early experiences on cosmo hybrid parallelization at caspur/usam stefano zampini ph.d. caspur...
TRANSCRIPT

Early experiences onCOSMO hybrid
parallelization at CASPUR/USAM
Stefano Zampini Ph.D.CASPUR
COSMO-POMPA Kick-off Meeting,3-4 May 2011,Manno (CH)

Outline
• MPI and multithreading: comm/comp overlap • Benchmark on multithreaded halo swapping• Non-blocking collectives (NBC library)• Scalasca profiling of loop-level hybrid
parallelization of leapfrog dynamics.

Multithreaded MPI
• MPI 2.0 and multithreading: a different initialization
MPI_INIT_THREAD(required,provided)
– MPI_SINGLE: no support for multithreading (i.e. MPI_INIT)– MPI_FUNNELED: only the master thread can call MPI– MPI_SERIALIZED: each thread can call MPI but one at time– MPI_MULTIPLE: multiple threads can call MPI simultaneously
(then MPI performs them in some serial order)
Cases of interest: FUNNELED and MULTIPLE

Masteronly (serial comm.)doubleprecision dataSR(ie,je,ke) (iloc=ie-2*ovl, jloc=je-2*ovl)doubleprecision dataARP,dataARScall MPI_INIT_THREAD(MPI_FUNNELED,…)…call MPI_CART_CREATE(…….,comm2d,…)…!$omp parallel shared(dataSR,dataARS,dataARP)…!$omp masterinitialize derived datatypes for SENDRECV as for pure MPI !$omp end master…!$omp mastercall SENDRECV(dataSR(..,..,1),1,……,comm2d)call MPI_ALLREDUCE(dataARP,dataARS…,comm2d)!$omp end master!$omp barrierdo some COMPUTATION (involving dataSR, dataARS and dataARP)!$omp end parallel…call MPI_FINALIZE(…)

Masteronly (with overlap)doubleprecision dataSR(ie,je,ke) (iloc=ie-2*ovl, jloc=je-2*ovl)doubleprecision dataARP,dataARScall MPI_INIT_THREAD(MPI_FUNNELED,…)…call MPI_CART_CREATE(…….,comm2d,…)…!$omp parallel shared(dataSR,dataARS,dataARP)…!$omp master ( can be generalized to a subteam with !$omp if(lcomm.eq.true.) )initialize derived datatypes for SENDRECV as for pure MPI !$omp end master…!$omp master (other threads skip the master construct and begin computing)call SENDRECV(dataSR(..,..,1),1,……,comm2d)call MPI_ALLREDUCE(dataARP,dataARS…,comm2d)!$omp end masterdo some COMPUTATION (not involving dataSR, dataARS and dataARP)…!$omp end parallel…call MPI_FINALIZE(…)

A multithreaded approach
A simple alternative: use !$OMP SECTIONS without modifying
COSMO code (you can control for # of communicating threads)
Requires explicit codingfor loop level parallelization
to be cache-friendly

doubleprecision dataSR(ie,je,ke) (iloc=ie-2*ovl, jloc=je-2*ovl)doubleprecision dataARP,dataARS(nth)call MPI_INIT_THREAD(MPI_MULTIPLE,…)…call MPI_CART_CREATE(…….,comm2d,…)perform some domain decomposition…!$omp parallel private(dataARP),shared(dataSR,dataARS) …iam=OMP_GET_THREAD_NUM()nth=OMP_GET_NUM_THREADS()startk=ke*iam/nth+1endk=ke*(iam+1)/nth (distribute the halo wall between a team of nth threads)totk=endk-startk…initialize datatypes for SENDRECV (each thread has its own 1/nth part of the wall)duplicate MPI communicator for threads with same thread number and different MPI rank…call SENDRECV(dataSR(..,..,startk),1,……,mycomm2d(iam+1)…) (all threads call MPI)call MPI_ALLREDUCE(dataARP,dataARS(iam+1),….,mycomm2d(iam+1),….)… (each group of thread can perform a different collective operation)!$omp end parallel…call MPI_FINALIZE(…)
A multithreaded approach (cont’d)

Experimental setting• Benchmark runs on
• Linux cluster MATRIX (CASPUR): 256 dual-socket quad-core
AMD Opteron @ 2.1 Ghz (Intel compiler 11.1.064, OpenMPI 1.4.1)
• Linux cluster PORDOI (CNMCA): 128 dual-socket quad-core
Intel Xeon E5450 @ 3.00 Ghz (Intel compiler 11.1.064,HP-MPI)
• Only one call to sendrecv operation (to avoid meaningless results)
• We can control for MPI processes/cores binding
• We cannot explicitly control for threads/cores binding with AMD: it is
possible with Intel CPUs either as a compiler directive (-par-affinity
option), or at runtime (KMP_SET_AFFINITY env. variable).
• not a major issue from early results on hybrid loop level
parallelization of Leapfrog dynamics in COSMO.

Experimental results (MATRIX)
8 threads per MPI proc(1 MPI proc per node)
4 threads per MPI proc(1 MPI proc per socket)
2 threads per MPI proc(2 MPI procs per socket)
Comparison of average times for point to point communications
• MPI_MULTIPLE overhead for large number of processes• Computational times are comparable until 512 cores (at least).• In test case considered, message sizes were always under the eager limit• MPI_MULTIPLE will benefit if it determines the protocol switching.

Experimental results (PORDOI)
8 threads per MPI proc(1 MPI proc per node)
4 threads per MPI proc(1 MPI proc per socket)
2 threads per MPI proc(2 MPI procs per socket)
Comparison of average times for point to point communications
• MPI_MULTIPLE overhead for large number of processes• Computational times are comparable until 1024 cores (at least).

LibNBC
• Collective communications implemented in LibNBC library using a
schedule of rounds: each round made by non-blocking point to point
communications
• Progress in background can be advanced using functions similar to
MPI_Test (local operations)
• Completion of collective operation through MPI_WAIT (non-local)
• Fortran binding not completely bug-free
• For additional details: www.unixer.de/NBC

Possible strategies (with leapfrog)• One ALLREDUCE operation per time step on variable
zuvwmax(0:ke) (0 index CFL, 1:ke needed for satad)• For Runge-Kutta module only zwmax(1:ke) variable (satad)
COSMO CODE
call global_values (zuvwmax(0:ke),….)
…
CFL check with zuvwmax(0)
… many computations (incl fast_waves)
do k=1,ke
if(zuvwmax(k)….) kitpro=…
call satad (…,kitpro,..)
enddo
COSMO-NBC (no overlap)
handle=0
call NBC_IALLREDUCE(zuvwmax(0:ke), …,handle,…)
call NBC_TEST(handle,ierr)
if(ierr.ne.0) call NBC_WAIT(handle,ierr)
…
CFL check with zuvwmax(0)
… many computations (incl fast_waves)
do k=1,ke
if(zuvwmax(k)….) kitpro=…
call satad (…,kitpro,..)
enddo
COSMO-NBC (with overlap)
call global_values(zuvwmax(0),…)
handle=0
call NBC_IALLREDUCE(zuvwmax(1:ke), …, handle,…)
…
CFL check with zuvwmax(0)
… many computations (incl fast_waves)
call NBC_TEST(handle,ierr)
if(ierr.ne.0) call NBC_WAIT(handle,ierr)
do k=1,ke
if(zuvwmax(k)….) kitpro=…
call satad (…,kitpro,..)
enddo

Early results• Preliminary results with 504 computing cores, 20x25 PEs, and
global grid: 641x401x40. 24 hours of forecast simulation• Results from MATRIX with COSMO yutimings (similar for PORDOI)
avg comm dyn (s) total time (s)
COSMO 63,31 611,23
COSMO-NBC (no ovl) 69,10 652,45
COSMO-NBC (with ovl) 54,94 611,55
• No benefits without changing the source code (synchronization in MPI_Allreduce on zuvwmax(0) )
• We must identify the right place in COSMO where to issue NBC calls (post operation and then tests)

Calling tree for Leapfrog dynamics
Preliminary parallelization has been performed inserting openMP directives
without modifying the preexisting COSMO code.
Orphan directives cannot be implemented in the subroutines due to a great number of
automatic variables
Master only approach for MPI communications.
Parallelized subroutines

Loop level parallelization
• Leapfrog dynamical core in COSMO code possesses many grid sweeps over the local (possibly including halo dofs) part of the domain
• Much of the grid sweeps can be parallelized on the outermost (vertical) loop
!$omp do
do k=1,ke
do j=1,je
do i=1,ie
perform something…
enddo
enddo
enddo
!$omp end do
• Much of the grid sweeps are well load-balanced
• About 350 openMP directives inserted into the code
• Hard tuning not yet performed (waiting for the results of other tasks)

Preliminary results from MATRIX1 hour of forecast
global grid 641x401x40fixed number of computing cores 192
Pure MPI 12x16
Hybrid 2 threads 8x12
Hybrid 4 threads 6x8
Hybrid 8 threads 4x6
Domaindecompositions
Plot of ratios: Hybrid times / MPI times of dynamical core from COSMO YUTIMING

Preliminary results from PORDOI
• Scalasca toolset used to profile the hybrid version of COSMO– Easy-to-use– Produces a fully surfable calling tree using different metrics– Automatically profiles each openMP construct using OPARI – User friendly GUI (cube3)
• For details, see http://www.scalasca.org/
• Computational domain considered 749x401x40• Results shown for a test case of 2 hours of forecast and fixed
number of computing cores (400=MPIxOpenMP)• Issues of internode scalability for fast waves highlighted

Scalasca profiling

Scalasca profiling

Scalasca profiling

Scalasca profiling

Scalasca profiling
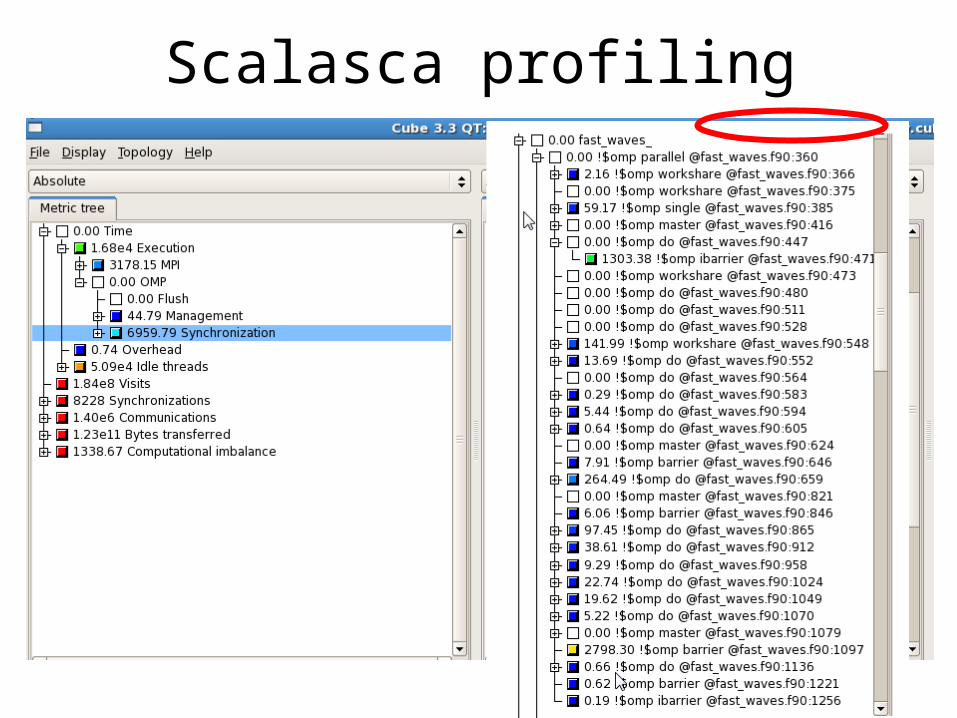
Scalasca profiling

Observations
• Timing results with 2 or 4 threads are comparable with the pure MPI
case. Poor results on hybrid speedup with 8 threads. Same
conclusions with fixed number of MPI procs and growing with the
number of threads and cores. (poor internode scalability)
• COSMO code needs to be modified to eliminate wasting of CPU
time at explicit barriers (use more threads to communicate?).
• Use dynamic scheduling and explicit control of shared variable (see
next slide) as a possible overlap strategy avoiding implicit barriers.
• OpenMP overhead (threads wake up, loop scheduling) negligible
• Try to avoid !$omp workshare -> write explicitly each array sintax
• Keep as low as possible the number of !$omp single constructs
• Segmentation faults experienced using collapse directives. Why?

• Thread subteams not yet a standard in openMP 3.0• How we can avoid wasting of CPU time when master thread is communicating
without major modifications to the code and with minor overhead?
chunk=ke/(numthreads-1)+1
!$ checkvar(1:ke)=.false.
!$omp parallel private(checkflag,k)
………….
!$omp master
! Exchange halo for variables needed later in the code (not AA)
!$omp end master
!$ checkflag=.false.
!$omp do schedule(dynamic,chunk)
do k=1,ke
! Perform something writing in variable AA
!$ checkvar(k)=.true.
enddo
!$omp end do nowait
!$ do while(.not.checkflag) (Each thread loops separately until previous loop is finished)
!$ checkflag=.true.
!$ do k=1,ke
!$ checkflag = checkflag.and.checkvar(k)
!$ end do
!$ end do
!$omp do schedule(dynamic,chunk) (Now we can enter this loop safely)
do k=1,ke
! Perform something else reading from variable AA
enddo
!$omp end do nowait
………….
!$omp end parallel

Thank you for your attention!