the system. Extracting only the instances
where there is a word alignment between an English and a German verb would hence
considerably reduce our data set. Instead, we rely on the extracted syntactic relations
and on the intuition that the verbs are aligned if any of the constituents which depend
on them are aligned. With this definition of instance alignment, we also take advantage
of our own finding that nouns (the heads of the depending constituents are nouns) are
generally better aligned than verbs, as discussed in Chapter 4.
Sentence ID Verb Form Verb instance Subject Object
96-11-14.867 intensify CAUS 7 5 8
96-11-14.859 beschleunigen CAUS 6 2 5
Table 5.4.: An example of an extracted instance of an English alternating verb and itstranslation to German. The numbers under the elements of the realisationsof the verbs indicate their position in the sentence. For example, the objectof the English verb is the eight word in the sentence 96-11-14.867, and theobject of the German verb is the fifth word in the sentence 96-11-14.859.
A pair of extracted aligned instances is illustrated in Table 5.4. The first column is the
sentence identifier, the second column is the verb found in the instance, the third column
is the form of the verb in the instance, and the following three columns are the positions
of the verb, the head of its subject and the head of its object in the sentence.
One more processing step was needed to identify sentence constituents which are word-
aligned because the word alignments and the syntactic analysis did not refer to the same
positions. This is caused by the fact that sentence alignment was often not one-to-one.
In the cases where more than one English sentence were aligned with a single German
sentence, or the other way around, the positions of words were determined with respect
to the alignment chunk, and not with respect to the individual sentences. For example,
if two English sentences were aligned with a German sentence, with eight words in the
first sentences and seven in the second. The position of the first word in the second
195

5. Likelihood of external causation and the cross-linguistic variation in lexical causatives
Sp En De1.20 pass intrans1.97 trans trans0.71 trans trans
-0.05 pass pass0.71 trans trans
-0.09 trans pass-0.14 trans intrans-3.91 intrans intrans0.39 pass intrans
-1.76 intrans trans
Table 5.5.: Examples of parallel instances of lexical causatives.
sentence is indicated as 9. In the syntactic parse, on the other hand, these two sentences
are not grouped together, so the position of the same word is indicated as 1. We restored
the original sentence-based word enumeration in the word alignments before extracting
the alignment of the constituents.
Applying the described methods allows us to extract only translations with limited
cross-linguistic variation. Only the instances of English verbs that are translated with
a corresponding finite verb form in German are extracted, excluding the cases where
English verbs are translated into German with a corresponding non-finite form such as
infinitive, nominalization, or participle in German.
The extracted parallel instance were then combined with the information about the Sp-
value for each verb to form the final data source for our study, as illustrated in Table
5.5. Each line represents one instance of an alternating English verb found in the corpus
and its translation to German. The full data set contains 13033 such items. The first
column contains the spontaneity value of the verb found in the instance. The second
column represents the form in which the English verb is realised in the instance. The
third column represents the form of the German translation of the English verb. Figure
5.3 shows the main steps in the data collecting work flow.
196

5.3. Experiments
Validation of the collected data. Since all the data used in our study are collected
automatically from an automatically parsed and word-aligned corpus, they necessarily
include processing-related errors. The best reported labelled attachment score of the
MaltParser system for English is 88.11 (CoNLL Shared Task 2007) and for German 85.82
(CoNLL-X Shared Task 2006).We perform a manual evaluation of a sample of randomly
selected instances to asses to what degree they correspond to the actual analyses.
One hundred parallel instances were randomly selected from the total of 13033 extracted
instances. The following categories were evaluated:
• The form of the clause in the English instance
• The form of the clause of the German translation
The extraction script assigned a wrong form to 8/100 English instances (error rate 8%).
In 7 cases out of 8 errors, the wrong form was assigned due to parsing errors. One error
was due to the fact that the parser’s output does not include information about traces.
For example, in a sentence such as That is something we must change, the anticausative
form is assigned to the instance of the verb change instead of the causative form. In four
out of the seven parsing errors the actual forms found in the instances were not verbs
but adjectives (open, close, clear, worry).
The evaluation of the translation extraction was performed only for the cases where the
English instance actually contained a verbal form (96 instances). A wrong form was
assigned to the German translation in 13/96 cases (error rate 13.5%). In 7 of the 13
wrong assignments, a wrong form was assigned to the translation due to parsing errors
in German. The errors in 3 cases were due to the fact that German passive forms headed
by the verb sein, as in Das Team war gespalten for English The team was split, were not
recognised as passive, but they were identified as anticausative instead. The ambiguity
between such forms and anticausative past tense formed with the sein auxilliary verb
cannot be resolved in our current extraction method. In the last 3 cases, the error
was due to the fact that the corresponding German form was not a clause. In these
cases, the English verb is aligned to a word with a different category (an adverb and a
nominalization) or entirely left out in the German sentence (a verb such as sit in We sit
here and produce...). The form that is assigned to the translation in these cases is the
197
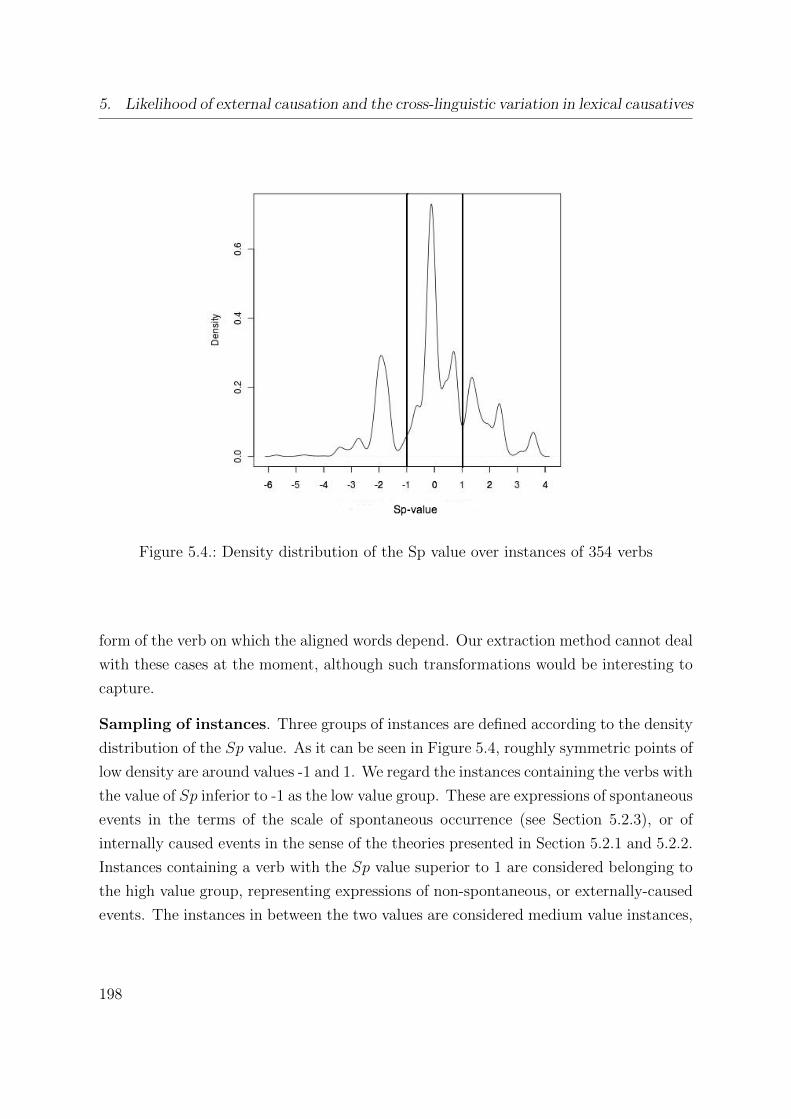
5. Likelihood of external causation and the cross-linguistic variation in lexical causatives
Figure 5.4.: Density distribution of the Sp value over instances of 354 verbs
form of the verb on which the aligned words depend. Our extraction method cannot deal
with these cases at the moment, although such transformations would be interesting to
capture.
Sampling of instances. Three groups of instances are defined according to the density
distribution of the Sp value. As it can be seen in Figure 5.4, roughly symmetric points of
low density are around values -1 and 1. We regard the instances containing the verbs with
the value of Sp inferior to -1 as the low value group. These are expressions of spontaneous
events in the terms of the scale of spontaneous occurrence (see Section 5.2.3), or of
internally caused events in the sense of the theories presented in Section 5.2.1 and 5.2.2.
Instances containing a verb with the Sp value superior to 1 are considered belonging to
the high value group, representing expressions of non-spontaneous, or externally-caused
events. The instances in between the two values are considered medium value instances,
198

5.3. Experiments
representing what Alexiadou (2010) refers to as cause unspecified events (see Section
5.2.2).
This division gives symmetric sub-samples of comparable size: similar number of exam-
ples for the two extreme values (3’107 instances with high Sp values, 2’822 instances with
low Sp values) and roughly double this number for non-extreme values (7’104 instances
with medium Sp values).
Results and discussion
Table 5.6 shows the frequencies of the realisations of lexical causatives in parallel En-
glish and German instances for the whole sample of instances, as well as for the three
sub-samples. The three most frequent combinations of forms in each group of parallel
instances are highlighted to show the changes in the distribution of combinations of
forms in the two languages across groups.
The overview of the frequencies suggests that lexical properties of verbs influence their
cross-linguistic realisations.
The table that shows occurrences over the whole sample indicates that, both in English
and in German, intransitives are more frequent than transitives, which are, in turn, more
frequent than passives (marginal distributions). The non-parallel translations cover 32%
of the cases.
When we partition the occurrences by the spontaneity of the event, the distribution
changes, despite the fact that these are distributions in translations, and therefore sub-
ject to very strong pressure in favour of parallel constructions.
In the group of instances containing verbs that describe events around the middle of the
scale of spontaneous occurrences, the parallel combinations are the most frequent, as
in the distribution of the whole set, with an even more markedly uniform distribution
(29% of non-parallel translations). This means that the verbs which describe events
which are neither spontaneous or non-spontaneous tend to be used in the same form
across languages. The probabilities of the two realisations are similar in these verbs,
which means that they can be expected to occur with similar frequency across languages.
199
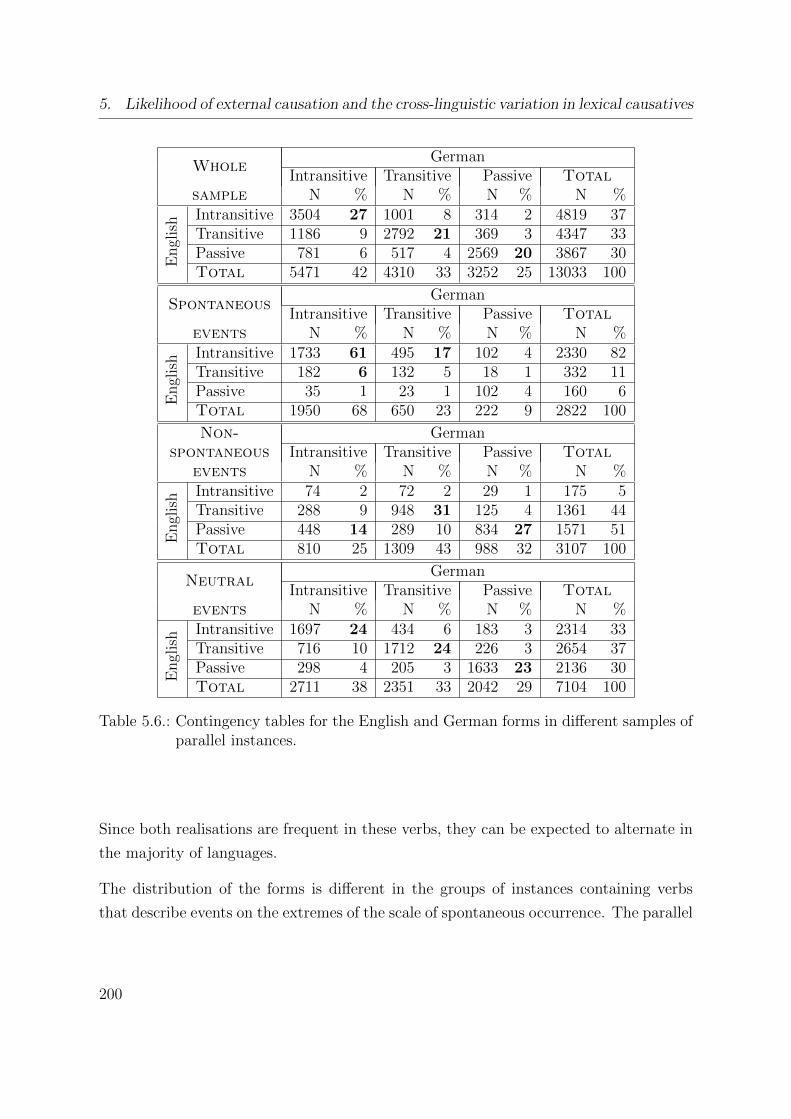
5. Likelihood of external causation and the cross-linguistic variation in lexical causatives
WholeGerman
Intransitive Transitive Passive Totalsample N % N % N % N %
Engl
ish Intransitive 3504 27 1001 8 314 2 4819 37
Transitive 1186 9 2792 21 369 3 4347 33Passive 781 6 517 4 2569 20 3867 30Total 5471 42 4310 33 3252 25 13033 100
SpontaneousGerman
Intransitive Transitive Passive Totalevents N % N % N % N %
Engl
ish Intransitive 1733 61 495 17 102 4 2330 82
Transitive 182 6 132 5 18 1 332 11Passive 35 1 23 1 102 4 160 6Total 1950 68 650 23 222 9 2822 100
Non- Germanspontaneous Intransitive Transitive Passive Total
events N % N % N % N %
Engl
ish Intransitive 74 2 72 2 29 1 175 5
Transitive 288 9 948 31 125 4 1361 44Passive 448 14 289 10 834 27 1571 51Total 810 25 1309 43 988 32 3107 100
NeutralGerman
Intransitive Transitive Passive Totalevents N % N % N % N %
Engl
ish Intransitive 1697 24 434 6 183 3 2314 33
Transitive 716 10 1712 24 226 3 2654 37Passive 298 4 205 3 1633 23 2136 30Total 2711 38 2351 33 2042 29 7104 100
Table 5.6.: Contingency tables for the English and German forms in different samples ofparallel instances.
Since both realisations are frequent in these verbs, they can be expected to alternate in
the majority of languages.
The distribution of the forms is different in the groups of instances containing verbs
that describe events on the extremes of the scale of spontaneous occurrence. The parallel
200

5.3. Experiments
Figure 5.5.: Joint distribution of verb instances in the parallel corpus. The size of theboxes in the table represents the proportion of parallel instances in eachsub-sample.
realisations are frequent only for the forms that are consistent with the lexical properties
(intransitive for spontaneous events and transitive for non-spontaneous events). An
atypical instance of a verb in one language (e.g. transitive instance of a verb that
describes a spontaneous event) is not preserved across languages. These realisations
tend to be transformed into the typical form in another language. For example, German
transitives are much less frequent in the spontaneous events group than in the non-
spontaneous events group, while English intransitive non-spontaneous verbs are only
5% compared to 82% of the spontaneous group. The atypical realisations of these verbs
are thus rare across languages, which means that they might be entirely absent in some
languages. In the languages in which these realisations are found, the verbs alternate,
while in the languages where these realisations are not found the verbs do not alternate.
This means that the verbs describing events on the extremes of the scale of spontaneous
occurrence can be expected to alternate in a smaller range of languages.
We conclude that the analysis of the realisations of lexical causatives in a parallel corpus
provides evidence that the probability of occurrence of an external cause in the event
described by a verb (the spontaneity of the event) is a grammatically relevant lexical
property. The cross-linguistic variation in the availability of the alternation is influenced
by this property. Verbs that describe events on the extremes of the scale of spontaneous
occurrence are more likely to have different realisations across languages than those that
describe events in the middle of the scale.
201

5. Likelihood of external causation and the cross-linguistic variation in lexical causatives
5.3.4. Experiment 4: Learning spontaneity with a probabilistic
model
In Section 5.3.1 and Section 5.3.2, we have shown that the spontaneity value of verbs
can be estimated from the information about the distribution of the causative and an-
ticausative instances of verbs in a corpus. These estimations, however, are based on
the data from only one language. Given that realisations of the alternation in different
languages is influenced by unknown factors, resulting in the observed cross-linguistic
variation, the estimation based on the data from a single language can be expected
to be influenced by language-specific factors. As we could see in Section 5.3.1 the es-
timation of the spontaneity value based on English corpus data is correlated with an
estimation based on the data from many different languages. The correlation, however,
is not perfect and the reason for this could be the deviation of the realisations in English
from the general tendencies. For example, it has been established that English prefers
causative realisations of some verbs compared to other languages (Bowerman and Croft
2008; Wolff et al. 2009a; Wolff and Ventura 2009b). As a result, estimations based on
English data can give lower spontaneity values compared to the universal value.
Another indication of potential language-specific factors which influence the way lexical
causatives are realised in a language can be found in the results of the experiment
presented in Section 5.3.3. While this experiment shows that the spontaneity value
influences the cross-linguistic realisations, we can also see that there is a number of
realisations which are divergent across languages. As discussed in Section 5.3.3, the
realisations which are not consistent with the spontaneity value in one language tend
to be transformed into realisations consistent with the spontaneity value in the other
language. However, the factors which give rise to the realisations inconsistent with the
spontaneity are not known.
To address the issue of potential influence of language-specific factors on corpus-based
estimation of the spontaneity value of events described by alternating verbs, we extend
the corpus based approach to the cross-lingsuitc domain. We collect the information
about the realisations of the alternating verbs in a parallel corpus, as described in Section
5.3.3. The extended data set is expected to provide a better estimation of the universal
spontaneity value than the monolingual set, neutralising the language-specific influences.
202

5.3. Experiments
Naturally, including more languages would be expected to give even better estimates.
In this study, however, we consider only two languages as a first step towards a richer
cross-linguistic setting.
A simple approach to integrating cross-linguistic corpus data would be to calculate the
ratio of causative to anticausative uses by adding up the counts from different languages.
For instance, if a verb is found as transitive four times in one language and the trans-
lations of these four instances were two times transitive and two times intransitive, the
count of transitive instance of these verb would be six. The two intransitive translations
would be added to the counts of intransitive instances. In this approach, however, the
information about which instances were observed in which language is lost. This knowl-
edge, however, can be very important for isolating language-specific factors and using
this information to predict cross-linguistic transformations of phrases containing verbs
with causative meaning. Another disadvantage of such an approach, which applies to
all the estimations performed in this study so far, is that they do not provide a straight-
forward way of grouping the verbs into classes, which is one of the major concerns in
the representation of lexical knowledge (see Section 5.2 in this chapter and also Section
2.2.1 in Chapter 2).
To take into account both potential language specific factors and potential grouping of
verbs we design a probabilistic model which estimates the spontaneity value on the basis
of cross-linguistic data and generates a probability distribution over a given number of
spontaneity classes for each verb in a given set of verbs.
The number of classes. Two main proposals concerning the classification of alternat-
ing verbs have been put forward in the linguistic literature. As discussed in Section 5.2,
Levin and Rappaport Hovav (1994) use the distinction between externally and internally
caused events to explain a set of observations concerning the alternating verbs. Alexi-
adou (2010), however, points out that a range of cross-linguistic phenomena are better
explained by introducing a third semantic class, the cause-unspecified verbs. The dis-
tinctions argued for in the linguistic literature can be roughly related to the spontaneity
feature in our account, so that externally caused events correspond to non-spontaneous,
internally caused to spontaneous and cause unspecified to medium-spontaneity events.
203

5. Likelihood of external causation and the cross-linguistic variation in lexical causatives
The model
As it can be seen in its graphical representation in Figure 5.6, the model consists of four
variables.
V
Sp
En Ge
Figure 5.6.: Bayesian net model for learning spontaneity.
The first variable is the set of considered verbs V . This can be any given set of verbs.
The second variable is the spontaneity class of the verb, for which we use the symbol
Sp. The values of this variable depend on the assumed classification.
The third (En) and the fourth (Ge) variables are the surface realisations of the verbs in
parallel instances. These variables take three values: causative for active transitive use,
anticausative for intransitive use, and passive for passive use.
We represent the relations between the variables by constructing a Bayesian network
(for more details on Bayesian networks, see Section 3.4.3 in Chapter 3), shown in Figure
5.6. The variable that represents the spontaneity class of verbs (Sp) is treated as an
unobserved variable. The values for the other three variables are observed in the data
source. Note that the input to the model, unlike the information extracted for the anal-
ysis in Section 5.3.3, does not contain the information about the spontaneity (compare
Table 5.7 with Table 5.5).
204

5.3. Experiments
The dependence between En and Ge represents the fact that the two instances of a
verb are translations of each other, but does not represent the direction of translation.
The form of the instance in one language depends on the form of the parallel instance
because they express the same meaning in the same context, regardless of the direction
of translation.
Assuming that the variables are related as in Figure 5.6, En and Ge are conditionally
independent of V given Sp, so we can calculate the probability of the model as in
(5.16).
P (v, sp, en, ge) = P (v) · P (sp|v) · P (en|sp) · P (ge|sp, en) (5.16)
Since the value of spontaneity is not observed, the parameters of the model that involve
this value need to be estimated so that the probability of the whole model is maximised.
We estimate the Sp-value for each instance of a verb by querying the model, as shown
in (5.17).
P (sp|v, en, ge) =P (v, sp, en, ge)∑sp P (v, sp, en, ge)
(5.17)
Applying the independence relations defined in the Bayesian net (Figure 5.6), the most
probable spontaneity class in each instance is calculated as shown in (5.18).
sp = arg maxsp
P (v) · P (en|sp) · p(ge|sp, en)∑sp P (v) · P (en|sp) · p(ge|sp, en)
(5.18)
Having estimated the Sp-value for each verb instance, we assign to each verb the average
spontaneity value across instances, as shown in (5.19).
sp class(verb) =
∑en
∑ge p(sp|v, en, ge)F (v)
(5.19)
where F (v) is the number of occurrences of the verb in the training data.
205

5. Likelihood of external causation and the cross-linguistic variation in lexical causatives
All the variables in the model are defined so that the parameters can be estimated
on the basis of frequencies of instances of verbs automatically extracted from parsed
corpora. The corpus used as input does not need to be annotated with classes, since the
parameters are estimated treating the class variable as unobserved.
The model described in this section includes only two languages because we apply it to
the two languages that we choose as a minimal pair (English and German), but it can
be easily extended to include any number of languages.
Experimental evaluation
The accuracy of the predictions of the model is evaluated in an experiment. We imple-
ment a classifier based on the model, which we train and test using the data extracted
from the syntactically parsed and word-aligned parallel corpus of English and German,
as described in Section 5.3.3. To address the discussion on the number of classes of
alternating verbs (see Section 5.2.2), we test two versions of the model. In one version,
the model performs a two-way classification which corresponds to the binary distinction
between externally and internally caused events. In the other version, the model per-
forms a three-way classification which corresponds to the distinction between internally
caused, externally caused, and cause-unspecified events.
The verbs for which we calculate the spontaneity class in the experimental evaluation
of the model are the 354 verbs that participate in the causative alternation in English,
as listed in Levin (1993).
We estimate the parameters of the model by implementing an expectation-maximisation
algorithm, which we run for 100 iterations. (Using the algorithm to estimate the prob-
abilities in a Bayesian model are explained in Section 3.4.2 in Chapter 3.) We initialise
the algorithm according to the available knowledge about the parameters. The proba-
bility P (v) is set to the prior probability of each verb estimated as the relative frequency
of the verb in the corpus. The probability P (sp|v) is set so that causative events are
slightly more probable than anticausative events in the two-way classification, and so
that that cause-unspecified events are slightly more probable than the other two kinds
206

5.3. Experiments
V En Demove pass intransalter trans transimprove trans transincrease pass passimprove trans transbreak trans passchange trans intransgrow intrans intransclose pass intranssplit intrans trans
Table 5.7.: Examples of the cross-linguistic input data
of events in the three-way classification. The values of P (en|sp) and P (ge|sp, en) are
initialised randomly.
For the set of verbs for which the typological information is available, we compare
the classification of verbs learned by the model both with the typology-based ranking
and with the rankings based on the monolingual corpus-based Sp-value, automatically
calculated in the second experiment (see Section 5.3.2 for more details). Since the set of
verbs for which it is possible to perform a direct evaluation against typological data is
relatively small (the data for 26 verbs are available), we measure the agreement between
the classification learned by the model and the rankings based on the monolingual corpus-
based Sp-value for the set of verbs which are found in the parallel corpus (203 verbs).
This measure is expected to provide an indirect assessment of how distinguished the
supposed classes of verbs are.
Table 5.8 shows all the classifications performed automatically in comparison with the
classifications based on the typology rankings. Since the typology-based and the mono-
lingual corpus-based measures do not classify, but only rank the verbs, the classes based
on these two measures are obtained by dividing the ranked verbs according to arbi-
trary thresholds. The thresholds for classifying the verbs according to the monolingual
corpus-based Sp-value are determined in the same way as in the third experiment (see
Section 5.3.3). In the two-way classification, the threshold is Sp = −1. The verbs with
207
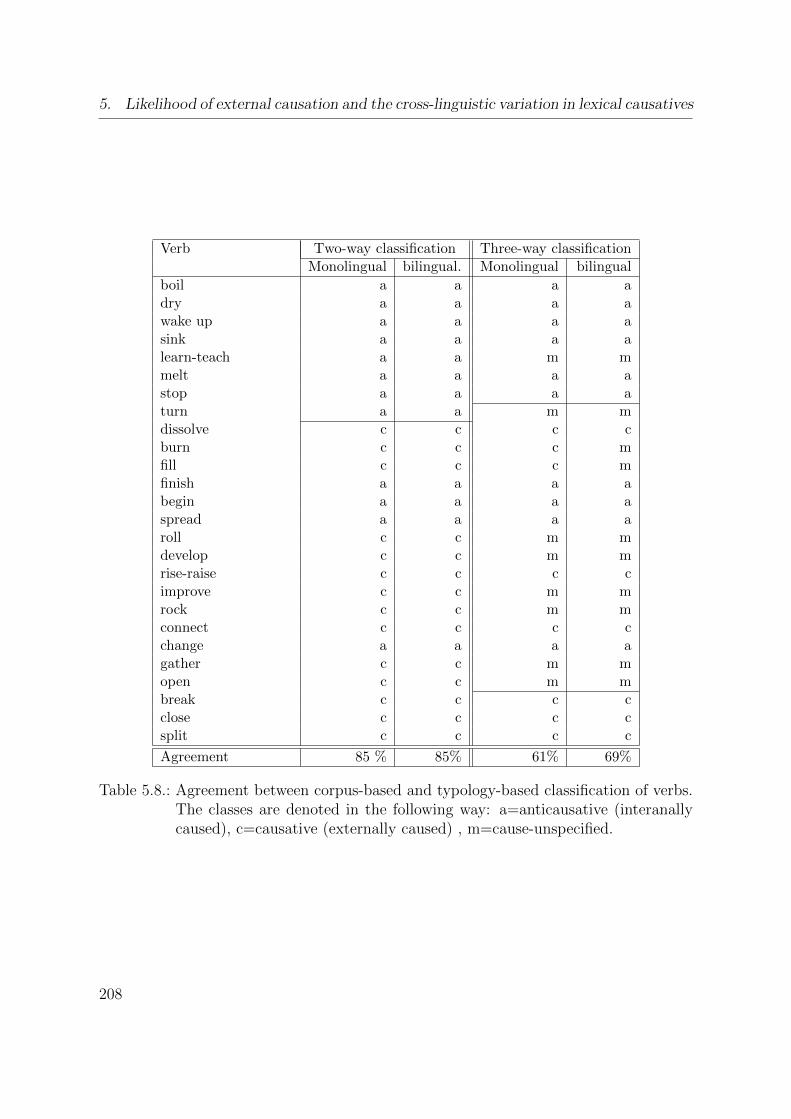
5. Likelihood of external causation and the cross-linguistic variation in lexical causatives
Verb Two-way classification Three-way classificationMonolingual bilingual. Monolingual bilingual
boil a a a adry a a a awake up a a a asink a a a alearn-teach a a m mmelt a a a astop a a a aturn a a m mdissolve c c c cburn c c c mfill c c c mfinish a a a abegin a a a aspread a a a aroll c c m mdevelop c c m mrise-raise c c c cimprove c c m mrock c c m mconnect c c c cchange a a a agather c c m mopen c c m mbreak c c c cclose c c c csplit c c c c
Agreement 85 % 85% 61% 69%
Table 5.8.: Agreement between corpus-based and typology-based classification of verbs.The classes are denoted in the following way: a=anticausative (interanallycaused), c=causative (externally caused) , m=cause-unspecified.
208

5.3. Experiments
the Sp-value below -1 are considered anticausative, the other verbs are causative. In the
three-way classification the causative class is split into two classes using the threshold
Sp = 1. The verbs with the Sp-value between -1 and 1 are considered cause-unspecified,
while the verbs with the Sp-value above 1 are causative.
The thresholds for classifying the verbs according to the typology-based ranking are
determined for each evaluation separately so that the agreement is maximised. For
example, threshold is set after the verb turn in the first two columns of Table 5.8.
All the verbs ranked higher than turn are considered anitcausative. The others are
causative.
In the two-way classification, the two versions of the model, with monolingual and with
bilingual input, result in identical classifications. The agreement of the models with
the typological ranking can be considered very good (85%). The optimal threshold
divides the verbs into two asymmetric classes: eight verbs in the internally caused class
and eighteen in the externally caused class. The agreement is better for the internally
caused class.
In the three way-classification, the performance of both versions of the model drops.
In this setting, the output of the two versions differs: there are two verbs which are
classified as externally caused by the monolingual version and as cause-unspecified by
the bilingual version, which results in a slightly better performance of the bilingual
version. Given the small number of evaluated verbs, however, this tendency cannot be
considered significant.
The three-way classification seems more difficult for both methods. The difficulty is
not only due to the number of classes, but also to the fact that two classes are not
well-distinguished in the data. While the class of anticausative verbs is relatively easily
distinguished (small number of errors in all classifications), the classes of causative and
cause-unspecified verbs are hard to distinguish. This finding supports the two-way clas-
sification argued for in the literature. However, the classification performed by the model
indicates that the distinction between causative and cause-unspecified verbs might still
exist. Compared to the classification based on monolingual Sp-value, more verbs are
classified as cause-unspecified, and they are more densely distributed on the typological
scale. Since the model takes into account cross-linguistic variation in the realisations of
209

5. Likelihood of external causation and the cross-linguistic variation in lexical causatives
Monolingual Sp classAnticausative Causative
Parallel Anticausative 64 13Sp class Causative 14 112
Table 5.9.: Confusion matrix for the monolingual corpus-based measure of spontaneityand the 2-class bi-lingual model classification for 203 verbs found in theparallel corpus.
Monolingual Sp classAnticausative Unspecified Causative
Parallel Anticausative 52 19 0Sp class Unspecified 1 32 35
Causative 6 24 34
Table 5.10.: Confusion matrix the monolingual corpus-based measure of spontaneity andthe 3-class bi-lingual model classification for 203 verbs found in the parallelcorpus.
lexical causatives, the observed difference in performance could be interpreted as a sign
that the distinction between cause-unspecified and causative verbs does emerge in the
cross-linguistic context.
The performance of the two automatic classifiers on all the alternating verbs found in
the parallel corpus is compared in Tables 5.9 and 5.10. The agreement between the two
automatic methods is 87% in the two-class setting and 58 % in the three-class setting.
Again, the class of anticausative verbs is rarely confused with the other two classes, while
causative and cause-unspecified verbs are frequently confused (the agreement between
the two classifications is at the chance level). The lack of agreement between the two
methods, however, does not necessarily mean that the two classes are not distinguishable.
It can also mean that the bi-lingual probabilistic model distinguishes between the two
classes better than the monolingual ratio-based measure. The direct comparison of the
two methods with the typology scale points in the same direction.
210

5.4. General discussion
Figure 5.7.: The relationship between the syntactic realisations, the morphological formand the meaning of lexical causatives.
5.4. General discussion
The experiments performed in our study of morpho-syntactic realisations of lexical
causatives relate various factors involved in the causative alternation. We have estab-
lished a statistically significant correlation between frequency distribution of syntactic
alternants in a monolingual corpus and frequency distribution of morphological marking
on the verbs which participate in the causative alternation across languages. The verbs
which tend to be used in intransitive clauses tend to bear causative marking across lan-
guages. The verbs which tend to be used in transitive clauses tend to bear anticausative
marking across languages.
This finding suggests that the underlying cause of both distributions is the meaning of
verbs, as illustrated in Figure 5.7. The fact that a verb which describes an event in
which an external causer is very unlikely could be the reason why the verb occurs in in-
transitive clauses and why it bears causative marking across languages. The intransitive
realisations could be due to the fact that the meaning of the verb is such that an external
causer does not need to be expressed in most of its uses. This further implies that only
one argument of the verb is expressed and that the opposition between the subject and
the object is not needed, which gives rise to an intransitive structure. However, there is
still a possibility for such a verb to be realised so that the external causer of the event is
expressed (typically in a transitive clause). The realisations which are default for these
verbs (intransitive) are not morphologically marked because they correspond to the gen-
eral expectation. The realisations with an explicit external causer are morphologically
211

5. Likelihood of external causation and the cross-linguistic variation in lexical causatives
marked because they are unexpected. For the same reasons the verbs which describe
events in which an external causer is very likely tend to occur in transitive clauses, but
when they are used as intransitive, they tend to be morphologically marked. Although
we have not excluded other possible explanations, the likelihood of an external causer
in an event described by a verb seems to be a plausible underlying cause of the observed
correlation.
5.4.1. The scale of external causation and the classes of verbs
The results of our experiments suggest that the alternating verbs are spread on a scale
of the likelihood of external causation. The distribution of the corpus-based measure
of the likelihood of external causation (the term Sp-value is used in our experiments)
over a large number of verb instances in a corpus is normal, which implies that the
most likely value is the mean value, and that both extremely low and extremely high
values are equally likely. This finding suggests that most of the alternating verbs can be
expected to describe events in which there is around 50% chance for an external causer
to occur. These are the verbs which alternate in the majority of languages. However,
the probability of an external causer can be very small for some verbs. These are the
verbs which alternate only in some languages, while they do not alternate in the majority
of languages. The same can be claimed for the verbs describing events with extremely
likely external causers. Thus, the likelihood of external causation in the meaning of
verbs explains the observed cross-linguistic variation in the availability of the causative
alternation. The verbs which do not alternate in English can be expected not to alternate
in a number of other languages too. The number of languages in which a verb can be
expected not to alternate can be predicted from the likelihood of external causation in
the event which it describes.
Although the scale of likelihood of external causation seems to be continuous based
on the fact that many different verbs are assigned distinct values, the results of our
experiments on classification suggest that some values can be grouped together. The
anticausative part of the scale seems to be distinguishable from the rest of the scale.
The verbs classified as anticausative in our experiments can be related to verbs describ-
ing internally-caused events discussed in the literature. Relating these two categories,
212

5.4. General discussion
however, requires redefining the role of internal causation in the account of the causative
alternation. The verbs which are classified as anticausative in our experiments do alter-
nate in English, while internal causation has been used to explain why some verbs do
not alternate in English (see Section 5.2.1). Anticausative verbs include both the verbs
which do and which do not alternate in English, but all of these verbs can be expected
to alternate in fewer languages than the verbs in the middle of the scale.
The question of whether there is a difference between the class of cause-unspecified
and causative verbs remains open leading to another potential question. If it turns out
that these two classes cannot be distinguished, this raises the question of why the two
extremes of the scale behave differently with respect to classification. The data collected
in our experiments do not seem to provide enough empirical evidence to address these
issues. Although some tendencies seem to emerge in our classification experiments,
more data from more languages would need to be analysed before some answers to these
questions can be offered.
5.4.2. Cross-linguistic variation in English and German
Unlike the previous research which is either monolingual or typological, we choose to take
a micro-comparative approach and to study the use of lexical causatives in English and
German at the level of token. We consider these two languages, which are genetically
and geographically very close, a minimal pair. We can expect fewer lexical types to
be differently realised in English and German than it would be the case in two distant
languages, with fewer potential sources of variation. On the other hand, if a lexical type
is inconsistently used in English and German, inconsistent realisations of the type can
be expected in any two languages. This approach is in line with some recent trends in
theoretical linguistics (discussed in Section 3.1.1 in Chapter 3).
Despite the fact that English and German are closely related languages, systematically
different realisations of lexical causatives could be expected on the basis of the grammat-
ical and lexical differences that have already been identified in the literature. It has been
noticed that the sets of alternating verbs in these languages are not the same (Schafer
2009). English verbs of moving, such as run, swim, walk, fly alternate, having both
213

5. Likelihood of external causation and the cross-linguistic variation in lexical causatives
anticausative and causative version. Their lexical counterparts in German can only be
found as intransitive. The causative use of these verbs in English necessarily requires a
transformation in the German translation. On the other hand, some verbs can alternate
in German, but not in English. For example, the verb verstarken (’reinforce’) in German
can have the anticausative version (sich verstarken), while in English, only the causative
version is possible. The equivalent of the German anticausative verb is the expression
become strong. At a more general level, it has been claimed that the relations between
the elements of the argument structure of German verbs are more specified than those
in English verbs, especially in prefixed verbs (Hawkins 1986). Given the opinions that
the degree of specificity of verbs’ meaning can influence the alternation, which have been
put forward in the qualitative analyses of lexical causatives (see Section 5.2 for more
details), this difference might have influence on the way the verbs are realised in the two
languages. From the morphological point of view, the alternation is differently marked
in the two languages. While English shows preference for labile verb pairs (see Section
5.5), German uses both anticausative marking and labil pairs. This difference is another
factor than could potentially influence the realisations of the verbs.
Although we have not examined the influence of these factors directly, the results of our
experiments suggest that including the data from German in the automatic estimation of
the likelihood of external causation changes the estimation so that it corresponds better
to the typological ranking of verbs in the three-way classification setting. This can be
interpreted as an indication that lexical causatives are realised differently in English
and German, despite the fact that the two languages are similar in many respects. The
difference is big enough to neutralise some language-specific trends in the realisations of
lexical causatives, such as, for example, the preference for transitive clauses in English,
discussed in the beginning of Section 5.3.4.
5.4.3. Relevance of the findings to natural language processing
Studying the alternation in lexical causatives is not only interesting for theoretical lin-
guistics. As discussed in Chapter 2, formal representation of the meaning of verbs are
extensively used in natural language processing too. Analysing the predicate-argument
214

5.5. Related work
structure of verbs proves important for tasks such as word sense disambiguation (La-
pata and Brew 2004), semantic role labelling (Marquez et al. 2008), cross-linguistic
transfer of semantic annotation (Pado and Lapata 2009; Fung et al. 2007; van der Plas
et al. 2011). Several large-scale projects have been undertaken to represent semantic
properties of verbs explicitly in lexicons such as Word Net (Fellbaum 1998), Verb Net
(Kipper Schuler 2005), and PropBank Palmer et al. (2005a).
Since the causative alternation involves most of verbs, identifying the properties of verbs
which allow them to alternate is important for developing representations of the meaning
of verbs in general. The findings of our experiments provide new facts which could be
useful in two natural language processing domains. First, the position of a verb on the
scale of the likelihood of external causation can be used to predict the likelihood for a
clause to be transformed across languages. Generally, the verbs which are in the middle
of the scale can be expected to be used in a parallel fashion across languages, while
placement of a verb on the extremes of the scale gives rise to divergent realisations.
However, studying other factors involved in the realisations in each particular language
would be required to predict the exact transformation. Second, the knowledge about
the likelihood of external causation might be helpful in the task of detecting implicit
arguments of verbs and, especially deverbal nouns (Gerber and Chai 2012; Roth and
Frank 2012). Knowing, for example, that a verb is on the causative side of the scale
increases the probability of an implicit causer if an explicit causer is not detected in a
particular instance of the verb.
5.5. Related work
Frequency distributions of transitive and intransitive realisations of lexical causatives in
language corpora have been extensively studied in natural language processing, start-
ing with the work on verb subcategorisation (Briscoe and Carroll 1997) and argument
alternations (McCarthy and Korhonen 1998; Lapata 1999) to current general distribu-
tional approaches to the meaning of words (Baroni and Lenci 2010) (see Section 2.3 in
Chapter 2 for more details). Here we focus on the work which addresses the notion of
external causation itself in a theoretical framework.
215

5. Likelihood of external causation and the cross-linguistic variation in lexical causatives
McKoon and Macfarland (2000) address the distinction between verbs denoting inter-
nally caused and externally caused events. Their corpus study of twenty-one verb defined
in the linguistic literature as internally caused change-of-state verbs and fourteen verbs
defined as externally caused change-of-state verbs, show that the appearance of these
verbs as causative (transitive) and anticausative (intransitive) cannot be used as a di-
agnostic for the kind of meaning that they are attributed.
Since internally caused change-of-state verbs do not enter the alternation, they were
expected to be found in intransitive clauses only. This, however, was not the case. The
probability for some of these verbs to occur in a transitive clause is actually quite high
(0.63 for the verb corrode, for example). More importantly, no difference was found in
the probability of the verbs denoting internally caused and externally caused events to
occur as transitive or as intransitive. This means that the acceptability judgements used
in the qualitative analysis do not apply to all the verbs in question, and, also, not to all
the instances of these verbs.
Even though the most obvious prediction concerning the corpus instances of the two
groups of verbs was not confirmed, the corpus data were still found to support the dis-
tinction between the two groups. Examining 50 randomly selected instances of transitive
uses of each of the studied verbs, McKoon and Macfarland (2000) find that, when used in
a transitive clause, internally caused change-of-state verbs tend to occur with a limited
set of subjects, while externally caused verbs can occur with a wider range of subjects.
This difference is statistically significant.
The relation between frequencies of certain uses and the lexical semantics of English
verbs is explored by Merlo and Stevenson (2001) in the context of automatic verb clas-
sification. Merlo and Stevenson (2001) show that information collected from instances
of verbs in a corpus can be used to distinguish between three different classes which
all include verbs that alternate between transitive and intransitive use. The classes in
question are manner of motion verbs (5.20), which alternate only in a limited number of
languages, externally caused change of state verbs (5.21), alternating across languages,
and performance/creation verbs, which are not lexical causatives (5.22).
(5.20) a. The horse raced past the barn.
b. The jockey raced the horse past the barn.
216

5.5. Related work
(5.21) a. The butter melted in the pan.
b. The cook melted the butter in the pan.
(5.22) a. The boy played.
b. The boy played soccer.
In the classification task, the verbs are described in terms of features that quantify the
relevant aspects of verbs’ use on the basis of corpus data. The three main features
are derived from the linguistic analysis of the verbs’ argument structure. The feature
transitivity is used to capture the fact that transitive use is not equally common for all
the verbs. It is very uncommon for manner of motion verbs (5.20b), much more common
for change of state verbs (5.21b), and, finally, very common for performance/creation
verbs (5.22b). This means that manner of motion verbs are expected to have consistently
a low value for this feature. Change of state verbs are expected to have a middle value
for this feature, while a high value of this feature is expected for performance/creation
verbs. The feature causativity represents the fact that, in the causative alternation, the
same lexical items can occur both as subjects and as objects of the same verb. This
feature is expected to distinguish between the two causative classes and the performance
class. The feature animacy is used to distinguish between the verbs that tend to have
animate subjects (manner of motion and performance verbs) and those that do not
(change of state verbs).
The results of the study show that the classifier performs best if all the features are
used. They also show that the discriminative value of the features differs when they are
used separately and when they are used together, which means that information about
the use of verbs that they encode is partially overlapping.
In our study, we draw on the fact that the lexical properties of verbs are reflected in
the way they are used in a corpus, established by the presented empirical approaches to
the causative alternation. As in these studies, we consider frequencies of certain uses of
verbs an observable and measurable property which serves as empirical evidence of the
lexical properties. We explore this relationship further, relating it to a deeper level of
theoretical semantic analysis of verbs and to the typological distribution of grammatical
features.
217

5. Likelihood of external causation and the cross-linguistic variation in lexical causatives
5.6. Summary of contributions
The experiments presented in this chapter provide empirical evidence that contribute
to better understanding of the relationship between the semantics of lexical causatives,
their formal morphological and syntactic properties, and the variation in their use. First,
we have shown that the distribution of morphological marking on lexical causatives
across a wide range of languages correlates with the distribution of their two syntactic
realisations (transitive and intransitive) in a corpus of a single language. We have argued
that the underlying cause of this correlation can be the meaning of lexical causatives,
more precisely, the likelihood of an external causer in an event described by a verb.
We have then proposed a monolingual corpus-based measure of the likelihood of an
external causer which is automatically calculated for a wide range of alternating verbs.
Having assigned the likelihood values to a large sample of verbs, we have analysed the
distribution of the syntactic alternants of the verbs in the cross-linguistic English and
German realisations. The analysis was performed on data automatically extracted from
parallel corpora. It showed that the likelihood of external causation in the meaning of
verbs influences the cross-linguistic variation. The realisations which are consistent with
this value tend to be realised across languages in a parallel fashion. Contrary to this,
the realisations in one language which are not consistent with the meaning of the verb
tend to be transformed into consistent realisations in the other language.
We have shown that automatic assessment of the likelihood of external causation in
the meaning of verbs is more congruent with the typological data if it is based on the
information on the realisations of lexical causatives in two languages than if it ist based
on the monolingual information, despite the fact that the two studied languages, English
and German, are typologically and geographically very close. To demonstrated this, we
have designed a probabilistic model which classifies verbs into external causation classes
taking into account cross-linguistic data. We have then evaluated the classification
against verb ordering based on the typological distribution of causative and anticausative
morphological marking of lexical causatives, as well as with the ordering based on the
distribution of the syntactic alternants of lexical causatives in a monolingual corpus.
To address the ongoing theoretical discussion on the number of semantic classes of lexical
218

5.6. Summary of contributions
causatives, we have tested two versions of the model: a two-class and a three-class
version. These tests have not provided conclusive results, but they have pointed out
some potential tendencies which can be further investigated.
219


6. Unlexicalised learning of event
duration using parallel corpora
6.1. Introduction
Sentences denote events and states that can last from less than a second to an unlimited
time span. The time span in which an event or a state takes place is understood mostly
implicitly. The interpretation of the time in which the event takes place is sometimes
influenced by the adverbials found in the sentence or by other structural elements, but the
time span itself is hardly ever explicitly formulated. Consider the following example:
(6.1) Winston stayed in the shop for two hours.
The time span for which the relation expressed in (6.1) holds is specified with the
adverbial two hours. However, even in this sentence, where the time adverbial is as
explicit as it can be in natural language, we understand that Winston stayed in the shop
some time “around two hours and not more” due to the automatic inference mechanisms
called conversational implicatures (Grice 1975; Levinson 1983; Moeschler and Reboul
1994). The time span in this sentence is clearly not meant to be interpreted as “at least
two hours”, which is, in fact, the truth-conditional meaning of the adverbial. Eliminating
this second interpretation is based on implicit understanding.
Sentences of natural language provide various clues to infer the implied time interpreta-
tion. We illustrate how the clues guide our interpretation with the examples in (6.2).
(6.2) a. Winston looked around himself for a while before he quickly put the book in
the bag.
221

6. Unlexicalised learning of event duration using parallel corpora
b. Winston looked around himself quickly before he started putting the book
in the bag.
c. Winston looked around himself quickly before he started putting the books
in the bag.
The adverbials for a while and quickly in (6.2a) do not directly quantify the duration
of the events of looking around and putting the book in the bag respectively, but rather
suggest appropriate readings. For instance, it is appropriate to understand that the
former event lasted longer than the latter and that both of them did not last more
than a minute. If we rearrange the constituents as in (6.2b), then the appropriate
understanding is that the former event was shorter than the latter. The event of putting
the book in the bag is obviously longer in (6.2b) than in (6.2a), but its duration is also
less specified. The event of putting the books in the bag in (6.2c) is interpreted as the
longest of the three, which is due to the plural form of the head of the direct object
(books) (See Krifka (1998) for more details on the relationship between the meaning of
the direct object of a verb and the temporal properties of the event described by the
verb.)
The examples in (6.2) show that the interpretation of the duration of an event depends
not just on the time adverbials, but also on the semantics of the verbs, and even on the
semantics of their complements. All the events in (6.2) are interpreted as lasting up to
several minutes, with the described variation. The common time range can be related to
the meaning of the verbs which are used to describe the events. The time span is more
specified with the time adverbials that are used in the sentences, with each adverbial
setting resulting in a slightly different interpretation, as in (6.2a-b). Finally, as we see
in (6.2c), a particular interpretation can be the result of a verb-object combination.
While time adverbials can guide our intuition in selecting the most appropriate time
interpretation, they cannot be taken as reliable quantifiers of events. The time span
over which an event holds can be underspecified, despite a very precise time expressed
by the time adverbial. This is the case in (6.3a).
(6.3) a. On 29th November 1984 at 7:55, Winston turned the switch.
222

6.1. Introduction
b. On 29th November 1984 at 7:55, Winston turned the switch and the whole
building disappeared.
The default interpretation of (6.3a) is that the event is very short, shorter than a minute,
and that it takes place at some time around 7:55. This interpretation is suggested in
the context given in (6.3b). Note that the causal relation between Winston turning the
switch and the building disappearing is inferred rather than encoded (Lascarides and
Asher 1993; Wilson and Sperber 1998). The same sentence can denote a situation
where the two events are unrelated. Nevertheless, the causal relation is automatically
inferred as a conversational implicature, which then suggests that everything, including
the turning of the switch, happened in a very short time span.
Without additional contextual elements, the sentence in (6.3a) can be assigned another
interpretation. It can denote a situation where Winston turned the switch over an
unlimited time span which includes the point described with the time adverbial. We do
not know when the event started, we know that it is true on 29th November 1984 at
7:55, and we do not know whether (and when) it ended.
The essentially implicit nature of understanding how long an event lasted is what makes
the task of automatic identification of event duration especially difficult. In automatic
processing of natural language, the intuition used by a human interpreter to detect the
intended implicit meaning has to be replaced by more explicit and rational reasoning in
which the relationship between the linguistic clues and the time interpretation has to be
fully specified. Yet the information about the duration of an event can rarely be read
directly from the lexical representation of the time adverbials in the sentences, as the
examples listed above show. Some reasoning is required to assign the correct intended
interpretation even to time adverbials such as two hours in (6.1), which appear explicit
and straightforward. The relationship between the linguistic clues and the resulting
time interpretation is even less specified in (6.2), and it is unspecified in (6.3a), where
it cannot be used for narrowing down the possible interpretations. Apart from the fact
that one of the two interpretations is generally more likely, the sentence (6.3a) does not
contain any elements which can point to the interpretation which is appropriate in the
given contexts. Even though there is a time adverbial in the sentence, it is not useful
223

6. Unlexicalised learning of event duration using parallel corpora
for disambiguating between the two interpretations. The clues for the disambiguation
would have to be found elsewhere.
The work on automatic identification of event duration, despite the difficulty, is moti-
vated by the importance that it has in natural language understanding. Using natural
language sentences as statements on the basis of which we want to infer some actual
state of affairs often requires knowing the time span over which a certain situation or
event is true. For instance, the sentence in (6.3a) can be taken as a basis for inferring
the state of the switch at 8:00, or whether Winston still turned the switch at 8:30. The
interpretation suggested in (6.3b) makes it almost certain that the switch is in a different
position at 8:00 than it was before 7:55, and also that the event of Winston turning the
switch is not true at 8:30. These inferences cannot be made starting with the temporally
unbounded interpretation of the same sentence.
One approach to dealing with the incomplete information about the time value of a
natural language sentence is to rely on the semantic representation of the whole discourse
to which the sentence in question belongs. The interpretation of the time expressed in
the sentence is deduced from the representation of the time adverbials (or, possibly,
other linguistic units which can point to the relevant time) found in other sentences,
and from certain knowledge about the structure of the discourse. A narrative discourse
would impose chronological sequencing of sentences, while the sentence sequencing in
an argumentative discourse would be only partly chronological, with many inversions
(stepping back in time). Knowing how the events are sequenced is helpful in determining
which one is true at which point in time. There are, however, two problems with this
approach. First, it is computationally complex, because it requires working with complex
representations of big chunks of discourse at the same time. Second, pieces of discourse
usually do not belong to a single type, but rather include the characteristics of several
types at the same time (Biber 1991). With multiple types present in the same sequence
of sentences, it is hard to see which type should be used for which sentence.
Another approach, the one which we pursue in this study, is to rely on an elaborate
semantic representation of verbal predicates, which are at the core of event denotation.
In this study, we search for the elements of the lexical representation of verbs which can
provide useful information for determining the duration of the events that they describe.
224

6.1. Introduction
We make hypotheses about the nature of these elements on the basis of theoretical
arguments put forward in the linguistic literature. More specifically, we study verb
aspect as a lexical and grammatical category that has been widely discussed in relation
with temporal properties of the meaning of verbs. We consider a range of theoretical
insights about what semantic traits are encoded by verb aspect and how these traits can
be related to event duration, which is a category of interest for automatic construction
of real-world representations in natural language understanding.
In the experiment presented in this study, we explore linguistic encoding and the pos-
sibility of cross-linguistic transfer of aspect information. It is a well-known fact that
Slavic languages encode verb aspect in a much more consistent way than most of the
other European languages. However, the mechanism which is used to encode aspect in
Slavic languages is lexical derivation of verbs, not syntactic or morphological rules. The
consequence of the lexical nature of aspect encoding is that the derivational patterns
are not regular, but rather idiosyncratic and unpredictable, presenting numerous chal-
lenges for generalisations. In our study, we take a data-driven probabilistic approach to
aspect encoding in Serbian as a Slavic language. We develop a cross-linguistic aspectual
representation of verbs using automatic token-level alignment of verbs in English and
Serbian. We then apply this representation to model and predict event duration classes.
This approach is based on an assumption that aspectual meaning is preserved across
languages at the level of lexical items (see Section 3.1 in Chapter 3 for a more elaborate
discussion).
In the remaining of this chapter, we first explain the theoretical notions on which our
experiments are based. In Section 6.2.1, we present aspectual classes of verbs most
commonly referred to in the literature and describe their potential relationship with
event duration. The observable properties of semantic aspectual classification of verbs
in general are discussed in Section 6.2.2. Since, unlike English, Serbian encodes temporal
properties of verb meaning in a relatively consistent way, we then show how aspectual
information is encoded in the morphology of Serbian verbs in Section 6.2.3. After laying
down the theoretical foundations, we describe our cross-linguistic data driven approach
to representing verb aspect (Section 6.3). We proceed by describing the experiment
performed to test whether event duration is predictable from the representation of aspect
in Section 6.4. Our statistical model which is designed to learn event duration from the
225

6. Unlexicalised learning of event duration using parallel corpora
representation of aspect is described in Section 6.4.1. In Section 6.4.2, we describe the
data used for the experiment, as well as various experimental settings. The results of
the evaluation are discussed in Section 6.4.2. After general discussion (Section 6.5), our
approach is compared to related work in Section 6.6.
6.2. Theoretical background
Events described by verbs have different temporal properties: they can start and end
at some point in time, they can be long, short, instantaneous, or somewhere in between
these categories, they can overlap with other events or a particular point in time, the
overlap can be partial or full, and so on. However, not all of these properties are
equally relevant for the grammatical meaning of verb. Some temporal properties give
rise to certain grammatical structures, while others are grammatically irrelevant. The
main issue in linguistic theory of verb aspect is the kind of temporal meaning which it
encodes. In this section, we give an overview of the main accounts of the relationship
between the temporal meaning and the form of verbs.
6.2.1. Aspectual classes of verbs
It has been argued in the linguistic literature that verbs can be divided into a (small)
number of aspectual classes. A verb’s membership in an aspectual class is argued to play
an important role in interpreting time relations in discourse. Dowty (1986) discusses
contrasts such as the one shown in the sentences in (6.4a-b).
(6.4) a. John entered the president’s office. The president woke up.
b. John entered the president’s office. The clock on the wall ticked loudly.
The interpretation of (6.4a) is that the president woke up after John entered his office,
while the interpretation of (6.4b) is that the clock ticked loudly before and at the same
time with John’s entering the president’s office. Dowty (1986) argues that the contrast
226

6.2. Theoretical background
Eventuality described by a verb
Unbounded Bounded
Statehave,know,believe
Activityswim,walk,talk
Achievementarrive,realise,learn
Accomplishmentgive,teach,paint
Figure 6.1.: Traditional lexical verb aspect classes, known as Vendler’s classes
is due to the fact that the verbs wake up and tick belong to two different aspectual
classes.
The aspectual classification of verbs depends on a set of lexical properties which describe
the dynamics and the duration of the event which is described by the verb. A verb
can describe a stative relation (as in (6.1)). We say that these verbs describe states.
Otherwise, a verb can describe a dynamic action (as in (6.2-6.4)). States are usually
considered temporally unbounded, while actions can be unbounded and bounded.1
The temporal boundaries to which we refer here are those that are implicit to the
meaning of the verb. Although the state in (6.1), for example, is temporally bounded
to two hours, this is imposed by the time adverbial. The meaning of the verb stay itself
does not imply that there is a start or an end point of the state described by it. In
contrast to this, the meaning of a verb such as wake up in (6.4a) does imply that there
is a point in time where the action described by the verb (waking up in this case) is
completed. Such verbs are said to describe temporally bounded events, usually termed
as telic actions in the literature. (In this sense, states are always atelic.) Actions can
1The term event, as it is used in the linguistic literature, sometimes does not include states, butonly dynamic aspectual types. The general term which includes all aspectual types is eventuality.However, this distinction is not always made, especially not in computational approaches, and theterm event is used in the more general sense, the one covering all aspectual types. In our study, weuse the term event in the general sense.
227

6. Unlexicalised learning of event duration using parallel corpora
also be temporally unbounded (atelic). This is the case with the clock ticking in (6.4b).
Even though this action consists of repeated, temporally bounded actions of ticking, the
verb is understood as describing a single temporally unbounded action, usually termed
as an activity. The difference in the existence of an implicit time boundary in the
interpretation of the verbs wake up and tick is precisely what creates the difference in
the interpretation of the event ordering in (6.4a) and (6.4b).
Temporally bounded actions can be bounded in different ways. Most commonly a dis-
tinction is made between the actions that last for some time before they finish, known
as accomplishments and the actions which both begin and end in a single point of time,
known as achievements. Typical examples of verbs that describe accomplishments are
build, give, teach, paint, and those that describe achievements are arrive, realise, learn.
Accomplishments are usually thought of as telic actions, as they point to the end of an
action. Achievements, on the other hand, are frequently described as inchoative, which
means that they point to the beginning of an action.
This taxonomy of four aspectual types, summarised in Fig 6.1, is often referred to as
Vendler’s aspectual classes (Vendler 1967). It has a long tradition in the linguistic
theory, but it cannot be taken as a reference classification, as more recent work on verb
aspect shows.
The distinction between the entities which are temporally unbounded and those which
are bounded seems much easier to make than the distinctions referred to at the sec-
ond level of the classification. Dowty (1986) proposes a precise semantic criterion for
distinguishing between the two:
(a) A sentence2 ϕ is stative iff it follows from the truth of ϕ at an interval I
that ϕ is true at all subintervals of I. (e.g. if John was asleep from 1:00
until 2:00PM, then he was asleep at all subintervals of this interval: be
asleep is a stative).
(b) A sentence ϕ is an activity (or energeia) iff it follows from the truth
of ϕ at an interval I that ϕ is true of all subintervals of I down to a
2Although the units discussed here are sentences, Dowty (1986) explicitly applies the same criteria tolexical items and functional categories.
228

6.2. Theoretical background
certain limit in size (e.g. if John walked from 1:00 until 2:00 PM, then
most subintervals of this time are times at which John walked; walk is
an activity.)
(c) A sentence ϕ is an accomplishment/achievement (or kinesis) iff it follows
from the truth of ϕ at an interval I that ϕ is false at all subintervals of
I. (E.g. if John built a house in exactly the interval from September 1
until June 1, then it is false that he built a house in any subinterval of
this interval: build a house is an accomplishment/achievement.)
(Dowty 1986: p. 42)
There are two points to note about this criterion. First, the main difference is made
between (a) and (b) on one side and (c) on the other. The difference between (a)
and (b) is only in the degree to which the implication is true: in (a) it is true for all
subintervals, while in (b), it is true for most subintervals. This difference does not matter
in the contrasts illustrated in (6.4). With respect to the interpretation of time ordering,
items defined in (a) and in (b) behave in the same way. Second, the distinction between
accomplishments and achievements is not made at all. The reason for this is not just
the fact that the distinction, like the distinction between (a) and (b), does not play a
role in the contrasts addressed in Dowty’s study, but also the fact that there are no
clear criteria for distinguishing between the two. Dowty (1986) argues that the duration
criterion evoked in the literature does not apply.
Relating the distinction between bounded and unbounded entities to only dynamic types,
as we have been doing so far for clarity of presentation of the traditional taxonomy, does
not entirely correspond to the real semantics of verbal predicates. Marın and McNally
(2011) show that some verbs which would traditionally be classified as achievements
(Spanish aburrirse ‘to be/become bored’ and enfadarse ‘to become angry’) are states,
in fact, even though they are temporally bounded (inchoative). Other authors have
proposed other criteria for defining aspectual classes. Most approaches analyse events
in an attempt to define their components, such as start, or result. The classes are
then derived as different combination of the components (Pustejovsky 1995; Rothstein
2008; Ramchand 2008).
229

6. Unlexicalised learning of event duration using parallel corpora
In our study, no particular classification or event structure is adopted. We use the notions
of temporal boundedness and duration, which are well defined and endorsed by most of
the studies discussed above, but we do not adopt any of the traditional classes which are
defined by particular combinations of the values of these categories. Since traditional
aspectual classes are questionable, as shown in the discussion above, we propose our own
approach to combining the values of boundedness and duration in forming aspectual
classes. Our representation of aspect is based on the traditionally discussed notions, but
the resulting categories do not correspond to any of the traditionally defined clsasses.
As opposed to Dowty (1986), our study does not address orderings of events. We are
interested in the duration of each event separately. Regarding the examples in (6.4),
for instance, we are not interested in knowing whether the president woke up before or
after John entered his office. Our questions are: How long does John’s entering the
president’s office last? How long is the president’s waking up and the clock’s ticking?
They are related to the sequencing of the parts of discourse, but they can be treated
separately.
We try to answer these questions using the knowledge about verbs’ aspectual classes,
which are defined based on the notion of temporal boundedness. The intuition behind
this goal is that temporal boundedness and duration are related. It is reasonable to
expect that short events are temporally bounded. It is easier to imagine a time boundary
in something that lasts several seconds than in something that lasts a hundred years.
Long events can be expected to be less temporally bounded. Note that our expectations
are probabilistic. We do not exclude the possibility for a short event to be temporally
unbounded and for a long event to be bounded. However, we expect short temporally
unbounded events to be less likely than than short temporally bounded events and long
temporally bounded events to be less likely than long temporally unbounded event. We
expect these dependencies to be strong enough so that the duration of an event can be
predicted from aspectual properties of the verb that expresses it.
230

6.2. Theoretical background
Tense Aspectual interpretation
Present/Past Simple unspecifiedPresent/Past Continuous → ActivitiesPresent/Past Perfect → Bounded (achievements/accomplishments)
Table 6.1.: A relationship between English verb tenses and aspectual classes.
6.2.2. Observable traits of verb aspect
The criterion for distinguishing temporally bounded and unbounded verbs defined by
Dowty (1986) is a truth-conditional test which is well suited for querying human logical
intuition. To perform such a test automatically, a system would need a comprehensive
knowledge database, with all truth-conditions and inference rules explicitly encoded for
each expression. The size of such a database and the resources needed to create it, as
well as to search it, are hard to asses, but such a project would certainly be a challenging
one. What would be more suitable for automatic identification of temporal boundedness
is to be able to observe formal differences between unbounded and bounded events. This
brings up the question of how aspectual classes can be observed in verbs.
The form of the verbs listed in Fig. 6.1, for example, clearly does not vary depending
on the class membership: verbs belonging to the same class have nothing in common.
By considering only the form of a verb, we cannot determine its aspectual class.
When verbs are used in a sentence, however, they receive a tense form, and some of the
verb tenses in English do encode certain aspectual properties. As illustrated in Table
6.1, continuous tenses tend to refer to activities, while perfect tenses indicate that the
event is temporally bounded.
The tense with which a verb is used can override the inherent aspectual class of the verb
lexical entry. For example, the verb realise is usually classified as an achievement, but
the Present Continuous Tense form as the one in (6.5), cannot be assigned this class.
(6.5) People are slowly realising what is going on.
231

6. Unlexicalised learning of event duration using parallel corpora
The tense form of English verbs is a useful marker for identifying their aspect, but the
range of the examples in which this relation can be used for automatic identification
is limited to the sentences which contain either continuous or perfect tense. However,
sentences with marked continuous or perfect tense are far less frequent than sentences
with simple or bare forms, which do not point to any particular aspectual class.
Another potential source of observations are distributional properties of verbs. A number
of distributional tests to identify aspectual classes have been proposed in the literature,
starting with Dowty (1979). Interestingly, the proposed tests do not make reference
to the distinction between bounded and unbounded events, but to the second level
of the traditional taxonomy (Fig. 6.1). For example, the most famous test of com-
patibility with in-adverbials vs. for-adverbials, shown in (6.6), differentiates between
states and activities on one side and accomplishments on the other. States and activites
are compatible with the for-adverbials, and accomplishments are compatible with the
in-adverbials. This test does not apply to achievements. Other tests will distinguish
between, for example, states and other classes and so on.
(6.6) a. State:
Winston stayed in the shop for two hours / ??in two hours.
b. Activity :
The clock in the presidents office ticked for two hours / ??in two hours.
c. Accomplishment :
Winston put the books in the bag ??for two seconds / in two seconds.
c. Achievement :
The president woke up ??for two seconds / ??in two seconds.
Apart from the fact that the categories which are identified with the distributional tests
are not clearly defined, the problem with such tests is that English verbs are highly
ambiguous between different aspectual readings so that adverbials can impose almost
any given reading. The use of the verbs in (6.6) with the compatible adverbials is
preferred, but the use with the incompatible adverbials is not ungrammatical. The
incompatible adverbial imposes a less expected, potentially marginal reading, but, with
232

6.2. Theoretical background
this reading, the sentence remains grammatical. Moreover, many verbs are perfectly
compatible with different contexts, such as write in (6.7).
(6.7) a. Activity:
Winston wrote the message for two hours.
b. Accomplishment:
Winston wrote the message in two hours.
Unlike English, other languages make formal differences between aspectual classes and
these differences can be observed in the structure of verbal lexical entries. The form of
verbs in Slavic languages, for example, famously depends on some aspectual properties
of the events that they describe. In the remaining of this section, we show how this
marking is realised in Serbian, as one of the Slavic languages.
6.2.3. Aspect encoding in the morphology of Serbian verbs
The inventory of Serbian verbs contains different entries for describing temporally un-
bounded and temporally bounded events. Consider, for example, the Serbian equivalents
of the sentence in (6.7), given in (6.8-6.9). The verbs pisao in (6.8) and napisao in (6.9)
constitute a pair of lexical entries in fully complementary distribution: pisati (infinitive
form of pisao) is used for temporally unbounded events, and napisati is used for tem-
porally bounded events. As we can see in (6.8-6.9), exchanging the forms between the
unbounded and bounded contexts makes the sentences ungrammatical. The forms that
are used in the temporally unbounded context are called imperfective and those that are
used in the temporally bounded context are called perfective.
(6.8) VinstonWinston-nom
jeaux
pisao/*napisaowrote
porukumessage-acc
dvatwo
sata.hours.
Winston wrote a message for two hours.
(6.9) VinstonWinston-nom
jeaux
napisao/*pisaowrote
porukumessage-acc
zafor
dvatwo
sata.hours.
Winston wrote a message in two hours.
233
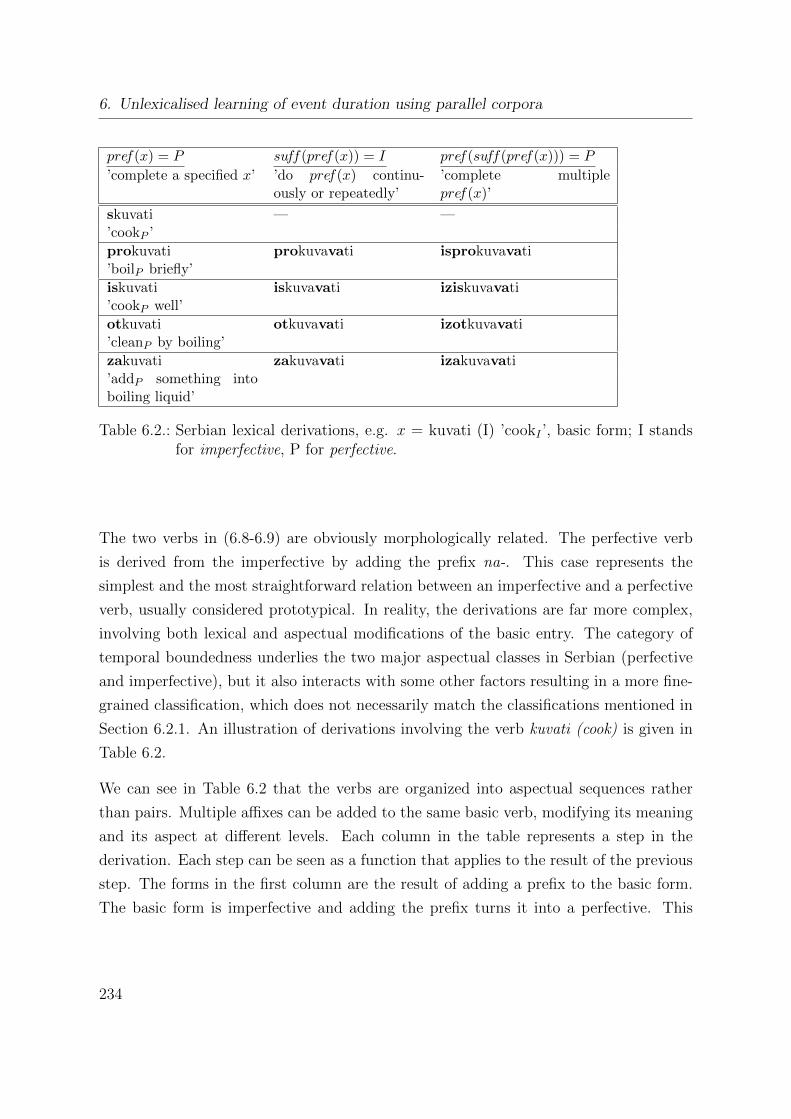
6. Unlexicalised learning of event duration using parallel corpora
pref(x) = P suff(pref(x)) = I pref(suff(pref(x))) = P
’complete a specified x’ ’do pref(x) continu-ously or repeatedly’
’complete multiplepref(x)’
skuvati — —’cookP ’
prokuvati prokuvavati isprokuvavati’boilP briefly’
iskuvati iskuvavati iziskuvavati’cookP well’
otkuvati otkuvavati izotkuvavati’cleanP by boiling’
zakuvati zakuvavati izakuvavati’addP something intoboiling liquid’
Table 6.2.: Serbian lexical derivations, e.g. x = kuvati (I) ’cookI ’, basic form; I standsfor imperfective, P for perfective.
The two verbs in (6.8-6.9) are obviously morphologically related. The perfective verb
is derived from the imperfective by adding the prefix na-. This case represents the
simplest and the most straightforward relation between an imperfective and a perfective
verb, usually considered prototypical. In reality, the derivations are far more complex,
involving both lexical and aspectual modifications of the basic entry. The category of
temporal boundedness underlies the two major aspectual classes in Serbian (perfective
and imperfective), but it also interacts with some other factors resulting in a more fine-
grained classification, which does not necessarily match the classifications mentioned in
Section 6.2.1. An illustration of derivations involving the verb kuvati (cook) is given in
Table 6.2.
We can see in Table 6.2 that the verbs are organized into aspectual sequences rather
than pairs. Multiple affixes can be added to the same basic verb, modifying its meaning
and its aspect at different levels. Each column in the table represents a step in the
derivation. Each step can be seen as a function that applies to the result of the previous
step. The forms in the first column are the result of adding a prefix to the basic form.
The basic form is imperfective and adding the prefix turns it into a perfective. This
234

6.2. Theoretical background
derivation is in many ways similar to the attachment of particles to English verbs, as
the translations of the prefixed forms suggest (Milicevic 2004). Adding a prefix results
in a more specified meaning of the basic verb by introducing an additional resultative
predication into the verb’s lexical representation (Arsenijevic 2007). We say that this
derivation indirectly encodes verb aspect because prefixes are not aspectual morphemes.
The change of the aspect is a consequence of the fact that the result state introduced
by the prefix makes the event temporally bounded.
In some cases, this derivation can be further modified as shown in the second column. By
attaching a suffix, the verb receives a new imperfective interpretation which is ambiguous
between progressive and iterative meaning, similar to the interpretation of tick in (6.4b).
(Historically, the suffix is iterative.) This new imperfective, sometimes referred to as
secondary imperfective, is necessarily different than the starting imperfective of the basic
form. The forms in the second column express events containing the resultative predicate
introduced by the prefix, but with the time boundary suppressed by the suffix.
Finally, the forms in the third column are again perfective, but this perfective is different
from the one in the first column. These forms can be regarded as describing plural
bounded events. In actual language use, these forms are much less frequent than the
others. They can be found only in big samples of text, which is why we do not consider
them in our experiments.
Examples in (6.10-6.13) illustrate typical uses of the described forms of Serbian verbs.
(6.10) Basic imperfective:
VinstonWinston-nom
jeaux
cestooften
kuvao.cooked.
Winston often cooked.
(6.11) Prefixed perfective:
VinstonWinston-nom
jeaux
prokuvaoboiled
casuglass-acc
vode.water-gen.
Winston boiled a glass of water.
(6.12) Secondary imperfective:
235

6. Unlexicalised learning of event duration using parallel corpora
VinstonWinston-nom
jeaux
prokuvavaoboiled
casuglass-acc
vodewater-gen
(kada(when
jeaux
cuoheard
glas).sound-acc).
Winston was boiling a glass of water when he heard the sound.
(6.13) Double-prefix plural perfective:
VinstonWinston-nom
jeaux
isprokuvavaoboiled
sveall-acc
caseglasses-acc
vode.water-gen.
Winston boiled all the glasses of water.
Not all prefixed verbs can be further modified. The verb skuvati in Table 6.2, for exam-
ple, does not have the forms which would belong to the second and the third column.
This phenomenon has been widely discussed in the literature, with many authors trying
to determine what exactly blocks further derivations. It has been argued that prefixes
can be divided into lexical (or inner) and superlexical (or outer) and that further deriva-
tions are not possible if the prefix is superlexical. This account, however, remains subject
of debate (Svenonius 2004b; Arsenijevic 2006; Zaucer 2010). We ignore this difference
considering that there are no structural differences between the prefixes.
Lexical and aspectual derivations are also possible with verbs whose basic form has
perfective meaning. An illustration of this paradigm is given in Table 6.3. The aspect
does not change for these verbs when they are prefixed. The verbs in the first column
are perfective just like the basic form. The rest of derivations proceed in the same way
as for the imperfective basic forms.
There are other patterns of lexical expression of aspectual classes in Serbian. For in-
stance, some verbs are attached a perfective suffix (rather than a prefix) directly to
the basic form (usually used to express very short, semelfactive events), some verbs do
not have the basic form, they are found only with prefixes, some perfective verbs have
no imperfective counterparts and vice versa, etc. However, the examples listed in this
section form a general picture of how aspectual classes are morphologically marked in
Serbian. The summary of possible verb forms is given in Fig. 6.2.
What is important for our study is the fact that aspectual classes are observable in the
verb forms, although the relationship between the form and the meaning is not simple.
236
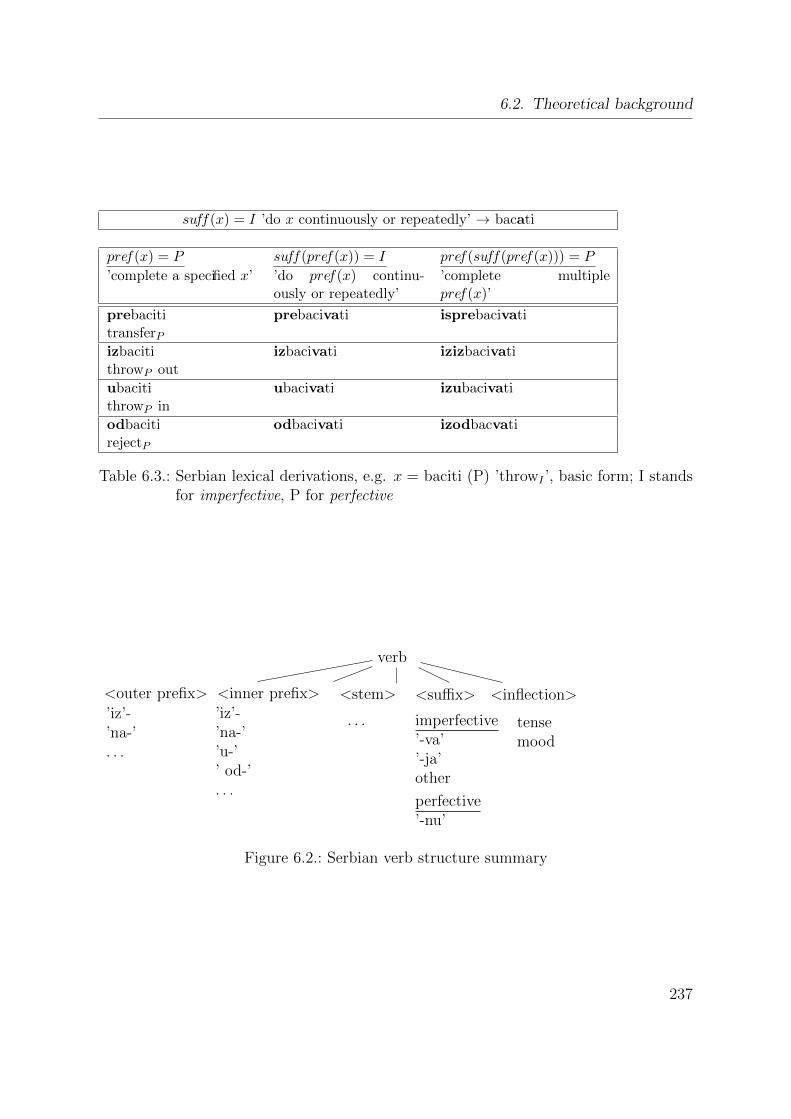
6.2. Theoretical background
suff(x) = I ’do x continuously or repeatedly’ → bacati
pref(x) = P suff(pref(x)) = I pref(suff(pref(x))) = P
’complete a specified x’ ’do pref(x) continu-ously or repeatedly’
’complete multiplepref(x)’
prebaciti prebacivati isprebacivatitransferPizbaciti izbacivati izizbacivatithrowP out
ubaciti ubacivati izubacivatithrowP in
odbaciti odbacivati izodbacvatirejectP
Table 6.3.: Serbian lexical derivations, e.g. x = baciti (P) ’throwI ’, basic form; I standsfor imperfective, P for perfective
verb
<outer prefix> <inner prefix> <stem> <suffix> <inflection>
imperfective’-va’’-ja’other
perfective’-nu’
’iz’-’na-’. . .
’iz’-’na-’’u-’’ od-’. . .
. . . tensemood
Figure 6.2.: Serbian verb structure summary
237

6. Unlexicalised learning of event duration using parallel corpora
Serbian verb morphology encodes aspect only indirectly, but, unlike with English verb
tenses, some kind of aspect information is present in almost all verb uses. Morphological
expression of aspect in Serbian is also potentially less ambiguous, hence more helpful in
determining verb aspect than time adverbials and other elements which can be found in
the context in which the verb is used.
The described derivations can potentially encode numerous aspectual classes. Minimally,
the verbs are divided into temporally bounded (perfective) and temporally unbounded
(imperfective). However, combinations of different stems, prefixes and suffixes can result
in more fine-grained classes. For example, the secondary imperfectives (the third column
in Table 6.2) do not have the same temporal properties as the starting, basic imperfec-
tive. As discussed above, the secondary imperfective contains the resultative meaning
introduced by the prefix, while the bare form does not. As a consequence, the meaning
of the secondary imperfective is more specified and more anchored in the context. This
distinction might prove relevant for event duration. We can expect prefixed imperfective
verbs to describe shorter events than basic imperfective verbs. Further distinctions can
be encoded by potential dependencies between the prefixes and suffixes, or between the
stems and the structural elements.
In our study, we do not explore all the possible encoded meanings, but we do explore
distinctions which are more complex than the simplest distinction between imperfec-
tive and perfective meaning. We represent aspectual classes as combinations of three
attribute-value pairs. The attributes are defined on the basis of the analysis presented
in this section.
6.3. A quantitative representation of aspect based on
cross-linguistic data
Experimental approach to the temporal meaning which we adopt in our study requires
a relatively large set of examples of linguistically expressed events for which both event
duration and verb aspect are known and explicitly encoded. Compiling such a data set
is already a challenging task because we are dealing with intuitive notions referring to
238

6.3. A quantitative representation of aspect based on cross-linguistic data
the phenomena which are hard to observe and measure. Although we all might agree
that some events last longer than others, assessing exact duration of any particular
event is something that we do not normally do. Collecting such assessments for a
large number of cases is a task which requires significant efforts. Collecting verb aspect
assessments is even more complicated because this is a theoretical notion which cannot
be understood without linguistic training. Moreover, assessing an exact verb aspect
value for a particular verb use proves difficult even for trained linguists because there is
no general consensus in the theory on what values this category includes and how they
should be defined.
One of the objectives of our work is, thus, compiling a set of data for our experimental
work. The existing resources provide one part of the information that we need: human
judgments of event duration have been annotated for a set of event instances (Pan et al.
2011). We collect the information about verb aspect for the same set of instances.
We decide to collect our own verb aspect information because of the fact that no theo-
retical account of this category can be taken as standard. Using any existing annotation
necessarily means adopting the view of verb aspect inherent to the annotation. Instead,
we propose our own approach which is data-driven and based on observable structural
elements of verb forms. Since English verb morphology typically does not mark aspect,
we gather the information from the translations of English verbs into Serbian, where,
like in all other Slavic languages, verb aspect is indirectly encoded in the verbs’ mor-
phology. Instead of collecting human judgements, we observe natural language encoding
of verb aspect in Serbian and use these observations to assign verb aspect properties to
the verbs both in Serbian and English. The information used for assignment is automat-
ically extracted from language corpora, which makes this approach especially suitable
for annotating a large number of examples.
We represent aspectual classes of verbs as combinations of values of three attributes.
The first attribute is the binary classification into grammatical perfective and impere-
fective classes. The second and the third attribute (morphological attributes) specify
whether the verb in question is used with a prefix or/and with a suffix respectively. The
combinations of the values of the three attributes represent aspectual classes. We use
these classes to predict event duration, but we do not identify them with any aspectual
239

6. Unlexicalised learning of event duration using parallel corpora
classes already proposed in the literature. The values for the three attributes are as-
sessed on the basis of the instances of verbs in a parallel corpus, which is described in
the following section.
The values for aspectual attributes of verbs are determined automatically on the basis
of cross-linguisitc realisations of verbs in English and Serbian. Cross-linguistic assign-
ment of aspectual classes is possible due to the fact that aspect is a property of the
meaning of verbs, and the meaning is what is preserved in translating from one lan-
guage to another, while the forms of its expression change. In our case, verb aspect
is morphologically encoded in Serbian verbs, but the same aspectual class can be as-
signed to the corresponding English verbs. In this section, we describe our approach to
cross-linguistic aspectual classification of verbs based on the described representation of
aspect decomposed into attributes.
6.3.1. Corpus and processing
For transferring verb aspect classification from Serbian to English, we need to know
which Serbian verb is the translation of an English verb in a given context. This kind of
information can be obtained from a corpus of translated sentences — a parallel corpus
— which is aligned at the word level, so that the translation is known for each word of
each sentence. For the purpose of predicting event duration on the basis of aspectual
properties of verbs, which is the goal of our experiments, we need a word-aligned parallel
corpus with annotated event duration on one side of the corpus. Such a corpus, however,
does not exist. Examples of annotated event duration are available in English and we
do not have Serbian translations of these sentences. We have to use other resources.
There are several parallel English-Serbian corpora which are currently available (Tiede-
mann 2009; Erjavec 2010). In our current study we only use the Serbian translation
of the novel “1984” by George Orwell, which is created in the MULTEXT-East project
(Krstev et al. 2004; Erjavec 2010). We use this corpus for the convenience of the
manual annotation and literary text genre, which is known to be rich in verbs (Biber
1991). In principle, our methods are applicable to all available parallel corpora.
240
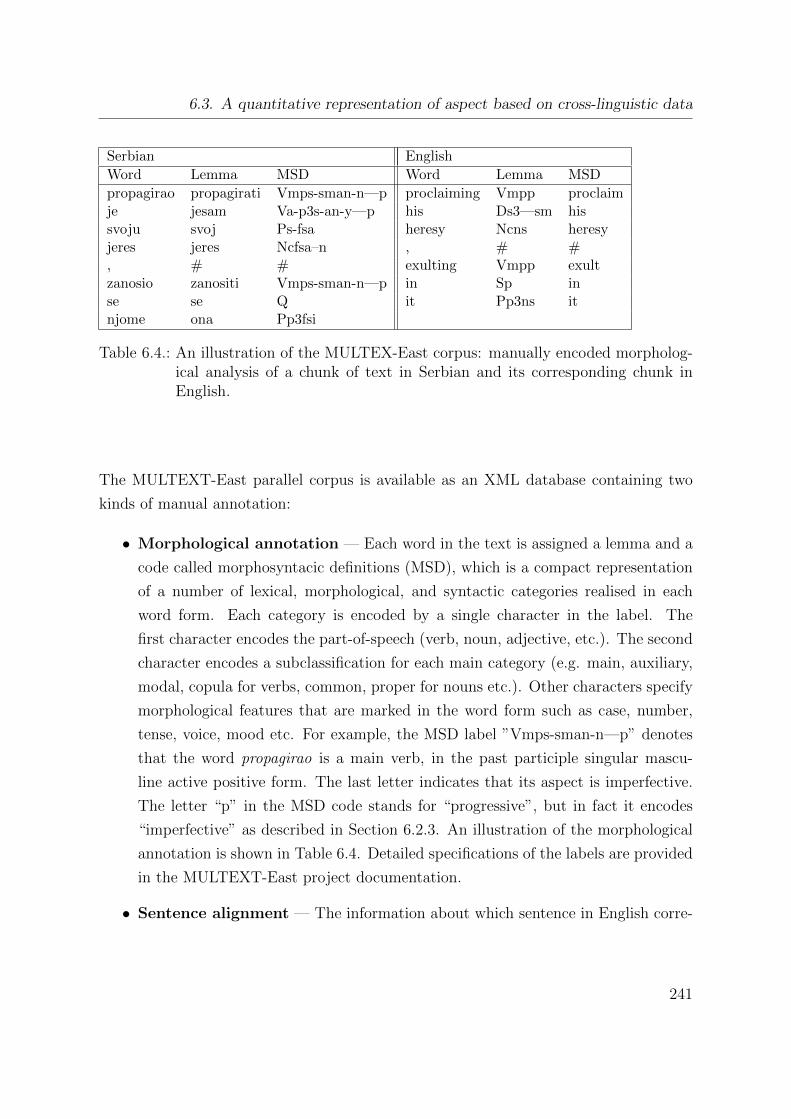
6.3. A quantitative representation of aspect based on cross-linguistic data
Serbian English
Word Lemma MSD Word Lemma MSD
propagirao propagirati Vmps-sman-n—p proclaiming Vmpp proclaimje jesam Va-p3s-an-y—p his Ds3—sm hissvoju svoj Ps-fsa heresy Ncns heresyjeres jeres Ncfsa–n , # #, # # exulting Vmpp exultzanosio zanositi Vmps-sman-n—p in Sp inse se Q it Pp3ns itnjome ona Pp3fsi
Table 6.4.: An illustration of the MULTEX-East corpus: manually encoded morpholog-ical analysis of a chunk of text in Serbian and its corresponding chunk inEnglish.
The MULTEXT-East parallel corpus is available as an XML database containing two
kinds of manual annotation:
• Morphological annotation — Each word in the text is assigned a lemma and a
code called morphosyntacic definitions (MSD), which is a compact representation
of a number of lexical, morphological, and syntactic categories realised in each
word form. Each category is encoded by a single character in the label. The
first character encodes the part-of-speech (verb, noun, adjective, etc.). The second
character encodes a subclassification for each main category (e.g. main, auxiliary,
modal, copula for verbs, common, proper for nouns etc.). Other characters specify
morphological features that are marked in the word form such as case, number,
tense, voice, mood etc. For example, the MSD label ”Vmps-sman-n—p” denotes
that the word propagirao is a main verb, in the past participle singular mascu-
line active positive form. The last letter indicates that its aspect is imperfective.
The letter “p” in the MSD code stands for “progressive”, but in fact it encodes
“imperfective” as described in Section 6.2.3. An illustration of the morphological
annotation is shown in Table 6.4. Detailed specifications of the labels are provided
in the MULTEXT-East project documentation.
• Sentence alignment — The information about which sentence in English corre-
241

6. Unlexicalised learning of event duration using parallel corpora
sponds to which sentence in Serbian is provided as an additional layer of annota-
tion.
The corpus is not aligned at the word level. We obtain word alignments, which is the last
piece of information needed for our study, automatically, using the methods described
in the following subsection.
Automatic alignment of English and Serbian verbs in a parallel corpus. We
extract the information about word alignments in the manually aligned Serbian and
English sentences using the system GIZA++ (Och2003), the same tool which is used
in the previous two studies. The input to the system are tokenised sentence-aligned
corpora in the plain text format, with one sentence alignment chunk per line. We use
the XML pointers in the manual alignment file of the MULTEXT-East corpus to convert
the Serbian and English text to the format required by GIZA++. The conversion also
includes removing the morphological annotation temporarily. We then perform word
alignment in both directions: with English as the target language and Serbian as the
target language.
Given the formal definition of word alignment which is used by the system (see Section
3.2 in Chapter 3), the amount and the correctness of word alignment depends very
much on the given direction. It is common practice in machine translation and in other
tasks involving automatic word alignments to use the intersection of both directions
of alignment, that is only the alignments between the words which are aligned in both
directions (Och and Ney 2003; Pado 2007; Bouma et al. 2010; van der Plas et al. 2011).
This approach gives very precise alignments, but only for a relatively small number of
words. We do not follow this approach, since it leaves out many correct alignments
which are potentially useful for our study, as shown in Chapter 4. Instead, we convert
the alignment output into a format suitable for manual inspection. We then manually
compare a sample of the alignments in the two directions and choose the one which gives
more correct alignments. This, in our case, was the alignment with English as the target
language.
Once we have obtained word alignments, we combine them with the morphological anno-
tation from the original corpus to extract only those alignments of English verbs which
are aligned with Serbian verbs. In other words, we only keep alignments between the
242

6.3. A quantitative representation of aspect based on cross-linguistic data
words which both contain the “Vm” code in their respective morphosyntactic definitions
(see Table 6.4). This simple method does not only select verbs, which we are interested
in in our study, but it also eliminates potentially wrong alignments. If a system aligns
a verb with a noun, or an adjective, or any other category, chances are that this is a
wrong alignment. On the other hand, even if it is possible for a verb in one language
to be aligned with a wrong verb in another language in a sentence which contains more
than one verb, this happens relatively rarely in practice.
6.3.2. Manual aspect classification in Serbian
With word-to-word alignment between English and Serbian verbs and with the manually
annotated aspect code, which is contained in the morphological description of the words
on the Serbian side, we can now see whether English verbs are aligned with perfective or
imperfective Serbian verbs. This will determine the value of the first aspectual attribute
(simple binary aspect classification). We collect the following counts:
• For each verb form on the English side of the corpus:
– the number of times it is aligned with a perfective Serbian verb
– the number of times it is aligned with an imperfective Serbian verb
• For each verb lemma on the English side of the corpus:
– the sum of the alignments of all the forms with a perfective Serbian verb
– the sum of the alignments of all the forms with a perfective Serbian verb
We collect the counts at the level of verb type because some of the verb tenses in English
can indicate a particular aspectual context, as shown in Section 6.2.2. This implies that
aspectual classes assigned to verb forms separately are expected to be more precise than
assigning the same class to all the forms of one lemma.
Summing up the counts for each lemma, on the other hand, is useful as a kind of back-off
for classifying verb forms which are not observed in the parallel corpus. If any other form
243

6. Unlexicalised learning of event duration using parallel corpora
of the same lemma is observed, then the count of alignments for the lemma is not zero
and the unobserved form can be assigned the value which is assigned to the lemma.
6.3.3. Morphological attributes
The binary grammatical category of perfective and imperfective aspect does not repre-
sent all the aspectual properties of Serbian verbs which are encoded in the morphology.
As shown in Section 6.2.3, these categories interact with other factors and the resulting
morphology encodes a more fine-grained classification. Perfective verbs, for instance, can
be divided into those that are perfective in their basic form (such as baciti in Table 6.3),
those that have become perfective by attaching a prefix (the first column in Table 6.2
and 6.3), or those that are attached a perfective suffix (see Fig. 6.2, these verbs usually
do not have bare forms). Similarly, verbs can be imperfective in their basic form such as
kuvati in Table 6.2, or after they have been attached both a prefix and an imperfective
suffix. We take the presence or the absence of the relevant morphological units in the
structure of Serbian verbs as indicators of different aspectual properties.
For these reasons, in addition to the simple perfectivity, we define two more attributes
for encoding more fine-grained aspectual distinctions of verbs. To collect the counts
needed for this description, we analyse all the Serbian verbs which are identified as
aligned with English verbs in the parallel corpus. We perform the analysis automatically
using our own analyser which implements the rules described in Section 6.2.3. The
structure obtained with our analyser cannot be considered the true structure but rather
an approximation of it. Due to historical changes, some morphemes that are known
to have existed in the structure are not easily recognisable in the present-day forms.
We ignore these elements and treat these verbs as uncompositional. By identifying the
visible morphological segments only, we can still analyse most Serbian verbs.
With the identified segments of the morphological structure of Serbian verbs, we can
now collect the following counts:
• For each verb form on the English side of the corpus:
– the number of times it is aligned with a prefixed Serbian verb
244

6.3. A quantitative representation of aspect based on cross-linguistic data
– the number of times it is aligned with a suffixed Serbian verb
• For each verb lemma on the English side of the corpus:
– the sum of the alignments of all the forms with a prefixed Serbian verb
– the sum of the alignments of all the forms with a suffixed Serbian verb
Knowing the value of each of the three aspectual attributes of the Serbian alignment of
an English verb form, that is knowing if the Serbian translation of an English verb has
a prefix or not, if it has a suffix or not, and if it is perfective or imperfective, we can
now describe English forms in terms of these attributes, and then use them to predict
the duration of the events expressed by the verbs. We assign to each English verb form
and to each lemma a single value for each of the three aspectual attributes. The values
represent the total of the corpus counts for each type. We explain in the following
subsection how the values are calculated.
6.3.4. Numerical values of aspect attributes
In our cross-linguistic representation, aspect of each English verb form is defined by
a vector of three numbers between 0 and 1. Each number expresses the value of one
attribute. The values are determined based on the observations made in the parallel
corpus. We quantify three aspect attribute in the following way:
• Prefix: This attribute encodes the tendency of English verbs to be word-aligned
with prefixed Serbian verbs. Given the role of prefixes in the derivation of Serbian
verbs, described in Section 6.2.3, such tendency provides two pieces of information
about the event which is described by the English verb:
a) The event is more specified than those that are aligned with Serbian bare
verbs.
b) The event is temporally bounded, unless the verb also tends to be associated
with an imperfective suffix, which can remove the temporal boundary imposed
by the prefix.
245

6. Unlexicalised learning of event duration using parallel corpora
The value of this attribute is calculated as the proportion of prefixed verbs in the
set of verb alignments for each verb form in English, as shown in (6.14).
Pf(e) =F (sr pref(e))
F (sr(e))(6.14)
where F stands for frequency (= total count in the corpus), e is an English verb,
sr pref(e) is a prefixed Serbian verb aligned with the English verb e, and sr(e) is
any Serbian verb aligned with the English verb e. For example, if an English verb
form is aligned with a Serbian verb in a parallel corpus 9 times, and 7 of these
alignments are Serbian prefixed verbs, the value of Pf = 79
= 0.8.
• Suffix: This attribute encodes the tendency of English verbs to be word-aligned
with Serbian verbs which are attached a suffix. The presence of suffixes in the
Serbian translations of English verbs can mean two opposite things:
a) The event described by the English verb is temporally unbounded, but spec-
ified. This is the case when the suffix is added to derive the secondary imper-
fective in Serbian (the second column in Table 6.2 and 6.3).
b) The event is temporally bounded and very short, which is the case when the
suffix is added to the bare form directly.
The value of this attribute is calculated, similarly to prefix alignments, as the
proportion of verbs containing a suffix in the set of verbs with which an English
verb is aligned, as shown in (6.15).
Sf(e) =F (sr sf(e))
F (sr(e))(6.15)
where e is an English verb, sr suff(e) is a Serbian verb which contains a suffix and
which is aligned with the English verb e, and sr(e) is any Serbian verb aligned with
the English verb e. For example, if the same English verb for which we calculated
the prefix value is aligned with a suffixed Serbian verb 4 times, the value of the
suffix attribute is Sf = 49
= 0.4.
246

6.3. A quantitative representation of aspect based on cross-linguistic data
• Aspect: This attribute encodes the information extracted from the manually
annotated morphological description of Serbian verbs. It represents the tendency
of an English verb form to be aligned with Serbian verbs tagged as perfective.
This information is especially useful in the case of bare verbs in Serbian, where the
structural information is missing. It is calculated in a similar way as the previous
two values, as shown in (6.16).
Asp(e) =F (sr asp(e))
F (sr(e))(6.16)
where e is an English verb, sr asp(e) is a the perfective aspect annotation of
a Serbian verb aligned with the English verb e, and sr(e) is any Serbian verb
aligned with the English verb e. If the same verb is seen 5 times aligned with
a Serbian perfective verb, the value is calculated as Asp = 59
= 0.5. Note that,
since all the verbs in the corpus are tagged either as perfective or imperfective,
this value determines at the same time the tendency of a verb to be aligned with
imperfective forms in Serbian.
We do not set any threshold to the number of observations that are included in the
measures. We calculate all the three values for all English forms (or lemmas) which are
observed at least once in the parallel corpus. To deal with low frequency items and zero
counts, we apply additive smoothing, which is calculated as in (6.17):
Θi =xi + 1
n+ 2(6.17)
where i ∈ {Pf, Sf,Asp} is one of the aspect attributes, x is the number of observed
alignments of an English verb with a specific value of the attribute, and n is the number
of times the English verb is seen in the parallel corpus. The smoothed values for the
examples used above are ΘPf = 7+19+2
= 0.7, ΘSf = 4+19+2
= 0.4, and ΘAsp = 5+19+2
= 0.5.
We illustrate the resulting aspectual definitions of English verbs with a sample of data
in Table 6.5. The zero values that can be seen in the table are the result of rounding.
247
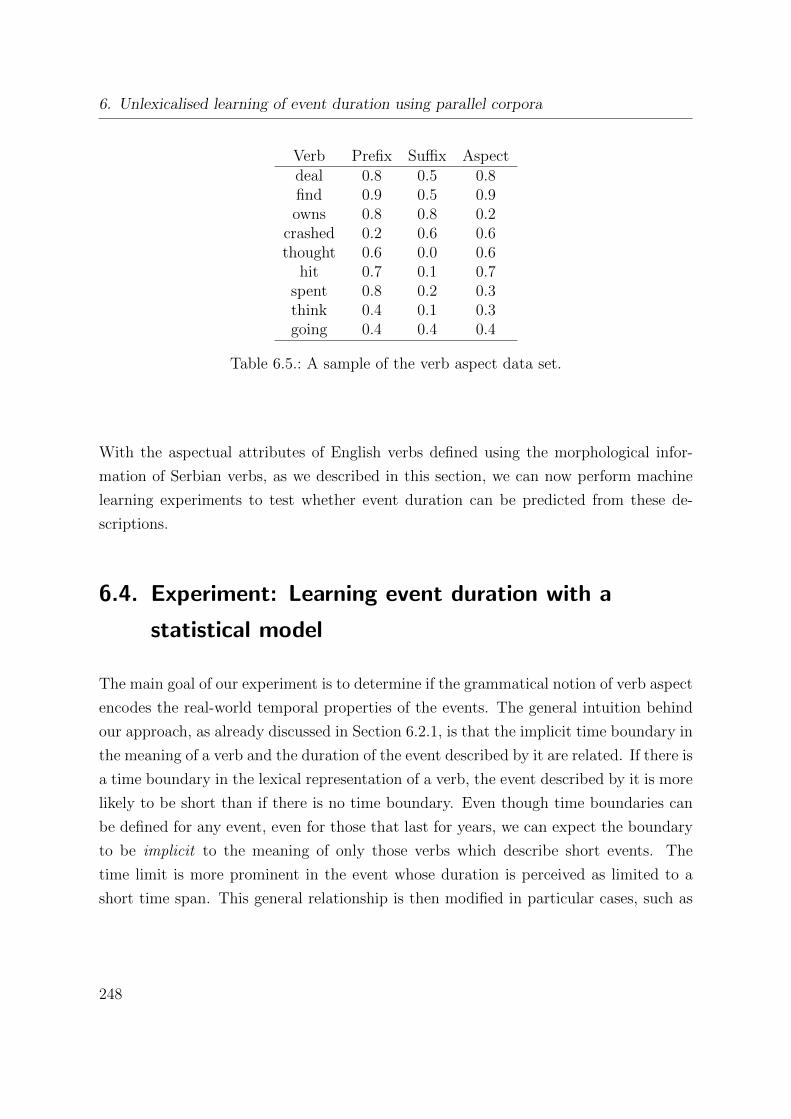
6. Unlexicalised learning of event duration using parallel corpora
Verb Prefix Suffix Aspectdeal 0.8 0.5 0.8find 0.9 0.5 0.9owns 0.8 0.8 0.2
crashed 0.2 0.6 0.6thought 0.6 0.0 0.6
hit 0.7 0.1 0.7spent 0.8 0.2 0.3think 0.4 0.1 0.3going 0.4 0.4 0.4
Table 6.5.: A sample of the verb aspect data set.
With the aspectual attributes of English verbs defined using the morphological infor-
mation of Serbian verbs, as we described in this section, we can now perform machine
learning experiments to test whether event duration can be predicted from these de-
scriptions.
6.4. Experiment: Learning event duration with a
statistical model
The main goal of our experiment is to determine if the grammatical notion of verb aspect
encodes the real-world temporal properties of the events. The general intuition behind
our approach, as already discussed in Section 6.2.1, is that the implicit time boundary in
the meaning of a verb and the duration of the event described by it are related. If there is
a time boundary in the lexical representation of a verb, the event described by it is more
likely to be short than if there is no time boundary. Even though time boundaries can
be defined for any event, even for those that last for years, we can expect the boundary
to be implicit to the meaning of only those verbs which describe short events. The
time limit is more prominent in the event whose duration is perceived as limited to a
short time span. This general relationship is then modified in particular cases, such as
248

6.4. Experiment: Learning event duration with a statistical model
English verb tenses (see Section 6.2.2) or secondary imperfectives in Serbian (see Section
6.2.3).
We formalise our hypotheses about the relation between verb aspect and event duration
by means of a statistical model. Representing the aspect attributes with the quantities
based on corpus counts, as described in Section 6.3, is already one part of the model.
The attributes Prefix, Suffix, and Aspect, which we propose, are, in fact, a model of
grammatical aspect. What remains to be specified, in order to construct a full model
of all the notions examined in our research, is how the aspect attributes are related to
event duration, and also how they are related to each other.
The interest for developing such a model is not only practical, but also theoretical. A
model with a sound theoretical background, if successful, is not only expected to make
good predictions improving the performance in the tasks related to natural language
understanding. Such a model, making reference to specific theoretical notions, is also
a means of testing whether these notions actually play a role in the empirical reality.
Being a model of the relationship between the categories in the domain of grammar of
language and those that belong to world knowledge, it can provide new insights into the
functioning of the interface between these two domains.
In the remaining of this section, we first describe the full model which is tested in the
experiment. We then describe the algorithms and the data sets used in the experimental
evaluation, and, in the last subsection, the results of the evaluation.
6.4.1. The model
The full model of the relationship between verb aspect properties and event duration
consists of four variables. The three aspect properties described in Section 6.3 are in-
cluded in the model as separate variables. The fourth variable represents event duration.
In the following list we introduce the notation that we use, summarising the variables,
their values and the expected relationships between them.
T: for Time. This variable represents the information about event duration as assessed
by human annotators. It can take the values “short” and “long”.
249

6. Unlexicalised learning of event duration using parallel corpora
Pf : for Prefix. This variable encodes the tendency of English verbs to be word-aligned
with prefixed Serbian verbs. It can take the values between 0 and 1, as described
in Section 6.3.
Since the presence of a prefix in Serbian verbs indirectly indicates perfective aspect,
as we show in Section 6.2.3, we expect that higher values of this variable provide
a signal of short event duration, and lower values of long duration.
Sf : for Suffix. This variable encodes the proportion of suffixed verbs in the set of
Serbian verbs with which an English verb form is aligned (Section 6.3).
The expected contribution of this variable to the model is based on the interaction
between verb prefixes and suffixes which is observed in the grammar of Serbian
aspectual derivations. As described in Section 6.2.3, suffixes can be attached to
the verbs which are already attached a prefix, resulting in what is usually called
secondary imperfective. Otherwise, suffixes can be attached to bare forms resulting
in perfective interpretation (see Fig. 6.2). Crossing the values of Pf and Sf is thus
expected to yield a more accurate representation of the temporal properties of
verbs than using any one of the two variables.
Asp: for Aspect. In addition to the formal grammatical elements that indicate the
aspectual class of the Serbian alignments of English verb forms, the model contains
a variable which encodes directly whether the alignments tend to be perfective
or imperfective. Higher values of Asp indicate that the English form tends to
be aligned with perfective Serbian verbs and lower values indicate imperfective
alignments.
The information from this variable is expected to be useful in the cases where
English verb forms are aligned with Serbian verbs which do not bear any formal
marking, but which are still specified for aspect, such as basic forms in Table 6.2
and Table 6.3.
Note that the model does not include any lexical information. We do not use the
information about lexical entries either of English or of Serbian verbs. We also do not
use the form of Serbian prefixes and suffixes, we only observe whether any affix appears
in a verb or not.
250

6.4. Experiment: Learning event duration with a statistical model
T
Pf Sf
Asp
Figure 6.3.: Bayesian net model for learning event duration
We formalise the described relationships between the variables in the model by means of
a Bayesian net, shown in Figure 6.3. The general principles of constructing the Bayesian
net model representation are discussed in more detail in Section 3.4.3 in Chapter 3.
As represented by the arrows in Figure 6.3, we assume that Asp and T are conditionally
independent given Pf and Sf. This relationship captures the fact that the information
about verb aspect is important only when the information about verb affixes is not
available. We assume that Sf depends both on T and Pf, which represents the fact that
a suffix can be added for two reasons. First, it can be added as a means of deriving
secondary imperfectives, and this is the case where a prefix is already attached to the
verb. Second, a suffix can be added to a bare form, and, in this cases, it can result
in a perfective. Pf depends only on T, meaning that a prefix is attached only to the
verbs which express events with particular durations (short events). The variable whose
values we predict in the machine learning experiments is T , and the predictors are the
other three variables.
The Bayesian net classifier
We build a supervised classifier which is an implementation of our Bayesian net model
described in Section 6.4.1. Assuming the independence relationships expressed in the
Bayesian net (Figure 6.3), we can decompose the model into smaller factors and calculate
its probability as the product of the probabilities of the factors, as shown in (6.18).
251

6. Unlexicalised learning of event duration using parallel corpora
P (T, Pf, Sf,Asp) = P (T ) · P (Pf |T ) · P (Sf |Pf, T ) · P (Asp|Pf, Sf) (6.18)
The probability of each factor of the product is assessed on the basis the relative fre-
quency of the values of the variables in the training set. The prior probability of event
duration T is calculated as the relative frequency of the duration in the training sample
(Total), as shown in (6.19).
P (T ) =F (T )
Total(6.19)
The conditional probability of the other factors are calculated from the joint probability,
which is estimated for each value of each variable as the joint relative frequency of the
values in the sample, as shown in (6.20-6.22).
P (Pf |T ) =F (Pf, T )
F (T )(6.20)
P (Sf |Pf, T ) =F (Sf, Pf, T )
F (Pf, T )(6.21)
P (Asp|Pf, Sf) =F (Asp, Pf, Sf)
F (Pf, Sf)(6.22)
In testing, the predicted time value is the one which is most likely, given the values of
the three aspect attributes observed in the test data:
duration class(instance) = arg maxt
P (t|pf, sf, asp) (6.23)
The conditional probability of each value t ∈ T is calculated applying the general con-
ditional probability rule, factorised according to the independence assumptions in the
Bayes’ net (see Figure 6.3), as shown in (6.24).
252

6.4. Experiment: Learning event duration with a statistical model
P (t|pf, sf, asp) =P (t) · P (pf |t) · P (sf |pf, t) · P (asp|pf, sf)∑t P (t) · P (pf |t) · P (sf |pf, t) · P (asp|pf, sf)
(6.24)
If one of the values of the three predictor variables is unseen in the training data, we
eliminate this variable from the evidence and calculate the conditional probability of t
given the remaining two variables, as shown in (6.25)-(6.27):
P (t|pf, sf) =
∑asp P (t) · P (pf |t) · P (sf |pf, t) · P (asp|pf, sf)∑
asp
∑t P (t) · P (pf |t) · P (sf |pf, t) · P (asp|pf, sf)
(6.25)
P (t|pf, asp) =
∑sf P (t) · P (pf |t) · P (Sf |pf, t) · P (asp|pf, sf)∑
sf
∑t P (t) · P (pf |t) · P (sf |pf, t) · P (asp|pf, sf)
(6.26)
P (t|sf, asp) =
∑pf P (t) · P (pf |t) · P (sf |pf, t) · P (asp|pf, sf)∑
pf
∑t P (t) · P (pf |t) · P (sf |pf, t) · P (asp|pf, sf)
(6.27)
In principle, the same variable elimination procedure can be applied also when two values
are unseen, but this was not necessary in our experiments.
6.4.2. Experimental evaluation
In the experimental evaluation, we train the model on a set of examples and then test
its predictions on an independent test set. In all the settings of the experiment, the
learning task is defined as supervised classification. The learning systems are trained on
a set of examples where the values of the target variable are observed together with the
values of the predictor variables. The predictions are then performed on a new set of
examples for which only the values of the predictor variables are observed.
The way the information from the predictors is used to predict values of the target
variable depends on the classification approach and on the machine learning algorithm
which is used. Some algorithms can be better suited for certain kinds of data than
others. (Hall et al. 2009). To determine which classification approach is the best
for our predictions, we perform several experiments. In addition to our Bayesian net
253

6. Unlexicalised learning of event duration using parallel corpora
classifier, we test three more methods on two versions of the data. Our experimental
set-up is described in more detail in the following subsections.
Materials and methods
We test our model on a set of examples with manually annotated event duration provided
by Pan et al. (2011) to which we assign verb aspect values acquired from Serbian verb
morphology through a parallel corpus as described in Section 6.3. The full set of data
which were used in the experiments is given in Appendix C.
Corpus and processing. The examples annotated with event duration are part of
the TimeBank corpus (Pustejovsky et al. 2003). The annotation of duration is, in
fact, added to the already existing TimeBank annotation. An example of an annotated
event is given in (6.28) (the mark-up language is XML). The part of the annotation in
bold face is the added duration information, the rest belongs to the original TimeBank
annotation.
(6.28) There’s nothing new on why the plane <EVENT eid=“e3”
class=“OCCURRENCE” lowerBoundDuration=“PT1S”
upperBoundDuration=“PT10S”>exploded</EVENT>.
In annotating event duration, the annotators were asked to assess a possible time span
over which the event expressed in a particular sentence can last. They were asked to
determine the lower and the upper bound of the span. We can see in the annotation of
the event in (6.28), for example, that the event of exploding is assessed to last between
one and ten seconds. Such annotations are provided for 2’132 event instances.
The agreement between three annotators is measured on a sample of around 10% of
instances. To measure the agreement, the seven time units (second, minute, hour, day,
week, month, year) were first converted into seconds. Then the mean value (between
the lower and upper bound) was taken as a single duration value. To account for the
different perception of the time variation in the short and long time spans, that is for
the fact that the difference between 3 and 5 seconds is perceived as more important
than the difference between 533 and 535 seconds, the values in seconds were converted
254

6.4. Experiment: Learning event duration with a statistical model
into their natural logarithms. The values on the logarithmic scale were then used to
define a threshold and divide all events into two classes: those that were assigned a
value less than 11.4 (which roughly corresponds to a day) were classified as short events
and the others were classified as long events. Pan et al. (2011) report a proportion of
agreement between the annotators of 0.877 on the two classes, which corresponds to the
κ-score of 0.75 when taking into account the expected agreement. This agreement can
be considered strong. It confirms that people do have common intuitions on how long
events generally last.
The events which are annotated by Pan et al. (2011) are expressed with different gram-
matical categories, including nouns (such as explosion), adjectives (such as worth), and
others. For testing our model, we select only those events which are expressed with
verbs, that is those instances which are assigned a verb tense value in an additional
layer of annotation, not shown in (6.28). We limit our data set to verbs because the the-
oretical notion of aspect, which we examine in our study, is essentially verbal. Category
changing is known to have considerable influence on certain elements of lexical structure
of words (Grimshaw 1990). Given the place it takes in the lexical representation of verbs
(Ramchand 2008), aspect can be expected to be one of the elements that are affected
by category changing. We thus use only the instances of events which are expressed by
verbs to avoid unnecessary noise in the data.
After eliminating non-verb events from the original Pan et al. (2011)’s corpus, the num-
ber of instances with annotated event duration were reduced to 1’121. We had to further
eliminate a number of these instance because we could only test our model on those verbs
for which we had acquired aspect information from the parallel corpus. Those are the
verbs which occur both in the TimeBank and in the MULTEXT-East corpus and which
are word-aligned with Serbian verbs (see Section 6.3). After eliminating the instances
for which we did not have Serbian alignments, we obtained the definitive set of data
which we used in the experiments, a total of 918 instances.
We follow Pan et al. (2011) in dividing all the events into two classes: short and long.
This decision is based on the fact that the inter-annotator agreement on more fine-
grained distinctions is much weaker than in the case of the binary classification. Pan
et al. (2011) also report agreement based on the overlap between the distributions of
255
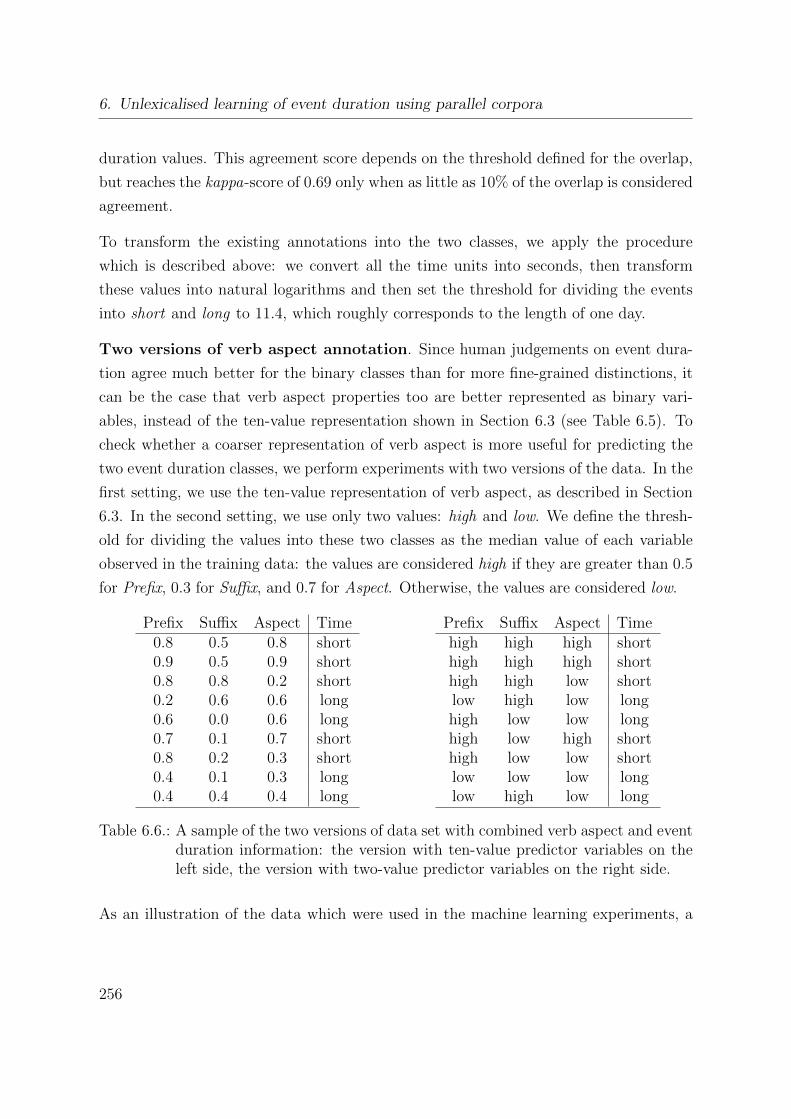
6. Unlexicalised learning of event duration using parallel corpora
duration values. This agreement score depends on the threshold defined for the overlap,
but reaches the kappa-score of 0.69 only when as little as 10% of the overlap is considered
agreement.
To transform the existing annotations into the two classes, we apply the procedure
which is described above: we convert all the time units into seconds, then transform
these values into natural logarithms and then set the threshold for dividing the events
into short and long to 11.4, which roughly corresponds to the length of one day.
Two versions of verb aspect annotation. Since human judgements on event dura-
tion agree much better for the binary classes than for more fine-grained distinctions, it
can be the case that verb aspect properties too are better represented as binary vari-
ables, instead of the ten-value representation shown in Section 6.3 (see Table 6.5). To
check whether a coarser representation of verb aspect is more useful for predicting the
two event duration classes, we perform experiments with two versions of the data. In the
first setting, we use the ten-value representation of verb aspect, as described in Section
6.3. In the second setting, we use only two values: high and low. We define the thresh-
old for dividing the values into these two classes as the median value of each variable
observed in the training data: the values are considered high if they are greater than 0.5
for Prefix, 0.3 for Suffix, and 0.7 for Aspect. Otherwise, the values are considered low.
Prefix Suffix Aspect Time0.8 0.5 0.8 short0.9 0.5 0.9 short0.8 0.8 0.2 short0.2 0.6 0.6 long0.6 0.0 0.6 long0.7 0.1 0.7 short0.8 0.2 0.3 short0.4 0.1 0.3 long0.4 0.4 0.4 long
Prefix Suffix Aspect Timehigh high high shorthigh high high shorthigh high low shortlow high low longhigh low low longhigh low high shorthigh low low shortlow low low longlow high low long
Table 6.6.: A sample of the two versions of data set with combined verb aspect and eventduration information: the version with ten-value predictor variables on theleft side, the version with two-value predictor variables on the right side.
As an illustration of the data which were used in the machine learning experiments, a
256

6.4. Experiment: Learning event duration with a statistical model
sample of instances is shown in Table 6.6. The first three columns of the two panels
contain the two versions of the representation of aspectual properties of English verbs
acquired from the morphological structure of their Serbian counterparts. The fourth
column contains human judgements of whether the events described by the verbs last
less or more than a day.
Comparison with other classifications methods. To assess whether our learning
approach is well-adapted to the kind of predictions that we make in our tests, we perform
the same classification of verbs into “short” and “long” but using different methods. In
all the methods with which we compare our Bayes net classifier, the representation of
aspect is the one described in Section 6.3.
The first classification method which we test is a simple rule-based classifier which does
not use the information about the morphological structure of Serbian verbs, but only
the binary classification into imperfective and perfective verbs. We classify as “short”
all English verbs which tend to be aligned with Serbian perfective verbs (these are the
verbs which are assigned 0.7 or more for the attribute Aspect as described in 6.3). The
other verbs are classified as “long”.
In addition to the Bayes net classifier and the simple rule-based classifier just described,
we train two machine learning algorithms: Decision Tree and Naıve Bayes classifiers.
Both algorithms are described in more detail in Section 3.4.1 in Chapter 3. We choose
these two algorithms because they are known to perform very well on a wide range of
learning tasks, despite their relative simplicity.
It is important to note that these two algorithms use our representation of aspect in
different ways. As discussed in Section 3.4.1, the Naıve Bayes approach is based on
the assumption that all the predictor variables are independent. Contrary to this, the
Bayesian net classifier includes the specific dependencies which we believe to exist in the
reality. This, if the dependencies are correctly identified, can be an advantage for the
Bayesian net classifier.
Another important difference is between Decision Tree on one side and both Bayesian
algorithms on the other. In the setting with the ten-value aspect attributes, values of
the variables are treated as real numbers in the Decision Tree experiments, while they
257

6. Unlexicalised learning of event duration using parallel corpora
Mean accuracy score (%)Ten-value setting Two-value setting
Bayesian Net 83 79Decision Tree 83 79Naıve Bayes 79 76Binary aspect 70 70
Baseline 65 65
Table 6.7.: Results of machine learning experiments with 5-fold cross-validation (roughly80% of data for training and 20% for testing.
are treated as nominal values in both Bayesian experiments. To give an example, the
Decision Tree classifier “knows” that the value 0.8 is greater than 0.4, while Bayesian
classifiers treat these two numbers just as strings representing two different classes. This
difference can turn into an advantage for the Decision Tree classifier, because the true
nature of these values is ordinal.
We run the two classifiers using the packages available in the system Weka (Hall et al.
2009). The performance of all the three classifiers is reported in Table 6.7.
Training and test set, baseline. We evaluate the performance of the classifier on
the data set which consists of 918 instances for which both time annotation and cross-
linguistic data are available (see Section 6.4.2). The data set is split into the training
set (around 80%) and the test set (around 20%) using random choice of instances. To
account for the potential influence of the data split on the observed results, we perform
a five-fold cross-validation.3 In Table 6.7, we report the mean accuracy scores.
The baseline is defined as the proportion of the more common class in the data set.
Since 65% of instances belong to long events, if we assigned this label to all instances,
the accuracy of the classification would be 65%.
258

6.4. Experiment: Learning event duration with a statistical model
Results and discussion
We can see in Table 6.7 that all four classifiers outperform the baseline in both settings.
The Bayesian Net and Decision Tree classifier perform better than Naıve Bayes classifier
(83% vs. 79%. mean accuracy score). This difference is statistically significant, as
determined by the t-test (t = 2.79, p < 0.01). The performance of all the three classifiers
is significantly better in the ten-value setting than in the two-value setting.
The differences in the performance of the four classifiers indicate that all the information
included in the model is useful. First, the simple rule-based classification gives the lowest
results, but still above the baseline. This indicates that there is a certain relationship
between the duration of an event and the perfective vs. imperfective interpretation of
Serbian verb which express it. However, the other methods, which combine the binary
division into perfective and imperfective with the morphological attributes, perform
much better.
The worst performing out of the three machine-learning classifiers is Naıve Bayes which
simplifies most the relationships between the properties, treating them as independent.
The fact that the Bayesian net classifier makes more correct predictions than Naıve
Bayes is likely to be due to the fact that the dependencies specified in the model express
true relationships between the structural elements. The fact that Decision Tree reaches
the same performance as our Bayesian net can be explained by the hierarchical nature
of the decisions taken by this classifier.
Finally, the consistent difference in the performance of all the three classifiers on the two
versions of data indicates that representing aspectual properties with only two values
is an oversimplification which results in more errors in predictions. Verb aspect clearly
cannot be described in terms of a single binary attribute, such as, for example, the
temporal boundedness, which is used in our study. Finer distinctions contain more
information which proves useful for predicting event duration.
3In five-fold cross validation, the data set is split in five portions. Each time the classifier is run oneportion is taken as the test set and all the other portions serve as the training test. The classifier isrun five time, once for each test set.
259

6. Unlexicalised learning of event duration using parallel corpora
6.5. General discussion
The results of the experiments can be interpreted in the light of several questions which
have been examined in our study. First of all, they clearly show that natural language
does encode those temporal properties of events about which people have common in-
tuitions and which are relevant for the representation of real world. The 83% accuracy
in predictions realised by the two best classifiers is much closer to the upper bound
of the performance on this task (the proportion of inter-annotator agreement of 0.877
measured by Pan et al. (2011) would correspond to an accuracy score of 87.7%) than
to the baseline (65%). This shows that the relevance of the linguistic encoding can be
learned and exploited by the systems for automatic identification of event duration.
Using Serbian language data to classify events expressed in English is based on the
assumption that verb aspect is an element of general structure of language and that
it has the same role in the languages where it is morphologically encoded as in the
languages which do not exhibit it in their observable morphological structure. This
assumption underlies all general linguistic accounts of verb aspect which we have taken
into consideration in our study. Successful transfer of the representation of aspect from
Serbian to English can be interpreted as a piece of empirical evidence in favour of this
assumption.
6.5.1. Aspectual classes
A careful analysis of the linguistic structure, guided by established theoretical notions,
proves useful in identifying the elements of the linguistic structure which are relevant
for temporal encoding. The temporal meaning of Serbian verb morphemes, which is
exploited by the systems in our experiments, becomes clear only in the context of the
general theory of verb aspect. The morphemes themselves are ambiguous and do not
constitute a temporal paradigm. However, the frequency distribution of the morphemes
in the cross-linguistic realisations of verbs clearly depends on the temporal properties
of the events described by the verbs and it does provide an observable indicator of the
temporal meaning of verbs.
260

6.5. General discussion
The results of the experiments suggest that the three-attribute representation of aspect
which we propose, captures the relationships between the structural elements in Serbian
verbs which are relevant for time encoding. The simple binary classification is clearly
not an adequate level of aspectual classification. However, the set of ten values which
we have used, is not necessarily the best representation either. Our decision to group
the values into ten classes is arbitrary. It is possible that the classifiers do not use all
the ten values and that some of them are more informative than others. A systematic
approach to identifying the best representation of aspectual properties of verbs could help
identifying the elements of the lexical representation which interact with the temporal
boundedness in a systematic way to form fully specified aspectual classes. This would
improve our understanding of what kinds of aspectual classes exist and what kinds of
meaning they express.
6.5.2. Relevance of the findings to natural language processing
Our results indicate that the kind of information elicited from human judges in anno-
tating event duration is represented mostly at the word level in the linguistic structure.
The event duration annotation which is used in our experiments is instance-based. The
annotators could assign different classes to different instances of the same verb form,
depending on the context of the form in a particular instance. This was not possible
in our approach to verb aspect. In order to transfer the acquired information from the
parallel corpus to the corpus which contains event annotation, we separated the aspect
representation from the context and tied it to verb types, assigning the same values to all
instances of the same type. The automatic classifiers were able to learn the relationship
between the two annotations despite this simplification, which indicates that the human
annotations were more influenced by the lexical properties of verbs than by the con-
text. This information could be useful in designing future approaches to identification
of temporal properties in natural language.
It should be noted that, even though we work with the representations at the word level,
our model is unlexicalised. We do not use the information contained in the idiosyncratic
lexical meaning of verbs, but more general elements of the representation shared by
different lexical items. As a consequence, a relatively small size of the training corpus
261

6. Unlexicalised learning of event duration using parallel corpora
needed for learning both the empirical representation of verb aspect and its relation to
event duration. However, the word-level representation is, at the same time, a limitation
of our approach. Not all the information about event duration can be found at the
word level. A full model of linguistic encoding of time will have to take into account
observations at the higher levels of the structure of language too.
6.6. Related work
Pan et al. (2011) use the corpus described in Section 6.4.2 to perform machine learning
experiments. They define a set of features representing event instances which are used to
learn a classification of the events into short and long (see Section 6.4.2). The features
used in the event instance representation are: the lexical item which expresses the event,
its part-of-speech tag and lemma, the same information for the words in the immediate
context of the event item (in the window of size four), some syntactic dependencies of
the event item (such as its direct object, for example), and the WordNet (Fellbaum
1998) hypernyms of the event item. The classification is learned using three different
supervised algorithms: Decision Tree, Naıve Bayes, and Support Vector Machines. The
best performance is obtained by Support Vector Machines on the class of long events,
with an F-score of 0.82. Although the overall performance is not reported, it can be
expected to be lower than this score, given that the performance on the short events is
measured as an F-score of 0.65 (weighted average of the two scores is 0.75).
Our results are not directly comparable with the results of Pan et al. (2011). Our best
accuracy score corresponds to an overall F-score of 0.83 on both kinds of events, but
we do not use exactly the same training and test set. Since we have selected only the
instances of events expressed by verbs, we use only a portion of Pan et al. (2011)’s data
both for training and testing. Although we obtain a better score with a smaller data
set, we do not know what exactly causes the difference. A more thorough comparison
would be necessary to determine whether the task is easier on the instances which we
selected. This would justify our decision and underline the need for a different approach
to categories other than verbs. Otherwise, our approach could be judged as better, but
it should be extended to other categories.
262

6.6. Related work
Gusev et al. (2011) use predefined word patterns as indicators of event duration. One
of the patterns used, for example, is Past Tense + yesterday. If an event expressing
item shows a tendency to occur with this pattern, it can be taken to express a short
event in the sense of Pan et al. (2011). The occurrence data are extracted from the web
using the Yahoo! search engine. Gusev et al. (2011) train learning algorithms on the
instances where the event duration annotation is replaced by the pattern definitions. A
maximum entropy algorithm performs better than Support Vector Machines reaching
the best performance of 74.8%, which is not significantly different from the performance
on the hand annotated data set. Gusev et al. (2011) also try learning finer-grained
classes, but the accuracy scores are much lower (below 70%).
Feature analysis by both Pan et al. (2011) and Gusev et al. (2011) indicates that enrich-
ing the models with context information brings little or no improvement in the results,
which is in agreement with our own findings.
Williams and Katz (2012) explore other word patterns which indicate event duration for
classifying events into habitual and episodic. The data are extracted from a corpus of
Twitter messages and classified using a semi-supervised approach. The study suggests
that most verbs are used in both senses and proposes a lexicon of mean duration of
episodes and habits expressed by a set of verbs. These temporal quantifications, however,
are not directly evaluated against human judgments.
The work on verb aspect is mostly concerned with using elements of the context to
detect certain aspectual classes. The work of Siegel and McKeown (2000), for example,
addresses the aspectual classes proposed by Moens and Steedman (1988), showing, by
means of a regression analysis, that the context indicators which distinguish between
dynamic and stative events are different from the indicators which distinguish between
culminated and nonculminated events (the notion of a culminated event roughly cor-
responds to the notion of a temporally bounded event discussed in our study). Siegel
and McKeown (2000) also show that it is harder to distinguish between culminated and
non-culminated than between static and dynamic events. Kozareva and Hovy (2011)
propose a semi-supervised method for extracting word patterns correlated with a set
of aspectual classes, but their classes do not make reference to the classes discussed by
Siegel and McKeown (2000) nor to other classes argued for in the linguistic theory.
263

6. Unlexicalised learning of event duration using parallel corpora
A possibility of cross-linguistic transfer of verb aspect through parallel corpora is ex-
plored by Stambolieva (2011), but the study is not conducted in the experimental frame-
work and does not report on automatic data processing.
6.7. Summary of contributions
In this study, we have explored the relationship between verb aspect, as an element
of the grammar of natural language, and the more general cognitive notion of event
duration. We have shown that this relationship can be explicitly formulated in terms
of a probabilistic model which predicts the duration of an event on the basis of the
aspectual representation of the verb which is used to express it. With the accuracy of
83%, the model’s predictions can be considered successful. The model’s accuracy score is
much closer to the upper bound, defined as the agreement between human classification
(88%), than to the baseline, defined as the proportion of the most frequent class (65%).
For the purpose of our experimental study, we have developed a quantitative represen-
tation of verb aspect which is based on the distribution of morphosyntactic realisations
of Serbian verbs in parallel English-Serbian instances of verbs. Contrary to other ap-
proaches to automatic identification of event duration, which have explored the observ-
able indicators at the syntactic and at the discourse level of linguistic structure, we have
identified observable indicators of event duration at the word level. We have shown that
a good proportion of temporal information which is implicitly understood in language
use is, in fact, contained in the grammar of lexical derivation of verbs in Serbian. This
information can be automatically acquired and ported across languages using parallel
corpora. The accuracy of the prediction based on our bi-lingual model is superior to the
best performing monolingual model.
264

7. Conclusion
In this dissertation, we have proposed a computational method for identifying gram-
matically relevant components of the meaning of verbs by observing the variation in
samples of verbs’ instances in parallel corpora. The core of our proposal is a formalisa-
tion of the relationship between the meaning of verbs and the variation, cross-linguistic
as well as language-internal, in their morphosyntactic realisations. We have used stan-
dard and Bayesian inferential statistics to provide empirical evidence of a number of
semantic components of the lexical representation of verbs which are grammatically rel-
evant because they play a role in the verbs’ predicate-argument structure. In particular,
we have shown that frequency distributions of morphosyntactic alternants in argument
alternations depend on the properties of events described by the alternating verbs.
Identifying grammatically relevant components of the meaning of verbs is one of the
core issues in linguistic theory due to the evident relationship between the meaning of
verbs and the structure of the clauses that they form. In order to understand how
basic clauses are structured, one needs to account for the differences in the number of
constituents which are realised. Such an account involves explaining why some clauses
are intransitive, some are transitive, and some are ditransitive. The explanation leads
to the lexical properties of the main verb which heads a clause. Intransitive clauses
are typically formed with the verbs such as go, swim, cough, laugh. Transitive clauses
are formed with verbs such as make, break, see. Ditransitive clauses are formed with
verbs such as give, tell. However, one needs to take into account also the fact that
one verb is rarely associated with only one type of a clause. It is much more often the
case that the same verb is associated with alternating clausal structures. For example,
the verb break can be realised in both a transitive clause (e.g. Adam broke the laptop)
and in a semantically related intransitive clause (e.g. The laptop broke). Alternative
265

7. Conclusion
morphosyntactic realisations of semantically equivalent units are not only found within
a single language, but also across languages. Although associating the meaning of verbs
with the types of clauses which they form is necessary for formulating the rules of clausal
structure, defining precise rules to link the elements of a phrase structure to the elements
of the lexical representation of verbs proves to be a challenging task.
The work on the interface between the lexicon and the rules of grammar has resulted
in numerous proposals regarding the grammatically relevant elements of the lexical rep-
resentation of verbs. It is widely accepted that the meaning of a verb is related to the
grammar of a clause through a layer in the lexical representation of verbs which is usu-
ally called the predicate-arguments structure. However, the views of what exactly the
elements of the predicate-argument structure are differ very much.
The nature of the predicate-argument relations in the representation of the meaning
of verbs has been described in various frameworks, starting with the naıve analyses of
semantic roles of verbs’ arguments (Fillmore 1968; Baker et al. 1998) to more general
approaches based on semantic decomposition of the predicate-argument relations. Sev-
eral attributes of the meaning of verbs have been proposed as relevant for the predicate
arguments structure. It has been argued, for example, that these attributes include vo-
lition (Dowty 1991) or, more generally, mental state (Reinhart 2002), change (Dowty
1991; Reinhart 2002; Levin and Rappaport Hovav 1994), causation (Talmy 2000;
Levin and Rappaport Hovav 1994). The fact that the morphosyntactic realisations of
verbs are influenced by the values of these attributes makes these semantic components
grammatically relevant (Pesetsky 1995; Levin and Rappaport Hovav 2005). For exam-
ple, a verb can be expected to form intransitive clauses if it describes an event which
does not involve somebody’s volition. The attributes can interact between themselves
and also with other factors, which results in a complex relationship between the lexical
representation of verbs and the structure of a clause.
In more recent accounts, the components of the predicate-argument structure have been
reinterpreted in terms of temporal decomposition of events described by verbs (Krifka
1998; Ramchand 2008; Arsenijevic 2006). The notion of causation, for example, is iden-
tified with the notion of temporal precedence, while the notion of change is reanalysed
as a result. The structural elements proposed in the temporal account of the predicate-
266

7.1. Theoretical contribution
argument relations are usually called sub-events. The defined relations hold between the
sub-events.
We have proposed an empirical statistical method to test theoretical proposals regarding
the relationship between the lexical structure of verbs and the structure of a clause on
a large scale. Following the influential study on large-scale semantic classification of
verbs (Levin 1993), we have based our approach on the assumption that the meaning
of a verb determines the syntactic variation in the structure of the clauses that it forms
and that, therefore, the grammatically relevant components of the meaning of a verb
can be identified by observing the variation in its syntactic behaviour. The validity
of this general assumption has already been tested in the context of automatic verb
classification (Merlo and Stevenson 2001). In this dissertation, we have formulated
and tested experimentally a number of specific hypotheses showing that the frequency
distribution of syntactic alternants in the morphosyntactic realisations of verbs can be
predicted from some particular properties of the meaning of verbs. We have applied our
approach to two general properties of events which have been widely discussed in the
recent literature: causation and temporal structure. The contribution of our work with
respect to the existing work is both theoretical and methodological.
7.1. Theoretical contribution
With respect to previous theoretical approaches to the predicate-argument structure
of verbs, the main novelty of our work is the demonstrated grammatical relevance of
certain attributes of the meaning of verbs. Using statistical inference, we have formalised
the relationship between the meaning of verbs, their use, represented by the frequency
distribution of their instances in a corpus, and their formal properties (such as causative
or aspectual marking), showing how the three sources of data can be combined in a
unified account of the interface between the lexicon and the grammar.
In an analysis of the relationship between the kind of causation and the variation in mor-
phosyntactic realisations of light verb constructions, we have found empirical evidence of
the presence of two force-dynamics schemata in light verbs. The meaning of light verbs
such as take can be described as self-oriented (Talmy 2000; Brugman 2001) because the
267

7. Conclusion
dynamics of the event is oriented towards its causer (or agent). As opposed to this, the
meaning of light verbs such as make can be described as directed because the dynamics
of the event is not oriented towards the causer, but towards another participant in the
event. Our experiments have shown that the frequency distribution of cross-linguistic
morphosyntactic alternants of light verbs depend on their force-dynamics schemata.
In an analysis of cross-linguistic morphosyntactic realisations of lexical causatives, we
have taken a closer look into the notion of external causation (Haspelmath 1993; Levin
and Rappaport Hovav 1994; Alexiadou 2010). We have argued, based on the results of
a series of experiments, that the likelihood of an external causer in an event described
by a verb is a semantic property which underlies two correlated frequency distributions:
the distribution of morphological marking on lexical causatives across a wide range of
languages and the distribution of clause types in a sample of verb instances in any single
language. The contribution of this piece of work is twofold. First, we have shown that
there is a relationship between a semantic attribute of lexical causatives and their mor-
phosyntactic form. Specifically, the observed variation in the cross-linguistic realisations
of a verb depends on the likelihood of external causation of the event described by the
verb. Second, we have shown that the likelihood of external causation can be estimated
for a wide range of verbs by means of a statistical model.
The temporal structure of events is analysed in the third case study. The main contri-
bution of this study is the established relationship between formal aspectual marking on
a verb and the duration of the event described by the verb. More specifically, we have
designed a statistical model which predicts the duration of an event described by an
English verb on the basis of the observed frequency distribution of formal morphosyn-
tactic aspectual markers in the aligned Serbian verbs. In an experimental evaluation,
the model is shown to make better predictions than the best performing monolingual
model.
We have developed corpus-based measures of the values of the three semantic attributes
of verbs which we have studied. These values are calculated automatically and they can
be assigned to a large number of verbs.
268

7.2. Methodological contribution
7.2. Methodological contribution
The main methodological contribution of this dissertation is that it combines theoretical
linguistic goals with the sound modelling and experimental methodology developed in
computational linguistics. The methodology which we have used in this dissertation is
not new in itself, but its application to testing theoretical hypotheses is novel in three
ways.
First, while frequency distributions of syntactic realisations of verbs have been exten-
sively studied and used in the context of developing practical applications in the domain
of automatic natural language processing, this kind of evidence is not commonly used
in theoretical linguistics. In our experiments, we have demonstrated that a statistical
analysis of a large number of verb instances can be used to study structural components
in the lexical representation of verbs. We have quantified and measured the semantic
phenomena which we have studied using the methods and the techniques developed in
natural language processing. We have used statistical models and tests to capture the
generalisations in large data sets. We have estimated the parameters of the models by
applying machine learning techniques. We have tested and explicitly evaluated the pre-
dictions of the models. These methods constitute the standard experimental paradigm
in computational linguistics. In this dissertation, we have shown that their application
to addressing theoretical questions can lead to extending our knowledge about language.
Combining various sources of data in a large-scale analysis can shed some new light on
the nature of the interface between the lexicon and the grammar, which involves complex
interactions of multiple factors.
Second, the data sets which are used in the standard linguistic approaches are usually
much smaller than those which are used in our experiments. The methodological ad-
vantage of large data sets is that they are more likely to be representative of linguistic
phenomena than small samples which are manually analysed. By using computer-based
language technology, we can now observe the variation in the use of linguistic units
on a large scale, applying inductive reasoning in defining generalisations. In this dis-
sertation, we have shown how the tools and resources developed in natural language
processing can be used to compose large experimental data sets for theoretical linguistic
research. We have used existing parallel corpora, an automatic alignment tool, syntactic
269

7. Conclusion
parsers, morphological analysers, as well as our own scripts for automatic extraction of
the experimental data from parallel corpora. With the rapidly developing language tech-
nology, such resources can be expected to grow and to be increasingly available in the
future. The data and the tools accumulated in developing language technology represent
extremely rich new resource for future linguistic research.
Third, we have extended the corpus-based quantitative approach to linguistic analysis to
the cross-linguistic domain. This is a necessary step for formulating generalisations which
hold across languages. We have achieved this by collecting data from parallel corpora.
We have shown that parallel corpora represent a valuable source of information for a
systematic study of the structural sources of cross-linguistic microvariation, despite the
fact that the observed variation can be influenced by some non-linguistic factors (such
as translators’ choice) as well.
7.3. Directions for future work
We define the directions for continuing the work presented in this dissertation in two
ways. On the one hand, our approach can be extended to include more languages and
to more complex modelling. On the other hand, our findings have opened new questions
which could be pursued further in future work.
Although our approach is cross-linguistic in the sense that we analyse the data from at
least two languages in all our experiments, our data come from only a few languages: En-
glish, German, and Serbian. We have used only a small sample of languages because the
focus of our work has been on developing and testing the methodology of cross-linguistic
corpus-based linguistic research. Applying the methods proposed in this dissertation to
a larger sample of languages is a natural next step in future research.
Increasing the number of languages included in an analysis would enrich the data sets not
only because more instances of linguistic phenomena would be analysed, but also because
more linguistic information can be automatically extracted. For example, morphological
marking, which is often not available in English, can be extracted from other languages.
Although we have not used morphological marking in a systematic way, the results
270

7.3. Directions for future work
of our experiments suggest that it can be a valuable source of information to study
various elements of the grammar of language, which is in accordance with some recent
broad typological studies (Bickel et al. 2013; To appear). Parallel corpora of numerous
languages already exist (for example, the current version of the corpus Europarl contains
21 languages) and they are constantly growing.
Since statistical modelling has not been widely used in theoretical linguistic research so
far, the focus of this dissertation has been on demonstrating how statistical inference
can be used to address theoretical issues. To this end, we have formulated relatively
narrow theoretical questions which could have been addressed using simple statistical
and computational approaches. This allowed us to establish a straightforward relation-
ship between theoretical notions which we studied and the components of the models.
However, our approach can be extended to more general questions involving more fac-
tors. This can be done by applying more advanced modelling approaches such as those
which are currently being proposed in computational linguistics and in other disciplines
dealing with large-scale data analysis.
By analysing the data in our experiments, we have noticed several phenomena which
call for further investigation, but which we could not address directly because this work
would fall out of the scope of the dissertation. Such a phenomenon is, for example,
the fact that nouns are aligned better than verbs in automatic alignment in general.
It would be worth exploring in future work whether this fact can be related to some
known distributional differences between these two classes or not. It might also mean
that nominal lexical items are more stable across languages than verbal ones.
Another phenomenon which would be worth exploring in future research became evident
while we were studying the data on lexical causatives. We have noticed that the quantity
of anticausative morphological marking varies in European languages. The number of
lexical causatives which are attached a reflexive particle in the citation form, such as
sich offnen ’open’ in German, varies across European languages. There are, for example,
many more such verbs in Serbian than in German, while there are almost none in English.
Possible explanation for this variation is the difference in the morphological richness
between the three languages, given that Serbian is usually considered morphologically
richer than German, and German richer than English. Based on our results, this marking
271

7. Conclusion
could be expected to be related to the likelihood of external causation too. The verbs
which describe an event with a low likelihood of an external causer are expected to occur
without a marker more than the verbs describing an event with a high likelihood of an
external causer. The morphological markings should, thus, be distributed in a continuous
fashion over the scale of likelihood of external causation, covering different portions of
the scale in different languages. Addressing these relations directly in an experiment
might result in new findings pointing to some structural constraints on cross-linguistic
variation.
Finally, in the study of temporal properties of the meaning of verbs, we have proposed
a quantitative representation of verb aspect classes based on frequency distribution of
morphological marking in Serbian verbs. This representation proved useful for the goals
of our experiments. However, we have not fully examined the theoretical aspects of our
proposal. What remains as an open question for future research is the source of the
quantities which have been observed in our experiments as the values of the aspectual
attributes. Exploring this question further could point to new findings on how mor-
phological marking patterns can be used for determining which aspectual classes exist
in language and what their meaning is. This should provide a clearer picture of the
semantic representation of time in language in general.
272

Bibliography
Steven Abney. Data-intensive experimental linguistics. Linguistic Issues in Language
Technology — LiLT, 6(2):1–30, 2011.
Enoch Olade Aboh. Clause structure and verb series. Linguistic Inquiry, 40(1):1–33,
2009.
Artemis Alexiadou. On (anti-)causative alternations, 2006a. Presentation, Ecole
d’automne de linguistique, Paris.
Artemis Alexiadou. On the morpho-syntax of (anti-)causative verbs. In Malka Rappa-
port Hovav, Edit Doron, and Ivy Sichel, editors, Syntax, Lexical Semantics and Event
Structure, pages 177–203, Oxford, 2010. Oxford University Press.
Artemis Alexiadou, Elena Anagnostopoulou, and Florian Schafer. The properties of
anticausatives crosslinguistically. In Mara Frascarelli, editor, Phases of Interpretation,
pages 187–212, Berlin, New York, 2006. Mouton de Gruyter.
Alex Alsina. A theory of complex predicates: evidence from causatives in Bantu and
Romance. In Alex Alsina, Joan Bresnan, and Peter Sells, editors, Complex predicates,
pages 203–247, Stanford, California, 1997. CSLI Publications.
Boban Arsenijevic. Inner aspect and telicity: The decompositional and the quantifica-
tional nature of eventualities at the syntax-semantics interface. LOT, Utrecht, 2006.
Boban Arsenijevic. Slavic verb prefixes are resultative. Cahiers Chronos, 17:197–213,
2007.
Harald Baayen. Analyzing Linguistic Data. A Practical Introduction to Statistics using
R. Cambridge University Press, Cambridge, 2008.
273

Bibliography
Collin F. Baker, Charles J. Fillmore, and John B. Lowe. The berkeley framenet project.
In Proceedings of the 36th Annual Meeting of the Association for Computational Lin-
guistics and 17th International Conference on Computational Linguistics, pages 86–90,
Montreal, Canada, 1998. ACL / Morgan Kaufmann Publishers.
Mark Baker. Thematic roles and syntactic structure. In Liliane Haegeman, editor,
Elements of Grammar, pages 73–137, Dordrecht, 1997. Kluwer.
Mark C. Baker. Incorporation — A Theory of Grammatical Function Changing. The
University of Chicago Press, Chicago, London, 1988.
Mark C. Baker. The atoms of language. Basic Books, New York, 2001.
Marco Baroni and Silvia Bernardini. A new approach to the study of translationese:
Machine-learning the difference between original and translated text. Literary and
Linguistic Computing, 21(3):259–274, 2006.
Marco Baroni and Alessandro Lenci. Distributional memory: A general framework for
corpus-based semantics. Computational Linguistics, 36(4):673–722, 2010.
John Beavers. Argument/Oblique Alternations and the Structure of Lexical Meaning.
PhD thesis, Stanford University, 2006.
Douglas Biber. Variation across Speech and Writing. Cambridge University Press,
Cambridge, 1991.
Theresa Biberauer, editor. The Limits of Syntactic Variation, Amsterdam, 2008. John
Benjamins.
Balthasar Bickel, Giorgio Iemmolo, Taras Zakharko, and Alena Witzlack-Makarevich.
Patterns of alignment in verb agreement. In Dik Bakker and Martin Haspelmath,
editors, Languages across boundaries: studies in the memory of Anna Siewierska,
pages 15–36. De Gruyter Mouton, Berlin, 2013.
Balthasar Bickel, Taras Zakharko, Lennart Bierkandt, and Alena Witzlack-Makarevich.
Semantic role clustering: an empirical assessments of semantic role types in non-
default case assignment, To appear.
274

Bibliography
Claire. Bonial, William. Corvey, Martha. Palmer, Volha V. Petukhova, and Harry Bunt.
A hierarchical unification of lirics and verbnet semantic roles. In Semantic Computing
(ICSC), 2011 Fifth IEEE International Conference on, pages 483–489, Sept 2011. doi:
10.1109/ICSC.2011.57.
Gerlof Bouma, Lilja Øvrelid, and Jonas Kuhn. Towards a large parallel corpus of cleft
constructions. In Proceedings of the Seventh conference on International Language
Resources and Evaluation (LREC’10), Valletta, Malta, 2010. European Language Re-
sources Association.
Melissa Bowerman and William Croft. The acquisition of the English causative alterna-
tion. In Melissa Bowerman and Penelope Brown, editors, Crosslinguistic perspectives
on argument structure: Implications for learnability, pages 279–306, New York, NY,
2008. Lawrence Erlbaum Associates.
Michael R. Brent. From grammar to lexicon: Unsupervised learning of lexical syntax.
Computational Linguistics, 19(3):243–262, 1993.
Joan Bresnan. Is syntactic knowledge probabilistic? Experiments with the English dative
alternation. In Sam Featherston and Wolfgang Sternefeld, editors, Roots: Linguistics
in Search of Its Evidential Base, Studies in Generative Grammar, pages 77–96, Berlin,
2007. Mouton de Gruyter.
Joan Bresnan and Tatiana Nikitina. The gradience of the dative alternation. In Linda
Uyechi and Lian Hee Wee, editors, Reality Exploration and Discovery: Pattern Inter-
action in Language and Life, pages 161–184, Stanford, 2009. CSLI Publications.
Ted Briscoe and John Carroll. Automatic extraction of subcategorization from corpora.
In Proceedings of the 5th ACL Conference on Applied Natural Language Processing,
pages 356–363, 1997.
Peter F. Brown, Stephen A. Della-Pietra, Vincent J. Della-Pietra, and Robert L. Mercer.
The mathematics of statistical machine translation. Computational Linguistics, 19(2):
263–313, 1993.
Claudia Brugman. Light verbs and polysemy. Language Science, 23:551–578, 2001.
275

Bibliography
Aljoscha Burchardt, Katrin Erk, Anette Frank, Andrea Kowalski, Sebastian Pado, and
Manfred Pinkal. Using frameNet for the semantic analysis of German: Annotation,
representation and automation. In Hans Boas, editor, Multilingual FrameNets in
computational lexicography, pages 209–244. Mouton de Guyter, 2009.
Lou Burnard. Reference guide for the British National Corpus (XML edition), 2007.
URL http://www.natcorp.ox.ac.uk/XMLedition/URG/.
Miriam Butt and Wilhelm Geuder. On the (semi)lexical status of light verbs. In Norbert
Corver and Henk van Riemsdijk, editors, Semilexical Categories: On the content of
function words and the function of content words, pages 323–370, Berlin, 2001. Mouton
de Gruyter.
Xavier Carreras and Lluis Marquez. Introduction to the CoNLL-2005 shared task: Se-
mantic role labeling. In Proceedings of the 9th conference on computational natural
language learning (CONLL), pages 152–164, Ann Arbor, 2005. Association for com-
putational linguistics.
Noam Chomsky. Remarks on nominalization. In Roderick Jacobs and Peter Rosen-
baum, editors, Readings in English Transformational Grammar, Waltham, MA, 1970.
Blaisdell.
Noam Chomsky. Knowledge of language: its nature, origin and use. Praeger, New York,
1986.
Noam Chomsky. The minimalist program. MIT Press, Cambridge, Massachusetts, 1995.
Kenneth W. Church and Patrick Hanks. Word association norms, mutual information,
and lexicography. Computational Linguistics, 16(1):22–29, 1990.
Trevor Cohn and Mirella Lapata. Machine translation by triangulation: Making effec-
tive use of multi-parallel corpora. In Proceedings of the 45th Annual Meeting of the
Association of Computational Linguistics, pages 728–735, Prague, Czech Republic,
June 2007. Association for Computational Linguistics.
Chris Collins. Argument sharing in serial verb constructions. Linguistic Inquiry, 28:
461–497, 1997.
276

Bibliography
Michael Collins, Philipp Koehn, and Ivona Kucerova. Clause restructuring for statistical
machine translation. In Proceedings of the Annual Meeting of the Association for
Computational Linguistics (ACL), pages 531–540, Ann Arbor, 2005. Association for
Computational Linguistics.
Michael Cysouw and Bernhard Walchli, editors. Parallel Texts. Using Translational
Equivalents in Linguistic Typology, volume Theme issue in Sprachtypologie und Uni-
versalienforschung (STUF) 60(2), 2007. Akademie Verlag GMBH.
David Dowty. Thematic proto-roles and argument selection. Language, 67(3):547–619,
1991.
David R Dowty. Word meaning and Montague grammar: the semantics of verbs and
times in generative semantics and in Montague’s PTQ. D. Reidel, cop., Dordrecht,
Boston, 1979.
David R. Dowty. The effects of aspectual class on the temporal structure of discourse:
semantics or pragmatics. Linguistics and Philosophy, 9:37–61, 1986.
Tomaz Erjavec. MULTEXT-East version 4: Multilingual morphosyntactic specifications,
lexicons and corpora. In Nicoletta Calzolari (Conference Chair), Khalid Choukri,
Bente Maegaard, Joseph Mariani, Jan Odijk, Stelios Piperidis, Mike Rosner, and
Daniel Tapias, editors, Proceedings of the Seventh conference on International Lan-
guage Resources and Evaluation (LREC’10), pages 2544–2547, Valletta, Malta, 2010.
European Language Resources Association (ELRA).
Afsaneh Fazly. Automatic acquisition of lexical knowledge about multiword predicates.
PhD thesis, University of Toronto, 2007.
Christiane Fellbaum, editor. WordNet: An Electronic Lexical Database. MIT Press,
Cambridge, Mass., 1998.
Charles Fillmore. The case for case. In Emmon Bach and Robert T. Harms, editors,
Universals in linguistic theory, pages 1–88, New York, 1968. Holt, Rinehart and Win-
ston.
277

Bibliography
Charles J. Fillmore. Frame semantics. In Linguistics in the Morning Calm, pages 111–
137, Seoul, 1982. Hanshin Publishing Co.
Pascale Fung, Zhaojun Wu, Yongsheng Yang, and Dekai Wu. Learning bilingual semantic
frames: Shallow semantic parsing vs. semantic role projection. In 11th Conference on
Theoretical and Methodological Issues in Machine Translation (TMI 2007), pages 75–
84, Skovde, Sweden, 2007.
Nikhil Garg and James Henderson. Unsupervised semantic role induction with global
role ordering. In Proceedings of the 50th Annual Meeting of the Association for Com-
putational Linguistics (Volume 2: Short Papers), pages 145–149, Jeju Island, Korea,
July 2012. Association for Computational Linguistics. URL http://www.aclweb.
org/anthology/P12-2029.
Matthew Gerber and Joyce Y. Chai. Semantic role labeling of implicit arguments for
nominal predicates. Computational Linguistics, 38(4):755–798, 2012.
Daniel Gildea and Daniel Jurafsky. Automatic labeling of semantic roles. Computational
Linguistics, 28(3):245–288, 2002.
Gregory Grefenstette and Simone Teufel. Corpus-based method for automatic identifi-
cation of support verbs for nominalization. In Proceedings of the 7th Meeting of the
European Chapter of the Association for Computational Linguistics, pages 98–103,
Dublin, Irland, 1995. Association for Computational Linguistics.
H. Paul Grice. Logic and conversation. In Peter Cole and Jerry L. Morgan, editors,
Syntax and Semantics 3: Speech Acts, pages 41–58, New York, 1975. Academic Press.
Jane Grimshaw. Argument Structure. MIT Press, Cambridge, Mass., 1990.
Jane Grimshaw and Armin Mester. Light verbs and theta-marking. Linguistic Inquiry,
19:205–232, 1988.
Andrey Gusev, Nathaniel Chambers, Pranav Khaitan, Divye Khilnani, Steven Bethard,
and Dan Jurafsky. Using query patterns to learn the durations of events. In IEEE
IWCS-2011, 9th International Conference on Web Service, pages 145–155, Oxford,
UK, 2011. Institute of Electrical and Electronics Engineers (IEEE ).
278

Bibliography
Jan Hajic, Massimiliano Ciaramita, Richard Johansson, Daisuke Kawahara,
Maria Antonia Martı, Lluıs Marquez, Adam Meyers, Joakim Nivre, Sebastian Pado,
Jan Stepanek, Pavel Stranak, Mihai Surdeanu, Nianwen Xue, and Yi Zhang. The
CoNLL-2009 shared task: Syntactic and semantic dependencies in multiple languages.
In Proceedings of the Thirteenth Conference on Computational Natural Language
Learning (CoNLL 2009): Shared Task, pages 1–18, Boulder, Colorado, June 2009.
Association for Computational Linguistics.
Kenneth Hale and Samuel Jay Keyser. On argument structure and the lexical represen-
tation of syntactic relations. In Kenneth Hale and Samuel Jay Keyser, editors, The
View from Building 20, pages 53–110. MIT Press, 1993.
Mark Hall, Eibe Frank, Geoffrey Holmes, Bernhard Pfahringer, Peter Reutemann, and
Ian H. Witten. The WEKA data mining software: An update. SIGKDD Explorations,
11(1), 2009.
Martin Haspelmath. More on typology of inchoative/causative verb alternations. In
Bernard Comrie and Maria Polinsky, editors, Causatives and transitivity, volume 23,
pages 87–121, Amsterdam/Philadelphia, 1993. John Benjamins Publishing Co.
John A. Hawkins. A comparative typology of English and German : unifying the con-
trasts. Croom Helm, London ; Sydney, 1986.
James Henderson, Paola Merlo, Gabriele Musillo, and Ivan Titov. A latent variable
model of synchronous parsing for syntactic and semantic dependencies. In Alex Clark
and Kristina Toutanova, editors, Proceedings of the Twelfth Conference on Compu-
tational Natural Language Learning (CONLL 2008), page 178–182, Manchester, UK,
2008.
Rebecca Hwa, Philip Resnik, Amy Weinberg, and Okan Kolak. Evaluation translational
correspondance using annotation projection. In Proceedings of the 40th Annual Meet-
ing of the Association for Computational Linguistics, pages 392–399, Philadelphia,
PA, 2002. Association for Computational Linguistics.
Jena D. Hwang, Archna Bhatia, Claire Bonial, Aous Mansouri, Ashwini Vaidya, Ni-
anwen Xue, and Martha Palmer. PropBank annotation of multilingual light verb
279

Bibliography
constructions. In Proceedings of the Fourth Linguistic Annotation Workshop, pages
82–90, Uppsala, Sweden, July 2010. Association for Computational Linguistics.
Ray Jackendoff. X syntax : a study of phrase structure. MIT Press, Cambridge Mass.,
1977.
Eric Joanis and Suzanne Stevenson. A general feature space for automatic verb clas-
sification. In Proceedings of The 10th Conference of the European Chapter of the
Association for Computational Linguistics (EACL 2003), pages 163–170, Budapest,
Hungary, 2003. Association for Computational Linguistics.
Eric Joanis, Suzanne Stevenson, and David James. A general feature space for automatic
verb classification. Natural Language Engineering, 14(3):337–367, 2008.
Richard Kayne. The Oxford Handbook of Comparative Syntax, chapter Some notes on
comparative syntax, with special reference to English and French. Oxford University
Press, 2005.
Kate Kearns. Light verbs in english. Manuscript, 2002.
Karin Kipper Schuler. VerbNet: A broad-coverage, comprehensive verb lexicon. PhD
thesis, University of Pennsylvania, 2005.
Dan Klein. The unsupervised learning of natural language structure. PhD thesis, Stanford
University, 2005.
Philipp Koehn. Europarl: A parallel corpus for statistical machine translation. In
Proceedings of MT Summit 2005, Phuket, Thailand, 2005.
Zornitsa Kozareva and Eduard Hovy. Learning temporal information for states and
events. In Proceedings of the Workshop on Semantic Annotation for Computational
Linguistic Resources (ICSC 2011), Stanford, 2011.
Manfred Krifka. The origins of telicity. In Susan Rothstein, editor, Events and Grammar,
pages 197–235, Dordrecht, 1998. Kluwer.
280

Bibliography
Cvetana Krstev, Dusko Vitas, and Tomaz Erjavec. MULTEXT-East resources for Ser-
bian. In Proceedings of 8th Informational Society - Language Technologies Conference,
IS-LTC, pages 108–114, Ljubljana, Slovenia, 2004.
Jonas Kuhn. Experiments in parallel-text based grammar induction. In Proceedings of
the 42nd Meeting of the Association for Computational Linguistics (ACL’04), Main
Volume, pages 470–477, Barcelona, Spain, July 2004.
Joel Lang and Mirella Lapata. Unsupervised semantic role induction via split-merge
clustering. In Proceedings of the 49th Annual Meeting of the Association for Com-
putational Linguistics: Human Language Technologies, pages 1117–1126, Portland,
Oregon, USA, June 2011. Association for Computational Linguistics. URL http:
//www.aclweb.org/anthology/P11-1112.
Maria Lapata. Acquiring lexical generalizations from corpora: A case study for diathe-
sis alternations. In Proceedings of the 37th Annual Meeting of the Association for
Computational Linguistics, pages 397–404, College Park, Maryland, USA, June 1999.
Association for Computational Linguistics.
Mirella Lapata and Chris Brew. Verb class disambiguation using informative priors.
Computational Linguistics, 30(1):45–73, 2004.
Richard K. Larson. On the double object construction. Linguistic Inquiry, 19:335–391,
1988.
Alex Lascarides and Nicholas Asher. Temporal interpretation, discourse relations and
commonsense entailment. Linguistics and Philosophy, 16(5):437–493, 1993.
Beth Levin. English verb classes and alternations : a preliminary investigation. The
University of Chicago Press, Chicago, 1993.
Beth Levin and Malka Rappaport Hovav. A preliminary analysis of causative verbs in
English. Lingua, 92:35–77, 1994.
Beth Levin and Malka Rappaport Hovav. Unaccusativity : at the syntax-lexical semantics
interface. MIT Press, Cambridge, Mass., 1995.
281

Bibliography
Beth Levin and Malka Rappaport Hovav. Argument realization. Cambridge University
Press, Cambridge, 2005.
Stephen C. Levinson. Pragmatics. Cambridge Textbooks in Linguistics. Cambridge
University Press, Cambridge, 1983.
Jianguo Li and Chris Brew. Which are the best features for automatic verb classification.
In Proceedings of ACL-08: HLT, pages 434–442, Columbus, Ohio, June 2008. Associ-
ation for Computational Linguistics. URL http://www.aclweb.org/anthology/P/
P08/P08-1050.
Edward Loper, Szu-Ting Yi, and Martha Palmer. Combining lexical resources: Mapping
between propbank and verbnet. In Proceedings of the 7th International Workshop on
Computational Linguistics, Tilburg, the Netherlands, 2007.
Catherine Macleod, Ralph Grishman, Adam Meyers, Leslie Barrett, and Ruth Reeves.
NOMLEX: A lexicon of nominalizations. In In Proceedings of Euralex98, pages 187–
193, 1998.
Christopher D. Manning. Automatic acquisition of a large subcategorization dictionary
from corpora. In Proceedings of the 31st Annual Meeting of the Association for Com-
putational Linguistics, pages 235–242, Columbus, Ohio, USA, June 1993. Association
for Computational Linguistics.
Mitchell Marcus, Beatrice Santorini, and Mary Ann Marcinkiewicz. Building a large
annotated corpus of english: the penn treebank. Computational Linguistics, 19(2):
313–330, 1994.
Rafael Marın and Louise McNally. Inchoativity, change of state, and telicity: Evidence
from Spanish reflexive psychological verbs. Natural Language and Linguistic Theory,
29:467–502, 2011.
Lluıs Marquez, Xavier Carreras, Kenneth C. Litkowski, and Suzanne Stevenson. Seman-
tic role labeling: An introduction to the special issue. Computational Linguistics, 34
(2):145–159, 2008.
282

Bibliography
Diana McCarthy and Anna Korhonen. Detecting verbal participation in diathesis al-
ternations. In Proceedings of the 36th Annual Meeting of the Association for Compu-
tational Linguistics and 17th International Conference on Computational Linguistics,
Volume 2, pages 1493–1495, Montreal, Quebec, Canada, August 1998. Association for
Computational Linguistics.
Gail McKoon and Talke Macfarland. Externally and internally caused change of state
verbs. Language, 76(4):833–858, 2000.
Paola Merlo and Gabriele Musillo. Semantic parsing for high-precision semantic role
labelling. In Proceedings of the 12th conference on computational natural language
learning (CONLL), pages 1–8, Manchester, 2008. Association for Computational Lin-
guistics.
Paola Merlo and Susanne Stevenson. Automatic verb classification based on statistical
distribution of argument structure. Computational Linguistics, 27(3):373–408, 2001.
Paola Merlo and Lonneke van der Plas. Abstraction and generalization in semantic role
labels: PropBank, VerbNet or both? In Proceedings of the Joint Conference of the 47th
Annual Meeting of the ACL and the 4th International Joint Conference on Natural
Language Processing of the AFNLP, pages 288–296, Singapore, 2009. Association for
Computational Linguistics.
Paola Merlo, Suzanne Stevenson, Vivian Tsang, and Gianluca Allaria. A multilin-
gual paradigm for automatic verb classification. In Proceedings of 40th Annual
Meeting of the Association for Computational Linguistics, pages 207–214, Philadel-
phia, Pennsylvania, USA, July 2002. Association for Computational Linguistics. doi:
10.3115/1073083.1073119. URL http://www.aclweb.org/anthology/P02-1027.
Natasa Milicevic. The lexical and superlexical verbal prefix iz- and its role in the stacking
of prefixes. Nordlyd, 32(2):279–300, 2004.
Tom T. Mitchell. Machine Learning. McGraw-Hill, Boston, Mass., 1997.
Marc Moens and Mark Steedman. Temporal ontology and temporal reference. Compu-
tational Linguistics, 14(2):15–28, June 1988.
283

Bibliography
Jacques Moeschler and Anne Reboul. Dictionnaire encyclopedique de pragmatique. Ed.
du Seuil, Paris, 1994.
Paola Monachesi, Gerwert Stevens, and Jantine Trapman. Adding semantic role an-
notation to a corpus of written Dutch. In Proceedings of the Linguistic Annotation
Workshop (LAW), pages 77–84, Prague, Czech Republic, 2007. Association for Com-
putational Linguistic.
Joakim Nivre, Johan Hall, Jens Nilsson, Chanev Atanas, Gulesen Eryigit, Sandra
Kubler, Svetoslav Marinov, and Erwin Marsi. MaltParser: A language-independent
system for data-driven dependency parsing. Natural Language Engineering, 13(2):
95–135, 2007.
Franz Josef Och and Hermann Ney. A systematic comparison of various statistical
alignment models. Computational Linguistics, 29(1):19–52, 2003.
Sebastian Pado. Cross-Lingual Annotation Projection Models for Role-Semantic Infor-
mation. PhD thesis, Saarland University, 2007.
Sebastian Pado and Mirella Lapata. Cross-lingual annotation projection of semantic
roles. Journal of Artificial Intelligence Research, 36:307–340, 2009.
Martha Palmer, Daniel Gildea, and Paul Kingsbury. The Proposition Bank: An anno-
tated corpus of semantic roles. Computational Linguistics, 31(1):71–105, 2005a.
Martha Palmer, Nianwen Xue, Olga Babko-Malaya, Jinying Chen, and Benjamin Sny-
der. A parallel Proposition Bank II for Chinese and English. In Proceedings of the
Workshop on Frontiers in Corpus Annotations II: Pie in the Sky, pages 61–67, Ann
Arbor, Michigan, June 2005b. Association for Computational Linguistics.
Martha Palmer, Dan Gildea, and Nianwen Xue. Semantic role labeling. Morgan &
Claypool Publishers, 2010.
Feng Pan, Rutu Mulkar-Mehta, and Jerry R. Hobbs. Annotating and learning event
durations in text. Computational Linguistics, 37(4):727–753, 2011.
David Pesetsky. Zero syntax: Experiencers and cascades. MIT Press, Cambridge Mass.,
1995.
284

Bibliography
James Pustejovsky. The generative lexicon. MIT Press, Cambridge, MA, 1995.
James Pustejovsky, Patrik Hanks, Roser Saurı, Andrew See, Robert Gaizauskas, Andrea
Setzer, Dragomir R. Radev, Beth Sundheim, David Day, Lisa Ferro, and Marzia Lazo.
The TIMEBANK corpus. In Corpus Linguistics, page 647–656, 2003.
Andrew Radford. Minimalist Syntax. Cambridge University Press, Cambridge, 2004.
Gillian Ramchand. Verb Meaning and the Lexicon: A First Phase Syntax. Cambridge
Studies in Linguistics. Cambridge University Press, Cambridge, 2008.
Tanja Reinhart. The theta system — An overview. Theoretical linguistics, 28:229–290,
2002.
Douglas LT Rohde. Tgrep2 user manual, 2004. URL http://tedlab.mit.edu/~dr/
Tgrep2/tgrep2.pdf.
Eleanor Rosch. Natural categories. Cognitive Psychology, 4(3):328–350, 1973.
Michael Roth and Anette Frank. Aligning predicate argument structures in monolin-
gual comparable texts: A new corpus for a new task. In *SEM 2012: The First Joint
Conference on Lexical and Computational Semantics – Volume 1: Proceedings of the
main conference and the shared task, and Volume 2: Proceedings of the Sixth Interna-
tional Workshop on Semantic Evaluation (SemEval 2012), pages 218–227, Montreal,
Canada, 7-8 June 2012. Association for Computational Linguistics.
Susan Rothstein. Telicity and atomicity. In Susan Rothstein, editor, Theoretical and
crosslinguistic approaches to the semantics of aspect, pages 43–78, Amsterdam, 2008.
John Benjamins.
Josef Ruppenhofer, Michael Ellsworth, Miriam R. L. Petruck, Christopher R. Johnson,
and Jan Scheffczyk. FrameNet II: Extended theory and practice, 2005. URL http:
//framenet.icsi.berkeley.edu/book/book.pdf.
Stuart J. Russell and Peter Norvig. Artificial intelligence : a modern approach. Prentice
Hall Pearson, Upper Saddle River, N.J., 2010.
285

Bibliography
Tanja Samardzic. Light verb constructions in English and Serbian. In English Language
and Literature Studies – Structures across Cultures, pages 59–73, Belgrade, 2008.
Faculty of Philology.
Tanja Samardzic, Lonneke van der Plas, Goldjihan Kashaeva, and Paola Merlo. The
scope and the sources of variation in verbal predicates in English and French. In
Markus Dickinson, Kaili Muurisep, and Marco Passarotti, editors, Proceedings of the
Ninth International Workshop on Treebanks and Linguistic Theories, volume 9, pages
199–211, Tartu, Estonia, 2010. Northern European Association for Language Tech-
nology (NEALT).
Tanja Samardzic and Paola Merlo. The meaning of lexical causatives in cross-linguistic
variation. Linguistic Issues in Language Technology, 7(12):1–14, 2012.
Florian Schafer. The causative alternation. In Language and Linguistics Compass,
volume 3, pages 641–681. Blackwell Publishing, 2009.
Sabine Schulte im Walde. Experiments on the choice of features for learning verb classes.
In Proceedings of The 10th Conference of the European Chapter of the Association for
Computational Linguistics (EACL 2003), pages 315–322, Budapest, Hungary, 2003.
Association for Computational Linguistics.
Sabine Schulte im Walde. Experiments on the automatic induction of German semantic
verb classes. Computational Linguistics, 32(2):159–194, 2006.
Sabine Schulte im Walde, Christian Hying, Christian Scheible, and Helmut Schmid.
Combining EM training and the MDL principle for an automatic verb classification
incorporating selectional preferences. In Proceedings of ACL-08: HLT, pages 496–
504, Columbus, Ohio, June 2008. Association for Computational Linguistics. URL
http://www.aclweb.org/anthology/P/P08/P08-1057.
Violeta Seretan. Syntax-Based Collocation Extraction. Text, Speech and Language
Technology. Springer, Dordrecht, 2011.
Eric V. Siegel and Kathleen R. McKeown. Learning methods to combine linguistic
indicators: improving aspectual classification and revealing linguistic insights. Com-
putational Linguistics, 26(4):595–628, 2000.
286

Bibliography
Nate Silver. The Signal and the Noise: Why So Many Predictions Fail — but Some
Don’t. The Penguin Press, New York, 2012.
Benjamin Snyder, Tahira Naseem, Jacob Eisenstein, and Regina Barzilay. Unsupervised
multilingual learning for pos tagging. In Proceedings of the 2008 Conference on Em-
pirical Methods in Natural Language Processing, pages 1041–1050, Honolulu, 2008.
Association for Computational Linguistics.
Benjamin Snyder, Tahira Naseem, and Regina Barzilay. Unsupervised multilingual
grammar induction. In Proceedings of the Joint Conference of the 47th Annual Meeting
of the ACL and the 4th International Joint Conference on Natural Language Process-
ing of the AFNLP, pages 73–81, Suntec, Singapore, August 2009. Association for
Computational Linguistics.
Maria Stambolieva. Parallel corpora in aspectual studies of non-aspect languages. In
Proceedings of The Second Workshop on Annotation and Exploitation of Parallel Cor-
pora, pages 39–42, Hissar, Bulgaria, September 2011.
Suzanne Stevenson and Eric Joanis. Semi-supervised verb class discovery using noisy
features. In Walter Daelemans and Miles Osborne, editors, Proceedings of the Seventh
Conference on Natural Language Learning at HLT-NAACL 2003, pages 71–78, 2003.
URL http://www.aclweb.org/anthology/W03-0410.pdf.
Suzanne Stevenson, Afsaneh Fazly, and Ryan North. Statistical measures of the semipro-
ductivity of light verb constructions. In Proceedings of the ACL’04 Workshop on Mul-
tiword Expressions: Integrating Processing, pages 1–8. Association for Computational
Linguistics, 2004.
Lin Sun and Anna Korhonen. Improving verb clustering with automatically acquired
selectional preferences. In Proceedings of the 2009 Conference on Empirical Methods
in Natural Language Processing, pages 638–647, Singapore, August 2009. Association
for Computational Linguistics. URL http://www.aclweb.org/anthology/D/D09/
D09-1067.
Peter Svenonius. Slavic prefixes inside and outside VP. Nordlyd, 32(2):205–253, 2004b.
Leonard Talmy. Towards a cognitive semantics. The MIT Press, Cambridge Mass., 2000.
287

Bibliography
Pasi Tapanainen, Jussi Piitulainen, and Timo Jarvinen. Idiomatic object usage and sup-
port verbs. In Proceedings of the 36th Annual Meeting of the Association for Compu-
tational Linguistics and 17th International Conference on Computational Linguistics,
Volume 2, pages 289–1293, Montreal, Quebec, Canada, August 1998. Association for
Computational Linguistics.
Jorg Tiedemann. News from OPUS - A collection of multilingual parallel corpora with
tools and interfaces. In Nicolas Nicolov, Kalina Bontcheva, Galia Angelova, and Ruslan
Mitkov, editors, Recent Advances in Natural Language Processing, volume V, pages
237–248, Borovets, Bulgaria, 2009. John Benjamins, Amsterdam/Philadelphia.
Ivan Titov and James Henderson. Constituent parsing with incremental sigmoid belief
networks. In Proceedings of the 45th Annual Meeting of the Association of Compu-
tational Linguistics, pages 632–639, Prague, Czech Republic, June 2007. Association
for Computational Linguistics.
Ivan Titov and Alexandre Klementiev. A Bayesian approach to unsupervised seman-
tic role induction. In Proceedings of the 13th Conference of the European Chapter of
the Association for Computational Linguistics, pages 12–22, Avignon, France, April
2012. Association for Computational Linguistics. URL http://www.aclweb.org/
anthology/E12-1003.
Kristina Toutanova, Aria Haghighi, and Christopher Manning. Joint learning improves
semantic role labeling. In Proceedings of the 43rd Annual Meeting of the Associa-
tion for Computational Linguistics (ACL’05), pages 589–596, Ann Arbor, Michigan,
June 2005. Association for Computational Linguistics. URL http://www.aclweb.
org/anthology/P/P05/P05-1073.
Graham Upton and Ian Cook. Understanding statistics. Oxford University Press, Oxford,
1996.
Lonneke van der Plas and Jorg Tiedemann. Finding synonyms using automatic word
alignment and measures of distributional similarity. In Proceedings of the COL-
ING/ACL 2006 Main Conference Poster Sessions, pages 866–873, Sydney, Australia,
July 2006. Association for Computational Linguistics.
288

Bibliography
Lonneke van der Plas, Tanja Samardzic, and Paola Merlo. Cross-lingual validity of
PropBank in the manual annotation of French. In Proceedings of the Fourth Lin-
guistic Annotation Workshop, pages 113–117, Uppsala, Sweden, 2010. Association for
Computational Linguistics.
Lonneke van der Plas, Paola Merlo, and James Henderson. Scaling up automatic cross-
lingual semantic role annotation. In Proceedings of the 49th Annual Meeting of the As-
sociation for Computational Linguistics: Human Language Technologies, pages 299–
304, Portland, Oregon, USA, June 2011. Association for Computational Linguistics.
Zeno Vendler. Linguistics in Philosophy. Cornell University Press, Ithaca, 1967.
Ruprecht von Waldenfels. Aspect in the imperative across Slavic - a corpus driven pilot
study. Oslo Studies in Language, 4(1):141–155, 2012.
Rok Zaucer. The reflexive-introducing na- and the distinction between internal and ex-
ternal Slavic prefixes. In Anastasia Smirnova, Vedrana Mihalicek, and Lauren Ressue,
editors, Formal Studies in Slavic Linguistics, pages 54–102, Newcastle upon Tyne,
2010. Cambridge Scholars Publishing.
Anna Wierzbicka. Why can you have a drink when you can’t *have an eat? Language,
58(4):753–799, 1982.
Edwin Williams. Lexical and synatctic complex predicates. In Alex Alsina, Joan Bres-
nan, and Peter Sells, editors, Complex predicates, pages 13–29, Stanford, California,
1997. CSLI Publications.
Jennifer Williams and Graham Katz. Extracting and modeling durations for habits and
events from twitter. In Proceedings of the 50th Annual Meeting of the Association
for Computational Linguistics (Volume 2: Short Papers), pages 223–227, Jeju Island,
Korea, July 2012. Association for Computational Linguistics.
Deirdre Wilson and Dan Sperber. Pragmatics and time. In Robyn Carston and Seiji
Uchida, editors, Relevance Theory: Applications and Implications, Amsterdam, 1998.
John Benjamins.
289

Bibliography
Ian H. Witten and Eibe Frank. Data mining : practical machine learning tools and
techniques. Morgan Kaufmann Publishers, San Francisco, 2005.
Phillip Wolff and Tatyana Ventura. When Russians learn English: How the semantics of
causation may change. Bilingualism: Language and Cognition, 12(2):153–176, 2009b.
Phillip Wolff, Ga-Hyun Jeon, and Yu Li. Causal agents in English, Korean and Chinese:
The role of internal and external causation. Language and Cognition, 1(2):165–194,
2009a.
Shumin Wu and Martha Palmer. Semantic mapping using automatic word alignment
and semantic role labeling. In Proceedings of Fifth Workshop on Syntax, Semantics
and Structure in Statistical Translation, pages 21–30, Portland, Oregon, USA, June
2011. Association for Computational Linguistics.
Nianwen Xue and Martha Palmer. Calibrating features for semantic role labeling. In
Dekang Lin and Dekai Wu, editors, Proceedings of Empirical Methods in Natural Lan-
guage Processing (EMNLP) 2004, pages 88–94, Barcelona, Spain, July 2004. Associ-
ation for Computational Linguistics.
David Yarowsky, Grace Ngai, and Richard Wicentowski. Inducing multilingual text
analysis tools via robust projection across aligned corpora. In Proceedings of the 1st
international conference Human Language Technology, pages 161–168, San Diego, CA,
2001. Association for Computational Linguistics.
Benat Zapirain, Eneko Agirre, and Lluıs Marquez. Robustness and generalization of
role sets: PropBank vs. VerbNet. In Proceedings of the Annual Meeting of the As-
sociation for Computational Linguistics (ACL) and the Human Language Technology
Conference, pages 550–558, Columbus, Ohio, 2008. Association for Computational
Linguistics. URL http://www.aclweb.org/anthology/P/P08/P08-1063.
Sina Zarrieß and Jonas Kuhn. Exploiting translational correspondences for pattern-
independent mwe identification. In Proceedings of the Workshop on Multiword Expres-
sions: Identification, Interpretation, Disambiguation and Applications, pages 23–30,
Singapore, August 2009. Association for Computational Linguistics.
290

Bibliography
Sina Zarrieß, Aoife Cahill, Jonas Kuhn, and Christian Rohrer. A cross-lingual induction
technique for german adverbial participles. In Proceedings of the 2010 Workshop on
NLP and Linguistics: Finding the Common Ground, pages 34–42, Uppsala, Sweden,
July 2010. Association for Computational Linguistics.
291


A. Light verb constructions data
A.1. Word alignment of the constructions with ’take’
Mapping EN DE Target DE Target EN
v n v n
2 – 2 taken account berucksichtigung finden no no bad good
2 – 1 take account berucksichtigen no good good good
2 – 1 take account berucksichtigen no no good good
2 – 1 taken action aktion no good bad good
2 – 2 take check kontrolle durchzufuhren no no bad bad
2 – 2 taken initiative initiative ergriffen no good good good
2 – 1 take precedence dominieren no no bad good
2 – 2 take decision beschluss fassen no good bad good
2 – 2 take account rechnung tragen no good bad good
2 – 2 take initiative initiative ergriffen no good good good
2 – 1 take seat sitzen no bad bad bad
2 – 2 approach taken kurs verfolgt no bad bad bad
2 – 1 decision taken beschlossen no bad good bad
2 – 2 take account rechnung tragen no good bad good
2 – 2 take note nehmen (zur) kenntnis no good good good
2 – 1 initiative taken initiative no good bad good
2 – 2 take view sind (der) ansicht no good bad good
2 – 1 take account berucksichtigen no no good good
2 – 1 take account berucksichtigt no no good good
293
A. Light verb constructions data
2 – 2 take action maßnahmen ergreifen good good good good
2 – 2 taken view meinung vertreten no good good good
2 – 1 taken initiative vorantreiben no no bad bad
2 – 2 take view vetreten meinung no good good good
2 – 1 take action aufarbeitet no no good good
2 – 2 took account rechnung tragen no no good good
2 – 2 took steps schritte unternahme no good good good
2 – 2 taken note (zur) kenntnis genommen no no good good
2 – 1 taken initiative initiative no good bad bad
2 – 2 take view bin (der) ansicht no good bad good
2 – 2 take steps schritte unternehmen no good bad good
2 – 1 take decision entscheiden no no good good
2 – 1 take cognisance berucksichtigen no bad bad bad
2 – 1 take account berucksichtigen no good good good
2 – 2 decision taken entscheidung getroffen good good good good
2 – 1 decision taken entscheiden no no good good
2 – 0 actions take no translation no no bad bad
2 – 2 taken step schritt kommen no good bad good
2 – 1 steps taken schritte no good bad good
2 – 1 take decisions beschließen no no good good
2 – 1 take care kummert no no good good
2 – 2 decision taken beschlusse fassen no good bad bad
2 – 2 taken note (zur) kenntnis genommen no good good good
2 – 0 taken decisions no translation no no bad bad
2 – 2 take action maßnahmen ergriffen no good good good
2 – 2 take steps schritte unternehmen no good bad good
2 – 2 decision taken gefaßten beschlussen no good good good
2 – 2 decision taken entscheidung getroffen good good good good
2 – 2 decision taken getroffenen entscheidung good good good good
2 – 2 steps taken schritte vollziehen no good bad good
2 – 1 take decision entscheidung no good bad good
2 – 1 take approach herantreten no bad bad bad
2 – 2 take break pause einlegen no good good good
294
A.1. Word alignment of the constructions with ’take’
2 – 1 take (into) account berucksichtigt no good good good
2 – 2 action taken sanktionen verhangt good bad good good
2 – 2 steps taken maßnahmen ergriffen no good good good
2 – 2 take decision entscheidung treffen no good good good
2 – 1 take action einschreiten no no bad bad
2 – 1 take notice berucksichtigen no no good good
2 – 2 take view sind (der) ansicht no good bad good
2 – 2 decisions taken beschlusse gefaßt no good good good
2 – 1 take (into) account ubernehmen no no good bad
2 – 2 decision taken entscheidung getroffen good good good good
2 – 2 take view (um) standpunkt vertreten no no bad good
2 – 1 taken (into) account berucksichtigt no no good good
2 – 2 decision taken beschluß angenommen no good good good
2 – 1 taken account berucksichtigt no good good good
2 – 2 decision taken beschlusse getroffen no good good good
2 – 2 steps taken hurden nehmen no no bad bad
2 – 2 steps take schritte unternimmt bad good good good
2 – 2 took view ansicht vertreten bad good good good
2 – 2 took decision beschluß gefaßt bad good good good
2 – 1 approach took vorgehen no no bad bad
2 – 1 took account erortert bad no good good
2 – 2 take steps maßnahmen ergriffen no good good good
2 – 2 decisions taken entscheidungen getroffen no good good good
2 – 2 vote taken abstimmung findet-statt no good good good
2 – 1 take (into) account berucksichtigen no good good good
2 – 2 samples taken proben gezogen no good bad good
2 – 1 take look anschaut no good bad good
2 – 2 obligations take verpflichtungen
wahrnehmen
no good good good
2 – 1 takes account berucksichtigt no good good good
2 – 2 decision taken getroffene entscheidung no good good good
2 – 1 action taken maßnahmen no good bad bad
2 – 0 action taken no translation no no bad bad
295

A. Light verb constructions data
2 – 2 take decisions entscheidungen treffen no good good good
2 – 1 take (into) account einbezogen no no bad bad
2 – 1 taken note notiert no good good good
2 – 2 decisions taken getroffene beschlusse no no good good
2 – 2 take notice berucksichtigen no no bad bad
2 – 2 took step schritt vollzogen no good bad good
2 – 2 take control kontrolle bringen no good bad good
2 – 0 step take no translation bad bad bad bad
2 – 1 taken (into) account berucksichtigt no good good good
2 – 0 action taken no translation no no bad bad
2 – 2 take account rechnung tragen no good bad good
2 – 2 decisions taken getroffene entscheidungen no good bad good
2 – 2 decisions taken gefallten entscheidungen no good bad good
2 – 1 take account berucksichtigen no no good good
2 – 2 took decision beschluß gefaßt bad good good good
2 – 1 decisions taken beschlusse bad good good good
296
A.2. Word alignment of the constructions with ’make’
A.2. Word alignment of the constructions with ’make’
Mapping EN DE Target DE Target EN
v n v n
2 – 1 make choices auszuwahlen no no good good
2 – 0 make use no translation no no bad bad
2 – 1 make progress vorankommen no no good good
2 – 2 makes cuts kurzungen vornimmt no no bad bad
2 – 2 make decisions entscheiden betreffen no no bad bad
2 – 1 make contribution beitragen no bad bad bad
2 – 2 make decisions entscheidungen treffen no good good good
2 – 1 make reduction reduziert no no bad bad
2 – 1 make start anfangen no no bad bad
2 – 2 make points punkte ansprechen no good good good
2 – 1 make use einsetzen no no bad bad
2 – 2 make point verfahrensfrage anzus-
prechen
no good good good
2 – 2 make contribution beitrag geleistet no good bad good
2 – 1 speech made rede no good bad bad
2 – 2 comparison made vergleich anstellen no good good good
2 – 1 investments made investiert no bad bad bad
2 – 2 progress made fortschritte erzielt no good good good
2 – 2 make comments bemerkungen machen no good good good
2 – 1 make decisions entscheiden no no good good
2 – 1 make comment sagen no good good good
2 – 1 make provision einrichten no no bad bad
2 – 1 comments make anmerkungen no good good good
2 – 1 proposal makes vorschlag no good bad good
2 – 2 make suggestion anmerkungen machen no no good bad
2 – 2 make checks prufungen vornehmen no no good bad
2 – 2 make progress schritt getan no no bad bad
2 – 1 make changes korrekturen no no bad good
297

A. Light verb constructions data
2 – 1 comments made aussagen no good good good
2 – 1 choice made entscheidung bad good bad bad
2 – 1 changes made geandert no no good good
2 – 1 attempts made versucht no good bad bad
2 – 2 made request forderung erhoben no bad good bad
2 – 1 attempts made versucht no good good bad
2 – 1 investments made investitionen no good bad good
2 – 1 points made gesagt no no bad bad
2 – 2 made contribution beitrag geleistet no good good good
2 – 1 investments made investiert no no bad bad
2 – 2 gains made erzielten erfolge no no good bad
2 – 2 made progress kommt voran no no bad good
2 – 0 makes fuss no translation no no bad bad
2 – 1 makes reference befaßt no no bad bad
2 – 2 make statement erklarung abgegeben bad good bad bad
2 – 1 make inspections kontrollen bad good bad bad
2 – 2 make assessment bilanz ziehen no bad bad bad
2 – 1 make statement (um) wort no no bad bad
2 – 1 make remarks eingehen no no bad bad
2 – 2 make observation bemerkung machen no good good bad
2 – 2 made contribution beitrag leisten no good good good
2 – 2 made start hat start no no bad good
2 – 1 suggestion made anregung no good good good
2 – 1 mistakes made fehler no good good good
2 – 1 comment made anmerkung bad good good good
2 – 2 progress made fortschritte erzielt bad good good good
2 – 1 reference made erwahnt bad no bad bad
2 – 1 appeal made aufruf no good good good
2 – 1 references made verweis no good good good
2 – 2 appointments made einstellungen vorgenom-
men
no good good good
2 – 2 progress made fortschritte erzielt no good bad good
298
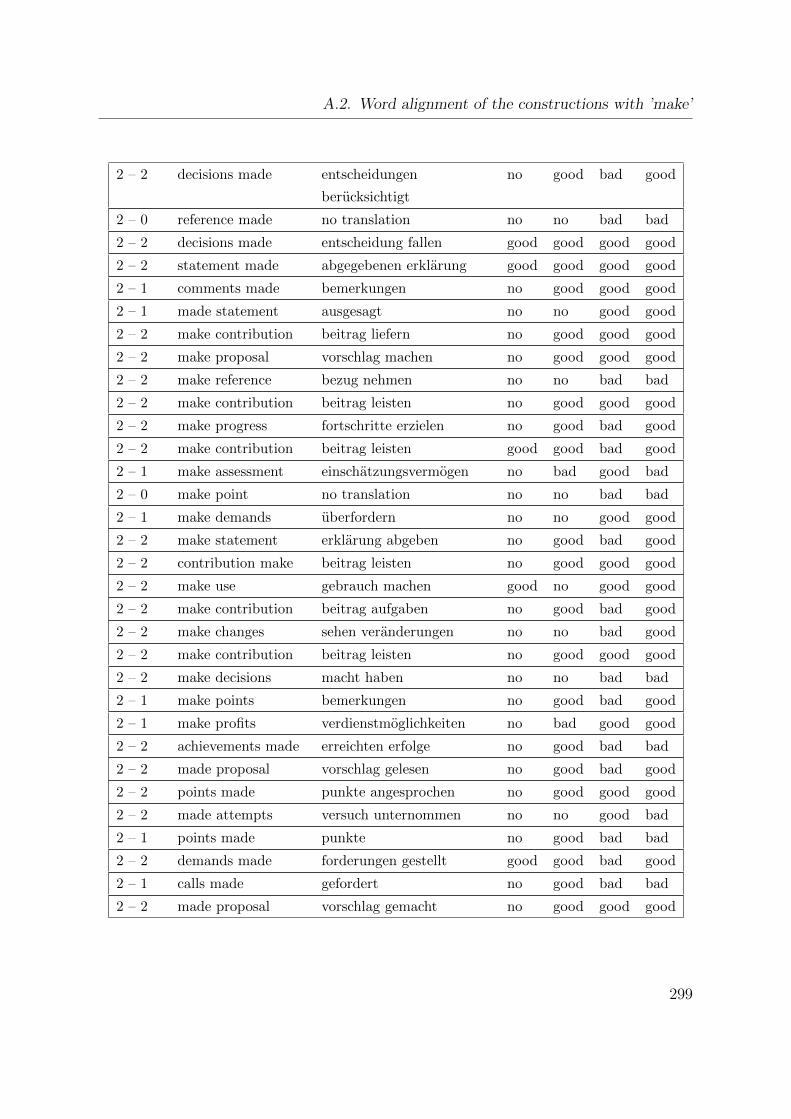
A.2. Word alignment of the constructions with ’make’
2 – 2 decisions made entscheidungen
berucksichtigt
no good bad good
2 – 0 reference made no translation no no bad bad
2 – 2 decisions made entscheidung fallen good good good good
2 – 2 statement made abgegebenen erklarung good good good good
2 – 1 comments made bemerkungen no good good good
2 – 1 made statement ausgesagt no no good good
2 – 2 make contribution beitrag liefern no good good good
2 – 2 make proposal vorschlag machen no good good good
2 – 2 make reference bezug nehmen no no bad bad
2 – 2 make contribution beitrag leisten no good good good
2 – 2 make progress fortschritte erzielen no good bad good
2 – 2 make contribution beitrag leisten good good bad good
2 – 1 make assessment einschatzungsvermogen no bad good bad
2 – 0 make point no translation no no bad bad
2 – 1 make demands uberfordern no no good good
2 – 2 make statement erklarung abgeben no good bad good
2 – 2 contribution make beitrag leisten no good good good
2 – 2 make use gebrauch machen good no good good
2 – 2 make contribution beitrag aufgaben no good bad good
2 – 2 make changes sehen veranderungen no no bad good
2 – 2 make contribution beitrag leisten no good good good
2 – 2 make decisions macht haben no no bad bad
2 – 1 make points bemerkungen no good bad good
2 – 1 make profits verdienstmoglichkeiten no bad good good
2 – 2 achievements made erreichten erfolge no good bad bad
2 – 2 made proposal vorschlag gelesen no good bad good
2 – 2 points made punkte angesprochen no good good good
2 – 2 made attempts versuch unternommen no no good bad
2 – 1 points made punkte no good bad bad
2 – 2 demands made forderungen gestellt good good bad good
2 – 1 calls made gefordert no good bad bad
2 – 2 made proposal vorschlag gemacht no good good good
299
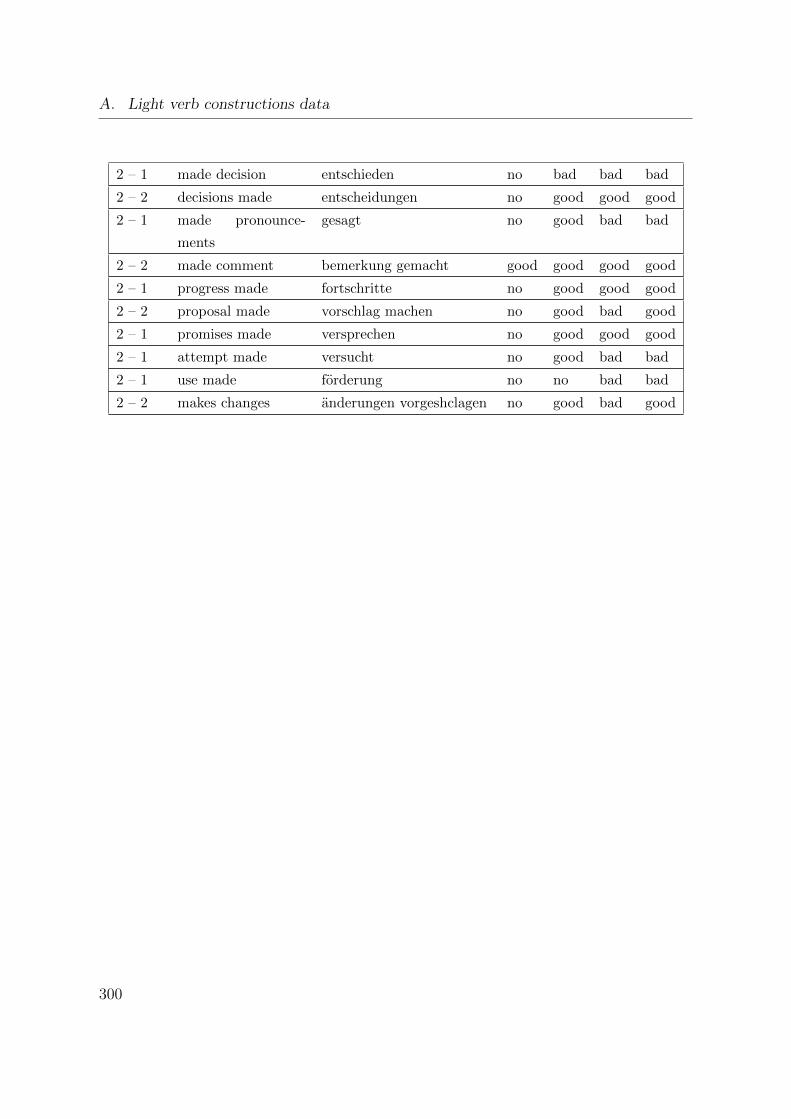
A. Light verb constructions data
2 – 1 made decision entschieden no bad bad bad
2 – 2 decisions made entscheidungen no good good good
2 – 1 made pronounce-
ments
gesagt no good bad bad
2 – 2 made comment bemerkung gemacht good good good good
2 – 1 progress made fortschritte no good good good
2 – 2 proposal made vorschlag machen no good bad good
2 – 1 promises made versprechen no good good good
2 – 1 attempt made versucht no good bad bad
2 – 1 use made forderung no no bad bad
2 – 2 makes changes anderungen vorgeshclagen no good bad good
300
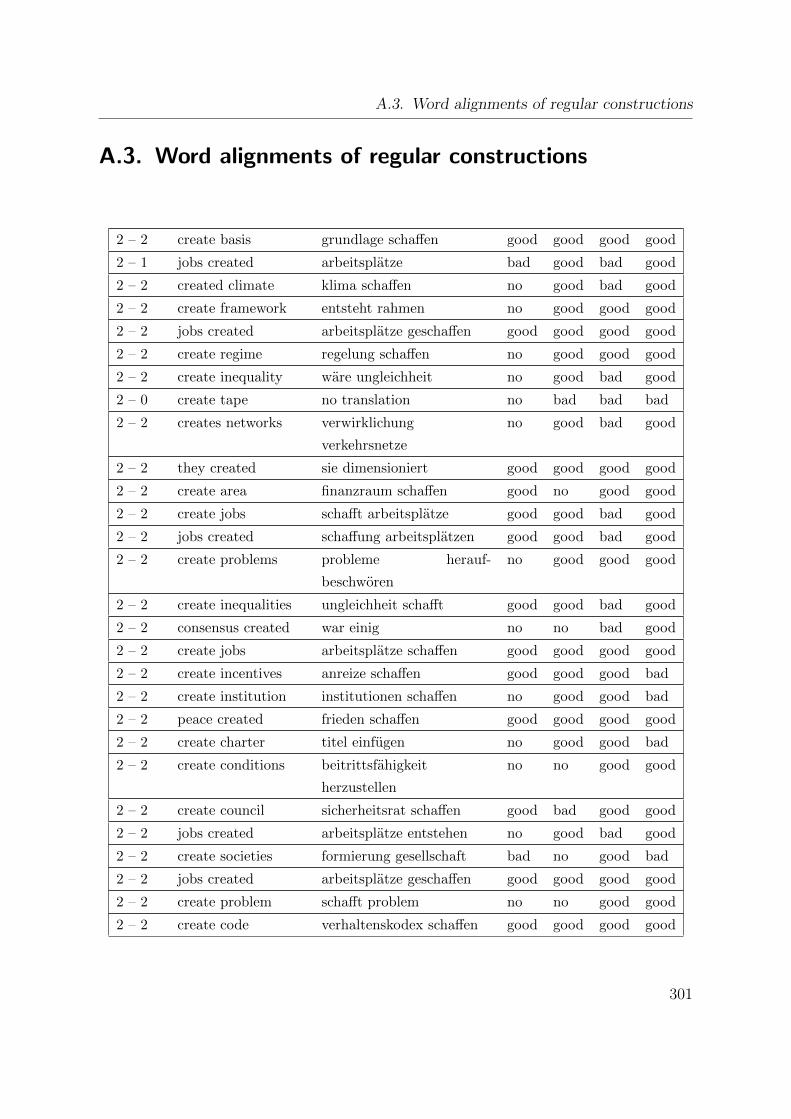
A.3. Word alignments of regular constructions
A.3. Word alignments of regular constructions
2 – 2 create basis grundlage schaffen good good good good
2 – 1 jobs created arbeitsplatze bad good bad good
2 – 2 created climate klima schaffen no good bad good
2 – 2 create framework entsteht rahmen no good good good
2 – 2 jobs created arbeitsplatze geschaffen good good good good
2 – 2 create regime regelung schaffen no good good good
2 – 2 create inequality ware ungleichheit no good bad good
2 – 0 create tape no translation no bad bad bad
2 – 2 creates networks verwirklichung
verkehrsnetze
no good bad good
2 – 2 they created sie dimensioniert good good good good
2 – 2 create area finanzraum schaffen good no good good
2 – 2 create jobs schafft arbeitsplatze good good bad good
2 – 2 jobs created schaffung arbeitsplatzen good good bad good
2 – 2 create problems probleme herauf-
beschworen
no good good good
2 – 2 create inequalities ungleichheit schafft good good bad good
2 – 2 consensus created war einig no no bad good
2 – 2 create jobs arbeitsplatze schaffen good good good good
2 – 2 create incentives anreize schaffen good good good bad
2 – 2 create institution institutionen schaffen no good good bad
2 – 2 peace created frieden schaffen good good good good
2 – 2 create charter titel einfugen no good good bad
2 – 2 create conditions beitrittsfahigkeit
herzustellen
no no good good
2 – 2 create council sicherheitsrat schaffen good bad good good
2 – 2 jobs created arbeitsplatze entstehen no good bad good
2 – 2 create societies formierung gesellschaft bad no good bad
2 – 2 jobs created arbeitsplatze geschaffen good good good good
2 – 2 create problem schafft problem no no good good
2 – 2 create code verhaltenskodex schaffen good good good good
301
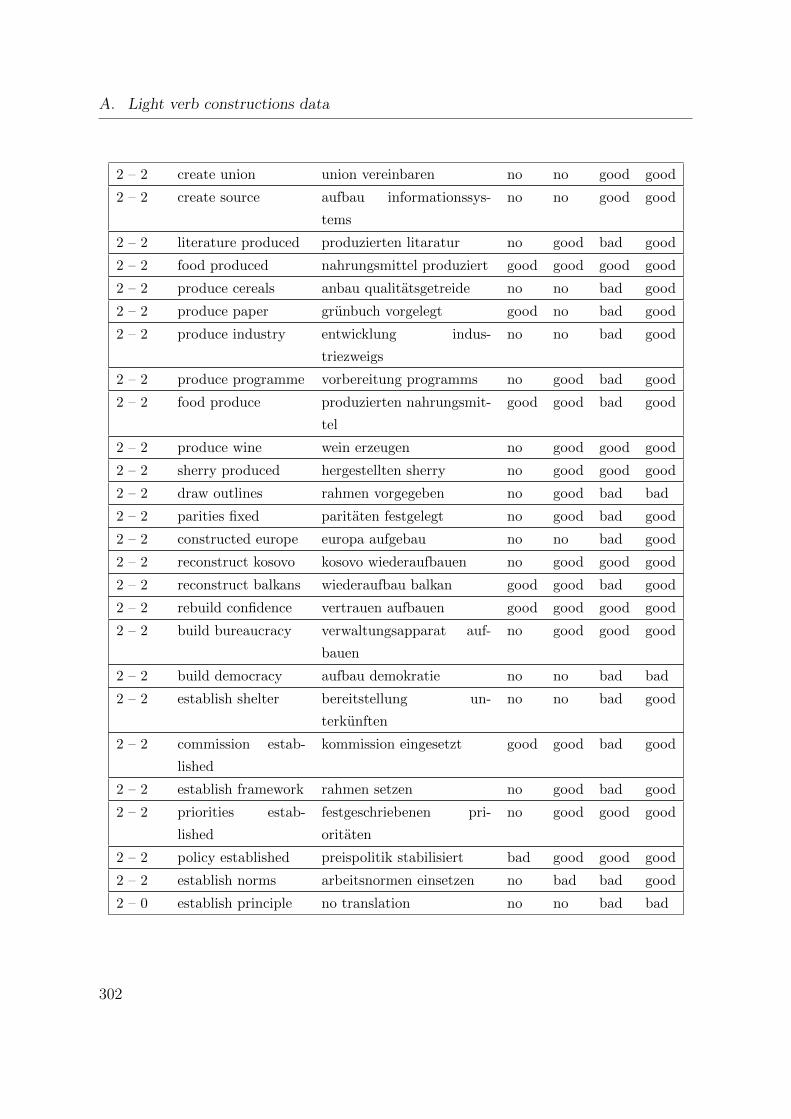
A. Light verb constructions data
2 – 2 create union union vereinbaren no no good good
2 – 2 create source aufbau informationssys-
tems
no no good good
2 – 2 literature produced produzierten litaratur no good bad good
2 – 2 food produced nahrungsmittel produziert good good good good
2 – 2 produce cereals anbau qualitatsgetreide no no bad good
2 – 2 produce paper grunbuch vorgelegt good no bad good
2 – 2 produce industry entwicklung indus-
triezweigs
no no bad good
2 – 2 produce programme vorbereitung programms no good bad good
2 – 2 food produce produzierten nahrungsmit-
tel
good good bad good
2 – 2 produce wine wein erzeugen no good good good
2 – 2 sherry produced hergestellten sherry no good good good
2 – 2 draw outlines rahmen vorgegeben no good bad bad
2 – 2 parities fixed paritaten festgelegt no good bad good
2 – 2 constructed europe europa aufgebau no no bad good
2 – 2 reconstruct kosovo kosovo wiederaufbauen no good good good
2 – 2 reconstruct balkans wiederaufbau balkan good good bad good
2 – 2 rebuild confidence vertrauen aufbauen good good good good
2 – 2 build bureaucracy verwaltungsapparat auf-
bauen
no good good good
2 – 2 build democracy aufbau demokratie no no bad bad
2 – 2 establish shelter bereitstellung un-
terkunften
no no bad good
2 – 2 commission estab-
lished
kommission eingesetzt good good bad good
2 – 2 establish framework rahmen setzen no good bad good
2 – 2 priorities estab-
lished
festgeschriebenen pri-
oritaten
no good good good
2 – 2 policy established preispolitik stabilisiert bad good good good
2 – 2 establish norms arbeitsnormen einsetzen no bad bad good
2 – 0 establish principle no translation no no bad bad
302

A.3. Word alignments of regular constructions
2 – 2 establish consis-
tency
konsequenz verstarkt no good bad good
2 – 2 establish systems identifizierungssysteme
festgelegt
bad no bad good
2 – 2 establish vanguard bildung vorhut no good good good
2 – 2 primacy established primat herausgestellt no no good good
2 – 2 multinationals
established
konzerne niedergelassen no no bad bad
2 – 2 establish founda-
tions
grundlagen schaffen good good good good
2 – 2 establish policy umweltpolitik machen no bad bad good
2 – 2 establish clarity klarheit schaffen no good bad good
2 – 2 they established sie aufgebaut good good good good
2 – 2 establish procedures verfahren hervorgebracht no good bad good
2 – 2 established stages phasen festgelegt good good bad good
2 – 2 criteria established aufgestellten kriterien no good good good
2 – 2 established perspec-
tives
vorausschau aufgestellt bad good bad good
2 – 2 procedures estab-
lished
vereinbarenden ver-
fahrensweiseg
good no good good
2 – 2 establish conditions bedingungen schafft no good bad good
2 – 2 partnerships estab-
lished
beitrittspartnerschaft
besteht
no bad bad good
2 – 2 establish itself sich festigen no no bad bad
2 – 2 create situation situation herauf-
beschworen
bad good good good
2 – 2 create peace schaffung friedens good good good good
2 – 2 created alternatives alternativen geschaffen good good good good
2 – 2 sherry produced hergestellten sherry no good good good
2 – 2 establish system system schaffen good good bad good
2 – 2 establish court satzung strafgerichtshofs no good good good
2 – 2 create fund schaffung fonds good good good good
303
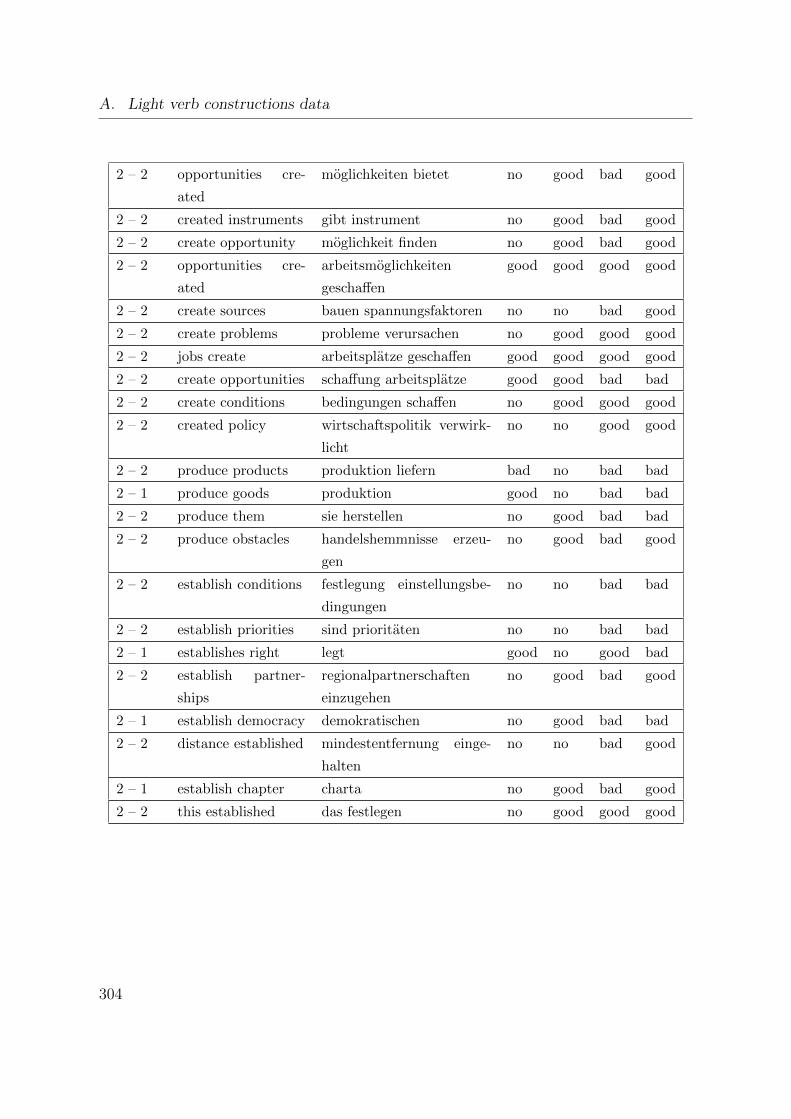
A. Light verb constructions data
2 – 2 opportunities cre-
ated
moglichkeiten bietet no good bad good
2 – 2 created instruments gibt instrument no good bad good
2 – 2 create opportunity moglichkeit finden no good bad good
2 – 2 opportunities cre-
ated
arbeitsmoglichkeiten
geschaffen
good good good good
2 – 2 create sources bauen spannungsfaktoren no no bad good
2 – 2 create problems probleme verursachen no good good good
2 – 2 jobs create arbeitsplatze geschaffen good good good good
2 – 2 create opportunities schaffung arbeitsplatze good good bad bad
2 – 2 create conditions bedingungen schaffen no good good good
2 – 2 created policy wirtschaftspolitik verwirk-
licht
no no good good
2 – 2 produce products produktion liefern bad no bad bad
2 – 1 produce goods produktion good no bad bad
2 – 2 produce them sie herstellen no good bad bad
2 – 2 produce obstacles handelshemmnisse erzeu-
gen
no good bad good
2 – 2 establish conditions festlegung einstellungsbe-
dingungen
no no bad bad
2 – 2 establish priorities sind prioritaten no no bad bad
2 – 1 establishes right legt good no good bad
2 – 2 establish partner-
ships
regionalpartnerschaften
einzugehen
no good bad good
2 – 1 establish democracy demokratischen no good bad bad
2 – 2 distance established mindestentfernung einge-
halten
no no bad good
2 – 1 establish chapter charta no good bad good
2 – 2 this established das festlegen no good good good
304
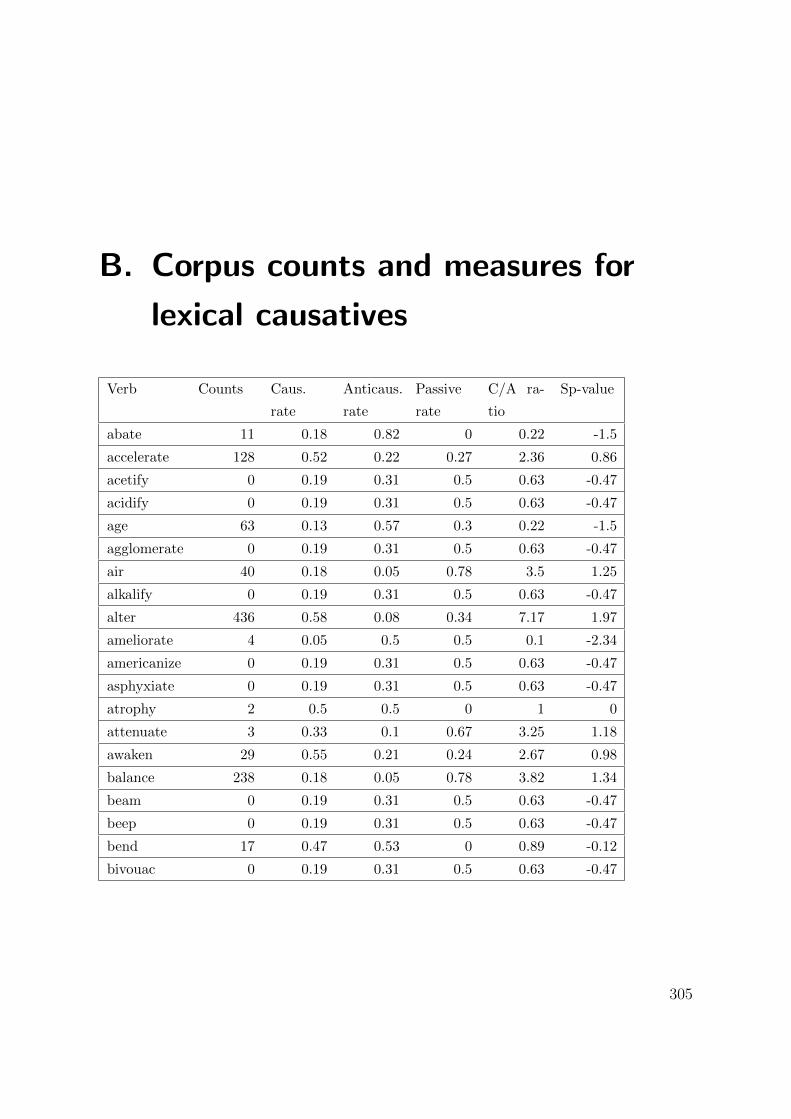
B. Corpus counts and measures for
lexical causatives
Verb Counts Caus.
rate
Anticaus.
rate
Passive
rate
C/A ra-
tio
Sp-value
abate 11 0.18 0.82 0 0.22 -1.5
accelerate 128 0.52 0.22 0.27 2.36 0.86
acetify 0 0.19 0.31 0.5 0.63 -0.47
acidify 0 0.19 0.31 0.5 0.63 -0.47
age 63 0.13 0.57 0.3 0.22 -1.5
agglomerate 0 0.19 0.31 0.5 0.63 -0.47
air 40 0.18 0.05 0.78 3.5 1.25
alkalify 0 0.19 0.31 0.5 0.63 -0.47
alter 436 0.58 0.08 0.34 7.17 1.97
ameliorate 4 0.05 0.5 0.5 0.1 -2.34
americanize 0 0.19 0.31 0.5 0.63 -0.47
asphyxiate 0 0.19 0.31 0.5 0.63 -0.47
atrophy 2 0.5 0.5 0 1 0
attenuate 3 0.33 0.1 0.67 3.25 1.18
awaken 29 0.55 0.21 0.24 2.67 0.98
balance 238 0.18 0.05 0.78 3.82 1.34
beam 0 0.19 0.31 0.5 0.63 -0.47
beep 0 0.19 0.31 0.5 0.63 -0.47
bend 17 0.47 0.53 0 0.89 -0.12
bivouac 0 0.19 0.31 0.5 0.63 -0.47
305
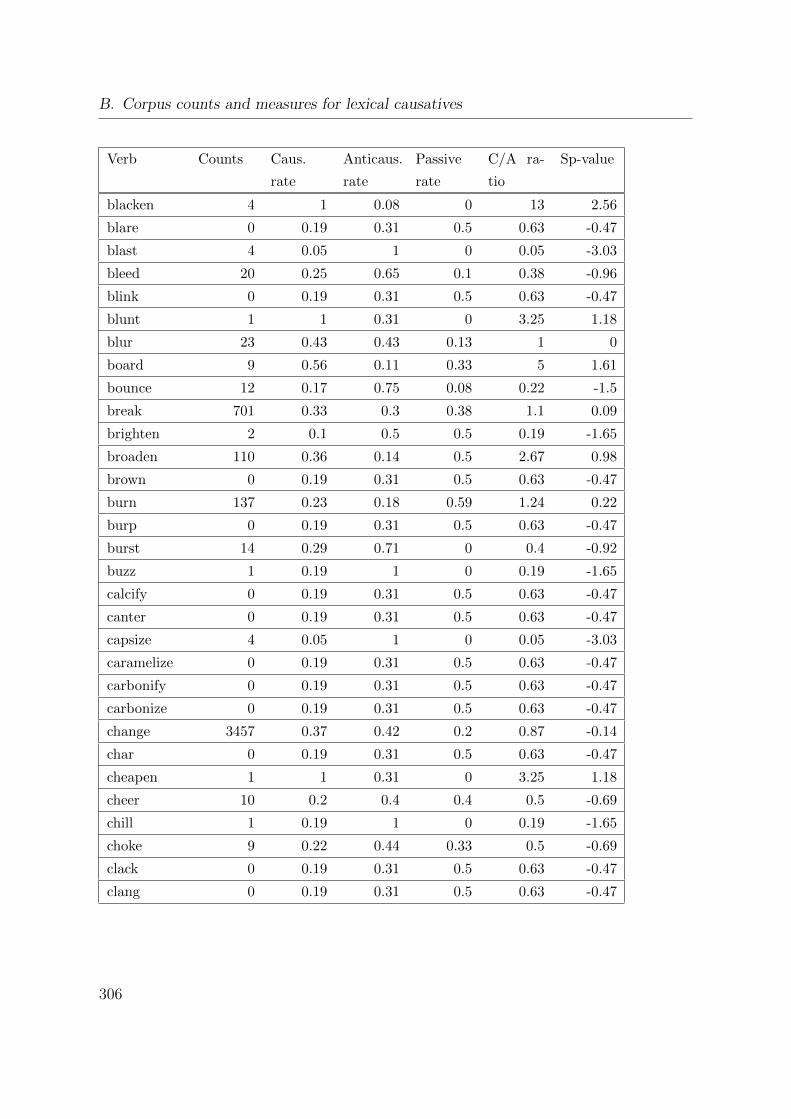
B. Corpus counts and measures for lexical causatives
Verb Counts Caus.
rate
Anticaus.
rate
Passive
rate
C/A ra-
tio
Sp-value
blacken 4 1 0.08 0 13 2.56
blare 0 0.19 0.31 0.5 0.63 -0.47
blast 4 0.05 1 0 0.05 -3.03
bleed 20 0.25 0.65 0.1 0.38 -0.96
blink 0 0.19 0.31 0.5 0.63 -0.47
blunt 1 1 0.31 0 3.25 1.18
blur 23 0.43 0.43 0.13 1 0
board 9 0.56 0.11 0.33 5 1.61
bounce 12 0.17 0.75 0.08 0.22 -1.5
break 701 0.33 0.3 0.38 1.1 0.09
brighten 2 0.1 0.5 0.5 0.19 -1.65
broaden 110 0.36 0.14 0.5 2.67 0.98
brown 0 0.19 0.31 0.5 0.63 -0.47
burn 137 0.23 0.18 0.59 1.24 0.22
burp 0 0.19 0.31 0.5 0.63 -0.47
burst 14 0.29 0.71 0 0.4 -0.92
buzz 1 0.19 1 0 0.19 -1.65
calcify 0 0.19 0.31 0.5 0.63 -0.47
canter 0 0.19 0.31 0.5 0.63 -0.47
capsize 4 0.05 1 0 0.05 -3.03
caramelize 0 0.19 0.31 0.5 0.63 -0.47
carbonify 0 0.19 0.31 0.5 0.63 -0.47
carbonize 0 0.19 0.31 0.5 0.63 -0.47
change 3457 0.37 0.42 0.2 0.87 -0.14
char 0 0.19 0.31 0.5 0.63 -0.47
cheapen 1 1 0.31 0 3.25 1.18
cheer 10 0.2 0.4 0.4 0.5 -0.69
chill 1 0.19 1 0 0.19 -1.65
choke 9 0.22 0.44 0.33 0.5 -0.69
clack 0 0.19 0.31 0.5 0.63 -0.47
clang 0 0.19 0.31 0.5 0.63 -0.47
306
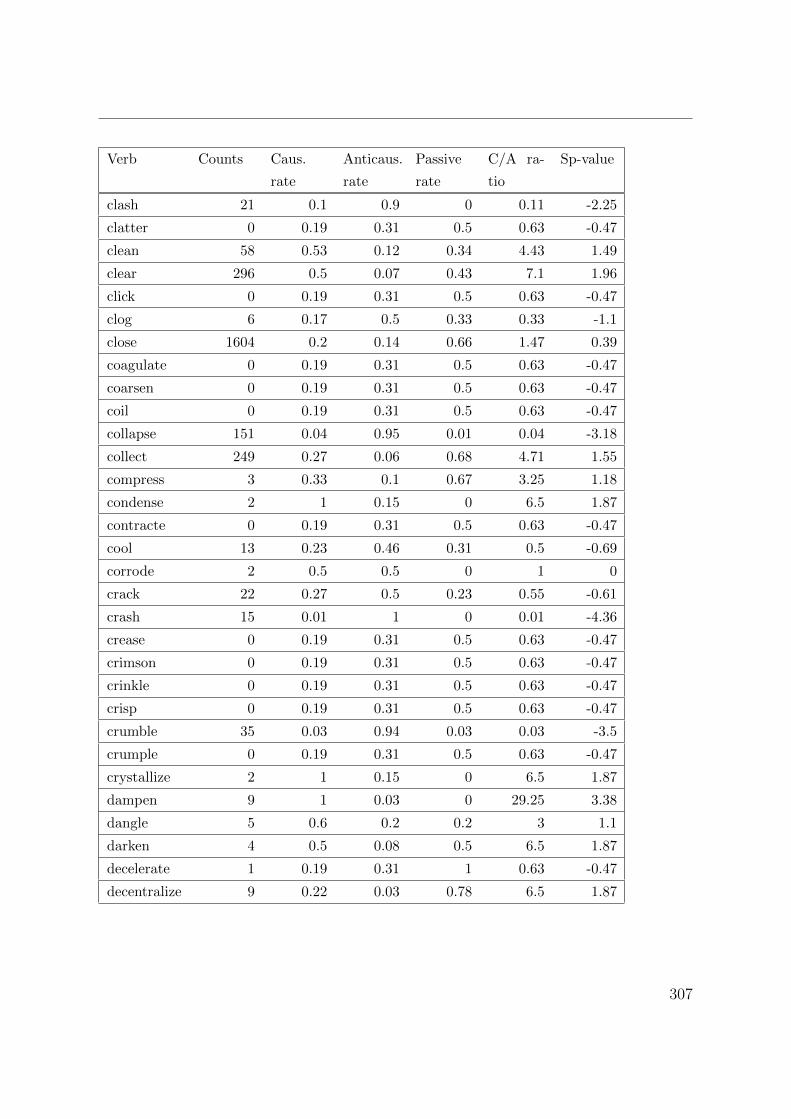
Verb Counts Caus.
rate
Anticaus.
rate
Passive
rate
C/A ra-
tio
Sp-value
clash 21 0.1 0.9 0 0.11 -2.25
clatter 0 0.19 0.31 0.5 0.63 -0.47
clean 58 0.53 0.12 0.34 4.43 1.49
clear 296 0.5 0.07 0.43 7.1 1.96
click 0 0.19 0.31 0.5 0.63 -0.47
clog 6 0.17 0.5 0.33 0.33 -1.1
close 1604 0.2 0.14 0.66 1.47 0.39
coagulate 0 0.19 0.31 0.5 0.63 -0.47
coarsen 0 0.19 0.31 0.5 0.63 -0.47
coil 0 0.19 0.31 0.5 0.63 -0.47
collapse 151 0.04 0.95 0.01 0.04 -3.18
collect 249 0.27 0.06 0.68 4.71 1.55
compress 3 0.33 0.1 0.67 3.25 1.18
condense 2 1 0.15 0 6.5 1.87
contracte 0 0.19 0.31 0.5 0.63 -0.47
cool 13 0.23 0.46 0.31 0.5 -0.69
corrode 2 0.5 0.5 0 1 0
crack 22 0.27 0.5 0.23 0.55 -0.61
crash 15 0.01 1 0 0.01 -4.36
crease 0 0.19 0.31 0.5 0.63 -0.47
crimson 0 0.19 0.31 0.5 0.63 -0.47
crinkle 0 0.19 0.31 0.5 0.63 -0.47
crisp 0 0.19 0.31 0.5 0.63 -0.47
crumble 35 0.03 0.94 0.03 0.03 -3.5
crumple 0 0.19 0.31 0.5 0.63 -0.47
crystallize 2 1 0.15 0 6.5 1.87
dampen 9 1 0.03 0 29.25 3.38
dangle 5 0.6 0.2 0.2 3 1.1
darken 4 0.5 0.08 0.5 6.5 1.87
decelerate 1 0.19 0.31 1 0.63 -0.47
decentralize 9 0.22 0.03 0.78 6.5 1.87
307
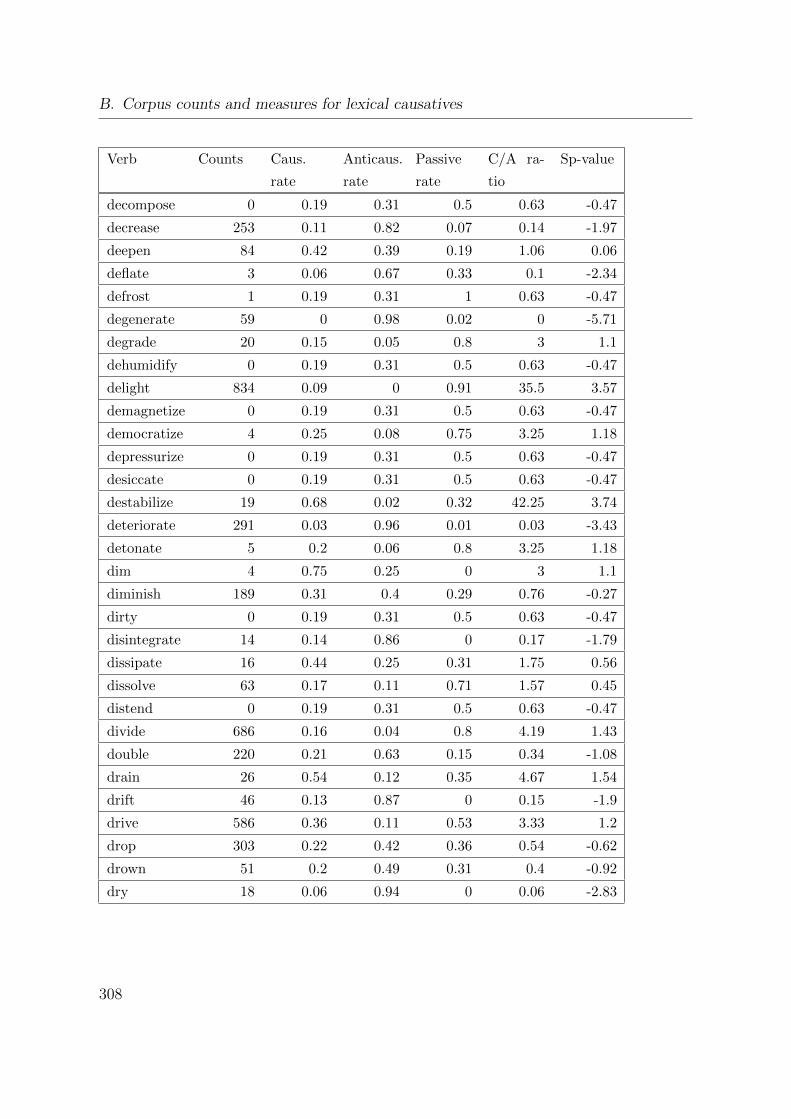
B. Corpus counts and measures for lexical causatives
Verb Counts Caus.
rate
Anticaus.
rate
Passive
rate
C/A ra-
tio
Sp-value
decompose 0 0.19 0.31 0.5 0.63 -0.47
decrease 253 0.11 0.82 0.07 0.14 -1.97
deepen 84 0.42 0.39 0.19 1.06 0.06
deflate 3 0.06 0.67 0.33 0.1 -2.34
defrost 1 0.19 0.31 1 0.63 -0.47
degenerate 59 0 0.98 0.02 0 -5.71
degrade 20 0.15 0.05 0.8 3 1.1
dehumidify 0 0.19 0.31 0.5 0.63 -0.47
delight 834 0.09 0 0.91 35.5 3.57
demagnetize 0 0.19 0.31 0.5 0.63 -0.47
democratize 4 0.25 0.08 0.75 3.25 1.18
depressurize 0 0.19 0.31 0.5 0.63 -0.47
desiccate 0 0.19 0.31 0.5 0.63 -0.47
destabilize 19 0.68 0.02 0.32 42.25 3.74
deteriorate 291 0.03 0.96 0.01 0.03 -3.43
detonate 5 0.2 0.06 0.8 3.25 1.18
dim 4 0.75 0.25 0 3 1.1
diminish 189 0.31 0.4 0.29 0.76 -0.27
dirty 0 0.19 0.31 0.5 0.63 -0.47
disintegrate 14 0.14 0.86 0 0.17 -1.79
dissipate 16 0.44 0.25 0.31 1.75 0.56
dissolve 63 0.17 0.11 0.71 1.57 0.45
distend 0 0.19 0.31 0.5 0.63 -0.47
divide 686 0.16 0.04 0.8 4.19 1.43
double 220 0.21 0.63 0.15 0.34 -1.08
drain 26 0.54 0.12 0.35 4.67 1.54
drift 46 0.13 0.87 0 0.15 -1.9
drive 586 0.36 0.11 0.53 3.33 1.2
drop 303 0.22 0.42 0.36 0.54 -0.62
drown 51 0.2 0.49 0.31 0.4 -0.92
dry 18 0.06 0.94 0 0.06 -2.83
308
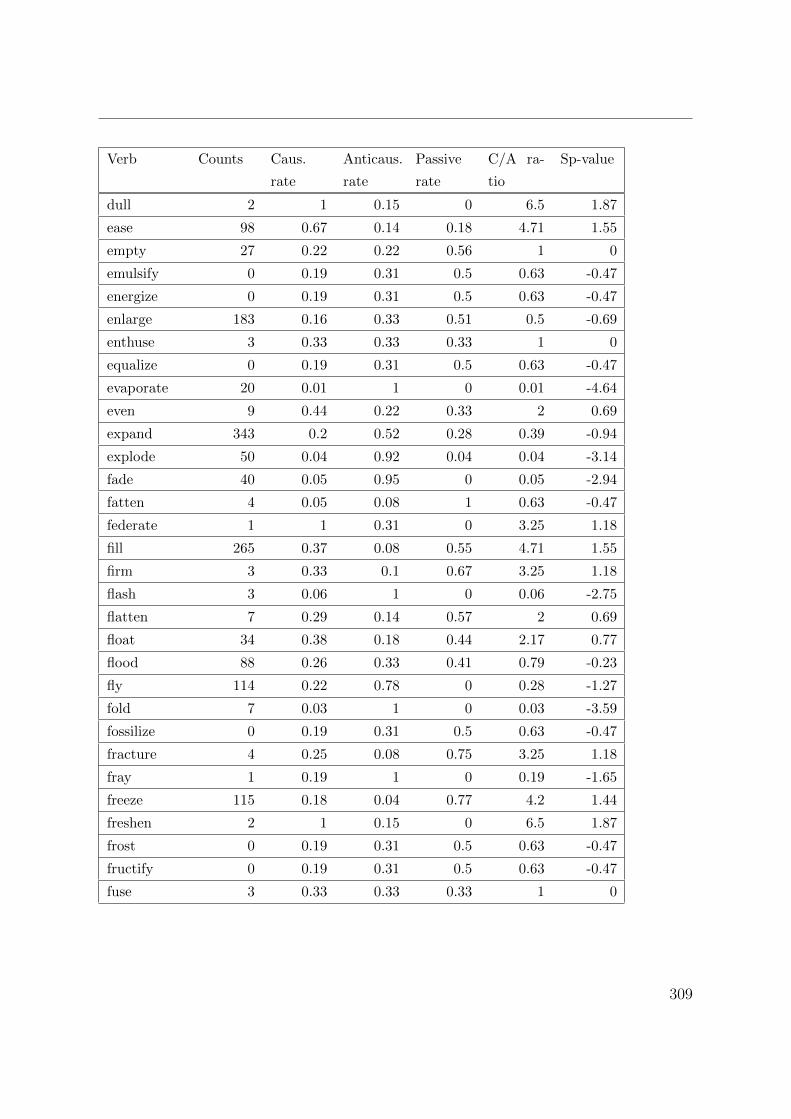
Verb Counts Caus.
rate
Anticaus.
rate
Passive
rate
C/A ra-
tio
Sp-value
dull 2 1 0.15 0 6.5 1.87
ease 98 0.67 0.14 0.18 4.71 1.55
empty 27 0.22 0.22 0.56 1 0
emulsify 0 0.19 0.31 0.5 0.63 -0.47
energize 0 0.19 0.31 0.5 0.63 -0.47
enlarge 183 0.16 0.33 0.51 0.5 -0.69
enthuse 3 0.33 0.33 0.33 1 0
equalize 0 0.19 0.31 0.5 0.63 -0.47
evaporate 20 0.01 1 0 0.01 -4.64
even 9 0.44 0.22 0.33 2 0.69
expand 343 0.2 0.52 0.28 0.39 -0.94
explode 50 0.04 0.92 0.04 0.04 -3.14
fade 40 0.05 0.95 0 0.05 -2.94
fatten 4 0.05 0.08 1 0.63 -0.47
federate 1 1 0.31 0 3.25 1.18
fill 265 0.37 0.08 0.55 4.71 1.55
firm 3 0.33 0.1 0.67 3.25 1.18
flash 3 0.06 1 0 0.06 -2.75
flatten 7 0.29 0.14 0.57 2 0.69
float 34 0.38 0.18 0.44 2.17 0.77
flood 88 0.26 0.33 0.41 0.79 -0.23
fly 114 0.22 0.78 0 0.28 -1.27
fold 7 0.03 1 0 0.03 -3.59
fossilize 0 0.19 0.31 0.5 0.63 -0.47
fracture 4 0.25 0.08 0.75 3.25 1.18
fray 1 0.19 1 0 0.19 -1.65
freeze 115 0.18 0.04 0.77 4.2 1.44
freshen 2 1 0.15 0 6.5 1.87
frost 0 0.19 0.31 0.5 0.63 -0.47
fructify 0 0.19 0.31 0.5 0.63 -0.47
fuse 3 0.33 0.33 0.33 1 0
309

B. Corpus counts and measures for lexical causatives
Verb Counts Caus.
rate
Anticaus.
rate
Passive
rate
C/A ra-
tio
Sp-value
gallop 5 0.2 0.8 0 0.25 -1.39
gasify 0 0.19 0.31 0.5 0.63 -0.47
gelatinize 0 0.19 0.31 0.5 0.63 -0.47
gladden 1 0.19 0.31 1 0.63 -0.47
glide 0 0.19 0.31 0.5 0.63 -0.47
glutenize 0 0.19 0.31 0.5 0.63 -0.47
granulate 0 0.19 0.31 0.5 0.63 -0.47
gray 0 0.19 0.31 0.5 0.63 -0.47
green 0 0.19 0.31 0.5 0.63 -0.47
grieve 6 0.17 0.67 0.17 0.25 -1.39
grow 1379 0.14 0.78 0.08 0.19 -1.68
halt 130 0.35 0.05 0.61 7.5 2.01
hang 106 0.25 0.62 0.12 0.41 -0.89
harden 14 0.21 0.64 0.14 0.33 -1.1
harmonize 89 0.28 0.07 0.65 4.17 1.43
hasten 23 0.3 0.65 0.04 0.47 -0.76
heal 31 0.29 0.39 0.32 0.75 -0.29
heat 26 0.27 0.27 0.46 1 0
heighten 59 0.53 0.07 0.41 7.75 2.05
hoot 0 0.19 0.31 0.5 0.63 -0.47
humidify 0 0.19 0.31 0.5 0.63 -0.47
hush 18 0.01 0.11 0.89 0.1 -2.34
hybridize 0 0.19 0.31 0.5 0.63 -0.47
ignite 6 0.83 0.17 0 5 1.61
improve 3021 0.45 0.22 0.33 2.03 0.71
increase 4292 0.39 0.41 0.2 0.95 -0.05
incubate 4 0.5 0.5 0 1 0
inflate 12 0.42 0.08 0.5 5 1.61
intensify 242 0.46 0.24 0.31 1.95 0.67
iodize 0 0.19 0.31 0.5 0.63 -0.47
ionize 2 0.1 0.15 1 0.63 -0.47
310
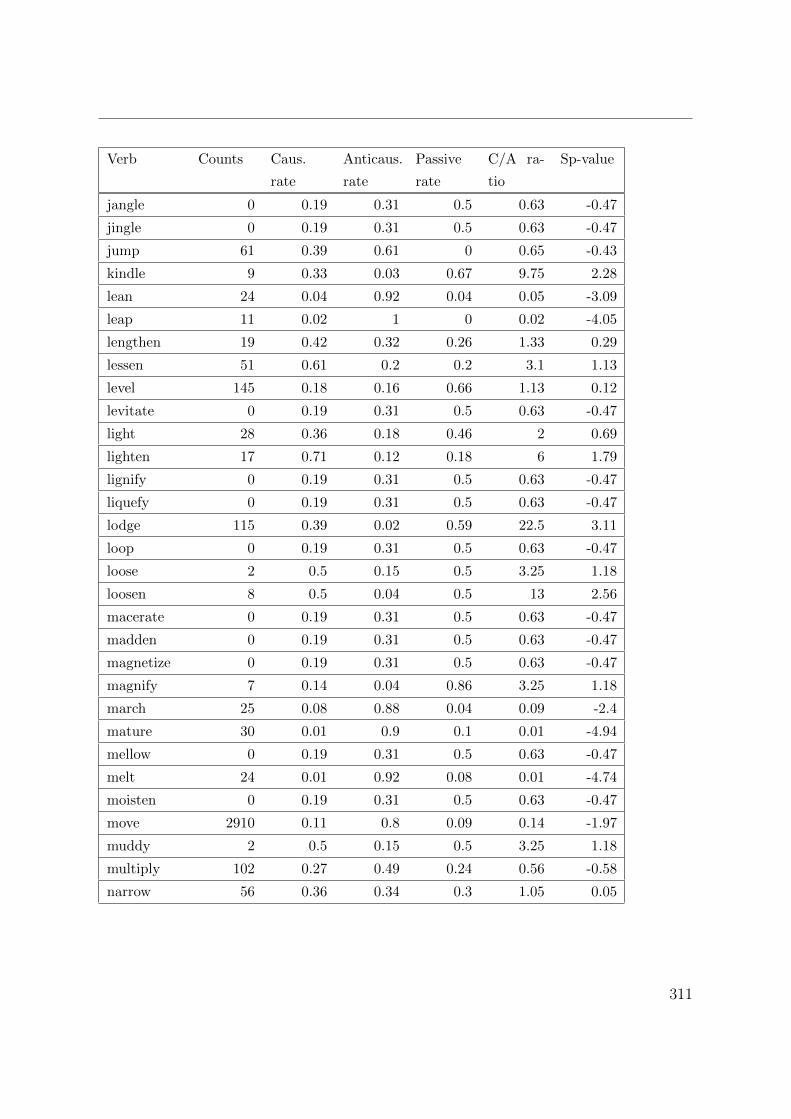
Verb Counts Caus.
rate
Anticaus.
rate
Passive
rate
C/A ra-
tio
Sp-value
jangle 0 0.19 0.31 0.5 0.63 -0.47
jingle 0 0.19 0.31 0.5 0.63 -0.47
jump 61 0.39 0.61 0 0.65 -0.43
kindle 9 0.33 0.03 0.67 9.75 2.28
lean 24 0.04 0.92 0.04 0.05 -3.09
leap 11 0.02 1 0 0.02 -4.05
lengthen 19 0.42 0.32 0.26 1.33 0.29
lessen 51 0.61 0.2 0.2 3.1 1.13
level 145 0.18 0.16 0.66 1.13 0.12
levitate 0 0.19 0.31 0.5 0.63 -0.47
light 28 0.36 0.18 0.46 2 0.69
lighten 17 0.71 0.12 0.18 6 1.79
lignify 0 0.19 0.31 0.5 0.63 -0.47
liquefy 0 0.19 0.31 0.5 0.63 -0.47
lodge 115 0.39 0.02 0.59 22.5 3.11
loop 0 0.19 0.31 0.5 0.63 -0.47
loose 2 0.5 0.15 0.5 3.25 1.18
loosen 8 0.5 0.04 0.5 13 2.56
macerate 0 0.19 0.31 0.5 0.63 -0.47
madden 0 0.19 0.31 0.5 0.63 -0.47
magnetize 0 0.19 0.31 0.5 0.63 -0.47
magnify 7 0.14 0.04 0.86 3.25 1.18
march 25 0.08 0.88 0.04 0.09 -2.4
mature 30 0.01 0.9 0.1 0.01 -4.94
mellow 0 0.19 0.31 0.5 0.63 -0.47
melt 24 0.01 0.92 0.08 0.01 -4.74
moisten 0 0.19 0.31 0.5 0.63 -0.47
move 2910 0.11 0.8 0.09 0.14 -1.97
muddy 2 0.5 0.15 0.5 3.25 1.18
multiply 102 0.27 0.49 0.24 0.56 -0.58
narrow 56 0.36 0.34 0.3 1.05 0.05
311

B. Corpus counts and measures for lexical causatives
Verb Counts Caus.
rate
Anticaus.
rate
Passive
rate
C/A ra-
tio
Sp-value
neaten 0 0.19 0.31 0.5 0.63 -0.47
neutralize 4 0.25 0.08 0.75 3.25 1.18
nitrify 0 0.19 0.31 0.5 0.63 -0.47
obsess 26 0.04 0.01 0.96 3.25 1.18
open 1627 0.54 0.14 0.32 3.79 1.33
operate 994 0.1 0.84 0.06 0.12 -2.16
ossify 1 0.19 0.31 1 0.63 -0.47
overturn 78 0.29 0.01 0.69 23 3.14
oxidize 0 0.19 0.31 0.5 0.63 -0.47
pale 1 0.19 1 0 0.19 -1.65
perch 1 0.19 0.31 1 0.63 -0.47
petrify 1 0.19 0.31 1 0.63 -0.47
polarize 0 0.19 0.31 0.5 0.63 -0.47
pop 4 0.25 0.75 0 0.33 -1.1
proliferate 20 0.15 0.85 0 0.18 -1.73
propagate 13 0.38 0.08 0.54 5 1.61
purify 1 0.19 0.31 1 0.63 -0.47
purple 0 0.19 0.31 0.5 0.63 -0.47
putrefy 1 0.19 1 0 0.19 -1.65
puzzle 30 0.17 0.07 0.77 2.5 0.92
quadruple 10 0.4 0.6 0 0.67 -0.41
quicken 3 0.67 0.33 0 2 0.69
quiet 1 0.19 1 0 0.19 -1.65
quieten 2 0.1 1 0 0.1 -2.34
race 6 0.17 0.5 0.33 0.33 -1.1
redden 0 0.19 0.31 0.5 0.63 -0.47
regularize 3 0.06 0.33 0.67 0.19 -1.65
rekindle 13 0.54 0.08 0.38 7 1.95
reopen 95 0.45 0.08 0.46 5.38 1.68
reproduce 47 0.3 0.3 0.4 1 0
rest 258 0.05 0.94 0 0.06 -2.85
312
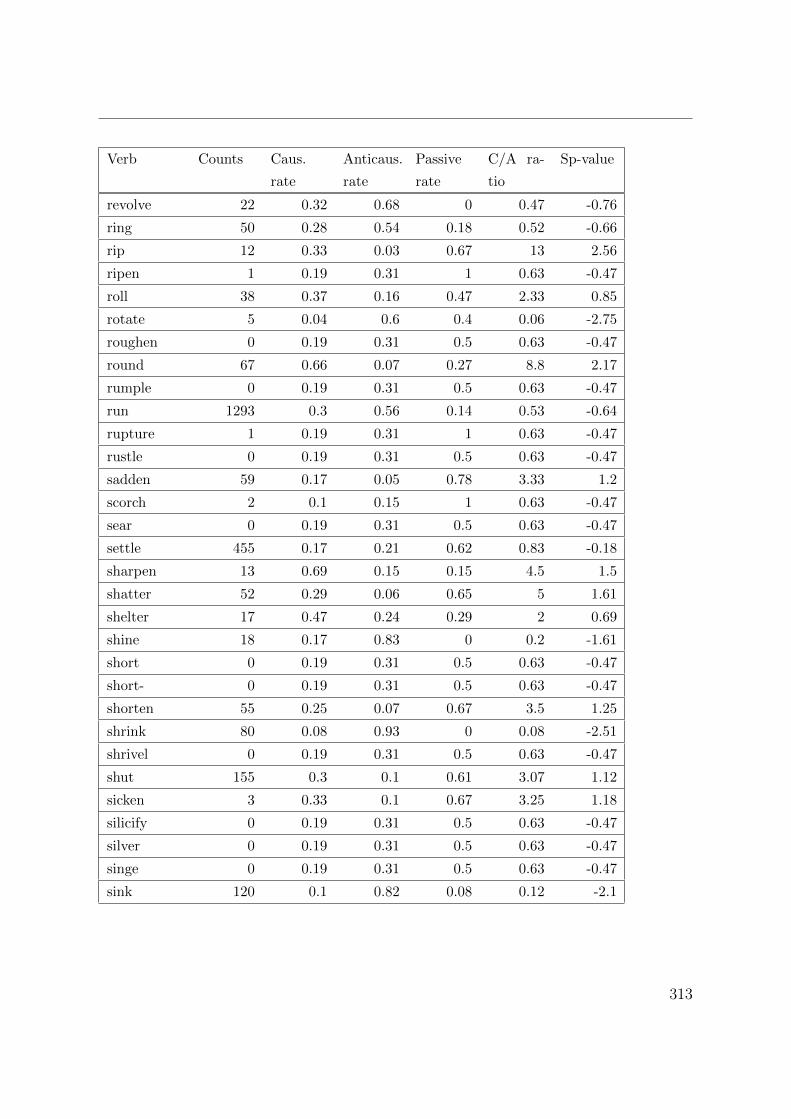
Verb Counts Caus.
rate
Anticaus.
rate
Passive
rate
C/A ra-
tio
Sp-value
revolve 22 0.32 0.68 0 0.47 -0.76
ring 50 0.28 0.54 0.18 0.52 -0.66
rip 12 0.33 0.03 0.67 13 2.56
ripen 1 0.19 0.31 1 0.63 -0.47
roll 38 0.37 0.16 0.47 2.33 0.85
rotate 5 0.04 0.6 0.4 0.06 -2.75
roughen 0 0.19 0.31 0.5 0.63 -0.47
round 67 0.66 0.07 0.27 8.8 2.17
rumple 0 0.19 0.31 0.5 0.63 -0.47
run 1293 0.3 0.56 0.14 0.53 -0.64
rupture 1 0.19 0.31 1 0.63 -0.47
rustle 0 0.19 0.31 0.5 0.63 -0.47
sadden 59 0.17 0.05 0.78 3.33 1.2
scorch 2 0.1 0.15 1 0.63 -0.47
sear 0 0.19 0.31 0.5 0.63 -0.47
settle 455 0.17 0.21 0.62 0.83 -0.18
sharpen 13 0.69 0.15 0.15 4.5 1.5
shatter 52 0.29 0.06 0.65 5 1.61
shelter 17 0.47 0.24 0.29 2 0.69
shine 18 0.17 0.83 0 0.2 -1.61
short 0 0.19 0.31 0.5 0.63 -0.47
short- 0 0.19 0.31 0.5 0.63 -0.47
shorten 55 0.25 0.07 0.67 3.5 1.25
shrink 80 0.08 0.93 0 0.08 -2.51
shrivel 0 0.19 0.31 0.5 0.63 -0.47
shut 155 0.3 0.1 0.61 3.07 1.12
sicken 3 0.33 0.1 0.67 3.25 1.18
silicify 0 0.19 0.31 0.5 0.63 -0.47
silver 0 0.19 0.31 0.5 0.63 -0.47
singe 0 0.19 0.31 0.5 0.63 -0.47
sink 120 0.1 0.82 0.08 0.12 -2.1
313
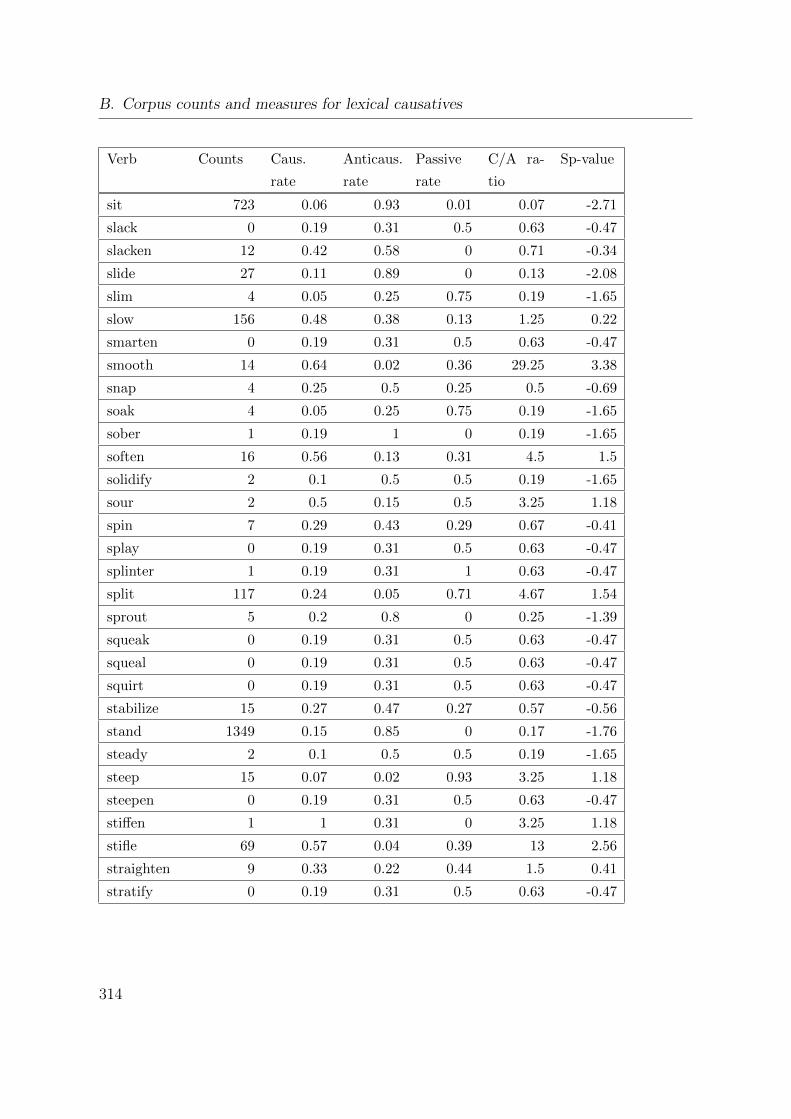
B. Corpus counts and measures for lexical causatives
Verb Counts Caus.
rate
Anticaus.
rate
Passive
rate
C/A ra-
tio
Sp-value
sit 723 0.06 0.93 0.01 0.07 -2.71
slack 0 0.19 0.31 0.5 0.63 -0.47
slacken 12 0.42 0.58 0 0.71 -0.34
slide 27 0.11 0.89 0 0.13 -2.08
slim 4 0.05 0.25 0.75 0.19 -1.65
slow 156 0.48 0.38 0.13 1.25 0.22
smarten 0 0.19 0.31 0.5 0.63 -0.47
smooth 14 0.64 0.02 0.36 29.25 3.38
snap 4 0.25 0.5 0.25 0.5 -0.69
soak 4 0.05 0.25 0.75 0.19 -1.65
sober 1 0.19 1 0 0.19 -1.65
soften 16 0.56 0.13 0.31 4.5 1.5
solidify 2 0.1 0.5 0.5 0.19 -1.65
sour 2 0.5 0.15 0.5 3.25 1.18
spin 7 0.29 0.43 0.29 0.67 -0.41
splay 0 0.19 0.31 0.5 0.63 -0.47
splinter 1 0.19 0.31 1 0.63 -0.47
split 117 0.24 0.05 0.71 4.67 1.54
sprout 5 0.2 0.8 0 0.25 -1.39
squeak 0 0.19 0.31 0.5 0.63 -0.47
squeal 0 0.19 0.31 0.5 0.63 -0.47
squirt 0 0.19 0.31 0.5 0.63 -0.47
stabilize 15 0.27 0.47 0.27 0.57 -0.56
stand 1349 0.15 0.85 0 0.17 -1.76
steady 2 0.1 0.5 0.5 0.19 -1.65
steep 15 0.07 0.02 0.93 3.25 1.18
steepen 0 0.19 0.31 0.5 0.63 -0.47
stiffen 1 1 0.31 0 3.25 1.18
stifle 69 0.57 0.04 0.39 13 2.56
straighten 9 0.33 0.22 0.44 1.5 0.41
stratify 0 0.19 0.31 0.5 0.63 -0.47
314

Verb Counts Caus.
rate
Anticaus.
rate
Passive
rate
C/A ra-
tio
Sp-value
strengthen 1670 0.52 0.05 0.43 10.47 2.35
stretch 90 0.41 0.24 0.34 1.68 0.52
submerge 12 0.02 0.08 0.92 0.19 -1.65
subside 10 0.02 1 0 0.02 -3.95
suffocate 25 0.32 0.28 0.4 1.14 0.13
sweeten 2 0.5 0.15 0.5 3.25 1.18
swim 20 0.01 1 0 0.01 -4.64
swing 15 0.13 0.87 0 0.15 -1.87
tame 4 0.75 0.08 0.25 9.75 2.28
tan 0 0.19 0.31 0.5 0.63 -0.47
taper 0 0.19 0.31 0.5 0.63 -0.47
tauten 0 0.19 0.31 0.5 0.63 -0.47
tear 95 0.31 0.03 0.66 9.67 2.27
tense 0 0.19 0.31 0.5 0.63 -0.47
thaw 0 0.19 0.31 0.5 0.63 -0.47
thicken 1 0.19 0.31 1 0.63 -0.47
thin 1 0.19 0.31 1 0.63 -0.47
thrill 11 0.18 0.03 0.82 6.5 1.87
tighten 175 0.38 0.07 0.55 5.58 1.72
tilt 7 0.43 0.29 0.29 1.5 0.41
tinkle 0 0.19 0.31 0.5 0.63 -0.47
tire 36 0.06 0.47 0.47 0.12 -2.14
topple 19 0.16 0.11 0.74 1.5 0.41
toughen 7 0.57 0.14 0.29 4 1.39
triple 19 0.21 0.74 0.05 0.29 -1.25
trot 15 0.2 0.13 0.67 1.5 0.41
turn 2003 0.37 0.48 0.15 0.77 -0.26
twang 0 0.19 0.31 0.5 0.63 -0.47
twirl 0 0.19 0.31 0.5 0.63 -0.47
twist 8 0.63 0.04 0.38 16.25 2.79
ulcerate 0 0.19 0.31 0.5 0.63 -0.47
315
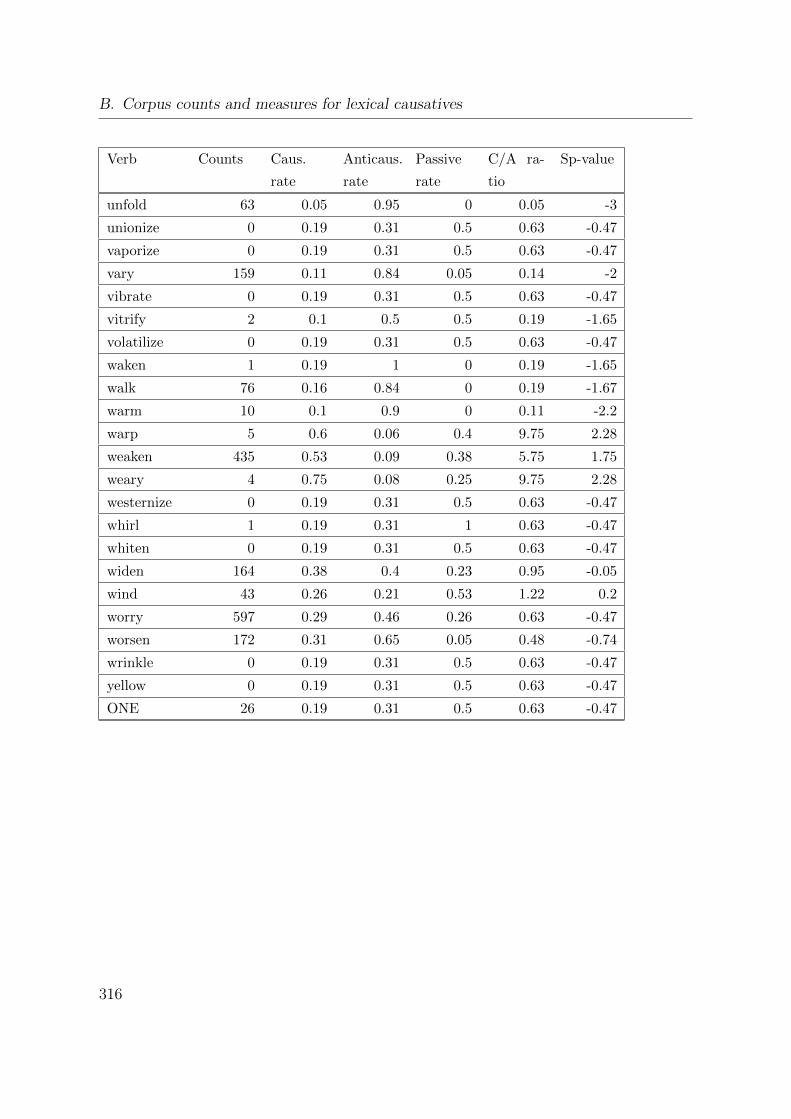
B. Corpus counts and measures for lexical causatives
Verb Counts Caus.
rate
Anticaus.
rate
Passive
rate
C/A ra-
tio
Sp-value
unfold 63 0.05 0.95 0 0.05 -3
unionize 0 0.19 0.31 0.5 0.63 -0.47
vaporize 0 0.19 0.31 0.5 0.63 -0.47
vary 159 0.11 0.84 0.05 0.14 -2
vibrate 0 0.19 0.31 0.5 0.63 -0.47
vitrify 2 0.1 0.5 0.5 0.19 -1.65
volatilize 0 0.19 0.31 0.5 0.63 -0.47
waken 1 0.19 1 0 0.19 -1.65
walk 76 0.16 0.84 0 0.19 -1.67
warm 10 0.1 0.9 0 0.11 -2.2
warp 5 0.6 0.06 0.4 9.75 2.28
weaken 435 0.53 0.09 0.38 5.75 1.75
weary 4 0.75 0.08 0.25 9.75 2.28
westernize 0 0.19 0.31 0.5 0.63 -0.47
whirl 1 0.19 0.31 1 0.63 -0.47
whiten 0 0.19 0.31 0.5 0.63 -0.47
widen 164 0.38 0.4 0.23 0.95 -0.05
wind 43 0.26 0.21 0.53 1.22 0.2
worry 597 0.29 0.46 0.26 0.63 -0.47
worsen 172 0.31 0.65 0.05 0.48 -0.74
wrinkle 0 0.19 0.31 0.5 0.63 -0.47
yellow 0 0.19 0.31 0.5 0.63 -0.47
ONE 26 0.19 0.31 0.5 0.63 -0.47
316

C. Verb aspect and event duration
data
317

C. Verb aspect and event duration data
Verb Pref. Suff. Asp. Dur.
believe 0.3 0.9 0.1 LONG
is 0.6 0.1 0.3 LONG
sold 0.9 0.3 0.7 LONG
deal 0.8 0.5 0.8 LONG
find 0.9 0.5 0.9 LONG
owns 0.8 0.8 0.2 LONG
crashed 0.2 0.6 0.6 LONG
thought 0.6 0.0 0.6 LONG
hit 0.7 0.1 0.7 LONG
thought 0.6 0.0 0.6 LONG
spent 0.8 0.2 0.3 LONG
think 0.4 0.1 0.3 LONG
going 0.4 0.4 0.4 LONG
think 0.4 0.1 0.3 LONG
talking 0.9 0.1 0.3 LONG
estimates 0.7 0.3 0.7 LONG
is 0.6 0.1 0.3 LONG
going 0.4 0.4 0.4 LONG
believe 0.3 0.9 0.1 LONG
lost 0.8 0.1 0.8 LONG
are 0.6 0.2 0.3 LONG
helping 0.7 0.3 0.3 LONG
fallen 0.4 0.1 0.9 LONG
are 0.6 0.2 0.3 LONG
turning 0.4 0.2 0.2 LONG
plunged 0.3 0.3 0.3 LONG
soared 0.7 0.3 0.3 LONG
said 0.2 0.8 0.9 SHORT
double 0.7 0.3 0.7 LONG
means 0.4 0.4 0.1 LONG
spending 0.9 0.1 0.4 LONG
Verb Pref. Suff. Asp. Dur.
get 0.7 0.4 0.8 LONG
goes 0.5 0.3 0.2 LONG
saw 0.2 0.1 0.8 SHORT
calls 0.4 0.2 0.2 SHORT
saw 0.2 0.1 0.8 SHORT
blew 0.8 0.2 0.8 SHORT
became 0.9 0.1 0.8 SHORT
released 0.2 0.2 0.6 SHORT
exploded 0.3 0.7 0.7 SHORT
went 0.7 0.4 0.8 SHORT
said 0.2 0.8 0.9 SHORT
hear 0.1 0.9 0.9 SHORT
went 0.7 0.4 0.8 SHORT
tries 0.8 0.3 0.4 SHORT
asks 0.4 0.1 0.3 SHORT
believe 0.3 0.9 0.1 LONG
make 0.6 0.1 0.7 LONG
give 0.6 0.3 0.6 LONG
kept 0.6 0.2 0.4 LONG
see 0.1 0.0 0.9 LONG
see 0.1 0.0 0.9 LONG
want 0.4 0.1 0.2 LONG
says 0.1 0.3 0.8 SHORT
invited 0.7 0.7 0.3 LONG
predicted 0.7 0.7 0.3 LONG
tried 0.9 0.3 0.5 LONG
said 0.2 0.8 0.9 LONG
tried 0.9 0.3 0.5 LONG
endures 0.9 0.1 0.7 LONG
persuade 0.7 0.5 0.5 LONG
flew 0.7 0.3 0.7 LONG
318

Verb Pref. Suff. Asp. Dur.
say 0.2 0.3 0.9 SHORT
become 1.0 0.1 0.9 LONG
held 0.4 0.3 0.3 LONG
included 0.8 0.2 0.5 LONG
chosen 0.7 0.7 0.3 LONG
learned 0.9 0.1 0.8 SHORT
named 0.5 0.5 0.5 SHORT
taken 0.7 0.2 0.8 SHORT
hurried 0.6 0.2 0.6 LONG
makes 0.7 0.3 0.2 LONG
picked 0.8 0.6 0.9 LONG
followed 0.6 0.4 0.4 LONG
doing 0.3 0.2 0.4 LONG
was 0.1 0.0 0.1 LONG
has 0.6 0.2 0.7 LONG
said 0.2 0.8 0.9 SHORT
said 0.2 0.8 0.9 SHORT
said 0.2 0.8 0.9 SHORT
saw 0.2 0.1 0.8 LONG
come 0.8 0.5 0.8 LONG
said 0.2 0.8 0.9 SHORT
committed 0.9 0.1 0.9 LONG
expected 0.9 0.9 0.1 LONG
said 0.2 0.8 0.9 SHORT
indicated 0.6 0.2 0.6 SHORT
told 0.5 0.5 0.7 SHORT
hopes 0.3 0.7 0.7 LONG
comes 0.3 0.7 0.2 LONG
arrive 0.6 0.6 0.8 LONG
said 0.2 0.8 0.9 SHORT
said 0.2 0.8 0.9 SHORT
Verb Pref. Suff. Asp. Dur.
shipping 0.4 0.2 0.4 LONG
said 0.2 0.8 0.9 SHORT
stopped 0.8 0.1 0.8 LONG
said 0.2 0.8 0.9 SHORT
number 0.6 0.3 0.3 LONG
told 0.5 0.5 0.7 SHORT
met 0.6 0.2 0.9 LONG
bring 0.9 0.3 0.8 LONG
led 0.4 0.1 0.4 LONG
believe 0.3 0.9 0.1 LONG
called 0.3 0.1 0.2 SHORT
appears 0.8 0.2 0.7 SHORT
say 0.2 0.3 0.9 SHORT
engaged 0.4 0.2 0.2 LONG
want 0.4 0.1 0.2 LONG
retreated 0.7 0.7 0.7 LONG
told 0.5 0.5 0.7 SHORT
said 0.2 0.8 0.9 SHORT
said 0.2 0.8 0.9 SHORT
fear 0.4 0.2 0.4 LONG
said 0.2 0.8 0.9 SHORT
denied 0.8 0.6 0.6 LONG
said 0.2 0.8 0.9 SHORT
continue 0.8 0.2 0.6 LONG
receive 0.8 0.2 0.2 LONG
pushed 0.5 0.7 0.7 LONG
plans 0.5 0.8 0.5 LONG
occurred 0.5 0.3 0.9 LONG
say 0.2 0.3 0.9 SHORT
streamed 0.2 0.2 0.2 LONG
quoted 0.3 0.7 0.3 LONG
319
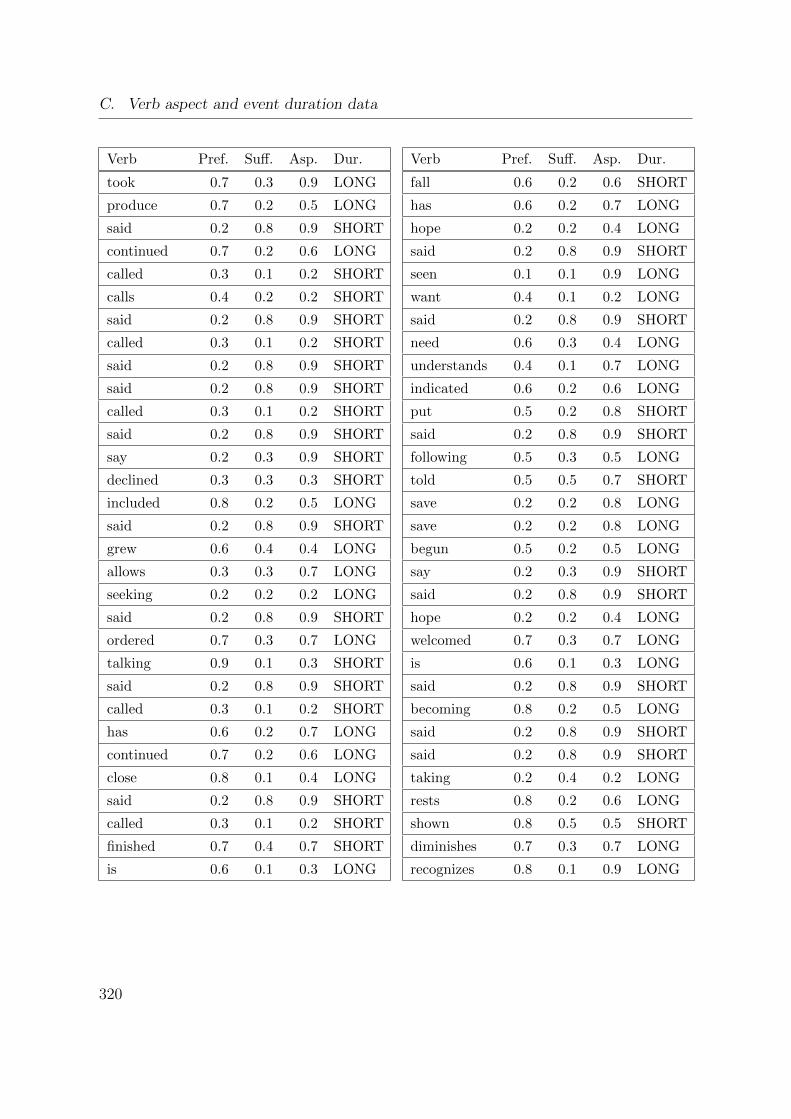
C. Verb aspect and event duration data
Verb Pref. Suff. Asp. Dur.
took 0.7 0.3 0.9 LONG
produce 0.7 0.2 0.5 LONG
said 0.2 0.8 0.9 SHORT
continued 0.7 0.2 0.6 LONG
called 0.3 0.1 0.2 SHORT
calls 0.4 0.2 0.2 SHORT
said 0.2 0.8 0.9 SHORT
called 0.3 0.1 0.2 SHORT
said 0.2 0.8 0.9 SHORT
said 0.2 0.8 0.9 SHORT
called 0.3 0.1 0.2 SHORT
said 0.2 0.8 0.9 SHORT
say 0.2 0.3 0.9 SHORT
declined 0.3 0.3 0.3 SHORT
included 0.8 0.2 0.5 LONG
said 0.2 0.8 0.9 SHORT
grew 0.6 0.4 0.4 LONG
allows 0.3 0.3 0.7 LONG
seeking 0.2 0.2 0.2 LONG
said 0.2 0.8 0.9 SHORT
ordered 0.7 0.3 0.7 LONG
talking 0.9 0.1 0.3 SHORT
said 0.2 0.8 0.9 SHORT
called 0.3 0.1 0.2 SHORT
has 0.6 0.2 0.7 LONG
continued 0.7 0.2 0.6 LONG
close 0.8 0.1 0.4 LONG
said 0.2 0.8 0.9 SHORT
called 0.3 0.1 0.2 SHORT
finished 0.7 0.4 0.7 SHORT
is 0.6 0.1 0.3 LONG
Verb Pref. Suff. Asp. Dur.
fall 0.6 0.2 0.6 SHORT
has 0.6 0.2 0.7 LONG
hope 0.2 0.2 0.4 LONG
said 0.2 0.8 0.9 SHORT
seen 0.1 0.1 0.9 LONG
want 0.4 0.1 0.2 LONG
said 0.2 0.8 0.9 SHORT
need 0.6 0.3 0.4 LONG
understands 0.4 0.1 0.7 LONG
indicated 0.6 0.2 0.6 LONG
put 0.5 0.2 0.8 SHORT
said 0.2 0.8 0.9 SHORT
following 0.5 0.3 0.5 LONG
told 0.5 0.5 0.7 SHORT
save 0.2 0.2 0.8 LONG
save 0.2 0.2 0.8 LONG
begun 0.5 0.2 0.5 LONG
say 0.2 0.3 0.9 SHORT
said 0.2 0.8 0.9 SHORT
hope 0.2 0.2 0.4 LONG
welcomed 0.7 0.3 0.7 LONG
is 0.6 0.1 0.3 LONG
said 0.2 0.8 0.9 SHORT
becoming 0.8 0.2 0.5 LONG
said 0.2 0.8 0.9 SHORT
said 0.2 0.8 0.9 SHORT
taking 0.2 0.4 0.2 LONG
rests 0.8 0.2 0.6 LONG
shown 0.8 0.5 0.5 SHORT
diminishes 0.7 0.3 0.7 LONG
recognizes 0.8 0.1 0.9 LONG
320
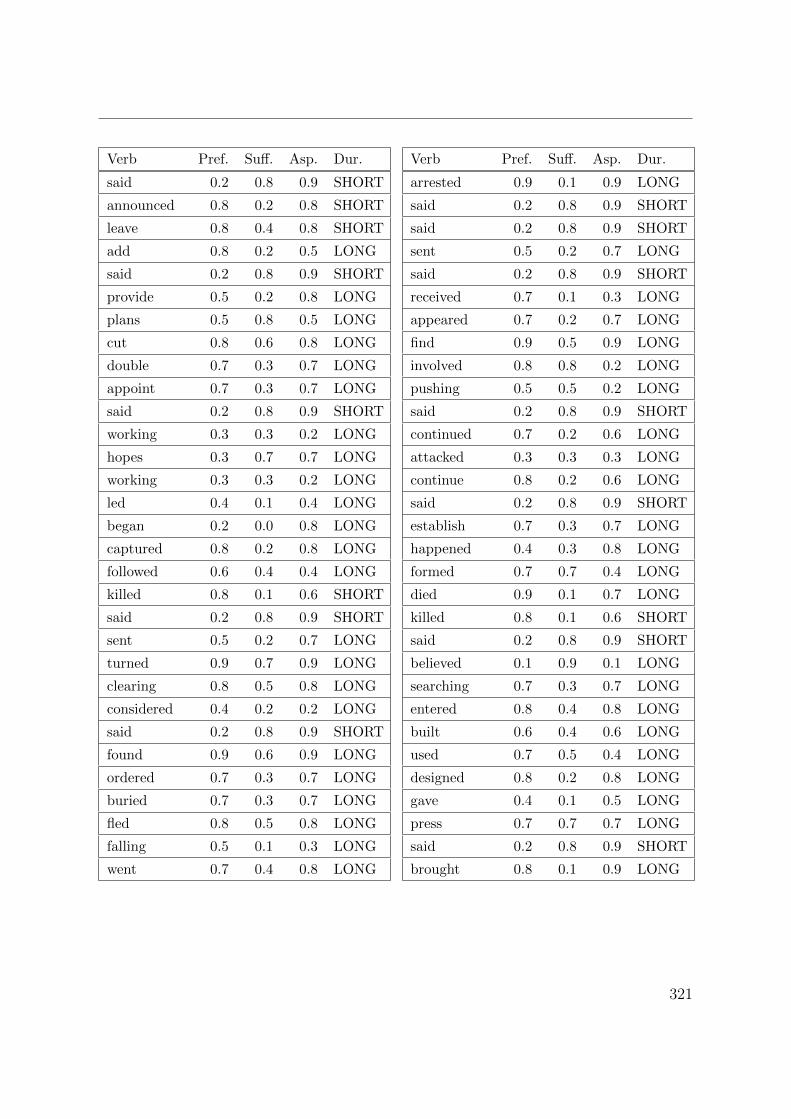
Verb Pref. Suff. Asp. Dur.
said 0.2 0.8 0.9 SHORT
announced 0.8 0.2 0.8 SHORT
leave 0.8 0.4 0.8 SHORT
add 0.8 0.2 0.5 LONG
said 0.2 0.8 0.9 SHORT
provide 0.5 0.2 0.8 LONG
plans 0.5 0.8 0.5 LONG
cut 0.8 0.6 0.8 LONG
double 0.7 0.3 0.7 LONG
appoint 0.7 0.3 0.7 LONG
said 0.2 0.8 0.9 SHORT
working 0.3 0.3 0.2 LONG
hopes 0.3 0.7 0.7 LONG
working 0.3 0.3 0.2 LONG
led 0.4 0.1 0.4 LONG
began 0.2 0.0 0.8 LONG
captured 0.8 0.2 0.8 LONG
followed 0.6 0.4 0.4 LONG
killed 0.8 0.1 0.6 SHORT
said 0.2 0.8 0.9 SHORT
sent 0.5 0.2 0.7 LONG
turned 0.9 0.7 0.9 LONG
clearing 0.8 0.5 0.8 LONG
considered 0.4 0.2 0.2 LONG
said 0.2 0.8 0.9 SHORT
found 0.9 0.6 0.9 LONG
ordered 0.7 0.3 0.7 LONG
buried 0.7 0.3 0.7 LONG
fled 0.8 0.5 0.8 LONG
falling 0.5 0.1 0.3 LONG
went 0.7 0.4 0.8 LONG
Verb Pref. Suff. Asp. Dur.
arrested 0.9 0.1 0.9 LONG
said 0.2 0.8 0.9 SHORT
said 0.2 0.8 0.9 SHORT
sent 0.5 0.2 0.7 LONG
said 0.2 0.8 0.9 SHORT
received 0.7 0.1 0.3 LONG
appeared 0.7 0.2 0.7 LONG
find 0.9 0.5 0.9 LONG
involved 0.8 0.8 0.2 LONG
pushing 0.5 0.5 0.2 LONG
said 0.2 0.8 0.9 SHORT
continued 0.7 0.2 0.6 LONG
attacked 0.3 0.3 0.3 LONG
continue 0.8 0.2 0.6 LONG
said 0.2 0.8 0.9 SHORT
establish 0.7 0.3 0.7 LONG
happened 0.4 0.3 0.8 LONG
formed 0.7 0.7 0.4 LONG
died 0.9 0.1 0.7 LONG
killed 0.8 0.1 0.6 SHORT
said 0.2 0.8 0.9 SHORT
believed 0.1 0.9 0.1 LONG
searching 0.7 0.3 0.7 LONG
entered 0.8 0.4 0.8 LONG
built 0.6 0.4 0.6 LONG
used 0.7 0.5 0.4 LONG
designed 0.8 0.2 0.8 LONG
gave 0.4 0.1 0.5 LONG
press 0.7 0.7 0.7 LONG
said 0.2 0.8 0.9 SHORT
brought 0.8 0.1 0.9 LONG
321
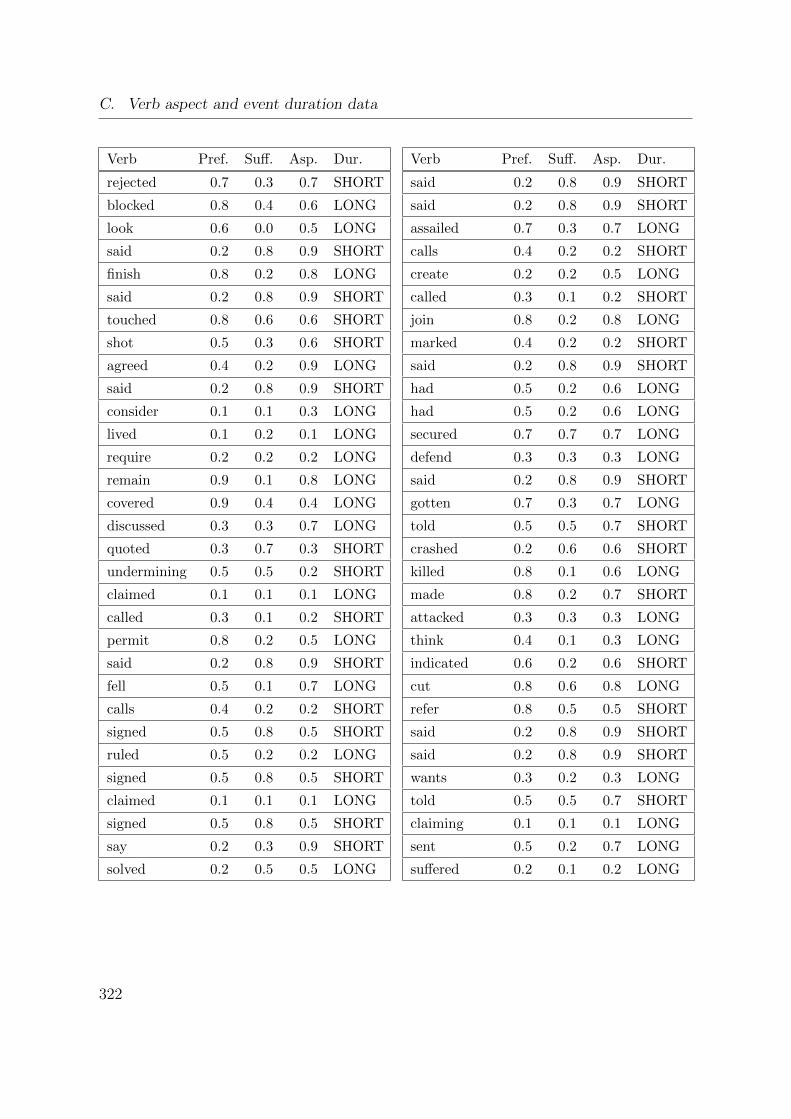
C. Verb aspect and event duration data
Verb Pref. Suff. Asp. Dur.
rejected 0.7 0.3 0.7 SHORT
blocked 0.8 0.4 0.6 LONG
look 0.6 0.0 0.5 LONG
said 0.2 0.8 0.9 SHORT
finish 0.8 0.2 0.8 LONG
said 0.2 0.8 0.9 SHORT
touched 0.8 0.6 0.6 SHORT
shot 0.5 0.3 0.6 SHORT
agreed 0.4 0.2 0.9 LONG
said 0.2 0.8 0.9 SHORT
consider 0.1 0.1 0.3 LONG
lived 0.1 0.2 0.1 LONG
require 0.2 0.2 0.2 LONG
remain 0.9 0.1 0.8 LONG
covered 0.9 0.4 0.4 LONG
discussed 0.3 0.3 0.7 LONG
quoted 0.3 0.7 0.3 SHORT
undermining 0.5 0.5 0.2 SHORT
claimed 0.1 0.1 0.1 LONG
called 0.3 0.1 0.2 SHORT
permit 0.8 0.2 0.5 LONG
said 0.2 0.8 0.9 SHORT
fell 0.5 0.1 0.7 LONG
calls 0.4 0.2 0.2 SHORT
signed 0.5 0.8 0.5 SHORT
ruled 0.5 0.2 0.2 LONG
signed 0.5 0.8 0.5 SHORT
claimed 0.1 0.1 0.1 LONG
signed 0.5 0.8 0.5 SHORT
say 0.2 0.3 0.9 SHORT
solved 0.2 0.5 0.5 LONG
Verb Pref. Suff. Asp. Dur.
said 0.2 0.8 0.9 SHORT
said 0.2 0.8 0.9 SHORT
assailed 0.7 0.3 0.7 LONG
calls 0.4 0.2 0.2 SHORT
create 0.2 0.2 0.5 LONG
called 0.3 0.1 0.2 SHORT
join 0.8 0.2 0.8 LONG
marked 0.4 0.2 0.2 SHORT
said 0.2 0.8 0.9 SHORT
had 0.5 0.2 0.6 LONG
had 0.5 0.2 0.6 LONG
secured 0.7 0.7 0.7 LONG
defend 0.3 0.3 0.3 LONG
said 0.2 0.8 0.9 SHORT
gotten 0.7 0.3 0.7 LONG
told 0.5 0.5 0.7 SHORT
crashed 0.2 0.6 0.6 SHORT
killed 0.8 0.1 0.6 LONG
made 0.8 0.2 0.7 SHORT
attacked 0.3 0.3 0.3 LONG
think 0.4 0.1 0.3 LONG
indicated 0.6 0.2 0.6 SHORT
cut 0.8 0.6 0.8 LONG
refer 0.8 0.5 0.5 SHORT
said 0.2 0.8 0.9 SHORT
said 0.2 0.8 0.9 SHORT
wants 0.3 0.2 0.3 LONG
told 0.5 0.5 0.7 SHORT
claiming 0.1 0.1 0.1 LONG
sent 0.5 0.2 0.7 LONG
suffered 0.2 0.1 0.2 LONG
322
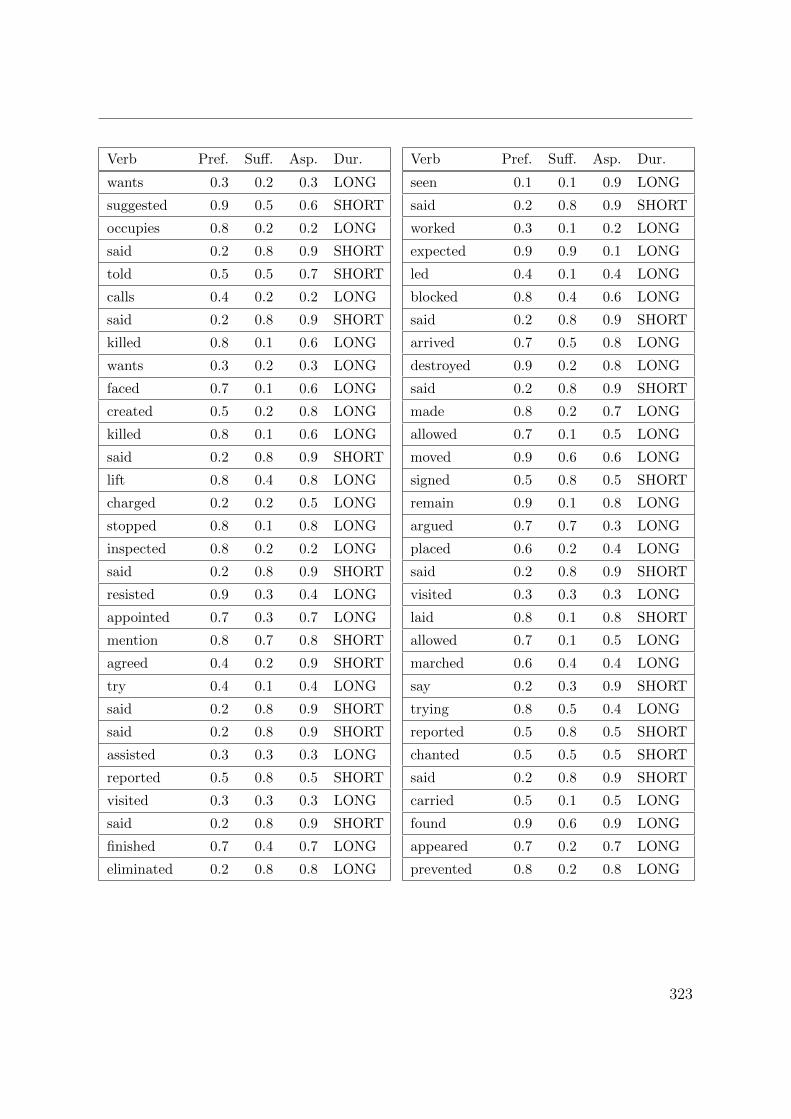
Verb Pref. Suff. Asp. Dur.
wants 0.3 0.2 0.3 LONG
suggested 0.9 0.5 0.6 SHORT
occupies 0.8 0.2 0.2 LONG
said 0.2 0.8 0.9 SHORT
told 0.5 0.5 0.7 SHORT
calls 0.4 0.2 0.2 LONG
said 0.2 0.8 0.9 SHORT
killed 0.8 0.1 0.6 LONG
wants 0.3 0.2 0.3 LONG
faced 0.7 0.1 0.6 LONG
created 0.5 0.2 0.8 LONG
killed 0.8 0.1 0.6 LONG
said 0.2 0.8 0.9 SHORT
lift 0.8 0.4 0.8 LONG
charged 0.2 0.2 0.5 LONG
stopped 0.8 0.1 0.8 LONG
inspected 0.8 0.2 0.2 LONG
said 0.2 0.8 0.9 SHORT
resisted 0.9 0.3 0.4 LONG
appointed 0.7 0.3 0.7 LONG
mention 0.8 0.7 0.8 SHORT
agreed 0.4 0.2 0.9 SHORT
try 0.4 0.1 0.4 LONG
said 0.2 0.8 0.9 SHORT
said 0.2 0.8 0.9 SHORT
assisted 0.3 0.3 0.3 LONG
reported 0.5 0.8 0.5 SHORT
visited 0.3 0.3 0.3 LONG
said 0.2 0.8 0.9 SHORT
finished 0.7 0.4 0.7 LONG
eliminated 0.2 0.8 0.8 LONG
Verb Pref. Suff. Asp. Dur.
seen 0.1 0.1 0.9 LONG
said 0.2 0.8 0.9 SHORT
worked 0.3 0.1 0.2 LONG
expected 0.9 0.9 0.1 LONG
led 0.4 0.1 0.4 LONG
blocked 0.8 0.4 0.6 LONG
said 0.2 0.8 0.9 SHORT
arrived 0.7 0.5 0.8 LONG
destroyed 0.9 0.2 0.8 LONG
said 0.2 0.8 0.9 SHORT
made 0.8 0.2 0.7 LONG
allowed 0.7 0.1 0.5 LONG
moved 0.9 0.6 0.6 LONG
signed 0.5 0.8 0.5 SHORT
remain 0.9 0.1 0.8 LONG
argued 0.7 0.7 0.3 LONG
placed 0.6 0.2 0.4 LONG
said 0.2 0.8 0.9 SHORT
visited 0.3 0.3 0.3 LONG
laid 0.8 0.1 0.8 SHORT
allowed 0.7 0.1 0.5 LONG
marched 0.6 0.4 0.4 LONG
say 0.2 0.3 0.9 SHORT
trying 0.8 0.5 0.4 LONG
reported 0.5 0.8 0.5 SHORT
chanted 0.5 0.5 0.5 SHORT
said 0.2 0.8 0.9 SHORT
carried 0.5 0.1 0.5 LONG
found 0.9 0.6 0.9 LONG
appeared 0.7 0.2 0.7 LONG
prevented 0.8 0.2 0.8 LONG
323

C. Verb aspect and event duration data
Verb Pref. Suff. Asp. Dur.
ruled 0.5 0.2 0.2 LONG
pushed 0.5 0.7 0.7 LONG
said 0.2 0.8 0.9 SHORT
said 0.2 0.8 0.9 SHORT
marched 0.6 0.4 0.4 LONG
supposed 0.2 0.1 0.3 LONG
said 0.2 0.8 0.9 SHORT
hit 0.7 0.1 0.7 SHORT
caused 0.9 0.6 0.9 SHORT
demanded 0.5 0.5 0.2 LONG
said 0.2 0.8 0.9 SHORT
seized 0.9 0.1 0.9 SHORT
bombed 0.3 0.7 0.7 SHORT
invited 0.7 0.7 0.3 LONG
kept 0.6 0.2 0.4 LONG
threatening 0.8 0.2 0.5 LONG
say 0.2 0.3 0.9 SHORT
wants 0.3 0.2 0.3 LONG
said 0.2 0.8 0.9 SHORT
want 0.4 0.1 0.2 LONG
move 0.5 0.5 0.5 LONG
sent 0.5 0.2 0.7 LONG
served 0.7 0.3 0.7 LONG
spent 0.8 0.2 0.3 LONG
expressed 0.7 0.7 0.3 SHORT
part 0.8 0.4 0.6 LONG
set 0.6 0.2 0.7 LONG
said 0.2 0.8 0.9 SHORT
said 0.2 0.8 0.9 SHORT
leaving 0.7 0.4 0.7 LONG
ordered 0.7 0.3 0.7 LONG
Verb Pref. Suff. Asp. Dur.
go 0.6 0.5 0.5 LONG
made 0.8 0.2 0.7 LONG
appointed 0.7 0.3 0.7 LONG
become 1.0 0.1 0.9 LONG
add 0.8 0.2 0.5 LONG
use 0.5 0.4 0.2 LONG
set 0.6 0.2 0.7 LONG
place 0.5 0.2 0.4 LONG
ensure 0.3 0.7 0.7 LONG
provide 0.5 0.2 0.8 LONG
emerge 0.5 0.2 0.8 LONG
emerged 0.8 0.2 0.8 LONG
help 0.8 0.4 0.8 LONG
has 0.6 0.2 0.7 LONG
beginning 0.7 0.3 0.3 LONG
come 0.8 0.5 0.8 LONG
reaching 0.5 0.5 0.8 LONG
create 0.2 0.2 0.5 LONG
prove 0.8 0.2 0.8 LONG
need 0.6 0.3 0.4 LONG
wrote 0.8 0.8 0.8 LONG
reported 0.5 0.8 0.5 LONG
organising 0.2 0.8 0.8 LONG
have 0.6 0.2 0.6 LONG
invited 0.7 0.7 0.3 LONG
held 0.4 0.3 0.3 LONG
interpret 0.3 0.3 0.3 LONG
do 0.3 0.2 0.4 LONG
reproduced 0.3 0.7 0.7 SHORT
said 0.2 0.8 0.9 LONG
said 0.2 0.8 0.9 SHORT
324
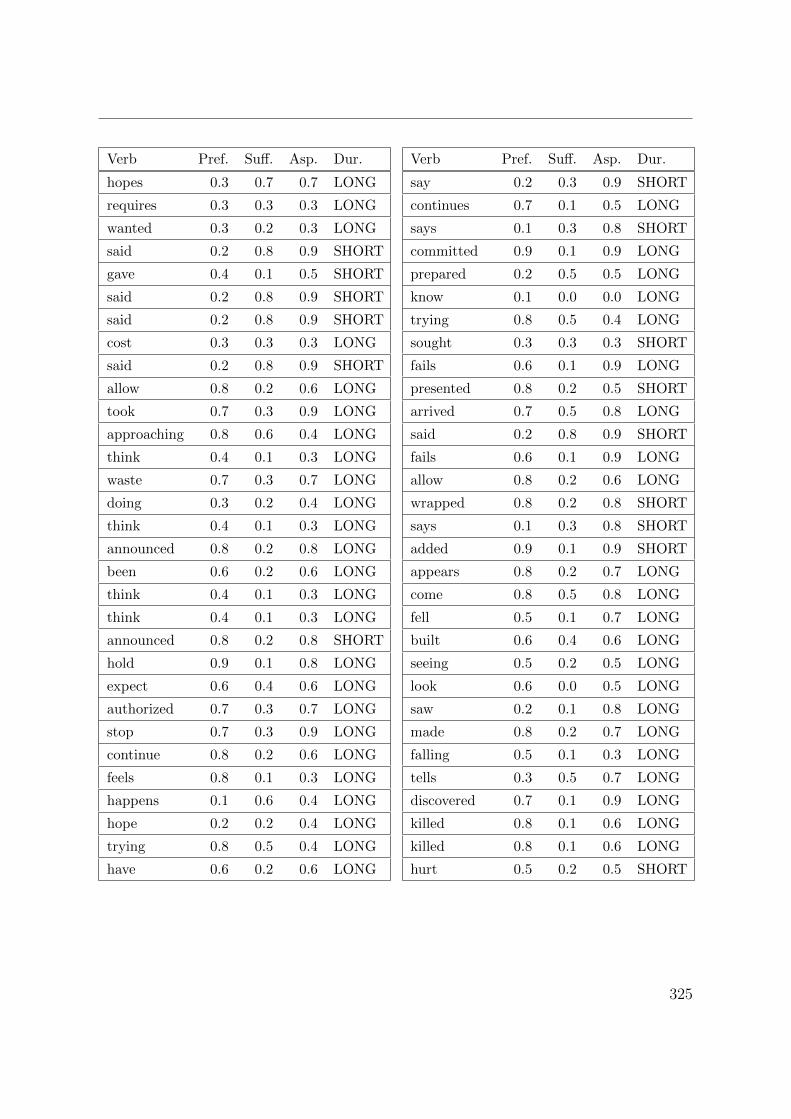
Verb Pref. Suff. Asp. Dur.
hopes 0.3 0.7 0.7 LONG
requires 0.3 0.3 0.3 LONG
wanted 0.3 0.2 0.3 LONG
said 0.2 0.8 0.9 SHORT
gave 0.4 0.1 0.5 SHORT
said 0.2 0.8 0.9 SHORT
said 0.2 0.8 0.9 SHORT
cost 0.3 0.3 0.3 LONG
said 0.2 0.8 0.9 SHORT
allow 0.8 0.2 0.6 LONG
took 0.7 0.3 0.9 LONG
approaching 0.8 0.6 0.4 LONG
think 0.4 0.1 0.3 LONG
waste 0.7 0.3 0.7 LONG
doing 0.3 0.2 0.4 LONG
think 0.4 0.1 0.3 LONG
announced 0.8 0.2 0.8 LONG
been 0.6 0.2 0.6 LONG
think 0.4 0.1 0.3 LONG
think 0.4 0.1 0.3 LONG
announced 0.8 0.2 0.8 SHORT
hold 0.9 0.1 0.8 LONG
expect 0.6 0.4 0.6 LONG
authorized 0.7 0.3 0.7 LONG
stop 0.7 0.3 0.9 LONG
continue 0.8 0.2 0.6 LONG
feels 0.8 0.1 0.3 LONG
happens 0.1 0.6 0.4 LONG
hope 0.2 0.2 0.4 LONG
trying 0.8 0.5 0.4 LONG
have 0.6 0.2 0.6 LONG
Verb Pref. Suff. Asp. Dur.
say 0.2 0.3 0.9 SHORT
continues 0.7 0.1 0.5 LONG
says 0.1 0.3 0.8 SHORT
committed 0.9 0.1 0.9 LONG
prepared 0.2 0.5 0.5 LONG
know 0.1 0.0 0.0 LONG
trying 0.8 0.5 0.4 LONG
sought 0.3 0.3 0.3 SHORT
fails 0.6 0.1 0.9 LONG
presented 0.8 0.2 0.5 SHORT
arrived 0.7 0.5 0.8 LONG
said 0.2 0.8 0.9 SHORT
fails 0.6 0.1 0.9 LONG
allow 0.8 0.2 0.6 LONG
wrapped 0.8 0.2 0.8 SHORT
says 0.1 0.3 0.8 SHORT
added 0.9 0.1 0.9 SHORT
appears 0.8 0.2 0.7 LONG
come 0.8 0.5 0.8 LONG
fell 0.5 0.1 0.7 LONG
built 0.6 0.4 0.6 LONG
seeing 0.5 0.2 0.5 LONG
look 0.6 0.0 0.5 LONG
saw 0.2 0.1 0.8 LONG
made 0.8 0.2 0.7 LONG
falling 0.5 0.1 0.3 LONG
tells 0.3 0.5 0.7 LONG
discovered 0.7 0.1 0.9 LONG
killed 0.8 0.1 0.6 LONG
killed 0.8 0.1 0.6 LONG
hurt 0.5 0.2 0.5 SHORT
325
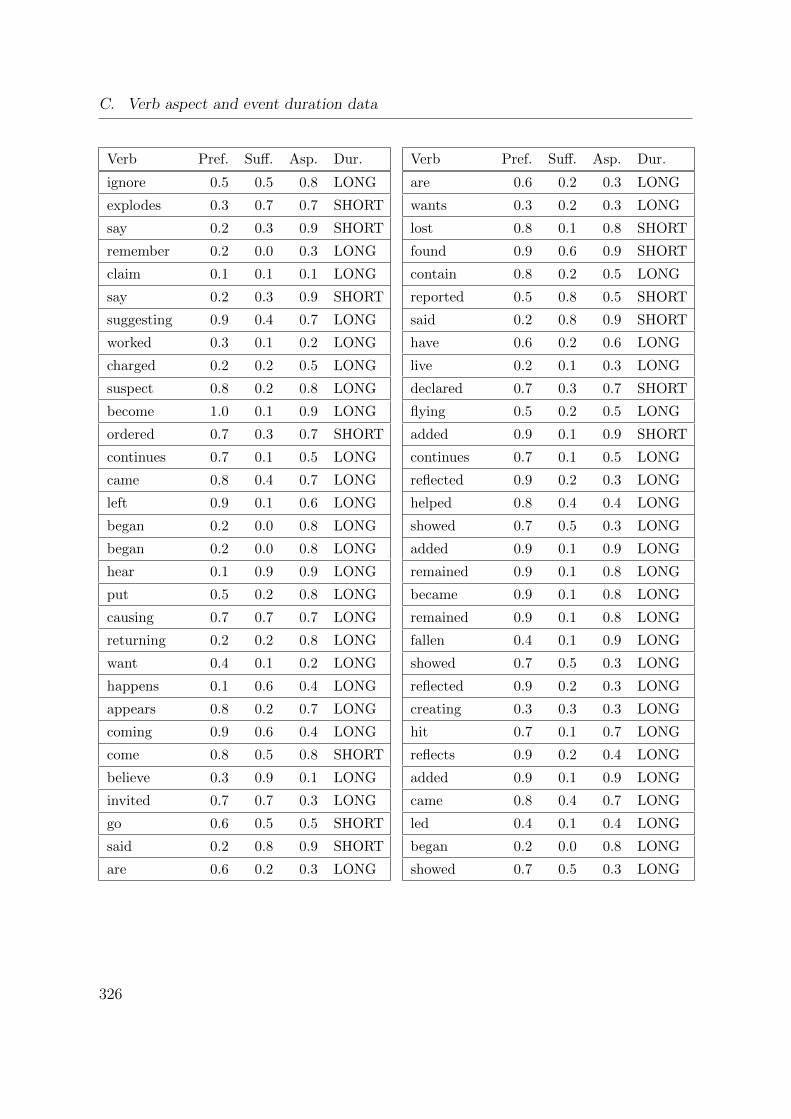
C. Verb aspect and event duration data
Verb Pref. Suff. Asp. Dur.
ignore 0.5 0.5 0.8 LONG
explodes 0.3 0.7 0.7 SHORT
say 0.2 0.3 0.9 SHORT
remember 0.2 0.0 0.3 LONG
claim 0.1 0.1 0.1 LONG
say 0.2 0.3 0.9 SHORT
suggesting 0.9 0.4 0.7 LONG
worked 0.3 0.1 0.2 LONG
charged 0.2 0.2 0.5 LONG
suspect 0.8 0.2 0.8 LONG
become 1.0 0.1 0.9 LONG
ordered 0.7 0.3 0.7 SHORT
continues 0.7 0.1 0.5 LONG
came 0.8 0.4 0.7 LONG
left 0.9 0.1 0.6 LONG
began 0.2 0.0 0.8 LONG
began 0.2 0.0 0.8 LONG
hear 0.1 0.9 0.9 LONG
put 0.5 0.2 0.8 LONG
causing 0.7 0.7 0.7 LONG
returning 0.2 0.2 0.8 LONG
want 0.4 0.1 0.2 LONG
happens 0.1 0.6 0.4 LONG
appears 0.8 0.2 0.7 LONG
coming 0.9 0.6 0.4 LONG
come 0.8 0.5 0.8 SHORT
believe 0.3 0.9 0.1 LONG
invited 0.7 0.7 0.3 LONG
go 0.6 0.5 0.5 SHORT
said 0.2 0.8 0.9 SHORT
are 0.6 0.2 0.3 LONG
Verb Pref. Suff. Asp. Dur.
are 0.6 0.2 0.3 LONG
wants 0.3 0.2 0.3 LONG
lost 0.8 0.1 0.8 SHORT
found 0.9 0.6 0.9 SHORT
contain 0.8 0.2 0.5 LONG
reported 0.5 0.8 0.5 SHORT
said 0.2 0.8 0.9 SHORT
have 0.6 0.2 0.6 LONG
live 0.2 0.1 0.3 LONG
declared 0.7 0.3 0.7 SHORT
flying 0.5 0.2 0.5 LONG
added 0.9 0.1 0.9 SHORT
continues 0.7 0.1 0.5 LONG
reflected 0.9 0.2 0.3 LONG
helped 0.8 0.4 0.4 LONG
showed 0.7 0.5 0.3 LONG
added 0.9 0.1 0.9 LONG
remained 0.9 0.1 0.8 LONG
became 0.9 0.1 0.8 LONG
remained 0.9 0.1 0.8 LONG
fallen 0.4 0.1 0.9 LONG
showed 0.7 0.5 0.3 LONG
reflected 0.9 0.2 0.3 LONG
creating 0.3 0.3 0.3 LONG
hit 0.7 0.1 0.7 LONG
reflects 0.9 0.2 0.4 LONG
added 0.9 0.1 0.9 LONG
came 0.8 0.4 0.7 LONG
led 0.4 0.1 0.4 LONG
began 0.2 0.0 0.8 LONG
showed 0.7 0.5 0.3 LONG
326

Verb Pref. Suff. Asp. Dur.
allowed 0.7 0.1 0.5 LONG
move 0.5 0.5 0.5 LONG
broke 0.8 0.2 0.8 LONG
said 0.2 0.8 0.9 SHORT
dropped 0.8 0.3 0.8 LONG
reported 0.5 0.8 0.5 SHORT
withstood 0.7 0.3 0.7 LONG
created 0.5 0.2 0.8 LONG
caused 0.9 0.6 0.9 LONG
extended 0.7 0.3 0.3 LONG
rose 0.4 0.2 0.5 LONG
suggested 0.9 0.5 0.6 LONG
intend 0.7 0.7 0.3 LONG
set 0.6 0.2 0.7 LONG
said 0.2 0.8 0.9 SHORT
edged 0.7 0.3 0.3 LONG
helped 0.8 0.4 0.4 LONG
rose 0.4 0.2 0.5 LONG
welcomed 0.7 0.3 0.7 LONG
said 0.2 0.8 0.9 SHORT
expects 0.9 0.8 0.2 LONG
made 0.8 0.2 0.7 LONG
raise 0.8 0.7 0.8 LONG
said 0.2 0.8 0.9 SHORT
disregarded 0.7 0.3 0.7 SHORT
expected 0.9 0.9 0.1 LONG
running 0.5 0.2 0.3 LONG
said 0.2 0.8 0.9 SHORT
left 0.9 0.1 0.6 LONG
extending 0.6 0.2 0.4 LONG
given 0.6 0.5 0.9 LONG
Verb Pref. Suff. Asp. Dur.
rose 0.4 0.2 0.5 LONG
lost 0.8 0.1 0.8 LONG
exhaust 0.7 0.7 0.3 LONG
start 0.5 0.4 0.6 LONG
declined 0.3 0.3 0.3 LONG
showed 0.7 0.5 0.3 LONG
tried 0.9 0.3 0.5 LONG
believes 0.2 0.9 0.1 LONG
asked 0.6 0.1 0.3 SHORT
want 0.4 0.1 0.2 SHORT
made 0.8 0.2 0.7 SHORT
know 0.1 0.0 0.0 LONG
stated 0.4 0.8 0.8 SHORT
pleased 0.3 0.1 0.1 SHORT
removed 0.6 0.2 0.6 LONG
intended 0.7 0.2 0.3 LONG
lives 0.8 0.3 0.8 LONG
said 0.2 0.8 0.9 SHORT
took 0.7 0.3 0.9 SHORT
waiting 0.1 0.1 0.1 SHORT
looks 0.7 0.3 0.3 LONG
said 0.2 0.8 0.9 SHORT
said 0.2 0.8 0.9 SHORT
said 0.2 0.8 0.9 SHORT
finished 0.7 0.4 0.7 SHORT
emptied 0.8 0.2 0.8 SHORT
appeared 0.7 0.2 0.7 SHORT
said 0.2 0.8 0.9 SHORT
watching 0.9 0.1 0.1 SHORT
killed 0.8 0.1 0.6 SHORT
327
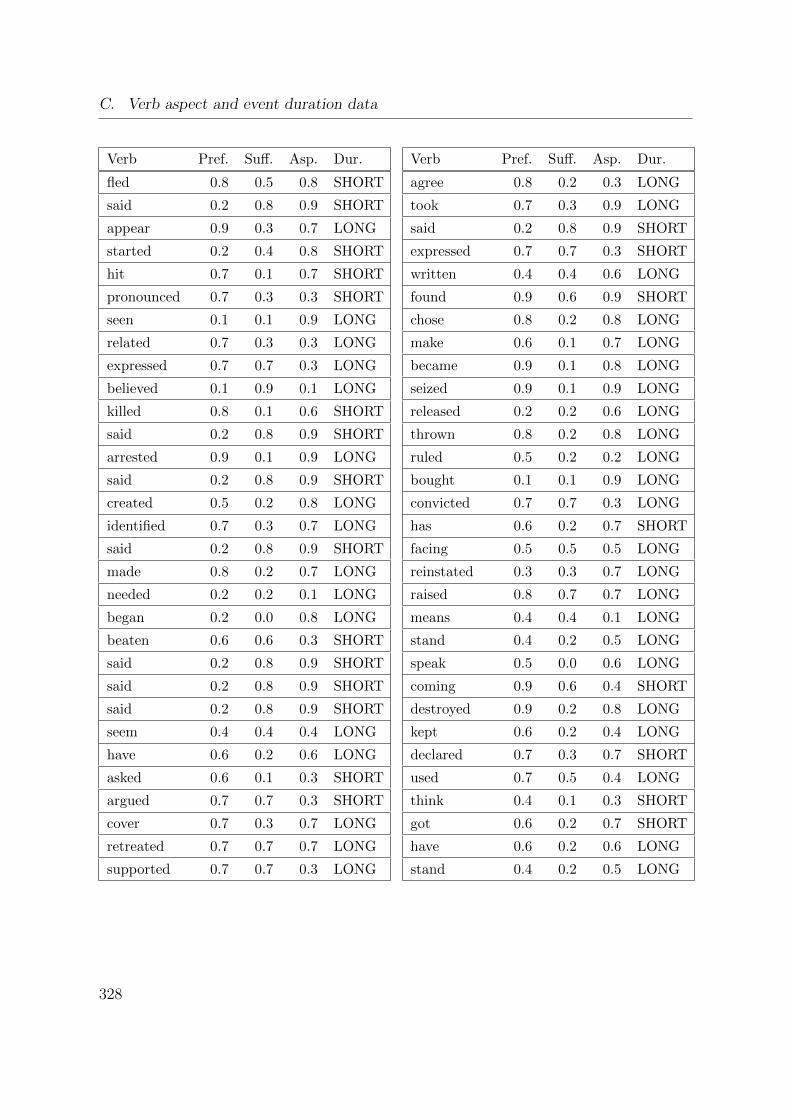
C. Verb aspect and event duration data
Verb Pref. Suff. Asp. Dur.
fled 0.8 0.5 0.8 SHORT
said 0.2 0.8 0.9 SHORT
appear 0.9 0.3 0.7 LONG
started 0.2 0.4 0.8 SHORT
hit 0.7 0.1 0.7 SHORT
pronounced 0.7 0.3 0.3 SHORT
seen 0.1 0.1 0.9 LONG
related 0.7 0.3 0.3 LONG
expressed 0.7 0.7 0.3 LONG
believed 0.1 0.9 0.1 LONG
killed 0.8 0.1 0.6 SHORT
said 0.2 0.8 0.9 SHORT
arrested 0.9 0.1 0.9 LONG
said 0.2 0.8 0.9 SHORT
created 0.5 0.2 0.8 LONG
identified 0.7 0.3 0.7 LONG
said 0.2 0.8 0.9 SHORT
made 0.8 0.2 0.7 LONG
needed 0.2 0.2 0.1 LONG
began 0.2 0.0 0.8 LONG
beaten 0.6 0.6 0.3 SHORT
said 0.2 0.8 0.9 SHORT
said 0.2 0.8 0.9 SHORT
said 0.2 0.8 0.9 SHORT
seem 0.4 0.4 0.4 LONG
have 0.6 0.2 0.6 LONG
asked 0.6 0.1 0.3 SHORT
argued 0.7 0.7 0.3 SHORT
cover 0.7 0.3 0.7 LONG
retreated 0.7 0.7 0.7 LONG
supported 0.7 0.7 0.3 LONG
Verb Pref. Suff. Asp. Dur.
agree 0.8 0.2 0.3 LONG
took 0.7 0.3 0.9 LONG
said 0.2 0.8 0.9 SHORT
expressed 0.7 0.7 0.3 SHORT
written 0.4 0.4 0.6 LONG
found 0.9 0.6 0.9 SHORT
chose 0.8 0.2 0.8 LONG
make 0.6 0.1 0.7 LONG
became 0.9 0.1 0.8 LONG
seized 0.9 0.1 0.9 LONG
released 0.2 0.2 0.6 LONG
thrown 0.8 0.2 0.8 LONG
ruled 0.5 0.2 0.2 LONG
bought 0.1 0.1 0.9 LONG
convicted 0.7 0.7 0.3 LONG
has 0.6 0.2 0.7 SHORT
facing 0.5 0.5 0.5 LONG
reinstated 0.3 0.3 0.7 LONG
raised 0.8 0.7 0.7 LONG
means 0.4 0.4 0.1 LONG
stand 0.4 0.2 0.5 LONG
speak 0.5 0.0 0.6 LONG
coming 0.9 0.6 0.4 SHORT
destroyed 0.9 0.2 0.8 LONG
kept 0.6 0.2 0.4 LONG
declared 0.7 0.3 0.7 SHORT
used 0.7 0.5 0.4 LONG
think 0.4 0.1 0.3 SHORT
got 0.6 0.2 0.7 SHORT
have 0.6 0.2 0.6 LONG
stand 0.4 0.2 0.5 LONG
328
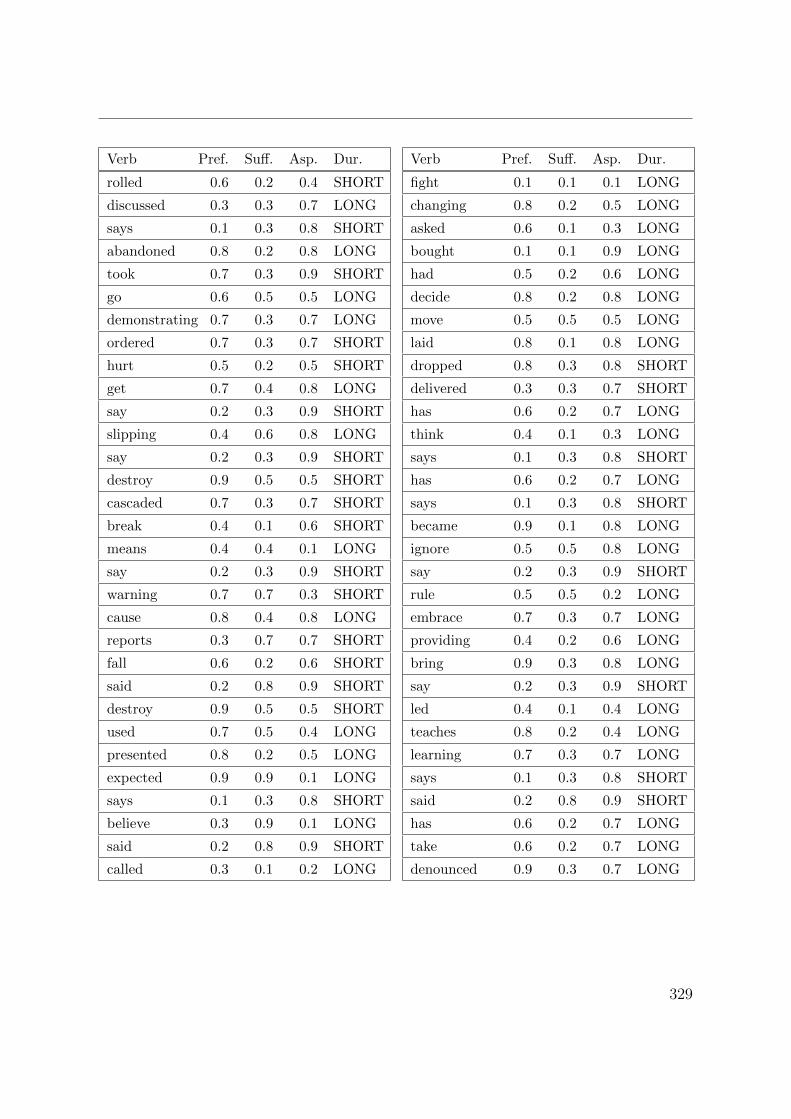
Verb Pref. Suff. Asp. Dur.
rolled 0.6 0.2 0.4 SHORT
discussed 0.3 0.3 0.7 LONG
says 0.1 0.3 0.8 SHORT
abandoned 0.8 0.2 0.8 LONG
took 0.7 0.3 0.9 SHORT
go 0.6 0.5 0.5 LONG
demonstrating 0.7 0.3 0.7 LONG
ordered 0.7 0.3 0.7 SHORT
hurt 0.5 0.2 0.5 SHORT
get 0.7 0.4 0.8 LONG
say 0.2 0.3 0.9 SHORT
slipping 0.4 0.6 0.8 LONG
say 0.2 0.3 0.9 SHORT
destroy 0.9 0.5 0.5 SHORT
cascaded 0.7 0.3 0.7 SHORT
break 0.4 0.1 0.6 SHORT
means 0.4 0.4 0.1 LONG
say 0.2 0.3 0.9 SHORT
warning 0.7 0.7 0.3 SHORT
cause 0.8 0.4 0.8 LONG
reports 0.3 0.7 0.7 SHORT
fall 0.6 0.2 0.6 SHORT
said 0.2 0.8 0.9 SHORT
destroy 0.9 0.5 0.5 SHORT
used 0.7 0.5 0.4 LONG
presented 0.8 0.2 0.5 LONG
expected 0.9 0.9 0.1 LONG
says 0.1 0.3 0.8 SHORT
believe 0.3 0.9 0.1 LONG
said 0.2 0.8 0.9 SHORT
called 0.3 0.1 0.2 LONG
Verb Pref. Suff. Asp. Dur.
fight 0.1 0.1 0.1 LONG
changing 0.8 0.2 0.5 LONG
asked 0.6 0.1 0.3 LONG
bought 0.1 0.1 0.9 LONG
had 0.5 0.2 0.6 LONG
decide 0.8 0.2 0.8 LONG
move 0.5 0.5 0.5 LONG
laid 0.8 0.1 0.8 LONG
dropped 0.8 0.3 0.8 SHORT
delivered 0.3 0.3 0.7 SHORT
has 0.6 0.2 0.7 LONG
think 0.4 0.1 0.3 LONG
says 0.1 0.3 0.8 SHORT
has 0.6 0.2 0.7 LONG
says 0.1 0.3 0.8 SHORT
became 0.9 0.1 0.8 LONG
ignore 0.5 0.5 0.8 LONG
say 0.2 0.3 0.9 SHORT
rule 0.5 0.5 0.2 LONG
embrace 0.7 0.3 0.7 LONG
providing 0.4 0.2 0.6 LONG
bring 0.9 0.3 0.8 LONG
say 0.2 0.3 0.9 SHORT
led 0.4 0.1 0.4 LONG
teaches 0.8 0.2 0.4 LONG
learning 0.7 0.3 0.7 LONG
says 0.1 0.3 0.8 SHORT
said 0.2 0.8 0.9 SHORT
has 0.6 0.2 0.7 LONG
take 0.6 0.2 0.7 LONG
denounced 0.9 0.3 0.7 LONG
329
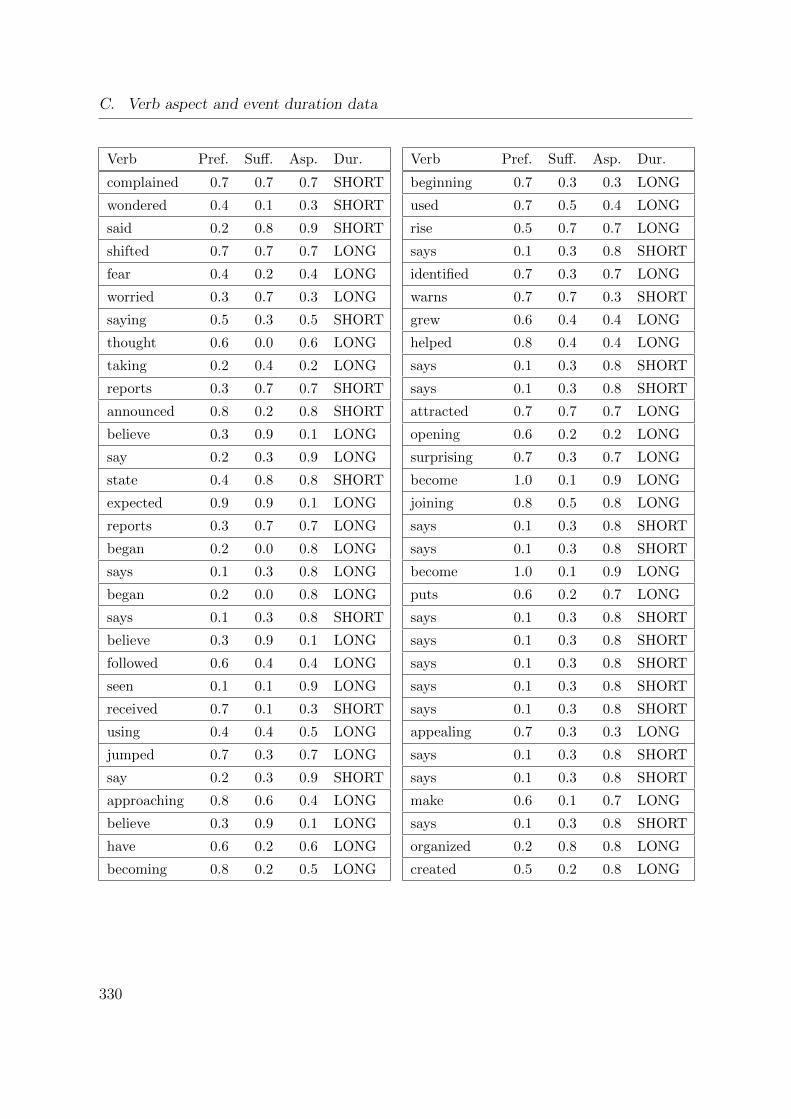
C. Verb aspect and event duration data
Verb Pref. Suff. Asp. Dur.
complained 0.7 0.7 0.7 SHORT
wondered 0.4 0.1 0.3 SHORT
said 0.2 0.8 0.9 SHORT
shifted 0.7 0.7 0.7 LONG
fear 0.4 0.2 0.4 LONG
worried 0.3 0.7 0.3 LONG
saying 0.5 0.3 0.5 SHORT
thought 0.6 0.0 0.6 LONG
taking 0.2 0.4 0.2 LONG
reports 0.3 0.7 0.7 SHORT
announced 0.8 0.2 0.8 SHORT
believe 0.3 0.9 0.1 LONG
say 0.2 0.3 0.9 LONG
state 0.4 0.8 0.8 SHORT
expected 0.9 0.9 0.1 LONG
reports 0.3 0.7 0.7 LONG
began 0.2 0.0 0.8 LONG
says 0.1 0.3 0.8 LONG
began 0.2 0.0 0.8 LONG
says 0.1 0.3 0.8 SHORT
believe 0.3 0.9 0.1 LONG
followed 0.6 0.4 0.4 LONG
seen 0.1 0.1 0.9 LONG
received 0.7 0.1 0.3 SHORT
using 0.4 0.4 0.5 LONG
jumped 0.7 0.3 0.7 LONG
say 0.2 0.3 0.9 SHORT
approaching 0.8 0.6 0.4 LONG
believe 0.3 0.9 0.1 LONG
have 0.6 0.2 0.6 LONG
becoming 0.8 0.2 0.5 LONG
Verb Pref. Suff. Asp. Dur.
beginning 0.7 0.3 0.3 LONG
used 0.7 0.5 0.4 LONG
rise 0.5 0.7 0.7 LONG
says 0.1 0.3 0.8 SHORT
identified 0.7 0.3 0.7 LONG
warns 0.7 0.7 0.3 SHORT
grew 0.6 0.4 0.4 LONG
helped 0.8 0.4 0.4 LONG
says 0.1 0.3 0.8 SHORT
says 0.1 0.3 0.8 SHORT
attracted 0.7 0.7 0.7 LONG
opening 0.6 0.2 0.2 LONG
surprising 0.7 0.3 0.7 LONG
become 1.0 0.1 0.9 LONG
joining 0.8 0.5 0.8 LONG
says 0.1 0.3 0.8 SHORT
says 0.1 0.3 0.8 SHORT
become 1.0 0.1 0.9 LONG
puts 0.6 0.2 0.7 LONG
says 0.1 0.3 0.8 SHORT
says 0.1 0.3 0.8 SHORT
says 0.1 0.3 0.8 SHORT
says 0.1 0.3 0.8 SHORT
says 0.1 0.3 0.8 SHORT
appealing 0.7 0.3 0.3 LONG
says 0.1 0.3 0.8 SHORT
says 0.1 0.3 0.8 SHORT
make 0.6 0.1 0.7 LONG
says 0.1 0.3 0.8 SHORT
organized 0.2 0.8 0.8 LONG
created 0.5 0.2 0.8 LONG
330

Verb Pref. Suff. Asp. Dur.
become 1.0 0.1 0.9 LONG
says 0.1 0.3 0.8 SHORT
facing 0.5 0.5 0.5 LONG
forbidden 0.8 0.2 0.8 LONG
have 0.6 0.2 0.6 LONG
torn 0.4 0.4 0.4 LONG
gets 0.3 0.7 0.3 LONG
forced 0.8 0.5 0.3 LONG
become 1.0 0.1 0.9 LONG
runs 0.5 0.2 0.6 LONG
says 0.1 0.3 0.8 SHORT
put 0.5 0.2 0.8 LONG
do 0.3 0.2 0.4 LONG
works 0.3 0.7 0.3 LONG
gave 0.4 0.1 0.5 LONG
says 0.1 0.3 0.8 SHORT
said 0.2 0.8 0.9 SHORT
served 0.7 0.3 0.7 LONG
made 0.8 0.2 0.7 LONG
works 0.3 0.7 0.3 LONG
says 0.1 0.3 0.8 SHORT
announced 0.8 0.2 0.8 SHORT
need 0.6 0.3 0.4 LONG
have 0.6 0.2 0.6 LONG
treated 0.8 0.2 0.5 LONG
says 0.1 0.3 0.8 SHORT
doing 0.3 0.2 0.4 LONG
waiting 0.1 0.1 0.1 LONG
do 0.3 0.2 0.4 LONG
save 0.2 0.2 0.8 LONG
begins 0.8 0.2 0.2 LONG
Verb Pref. Suff. Asp. Dur.
is 0.6 0.1 0.3 LONG
accumulate 0.7 0.3 0.7 LONG
see 0.1 0.0 0.9 LONG
called 0.3 0.1 0.2 SHORT
asked 0.6 0.1 0.3 LONG
expects 0.9 0.8 0.2 LONG
suggested 0.9 0.5 0.6 SHORT
said 0.2 0.8 0.9 SHORT
says 0.1 0.3 0.8 SHORT
meet 0.5 0.2 0.7 LONG
remain 0.9 0.1 0.8 LONG
paid 0.9 0.4 0.2 LONG
had 0.5 0.2 0.6 LONG
purchased 0.3 0.3 0.7 LONG
said 0.2 0.8 0.9 SHORT
denied 0.8 0.6 0.6 LONG
said 0.2 0.8 0.9 SHORT
decided 0.5 0.2 0.8 SHORT
turned 0.9 0.7 0.9 SHORT
came 0.8 0.4 0.7 SHORT
said 0.2 0.8 0.9 SHORT
produced 0.9 0.1 0.5 LONG
approved 0.7 0.3 0.7 SHORT
said 0.2 0.8 0.9 SHORT
begun 0.5 0.2 0.5 LONG
said 0.2 0.8 0.9 SHORT
narrowed 0.7 0.7 0.3 LONG
reported 0.5 0.8 0.5 SHORT
said 0.2 0.8 0.9 SHORT
said 0.2 0.8 0.9 SHORT
closed 0.7 0.2 0.5 SHORT
331
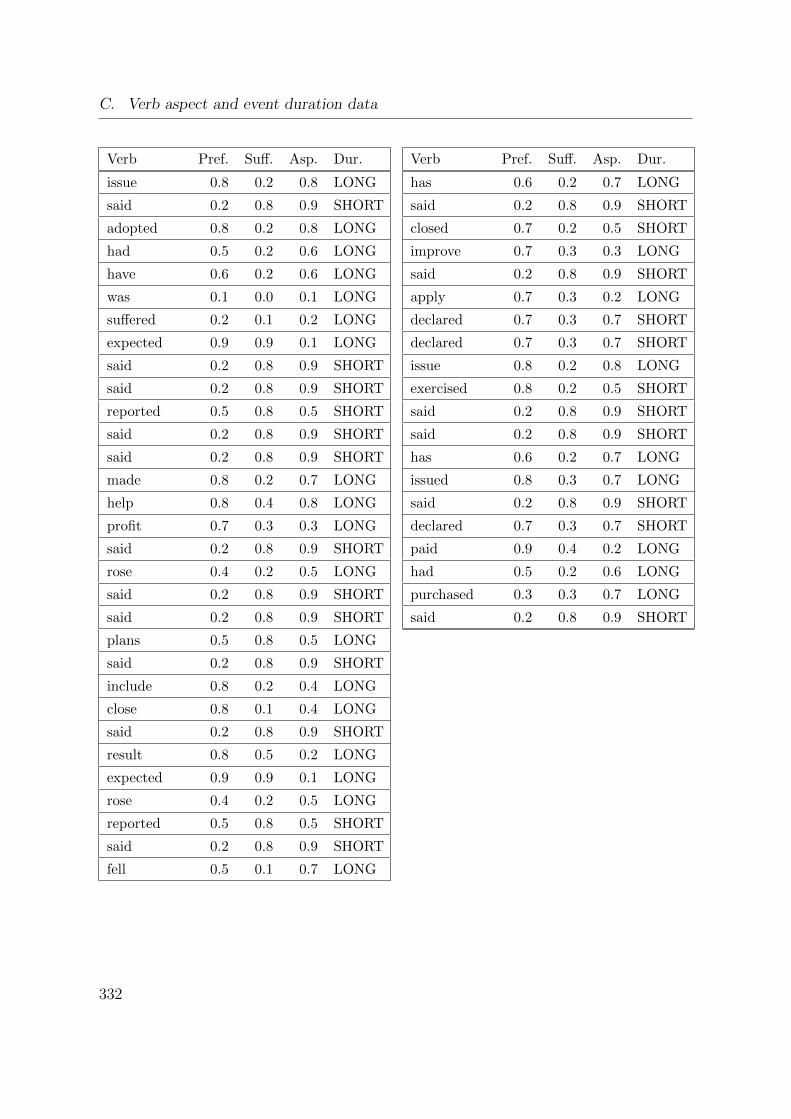
C. Verb aspect and event duration data
Verb Pref. Suff. Asp. Dur.
issue 0.8 0.2 0.8 LONG
said 0.2 0.8 0.9 SHORT
adopted 0.8 0.2 0.8 LONG
had 0.5 0.2 0.6 LONG
have 0.6 0.2 0.6 LONG
was 0.1 0.0 0.1 LONG
suffered 0.2 0.1 0.2 LONG
expected 0.9 0.9 0.1 LONG
said 0.2 0.8 0.9 SHORT
said 0.2 0.8 0.9 SHORT
reported 0.5 0.8 0.5 SHORT
said 0.2 0.8 0.9 SHORT
said 0.2 0.8 0.9 SHORT
made 0.8 0.2 0.7 LONG
help 0.8 0.4 0.8 LONG
profit 0.7 0.3 0.3 LONG
said 0.2 0.8 0.9 SHORT
rose 0.4 0.2 0.5 LONG
said 0.2 0.8 0.9 SHORT
said 0.2 0.8 0.9 SHORT
plans 0.5 0.8 0.5 LONG
said 0.2 0.8 0.9 SHORT
include 0.8 0.2 0.4 LONG
close 0.8 0.1 0.4 LONG
said 0.2 0.8 0.9 SHORT
result 0.8 0.5 0.2 LONG
expected 0.9 0.9 0.1 LONG
rose 0.4 0.2 0.5 LONG
reported 0.5 0.8 0.5 SHORT
said 0.2 0.8 0.9 SHORT
fell 0.5 0.1 0.7 LONG
Verb Pref. Suff. Asp. Dur.
has 0.6 0.2 0.7 LONG
said 0.2 0.8 0.9 SHORT
closed 0.7 0.2 0.5 SHORT
improve 0.7 0.3 0.3 LONG
said 0.2 0.8 0.9 SHORT
apply 0.7 0.3 0.2 LONG
declared 0.7 0.3 0.7 SHORT
declared 0.7 0.3 0.7 SHORT
issue 0.8 0.2 0.8 LONG
exercised 0.8 0.2 0.5 SHORT
said 0.2 0.8 0.9 SHORT
said 0.2 0.8 0.9 SHORT
has 0.6 0.2 0.7 LONG
issued 0.8 0.3 0.7 LONG
said 0.2 0.8 0.9 SHORT
declared 0.7 0.3 0.7 SHORT
paid 0.9 0.4 0.2 LONG
had 0.5 0.2 0.6 LONG
purchased 0.3 0.3 0.7 LONG
said 0.2 0.8 0.9 SHORT
332