effects of pitch and speech rate on personal attributions · effects of pitch and speech rate on...
TRANSCRIPT

Journal of Personality and Social Psychology1979, Vol. 37, No. 5, 715-727
Effects of Pitch and Speech Rate on Personal Attributions
William AppleColumbia University
Lynn A. StreeterBell Laboratories
Murray Hill, New Jersey
Robert M. KraussColumbia University
In three experiments, subjects listened to recordings of male speakers answeringtwo interview questions and rated the speakers on a variety of scales. The re-cordings had been altered so that the pitch of the speakers' voices was raised orlowered by 20% or left at its normal level, and speech rate was expanded orcompressed by 30% or left at its normal rate. The results provided clear evi-dence that listeners use these acoustic properties in making personal attributionsto speakers. Speakers with high-pitched voices were judged less truthful, lessemphatic, less "potent" (smaller, thinner, faster), and more nervous. Slow-talk-ing speakers were judged less truthful, less fluent, and less persuasive and wereseen as more "passive" (slower, colder, passive, weaker) but more "potent."However, the effects of the acoustic manipulations on personal attributions alsodepended on the particular question that elicited the response.
Human speech provides a listener with atleast two sources of information: a verbalchannel, encoding the message's linguistic con-tent, and a vocal channel, conveying paralin-guistic information by variations in pitch,speech rate, loudness, and the like.
One important type of information com-municated via the vocal channel concerns aspeaker's affective state. The vocal character-istics associated with the expression of emo-tion are beginning to be understood (see, forexample, Fairbanks, 1940; Hecker, Stevens,von Bismarck, & Williams, 1968; Williams &Stevens, 1972). It is now reasonably wellestablished that stressful situations raise thevoice's fundamental frequency (the numberof glottal pulses per second) and that "ac-tive" emotions such as anger and fear tendto be reflected in increased mean pitch and
We wish to thank John Lin and Nina Macdonaldfor their valuable assistance. We are also grateful toMyron Wish, Nancy Morency, and four anonymousreviewers for their helpful comments.
Requests for reprints should be sent to Robert M.Krauss, Department of Psychology, 400 Schermer-horn Hall, Columbia University, New York, NewYork 10027.
pitch variance, whereas "low energy" statessuch as sorrow and indifference are associatedwith a lower mean pitch and a slower speechrate.
Given that emotional states do differ re-liably in their paralinguistic expression, towhat extent do listeners use these vocal cuesin judging the immediate affective state ormore enduring personality traits of a speaker?An early investigation of the noncontent as-pects of speech by Allport and Cantril (1934)demonstrated that listeners could judge, atbetter than chance levels, a speaker's age andat least some personality characteristics fromvoice alone: In four of six experiments, speak-ers' scores on a test of ascendance-submis-sion (Allport's A-S reaction study) werejudged with significant accuracy. However,reviewing much of the voice-attribution work,Kramer (1963) concluded that more com-mon than accuracy in such judgment studieswas the finding of "vocal stereotypes." Thatis, certain voices were reliably, though some-times incorrectly, judged as belonging to cer-tain personality types.
Unfortunately, as Kramer noted, the de-scription of the vocal parameters that under-
Copyright 1979 by the American Psychological Association, Inc. 0022-3514/79/3705-0715$00.75
715

716 W. APPLE, L. STREETER, AND R. KRAUSS
He such stereotypes leaves much to be desired.While not all the earlier research on voiceattributions can be faulted on these grounds,studies attempting to specify critical stimu-lus dimensions often have neglected or con-founded important paralinguistic cues. Forexample, in reporting two recent field experi-ments, Miller, Maruyama, Beaber, and Va-lone (1976) concluded that the persuasive-ness of a communication can be directly re-lated to the rate at which it is delivered. Morerapid speech was found to be more persuasive,presumably because a fast talker is viewed asmore credible. Although Miller et al. haveruled out certain alternative explanations(such as the effect of having limited oppor-tunity to counterargue against a rapid pre-sentation), the stimulus materials used intheir experiments warrant closer examina-tion. In both experiments the persuasive mes-sages were recorded by the same speaker ateither a slow or a fast speech rate. This wasaccomplished "by simply instructing thespeaker to practice delivering the same speechas rapidly and slowly as possible while con-trolling his level of enthusiasm and involve-ment" (Miller et al, 1976, p. 618). The stim-ulus recordings in the two conditions do, ofcourse, differ in speech rate, but it is quitelikely that they differ in other respects as well.In natural speech, such vocal parameters asamplitude, pitch, and rate tend to covary.For example, rapid speech is likely to belouder and higher pitched than normal speech(Black, 1961). Consequently, it is quite pos-sible that subjects in the Miller et al. studywere responding to pitch and/or loudness cuesas well as to rate.
Because it is so difficult to assess, in a con-trolled way, the contribution of various vocalparameters to the attribution process usingnatural speech, a number of workers have at-tempted to deal with the problem by usingnonspeech stimuli. For example, Scherer(1974) presented listeners with simple tonesequences generated on a Moog synthesizer,in which a minimal set of acoustic cues(pitch level and variation, amplitude leveland variation, and tempo) were varied fac-torially; listeners rated the emotional qualityof these tone sequences on a set of semantic
differential scales. Scherer found that judg-ments were most influenced by tempo andpitch variations: Fast tempo led to attribu-tions of highly active and potent emotions(e.g., interest, anger, and happiness) andslow tempo to attributions of sadness, disgust,and boredom; extreme pitch variation withrising contours produced ratings of highlypleasant, active, and potent emotions (hap-piness, surprise, interest). Other parametersinfluenced the perception of specific emotionalqualities. While Scherer's method effectivelydeals with the confounding of vocal qualitiesin natural speech and suggests the effect thatindependently varied acoustic cues can exert,in view of the artificial nature of the stimuliused, it is not clear how directly the resultscan be generalized to the processing of speech.
Other investigators, using natural speech,have achieved a degree of control over stimu-lus materials by means of editing techniques.For example, investigators have added orremoved such speech disfluencies as filledpauses and repetitions from stimulus audio-tapes and asked listeners to judge speakers'credibility and other personal attributes (Lay& Burron, 1968; Miller & Hewgill, 1964).Typically, highly hesitant or disfluent speak-ers are assigned relatively undesirable per-sonality traits, and their communications arejudged to be low in credibility.
While the methods thus far described haveall afforded some degree of stimulus control,recent developments in speech synthesis tech-nology permit investigators to vary indepen-dently one or more parameters of naturalspeech. This approach has been exploited byBrown and his colleagues (Brown, Strong, &Rencher, 1973, 1974; Smith, Brown, Strong,& Rencher, 1975), who have manipulatedspeech rate, mean fundamental frequency,and fundamental frequency variance, usinga computer-based analysis-synthesis system.Two major personality dimensions (termed"competence" and "benevolence") haveemerged from factor analyses of judgmentsof such manipulated speech. Generally speak-ing, higher pitch seems to result in a speakerbeing judged less competent and less benev-olent (Brown et al., 1974), whereas fasterspeech rates produce judgments of higher

PITCH AND SPEECH RATE 717
competence but yielded an inverted-U rela-tionship on the benevolence dimension (Smithetal., 1975).
The studies of Brown and his associatesmake an important contribution to our under-standing of the significance that listenersascribe to vocal qualities. Nevertheless, theyare not free of methodological problems.They typically have relied on a small numberof stimulus voices, all of whose acoustic per-mutations are presented to the same raters.For example, the Brown et al. (1974) studyused only two adult male speakers utteringthe same sentence ("We were away a yearago"), which was then manipulated to fillthe 27 cells of a 3 X 3 X 3 factorial design.It is not clear that judgments based on hear-ing 54 repetitions of the same content bearmuch similarity to the kinds of everyday per-sonality ascriptions listeners make under morenatural conditions. Additionally, the particu-lar parametric values used in these studiesare problematic. Brown et al. (1974) reportedthat in the high-pitch condition, the originalfundamental frequency was multiplied by afactor of 1.8. Although they did not reportaverage fundamental frequency values fortheir two speakers, assuming that they fellinto the normal range for .males, Brown etal.'s high-pitch manipulation would haveraised a male voice into the female range.Similar criticisms apply to their choice ofspeech-rate scale factors.
The present article reports an exploratoryseries of experiments designed to demonstratethe effects of two acoustic parameters—aver-age fundamental frequency and speech rate—on judgments of several state and trait vari-ables. It was hoped that by using a largenumber of speakers and naturally producedutterances, together with more conservativevalues for acoustic alteration, and by inde-pendently manipulating the two parametersfactorially, we could overcome the methodo-logical problems noted above.
Experiment 1
Experiment 1 derives from a finding re-ported by Streeter, Krauss, Geller, Olson, andApple (1977), who demonstrated that the
mean fundamental frequency of speakers'voices increased when they lied, relative toa truth-telling baseline, and that this effectwas stronger when the speaker had been mo-tivated to lie effectively. In addition, Streeteret al. found that although judges' ratings oftruthfulness were essentially uncorrelatedwith pitch level, there was a significant nega-tive correlation between judged truthfulnessand average pitch for listeners who heard thespeech after it had been passed through a con-tent filter—a device that destroys intelligibil-ity without affecting vocal features of theutterances. Apparently, the natural pitch in-crements during lying (on the average about3 Hz) were too small to affect the judgmentsof listeners who had content available butwere taken into account by listeners whocould not understand the responses' verbalcontent. However, since pitch increments andspeech rate decrements were correlated intheir data, Streeter et al. could not rule outthe possibility that listeners were attendingto rate differences rather than pitch differencesbetween true and false utterances. From thefinding of Miller et al. (1976), one wouldexpect slower speech to result in lower per-ceived speaker credibility. In Experiment 1we assessed the effects of these two variableson truthfulness judgments.
Method
Stimulus materials. Forty male Columbia Col-lege undergraduates, all native speakers of English,answered questions for use as stimulus materials. Theywere individually recorded in a sound-isolated boothon high-quality audio equipment, and they receivedcourse credit for their participation. Each speakeranswered six standard questions dealing with hisopinion on a range of topics. The questions wereadministered in a fixed order, and speakers were in-structed to answer all questions honestly and frankly.They were told to give brief answers, but to givemore than a yes-or-no response. All speakers weredebriefed concerning how their interviews might beused and signed informed-consent releases permittingthe later use of the recordings.
Two of the six interview questions were selectedfor use in the experiment. One asked the subject'sopinion of college admissions quotas designed tofavor minority groups (Question 3) ; the other askedthe subject what he would do if he suddenly wonor inherited a large sum of money (Question 6).These two questions were chosen because both eliciteda diversity of responses and because the two differed

718 W. APPLE, L. STREETER, AND R. KRAUSS
on a dimension of personal salience for the respon-dents. (The question of quotas is a matter of gen-uine concern and frequent discussion among Co-lumbia undergraduates.) Twenty-seven speakers, whogave responses that were not excessively long andrepresented the spectrum of opinions on the twoquestions, were selected.
Each of the 27 speakers was then randomly as-signed to one of nine cells of a 3 (rate: slow, un-manipulated, fast) X 3 (pitch: low, unmanipulated,high) completely crossed factorial design, with threespeakers in each cell. All speech material was digitizedand analyzed by the linear predictive coding (LPC)method of Atal and Hanauer (1971). (The LPCanalysis calculates 14 parameters every 10 msec.Twelve of these parameters represent pseudoareafunctions of the vocal tract; the other two arevalues for amplitude and fundamental frequency.The advantage of LPC analysis is that such vari-ables as rate, pitch, and amplitude can be manipu-lated without changing other voice parameters. Inaddition, since the parameters are derived fromthe original speech, the quality of the resulting syn-thesis is high.) The two responses of each speakerwere manipulated on a DDP-224 computer using aninteractive program (Nakatani, Note 1) that displaysthe parameters as functions of time and allows theuser to manipulate any or all of the 14 parametersas well as to linearly expand or compress thetime base. The altered utterances can then be syn-thesized and recorded on audiotape.
The scale factors chosen for the low- and high-pitch manipulations were 80% and 120%, respec-tively, of the speaker's unmanipulated fundamentalfrequency. The values chosen for the slow and fastspeech rate manipulations were 70% compressionand 130% expansion, respectively, of the utterance'stime base, resulting in speech rates that were 77%and 143% of the unmanipulated rates.1 These scalevalues were chosen because the resulting speech stillsounded natural and the acoustic properties remainedmore or less within the normal range of values. (SeeHanley, 1951; Mysak, 19S9; Peterson & Barney,19S2; and Terango, 1966, for data on pitch andGoldman Eisler, 1968, for normative speech ratedata.) The mean premanipulation fundamental fre-quency and speech rate for our speakers were 109.79Hz (SD = 14.82) and 3.27 syllables/sec (SD = .66).Following manipulation, all utterances were resyn-thesized to produce a stimulus audiotape of theanswers to the quota question (in one randomorder) and a tape of the answers to the moneyquestion (in a different order). The tapes were for-matted to allow IS sec of silence between each re-sponse.
Procedure, Twenty undergraduates, 14 males and6 females, were paid for their participation.2 Raterswere run in groups of three to seven. They were toldthat the purpose of the study was to determine howwell people can tell, from the sound of the speaker'svoice, whether someone is lying or telling the truth.They were informed that approximately half the
speakers had been instructed to tell the truth, whereasthe remaining half had been told to lie—that is, togive answers that did not correspond to their actualbeliefs or feelings.
The two stimulus tapes were played over high-quality audio equipment with the order of tapepresentation counterbalanced. A SOO-Hz warning tonepreceded and followed each answer by 1 sec. Raterswere given IS sec in which to rate the truthfulnessof the answer on a 7-point scale ranging from "notat all truthful" (1) to "entirely truthful" (7).
Because of variations in the quality of the record-ings, raters were also told that recordings had beenmade using a variety of equipment in several differ-ent environments.3 The experimental session lastedabout an hour, and there was a S-min. rest periodbetween tapes. Participants in the three rating studieswere sent a report describing the purpose and detail-ing some of the findings of the study several weeksafter its conclusion.
Results
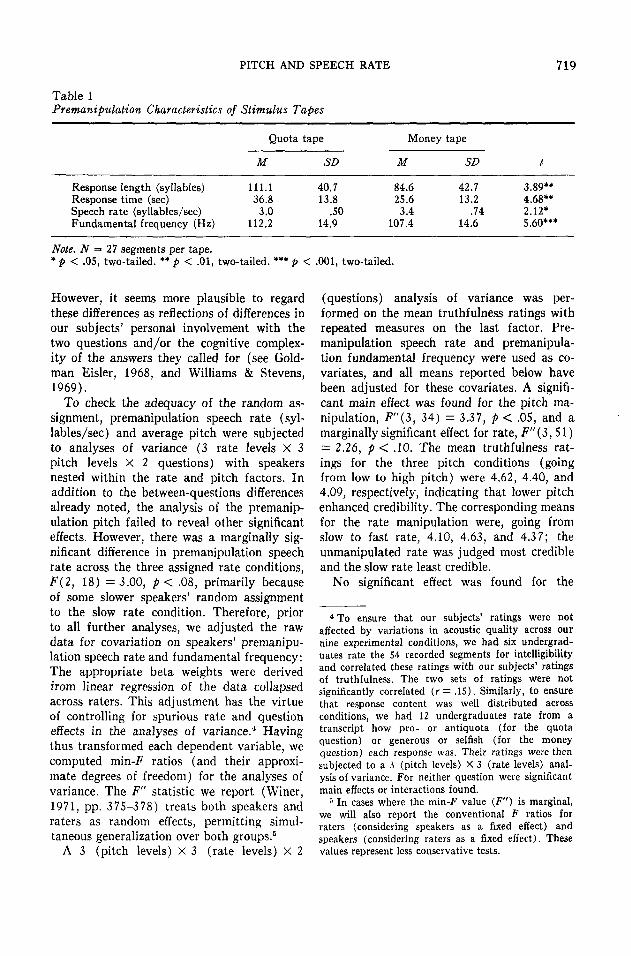
Some of the premanipulation characteristicsof the stimulus materials are summarized inTable 1. Note that the more involving topic,college admissions quotas, resulted in signifi-cantly longer, slower, and higher pitched re-sponses. Since the quota topic always precededthe money topic in the original order, wecannot rule out the possibility that these dif-ferences are due to serial position effects.
1 The rate manipulation algorithm linearly ex-panded or compressed consonant and vowel informa-tion alike. In natural speech, rate variation tends tobe reflected more in changes of vowel duration thanin consonant duration. However, the rate manipula-tion used resulted in reasonably natural-soundingspeech.
It may not be immediately apparent why 70%compression of an utterance's time base results ina speech rate that is 143% of the original. Con-sider a response consisting of » syllables spoken over sseconds of time; that utterance's rate would be n/ssyllables/sec. Seventy-percent compression changesthe rate to n/(.1s), or 1.43 n/s—a faster speech ratethat is 143% of the original. Likewise, a 130% ex-pansion of an utterance's time base results in aslower speech rate that is 77% of the original rate.
- One additional rater was run, but his data werediscarded after he expressed some suspicion regard-ing possible splicing of the tapes. No other ratersvoiced any suspicion that the stimuli had beenaltered.
3 There is some quality variation across speakers inthe LPC synthesis; in particular, speakers who tendto mumble and have a high degree of nasalizationseem to suffer the greatest quality degradation.
PITCH AND SPEECH RATE 719
Table 1Premanipulation Characteristics of Stimulus Tapes
Quota tape
M SD
Money tape
M
Note. N = 27 segments per tape.* p < .05, two-tailed. ** p < .01, two-tailed. *** p < .001, two-tailed.
SD
Response length (syllables)Response time (sec)Speech rate (syllables/sec)Fundamental frequency (Hz)
111.136.83.0
112.2
40.713.8
.5014.9
84.625.63.4
107.4
42.713.2
.7414.6
3.89**4.68**2.12*5.60***
However, it seems more plausible to regardthese differences as reflections of differences inour subjects' personal involvement with thetwo questions and/or the cognitive complex-ity of the answers they called for (see Gold-man Eisler, 1968, and Williams & Stevens,1969).
To check the adequacy of the random as-signment, premanipulation speech rate (syl-lables/sec) and average pitch were subjectedto analyses of variance (3 rate levels X 3pitch levels X 2 questions) with speakersnested within the rate and pitch factors. Inaddition to the between-questions differencesalready noted, the analysis of the premanip-ulation pitch failed to reveal other significanteffects. However, there was a marginally sig-nificant difference in premanipulation speechrate across the three assigned rate conditions,F(2, 18) = 3.00, p < .08, primarily becauseof some slower speakers' random assignmentto the slow rate condition. Therefore, priorto all further analyses, we adjusted the rawdata for covariation on speakers' premanipu-lation speech rate and fundamental frequency:The appropriate beta weights were derivedfrom linear regression of the data collapsedacross raters. This adjustment has the virtueof controlling for spurious rate and questioneffects in the analyses of variance.'* Havingthus transformed each dependent variable, wecomputed min-/? ratios (and their approxi-mate degrees of freedom) for the analyses ofvariance. The F" statistic we report (Winer,1971, pp. 375-378) treats both speakers andraters as random effects, permitting simul-taneous generalization over both groups.5
A 3 (pitch levels) X 3 (rate levels) X 2
(questions) analysis of variance was per-formed on the mean truthfulness ratings withrepeated measures on the last factor. Pre-manipulation speech rate and premanipula-tion fundamental frequency were used as co-variates, and all means reported below havebeen adjusted for these covariates. A signifi-cant main effect was found for the pitch ma-nipulation, F"(3, 34) = 3.37, p < .05, and amarginally significant effect for rate, F"(3,51)= 2.26, p < .10. The mean truthfulness rat-ings for the three pitch conditions (goingfrom low to high pitch) were 4.62, 4.40, and4.09, respectively, indicating that lower pitchenhanced credibility. The corresponding meansfor the rate manipulation were, going fromslow to fast rate, 4.10, 4.63, and 4.37; theunmanipulated rate was judged most credibleand the slow rate least credible.
No significant effect was found for the
*To ensure that our subjects' ratings were notaffected by variations in acoustic quality across ournine experimental conditions, we had six undergrad-uates rate the 54 recorded segments for intelligibilityand correlated these ratings with our subjects' ratingsof truthfulness. The two sets of ratings were notsignificantly correlated (r— .15). Similarly, to ensurethat response content was well distributed acrossconditions, we had 12 undergraduates rate from atranscript how pro- or antiquota (for the quotaquestion) or generous or selfish (for the moneyquestion) each response was. Their ratings were thensubjected to a 3 (pitch levels) X 3 (rate levels) anal-ysis of variance. For neither question were significantmain effects or interactions found.
•' In cases where the min-F value (F") is marginal,we will also report the conventional F ratios forraters (considering speakers as a fixed effect) andspeakers (considering raters as a fixed effect). Thesevalues represent less conservative tests.

720 W. APPLE, L. STREETER, AND R. KRAUSS
i
aUJ
5.5
c/> 5.0(OUJH
4.0
3.5
LEGEND'QUOTA= MONEY
LOW NORMAL H\GH
PITCH CONDITION
Figure 1. Average rated truthfulness plotted as afunction of pitch condition (low, normal, high) foreach of the two question topics.
Pitch X Rate interaction. However, there wasa nearly significant Pitch X Question effect,F"(2, 32) = 3.02, p < .10; raters' F ( 2 , 38)= 10.25, p< .001; speakers' F ( 2 , 18) =3.84,p < .05. For the quota question, truthfulnessratings and pitch were curvilinearly related;for the money question, low-pitched speakerswere judged as most truthful. The two setsof means are shown in Figure 1 .°
Discussion
The results demonstrate that the acousticmanipulations performed on the speech stimuliaffected judgments of truthfulness. Consistentwith the findings of Streeter et al. (1977),judges rated high-pitched voices as less truth-ful than lower pitched voices. Perhaps listen-ers perceived high pitch to be an indication ofstress and attributed such stress to attempteddeception. The pitch manipulations used, al-though not extreme enough to place voicesoutside the normal male pitch range, wereevidently large enough to produce attribu-tions of lying from naive listeners. It will berecalled that the smaller, naturally occurringpitch increments accompanying deception inthe Streeter et al. experiment did not evokesuch attributions, except in the filtered listen-ing condition, in which verbal content was un-intelligible.
While the rate effect was only marginallysignificant, it appears that the effect of rateon truthfulness judgments is not linear;rather, the pattern is an inverted-U function,with slower speech perceived as least credible.These results are consistent with the findingsof Miller et al. (1976), who demonstratedthat a faster speaker was perceived as moreintelligent, knowledgeable, and objective thana slower speaker. Since Miller et al. used onlytwo levels of speech rate, it is, of course, notpossible to establish the effect of intermediaterates on credibility judgments in their study.It is relevant, however, that Brown and co-workers have reported a similar inverted-Urelationship between manipulated speech rateand their "benevolence" dimension, on whichthe adjective pair sincere-insincere loads sig-nificantly (see Smith, Brown, Strong &Rencher, 1975). To the extent that ratingsof sincerity correspond to this study's truth-fulness measure, the two results are consistent.
The most plausible explanation of the Ques-tion X Pitch interaction (Figure 1) is thatlisteners took question content into considera-tion in making their truthfulness judgments:When listening to a potentially "loaded" topic(quota question), raters were willing to callboth low- and normal-pitched voices moretruthful than high-pitched voices. For the lessinvolving question (money), raters were will-ing to call only low voices more truthful. Thisinteraction argues for a pitch threshold, abovewhich deception is signaled to raters. Such athreshold would interact with response con-tent, so that for an emotionally involvingtopic, it would be set higher than for a lessinvolving topic. With an emotionally involv-ing topic, some of the vocally reflected stresscan be attributed to the topic; given a non-involving topic, the high-pitch responses arelikely to be attributed to attempted decep-tion. However, since only two questions wereused, further research is needed to test thiscontent-attribution hypothesis.
The truthfulness ratings reflect judgment
6 The corresponding analysis performed on the in-telligibility ratings revealed a significant effect onlyfor the rate manipulation, with fastest speech suffer-ing greatest loss in intelligibility.

PITCH AND SPEECH RATE 721
processes that give rise to attributions of aspeaker's transient state. If listeners had notbeen told that certain speakers were lying,differences in the acoustically manipulatedvariables might have been seen as enduringvocal properties reflecting stable personal pre-dispositions. Such properties have been re-ferred to by the linguist Trager (1958) asthe "voice set" and involve "the physiologi-cal and physical peculiarities resulting in thepatterned identification of individuals as ...persons of a certain sex, age, state of health,body build, rhythm state" (p. 4). The voiceset, therefore, acts as a relatively permanentbackground against which transient vocalchanges are superimposed. In the absence ofsituational factors (e.g., the possibility thatthe speaker was lying) that could explain thevoice qualities produced by our acoustic ma-nipulations, listeners would be likely to as-cribe such qualities to the voice set. Howsuch variables affect person perception andcontribute to vocal stereotypes was explored inExperiment 2.
Experiment 2
Method
Stimulus materials. The quota and money tapesfrom Experiment 1 were used.
Procedure. Eleven college students, nine males andtwo females, were paid for their participation asraters. The procedure was essentially the same asthat used in Experiment 1, with the following dif-ferences: Raters were instructed that the study'spurpose was to investigate how listeners form im-pressions of speakers from the things they say aswell as from the way they say them. Accordingly,raters were told to focus both on content and de-livery when making their judgments.
The speaker of each recorded segment was ratedon nine bipolar adjective pairs taken from the se-mantic differential (Osgood, Suci, & Tannenbaum,19S7); scales were chosen that had high loadings onone of Osgood et al.'s semantic space factors andrelatively low loadings on the other two. The scalesfor the evaluation factor were sour-sweet, awful-nice,and bad-good. Scales for the potency factor werethin-thick, small-large, and weak-strong. Those forthe activity factor were slow-fast, cold-hot, andpassive-active.
A warning tone followed each recorded segment,signaling judges to begin making the nine ratings on7-point scales. (The second adjective of each pairwas scored as 7.) Instructions stressed that ratingsshould reflect the listener's impression of the speaker
and not agreement or disagreement with the con-tent of the answer. Subjects were told that allspeakers had answered the questions truthfully.
Results
Means of the nine scales were computedfor each recorded segment, and the intercor-relation matrix was factor analyzed usingprincipal factoring followed by a varimax rota-tion. A three-factor solution accounted for84.5 % of the total variance and roughly cor-responded to the three dimensions of Osgoodet al.'s (19S7) semantic space. We chosescales loading greater than .60 (in absolutevalue) as representative of the respective fac-tors. Using that cutoff, Factor 1 consisted ofall three activity scales (slow-fast, cold-hot,and passive-active) as well as the strong-weak scale; it accounted for 54.4% of thevariance. Factor 2 was a pure evaluation di-mension (with only the three evaluative scalesloading appreciably: sour-sweet, awful-nice,bad-good); it accounted for 20.2% of thevariance. The third factor consisted of twopotency scales (thin-thick, small-large) andan activity scale (slow-fast); it accountedfor 9.9% of the variance.
Each rater's data were reduced to threefactor scores weighting the original scales bythe factor loadings; the factor scores were ad-justed for covariates (as in Experiment 1)and entered into univariate analyses of vari-ance of the same design as that used in Ex-periment 1.
For Factor 1, a significant rate effect,F"(2, 32) = 10.49, p< .001, and a nearlysignificant Rate X Question interaction,F"(2, 31) =3.02, p<.lO, were obtained;raters' F ( 2 , 20) = 9.72, p < .01; speakers'F ( 2 , 18) =3.87, p< .05. The configurationof means is shown in Figure 2. In both cases,slow speakers were perceived as less active.No significant main effects of interactionswere found for Factor 2, For Factor 3, signifi-cant main effects were found for rate, F" (2,3 6)= 12.87, p< .001, and pitch, F"(2, 33) =7.94, p < .01. In both cases the relationshipwas monotonic, with increasing pitch andrate resulting in judgments of decreasing po-tency. No other significant effects were found.

722 W. APPLE, L. STREETER, AND R. KRAUSS
12.5 r
11.5
10.5
9.5
8.5
75
6.5
5.5 _L _LSLOW NORMAL FAST
RATE CONDITION
Figure 2. Averages for the activity factor plotted asa function of rate condition (slow, normal, fast)and question topic.
Discussion
These results extend the findings of Ex-periment 1 to judgments of more stablespeaker dispositions. Men speaking in higherpitched voices were perceived as less potent(smaller, thinner, slower) and slow-speakingmen were perceived as more passive (slower,colder, more passive, weaker) and morepotent.
These findings are to some extent con-sistent with correlational evidence providedby Scherer, Koivumaki, and Rosenthal(1972). In their experiment, listeners ratedtaped segments, taken from a recorded play,on semantic differential scales similar to theones used here, as well as on scales reflectingthe segments' acoustic properties (e.g., bass-treble, soft-loud). Unlike the present study,raters judged the emotion portrayed and nottheir impression of the speaker, and a varietyof listening conditions were used to degradesemantic content and prosodic features.Nevertheless, Scherer et al. found a marginallysignificant relationship between pitch rating(bass-treble) and potency ratings (strong-weak) paralleling the main effect reportedabove: Lower pitched speech was placed to-ward the "stronger" pole in the potency di-mension of the emotional-meaning space. Incontrast to our results, they also found amarginal correlation between articulation rate
(slow-fast) and potency ratings: Segmentswith slower speech were rated as "weaker."Not surprisingly, Scherer et al. also foundthat segments with faster speech were heavilyloaded on the activity dimension.
Our findings are likewise consistent withthe results of Brown et al' (1974). Althoughthe methodological differences previouslynoted preclude direct comparison, Brownfound that high fundamental frequency de-creased competence ratings—a scale probablyrelated to our potency dimension.
The Rate X Question interaction (Figure2) again suggests the influence that con-tent exerts on raters' judgments: When speak-ers talked about quotas, ratings on the pas-sive-active dimension were linear with ma-nipulated rate; for the money question, theywere not.
Experiment 3
Experiment 3 returned this work to thearea of judgments of the speaker's affectivestate. Impressions of nervousness, emphatic-ness, seriousness, fluency, and persuasivenessillustrate how these acoustic variables serveto convey a speaker's self-presentation underconditions in which raters believe that an-swers are being given honestly. These stateratings (with the exception of persuasiveness)were chosen because Krauss, Geller, and Olson(Note 2) found significant correlations be-tween them and truthfulness ratings in aprevious study of deception interactions.
Method
Stimulus materials. The quota and money tapesfrom Experiment 1 were used.
Procedure. Ten college-student subjects, two malesand eight females, were paid to rate all segments onfive state variables: fluency, emphaticness, persua-siveness, nervousness, and seriousness. The ratingscales spanned 7 points, with 1 indicating that thesmallest amount of a variable was judged and 7 in-dicating that the largest amount was judged. Forexample, anchors of the nervousness scale were "Notat all nervous" and "Very nervous." Subjects wereencouraged to adopt their own criteria for all rat-ings; no external standards were given. Instructionswere virtually identical to those used in Experi-ment 2. Again, listeners were asked to take intoconsideration both the content of an answer andthe manner in which it was delivered.
PITCH AND SPEECH RATE 723
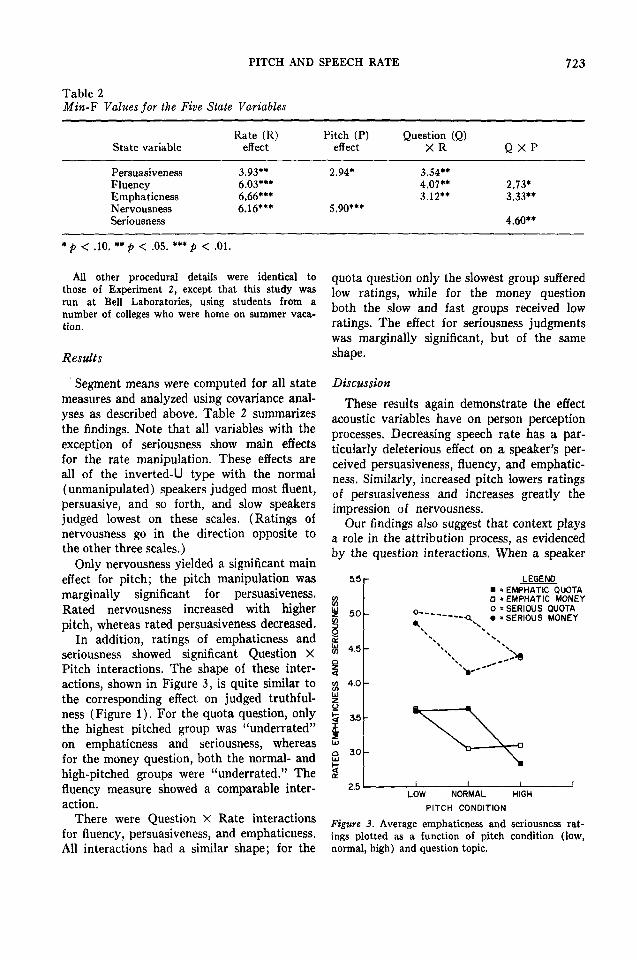
Table 2Min-¥ Values for the Five State Variables
State variable
PersuasivenessFluencyEmphaticnessNervousnessSeriousness
Rate (R)effect
3.93**6.03***6.66***6.16***
Pitch (P)effect
2.94*
5.90***
Question (Q)X R
3.54**4.07**3.12**
Q X P
2.73*3.33**
4.60**
*p < .10. **/> < .OS.***p < .01.
All other procedural details were identical tothose of Experiment 2, except that this study wasrun at Bell Laboratories, using students from anumber of colleges who were home on summer vaca-tion.
Results
Segment means were computed for all statemeasures and analyzed using covariance anal-yses as described above. Table 2 summarizesthe findings. Note that all variables with theexception of seriousness show main effectsfor the rate manipulation. These effects areall of the inverted-U type with the normal(unmanipulated) speakers judged most fluent,persuasive, and so forth, and slow speakersjudged lowest on these scales. (Ratings ofnervousness go in the direction opposite tothe other three scales.)
Only nervousness yielded a significant maineffect for pitch; the pitch manipulation wasmarginally significant for persuasiveness.Rated nervousness increased with higherpitch, whereas rated persuasiveness decreased.
In addition, ratings of emphaticness andseriousness showed significant Question XPitch interactions. The shape of these inter-actions, shown in Figure 3, is quite similar tothe corresponding effect on judged truthful-ness (Figure 1). For the quota question, onlythe highest pitched group was "underrated"on emphaticness and seriousness, whereasfor the money question, both the normal- andhigh-pitched groups were "underrated." Thefluency measure showed a comparable inter-action.
There were Question X Rate interactionsfor fluency, persuasiveness, and emphaticness.All interactions had a similar shape; for the
quota question only the slowest group sufferedlow ratings, while for the money questionboth the slow and fast groups received lowratings. The effect for seriousness judgmentswas marginally significant, but of the sameshape.
Discussion
These results again demonstrate the effectacoustic variables have on person perceptionprocesses. Decreasing speech rate has a par-ticularly deleterious effect on a speaker's per-ceived persuasiveness, fluency, and emphatic-ness. Similarly, increased pitch lowers ratingsof persuasiveness and increases greatly theimpression of nervousness.
Our findings also suggest that context playsa role in the attribution process, as evidencedby the question interactions. When a speaker
5.5
50
cett 4.5
i<t</> 4.0
UJzoS 3.5
UJ
o 3.0
o
LEGEND• » EMPHATIC QUOTAD * EMPHATIC MONEYO * SERIOUS QUOTA• = SERIOUS MONEY
v-
LOW NORMAL HIGH
PITCH CONDITION
Figure 3. Average emphaticness and seriousness rat-ings plotted as a function of pitch condition (low,normal, high) and question topic.

724 W. APPLE, L. STREETER, AND R. KRAUSS
answered the quota question, higher pitchlevels could be discounted by attributing themto the stressfulness of the topic. Similarly,it may have been inappropriate on the moneytopic to talk too slowly, (perhaps because ofthe topic's relative simplicity) or too rapidly(perhaps because rapid speech is perceivedas an attempt to be inappropriately seriousor persuasive). On the other hand, rapidspeech on the quota question might have beenattributed to the speaker's conviction regard-ing his argument.
General Discussion
The three experiments taken as a wholeprovide clear evidence that acoustic propertiesof a message have considerable impact onjudgments of a variety of state and trait vari-ables. The impressions of high-pitched orslow-talking speakers seem particularly nega-tive. For example, men with high-pitchedvoices are judged less truthful, less persua-sive, weaker, and more nervous. Similarly,slow-talking men are judged to be less truth-ful, fluent, emphatic, serious, and persuasive,and more passive, although they are also seenas more potent.
By using a large number of speakers andfactorially varying speech rate and pitch, wehave a reasonable measure of confidence inthe validity of our findings. However, sinceno female voices were used, we cannot gen-eralize these results to women; it is conceiv-able that these same acoustic variables wouldproduce different effects on perceptions ofwomen speakers.
Message context, presumably mediated bythe two question topics, was also demonstratedto influence attribution processes. However,since there was only one question of eachtype, what follows must remain somewhatspeculative. The question interactions sug-gest an interpretation along the lines of Kel-ley's (1971) discounting principle. Kelleysuggests that the more factors a situationcontains—any one of which might plausiblyhave resulted in an observed outcome—theless likely is any one factor to be perceived asthe cause of that outcome. With fewer pos-sible causes present, the cause-to-effect at-tribution is more compelling. We hoped that
our acoustic manipulations would be potentenough to affect speaker state or trait at-tributions. However, it is evident that list-eners may have, at least partially, attributedour acoustic alterations to the question topic.The quota question called for an answer thatwas both complex and emotionally involvingfor our college-student speakers and raters.As Table 1 shows, before any manipulationswere done, the quota answers were longer andslower (suggesting greater cognitive complex-ity; see Goldman Eisler, 1968) and higherpitched (suggesting greater stressfulness; seeHecker et al., 1968). Because of this, slowerand higher pitched answers might have beenperceived as more appropriate for quota re-sponses than for money responses.' But evenwhen premanipulation speech rate and pitchwere covaried, the question interactions re-mained, supporting the discounting principle.For example, higher pitch levels seemed tobe discounted on ratings of truthfulness,fluency, emphaticness, and seriousness forspeakers answering the quota, but not themoney, question.
It should be noted that manipulating fun-damental frequency by multiplying by a scalefactor as we did has the effect of multiplyingthe variance of the fundamental frequency bythe square of the scale factor. Thus, high-pitched segments were both high-pitched andhigh pitch-variance segments, and vice versa.Thus, we cannot rule out the interpretationthat the pitch effects observed could be pitch-variance effects. However, this interpretationseems unlikely considering the findings ofBrown et al. (1974), who did the appropriatefactorial experiment and found that increasedmean fundamental frequency lowered judg-ments of speakers' competence and benevo-lence, while decreased variance also loweredthese ratings. Thus, it seems that averagepitch and pitch variance affect judgments on
7 Subsequently, in connection with another study,we had 12 undergraduates rate a long list of po-tential interview topics (including the two used inthe present study) as to how stressful and how com-plex they would be for a typical Columbia under-graduate to discuss. Subjects judged the quota ques-tion to be significantly more stressful and more com-plex than the money question.

PITCH AND SPEECH RATE 725
a wide range of scales in opposite ways. In thepresent study, in which both pitch and pitchvariance were positively correlated, the pitch-correlated variance could only have attenuatedthe effects of average pitch.
Given that the experimental manipulationsused here affected the perception of speakers'personality and state, it remains to be ex-plained why these particular data patternswere observed. Miller et al. (1976), for ex-ample, conclude that the effect of speech rateon message persuasiveness is mediated by theeffect that variable has on the perception ofa speaker's credibility. This, they assert, is a"less rationalistic view" of attitude changethan other interpretations (e.g., change medi-ated by comprehension effects or counterargu-ment disruption—two hypotheses their experi-ments ruled out).
Certainly such a conclusion would be jus-tified if it were the case that variations invoice quality bore no relation to the actualinternal state or predisposition of the speaker.However, there is considerable evidence thatstressful situations do produce discerniblechanges in voice quality (Fairbanks, 1940;Hecker et al., 1968; Williams & Stevens,1969, 1972), and it seems reasonable to as-sume that listeners in the present study usedsuch variations appropriately to infer a speak-er's state from the quality of his speech. Forexample, Hecker et al. demonstrated thattask-induced stress raised the fundamentalfrequency of those speakers who did not talkmore softly under stress. In our experi-ment, attributions of increased nervousness tohigher-pitched speakers are quite "rational-istic," given the similarity of our pitch ma-nipulations to the effect of real-life stress.Similarly, Streeter et al. (1977) demonstratedthat pitch increments accompany deceptiveresponses; listeners' truthfulness judgmentsin Experiment 1 appropriately reflect this re-lationship.
The effects of speech rate can be similarlyinterpreted in light of Goldman Eisler's(1968) finding that rate and the cognitivecomplexity of the topic were negatively re-lated. Listeners may have assumed that lyingincreases speakers' cognitive load, resulting inslower rates. Unpublished speech rate data
from the Streeter et al. (1977) study lendplausibility to this argument. A marginallysignificant interaction (p < .08) indicatedthat subjects did, in fact, speak more slowlywhen lying than when telling the truth, pro-vided they had been given instructions engag-ing their motivation to lie effectively. How-ever, speakers not receiving such instructionsspoke more rapidly when lying.
Judgments of what is or is not "rational-istic" are probably to a large extent mattersof personal preference, but it does seem tous that a listener would be ill-advised to ig-nore reliable information concerning a speak-er's internal state in evaluating the speaker'smessage, especially when the internal stateseems incongruent with the situation or withthe message's content.
Furthermore, the significant Question XManipulation interactions for ratings of statevariables suggest some qualifications on thefindings of Miller et al. (1976). Fast speakersare not always more persuasive; talking tooquickly in response to the money questionproduced lower persuasiveness ratings thandid responses at a normal rate. Apparently,listeners take more into account than meetsthe ear—at least, more than simply theacoustic data.
Evidence of veridicality for vocally basedattributions of enduring personality traits isless firm. We have found no reliable data toindicate that fast talkers actually are moreactive people or that higher pitched men areweaker than their lower pitched counterparts.Apart from studies of psychiatric patients,much of the work in this area deals with thetraits of introversion-extraversion and domi-nance. Mallory and Miller (1958) foundsmall but significant negative correlations be-tween judged pitch and rate and the domi-nance scale of the Bernreuter Personality In-ventory. While these findings support our re-sults on judged potency along the pitchdimension (Experiment 2 ) , it is possible thatMallory and Miller's acoustic judgments areeither inaccurate or subject to biasing effectsfrom other sources, since raters judged speak-ers in a live situation. Furthermore, our re-sults for judged potency on the speech-ratevariable appear opposite to Mallory and

726 W. APPLE, L. STREETER, AND R. KRAUSS
Miller's. A more recent study (Ramsay, 1966)found that the speech of subjects classified asextraverts on the Eysenck Personality Inven-tory had longer unbroken phonation timesand shorter silences than those of introvertsacross a variety of speaking tasks; no data onspeech rates were presented.
The acoustic stimulus, of course, containsmore information than average pitch and rate.In addition, there is sequential information(provided by intonation contours and dura-tion pattern), loudness, and variability ofboth pitch and loudness over time. There isalso voice quality information (e.g. "breathy"or "raspy" voices) that may not be so readilyspecified in terms of physical parameters. Allof these factors can be expected to enter intothe person perception process via stereotypeswith larger or smaller kernels of truth.
On none of the measures we examined wasthe Rate X Pitch interaction statistically sig-nificant. The median F interaction was 1.12—close to its expected value under the null hy-pothesis. This absence of interaction arguesfor an additive model, in which pitch andrate exert independent effects on listeners'judgments. It remains to be seen whethersupport for such a model will continue as therole of additional vocal factors is explored.
Reference Notes
1. Nakatani, L. H. SYNLOG: An interactive systemfor manipulating speech. Unpublished manuscript,Bell Laboratories, Murray Hill, N.J., 1976.
2. Krauss, R. M., Geller, V., & Olson, C. T. Modal-ities and cues in the detection of deception. Paperpresented at the meeting of the American Psy-chological Association. Washington, B.C., Sep-tember 1976.
References
Allport, G. W., & Cantril, H. Judging personalityfrom voice. Journal of Social Psychology, 1934, 5,37-55.
Atal, B. S., & Hanauer, S. L. Speech analysis andsynthesis by linear prediction of the speech wave.Journal of the Acoustical Society of America, 1971,SO, 637-655.
Black, J. W. Relationships among fundamental fre-quency, vocal sound pressure, and rate of speak-ing. Language and Speech, 1961, 4, 196-199.
Brown, B. L., Strong, W. J., & Rencher, A. C. Per-ceptions of personality from speech: Effects of
manipulations of acoustical . parameters. Journalof the Acoustical Society of America, 1973, 54,29-35.
Brown, B. L., Strong, W. J., & Rencher, A. C. Fifty-four voices from two: The effects of simultaneousmanipulations of rate, mean fundamental fre-quency, and variance of fundamental frequency onratings of personality from speech. Journal of theAcoustical Society of America, 1974, 55, 313-318.
Fairbanks, G. Recent, experimental investigations ofvocal pitch in speech. Journal of the AcousticalSociety of America, 1940,11, 457-466.
Goldman Eisler, F. Psycholinguistics: Experiments inspontaneous speech. London: Academic Press, 1968.
Hanley, T. D. An analysis of vocal frequency andduration characteristics of selected samples ofspeech from three American dialect regions. SpeechMonographs, 1951, 18, 78-93.
Hecker, M. H. L., Stevens, K. N., von Bismarck, G.,& Williams, C. E. Manifestations of task-inducedstress in the acoustic speech signal. Journal of theAcoustical Society of America, 1968, 44, 993-1001.
Kelley, H. H. Attribution in social interaction. Mor-ristown, N.J.: General Learning Press, 1971.
Kramer, E. Judgment of personal characteristics andemotions from nonverbal properties of speech.Psychological Bulletin, 1963, 60, 408-420.
Lay, C. H., & Burron, B. F. Perception of the per-sonality of the hesitant speaker. Perceptual andMotor Skills, 1968, 26, 951-956.
Mallory, E. B., & Miller, V. R. A possible basis forthe association of voice characteristics and per-sonality traits. Speech Monographs, 1958, 25, 255-260.
Miller, G. R., & Hewgill, M. A. The effect of varia-tions in nonfluency on audience ratings of sourcecredibility. Quarterly Journal of Speech, 1964, 50,36-44.
Miller, N., Maruyama, G., Beaber, R. J., & Valone,K. Speed of speech and persuasion. Journal of Per-sonality and Social Psychology, 1976, 34, 615-624.
Mysak, E. Pitch and duration characteristics ofolder males. Journal of Speech and Hearing Re-search, 1959, 2, 46-54.
Nakatani, L. H. Computer-aided signal handling forspeech research. Journal of the Acoustical Societyof America, 1977, 61, 1057-1062.
Osgood, C. E., Suci, G. J., & Tannenbaum, P. H.The measurement of meaning. Urbana: Universityof Illinois Press, 1957.
Peterson, G. E., & Barney, H. L. Control methodsused in a study of the vowels. Journal of theAcoustical Society of America, 1952, 24, 175-184.
Ramsay, R. W. Personality and speech. Journal ofPersonality and Social Psychology, 1966, 4, 116-118.
Scherer, K. R. Acoustic concomitants of emotionaldimensions: Judging affect from synthesized tonesequences. In S. Weitz (Ed.), Nonverbal com-munication. New York: Oxford University Press,1974.

PITCH AND SPEECH RATE 727
Scherer, K. R., Koivumaki, J., & Rosenthal, RMinimal cues in the vocal communication of af-
fect: Judging emotions from content-maskedspeech. Journal of Psycholinguistic Research, 1972,7, 269-285.
Smith, B. L., Brown, B. L., Strong, W. J., & Rencher,A. C. Effects of speech rate on personality percep-tion. Language and Speech, 197S, 18, 145-152.
Streeter, L. A., Krauss, R. M., Geller, V., Olson, C.,& Apple, W. Pitch changes during attempted de-ception. Journal of Personality and Social Psy-chology, 1977, 35, 345-350.
Terango, L. Pitch and duration characteristics of theoral reading of males on a masculinity-femininity
dimension. Journal of Speech and Hearing Re-search, 1966, 9, 590-595.
Trager, G. L. Paralanguage: A first approximation.Studies in Linguistics, 1958,13, 1-12.
Williams, C. E., & Stevens, K. N. On determining theemotional state of pilots during flight. An explora-tory study. Aerospace Medicine, 1969, 40, 1369-1372.
Williams, C. E., & Stevens, K. N. Emotions andspeech: Some acoustical correlates. Journal of theAcoustical Society of America, 1972, 52, 1238-1250.
Winer, B. J., Statistical principles in experimental de-sign (2nd ed.), New York: McGraw-Hill, 1971.
Received January 18, 1978 •
Corrections to Koretzky, Kohn, and Jeger
In the article "Cross-Situational Consistency Among Problem Adolescents:An Application of the Two-Factor Model" by Martin B. Koretzky, MartinKohn, and Abraham M. Jeger (Journal of Personality and Social Psychology,1978, Vol. 36, No. 9, pp. 1054-1059), there are errors in two correlations re-ported in the first paragraph on page 1058. The Factor I and Factor II scoresfor the Koretzky (1976) study cited there should be reversed. The correct cor-relation for Factor I is .40, and for Factor II it is .60. Thus, the sentenceshould read, "Consistency correlations between classroom and residence settingswere even stronger in this experiment for Factor II (r = .60) and were alsorespectable for Factor I (r — .40)."
Martin B. Koretzky's affiliation was erroneously given as the Veterans Ad-ministration Hospital, Bronx, New York. His affiliation at the time of theoriginal research was the State University of New York at Stony Brook.