efficient mapping of heuristic packet classifier on network processor based router to enhance qos...
TRANSCRIPT

8/8/2019 Efficient Mapping of Heuristic Packet Classifier on Network Processor based Router to enhance QoS for Multimedia …
http://slidepdf.com/reader/full/efficient-mapping-of-heuristic-packet-classifier-on-network-processor-based 1/7
JOURNAL OF COMPUTING, VOLUME 2, ISSUE 9, SEPTEMBER 2010, ISSN 2151-9617HTTPS://SITES.GOOGLE.COM/SITE/JOURNALOFCOMPUTING/ WWW.JOURNALOFCOMPUTING.ORG 107
Efficient Mapping of Heuristic PacketClassifier on Network Processor basedRouter to enhance QoS for Multimedia
ApplicationsR. Avudaiammal, P. Seethalakshmi
Research Scholar, Professor,
Anna University Tiruchirappalli
Abstract— Packet classification is an important function performed by network devices such as edge router, firewalls and intrusion detec-
tion systems to provide QoS and network security. With its complexity, the exponential growth of link speed and diversified services offered by
the Internet, Packet classification is becoming a major bottleneck in the router performance. Traditional router performs this classification
using Application Specific Integrated Circuits (ASICs), which suffers from lack of flexibility. Powerful Embedded Network Processor (NPs) a
flexible and cost efficient network appliance has been introduced by many companies that can be an alternative to implement the packet
classification at nearly link speed. The objective of this paper is to design and implement a new low complexity packet classification algorithm
of heuristic type named Trie based Tuple Space Search (TTSS) and to efficiently map this Packet classifier component on Network Proces-
sor based router. The performance is evaluated using Intel’s IXP2400 NP Simulator. The results demonstrate that, TTSS outperforms the
other heuristic packet classification algorithms. Parallel mapping of TTSS on Network processor based router gives better performance than
its pipelined mapping which is more suitable to enhance QoS for multimedia applications.
Index Terms — Multimedia, QoS, Packet Classification, TTSS, Network Processor, and IXP 2400.
1 INTRODUCTION
nternet traffic has become high in recent times due tothe growth of real-time multimedia applications suchas Video on demand , Video telephony, Video stream-
ing and e-learning that require guaranteed QoS.Processing of the packets at router level such as ReceivingIP packets from incoming links, classifying the packets,Scheduling, Routing and output porting are to be per-formed at high speed to satisfy the QoS requirements.Packet classification is an important function performed
by network devices such as edge router, firewalls andintrusion detection systems to provide QoS and networksecurity. The packets that arrive at the input port of therouter are classified into different flows by a classifier, bycomparing the fields in the L3 / L4 header of the incom-ing packet. Flow is a sequence of packets that belong tothe same logical stream and should be treated similarlyby the network. A set of rules named as Filters (F) havingthe attributes of the packets such as Source IP, Destina-tion IP are stored as fields in the router table for the pur-pose of classifying the incoming packets. The classifierextracts relevant fields from the header of the incomingpacket in the order same as in the Filter to perform multi-
dimensional Packet Classification algorithm. Packet Clas-sification is carried out by considering the source anddestination address, protocol type of L3 and source portand destination port of L4. This classification of packetsinvolves complex tasks such as Longest Prefix Matching(LPM) for source and destination address, Exact Matching(EM) for protocol and Range Matching (RM) for port.With large matching conditions, the best matching rulebased on filters is chosen. In addition to this complex
task, the packet classification has to be done at wire speedwhich is a bottleneck at routers.Currently, Routers are mainly based on Applica-
tion Specific Integrated Circuits (ASICs) that are custommade and are not flexible to support diversified Internet-working services. Earlier General Purpose Processor(GPP) based routers offer flexibility in supporting newfeatures by simply upgrading the software, but has diffi-culties in supporting higher bandwidth [1]. EmbeddedNetwork Processors have recently emerged to provideboth the performance of ASICs and the programmabilityof GPPs [2]. Powerful Embedded Network Processorshave been introduced by many companies that can be
I

8/8/2019 Efficient Mapping of Heuristic Packet Classifier on Network Processor based Router to enhance QoS for Multimedia …
http://slidepdf.com/reader/full/efficient-mapping-of-heuristic-packet-classifier-on-network-processor-based 2/7
JOURNAL OF COMPUTING, VOLUME 2, ISSUE 9, SEPTEMBER 2010, ISSN 2151-9617HTTPS://SITES.GOOGLE.COM/SITE/JOURNALOFCOMPUTING/ WWW.JOURNALOFCOMPUTING.ORG 108
placed in routers to execute various network related tasksat packet level. The design and development of routersusing Network Processor has gained significance due toits high performance.
Network Processors (NPs) have a high-performance parallel processing architecture on a singlechip which is more suitable for detailed packet inspection,processing having complex algorithms and forwarding atwire speed. Network Processors have a set of hierarchi-cally distributed memory devices, a set of on-chip proces-sors (Micro Engines) to carry out packet level parallelprocessing operations through multitasking and multith-readed programming [16]. Each Micro Engine (ME) hasmultiple hardware thread contexts that enable threadcontext switches with zero or minimal overhead [3]. Mi-cro Engines can examine and forward packets indepen-dently without using the host processor, bus, or memory.All these features reveal that, Micro Engines in the Net-work Processor can be assigned different packetprocessing functionalities so that classification of packetscan be done efficiently to provide QoS. Studies [16-19]
have focused on implementing the networking servicesusing programmable network processors.
The work presented in this paper is based on thefully programmable Intel ® IXP 2400 processor. The In-tel® IXP2400 is a member of the Intel’s second generationnetwork processor family. The architecture of this inte-grated network processor IXP2400 [4] shown in Figure 1has a single 32-bit XScale core processor, eight 32-bit Mi-croEngines (MEs) organized as two clusters, standardmemory interfaces and high speed bus interfaces. EachME has eight hardware-assisted threads and 4KB localmemory. Each microengine has 256 general purpose reg-isters that are equally shared between eight threads. Mi-
croengines exchange information by using either an on-chip scratchpad memory or 128 special purpose nextneighbor registers. Data transferring across the MEs andlocations external to the ME, (for eg DRAMs, SRAMs etc.)are done by using 512 Transfer Registers. The Xscale coreis responsible for initializing and managing the chip,handling control and management functions and loadingthe ME instructions.
IXP2400 chip has a pair of buffers (BUF), ReceiveBUF (RBUF) and Transmit BUF (TBUF) that are used tosend / receive packets to / from the network ports witheach of size 8 Kbytes. The packets are injected into theNetwork Processor from the network through the Media
Switch Fabric Interface and then forwarded to the Micro-Engines for processing. All threads in a particular MEexecute program code called microblock stored in thelocal memory of that ME. Finally the processed packetsare driven into the network by Media Switch Fabric Inter-face (MSF) at output port.
In this work, the heuristic Packet clas-sifier named Trie based Tuple Space Search(TTSS) hasbeen proposed and implemented on the IXP 2400 Proces-sor with two supporting microblocks namely Packet Re-ceive and Packet Transmit. In the router, packet arrivaland departure can occur simultaneously; hence to utilizethe parallel processing of Network processor effectively,
the microblocks are arranged in a pipeline. For example,when the arrival of a new packet is being handled by areceive microengine, an existing packet can be classifiedand transmitted by the respective microblocks simulta-neously, which entails interaction between microblocks inthe form of pipeline. Also the impact of different designmappings namely parallel and pipelined mapping of thepacket classification on the Microengines has been ex-amined and the performance measures show that the pa-rallel design mapping of Microengines has better packetprocessing rate than the pipelined mapping.
The remainder of this paper is organized as fol-lows: Section 2 presents the background concept of packetclassification. Section 3 and 4 describes the proposedpacket classification algorithm and its implementationdetails. The performance analysis is presented in section 5and conclusion in Section 6.
2 RELATED WORK
his section presents a brief overview of the PacketClassification algorithms. Survey on packet classifica-tion algorithms [5], [6], [7] and [8] shows that the
Packet Classification problem is inherently hard. Linearsearch is the simplest method of packet classification thatuses linked list to perform searching through a set ofrules. If ‘N’ is the number of rules, then its spatial andtemporal complexity is O (N). Tuple Space (TS), a heuris-tic for packet classification [9] maps the set of rules to aTuple that is stored in a Hash table. As the number ofdistinct Tuples is much lesser than the number of rules,even a simple linear search in the Tuple Space provides asignificant increase in speed of packet classification. It hasthe time complexity reduced with order O (Wk) where Wis the length of the IP prefix and ‘k’ is the number of fieldsused in classification. Another search namely PrunedTuple Space Search (PTS) [10] has the time complexityreduced further by performing searches on the subset ofthe Tuples. Though any field or combination of fieldsmay be used for pruning, it is found that pruning onsource and destination address strikes a favorable balancebetween the reduction in number of Tuples and overheadfor the pruning steps. Tuple-pruning algorithm is able to
T
Figure 1. Architecture of IXP2400

8/8/2019 Efficient Mapping of Heuristic Packet Classifier on Network Processor based Router to enhance QoS for Multimedia …
http://slidepdf.com/reader/full/efficient-mapping-of-heuristic-packet-classifier-on-network-processor-based 3/7
JOURNAL OF COMPUTING, VOLUME 2, ISSUE 9, SEPTEMBER 2010, ISSN 2151-9617HTTPS://SITES.GOOGLE.COM/SITE/JOURNALOFCOMPUTING/ WWW.JOURNALOFCOMPUTING.ORG 109
achieve good performance in practical environment:however its worst-case speed is not guaranteed. Triesearch is another most popular high speed IP route look-up scheme for packet classification that uses Tree dataStructure with individual bit look-up[11].
Some of the trie-based algorithms follow the hie-rarchical approach of the packet classification which re-cursively performs search in each field. In [12-15], triebased classification algorithm suitable for high speed twodimensional packet classifications have been described. Aone-dimensional 1-bit trie is a binary tree like structure,in which each node has two element fields, le(the leftelement) and re (the right element), and each elementfield has the components child and data. Branching isdone based on the bits in the search key. If the ith bit of thesearch key is 0, then at level i child branch followed at anode is from left-element (the root is at level 0); other-wise, from right element. In One-Dimensional MultibitTries the branching is based on the number of bits knownas “stride”. Multi Dimensional Multibit Trie (MDMT)search [13-15] is a Trie Search where the packets are clas-
sified by searching the Destination Trie, Source Trie, Pro-tocol Trie and Port Trie at different levels using stride. Ithas time complexity O (W/L) and space complexity O (N(W/L) 2(k-1)), where ‘L’ is the average length of strides.Though there are several algorithms specialized for thecase of rules on two fields (e.g. Source and destination IPaddress only), it is necessary to design a packet classifica-tion algorithm that uses more number of header fields toprovide support for diversified services with the re-quirement of both low memory space and low accessoverhead[21]. A new low complexity Trie Based TupleSpace Search (TTSS) Packet classification algorithm hasbeen proposed to give a remarkable enhancement to the
existing Trie based and Tuple based algorithms to sup-port QoS of multimedia applications.
3 TRIE BASED TUPLE SPACE SEARCH
ALGORITHM
his section presents the proposed TTSS packet classi-fication algorithm that accelerates the lookup time.This is achieved by simplifying the lookup procedure
and avoiding unnecessary tuple probing. It is achieved bydividing the Tuple space into multiple subspaces. Sinceeach rule is having two major components called an ap-
plication specification and an address prefix pair, classifi-cation is done in two stages namely: Application fieldlook up and prefix-pair look up respectively. This appli-cation specification identifies a specific application ses-sion by transport protocol, source port and destinationport. Address prefix pair identifies the communicatingsubnets by specifying a source address prefix and a desti-nation address prefix or address prefix pair. The imple-mentation of the TTSS classifier includes IP destina-tion/source address, Source/destination port and proto-col as filter/rule fields. TTSS uses hierarchical trie struc-ture to store the rules and traverses a trie through a set ofrules for classifying each incoming packet. In TTSS, Exact
Matching is carried out at first level for Protocol and Pre-fix Matching is carried out at the next level for the IP ad-dress.
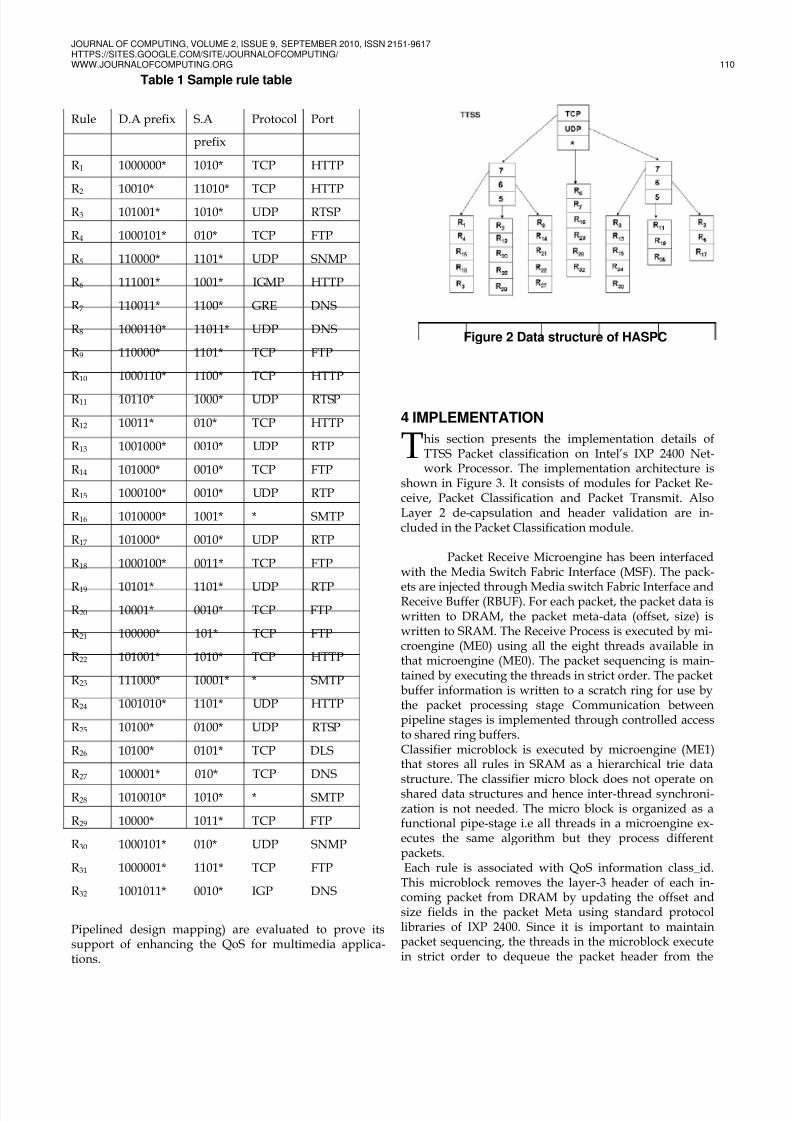
Taylor and Turner have given useful characteris-tics of the filter [22], by analyzing rule sets provided byISPs, network equipment vendor, and other researchersworking in the field to verify and compare the perfor-mance of the proposed classification algorithms. From[22] it is observed that even though the transport-layerfields have a wide variety of specifications, the mostcommon are TCP (49%), followed by UDP (27%), thewildcard (13%), ICMP (10%) and the other protocols suchas OSPF, IGMP, etc are lesser than 1% of the filters. Be-cause of the small number of protocol types, node of thetrie at level 1 splits the rule set based on the protocol fieldof the header that reduces the number of rules to besearched to 50% at the next level of the trie. The samplerule table and the associated data structure of TTSS areshown in Figure 2.
Moreover the speed and efficiency of several
longest prefix matching and packet processing algorithmsdepend upon the number of unique prefix lengths andthe distribution of rules across those unique values. Amajority of the rule sets specify fewer than 15 unique pre-fix lengths for either source or destination address prefix-es [16]. The number of unique source/destination prefixpair lengths is generally lesser than 32, which is smallercompared to the filter size and 8% of the rules are redun-dant. According to classic IP addressing structure, in [11]it has been shown that most of the rules ignore subnet-ting.
Based on these observations [16] and [22], eachnode of the trie at level 2 has been constructed with mul-
tiple elements referring hash tables of prefix pair and pre-fix length to further reduce the lookup time by reducingthe search space. A node with prefix length ‘w’ has 2w
element fields. All matching candidate rules are identifiedby using the destination prefix length ‘w’ as a search keyand for those candidates, rules are further filtered usingthe source prefix field. Left most element of the node hasthe hash table with prefix length ‘i’ and the hash tables ofother elements will have the rules with prefix length ‘j’,and the hash tables always satisfy the inequality i > j.Longest Prefix matching (LPM) is preferred for Addresslookup and hence Packet classification has been per-formed by traversing the trie from left to right and from
top to bottom using the tuple to reduce the time complex-ity. This technique drives the algorithm to have the spaceand time complexity as O (N) and as (log W) respectively.With this low complexity, TTSS could be effective forhigh speed classification compared to other Multidimen-sional Multibit Trie (MDMT) packet classification algo-rithms [11-15].
In this paper, TTSS algorithm has been imple-mented on the IXP 2400 Network processor platform be-cause the algorithm is feasible for parallel implementa-tion. Also the achievement of its performance improve-ment such as throughput and packet classification rate onthe IXP 2400 with different design mappings (parallel and
T
8/8/2019 Efficient Mapping of Heuristic Packet Classifier on Network Processor based Router to enhance QoS for Multimedia …
http://slidepdf.com/reader/full/efficient-mapping-of-heuristic-packet-classifier-on-network-processor-based 4/7
JOURNAL OF COMPUTING, VOLUME 2, ISSUE 9, SEPTEMBER 2010, ISSN 2151-9617HTTPS://SITES.GOOGLE.COM/SITE/JOURNALOFCOMPUTING/ WWW.JOURNALOFCOMPUTING.ORG 110
Pipelined design mapping) are evaluated to prove itssupport of enhancing the QoS for multimedia applica-tions.
4 IMPLEMENTATION
his section presents the implementation details ofTTSS Packet classification on Intel’s IXP 2400 Net-work Processor. The implementation architecture is
shown in Figure 3. It consists of modules for Packet Re-ceive, Packet Classification and Packet Transmit. AlsoLayer 2 de-capsulation and header validation are in-cluded in the Packet Classification module.
Packet Receive Microengine has been interfacedwith the Media Switch Fabric Interface (MSF). The pack-
ets are injected through Media switch Fabric Interface andReceive Buffer (RBUF). For each packet, the packet data iswritten to DRAM, the packet meta-data (offset, size) iswritten to SRAM. The Receive Process is executed by mi-croengine (ME0) using all the eight threads available inthat microengine (ME0). The packet sequencing is main-tained by executing the threads in strict order. The packetbuffer information is written to a scratch ring for use bythe packet processing stage Communication betweenpipeline stages is implemented through controlled accessto shared ring buffers.Classifier microblock is executed by microengine (ME1)that stores all rules in SRAM as a hierarchical trie data
structure. The classifier micro block does not operate onshared data structures and hence inter-thread synchroni-zation is not needed. The micro block is organized as afunctional pipe-stage i.e all threads in a microengine ex-ecutes the same algorithm but they process differentpackets.Each rule is associated with QoS information class_id.
This microblock removes the layer-3 header of each in-coming packet from DRAM by updating the offset andsize fields in the packet Meta using standard protocollibraries of IXP 2400. Since it is important to maintainpacket sequencing, the threads in the microblock executein strict order to dequeue the packet header from the
Rule D.A prefix S.A
prefix
Protocol Port
R1 1000000* 1010* TCP HTTP
R2 10010* 11010* TCP HTTP
R3 101001* 1010* UDP RTSP
R4 1000101* 010* TCP FTP
R5 110000* 1101* UDP SNMP
R6 111001* 1001* IGMP HTTP
R7 110011* 1100* GRE DNS
R8 1000110* 11011* UDP DNS
R9 110000* 1101* TCP FTP
R10 1000110* 1100* TCP HTTP
R11 10110* 1000* UDP RTSP
R12 10011* 010* TCP HTTP
R13 1001000* 0010* UDP RTP
R14 101000* 0010* TCP FTP
R15 1000100* 0010* UDP RTP
R16 1010000* 1001* * SMTP
R17 101000* 0010* UDP RTP
R18 1000100* 0011* TCP FTP
R19 10101* 1101* UDP RTP
R20 10001* 0010* TCP FTP
R21 100000* 101* TCP FTP
R22 101001* 1010* TCP HTTP
R23 111000* 10001* * SMTP
R24 1001010* 1101* UDP HTTP
R25 10100* 0100* UDP RTSP
R26 10100* 0101* TCP DLS
R27 100001* 010* TCP DNS
R28 1010010* 1010* * SMTP
R29 10000* 1011* TCP FTP
R30 1000101* 010* UDP SNMP
R31 1000001* 1101* TCP FTP
R32 1001011* 0010* IGP DNS
T
Figure 2 Data structure of HASPC
Table 1 Sample rule table

8/8/2019 Efficient Mapping of Heuristic Packet Classifier on Network Processor based Router to enhance QoS for Multimedia …
http://slidepdf.com/reader/full/efficient-mapping-of-heuristic-packet-classifier-on-network-processor-based 5/7
JOURNAL OF COMPUTING, VOLUME 2, ISSUE 9, SEPTEMBER 2010, ISSN 2151-9617HTTPS://SITES.GOOGLE.COM/SITE/JOURNALOFCOMPUTING/ WWW.JOURNALOFCOMPUTING.ORG 111
DRAM for performing packet classification. Packet clas-sifier validates the IP header of esch incoming packetbased on RFC 1812[5]. If the validity check fails, then thepacket is dropped. Otherwise, the packet is classified intodifferent traffic flows based on the IP header and is en-queued in the respective queue using the proposed pack-et classification algorithm. For each valid packet, the mi-cro block then builds a hash input from the header andthen compares IP header fields with the rule stored in thehash entry. If a matching entry is found then the classifierwrites selected dispatch loop variables with data stored ina hash entry and enqueues the packet in the queue ac-cording to class_id field of the rule for further processingby the router. Otherwise, if matching fails the algorithmloads the next hash entry in a chain as indicated bynext_entry_ptr and repeats the entry matching procedure.If a classifier reaches end of chain without finding amatching entry, a default rule is applied.
Then the Packet Transmit microblock is executedby microengine (ME3) that moves packet into TBUFs fortransmitting over the media interface through different
ports. The MSF is monitored by the packet Transmittermicroblock to stop the transmission on that port if theTBUF threshold for specific ports has been exceeded andif so it queues up the requests to transmit packets on thatport in local memory. The Packet Transmitter microblockperiodically updates the classifier with information abouthow many packets have been transmitted.
4.1 Implementation Environment
IXA 3.51 SDK is a cycle based simulator [18] inwhich IXP2400 is set to run under the following condi-tions: PLL output frequency: 1200 MHz, ME frequency:600 MHz, Xscale Frequency: 600 MHz. SRAM frequen-
cies: 200 MHz, two channels, 64 MB per channel, DRAMFrequency: 150 MHz, 64 MB. The configuration for thedevice type is x32 MPHY4 with bus mode 1x32 to sendand receive packets from the simulator. A device with 4ports, each with a data rate of 1000 Mbps and receive andtransmit buffer sizes of 128KB chosen for this application.The simulator is configured to send packet streams toports 0 through 3 of the device. Implementation assignsindividual blocks from the fast path pipeline to separatemicroengines on the IXP2400 NPs.
Traffic generated in this work includes uniformlydistributed RTP/UDP packets, UDP packets, TCP pack-ets, etc and all types of classIP addresses.. Traffic is gen-erated with a constant rate of 1000Mb/s and inter-packetgap is set to 96 ns.
5 PERFORMANCE EVALUATION
n order to evaluate the performance of the algorithm, 5-tuple header field consisting of IP source and destina-tion address, protocol type, source and destination
ports is considered because these five fields are commonfields under literature even though higher number offields is possible [11]. Prefix match is used for IP source
and destination addresses and exact match is used forprotocol flag.
5.1 Design Mappings
The implementation of the classification phase onthe IXP2400 can be done in different ways namely parallelmapping and pipeline mapping. In both the cases, Pack-et Rx and Packet Tx are processed by microengine 0
(ME0) and microengine 3 (ME3) and the microenginesME1 and ME2 are used for classification purpose. In pa-rallel mapping, all the classification steps for a singlepacket are processed by the single microengine and henceME1 and ME2 perform the classification of differentpackets simultaneously.In pipelined mapping, the classification of a single packetis done by two different micro engines. ME1 and ME2,one is for Field Extraction and the other is for Header va-lidation (according to RFC1812 [5]) and for table lookup.
The four (LS, TSS, PTS and TTSS) algorithms areimplemented using single microengine, parallel and pipe-lined design mapping as shown in Figure 4. Figure 5shows that at the end of 60,000 microengine cycles,Throughput using TSS is 34.15% more than LS, using PTSis 67.85% more than LS and it is 73.5% more in TTSS.Throughput in TTSS is 59.8% and 17.6% more than TSSand PTS respectively.
TTSS outperforms the LS, TSS and PTS based
I
PC
TX
PC
Figure 4. Parallel and Pipelined Mapping
THROUGHPUT
0
20
40
60
80
100
120
20000 40000 60000
Simulati on ti me (cycl es)
LS TSS PTS TTSS
Figure 5 Throughput

8/8/2019 Efficient Mapping of Heuristic Packet Classifier on Network Processor based Router to enhance QoS for Multimedia …
http://slidepdf.com/reader/full/efficient-mapping-of-heuristic-packet-classifier-on-network-processor-based 6/7
JOURNAL OF COMPUTING, VOLUME 2, ISSUE 9, SEPTEMBER 2010, ISSN 2151-9617HTTPS://SITES.GOOGLE.COM/SITE/JOURNALOFCOMPUTING/ WWW.JOURNALOFCOMPUTING.ORG 112
packet classification algorithms and hence the perfor-mance of the different design mappings is analyzed withTTSS classification algorithm and is shown in Figure 6.
Table 2 shows that the speedup factor [20] ofTTSS in parallel mapping is 2.18 and in pipelined map-ping is 1.52 compared to TTSS classification using singlemicroengine. From the table it is also inferred that classi-fication rate in TTSS is 2788 KPPS (Kilo Packets per Sec)and 1937 KPPS in parallel and pipelined mapping respec-tivelyThe pipelined mapping seems to be an ideal map-ping for the algorithm, in which the various steps inprocessing a packet has been split and assigned acrossmicroengines. However, the packet processing speed ofTTSS is reduced by 31.25% in pipelined mapping than inparallel mapping as shown in Figure 7. This is due to thefact that the access of SRAM occurs only once in parallelmapping to read the packet header whereas in pipelinedmapping it occurs more than once for a single packet.
Microengine being the most important resourceof NP, its utilization factor can be described by its idletime as shown in Figure 8a. and 8b. In TTSS Idle time ofME2 is almost 25% lesser than in other algorithms and forME3 it is 32% lesser. The packet classifier in pipelinedmapping exhibits more idle time than that in parallelmapping. It is clear from Figure 7a and 7b that the idletime in ME2 and ME3 in Parallel mapping is 21% and32% lesser than that of pipelined mapping respectively.
This is due to the fact that in pipelined mapping, a newpacket cannot be handled by microengines earlier in thepipeline until the availability of inter-microengine bufferentries. These entries are available only when the entireprocessing for that packet is completed by all microen-gines.
On analysis, it is seen that Trie based Tuple SpaceSearch achieves high speed packet classification usingEmbedded Network Processor in parallel mapping.
6 CONCLUSION
etwork devices such as edge router, firewalls andintrusion detection systems devices can utilize pro-grammable Network Processors (NP) to implement
a computationally intensive packet classification algo-
N
TH R O U G H PU T
0
50
100
150
200
250
LS TSS PTS TTSS
Algorithms
Pipelined Mapping Parallel Mapping
Figure 6 Throughput
Table 2 Comparison of Performance parameters
P A C K E T S E N T / R E C E I V E R A T I O
0
0.2
0.4
0.6
0.8
11.2
LS TSS PTS TTSS
Packet Classification Algorithms
P arallel M a pping P ipelined M a pping
I D LE T IM E ( M E 2 )
0
10
20
30
40
50
60
70
80
90
LS TSS PTS TTSS
Algorithms
Pipelined Mapping Parallel Mapping
I D LE T IM E ( M E 3 )
0
20
40
60
80
100
120
LS TSS PTS TTSS
Algorithms
Pipelined Mapping Parallel Mapping
Figure 7 Packet Sent/Receive Ratio
Figure 8 Idle Time of ME2
Figure 8 Idle Time of ME3

8/8/2019 Efficient Mapping of Heuristic Packet Classifier on Network Processor based Router to enhance QoS for Multimedia …
http://slidepdf.com/reader/full/efficient-mapping-of-heuristic-packet-classifier-on-network-processor-based 7/7
JOURNAL OF COMPUTING, VOLUME 2, ISSUE 9, SEPTEMBER 2010, ISSN 2151-9617HTTPS://SITES.GOOGLE.COM/SITE/JOURNALOFCOMPUTING/ WWW.JOURNALOFCOMPUTING.ORG 113
rithm at line speeds to provide QoS and Network securi-ty. This paper describes the design of Packet Classifiercomponent on Network based Router and its perfor-mance enhancement. The proposed low complexity heu-ristic Trie based Tuple Space Search (TTSS) packet classi-fication has been implemented on Intel’s IXP 2400 Net-work Processor to improve the performance of Router.By dividing the tuple space into multiple subspaces, thespace complexity and the time complexity achieved byTTSS is O (N) and O (log W) respectively. The implemen-tation results lead to the observation that Throughput ofTrie based Tuple Space search (TTSS) is almost 60% more,compared to TSS and PTS. In this work, the performanceof TTSS is also evaluated using pipelined as well as paral-lel design mapping. The results show that the speedupfactor of TTSS in parallel mapping is 2.18 and in pipelinedmapping is 1.52 compared to TTSS classification usingsingle microengine. Results prove that classification ratein TTSS is 2788 KPPS (Kilo Packets per Sec) and 1937KPPS in parallel and pipelined mapping respectively.Moreover, the pipelined design mapping has a packet
processing rate of 31.25% lesser than the parallel map-ping, primarily due to multiple memory reads per packetin the latter. As compared with the pipelined mapping,parallel mapping of TTSS classifier can provide higherThroughput and classification rate. Thus the work sug-gests that TTSS based packet classification in parallelmapping is efficient for enhancing QoS of multimediaapplications.
REFERENCES[1]. Michael Coss and Ron Sharp, “The Network ProcessorDecision”, Bell Labs Technical Journal, pp: 177-189, 2004[2]. Douglas.E. Comer, “Network Systems Design Using Net-
work Processors”. Pearson Education, 2003.[3]. E.J. Johnson and A.R. Kunze, “IXP2400/ 2850 Program-ming”, Intel Press, 2004.[4]. Intel IXP 2400/ IXP2800 Network Processor “HardwareReference manual”, Intel Corporation 2003.[5]. F. Baker “Requirement for IP Version 4 Router” June 1995.Intenet Ingineering Task Force, ftp://ftp,ietf.org/rfc/rfc1812.txt.[6]. David E. Taylor “Survey & Taxonomy of Packet Classifica-tion Techniques” ACM Comput. Survey. Vol 37, No 5, pp. 238-275,Sep 2005.[7]. Pankaj Gupta and Nick Mc Keown “Algorithm for PacketClassification” IEEE Network Magazine, Vol 15,no2,pp.24-32, Apirl,2001.[8]. M.A. Ruiz-Sanchez, E.W. Biersack, W.Dabbous, “Surveyand Taxonomy of IP Address Lookup Algorithms” IEEE Network,Vol.15, No2,.pp.8-23,April 2001.[9]. V.Srinivasan, S.Suri and G.Varghese “Packet Classification
Using Tuple Space Search” ACM SIGCOMM, September1999,pp.135-146.[10]. Pi-Chung Wang, Chia-Tai Chan, Chun-Liang Lee, andHung-Yi Chang “Scalable Packet Classification for Enabling InternetDifferentiated Services” IEEE Trans, Multimedia, vol.8, no.8,pp.1239-1249, Dec 2006.[11]. Stefano Giordano, Gregorio Procissi, Federico Rossi, andFabio Vitucci “ Design of a Multi-Dimensional Packet Classifier forNetwork Processors” in Proc. IEEE ICC 2006, pp. 503-508.[12]. W.Lu and S. Sahni, “Efficient Construction of PipelinedMultibit-Trie Router Tables,” IEEE Trans. Computers, vol. 56, no. 1,pp. 32-43, Jan. 2007.[13]. W. Lu and S. Sahni, “Packet Classification Using Two-Dimensional Multibit Tries,” Proc. 10th IEEE Symp. Computers andComm., 2005.[14]. W. Lu and S. Sahni, “Packet Classification Using Pipelined
Two-Dimensional Multibit Tries,” http://www.cise.ufl.edu/~wlu/ pa-pers/p-2dtries.pdf, 2008.[15]. W. Lu and S. Sahni, “Packet Classification Using Space-Efficient pipelined Multibit Tries,” IEEE Transactions on Computers,Vol. 57, No.5, May 2008.[16]. Intel Corporation. Intel Network Processors Product Infor-mation. http:/ /www.intel.com/design/ network/ products/npfamily.[17]. “Microengine version 2 (MEv2) Assembly Language cod-ing Standards. Revision 1.01g” Intel Corporation, June2003.[18]. “Intel IXP2400/IXP2800 Network Processors - Develop-
ment Tool User Guide” Intel Corporation, March 2004.[19]. Intel Corporation, “Intel IXP2400 & IXP2800 Network Proces-sors Programmer’s Reference Manual” 2004.[20]. John.L.Hennessy and David.A.Patterson” Computer Archi-tecture Quantitative Apporach “3/e Morgan Kaufmann Publishers2003.[21]A.Feldman and S.Muthukrishnan, “Tradeoffs for Packet Classifi-cation” in IEEE INFOCOM, pp. 1193-1202, March 2000[22]. D.E Taylor, J.S Turner “Class Bench, A packet classificationBenchmark”, in IEEE INFOCOM, vol 3, March 2005, PP. 2068-2079.[23]. Pankaj Gupta and n.Mckeown, “Packet classification on mul-tiple fields”ACM SIGCOMM, pp. 147-160, August 99.[24]. Atsushi Yoshioka, Shariful Hasan Shakot, and Min Sik Kim“Rule Hashing for Efficient Packet Classification in Network IntrusionDetection”, IEEE 2008.
Mrs. R. Avudaiammal has received her
B.E. degree in Electronics and Communication Engineering from
Madurai Kamaraj University, India in 1992 and M.E. degree in Ap-
plied Electronics from Bharathiar University, India in 2000. She is an
Associate Professor at St.Joseph’s College of Engineering, Chennai,
India. She has 17 years of teaching experience. She has published
books on Microprocessors with Dhanpatrai publication and on Infor-
mation coding Techniques with TMH Publishers. She is currently
pursuing her research at Anna University Tiruchirappalli , India. Her
research interests are in Embedded systems, Multimedia Networks
and Network Processor .
Dr.P. Seethalakshmi has received
her B.E. degree in Electronics and Communication Engineering in
1991 and M.E. degree in Applied Electronics in 1995 from Bhara-
thiar University, India. She obtained her doctoral degree from Anna
University Chennai, India in the year 2004. She has 15 years of
teaching experience. She is Director/ CAE, Anna University Thiruchi-
rappalli. Her areas of research includes Multimedia Streaming, Wire-
less Networks, Network Processors and Web Services.