efficient inference for general hybrid bayesian networks
DESCRIPTION
Efficient Inference for General Hybrid Bayesian Networks. Wei Sun PhD in Information Technology [email protected] George Mason University, 2007. Acknowledgements. Sincere gratitude goes to: Dr. KC Chang Dr. Kathryn Laskey Dr. Kristine Bell Dr. James Gentle. Overview. - PowerPoint PPT PresentationTRANSCRIPT

Efficient Inference for General Efficient Inference for General Hybrid Bayesian NetworksHybrid Bayesian Networks
Wei SunWei Sun
PhD in Information TechnologyPhD in Information Technology
[email protected]@gmu.edu
George Mason University, 2007George Mason University, 2007

2
Acknowledgements
Sincere gratitude goes to:Dr. KC ChangDr. Kathryn LaskeyDr. Kristine BellDr. James Gentle

3
Overview
Inference algorithms development Probabilistic inference for Bayesian network (BN) is NP-hard in
general
It is well known that no exact solution is possible in nonlinear, non-Gaussian case.
This dissertation focuses on development of efficient approximate inference algorithms for general hybrid BN in which arbitrary continuous variables with typical nonlinear relationship mixed with discrete variables.
Model performance evaluation for hybrid BN Extensive simulation with possibly complicated inference
algorithms Approximate analytical performance modeling with Gaussian
mixture models.

4
Outline
Background
Research objective and contributions
Literature review
Efficient inference algorithms for general hybrid BN.
BN model performance evaluation.
Summary

5
Simple Example of BN
Vehicle Identification

6
Advantages using BN Model
Conditional independence simplifies specification and inference.
Joint distribution using general probability model: 2*2*2*3*3=72 71 probabilities need to be specified.
BN model: P(T,W,F,R,S)=P(T)P(W)P(R|T,W)P(F|T)P(S|T,F)only 22 probabilities need to be specified.Note: for real-life problems, the savings could be significant.
Modularity, decomposability, transparent modeling, efficient reasoning.
7
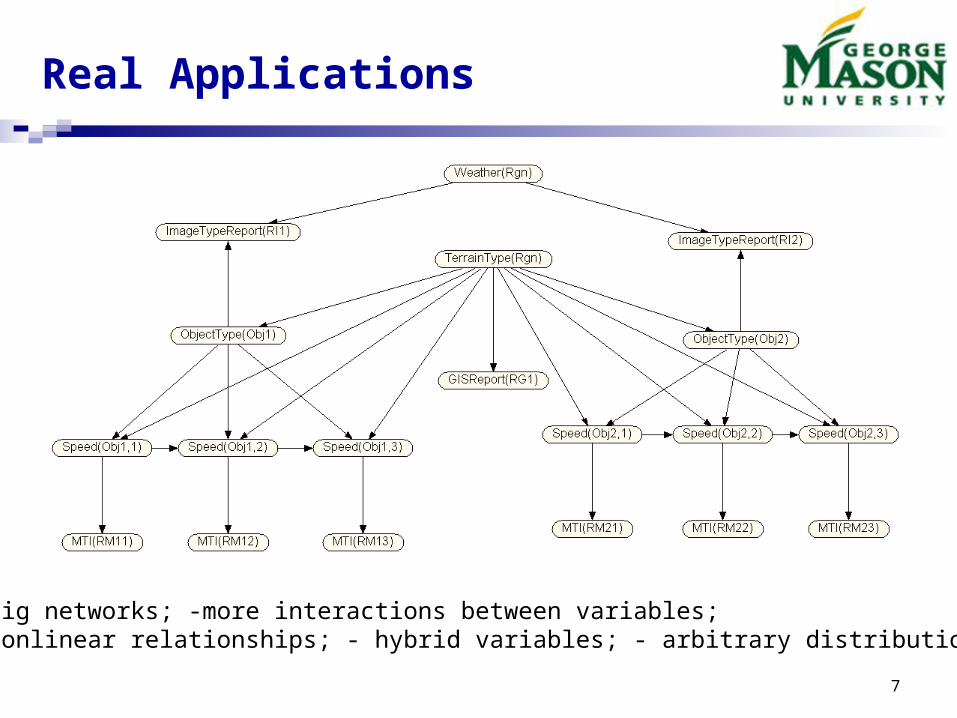
Real Applications
- big networks; -more interactions between variables; - nonlinear relationships; - hybrid variables; - arbitrary distributions.

8
Research Overview
Many real-world problems are naturally modeled by hybrid BN with both categorical and continuous variables: nonlinear relationships, arbitrary distributions, big size.
Objective: developing efficient approximate inference algorithms that can cope with nonlinearity, heterogeneity, and non-Gaussian variable with acceptable performance.
Approach: message passing, unscented transformation, function estimation, Gaussian mixture model are integrated in a unified manner.

9
Contributions
Novel Inference Algorithms development Unscented message passing (UMP-BN) for arbitrary continuous
Bayesian networks Hybrid message passing (HMP-BN) for general mixed Bayesian
networks.
Performance evaluation methods Approximate analytical method to predict BN model performance
without extensive simulations. It can help the decision maker to understand the model
prediction performance and help the modeler to build and validate model effectively.
Software development Inference algorithms coding in MATLAB are added in BN
Toolbox as extra inference engines.

10
Literature Review

11
Definition of BN
A Bayesian network is a directed, acyclic graph consisting of nodes and arcs: Nodes: variables Arcs: probabilistic dependence relationships. Parameters: for each node, there is a conditional probability distribution
(CPD) associated with.
CPD of Xi: P(Xi|Pa(Xi)) where Pa(Xi) represents all parents of Xi
Discrete: CPD is usually represented as a table, also called CPT. Continuous: CPD involves functions, P(Xi|Pa(Xi)) = f(Pa(Xi), w) where w
is a random noise.
Joint distribution of variables in BN is

12
Probabilistic Inference in BN
Task: find the posterior distributions of query nodes given evidence. Bayes’ Rule:
Both exact and approximate inference using BNs are NP-hard. Only for special classes of BNs, inference algorithms are tractable.
13
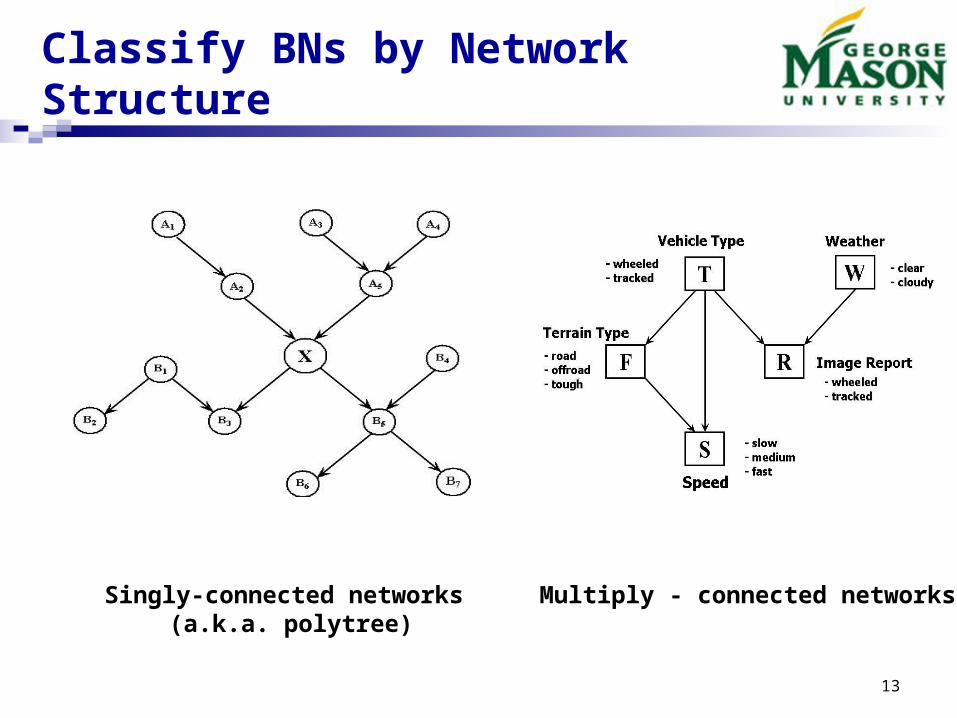
Classify BNs by Network Structure
Multiply - connected networksSingly-connected networks (a.k.a. polytree)

14
Classify BNs by Node Types
Node types Discrete: conditional probability
distribution is usually represented as a table.
Continuous: Gaussian or non-Gaussian distribution; conditional probability distribution is specified using functions:
P(Xi|Pa(Xi)) = f(Pa(Xi), w) where w is a random noise; the function could be linear/nonlinear.
Hybrid model: mixed discrete and continuous variables.

15
Conditional Linear Gaussian (CLG) Model
CLG – Conditional Linear Gaussian model is the simplest hybrid Bayesian networks: All continuous variable are Gaussian The functional relationships between continuous variables and
their parents are linear. No continuous parent for discrete variable
Given any assignment of all discrete variables in CLG, it represents a multivariate Gaussian distribution.

16
CLG Example
General hybrid model CLG model
17
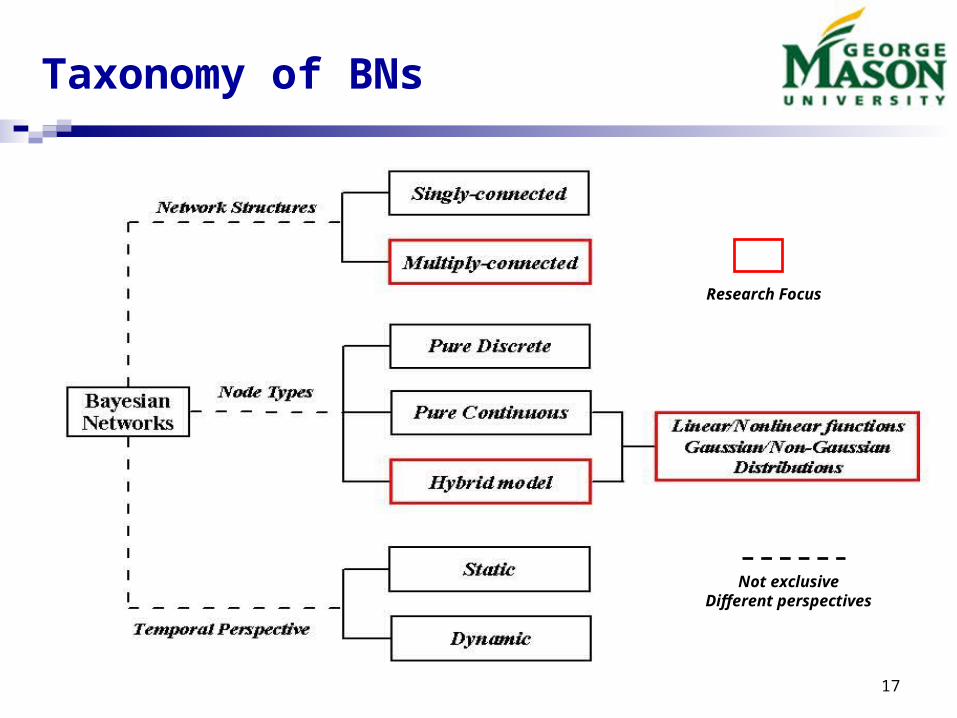
Taxonomy of BNs
Research Focus
Not exclusiveDifferent perspectives

18
Inference Algorithms Review - 1 Exact Inference
Pearl’s message passing algorithm (MP) [Pearl88] In MP, messages (probabilities/likelihood) propagate between variables. After
finite number of iterations, each node has its correct beliefs. It only works for pure discrete or pure Gaussian and singly-connected network
(inference is done in linear time).
Clique tree (a.k.a. Junction tree) [LS88,SS90,HD96] and related algorithms Includes variable elimination, arc reversal, symbolic probabilistic inference
(SPI). It only works on pure discrete or pure Gaussian networks or simple CLGs For CLGs, clique tree algorithm is also called Lauritzen’s algorithm (1992). It
returns the correct mean and variance of the posterior distributions for continuous variables even though the true distribution might be Gaussian mixture.
It does not work for general hybrid model or complicated CLGs

19
Inference Algorithms Review - 2
Approximate Inference Model simplification
Discretization, linearization, arc removal etc. Performance degradation could be significant.
Sampling method Logic sampling [Hen88] Likelihood weighting [FC89] Adaptive Importance Sampling (AIS-BN) [CD00], EPIS-BN [YD03], Cutset
sampling [BD06] Performs well in case of unlikely evidence, but only work for pure discrete
networks Markov chain Monte Carlo.
Loopy propagation [MWJ99]: use Pearl’s message passing algorithm for the networks with loops. This become a popular topic recently.
For pure discrete or pure Gaussian networks with loops, it usually converges to approximate answers in several iterations.
For hybrid model, message representation and integration are open issues. Numerical hybrid loopy propagation [YD06], computational intensive.

20
Methodologies for efficient inferencein hybrid BN models

21
Pearl’s Message Passing Algorithm
In polytree, any node d-separate the sub-network above it from the sub-network below it. For a typical node X in a polytree, evidence can be divided into two exclusive sets, and processed separately:
Define messages and messages as:
Multiply-connected network may not be partitioned into two separate sub-networks by a node.
Then the belief of node X is:

22
Pearl’s Message Passing in BNs
In message passing algorithm, each node maintains Lambda message and Pi message for itself. Also it sends Lambda message to every parent it has and Pi message to its children.
After finite-number iterations of message passing, every node obtains its correct belief.
For polytree, MP returns exact For polytree, MP returns exact belief; belief; For networks with loop, MP is For networks with loop, MP is called loopy propagation that often called loopy propagation that often gives good approximation to gives good approximation to posterior distributions.posterior distributions.

23
Message is represented by “MEAN” and “VARIANCE” regardless of the distribution.
Message propagations between continuous variables are equivalent to fusing multiple estimates and estimating functional transformation of distributions.
Unscented transformation uses deterministic sampling scheme to obtain good estimates of the first two moments of continuous random variable subject to an nonlinear function transformation.
Continuous Message Representation and Propagation

24
Unscented Transformation (UT)
Unscented transformation is a Unscented transformation is a deterministic sampling deterministic sampling methodmethod Approximate the first two Approximate the first two
moments of a continuous moments of a continuous random variable transformed random variable transformed via an arbitrary nonlinear via an arbitrary nonlinear function. function.
UT bases on the principle UT bases on the principle that it is easier to that it is easier to approximate a probability approximate a probability distribution than a nonlinear distribution than a nonlinear function.function.
deterministic sample deterministic sample points are chosen and points are chosen and propagated via the nonlinear propagated via the nonlinear function.function.
25
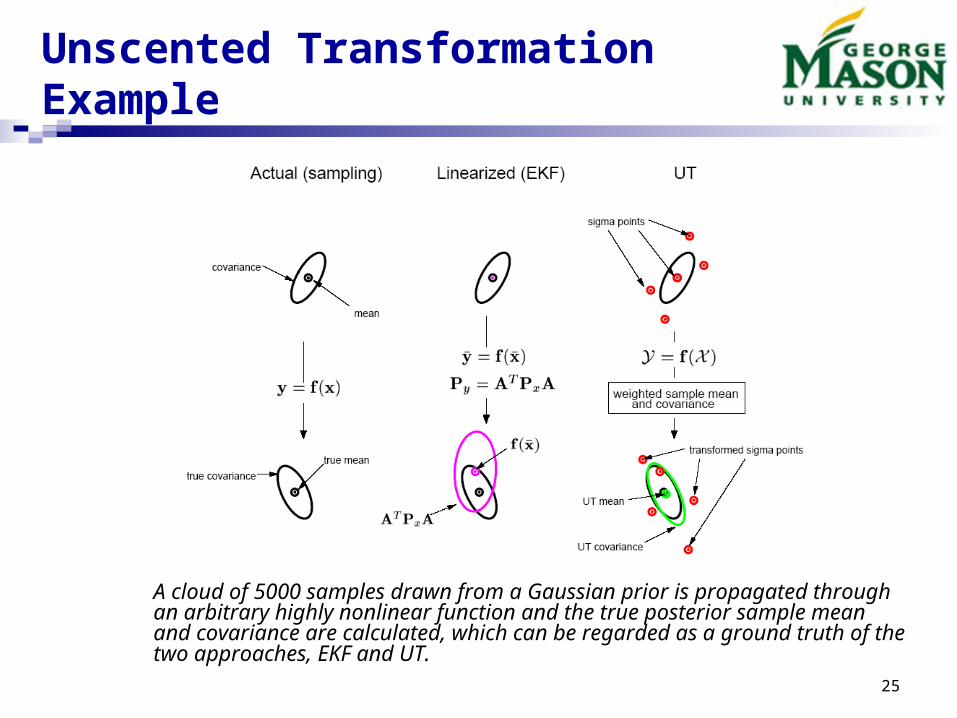
Unscented Transformation Example
A cloud of 5000 samples drawn from a Gaussian prior is propagated through an arbitrary highly nonlinear function and the true posterior sample mean and covariance are calculated, which can be regarded as a ground truth of the two approaches, EKF and UT.

26
Unscented Message Passing (UMP-BN)(For arbitrary continuous BN)
Conventional Pearl’s EquationsConventional Pearl’s Equations Derived generalized Equations to Derived generalized Equations to handle continuous variables.handle continuous variables.

27
UMP-BN Algorithm
Wei Sun and KC Chang. “Wei Sun and KC Chang. “Unscented Message Passing for Arbitrary Continuous Variables in Bayesian NetworksUnscented Message Passing for Arbitrary Continuous Variables in Bayesian Networks””In Proceedings of the 22nd AAAI Conference on Artificial Intelligence, Vancouver, Canada, July 2007. In Proceedings of the 22nd AAAI Conference on Artificial Intelligence, Vancouver, Canada, July 2007.

28
UMP-BN: Numerical Experiments

29
Numerical Results - 1

30
Numerical Results - 2

31
Hybrid Message Passing
Message passing in pure discrete networks is well established.
Message passing in pure continuous networks could be approximated using UMP-BN.
So why not partitioning the network, passing messages separately, then fusing intermediate messages.

32
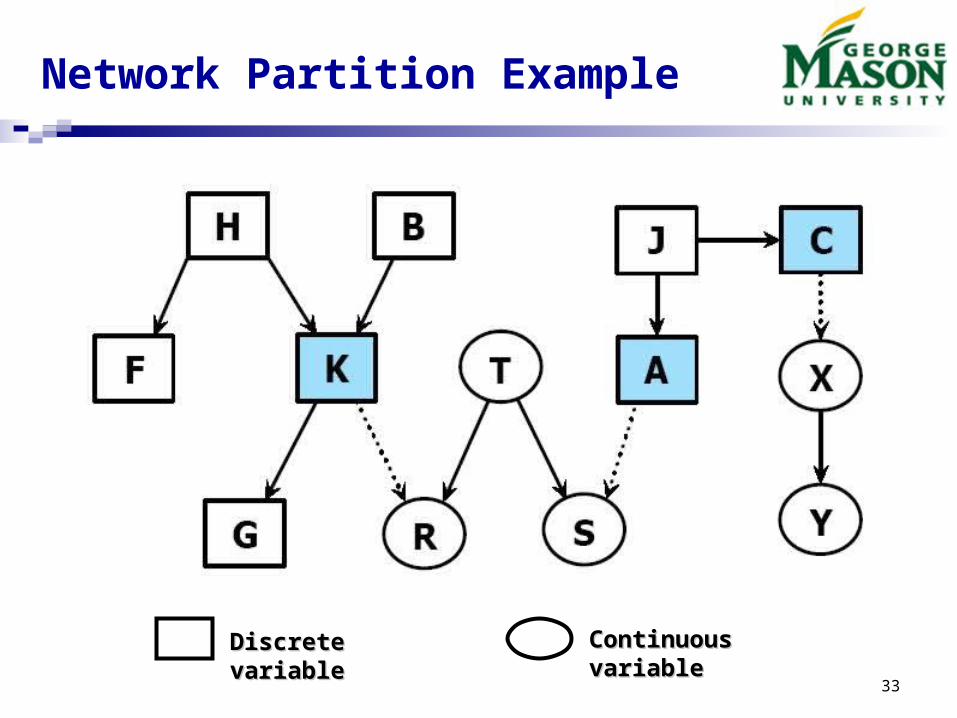
Network Partition for Hybrid BN
Assumption: there is no discrete child for any continuous variables in the networks, which implies that discrete variable only has discrete parents, but it may have continuous child.
Definition: a discrete variable is called a discrete parent if and only if it has at least one continuous child.
The set of all discrete parents in the hybrid Bayesian network model can partition the network into separated network segments each one has either pure discrete or pure continuous variables.
We call the set of all discrete parents in the hybrid network the interface nodes. The interface nodes “d-separate” the network into independent network segments.
33
Network Partition Example
Discrete Discrete variablevariable
Continuous Continuous variablevariable
34
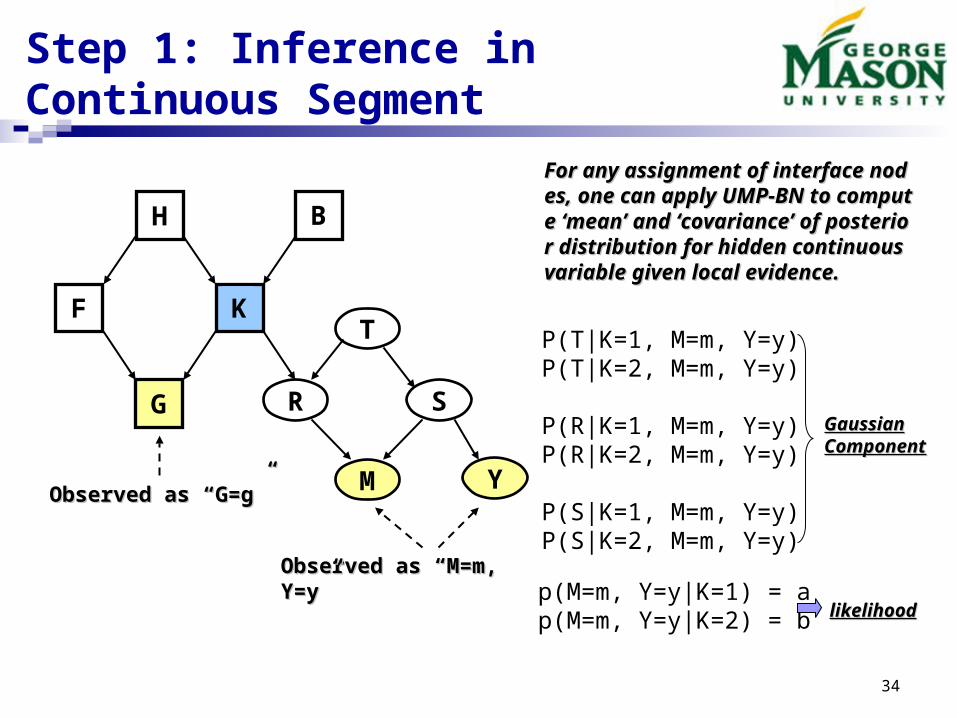
Step 1: Inference in Continuous Segment
T
H
F K
B
G R S
M YObserved as Observed as “G=g”“G=g”
Observed as “M=m, Observed as “M=m, Y=y”Y=y”
For any assignment of interface noFor any assignment of interface nodes, one can apply UMP-BN to comdes, one can apply UMP-BN to compute ‘mean’ and ‘covariance’ pute ‘mean’ and ‘covariance’ of posterior distribution for hidden of posterior distribution for hidden continuous variable given local evicontinuous variable given local evidence.dence.
P(T|K=1, M=m, Y=y)P(T|K=2, M=m, Y=y)
P(R|K=1, M=m, Y=y)P(R|K=2, M=m, Y=y)
P(S|K=1, M=m, Y=y)P(S|K=2, M=m, Y=y)
GaussianGaussianComponentComponent
p(M=m, Y=y|K=1) = ap(M=m, Y=y|K=2) = b likelihoodlikelihood

35
Step 2: Network Transformation
T
H
F K
B
G R S
M YObserved as “G=g”Observed as “G=g”
Observed as “M=m, Observed as “M=m, Y=y”Y=y”
Dummy
H
F K
B
G
Where is a normalizing Where is a normalizing constant.constant.

36
Step 3: Messages Integration
TK
R S
M Y
Observed as “M=m, Observed as “M=m, Y=y”Y=y”
Now “K” has the posterior distribution Now “K” has the posterior distribution given all evidence saved as the mixing given all evidence saved as the mixing prior for the intermediate messages of prior for the intermediate messages of hidden continuous variables. hidden continuous variables.
P(K = i | E)P(K = i | E)
Mean and variance of Mean and variance of the Gaussian mixture.the Gaussian mixture.
Mean and variance of the Mean and variance of the iithth Gaussian component. Gaussian component.
Mixing Mixing prior prior

37
Hybrid Message Passing Algorithm (HMP-BN)
Wei Sun and KC Chang. “Wei Sun and KC Chang. “Hybrid Message Passing for Mixed Bayesian NetworksHybrid Message Passing for Mixed Bayesian Networks”. In Proceedings of ”. In Proceedings of the 10th International Conference on Information Fusion, Quebec, Canada, July 2007.the 10th International Conference on Information Fusion, Quebec, Canada, July 2007.
Wei Sun and KC Chang. “Wei Sun and KC Chang. “Message Passing for General Bayesian Networks: Representation, Propagation Message Passing for General Bayesian Networks: Representation, Propagation and Integrationand Integration”. Submitted to IEEE Transactions on Aerospace Electronic Systems. September, 2007.”. Submitted to IEEE Transactions on Aerospace Electronic Systems. September, 2007.

38
Numerical Experiment - I
T
H
F K
B
G R S
M YObserved as “G=g”Observed as “G=g”
Observed as “M=m, Observed as “M=m, Y=y”Y=y”
Synthetic Hybrid Model Synthetic Hybrid Model - 1- 1

39
Results of Model I

40
Results of Model I – Cont.
41
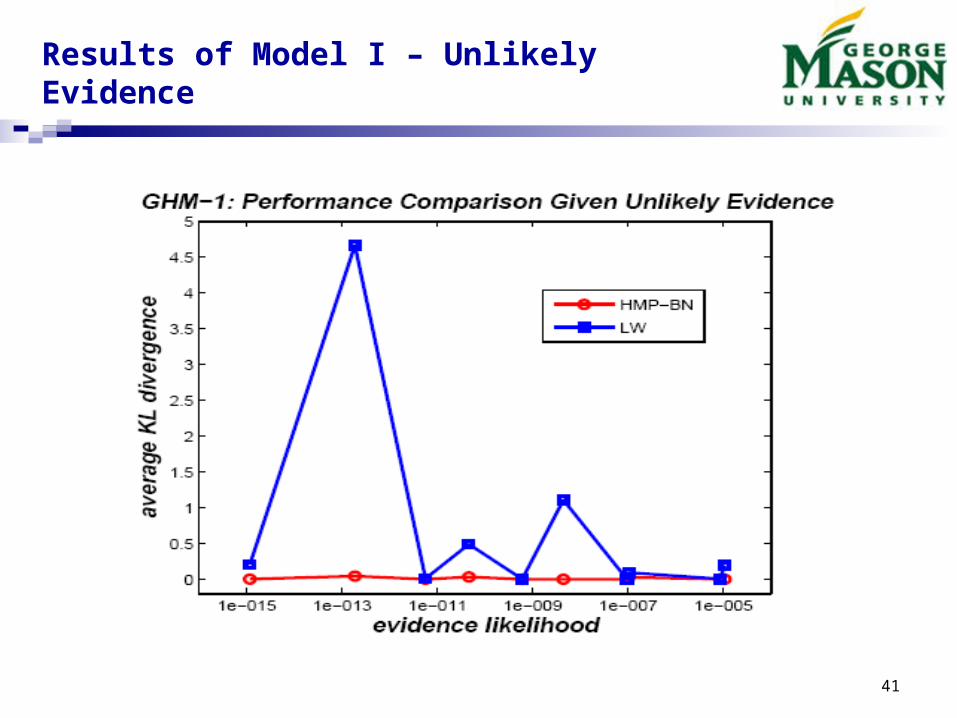
Results of Model I – Unlikely Evidence
42
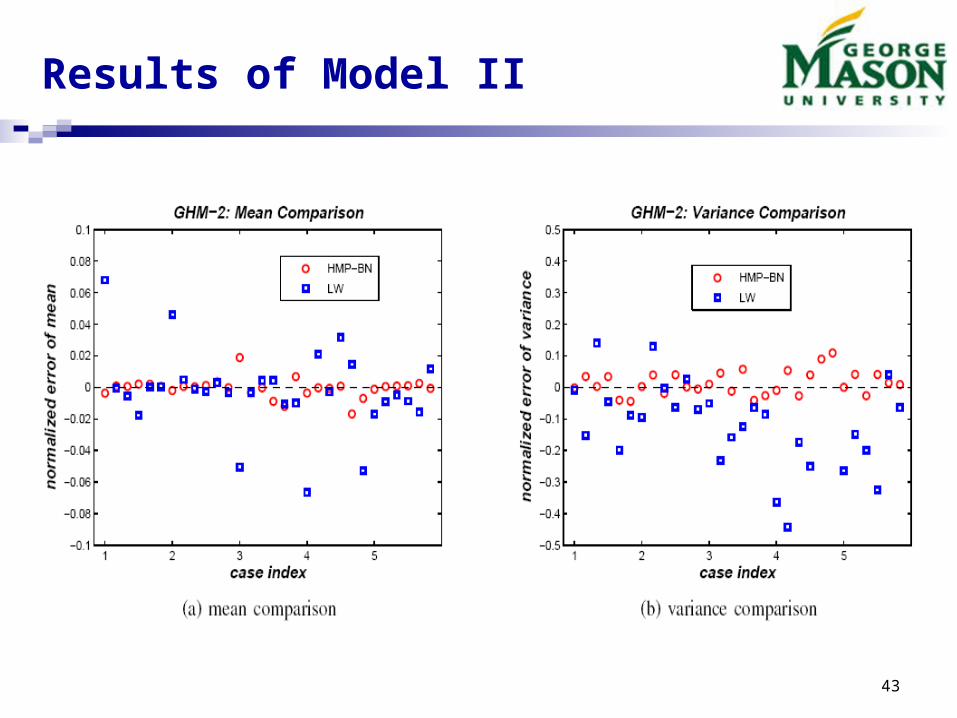
Numerical Experiment - II
Synthetic Hybrid Model - Synthetic Hybrid Model - 22
43
Results of Model II

44
Performance Summary
45
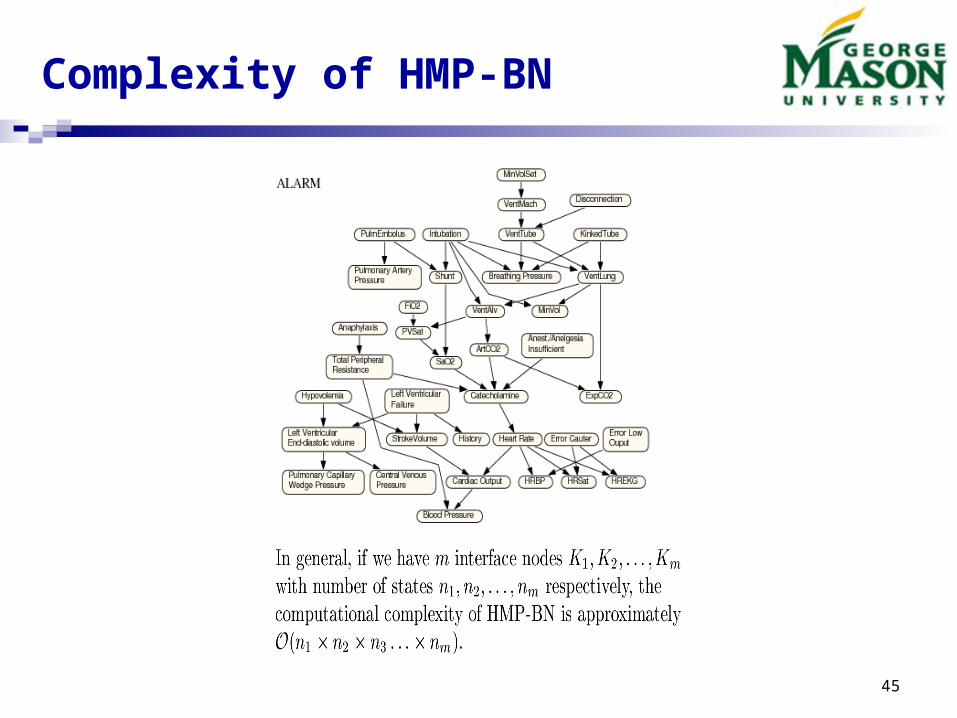
Complexity of HMP-BN

46
Performance Evaluation for hybrid BN model

47
Performance Metric
- Probability of Correct Classification
(Pcc):
For discrete variable For discrete variable TT in a hybrid BN, in a hybrid BN,
Pcc is the probability mass function of T Pcc is the probability mass function of T
given each state of given each state of TT. .
Diagonal of Pcc = [0.69, 0.75, 0.77, 0.82, 0.78]Diagonal of Pcc = [0.69, 0.75, 0.77, 0.82, 0.78]
An example of Pcc:An example of Pcc:

48
Theoretical Pcc Computing
T: discrete target variable. E: evidence set {Ed, Ec}.

49
Continuous Evidence Only

50
Approximation with Gaussian Mixture
Approximate analytical performance prediction. Approximate analytical performance prediction.
KC Chang and Wei Sun. “KC Chang and Wei Sun. “Performance Modeling for Dynamic Bayesian NetworksPerformance Modeling for Dynamic Bayesian Networks”. ”. In Proceedings of SPIE Conference, Volume 5429, Orlando, 2004.In Proceedings of SPIE Conference, Volume 5429, Orlando, 2004.

51
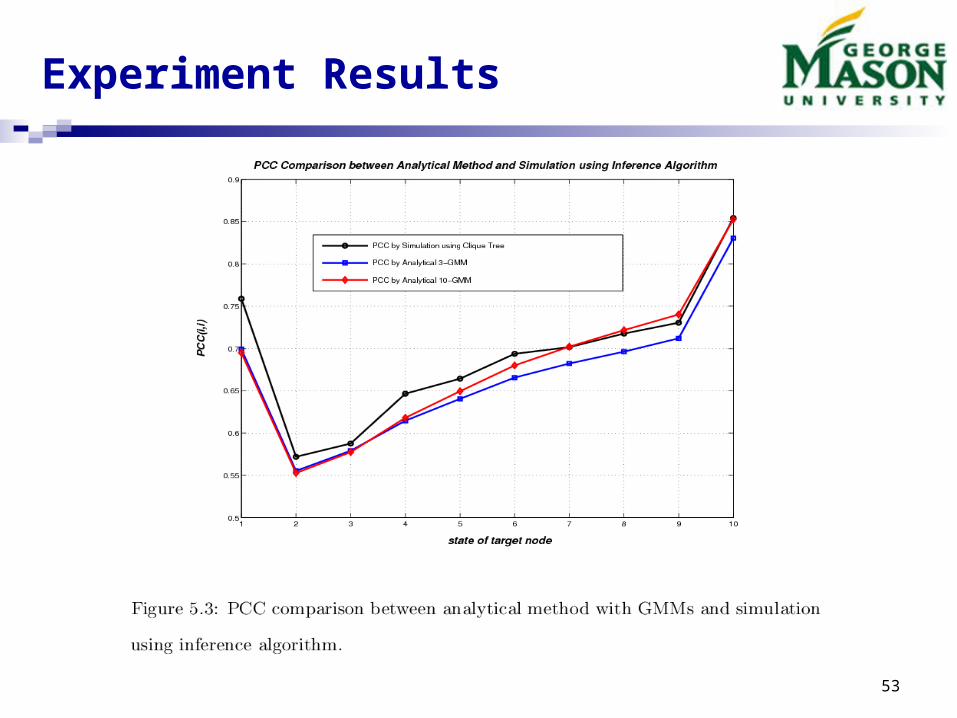
Numerical Experiment

52
Gaussian Mixture Example
53
Experiment Results

54
Summary
This dissertation focuses on hybrid BN model inference. Develop novel inference algorithms
UMP-BN [SC07a]: efficient message passing for arbitrary continuous BNs.
HMP-BN [SC07b]: partitioning the network into separated network segments each part is either pure discrete or pure continuous; conducting message passing in each segment; message integration via the set of interface nodes.
Evaluate hybrid BN model performance Predict probability of correct classification (Pcc) Approximate analytical performance prediction using
Gaussian mixture. Avoid extensive simulations with possibly complicated
inference algorithm.

55
Future Research Directions
Theoretical convergence study of loopy belief propagation will be fruitful.
Current results by UMP-BN and HMP-BN can be applied for further importance sampling.
For network where discrete variable has continuous parents, our network partition method can not be applied. Further development of efficient message passing between different types of variable is needed.
Dynamic BN inference typically use sequential estimation methods. The algorithms proposed in this dissertation could be integrated with other approaches for DBN inference.

56
Publications
Wei Sun and KC Chang. “Message Passing for General Hybrid Bayesian networks: Representations, Propagations and Integrations”. Submitted to IEEE Transactions on Aerospace and Electronic Systems, September, 2007.
Wei Sun and KC Chang. “Convergence Study of Message Passing in Arbitrary Continuous Bayesian Networks.” To appear in SPIE Conference, Orlando, March, 2008.
Wei Sun and KC Chang. “Hybrid Message Passing for General Mixed Bayesian Networks”. In Proceedings of the 10th International Conference on Information Fusion, Quebec, Canada, 2007.
Wei Sun and KC Chang. “Unscented Message Passing for Arbitrary Continuous Bayesian Networks”. In Proceedings of the 22nd AAAI Conference on Artificial Intelligence, Vancouver, Canada, 2007.
Wei Sun and KC Chang. “Probabilistic Inference Using Importance Sampling for Hybrid Bayesian Networks”. In Proceedings of SPIE Conference, Volume 5809, Orlando, 2005.
KC Chang and Wei Sun. “Performance Modeling for Dynamic Bayesian Networks”. In Proceedings of SPIE Conference, Volume 5429, Orlando, 2004.
KC Chang and Wei Sun. “Comparing Probabilistic Inference for Mixed Bayesian Networks”. In Proceedings of SPIE Conference, Volume 5096, Orlando, 2003. .

57
Thank Thank you!you!