efficient xml storage, query, and update shi xu heng yuan spring 2004 cs240b prof. zaniolo
Post on 20-Dec-2015
219 views
TRANSCRIPT

Efficient XML Efficient XML Storage, Query, Storage, Query,
and Updateand UpdateShi XuShi Xu
Heng YuanHeng YuanSpring 2004 CS240BSpring 2004 CS240B
Prof. ZanioloProf. Zaniolo

XML Storage MethodsXML Storage Methods
Flat StreamsFlat Streams MetamodelingMetamodeling MixedMixed
RedundantRedundant HybridHybrid

Method CoveredMethod Covered
““Efficient storage of XML data” Efficient storage of XML data” covers hybrid method using a covers hybrid method using a custom made storage system called custom made storage system called Natix.Natix.
““Efficient relational storage and Efficient relational storage and retrieval of XML documents” covers retrieval of XML documents” covers Metamodeling using their Monet Metamodeling using their Monet database.database.

Natix OverviewNatix Overview
Natix is an efficient, native Natix is an efficient, native repository for storing, retrieving and repository for storing, retrieving and managing XML documents.managing XML documents.
It supports tree-structured objects It supports tree-structured objects like XML documents at low like XML documents at low architecture level.architecture level.

Natix architectural Natix architectural overviewoverview

Logic ModelLogic Model
Tree is often used in logic model of Tree is often used in logic model of semistructured data.semistructured data.
Each non-leaf node is labeled with a Each non-leaf node is labeled with a symbol taken from an alphabet symbol taken from an alphabet DTD.DTD.
Leaf nodes can be labeled as the Leaf nodes can be labeled as the data itself. data itself.

A sample XML with its A sample XML with its associated logical treeassociated logical tree
Example XML:
<SPEECH><SPEAKER>OTHELLO</SPEAKER><LINE>Let me see your eyes;</LINE><LINE>Look in my face.</LINE>
</SPEECH>

Physical ModelPhysical Model Object Content:Object Content:
NodeNode and and objectsobjects are used interchangeably. are used interchangeably. A A recordrecord contains a set of nodes/objects. contains a set of nodes/objects. Aggregate nodesAggregate nodes are inner nodes of the are inner nodes of the
tree. They contain their respective child tree. They contain their respective child nodes.nodes.
Literal nodesLiteral nodes are leaf nodes containing an are leaf nodes containing an uninterpreted stream of bytes, like text uninterpreted stream of bytes, like text strings, graphics, etc.strings, graphics, etc.
Proxy nodesProxy nodes are nodes which point to are nodes which point to different records.different records.

Node RepresentationNode Representation
Whole documents (or subtrees of Whole documents (or subtrees of documents) can be stored in one record.documents) can be stored in one record.
Each record contains exactly one subtree.Each record contains exactly one subtree. The root nodes of each record’s subtree The root nodes of each record’s subtree
are called are called standalone objectsstandalone objects, other , other nodes are called nodes are called embedded objectsembedded objects..
The record size has an upper limit, the The record size has an upper limit, the page sizepage size..

Large TreesLarge Trees
For a large tree, physical model must For a large tree, physical model must provide a mechanism for distributing provide a mechanism for distributing data trees over several pages.data trees over several pages.
Method 1: “flat” representation. It Method 1: “flat” representation. It wastes the available structural wastes the available structural information about the data.information about the data.
Method 2: split large objects based on Method 2: split large objects based on the underlying tree structure.the underlying tree structure. Use proxy objects to connect subtrees of Use proxy objects to connect subtrees of
the large object residing in other records.the large object residing in other records.
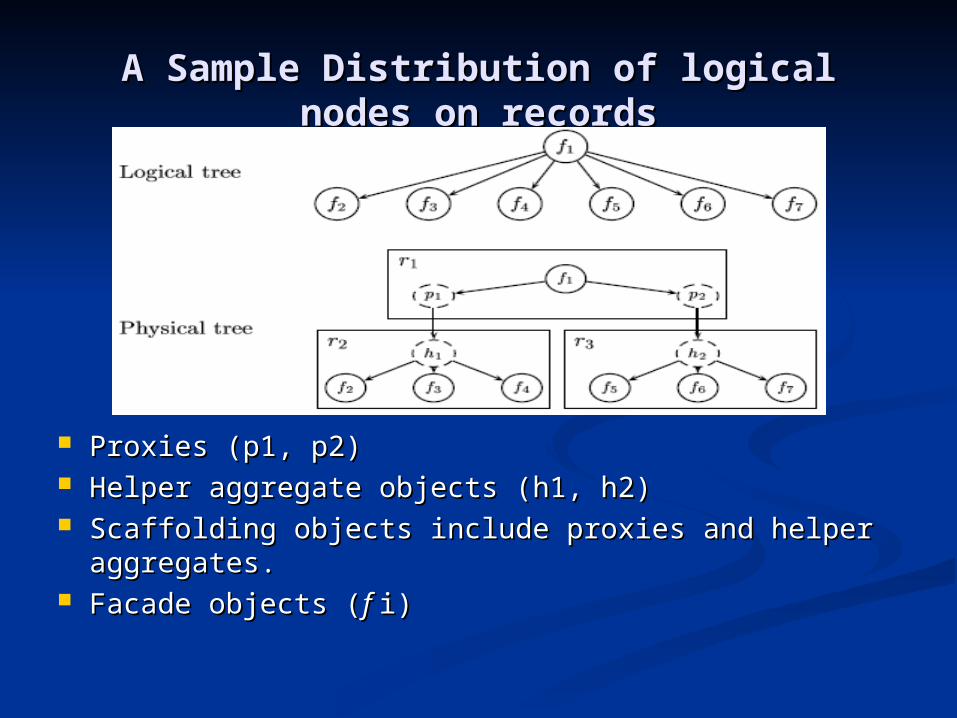
A Sample Distribution of logical nodes A Sample Distribution of logical nodes on recordson records
Proxies (p1, p2)Proxies (p1, p2) Helper aggregate objects (h1, h2)Helper aggregate objects (h1, h2) Scaffolding objects include proxies and helper Scaffolding objects include proxies and helper
aggregates.aggregates. Facade objects (Facade objects (f f i)i)

Dynamic maintenance of an Dynamic maintenance of an efficient storageefficient storage
The principle problem is that a The principle problem is that a record containing a subtree can record containing a subtree can grow larger than a page if a node is grow larger than a page if a node is added or grows.added or grows.
Subtree contains in the record has to Subtree contains in the record has to be partitioned into several subtrees. be partitioned into several subtrees.
Scaffolding nodes link the new Scaffolding nodes link the new records together in the physical records together in the physical tree.tree.
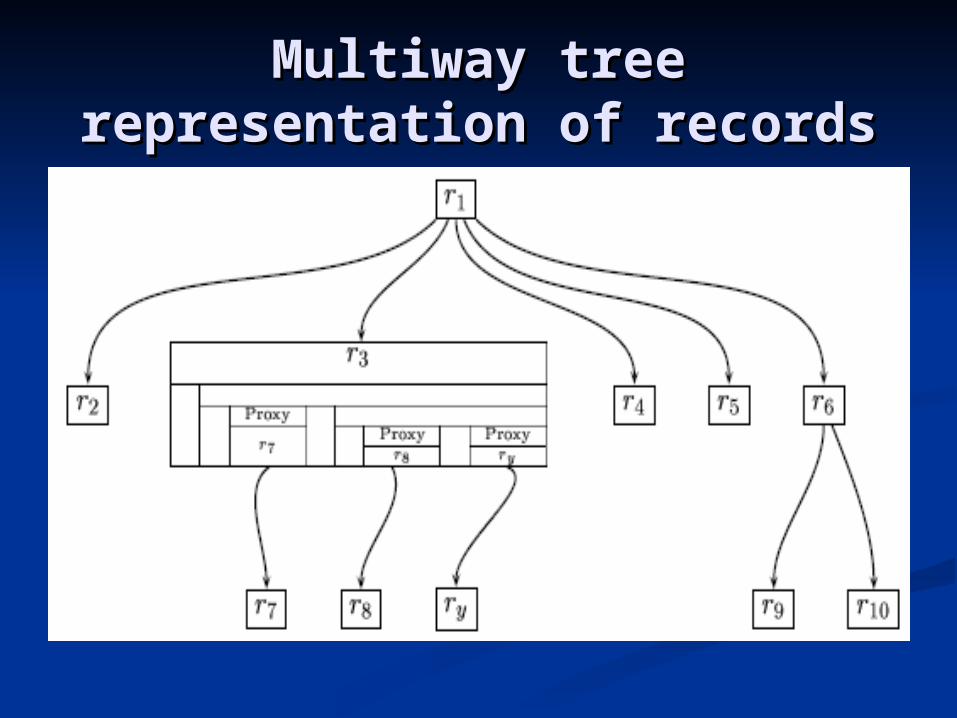
Multiway tree Multiway tree representation of recordsrepresentation of records

Tree Growth ProcedureTree Growth Procedure
Step 1: Determine the record r into which the Step 1: Determine the record r into which the node has to be inserted.node has to be inserted.
Step 2: If there is not enough on the page, try Step 2: If there is not enough on the page, try to move r. If the record still does not fit, split to move r. If the record still does not fit, split the record:the record: (a) Determine the separator by recursively (a) Determine the separator by recursively
descending into the r’s subtreedescending into the r’s subtree (b) Distribute the resulting partitions onto records(b) Distribute the resulting partitions onto records (c) Insert the separator into the parent record, (c) Insert the separator into the parent record,
recursively calling this procedurerecursively calling this procedure Step 3: Insert the new nodeStep 3: Insert the new node
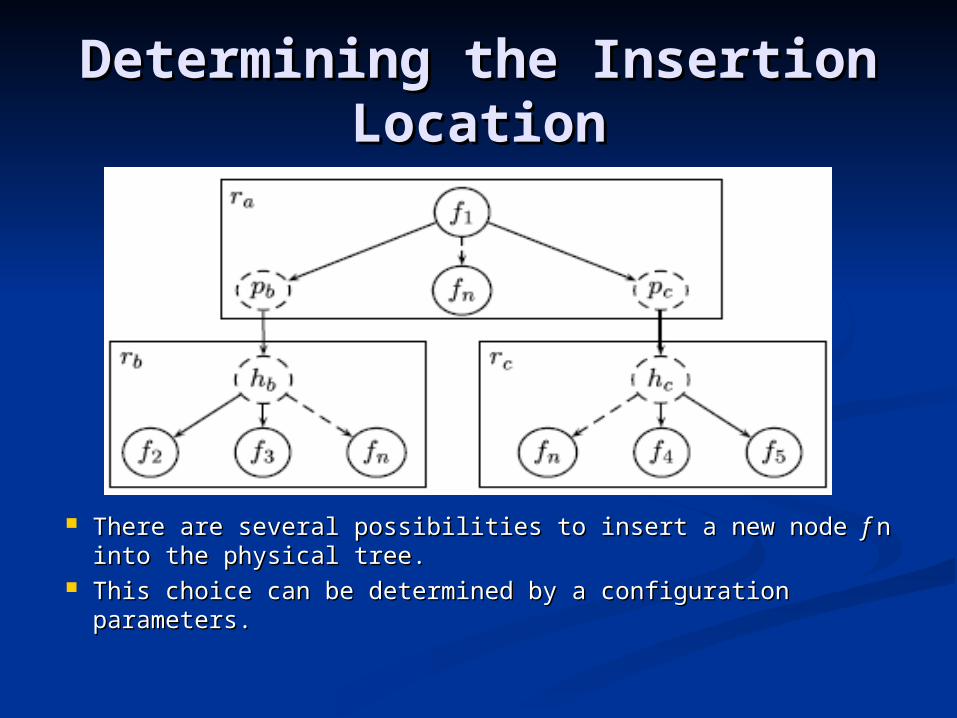
Determining the Insertion Determining the Insertion LocationLocation
There are several possibilities to insert a new node There are several possibilities to insert a new node f f n into n into the physical tree.the physical tree.
This choice can be determined by a configuration parameters.This choice can be determined by a configuration parameters.

Determining the Determining the separatorseparator
Separator – a tree structure with Separator – a tree structure with proxies pointing to the new records proxies pointing to the new records to indicate where which part of the to indicate where which part of the old record was moved.old record was moved.
Consists of all the nodes on the path Consists of all the nodes on the path from d to the subtree’s root.from d to the subtree’s root.
Partition the tree into left partition Partition the tree into left partition L, right partition R and Separator S.L, right partition R and Separator S.

A record’s subtree before a A record’s subtree before a split occurssplit occurs

Splitting a RecordSplitting a Record
Distributing the nodes on recordsDistributing the nodes on records After determining the partitioning, the After determining the partitioning, the
contents of the record has to be contents of the record has to be distributed onto new records.distributed onto new records.
Each resulting subtree is then stored in Each resulting subtree is then stored in its own record, called partition records.its own record, called partition records.
Inserting the separatorInserting the separator The separator is moved to the parent The separator is moved to the parent
record.record.

Split AlgorithmSplit Algorithm
Find a node d, such that the Find a node d, such that the resulting L and R.resulting L and R.
The ratio between the sizes of L and The ratio between the sizes of L and R is determined by a configuration R is determined by a configuration parameter (split target).parameter (split target).
Another configuration parameter Another configuration parameter Split tolerance specifies the Split tolerance specifies the minimum size for the subtree of d. minimum size for the subtree of d. It is used to prevent fragmentation.It is used to prevent fragmentation.
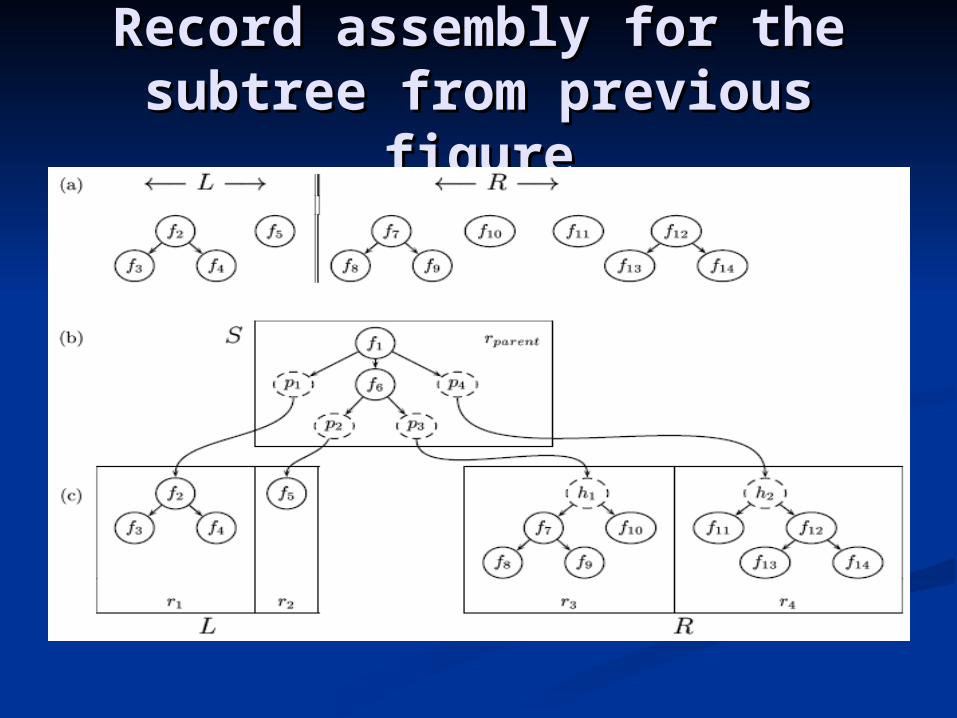
Record assembly for the Record assembly for the subtree from previous subtree from previous
figurefigure

Physical storage of the tree Physical storage of the tree represented inside one represented inside one
recordrecord

Performance TestPerformance Test
XML markup version of XML markup version of Shakspeare’s play with 8MB with Shakspeare’s play with 8MB with 320,000 nodes.320,000 nodes.
Pentium-II 333Mhz with 128MB Pentium-II 333Mhz with 128MB under Windows NT4.0 with IBM under Windows NT4.0 with IBM DCAS 34330 disk.DCAS 34330 disk.
The implementation of the record The implementation of the record and tree storage managers was done and tree storage managers was done in C++.in C++.

Test ConditionsTest Conditions
Record:Node 1:1 indicating smart Record:Node 1:1 indicating smart record splitting being inhibited.record splitting being inhibited.
Record:Node 1:n indicating that the Record:Node 1:n indicating that the algorithm has full control over algorithm has full control over distribution of nodes on records.distribution of nodes on records.
Incremental updates distributed Incremental updates distributed over the whole document.over the whole document.
Updates in pre-order (append).Updates in pre-order (append).
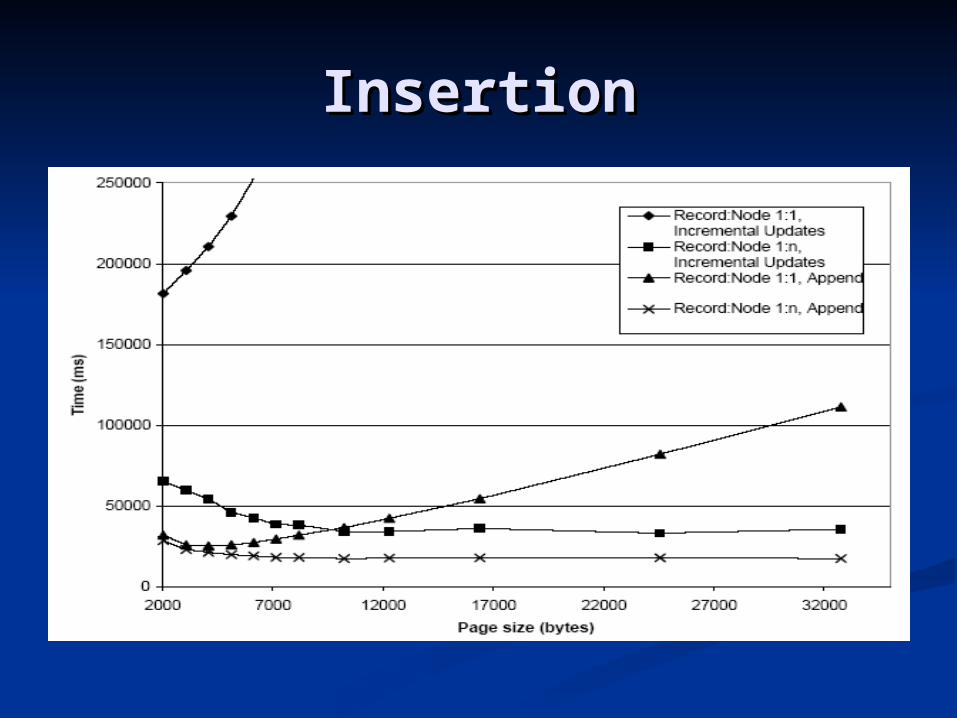
InsertionInsertion
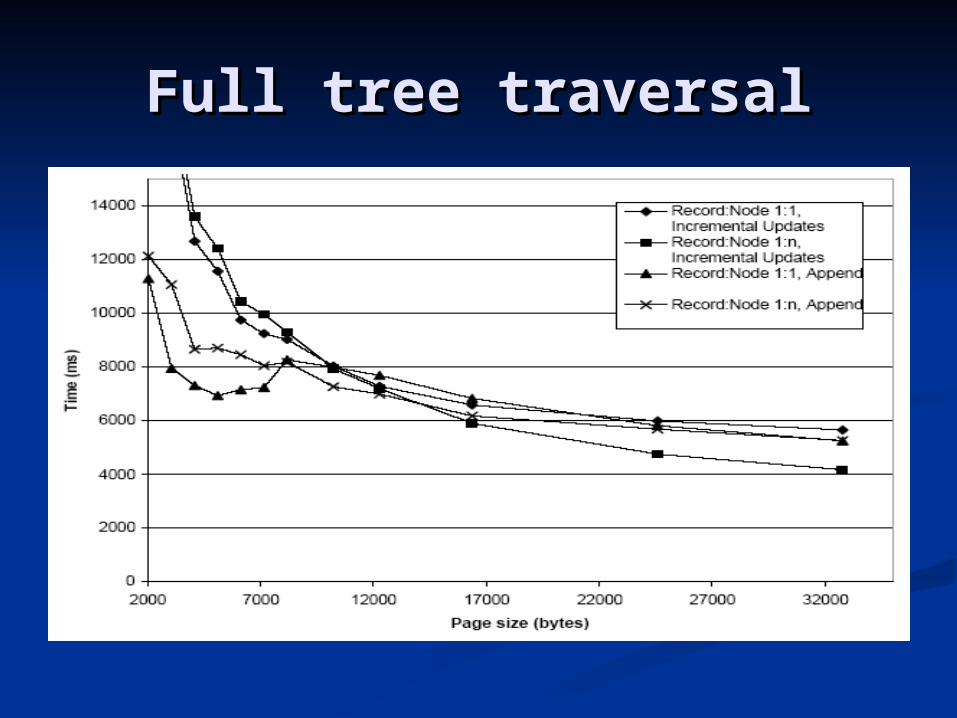
Full tree traversalFull tree traversal

QueriesQueries
Retrieve all speakers in the third act and Retrieve all speakers in the third act and second scene of every play, which means it second scene of every play, which means it accesses all leaf nodes of a certain type in accesses all leaf nodes of a certain type in one selected subtree of the document.one selected subtree of the document.
Recreate the textual representation of the Recreate the textual representation of the complete first speech in every scene, hence complete first speech in every scene, hence reading a lot of small contiguous fragments reading a lot of small contiguous fragments of each document.of each document.
A simple path query was evaluated by A simple path query was evaluated by reading only the opening speech of each reading only the opening speech of each play.play.
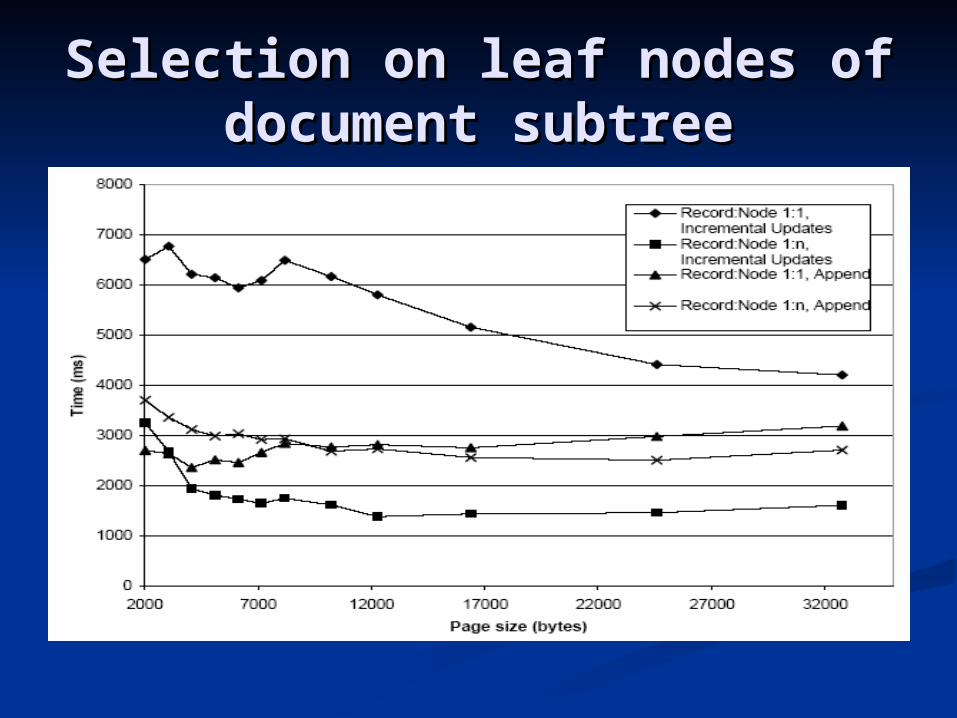
Selection on leaf nodes of Selection on leaf nodes of document subtreedocument subtree
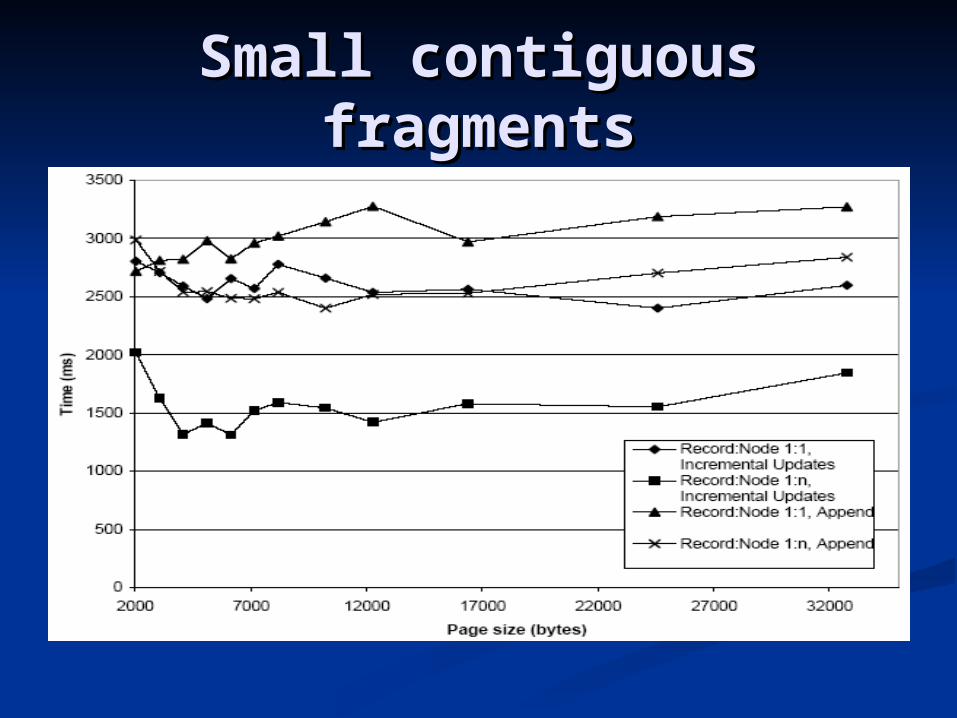
Small contiguous Small contiguous fragmentsfragments

Single path for each Single path for each documentdocument
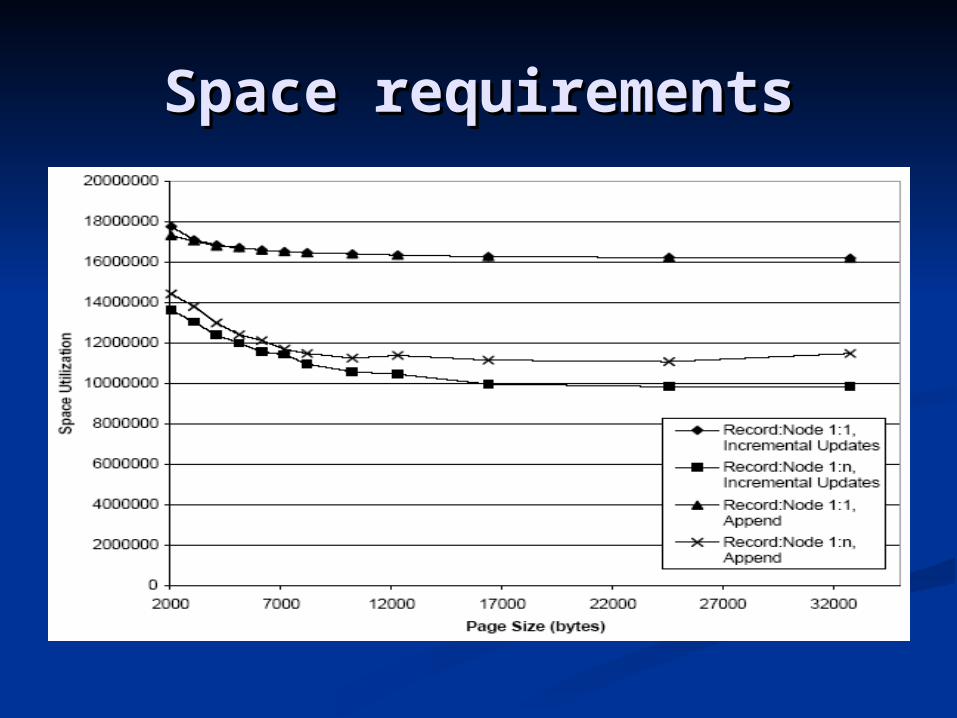
Space requirementsSpace requirements

Monet ModelMonet Model
XML document is decomposed into XML document is decomposed into binary relations.binary relations.
Efficient for storage and retrieval of Efficient for storage and retrieval of XML documents in a relational XML documents in a relational database.database.
The database used is their Monet The database used is their Monet database server which supports the database server which supports the Monet model.Monet model.

Some DefinitionsSome Definitions
An XML document is a rooted treeAn XML document is a rooted treed = (V, E, r, labeld = (V, E, r, labelEE, label, labelAA, rank) with nodes V , rank) with nodes V and edges Eand edges EVVV and a distinguished node V and a distinguished node rrV.V.
The function labelThe function labelEE : V : Vstringstring assigns labels to assigns labels to nodesnodes
labellabelAA : V : Vstringstringstringstring assigns pairs of assigns pairs of strings, attributes and their values, to nodes.strings, attributes and their values, to nodes.
rank : Vrank : Vintint establishes a ranking to allow for establishes a ranking to allow for an order among nodes with the same parent an order among nodes with the same parent node.node.

A sample XML documentA sample XML document
<bibliography><article key=“BB88”>
<author>Ben Bit</author><title>How to Hack</title>
</article><article key=“BK99”>
<editor>Ed Itor</editor><author>Bob Byte</author><author>Ken Key</author><title>Hacking & RSI</title>
</article></bibliography>
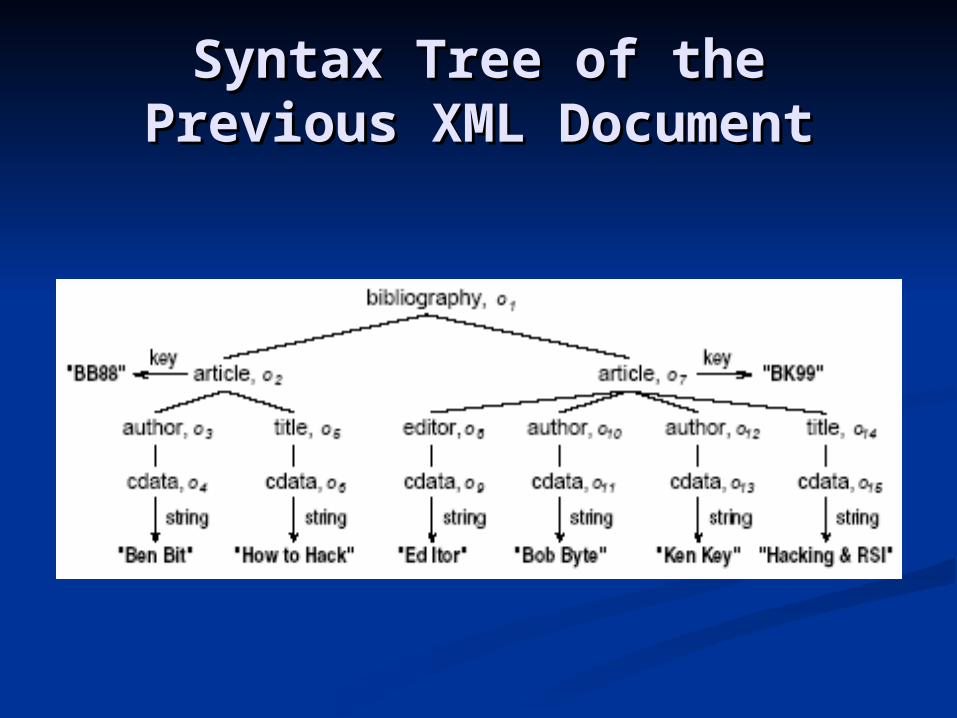
Syntax Tree of the Previous Syntax Tree of the Previous XML DocumentXML Document

Monet TransformMonet Transform
Given an XML document d, the Monet Given an XML document d, the Monet transform is a quadruple transform is a quadruple MMtt(d)=((d)=(rr,,RR,,AA,,TT) where) where RR is the set of binary relations that contain is the set of binary relations that contain
all associations between nodes;all associations between nodes; AA is the set of binary relations that contain is the set of binary relations that contain
all associations between nodes and their all associations between nodes and their attribute values, including character data;attribute values, including character data;
TT is set of binary relations that contain all is set of binary relations that contain all pairs of nodes and their rank;pairs of nodes and their rank;
rr is the root of the document; is the root of the document;

Monet Transform of the Monet Transform of the Example DocumentExample Document

OQL-like queryOQL-like query

Query HandlingQuery Handling

AssessmentAssessment
Implemented within the Monet Implemented within the Monet database serverdatabase server
Tested on 550 MHz Silicon Graphics Tested on 550 MHz Silicon Graphics 1400 Server with 1 GB main 1400 Server with 1 GB main memory.memory.
Also used Sun UltraSparc-IIi with Also used Sun UltraSparc-IIi with 360 MHz and 256 MB main memory 360 MHz and 256 MB main memory to contrast with a related work.to contrast with a related work.

Size of document Size of document collections in XML and collections in XML and
Monet XML formatMonet XML format
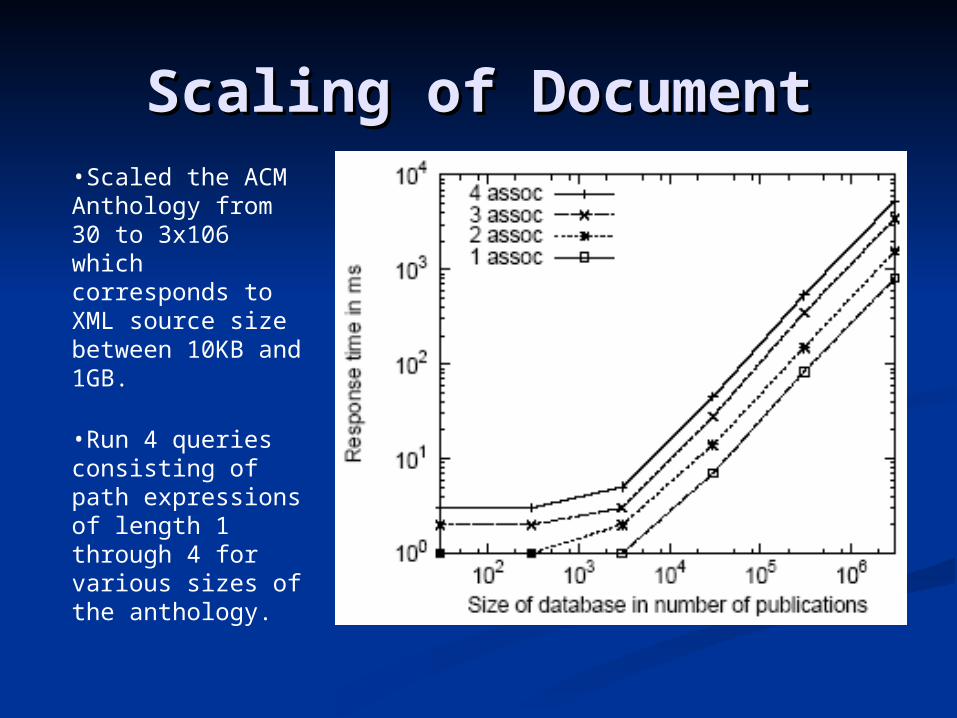
Scaling of DocumentScaling of Document•Scaled the ACM Anthology from 30 to 3x106 which corresponds to XML source size between 10KB and 1GB.
•Run 4 queries consisting of path expressions of length 1 through 4 for various sizes of the anthology.
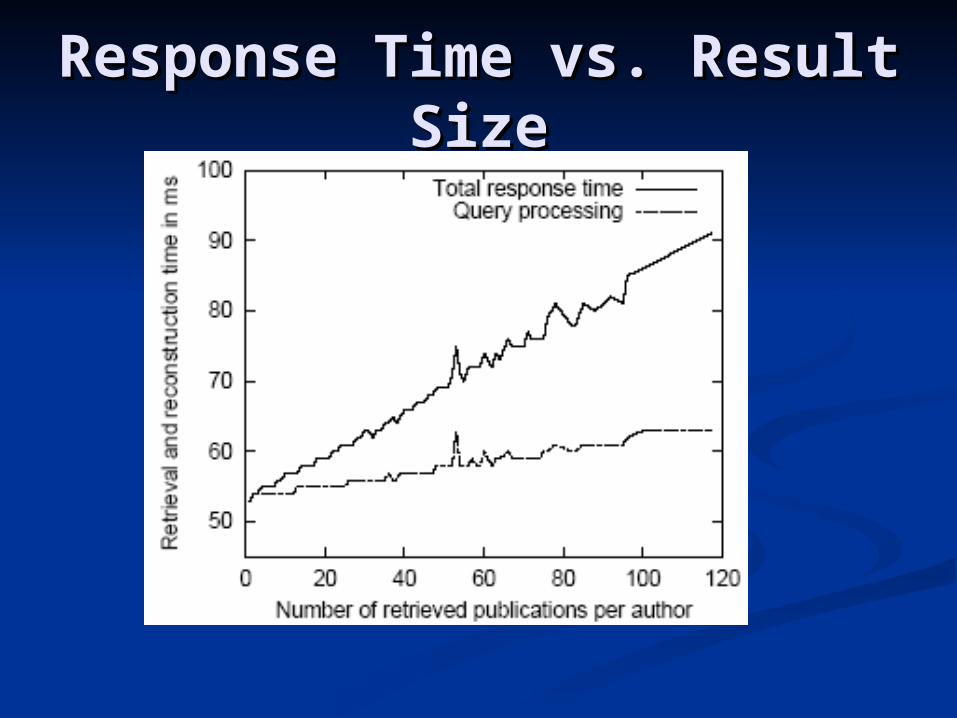
Response Time vs. Result Response Time vs. Result SizeSize

Comparison of response Comparison of response time for query set of SYU, time for query set of SYU,
another method for another method for storage/retrieval of XML storage/retrieval of XML
document.document.

Compare/Contrast Natix Compare/Contrast Natix and Monetand Monet
Natix uses custom database while Monet Natix uses custom database while Monet is built on top of relational databaseis built on top of relational database
Neither uses DTD.Neither uses DTD. Natix focuses on XML query as well as Natix focuses on XML query as well as
update.update. Monet focuses on XML storage and query.Monet focuses on XML storage and query. Though lacking equivalent test, Monet is Though lacking equivalent test, Monet is
faster than Natix on query.faster than Natix on query. Monet seems to be more space efficient Monet seems to be more space efficient
than Natix as well.than Natix as well.

ReferencesReferences
““Efficient storage of XML data” By Carl-Efficient storage of XML data” By Carl-Christian Kanne, et al. ICDE 2000 Christian Kanne, et al. ICDE 2000 http://citeseer.nj.nec.com/kanne99efficienhttp://citeseer.nj.nec.com/kanne99efficient.htmlt.html
““Efficient Relational Storage and Efficient Relational Storage and Retrieval of XML Documents” By Albrecht Retrieval of XML Documents” By Albrecht Schmidt, et al. WebDB 2000 Schmidt, et al. WebDB 2000 http://www.research.att.com/conf/webdb2http://www.research.att.com/conf/webdb2000/program.html000/program.html