ece 570: advanced computer...
TRANSCRIPT

ECE 570: Advanced Computer Architecture
Advanced Pipelining: Dynamic Scheduling
Joe Crop
Slides taken from:
Ioannis Papaefstathiou & Ben Lee

Chap. 4 - Pipelining II 2
Instruction Level Parallelism
ILP is the principle that there are many instructions in code that don’t depend on each other. That means it’s possible to execute those instructions in parallel.
This is easier said than done: Issues include: • Building compilers to analyze the code, • Building hardware to be even smarter than that code. This section looks at some of the problems to be solved.

Chap. 4 - Pipelining II 3
Terminology
Instruction Level Parallelism
Pipeline Scheduling and Loop Unrolling
Basic Block - That set of instructions between entry points and between branches. A basic block has only one entry and one exit. Typically this is about 6 instructions long.
Loop Level Parallelism - Parallelism that exists within a loop. Such
parallelism can cross loop iterations. Loop Unrolling - Either the compiler or the hardware is able to exploit the
parallelism inherent in the loop.

Chap. 4 - Pipelining II 4
Simple Loop and its Assembler Equivalent for (i=1; i<=1000; i++)
x(i) = x(i) + s; !
Loop: LD F0,0(R1) ;F0=vector element ADDD F4,F0,F2 ;add scalar from F2 SD 0(R1),F4 ;store result SUBI R1,R1,8 ;decrement pointer 8bytes (DW) BNEZ R1,Loop ;branch R1!=zero NOP ;delayed branch slot
Instruction Level Parallelism
Pipeline Scheduling and Loop Unrolling
This is a clean and simple example!

Chap. 4 - Pipelining II 5
Loop: LD F0,0(R1) ;F0=vector element ADDD F4,F0,F2 ;add scalar in F2 SD 0(R1),F4 ;store result SUBI R1,R1,8 ;decrement pointer 8B (DW) BNEZ R1,Loop ;branch R1!=zero NOP ;delayed branch slot
FP Loop Hazards
Instruction Level Parallelism
Pipeline Scheduling and Loop Unrolling
Instruction Instruction Latency in producing result using result clock cycles FP ALU op Another FP ALU op 3 FP ALU op Store double 2 Load double FP ALU op 1 Load double Store double 0 Integer op Integer op 0
Where are the stalls?

Chap. 4 - Pipelining II 6
FP Loop Showing Stalls
10 cycles: Rewrite code to minimize stalls?
1 Loop: LD F0,0(R1) ;F0=vector element 2 stall 3 ADDD F4,F0,F2 ;add scalar in F2 4 stall 5 stall 6 SD 0(R1),F4 ;store result 7 SUBI R1,R1,8 ;decrement pointer 8Byte (DW) 8 stall 9 BNEZ R1,Loop ;branch R1!=zero 10 stall ;delayed branch slot
Instruction Level Parallelism Pipeline Scheduling and
Loop Unrolling
Instruction Instruction Latency in producing result using result clock cycles FP ALU op Another FP ALU op 3 FP ALU op Store double 2 Load double FP ALU op 1 Load double Store double 0 Integer op Integer op 0

Chap. 4 - Pipelining II 7
Scheduled FP Loop Minimizing Stalls
Now 6 cycles: Unroll loop 4 times to make faster.
Instruction Instruction Latency in producing result using result clock cycles FP ALU op Another FP ALU op 3 FP ALU op Store double 2 Load double FP ALU op 1
1 Loop: LD F0,0(R1) 2 SUBI R1,R1,8 3 ADDD F4,F0,F2 4 stall 5 BNEZ R1,Loop ;delayed branch 6 SD 8(R1),F4 ;altered when move past SUBI
Swap BNEZ and SD by changing address of SD
Instruction Level Parallelism
Pipeline Scheduling and Loop Unrolling
Stall is because SD can’t proceed.

Chap. 4 - Pipelining II 8
Unroll Loop Four Times (straightforward way)
Rewrite loop to minimize stalls.
1 Loop: LD F0,0(R1) 2 stall 3 ADDD F4,F0,F2 4 stall 5 stall 6 SD 0(R1),F4 7 LD F6,-8(R1) 8 stall 9 ADDD F8,F6,F2 10 stall 11 stall 12 SD -8(R1),F8 13 LD F10,-16(R1) 14 stall
Instruction Level Parallelism
Pipeline Scheduling and Loop Unrolling
15 + 4 x (1+2) +1 = 28 clock cycles, or 7 per iteration Assumes R1 is multiple of 4
15 ADDD F12,F10,F2 16 stall 17 stall 18 SD -16(R1),F12 19 LD F14,-24(R1) 20 stall 21 ADDD F16,F14,F2 22 stall 23 stall 24 SD -24(R1),F16 25 SUBI R1,R1,#32 26 BNEZ R1,LOOP 27 stall 28 NOP

Chap. 4 - Pipelining II 9
Unrolled Loop That Minimizes Stalls What assumptions made when
moved code? – OK to move store past SUBI
even though changes register – OK to move loads before
stores: get right data? – When is it safe for compiler to
do such changes?
1 Loop: LD F0,0(R1) 2 LD F6,-8(R1) 3 LD F10,-16(R1) 4 LD F14,-24(R1) 5 ADDD F4,F0,F2 6 ADDD F8,F6,F2 7 ADDD F12,F10,F2 8 ADDD F16,F14,F2 9 SD 0(R1),F4 10 SD -8(R1),F8 11 SD -16(R1),F12 12 SUBI R1,R1,#32 13 BNEZ R1,LOOP 14 SD 8(R1),F16 ; 8-32 = -24 14 clock cycles, or 3.5 per iteration
Instruction Level Parallelism
Pipeline Scheduling and Loop Unrolling
No Stalls!!

Chap. 4 - Pipelining II 10
Summary of Loop Unrolling Example • Determine that it was legal to move the SD after the SUBI and BNEZ,
and find the amount to adjust the SD offset. • Determine that unrolling the loop would be useful by finding that the
loop iterations were independent, except for the loop maintenance code.
• Use different registers to avoid unnecessary constraints that would be forced by using the same registers for different computations.
• Eliminate the extra tests and branches and adjust the loop maintenance code.
• Determine that the loads and stores in the unrolled loop can be interchanged by observing that the loads and stores from different iterations are independent. This requires analyzing the memory addresses and finding that they do not refer to the same address.
• Schedule the code, preserving any dependences needed to yield the same result as the original code.
Instruction Level Parallelism
Pipeline Scheduling and Loop Unrolling

Chap. 4 - Pipelining II 11
Compiler Perspectives on Code Movement Compiler concerned about dependencies in program. Not concerned if a
HW hazard depends on a given pipeline. • Tries to schedule code to avoid hazards. • Looks for Data dependencies (RAW if a hazard for HW)
– Instruction i produces a result used by instruction j, or – Instruction j is data dependent on instruction k, and instruction k is data
dependent on instruction i. • If dependent, can’t execute in parallel • Easy to determine for registers (fixed names) • Hard for memory:
– Does 100(R4) = 20(R6)? – From different loop iterations, does 20(R6) = 20(R6)?
Instruction Level Parallelism
Dependencies

Chap. 4 - Pipelining II 12
Compiler Perspectives on Code Movement
1 Loop: LD F0,0(R1) 2 ADDD F4,F0,F2 3 SUBI R1,R1,8 4 BNEZ R1,Loop ;delayed branch 5 SD 8(R1),F4 ;altered when move past SUBI
Instruction Level Parallelism
Data Dependencies
Where are the data dependencies?

Chap. 4 - Pipelining II 13
Compiler Perspectives on Code Movement
• Another kind of dependence called name dependence: two instructions use same name (register or memory location) but don’t exchange data
• Anti-dependence (WAR if a hazard for HW) – Instruction j writes a register or memory location that instruction i reads from
and instruction i is executed first • Output dependence (WAW if a hazard for HW)
– Instruction i and instruction j write the same register or memory location; ordering between instructions must be preserved.
Instruction Level Parallelism
Name Dependencies

Chap. 4 - Pipelining II 14
Compiler Perspectives on Code Movement 1 Loop: LD F0,0(R1) 2 ADDD F4,F0,F2 3 SD 0(R1),F4 4 LD F0,-8(R1) 5 ADDD F4,F0,F2 6 SD -8(R1),F4 7 LD F0,-16(R1) 8 ADDD F4,F0,F2 9 SD -16(R1),F4 10 LD F0,-24(R1) 11 ADDD F4,F0,F2 12 SD -24(R1),F4 13 SUBI R1,R1,#32 14 BNEZ R1,LOOP 15 NOP How can we remove these dependencies?
Instruction Level Parallelism
Name Dependencies
Where are the name dependencies?
No data is passed in F0, but can’t reuse F0 in cycle 4.
(WAR)

Chap. 4 - Pipelining II 15
Where are the name dependencies? 1 Loop: LD F0,0(R1)
2 ADDD F4,F0,F2 3 SD 0(R1),F4 4 LD F6,-8(R1) 5 ADDD F8,F6,F2 6 SD -8(R1),F8 7 LD F10,-16(R1) 8 ADDD F12,F10,F2 9 SD -16(R1),F12 10 LD F14,-24(R1) 11 ADDD F16,F14,F2 12 SD -24(R1),F16 13 SUBI R1,R1,#32 14 BNEZ R1,LOOP 15 NOP Called “register renaming”
Instruction Level Parallelism
Name Dependencies
Compiler Perspectives on Code Movement
Now there are data dependencies only. F0 exists only in instructions 1 and 2.

Chap. 4 - Pipelining II 16
Compiler Perspectives on Code Movement • Again Name Dependencies are Hard for Memory Accesses
– Does 100(R4) = 20(R6)? – From different loop iterations, does 20(R6) = 20(R6)?
• Our example required compiler to know that if R1 doesn’t change then: 0(R1) ≠ -8(R1) ≠ -16(R1) ≠ -24(R1) !
There were no dependencies between some loads and stores so they could be moved around each other
Instruction Level Parallelism
Name Dependencies

Chap. 4 - Pipelining II 17
• Final kind of dependence called control dependence • Example ! !if p1 {S1;};!! !if p2 {S2;};
S1 is control dependent on p1 and S2 is control dependent on p2 but not on p1.
Instruction Level Parallelism
Control Dependencies
Compiler Perspectives on Code Movement

Chap. 4 - Pipelining II 18
• Two (obvious) constraints on control dependences: – An instruction that is control dependent on a branch cannot be moved
before the branch so that its execution is no longer controlled by the branch.
– An instruction that is not control dependent on a branch cannot be moved to after the branch so that its execution is controlled by the branch.
• Control dependencies relaxed to get parallelism; get same effect if preserve order of exceptions (address in register checked by branch before use) and data flow (value in register depends on branch)
Instruction Level Parallelism
Control Dependencies
Compiler Perspectives on Code Movement

Chap. 4 - Pipelining II 19
Where are the control dependencies?
1 Loop: LD F0,0(R1) 2 ADDD F4,F0,F2 3 SD 0(R1),F4 4 SUBI R1,R1,8 5 BEQZ R1,exit 6 LD F0,0(R1) 7 ADDD F4,F0,F2 8 SD 0(R1),F4 9 SUBI R1,R1,8 10 BEQZ R1,exit 11 LD F0,0(R1) 12 ADDD F4,F0,F2 13 SD 0(R1),F4 14 SUBI R1,R1,8 15 BEQZ R1,exit ....
Instruction Level Parallelism
Control Dependencies
Compiler Perspectives on Code Movement

Chap. 4 - Pipelining II 20
When Safe to Unroll Loop? • Example: Where are data dependencies?
(A,B,C distinct & non-overlapping)
1. S2 uses the value, A[i+1], computed by S1 in the same iteration. 2. S1 uses a value computed by S1 in an earlier iteration, since
iteration i computes A[i+1] which is read in iteration i+1. The same is true of S2 for B[i] and B[i+1]. This is a “loop-carried dependence” between iterations
• Implies that iterations are dependent, and can’t be executed in parallel
• Note the case for our prior example; each iteration was distinct
Instruction Level Parallelism
Loop Level Parallelism
for (i=1; i<=100; i=i+1) { A[i+1] = A[i] + C[i]; /* S1 */ B[i+1] = B[i] + A[i+1]; /* S2 */
}

Chap. 4 - Pipelining II 21
When Safe to Unroll Loop? • Example: Where are data dependencies?
(A,B,C,D distinct & non-overlapping)
1. No dependence from S1 to S2. If there were, then there would be a
cycle in the dependencies and the loop would not be parallel. Since this other dependence is absent, interchanging the two statements will not affect the execution of S2.
2. On the first iteration of the loop, statement S1 depends on the value of B[1] computed prior to initiating the loop.
Instruction Level Parallelism
Loop Level Parallelism
for (i=1; i<=100; i=i+1) { A[i+1] = A[i] + B[i]; /* S1 */ B[i+1] = C[i] + D[i]; /* S2 */
}

Chap. 4 - Pipelining II 22
Now Safe to Unroll Loop? (p. 240)
A[1] = A[1] + B[1]; for (i=1; i<=99; i=i+1) {
B[i+1] = C[i] + D[i]; A[i+1] = + A[i+1] + B[i+1];
} B[101] = C[100] + D[100];
for (i=1; i<=100; i=i+1) { A[i+1] = A[i] + B[i]; /* S1 */ B[i+1] = C[i] + D[i];} /* S2 */���
OLD:
NEW:
Instruction Level Parallelism
Loop Level Parallelism
No circular dependencies.
Loop caused dependence on B.
Have eliminated loop dependence.

Chap. 4 - Pipelining II 23
Dynamic Scheduling
Dynamic Scheduling is when the hardware rearranges the order of instruction execution to reduce stalls.
Advantages: • Dependencies unknown at compile time can be handled
by the hardware. • Code compiled for one type of pipeline can be efficiently
run on another.
Disadvantages: • Hardware much more complex.

Chap. 4 - Pipelining II 24
Dynamic Scheduling
• Why in HW at run time? – Works when can’t know real dependence at compile time – Compiler simpler – Code for one machine runs well on another
• Key Idea: Allow instructions behind stall to proceed. • Key Idea: Instructions executing in parallel. There are multiple
execution units, so use them.
! !DIVD !F0,F2,F4!! !ADDD !F10,F0,F8!! !SUBD !F12,F8,F14!
– Enables out-of-order execution => out-of-order completion
The idea:
HW Schemes: Instruction Parallelism

Chap. 4 - Pipelining II 25
Dynamic Scheduling
• Out-of-order execution divides ID stage: 1. Issue—decode instructions, check for structural hazards 2. Read operands—wait until no data hazards, then read operands
• Scoreboards allow instruction to execute whenever 1 & 2 hold, not waiting for prior instructions.
• A scoreboard is a “data structure” that provides the information necessary for all pieces of the processor to work together.
• We will use In order issue, out of order execution, out of order commit/completion
The idea:
HW Schemes: Instruction Parallelism

26
Mul$cycle Opera$on Assump$ons
• Out-of-order completions
• WAW hazards possible.
• Structure hazard (not pipelined).
• Longer latency implies more frequent stalls for RAW hazards

Chap. 4 - Pipelining II 27
Scoreboard Implications • Out-of-order completion => WAR, WAW hazards? • Solutions for WAR
– Queue both the operation and copies of its operands – Read registers only during Read Operands stage
• For WAW, must detect hazard: stall until other completes • Need to have multiple instructions in execution phase => multiple
execution units or pipelined execution units • Scoreboard keeps track of dependencies, state or operations • Scoreboard replaces ID, EX, WB with 4 stages
Dynamic Scheduling Using A Scoreboard

Chap. 4 - Pipelining II 28
Four Stages of Scoreboard Control 1. Issue —decode instructions & check for structural hazards (ID1)
If a functional unit for the instruction is free and no other active instruction has the same destination register (WAW), the scoreboard issues the instruction to the functional unit and updates its internal data structure.
If a structural or WAW hazard exists, then the instruction issue
stalls, and no further instructions will issue until these hazards are cleared.
Dynamic Scheduling Using A Scoreboard

Chap. 4 - Pipelining II 29
Four Stages of Scoreboard Control 2. Read operands —wait until no data hazards, then read
operands (ID2)
A source operand is available if no earlier issued active instruction is going to write it, or if the register containing the operand is being written by a currently active functional unit.
When the source operands are available, the scoreboard tells
the functional unit to proceed to read the operands from the registers and begin execution. The scoreboard resolves RAW hazards dynamically in this step, and instructions may be sent into execution out of order.
Dynamic Scheduling Using A Scoreboard

Chap. 4 - Pipelining II 30
Four Stages of Scoreboard Control 3. Execution —operate on operands (EX)
The functional unit begins execution upon receiving operands. When the result is ready, it notifies the scoreboard that it has completed execution.
4. Write result —finish execution (WB)
Once the scoreboard is aware that the functional unit has completed execution, the scoreboard checks for WAR hazards. If none, it writes results. If WAR, then it stalls the instruction. Example:
DIVD F0,F2,F4 ADDD F10,F0,F8 SUBD F8,F8,F14 Scoreboard would stall SUBD until ADDD reads operands
Dynamic Scheduling Using A Scoreboard

Chap. 4 - Pipelining II 31
Three Parts of the Scoreboard
1. Instruction status—which of 4 steps the instruction is in
2. Functional unit status—Indicates the state of the functional unit (FU). 9 fields for each functional unit Busy—Indicates whether the unit is busy or not Op—Operation to perform in the unit (e.g., + or –) Fi—Destination register Fj, Fk—Source-register numbers Qj, Qk—Functional units producing source registers Fj, Fk Rj, Rk—Flags indicating when Fj, Fk are ready
3. Register result status—Indicates which functional unit will write each register, if one exists. Blank when no pending instructions will write that register
Dynamic Scheduling Using A Scoreboard

Chap. 4 - Pipelining II 32
Detailed Scoreboard Pipeline Control
Read operands Execution complete
Instruction status
Write result
Issue
Bookkeeping
Rj← No; Rk← No
∀f(if Qj(f)=FU then Rj(f)← Yes); ∀f(if Qk(f)=FU then Rj(f)← Yes);
Result(Fi(FU))← 0; Busy(FU)← No
Busy(FU)← yes; Op(FU)← op; Fi(FU)← `D’; Fj(FU)← `S1’;
Fk(FU)← `S2’; Qj← Result(‘S1’); Qk← Result(`S2’); Rj← not Qj; Rk← not Qk; Result(‘D’)← FU;
Rj and Rk
Functional unit done
Wait until
∀f((Fj( f )≠Fi(FU) or Rj( f )=No) &
(Fk( f ) ≠Fi(FU) or Rk( f )=No))
Not busy (FU) and not result(D)
Dynamic Scheduling Using A Scoreboard

Chap. 4 - Pipelining II 33
Scoreboard Example Dynamic Scheduling Using A Scoreboard
This is the sample code we’ll be working with in the example: LD F6, 34(R2) LD F2, 45(R3) MULT F0, F2, F4 SUBD F8, F6, F2 DIVD F10, F0, F6 ADDD F6, F8, F2 What are the hazards in this code?
Latencies (clock cycles): LD 1 MULT 10 SUBD 2 DIVD 40 ADDD 2

Chap. 4 - Pipelining II 34
Scoreboard Example
Instruction status Read ExecutionWriteInstruction j k Issue operandscompleteResultLD F6 34+ R2LD F2 45+ R3MULTDF0 F2 F4SUBD F8 F6 F2DIVD F10 F0 F6ADDD F6 F8 F2Functional unit status dest S1 S2 FU for j FU for k Fj? Fk?
Time Name Busy Op Fi Fj Fk Qj Qk Rj RkInteger NoMult1 NoMult2 NoAdd NoDivide No
Register result statusClock F0 F2 F4 F6 F8 F10 F12 ... F30
FU
Dynamic Scheduling Using A Scoreboard

Chap. 4 - Pipelining II 35
Scoreboard Example Cycle 1
Instruction status Read ExecutionWriteInstruction j k Issue operandscompleteResultLD F6 34+ R2 1LD F2 45+ R3MULTDF0 F2 F4SUBD F8 F6 F2DIVD F10 F0 F6ADDD F6 F8 F2Functional unit status dest S1 S2 FU for j FU for k Fj? Fk?
Time Name Busy Op Fi Fj Fk Qj Qk Rj RkInteger Yes Load F6 R2 YesMult1 NoMult2 NoAdd NoDivide No
Register result statusClock F0 F2 F4 F6 F8 F10 F12 ... F30
1 FU Integer
Dynamic Scheduling Using A Scoreboard
Issue LD #1
Shows in which cycle the operation occurred.

Chap. 4 - Pipelining II 36
Scoreboard Example Cycle 2
Instruction status Read ExecutionWriteInstruction j k Issue operandscompleteResultLD F6 34+ R2 1 2LD F2 45+ R3MULTDF0 F2 F4SUBD F8 F6 F2DIVD F10 F0 F6ADDD F6 F8 F2Functional unit status dest S1 S2 FU for j FU for k Fj? Fk?
Time Name Busy Op Fi Fj Fk Qj Qk Rj RkInteger Yes Load F6 R2 YesMult1 NoMult2 NoAdd NoDivide No
Register result statusClock F0 F2 F4 F6 F8 F10 F12 ... F30
2 FU Integer
Dynamic Scheduling Using A Scoreboard
LD #2 can’t issue since integer unit is busy. MULT can’t issue because we require in-order issue.

Chap. 4 - Pipelining II 37
Scoreboard Example Cycle 3
Instruction status Read ExecutionWriteInstruction j k Issue operandscompleteResultLD F6 34+ R2 1 2 3LD F2 45+ R3MULTDF0 F2 F4SUBD F8 F6 F2DIVD F10 F0 F6ADDD F6 F8 F2Functional unit status dest S1 S2 FU for j FU for k Fj? Fk?
Time Name Busy Op Fi Fj Fk Qj Qk Rj RkInteger Yes Load F6 R2 YesMult1 NoMult2 NoAdd NoDivide No
Register result statusClock F0 F2 F4 F6 F8 F10 F12 ... F30
3 FU Integer
Dynamic Scheduling Using A Scoreboard

Chap. 4 - Pipelining II 38
Scoreboard Example Cycle 4
Instruction status Read ExecutionWriteInstruction j k Issue operandscompleteResultLD F6 34+ R2 1 2 3 4LD F2 45+ R3MULTDF0 F2 F4SUBD F8 F6 F2DIVD F10 F0 F6ADDD F6 F8 F2Functional unit status dest S1 S2 FU for j FU for k Fj? Fk?
Time Name Busy Op Fi Fj Fk Qj Qk Rj RkInteger Yes Load F6 R2 YesMult1 NoMult2 NoAdd NoDivide No
Register result statusClock F0 F2 F4 F6 F8 F10 F12 ... F30
4 FU Integer
Dynamic Scheduling Using A Scoreboard

Chap. 4 - Pipelining II 39
Scoreboard Example Cycle 5
Instruction status Read ExecutionWriteInstruction j k Issue operandscompleteResultLD F6 34+ R2 1 2 3 4LD F2 45+ R3 5MULTDF0 F2 F4SUBD F8 F6 F2DIVD F10 F0 F6ADDD F6 F8 F2Functional unit status dest S1 S2 FU for j FU for k Fj? Fk?
Time Name Busy Op Fi Fj Fk Qj Qk Rj RkInteger Yes Load F2 R3 YesMult1 NoMult2 NoAdd NoDivide No
Register result statusClock F0 F2 F4 F6 F8 F10 F12 ... F30
5 FU Integer
Dynamic Scheduling Using A Scoreboard
Issue LD #2 since integer unit is now free.
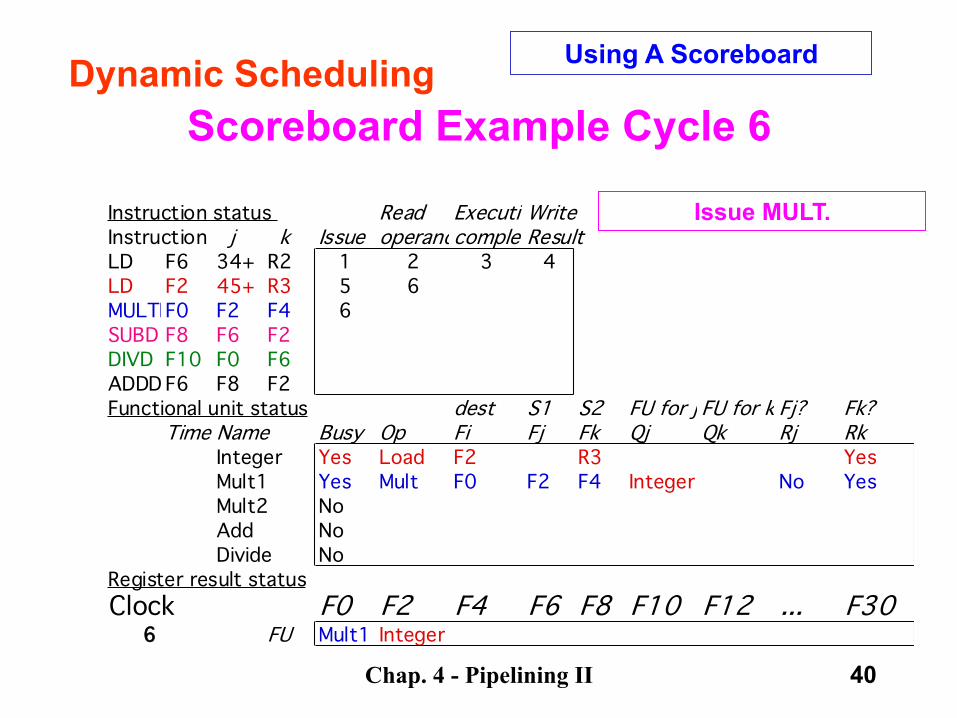
Chap. 4 - Pipelining II 40
Scoreboard Example Cycle 6
Instruction status Read ExecutionWriteInstruction j k Issue operandscompleteResultLD F6 34+ R2 1 2 3 4LD F2 45+ R3 5 6MULTDF0 F2 F4 6SUBD F8 F6 F2DIVD F10 F0 F6ADDD F6 F8 F2Functional unit status dest S1 S2 FU for j FU for k Fj? Fk?
Time Name Busy Op Fi Fj Fk Qj Qk Rj RkInteger Yes Load F2 R3 YesMult1 Yes Mult F0 F2 F4 Integer No YesMult2 NoAdd NoDivide No
Register result statusClock F0 F2 F4 F6 F8 F10 F12 ... F30
6 FU Mult1 Integer
Dynamic Scheduling Using A Scoreboard
Issue MULT.

Chap. 4 - Pipelining II 41
Scoreboard Example Cycle 7
Instruction status Read ExecutionWriteInstruction j k Issue operandscompleteResultLD F6 34+ R2 1 2 3 4LD F2 45+ R3 5 6 7MULTDF0 F2 F4 6SUBD F8 F6 F2 7DIVD F10 F0 F6ADDD F6 F8 F2Functional unit status dest S1 S2 FU for j FU for k Fj? Fk?
Time Name Busy Op Fi Fj Fk Qj Qk Rj RkInteger Yes Load F2 R3 YesMult1 Yes Mult F0 F2 F4 Integer No YesMult2 NoAdd Yes Sub F8 F6 F2 Integer Yes NoDivide No
Register result statusClock F0 F2 F4 F6 F8 F10 F12 ... F30
7 FU Mult1 Integer Add
Dynamic Scheduling Using A Scoreboard
MULT can’t read its operands (F2) because LD #2 hasn’t finished.

Chap. 4 - Pipelining II 42
Scoreboard Example Cycle 8a
Instruction status Read ExecutionWriteInstruction j k Issue operandscompleteResultLD F6 34+ R2 1 2 3 4LD F2 45+ R3 5 6 7MULTDF0 F2 F4 6SUBD F8 F6 F2 7DIVD F10 F0 F6 8ADDD F6 F8 F2Functional unit status dest S1 S2 FU for j FU for k Fj? Fk?
Time Name Busy Op Fi Fj Fk Qj Qk Rj RkInteger Yes Load F2 R3 YesMult1 Yes Mult F0 F2 F4 Integer No YesMult2 NoAdd Yes Sub F8 F6 F2 Integer Yes NoDivide Yes Div F10 F0 F6 Mult1 No Yes
Register result statusClock F0 F2 F4 F6 F8 F10 F12 ... F30
8 FU Mult1 Integer Add Divide
Dynamic Scheduling Using A Scoreboard
DIVD issues. MULT and SUBD both waiting for F2.

Chap. 4 - Pipelining II 43
Scoreboard Example Cycle 8b
Instruction status Read ExecutionWriteInstruction j k Issue operandscompleteResultLD F6 34+ R2 1 2 3 4LD F2 45+ R3 5 6 7 8MULTDF0 F2 F4 6SUBD F8 F6 F2 7DIVD F10 F0 F6 8ADDD F6 F8 F2Functional unit status dest S1 S2 FU for j FU for k Fj? Fk?
Time Name Busy Op Fi Fj Fk Qj Qk Rj RkInteger NoMult1 Yes Mult F0 F2 F4 Yes YesMult2 NoAdd Yes Sub F8 F6 F2 Yes YesDivide Yes Div F10 F0 F6 Mult1 No Yes
Register result statusClock F0 F2 F4 F6 F8 F10 F12 ... F30
8 FU Mult1 Add Divide
Dynamic Scheduling Using A Scoreboard
LD #2 writes F2.

Chap. 4 - Pipelining II 44
Scoreboard Example Cycle 9 Instruction status Read ExecutionWriteInstruction j k Issue operandscompleteResultLD F6 34+ R2 1 2 3 4LD F2 45+ R3 5 6 7 8MULTDF0 F2 F4 6 9SUBD F8 F6 F2 7 9DIVD F10 F0 F6 8ADDD F6 F8 F2Functional unit status dest S1 S2 FU for j FU for k Fj? Fk?
Time Name Busy Op Fi Fj Fk Qj Qk Rj RkInteger No
10 Mult1 Yes Mult F0 F2 F4 Yes YesMult2 No
2 Add Yes Sub F8 F6 F2 Yes YesDivide Yes Div F10 F0 F6 Mult1 No Yes
Register result statusClock F0 F2 F4 F6 F8 F10 F12 ... F30
9 FU Mult1 Add Divide
Dynamic Scheduling Using A Scoreboard
Now MULT and SUBD can both read F2. How can both instructions do this at the same time??
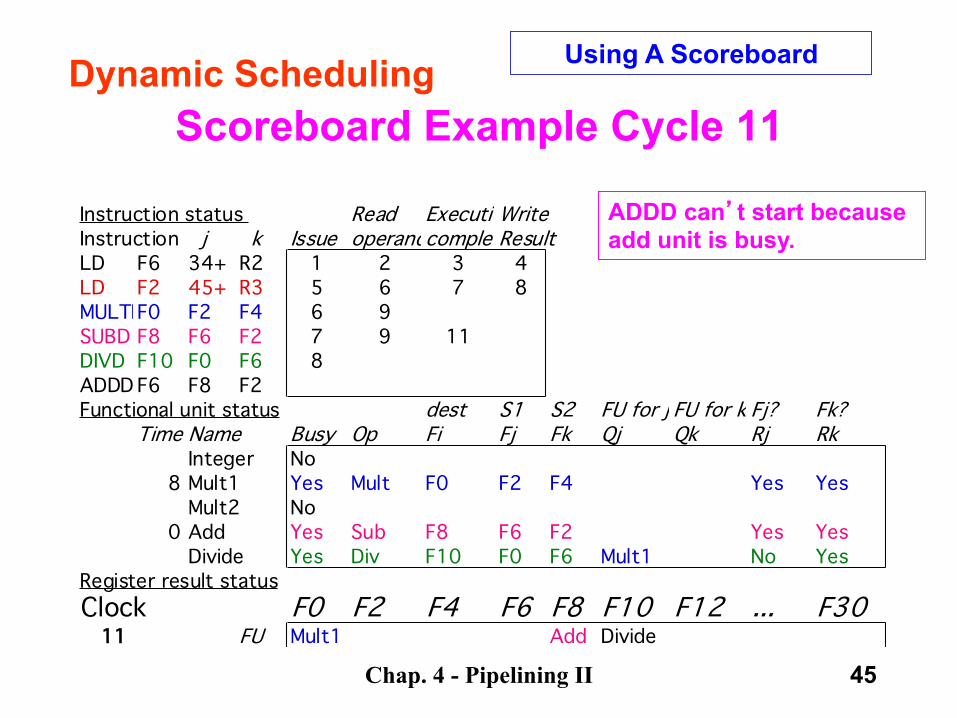
Chap. 4 - Pipelining II 45
Scoreboard Example Cycle 11
Instruction status Read ExecutionWriteInstruction j k Issue operandscompleteResultLD F6 34+ R2 1 2 3 4LD F2 45+ R3 5 6 7 8MULTDF0 F2 F4 6 9SUBD F8 F6 F2 7 9 11DIVD F10 F0 F6 8ADDD F6 F8 F2Functional unit status dest S1 S2 FU for j FU for k Fj? Fk?
Time Name Busy Op Fi Fj Fk Qj Qk Rj RkInteger No
8 Mult1 Yes Mult F0 F2 F4 Yes YesMult2 No
0 Add Yes Sub F8 F6 F2 Yes YesDivide Yes Div F10 F0 F6 Mult1 No Yes
Register result statusClock F0 F2 F4 F6 F8 F10 F12 ... F30
11 FU Mult1 Add Divide
Dynamic Scheduling Using A Scoreboard
ADDD can’t start because add unit is busy.
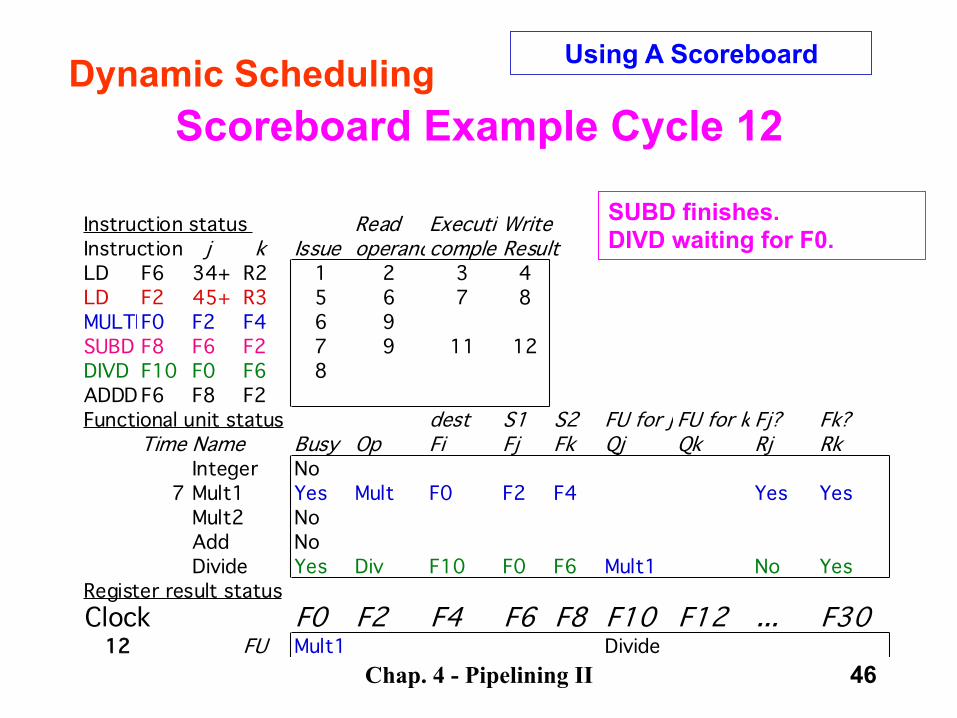
Chap. 4 - Pipelining II 46
Scoreboard Example Cycle 12
Instruction status Read ExecutionWriteInstruction j k Issue operandscompleteResultLD F6 34+ R2 1 2 3 4LD F2 45+ R3 5 6 7 8MULTDF0 F2 F4 6 9SUBD F8 F6 F2 7 9 11 12DIVD F10 F0 F6 8ADDD F6 F8 F2Functional unit status dest S1 S2 FU for j FU for k Fj? Fk?
Time Name Busy Op Fi Fj Fk Qj Qk Rj RkInteger No
7 Mult1 Yes Mult F0 F2 F4 Yes YesMult2 NoAdd NoDivide Yes Div F10 F0 F6 Mult1 No Yes
Register result statusClock F0 F2 F4 F6 F8 F10 F12 ... F30
12 FU Mult1 Divide
Dynamic Scheduling Using A Scoreboard
SUBD finishes. DIVD waiting for F0.
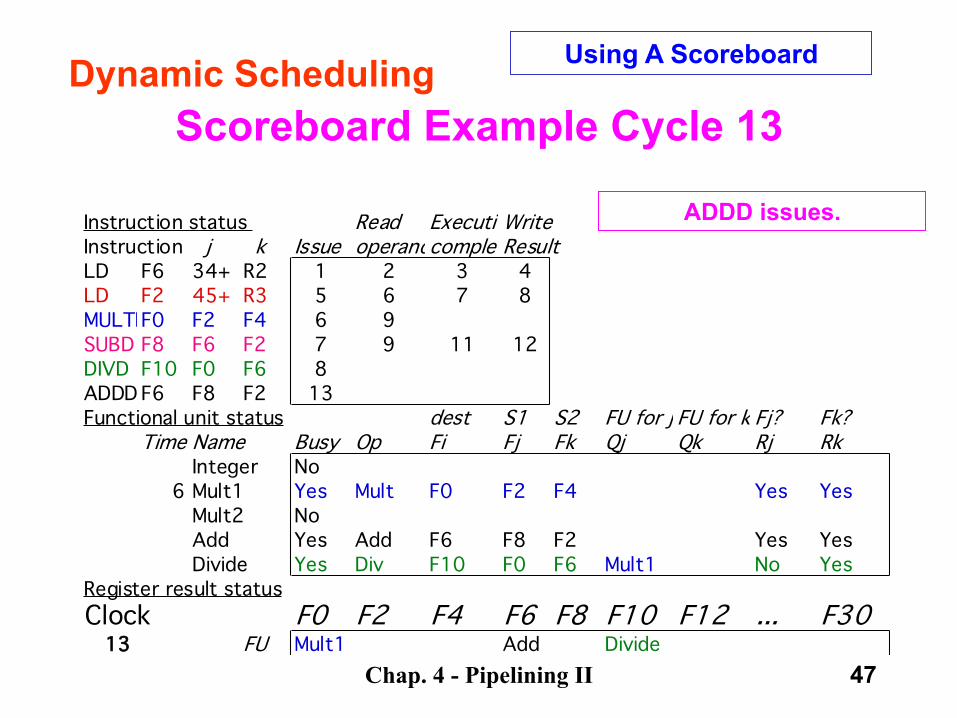
Chap. 4 - Pipelining II 47
Scoreboard Example Cycle 13
Instruction status Read ExecutionWriteInstruction j k Issue operandscompleteResultLD F6 34+ R2 1 2 3 4LD F2 45+ R3 5 6 7 8MULTDF0 F2 F4 6 9SUBD F8 F6 F2 7 9 11 12DIVD F10 F0 F6 8ADDD F6 F8 F2 13Functional unit status dest S1 S2 FU for j FU for k Fj? Fk?
Time Name Busy Op Fi Fj Fk Qj Qk Rj RkInteger No
6 Mult1 Yes Mult F0 F2 F4 Yes YesMult2 NoAdd Yes Add F6 F8 F2 Yes YesDivide Yes Div F10 F0 F6 Mult1 No Yes
Register result statusClock F0 F2 F4 F6 F8 F10 F12 ... F30
13 FU Mult1 Add Divide
Dynamic Scheduling Using A Scoreboard
ADDD issues.
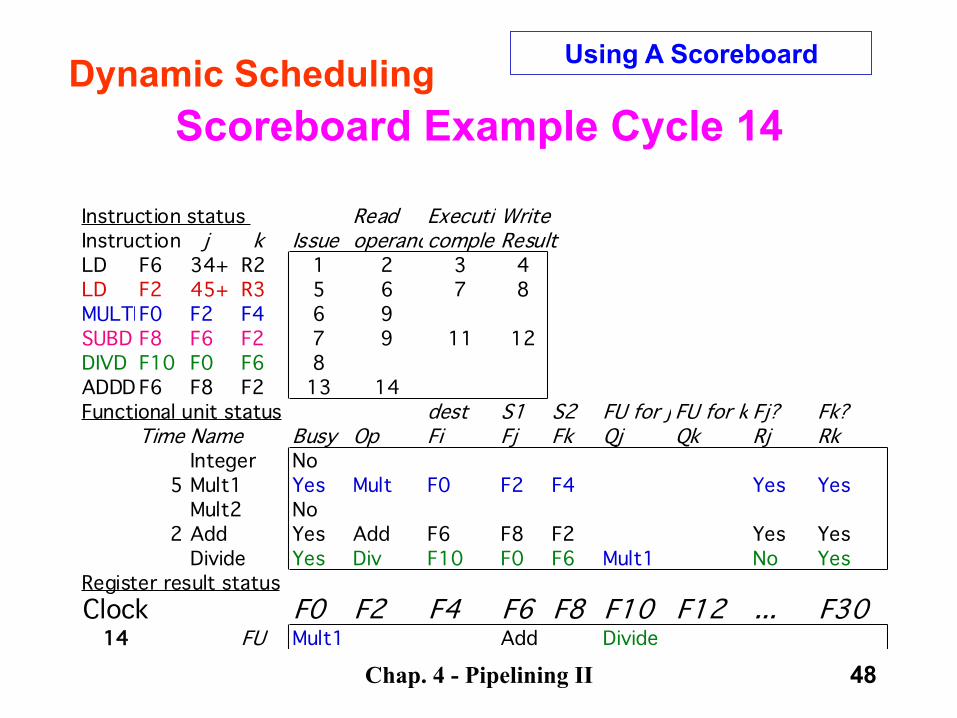
Chap. 4 - Pipelining II 48
Scoreboard Example Cycle 14
Instruction status Read ExecutionWriteInstruction j k Issue operandscompleteResultLD F6 34+ R2 1 2 3 4LD F2 45+ R3 5 6 7 8MULTDF0 F2 F4 6 9SUBD F8 F6 F2 7 9 11 12DIVD F10 F0 F6 8ADDD F6 F8 F2 13 14Functional unit status dest S1 S2 FU for j FU for k Fj? Fk?
Time Name Busy Op Fi Fj Fk Qj Qk Rj RkInteger No
5 Mult1 Yes Mult F0 F2 F4 Yes YesMult2 No
2 Add Yes Add F6 F8 F2 Yes YesDivide Yes Div F10 F0 F6 Mult1 No Yes
Register result statusClock F0 F2 F4 F6 F8 F10 F12 ... F30
14 FU Mult1 Add Divide
Dynamic Scheduling Using A Scoreboard

Chap. 4 - Pipelining II 49
Scoreboard Example Cycle 15
Instruction status Read ExecutionWriteInstruction j k Issue operandscompleteResultLD F6 34+ R2 1 2 3 4LD F2 45+ R3 5 6 7 8MULTDF0 F2 F4 6 9SUBD F8 F6 F2 7 9 11 12DIVD F10 F0 F6 8ADDD F6 F8 F2 13 14Functional unit status dest S1 S2 FU for j FU for k Fj? Fk?
Time Name Busy Op Fi Fj Fk Qj Qk Rj RkInteger No
4 Mult1 Yes Mult F0 F2 F4 Yes YesMult2 No
1 Add Yes Add F6 F8 F2 Yes YesDivide Yes Div F10 F0 F6 Mult1 No Yes
Register result statusClock F0 F2 F4 F6 F8 F10 F12 ... F30
15 FU Mult1 Add Divide
Dynamic Scheduling Using A Scoreboard

Chap. 4 - Pipelining II 50
Scoreboard Example Cycle 16
Instruction status Read ExecutionWriteInstruction j k Issue operandscompleteResultLD F6 34+ R2 1 2 3 4LD F2 45+ R3 5 6 7 8MULTDF0 F2 F4 6 9SUBD F8 F6 F2 7 9 11 12DIVD F10 F0 F6 8ADDD F6 F8 F2 13 14 16Functional unit status dest S1 S2 FU for j FU for k Fj? Fk?
Time Name Busy Op Fi Fj Fk Qj Qk Rj RkInteger No
3 Mult1 Yes Mult F0 F2 F4 Yes YesMult2 No
0 Add Yes Add F6 F8 F2 Yes YesDivide Yes Div F10 F0 F6 Mult1 No Yes
Register result statusClock F0 F2 F4 F6 F8 F10 F12 ... F30
16 FU Mult1 Add Divide
Dynamic Scheduling Using A Scoreboard

Chap. 4 - Pipelining II 51
Scoreboard Example Cycle 17
Instruction status Read ExecutionWriteInstruction j k Issue operandscompleteResultLD F6 34+ R2 1 2 3 4LD F2 45+ R3 5 6 7 8MULTDF0 F2 F4 6 9SUBD F8 F6 F2 7 9 11 12DIVD F10 F0 F6 8ADDD F6 F8 F2 13 14 16Functional unit status dest S1 S2 FU for j FU for k Fj? Fk?
Time Name Busy Op Fi Fj Fk Qj Qk Rj RkInteger No
2 Mult1 Yes Mult F0 F2 F4 Yes YesMult2 NoAdd Yes Add F6 F8 F2 Yes YesDivide Yes Div F10 F0 F6 Mult1 No Yes
Register result statusClock F0 F2 F4 F6 F8 F10 F12 ... F30
17 FU Mult1 Add Divide
Dynamic Scheduling Using A Scoreboard
ADDD can’t write because of DIVD. RAW!
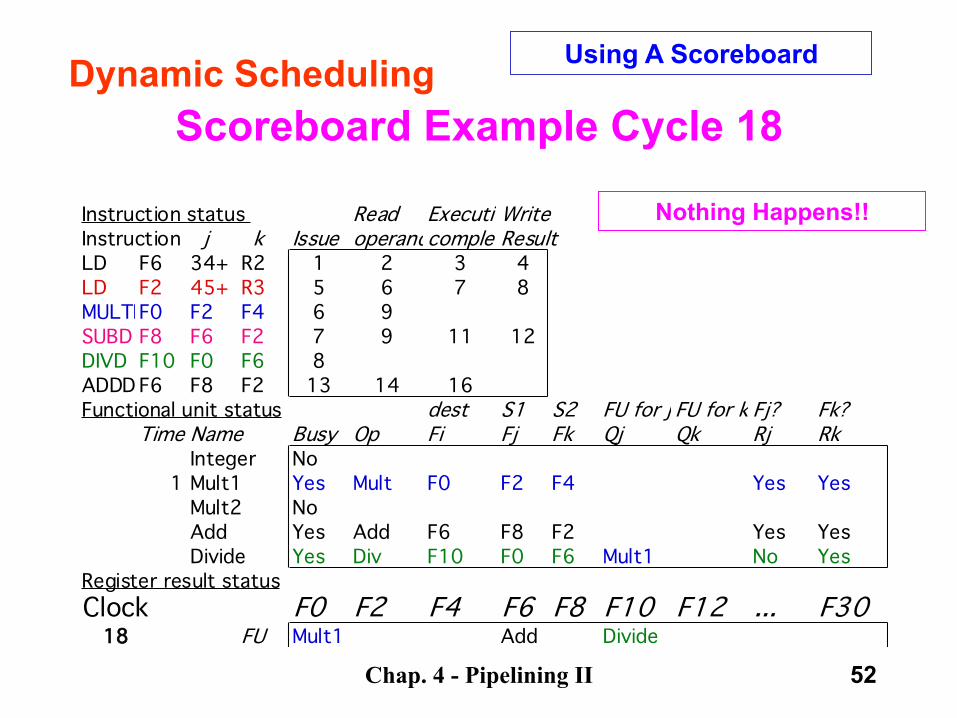
Chap. 4 - Pipelining II 52
Scoreboard Example Cycle 18
Instruction status Read ExecutionWriteInstruction j k Issue operandscompleteResultLD F6 34+ R2 1 2 3 4LD F2 45+ R3 5 6 7 8MULTDF0 F2 F4 6 9SUBD F8 F6 F2 7 9 11 12DIVD F10 F0 F6 8ADDD F6 F8 F2 13 14 16Functional unit status dest S1 S2 FU for j FU for k Fj? Fk?
Time Name Busy Op Fi Fj Fk Qj Qk Rj RkInteger No
1 Mult1 Yes Mult F0 F2 F4 Yes YesMult2 NoAdd Yes Add F6 F8 F2 Yes YesDivide Yes Div F10 F0 F6 Mult1 No Yes
Register result statusClock F0 F2 F4 F6 F8 F10 F12 ... F30
18 FU Mult1 Add Divide
Dynamic Scheduling Using A Scoreboard
Nothing Happens!!

Chap. 4 - Pipelining II 53
Scoreboard Example Cycle 19
Instruction status Read ExecutionWriteInstruction j k Issue operandscompleteResultLD F6 34+ R2 1 2 3 4LD F2 45+ R3 5 6 7 8MULTDF0 F2 F4 6 9 19SUBD F8 F6 F2 7 9 11 12DIVD F10 F0 F6 8ADDD F6 F8 F2 13 14 16Functional unit status dest S1 S2 FU for j FU for k Fj? Fk?
Time Name Busy Op Fi Fj Fk Qj Qk Rj RkInteger No
0 Mult1 Yes Mult F0 F2 F4 Yes YesMult2 NoAdd Yes Add F6 F8 F2 Yes YesDivide Yes Div F10 F0 F6 Mult1 No Yes
Register result statusClock F0 F2 F4 F6 F8 F10 F12 ... F30
19 FU Mult1 Add Divide
Dynamic Scheduling Using A Scoreboard
MULT completes execution.
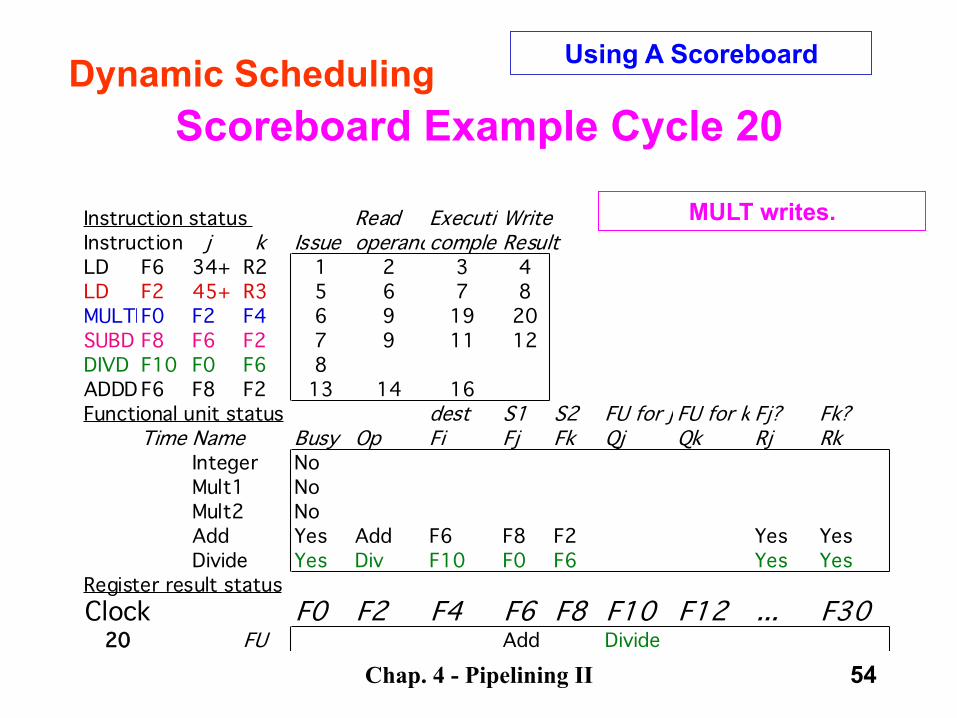
Chap. 4 - Pipelining II 54
Scoreboard Example Cycle 20
Instruction status Read ExecutionWriteInstruction j k Issue operandscompleteResultLD F6 34+ R2 1 2 3 4LD F2 45+ R3 5 6 7 8MULTDF0 F2 F4 6 9 19 20SUBD F8 F6 F2 7 9 11 12DIVD F10 F0 F6 8ADDD F6 F8 F2 13 14 16Functional unit status dest S1 S2 FU for j FU for k Fj? Fk?
Time Name Busy Op Fi Fj Fk Qj Qk Rj RkInteger NoMult1 NoMult2 NoAdd Yes Add F6 F8 F2 Yes YesDivide Yes Div F10 F0 F6 Yes Yes
Register result statusClock F0 F2 F4 F6 F8 F10 F12 ... F30
20 FU Add Divide
Dynamic Scheduling Using A Scoreboard
MULT writes.

Chap. 4 - Pipelining II 55
Scoreboard Example Cycle 21
Instruction status Read ExecutionWriteInstruction j k Issue operandscompleteResultLD F6 34+ R2 1 2 3 4LD F2 45+ R3 5 6 7 8MULTDF0 F2 F4 6 9 19 20SUBD F8 F6 F2 7 9 11 12DIVD F10 F0 F6 8 21ADDD F6 F8 F2 13 14 16Functional unit status dest S1 S2 FU for j FU for k Fj? Fk?
Time Name Busy Op Fi Fj Fk Qj Qk Rj RkInteger NoMult1 NoMult2 NoAdd Yes Add F6 F8 F2 Yes YesDivide Yes Div F10 F0 F6 Yes Yes
Register result statusClock F0 F2 F4 F6 F8 F10 F12 ... F30
21 FU Add Divide
Dynamic Scheduling Using A Scoreboard
DIVD loads operands

Chap. 4 - Pipelining II 56
Scoreboard Example Cycle 22
Instruction status Read ExecutionWriteInstruction j k Issue operandscompleteResultLD F6 34+ R2 1 2 3 4LD F2 45+ R3 5 6 7 8MULTDF0 F2 F4 6 9 19 20SUBD F8 F6 F2 7 9 11 12DIVD F10 F0 F6 8 21ADDD F6 F8 F2 13 14 16 22Functional unit status dest S1 S2 FU for j FU for k Fj? Fk?
Time Name Busy Op Fi Fj Fk Qj Qk Rj RkInteger NoMult1 NoMult2 NoAdd No
40 Divide Yes Div F10 F0 F6 Yes YesRegister result statusClock F0 F2 F4 F6 F8 F10 F12 ... F30
22 FU Divide
Dynamic Scheduling Using A Scoreboard
Now ADDD can write since WAR removed.

Chap. 4 - Pipelining II 57
Scoreboard Example Cycle 61
Instruction status Read ExecutionWriteInstruction j k Issue operandscompleteResultLD F6 34+ R2 1 2 3 4LD F2 45+ R3 5 6 7 8MULTDF0 F2 F4 6 9 19 20SUBD F8 F6 F2 7 9 11 12DIVD F10 F0 F6 8 21 61ADDD F6 F8 F2 13 14 16 22Functional unit status dest S1 S2 FU for j FU for k Fj? Fk?
Time Name Busy Op Fi Fj Fk Qj Qk Rj RkInteger NoMult1 NoMult2 NoAdd No
0 Divide Yes Div F10 F0 F6 Yes YesRegister result statusClock F0 F2 F4 F6 F8 F10 F12 ... F30
61 FU Divide
Dynamic Scheduling Using A Scoreboard
DIVD completes execution

Chap. 4 - Pipelining II 58
Scoreboard Example Cycle 62
Instruction status Read ExecutionWriteInstruction j k Issue operandscompleteResultLD F6 34+ R2 1 2 3 4LD F2 45+ R3 5 6 7 8MULTDF0 F2 F4 6 9 19 20SUBD F8 F6 F2 7 9 11 12DIVD F10 F0 F6 8 21 61 62ADDD F6 F8 F2 13 14 16 22Functional unit status dest S1 S2 FU for j FU for k Fj? Fk?
Time Name Busy Op Fi Fj Fk Qj Qk Rj RkInteger NoMult1 NoMult2 NoAdd No
0 Divide NoRegister result statusClock F0 F2 F4 F6 F8 F10 F12 ... F30
62 FU
Dynamic Scheduling Using A Scoreboard
DONE!!

View In Time Domain
59
Inst. No. 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 LD F6, 34+, R2 IS RO EX WB
LD F2, 45+, R3 IS RO EX WB MULT F0, F2, F4 IS RO EX EX EX EX EX EX …
SUBD F8, F6, F2 IS RO EX EX WB DIVD F10, F0, F6 IS
ADDD F6, F8, F2 IS RO EX …
Inst. No. 16 17 18 19 20 21 22 … … 61 62 LD F6, 34+, R2
LD F2, 45+, R3 MULT F0, F2, F4 EX EX EX EX WB
SUBD F8, F6, F2 DIVD F10, F0, F6 RO EX … … EX WB
ADDD F6, F8, F2 EX STALL… … … … WB

Chap. 4 - Pipelining II 60
Another Dynamic Algorithm: Tomasulo Algorithm
• For IBM 360/91 about 3 years after CDC 6600 (1966)
• Goal: High Performance without special compilers
• Why Study? lead to Alpha 21264, HP 8000, MIPS 10000, Pentium II, PowerPC 604, …
Dynamic Scheduling Using A Scoreboard

Chap. 4 - Pipelining II 61
Tomasulo Algorithm vs. Scoreboard
• Control & buffers distributed with Function Units (FU) vs. centralized in scoreboard; – FU buffers called “reservation stations”; have pending operands
• Registers in instructions replaced by values or pointers to reservation stations(RS); called register renaming ; – avoids WAR, WAW hazards – More reservation stations than registers, so can do optimizations
compilers can’t • Results to FU from RS, not through registers, over Common
Data Bus that broadcasts results to all FUs • Load and Stores treated as FUs with RSs as well • Integer instructions can go past branches, allowing
FP ops beyond basic block in FP queue
Dynamic Scheduling Using A Scoreboard

62
Tomasulo Organization Dynamic Scheduling Using A Scoreboard
Chap. 4 - Pipelining II

Chap. 4 - Pipelining II 63
Reservation Station Components
Op—Operation to perform in the unit (e.g., + or –) Vj, Vk—Value of Source operands
– Store buffers have V field, result to be stored Qj, Qk—Reservation stations producing source registers (value to be
written) – Note: No ready flags as in Scoreboard; Qj,Qk=0 => ready – Store buffers only have Qi for RS producing result
Busy—Indicates reservation station or FU is busy
Register result status—Indicates which functional unit will write each register, if one exists. Blank when no pending instructions that will write that register.
Dynamic Scheduling Using A Scoreboard

Chap. 4 - Pipelining II 64
Three Stages of Tomasulo Algorithm 1. !Issue—get instruction from FP Op Queue
If reservation station free (no structural hazard), control issues instruction & sends operands (renames registers).
2. !Execution—operate on operands (EX) When both operands ready then execute;
if not ready, watch Common Data Bus for result 3. !Write result—finish execution (WB)
Write on Common Data Bus to all awaiting units; mark reservation station available
• Normal data bus: data + destination (“go to” bus) • Common data bus: data + source (“come from” bus)
– 64 bits of data + 4 bits of Functional Unit source address – Write if matches expected Functional Unit (produces result) – Does the broadcast
Dynamic Scheduling Using A Scoreboard
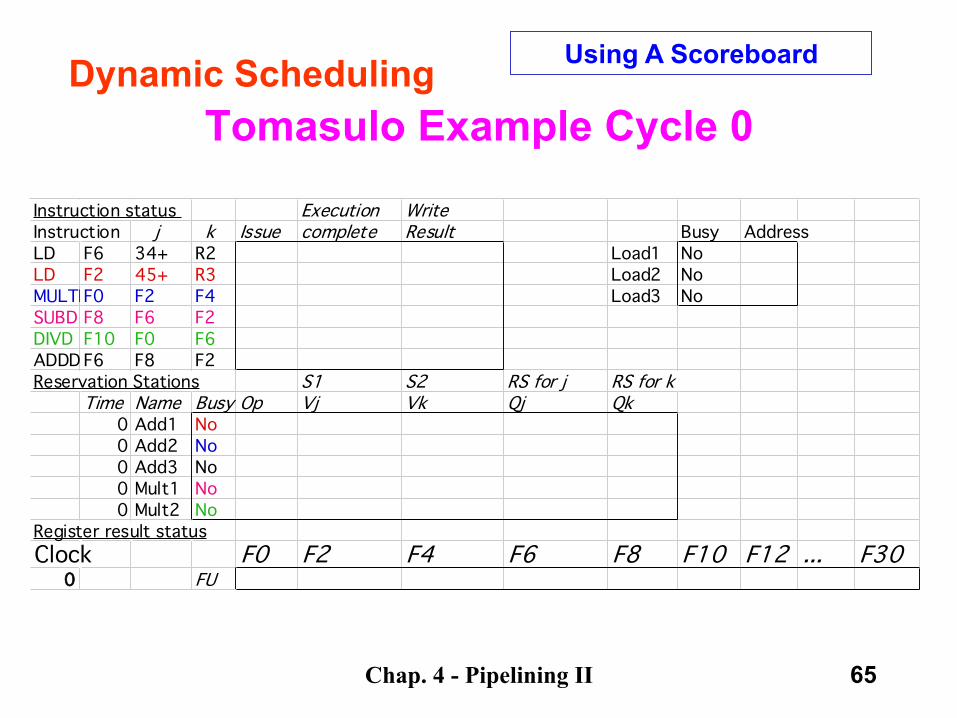
Chap. 4 - Pipelining II 65
Tomasulo Example Cycle 0
Instruction status Execution WriteInstruction j k Issue complete Result Busy AddressLD F6 34+ R2 Load1 NoLD F2 45+ R3 Load2 NoMULTDF0 F2 F4 Load3 NoSUBD F8 F6 F2DIVD F10 F0 F6ADDD F6 F8 F2Reservation Stations S1 S2 RS for j RS for k
Time Name Busy Op Vj Vk Qj Qk0 Add1 No0 Add2 No0 Add3 No0 Mult1 No0 Mult2 No
Register result statusClock F0 F2 F4 F6 F8 F10 F12 ... F30
0 FU
Dynamic Scheduling Using A Scoreboard

Chapter 3 - Exploiting ILP 66
Just when ADD.D is issued at cycle 5, we have
Instruction statusInstruction Issue Execution complete Write resultL.D F6,34(R2) √ √ √L.D F2,45(R3) √ √MULT.D F0,F2,F4 √SUB.D F8,F6,F2 √DIV.D F10,F0,F6 √ADD.D F6,F8,F2 √
Reservation stationsName Busy Op V j Vk Qj Qk
Add1 Y SUB.D Mem[34+Reg[R2]] Load2Add2 Y ADD.D Add1 Load2Add3 NMult1 Y MULT.D Reg[F4] Load2Mult2 Y DIV.D Mem[34+Reg[R2]] Mult1
Register statusF0 F2 F4 F6 F8 F10 F12 ...
Qi Mult1 Load2 Add2 Add1 Mult2
Example

Chapter 3 - Exploiting ILP 67
When MULT.D is ready to write the result at cycle 17 we have:
Instruction statusInstruction Issue Execution complete Write resultL.D F6,34(R2) √ √ √L.D F2,45(R3) √ √ √MULT.D F0,F2,F4 √ √SUB.D F8,F6,F2 √ √ √DIV.D F10,F0,F6 √ADD.D F6,F8,F2 √ √ √
Reservation stationsName Busy Op V j Vk Qj Qk
Add1 NAdd2 NAdd3 NMult1 Y MULT.D Mem[45+Reg[R3]] Reg[F4]Mult2 Y DIV.D Mem[34+Reg[R2]] Mult1
Register statusF0 F2 F4 F6 F8 F10 F12 ...
Qi Mult1 Mult2
Example

View In Time Domain
68
Inst. No. 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 LD F6, 34+, R2 IS EX WR
LD F2, 45+, R3 IS EX WR MULT F0, F2, F4 IS EX EX
SUBD F8, F6, F2 IS EX EX DIVD F10, F0, F6 IS
ADDD F6, F8, F2 IS
Inst. No. 16 17 18 19 20 21 22 … LD F6, 34+, R2
LD F2, 45+, R3 MULT F0, F2, F4
SUBD F8, F6, F2 DIVD F10, F0, F6
ADDD F6, F8, F2

Chap. 4 - Pipelining II 69
Review: Tomasulo
• Prevents Register as bottleneck • Avoids WAR, WAW hazards of Scoreboard • Allows loop unrolling in HW • Not limited to basic blocks (provided branch prediction) • Lasting Contributions
– Dynamic scheduling – Register renaming – Load/store disambiguation
• 360/91 descendants are PowerPC 604, 620; MIPS R10000; HP-PA 8000; Intel Pentium Pro
Dynamic Scheduling Using A Scoreboard